
Machine Learning for Simulation of Urban Heat Island Dynamics Based on Large-Scale Meteorological Conditions



Abstract
:1. Introduction
2. Data and Methods
2.1. Study Area
2.2. Meteorological Data
2.3. Statement of the Machine Learning Problem
2.4. Predictors of the UHI Magnitude
2.5. Machine Learning Models
2.6. Model Evaluation
3. Results and Discussion
3.1. Overall Performance of the Different ML Models
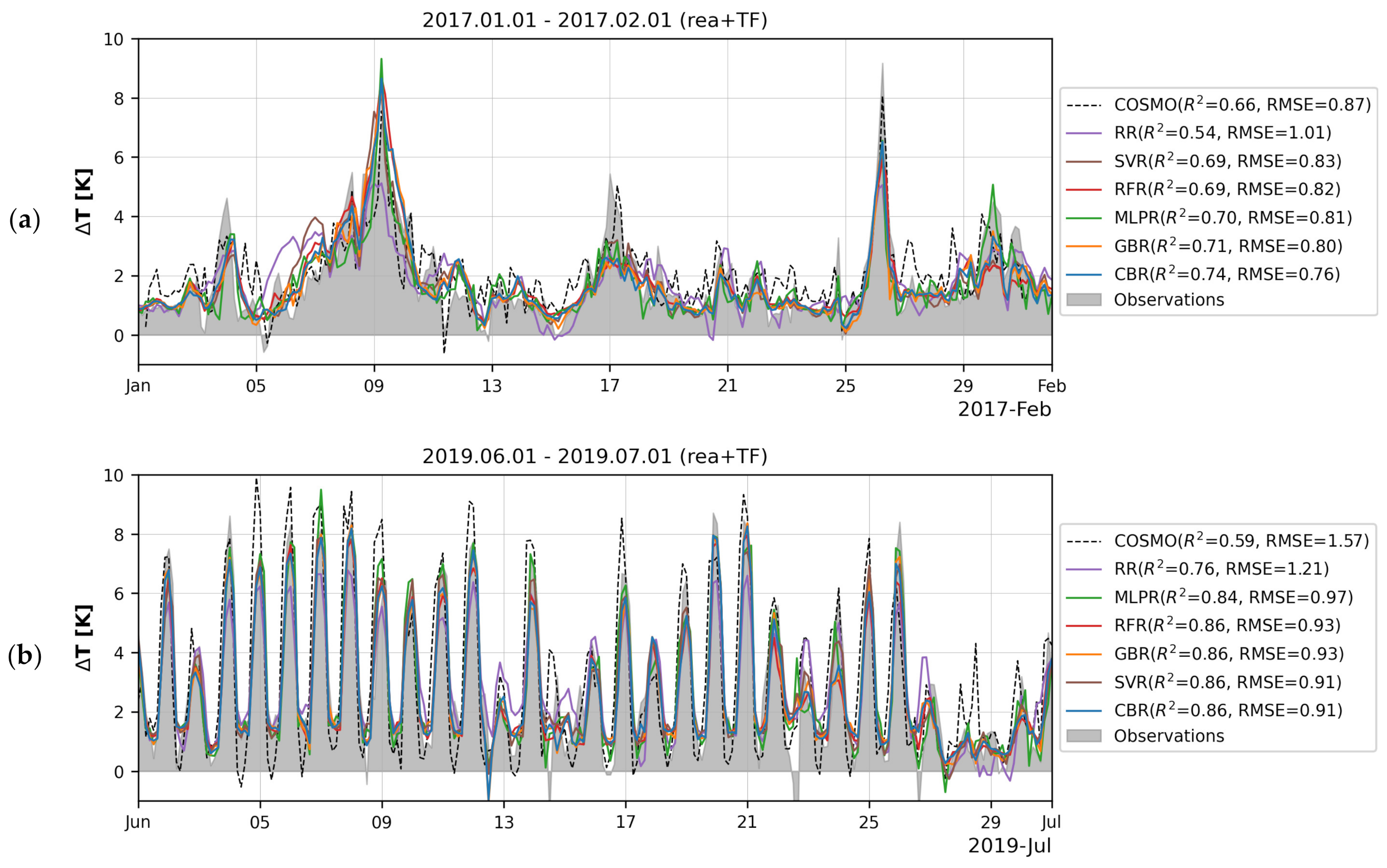
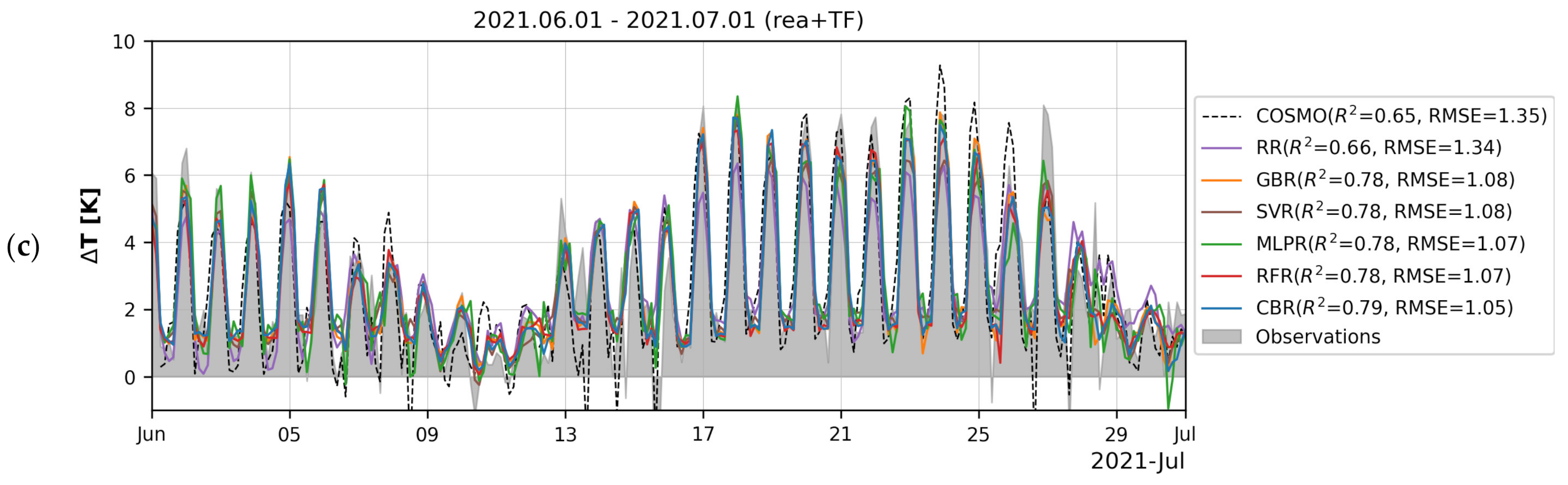
3.2. Temporal Variations of Models’ Quality
3.3. Importance of the Predictors
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Masson, V.; Lemonsu, A.; Hidalgo, J.; Voogt, J. Urban Climates and Climate Change. Annu. Rev. Environ. Resour. 2020, 45, 411–444. [Google Scholar] [CrossRef]
- Sangiorgio, V.; Fiorito, F.; Santamouris, M. Development of a Holistic Urban Heat Island Evaluation Methodology. Sci. Rep. 2020, 10, 17913. [Google Scholar] [CrossRef] [PubMed]
- Lokoshchenko, M.A.; Alekseeva, L.I. Influence of Meteorological Parameters on the Urban Heat Island in Moscow. Atmosphere 2023, 14, 507. [Google Scholar] [CrossRef]
- Wong, K.V.; Paddon, A.; Jimenez, A. Review of World Urban Heat Islands: Many Linked to Increased Mortality. J. Energy Resour. Technol. 2013, 135, 022101. [Google Scholar] [CrossRef]
- Gabriel, K.M.A.; Endlicher, W.R. Urban and Rural Mortality Rates during Heat Waves in Berlin and Brandenburg, Germany. Environ. Pollut. 2011, 159, 2044–2050. [Google Scholar] [CrossRef] [PubMed]
- Han, J.Y.; Baik, J.J.; Lee, H. Urban Impacts on Precipitation. Asia Pac. J. Atmos. Sci. 2014, 50, 17–30. [Google Scholar] [CrossRef]
- Liu, J.; Niyogi, D. Meta-Analysis of Urbanization Impact on Rainfall Modification. Sci. Rep. 2019, 9, 7301. [Google Scholar] [CrossRef] [PubMed]
- Melaas, E.K.; Wang, J.A.; Miller, D.L.; Friedl, M.A. Interactions between Urban Vegetation and Surface Urban Heat Islands: A Case Study in the Boston Metropolitan Region. Environ. Res. Lett. 2016, 11, 054020. [Google Scholar] [CrossRef]
- Zipper, S.C.; Schatz, J.; Singh, A.; Kucharik, C.J.; Townsend, P.A.; Loheide, S.P. Urban Heat Island Impacts on Plant Phenology: Intra-Urban Variability and Response to Land Cover. Environ. Res. Lett. 2016, 11, 054023. [Google Scholar] [CrossRef]
- Garuma, G.F. Review of Urban Surface Parameterizations for Numerical Climate Models. Urban Clim. 2017, 24, 830–851. [Google Scholar] [CrossRef]
- Tarasova, M.A.; Varentsov, M.I.; Stepanenko, V.M. Parameterization of the Interaction between the Atmosphere and the Urban Surface: Current State and Prospects. Izv. Atmos. Ocean. Phys. 2023, 59, 111–130. [Google Scholar] [CrossRef]
- Varentsov, M.; Wouters, H.; Platonov, V.; Konstantinov, P. Megacity-Induced Mesoclimatic Effects in the Lower Atmosphere: A Modeling Study for Multiple Summers over Moscow, Russia. Atmosphere 2018, 9, 50. [Google Scholar] [CrossRef]
- Rivin, G.S.; Rozinkina, I.A.; Vil’fand, R.M.; Kiktev, D.B.; Tudrii, K.O.; Blinov, D.V.; Varentsov, M.I.; Zakharchenko, D.I.; Samsonov, T.E.; Repina, I.A.; et al. Development of the High-Resolution Operational System for Numerical Prediction of Weather and Severe Weather Events for the Moscow Region. Russ. Meteorol. Hydrol. 2020, 45, 455–465. [Google Scholar] [CrossRef]
- Barlage, M.; Miao, S.; Chen, F. Impact of Physics Parameterizations on High-Resolution Weather Prediction over Two Chinese Megacities. J. Geophys. Res. Atmos. 2016, 121, 4487–4498. [Google Scholar] [CrossRef]
- Wouters, H.; De Ridder, K.; Poelmans, L.; Willems, P.; Brouwers, J.; Hosseinzadehtalaei, P.; Tabari, H.; Vanden Broucke, S.; van Lipzig, N.P.M.; Demuzere, M. Heat Stress Increase under Climate Change Twice as Large in Cities as in Rural Areas: A Study for a Densely Populated Midlatitude Maritime Region. Geophys. Res. Lett. 2017, 44, 8997–9007. [Google Scholar] [CrossRef]
- Zemtsov, S.; Shartova, N.; Varentsov, M.; Konstantinov, P.; Kidyaeva, V.; Shchur, A.; Timonin, S.; Grischchenko, M. Intraurban Social Risk and Mortality Patterns during Extreme Heat Events: A Case Study of Moscow, 2010–2017. Health Place 2020, 66, 102429. [Google Scholar] [CrossRef] [PubMed]
- Hamdi, R.; Van de Vyver, H.; De Troch, R.; Termonia, P. Assessment of Three Dynamical Urban Climate Downscaling Methods: Brussels’s Future Urban Heat Island under an A1B Emission Scenario. Int. J. Climatol. 2014, 34, 978–999. [Google Scholar] [CrossRef]
- Adachi, S.A.; Kimura, F.; Kusaka, H.; Inoue, T.; Ueda, H. Comparison of the Impact of Global Climate Changes and Urbanization on Summertime Future Climate in the Tokyo Metropolitan Area. J. Appl. Meteorol. Climatol. 2012, 51, 1441–1454. [Google Scholar] [CrossRef]
- Szymanowski, M.; Kryza, M. GIS-Based Techniques for Urban Heat Island Spatialization. Clim. Res. 2009, 38, 171–187. [Google Scholar] [CrossRef]
- Bottyán, Z.; Unger, J. A Multiple Linear Statistical Model for Estimating the Mean Maximum Urban Heat Island. Theor. Appl. Climatol. 2003, 75, 233–243. [Google Scholar] [CrossRef]
- Heusinkveld, B.G.; Steeneveld, G.J.; van Hove1, L.W.A.; Jacobs, C.M.J.; Holtslag, A.A.M. Spatial Variability of the Rotterdam Urban Heat Island as Influenced by Urban Land Use. J. Geophys. Res. Atmos. 2014, 119, 677–692. [Google Scholar] [CrossRef]
- Wilby, R.L. Past and Projected Trends in London’s Urban Heat Island. Weather 2003, 58, 251–260. [Google Scholar] [CrossRef]
- Wilby, R.L. Constructing Climate Change Scenarios of Urban Heat Island Intensity and Air Quality. Environ. Plan. B Plan. Des. 2008, 35, 902–919. [Google Scholar] [CrossRef]
- Hoffmann, P.; Krueger, O.; Schlünzen, K.H. A Statistical Model for the Urban Heat Island and Its Application to a Climate Change Scenario. Int. J. Climatol. 2012, 32, 1238–1248. [Google Scholar] [CrossRef]
- Bassett, R.; Janes-Bassett, V.; Phillipson, J.; Young, P.J.; Blair, G.S. Climate Driven Trends in London’s Urban Heat Island Intensity Reconstructed over 70 Years Using a Generalized Additive Model. Urban Clim. 2021, 40, 100990. [Google Scholar] [CrossRef]
- Theeuwes, N.E.; Steeneveld, G.J.; Ronda, R.J.; Holtslag, A.A.M. A Diagnostic Equation for the Daily Maximum Urban Heat Island Effect for Cities in Northwestern Europe. Int. J. Climatol. 2017, 37, 443–454. [Google Scholar] [CrossRef]
- Xu, R.; Chen, N.; Chen, Y.; Chen, Z. Downscaling and Projection of Multi-CMIP5 Precipitation Using Machine Learning Methods in the Upper Han River Basin. Adv. Meteorol. 2020, 2020, 8680436. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Zhang, Z.; Xu, C.Y.; Wang, B.; Yao, J. Estimation of Future Precipitation Change in the Yangtze River Basin by Using Statistical Downscaling Method. Stoch. Environ. Res. Risk Assess. 2011, 25, 781–792. [Google Scholar] [CrossRef]
- Zhang, G.; Zhu, S.; Zhang, N.; Zhang, G.; Xu, Y. Downscaling Hourly Air Temperature of WRF Simulations Over Complex Topography: A Case Study of Chongli District in Hebei Province, China. J. Geophys. Res. D Atmos. 2022, 127, e2021JD035542. [Google Scholar] [CrossRef]
- Salameh, T.; Drobinski, P.; Vrac, M.; Naveau, P. Statistical Downscaling of Near-Surface Wind over Complex Terrain in Southern France. Meteorol. Atmos. Phys. 2009, 103, 253–265. [Google Scholar] [CrossRef]
- Li, L. Geographically Weighted Machine Learning and Downscaling for High-Resolution Spatiotemporal Estimations of Wind Speed. Remote Sens. 2019, 11, 1378. [Google Scholar] [CrossRef]
- Wei, C.C. Study on Wind Simulations Using Deep Learning Techniques during Typhoons: A Case Study of Northern Taiwan. Atmosphere 2019, 10, 684. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A Neural Network Forecast for Daily Average PM10 Concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Bethel, B.J.; Sun, W.; Dong, C.; Wang, D. Forecasting Hurricane-Forced Significant Wave Heights Using a Long Short-Term Memory Network in the Caribbean Sea. Ocean Sci. 2022, 18, 419–436. [Google Scholar] [CrossRef]
- Martin, S.A.; Manucharyan, G.E.; Klein, P. Synthesizing Sea Surface Temperature and Satellite Altimetry Observations Using Deep Learning Improves the Accuracy and Resolution of Gridded Sea Surface Height Anomalies. J. Adv. Model Earth Syst. 2023, 15, e2022MS003589. [Google Scholar] [CrossRef]
- Venter, Z.S.; Brousse, O.; Esau, I.; Meier, F. Hyperlocal Mapping of Urban Air Temperature Using Remote Sensing and Crowdsourced Weather Data. Remote Sens. Environ. 2020, 242, 111791. [Google Scholar] [CrossRef]
- Gardes, T.; Schoetter, R.; Hidalgo, J.; Long, N.; Marquès, E.; Masson, V. Statistical Prediction of the Nocturnal Urban Heat Island Intensity Based on Urban Morphology and Geographical Factors—An Investigation Based on Numerical Model Results for a Large Ensemble of French Cities. Sci. Total Environ. 2020, 737, 139253. [Google Scholar] [CrossRef] [PubMed]
- Straub, A.; Berger, K.; Breitner, S.; Cyrys, J.; Geruschkat, U.; Jacobeit, J.; Kühlbach, B.; Kusch, T.; Philipp, A.; Schneider, A.; et al. Statistical Modelling of Spatial Patterns of the Urban Heat Island Intensity in the Urban Environment of Augsburg, Germany. Urban Clim. 2019, 29, 100491. [Google Scholar] [CrossRef]
- Zumwald, M.; Knüsel, B.; Bresch, D.N.; Knutti, R. Mapping Urban Temperature Using Crowd-Sensing Data and Machine Learning. Urban Clim. 2021, 35, 100739. [Google Scholar] [CrossRef]
- Yi, C.; Shin, Y.; Roh, J.W. Development of an Urban High-Resolution Air Temperature Forecast System for Local Weather Information Services Based on Statistical Downscaling. Atmosphere 2018, 9, 164. [Google Scholar] [CrossRef]
- Yasuda, Y.; Onishi, R.; Hirokawa, Y.; Kolomenskiy, D.; Sugiyama, D. Super-Resolution of near-Surface Temperature Utilizing Physical Quantities for Real-Time Prediction of Urban Micrometeorology. Build. Environ. 2022, 209, 108597. [Google Scholar] [CrossRef]
- Yasuda, Y.; Onishi, R.; Matsuda, K. Super-Resolution of Three-Dimensional Temperature and Velocity for Building-Resolving Urban Micrometeorology Using Physics-Guided Convolutional Neural Networks with Image Inpainting Techniques. Build. Environ. 2023, 243, 110613. [Google Scholar] [CrossRef]
- Vulova, S.; Meier, F.; Rocha, A.D.; Quanz, J.; Nouri, H.; Kleinschmit, B. Modeling Urban Evapotranspiration Using Remote Sensing, Flux Footprints, and Artificial Intelligence. Sci. Total Environ. 2021, 786, 147293. [Google Scholar] [CrossRef] [PubMed]
- Cox, W. Demographia World Urban Areas, 18th Annual Edition: July 2022. Demograpgia 2022, 18, 93. [Google Scholar]
- Lokoshchenko, M.A. Urban Heat Island and Urban Dry Island in Moscow and Their Centennial Changes. J. Appl. Meteorol. Climatol. 2017, 56, 2729–2745. [Google Scholar] [CrossRef]
- Varentsova, S.A.; Varentsov, M.I. A New Approach to Study the Long-Term Urban Heat Island Evolution Using Time-Dependent Spectroscopy. Urban Clim. 2021, 40, 101026. [Google Scholar] [CrossRef]
- Kislov, A.V.; Varentsov, M.I.; Gorlach, I.A.; Alekseeva, L.I. “Heat Island” of the Moscow Agglomeration and the Urban-Induced Amplification of Global Warming. Mosc. Univ. Vestn. Ser. 5 Geogr. 2017, 4, 12–19. (In Russian) [Google Scholar]
- Varentsov, M.I.; Grishchenko, M.Y.; Wouters, H. Simultaneous Assessment of the Summer Urban Heat Island in Moscow Megacity Based on in Situ Observations, Thermal Satellite Images and Mesoscale Modeling. Geogr. Environ. Sustain. 2019, 12, 74–95. [Google Scholar] [CrossRef]
- Varentsov, M.; Fenner, D.; Meier, F.; Samsonov, T.; Demuzere, M. Quantifying Local and Mesoscale Drivers of the Urban Heat Island of Moscow with Reference and Crowdsourced Observations. Front. Environ. Sci. 2021, 9, 7169681. [Google Scholar] [CrossRef]
- Varentsov, M.; Samsonov, T.; Demuzere, M. Impact of Urban Canopy Parameters on a Megacity’s Modelled Thermal Environment. Atmosphere 2020, 11, 1349. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R. Local Climate Zones for Urban Temperature Studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 Global Reanalysis. Q. J. R. Meteorol. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Delhasse, A.; Kittel, C.; Amory, C.; Hofer, S.; Van As, D.; Fausto, R.S.; Fettweis, X. Brief Communication: Evaluation of the near-Surface Climate in ERA5 over the Greenland Ice Sheet. Cryosphere 2020, 14, 957–965. [Google Scholar] [CrossRef]
- Molina, M.O.; Gutiérrez, C.; Sánchez, E. Comparison of ERA5 Surface Wind Speed Climatologies over Europe with Observations from the HadISD Dataset. Int. J. Climatol. 2021, 41, 4864–4878. [Google Scholar] [CrossRef]
- Olauson, J. ERA5: The New Champion of Wind Power Modelling? Renew. Energy 2018, 126, 322–331. [Google Scholar] [CrossRef]
- McNorton, J.; Agustí-Panareda, A.; Arduini, G.; Balsamo, G.; Bousserez, N.; Boussetta, S.; Chericoni, M.; Choulga, M.; Engelen, R.; Guevara, M. An Urban Scheme for the ECMWF Integrated Forecasting System: Global Forecasts and Residential CO2 Emissions. J. Adv. Model. Earth. Syst. 2023, 15, e2022MS003286. [Google Scholar] [CrossRef]
- Oke, T.R.; Mills, G.; Christen, A.; Voogt, J.A. Urban Climates; Cambridge University Press: Cambridge, UK, 2017; ISBN 9781139016476. [Google Scholar]
- Oke, T.R. An Algorithmic Scheme to Estimate Hourly Heat Island Magnitude. In Proceedings of the Preprints, Second Symposium on Urban Environment, Albuquerque, NM, USA, 2–5 November 1998; pp. 80–83. [Google Scholar]
- Oke, T.R.; Runnalls, K.E. Dynamics and Controls of the Near-Surface Heat Island of Vancouver, British Columbia. Phys. Geogr. 2000, 21, 283–304. [Google Scholar] [CrossRef]
- Wolpert, D.H. The Supervised Learning No-Free-Lunch Theorems. In Soft Computing and Industry; Springer: London, UK, 2002; pp. 25–42. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Marquardt, D.W.; Snee, R.D. Ridge Regression in Practice. Am. Stat. 1975, 29, 3–20. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Thomas, T.; Vijayaraghavan, A.P.; Emmanuel, S. Applications of Decision Trees. In Machine Learning Approaches in Cyber Security Analytics; Springer: Singapore, 2020; pp. 157–184. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: New York, NY, USA, 1984; ISBN 9781315139470. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Allen, E.B. Controlling Overfitting in Classification-Tree Models of Software Quality. Empir. Softw. Eng. 2001, 6, 59–79. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. Adv. Neural Inf. Process. Syst. 2017, 31, 6638–6648. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Cortes, C.; Vapnik, V.; Saitta, L. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Drucker, H.J.; Burges, C.; Kaufman, L.; Smola, A.; Vapnik, V. Support Vector Regression Machines. Adv. Neural Inf. Process. Syst. 1996, 9, 155–161. [Google Scholar]
- Vert, J.P.; Tsuda, K.; Schölkopf, B. A Primer on Kernel Methods. In Kernel Methods in Computational Biology; Vert, J., Tsuda, K., Schölkopf, B., Eds.; The MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Minsky, M.; Papert, S.A. Perceptrons; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Rosenblatt, F. The Perceptron, a Perceiving and Recognizing Automaton Project Para; Cornell Aeronautical Laboratory: Ithaca, NY, USA, 1957. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; Rumelhart, D.E., McClelland, J.L., The PDP Group, Eds.; MIT Press: Cambridge, MA, USA, 1985; pp. 318–362. [Google Scholar]
- Kolmogorov, A.N. On the Representation of Continuous Functions of Several Variables by Superposition of Continuous Functions of One Variable and Addition. Dokl. Akad. Nauk USSR 1957, 114, 679–681. [Google Scholar]
- Cybenko, G. Approximation by Superpositions of a Sigmoidal Function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Adv. Neural. Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Ozaki, Y.; Tanigaki, Y.; Watanabe, S.; Nomura, M.; Onishi, M. Multiobjective Tree-Structured Parzen Estimator. J. Artif. Intell. Res. 2022, 73, 1209–1250. [Google Scholar] [CrossRef]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar]
- Shekar, B.H.; Dagnew, G. Grid Search-Based Hyperparameter Tuning and Classification of Microarray Cancer Data. In Proceedings of the 2019 2nd International Conference on Advanced Computational and Communication Paradigms, ICACCP 2019, Gangtok, India, 25–28 February 2019. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and Tuning Strategies for Random Forest. Wiley Interdiscip. Rev. Data. Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Bernard, S.; Heutte, L.; Adam, S. Influence of Hyperparameters on Random Forest Accuracy. In Multiple Classifier Systems; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5519, pp. 171–180. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobot. 2013, 7, 63623. [Google Scholar] [CrossRef]
- Krinitskiy, M.A.; Stepanenko, V.M.; Malkhanov, A.O.; Smorkalov, M.E. A General Neural-Networks-Based Method for Identification of Partial Differential Equations, Implemented on a Novel AI Accelerator. Supercomput. Front. Innov. 2022, 9, 19–50. [Google Scholar] [CrossRef]
- Krinitskiy, M.; Koshkina, V.; Borisov, M.; Anikin, N.; Gulev, S.; Artemeva, M. Machine Learning Models for Approximating Downward Short-Wave Radiation Flux over the Ocean from All-Sky Optical Imagery Based on DASIO Dataset. Remote Sens. 2023, 15, 1720. [Google Scholar] [CrossRef]
- Oke, T.R. The Energetic Basis of the Urban Heat Island. Q. J. R. Meteorol. Soc. 1982, 108, 1–24. [Google Scholar] [CrossRef]
- Yushkov, V.P.; Kurbatova, M.M.; Varentsov, M.I.; Lezina, E.A.; Kurbatov, G.A.; Miller, E.A.; Repina, I.A.; Artamonov, A.Y.; Kallistratova, M.A. Modeling an Urban Heat Island during Extreme Frost in Moscow in January 2017. Izv. Atmos. Ocean. Phys. 2019, 55, 389–406. [Google Scholar] [CrossRef]
- Varentsov, M.; Vasenev, V.; Dvornikov, Y.; Samsonov, T.; Klimanova, O. Does Size Matter? Modelling the Cooling Effect of Green Infrastructures in a Megacity during a Heat Wave. Sci. Total Environ. 2023, 902, 165966. [Google Scholar] [CrossRef] [PubMed]
- Wouters, H.; Demuzere, M.; Blahak, U.; Fortuniak, K.; Maiheu, B.; Camps, J.; Tielemans, D.; van Lipzig, N.P.M. The Efficient Urban Canopy Dependency Parametrization (SURY) v1.0 for Atmospheric Modelling: Description and Application with the COSMO-CLM Model for a Belgian Summer. Geosci. Model Dev. 2016, 9, 3027–3054. [Google Scholar] [CrossRef]
- Garbero, V.; Milelli, M.; Bucchignani, E.; Mercogliano, P.; Varentsov, M.; Rozinkina, I.; Rivin, G.; Blinov, D.; Wouters, H.; Schulz, J.; et al. Evaluating the Urban Canopy Scheme TERRA_URB in the COSMO Model for Selected European Cities. Atmosphere 2021, 12, 237. [Google Scholar] [CrossRef]
- Chernokulsky, A.V.; Bulygina, O.N.; Mokhov, I.I. Recent Variations of Cloudiness over Russia from Surface Daytime Observations. Environ. Res. Lett. 2011, 6, 035202. [Google Scholar] [CrossRef]
- Gorbarenko, E.V. Sunshine Variability in Moscow in 1955–2017. Russ. Meteorol. Hydrol. 2019, 44, 384–393. [Google Scholar] [CrossRef]
- Gorbarenko, E.V. Climate Changes in Atmospheric Radiation Parameters from the MSU Meteorological Observatory Data. Russ. Meteorol. Hydrol. 2016, 41, 789–797. [Google Scholar] [CrossRef]
- Konstantinov, P.; Varentsov, M.; Esau, I. A High Density Urban Temperature Network Deployed in Several Cities of Eurasian Arctic. Environ. Res. Lett. 2018, 13, 075007. [Google Scholar] [CrossRef]
- Varentsov, M.; Konstantinov, P.; Baklanov, A.; Esau, I.; Miles, V.; Davy, R. Anthropogenic and Natural Drivers of a Strong Winter Urban Heat Island in a Typical Arctic City. Atmos. Chem. Phys. 2018, 18, 17573–17587. [Google Scholar] [CrossRef]
- Yang, X.; Chen, Y.; Peng, L.L.H.; Wang, Q. Quantitative Methods for Identifying Meteorological Conditions Conducive to the Development of Urban Heat Islands. Build. Environ. 2020, 178, 106953. [Google Scholar] [CrossRef]
- Ulpiani, G. On the Linkage between Urban Heat Island and Urban Pollution Island: Three-Decade Literature Review towards a Conceptual Framework. Sci. Total Environ. 2021, 751, 141727. [Google Scholar] [CrossRef] [PubMed]
- Varentsov, M.; Konstantinov, P.; Repina, I.; Artamonov, A.; Pechkin, A.; Soromotin, A.; Esau, I.; Baklanov, A. Observations of the Urban Boundary Layer in a Cold Climate City. Urban Clim. 2023, 47, 101351. [Google Scholar] [CrossRef]
- World Meteorological Organization. Guidance on Measuring, Modelling and Monitoring the Canopy Layer Urban Heat Island (CL-UHI) (WMO-No. 1292); World Meteorological Organization: Geneva, Switzerland, 2023; ISBN 978-92-63-11292-2. [Google Scholar]
- Skarbit, N.; Stewart, I.D.; Unger, J.; Gál, T. Employing an Urban Meteorological Network to Monitor Air Temperature Conditions in the ‘Local Climate Zones’ of Szeged, Hungary. Int. J. Climatol. 2017, 37, 582–596. [Google Scholar] [CrossRef]
- Fujibe, F. Urban Warming in Japanese Cities and Its Relation to Climate Change Monitoring. Int. J. Climatol. 2011, 31, 162–173. [Google Scholar] [CrossRef]
- Kalnay, E.; Ming, C. Impact of Urbanization and Land-Use Change on Climate. Nature 2003, 423, 528–531. [Google Scholar] [CrossRef] [PubMed]
- Yao, R.; Wang, L.; Huang, X.; Liu, Y.; Niu, Z.; Wang, S.; Wang, L. Long-Term Trends of Surface and Canopy Layer Urban Heat Island Intensity in 272 Cities in the Mainland of China. Sci. Total Environ. 2021, 772, 145607. [Google Scholar] [CrossRef] [PubMed]
- Hua, L.J.; Ma, Z.G.; Guo, W.D. The Impact of Urbanization on Air Temperature across China. Theor. Appl. Climatol. 2008, 93, 179–194. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, R.; Shen, C.; Da, L. Temporal and Spatial Characteristics of the Urban Heat Island during Rapid Urbanization in Shanghai, China. Environ. Monit. Assess. 2010, 169, 101–112. [Google Scholar] [CrossRef]
- Ünal, Y.S.; Sonuç, C.Y.; Incecik, S.; Topcu, H.S.; Diren-Üstün, D.H.; Temizöz, H.P. Investigating Urban Heat Island Intensity in Istanbul. Theor. Appl. Climatol. 2020, 139, 175–190. [Google Scholar] [CrossRef]
- Varentsov, M.I.; Samsonov, T.E.; Kargashin, P.E.; Korosteleva, P.A.; Varentsov, A.I.; Perkhurova, A.A.; Konstantinov, P.I. Citizen Weather Stations Data for Monitoring Applications and Urban Climate Research: An Example of Moscow Megacity. IOP Conf. Ser. Earth Environ. Sci. 2020, 611, 012055. [Google Scholar] [CrossRef]
- Constantinescu, D.; Cheval, S.; Caracaş, G.; Dumitrescu, A. Effective Monitoring and Warning of Urban Heat Island Effect on the Indoor Thermal Risk in Bucharest (Romania). Energy Build. 2016, 127, 452–468. [Google Scholar] [CrossRef]
- Matzarakis, A.; Laschewski, G.; Muthers, S. The Heat Health Warning System in Germany—Application and Warnings for 2005 to 2019. Atmosphere 2020, 11, 170. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Unit | Weather Station Observations | Reanalysis |
|---|---|---|---|---|
| t2m | Air temperature at 2-m height | °C | + | + |
| rh2m | Relative humidity at 2-m height | % | + | + |
| vel10m | Wind speed at 10-m height | m/s | + | + |
| Tcc | Total cloud cover fraction | unitless (0–1) | + | + |
| Lcc | Low cloud cover fraction | unitless (0–1) | + | + |
| Sp | Atmospheric pressure | hPa | − | + |
| Blh | Boundary layer height | m | − | + |
| Str | Net longwave radiation | W/m2 | − | + |
| ssr | Net shortwave radiation | W/m2 | − | + |
| strd | Downwelling longwave radiation | W/m2 | − | + |
| ssrd | Downwelling shortwave radiation | W/m2 | − | + |
| tp | 3-h precipitation sum | mm | − | + |
| ID | Set Name | Astronomical Predictors | Observations-Based Predictors | Reanalysis-Based Predictors | Temporal Features | Number of Features |
|---|---|---|---|---|---|---|
| 1a | obs | + | + | − | − | 9 |
| 1b | rea | + | − | + | − | 18 |
| 1c | obs&rea | + | + | + | − | 24 |
| 2a | obs + TF | + | + | − | + | 39 |
| 2b | rea + TF | + | − | + | + | 102 |
| 2c | obs&rea + TF | + | + | + | + | 138 |
| Model Name | Acronym | Tuned Hyperparameters and Their Values | Used to Analyze Feature Importance |
|---|---|---|---|
| Ridge Regression (baseline) | RR | - | − |
| Random Forest Regression | RFR | n_estimators [100, 200, 500] | + |
| Gradient Boosting Regression | RBR | n_estimators [100, 200, 500, 1000] | + |
| CatBoost Regression | CBR | n_estimators [100, 200, 500, 1000, 2000] | + |
| Support Vector Regression | SVR | - | − |
| Multi-Layer Perceptron Regression | MLPR | hidden_layer_sizes [100 × 3, 100 × 5, 100 × 7, 200 × 3, 200 × 5, 200 × 7]; max_iter [200, 500, 1000] | − |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varentsov, M.; Krinitskiy, M.; Stepanenko, V. Machine Learning for Simulation of Urban Heat Island Dynamics Based on Large-Scale Meteorological Conditions. Climate 2023, 11, 200. https://doi.org/10.3390/cli11100200
Varentsov M, Krinitskiy M, Stepanenko V. Machine Learning for Simulation of Urban Heat Island Dynamics Based on Large-Scale Meteorological Conditions. Climate. 2023; 11(10):200. https://doi.org/10.3390/cli11100200
Chicago/Turabian StyleVarentsov, Mikhail, Mikhail Krinitskiy, and Victor Stepanenko. 2023. "Machine Learning for Simulation of Urban Heat Island Dynamics Based on Large-Scale Meteorological Conditions" Climate 11, no. 10: 200. https://doi.org/10.3390/cli11100200
APA StyleVarentsov, M., Krinitskiy, M., & Stepanenko, V. (2023). Machine Learning for Simulation of Urban Heat Island Dynamics Based on Large-Scale Meteorological Conditions. Climate, 11(10), 200. https://doi.org/10.3390/cli11100200