2.1. Geography, Climate, and Dryland Farming of the Province
The province of Qazvin has an area of 15,821 km², located between 48–45 to 50–50 East of the Greenwich Meridian of longitude and 35–37 to 36–45 North latitude of the Equator. Its average altitude is 1278 m above sea level. It has a semi-arid climate with the annual mean precipitation, daily mean temperature, and relative humidity of 301 mm, 14.2 °C, and 51%, respectively. The province is affected by Siberian and Mediterranean winds, which are considerably important factors in controlling the climate of the province. The geographical situation of the studied area is shown in
Figure 1.
The total winter wheat yield of the province is 445 million kg, 364 million kg (82%) of which belongs to irrigated farming and 80.7 million kg (18%) to dryland farming. The total cultivated area for winter wheat is nearly 202,497 ha, 95792 ha and 106,704 ha of which are under irrigated and dryland farming, respectively. The average dryland winter wheat yield of the province is estimated to be 1541 kg ha−1.
2.2. Methodology
The daily mean temperature and precipitation data for 32 years (1985–2017) were collected from the six meteorological stations in the province (
Figure 1). Thereafter, the daily mean temperature and precipitation of all days of all years were calculated separately by the Thiessen polygons method using the software ArcGIS version 10 via Equations (1) and (2):
where
and
are the daily mean precipitation and temperature of the province, respectively; p
i and t
i are the daily mean precipitation and temperature in the station i, respectively; and A
i is the area of the province.
The HadCM3 and CanESM2 models were used to compare the scenarios. HadCM3 has a spatial resolution of 2.5° × 3.75° (latitude by longitude) and the representation produces a grid box resolution of 96 × 73 grid cells. This produces a surface spatial resolution of about 417 km × 278 km, reducing to 295 km × 278 km at 45 degrees North and South. In CanESM2, the long-term time series of standardized daily values are extracted into a one column text file per grid cell. The 128 × 64 grid cells cover global domain according to a T42 Gaussian grid. This grid is uniform along the longitude with a horizontal resolution of 2.81° and is nearly uniform along the latitude of roughly 2.81°. The calibration of the stations (points) against the grid-cells (pixels) was done by the downscaling of the SDSM linear regression model. Data from the years 2006–2015 and 2016–2017 were used for the calibration and validation of both models, respectively.
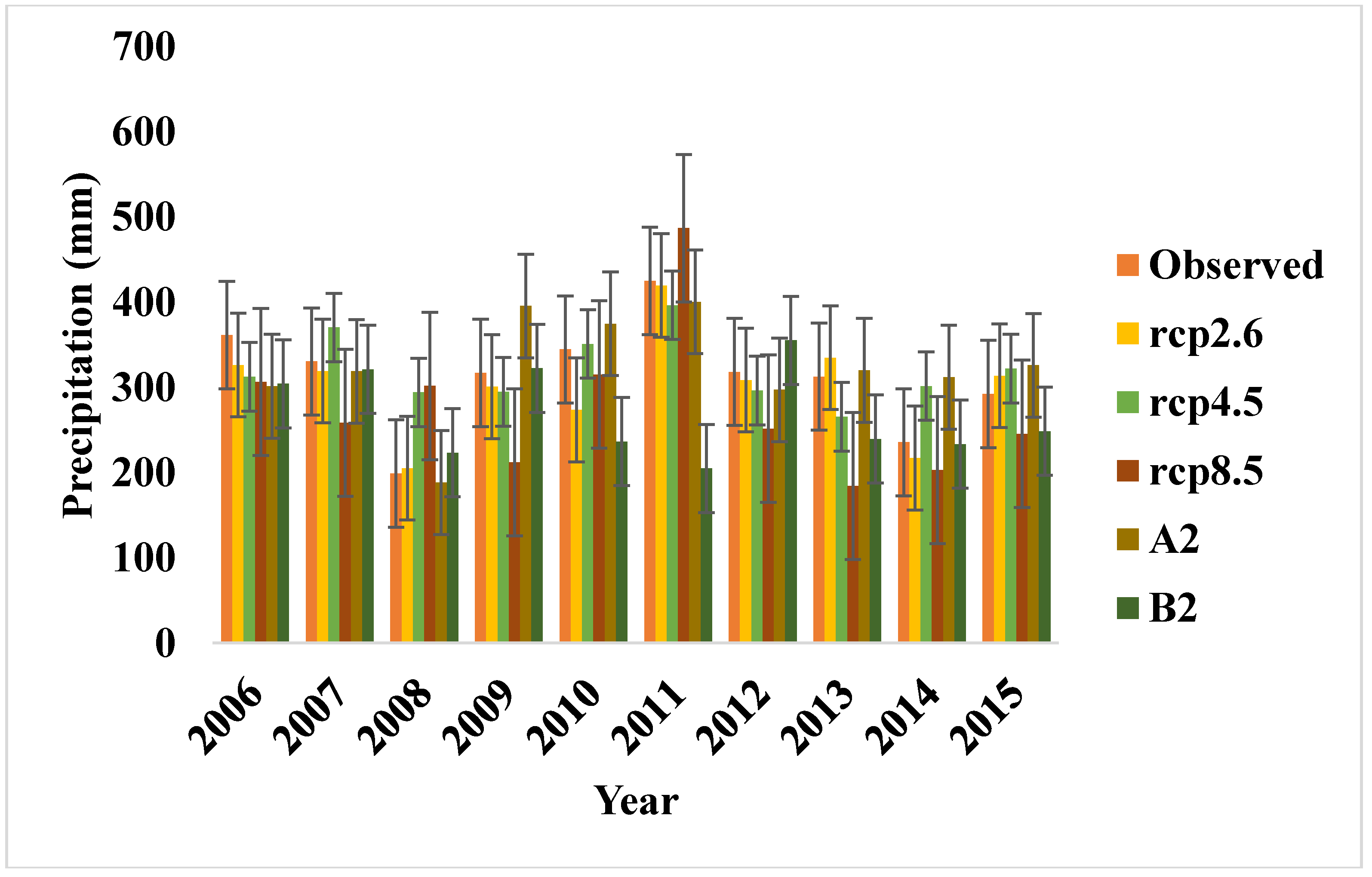
Figure 2 and
Figure 3 show the observed versus the simulated values of the temperature and precipitation for the years 2006–2015. Meanwhile, since 26 synoptic variables are considered as predictor variables in these models, having a unique equation was not logically possible because of the accumulated error. To solve this problem, only the predictor variables, being more correlative with the daily mean precipitation and temperature than others, were chosen. Then, the correlation between the variables was detected by Pearson’s correlation test (
p < 0.01) and the most important variables were selected according to the statistical significance between them and the dependent variables (
p < 0.01). To analyze the climatic data across the study, it was necessary to apply a Statistical Downscaling Model (SDSM). To do so, SDSM version 5.2 was used. SDSM is a decision support tool for assessing local climate change impacts using a powerful statistical downscaling technique. It has the potential to rapidly develop downscaled climatic data [
11]. To make statistical connections between the predictor and predicted variables, some regression equations were acquired to predict the climatic variables for the next few periods under the impact of climate change. After acquiring the regression equations and measuring their accuracy, the scenarios were produced through both models for the periods 2010–2039, 2040–2069, and 2070–2099. The properties of these scenarios are indicated in
Table 1.
The efficiency of the scenarios was compared and the most efficient scenario was recognized through the statistical indicators of Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Nash-Sutcliffe coefficient (NS), Coefficient of Determination (R
2), and Analysis of Variance (at
p < 0.01) as follows:
where Z
i is the standardized daily mean precipitation or temperature values; O
i and P
i are the observed and simulated daily mean precipitation or temperature values, respectively;
is the average of the observed daily mean precipitation or temperature values;
is the average of the simulated daily mean precipitation or temperature values; σ
O is the variance of the observed daily mean precipitation or temperature values; σ
P is the variance of the simulated daily mean precipitation and temperature values; and n is the number of data.
Isaaks and Serivastava [
23] suggested the MAE and RMSE as statistical indicators able to compare the accuracy of variables. Once the MAE and RMSE values are closer to zero in a scenario, the scenario would be more efficient for predicting climatic variables [
24]. When they are exactly 0, it means that there is no error in the predicting task [
24]. The Nash-Sutcliffe coefficient (NS) shows to what extent the regression line between the simulated data and measured data can be similar to the regression line 1:1. Its domain is from the negative infinity to 1, and NS = 1 reveals either a complete similarity or a perfect efficiency of a scenario [
25]. Meanwhile, R
2 gives information on the correlation between the observed and predicted data and its domain is from 0 to 1 [
26]. When R
2 becomes closer to 1, there will be a significant correlation between the data groups [
26]. Significant differences between the observed data and values of the predictor scenarios can be distinguished by the analysis of variance [
27]. Lack of any significant difference reveals a similarity between the predicted and observed data. In addition, to obtain more appropriate results for the prediction of precipitation, the occurrence of precipitation approach was used. This is a dichotomous method by which the accuracy of whether the occurrence or non-occurrence of precipitation is evaluated. If there is no occurrence of precipitation, then the answer is ‘NO’, while the answer ‘Yes’ is a sign of precipitation occurrence [
28]. There are four statuses when the observed data are compared with scenario predictions, where a couple of predictions could be true and the remaining predictions could be false. The scenario with a higher percentage of true predictions was selected as the most efficient scenario for predicting the precipitation.
Finally, to predict the dryland winter wheat yield of the province for the next decades and to make a connection between the climatic and yield data for the period 2005–2014, a linear regression model was used. Furthermore, Pearson’s correlation test (at p < 0.01) between the simulated and observed data, RMSE, and R-square were used to check the regression’s validity. All statistical analyses were performed by the software SPSS version 21 (IBM Inc., Chicago, IL, USA).






{kind=link}
{kind=link}
{kind=link}
{kind=link}