
Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model

Abstract
:1. Introduction
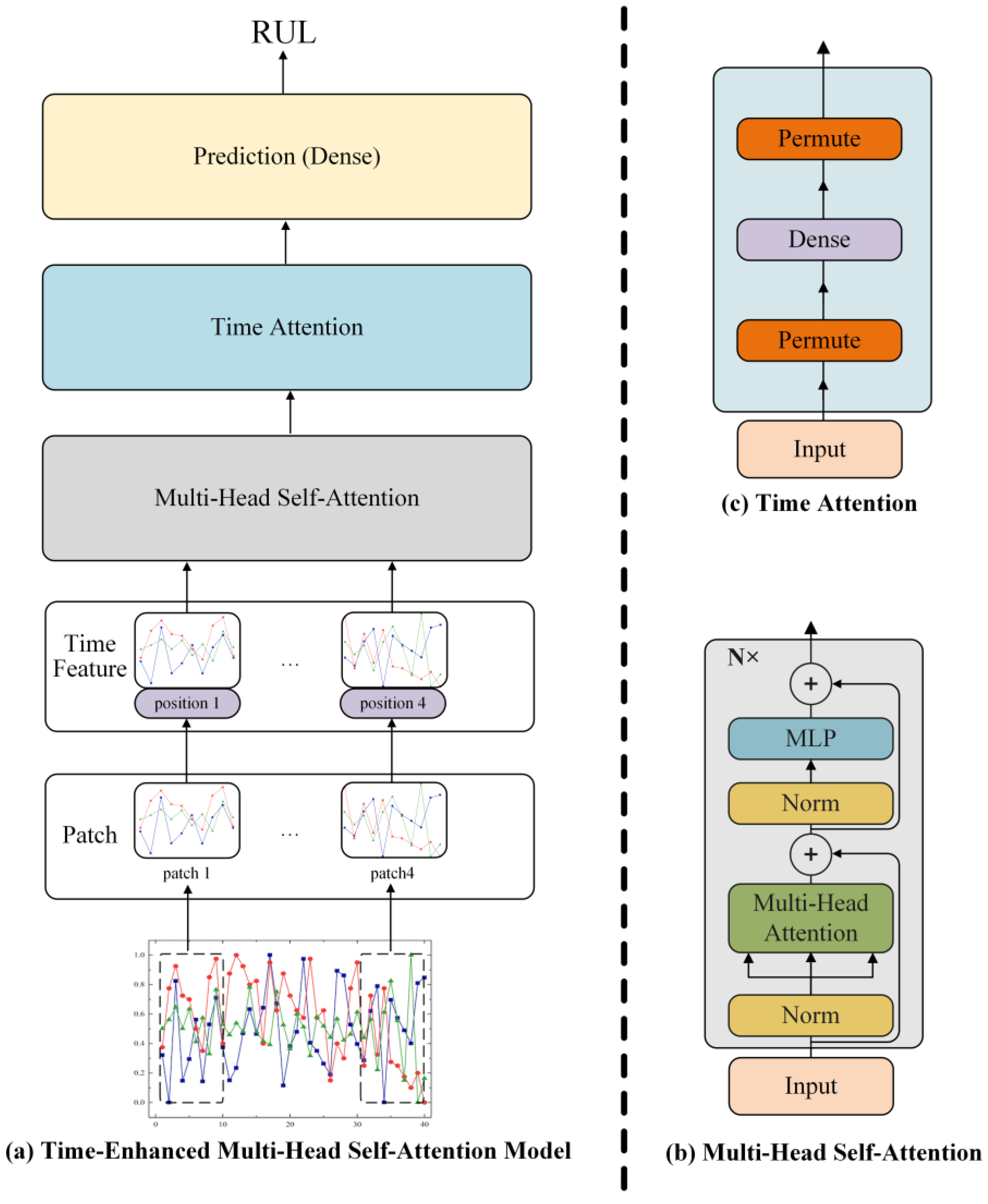
2. Architecture
2.1. Time-Enhanced Multi-Head Self-Attention Model
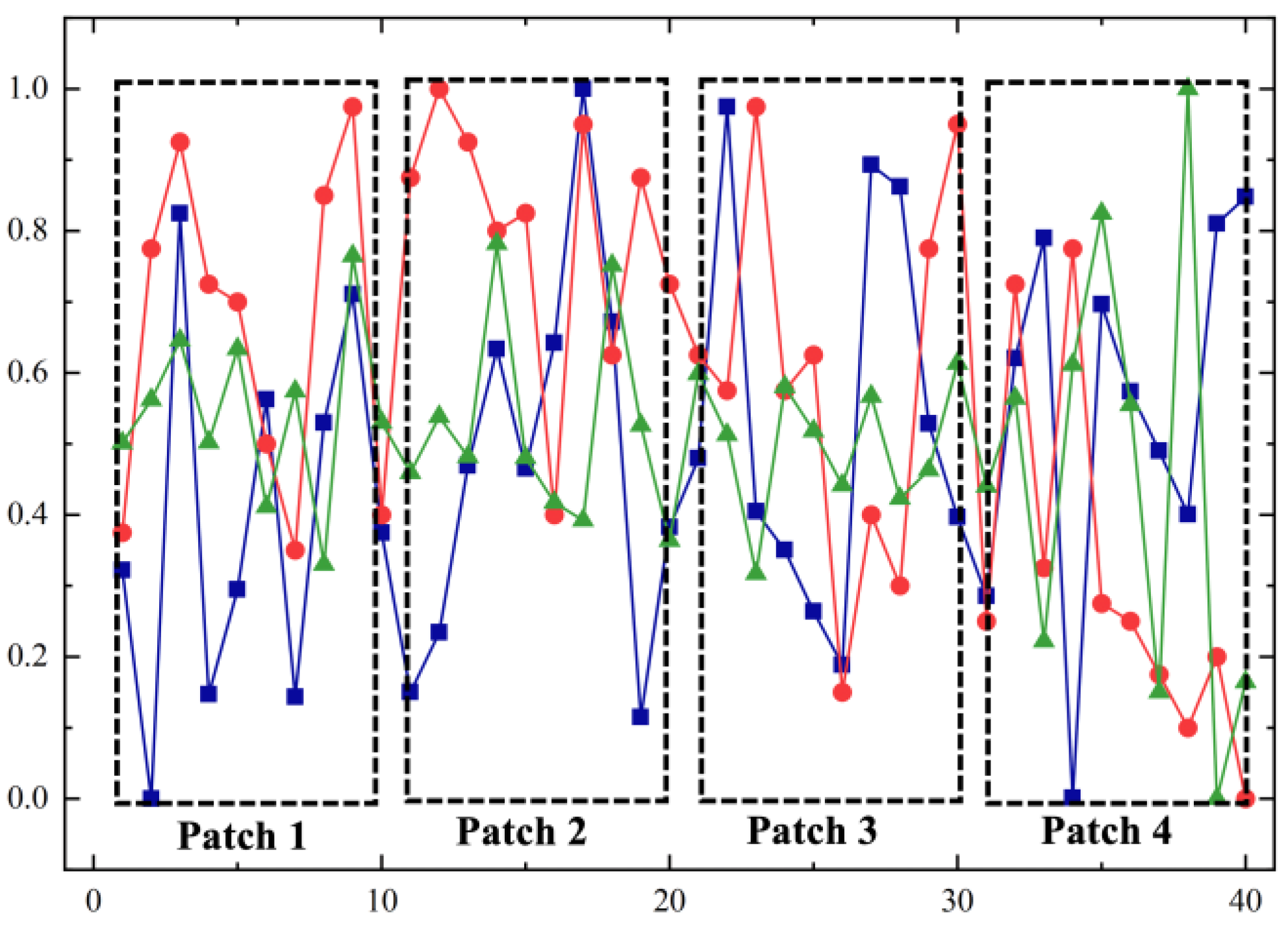
2.2. Data Time-Division Module
2.3. Time Feature Enhancement Module
2.4. Multi-Head Self-Attention Module
2.5. Time Attention Module
2.6. Prediction Network Module
2.7. Hyperparameter Selection
3. Experiments
3.1. Dataset Description
3.2. Data Preprocessing
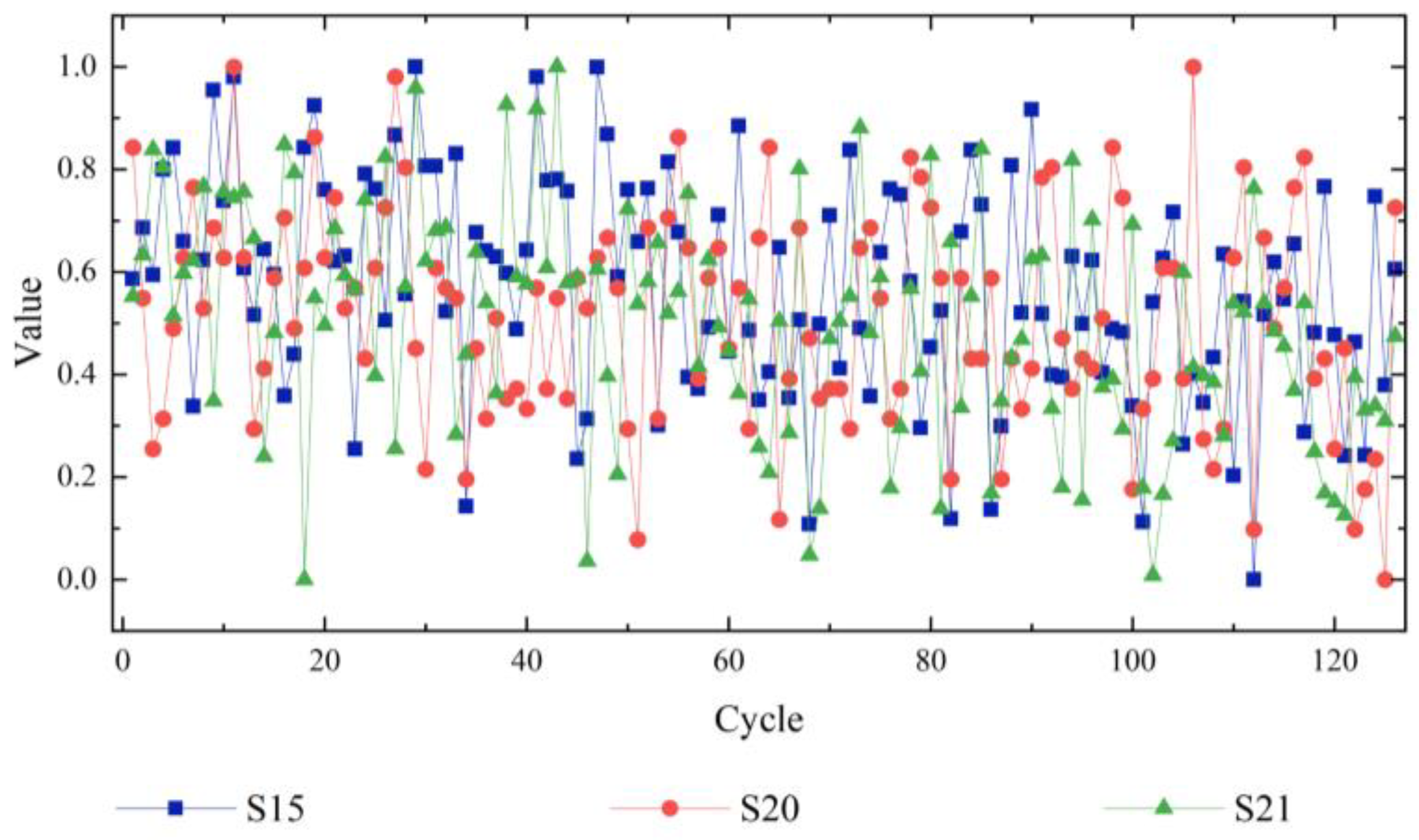
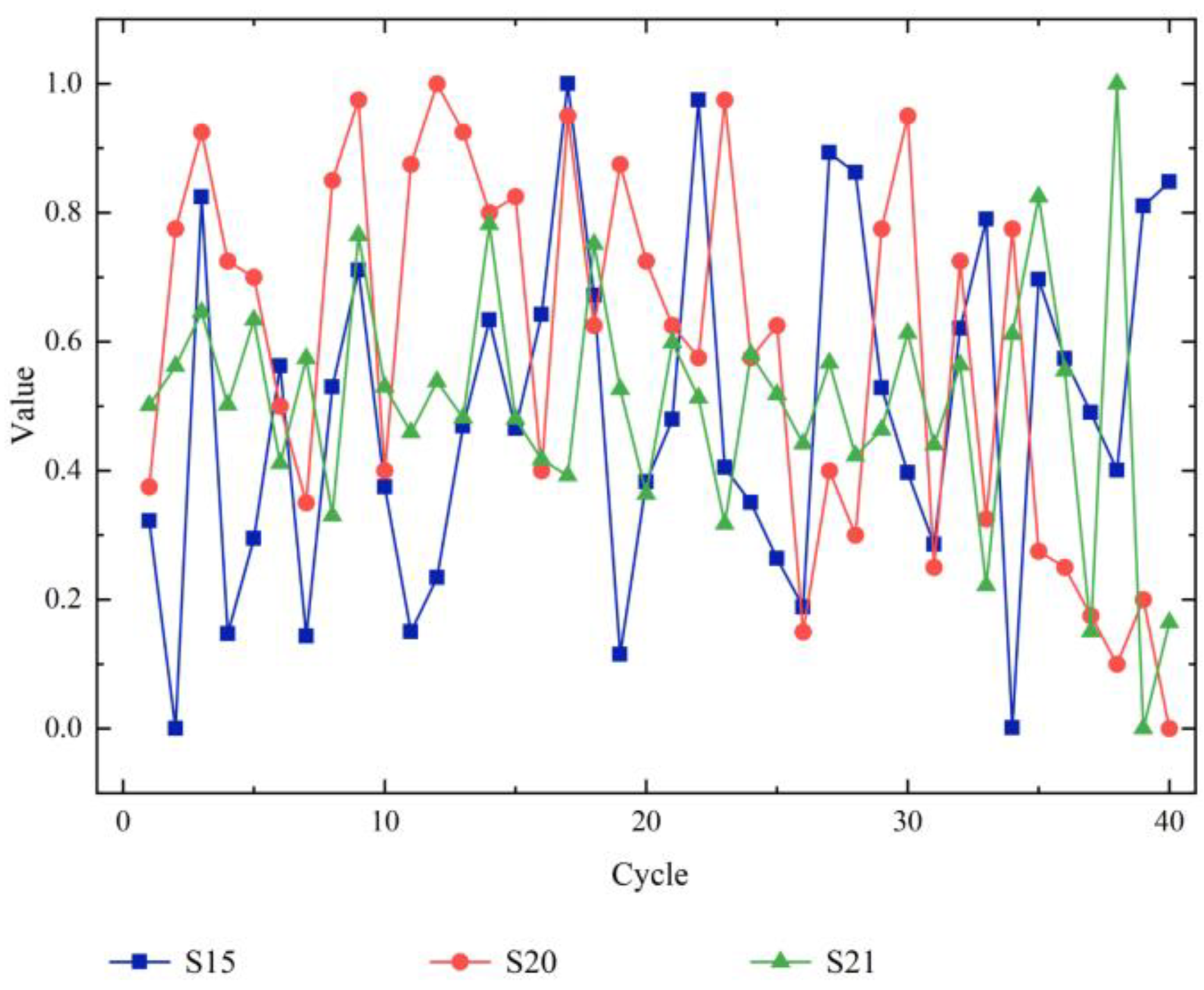
3.2.1. Feature Selection
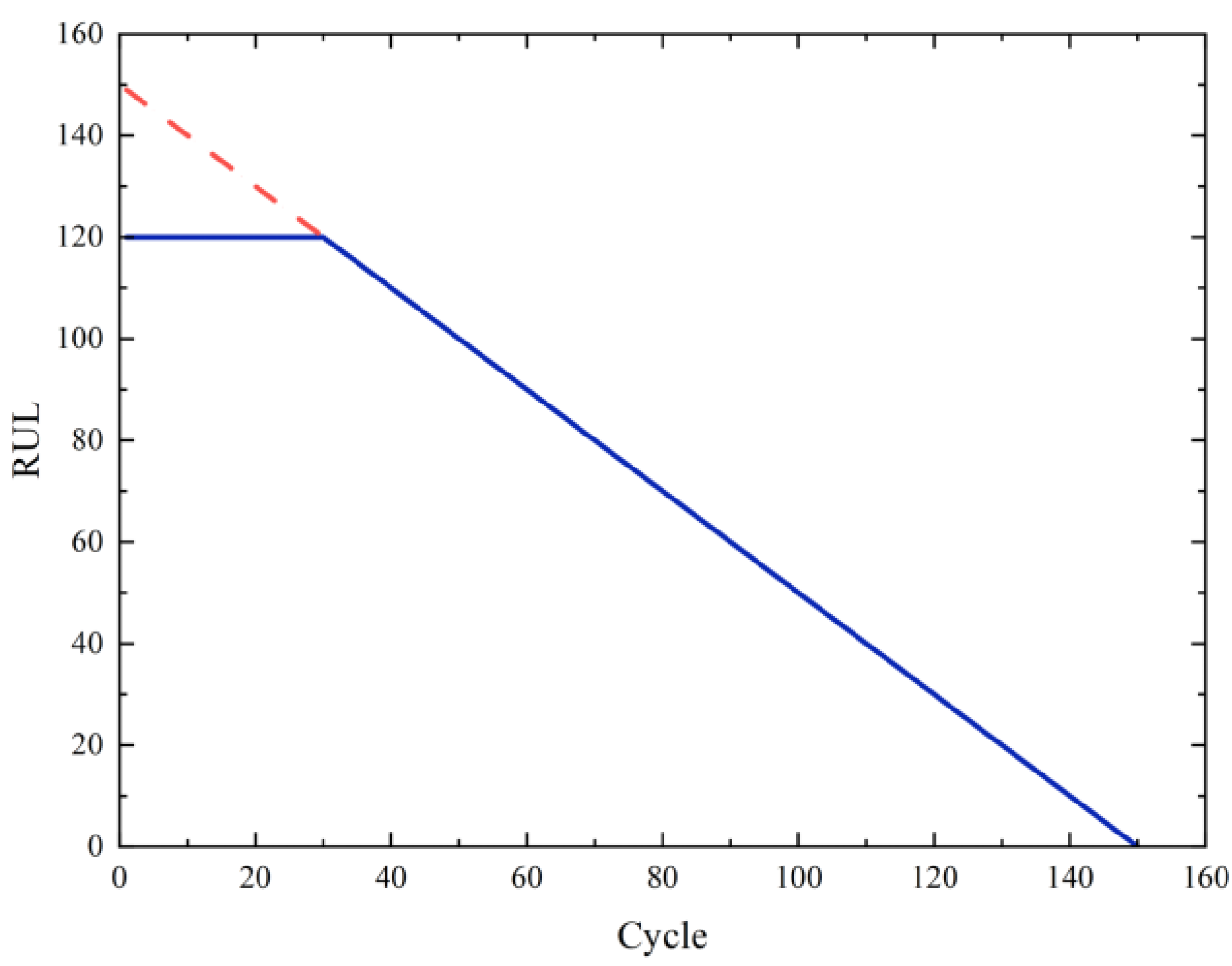
3.2.2. Calculating the Remaining Useful Life
3.2.3. Data Normalisation
3.2.4. Time Sliding Window
3.3. Optimisation Function
3.4. Performance Evaluation Index
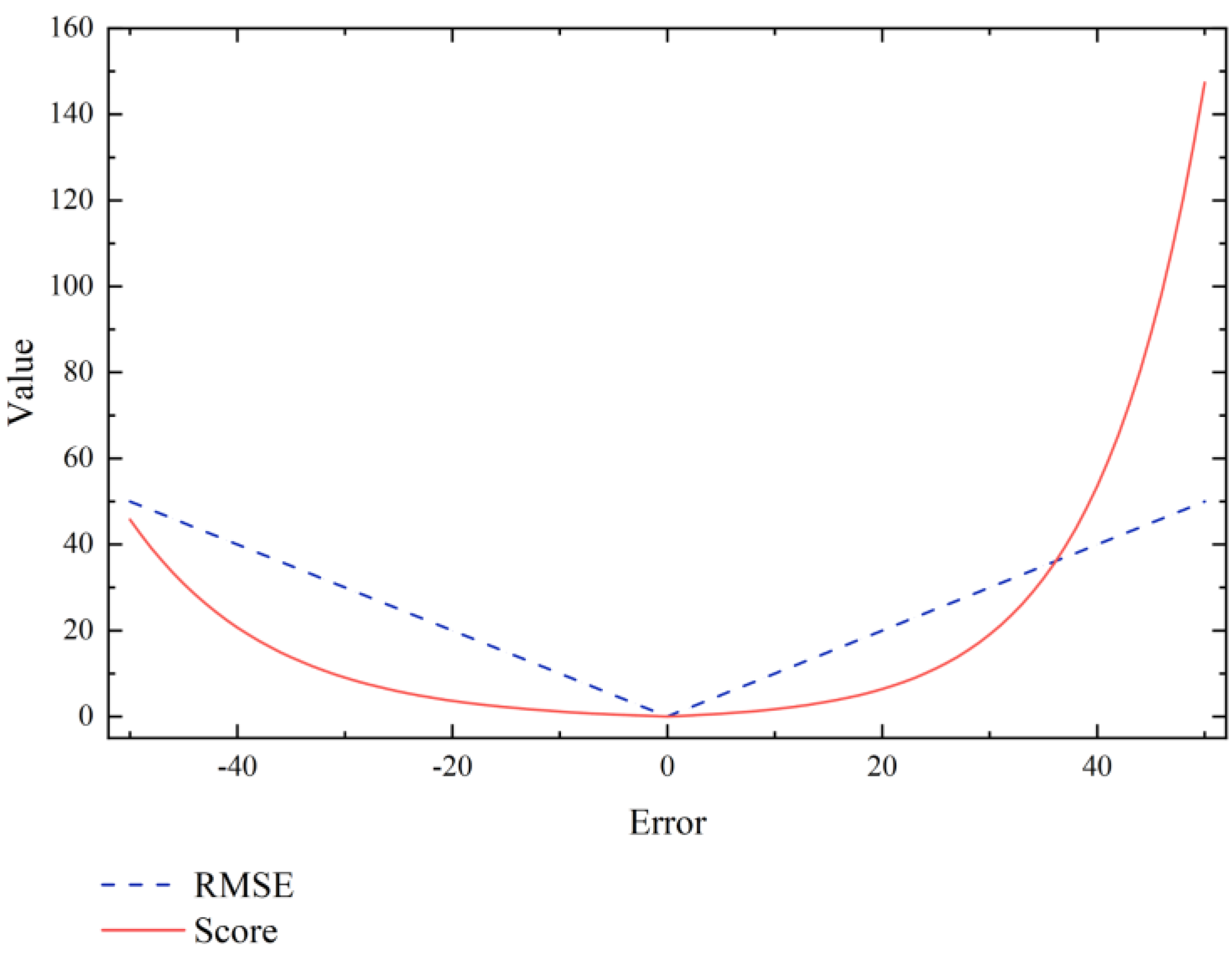
- The Root Mean Square Error (RMSE) was used to evaluate the experiment’s performance. The Root Mean Square Error (RMSE) is a frequently used performance metric for evaluating regression prediction models. It is equal to the square of the deviation and the square of the ratio of the predicted and actual values. It is used to quantify the deviation between predicted and observed values. The lower the deviation between the predicted and actual values, the more accurate the prediction model. The equation for the RMSE is as follows:
- 2.
- When predicting the RUL of an aero-engine, there are two possible outcomes: the predicted RUL is less than the actual RUL, or the predicted RUL is greater than the actual RUL. In both circumstances, the approach used by RMSE bears the same penalty. In practice, however, the underestimated RUL prediction benefits from having an early warning signal, hence decreasing the probability of fatalities caused due to engine damage. As a result, the scoring index score is proposed in Equation (8). The cost of an overestimated RUL prediction, on the other hand, is significantly higher than the cost of an underestimated one. This method is more practical and enables a more accurate evaluation of the model prediction effect.
4. Results
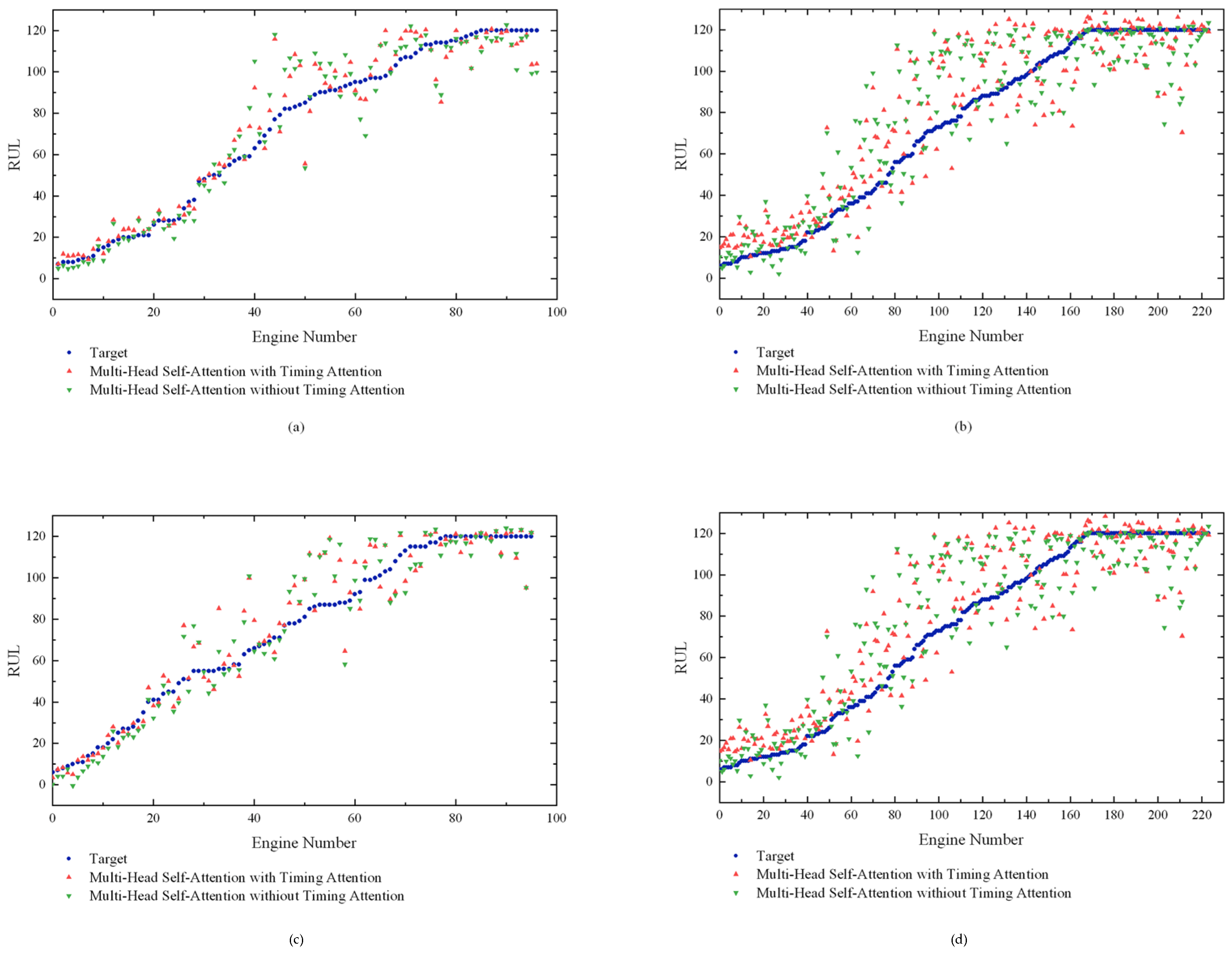
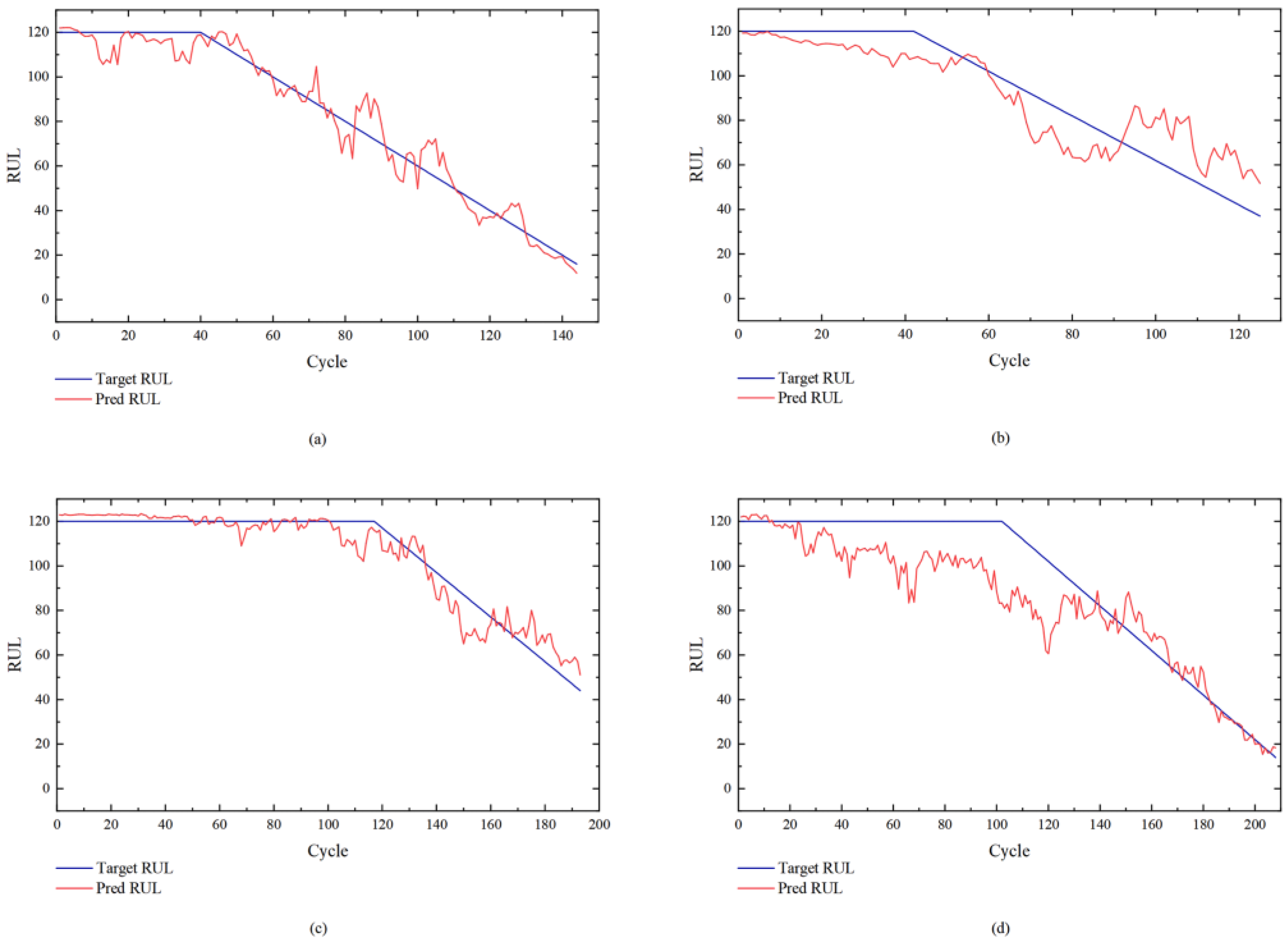
4.1. Experimental Results
4.2. Comparison with Previous Work
5. Conclusions and Future Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, D.; Tsui, K.-L.; Miao, Q. Prognostics and health management: A review of vibration based bearing and gear health indicators. IEEE Access 2017, 6, 665–676. [Google Scholar] [CrossRef]
- Pecht, M.G. A prognostics and health management roadmap for information and electronics-rich systems. IEICE ESS Fundam. Rev. 2009, 3, 25–32. [Google Scholar] [CrossRef] [Green Version]
- Lau, D.; Fong, B. Special issue on prognostics and health management. Microelectron. Reliab. 2011, 2, 253–254. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Saufi, M.S.R.M.; Hassan, K.A. Remaining useful life prediction using an integrated Laplacian-LSTM network on machinery components. Appl. Soft Comput. 2021, 112, 107817. [Google Scholar] [CrossRef]
- Ahn, G.; Yun, H.; Hur, S.; Lim, S. A Time-Series Data Generation Method to Predict Remaining Useful Life. Processes 2021, 9, 1115. [Google Scholar] [CrossRef]
- Fan, J.; Yung, K.C.; Pecht, M. Physics-of-failure-based prognostics and health management for high-power white light-emitting diode lighting. IEEE Trans. Device Mater. Reliab. 2011, 11, 407–416. [Google Scholar] [CrossRef]
- Miao, J.; Li, X.; Ye, J. Predicting research of mechanical gyroscope life based on wavelet support vector. In Proceedings of the 2015 First International Conference on Reliability Systems Engineering (ICRSE), Beijing, China, 21–23 October 2015. [Google Scholar]
- Nieto, P.G.; García-Gonzalo, E.; Lasheras, F.S.; de Cos Juez, F.J. Hybrid PSO–SVM-based method for forecasting of the remaining useful life for aircraft engines and evaluation of its reliability. Reliab. Eng. Syst. Saf. 2015, 138, 219–231. [Google Scholar] [CrossRef]
- Galar, D.; Kumar, U.; Fuqing, Y. RUL prediction using moving trajectories between SVM hyper planes. In Proceedings of the 2012 Annual Reliability and Maintainability Symposium, Reno, Nevada, 23–26 January 2012. [Google Scholar]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Lin, Y.; Koprinska, I.; Rana, M. Temporal convolutional attention neural networks for time series forecasting. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–23 July 2021. [Google Scholar]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A dual-stage attention-based recurrent neural network for time series prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Sateesh Babu, G.; Zhao, P.; Li, X.L. Deep convolutional neural network based regression approach for estimation of remaining useful life. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, L.; Song, X.; Zhou, Z. Aircraft engine remaining useful life estimation via a double attention-based data-driven architecture. Reliab. Eng. Syst. Saf. 2022, 221, 108330. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 32, 1997–2006. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013. [Google Scholar]
- Saxena, A.; Goebel, K. Turbofan Engine Degradation Simulation Dataset; NASA Ames Research Center: Moffett Field, CA, USA, 2008; pp. 1551–3203. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Astorga, N.O. Convolutional Recurrent Neural Networks for Remaining Useful Life Prediction in Mechanical Systems. Bachelor’s Thesis, Universidad de Chile, Santiago, Chile, 2018. [Google Scholar]
- Al-Dulaimi, A.; Zabihi, S.; Asif, A.; Mohammadi, A. Hybrid deep neural network model for remaining useful life estimation. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Yu, W.; Kim, I.Y.; Mechefske, C. Remaining useful life estimation using a bidirectional recurrent neural network based autoencoder scheme. Mech. Syst. Signal Process. 2019, 129, 764–780. [Google Scholar] [CrossRef]
- Ellefsen, A.L.; Bjørlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining useful life predictions for turbofan engine degradation using semi-supervised deep architecture. Reliab. Eng. Syst. Saf. 2019, 183, 240–251. [Google Scholar] [CrossRef]
- Li, H.; Zhao, W.; Zhang, Y.; Zio, E. Remaining useful life prediction using multi-scale deep convolutional neural network. Appl. Soft Comput. 2020, 89, 106113. [Google Scholar] [CrossRef]
- Song, Y.; Gao, S.; Li, Y.; Jia, L.; Li, Q.; Pang, F. Distributed attention-based temporal convolutional network for remaining useful life prediction. IEEE Internet Things J. 2020, 8, 9594–9602. [Google Scholar] [CrossRef]
- Cai, H.; Feng, J.; Li, W.; Hsu, Y.M.; Lee, J. Similarity-based particle filter for remaining useful life prediction with enhanced performance. Appl. Soft Comput. 2020, 94, 106474. [Google Scholar] [CrossRef]
- Shah, S.R.B.; Chadha, G.S.; Schwung, A.; Ding, S.X. A Sequence-to-Sequence Approach for Remaining Useful Lifetime Estimation Using Attention-Augmented Bidirectional LSTM. Intell. Syst. Appl. 2021, 10, 200049. [Google Scholar] [CrossRef]
- Liu, L.; Wang, L.; Yu, Z. Remaining Useful Life Estimation of Aircraft Engines Based on Deep Convolution Neural Network and LightGBM Combination Model. Int. J. Comput. Intell. Syst. 2021, 14, 165. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Hu, Z.; Zhang, H. Remaining useful life prediction of aero-engine enabled by fusing knowledge and deep learning models. Reliab. Eng. Syst. Saf. 2023, 229, 108869. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range | Interval |
|---|---|---|
| patch size | [1, 10] | 1 |
| d model | [128, 1024] | 64 |
| hidden layer | [128, 2048] | 64 |
| num layer | [2, 4, 8] | |
| num head | [2, 4, 8] | |
| learning rate | [0.05, 0.02, 0.01, 0.005, 0.002, 0.001] | |
| C-MAPSS | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|
| Number of engines in training set | 100 | 260 | 100 | 249 |
| Number of engines in testing set | 100 | 259 | 100 | 248 |
| Operating conditions | 1 | 6 | 1 | 6 |
| Fault modes | 1 | 1 | 2 | 2 |
| Training set size | 20,632 | 53,760 | 24,721 | 61,250 |
| Testing set size | 13,097 | 33,992 | 16,597 | 41,215 |
| Dataset | Train | Test |
|---|---|---|
| Input (simple num, window size, engine feature) | (11,631, 40, 21) | (96, 40, 21) |
| Output (simple num, RUL) | (11,631, 1) | (96, 1) |
| C-MAPSS | YEAR | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|---|
| ConvJANET E-D [24] | 2018 | 262.71 | 1401.95 | 333.79 | 2282.23 |
| HDNN [25] | 2019 | 245.00 | 1282.42 | 287.72 | 1527.42 |
| BiLSTM + ED [26] | 2019 | 273.00 | 3099.00 | 574.00 | 3202.00 |
| RBM + LSTM [27] | 2019 | 231.00 | 3366.00 | 251.00 | 2480.00 |
| MS-DCNN [28] | 2020 | 196.22 | 3747.00 | 241.89 | 2257.27 |
| DA-CNN [29] | 2020 | 229.48 | 1842.38 | 257.11 | 2317.32 |
| RBPF [30] | 2020 | 383.39 | 1226.97 | 375.29 | 2071.51 |
| Attention Bidirectional LSTM [31] | 2021 | 473 | 1223 | 676 | 2684 |
| DCNN-LightGBM [32] | 2021 | 232.0 | - | 277.8 | - |
| KGHM [33] | 2022 | 250.99 | 1131.03 | 333.44 | 3356.10 |
| Double Attention-based Architecture [18] | 2022 | 198 | 1575 | 290 | 1741 |
| Transformer Encoder | 2022 | 272.17 | 1045.70 | 228.92 | 2277.16 |
| Transformer Encoder + Attention (this paper) | 2022 | 183.75 | 1008.08 | 219.63 | 1751.23 |
| Compare with State of the Art | +6.36% | +3.40% | +4.06% | −14.60% |
| C-MAPSS | YEAR | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|---|
| ConvJANET E-D [24] | 2018 | 12.67 | 16.19 | 12.80 | 19.15 |
| HDNN [25] | 2019 | 13.02 | 15.24 | 12.22 | 18.15 |
| BiLSTM + ED [26] | 2019 | 14.47 | 22.07 | 17.48 | 23.49 |
| RBM + LSTM [27] | 2019 | 12.56 | 22.73 | 12.10 | 22.66 |
| MS-DCNN [28] | 2020 | 11.44 | 19.35 | 11.67 | 22.22 |
| DA-CNN [29] | 2020 | 11.78 | 16.95 | 11.56 | 18.23 |
| RBPF [30] | 2020 | 15.94 | 17.15 | 16.17 | 20.72 |
| Attention Bidirectional LSTM [31] | 2021 | 15.87 | 16.59 | 15.10 | 14.36 |
| GCU-Transformer [19] | 2021 | 11.27 | 22.81 | 11.42 | 24.86 |
| DCNN-LightGBM [32] | 2021 | 12.79 | - | 13.21 | - |
| KGHM [33] | 2022 | 13.18 | 13.25 | 13.54 | 19.96 |
| Double Attention-based Architecture [18] | 2022 | 12.25 | 17.08 | 13.39 | 19.86 |
| Transformer Encoder | 2022 | 12.05 | 16.72 | 11.82 | 18.27 |
| Transformer Encoder + Attention (this paper) | 2022 | 10.35 | 15.82 | 11.34 | 17.35 |
| Compare with State of the Art | +8.16% | −3.80% | +0.70% | −20.82% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Li, Y.; Xu, Y.; Liu, X.; Zheng, T.; Zheng, B. Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model. Aerospace 2023, 10, 80. https://doi.org/10.3390/aerospace10010080
Wang X, Li Y, Xu Y, Liu X, Zheng T, Zheng B. Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model. Aerospace. 2023; 10(1):80. https://doi.org/10.3390/aerospace10010080
Chicago/Turabian StyleWang, Xin, Yi Li, Yaxi Xu, Xiaodong Liu, Tao Zheng, and Bo Zheng. 2023. "Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model" Aerospace 10, no. 1: 80. https://doi.org/10.3390/aerospace10010080
APA StyleWang, X., Li, Y., Xu, Y., Liu, X., Zheng, T., & Zheng, B. (2023). Remaining Useful Life Prediction for Aero-Engines Using a Time-Enhanced Multi-Head Self-Attention Model. Aerospace, 10(1), 80. https://doi.org/10.3390/aerospace10010080