
Attrition Risk and Aircraft Suitability Prediction in U.S. Navy Pilot Training Using Machine Learning

 ,
,  , ,
, ,  ,
, 
Abstract
:1. Introduction and Motivation
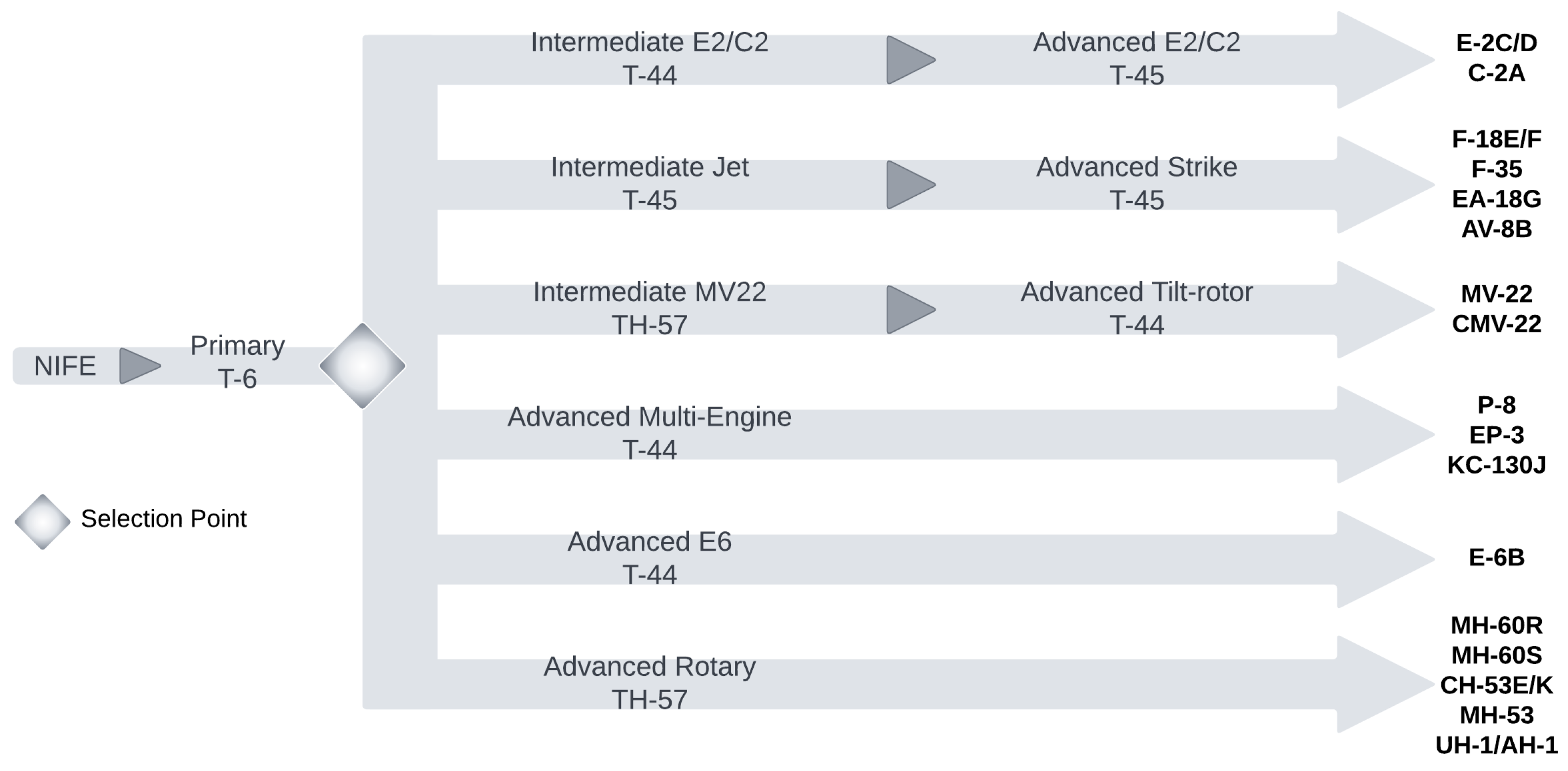
2. Background
3. Materials and Methods
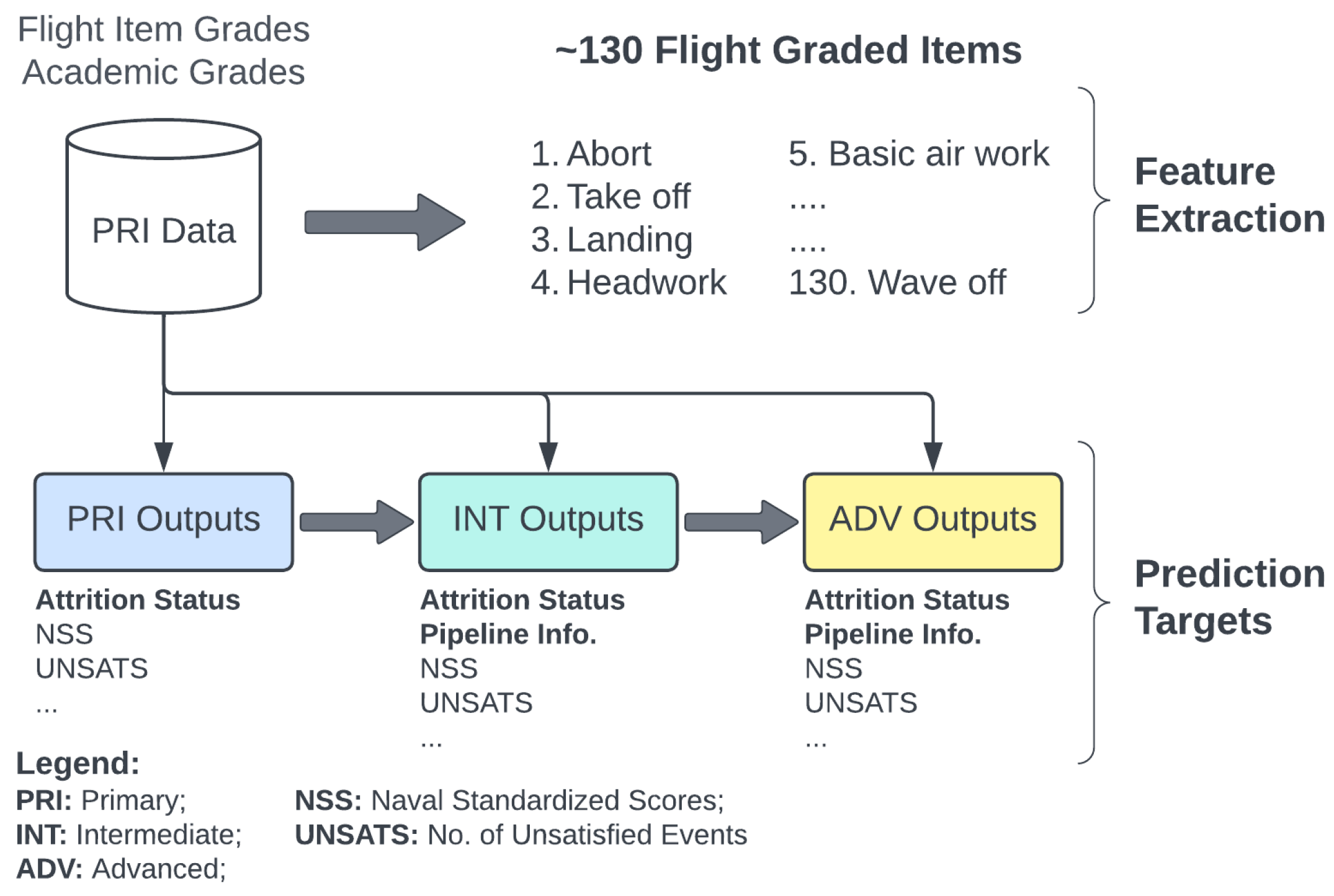
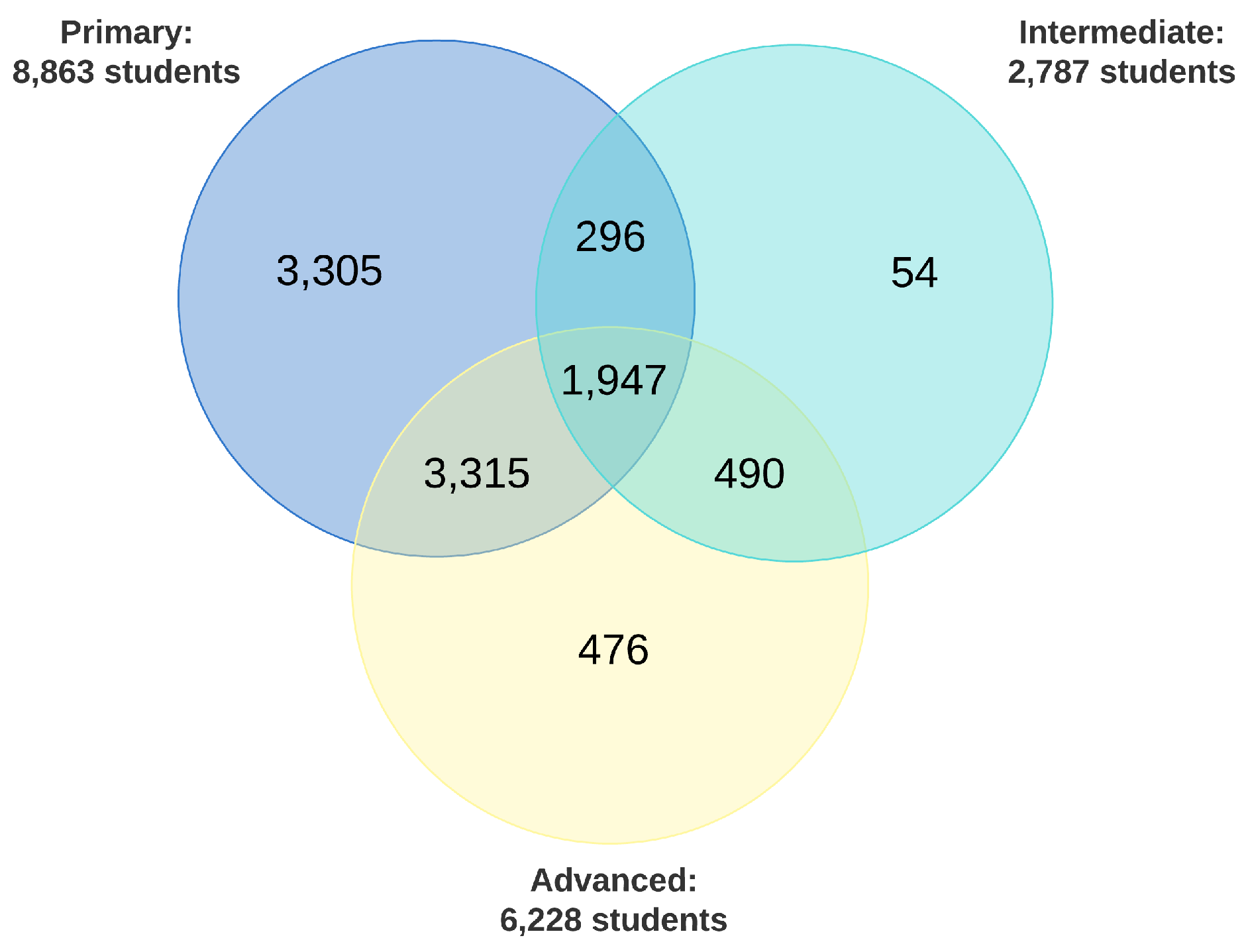
3.1. Datasets
3.1.1. Flight Grades Data
3.1.2. Academic Grades Data
3.1.3. Training Outcomes Data
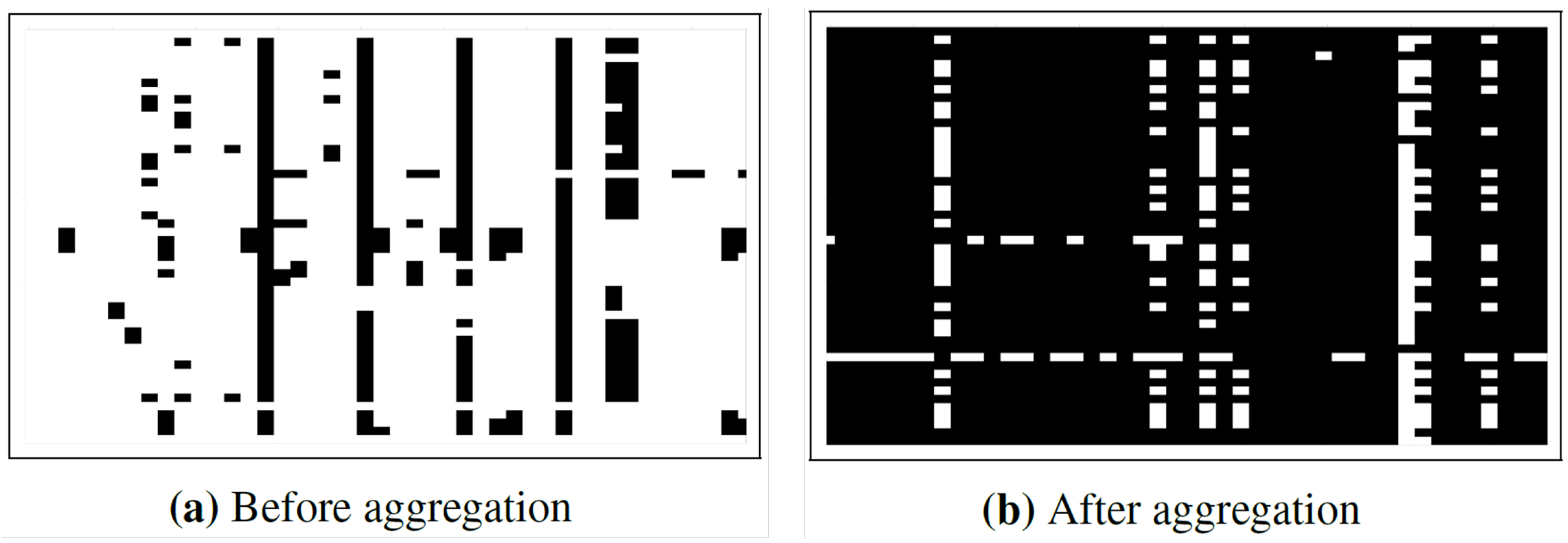
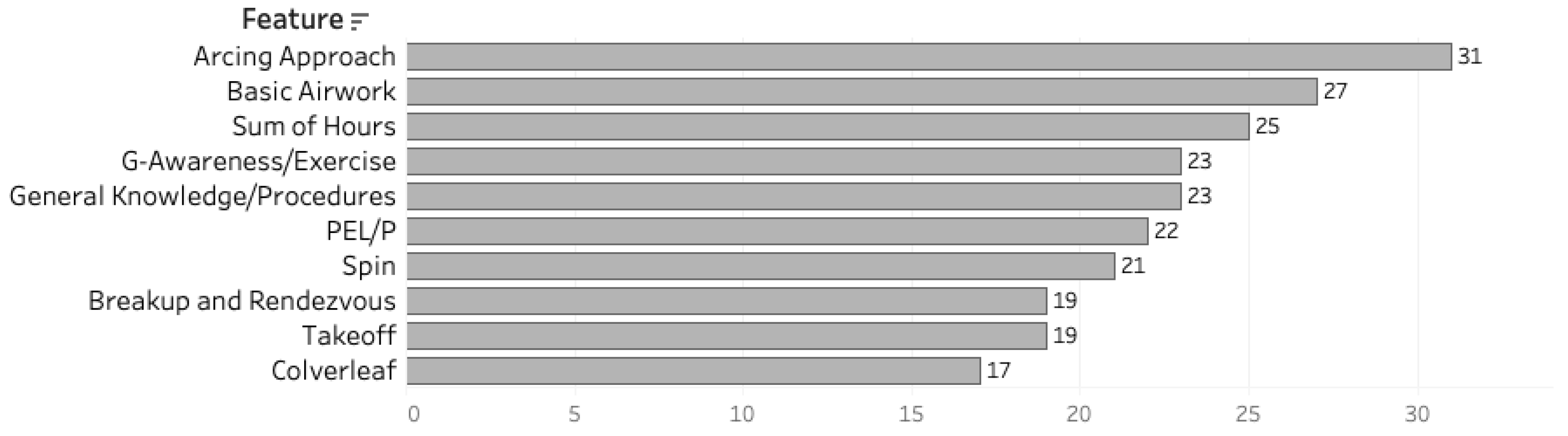
3.2. Data Cleansing and Features Extraction
- For the attrition prediction models: the syllabus completion status, which takes two values, “Complete” or “Attrite”, according to whether a student successfully completed all stages of training or not was used as the target.
- For the pipeline recommender models: each machine learning model pertained to one aircraft pipeline. For a selected aircraft pipeline, the student aviators that were successful were given a positive label and all other students were given a negative label, indicating that they were not suitable for that pipeline. Models trained using data labeled in this way would try to mimic the current selection process.
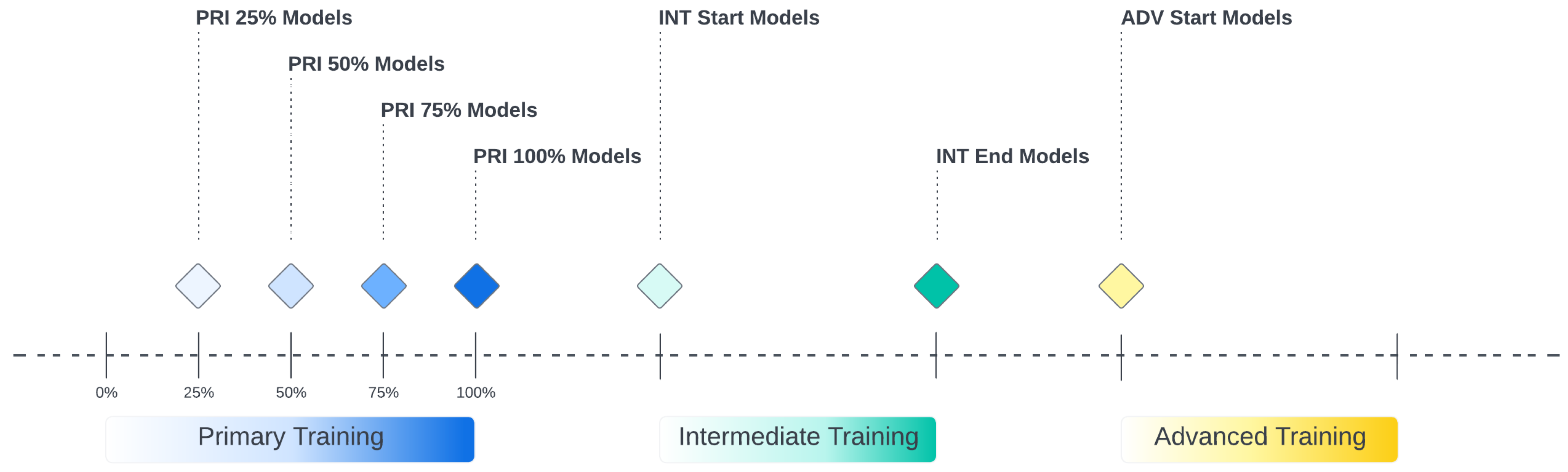
3.3. Training Machine Learning Models
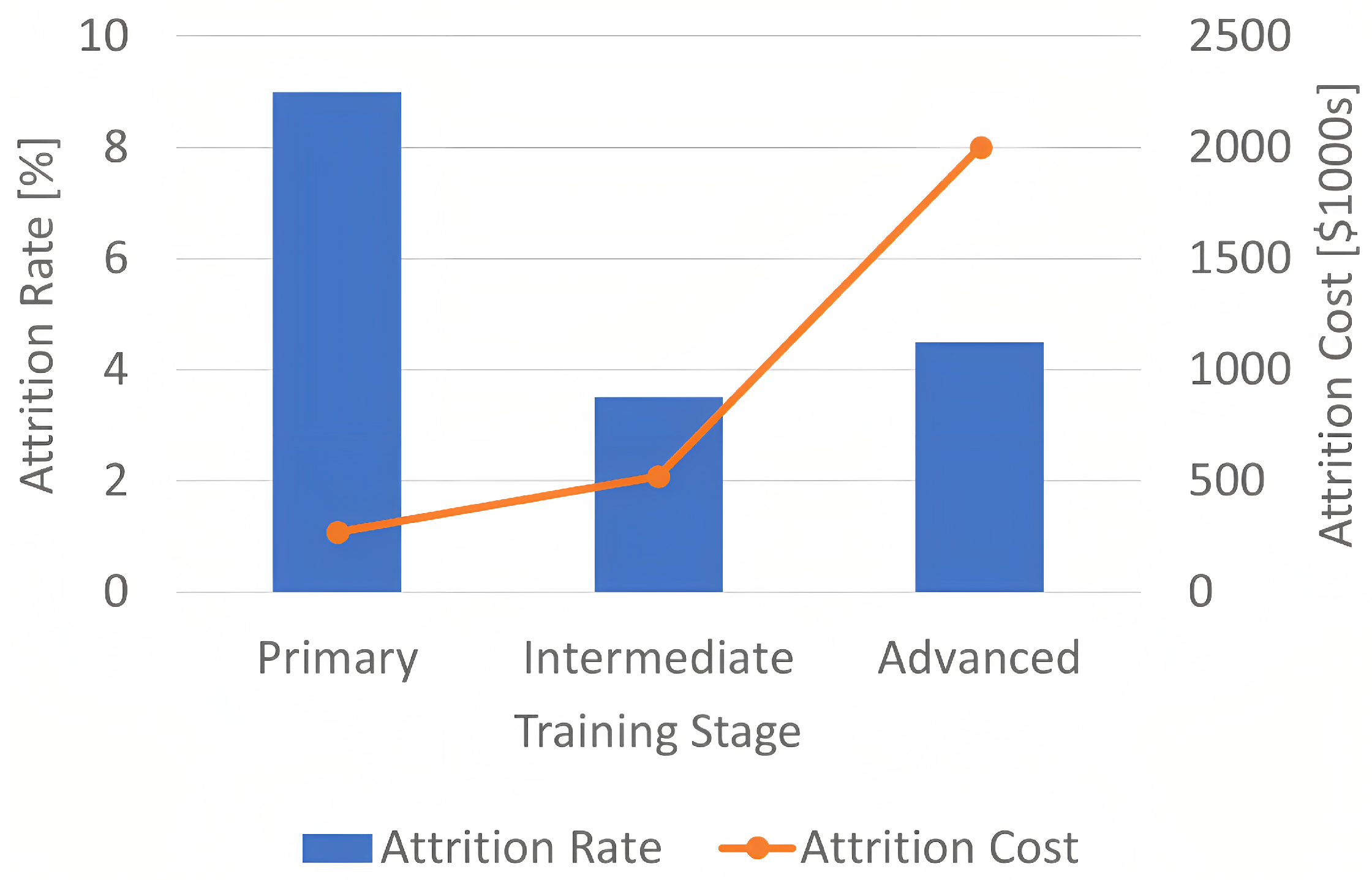
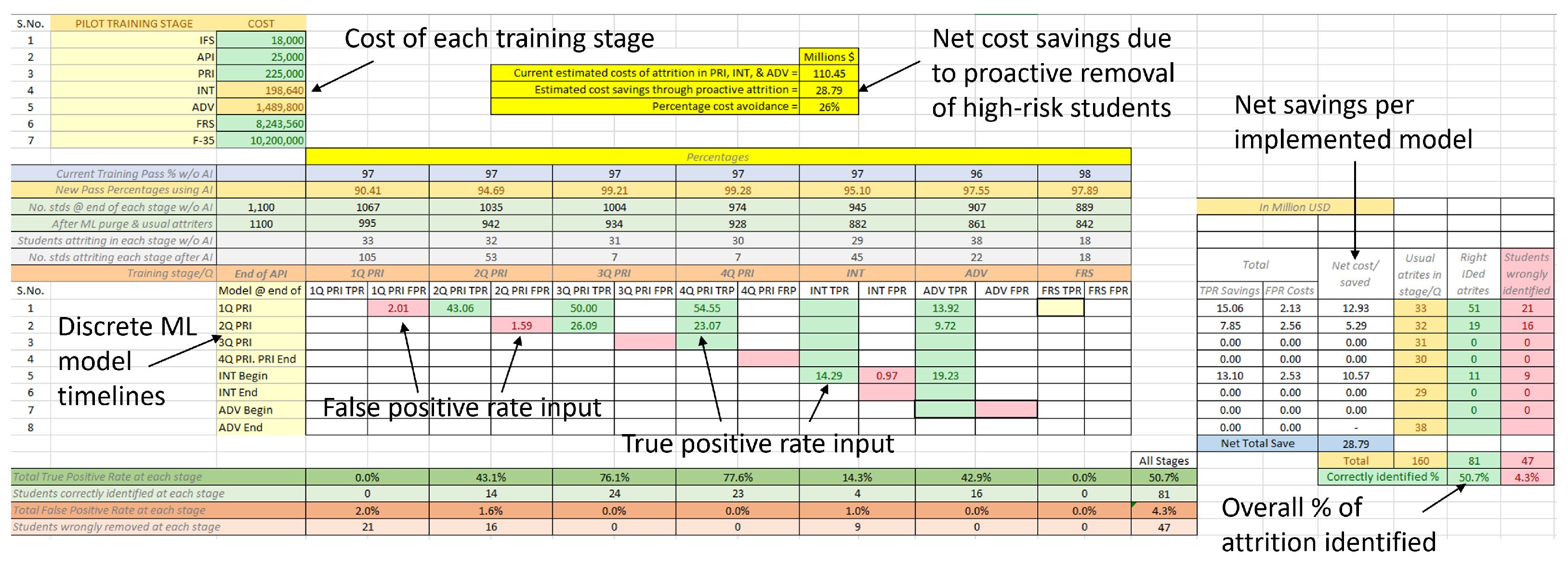
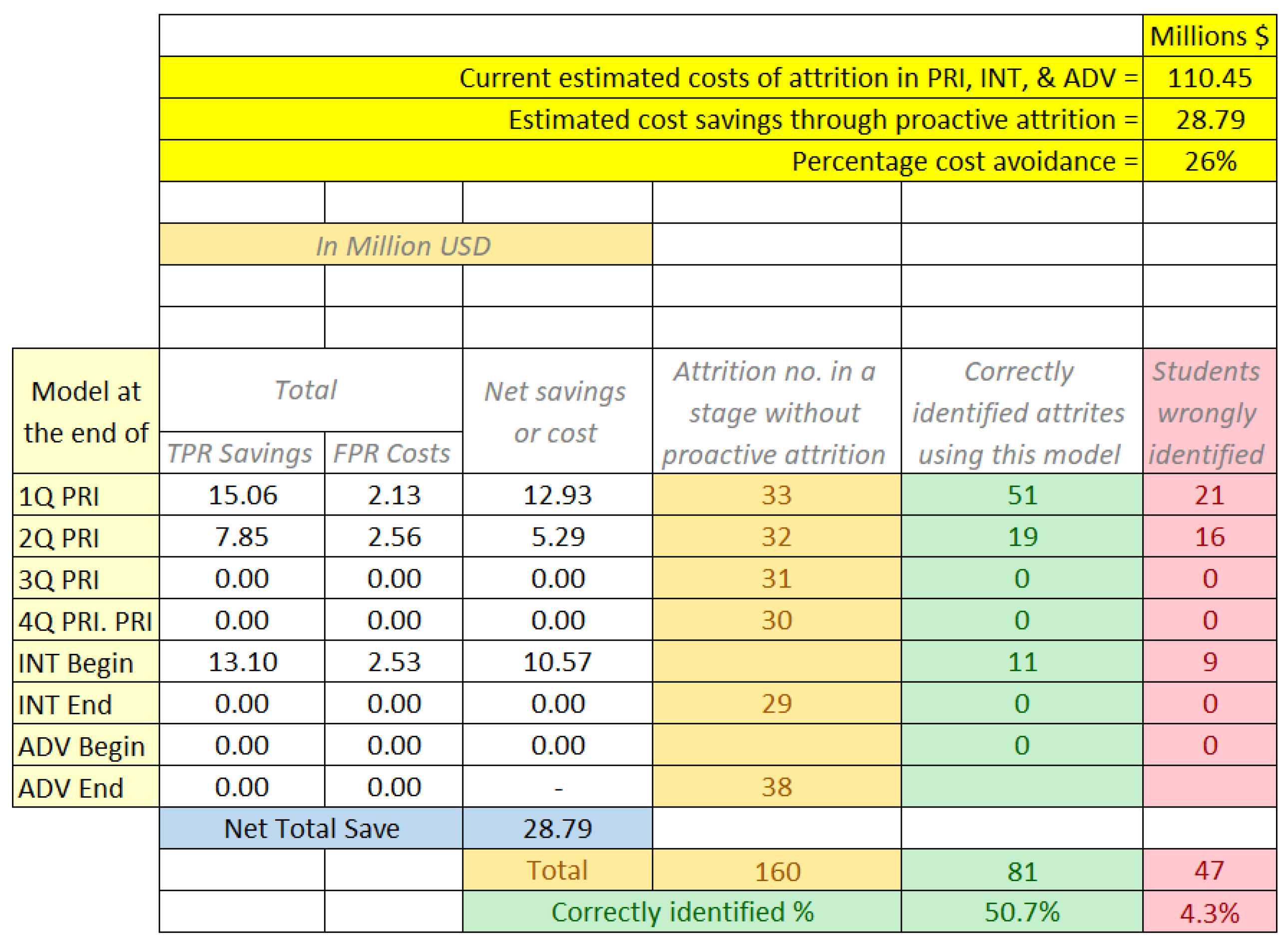
3.4. Attrition Costs Modeling and Savings Estimation
4. Results and Discussion
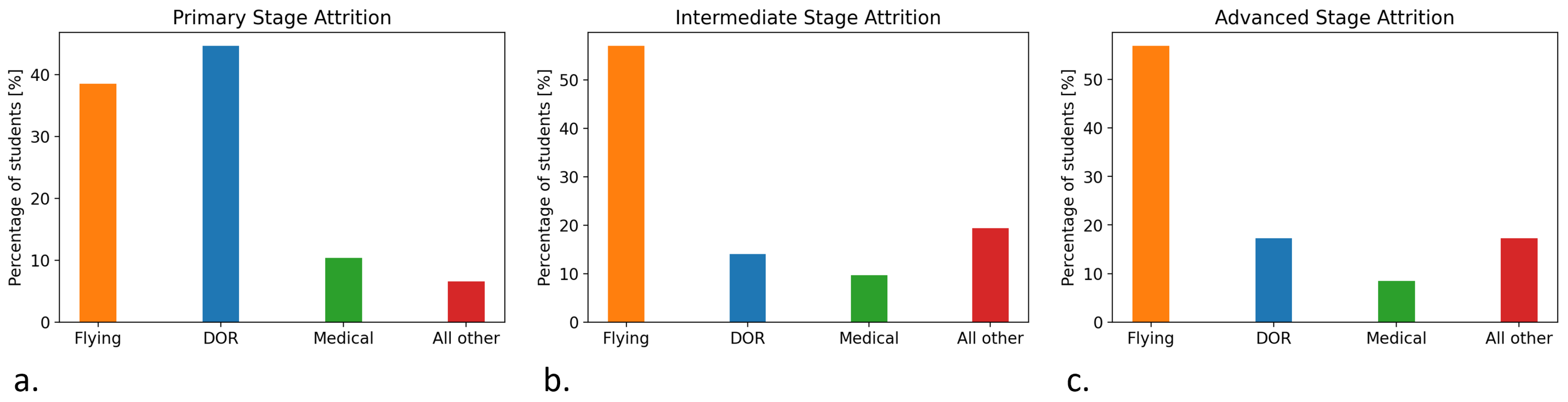
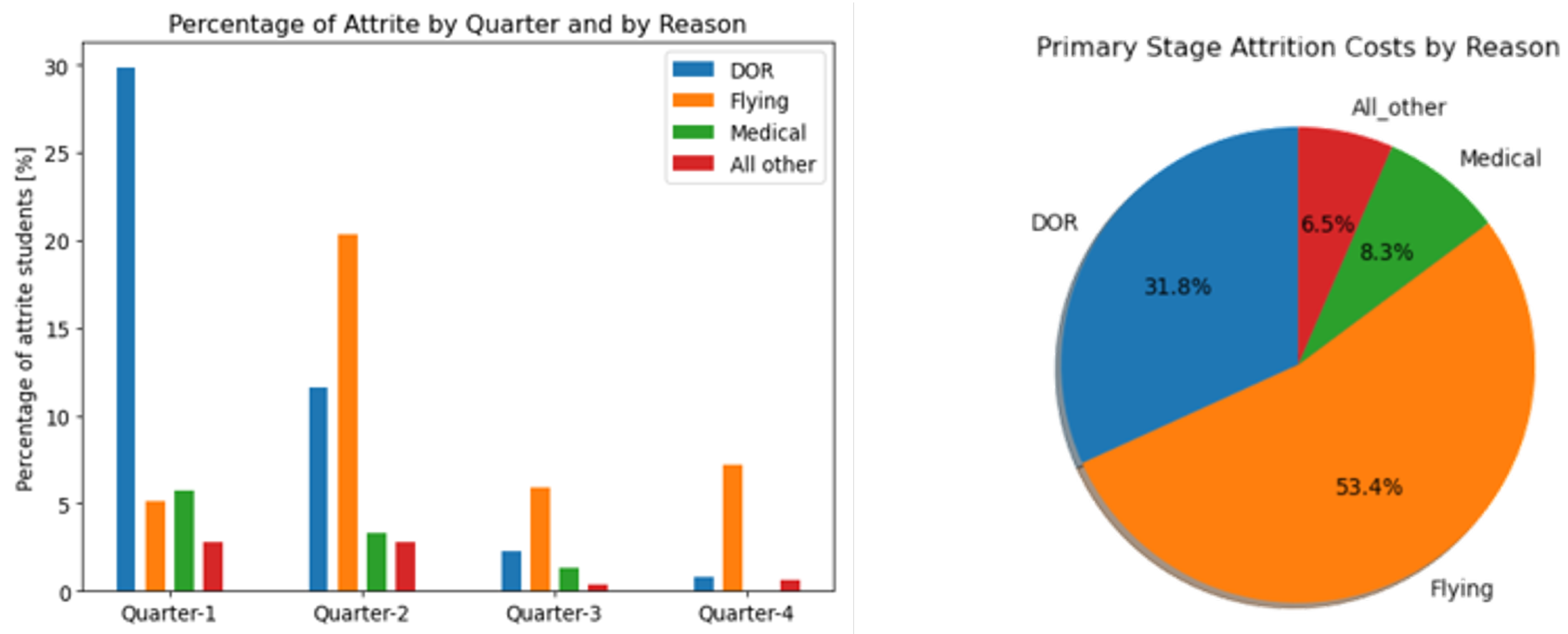
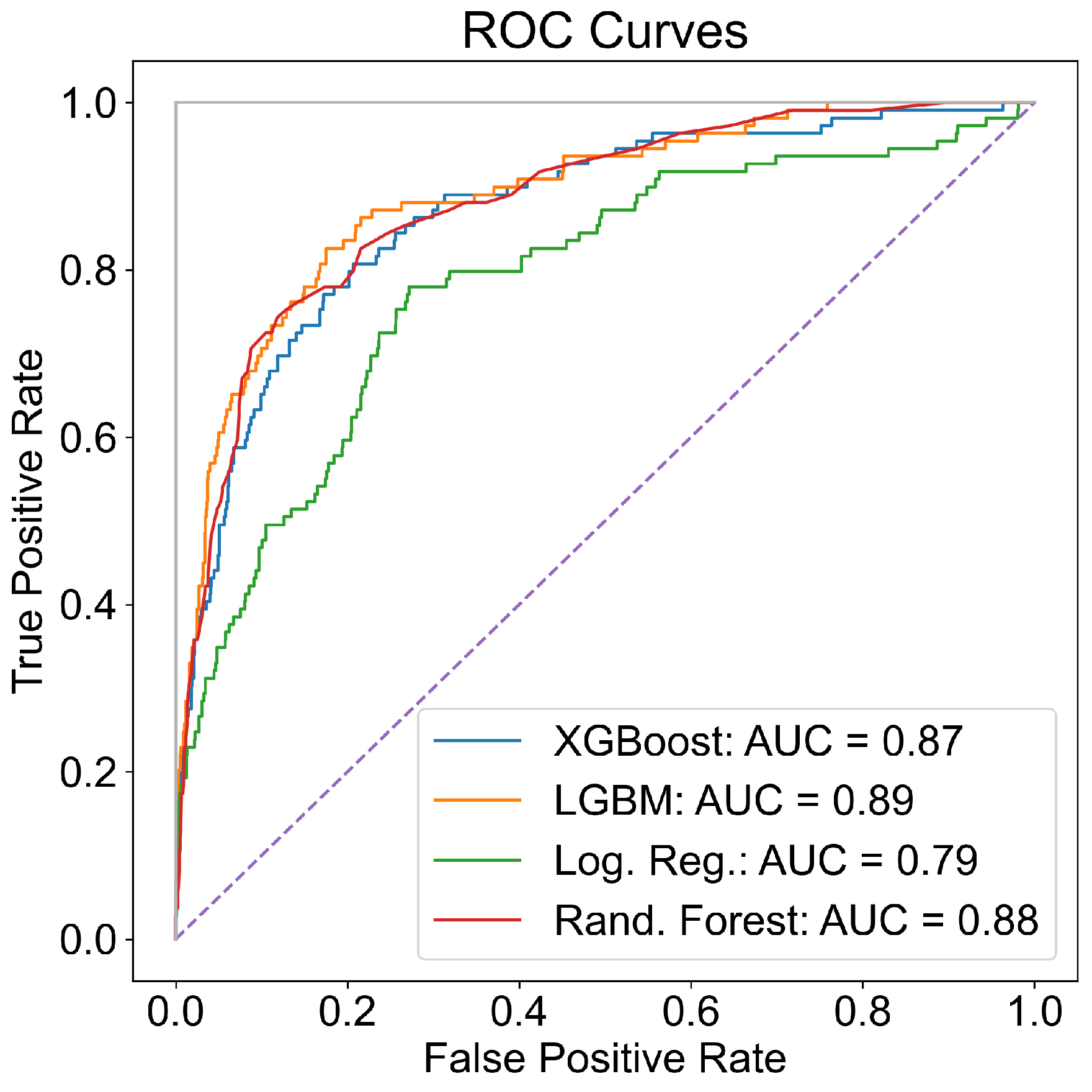
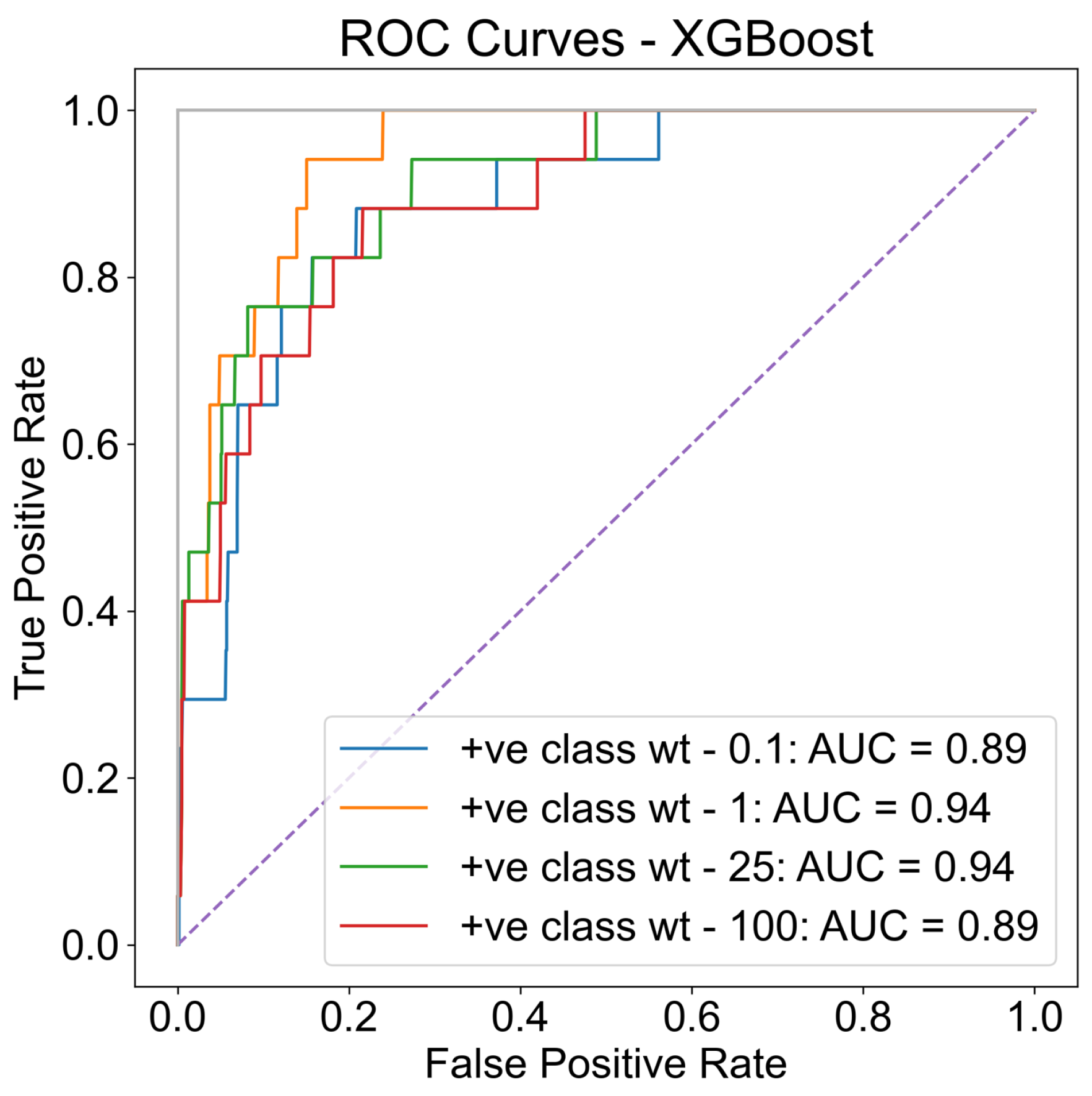
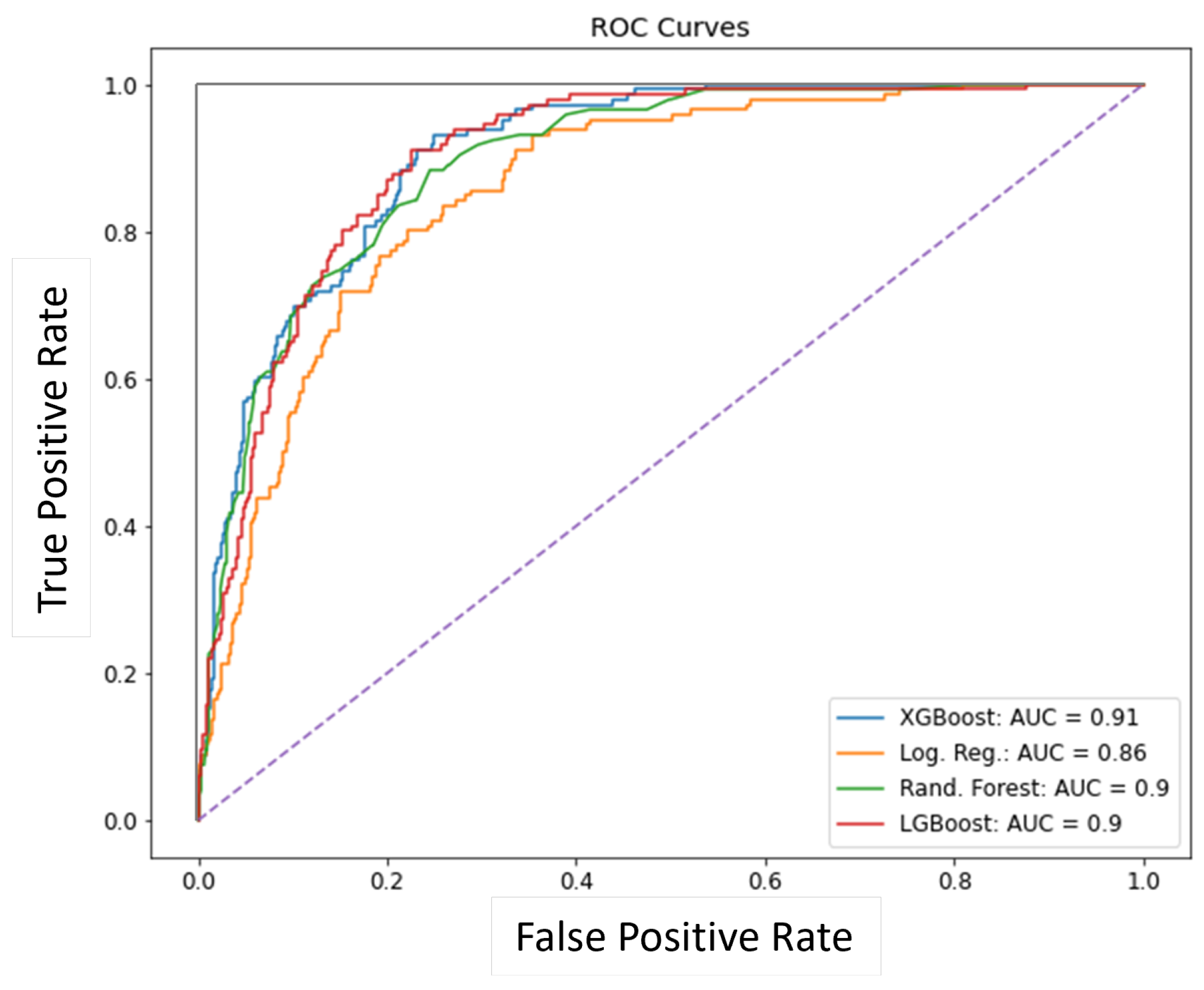
4.1. Attrition Prediction Results
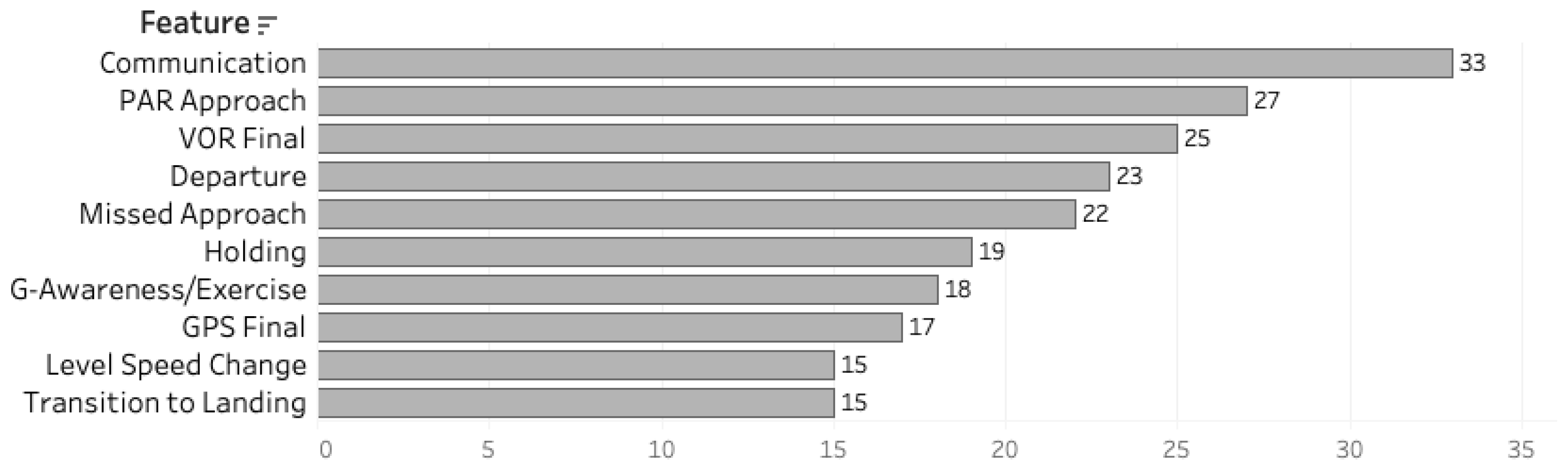
4.2. Pipeline Recommender Model Results
4.3. Potential Cost Savings Estimation
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADV | Advanced Training Stage |
| AUROC | Area Under the Receiver Operating Characteristic Curve |
| API | Aviation Preflight Indoctrination |
| ASTB | Aviation Selection Test Battery |
| CNATRA | Chief of Naval Air Training |
| DOR | Drop On Request |
| FNR | False Negative Rate |
| FPR | False Positive Rate |
| FRS | Fleet Replacement Squadron |
| IFS | Initial Flight School |
| INT | Intermediate Training Stage |
| MIF | Maneuver Item File |
| MCC | Matthews Correlation Coefficient |
| MLP | Multi-Layer Perceptron |
| NIFE | Naval Introductory Flight Evaluation |
| NSS | Naval Standardized Scores |
| PRI | Primary Training Stage |
| ROC | Receiver Operator Characteristic |
| SNA | Student Naval Aviators |
| SNFO | Student Naval Flight Officers |
| SVM | Support Vector Machine |
| TNR | True Negative Rate |
| TPR | True Positive Rate |
References
- Erjavec, S.J. Estimating the Probability that Naval Flight Students Will Pass Primary Flight Training at Three Key Milestones. Ph.D. Thesis, Naval Postgraduate School, Monterey, CA, USA, 2019. [Google Scholar]
- Kamel, M.N. Employing Machine Learning to Predict Student Aviator Performance; Technical Report; Naval Postgraduate School: Monterey, CA, USA, 2020. [Google Scholar]
- Judy, A.D.; Gollery, T. US Navy pilot competence: An exploratory study of flight simulation training versus actual aircraft training. J. Appl. Soc. Sci. Res. Pract. 2019, 1, 4. [Google Scholar]
- Arnold, R.D.; Phillips, J.B. Causes of Student Attrition in US Naval Aviation Training: A Five Year Review from FY 2003 to FY 2007; Technical Report; Naval Aerospace Medical Research Lab.: Pensacola, FL, USA, 2008. [Google Scholar]
- Griffin, G.R.; Mosko, J.D. Naval Aviation Attrition 1950–1976: Implications for the Development of Future Research and Evaluation; Technical Report; Naval Aerospace Medical Research Lab.: Pensacola, FL, USA, 1977. [Google Scholar]
- Mattock, M.G.; Asch, B.J.; Hosek, J.; Boito, M. The Relative Cost-Effectiveness of Retaining versus Accessing Air Force Pilots; Technical Report; RAND Corporation: Santa Monica, CA, USA, 2019. [Google Scholar]
- Report to Congressional Armed Services Committees on Initiatives for Mitigating Military Pilot Shortfalls. 2019. Available online: https://prhome.defense.gov/Portals/52/Documents/Report%20to%20Congress%20on%20Initiatives%20for%20Mitigating%20Military%20Pilot%20Shortfalls%20cleared%20for%20public%20release.pdf (accessed on 3 April 2023).
- Griffin, G.; McBride, D. Multitask Performance: Predicting Success in Naval Aviation Primary Flight Training; Technical Report; Naval Aerospace Medical Research Lab.: Pensacola, FL, USA, 1986. [Google Scholar]
- Delaney, H.D. Dichotic listening and psychomotor task performance as predictors of naval primary flight-training criteria. Int. J. Aviat. Psychol. 1992, 2, 107–120. [Google Scholar] [CrossRef]
- Carretta, T.R.; Ree, M.J. Air Force Officer Qualifying Test validity for predicting pilot training performance. J. Bus. Psychol. 1995, 9, 379–388. [Google Scholar] [CrossRef]
- Burke, E.; Hobson, C.; Linsky, C. Large sample validations of three general predictors of pilot training success. Int. J. Aviat. Psychol. 1997, 7, 225–234. [Google Scholar] [CrossRef] [PubMed]
- Hormann, H.J.; Maschke, P. On the relation between personality and job performance of airline pilots. Int. J. Aviat. Psychol. 1996, 6, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Bair, J.T.; Lockman, R.F.; Martoccia, C.T. Validity and factor analyses of naval air training predictor and criterion measurers. J. Appl. Psychol. 1956, 40, 213. [Google Scholar] [CrossRef]
- Rowe, N.C.; Das, A. Predicting success in training of Navy aviators. In Proceedings of the International Command and Control Research and Technology Symposium (ICCRTS), Virtual, 18–22 and 25–29 October 2021; Available online: https://faculty.nps.edu/ncrowe/oldstudents/ICCRTS_aviator_training_ncrowe_21.htm (accessed on 3 April 2023).
- Street, D., Jr.; Helton, K.; Dolgin, D. The Unique Contribution of Selected Personality Tests to the Prediction of Success in Naval Pilot Training; Technical Report; Naval Aerospace Medical Research Lab.: Pensacola, FL, USA, 1992. [Google Scholar]
- Bale, R.M.; Rickus, G.M.; Ambler, R.K. Prediction of advanced level aviation performance criteria from early training and selection variables. J. Appl. Psychol. 1973, 58, 347. [Google Scholar] [CrossRef]
- Hunter, D.R.; Burke, E.F. Meta Analysis of Aircraft Pilot Selection Measures; Technical Report; Army Research Institution for the Behavioral and Social Sciences: Alexandria, VA, USA, 1992.
- Caraway, C.L. A looming pilot shortage: It is time to revisit regulations. Int. J. Aviat. Aeronaut. Aerosp. 2020, 7, 3. [Google Scholar] [CrossRef]
- Owens, A. New Naval Introductory Flight Evaluation Program Provides Modern Foundation for Flight Training. Available online: https://www.navy.mil/Press-Office/News-Stories/Article/2410597/new-naval-introductory-flight-evaluation-program-provides-modern-foundation-for/ (accessed on 4 March 2023).
- Jenkins, P.R.; Caballero, W.N.; Hill, R.R. Predicting success in United States Air Force pilot training using machine learning techniques. Socio-Econ. Plan. Sci. 2022, 79, 101121. [Google Scholar] [CrossRef]
- Caballero, W.N.; Gaw, N.; Jenkins, P.R.; Johnstone, C. Toward Automated Instructor Pilots in Legacy Air Force Systems: Physiology-Based Flight Difficulty Classification via Machine Learning; SSRN 4170114; SSRN: Rochester, NY, USA, 2022. [Google Scholar]
- Akers, C.M. Undergraduate Pilot Training Attrition: An Analysis of Individual and Class Composition Component Factors; Airforce Institute of Technology: Washington, DC, USA, 2020. [Google Scholar]
- Rowe, N.C. Automated Trend Analysis for Navy-Carrier Landing Attempts. In Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC), Orlando, FL, USA, 2–6 December 2012; Available online: https://faculty.nps.edu/ncrowe/rowe_itsec12_paper12247.htm (accessed on 3 April 2023).
- Phillips, J.; Chernyshenko, O.; Stark, S.; Drasgow, F.; Phillips, I. Development of Scoring Procedures for the Performance Based Measurement (PBM) Test: Psychometric and Criterion Validity Investigation; Technical Report; Naval Medical Research Unit Dayton Wright-Patterson: Silver Spring, MD, USA, 2011. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1322–1328. [Google Scholar]
- Mishra, S. Handling imbalanced data: SMOTE vs. random undersampling. Int. Res. J. Eng. Technol. 2017, 4, 317–320. [Google Scholar]
- Keany, E. BorutaShap: A wrapper feature selection method which combines the Boruta feature selection algorithm with Shapley values. Zenodo 2020. [Google Scholar] [CrossRef]
- Verhaeghe, J.; Van Der Donckt, J.; Ongenae, F.; Van Hoecke, S. Powershap: A power-full shapley feature selection method. In Proceedings Part I, Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 71–87. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Timeline | PRI Grades | PRI Syllabus | PRI Outcome | INT Syllabus | INT Outcome | ADV Syllabus | Targets |
|---|---|---|---|---|---|---|---|
| During PRI | Yes | Yes | Attrition Risk, Pipeline Suitability | ||||
| End of PRI | Yes | Yes | Yes | Attrition Risk, Pipeline Suitability | |||
| During INT | Yes | Yes | Yes | Yes | Attrition Risk Predictor | ||
| End of INT | Yes | Yes | Yes | Yes | Yes | Attrition Risk Predictor | |
| During ADV | Yes | Yes | Yes | Yes | Yes | Yes | Attrition Risk Predictor |
| Model | FPR (%) | Q2 TPR (%) | Q3 TPR (%) | Q4 TPR (%) | Flight Attr. Id’ed | DOR Attr. Id’ed | MCC | F1 | AUROC |
|---|---|---|---|---|---|---|---|---|---|
| Ad BagOS | 5.35 | 36.84 | 35.29 | 37.50 | 26/66 | 8/23 | 0.31 | 0.36 | 0.83 |
| XG Boost | 1.08 | 36.84 | 41.18 | 62.5 | 33/66 | 7/23 | 0.51 | 0.52 | 0.87 |
| Log Reg | 5.52 | 39.47 | 35.29 | 43.758 | 27/66 | 7/23 | 0.29 | 0.35 | 0.79 |
| RF | 1.02 | 22.37 | 41.18 | 43.75 | 23/66 | 4/23 | 0.39 | 0.39 | 0.87 |
| Grad Boost | 1.08 | 27.63 | 35.29 | 43.75 | 25/66 | 5/23 | 0.41 | 0.42 | 0.87 |
| LGBM | 0.80 | 22.37 | 41.18 | 31.25 | 23/66 | 5/23 | 0.39 | 0.38 | 0.89 |
| MLP | 3.19 | 35.53 | 23.53 | 43.75 | 27/66 | 6/23 | 0.32 | 0.37 | 0.79 |
| S. No | Model | TPR (%) | FNR (%) | TNR (%) | FPR (%) | MCC | F1 | Recall | Precision | Accuracy | AUROC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | RF | 85.80 | 14.20 | 81.53 | 18.47 | 57.94 | 66.34 | 85.80 | 54.08 | 82.40 | 91.20 |
| 1 | AdBoost | 86.44 | 13.56 | 82.17 | 17.83 | 59.22 | 67.32 | 86.44 | 55.13 | 83.04 | 91.42 |
| 2 | XG Boost | 78.23 | 21.77 | 89.61 | 10.39 | 63.70 | 71.37 | 78.23 | 65.61 | 87.31 | 91.32 |
| 3 | LGBM | 80.76 | 19.24 | 87.21 | 12.79 | 61.83 | 69.85 | 80.76 | 61.54 | 85.91 | 91.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasad-Rao, J.; Pinon Fischer, O.J.; Rowe, N.C.; Williams, J.R.; Puranik, T.G.; Mavris, D.N.; Natali, M.W.; Tindall, M.J.; Atkinson, B.W. Attrition Risk and Aircraft Suitability Prediction in U.S. Navy Pilot Training Using Machine Learning. Aerospace 2023, 10, 379. https://doi.org/10.3390/aerospace10040379
Prasad-Rao J, Pinon Fischer OJ, Rowe NC, Williams JR, Puranik TG, Mavris DN, Natali MW, Tindall MJ, Atkinson BW. Attrition Risk and Aircraft Suitability Prediction in U.S. Navy Pilot Training Using Machine Learning. Aerospace. 2023; 10(4):379. https://doi.org/10.3390/aerospace10040379
Chicago/Turabian StylePrasad-Rao, Jubilee, Olivia J. Pinon Fischer, Neil C. Rowe, Jesse R. Williams, Tejas G. Puranik, Dimitri N. Mavris, Michael W. Natali, Mitchell J. Tindall, and Beth W. Atkinson. 2023. "Attrition Risk and Aircraft Suitability Prediction in U.S. Navy Pilot Training Using Machine Learning" Aerospace 10, no. 4: 379. https://doi.org/10.3390/aerospace10040379
APA StylePrasad-Rao, J., Pinon Fischer, O. J., Rowe, N. C., Williams, J. R., Puranik, T. G., Mavris, D. N., Natali, M. W., Tindall, M. J., & Atkinson, B. W. (2023). Attrition Risk and Aircraft Suitability Prediction in U.S. Navy Pilot Training Using Machine Learning. Aerospace, 10(4), 379. https://doi.org/10.3390/aerospace10040379