1. Introduction
In recent years, the manufacturing sectors have taken a new approach, involving technological innovations, aimed to modernize and optimize production. This new concept is characterized by automizing mechanical processes using artificial intelligence. These techniques allow what is called “Industry 4.0” for the evolution of maintenance, and, more particularly, predictive maintenance. Due to artificial intelligence, predictive maintenance can anticipate anomalies (e.g., the life of computer servers, and the electrical installation of dysfunctional subway trains). In addition, intelligent maintenance requires a multistep approach, from monitoring, through analysis and decision support, to validation and verification. These steps are part of a discipline called PHM (prognostics and health management), linking the study of failure mechanisms and life cycle management.
Prognostics, in general, require two types of techniques: (1) an application-dependent technique that aims to detect precursors to estimate the system’s health state, and (2) a prediction technique to predict the remaining useful life (RUL). Prognostic and health management (PHM) is an engineering field whose goal is to provide users with a thorough analysis of the health condition of a machine and its components [
1]. Relying on human operators to manage atypical events is quite difficult when dealing with complex equipment and attempting to retrieve information and patterns of different equipment failures. It aims to better manage the health status of physical systems while reducing operation and maintenance costs [
2]. The implementation of PHM solutions is becoming increasingly important, and the prognostic process is now considered one of the main levers of action in the quest for overall performance [
3]. It is generally described as a combination of seven layers that can be divided into three phases: observation, analysis, and action.
The remaining useful life (RUL) is the length of time a machine is likely to operate before it requires repair or replacement. By taking RUL into account, maintenance can be scheduled to optimize operating efficiency and avoid unplanned downtime. For this reason, estimating RUL is a top priority in predictive maintenance programs. Based on aging models (degradation of the monitored system), prognostics determine the health status of a system and predict the RUL. This prediction can be obtained using a physical-model-based approach [
4], a data-driven approach [
5], and a new hybrid approach [
6] merging the first two approaches. Data-driven algorithms can be divided into three categories: statistical methods including Markov models, Weibull distribution, and Kalman filters; machine-learning-based methods such as support vector machines (SVMs) [
7] and deep belief networks (DBNs) [
8]; and deep learning methods [
9]. Different works have shown the effectiveness of data-driven approaches [
10], and especially deep learning, in estimating the RUL of a turbofan engine. A turbofan engine consists of several key components including a fan, compressor, combustion chamber, turbine, exhaust nozzle, and bypass duct, as well as various sensors to understand the condition of the engine. One of the advantages of data-driven deep learning approaches over the physics-based approach is that they can take into account the complexity of the structure and variety of sensors, which can affect the RUL of the turbofan engine, including operating conditions, maintenance history, and design features of the engine. To predict the RUL of a turbofan engine, several deep learning algorithms have been used, such as multilayer perceptrons, long short-term memories (LSTMs) [
11], bidirectional LSTMs (Bi-LSTMs) [
12], and convolutional neural network (CNN) algorithms [
13], as well as combined algorithms to achieve higher accuracy. Advanced data-driven deep learning methods can have high predictive accuracy but are considered “black box” models because they suffer from a lack of interpretability. While these models can have high predictive accuracy, it can be difficult to understand how they arrive at their predictions, which can make it difficult to use the predictions to inform maintenance decisions. Explainable Artificial Intelligence (XAI) techniques such as SHapley Additive exPlanations (SHAP) values can be applied to explain the prediction process by providing information on how to estimate the contribution of each feature to the final prediction. However, their use in the predictive maintenance process has some limitations [
14]. SHAP values assume that each feature contributes to the prediction independently of the others and is not able to capture their interactions, which can limit their accuracy and usefulness. Indeed, features interact with each other in ways that can be challenging and can affect the final prediction. Similar to many other permutation-based interpretation methods, SHAP values methods suffer from including unrealistic data instances when features are correlated [
15]. They are also subject to limited human interpretation. These issues have received less attention in the scientific literature. To address these limitations, a deep-learning-based feature clustering with SHAP values approach is proposed to offer an efficient and interpretable model, leading to more accurate RUL predictions.
This study aims to answer questions about how to improve preprocessing to help with both interpretability and model performance as well as how to use predictions to build confidence in predictive maintenance models. The goal is to highlight the benefits of Explainable AI in the prognostic lifetime estimation of turbofan engines.
The accuracy of the model’s prediction depends on the quality and relevance of the data that influence the engine’s RUL. It is difficult to build accurate models with noisy data or complex features and to identify patterns. To address the challenge, a number of techniques can be used, such as dimensionality reduction, which reduces the number of dimensions. Unfortunately, popular techniques such as principal component analysis (PCA) would generally transform the data in a way that damages the interpretability of the model [
16]. This is because each transformed feature is a combination of all of the original features. Feature clustering tools capture relations between features that can preserve predictive power and yet retain interpretability.
The main contributions of this paper are summarized below:
We propose a deep-learning-based feature clustering with SHAP values to explain the model’s RUL estimation. Feature clustering is used to capture the relationship between features that can potentially influence the final prediction and improve interpretability, enabling a better understanding of feature contributions. It could be considered part of the Explainable AI field, as it promotes a better comprehension of the model. Using the feature clustering eliminates the need to use complex models; instead, an LSTM model with a single hidden layer is used. In the post-model phase, SHAP values are applied to facilitate the interpretation of RUL prediction and help determine the cause of the engine’s failure.
We discussed and analyzed the settings and effects of some critical parameters as well as the comparison with other methods. Therefore, we open the code of this experiment, in order to contribute to future developments.
To present our work, this paper is organized as follows:
Section 2 explains Explainable Artificial Intelligence’s (XAI’s) need in PHM and reviews related work in this field.
Section 3 provides an overview of previous related work to our study.
Section 4 outlines the techniques used in this study and the proposed framework. An overview of the dataset and experiments setting are illustrated in
Section 5. Results are presented and discussed in
Section 6.
Section 7 concludes the article.
2. Explainable Artificial Intelligence’s (XAI) Need in PHM
System prognostics is a safety-sensitive industry field. It is therefore crucial to ensure the use of a properly regulated AI in this area. Deep learning networks are artificial neural networks that include many hidden layers between the input and the output layers. These approaches often offer better performance but are accused of being black boxes. They suffer from a lack of interpretability and analysis of prediction results. It is difficult to know how information is processed in the hidden layer. Therefore, explanatory capabilities are needed in RUL prediction to improve system reliability and provide insight into the parts that caused the engine failure. Explainable AI (XAI) has been presented as a solution to this problem. It is able to analyze the black box inside, verify its processes, and provide an understandable explanation of the logic behind the prediction. Several approaches can be applied to Explainable AI systems for prediction [
17].
Carvalho et al. [
18] classified the interpretability methods into three groups according to the moment when these methods are applicable: before (pre-model), during (in-model), or after (post-model) the construction of the model to predict. Some authors [
18,
19], consider that PCA, distributed stochastic neighbor embedding (t-SNE), and clustering methods can be classified under pre-model interpretability and can be part of the XAI field. The field of in-model interpretability is mainly focused on intrinsically interpretable models that are specifically designed to be transparent, such as decision trees, rule-based models, Bayesian models, and hybrid models.
Post-model interpretability refers to the improvement of interpretability after a model has been built (post hoc). Two approaches can be model-specific or model-agnostic. Model-specific interpretability includes self-explanation as the additional output, such as attention mechanisms [
20] and capsule network (CapsNets) [
21] that focus on the most relevant parts of the input data when making a prediction. Other examples of model-specific interpretability techniques include saliency maps and layer-wise relevance propagation. The post hoc model-agnostic interpretability approach consists of analyzing root causes by manipulating inputs and visualizing outputs without relying on the trained model. These approaches include local model analysis, global model analysis, and feature importance analysis. These methods can be used to identify the input features that contribute to the predictions and have the greatest impact on the output of the model. In this study, SHAP values [
22] are used on synthetic features to identify their contribution to the prediction and find the key factors that affect the RUL of a turbofan engine.
3. Related Work
The C-MAPSS dataset is one of the most used datasets for the goal of improving RUL estimations. Whether using machine learning models or deep learning models, many approaches and methods have been developed and proposed throughout the years. Wang et al. [
23] built a fusion model that extracts features from the data based on a broad learning system (BLS) and integrates LSTM to process time series information. Heimes [
24] was the first to implement a recurrent neural network (RNN) for RUL prediction. de Oliveira da Costa et al. [
25] proposed a domain adversarial neural network (DANN) approach to learning domain-invariant features using LSTM. Jiang et al. [
26] used a fusion network combined with a bidirectional LSTM network to estimate the RUL with the use of sequenced data. Zhao et al. [
12] used a bidirectional LSTM (BiLSTM) approach for RUL estimation by taking sequence data in bidirection, and a model optimization was necessary to obtain the best results possible. Zhang et al. [
27] proposed an LSTM-fusion architecture, concatenating separate LSTM subnetworks, on sensor signals with feature window sizes. Listou Ellefsen et al. [
28] proposed a semisupervised approach based on LSTM using a genetic algorithm (GA) to adjust the diverse amount of hyperparameters in the training procedure. Zheng et al. [
29] used a deep LSTM model for RUL estimation feeding sequenced sensor data to the model to reveal hidden features when multiple operational conditions are present. Lee [
30] adopted a new approach by normalizing the sensor data per operational condition, as well as rectifying the RUL; it was achieved by setting an early RUL, removing the initial cycles where the engine is at a healthy state and only focusing on the degradation period. Recently, Palazuelos et al. [
31] extended capsule neural networks for fault prognostics, particularly remaining useful life estimation. Chen et al. [
32] applied an attention-based deep learning framework hybrid LSTM with feature fusion able to learn the importance of features. Quin et al. [
33] proposed a slow-varying dynamics-assisted temporal CapsNet (SD-TemCapsNet) to simultaneously learn the slow-varying dynamics and temporal dynamics from measurements for accurate RUL estimation. Li et al. [
34] proposed a cycle-consistent learning scheme to obtain a new representation space, considering variations in the degradation patterns of different entities. Ren et al. [
35] proposed a lightweight and adaptive knowledge distillation for enhancing industrial prediction accuracy. To address the sensor malfunction problem, the authors in [
36] introduced adversarial learning to extract generalized sensor-invariant features. To handle the presence of uncertainties and find the key features that contribute to the precipitation forecasting process. Manna et al. [
37] incorporated a rough ensemble on fuzzy approximation space (RSFAS) into the LSTM method.
6. Results Analysis
To better estimate the remaining useful life of the units, we study the effect of different parameters on the model’s performance, such as data smoothing parameter , the time window size, and the piecewise rectified RUL. The proposed model was used on our new preprocessed dataset containing synthetic features. Experimental results were averaged by 30 independent trials to ensure the accuracy of the results and reduce the effect of randomness.
6.1. Parameters Study
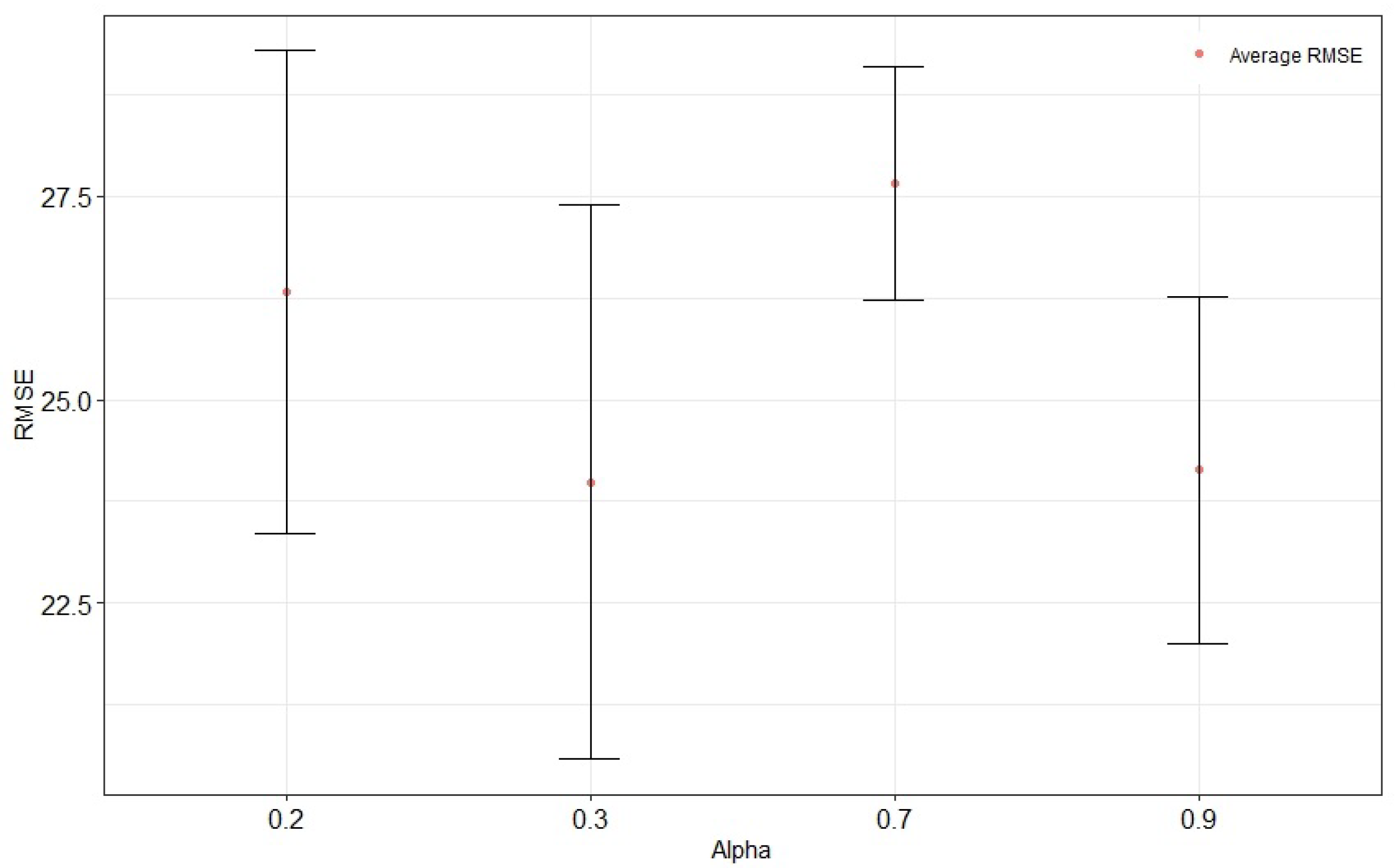
We first adjusted the data smoothing parameter
to 0.2, 0.3, 0.7, and 0.9, consistent with previous studies. After 30 independent trials, the results are shown in
Figure 6. The 95% confidence interval of the RMSE is displayed for each
value. The red dot indicates the average RMSE. The best value of the smoothing parameter
is equal to 0.3, which leads to the smallest root mean square error (RMSE).
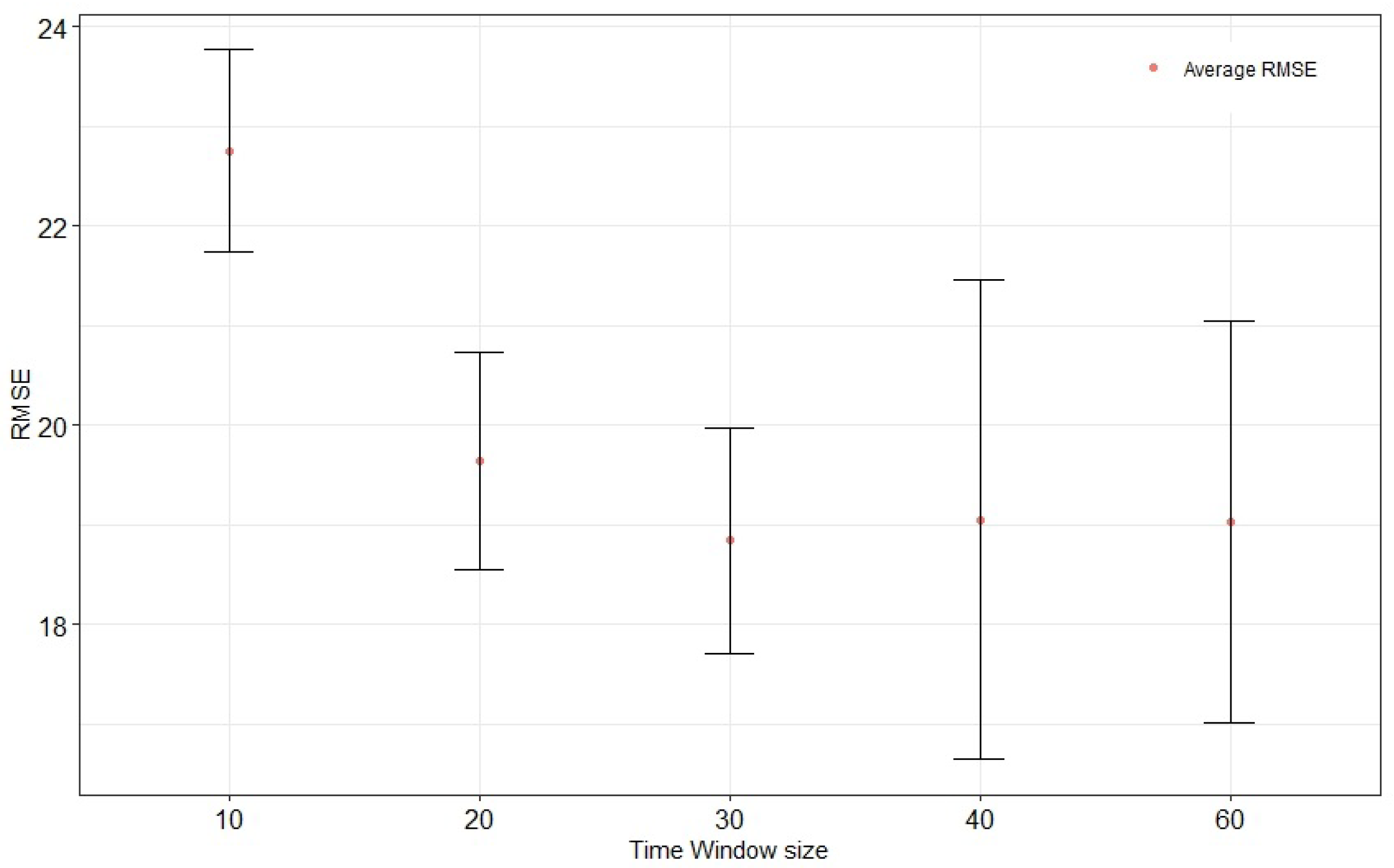
Regarding the size of the time window, most studies using the C-MAPSS FD004 database set it at 30. Nevertheless, we believe that this parameter should be investigated. Setting
to 0.3, we adjusted the time window to 10, 20, 30, 40, and 50. Each configuration was repeated 30 times independently. The results in
Figure 7 show that the RMSE first decreases as the window size increases and exceeds the value of 30, indicating that a window size that is too large does not help improve performance. This is because the current RUL is correlated with data from the most recent period, and the correlation decreases as the time interval increases. Including these data may result in too much noise. On the other side, the test results’ variance increases with the time window’s size, indicating that the model learning is indeed perturbed by noise. The best results are obtained with a time window size of 30.
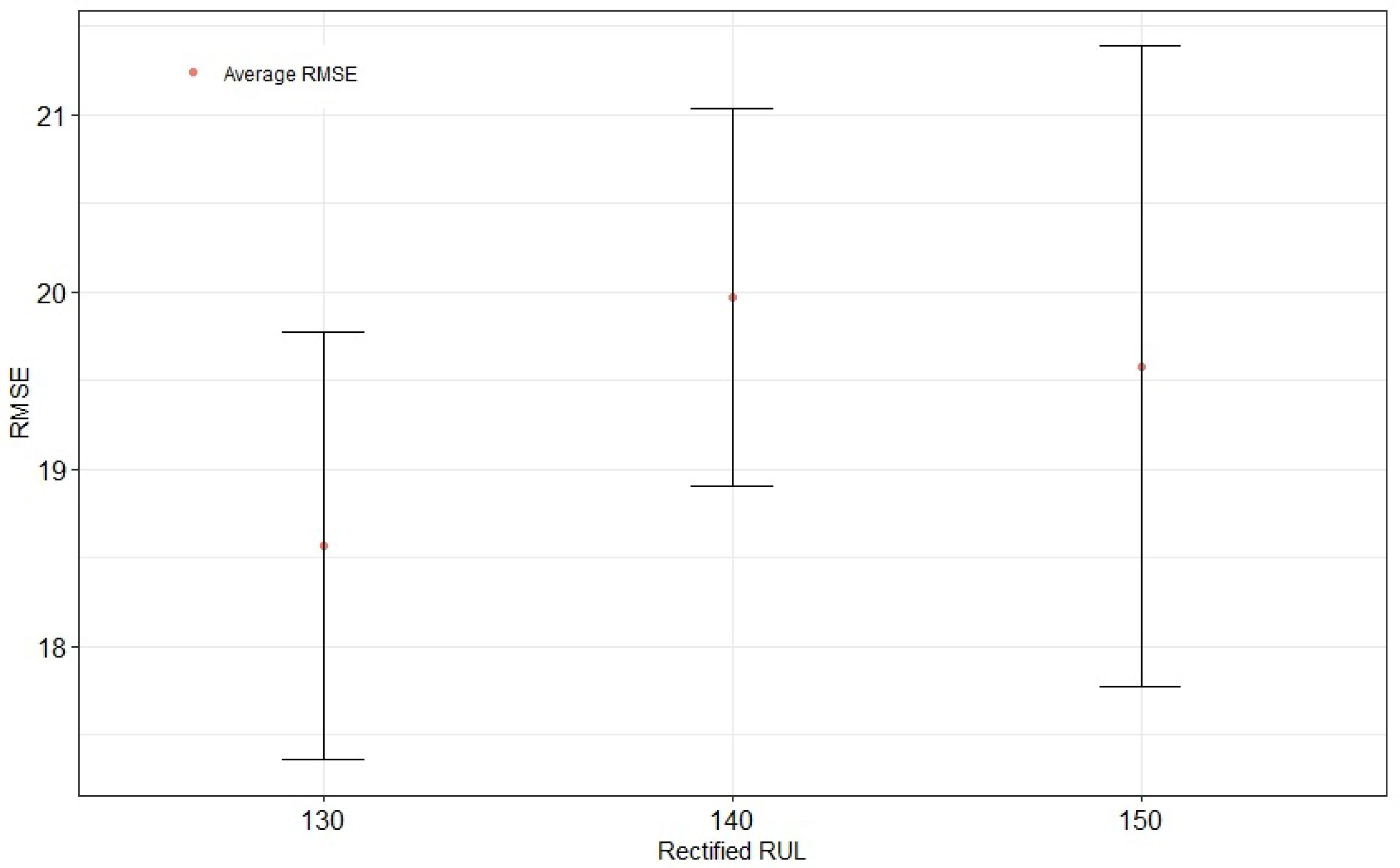
In addition, we studied the impact of the rectified RUL, as per the window size experiments. Setting a time window to 30, we adjusted RUL early to 130, 140, and 150 and repeated each trial 30 times independently. The results in
Figure 8 show that the lowest RMSE is achieved with a rectified RUL equal to 130.
6.2. Ablation Study
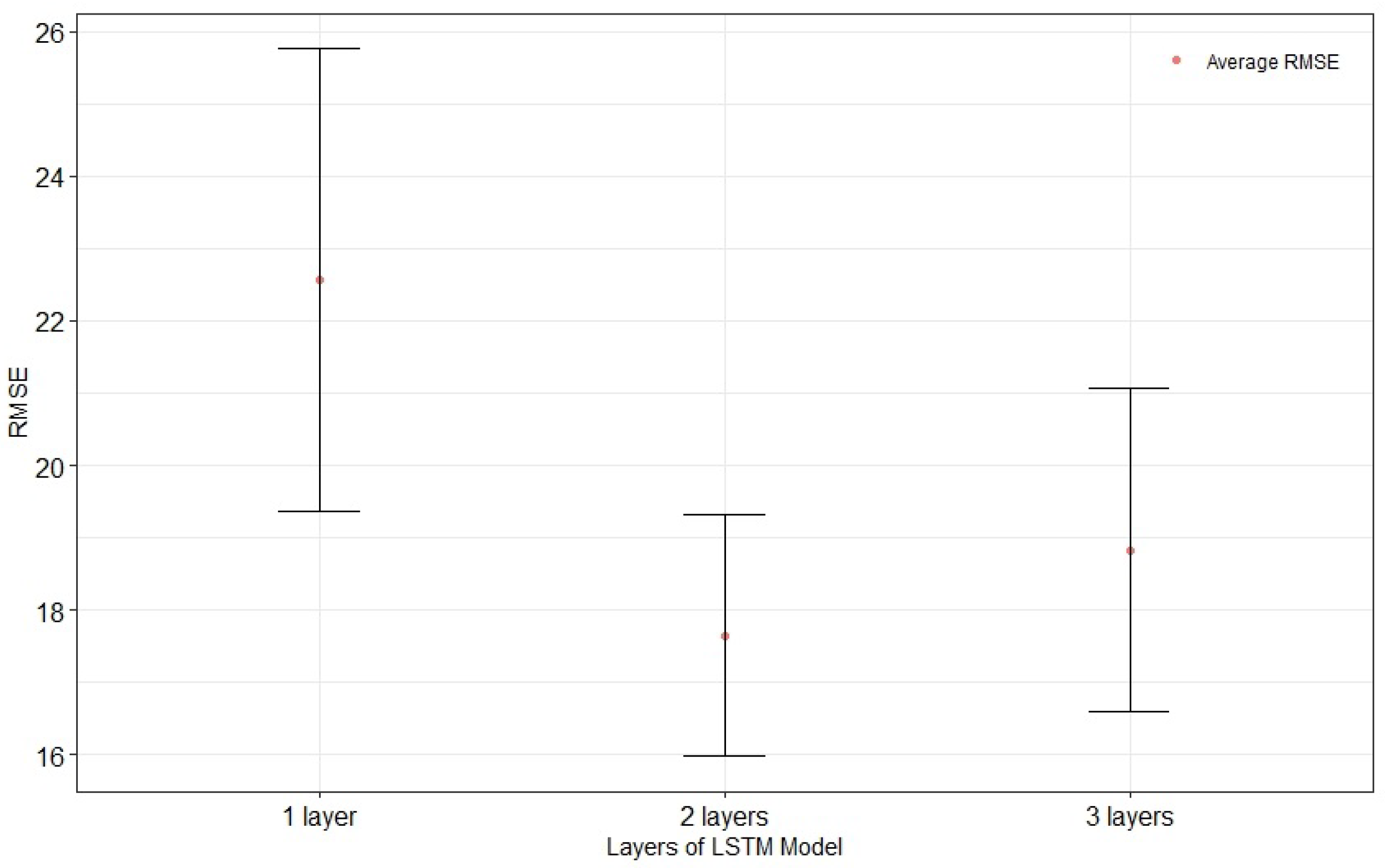
In this section, we perform an ablation study to show the effectiveness of using feature clustering in preprocessing, improving model performance and overfitting problems by reducing the influence of input sensors. First, our results are compared to those obtained by deploying a one, two, and three-hidden-layer LSTM network without dimension reduction, presented in
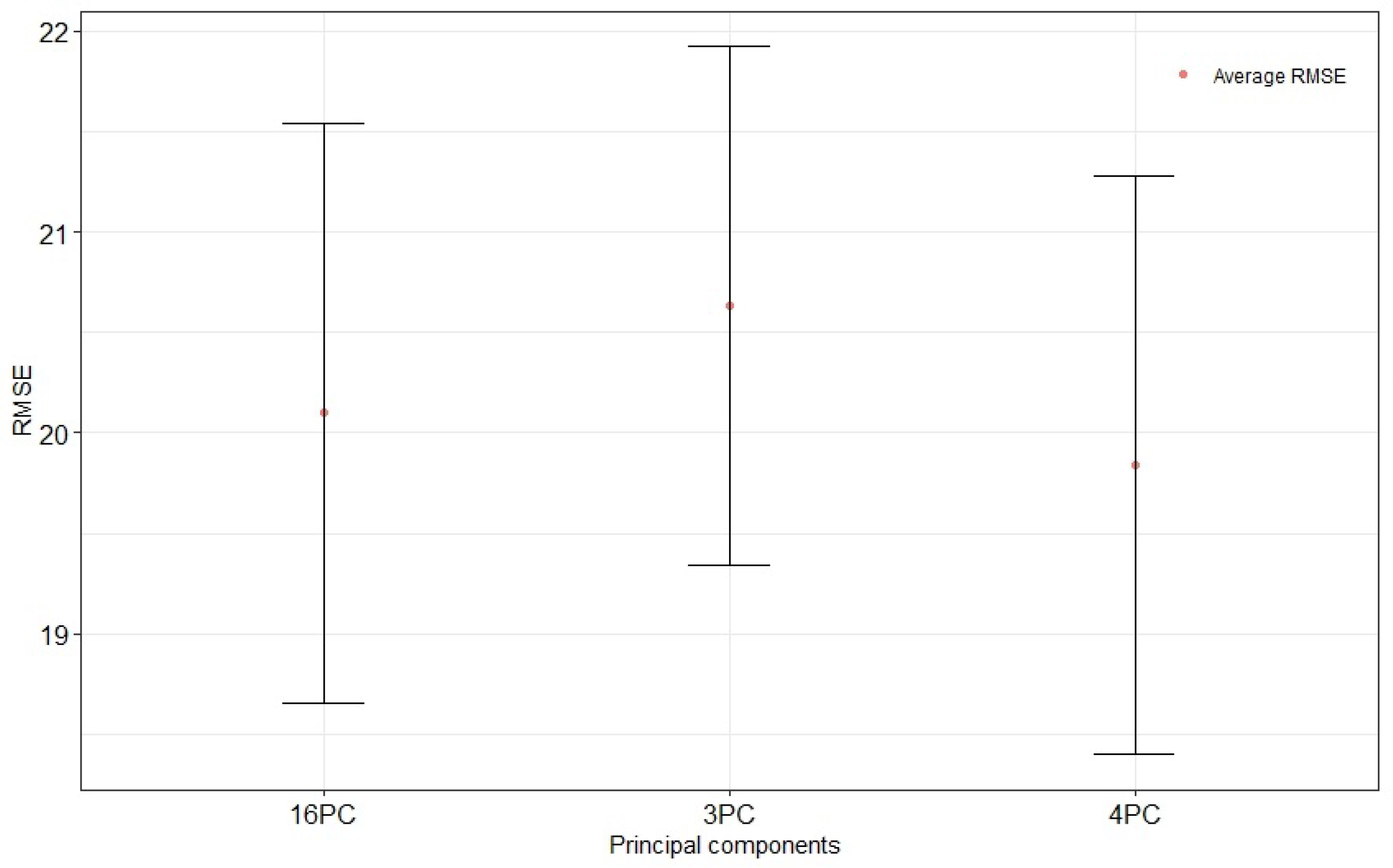
Figure 9. Second, the results are compared to those obtained by the PCA dimension reduction method with 3 PCs, 4 PCs, and 16 PCs using a single hidden layer LSTM network, found in
Figure 10. This comparison mainly shows the motivation behind using feature clustering. This approach extracts information from correlated features to reveal hidden patterns, thus providing a simpler model with fewer hidden layers. Our subsequent experiments validate this assumption.
The sensors were smoothed using
equal to 0.3, the time window equal to 30, and rectified RUL set to 130. The results in
Table 5 and
Figure 9 show that when no dimension reduction is performed, two layers are required to achieve better performance with the LSTM network. Furthermore, the experimental results in
Figure 11 show also that increasing the complexity of the LSTM network does not lead to the prediction accuracy found with feature clustering.
According to
Figure 10, the best results using the PCA method were obtained with four principal components catching all the variance in the original data. This result indicates that reducing the number of components reduces the complexity of the model, which improves the prediction accuracy. However, with excessive dimension reduction, the features required for the prediction cannot be learned. In addition, our model performed better than the model using PCA dimension reduction (
Figure 11).
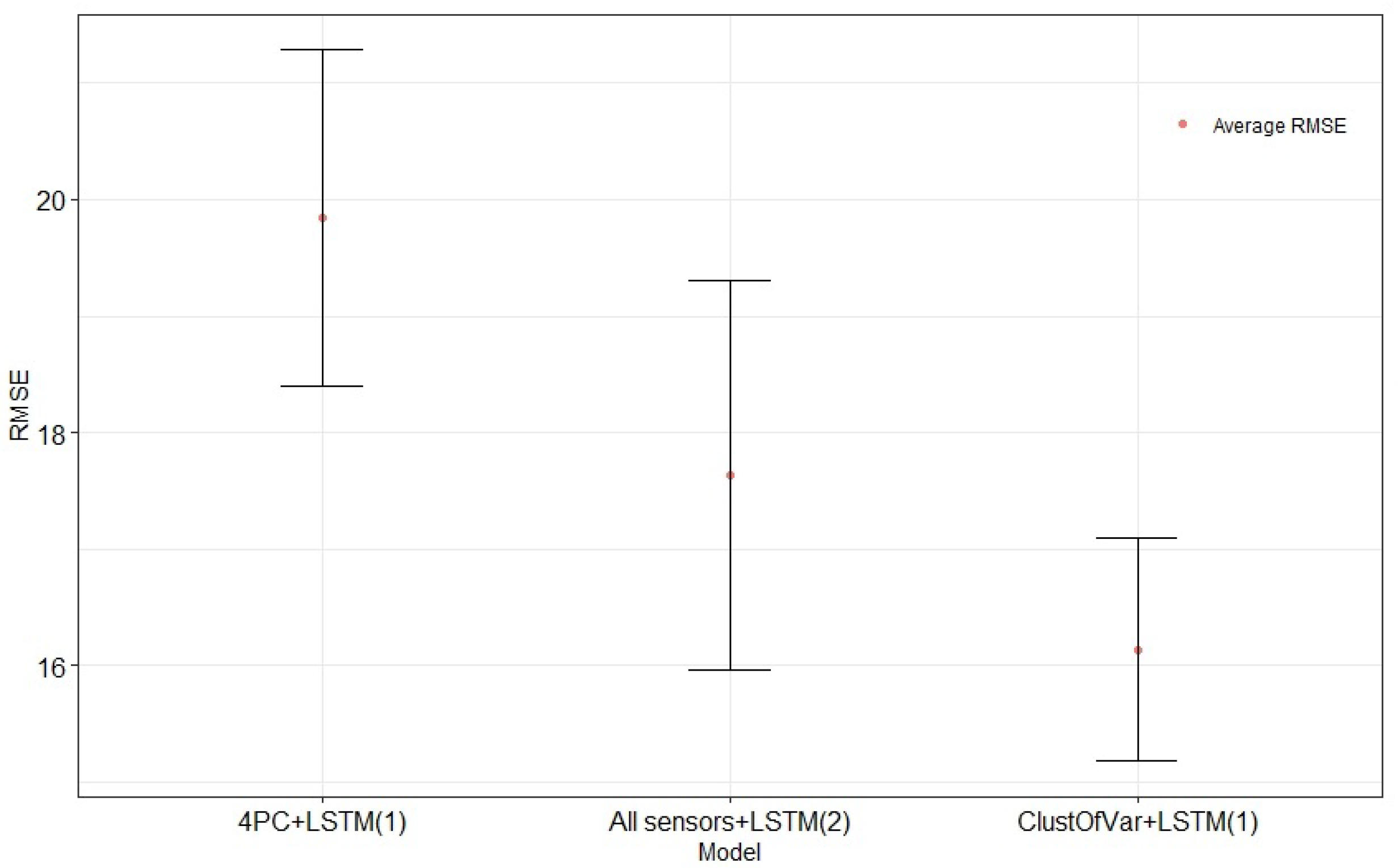
Compared to the other models, in
Table 5, the proposed model performs better, with the lowest average RMSE value (16.14) and the lowest average S-score (299.19). It also provides the smallest standard deviation (values in brackets), showing that the performance of our model is more accurate. These results indicate that, with feature clustering as a part of the preprocessing, reducing the complexity of the model does not decrease the information needed for learning.
6.3. Case Study
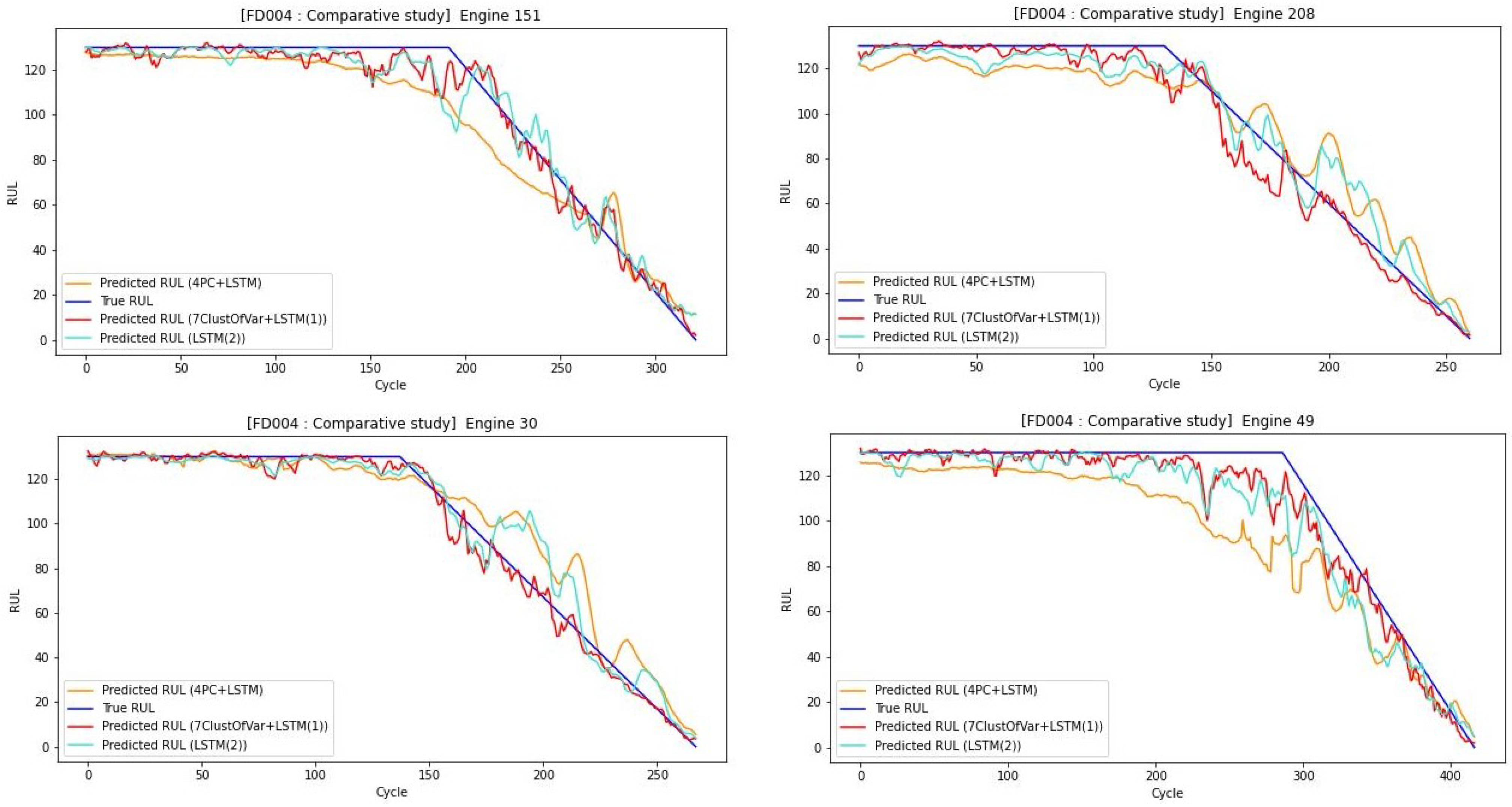
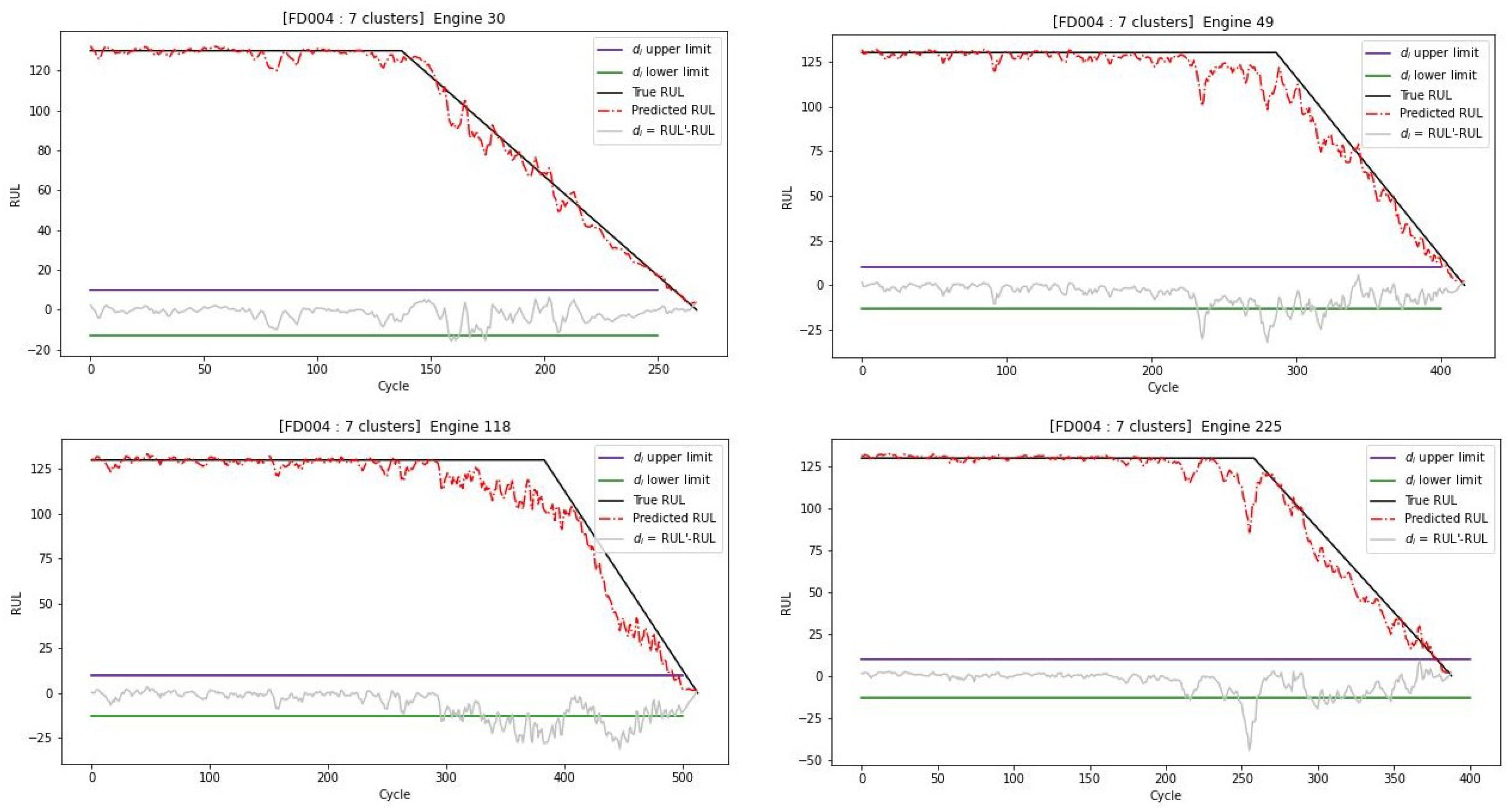
The estimated RUL values at each run are compared to the true RUL values for 4 different engines randomly selected, for the training subset of FD004, when using RUL. The aqua-clear blue, orange, and red lines correspond, respectively, to the estimated RUL values found by 2-layer all-sensor LSTM, 4PCA + LSTM (1 layer), and our proposed model with 7ClustOfVar + LSTM (1 layer).
The engines are sorted by ascending order of real RUL values and are represented in dark blue, demonstrating the lifetime of the aircraft engine until its failure. These real values are used to observe the performance of our model, indicating the error between the true and the predicted RUL.
The comparison between the estimated RUL using the different methods for randomly selected engines is shown in
Figure 12. It highlights that the estimated RUL values with the proposed method are closer to the true RUL values of the training subset than to those estimated using the four principal components or the LSTM model with two hidden layers without performing any type of dimension reduction as inputs.
Figure 12 indicates that when using the clustered features as input, the model tends to learn the hidden pattern available within these clusters well, whereas when using either four principal components an LSTM model with two hidden layers without performing any type of dimension reduction, it fails to learn well, and either estimates the RUL early or late, which can be an issue when considering the turbofan engines, as it can lead to a disastrous outcome in a real-life scenario.
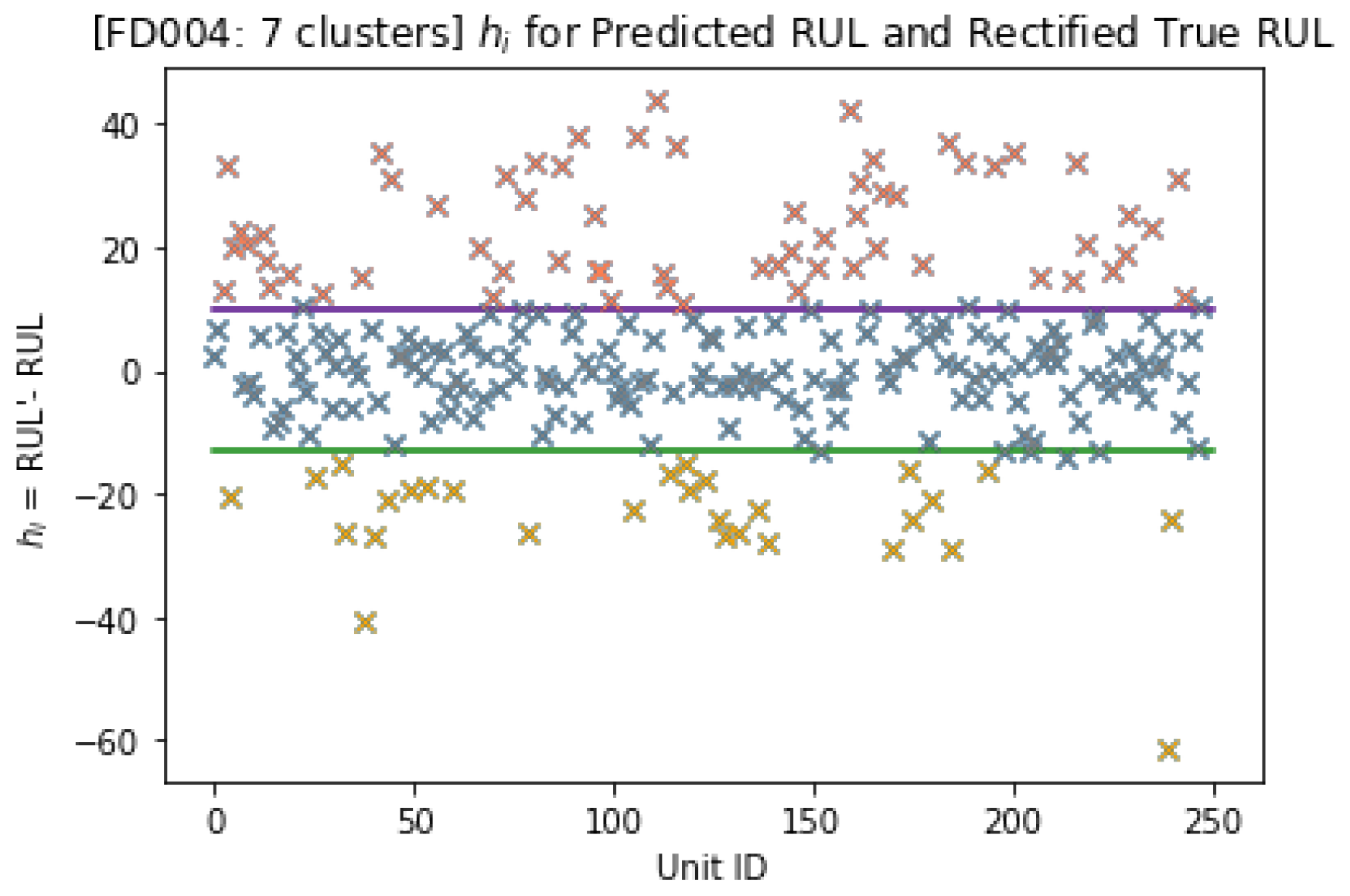
The prediction results of randomly selected engines from FD004 train sets are presented in
Figure 13. The majority of the errors based on [
46] fall within the confidence interval, defined by the lower bound
= −13 and the upper bound
= 10, proving that the model’s performance was well trained.
In order to evaluate the model’s performance, graphically, the predicted error for the test subset of FD004 is represented. The green and purple lines correspond, respectively, to the lower limit = −13 and the upper limit = 10.
As illustrated in
Figure 14, most of the values fall within this confidence interval determined with the lower and upper limit of
, showing the efficiency of the proposed model’s estimation. These values help identify the values that were correctly predicted within the confidence interval, with the blue color and those which were either an early or a late prediction, respectively with colors yellow and red. A comparison between the predicted RUL and the rectified true RUL can also be seen in
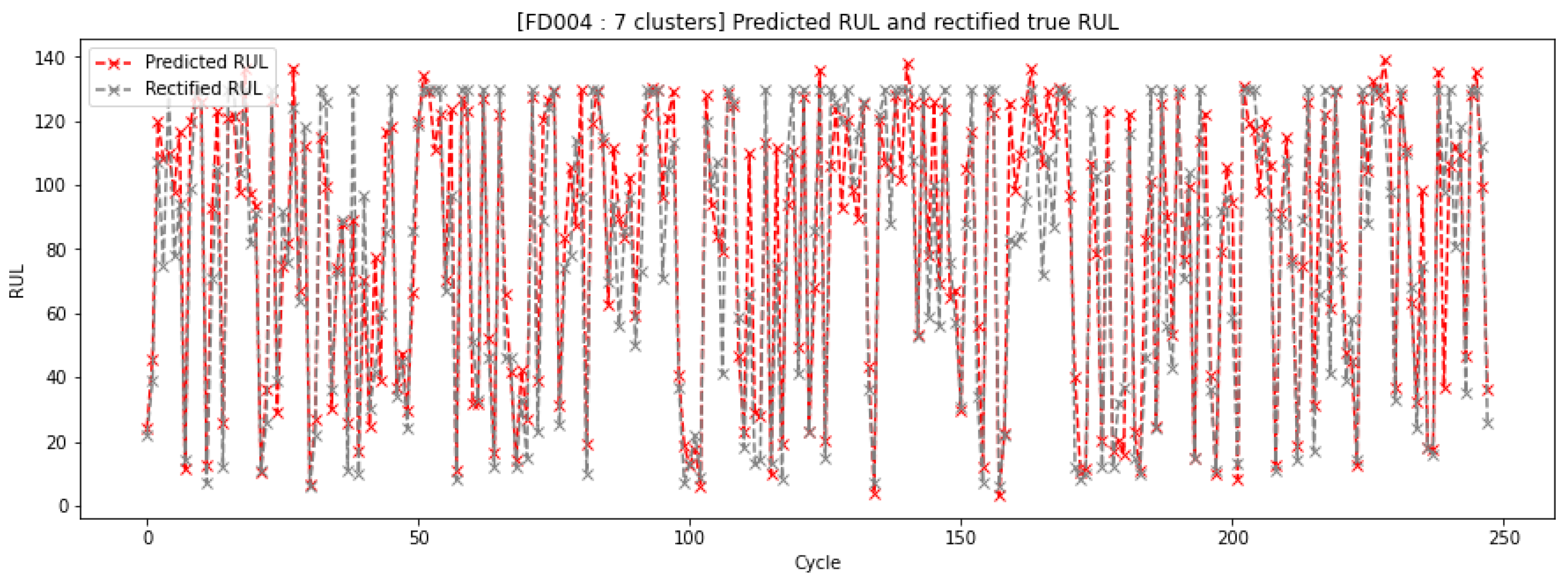
Figure 15.
After examining the predicted error values, it is necessary to evaluate how the error values are translated in terms of actual values, which is why a comparison between predicted and true RUL values is necessary. The dashed red colored line in
Figure 15 represents the predicted RUL values, and the dashed gray colored line represents the given ground truth RUL of the 248 engines of the test subset of FD004. Generally, the predicted values for each engine have a small difference from the true RUL, with some values that were predicted either early or late. Overall, our model performs well in estimating the remaining useful life of the engines, despite some engines being too noisy and affecting the model’s training and performance, especially when the model predicted fewer late RUL values.
6.4. Comparison with Other Work
A comparison of the proposed method with state-of-art studies is presented in
Table 6. It illustrates a comparison of works using the FD004 C-MAPSS dataset and summarizes the researcher with the publication date, network algorithm, predicted RMSE, and S-score results from previous studies. The value in brackets denotes the standard deviation of the metrics for the experiments in the study.
Accuracy has been improved by using advanced deep learning algorithms, with a deeper network layer or by using fusion algorithms. Compared with work carried out in recent years, the RUL predictions of turbofan engines show the effectiveness of our approach. As some methods tend to have a lower S-score or RMSE, the proposed method achieves better results in terms of the trade-off between performance and explainability, while using a simple architecture with only a single-layer LSTM. For a PHM solution, the more insightful the model, the greater its reliability.
6.5. Interpretability of Results
SHapely Additive exPlanation (SHAP) values are a great tool to understand complex tree-based and deep network model outputs. SHAP values can link local and global interpretations. Deep neural networks, known as black-box, are difficult to understand. However, they can be explained by SHAP values, which determine the factors responsible for the outcome and decision. SHAP values are used on independent synthetic features, preventing its limits, in order to understand the role of each factor in an aircraft’s turbofan engine.
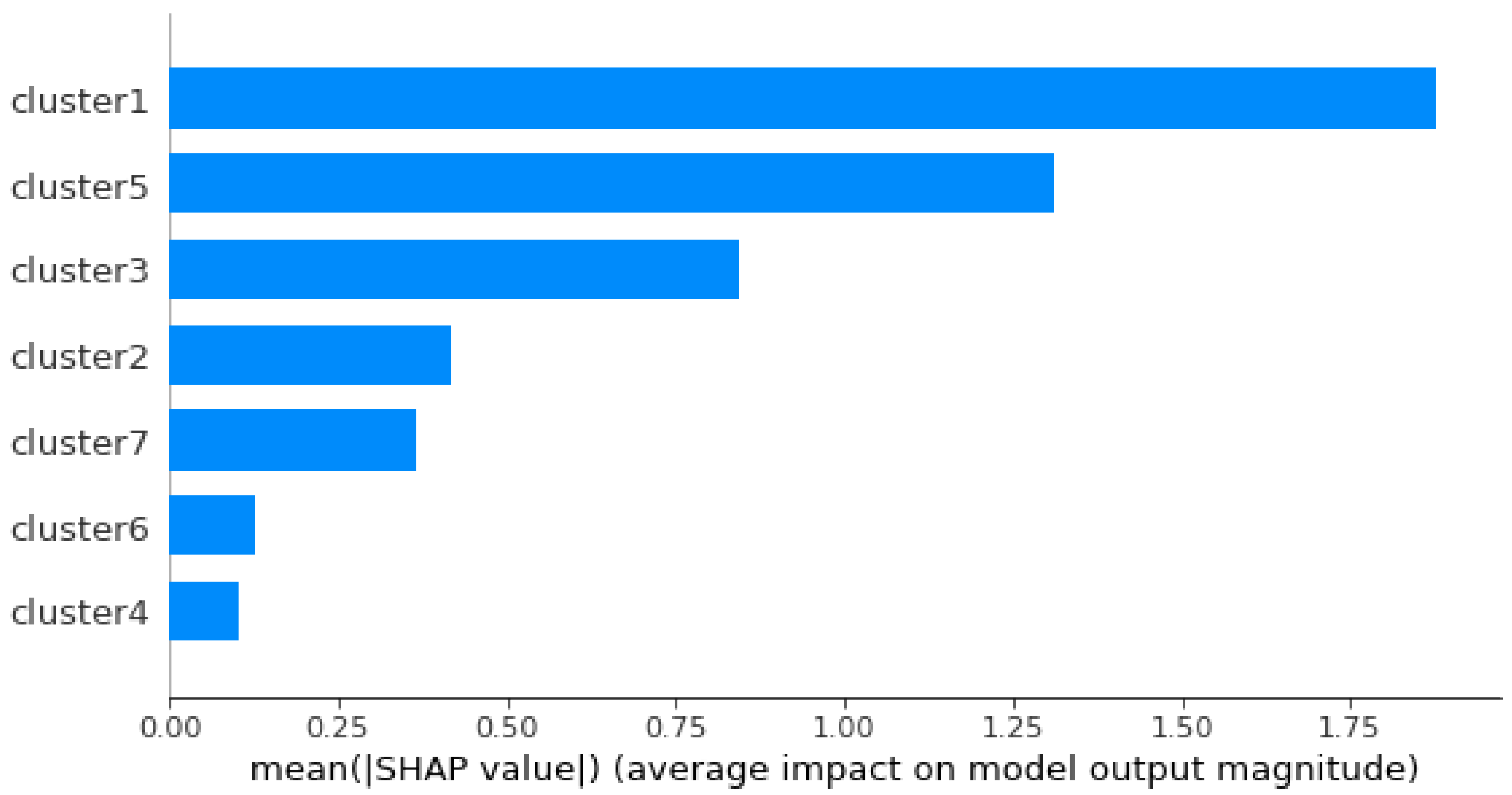
The results of the average SHAP values of the predictive model are shown in
Figure 16. It shows the clusters with the greatest influence on the RUL prediction, placing the largest cluster on top. The x-axis represents the average absolute SHAP values of each cluster. Clusters with larger absolute SHAP values correspond to the most important clusters. Cluster 1 represents the features that contribute the most to the prediction, followed by cluster 5, cluster 3, cluster 2, and cluster 7.
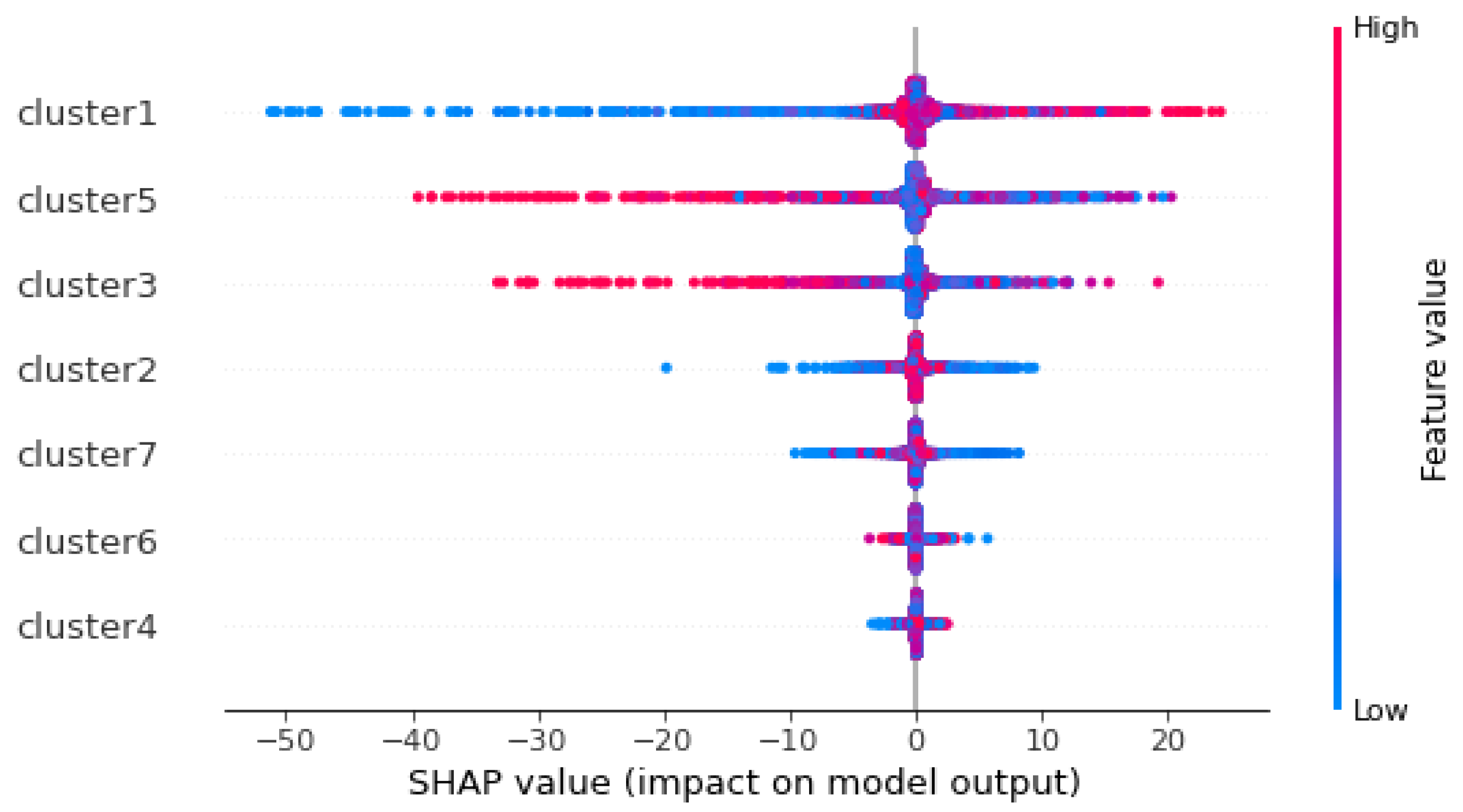
Based on
Figure 17, the x-axis represents the SHAP values, and the y-axis represents all clusters. Red color means a high value of a cluster; blue means a lower value of a cluster. Clusters are presented in order of importance of all clusters, with the first cluster being the most important and the last being the least important. This distribution shows the overall impact of the cluster directions. Clusters 1 and 7, with high values, contributed positively to the prediction, while with low values, they contribute negatively. On the other hand, clusters 5 and 3 have a negative influence on the prediction when they have high values, and a positive influence when they have low values.
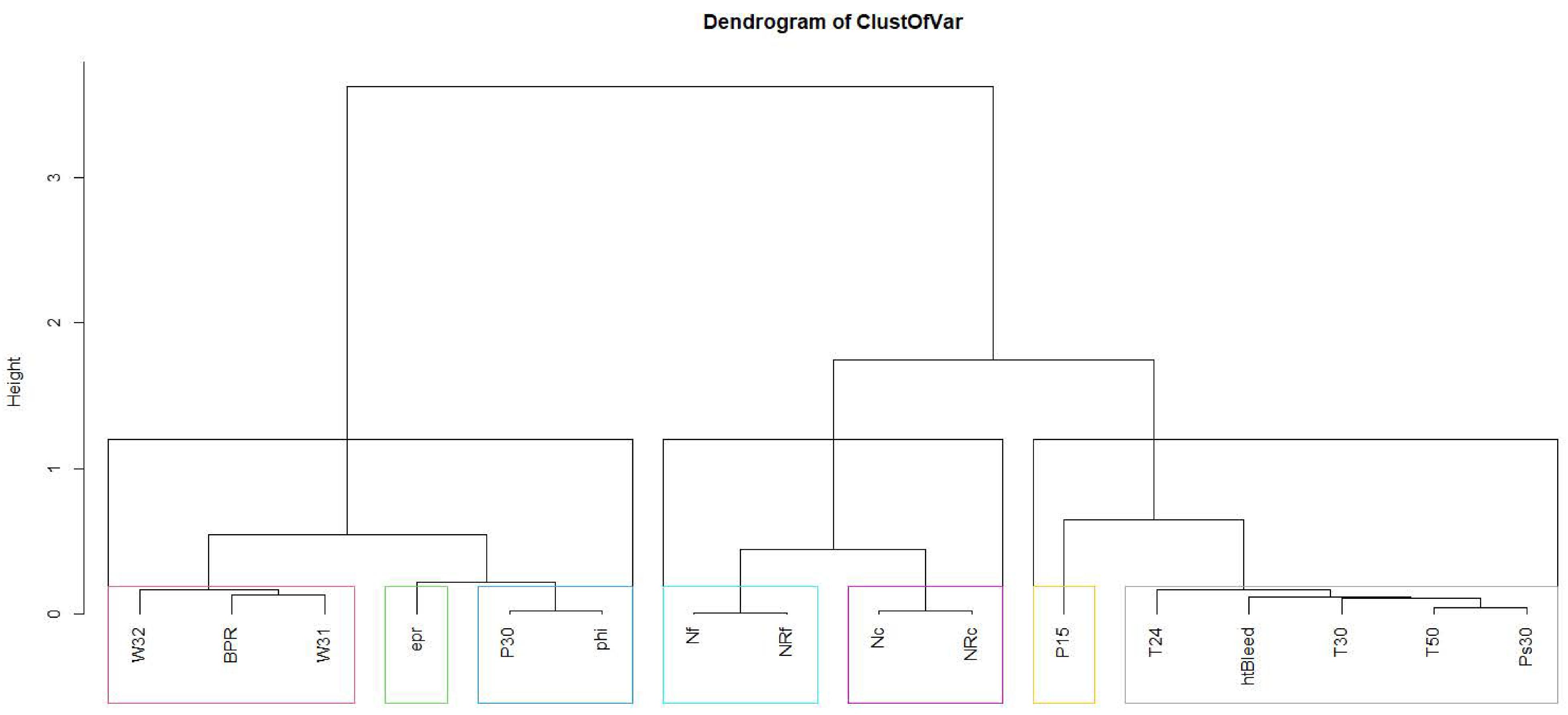
Cluster 2 has a low contribution to the prediction. Clusters 6 and 4 have almost no contribution to the prediction, whether their values are high or low. To relate these results to the initial features, we use the equations found by ClustOfVar in
Section 5.2.3. Cluster 1, represented in Equation (
10) by the combination of features T24, T30, T50, PS30, and htBleed, has a positive contribution when its values are high, and a strong negative contribution when its values are low. A high value of cluster 1 (for each additional value of these features, cluster 1 decreases by 9.6) corresponds to a low value of total LPC outlet temperature T24, total HPC outlet temperature T30, total LPT outlet temperature T50, static pressure at HPC outlet PS30, and purge enthalpy htBleed. They have the greatest power to predict failures; their higher values increase the remaining useful life and subsequently decrease failure degradation. Cluster 5 has a strong negative contribution when its values are high and a positive contribution when its values are low. A high value of Cluster 5 corresponds to a high value of the physical core speed Nc and a high value of the corrected core speed NRc. That means that a low core speed increases the remaining useful life and so the failure degradation decreases. Cluster 3 with low values does not contribute to prediction, but high values cannot specify contribution to the prediction. This cluster is represented in Equation (
12) by the ratio of fuel flow to Ps30 and the total pressure at the HPC outlet. Cluster 2 is represented in Equation (
11) by total bypass-duct. It has a low contribution to the prediction. A high value of total bypass-duct does not contribute to RUL prediction. On the other hand, a high value cannot confirm the way of contribution to the prediction. Cluster 7 is represented in Equation (
16) by bypass ratio, BPR, negatively, and strongly positively by HPT coolant bleed, W31, and LPT coolant bleed, W32. Low values of HPT coolant bleed and LPT coolant bleed correspond to decreased RUL and thus increased failure degradation. We can conclude that:
The higher the values of total LPC outlet temperature T24, total HPC outlet temperature T30, total LPT outlet temperature T50, static pressure at HPC outlet PS30, and purge enthalpy htBleed, the higher chance of failure due to degradation.
Higher values of physical core speed Nc and a high value of the corrected core speed NRc may result in lower RUL values and, therefore, a higher chance of failure due to degradation.
Higher values of , the ratio of fuel flow to static pressure at the HPC outlet, and P30, the total pressure at the HPC outlet, may result in a lower RUL values, resulting in a higher chance of failure due to degradation.
Low values of HPT coolant bleed, W31, and LPT coolant bleed, W32, correspond to decreased RUL and thus increased failure degradation.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}