1. Introudction
With the rapid development of UAV technology, UAVs have been widely used in agriculture, aerial photography, mapping, transportation and rescue fields [
1]. On this basis, UAV cluster technology has also been developed and widely used, such as UAV cluster light show, UAV cluster confrontation and so on [
2,
3]. Compared with manned aircraft, UAVs are cheaper, smaller, and require less of a flight environment. UAV swarms can not only perform complex, diverse and dangerous missions in the traditional sense, such as architectural design, but also play an important role in responding to emergencies [
4]. In the field of UAV cluster confrontation, currently related research is still in the early development stage, and its main difficulty lies in how to remove the traditional artificial path planning, and then realize the intelligent decision making and adaptive cooperation of the cluster itself. In addition, how to realize the optimization of the intelligent decision of cooperative maneuver confrontation in the dynamic confrontation process is also an important issue in the cooperative confrontation of UAV clusters.
From a systems science perspective [
5], unmanned aerial vehicle (UAV) cluster systems are characterized by multi-platform heterogeneity, numerous task demands, input situation changes, complex tactical objectives, and coupled constraint conditions. To address these issues, it is necessary to design an autonomous decision-making and planning framework for multi-task UAV clusters to reduce the complexity of system research. Reference [
6] established a UAV cluster adversarial game model based on uncertain offensive and defensive situation information, and designed a game cost function to calculate the optimal strategy. Reference [
7] proposed a multi-UAV distributed intelligent self-organization algorithm, which decomposes the optimization problem of the cluster reconnaissance-attack task into multiple local optimization problems, and realizes global optimization decision-making through information exchange between the cluster and the environment and within the cluster. Reference [
8] used a deep learning method to construct a task decision-making model for typical cluster tasks such as area reconnaissance, and then optimized the decision-making model based on a genetic algorithm, providing effective support for offline learning and online decision-making of the cluster. However, existing research on UAV cluster autonomous decision-making problems is relatively scarce from a multi-task perspective.
In this paper, we apply the ideas of game theory to the UAV cluster control problem. Game theory is a modern scientific system that originated in the early 20th century and has developed into a complete and rich theoretical science after World War II. Its application to military operations has become a research hotspot for scholars at home and abroad [
9,
10,
11,
12,
13]. Multi-UAV cooperation refers to two or more UAVs cooperating and coordinating with each other to accomplish tasks based on a certain type of motion [
6]. Compared with one-on-one confrontations, the most significant difference in multi-UAV cooperative confrontations is that multiple task goals need to be addressed by allocating targets and firepower among various friendly UAVs according to our resources. However, one of the key issues in the successful completion of tasks by multiple UAVs is the problem of proper coordination between UAVs [
14]. The hot research issue in the field of UAVs is how to use reasonable decision-making strategies to enable UAVs to coordinate with each other to complete complex tasks [
15].
In 1998, Jun Lung Hu [
16] proved that multi-intelligent collaboration converges to the Nash equilibrium point in a dynamic zero-sum game environment, which provides a theoretical basis for UAV cluster collaboration. At present, some constructive research results have been achieved in the field of UAV cluster collaborative countermeasures. Currently, there are four mainstream UAV cluster decision-making and control methods: expert system-based, population intelligence-based, neural network-based, and reinforcement learning-based [
17]. Hubert H. Chin and Bechtel R J et al. [
18,
19] proposed an expert system-based air combat decision-making method that combines fuzzy logic and an expert knowledge base to help pilots make maneuver decisions. Bhattacha- rjee et al. [
20] optimized multi-robot path planning by an artificial swarm method. In addition, particle swarm method [
21], firefly method [
22] and wolf pack method [
23] are also widely used for UAV cluster coordination control. In recent years, UAV cluster coordinated countermeasures have started to be studied using the ideas of real-time analysis of posture and dynamic games. Shao et al. [
4] used Bayesian inference to evaluate the air actual environment in real time by establishing a continuous decision process for multi-UAV cooperative air combat, and used the designed decision rules to make maneuver decisions. Chen Man et al. [
24] built a game model for multi-drone cooperative combat missions by establishing the capability function of UAVs, and gave the finite strategy static game model and pure strategy Nash equilibrium solution method. From the above study, it can be seen that capability and real-time situational analysis for UAV clusters is the basis of the model for dynamic cooperative cluster confrontation [
25].
By summarizing the above articles and existing research, the research in the field of UAV cooperative confrontation mainly has the following four characteristics:
(1). Most of the existing research in the field of UAV cooperative confrontation based on game theory assumes a zero-sum game. Characteristics of a zero-sum game.
(2). Most of the existing research is carried out under the condition of certain information. However, due to the complexity, concealment and transient nature of the battlefield environment, the information required for most UAV operations is often uncertain. Therefore, in the case of less information, considering the ambiguity of information in the process of UAV coordinated ground attack meets the actual combat needs.
(3). On the other hand, most of the existing research on UAV cooperative ground attack task assignment only focuses on unilateral action strategies, but due to the confrontational nature of the combat environment, it is very applicable to consider the opponent’s possible defense strategies when attacking modeling and analysis through game theory.
(4). For the solution of the Nash equilibrium of the game model, the traditional intelligent optimization algorithm still has the shortcomings of weak global search ability and an easy to fall into local optimum, which urgently needs further optimization.
This article mainly discusses the above four issues, and logically it is a layer-by-layer progressive relationship, as shown in
Figure 1,
Section 2. The main work of this paper is to conduct multi-attribute evaluation and target strategy selection on the decision-making set through the situation analysis of both parties, and establish the dynamic non-zero and Nash equilibrium maneuver decision-making model of both parties. On the basis of the first section, the second section mainly introduces the improved dynamic non-zero and Nash equilibrium maneuver decision-making model after considering the ambiguity of information in actual combat and the possible defense strategy of the opponent. In the third section, the improved particle swarm optimization algorithm is used to solve the model proposed in the second section. The last section verifies the advantages of this model algorithm over traditional algorithms with a simulation comparison experiment.
Based on the above analysis, this paper aims at the cooperative confrontation problem of UAV clusters. First, under ideal conditions, that is, the information of both sides of the confrontation is completely accurate and known. Through the situation analysis of both sides, the multi-attribute evaluation of the decision set and the selection of target strategies are carried out to establish a dynamic non-cooperative relationship between the two sides. A zero-sum Nash equilibrium maneuver decision model. On this basis, the ideal conditions are modified, that is, considering the actual environment of the battlefield, including the performance difference of the drones of the two sides of the game, it is impossible for us to grasp the accurate information of the opponent in time, and because the radio environment of the battlefield is relatively complex, there may be data errors caused by ground information warfare forces interfering with our information acquisition. This paper improve the dynamic non-zero and Nash equilibrium maneuver decision-making model. Afterwards, through the improved particle swarm optimization algorithm, the efficient calculation of the Nash equilibrium solution of the non-zero-sum game model is realized, and the optimal mixed strategy of both parties is obtained. Finally, the effectiveness of the proposed method is verified by numerical simulation experiments.
2. Mathematical Modeling of Dynamic Non-Zero-Sum Game and Nash Equilibrium Decision-Making under Ideal Conditions
Before discussing the model in this section in detail, the following definitions are given first:
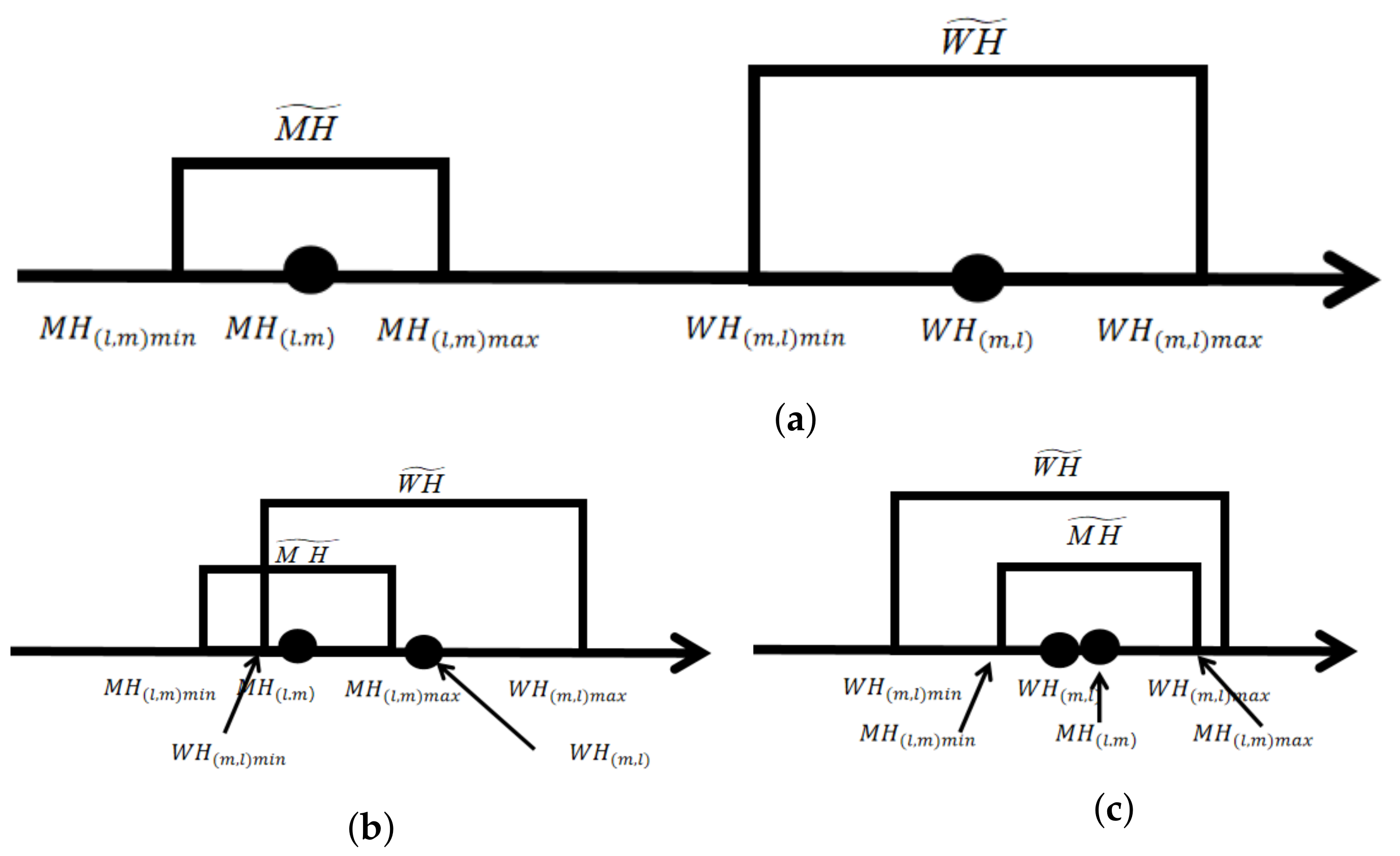
Definition 1. Non-zero-sum game [26]: Non-zero-sum game is opposite to zero-sum game. A zero-sum game means that the sum of the interests of all players in the game is fixed, that is, if one party gains something, the other party must lose something. A non-zero-sum game means that the sum of the gains of each player under different strategy combinations is an uncertain variable, also known as a variable-sum game. Definition 2. Nash Equilibrium [27] (Nash Equilibrium Point): It refers to the non-cooperative game (Non-cooperative game) involving two or more participants, assuming that each participant knows the equilibrium strategy of other participants, a conceptual solution in which no player can benefit himself by changing his strategy. Definition 3. The non-zero-sum attack-defense game model (NADG), is a quaternion = {W, M, S, WH}:
W and M are collectively referred to as participants, where W represents the attacker and M represents the defender.
is the strategy set. In this paper, the strategies of all participants are the same, which are maintaining the original flight state, accelerating, decelerating, turning left, turning right, climbing and diving.
is the income function matrix of both attackers and defenders.
2.1. Model Assumptions
(1) Under ideal conditions, it is assumed that both parties can grasp all the complete and accurate information of the other party, and the information is instantaneous, and there is no time difference in the dissemination of information.
(2) Assuming that the objective conditions (including weather, equipment, etc.) are good, the onboard computer can accurately calculate the relevant data based on the global information, and the error is negligible.
(3) Assuming that the UAV cluster flight trajectory is discretized, that is, the confrontation trajectory between the two sides is composed of several maneuvers.
2.2. Set of Maneuvering Strategies for Both Sides of the Game
For dynamic UAV confrontation, the strategy set of dynamic non-zero-sum game Nash equilibrium maneuvering decision needs to be established. The red and blue UAV swarms are named
W and
M, respectively, where the
W UAV swarm consists of
p individual UAVs and the
M UAV swarm consists of
q individual UAVs. In the process of confrontation between the two sides, by assumption (3), their flight trajectories can be considered as a combination of several consecutive maneuvers, which are maintaining the original flight state, accelerating, decelerating, turning left, turning right, climbing, and diving, in order to be recorded as
. In summary, the overall strategy set of the drone swarm can be expressed as
where the maneuvering strategy of individual square drones is
. Since the strategy number of each individual drone is 7, the strategy numbers of drone group
W and drone group
M are
and
, respectively.
2.3. Maneuver State Assessment of Both Sides of the Game
In the text, based on the research of Zhang Shuo et al. [
28], the situational advantage equation function is used to evaluate and qualitatively describe the state of maneuvering attributes of both players in the game. Assume that in the actual combat process, the maneuver attributes are mainly characterized qualitatively by distance advantage, speed advantage, and angle advantage, and each advantage is characterized by the existing situational advantage equation. By weighting and summing the above three advantages, the dominant state of the UAV group at a certain moment can be obtained.
Record the maneuvering attribute as
Q, distance advantage
D, speed advantage
V, and angle advantage
A.
Define
as the speed advantage of a single existing drone over a single enemy drone:
where
D is the Euclidean distance between the two sides of the game,
is the maximum starting distance,
is the minimum starting distance,
where
,
are, respectively, determined by the attribute parameters of the UAVs of both sides of the game.
Define
as the speed advantage of your own single UAV over the target UAV:
where
is the individual flight speed of
W UAV group and
is the individual flight speed of
M UAV group.
From the above speed advantage function, it can be seen that when the speed of the own drone is greater than 1.5 times the speed of the target drone, the speed advantage is the largest.
Define
as the speed advantage of a single UAV of one’s own side relative to a single UAV of the enemy.
Among them,
is the incident angle of the target, and
is the angle of view of the own side’s single UAV.
and
can be calculated from the real-time position, declination angle, pitch angle and other information of both parties. From the above angle advantage function, it can be found that when the target incident angle
is larger and the viewing angle
is smaller, the angle advantage
is greater.
2.4. Establishment of the Overall Dynamics and Payoff Matrix of a Single Game per Unit of Time
2.4.1. Overall Posture Matrix
From
Section 2.2, the number of strategies for UAV group
W and UAV group
M are
and
, respectively. When
W adopts the
l (
) strategy and
M adopts the
mth (
) strategy, the
ith (
) individual UAV in
W has the distance advantage, speed advantage and angle advantage for the
jth (
) individual UAV in
M. The distance advantage, speed advantage and angle advantage of the individual UAV are
, respectively. The overall posture can be obtained as follows.
where
are the overall posture weighting parameters, and
.
Therefore, the matrix WX is the overall posture matrix of the UAV swarm W when the UAV on the W side adopts the 1st strategy and the UAV on the M side adopts the m strategy.
The matrix WX is the overall posture of
W to
M. Similarly, the matrix MX can be built in the same steps.
jth individual of
, its distance advantage, speed advantage and angle advantage to
ith
individual UAVs of UAV group
W are
, and the overall posture can be calculated as
where
are the overall posture weighting parameters, respectively, and
.
Therefore, matrix WX is the overall posture matrix of UAV swarm M when UAV on M side adopts the m strategy and UAV on W side adopts the lst strategy. Therefore, the matrix is the overall situation matrix for the UAV group M when the M-side UAV adopts the Mth-th strategy and the W-side UAV adopts the lth strategy.
2.4.2. Overall Payoff Matrix
Based on the establishment of the overall situation matrix in the previous section, the income matrices (also called payment matrices) of W and M are, respectively, established according to different strategy sets. In actual scenarios, cluster confrontation strategies can be divided into global confrontation strategies, local confrontation strategies, global penetration strategies and local penetration strategies. The profit matrix under different strategies is different. This article mainly considers the global object, so the following mainly uses W as an example to introduce the establishment process of the profit matrix under the global confrontation strategy and the profit matrix under the global penetration strategy.
- (1)
Global confrontation strategy. The main objective of this strategy is to optimize the overall posture of our side, and according to this objective, the gain matrix of
W can be obtained:
- (2)
Global penetration strategy. The main objective of this strategy is the worst overall posture of the opponent, and according to this objective, the gain matrix of
W can be obtained:
Similarly, the payoff matrix of M under different strategies can be built based on the above steps. Similarly, in this paper, only the gain matrices of the global confrontation strategy and the global surprise strategy of M are illustrated.
- (3)
Global confrontation strategy. The main objective of this strategy is to optimize the overall posture of our side, and according to this objective, the gain matrix of
M can be obtained:
- (4)
Global penetration strategy. The main objective of this strategy is the worst overall posture of the opponent, and according to this objective, the gain matrix of
M can be obtained:
In summary, the preparation of the mathematical model for dynamic nonzero and Nash equilibrium decision making under ideal conditions is basically completed. Since the model in this section is based on the assumption of ideal conditions, the mathematical model will be improved in the next section of this paper to make it closer to the actual situation, which in turn makes the decision more accurate and informative.
5. Simulation Experiments of UAV Cooperative Dynamic Maneuver Decision Algorithm
Based on the UAV cluster adversarial algorithm model based on asymmetric uncertain information environment proposed in the previous two sections, numerical simulation experimental results are presented in this section to verify the validity of the model. The simulation experiments apply the game confrontation steps in
Section 3.3, in which the adaptive algorithm in
Section 4.2.2 is used to optimize the speed of the algorithm in “calculating the Nash equilibrium solution of the non-zero-sum game and obtaining the optimal hybrid strategy for both sides of the single-step game”.
In order to compare the superiority of the proposed algorithm,
W uses the “global adversarial strategy” of the UAV cluster adversarial algorithm based on asymmetric uncertain information environment proposed in this paper, and
M uses the classical global adversarial strategy based on the maximum–minimum pure strategy [
31]. The following
Table 1 shows the initial parameters of the numerical simulation experiment.
Substituting the initial conditions into Equations (
3)–(
5), we can see that
M has a clear advantage in angular posture in the initial stage of the confrontation. In the total 40 steps of the confrontation, they can be roughly divided into “posture equilibrium phase”, “cooperative confrontation phase” and “absolute advantage phase”, and part of the confrontation process is shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. The red “
” is the path trajectory position of
W at each step, and the blue “*” is the path trajectory position of
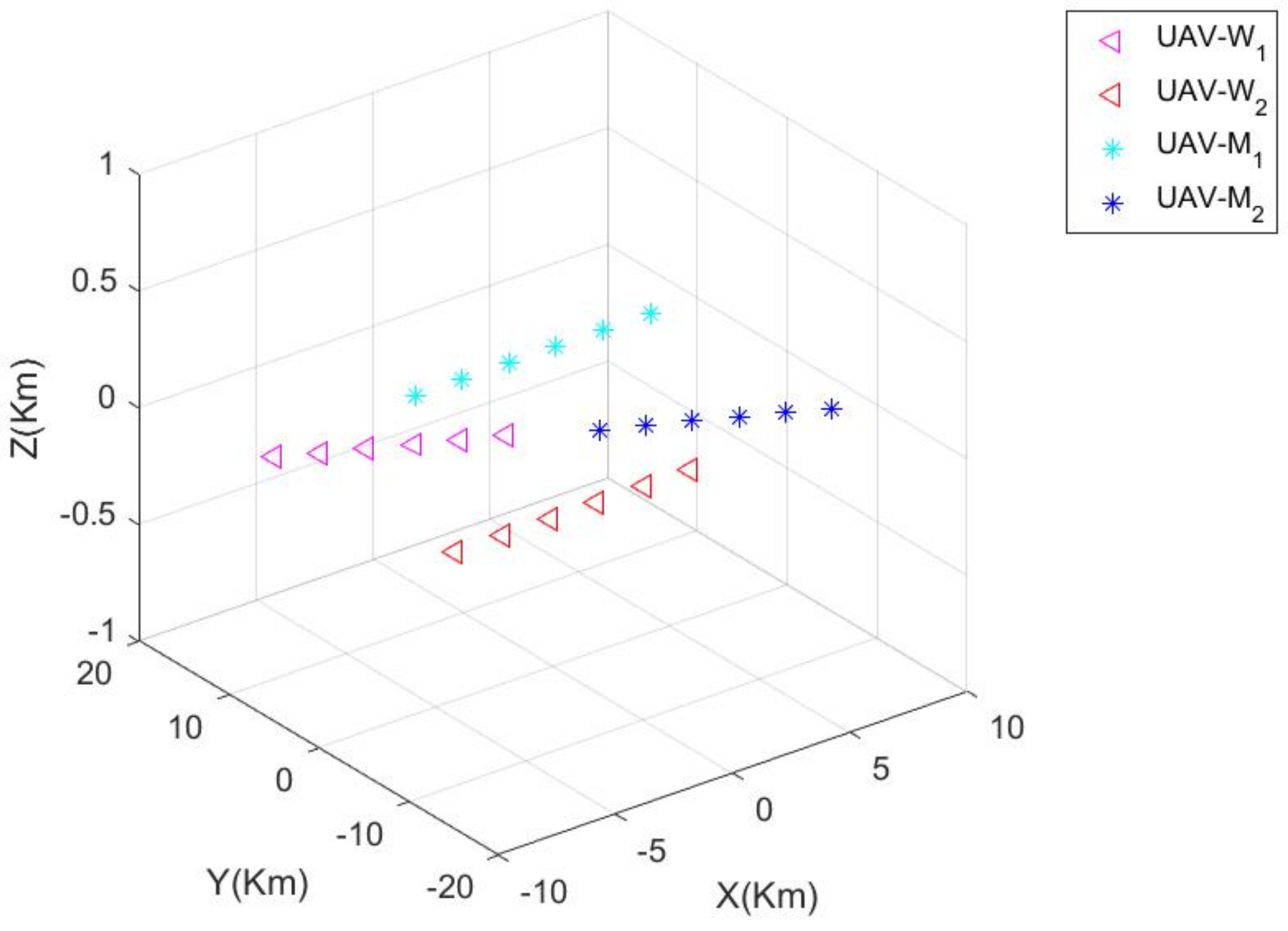
M at each step. The confrontation ends when one side has an absolute advantage over the other side or reaches the maximum number of confrontation steps.
The first stage is the situational balance stage (see
Figure 3 and
Figure 4). The initial positions of the two sides are far apart. In the fifth step, the two sides enter the opponent’s combat radius, and a confrontation situation occurs.
and
are close to each other and confront each other, and
and
approach each other against each other, as shown in
Figure 3.
When the first stage reaches the 10th step,
adjusts the pitch angle by a large margin in order to increase the advantage of the situation, and quickly raises the height of the UAV. Since
is relatively close to
, in order to maintain the overall advantage of
M and
W,
also quickly adjusts the pitch angle and follows
to reach a higher altitude; while
is responsible for continuing to approach
to expand its own advantages. At this time, due to the hysteresis of the
response,
has a greater advantage over
; while
is in a tracked state, therefore,
has a greater advantage over
. In the first stage, the two sides have not yet formed a cooperative confrontation, and are still in the stage of balanced confrontation. The confrontation process of step 10 is shown in
Figure 3.
The second phase is the postural equilibrium phase (see
Figure 5 and
Figure 6). At the 14th step,
is still at a disadvantage relative to
, but because
could not form an absolute advantage over
alone due to the large distance and the limitation of the single-step deflection angle change,
gave up the strategy of fighting
alone and makes a strategic adjustment of approaching
and cooperating with
to surround and fight
. And
could not change the direction in time to assist W1 due to the long distance; at this time,
and
as a whole maintain the advantage over
, as shown in
Figure 5.
Figure 6 shows the 20th step,
collaborates with
to approach
, at this time
completely removes
, and the
form is intertwined, the advantage of both sides is still not obvious, because the distance
in a shorter number of steps fails to approach
in time, and
together form a pincer attack on
. As shown in
Figure 6, at this time, the local gradually forms two against one state, and W’s overall posture advantage gradually forms.
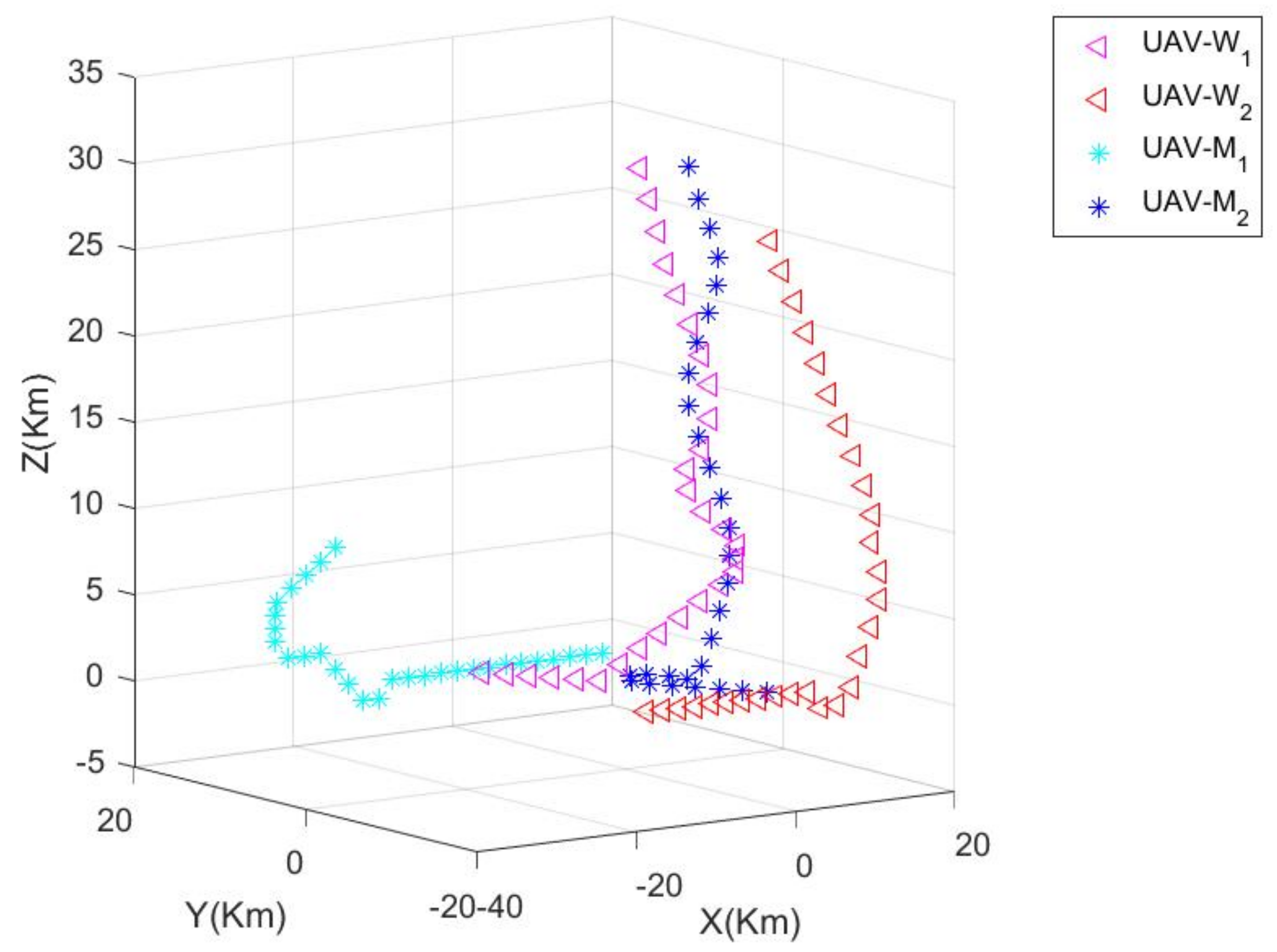
The third phase is the absolute advantage phase (see
Figure 7 and
Figure 8), in which
W maintains the absolute advantage of the overall posture. In step 31 (see
Figure 7),
W maintains the posture of pinning
, with two chasing one, and the threat to
W basically disappears as
maintains a large distance between
and
W.
W maintains the absolute advantage of the overall posture.
Figure 8 shows the course of the confrontation between the two sides at step 36. In terms of the overall confrontation posture,
W maintains the absolute advantage of the overall posture into the third phase. At this point, the confrontation ends.
6. Conclusions
In this paper, a more practical UAV cluster cooperative adversarial decision algorithm based on a dynamic non-zero-sum game under uncertain asymmetric information is proposed based on the actual situation. This article mainly completed the following work:
1. Firstly, based on the actual situation of the actual field, the posture advantage of the adversarial parties under ideal conditions is calculated, and thereafter the gain matrix of the adversarial parties under ideal conditions is further calculated.
2. Secondly, considering the uncertainty of both adversaries in acquiring information and the complexity and variability of the real-time field situation, the information acquired by both adversaries is not the exact value, and the gain matrices of both sides of the game are modified. Then, the particle swarm algorithm is improved to solve the dynamic non-zero and Nash equilibrium maneuver decision model efficiently and quickly to obtain the optimal hybrid strategy based on the actual situation.
3. Finally, a 2-to-2 unmanned cluster cooperative countermeasures simulation experiment is given to verify the superiority and realism of the algorithm proposed in this paper to solve the UAV cooperative countermeasures problem.
Based on the idea of non-zero-sum game, this model regards the solution of Nash equilibrium as the maneuvering action of the UAV cluster. Compared with the traditional model, it has the following advantages:
1. Optimal Strategy: A Nash Equilibrium is an optimal strategy in which each player cannot improve his individual payoff by changing his own strategy given the strategies of the other players. This means that the Nash equilibrium strategy adopted by drone clusters is not easy to be defeated, and it is a relatively stable strategy. It is more suitable for objects such as drones that require high stability.
2. Predictability: Nash equilibrium can be used to predict and understand various game scenarios, especially in complex environments where multiple parties interact. By analyzing and calculating the Nash equilibrium, the drone swarm can speculate on the possible behavior and outcomes of the participants, so as to better predict and plan the strategy of the swarm.
3. Stability: Nash equilibrium is theoretically stable. Even in the face of some disturbances or external pressures, participants will tend to stick to their equilibrium strategies. This stability can help maintain a balanced state of the game and reduce possible conflicts and confrontations. In a more complex actual environment, external disturbances or changes are very frequent. If the UAV cluster changes its strategy too frequently, it will cause damage to itself.
Although this paper has performed some research on the UAV swarm confrontation decision-making problem based on incomplete information, there are still some unresolved problems:
1. In this paper, incomplete information refers to unknowable information such as enemy strategy, enemy revenue, and the partially observable environment when making simultaneous decisions, and does not discuss in depth the unavailable information and untrustworthy information of incomplete information.
2. This paper simplifies the flight process in the UAV swarm air-to-air confrontation environment, and does not take into account the flight characteristics of the UAV itself. In future work, we will focus on a swarm confrontation that is closer to the real environment, including specific attack processes such as missile attacks. In addition, the complex environmental characteristics of the real battlefield have not been fully considered, such as electromagnetic space, weather effects, etc.
3. In the process of UAV swarm confrontation, problems such as large-scale (number greater than 1000) will lead to joint state-action dimensional explosion and dynamic changes in the number of UAVs (scalability) are not considered, which does not meet the requirements of swarm operations actual needs.
To sum up, although this paper has made further research on the basis of existing research, there is still a big gap with the actual environment. The above points will be the key issues of our next research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}