2.1. Models with Constant Probabilities of Correct and Incorrect Decisions
In this subsection, we analyze corrective and preventive maintenance models with constant conditional probabilities of correct and incorrect decisions during inspections.
Corrective maintenance involves fixing or replacing equipment or components after they have failed. It is a reactive approach to maintenance, where repairs are carried out in response to identified issues or failures during regular inspections or when equipment breaks down.
Preventive maintenance is a proactive maintenance strategy that involves regularly scheduled inspections, tests, and servicing of equipment to prevent potential failures before they occur. This approach aims to identify and address issues early, minimizing the risk of breakdowns and prolonging the lifespan of the equipment.
Given that the system inspection is presumed to be imperfect, it is possible to make both correct and incorrect decisions. To characterize incorrect decisions during the inspection of systems, such concepts as false positive and or false negative are usually used. It should be noted that these concepts are borrowed from classification theory. A false positive is an event in binary classification in which a test result incorrectly indicates the presence of a condition. A false negative is the opposite event, where the test result incorrectly indicates the absence of a condition when it is present. With respect to the inspection of system health, two interpretations are possible for the terms “false positive” and “false negative.”
False positive: The inspection’s decision incorrectly indicates an operable system condition when it is not operable.
False negative: The inspection’s decision incorrectly indicates an inoperable system condition when it is operable.
- 2.
If the condition is “system inoperability:”
False positive: The inspection’s decision incorrectly indicates an inoperable system condition when it is operable.
False negative: The inspection’s decision incorrectly indicates an operable system condition when it is inoperable.
In articles on maintenance models with imperfect inspections, the second interpretation of the concepts of false positives and false negatives is more often used. Therefore, in the survey, we will adhere to the second interpretation.
Let us represent the conditional probability of a false positive and a false negative as α and β, respectively.
When the system is inoperable (referred to as the “positive state”) and correctly identified as inoperable based on the inspection results (termed a “positive decision”), this occurrence is known as a true positive. We denote the conditional probability of this event as 1 − β.
When the system is operable (referred to as the “negative state”) and is correctly identified as operable based on the inspection results (termed a “negative decision”), this occurrence is known as a true negative. We denote the conditional probability of this event as 1 − α.
Table 1 shows the distribution of system states, inspection decisions, and corresponding conditional probabilities.
In 1961, ref. [
5] addressed an inspection scheduling problem involving a system with an operational lifespan not exceeding finite time
T. Assuming no prior knowledge of the probability density function (PDF) of the time to failure,
ω(
t), the author derived a minimax inspection policy that minimized the maximum potential expected cost across all conceivable density functions. The time of inspection,
xi, depended on the inspection cost, the penalty incurred due to the system being in a failed state per unit time, and the conditional probability of failure detection (
p = 1 −
β).
In 1962, ref. [
6] obtained the asymptotic availability of a system with exponential failure distribution, assuming a false negative error in the periodic inspection model.
In 1962, ref. [
7] proposed the following equation to calculate operational readiness, under which they understood the long-run availability:
where
λ is the rate of hidden failures,
T is the duration of the standby period,
Tc is the duration of the checkout period,
Tp is the duration of the replacement (repair) period,
q is the probability of failure during a checkout period,
pc is the probability of failure occurring before the actual test if the failure occurs during a checkout period, and
E = 1 −
β.
In 1968, ref. [
8] proved a theorem stating that if the following inequality is not fulfilled, the optimal checking policy will involve one or more inspections within the interval (0,
T):
where
T is the finite time,
x is the time of the first inspection,
F(
x) is the cumulative distribution function,
C1 is the cost of one inspection,
C2 is the loss cost per unit of time due to unrevealed failure, and
P is the conditional probability of detecting failure through one inspection. Obviously,
P = 1 −
β.
In 1974, ref. [
9] focused on determining the most effective inspection policies for a system in which the time spent on checking is non-negligible. The study considered the possibility of encountering two types of inspection errors: type I (false positive) and type II (false negative). The authors determined optimal inspection policies based on three distinct objective functions: expected loss per cycle, per unit of time, and per unit of productive time.
In 1979, ref. [
10] proposed the following equation for the achieved availability of a periodically inspected system with an exponential distribution of hidden failures:
where
τ is the periodicity of inspection,
tins is the average duration of inspection, and
tCR is the average time of a corrective repair.
In 1979, ref. [
11] delved into the problem of determining optimal inspection intervals for a technical system and analyzed how errors, such as false positives and false negatives, influenced maintenance costs. The research established optimal inspection strategies for various probability distributions of time to failure. Furthermore, the study explored the impact of probabilities
α and
β on inspection periodicity.
In 1981, ref. [
12] proposed a Markov model for calculating the average unit cost of corrective maintenance:
where
M1(
C0) is the mathematical expectation of costs per step for the case when the measured and actual states of the system coincide,
M2(
C0) is the mathematical expectation of costs in the presence of inspection errors, and
p is the probability of correctly determining the system’s state.
As we can see, Equation (4) does not consider the event of multiple inspections of the system during operation.
In 1981, ref. [
13] examined a one-unit system that encountered two types of failures: a type 1 failure that is immediately apparent and a type 2 failure that can only be identified through inspections. In the event of a type 2 failure, the system malfunctions. All failures adhere to an exponential distribution pattern. Inspections have a probability of detecting a type 2 failure, denoted as
p = 1 −
β. The study aimed to ascertain the long-term average cost per unit time.
In 1981, ref. [
14] (also referenced in [
15,
16]) proposed the following cost function of losses, considering the probabilities of inspection errors, for a minimax maintenance strategy in the interval (0,
T]:
where
n is the number of inspections in the interval (0,
T),
c is the cost of inspection,
S is the penalty for judging the system to be inoperable when it is operable,
c1 is the average loss per unit time due to the system being in a hidden failure state,
q =
α, 1 −
p =
β, and
ξ is the time of failure.
In 1981, ref. [
17] (pp. 129–136; also referenced in [
18]) examined a minimax maintenance strategy
involving imperfect inspections with a recheck of the rejected systems. The inspection schedule is planned within the time range (0,
T]. The initial inspection takes place at time
t1, where
t1 > 0, and the final inspection occurs at time
. The minimax inspection strategy (
) adheres to the following conditions:
- (1)
The quantity of checks within the interval (0,
T) is determined as the maximum positive integer
N* for which the inequality still holds:
- (2)
The inspection timings are determined through a recursive equation:
where
is the cost of inspection,
is the cost of recheck, and
Q is the average loss per unit time due to the system being in a hidden failure state.
Example 1. Calculation of minimax inspection policy schedule when T = 2000 h, Q = USD 60/h, , α = 0.03, and β = 0.05.
The minimax inspection policy schedule is as follows: , (145.4, 283.4, 414, 537.2, 653, 761.3, 862.2, 955.7, 1042, 1121, 1192, 1256, 1312, 1361, 1403, 1437, 1464, 1483, 1495).
In 1981, ref. [
19] proposed the following formula for calculating achieved availability, which considers the characteristics of current inspection and automated test equipment (ATE) self-testing:
where
R(
t) is the reliability function,
is the posterior probability of operability of the test object just after the current inspection,
is the posterior probability of the ATE operability that is self-tested just before the current inspection,
τ is the inspection periodicity, and
is the maintenance duration.
The posterior probability of the system operability is determined by the Bayes formula [
19]:
where
P is the prior probability of the system’s operability.
For instance, if , τ = 500 h, , , and , the achieved availability is 0.9.
In 1982, ref. [
20] addressed the challenge of determining the optimal inspection procedure for a system with an exponential random variable as its time to failure. The study devised a straightforward optimal inspection schedule, accounting for type II (false negative) inspection errors, with the objective function being the expected cost until failure detection.
In 1984, ref. [
21] (also referenced in [
22]) applied the technique of delay time analysis to industrial plant maintenance. A basic model of inspection maintenance was presented where inspections are independent of each other, and a defect is identified with the constant probability 1 −
β. The downtime per unit time is also determined.
In 1984, ref. [
23] (also referenced in [
24]) considered a maintenance model with imperfect inspections. It was assumed that system failure is detected by inspection with conditional probability 1 −
p and not detected with probability
p =
β. The optimal inspection policy that minimizes the total expected cost is determined.
In 1984, ref. [
25] examined a maintenance model in which inspections are conducted for a fixed duration, and the system’s failure cannot be detected with a constant probability of
p =
β. The total expected cost is also given.
In 1985, ref. [
26] (also referenced in [
27], p. 77) presented the following equation for the posterior reliability in the interval (
kτ,
t),
kτ <
t ≤ (
k + 1)
τ assuming the exponential distribution of time to hidden failure:
The term “a posteriori reliability,” as used by the author, refers to the conditional probability of the system’s continued non-failure operation within the interval (kτ, t). This condition holds provided that, based on the inspection results at moments τ,..., kτ, the system was deemed operable. This metric is typically employed for non-repairable systems.
The value of the posterior reliability is changed from a maximum when t = kτ to a minimum when t = (k + 1)τ. For example, when , α = 0.05, β = 0.02, and τ = 300 h, then PA(kτ, kτ) = 0.997 and PA[kτ, (k + 1)τ] = 0.858 for k = 1, 2, …
Figure 1 illustrates the dependence of posterior reliability on operating time.
In [
27] (p. 78), the steady-state value of posterior reliability was determined:
For instance, using the data in
Figure 1, one can calculate that
0.858.
In 1988, ref. [
28] explored the optimal inspection policy for a single-unit system that is prone to hidden failures over an infinite time horizon. In this model, the failure time of the system follows an exponential distribution. The inspections are not perfect; hence, there is a possibility of errors occurring with conditional probabilities
a =
α and
b =
β. The first inspection is carried out after a time interval of
x and, subsequently, inspections are conducted periodically with a time interval of
y. The overall expected cost from the start of the system’s operation at time 0 until the detection of the failure is calculated as follows:
where
cc is the inspection cost,
kr is the cost due to a false positive, and
kf is the cost per unit time incurred from the moment of the system failure to its detection,
, and
.
The optimal values of x and y are determined from the condition of minimizing the function C(x, y).
In 1988, ref. [
27] (p. 90; also referenced in [
29]) found that under three met conditions, the conditional probabilities of a false positive and a false negative at multiple inspections are independent of time. These conditions are as follows: firstly, the system’s time-to-failure distribution is exponential; secondly, the distribution density of the state parameter measurement error does not vary with time; and thirdly, the operability and inoperability states of the system correspond to only two different values of the system state parameter.
In 1988, ref. [
27] (pp. 63, 100; also referenced in [
30] (pp. 57, 58), [
31,
32]) considered a mathematical model of corrective maintenance in the interval (0, ∞) with multiple imperfect inspections for a system that can be in one of the following states:
Inspections are assumed to be periodic, and the inspection times are much less than the intervals between inspections. The average duration of the system’s stay in various states was determined with an exponential PDF of time to failure
ω(
t) =
λexp(−
λt) [
27].
The expected value of time spent by the system in state
S1:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
where
tFR is the average time to repair of a falsely rejected system and
tTR is the average time to repair of a failed system.
Table 2 shows the limit values of
MS1,...,
MS5 (see [
27], p. 101; [
30], p. 58; and [
31]).
Table 2 indicates that as
λ approaches 0, the duration of the system’s operable state is solely based on the
τ/
α ratio. For example, if
, 1/
λ = 100,000 h,
τ = 10 h, and
α = 0.01, then
τ/
α = 1000 h, which means that the mean time between removals is 100 times shorter than the mean time to failure.
Example 2. Calculation of MS1, …, MS5 for an avionic system if τ = 5 h, , tFR = 1 h, tTR = 2 h, tins = 0.25 h, and α = β = 0.0001, 0.001, and 0.01.
Table 3 shows the calculation results.
As shown in
Table 3, the conditional probabilities
α and
β significantly impact a system’s average duration in different states. For instance, when
α changes from 0 to 0.01, the average duration of a system in an operable state decreases by more than 40 times.
The formulas used to determine achieved availability, inherent availability, and average maintenance cost per unit time are given in [
27]:
where
CQ is the average loss per unit time due to the system being in a hidden failure state,
Cins is the cost of one inspection per unit time,
CFR is the cost of repairing a falsely rejected system per unit time,
CTR is the cost of repairing a failed system per unit time, and
is the average length of the regeneration cycle, which is determined as follows [
27]:
In deriving Equations (19)–(21), the authors utilized a well-known property of regenerative stochastic processes [
33]: in such processes that describe the evolution of a technical system over time, the proportion of time the system spends in any state is equal to the ratio of the average time spent in that state during the periods between moments of regeneration to the average duration of this period.
Example 3. Calculation of optimum periodicity to minimize average maintenance cost per unit time for a system with , CQ = USD 5000/h, CFR = USD 500/h, CTR = USD 2000/h, Cins = USD 250/h, and α = β = 0.0001 or 0.01.
Figure 2a shows the average maintenance cost per unit time dependence versus inspection periodicity. It shows that increasing the conditional probabilities
α and
β from 0.0001 to 0.01 results in an increase in the optimal inspection periodicity from 38 h to 41 h and an increase in the minimum average maintenance cost per unit time from USD 71.2/h to USD 85.1/h, i.e., an increase of 19.5%.
The equations for achieved availability and inherent availability of a single unit system are derived by substituting Equation (14) through (18) for Equations (19) and (20) ([
27], pp. 103, 104).
Example 4. Calculation of optimum periodicity to maximize achieved availability for a system with , tFR = 10 h, tTR = 50 h, tins = 5 h, and α = β = 0.0001 or 0.01.
Figure 2b shows the achieved availability dependence versus inspection periodicity.
From
Figure 2b, it follows that increasing the conditional probabilities
α and
β from 0.0001 to 0.01 results in a decrease in the maximum achieved availability from 0.911 to 0.899, a reduction of 1.3%. Thus, inspection trustworthiness has a relatively small impact on achieved availability.
In 1988, ref. [
27] (pp. 92, 97; also referenced in [
34]) determined
MS1,...,
MS5 for the finite-horizon maintenance policy with the system states in (13) and the exponential distribution of time to failure as follows:
The expected value of time spent by the system in state
S1:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
where
N =
T/
τ − 1 is the number of inspections in the interval (0,
T). Inspection is not conducted at time
T, and the system is renewed irrespective of its state.
When N ∞, the calculation results by Equations (25)–(29) are the same as those by Equations (14)–(18).
The maintenance efficiency indicators are determined by Equations (19)–(21).
One more indicator of the maintenance efficiency of aviation systems is the mean time between unscheduled removals (
MTBUR).
MTBUR, an operational metric, is calculated by dividing the total flight hours of a fleet by the number of unscheduled onboard component removals. Within the considered maintenance model,
MTBUR is determined as follows [
34]:
Table 4 shows the limit values of
MS1,...,
MS5 [
34].
Table 4 demonstrates that as λ approaches 0, the average durations of
,
,
, and
, are solely determined by the probability
α and the number of inspections
N within the interval (0,
T). Conversely, as
λ approaches infinity, the average durations of
,
, and
primarily depend on the probability
β and the number of inspections
N within the interval (0,
T).
Figure 3 illustrates the relationship between the average duration of stay of a single-unit avionics system in operability
(a) and hidden failure
(b) states and the number of checks within the interval of 0 to 4000 h, with a given value of
. Curves 1, 2, and 3 represent the scenarios where
α =
β = 0.001,
α =
β = 0.003, and
α =
β = 0.01, respectively.
As can be seen from
Figure 3a, with an increase in the number of checks (
N), the average time the system remains in an operational state decreases significantly. Furthermore, the rate of decrease is higher when the conditional probability of a false positive test result is greater.
Figure 3b illustrates that as the number of checks increases within the interval (0,
T), the average time the system remains in state
decreases more rapidly, with a higher probability
α. It is important to state that with fixed values of
α and
N, increasing probability
β leads to a rise in
. However, for large
N, the impact of
β is notably smaller compared to that of
α.
As it follows from
Figure 3, for large values of
N,
MTBUR is primarily determined by
. Therefore, it is crucial to focus on minimizing the conditional probability of false positives when selecting or designing inspection tools for aviation equipment.
In 1988, ref. [
27] (p. 355) developed a model for the posterior reliability of a single-unit system subject to both revealed and unrevealed failures that were distributed exponentially:
where
is the rate of revealed failures.
In 1988, ref. [
27] (pp. 362–364; also referenced in [
35]) examined mathematical maintenance models for a one-unit system with both revealed and unrevealed failures, as well as the trustworthiness of multiple inspections. The assumption was made that at any arbitrary time
t, the system can be in one of the following states:
In the case of the exponential distribution of time to both unrevealed and revealed failure,
F(
t) = 1 − exp(−
λt) and Φ(
t) = 1 − exp(−
t), the mean times of the system staying in states
S1,
S2,
S3,
S4,
S5, and
S6 in the interval (0, ∞), are as follows [
27,
35]:
The expected value of time spent by the system in state
S1:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
The expected value of time spent by the system in state
S6:
where
tUR is the average time of unscheduled repair due to a revealed failure.
When λ0 = 0, Formulas (33)–(38) are reduced to (14)–(18) and MS6 = 0.
In 1988, ref. [
27] (pp. 368–370; also referenced in [
36]) proposed a maintenance model of periodically inspecting systems subjected to both revealed and unrevealed failures to determine the operational reliability of repairable systems. Operational reliability is defined as the probability of system operation without failure in the interval (
kτ,
t), where
kτ <
t ≤ (
k + 1)
τ. This probability is calculated under the assumption that maintenance is carried out at times
kτ (where
k = 1, 2, …), including the inspection and restoration of both correctly and falsely rejected systems as well as the unscheduled restoration of failed systems after the occurrence of revealed failures.
With an exponential distribution of time to revealed and unrevealed failures, operational reliability has the following form [
27,
36]:
where
PR(
jτ) is the probability of system repair at time
jτ.
The probability
PR(
jτ) is given by
where
PFR(
jτ) and
PTR(
jτ) are the probabilities of repair for falsely rejected and failed systems, respectively.
The probabilities
PFR(
jτ) and
PTR(
jτ) are determined as follows [
27,
36]:
If only unrevealed failures are possible in the system, i.e.,
λ0 = 0, then (39) and (41) are simplified as in [
30] (p. 61) and [
36].
During long-term system operation, it is advisable to use the steady-state values of probabilities (43), (44), (42), and (40), determined as follows by [
27] (p. 115) and [
30] (p. 62):
In 1990, ref. [
37] presented a model for approximate periodic imperfect inspection policies with an exponential distribution of time to failure. The optimal inspection period
P =
τ is determined by solving the following equation:
where
C1 is the cost of each inspection,
C2 is the cost of each unit of time of system operation in an undetected failure state,
T0 = 1/
λ, and
w = 1 −
β.
In 1991, ref. [
38] researched the delay-time distribution of faults in repairable machinery. This study helped determine the probability of a sequence of events occurring, such as an inspection with no defect found, an inspection with a defect found, a breakdown, and the conclusion of the observation period. In this model, the inspection is assumed to be imperfect, meaning the defect is detected with a probability
r < 1, where
r = 1 −
β.
In 1991, ref. [
39] introduced a sequential approach to minimize costs in planning inspections for deteriorating structures. The primary goal of this method is to identify an optimal inspection strategy that minimizes the total expected cost between the current inspection and the next one. This optimization considers variables such as the inspection methods used in the current examination and the time interval until the next inspection. This optimization process is iteratively performed during each inspection. The most suitable inspection methods are chosen from a set of five options: (1) no inspection, (2) visual inspection, (3) mechanical inspection, (4) visual and conditional mechanical inspection, and (5) sampling mechanical inspection. Each inspection method is associated with a cost evaluation equation. The probabilities of detecting or not detecting a defect by different inspection methods are introduced into the cost functions. The total expected cost for the entire structure within an inspection interval is determined.
In 1992, ref. [
40] (p. 45) determined the long-term expected cost per unit time, considering only false positives (type I errors) and false negatives (type II errors). Further, optimal inspection policies were determined for each cost function. For example, the long-term expected cost per unit time considering only false negatives is given by
where
c1 is the cost of inspection, c
2 is the cost per unit time elapsed between system failure and its detection,
is the mean time to failure,
p2 = 1 −
β, and
q2 =
β.
In 1992, ref. [
30] developed a mathematical maintenance model for periodically inspected avionics systems, considering the system’s structure in terms of reliability and the availability of spare units in the airline’s hub spare part system. The continuous-time Markov chain modeled the spare part system. During the model’s construction, it was assumed that a line replaceable unit (LRU) within the system could exist in one of the states outlined in (13), and in addition in a state linked to the wait for a rejected unit’s replacement at the hub airport. This waiting state arose due to an unmet request for a spare unit from the warehouse.
Figure 4 demonstrates how the quantity of spare LRUs affects the achieved unavailability of a duplicated avionics system. This is observed under specific conditions: the number of aircraft in the airline is 10, the failure rate of an LRU is
, it takes 0.25 h to mount and dismantle an LRU onboard, it takes 0.2 h to test an LRU onboard, it takes 36 h for an LRU to be delivered from the manufacturer, the aircraft stops on the ground for 1 h, and the testing periodicity (
τ) equals 4 h, with
α and
β both set to 0.01.
In 1993, ref. [
41] examined the optimization of maintenance processes for avionics systems with built-in test equipment, considering both false positive and false negative scenarios and assuming an exponential distribution of time to failure. When constructing the maintenance models, the author examined scenarios where aircraft fly from the airline’s hub airport, make landings at transit airports, and then return to the hub airport. The avionics systems are expected to be tested using built-in test equipment before each aircraft takeoff. For avionics systems listed in the master minimum equipment list (MMEL) [
42], replacements of rejected LRUs are only conducted at the airline’s hub airport. It is important to note that the MMEL includes onboard systems in an aircraft that have little to no effect on the safety of operation. The dissertation defined indicators such as posterior reliability, operational reliability, achieved availability, and average cost per unit time.
For instance, the following formula determines the steady-state value of the operational reliability of a single-unit system during the operating interval
:
where
represents the duration between the aircraft’s takeoff and its landing at the airline’s hub airport,
determines the number of landings at transit airports within the interval between takeoff and landing at the hub airport,
τ is the average flight time of the aircraft between takeoff and landing, and
is the average regeneration cycle.
In 1995, ref. [
43] developed a cost-effective maintenance strategy for standby systems using an inspection–repair–replacement approach. The policy assumed that inspection correctly identifies the system’s downstate and upstate with a probability of
p = 1 −
β and
p’ = 1 −
α, respectively, while it can also make incorrect identifications with a probability of
q =
β and
q’ =
α, respectively. Should the system be rejected, it is replaced with a new one.
In 1996, ref. [
44] created a method to establish an inspection schedule for a deteriorating single-component system. The system has three states: normal, symptom, and failure. The transition of these states is described using a delay-time model. The maintenance model includes constant conditional probabilities of a false positive and a false negative. The approach is designed to minimize the long-term average cost per unit time while maintaining a constraint on inspection time.
In 1998, ref. [
45] proposed a maintenance model for a system with three states: good, faulty, and failed. The system undergoes periodic imperfect inspections, where false positives and false negatives may occur. Simple faults can be repaired, but there is a non-zero probability of a fault remaining after the repair. After a fixed number of inspections, the system is overhauled. Expressions were developed to calculate the average cost per unit time and, by minimizing the average cost, the optimal number of inspections before overhauling the system could be determined.
In 2001, ref. [
46] examined two maintenance models that involved imperfect inspections and calculated the minimax schedules. In both models, the inspections are considered imperfect, meaning that the probability of detecting system failures is noted as 1 −
p, where
p =
β. In the first model, the duration of the inspection is deemed negligible, while in the second model, the inspection duration is considered.
In 2001, ref. [
47] developed a maintenance model where failures are identified solely through inspection. The process involves periodic checks. However, these inspections are imperfect, potentially leading to type I and type II errors (false positives and false negatives). The model considers inspection costs, costs due to type I errors, downtime costs from missed failures, and corrective maintenance costs. The goal was to create an objective function measuring these costs over an infinite timeframe and then minimize them.
In 2002, ref. [
48] considered a maintenance model of a single-unit system with revealed and unrevealed failures and imperfect inspections. The model description is as follows. Whenever a failure becomes evident, corrective maintenance is implemented. When the unit reaches age
τ and no failures have been detected, an inspection is conducted to uncover hidden failures. If a failure is detected during the inspection, corrective maintenance is performed; otherwise, preventive maintenance is carried out. Thus, inspection and preventive maintenance occur periodically at
Nτ (where
N = 1, 2,...) only for failures that have not been revealed. However, if a failure has been revealed, the policy involves an inspection and preventive maintenance at the age of
τ. It is essential to note that if all failures are revealed, this maintenance strategy is equivalent to an age replacement policy.
The objective cost function
Q(
τ) is the cost per unit time for an infinite horizon:
where
c0 is the cost of inspection,
cn is the cost of preventive maintenance,
c1 is the cost of a type I error (false positive),
cr is the cost of corrective maintenance,
p is the probability of unrevealed failure,
τ is the age for inspection and maintenance,
R(
t) is the reliability function,
F(
t) is the unreliability function,
cd is the cost rate because of downtime, and
δ = 1/(1 −
β).
In 2003, ref. [
49] investigated a model for managing a deteriorating system with concealed failures. In this model, the system’s time to failure follows an increasing failure rate. Minimal repairs are made upon failure detection. The imperfect inspection process has a detection probability of
pd = 1 −
β and a misidentification probability of
qd =
β. Similarly, the operational state is identified with
pu = 1 −
α probability and misidentified with
qu =
α. The study aimed to find the most effective inspection policy to minimize the average long-term cost per unit time.
In 2005, ref. [
50] introduced a corrective maintenance model to calculate the total expected cost of one cycle. The cost equation comprises the cost of one inspection, the cost of time elapsed between failure and its detection per unit time, and the conditional probabilities of
α and
β, which are specifically associated with human errors.
In 2006, ref. [
51] devised an optimal inspection policy considering three types of inspections: partial, perfect, and imperfect. Perfect checks accurately diagnose the system, while partial inspections identify type I failures and imperfect inspections detect type II failures with a probability of (1 −
β). Type III failures are exclusively detected by perfect inspections. If a failure is identified, a repair is performed to restore the system to a condition close to new. Proactive age-based maintenance is applied, with preventive actions restoring the system to an as-good-as-new state. The authors analyzed factors in a regeneration cycle, including expected length, number of inspections, downtime, uptime, and cost, along with a cost rate function.
In 2007, ref. [
32] (also referenced in [
52]) developed a mathematical model of post-warranty maintenance to determine the availability of redundant avionics systems, considering the reliability and maintainability of LRUs, false positives and false negatives that occur during LRU testing, and the sufficiency of spare parts. The study explored the run-to-failure maintenance approach for avionics systems, analyzing three different variations of this strategy.
Figure 5 demonstrates the relationship between the optimal quantity of spare avionics LRUs in the warehouse and the number of aircraft in an airline, focusing on one of the variants [
32]. The curves on the graph represent different values of the probability
α. Key observations from the figure are that (a) the spare LRUs increase as an integer number, (b) higher
α values significantly boost spare LRUs (notably case
α = 0.01), and (c) the second scenario (
α = 0.01) is more responsive to increasing aircraft numbers in the airline compared to the first scenario (
α = 0.001).
This finding underscores the substantial impact of the trustworthiness of the LRU built-in test equipment (BITE) on the effectiveness of post-warranty maintenance processes.
In 2007, ref. [
53] developed a maintenance model with imperfect inspections to evaluate the reliability of and optimize the inspection schedule for a multi-defect component. The model utilizes a non-homogeneous Poisson process method in combination with a delay-time approach. The underlying assumption is that a defect can be identified only through inspection with a probability of 1 −
β (referred to as
β in the paper). When identified during an inspection, the defect will undergo minimal repairs. The research introduced an algorithm crafted to optimize inspection intervals, with the goal of maximizing the component’s reliability.
The following formula determines the reliability at any time
x:
where
is an imperfect inspection strategy and
is the expected number of failures over the inspection interval
.
The quantity
is given by
where
G(
t) is the cumulative distribution function of the delay time and
is the rate of defect occurrence at time
t.
In 2009, ref. [
54] proposed a theoretical framework to model the cost per unit time associated with two categories of inspection and repair. The first category is the minor inspections that address small flaws, while the second category is major inspections that are necessary for significant defects that may have been missed in minor inspections. Neglecting major defects could lead to process breakdowns, which is why it is crucial to address them. The paper also explored the relationship between major and minor defects, considering the imperfect nature of major inspections.
The study calculated the following expected renewal cycle cost:
where
r is the probability of a perfect major inspection (
r = 1 −
),
Cmi is the average cost of a minor inspection,
Cma is the average cost of a major inspection,
Cmr1 is the average cost of a major repair for a defect identified in a major inspection,
Cmr2 is the average cost of a major repair due to a major failure,
T is the major inspection periodicity,
f1(
x1) is the PDF of the random time to the initial point of a major defect, and
f2(
x2) and
F2(
x) are the PDF and the cumulative distribution function of the random time to failure from the initial point of a major defect, respectively.
E(
Cijs(
x1)) is the expected minor repair cost minus the expected profit when the major inspection repair is completed at
iT and
E(
Cijf(
x1,
x)) is the expected minor repair cost minus the expected profit.
In 2011, ref. [
55] considered a production process for a single item. Initially stable, it may shift to an unstable state during the cycle, producing non-conforming items. The transition time follows a random variable with an increasing hazard rate. Inspections at specific times trigger preventive maintenance. The cycle ends if (1) the system shifts to the second type of unstable state, (2) an error during maintenance causes a shift to an unstable state, or (3) after the
m-th inspection, whichever occurs first. To start a new cycle, additional work may be needed to return the system to a stable state. Preventive maintenance is not required during the last inspection if the system is already identified as being in the second type of unstable state.
The expected cost of maintenance for a regular production cycle is provided by
where
δ is the probability of preventive maintenance activity causing the system to shift to the out-of-control state,
pj is the conditional probability of the process transitioning to the out-of-control state within the time interval (
tj−1,
tj) (given that it was initially in the in-control state at time
tj−1),
θ is the probability of the system being in the second type of out-of-control state when it is judged to be out of control,
Cpm is the cost of the actual preventive maintenance activities, and
Cmr represents the cost incurred for implementing minimal repair per unit.
In 2012, ref. [
56] examined the mission availability. The authors defined the non-stationary mission availability as the probability that the interval of trouble-free system operation
θ entirely falls within one of the intervals between inspections [
kτ, (
k + 1)
τ],
k = 0, …,
N. The study showed that if the system has an exponential distribution of time to a hidden failure, then the following relation holds [
56]:
where
P(
kτ,
θ) is the non-stationary mission availability and
PR(
jτ) is determined by Equations (40), (42) and (44).
The average value of the non-stationary mission availability is given by [
56]
where
T = (
N + 1)
τ is the finite horizon of maintenance planning.
In the given example for an avionics system, T = 5000 h, λ = 0.0001 1/h, α = β = 0.005, τ = 10 h, and θ = 1 h. The calculated value is Am(T, θ) = 0.9994.
The stationary mission availability is given by the following limit [
56]:
It should be noted that stationary mission availability is also referred to as mission availability [
57].
When
θ <<
τ, from Equation (61), it follows that [
27] (p. 125)
where
MS1,
MS2,
MS4, and
MS5 are determined by Equations (14), (15), (17) and (18).
In 2012, ref. [
58] considered an inspection and replacement strategy for a protection system in which the inspection procedure is subject to errors, with conditional probabilities of
α and
β. The authors developed two models for a single-component system with unrevealed failures and perfect repair. In the first model, a false positive does not imply the renewal of the protection system; in the second, it does imply it. The authors considered two phases of inspections. In the first phase, the checks are carried out at times
jT1 (
j = 1,...,
M1) and, in the second, checks are carried out at times
jT2 +
M1T1 (
j = 1,...,
M2). The corrective maintenance policy’s decision variables are
M1,
T1,
M2, and
T2. The measures for maintenance effectiveness are the long-term cost per unit time and average availability.
In the second model, average availability is determined as follows. The expected uptime is given by
where
R(
t) is the reliability function.
The expected downtime is
where
E(
T) is the expected renewal cycle length.
The average availability is the ratio of the expected uptime to the average renewal cycle.
In 2013, ref. [
59] examined a system that can be in one of three states: good, defective, or failed. Failures are immediately detected when they happen. The defective state, however, can only be identified through inspections, and it does not hinder the system from performing its intended function. The maintenance model proposed involves periodic inspections to assess a system’s state, but these inspections are susceptible to errors. A false positive event would result in the system being replaced unnecessarily, while a false negative inspection result would fail to identify a defect that could impact reliability in the future. Using the delay time concept, the authors determined the average cost per unit time and the reliability function of a single-component system under three possible states, subject to periodic checking. For instance, the expected number of inspections during the regeneration cycle is determined as follows:
where
X is the duration between the replacement of the system and the occurrence of the defective state (assuming no inspection or replacement takes place during that period),
M − 1 is the number of inspections inside interval (0,
T),
K* is the number of inspections in a cycle when there is no inspection at
Mτ,
q = 1 −
α,
FX(
x) is the unreliability function,
is the reliability function,
D is the time delay between the arrival of a defect and the occurrence of a subsequent failure,
FD(
x) is the cumulative distribution function of random variable
D, and
.
In 2013, ref. [
60] investigated two types of imperfect maintenance policies for a single-component system with regular and irregular inspection intervals. In this model, the first policy prompts a validity check at an additional cost when an alarm is triggered, while the second policy restores the system after a false alarm. A comprehensive cost analysis was established to evaluate these policies, including penalties incurred due to unavailability.
Let us consider the second case as more general. The expected maintenance cost during the regeneration cycle is given by
where
c0 is the cost of inspection,
cd is the cost of a single unmet demand, and
cr is the cost of renewal of a failed system.
The expected length of the regeneration cycle is
The average cost per unit time is the ratio of C(T1, N1) to E(L). The research also considered a fluctuating inspection frequency, involving N1 inspections with intervals of T1, followed by N2 inspections separated by intervals of T2.
In 2013, ref. [
61] proposed an inspection–repair policy for corroded pipelines, considering errors in inspection results. The procedure enables a comparison of different strategies, including inspection techniques and frequencies, while determining expected costs for different situations.
The mathematical expectation of the total cost is as follows:
where
P(
Si) is the conditional probability of correct or incorrect decisions in terms of the pipe condition and inspection result (
i = 1, …, 6) and
Ci is the total cost of the
i-th scenario.
The conditional probabilities
P(
S1), …,
P(
S1) are determined as follows:
where
γ is the probability of defect existence at the inspection time,
PoD = 1 −
β, and
PFA =
α.
In 2014, ref. [
62] examined an inspection-based maintenance optimization model involving imperfect inspections and potential failure scenarios. The model adopts the fundamental delay-time approach, suggesting that a system can exist in three states: fully functional, defective, and failed. As the system degrades through these states, regular inspections are conducted. The inspection procedure involves a fixed, state-dependent probability of system failure. Alternatively, an inspection may incorrectly identify a functioning system as defective (false positive) or a defective system as functioning (false negative), with fixed probabilities. The system is replaced reactively upon failure or proactively at the
n-th inspection time or when an inspection reveals a defect, depending on which event occurs first. The objective is to determine an optimal preventive age replacement threshold and inspection interval that minimizes the long-term expected cost per unit time.
The following formula applies to calculate the expected long-term cost per unit time:
where
r1 and
r2 are the probabilities of system failure during an inspection and the occurrence of a false positive and false negative, respectively,
p =
α,
q = 1 −
β,
is the inspection cost,
is the preventive replacement cost,
is the penalty cost due to a false alarm,
is the inspection-induced failure cost,
is the internal/demand failure cost,
F(
x) and
f(
x) are the distribution function and density of the defect arrival time,
,
G(
y) is the distribution function of the internal failure (which occurs when the system is in a defective state), and
.
In 2014, ref. [
63] looked at how to inspect a single-component system with a two-level inspection policy. This policy includes minor and major inspections and is based on a three-stage failure process. The minor inspection can only identify the minor defective stage with a limited probability
γ = 1 −
β but can always identify the severe defective stage. On the other hand, a major inspection can always identify any defective stage, regardless of its severity. If the component is found to be in the minor defective stage during an inspection, a shortened inspection interval is introduced to increase the chances of identifying the severe defective stage before failure. In the event of failure, immediate repair or replacement is necessary to restore production. The research examined three distinct renewal scenarios occurring at the end of a renewal cycle: a failure renewal, an inspection renewal resulting from the identification of major defects during minor or major inspections, and a planned preventive maintenance renewal. The probabilities of possible renewals are also determined. The expected renewal cycle cost and expected renewal cycle length are determined based on different renewal probabilities.
In 2015, ref. [
64] investigated a comprehensive approach for jointly optimizing inspection and age-based replacement policies within a three-stage failure process: normal, minor defective, and severe defective. This analysis encompassed both perfect and imperfect inspection scenarios. Detection of the minor defective stage involved conducting inspections with a conditional probability
r = 1 −
β. System replacement occurred either upon failure or after reaching a predetermined age threshold. Once the severe defective stage was identified, repair actions were initiated. However, in the event of detecting the minor defective stage, two alternatives were explored for comparative analysis: either reducing the subsequent inspection interval by half or immediately conducting repairs. The long-term system availability was utilized as the fundamental criterion for jointly optimizing both inspection and replacement intervals.
In 2015, ref. [
65] explored a model involving regular inspections and periodic preventive maintenance to identify and fix hidden failures. The periodic checks take place and hidden failures are detected with a probability of
p = 1 −
β. The failed system is restored to an as-good-as-new level. The main goal of this study was to minimize the expected cost per unit time over an infinite period.
In 2015, ref. [
66] considered an inspection and preventive replacement policy for a one-component protection system. In this model, inspections are imperfect and susceptible to both false positives and false negatives, with constant conditional probabilities. The study primarily examined the quality of maintenance, particularly focusing on the inspection process’s quality. The indicators of maintenance effectiveness are the long-term cost per unit time and the operational reliability.
In 2016, ref. [
67] investigated an imperfect inspection policy applicable to systems exposed to numerous interconnected degradation processes. In this model, these degradation processes are defined by a multivariate Wiener process, and their interdependencies are outlined using a covariance matrix. Failure arises when any of the degradation levels surpass a defined threshold. The inspection process itself is imperfect, meaning that failures might not always be detected upon inspection. The optimal inspection interval is determined through the minimization of the long-term cost rate. Furthermore, the characteristics of this optimal inspection interval are analyzed, and the upper and lower limits of its optimal value are determined.
In 2017, ref. [
68] analyzed a system that undergoes periodic inspection. A delay-time-based maintenance model for a single-unit system with imperfect inspections was investigated. In this model, the maintenance policy involves regularly checking the system’s working status at fixed intervals of time. These inspections are not 100% perfect as the system defect may only be identified with a conditional probability of
pw = 1 −
β. The decision variable in this scenario is the duration of time between inspections. The objective function aims to determine the expected maintenance costs for the system during a single renewal period.
In 2018, ref. [
69] investigated a dual-component system where the breakdown of the initial component is initially concealed. The second component has three potential states: functioning properly, defective, and failed. The system transitions to a failed state only when a failure is revealed. Each revealed failure triggers a disturbance in the first component, increasing its failure rate. Periodic inspections are conducted to detect defects and hidden failures. The first component undergoes checks whenever the failure of the second component is revealed, recognizing that these inspections might be imperfect. The primary objective is to determine the optimal interval for periodic inspections, minimizing the overall cost over a finite period. The study explored how probabilities
α and
β impact the total maintenance costs.
In 2018, ref. [
70] examined a three-state component failure model, one of which states is a defective state that comes before actual failure. The inspection process is not perfect and can result in false positives or false negatives and may even create defects. To model the quality of replacement components, it was assumed that the components come from a population including both weak and strong items, with a mixing parameter that determines quality. The authors explored seven different scenarios of system replacement and calculated the associated maintenance costs for each one. Ultimately, they determined the total cost rate.
In 2018, ref. [
71] investigated the impact of a quality inspection strategy on an imperfect production system. This inspection approach allows for both type I and type II errors. Products are shipped for sale with a complimentary minimal repair warranty policy. After each production cycle, preventative maintenance is conducted. A minimal repair is conducted in the case of a breakdown in the production process before the cycle’s completion. A reserve inventory is established to meet demand during preventative maintenance. Additionally, defective items identified during inspection are directed for reworking. The model minimizes the expected total cost per item while adhering to an average outgoing quality restriction.
In 2019, ref. [
72] developed a maintenance framework for manufacturing systems that deals with defects. The system goes through a defective state before it ultimately fails. During the imperfect maintenance phase, a limited number of imperfect inspections are conducted to identify defects, and the system undergoes imperfect repairs once a defect is detected. These inspections are imperfect because they may not always detect a defective state (
q =
β > 0). In the second phase, preventive replacement occurs during a scheduled maintenance window. If a defect is discovered during this phase, preventive replacement is performed during the next scheduled maintenance window. The study calculated steady-state availability, expected maintenance costs in a renewal cycle, and expected net revenue.
In 2019, ref. [
73] investigated a model for the periodic inspection of protection systems. The objective was to determine the system state and assess if replacement is necessary, employing a delay-time approach. The accuracy of the inspection is gauged by the probability of a false positive and two distinct probabilities of a false negative, linking the system states to outcomes. The analysis explored how these probabilities influence inspection effectiveness, cost rate, and system availability.
In 2019, ref. [
74] developed a model to determine the optimal inspection intervals for a one-shot system with
n components that undergo periodic inspections. It was assumed that the failure times of all components in a series structure are independent and follow an exponential distribution. The inspection is imperfect, with a probability of not detecting a failure denoted as
, which is
β in terms of
Table 1. If failures go undetected, they can be identified at subsequent inspection times. The optimization criteria considered in this study were interval availability and life cycle cost, which were derived analytically.
In 2020, ref. [
75] introduced a model designed for the inspection and maintenance of a single-unit system that can experience two types of failures: minor failures that are revealed (
R) and catastrophic failures that remain unrevealed (
U). The probability of these failures occurring depends on the age of the system. If a failure occurs at time
t, it has a probability
p(
t) (where 0 ≤
p(
t) ≤ 1) of being a type
R-failure and a complementary probability
q(
t) = 1 −
p(
t) of being a type
U-failure. Periodic inspections are conducted at times
kT, where
k ranges from 1 to
M − 1, to detect
U-failures. In the event of an
R-failure, a minimal repair is executed to restore the system to its previous state, often referred to as “as-bad-as-old.” The maximum allowable number of minimal repairs is
N − 1. If a
U-failure is detected during inspection, if the
Nth
R-failure occurs, or if it is time for preventive maintenance at
MT, the system is replaced with a new one. The values of
T,
M, and
N are decision variables that require optimization. It is important to note that inspections may not be perfect, with a probability of
α for false positives and a probability of
β for false negatives. The objective function is to minimize the long-term cost per unit time.
In 2021, ref. [
76] developed a maintenance model for systems with multiple correlated degradation processes. The authors used a multivariate stochastic process and a covariance matrix to describe these processes’ interactions. System failure occurs when any degradation feature exceeds a set threshold. The inspections are imperfect concerning failure detection. The study’s goal was to calculate the expected long-term cost rate and determine theoretical boundaries for cost-optimal inspection intervals.
In 2021, ref. [
77] proposed a two-stage inspection policy model aimed at integrating inspection methods that vary in terms of accuracy and cost. Unlike traditional two-stage inspection policy models where the second stage is assumed to be perfect, this study developed a mathematical model in which the second stage can be imperfect. The study calculated the cost per unit time for the two-stage policy with imperfect inspections. Additionally, the study formulated a set of rules to aid decision making when searching for cost-effective parameters for the two-stage policy. The study introduced the conditional probabilities of a false positive diagnosis and a false negative diagnosis of either the one-stage or two-stage inspection policy into the cost function.
In 2021, ref. [
78] explored a delay-time maintenance model for a system undergoing three states: normal, defective, and failed. The authors examined a two-phase imperfect inspection policy, incorporating a hybrid preventive maintenance approach. This strategy involved both inspection-based replacement, triggered by true positives or false positives, and age-based replacement, scheduled after multiple imperfect inspections. The researchers jointly determined the inspection interval length and the number of inspections for each phase, aiming to minimize the cost rate over an infinite time horizon under this policy. Depending on various renewal points, the system maintenance can be classified into three scenarios: completing a renewal cycle through (1) replacement due to failure, (2) replacement based on inspection, or (3) replacement based on age. The corresponding average maintenance costs for these scenarios are calculated and analyzed. As an example, consider Scenario 2, where the renewal cycle concludes with an inspection-based replacement triggered by a false positive or a true positive event. In these instances, the system is renewed through replacement. There are five distinct types of sample paths possible in such cases. Let us focus on type 2 sample paths and their associated probabilities for illustration.
where
is the inspection interval in phase 1 and
and
are the cumulative distribution function of the time to defect
X and to delay time
Y, respectively.
In 2022, ref. [
79] developed a two-phase inspection and maintenance policy specifically designed for safety-critical systems. The aim of this policy is to prevent failures that may result in serious consequences. The two phases comprise constant-frequency inspections in the first phase and varying time intervals in the second phase. The authors presented two delay-time-based mathematical models in their study. Model 1 assumes an in-house inspection team with the autonomy to replace components, while Model 2 assumes a specialized team, often outsourced, responsible for replacements. The inspections are assumed to be imperfect, with false-positive and false-negative occurrences considered. The study determined the expected cost per unit time and the unavailability rate.
In 2022, ref. [
80] proposed a maintenance and statistical process control model for a production process with three states: in-control, out-of-control, and failure. The process operates in both in-control and out-of-control states but completely stops in the failure state. A control chart is used to judge the states based on the quality of the produced items, with the failure state being observable. When the process shifts to an out-of-control state and the control chart identifies this transition, minor repairs are conducted to restore the process to an in-control state and continue the production cycle. After each minor repair, the life of the production machine decreases stochastically. The model determines the optimal sample size, sampling interval, control chart limits, and maximum number of minor repairs during a process cycle. The maintenance model includes the control chart’s probabilities of type II error (
β) and type I error (
α).
In 2022, ref. [
81] created a preventive maintenance model combining condition monitoring and manual inspections. The model, employing a delay-time approach, uses white noise for normal state monitoring and drifted Brownian motion for the delay-time stage. The maintenance policy includes failure and preventive thresholds, initiating corrective or preventive actions. Imperfect manual inspections are described by a conditional probability
r =
β. The optimization goal is to minimize the expected cost per unit time by determining optimal condition monitoring intervals and preventive thresholds.
In 2023, ref. [
82] introduced a new approach for managing maintenance that optimizes both preventive maintenance and spare parts ordering strategies. This was achieved using a dynamic early warning period model that considers different equipment states. The model includes two maintenance approaches: normal ordering and emergency ordering, which are applied based on the equipment’s state. The model also accounts for the possibility of the imperfect detection of equipment states due to inaccurate monitoring. Imperfect inspections can result in a false negative event with a probability denoted as
p, which is
β. A two-phase inspection and spare parts ordering strategy minimize the expected cost per unit time.
2.2. Models with Non-Constant Probabilities of Correct and Incorrect Decisions
In 1981, ref. [
83] (pp. 4–12; also referenced in [
84]), explored one of the earliest maintenance models featuring non-constant probabilities of correct and incorrect decisions, denoted as 1 −
α(
t), 1 −
β(
t),
α(
t), and
β(
t). The authors investigated two maintenance models involving periodic imperfect inspections. In the first model, the system is rechecked after it is declared inoperable, which practically eliminates the occurrence of a repeated false positive. Therefore, after additional verification, the system is allowed to be used with almost unity probability. In the second model, after a false positive, the system is restored and becomes as-good-as-new. The total average costs over the interval (0,
T) during the regeneration cycle are determined for each model.
Probabilities
α(
t) and
β(
t) were determined for a one-parameter system for the following stochastic degradation process [
83]:
where
A0 and
A1 are independent random variables with normal distribution and
γ is a constant.
The mathematical expectation and standard deviation of the random process
X(
t) have the form [
83]
where
,
,
, and
are mathematical expectations and standard deviations of random variables
and
.
The studies [
83,
84] proposed approximating the cumulative distribution function of the random process (73) using the gamma distribution function, which effectively describes aging processes [
85]:
where
ns and
η are the shape and rate parameters of the Gamma distribution.
The parameters
η and
ns are determined based on the condition that the mathematical expectation
E[Ξ] of the random time to failure Ξ and variance
Var[Ξ] of the actual and approximated processes coincide [
83]. Therefore,
where
In Equation (79), Lx represents the functional failure threshold.
The probabilities α(t) and β(t) were calculated assuming an additive relationship, with no correlation between the system’s state parameter and the measurement error. The measurement error is a stationary random process with an expected value of zero and a standard deviation of .
The unconditional probabilities of a false positive and a false negative are computed using the following formulas by [
83] (p. 11) and [
84]:
The conditional probabilities of a false positive and a false negative are calculated using straightforward formulas [
83]:
where
R(
t) and
F(
t) are the reliability and unreliability functions, respectively.
The reliability function is determined by the following equation [
83]:
Figure 6a shows the dependencies of the unconditional probabilities of a false positive (FP) and a false negative (FN) on the operating time of the test object at
,
,
,
,
,
, and
[
83] (p. 12).
Figure 6b shows the dependencies of the conditional probabilities of a true negative (TN), true positive (TP), false positive (FP), and false negative (FN) on the operating time for the same data.
The conditional probabilities of true negatives, true positives, false positives, and false negatives are heavily influenced by time, as shown in
Figure 6b. Thus, maintenance models that assume a constant probability of these inspection errors regarding degrading systems are not accurate representations of reality.
In 1982, ref. [
86] considered a corrective maintenance model with periodic inspections. The following expression for inherent availability was obtained:
where
αn and
βn are the conditional probabilities of a false positive and a false negative at the
n-th inspection, respectively.
Pn is the reliability function during time
nτ and
τ is the inspection periodicity.
Equation (85) does not consider the system’s maintainability characteristics. Additionally, this mathematical model does not account for the extent of system restoration, which is essential for determining the reliability properties acquired by the system after restoration.
In 1983, ref. [
87] (also referenced in [
88]) developed mathematical models for calculating the operational reliability of redundant aviation systems with gradual failures, continuously monitored by built-in test equipment (BITE). These models account for false positives and false negatives in the BITE. Both cold and hot redundancy modes are considered. The state of a functional unit is determined by a vector of state parameters, each component of which represents a non-stationary monotonic stochastic process. The behavior of each random process is approximated by a Gamma process using the method of degradation level quantization [
89]. It is represented as a Markov process with a finite number of states and continuous time. The number of quantization levels for each random process and the intensity of the intersection of these levels, i.e., shape and rate parameters
ns and
η of the Gamma distribution, are determined based on the condition that the mathematical expectation and variance of the actual and approximated processes coincide. It is assumed that the BITE can be in an operational state, where errors such as false positives and false negatives result from the measuring path’s accuracy, or in inoperative states, where errors stem from hidden failures of the BITE.
The probabilities of the states of a functional unit are described by a system of differential equations with variable coefficients, solved using numerical methods. The formulas for false positive and false negative rates, when the state parameter crosses the
i-th quantization level, are as follows [
87,
88]:
where
and
are the conditional probabilities of a false positive and a false negative occurring in the BITE measuring channel when the state parameter crosses the
i-th quantization level, respectively. Formulas for calculating
and
are given.
Figure 7 shows the dependence of operational reliability on the operational time for a duplicated system with cold redundancy (curves 1 and 2). Curve 3 corresponds to a non-redundant functional unit without BITE.
The parameters of the Gamma distribution are and . The values of the quantization levels are , , , , , and . The measurement error is a stationary random process with zero mathematical expectation and a standard deviation of 0.5 W.
As can be seen from
Figure 7, the measurement error of the state parameter significantly reduces operational reliability.
In 1984, ref. [
90] (pp. 1–7; also referenced in [
91]) considered a maintenance strategy involving sequential imperfect inspections and the perfect repair of a multi-unit system within a finite time horizon. Each unit within the system can exist in one of several given states. Mathematical equations for the mean times spent by units in different states are derived, accounting for non-constant probabilities of false positives and false negatives. It is assumed that the unit failure occurred at time
and, at time
T, the system is renewed. In this strategy, a single-unit system or a unit within a multi-unit system can be in one of the states described in (13).
The expected value of time spent by the system in state
S1 [
90,
91]:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
Equation (92) requires some explanation because it does not include failure detection probabilities. The system is restored at time tj (j = k + 1,..., N) if, during the j-th inspection, a failure is detected (true positive) or at time T if a false negative event occurs during the inspection at time tN. Therefore, if ξ < T, the system will be restored with a probability of 1. However, the system can only enter state S5 if a true negative event occurred at time tk, the probability of which is .
For a single-unit system, achieved availability, inherent availability, and average maintenance cost per unit time are determined by Equations (19)–(21).
In [
90] (p. 7), the following equation was presented for posterior reliability in the interval (
tk,
t), where
tk <
t, assuming an arbitrary distribution of time to hidden failure:
When
α(
t) =
β(
t) = 0, Equation (91) is converted to the following form:
It should be especially noted that Equations (19)–(21) and (88)–(95) were included in the state regulatory document on determining the criteria and periodicity of diagnosing technical systems [
92].
In 1984, ref. [
93] (also referenced in [
88], pp. 63, 64) addressed the challenge of determining optimal inspection intervals for recoverable systems based on the “reliability-cost” criterion, particularly for systems impacting safety. This criterion utilizes two indicators of maintenance efficiency: one characterizes operational reliability, while the other assesses the unit costs associated with inspecting and restoring both correctly and falsely rejected systems. The study calculated maintenance efficiency indicators for cases involving both perfect and minimal repair.
In the case of perfect repair, operational reliability in the interval
and average cost per unit time are determined using the following formulas [
93]:
where
is the probability of the system repair at time
and
and
are the probabilities of repair for falsely rejected and failed systems at time
, respectively.
Probabilities
and
are determined by the method of mathematical induction.
The optimal inspection moments according to the “reliability-cost” criterion are determined by solving the following problem [
93]:
where
is the minimum permissible value of operational reliability.
In 1987, ref. [
94] (also referenced in [
27]) proposed a maintenance model featuring a sequential inspection schedule. The inspection policies are considered for both finite and infinite time horizons. In this model, the conditional probabilities of making correct or incorrect decisions depend not only on the timing of the inspections but also on the timing of hidden failures. This model is considered general because it provides mathematical formulas applicable to any distribution of failures and any arbitrary degradation process. The developed model is an extension of the model presented in [
90,
91,
92], wherein the conditional probabilities of correct and incorrect decisions depend on inspection times but not on the moment of failure.
In this model, a single-unit system can be in one of the states described in (13).
The expected value of time spent by the system in state
S1 [
27,
94]:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4.
The expected value of time spent by the system in state
S5:
The following notations are used in Equations (102)–(106):
is the conditional probability of the following events: the system being operable at time tν, the system being judged as operable at inspection times t1 to tν-1, and the system being judged as inoperable at inspection time tν, given that a failure occurred at time ξ.
is the conditional probability of the following events: the system being operable at time tk and being judged as operable at inspection times t1 to tk, given that a failure occurred at time ξ.
is the conditional probability of the following events: the system has failed until inspection time tj, the system has been judged as operable at inspection times t1,..., tj−1, and the system is judged as inoperable at inspection time tj, given that a failure occurred at time ξ.
is the conditional probability of the following events: the system has failed until inspection time tj and has been judged as operable at inspection times t1,..., tj, given that a failure occurred at time ξ.
For the infinite time horizon, the equations for through are as follows.
The expected value of time spent by the system in state
S1 [
27]:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
Probabilities
,
,
, and
are called by the name of the event at the last moment under consideration, i.e., “false positive”, “true negative”, “true positive”, and “false negative”, and are determined by the following formulas given by [
94], [
27] (p. 89), and [
29] (p. 17):
where
is the conditional PDF of the set of random variables
, given that a failure occurred at time
ξ and
.
The random variable
is the error in estimating the time to failure at inspection time
ti [
27,
29,
94]:
where Ξ represents the random time to system failure, while Ξ
i represents the random assessment of Ξ based on the results of the inspection at time
ti.
Random variables Ξ and Ξ
i are the smallest roots of the following stochastic equations [
27,
29]:
where
is the vector of the system state parameters,
represents the allowable range of variation for vector
,
is the vector of errors in measuring system state parameters, and
is the function of vectors
and
.
In [
29], a theorem was proven concerning the PDF of
. If
,...,
are independent random vectors, then the following relationship holds:
where
is a realization of the vector
and
is the conditional PDF of the error in estimating the time to failure at inspection time
ti, provided that Ξ =
ξ and
.
If for a fixed time to failure (Ξ =
ξ) there is only one realization of the random process
, then Equation (119) takes the form [
27,
29]
Examples of such processes are random degradation processes with monotonic realizations. For example, for the process (73) with
A0 =
a0 and
γ = 1, as described in [
29], we have [
27,
29]
where
represents the PDF of a measurement error at time
ti, i.e.,
.
Considering Equation (120), the equations for conditional probabilities—Equations (112)–(115)—are significantly simplified in [
94] and [
27] (p. 89):
where
represents the conditional probability of a false positive at time
given that the failure occurs at a time
, and
represents the conditional probability of a false negative at time
given that the failure occurs at a time
.
Figure 8 illustrates the dependencies of probabilities
and
on the current inspection number, with a periodicity of 100 h and using the same initial data (except
) as in
Figure 6. In
Figure 8a, the curves are plotted at
ξ = 1001 h, while in
Figure 8b, they are plotted at
ξ = 1090 h. Curves 1 and 2 are plotted when
, while curves 3 and 4 are plotted when
.
As
Figure 8 illustrates, the conditional probabilities of a true negative and a false positive depend not only on measurement accuracy and the inspection time but also on the timing of the system failure. Specifically, when the system failure occurs only 1 h after the last inspection, the probability of a false positive is higher, while the probability of a true negative is lower compared to the situation where the failure occurs 90 h after the last inspection.
It should be noted that if the system fails immediately after the inspection moment
, each of the conditional probabilities of a true negative,
, and a false positive,
, at the time of the last inspection equals 0.5 when using a symmetric PDF
. The latter is illustrated in
Figure 9a.
Figure 10 demonstrates how the probabilities
and
depend on the current inspection number, with a 100 h periodicity, utilizing the identical initial data as in
Figure 8. In
Figure 10a, the graphs are plotted when
ξ = 1099 h, whereas, in
Figure 10b, they are plotted at
ξ = 1010 h. Curves 1 and 2 correspond to
while curves 3 and 4 correspond to
.
Figure 10 illustrates that the conditional probabilities of a true positive and a false negative depend on measurement accuracy, inspection time, and the timing of the system failure. Specifically, when the system failure occurs only 1 h before the last inspection, as shown in
Figure 10a, the probability of a false negative is higher, and the probability of a true positive is lower compared to the situation where the failure occurs 90 h before the last inspection, as depicted in
Figure 10b. It is important to note that if the system fails just before the inspection moment
, each of the conditional probabilities of a true positive,
, and a false negative,
, at the time of the first inspection after failure equals 0.5 when using a symmetric PDF
, which is illustrated in
Figure 9b.
In [
27] (p. 76; also referenced in [
29]), it was demonstrated that for an exponential distribution of time to failure, the simplest representation of the system state parameter
X(
t) is as follows:
where
is the value of the system state parameter corresponding to its operable condition and
is the value of the system state parameter corresponding to its inoperable condition. Ξ is the random time to system failure and 1(Ξ −
t) is the unit step function taking two values, 1 and 0.
It should be noted that the probability that 1(Ξ − t) = 0.5 is zero.
If
X(
t) can be presented in the form of Equation (126), then the PDF
is determined by the following formula by [
27] (p. 76) and [
29]:
where
df is the delta function.
Substituting Equation (128) in Equations (122)–(125) and considering the property of the integral of the delta function gives [
27] (pp. 89, 90)
In this case, the conditional probabilities
and
are determined by the following formulas in [
27] (p. 75) and [
29]:
where
and
are the lower and higher tolerance limits of the system state parameter and
and
are the PDFs of the measurement error of the system state parameter at time
under the condition that
and
, respectively.
As demonstrated in [
27] (pp. 77, 90), if the PDFs of the measurement errors do not depend on time, i.e.,
and
, the conditional probabilities (129) through (132) can be expressed in the following manner [
27,
31,
32,
34,
35]:
It should be noted that Equations (14)–(18) and (25)–(29) are obtained by putting (136)–(139) into (107)–(111) and (102)–(109).
If
and
are random variables, i.e., the system state parameter
X(
t) is represented in the form [
29]
then Equations (129)–(132) are not valid.
In [
29], a theorem was proven that establishes the conditional probabilities of correct and incorrect decisions in the context of multiple imperfect inspections with consideration of Equation (140). For instance, the conditional probabilities of a false positive and a true negative are described by the following formulas:
where
represents the PDF of the random variable
and
denotes the conditional probability of a false positive at time
provided that
.
Since the system is operational at any value of
, it follows that
Figure 11 illustrates the dependence of the conditional probabilities of a false positive (curves 1 and 3) and a true negative (curves 2 and 4) on the number of inspections when using Equations (136) and (137) (curves 1 and 2) and (141) and (142) (curves 3 and 4), provided that the random process
X(
t) is represented by Equation (140). The used data are as follows: the mathematical expectation and standard deviation of random variable
are 20 W and 3 W, respectively; the standard deviation of measurement error is 1 W; and the lower tolerance limit of the system state parameter is 16 W. The random variable
has a truncated normal distribution.
Figure 11 illustrates that using simplified versions of Equations (136) and (137) in this context leads to significantly higher probabilities of false positives and reduces the probabilities of true negatives.
Indeed, assuming the number of inspections
k = 100, we obtain the following:
As can be seen in Equations (144) and (145), even with the exponential distribution of time to failure, Equations (136)–(137), in which the conditional probabilities of correct and incorrect decisions during multiple inspections are obtained by simply multiplying corresponding probabilities during single checks, can be used only in the case when the operable and inoperable states of the system correspond to two values of the system state parameter and , as per Equation (126).
In 1987, ref. [
95] (also referenced in [
27], p. 68) presented the following equation for posterior reliability in the interval (
kτ,
t),
kτ <
t ≤ (
k + 1)
τ for an arbitrary distribution of time to hidden failure:
If Equation (120) is satisfied, Equation (146) transforms as follows:
If the state of the system is described by a random process (126), then [
27] (p. 77)
If Equation (135) is satisfied, Equation (148) changes to become Equation (10).
In 1987, ref. [
95] (also referenced in [
27], p. 106) considered a mathematical model for determining operational reliability for a single-unit system with perfect repair on an infinite time horizon. The following formulas apply:
where
,
, and
share the same meanings as those described in Equations (39)–(42).
Note that Equations (42)–(44) are obtained by substituting Equations (136), (137) and (139) for Equations (152), (149) and (151).
In 1988, ref. [
27] (pp. 123–125; also referenced in [
56]) derived a general expression for mission availability, which refers to the probability that the system will be operational at moment
t and will function without failure for a specified time
θ, starting from moment
t.
It is important to mention that given an exponential distribution of time to failure and the satisfaction of Equations (126) and (137), Equation (153) is transformed into Equation (61).
In 1988, ref. [
27] (also referenced in [
96,
97]) developed maintenance models for various reliability structures of a multi-unit system, including series, parallel, “
h-out-of-
m,” series-parallel, and parallel-series configurations. The findings revealed that in a multi-unit system with a series reliability structure, the maintenance efficiency indicators can be determined as indicated below [
27]:
where
m is the number of units in the multi-unit system,
is the average regeneration cycle of the
i-th unit (
i = 1,…,
m),
is the expected value of time spent by the
i-th unit in state
, and
and
are the posterior reliability and operational reliability of the
i-th unit in the interval
, respectively.
The average regeneration cycle for the
i-th unit is given by [
27]
It should be noted that are calculated by Equations (102)–(106) or (107)–(111). Equations (146) and (149) calculate the probabilities of and , respectively.
For aircraft systems, the replacement of rejected units is possible while the aircraft is parked. Therefore, Equation (155) is simplified if the duration of replacing a rejected unit is shorter than the aircraft’s ground time; the repair of dismantled units can be conducted later in a repair shop [
27].
If a multi-unit system has a parallel reliability structure comprising
m identical items, the indicators of maintenance efficiency are expressed as follows [
27]:
where
and
are the posterior and operational reliability of one unit, respectively.
For aircraft systems, Equation (161) can be simplified analogously to Equation (159) [
27].
In 1988, ref. [
27] (pp. 355–360; also referenced in [
35]) proposed a mathematical model for a single-unit system that is subject to both revealed and unrevealed failures in addition to multiple imperfect inspections. The model presupposes that inspections can only identify hidden system failures. The revealed failures are followed by subsequent recovery. The assumption is also made that revealed and unrevealed failures are statistically independent. The repair is perfect.
The posterior probability is given by [
27]
where Φ(
t) is the distribution function of time until revealed failure.
If the state of the system is described by a random process (126), then [
27]
If Equation (135) is satisfied, Equation (166) changes to become Equation (31).
As supposed by [
27,
35], the system can exist in one of the states described in Equation (32). The mean duration of the system staying in states
S1,
S2,
S3,
S4,
S5, and
S6 were determined for both finite (0,
T) and infinite (0, ∞) horizons. Below are the formulas for an infinite maintenance scheduling interval [
27,
35].
The expected value of time spent by the system in state
S1:
The expected value of time spent by the system in state
S2:
The expected value of time spent by the system in state
S3:
The expected value of time spent by the system in state
S4:
The expected value of time spent by the system in state
S5:
The expected value of time spent by the system in state
S6:
It should be noted that Equations (33)–(38) are obtained by putting (136)–(139) into (167)–(172) when , F(t) = 1 − exp(−t), and Φ(t) = 1 − exp(−t).
In 1997, ref. [
98] introduced a technique for determining specific inspection time points for a deteriorating single-unit system. This system can exist in one of three states: normal (
), symptomatic (
), or failed (
). The transition between these states is described using a delay-time model. The system’s state, whether
or
, is ascertainable only through inspection. When the system is in state
, the probability of correctly diagnosing it as
is
. Conversely, if it is incorrectly diagnosed as
, the probability becomes
. Alternatively, if the system is in state
, the probability of accurately diagnosing it as
is
. However, if misdiagnosed as
, the probability is
. The method objective is to minimize the long-term average cost per unit time.
In 2010, ref. [
99] presented a time-delay maintenance model. This study made two important advancements. Firstly, the occurrence rate of hidden defects depends on the duration since the last preventive maintenance. Secondly, the probability of identifying defects, represented as
r(
h) = 1 −
β(
h) during an inspection, is influenced by the delay time
h. This design enables a higher probability of defect detection as the delay time approaches its end. The efficiency of maintenance is evaluated by measuring the expected downtime and associated costs, which are dependent on the estimated number of failures and defects.
For instance, the following formula estimates the expected number of failures over the interval
:
where
u is the initial point of a random defect,
is the defect arrival rate, and
is the delay time PDF of defects.
In 2017, ref. [
100] examined a single-component system that undergoes regular imperfect inspections. The authors conducted a detailed cost analysis for a maintenance policy that includes periodic imperfect inspections and preventive system maintenance. This approach was applied to the delay time maintenance model of a single-unit system, considering varying probabilities of false positives and false negatives. Additionally, the authors introduced a technique that enables a comparison between the model considering non-constant probabilities of correct and incorrect decisions and the approximate model, which assumes constant decision probabilities. The study objective was to minimize the average cost per unit time over an infinite time horizon.
To estimate expected cycle costs and durations between renewal cycles, six different event paths are analyzed. For instance, in the fifth scenario, the system enters a defective state at time
x within a specific time interval [(
i − 1)
T,
iT), where
i ranges from 1 to
M − 1. Here,
M − 1 represents the maximum number of inspections conducted before preventive maintenance is required. No false positives are generated before the defect’s arrival within this timeframe. The system’s defect becomes evident during inspection
j, where
j ranges from
i to
M − 1. This implies that the system’s delay time must exceed
jT −
x for the defect to be detected at time
jT. Notably, during inspections from
i to
j − 1, false negatives occur with varying probabilities. The probability expression for event path type 5 is formulated as follows:
where
is the PDF for the random time
X to defect arrival and
is the PDF of the system’s delay time
H.
By analyzing the expressions for the probabilities of the event paths, one can determine the expected cycle cost and renewal cycle length.
In 2018, ref. [
101] introduced a model for corrective maintenance that aims to identify optimal intervals for operability inspections in safety-critical systems. The main objective of this model is to ensure a specific level of operational reliability while minimizing maintenance costs over a finite time interval (0,
T). The criterion proposed for corrective maintenance efficiency considers the probabilities of correct and incorrect decisions, which depend on the inspection time and the degradation process parameters. Overall, this maintenance model offers an effective solution for safety-critical systems in terms of cost and reliability.
Operational reliability over the interval
with a sequential inspection schedule is determined by the following formula [
101]:
where
is determined by Equation (150).
Figure 12 illustrates the relationship between operational reliability and operational time for a degrading system in the interval (0, 5000) hours, where the state parameter is represented by the following stochastic equation [
101]:
where
,
, and
is the random degradation rate of the system state parameter (defined in the interval from 0 to ∞) with mathematical expectation
and standard deviation
. The random measurement error of the system state parameter has normal distribution, with zero mathematical expectation and standard deviation
. The minimum permissible value of operational reliability is 0.95.
The PDF of random errors in estimating time to failure
is given by [
101]
The PDF of the stochastic process (176) is [
83]
Figure 12 shows that operational reliability begins at a maximum value close to 1 after inspection and possibly restoration and gradually decreases to a minimum of 0.95 just before the next inspection.
Table 5 shows the optimal inspection times in the interval (0, 5000) hours.
As shown in
Table 5, the interval between operability inspections decreases and approaches approximately 80 h. It takes 43 operability checks to ensure the minimum permissible value of 0.95 in the interval (0, 5000) hours.
In 2019, ref. [
102] proposed a mathematical framework for the preventive maintenance of wind turbine components with imperfect continuous condition monitoring in the interval (0,
τ). The decision to perform maintenance on the wind turbine component relies on data obtained from the sensors. The article introduced general equations to compute the probabilities of false positives, true positives, false negatives, and true negatives during the continuous monitoring of a wind turbine component’s condition. The authors derived mathematical equations for determining the expected maintenance cost per unit time and the average lifetime maintenance cost, accommodating any distribution of time to degradation failure.
The average maintenance cost for one regeneration cycle is determined as follows [
102]:
where
and
represent the cost of preventive maintenance due to false positive and true negative events, respectively.
is the cost of corrective maintenance,
is the loss cost per unit time due to unrevealed failure,
is the conditional probability of a false negative in the interval
provided that
, and
,
, and
are the probabilities of true positive, false positive, and true negative in the interval (0,
τ), respectively.
The mean time of the regeneration cycle is given by [
102]
where
and
are the conditional probabilities of true positive and true negative in the interval
provided that
and
is a derivative of the cumulative distribution function of the time to a false positive under the condition that
.
The expected maintenance cost per unit time is calculated by dividing the average maintenance cost for the regeneration cycle by its average duration [
102].
In 2020, ref. [
103] presented a delay-time model for examining a three-state system that progresses from a defective state to a failed state. Within this framework, inspections are not perfect, and the probabilities of false positives and false negatives change with time. To tackle this issue, the authors introduced a hybrid preventive maintenance strategy that integrates imperfect repair and preventive replacement. Within this approach, the inspection interval and the number of inspections between two successive preventive replacements represent the variables for decision making. These variables are utilized to formulate the optimal policy by minimizing the cost rate over an infinite time.
The calculations for the expected cost per renewal cycle and the expected length of the renewal period are derived from all conceivable scenarios that transpire within a single cycle.
Consider, for instance, type 3 sample paths within the first scenario. A defect occurs at time
x within the time interval [(
j − 1)
T,
jT], where
j =1, 2,…,
M, and a failure takes place after
MT. From the moment the defect appears until time
MT, the system remains faulty, ensuring that there are no false positive detections in this trajectory. Furthermore, any inspection conducted between the intervals [
jT, (
M − 1)
T] either results in a false negative or detects the faulty state, leading to a “minimal repair.” The probability for type 3 sample paths can be expressed as follows:
where
is the cumulative distribution function of the time to defect
X and
is the cumulative distribution function of the delay time
Y.
In 2021, ref. [
104] presented a mathematical model designed to assess the trustworthiness indicators associated with operability checks for a system undergoing deterioration. An examination of mutually exclusive events during operability checks is carried out, with correct and incorrect decisions corresponding to events such as false positives, true negatives, false negatives, and true positives. The probabilities of decisions depend on the inspection time and failure time. The paper introduced general formulas for calculating the probabilities of different decisions during discrete-time operability checks. Additionally, the study introduced efficiency indicators for corrective maintenance, including average operating costs, total error probability, and the posterior probability of failure-free operation. To illustrate the developed approach, the study computed the probabilities of correct and incorrect decisions for a specific stochastic deterioration process.

















{kind=link}
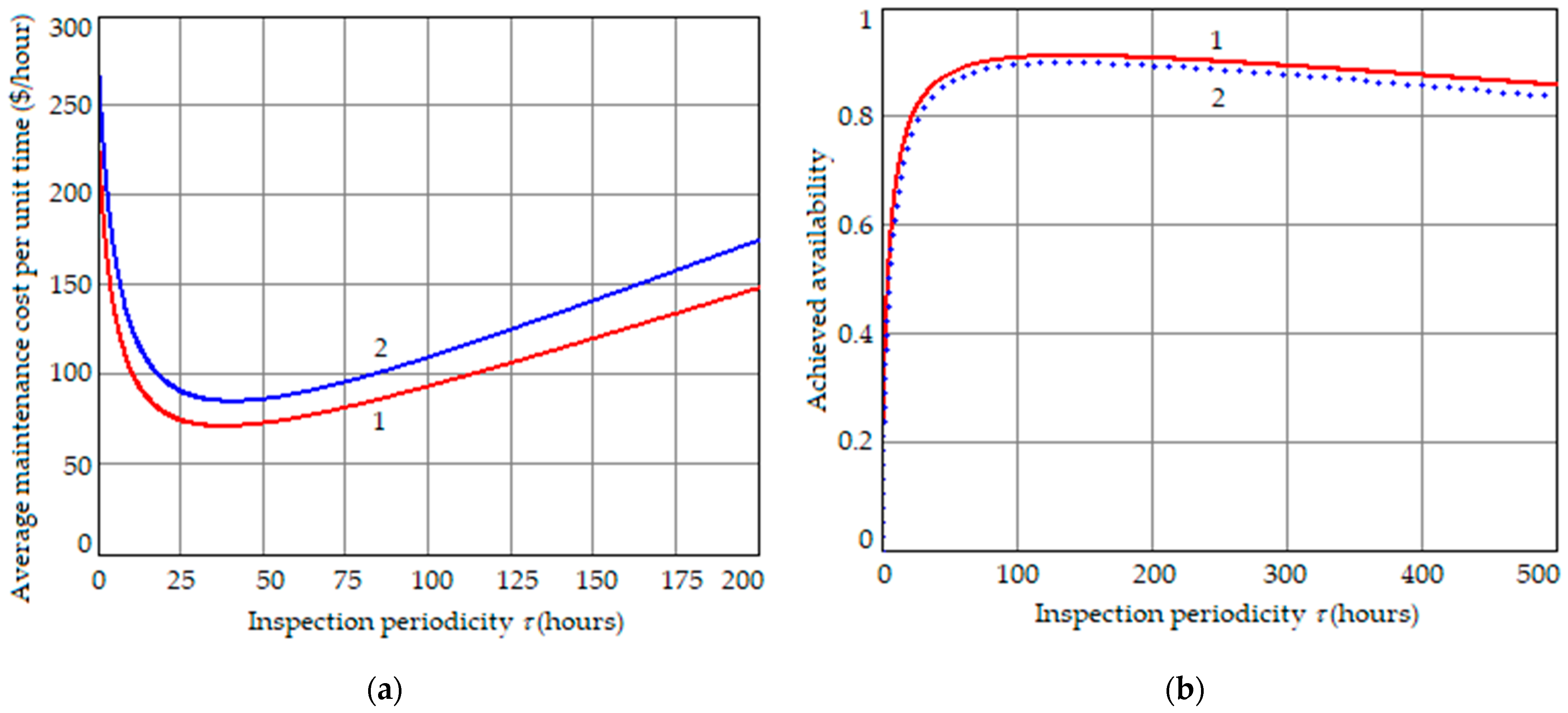{kind=link}
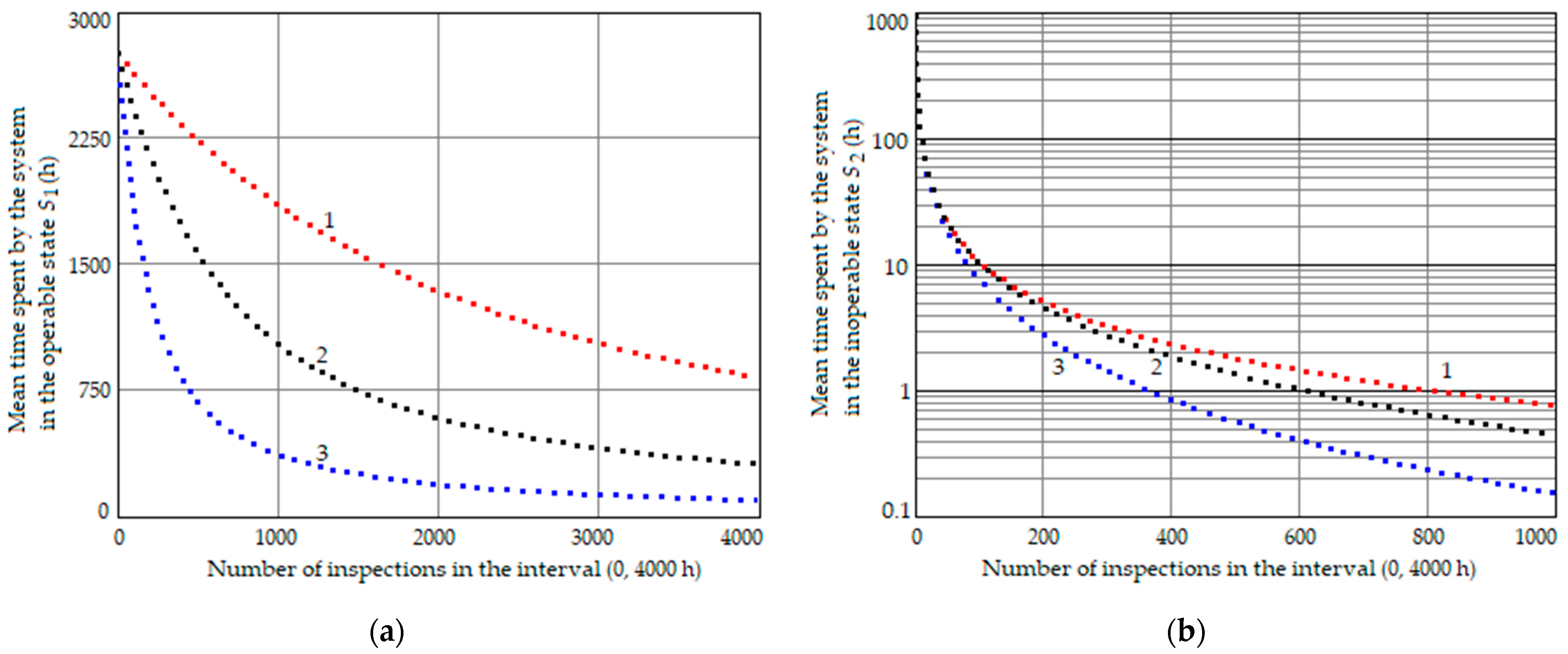{kind=link}
{kind=link}
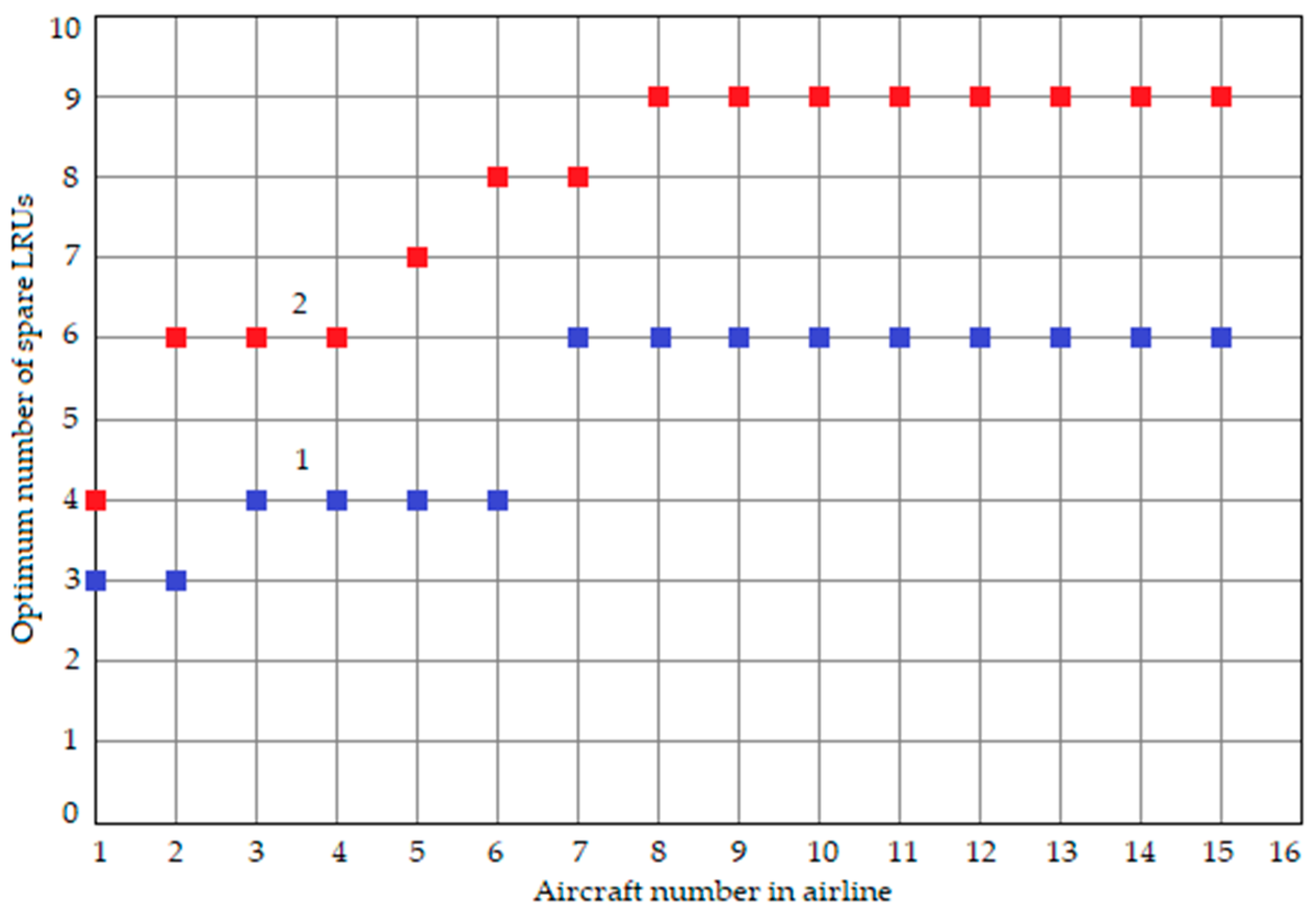{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}