1. Introduction
Aircraft attitude control is an important part of the design of aircraft autopilot. With the increase in aircraft flying altitude and speed, pure aerodynamic control has been unable to meet the tracking requirements of attitude control commands. Therefore, some scholars have proposed a dual-control strategy of direct force and aerodynamic force. When the aerodynamic force cannot meet the required overload, direct force is provided by the reaction jet to assist the aircraft in establishing the required attitude and improve system dynamic response performance [
1,
2,
3,
4,
5,
6].
In general, the aerodynamic force is generated by the attitude angle and tail fins of the aircraft, and the direct force is generated by the reaction jet. Due to the limitations of aircraft layout, the volume of the attitude control engine is generally small, and the fuel carried is also limited (the disposable solid fuel rocket is usually used). During the flight process of the aircraft, it is always accompanied by attitude adjustment. How to reduce the fuel consumption of the attitude control engine is the key problem in the design of the controller. Once the fuel is exhausted in advance, the dynamic response of the aircraft will decline, and even the controller will diverge. That is to say, how to ensure the optimality of control input is a key point of aircraft attitude control.
Since the optimal control theory was proposed in the 1950s, it has been widely used in the field of aircraft control. For linear systems, the most common method is to design a quadratic cost function and solve the linear Riccati equation to obtain the optimal control law. However, for nonlinear systems, solving the nonlinear partial differential Hamilton–Jacobi–Bellman (HJB) equation is a very complex problem, especially when considering external interference and system uncertainty, which make it more difficult to solve the equation and limit the practical application of the optimal control theory to a certain extent.
With the development of neural network techniques, reinforcement learning is a recently emerging near-optimal control method. Reinforcement learning algorithms are mainly divided into model-dependent and model-independent. Adaptive dynamic programming (ADP) is widely used as a model-based reinforcement learning algorithm. This method was first proposed by Werbos [
7]. Its basic logic is to use a neural network to approximate the optimal cost function, so as to avoid the “disaster of dimensionality” problem in dynamic programming calculation and provide a convenient and effective solution for the optimal control problem of high-dimensional nonlinear systems. This method combines modern control theory with an intelligent control algorithm, which is not a complete “black box” strategy, ensuring the credibility of the algorithm. Considering that the offline iterative ADP algorithm has difficulty in ensuring stability when the system structure changes or there is external interference, the online iterative ADP algorithm is gradually recognized by scholars and has been widely developed and applied [
8,
9,
10,
11,
12]. Pang [
13] used the ADP algorithm to solve the optimal control problem of continuous-time linear periodic systems. Rizvi [
14] used the ADP algorithm to solve linear zero-sum differential game problems, obtained complete system measurement values by introducing an observer, and proposed two ADP algorithms, namely the policy iteration and value iteration algorithms. For linear time-varying systems, Xie [
15] proposed an ADP algorithm that introduced a virtual system to replace the original system, thus avoiding the integration problem in iterative operation. In the article [
16], Jia designed a data-driven ADP algorithm to suppress the Pogo vibration of liquid rockets. Nie [
17] designed an ADP algorithm based on a model-free single-network adaptive critic method for non-affine systems such as solid-rocket-powered vehicles, which can achieve optimal control of trajectory tracking for solid-rocket-powered vehicles. In the article [
18], Xue designed a novel integral ADP scheme for input-saturated continuous-time nonlinear systems, and through event-triggered control law, the computational burden and communication cost were reduced. In the articles [
19,
20], the ADP scheme was applied to aircraft guidance law design. However, in the existing ADP algorithm, how to deal with the MIMO system is a problem to be solved. In the articles [
21,
22,
23,
24,
25,
26], the ADP technique was applied to the application control system, such as attitude control of hypersonic aircraft [
21], satellite control allocation [
22], multi-target cooperative control [
23], formation of quadrotor UAVs [
24], attitude control of morphing aircraft [
25], and air-breathing hypersonic vehicle tracking control [
26]. In these articles, although the processing system was a high-dimensional system, without exception, they all used a single control input, that is, a single-input multiple-output (SIMO) system. At present, the ADP algorithm for the MIMO system rarely appears. In the process of the author’s reproduction of the existing ADP algorithm, the MIMO system will cause the polynomial neural network to easily fall into saturation, and the convergence speed is very slow, even unable to converge. In this context, how to improve the network depth is an important problem to be solved to promote the application of the ADP algorithm.
To solve this problem, some scholars proposed to use other more complex neural networks instead of polynomial neural networks to improve the fitting ability of the ADP algorithm, such as RBF neural networks. In the article [
27], Zhang designed an ADP algorithm based on a sliding mode surface for nonlinear switched systems. The algorithm uses the integral sliding mode term to combat the disturbance of the system and ensure the stability of the system during the switching process and uses the ADP algorithm to ensure the optimality of the control input. In the ADP algorithm, the RBF neural network is used instead of the polynomial network to realize the optimal control of the MIMO-switched system. The simulation process uses a dual-inverted pendulum system instead of the actual application system.
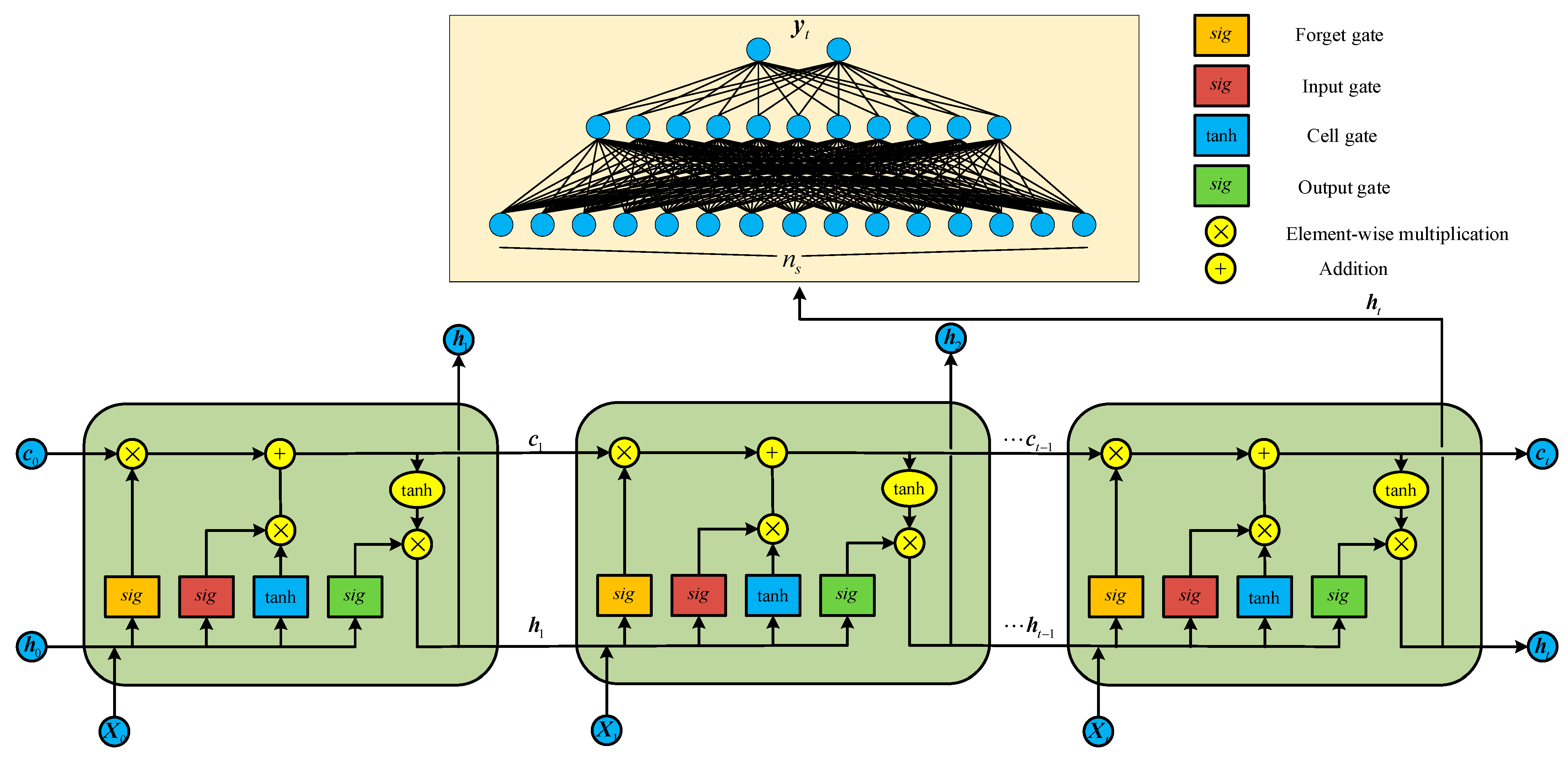
In fact, there is no essential difference between the chained neural network and the polynomial neural network, but the activation function is replaced, so the fitting ability of the network is slightly increased. In the existing article, the ADP algorithm based on the chained neural network has not been applied to the actual MIMO system. Considering the shortcomings of chained neural networks, this paper introduces a kind of recurrent network with gating units, namely the LSTM neural network [
28,
29,
30] instead of the polynomial network. As a complex network, the LSTM neural network has a strong fitting ability, which can effectively solve the problem of insufficient fitting ability of multinomial networks. An additional term is introduced into the optimal control law to ensure the boundedness of the closed-loop system.
When the neural network is replaced, the following problem is how to design the weight update law. In the existing ADP algorithm, the design method of weight update law is to take the value of the Hamilton function as the error and perform a partial derivative operation on the network weights, respectively, so as to obtain the gradient of weight decreasing along the error, and then obtain the update law of each weight of the network. This method is intuitive and effective, but when the complexity of the network increases, the calculation of the gradient becomes very complex, resulting in the gradient descent method no longer being applicable. At this time, a new design method of network weight update law is needed to replace the gradient descent method.
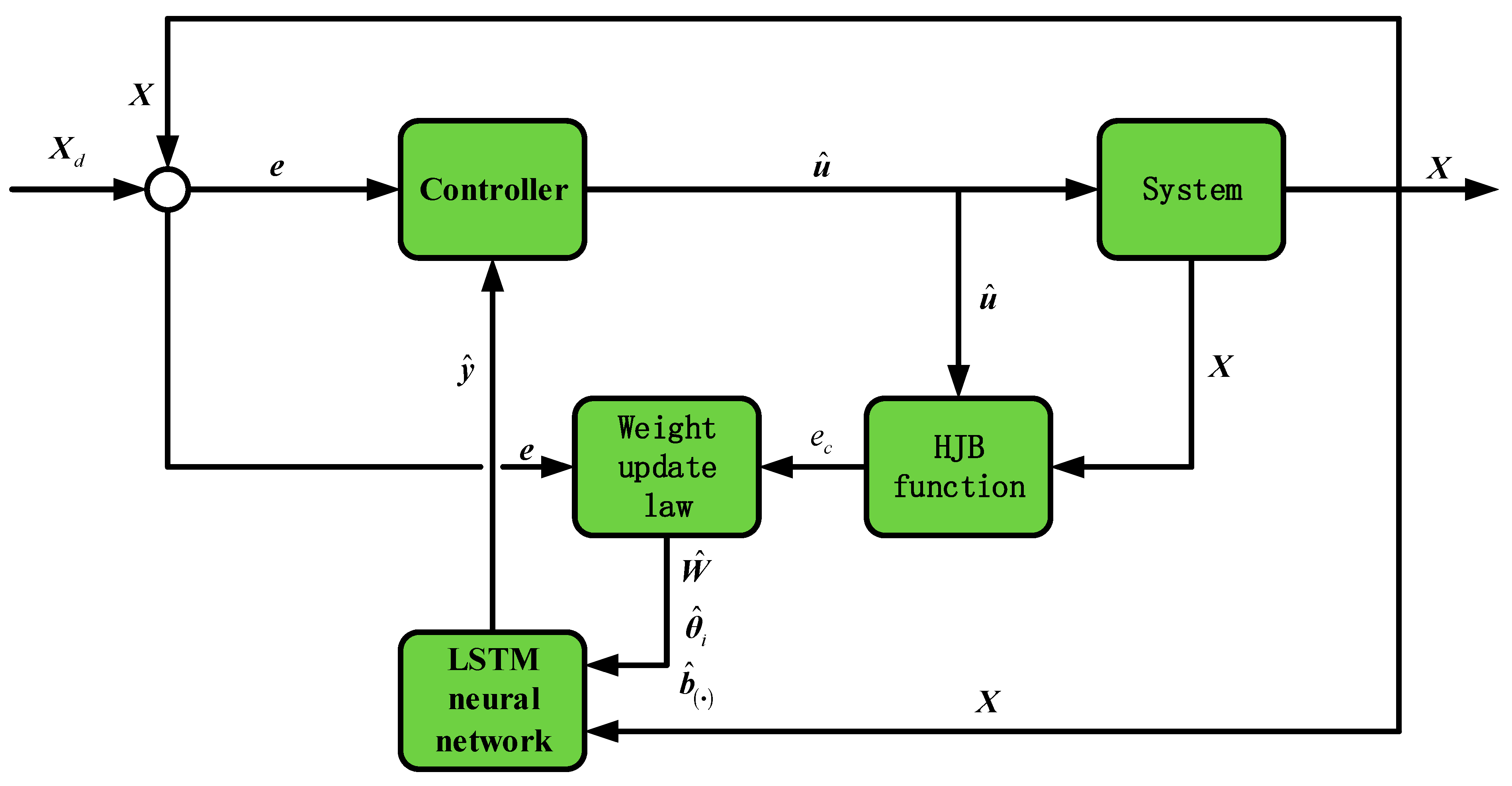
In this paper, an adaptive dynamic programming algorithm based on the LSTM neural network (ADP-LSTM) is proposed to solve the optimal 6-DoF attitude control problem of dual-control aircraft. The main contributions of this paper are as follows:
- (1)
A reinforcement learning near-optimal control method based on the LSTM neural network is proposed, which is applied to the 6-DoF attitude control of dual-control aircraft. Different from the existing algorithms, this algorithm does not need to decouple the nonlinear aircraft attitude dynamics model, and retains the internal characteristics of the system as much as possible. The algorithm can effectively solve the optimal control problem of the MIMO nonlinear control system.
- (2)
Based on the nonlinear optimal control theory, an additional term based on output feedback is introduced to ensure that the closed-loop system with disturbance is bounded and converges in the small neighborhood of the control command.
- (3)
Based on the Lyapunov method, the online adaptive updating law of LSTM neural network weights is given. All the updating laws are analytical, which avoids the excessive burden of system operation caused by large-scale real-time operation and proves the stability of the system.
- (4)
In the simulation analysis, it is verified that the algorithm can effectively solve the optimal 6-DoF attitude control problem of dual-control aircraft.
The rest of this paper is arranged as follows: In the
Section 2, the 6-DoF attitude dynamics model of dual-control aircraft is established. In the
Section 3, based on the nonlinear optimal control theory, the nonlinear partial differential HJB equation is designed, and the optimal controller is designed. In the
Section 4, the design method of a near-optimal controller based on the ADP-LSTM technique is given, the novel online update law of LSTM neural network weights is designed based on the Lyapunov method, and the stability of the system is proved. In the
Section 5, the ADP-LSTM is applied to the 6-DoF attitude control problem of dual-control aircraft, and the simulation process is analyzed. The
Section 6 is the conclusion.
2. Attitude Dynamics Model of Dual-Control Aircraft
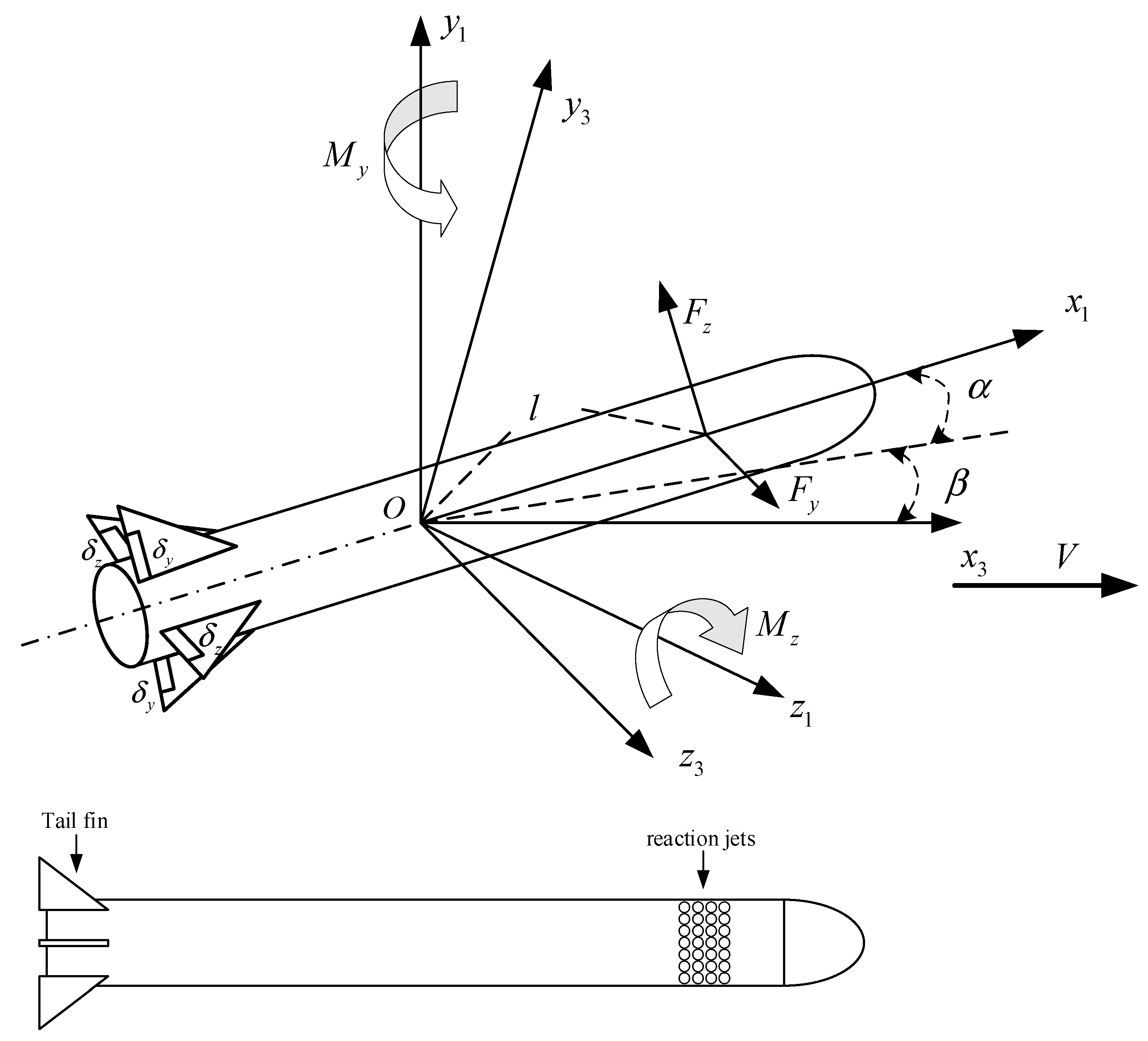
As shown in
Figure 1, dual-control aircraft’s pitch and yaw channels have two control inputs, i.e., tail fins and reaction jets. Since the direct force is perpendicular to the axis of the aircraft, it will not affect the rolling channel, so there is only one control input in the roll channel, i.e., tail fins. Among them, the aircraft has four tail fins in a cross layout. Two vertical fins provide
, two horizontal fins provide
, and
is generated by the differential between horizontal fins and vertical fins.
The missile body coordinate system
and the missile velocity coordinate system
are defined in
Figure 1. The axis
is the longitudinal axis of the missile and the axis
is along
, the velocity of the missile. The axis
is in the plane of symmetry of the missile. The relationship between the two coordinate systems is determined by two angles, i.e., the angle of attack
and the sideslip angle
. Let
denote the pitch rotational rate. We define the aerodynamic parameters in the elevation loop of the dual-control system as
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
.
Where is the partial derivative of the pitching moment with respect to the pitch rate , is the partial derivative of the pitching moment with respect to the angle of attack , is the partial derivative of the pitching moment with respect to the rudder deflection angle , is the partial derivative of the yaw moment with respect to the yaw rate , is the partial derivative of the yaw moment with respect to the sideslip angle , is the partial derivative of the yaw moment with respect to the rudder deflection angle , is the partial derivative of the roll moment with respect to the roll rate , is the partial derivative of the roll moment with respect to the rudder deflection angle , , and are the component of moment of inertia on axis , and respectively, and is the distance from the point of the lateral thrust to the mass center of the missile.
Considering entering the terminal guidance stage, the main engine of the aircraft is shut down, the aircraft mass and velocity are constant, and the attitude dynamics model of the dual-control aircraft is established through the above aerodynamic parameters.
The external forces on the missile are gravity, aerodynamic force, and direct force, so the missile overload dynamic model of the pitch channel can be written as
The derivative of Equation (6) is
By substituting Equations (1) and (3) into Equation (7), we can obtain
With further simplification, we obtain
The dynamic response of the controller actuator is considered as the inertial system, i.e.,
where
and
are the mechanical constants of the actuator, respectively.
By substituting Equation (6) into Equation (5), we obtain
Similarly, we can obtain the dynamic model of the yaw channel as
The attitude dynamics model of rolling channel considering three-channel coupling is
Finally, the aircraft attitude dynamics model is obtained as
We define
as the state vector, where
is the control vector, then Equation (18) can be written as the following state space model:
where
where
is the external disturbance.
3. Design of Optimal Control Law Based on HJB Equation
Consider continuous affine nonlinear systems with a class of uncertainties
where
is the state vector of the system,
is the control input vector, and
and
are the system function and control matrix, respectively.
Assumption 1. The nonlinear function satisfies the local Lipschitz condition in the set containing the origin and f(0) = 0. The control matrix is bounded.
Consider reference systems without uncertainties
Assumption 2. There is a symmetric positive definite matrix such that the system uncertainty satisfies and the system uncertainty is bounded, that is, .
Based on the above assumptions, the control system cost function is defined as
where
,
is a symmetric positive definite matrix, and
is defined as the tracking error.
Remark 1. The minimum value of the cost function is achieved by searching for the optimal control term . When designing the cost function, the tracking error of the system and the upper bound of the uncertainty of the system are described, and it can be seen from the definition that 0. Therefore, when the minimum cost function is obtained, the closed-loop system state can converge to a sufficiently small neighborhood of the control command, and the interference of uncertainty is considered to achieve the effect of interference suppression.
According to the optimal control theory of nonlinear systems, the Hamiltonian function of the design reference system is
where
is the partial derivative of the cost function
with respect to the state of the system
, i.e.,
.
The optimal cost function
can be obtained by solving the following Hamilton–Jacobi–Bellman (HJB) Equation (24):
According to the necessary conditions
0, the optimal control law is
By substituting Equation (25) into Equation (24), the HJB equation can be rewritten as
Remark 2. It can be seen that in order to obtain the optimal control law , the above HJB equation needs to be solved to obtain the optimal cost function and its partial derivative to the system state . However, for nonlinear systems, it is very difficult to solve the HJB equation, especially in the case of considering external disturbance, so the difficulty of solving the equation further increases. On the other hand, if we can find the cost function to ensure the Hamiltonian function , we can obtain the optimal control law . In other words, through this idea, the optimal control problem can be transformed into the problem of how to obtain the optimal cost function . In the next section, a reinforcement learning algorithm based on the LSTM neural network is proposed, which uses the LSTM neural network to fit the optimal cost function, so as to achieve approximate optimal control.
5. Simulation Analysis
In the simulation process, the 6-DoF attitude dynamics model of the dual-control aircraft mentioned in the
Section 2 is applied to verify the performance of the control law which is presented in this paper. The command signal is
, and all aerodynamic parameters are designed based on an aircraft flying altitude of 30 km.
When the aircraft flies at an altitude of 30 km, the thin atmospheric density results in a decrease in aerodynamic force. At this time, relying on pure aerodynamic control will seriously reduce the dynamic characteristics and control quality of the control system. Usually, the dual-control strategy is used to design the aircraft autopilot, because the direct force is generated by the reaction jet, which is not affected by the flight altitude, and can effectively compensate for the lack of control input caused by insufficient aerodynamic force.
Due to the volume limitation of the aircraft, it is impossible to place the orbit control engine with a large volume and weight. Therefore, the attitude control engine is used in this simulation, which only affects the attitude and has a very small direct impact on the overload. Therefore, the overload establishment of the aircraft still depends on the aerodynamic force; that is to say, in order to obtain enough overload, the aircraft will make a large angle of attack or sideslip angle maneuver. At this time, the assumption that the aerodynamic parameters are considered as constant or slow time variables is no longer tenable. Therefore, taking the aerodynamic parameters
and
as examples, we consider
and
as functions of the AOA and sideslip angle, i.e.,
We consider other aerodynamic parameters as perturbation parameters, i.e.,
As the roll angle and roll rate are both small, we consider and as constants. We consider that the external disturbance vector is Gaussian white noise.
The initial weights of the LSTM neural network are randomly selected in the closed interval . According to the practical application, the tail fin angle and the magnitude of the direct force are subject to saturation constraints, i.e., , , , , and . The initial state of the system is .
To verify the optimality of ADP-LSTM, the adaptive sliding mode control method (SMC-RNN) proposed in reference [
31] was applied to the attitude control model during the simulation process and compared with ADP-LSTM. The algorithm in reference [
31] combines sliding mode control and Recurrent Neural Networks (RNN), using RNNs to fit system terms and external disturbances to achieve adaptive control of the system model and external disturbances. However, it is important to note that the algorithm in reference [
31] did not consider energy optimization during its design process. Therefore, comparing it with ADP-LSTM can effectively reflect the energy-optimal control effect of ADP-LSTM.
The LSTM neural networks used in ADP-LSTM have eight input nodes, eight output nodes, and 10 cell states, making the system state
the input vector of the network. The RNNs also have eight input nodes, eight output nodes, and 10 hidden states; the structure of RNNs can be found in the article [
31].
To verify the control effectiveness of ADP-LSTM, two simulation scenarios are designed: tracking a fixed overload command and tracking a time-varying overload command. Both scenarios represent common target maneuver forms and can demonstrate the general applicability of the algorithm presented in this paper.
The aircraft parameters of the pitch channel can be seen in
Table 1. Considering that the aircraft has an axisymmetric shape, the pitch channel parameters are consistent with the yaw channel parameters.
5.1. Scenario 1: Tracking a Fixed Overload Command
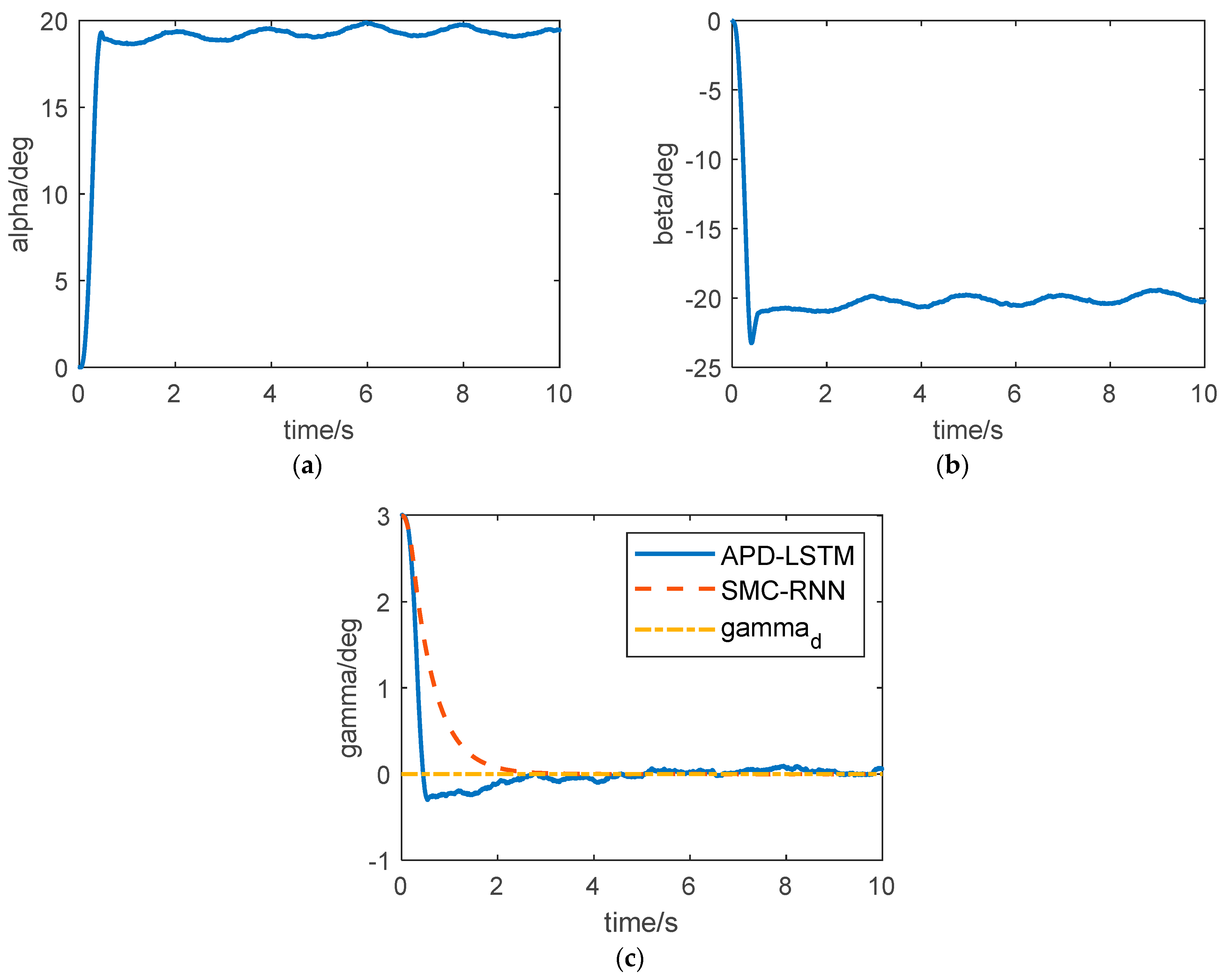
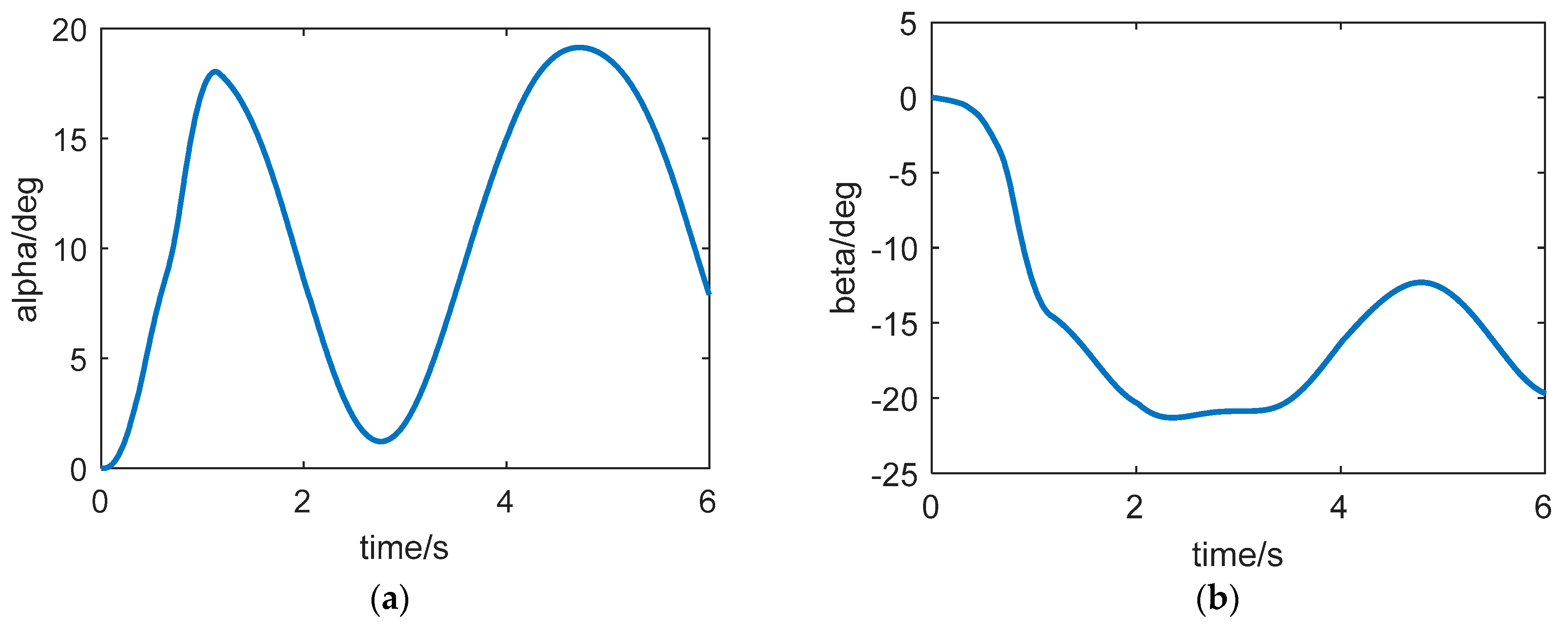
The curve of the angle of attack, sideslip angle, and roll angle are shown in
Figure 4. According to the previous introduction, the overload of the aircraft is established by the aerodynamic force, so in order to track the overload command as soon as possible, the angle of attack and sideslip angle of the aircraft need to respond quickly. In
Figure 4a,b, we can see that the angle of attack and sideslip angle both enter the steady state quickly. Like other STT aircraft, the controller designed in this paper ensures that the aircraft body axis does not roll; that is, the roll angle command is 0 deg. To verify the effect of the controller, the initial roll angle is set to 3 degrees. As can be seen from
Figure 4c, the controller can ensure that the roll angle converges to 0 deg. Both ADP-LSTM and SMC-RNN can achieve control of roll angle, among which ADP-LSTM has a faster convergence speed but some overshoot, while SCM-RNN, although it has no overshoot, has a slower convergence speed.
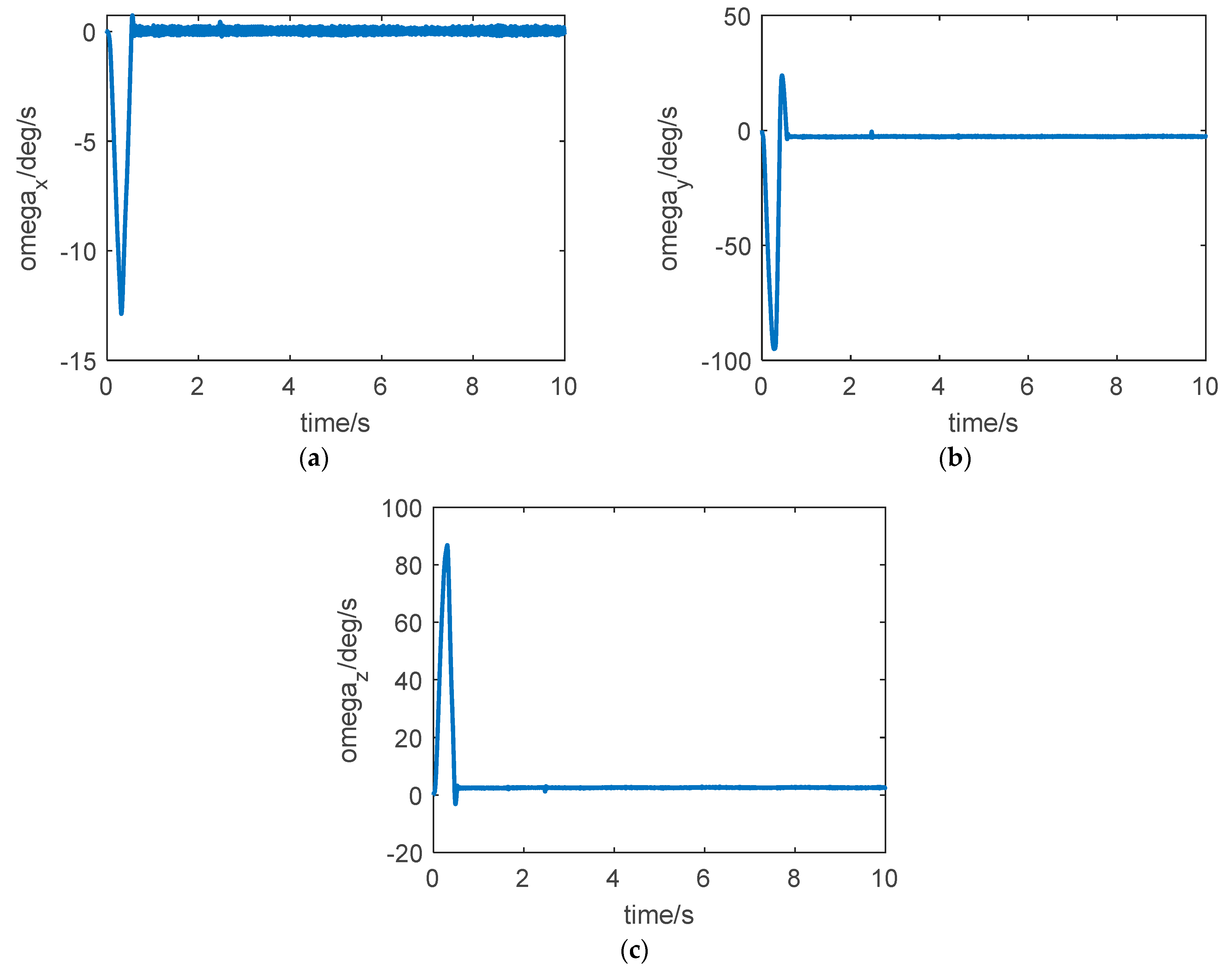
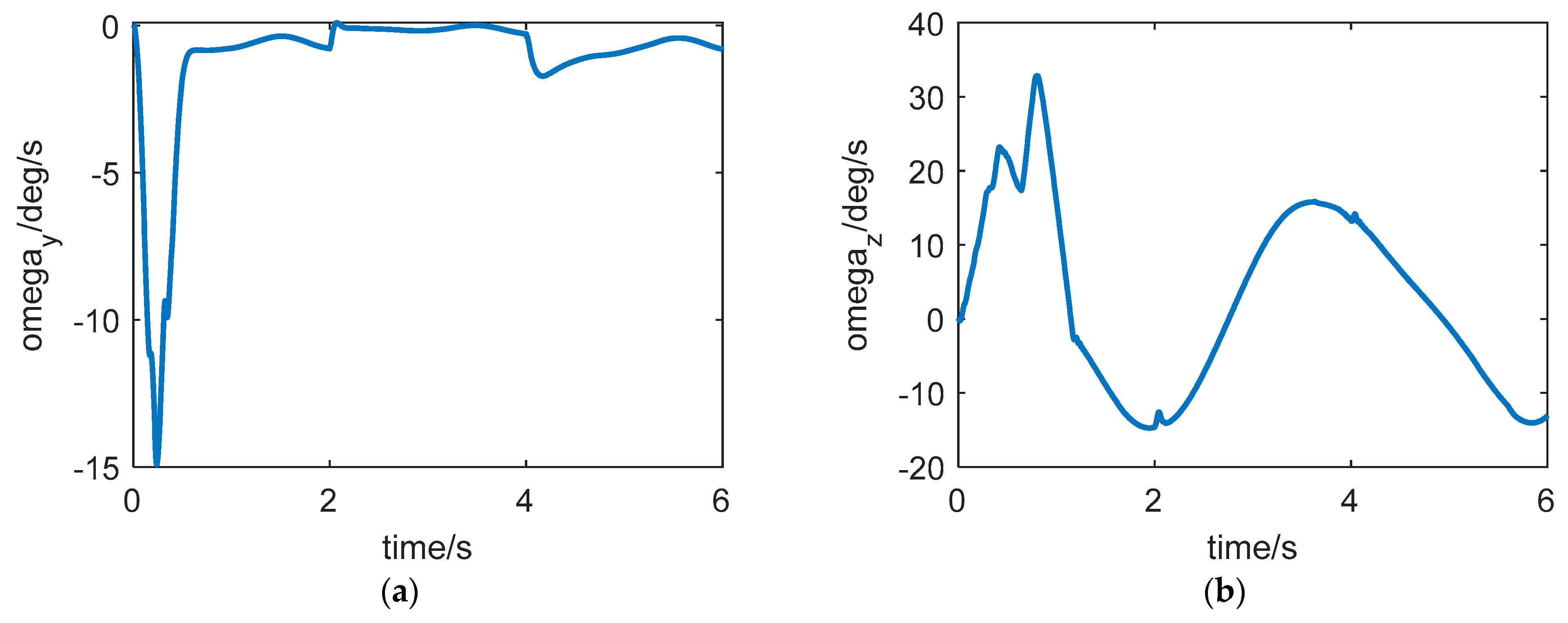
The curve of roll rate, yaw rate, and pitch rate are shown in
Figure 5. This state intuitively reflects the attitude agility of the aircraft. It can be seen from
Figure 5 that the aircraft has strong agility and fast attitude response speed under the effect of the dual-control strategy.
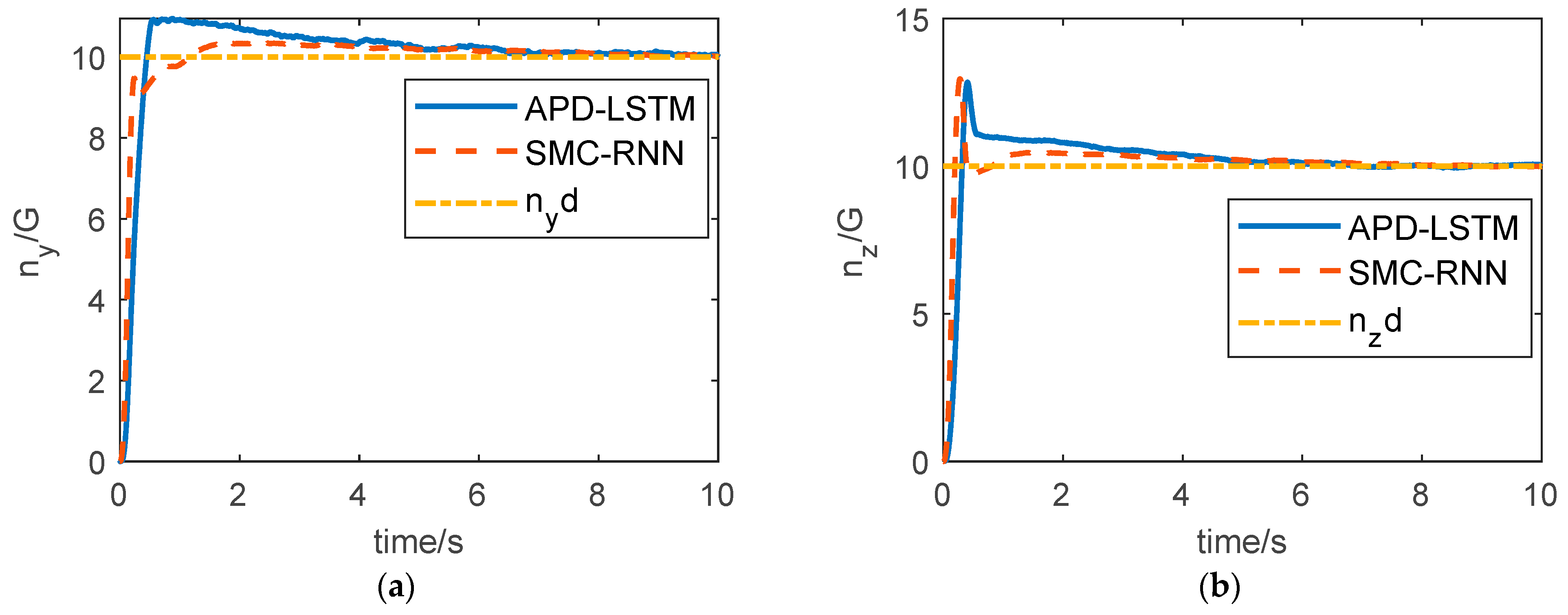
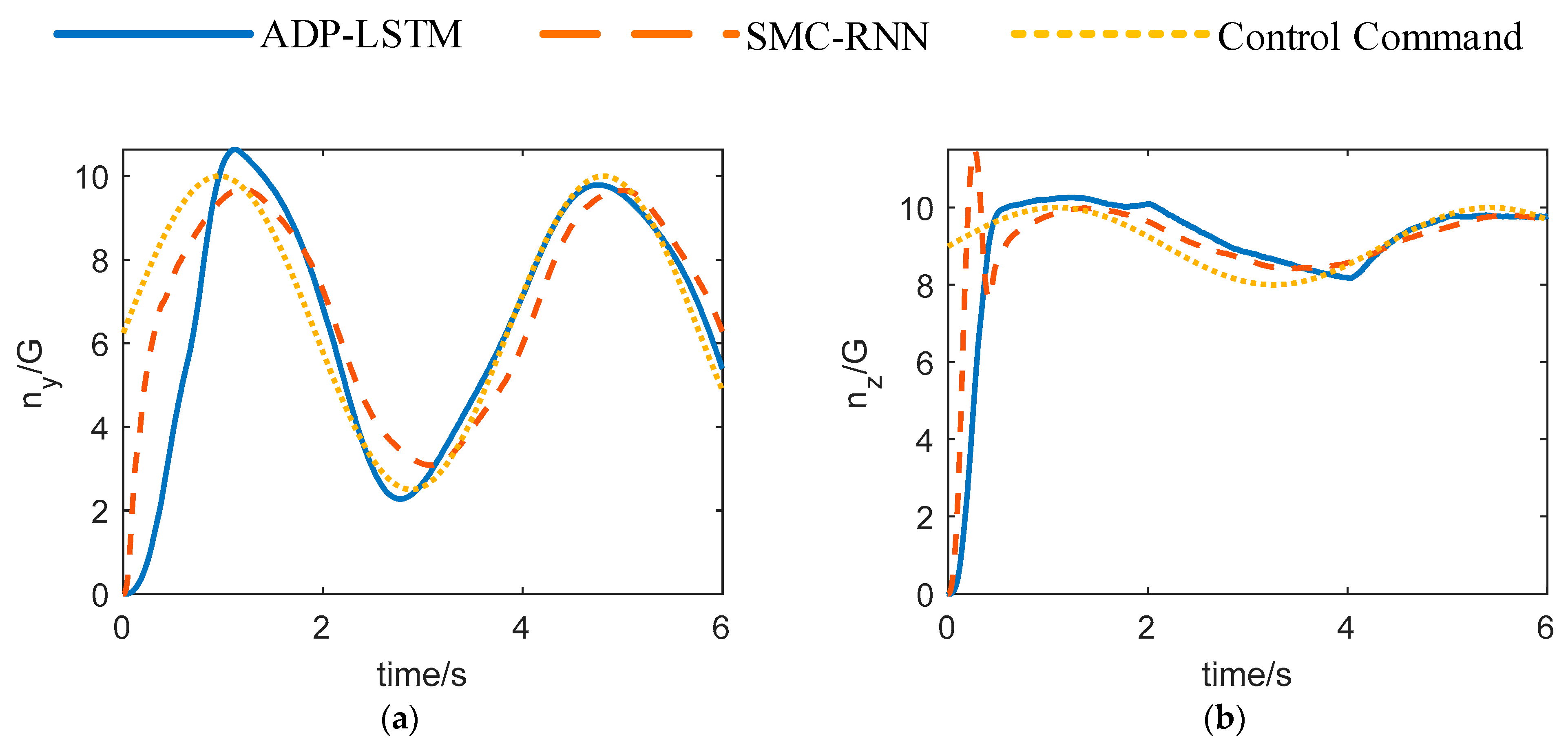
The overload curves of the two controllers are shown in
Figure 6. It can be seen from
Figure 6 that the aircraft overload can track the command signal by ADP-LSTM, but it has to be admitted that the convergence rate is slow for two reasons. First, according to the nonlinear system optimal control theory, when the Hamilton function tends to zero, the optimal control input
obtained at this time can only ensure that the tracking error
converges to 0 in infinite time, i.e.,
0. Second, there are coupling terms between the pitch, yaw, and roll channels of the aircraft, which reduce the control quality. Usually, when designing the autopilot, it is completed after decoupling the three channels. However, this will ignore some characteristics of the system, and obviously, this will reduce the robustness of the algorithm in practical applications. The advantage of the ADP-LSTM in this paper is that it does not need three-channel decoupling, retains the characteristics of the system, and does not need the necessary assumptions when decoupling, which widens the application scope of the algorithm and is more general. Meanwhile, we can observe that the control effect of SMC-RNN is better than that of ADP-LSTM. This is an unavoidable trade-off. In order to achieve optimal energy consumption for the system, some sacrifice in control effectiveness is inevitable. However, the control effectiveness of ADP-LSTM has not significantly decreased and still maintains steady-state error, with only a slight increase in convergence time.
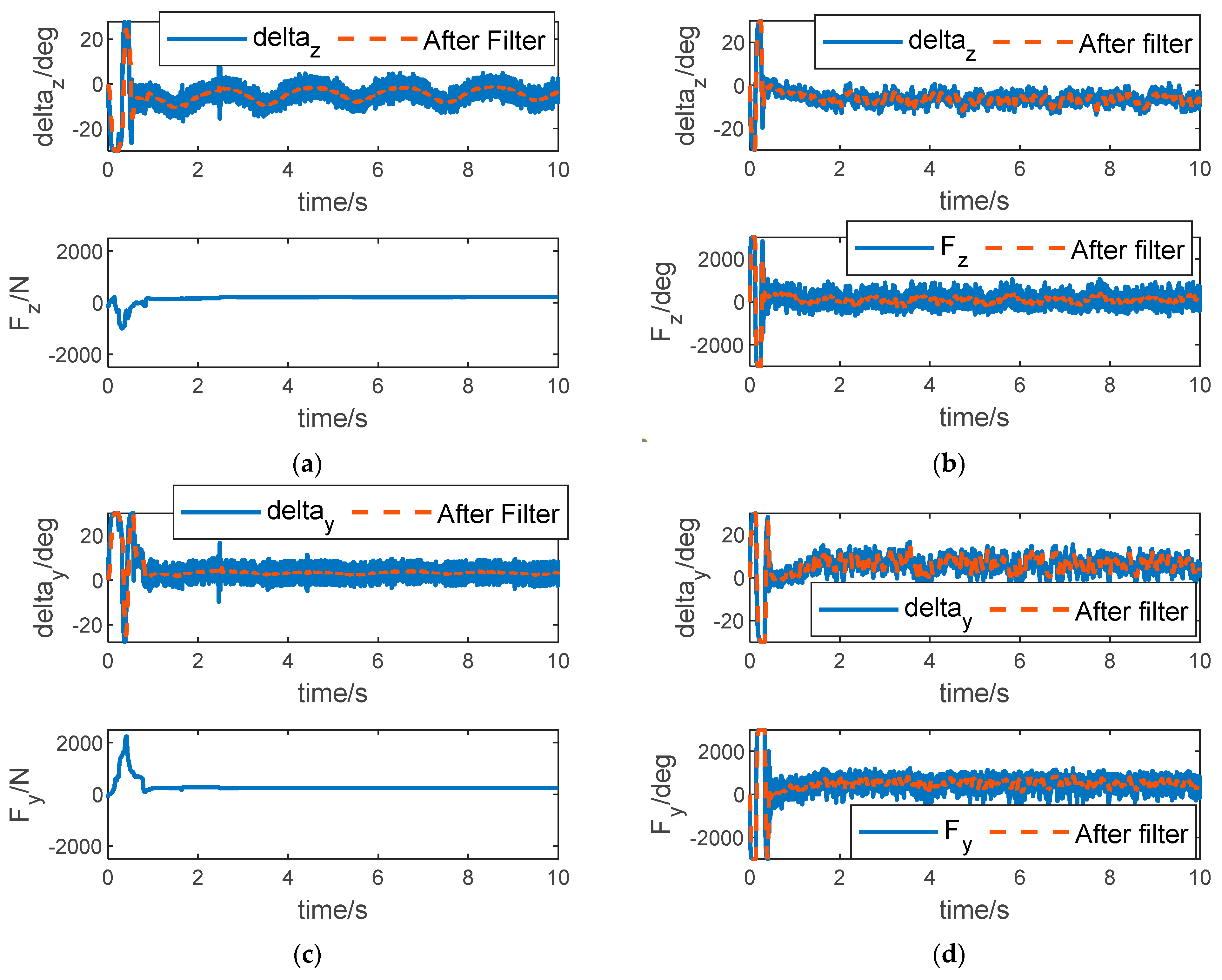
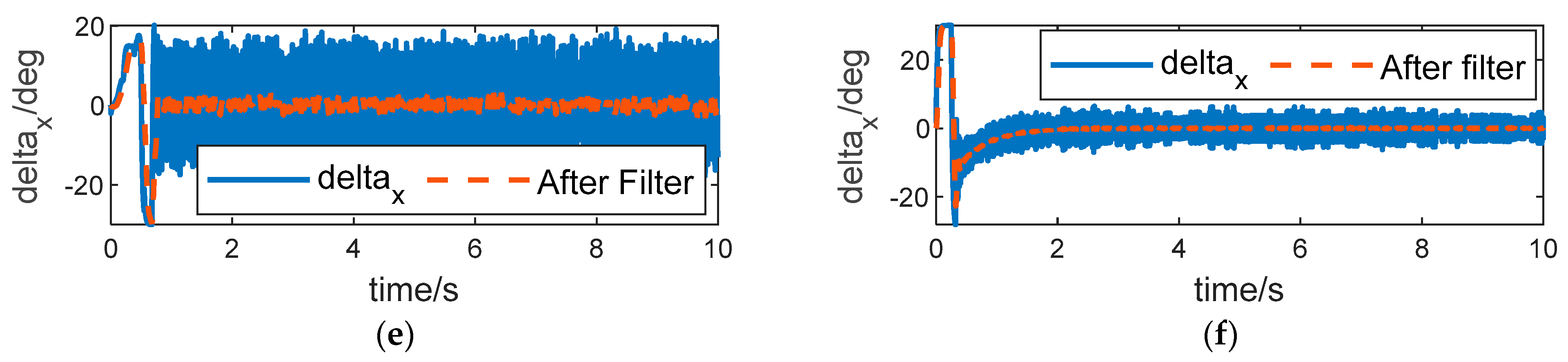
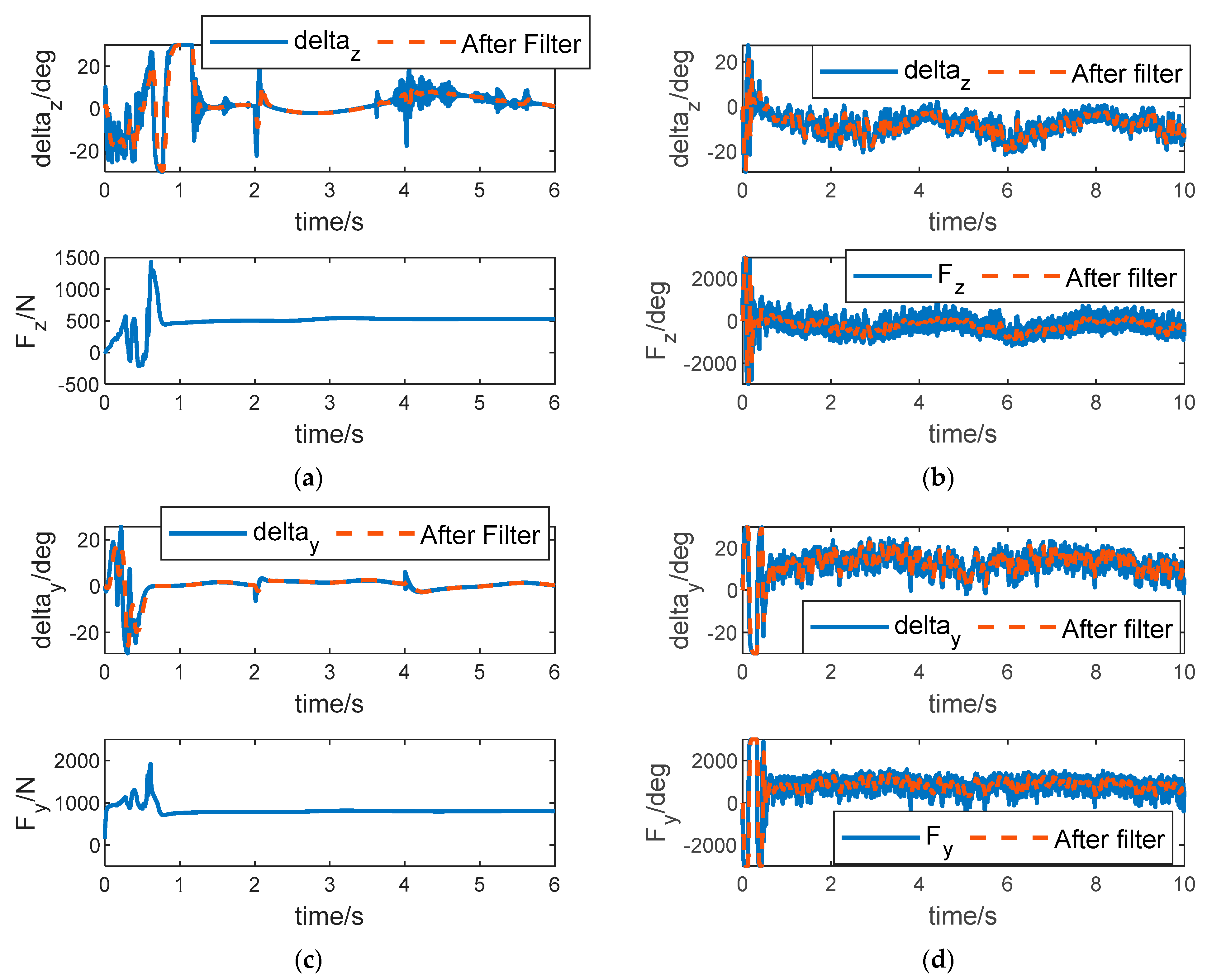
The control inputs of pitch, yaw, and roll channels of ADP-LSTM and SMC-RNN are shown in
Figure 7. And low-pass filters were introduced to better display the specific details of the curve. It can be seen from
Figure 7a,c,e that when the system enters the steady state, the control input of the tail fins has a chattering phenomenon, which is caused by external disturbance, and the control input shows a sinusoidal trend, which is caused by the perturbation of aerodynamic parameters. The direct force input will tend to a fixed value, and this value is very small. Intuitively, this avoids the waste of control energy. However, it is still impossible to determine whether the control input is optimal from the results of this figure alone. It is necessary to refer to whether the Hamiltonian function
converges to zero. In
Figure 7b,d,f, we can see that the control input of SMC-RNN is higher than that of ADP-LSTM, especially for direct force control input. The chattering phenomenon in the control input is more severe, and it does not significantly weaken after passing through the low-pass filter. This is due to the inherent defect of sliding mode control. Controlling the input chattering phenomenon can cause serious energy waste, and it is also very unfriendly to the actuator.
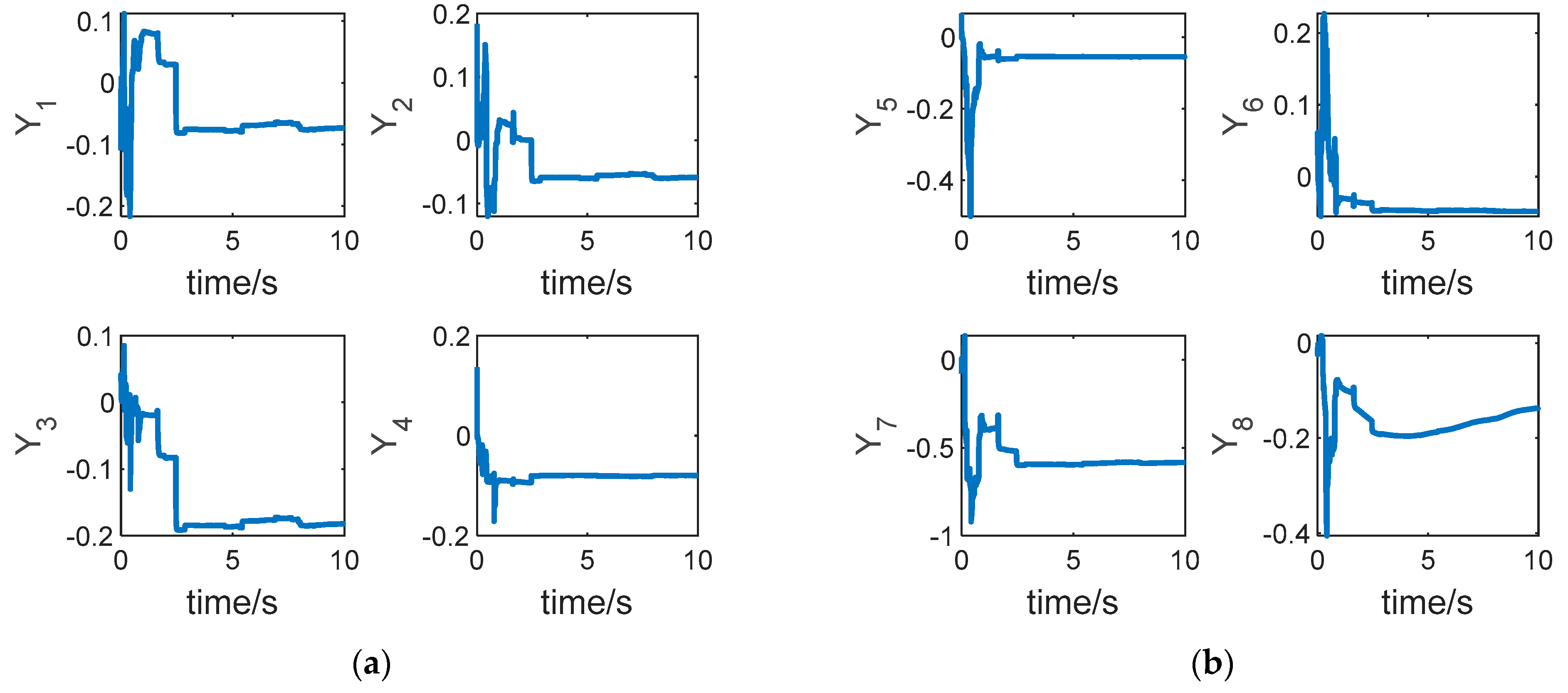
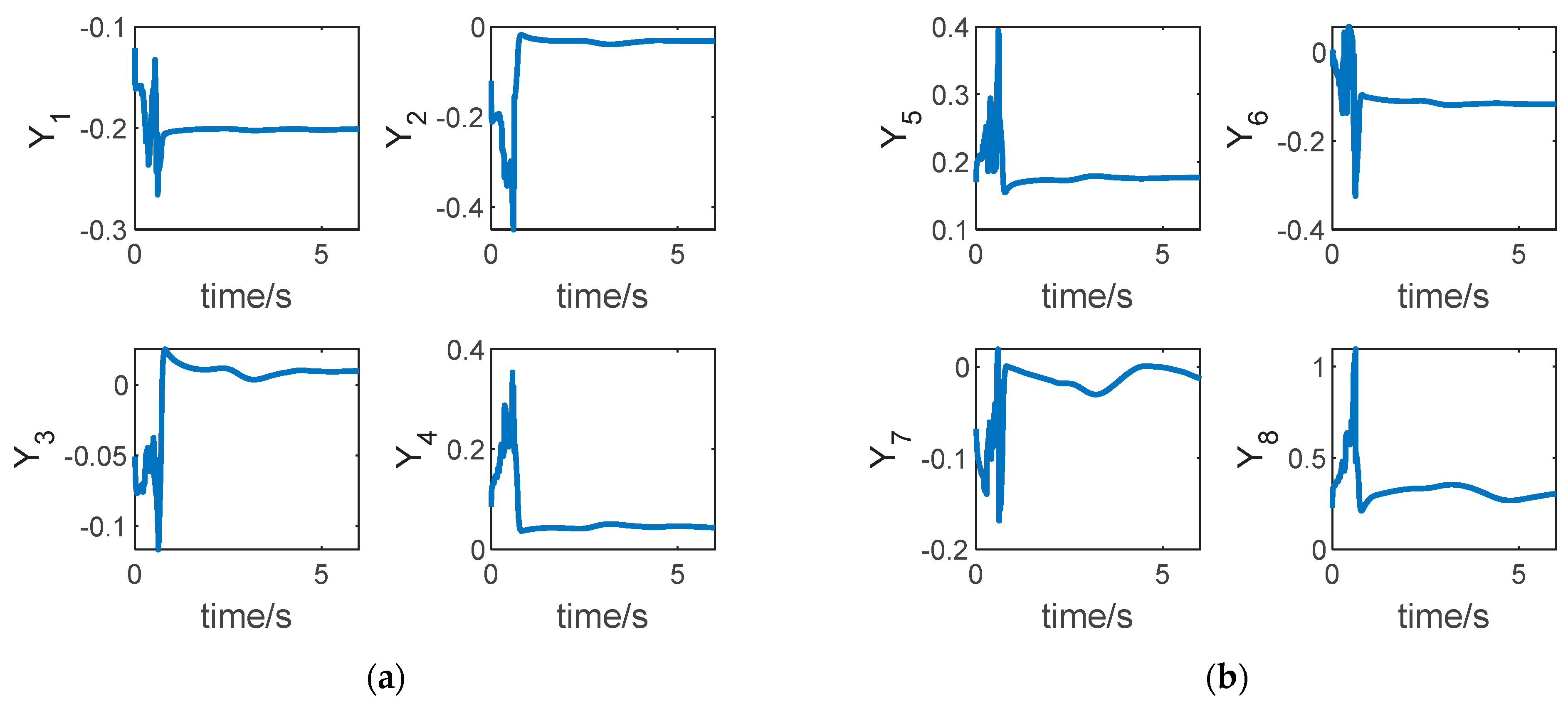
The outputs of the LSTM neural network are shown in
Figure 8. In this paper, the LSTM neural network is aimed to fit the partial derivative of the cost function
with respect to the state of the system
, i.e.,
. According to the definition of the system, we know that
, and there are eight output values of the LSTM neural network, i.e.,
. It can be seen from
Figure 7 that after a short dynamic process, the output value of the neural network is nearly stable, which shows that under the effect of the adaptive weight update law, the output value
gradually tends to the optimal value
.
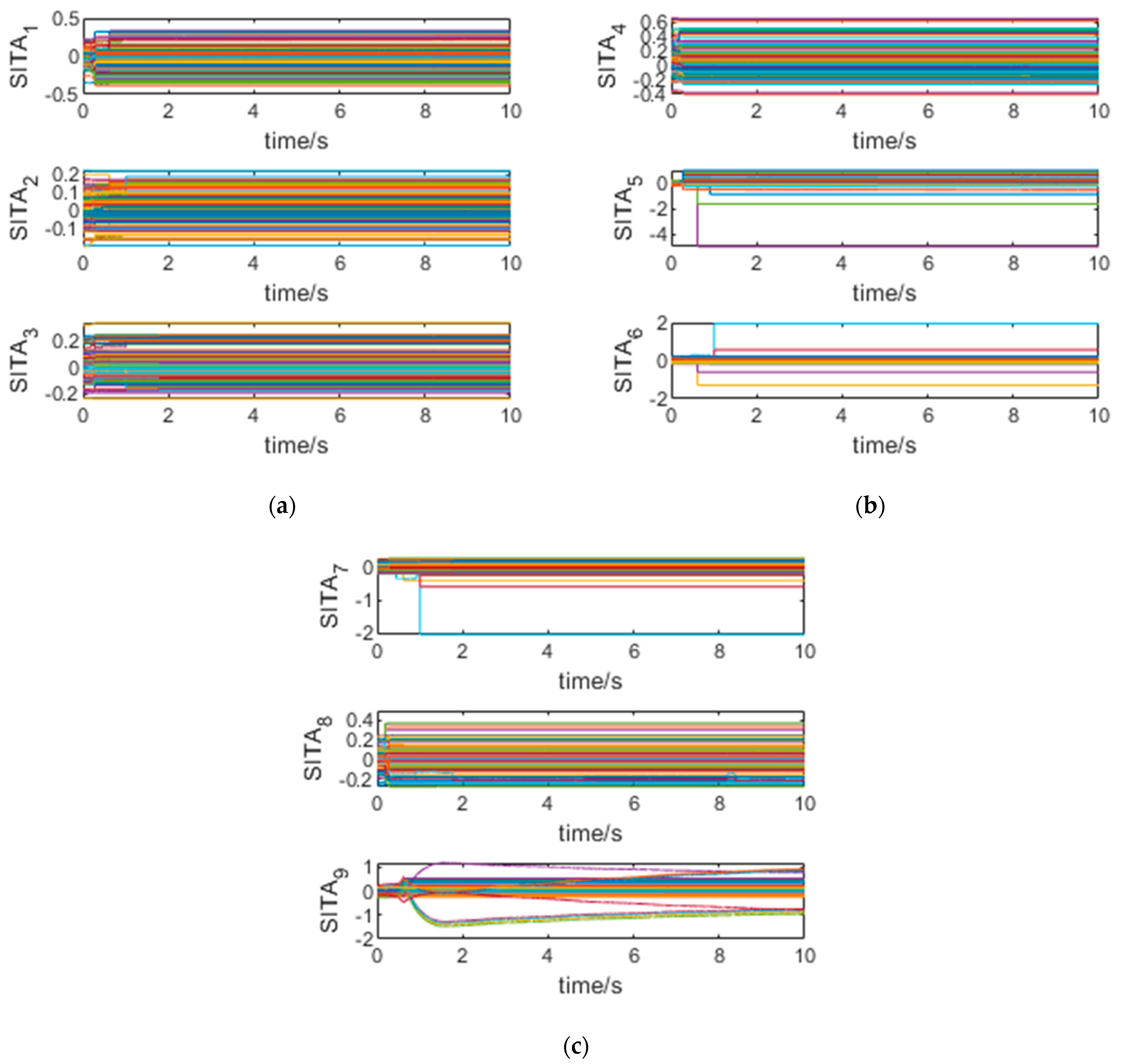
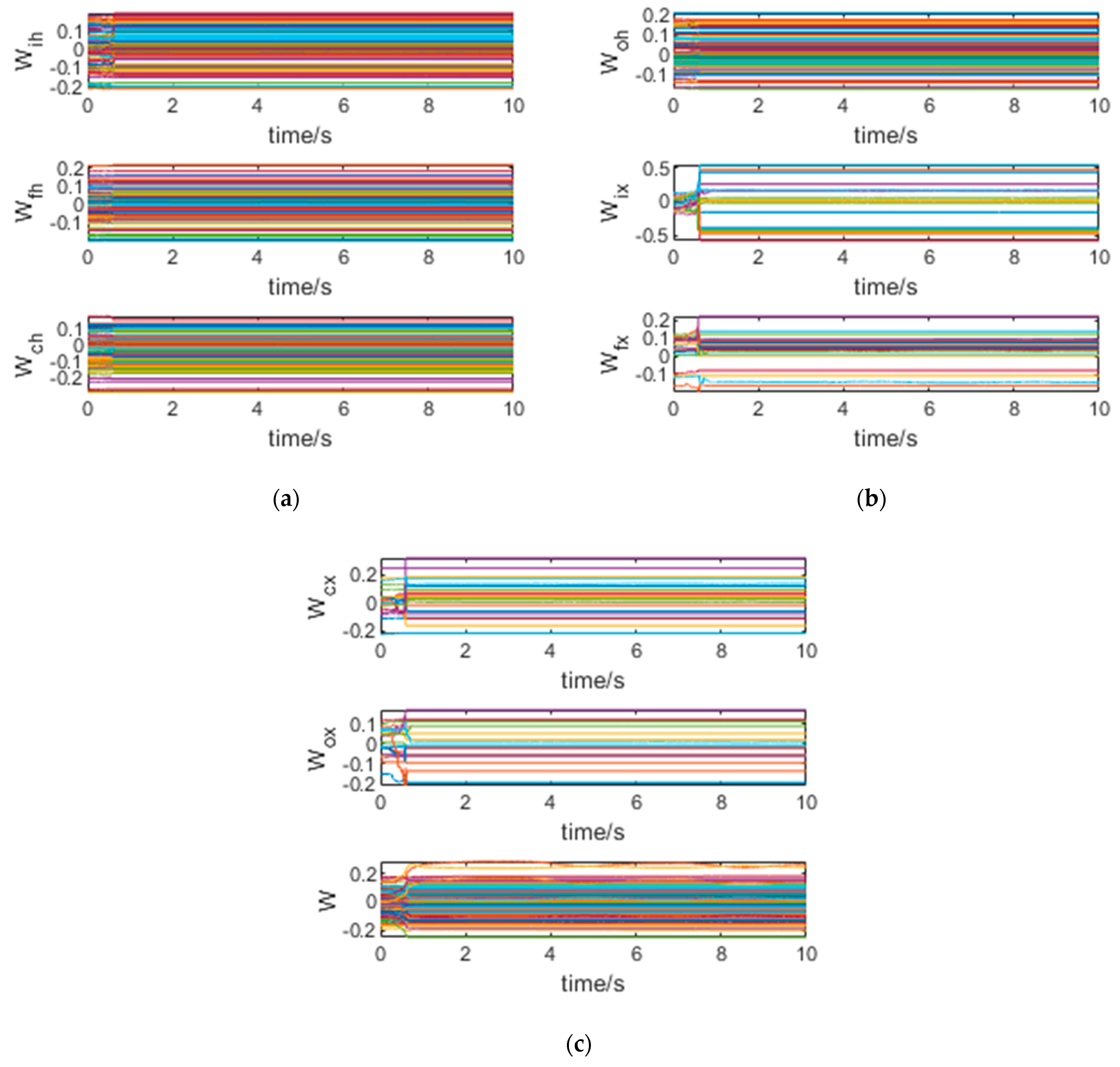
The training process is shown in
Figure 9. It can be seen from the figure that under the effect of the adaptive weight update law, most neural network weights converge in 1 s, which shows that the training efficiency is very high. Because the updated law of network weights is derived from the Lyapunov function, the training trend of network weights is very clear, which must have obvious advantages over the stochastic gradient descent (SDG) method, and there are no problems such as local optimization in the training process.
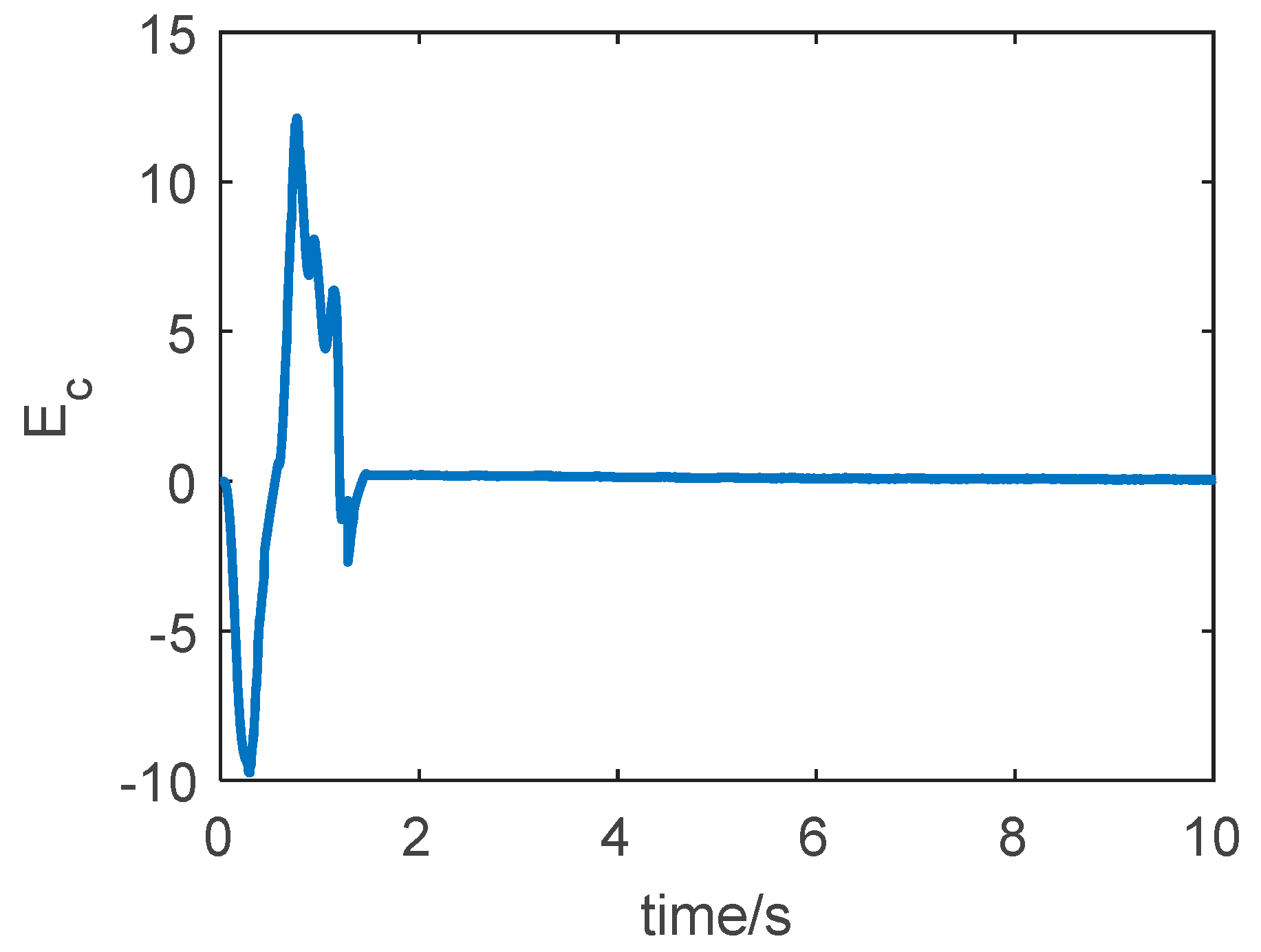
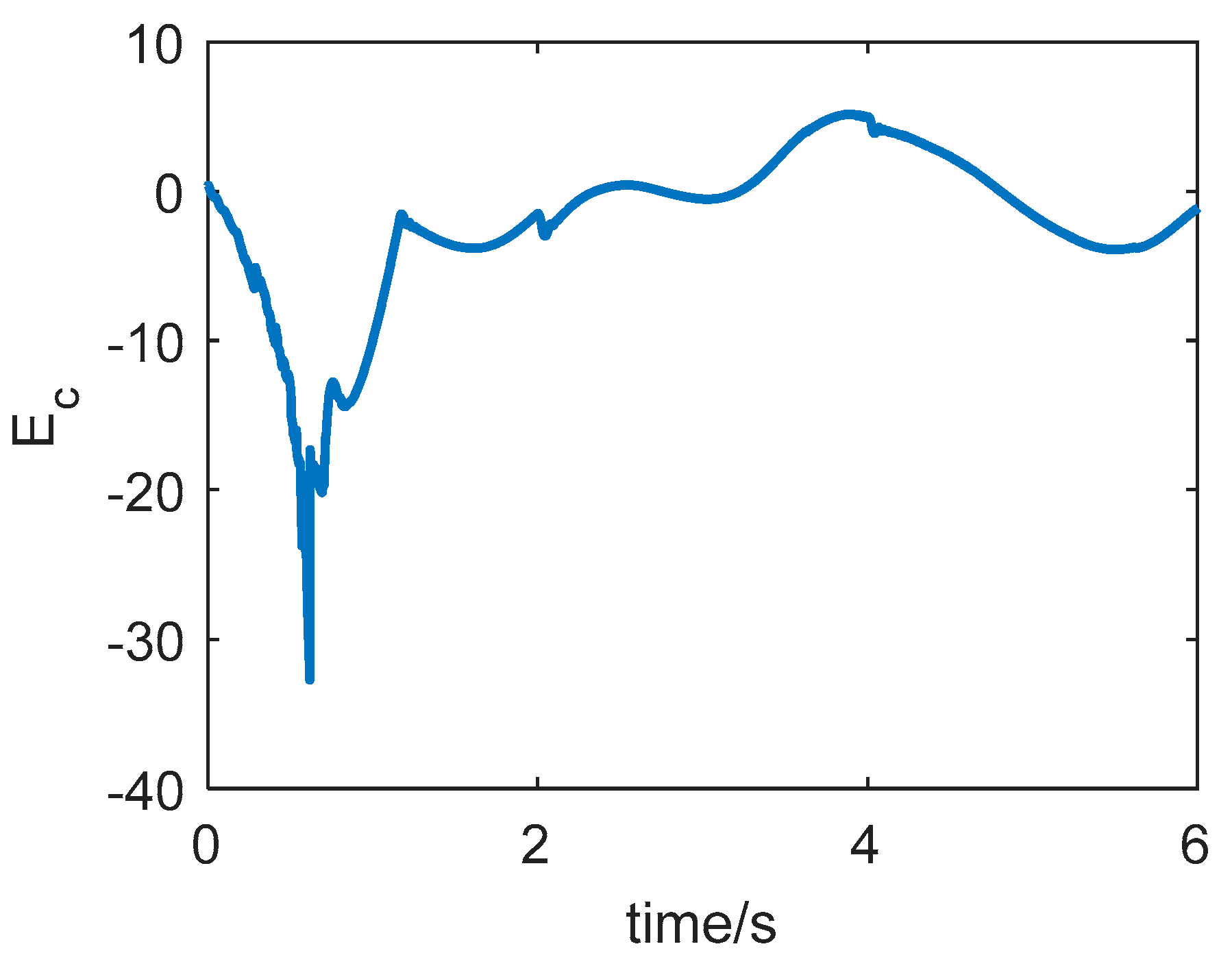
The curve of the Hamiltonian function is shown in
Figure 10. According to the nonlinear system optimal theory mentioned in
Section 3, the necessary condition for the optimal control input is that the Hamiltonian function tends to zero, i.e.,
and then
It can be seen from the figure that under the action of the LSTM neural network, the Hamiltonian function converges to 0 quickly, indicating that
and
, and at this time,
.
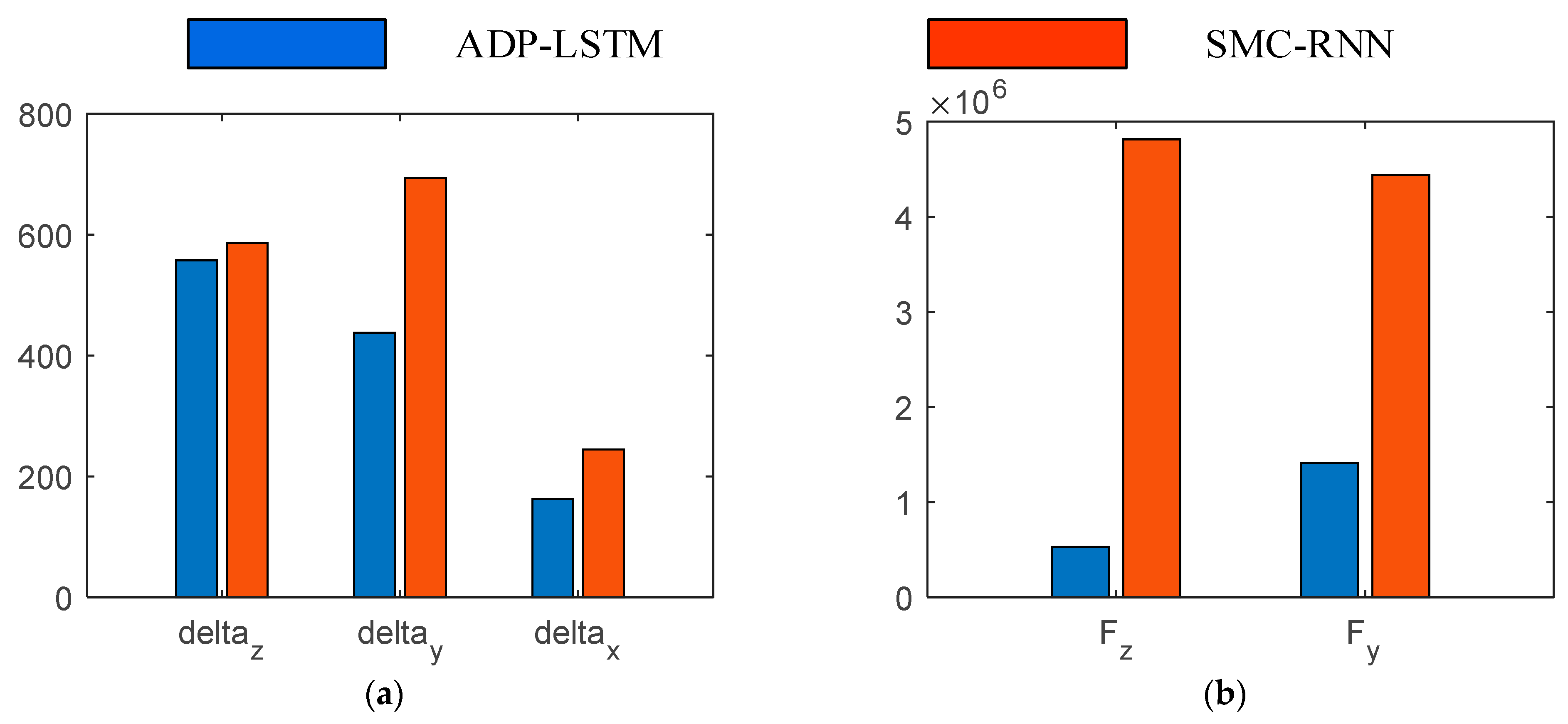
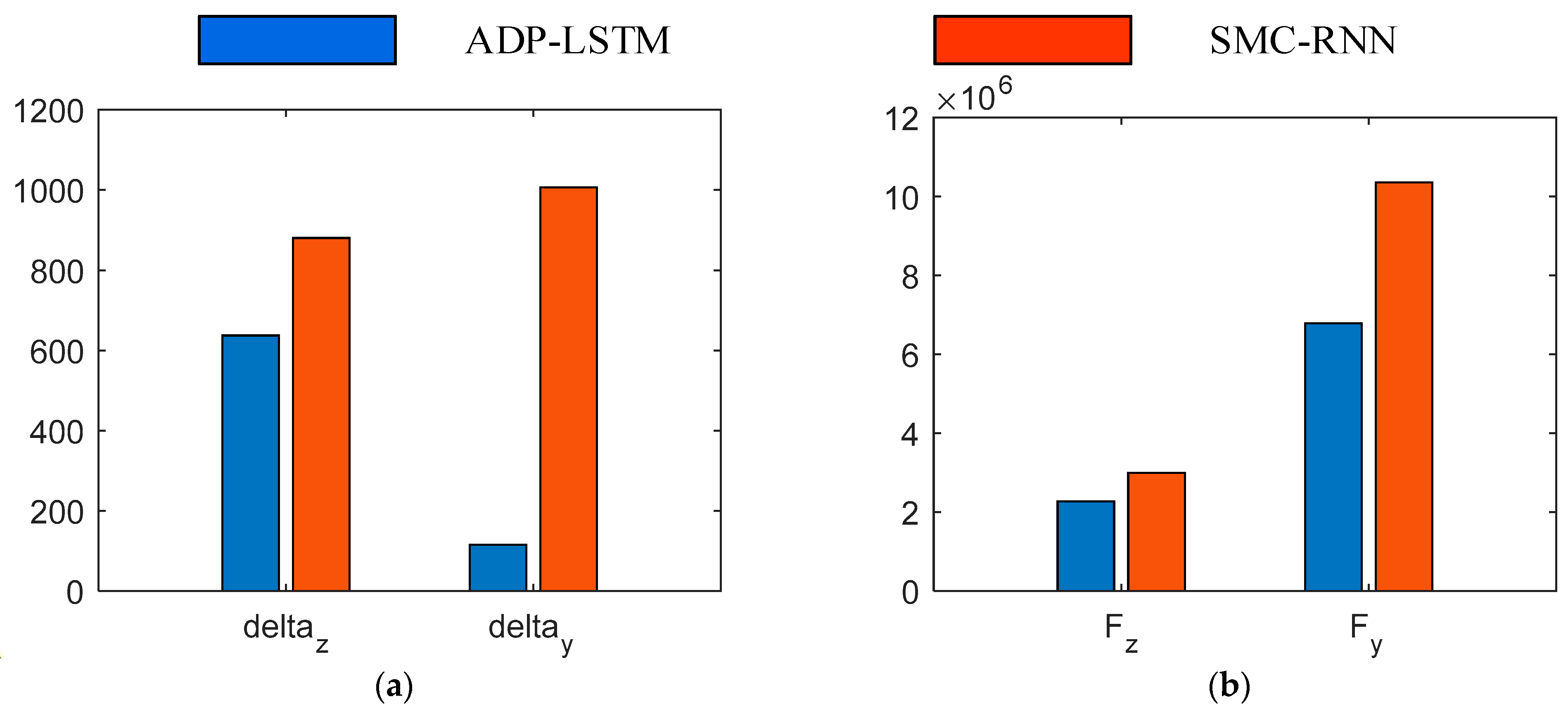
The energy consumption of the two control algorithms is shown in
Figure 11. To quantify energy consumption, the energy consumption indicator is defined as
.
Figure 7a illustrates the energy consumption of the tail fins, while
Figure 7b shows the energy consumption of the direct force. It is important to note that the values after low-pass filtering were used when calculating energy consumption. From
Figure 7, it is evident that the energy consumption of both the tail fins and direct force using ADP-LSTM is superior to that of SMC-RNN. Particularly in the case of direct force energy consumption, ADP-LSTM demonstrates clear advantages, effectively avoiding energy waste. While ADP-LSTM may be slightly inferior to SMC-RNN in terms of control effectiveness, it holds significant advantages in energy consumption. As previously introduced, the energy of direct force is limited, and the aircraft will encounter multiple attitude adjustments and overload command tracking in a complete working environment. Without limiting energy consumption, early depletion of aircraft fuel can occur, leading to a loss of partial tracking ability. Therefore, this article focuses on studying the optimal control of aircraft attitude.
The average single-step time of the two algorithms is ADP-LSTM 1.105 ms, and SMC-RNN 0.751 ms (simulation environment: Intel 12th i7-12700).
5.2. Scenario 2: Tracking a Time-Varying Overload Command
The simulation results for Scenario 2 are shown in
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18 and
Figure 19. Similar to Scenario 1, both ADP-LSTM and SMC-RNN can track time-varying overload commands. However, the control effectiveness of ADP-LSTM is slightly weaker than that of SMC-RNN. This can be attributed to two reasons: 1. The convergence speed of the LSTM neural network is slightly slower than that of a traditional RNN, especially under time-varying commands, which becomes more apparent. 2. To achieve energy-optimal control, it is necessary to sacrifice some control effectiveness, especially in terms of command tracking speed. From
Figure 14, it can be observed that although ADP-LSTM has a slightly slower convergence speed than SMC-RNN, there is no significant difference in their tracking accuracy, which is consistent with the performance in Scenario 1.
Figure 15 illustrates the control inputs of the two control algorithms. It is evident from the figure that SMC-RNN’s control input exhibits significant oscillations, similar to Scenario 1. This is unfriendly to the control execution mechanism and results in a significant waste of energy. In contrast, ADP-LSTM does not exhibit such oscillations. Furthermore, from
Figure 19, it can be seen that the energy consumption of ADP-LSTM is significantly lower than that of SMC-RNN (after the filtering of SMC-RNN’s control input). This demonstrates the significant advantage of ADP-LSTM in energy-optimal control.
Through the above two simulation scenarios, it is evident that ADP-LSTM can handle common aircraft overload commands and has a certain degree of generality.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}