Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection


Abstract
:1. Introduction
1.1. Automated Aircraft Maintenance Inspection
- Reduction of inspection time and AOG time: The sensors either on-board a drone or in a smart hangar can quickly reach difficult places such as the flight control surfaces in both wings and the empennage. This in turn can reduce the man hours and preparation time as engineers would need heavy equipment such as cherry pickers to have more scrutiny. The inspection time can be even further reduced if the automated inspection system is able to assess the severity of the damage and the affected aircraft structure with reference to both aircraft manuals (AMM and SRM), and recommend the course of action to the engineers. Time savings on inspection time would consequently lead to reductions of up to 90% in Aircraft-On-Ground times [2].
- Reduction of safety incidents and PPE related costs: Engineers would no longer need to work at heights or expose themselves to hazardous areas e.g., in case of dangerous aircraft conditions or the presence of toxic chemicals. This would also lead to important cost savings on Personal Protective Equipment.
- Reduction of decision time: Defect detection will be much more accurate and faster compared to the current visual inspection process. For instance, it takes operators between 8 and 12 h to locate lightning strike damage using heavy equipment such as gangways and cherry-pickers. This can be reduced by 75% if an automated drone-based system is used [3]. Such time savings can free up aircraft engineers from dull tasks and make them focus on more important tasks. This is especially desired given the projected need of aircraft engineers in various regions of the world which is 769,000 for the period 2019–2038 according to a recent Boeing study [4].
- Objective damage assessment and reduction of human error: If the dataset used by the neural network is annotated by a team of experts who had to reach consensus on what is damage and what is not, then detection of defects will be much more objective. Consequently, the variability of performance assessments by different inspectors will be significantly reduced. Furthermore, human errors such as failing to detect critical damage (for instance due to fatigue or time pressure) will be prevented. This is particularly important given the recurring nature of such incidents. For instance, the Australian Transport Safety Bureau (ATSB) recently reported a serious incident in which significant damage to the horizontal stabilizer went undetected during an inspection, and was only identified 13 flights later [5]. In [1], it was also shown that the model is able to detect dents which were missed the by experts during the annotations process.
- Augmentation of Novices Skills: It takes a novice 10,000 h to become an experienced inspector. Using a decision-support system that has been trained to classify defects on a large database can significantly augment the skills of novices.
1.2. Applications/Breakthroughs of Computer Vision
1.3. Research Objective
2. Methodology
2.1. Dent Detection within MASK R-CNN
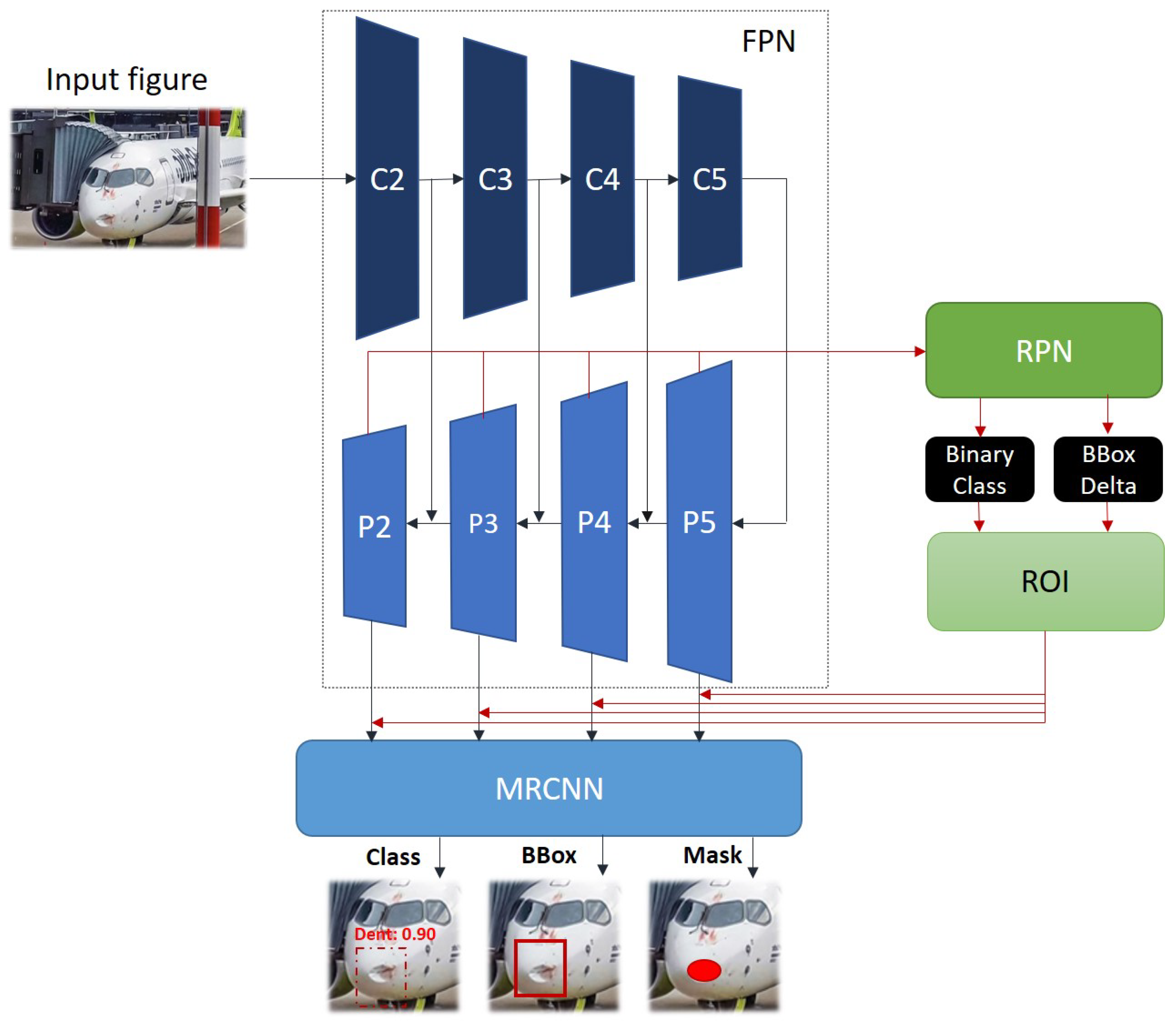
- FPN: The input image is fed into a a so-called FPN [22] that forms the backbone structure of the MASK R-CNN. An FPN or Feature Pyramid Network is a basic component needed in detecting objects at different scales. As shown in Figure 1, the FPN applied in the MASK R-CNN method consists of several convolution blocks (C2 up-to C5) and Pooling blocks (P2 up-to P5). There are in literature several candidates, like ResNet [23] or VGG [24], to represent the FPN. For this study, a ResNet101 network has been used as FPN.
- RPN: The image when passed through the FPN returns the feature maps. These are basically a relatively good initial estimate of regions within the image where one can look for the objects of interest. These feature maps are fed into an RPN, or Region Proposed Network, which are fully convolutional networks that simultaneously predict multiple Anchor boxes and object scores at each position.
- Binary Classification: The former mentioned Anchor boxes are assigned a probability arising from the object scores mentioned earlier, if the object found within the anchor belongs to an object class of interest YES or NO. For example, in our case study, the outcome would be a selection between ‘Dent’ or ‘aircraft skin / background without Dent’.
- BBox Delta: The RPN also returns a bounding box regressor for adjusting the anchors to better fit the object.
- ROI: Combining the information obtained from the Binary Classification and BBox Delta and passing it on to the ROI pooling layer, it is likely that, after the RPN step, there are proposals with no classes assigned to them. One can take each proposal and crop it such that each proposal contains an object. This is exactly what the ROI pooling layer does: It extracts fixed sized feature maps for each anchor.
- MRCNN: The results from the ROI pooling layer is directed toward the MRCNN layer and generates three output streams, i.e.
- Classification: The object is classified as being a ‘Dent’ or ‘No Dent’ with a certain probability assigned.
- Bounding Box: Around the object, a Bounding Box is generated with an optimal fit.
- Mask: Since aircraft dents don’t have a clearly defined shape, arriving at square/rectangular shaped Bounding Box is not sufficient. As a final step, a semantic segmentation is applied, i.e., pixel-wise shading of the class of interest.
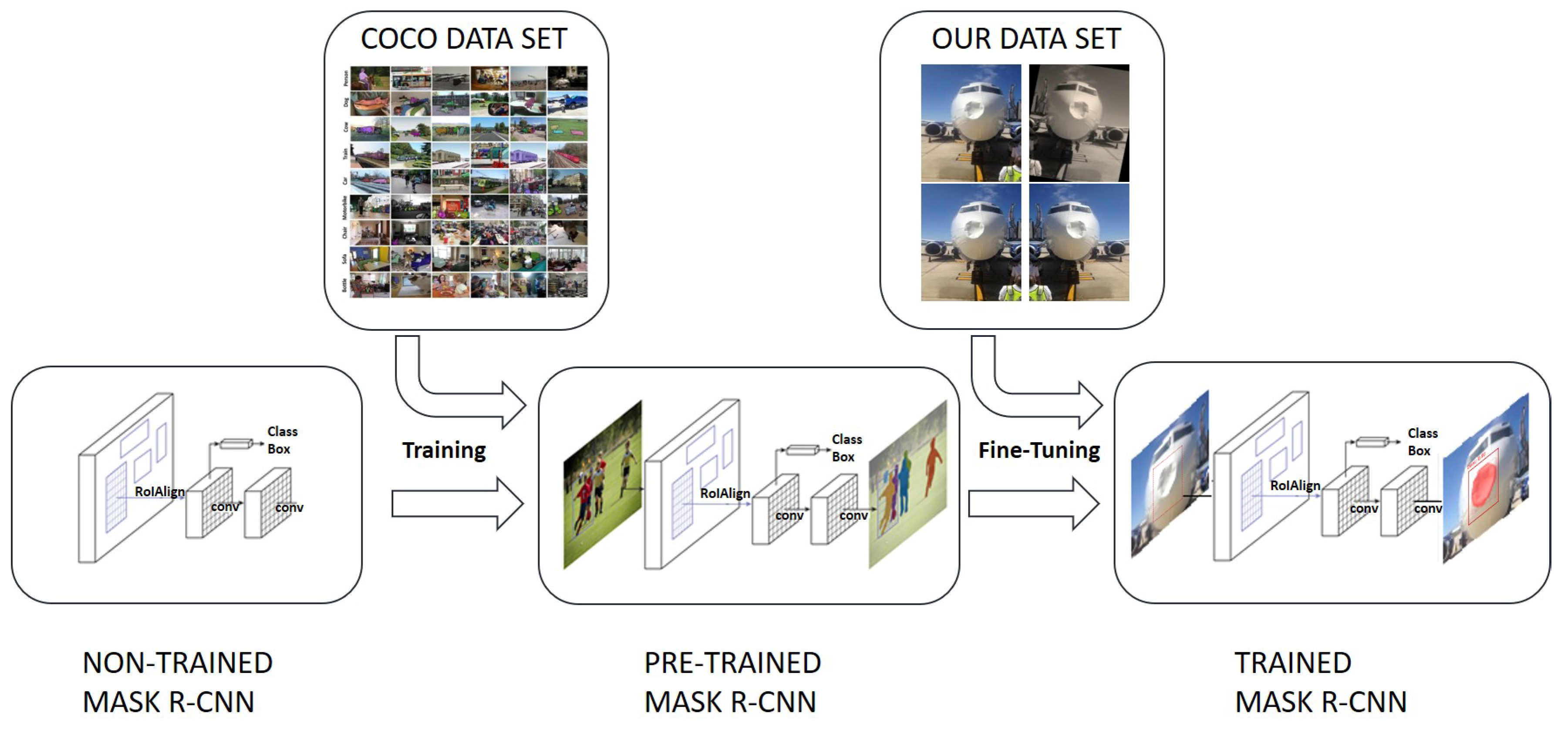
2.2. Data Processing for Prediction Improvement
2.2.1. Augmentation Methods
2.2.2. Hierarchical Modeling Approach
3. Experimental Results
3.1. Model Performance Evaluation
- TP: denotes the true positives and is equal to the number of truly detected dents (i.e., the number of dent predictions, which is correct according to the labeled data).
- FP: denotes the false positives and is equal to the number of falsely detected dents (i.e., the number of dent predictions, which are not correct accordingly to the labeled data).
- FN: denotes the false negatives and is equal to the number of dents, which are not detected by the model (i.e., the number of dents labeled in the original data, but the model could not detect them):
3.2. Experimental Setup
3.2.1. Data Collection and Annotation
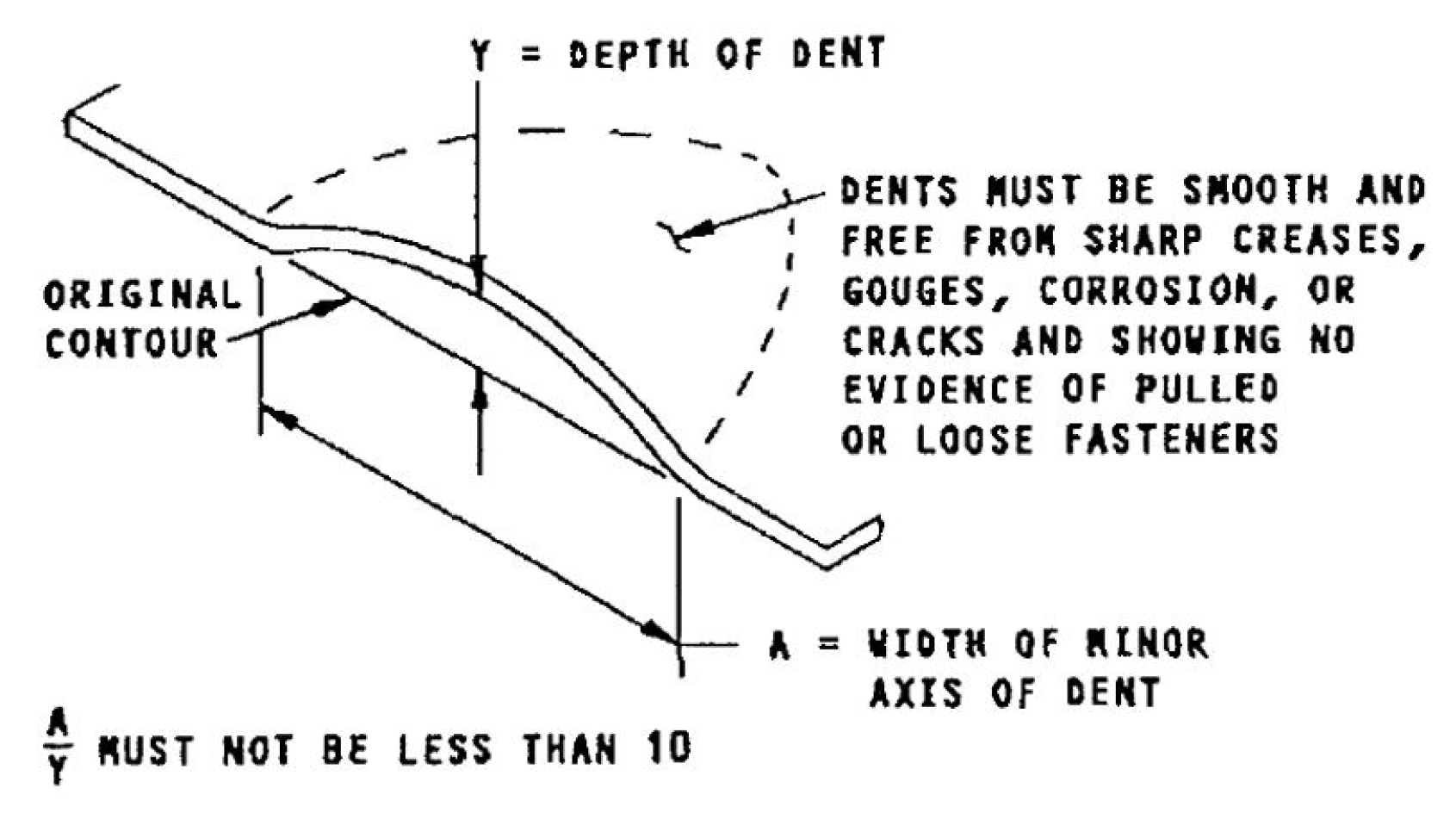
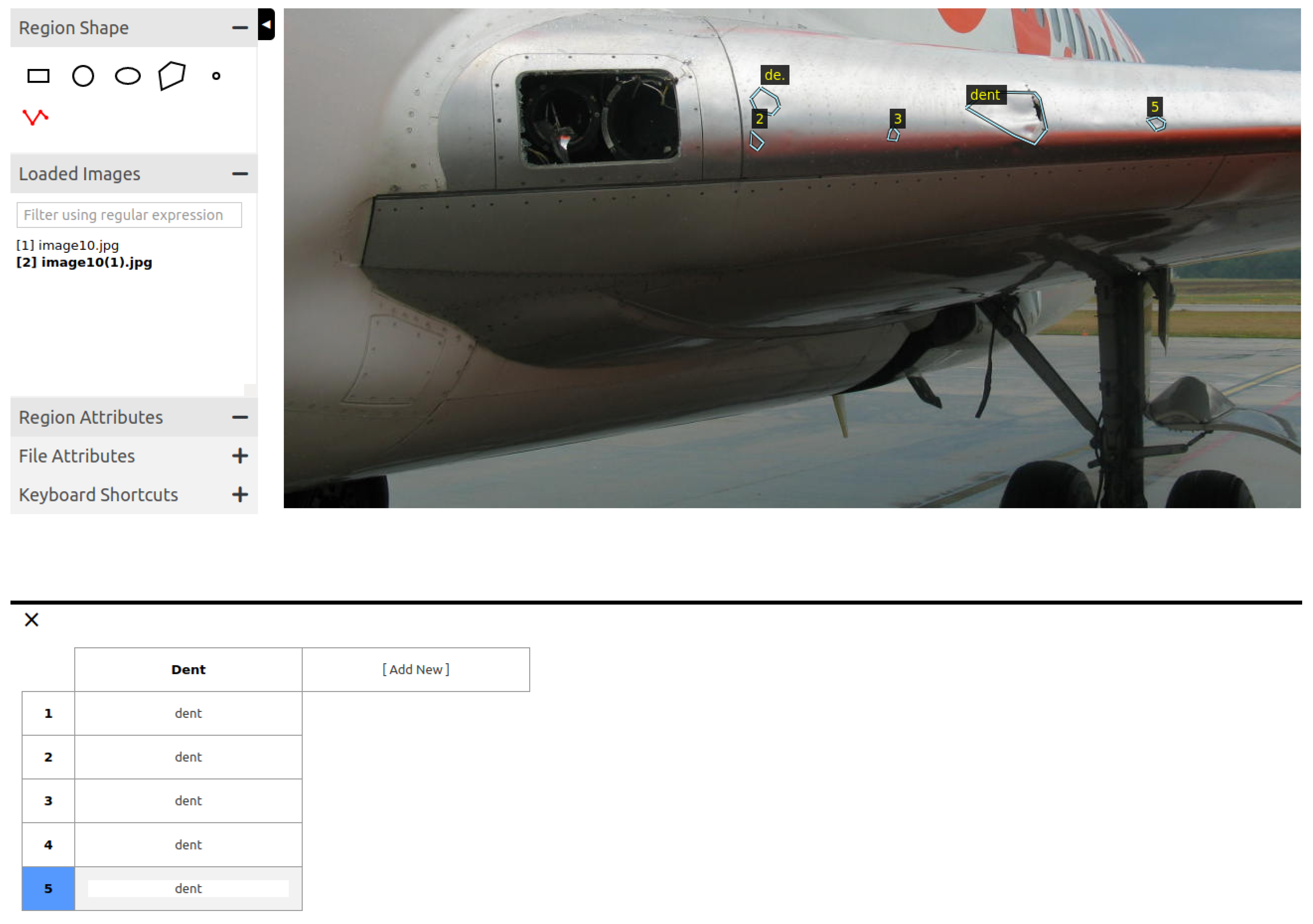
- Size of Dents: The deep learning model was trained with images of aircraft dents of varying sizes ranging from small to large. Figure 6 shows the smallest dents used in this study on the left-hand side, and the largest dents on the right-hand side. These were typically found on the aircraft radome. It should be noted that the aim of this paper was to detect both allowable and non-allowable dents (Figure 7). Additional functionalities can be added to the AI system to detect only critical dents when used in combination with 3D scanning technology.
- Location of Dents: The dents are located on five main areas in the aircraft, namely the Wing Leading Edge, radome, engine cowling, doors, and leading edge of the horizontal stabilizer. These are typical areas on the aircraft where dents can be found as a result of bird strike, hail damage, or ground accidents.
- Number of Dents: As can be seen in Figure 6, while some images only had one dent on them, other images had dozens of dent.
3.2.2. Datasets’ Characteristics
- Dataset 1: This dataset is a combination of the original dataset which contains 56 images of aircraft dents [1] and a new dataset of 49 images without dents. The annotation in the original dataset used in [1] has also been improved through involving more experts to reach consensus and later verified by another expert. Briefly, Dataset 1 has nearly balanced images with dents and without dents (105 images in total).
- Dataset 2: This dataset is a subset of dataset 1 and contains 46 wing images in total—26 that have dents, and 20 without dents.
- Dataset 4: This dataset contains all the images with dents in the original dataset (56 images with dents) in combination with their augmented version.
- Dataset 5: This dataset contains half the number of images in dataset 1 combined with the augmented images of the remaining half. This dataset contains both images with dents and without dents.
- Dataset 6: This dataset contains all the images with dents in dataset 1 (56 images with dents and 49 images without dents) in combination with their augmented version.
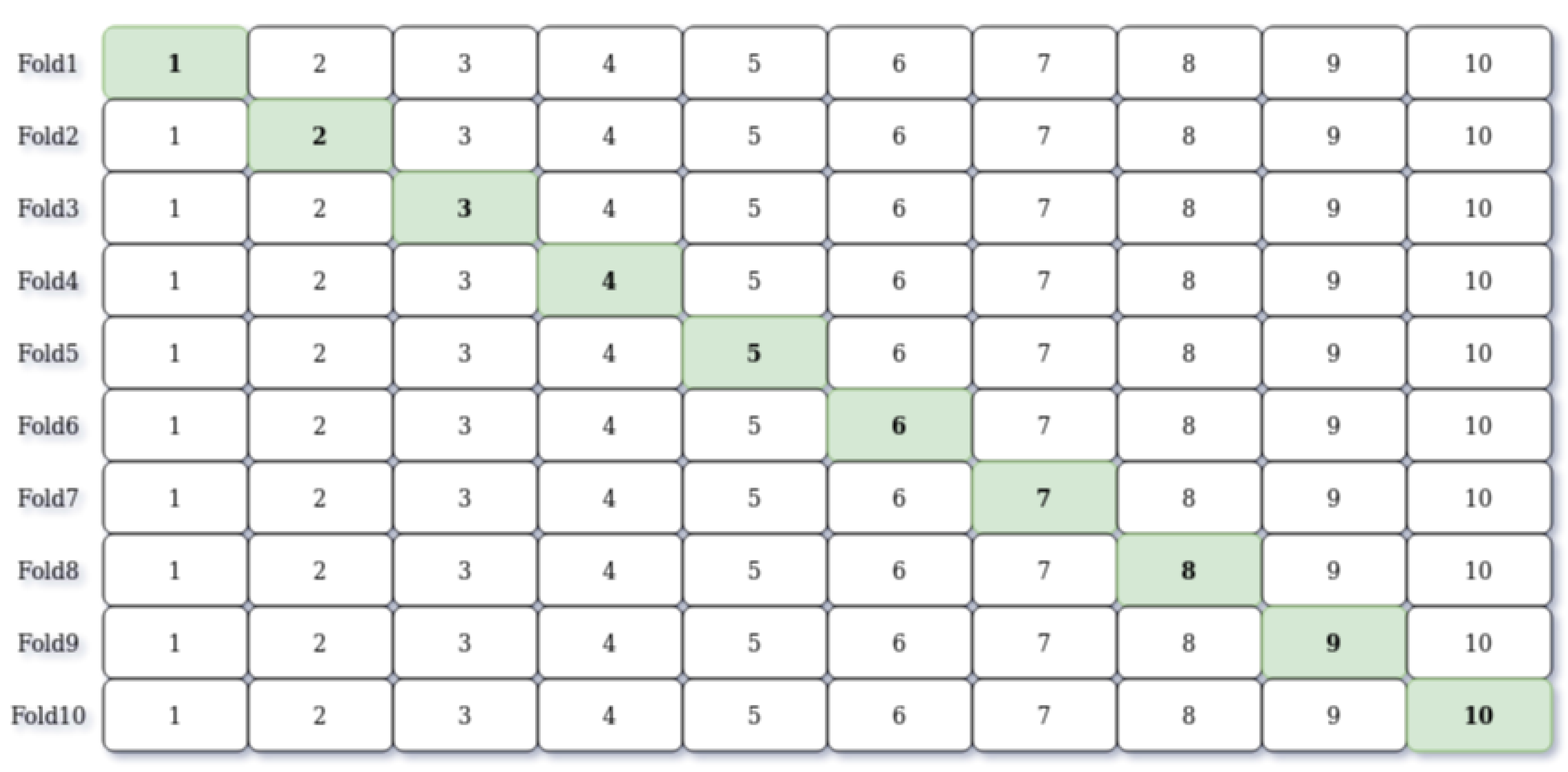
3.2.3. Training and Test Split
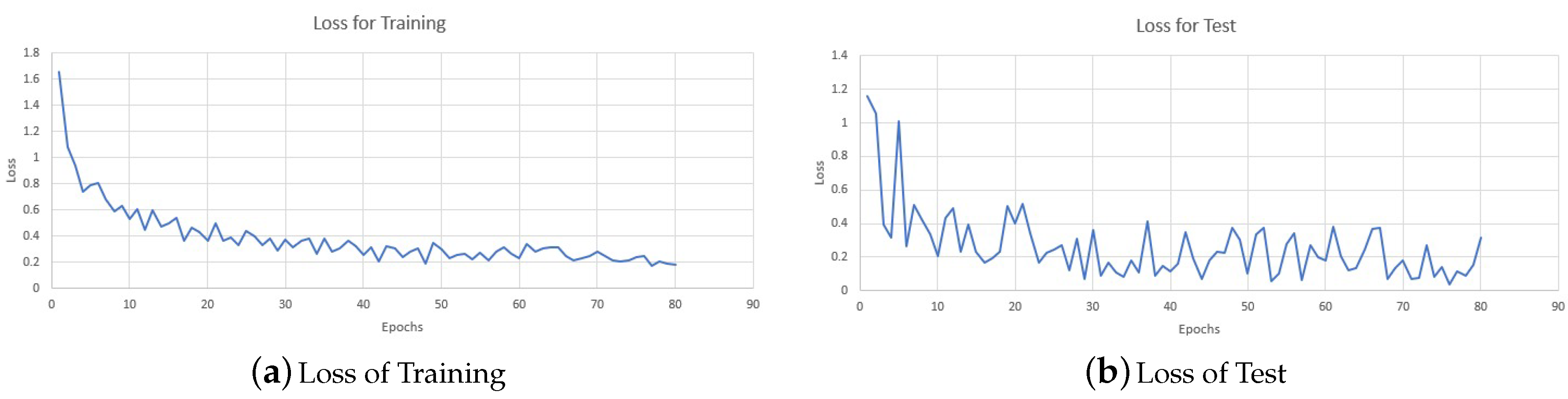
3.2.4. Training Approach
4. Experimental Results and Analysis
4.1. The Effect of Dataset Balance
4.2. The Effect of Specialization in the Dataset
4.3. The Effect of Augmentation Process
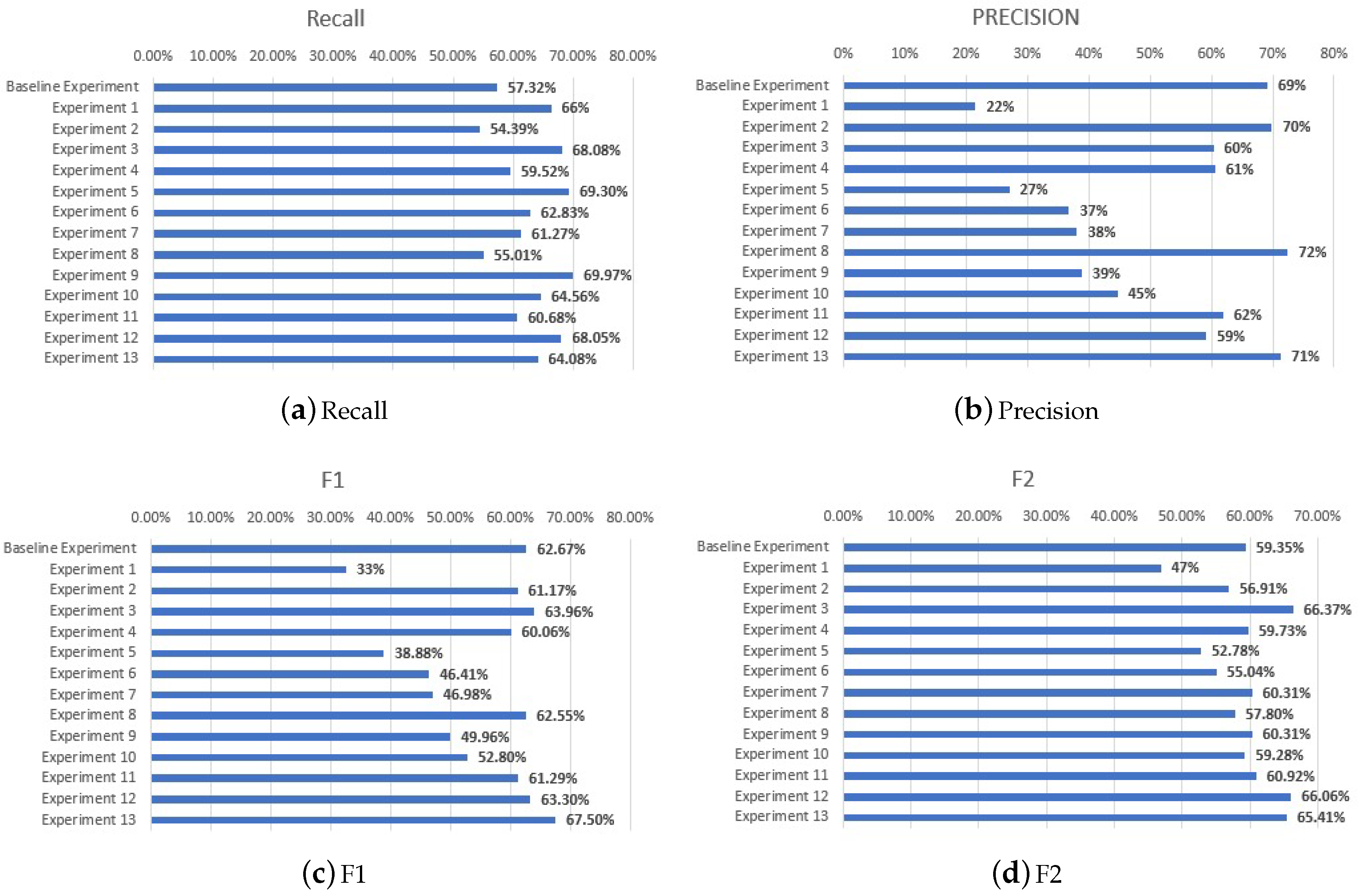
- Flipping, rotating, and blurring 50% of the dataset: Half of the images were transformed using three augmentation techniques namely flipping, rotating, and blurring (Section 2.2.1), while the other half remained the same resulting into a new dataset [Dataset 3]. The recall value and score is higher than the baseline experiment (68.08% versus 57.32% and 63.96% versus 62.67%). In addition, the highest score among all experiments are obtained in this experiment, although the precision is lower than the baseline experiment (60.32% versus 69.13%). The detailed results are shown in Table A3 (Recall: 68.08%; Precision: 60.32%; -Score: 63.97%; -Score: 66.37%).
- Flipping, rotating, and blurring the complete dataset: Instead of partially augmenting the dataset, we augment all images and use both original and augmented images for training. Consequently, the dataset [Dataset 4] becomes twice the size of original dataset [Dataset 4] in the training phrase. Note that the same image augmentation techniques have been used (flipping, rotating and blurring). The detailed results are shown in Table A4 (Recall: 59.52%; Precision: 60.60%; -Score: 60.06%; -Score: 59.73%).
- Flipping, rotating, and blurring 50% of the dataset containing images with and without dent: This experiment is a combination of the first augmentation approach and adding the images without a dent approach. In other words, the first image augmentation approach is applied on Dataset 1 which contains both 56 images with dents and 49 images without dents. The recall value is slightly higher than the first augmentation on the original dataset (69.30% versus 68.08%) while the precision value is much lower than the baseline experiment (27.02% versus 69.13%). The corresponding results are shown in Table A5 (Recall: 69.30%; Precision: 27.02%; -Score: 38.88%; -Score: 52.78%).
- Flipping, rotating, and blurring the complete dataset containing images with and without dents: This experiment is a combination of the second augmentation approach and adding additional images without a dent approach. In other words, the second image augmentation approach is applied on Dataset 1, which contains both 56 images with dent and 49 images without dent. In this case, the recall value is higher than the second augmentation on the original dataset (62.83% versus 59.52%), but the precision value is lower (36.80% versus 60.60%). Additionally, the recall is also higher than the baseline experiment [1] (62.83% versus 57.32%). The corresponding results are shown in Table A6 (Recall: 62.83%; Precision: 36.80%; -Score: 46.41%; -Score: 55.04%).
4.4. The Effect of Number of Epochs in Training
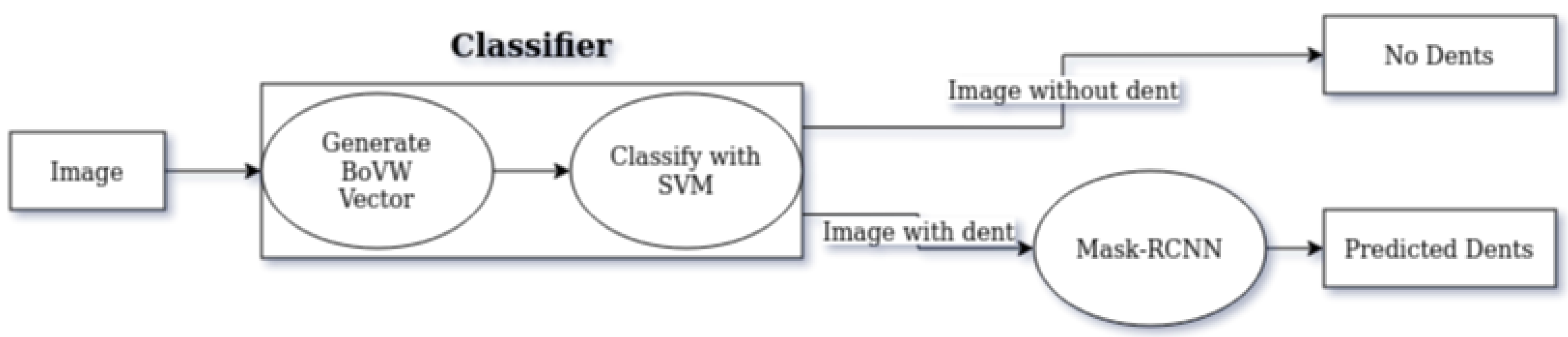
4.5. The Effect of the Pre-Classifier Approach
4.6. Overall Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 6 | 5 | 4 | 68 | 5 | 42 | 6 | 8 | 3 | 4 | 15.1 |
| FP | 68 | 72 | 21 | 26 | 37 | 34 | 37 | 46 | 32 | 45 | 41.8 |
| FN | 2 | 5 | 4 | 81 | 1 | 37 | 1 | 2 | 2 | 1 | 13.6 |
| Recall | 75.0% | 50.0% | 50.0% | 45.6% | 83.3% | 53.7% | 85.7% | 80.0% | 60.0% | 80.0% | 66.29% |
| Precision | 8.1% | 6.5% | 16.0% | 72.3% | 11.9% | 55.3% | 14.0% | 14.8% | 8.6% | 8.2% | 21.56% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 41 | 41 | 41 | 41 | 41 | 41 | 42 | 42 | 42 | 42 | 41.4 |
| Test Size | 5 | 5 | 5 | 5 | 5 | 5 | 4 | 4 | 4 | 4 | 4.6 |
| TP | 2 | 3 | 5 | 6 | 15 | 1 | 1 | 1 | 9 | 1 | 4.4 |
| FP | 2 | 0 | 2 | 1 | 5 | 1 | 5 | 0 | 0 | 1 | 1.7 |
| FN | 1 | 2 | 1 | 2 | 12 | 2 | 3 | 1 | 11 | 1 | 3.6 |
| Recall | 66.7% | 60.0% | 83.3% | 75.0% | 55.6% | 33.3% | 25.0% | 50.0% | 45.0% | 50.0% | 54.39% |
| Precision | 50.0% | 100.0% | 71.4% | 85.7% | 75.0% | 50.0% | 16.7% | 100.0% | 100.0% | 50.0% | 69.88% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 50 | 50 | 50 | 50 | 50 | 50 | 51 | 51 | 51 | 51 | 50.4 |
| Test Size | 6 | 6 | 6 | 6 | 6 | 6 | 5 | 5 | 5 | 5 | 5.6 |
| TP | 34 | 8 | 5 | 22 | 5 | 9 | 5 | 4 | 25 | 27 | 14.4 |
| FP | 2 | 12 | 5 | 13 | 5 | 4 | 2 | 16 | 18 | 4 | 8.1 |
| FN | 26 | 2 | 4 | 3 | 1 | 4 | 0 | 1 | 52 | 49 | 14.2 |
| Recall | 56.7% | 80.0% | 55.6% | 88.0% | 83.3% | 69.2% | 100.0% | 80.0% | 32.5% | 35.5% | 68.08% |
| Precision | 94.4% | 40.0% | 50.0% | 62.9% | 50.0% | 69.2% | 71.4% | 20.0% | 58.1% | 87.1% | 60.32% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 100 | 100 | 100 | 100 | 100 | 100 | 102 | 102 | 102 | 102 | 100.08 |
| Test Size | 6 | 6 | 6 | 6 | 6 | 6 | 5 | 5 | 5 | 5 | 5.6 |
| TP | 12 | 7 | 6 | 20 | 6 | 6 | 5 | 4 | 22 | 7 | 9.5 |
| FP | 3 | 13 | 8 | 9 | 3 | 4 | 1 | 11 | 12 | 2 | 6.6 |
| FN | 48 | 3 | 3 | 5 | 0 | 8 | 0 | 1 | 61 | 69 | 19.8 |
| Recall | 20.0% | 70.0% | 66.7% | 80.0% | 100.0% | 42.9% | 100.0% | 80.0% | 26.5% | 9.2% | 59.52% |
| Precision | 80.0% | 35.0% | 42.9% | 69.0% | 66.7% | 60.0% | 83.3% | 26.7% | 64.7% | 77.8% | 60.60% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 50 | 50 | 50 | 50 | 50 | 50 | 51 | 51 | 51 | 51 | 50.4 |
| Test Size | 6 | 6 | 6 | 6 | 6 | 6 | 5 | 5 | 5 | 5 | 5.6 |
| TP | 5 | 7 | 7 | 50 | 6 | 27 | 6 | 8 | 3 | 4 | 12.3 |
| FP | 41 | 44 | 19 | 29 | 17 | 33 | 14 | 28 | 15 | 22 | 26.2 |
| FN | 3 | 3 | 1 | 99 | 0 | 53 | 1 | 2 | 2 | 1 | 16.5 |
| Recall | 62.50% | 70.00% | 87.50% | 33.56% | 100.00% | 33.75% | 85.71% | 80.00% | 60.00% | 80.00% | 69.30% |
| Precision | 10.87% | 13.73% | 26.92% | 63.29% | 26.09% | 45.00% | 30.00% | 22.22% | 16.67% | 15.38% | 27.02% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 4 | 6 | 3 | 67 | 6 | 12 | 7 | 8 | 3 | 4 | 12 |
| FP | 14 | 23 | 6 | 9 | 27 | 10 | 17 | 17 | 6 | 7 | 13.6 |
| FN | 4 | 4 | 5 | 80 | 0 | 67 | 0 | 2 | 2 | 1 | 16.5 |
| Recall | 50.00% | 60.00% | 37.50% | 45.58% | 100.00% | 15.19% | 100.00% | 80.00% | 60.00% | 80.00% | 62.83% |
| Precision | 22.22% | 20.69% | 33.33% | 88.16% | 18.18% | 54.55% | 29.17% | 32.00% | 33.33% | 36.36% | 36.80% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 3 | 5 | 5 | 59 | 6 | 23 | 5 | 8 | 3 | 4 | 12.1 |
| FP | 14 | 21 | 12 | 6 | 8 | 19 | 13 | 5 | 22 | 12 | 13.2 |
| FN | 5 | 5 | 3 | 81 | 0 | 56 | 2 | 2 | 2 | 1 | 15.7 |
| Recall | 37.50% | 50.00% | 62.50% | 42.14% | 100.00% | 29.11% | 71.43% | 80.00% | 60.00% | 80.00% | 61.27% |
| Precision | 17.65% | 19.23% | 29.41% | 90.77% | 42.86% | 54.76% | 27.78% | 61.54% | 12.00% | 25.00% | 38.10% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 100 | 100 | 100 | 100 | 100 | 100 | 102 | 102 | 102 | 102 | 100.08 |
| Test Size | 6 | 6 | 6 | 6 | 6 | 6 | 5 | 5 | 5 | 5 | 5.6 |
| TP | 13 | 6 | 6 | 17 | 5 | 9 | 4 | 2 | 20 | 30 | 11.2 |
| FP | 1 | 3 | 6 | 4 | 2 | 4 | 1 | 3 | 6 | 1 | 3.1 |
| FN | 45 | 4 | 3 | 8 | 1 | 5 | 1 | 3 | 57 | 46 | 17.3 |
| Recall | 22.41% | 60.00% | 66.67% | 68.00% | 83.33% | 64.29% | 80.00% | 40.00% | 25.97% | 39.47% | 55.01% |
| Precision | 92.86% | 66.67% | 50.00% | 80.95% | 71.43% | 69.23% | 80.00% | 40.00% | 76.92% | 96.77% | 72.48% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 4 | 8 | 6 | 72 | 6 | 23 | 7 | 8 | 3 | 4 | 14.1 |
| FP | 17 | 18 | 11 | 13 | 13 | 13 | 17 | 8 | 9 | 17 | 13.6 |
| FN | 4 | 2 | 2 | 86 | 0 | 56 | 0 | 2 | 2 | 1 | 15.5 |
| Recall | 50.00% | 80.00% | 75.00% | 45.57% | 100.00% | 29.11% | 100.00% | 80.00% | 60.00% | 80.00% | 69.97% |
| Precision | 19.05% | 30.77% | 35.29% | 84.71% | 31.58% | 63.89% | 29.17% | 50.00% | 25.00% | 19.05% | 38.85% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 188 | 188 | 188 | 188 | 188 | 190 | 190 | 190 | 190 | 190 | 189 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 4 | 7 | 6 | 47 | 5 | 26 | 6 | 8 | 3 | 3 | 11.5 |
| FP | 11 | 14 | 10 | 7 | 17 | 8 | 14 | 12 | 3 | 4 | 10 |
| FN | 4 | 3 | 2 | 100 | 0 | 53 | 1 | 2 | 2 | 2 | 16.9 |
| Recall | 50.00% | 70.00% | 75.00% | 31.97% | 100.00% | 32.91% | 85.71% | 80.00% | 60.00% | 60.00% | 64.56% |
| Precision | 26.67% | 33.33% | 37.50% | 87.04% | 22.73% | 76.47% | 30.00% | 40.00% | 50.00% | 42.86% | 44.66% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 3 | 5 | 5 | 54 | 6 | 23 | 5 | 8 | 3 | 4 | 11.6 |
| FP | 8 | 2 | 6 | 4 | 3 | 3 | 5 | 4 | 7 | 1 | 4.3 |
| FN | 5 | 5 | 3 | 95 | 0 | 56 | 2 | 2 | 2 | 1 | 17.1 |
| Recall | 37.50% | 50.00% | 62.50% | 36.24% | 100.00% | 29.11% | 71.43% | 80.00% | 60.00% | 80.00% | 60.68% |
| Precision | 27.27% | 71.43% | 45.45% | 93.10% | 66.67% | 88.46% | 50.00% | 66.67% | 30.00% | 80.00% | 61.91% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 94 | 94 | 94 | 94 | 94 | 95 | 95 | 95 | 95 | 95 | 94.5 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 4 | 8 | 6 | 39 | 6 | 23 | 7 | 8 | 3 | 4 | 10.8 |
| FP | 11 | 7 | 7 | 6 | 6 | 3 | 9 | 2 | 3 | 2 | 5.6 |
| FN | 4 | 2 | 2 | 109 | 0 | 56 | 0 | 2 | 2 | 1 | 17.8 |
| Recall | 50.00% | 80.00% | 75.00% | 26.35% | 100.00% | 29.11% | 100.00% | 80.00% | 60.00% | 80.00% | 68.05% |
| Precision | 26.67% | 53.33% | 46.15% | 86.67% | 50.00% | 88.46% | 43.75% | 80.00% | 50.00% | 66.67% | 59.17% |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Size | 188 | 188 | 188 | 188 | 188 | 190 | 190 | 190 | 190 | 190 | 189 |
| Test Size | 11 | 11 | 11 | 11 | 11 | 10 | 10 | 10 | 10 | 10 | 10.5 |
| TP | 4 | 7 | 6 | 40 | 5 | 26 | 6 | 8 | 3 | 3 | 10.8 |
| FP | 7 | 5 | 3 | 3 | 3 | 0 | 5 | 4 | 0 | 1 | 3.1 |
| FN | 4 | 3 | 2 | 107 | 0 | 53 | 1 | 2 | 2 | 2 | 17.6 |
| Recall | 50.00% | 70.00% | 75.00% | 27.21% | 100.00% | 32.91% | 85.71% | 80.00% | 60.00% | 60.00% | 64.08% |
| Precision | 36.36% | 58.33% | 66.67% | 93.02% | 62.50% | 100.00% | 54.55% | 66.67% | 100.00% | 75.00% | 71.31% |
References
- Bouarfa, S.; Doğru, A.; Arizar, R.; Aydoğan, R.; Serafico, J. Towards Automated Aircraft Maintenance Inspection. A use case of detecting aircraft dents using Mask R-CNN. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020; p. 0389. [Google Scholar]
- Drone, M. MRO Drone: RAPID. Available online: https://www.mrodrone.net/ (accessed on 22 September 2020).
- Mainblades. Mainblades: Aircraft Lightning Strike Inspection. Available online: https://mainblades.com/lightning-strike-inspection/ (accessed on 22 September 2020).
- Boeing. Pilot & Technician Outlook 2019–2038. Available online: https://www.boeing.com/commercial/market/pilot-technician-outlook/ (accessed on 22 September 2020).
- Aeronews. ATR72 Missed Damage: Maintenance Lessons. Available online: http://aerossurance.com/safety-management/atr72-missed-damage/ (accessed on 25 September 2020).
- Aeronews. Google Brain Chief: AI Tops Humans in Computer Vision, and Healthcare Will Never Be the Same. Available online: https://siliconangle.com/2017/09/27/google-brain-chief-jeff-dean-ai-beats-humans-computer-vision-healthcare-will-never/ (accessed on 25 September 2020).
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Hoang, T.; Spencer, B., Jr. Vision-based structural inspection using multiscale deep convolutional neural networks. arXiv 2018, arXiv:1805.01055. [Google Scholar]
- Shihavuddin, A.; Chen, X.; Fedorov, V.; Nymark Christensen, A.; Andre Brogaard Riis, N.; Branner, K.; Bjorholm Dahl, A.; Reinhold Paulsen, R. Wind turbine surface damage detection by deep learning aided drone inspection analysis. Energies 2019, 12, 676. [Google Scholar] [CrossRef] [Green Version]
- Reddy, A.; Indragandhi, V.; Ravi, L.; Subramaniyaswamy, V. Detection of Cracks and damage in wind turbine blades using artificial intelligence-based image analytics. Measurement 2019, 147, 106823. [Google Scholar] [CrossRef]
- Makantasis, K.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Loupos, C. Deep convolutional neural networks for efficient vision based tunnel inspection. In Proceedings of the 2015 IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2015; pp. 335–342. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Stathaki, T. Automatic crack detection for tunnel inspection using deep learning and heuristic image post-processing. Appl. Intell. 2019, 49, 2793–2806. [Google Scholar] [CrossRef]
- Malekzadeh, T.; Abdollahzadeh, M.; Nejati, H.; Cheung, N.M. Aircraft fuselage defect detection using deep neural networks. arXiv 2017, arXiv:1712.09213. [Google Scholar]
- Miranda, J.; Larnier, S.; Herbulot, A.; Devy, M. UAV-based inspection of airplane exterior screws with computer vision. In Proceedings of the 14h International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech Republic, 25–27 February 2019. [Google Scholar]
- Miranda, J.; Veith, J.; Larnier, S.; Herbulot, A.; Devy, M. Machine learning approaches for defect classification on aircraft fuselage images aquired by an UAV. Proceedings the SPIE 11172, Fourteenth International Conference on Quality Control by Artificial Vision, Mulhouse, France, 16 July 2019. [Google Scholar] [CrossRef]
- Miranda, J.; Veith, J.; Larnier, S.; Herbulot, A.; Devy, M. Hybridization of deep and prototypical neural network for rare defect classification on aircraft fuselage images acquired by an unmanned aerial vehicle. J. Electron. Imaging 2020, 29, 041010. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrel, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. 2014. Available online: https://arxiv.org/pdf/1311.2524.pdf (accessed on 5 December 2020).
- Girshick, R. Fast R-CNN. 2015. Available online: https://arxiv.org/pdf/1504.08083.pdf (accessed on 5 December 2020).
- Shaoqing, R.; Kaiming, H.; Ross, G.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. 2016. Available online: https://arxiv.org/pdf/1506.01497.pdf (accessed on 5 December 2020).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified Real-Time Oblect Detection. 2016. Available online: https://arxiv.org/pdf/1506.02640v5.pdf (accessed on 5 December 2020).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. 2018. Available online: https://arxiv.org/pdf/1703.06870.pdf (accessed on 5 December 2020).
- Yin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. 2017. Available online: https://arxiv.org/pdf/1612.03144.pdf (accessed on 5 December 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2015. Available online: https://arxiv.org/pdf/1512.03385.pdf (accessed on 5 December 2020).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs.CV]. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 5 December 2020).
- CNN Application-Detecting Car Exterior Damage (Full Implementable Code). Available online: https://towardsdatascience.com/cnn-application-detecting-car-exterior-damage-full-implementable-code-1b205e3cb48c (accessed on 5 December 2020).
- Pan, S.J.; Yang, Q. A survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Github. Releases Mask R-CNN COCO Weights h5 File. 2019. Available online: https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5 (accessed on 5 December 2020).
- Agarwal, S.; Terrail, J.O.D.; Jurie, F. Recent Advances in Object Detection in the Age of Deep Convolutional Neural Networks. Available online: https://hal.archives-ouvertes.fr/hal-01869779v2/document (accessed on 23 October 2020).
- Jung, A.B. Imgaug. 2018. Available online: https://github.com/aleju/imgaug (accessed on 30 October 2018).
- Fei-Fei, L.; Fergus, R.; Torralba, A. Recognizing and Learning Object Categories. 2009. Available online: http://people.csail.mit.edu/torralba/shortCourseRLOC/ (accessed on 5 December 2020).
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Alpaydın, E. Introduction to Machine Learning, 4th ed.; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Dey, S. Car Damage Detection Using CNN. Available online: https://github.com/nitsourish/car-damage-detection-using-CNN (accessed on 8 November 2020).
- LandingAI. Redefining Quality Control with AI-Powered Visual Inspection for Manufacturing. Available online: https://landing.ai/wp-content/uploads/2020/04/LandingAI_WhitePaper_v2.0_FINAL.pdf (accessed on 23 October 2020).
- Güngör, O.; Akşanlı, B.; Aydoğan, R. Algorithm selection and combining multiple learners for residential energy prediction. Future Gener. Comput. Syst. 2019, 99, 391–400. [Google Scholar] [CrossRef]
- Güneş, T.; Arditi, E.; Aydoğan, R. Collective Voice of Experts in Multilateral Negotiation. In Proceedings of the PRIMA 2017: Principles and Practice of Multi-Agent Systems, Nice, France, 30 October–3 November 2017; Springer: Cham, Switzerland, 2017; pp. 450–458. [Google Scholar]











| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| Training | 97.04% | 97.0% | 97.0% | 97.0% |
| Test | 88.82% | 89.9% | 88.8% | 88.7% |
| Image with Dents | Images without Dents | Scope | |
|---|---|---|---|
| Dataset 1 | 56 | 49 | Aircraft |
| Dataset 2 | 26 | 20 | Wing |
| Dataset 3 | 56 | 0 | Aircraft |
| Dataset 4 | 56 | 0 | Aircraft |
| Dataset 5 | 56 | 49 | Aircraft |
| Dataset 6 | 56 | 49 | Aircraft |
| Dataset | Epoch | Train Size | Test Size | Precision | Recall | Score | Score |
|---|---|---|---|---|---|---|---|
| Original Dataset [1] | 15 + 5 | 49.5 | 5.5 | 69.13% | 57.32% | 62.67% | 59.35% |
| Dataset 1 | 15 + 5 | 94.5 | 10.5 | 21.56% | 66.29% | 32.54% | 46.85% |
| Dataset | Epoch | Train Size | Test Size | Precision | Recall | Score | Score |
|---|---|---|---|---|---|---|---|
| Dataset 1 | 15 + 5 | 94.5 | 10.5 | 21.56% | 66.29% | 32.54% | 46.85% |
| Dataset 2 | 15 + 5 | 41.4 | 4.6 | 69.88 % | 54.39% | 61.17% | 56.91% |
| Dataset | Augmentation | Epoch | Train Size | Test Size | Precision | Recall | Score | Score |
|---|---|---|---|---|---|---|---|---|
| Original Dataset [1] | No | 15 + 5 | 49.5 | 5.5 | 69.13% | 57.32% | 62.67% | 59.35% |
| Dataset 3 | Yes | 15 + 5 | 50.4 | 5.6 | 60.32% | 68.08% | 63.96% | 66.37% |
| Dataset 4 | Yes | 15 + 5 | 100.8 | 5.6 | 60.60% | 59.52% | 60.06% | 59.73% |
| Dataset 5 | Yes | 15 + 5 | 94.5 | 10.5 | 27.02% | 69.30% | 38.88% | 52.78% |
| Dataset 6 | Yes | 15 + 5 | 189 | 10.5 | 36.80% | 62.83% | 46.41% | 55.04% |
| Dataset | Augmentation | Epoch | Train Size | Test Size | Precision | Recall | Score | Score |
|---|---|---|---|---|---|---|---|---|
| Dataset 1 | No | 15 + 5 | 94.5 | 10.5 | 21.56% | 66.29% | 32.54% | 46.85% |
| Dataset 1 | No | 30 + 10 | 94.5 | 10.5 | 38.10% | 61.27% | 46.98% | 54.62% |
| Dataset 4 | Yes | 15 + 5 | 100.8 | 5.6 | 60.60% | 59.52% | 60.06% | 59.73% |
| Dataset 4 | Yes | 30 + 10 | 100.8 | 5.6 | 72.48% | 55.01% | 62.55% | 57.80% |
| Dataset 5 | Yes | 15 + 5 | 94.5 | 10.5 | 27.02% | 69.30% | 38.88% | 52.78% |
| Dataset 5 | Yes | 30 + 10 | 94.5 | 10.5 | 38.85% | 69.97% | 49.96% | 60.31% |
| Dataset 6 | Yes | 15 + 5 | 189 | 10.5 | 36.80% | 62.83% | 46.41% | 55.04% |
| Dataset 6 | Yes | 60 + 20 | 189 | 10.5 | 44.66% | 64.56% | 52.80% | 59.28% |
| Dataset | Augmentation | Classifier | Epoch | Train Size | Test Size | Precision | Recall | Score | Score |
|---|---|---|---|---|---|---|---|---|---|
| Dataset 1 | No | No | 30 + 10 | 94.5 | 10.5 | 38.10% | 61.27% | 46.98% | 54.62% |
| Dataset 1 | No | Yes | 30 + 10 | 94.5 | 10.5 | 61.91% | 60.68% | 61.29% | 60.92% |
| Dataset 5 | Yes | No | 30 + 10 | 94.5 | 10.5 | 38.85% | 69.97% | 49.96% | 60.31% |
| Dataset 5 | Yes | Yes | 30 + 10 | 94.5 | 10.5 | 59.17% | 68.05 | 63.30% | 66.06% |
| Dataset 6 | Yes | No | 60 + 20 | 189 | 10.5 | 44.66% | 64.56% | 52.80% | 59.28% |
| Dataset 6 | Yes | Yes | 60 + 20 | 189 | 10.5 | 71.31% | 64.08% | 67.50% | 65.41% |
| Research Hypothesis | Experiment ID | Dataset ID | Training Dataset | Test Dataset | Number of Epochs |
|---|---|---|---|---|---|
| Effect of dataset balance | Experiment 1 | 1 | 94.5 | 10.5 | 20 |
| Experiment 7 | 1 | 94.5 | 10.5 | 40 | |
| Effect of specialization | Experiment 2 | 2 | 41.4 | 4.6 | 20 |
| Effect of augmentation | Experiment 3 | 3 | 50.4 | 5.6 | 20 |
| Experiment 4 | 4 | 100.8 | 5.6 | 20 | |
| Experiment 5 | 5 | 94.5 | 10.5 | 20 | |
| Experiment 6 | 6 | 189 | 10.5 | 20 | |
| Experiment 8 | 4 | 100.8 | 5.6 | 40 | |
| Experiment 9 | 5 | 94.5 | 10.5 | 40 | |
| Experiment 10 | 6 | 189 | 10.5 | 80 | |
| Effect of a pre-classifier | Experiment 11 | 1 | 94.5 | 10.5 | 40 |
| Experiment 12 | 5 | 94.5 | 10.5 | 40 | |
| Experiment 13 | 6 | 189 | 10.5 | 80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doğru, A.; Bouarfa, S.; Arizar, R.; Aydoğan, R. Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace 2020, 7, 171. https://doi.org/10.3390/aerospace7120171
Doğru A, Bouarfa S, Arizar R, Aydoğan R. Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace. 2020; 7(12):171. https://doi.org/10.3390/aerospace7120171
Chicago/Turabian StyleDoğru, Anil, Soufiane Bouarfa, Ridwan Arizar, and Reyhan Aydoğan. 2020. "Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection" Aerospace 7, no. 12: 171. https://doi.org/10.3390/aerospace7120171
APA StyleDoğru, A., Bouarfa, S., Arizar, R., & Aydoğan, R. (2020). Using Convolutional Neural Networks to Automate Aircraft Maintenance Visual Inspection. Aerospace, 7(12), 171. https://doi.org/10.3390/aerospace7120171