2.1.1. Air Traffic Flow Management
As mentioned before, resiliency is a systematic concept that covers the questions of system functionality in the presence of disruptions. A resilient system accepts the inevitable challenges of its emergent dynamic states and adapts itself by changing operational processes to maintain its core functionality.
In Europe, stakeholders collaborate closely in different subsystems of the network. Network Manager Operations Centre (NMOC), Air Navigation Service Providers (ANSPs), airports, and airspace users deliver their services by eight subsystems [
1]:
Systems and procedures for airspace management;
Systems and procedures for ATFM;
Systems and procedures for air traffic services;
Communications systems and procedures;
Navigation systems and procedures;
Surveillance systems and procedures;
Systems and procedures for aeronautical information services;
Systems and procedures for the use of meteorological information.
In particular, ATFM is a service that ensures safe operation of airspace. It aims at maximizing the utilization of available capacity. In this regard, DCB contributes to ATFM to prevent the overdelivery of flights to the ANSPs. Air traffic flow and capacity management (ATFCM) is the extension of ATFM and carries out the function of balancing the capacity and demand through collaborative decision-making processes. It is implemented in different phases to manage the traffic: strategic, pre-tactical, tactical and postoperation.
In each phase (
Table A1), there are a number of ATFCM solutions to manage DCB issues. The various solutions to capacity shortfalls are defined in the ATFCM operations manual [
20]. The first set of solutions tries to optimize the utilization of capacity. This set is also supported by another group of solutions to improve the capacity (such as flight level management). If the imbalance is not resolved despite of these capacity measures, the next step is to put constraints on the demand. Capacity regulations (hereafter regulations) belong to this set of solutions. Another example of measures for demand is
cherry picking, but, unlike regulations, it is a measure to resolve short peaks of limited number of flights in congested areas.
2.1.2. Data Sets
In search of the most contributory type of data, we have selected the regulation data because they capture a large-scale measure that addresses the dynamic imbalances in the pre-tactical and especially in the tactical phase (day of operation). In other words, these regulations are applied as final solutions for complex network disruptions. There are two main channels to access the regulation data, ATFCM notification massages (ANMs) and postoperational recorded data.
ANMs are publicly available to all stakeholders of the network and they are published and constantly updated at the day of operation. The parameters of a regulation can be updated according to the actual traffic situation. They may even be removed from the active regulations list before reaching the initial duration. EUROCONTROL (NMOC) publishes ANMs on the network operations portal [
21].
Network manager interactive reporting (NMIR) [
22] offers different databases and provides more detailed information (
Table 1) on regulations compared to ANM but as postoperation records.
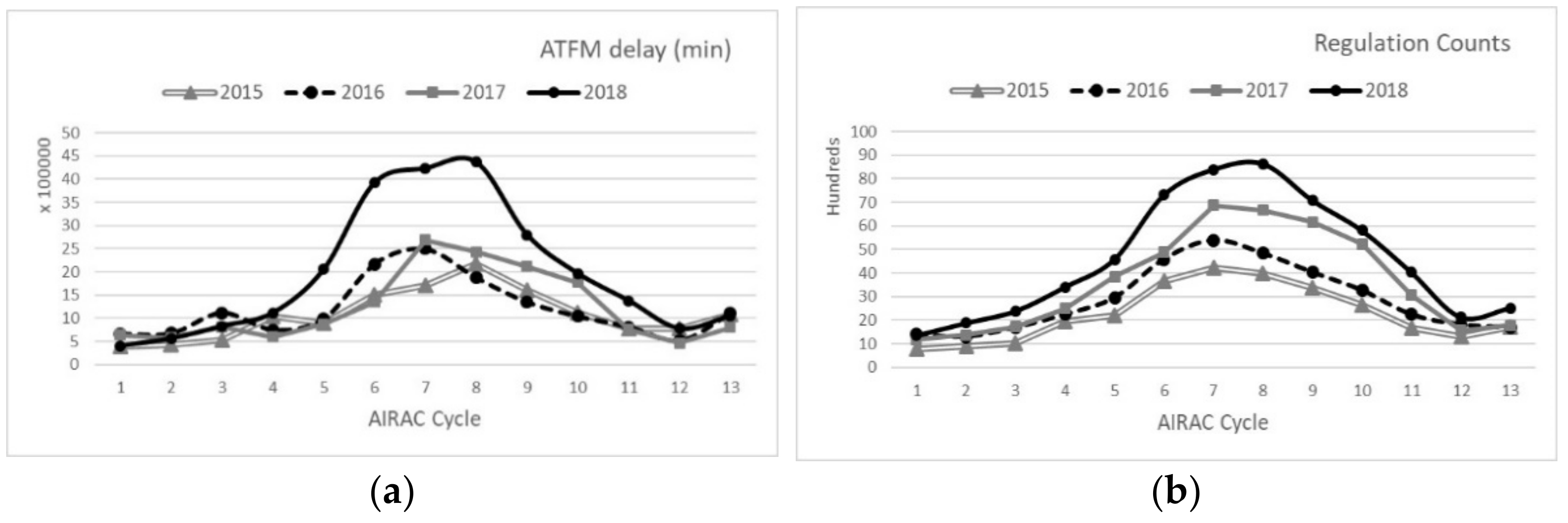
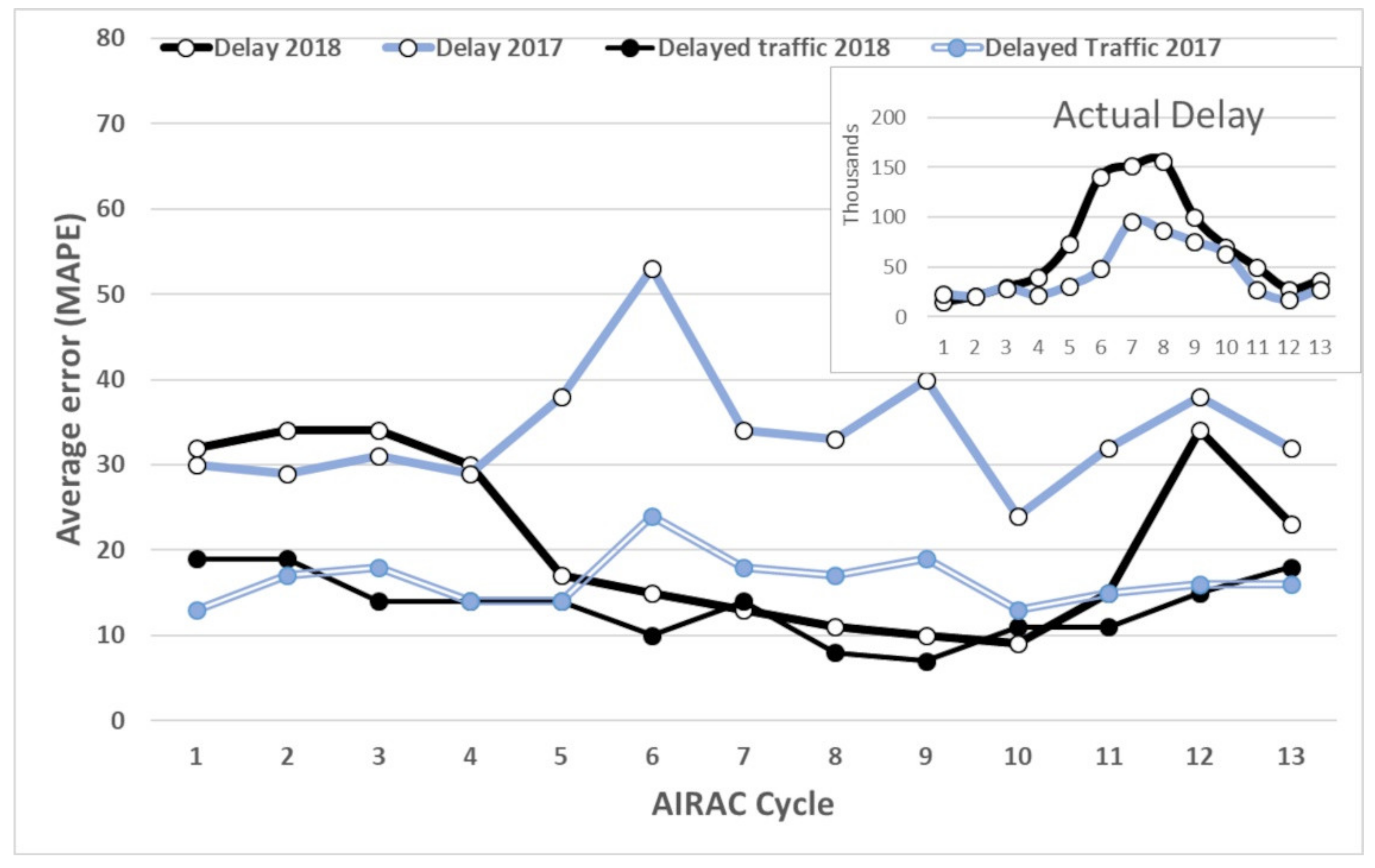
Before parsing the data, we did a general statistical survey on the data from 2015 to 2018. We used aeronautical information regulation and control (AIRAC) cycles. Each cycle is a twenty-eight day period, so a year has 13 cycles. The plans in European airspace are being finalized in different time frames. As provided in
Figure 1, different seasonal traffic pattern is also seen in both delay and count of regulations (summer season is from the fifth to tenth cycle). In general, ATFM delay and number of regulations are proportional to each other. However, an increase in the number of regulations is not necessarily followed by an increase in total delay in each cycle. For example, the delay in the sixth cycle of 2017 was less than the delay in the year 2016 for the same AIRAC, even though the number of regulations were more in 2017 compared to 2016. Another observation is the delay jump in 2018, which is regarded as an important sign of reaching a saturated network.
2.1.3. Data Preparation
From the initial survey, we got a better picture on choosing the right data range. The annual growth of delay, regulation counts, and persistent seasonal patterns suggest the use of most recent years. This trend is stronger in 2018 with the highest number of regulations and the highest amount of delay. In essence, supervised learning methods are set for generalization of the learned characteristics to the whole data. Therefore, we combined both the 2018 and 2017 list of regulations to not only support the generalization but also to provide more data points for train and test sets.
Daywise Features and Target Values
Let
dop represent the day of operation and
N be the number of such days in the post-operational regulations data from NMIR. The goal of our study is to predict the target values at the end of the day based on a set of pre-tactical regulations. This approach conceptually encapsulates all the dynamics of the tactical phase (
dop) as a black box for learning algorithm. Accordingly, each day is filtered for regulations activated before 6:00 UTC to obtain a set of features. The data is filtered by
regulation activation date (
Table 1) for each
dop. With this filtering, a new dataset is obtained, from which the daily aggregated features are formed with specified weekday and respective AIRAC cycle. This combination forms the feature vector for each
dop.
As explained, both ANM messages and NMIR provide regulation data. We take the similar features in both so that the final learning architecture can eventually take ANM messages as input vector for prediction at tactical phase (NMIR provides postoperational data). Therefore, the following aggregated features are obtained from NMIR data:
CountRegPub: Regulation count for each dop, which are activated from the pre-tactical phase up until 6:00 UTC in the tactical phase.
AvgRegDurPub: Average duration of all the regulations for each dop, which are activated from the pre-tactical phase up until 6:00 UTC in the tactical phase.
DopActivationCounts: Number of regulations activated in the tactical phase of operation, that is from 0:00 UTC up until 6:00 UTC for each dop.
CountNumACCPub: Number of ACCs that have activated regulations for each dop from the pre-tactical phase up until 6:00 UTC in the tactical phase.
RegulationTypes: Type-related regulation count activated up until 6:00 UTC for each
dop. There are total of 14 regulation types (
Table A2), and hence 14 features are obtained.
AIRAC: The AIRAC cycle (1 to 13) to which each
dop belongs. This feature is not available in the postoperational regulations data from NMIR and is added from a database, which can be found in (
Table A3). In the context of ML, the AIRAC cycle should be considered as categorical data. This is because AIRAC13 is not greater than AIRAC1, or vice versa in any sense. Therefore, this feature has to be encoded such that learning model can use it without giving numerical significance to the AIRAC number. The one-hot-encoding of Scikit-learn [
23] preprocessing module is used for this purpose. With such an encoding, any AIRAC is represented by a binary vector of length 13 and only one of the items in the vector will have a binary high.
Weekday: The weekday of each
dop. Sun et al. [
24] showed that there is weekday variation in the European air transportation network connectivity. Consequently, the weekday is also considered as a feature for the models. Like AIRAC, the seven weekdays are one-hot-encoded, resulting in a binary vector of length 7.
Daywise Target Values
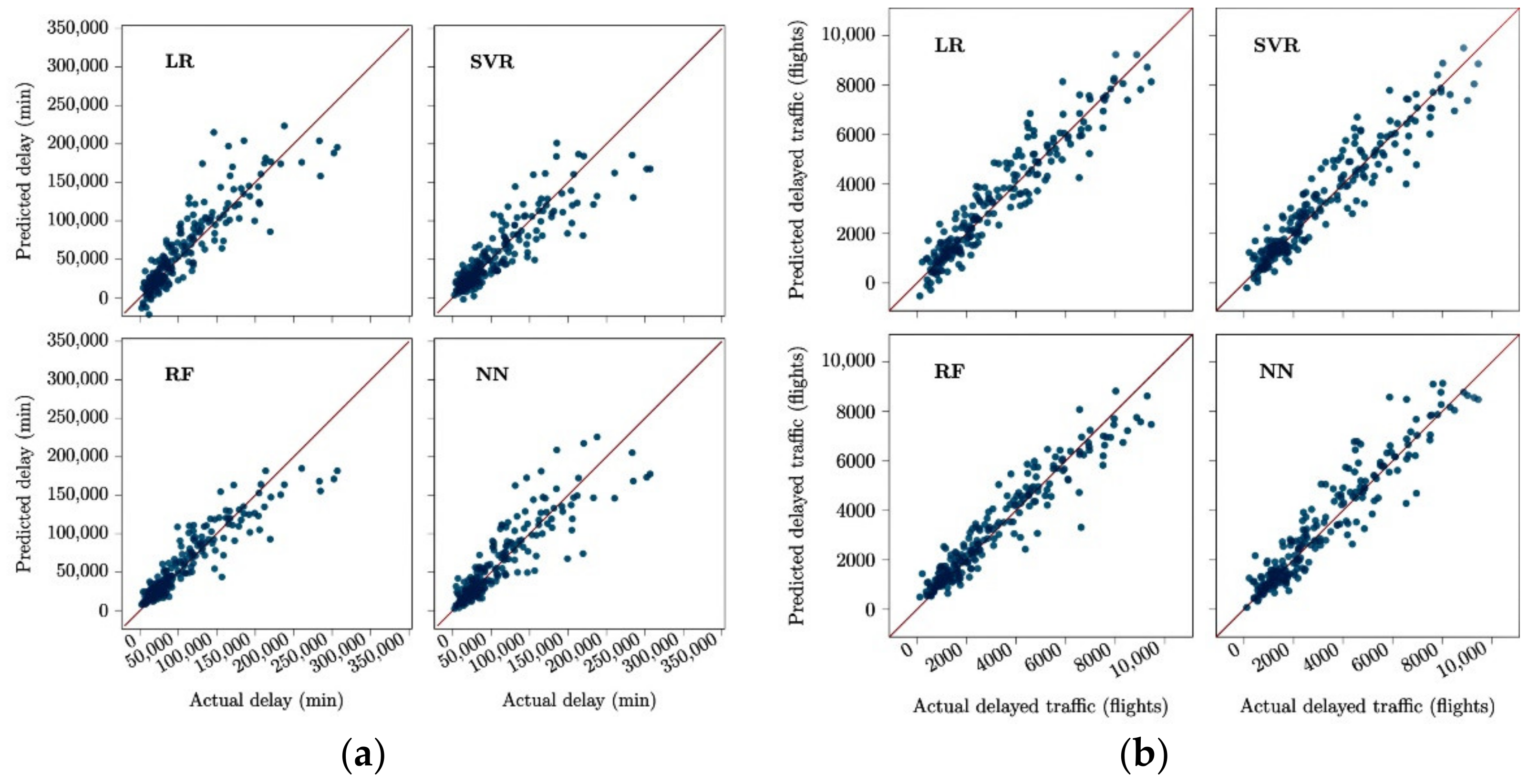
The total daily ATFM delay and most penalized (MP) delayed traffic (hereafter delay and delayed traffic) are considered as the target values (labels) to be predicted by supervised learning model. These values contribute to understanding the level of disruption in the whole network in terms of volume (delay) and extent (count of delayed flights). More specifically target values are:
Delay (min): The total daily ATFM delay in the network (24:00 UTC) for each dop.
Delayed Traffic (flights): The daily MP delayed traffic (24:00 UTC) for each dop. Note that a flight can be subject to more than one regulation. In such cases, only the most penalizing regulation is considered (to impose a delay), and other regulations are ignored for the flight.
Train-Test Split
With the procedure explained previously, a daily dataset of 730 days in total is prepared from NMIR data on 2017 and 2018. There are two important considerations that have to be made during the train-test split of this data.
The train-test split ratio in learning models is important, since a relatively larger training set compared to the testing set would increase the risk of overfitting and a smaller training set would challenge the generalization ability of the model. By considering the size of our dataset, we use 70% of the data for training and 30% for testing to address the above issues. Such a choice is not critical in this study because the seasonal trend in the data is evident and this relaxes the use of relatively smaller training set compared to a situation that data dispersion is not showing any meaningful trends.
Stratified Split
The method for splitting the data is also chosen in order to further consider the seasonal trend in regulation data. This is about how we select 70% of the data to form the training set and leaving the rest for test set. Instead of random splitting, the stratified split method is used. A random selection does not assure proper sampling that represents variations in the whole data. Therefore, we ruled out a random selection to maintain model generalization ability.
Stratified train-test split is a splitting method from the Scikit-learn library [
23]. It ensures that the variability in the training set is represented in the testing set and hence reduces the risk of underfitting in training set and provides homogeneous sets for both. The variability of the dataset means the distribution of the label values. The stratified split can be based on only one of the labels that is either the delay or delayed traffic. Since the delay has a wider range of values (1958 to 327,795 min), it is chosen as the (label) value on which the stratified split is performed.
The input values to the stratified split should be discrete subsets with at least two samples in each subset. Delays are integer values, and in order to make the subsets, daily values are divided by 20,000 and then rounded to upper integer. Also, after division, any value bigger than 10 is rounded to 10. This accounts for few days with high delay values. These steps led to ten discrete subsets as inputs for stratified split along with split ratio.
Feature Scaling
For each regulation there are numerical fields with different ranges (
Table 1). Therefore, it is necessary to use feature scaling to control the effect of various ranges. The risk is that the weights in the learning process tend to be affected more by larger values of features. However, not all learning models are exposed to this risk. This is more relevant to distance-based models such as neural networks (NNs). For instance, RF does not require feature scaling, since it is a tree-based model (nonparametric and nonlinear) and is not influenced by magnitude of the features.
Min-max scaling and standardization are the two common ways to perform feature scaling. In min-max scaling, the values of a feature are scaled to positive value smaller or equal to 1. Equation (1) converts each value from set
X to a scaled value
yi:
Similarly, standardization scales the values using the standard normal distribution. When the features contain outliers, the min-max scaling compresses the values to a small range. On the other hand, standardization is less sensitive to outliers but does not bind the values between 0 and 1. Consequently, we take the MinMaxScaler from Scikit-learn (for support vector regression, linear regression, and NN models) to ensure uniformity and especially to avoid instability in training of NNs. Accordingly, the scaling statistics are computed on the training set only, and the computed parameters are then used to transform the test set.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






