1. Introduction
With the rapid growth of global air traffic operations in the past five decades, the aviation industry has grown to become an integral part of the global economy. While the global air transportation operations at scale have greatly facilitated people’s travel and business, their negative environmental impact, also identified by some entities as the most significant adverse impact of aviation [
1], has emerged as a major concern internationally. The three primary aspects of aviation’s negative impacts on the environment are: (1) local air quality impacts that can exacerbate health-harming air pollution, (2) climate change impacts that can accelerate global warming, and (3) community noise impacts that can undermine affected population’s mental well-being [
2]. Undoubtedly, the aviation industry must keep the development momentum to meet the needs of a growing economy while simultaneously being more environmentally sustainable. The system must operate harmoniously within the constraints imposed by requisites such as clean air and water, limited noise impacts, and a livable climate.
Aircraft, ground vehicles, Ground Support Equipment (GSE), and other stationary sources at the airport produce emissions as a result of the combustion of fuel. Aircraft engines mainly produce carbon dioxide (CO
), which comprises around 70% of the exhaust, and water vapor (H
O), which comprises around 30% of the exhaust. Less than 1% of the emissions is composed of nitrogen oxides (NO
), carbon monoxide (CO), sulfur oxides (SO
), partially combusted or unburned hydrocarbons (HC), particulate matter (PM), other trace compounds, soot and sulfate aerosols, and increased cloudiness due to contrail formation [
2,
3]. These emissions undergo complex interactions among themselves and with the changing background atmosphere [
4]. Among the aircraft pollutant emissions, around 10% are emitted near the surface of earth (below 3000 ft above ground level) while the remaining 90% are emitted at above 3000 ft, mostly at cruise altitudes within the Upper Troposphere and the Lower Stratosphere (UTLS). While aviation technologies have become more fuel efficient, the overall emissions from aviation has risen due to the rapidly increasing volume of air travel. Statistics reveal that the annually averaged growth rate in global aviation CO
emissions was 2.2% per year over the period 1970 to 2012 and 5% per year for 2013 to 2018. In 2018, global aviation CO
emissions exceeded 1000 million tonnes per year for the first time, which accounts for approximately 2.4% of all anthropogenic emissions of CO
(including land use change) [
3]. These observations indicate that aviation emissions remains a challenging issue towards a more sustainable future of aviation.
Aircraft noise pollution refers to the “unwanted sound” produced by aircraft or its components in flight. In general, aircraft noise is produced by three main sources. Engine noise is the main source of aircraft noise. For propeller aircraft and helicopter, engine noise includes both aerodynamically induced noise from the propeller and mechanically induced noise from other moving parts of the engine. For jet aircraft, engine noise is dominated by jet noise from the gas turbine engines, which is responsible for much of the aircraft noise during takeoff and climb. Jet noise is caused by the high speed flow leaving the exhaust of the engine which is highly unstable and turbulent. Aerodynamic noise is the second source of aircraft noise. Aerodynamic noise arises from airflow around the aircraft fuselage and control surfaces and increases with aircraft speed and air density. Supersonic aircraft, such as fighter jets, often creates intense aerodynamic noise called sonic boom due to the formation of shock waves during supersonic flight. Aerodynamic noise can sometimes be mitigated by designing the shape of airframe. The third source of aircraft noise is the aircraft systems. Some examples include noises from the Auxiliary Power Unit (APU) and the cabin pressurization and conditioning systems. Aircraft noise can disrupt sleep, cause community annoyance, adversely affect academic performance of children, and could increase the risk for cardiovascular disease of people living in the vicinity of airports [
5].
Accurate modeling of aircraft environmental impacts—mainly fuel burn, emissions, and noise, is crucial in informing a number of new operational procedures, technologies, and policies to abate negative aviation environmental impacts. In the past decade, key breakthroughs in data-driven analysis have been catalyzed by (1) advances in data quantity and quality, (2) effective and scalable algorithms from applied mathematics and computer science, and (3) high-performance computation [
6]. The introduction of big data technologies in aviation industry has brought a good opportunity for aviation environmental impact modeling to more precisely reflect real-world operations. Two typical examples of rich datasets in aviation are Flight Operational Quality Assurance (FOQA) data and Automatic Dependent Surveillance—Broadcast (ADS–B) data [
7]. FOQA data consist of regularly recorded aircraft sensor measurements and switch settings. The data collected are a multivariate time series consists of thousands of parameters (numerical, discrete, categorical, text, etc.) recorded at a frequency of up to 16 Hz (typically at 1 Hz). ADS–B data collects the aircraft’s identification, altitude, position, and velocity in a lower resolution than FOQA. The data determined by satellite navigation or other sensors is periodically transmitted by the aircraft to ground-based stations. According Federal Aviation Administration (FAA) website, “Automatic Dependent Surveillance-Broadcast (ADS-B)”, because ADS-B improves the safety and efficiency of aviation infrastructure and operations, real-time ADS-B is now the preferred method of surveillance for air traffic control in the National Airspace System (NAS). A report from Oliver Wyman, “MRO Big Data—A Lion or a Lamb?”, estimates that the global fleet is likely to generate over 98 million terabytes of data by end of 2026, about ten times that of 2018, due to the increase in global fleet size and the deployment of new technologies to collect and transmit data. In this context, analytical methods from statistics, machine learning, and computing will keep playing an increasingly critical role to make future air transportation more environmentally friendly, more efficient, more predictable, and safer.
This paper is a survey of recent works which employ statistical and machine learning methods to make aviation environmental impact analysis more efficient and accurate [
8]. After years of progress, the opportunity to fill in this gap of the existing literature has matured. Through summarizing and classifying representative works in this area, the objective is to extract prevailing research trends regarding how statistical and machine learning methods function in advancing aviation environmental impact modeling and suggest research opportunities for the future. As a survey paper at the intersection of methodology and application, its content is planned to have the following features:
Summary of methodology: On the summary of methods from statistics and machine learning, the emphasis is to present a comprehensive landscape and development process for each field. There are many excellent textbooks and review papers in the literature which introduce the mathematical foundation, detailed algorithms, and experimental analysis of of the these methods. The summary of methodology in this paper is not an attempt to replicate or elevate those existing methodology-oriented review papers. Instead, from an engineering researcher’s perspective, the aim of this part is to clearly convey the basic ideas in the methods and the differences between them such that applied researchers can have a clearer big picture.
Organization of representative works: Most similar survey papers focusing on other application areas group relevant works in the literature by the type of method used. In that manner, the existing literature on aviation environmental impact analysis would be divided into, for example, the applications of regression analysis, clustering, dimensionality reduction, feature selection, neural networks, etc. In our approach, representative works in the literature are grouped by the purpose of applying statistical and machine learning methods, i.e., for what reasons were these method used to tackle different problems. Thus, the main section of this paper is organized into seven themes: data reduction, efficient computation, predictive modeling, uncertainty quantification, pattern discovery, verification and validation, and infrastructure and tools. For each theme, we present both the necessary background and the representative papers.
Diversity: This paper is by no means an exhaustive list of every relevant work in this area. The overarching objective is to summarize the overall research trends through representative works/projects. Under the premise that each selected work has enough quality and correct scope, we hope to present a diverse research portfolio which covers different methods, different application directions, and even different regions in the world (although with lower priority than the previous two aspects). For example, on the methodology side we cover from basic statistical analysis and regression models to unsupervised learning approaches such as clustering and dimensionality reduction, different types of neural networks (ordinary, convolutional, recurrent), and graphical model. On the application side we cover the modeling of fuel burn, emissions, and noise, for fixed-wing aircraft, helicopter, airport, and air transportation system. The selection range also covers works from different entities and regions to reflect the fact that sustainable aviation is a global effort.
While the focus of this paper is on the application of statistics and machine learning methods to make aviation environmental impact analysis more efficient, accurate, and interpretable, there are certain “closely-related” aspects that we do not cover. The following three topics are not included:
Optimization: There are three facets of analytics: descriptive, predictive, and prescriptive analytics. On the methodology side we only cover the former two facets of analytics. Optimization is at the kernel of prescriptive analytics. Although it also belongs to data-driven approaches, it is not covered here simply because it is a rich area that is worthy of an independent survey paper. Optimization methods have been used to design aircraft operations that reduce environmental impacts. A sample of such works include [
9,
10,
11,
12]. Reference [
13] is a recent survey paper on climate optimal aircraft trajectory planning.
Aircraft design: Since sustainable aviation became a major research area in the aerospace community, novel methods in aircraft design and Multidisciplinary Design Optimization (MDO) have started to incorporate environmental considerations into aircraft conceptual and preliminary design phases. An early work of this type [
14] dates back to almost two decades ago. Examples of some more recent works include [
15,
16,
17].
Physics-based methods: Under the category of efficient and accurate modeling of aviation environmental impacts, some recent progresses/capabilities are physics-based which do not involve much data-driven components discussed in this paper. This type of approaches is also a crucial and indispensable part of aviation environmental impact modeling. Interested readers can refer to [
18,
19,
20,
21] as starting point.
The remainder of the paper is organized as follows.
Section 2 contains a brief overview of methods from statistics and machine learning.
Section 3 introduces the seven main application themes of statistical and machine learning methods in aviation environmental impact analysis. Each subsection in
Section 3 includes an overview of an application theme and summarizes at most ten representative papers under the theme.
Section 4 discusses some future avenues of the research area before
Section 5 concludes the paper.
3. The Main Application Themes
In this section, we analyze representative papers in the literature which apply statistical and machine learning methods for efficient and/or accurate analysis of aviation environmental impacts. Here, instead of using traditional approach which groups the selected papers by the type of method involved (regression, clustering, neural networks, etc.), we classify representative papers by the application theme, i.e., the actual purpose those methods are used for. The seven resulting themes are: data reduction, efficient computation, predictive modeling, uncertainty quantification, pattern discovery, verification and validation, and infrastructure and tools. The discussion of each theme includes the introductory background information, primary research trends under the theme, and a summary table containing details of at most 10 featured papers for each theme. Please note that some selected papers may span across multiple themes. For example, a paper could belong to both data reduction and efficient computation. We discuss such papers in a theme that can best complement other papers in the theme and complete the narrative.
3.1. Data Reduction
Performing complex analysis and computation on large datasets can be impractical or infeasible. In such cases, data reduction is applied to obtain a reduced representation of the dataset that is much smaller in volume, yet still closely maintains the integrity of the original dataset [
37]. Applying a reduced dataset in analysis and computation trades accuracy for speed in response to the need of obtaining quick approximate answers to queries on large datasets. The development of data reduction techniques for science and engineering applications has gained increasing interest in the community. The motivation behind the trend is that contemporary operations, scientific observations, experiments, and simulations are generating unwieldy amounts of data which are beyond people’s capacity to store, stream, analyze, and archive. In the meantime, these massive datasets almost always contain redundancies and trivialities.
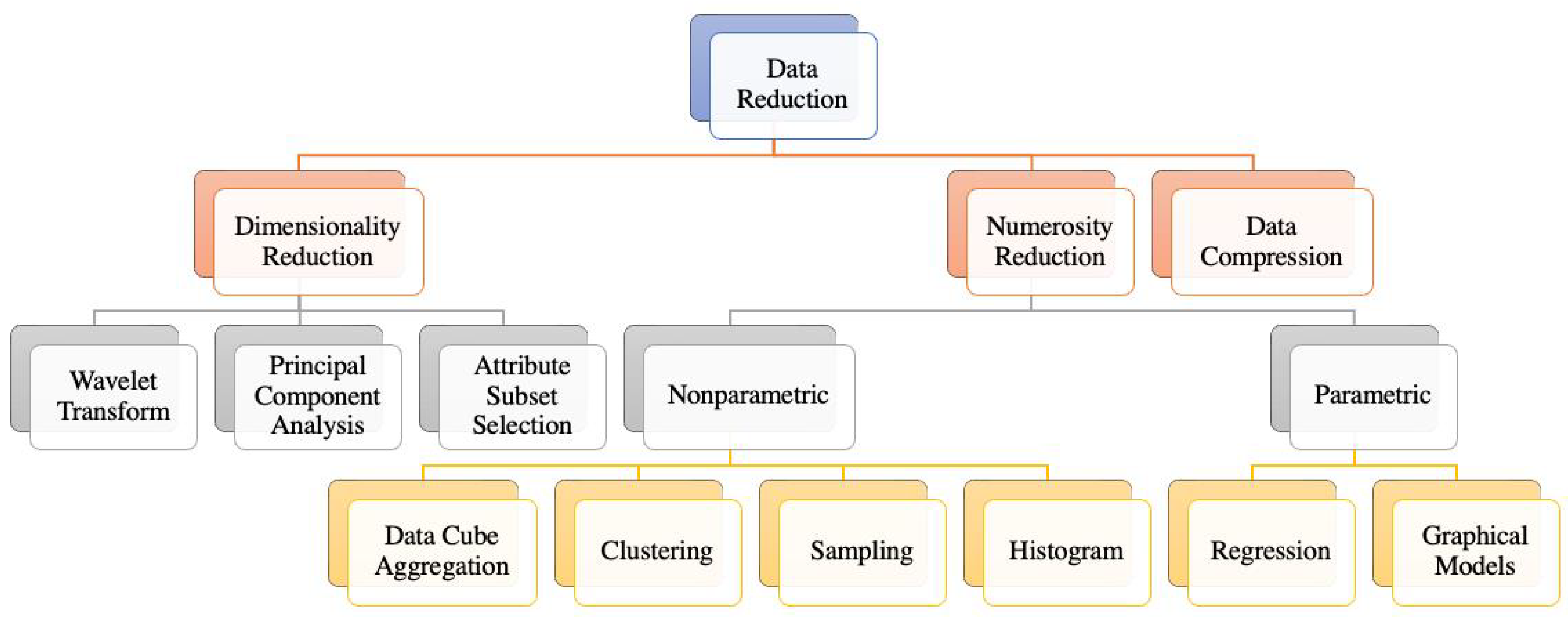
As shown in
Figure 4, data reduction strategies mainly include three broad categories: dimensionality reduction, numerosity reduction, and data compression. Dimensionality reduction techniques reduce the number of attributes/features
p under consideration. Some dimensionality reduction methods, such as Principal Components Analysis (PCA) and wavelet transform, aim to transform or project the original data onto a lower-dimensional space. Other methods such as attribute subset selection detect and remove non-informative, irrelevant, and redundant attributes from the full feature set. Numerosity reduction, on the other hand, reduces the number of data points
n in the original dataset. Numerosity reduction can be classified as either parametric or nonparametric. For parametric methods, the data is represented by a parametric model which consists of model form and model parameters. After the modeling process, only the model parameters are stored instead of the actual dataset, thus reducing the size of the data. Some examples of parametric data reduction methods include regression models, log-linear models, and graphical models. For nonparametric methods, the data reduction process does not assume a specific parametric model for the data. Therefore, nonparametric methods are overall more flexible yet more challenging. Some typical examples of nonparametric data reduction methods include histogram, clustering, sampling, and data cube aggregation. Data compression is the third category of methods which first transforms the original data into a compressed representation, then reconstructs the data in a later recovery process. Data compression belongs to either lossless or lossy, depending on whether the original data can be reconstructed from the compressed representation without any information loss. In general, the computational time of a data reduction process should not outweigh the amount of time saved by analyzing the reduced dataset.
A summary of representative papers in data reduction is given in
Table 2. In most cases, data reduction is a step before data-driven simulation for estimating aviation environmental impacts, on either the aircraft-level or the fleet-level. The data-driven simulation relies on aircraft flight data to ensure that the simulation result can closely reflect real-world operations. Nevertheless, conducting computation and evaluation for a massive amount of operations and models can be infeasible. Therefore, data reduction is necessary to extract a small amount of representative data and models for efficient yet accurate analysis. Overall, there have been three primary usages of data reduction in aviation environmental impact analysis: representative data, representative models, and representative operations. Representative data refers to a small subset of data points which can closely maintain certain characteristics of the population. For example, in probabilistic analysis and many common scenarios, the small subset should retain the same data distribution as the complete dataset. Reference [
38] proposes a distributional data reduction method PREM which outperforms random sampling at very small sample sizes. PREM enables efficient simulation-based uncertainty propagation in the uncertainty quantification of aircraft fuel burn and emissions in real-world operations. Representative models involve both numerosity reduction and dimensionality reduction. The need for numerosity reduction is due to the fact that there exists a substantial amount of aircraft types to model, where each aircraft type is a unique combination of airframe and engine. Because building aircraft noise and performance (ANP) model for each aircraft type takes a long and rigorous process, Reference [
39] selects a small proportion of representative aircraft models that can sufficiently cover the richness and complexity in the population for detailed modeling. References [
40,
41] select representative aircraft types for efficient fleet-level noise contour and emissions computation. On dimensionality reduction, Reference [
42] conducts a feature selection study to find a reduced set of aircraft features which are most influential to different environmental impact metrics. Representative operations refer to the flight procedures, trajectories, or profiles that can be utilized to model aircraft fuel burn, emissions, and noise. References [
40,
43,
44,
45] apply clustering on large datasets to group flight trajectories and extract the most representative trajectories. Some works, such as [
43,
44], take a step forward to convert the representative flight profiles into parameterized forms. Reference [
46] also applies probabilistic modeling on the representative mission profiles and account for uncertainty in the process. These representative information from real-world operations have made aviation environmental impact modeling closer to the reality in an efficient manner.
3.2. Efficient Computation
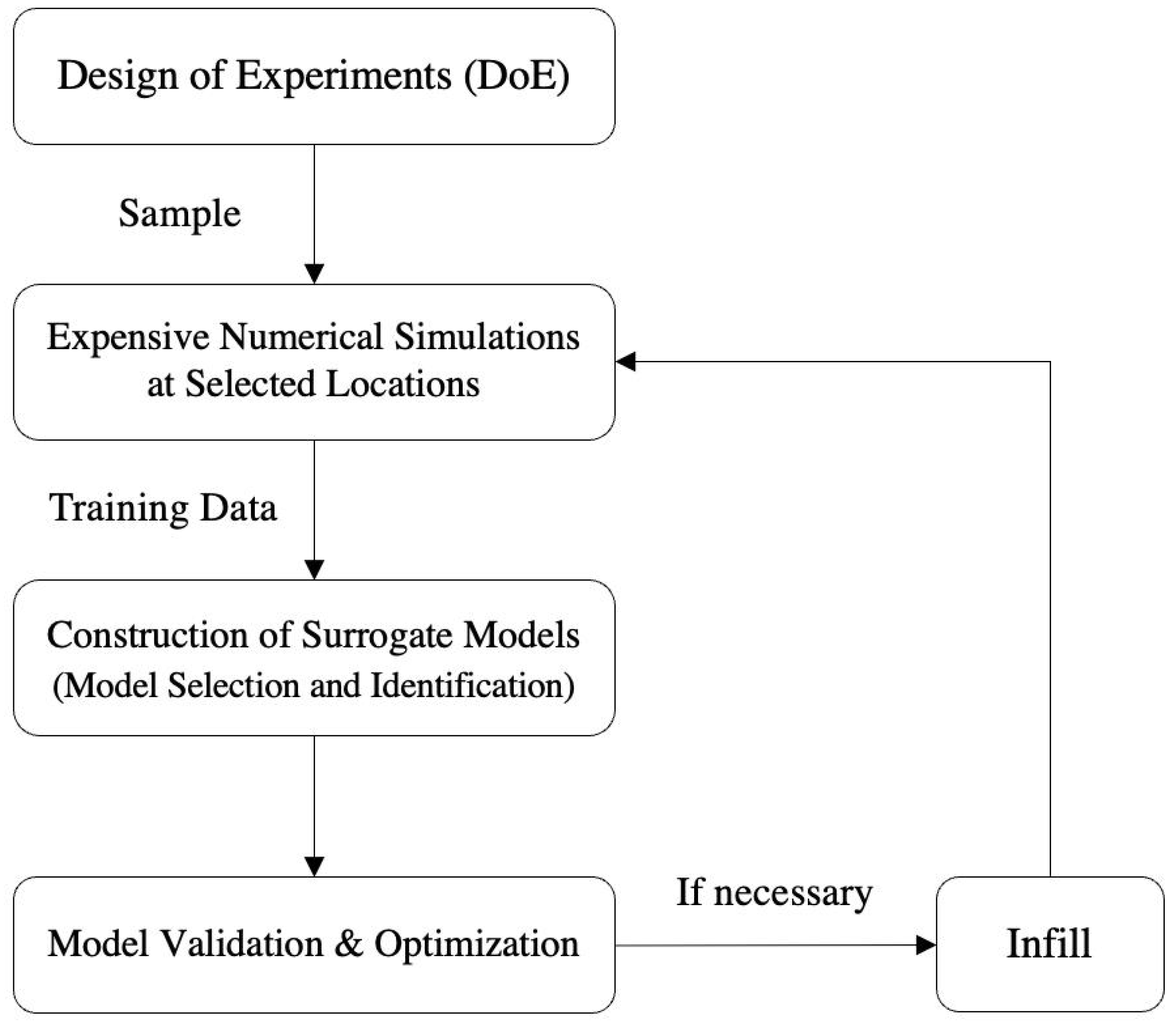
Since computer simulation/experiment became an indispensable part in contemporary engineering design optimization and systems analysis problems, computational efficiency has been a major concern in such processes due to two main reasons. First, high-fidelity simulation and analysis models are typically computationally expensive and time consuming. One common approach to tackle this challenge is the Surrogate-Based Analysis and Optimization (SBAO) [
48] approach depicted in
Figure 5 which relies on surrogate models to provide fast approximations of the sophisticated high-fidelity models. Second, the design optimization of a complex system inevitably involves the exploration of a broad design space. This usually translates to a large number of candidate design points and simulation runs, depending on the actual size of the design space and the number of design parameters. Some statistical and data-driven approaches can further reduce the number of simulation runs to improve the efficiency. Overall, these two facts can lead to excessive computational costs and prohibitive run times in engineering design and analysis process. Two typical examples of the computationally expensive simulations in the design and analysis of aerospace systems are Computational Fluid Dynamics (CFD) and multidisciplinary vehicle modeling.
Aviation environmental impact analysis can also be computationally expensive, because performing high-fidelity fuel burn, emissions, and noise analyses for a air transportation system is a massive task. Take aircraft noise modeling as an example, depending on factors such as the number of aircraft operations, the size of the region, the length of the time interval, and the fidelity level of the models, the current state-of-the-art noise modeling capabilities could require long setup and computational times for a single case study. A previous study [
49] reported that running the high-fidelity Integrated Noise Model (INM) to perform airport-level noise study for a four-parallel-runway airport in crossflow takes between two days to two weeks to finish. Another example is the Aviation Environmental Design Tool (AEDT), a software system that models aircraft performance in space and time to estimate noise, fuel consumption, emissions, and air quality consequences [
50]. A study [
51] reported that on the AEDT, a national-level noise study comprising a moderate number of airports and flights could take several days to complete.
A summary of representative papers in efficient computation is given in
Table 3. These representative works involving efficient computation can be classified into three generic groups. The first group employs surrogate models or reduced-order models (ROMs) to reduce the computational complexity of the complicated models and therefore reducing the computational time. In some literature, this is also referred to as “meta modeling”. The authors of [
52] construct a response surface model to approximate the computationally expensive Community Multiscale Air Quality (CMAQ) modeling system for fast evaluations of aviation’s impacts on air quality. The authors of [
51] apply ROM on AEDT’s noise model to develop a rapid noise prediction capability. The second group builds rapid integrated analysis capabilities for fleet-level aviation environmental impact modeling. Such rapid fleet-level analysis capabilities could consist of elements such as simplified models, generic aircraft and operations (with connections to data reduction), and some pre-computed outcomes. The authors of [
49] develop the airport noise grid integration method (ANGIM) which uses simplified methods and offline computational results for generic aircraft operations to enable rapid fleet-level noise modeling. The authors of [
53] propose the GENERICA method which leverages methods such as classification algorithms, designs of experiments, surrogate models, and multi-criteria decision-making to identify better baseline models than the traditional representative-in-class vehicles, also called “average generic vehicles”, for more realistic approximation of fleet-level environmental impact results. The authors of [
54] develop the Rapid Environmental impact on Airport Community Tradeoff (REACT) environment to conduct rapid tradeoff by modeling different noise mitigation strategies’ noise exposure on the airport community. The third group is hybrid data-driven approaches for efficient modeling. The authors of [
55] use performance and acoustic data from flight and wind tunnel tests to develop an efficient analytical model for helicopter Blade–Vortex Interaction (BVI) noise during maneuvering flight. The authors of [
56] combine physics-based model and aircraft performance data to build an efficient and accurate “data-enhanced surrogate model” for aircraft fuel consumption. The authors of [
57] develop Fuel Estimation in Air Transportation (FEAT), a rapid analysis framework, by using a high fidelity flight profile simulator and a reduced order fuel burn model. These efficient models have contributed to the aviation environmental analysis tool-suite that enable rapid assessment and evaluation, which is crucial especially for preliminary analysis.
3.3. Predictive Modeling
With the ultimate objective of making accurate predictions, predictive modeling is one of the most typical tasks of machine learning. In contrast to the specific machine learning or data mining techniques which uncover patterns in data, predictive modeling encompasses the entire process of developing a mathematical model in a way that we can understand and quantify the model’s accuracy on predicting future, yet-to-be-seen data [
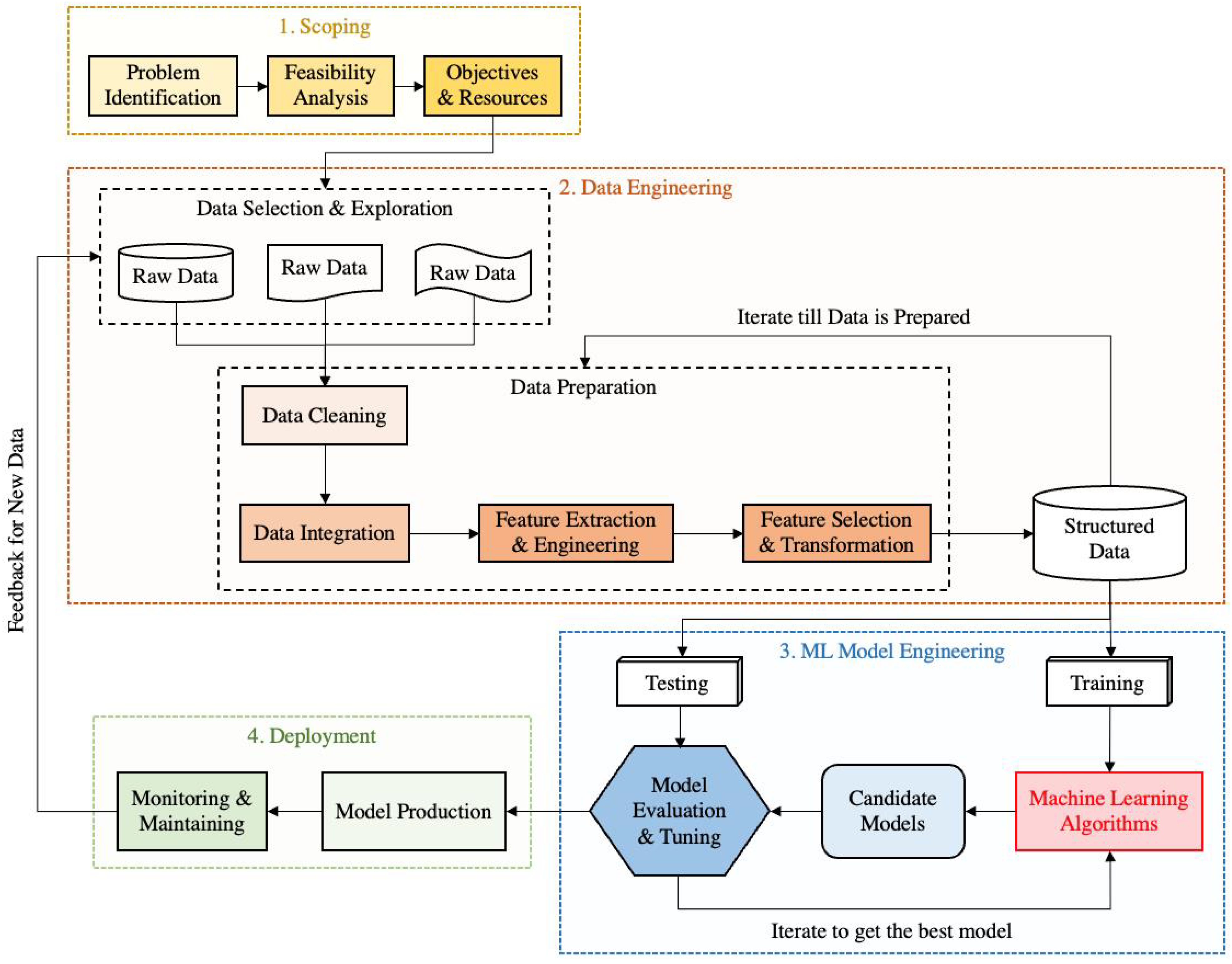
58]. Steps such as data pre-processing, model tuning, performance measurement, and model selection are of critical importance in the predictive modeling process. Therefore, to a certain degree, predictive modeling is highly similar to the machine learning engineering process depicted in
Figure 3. Although the foremost objective of predictive modeling is to make accurate predictions, a secondary interest is to interpret the model and understand how it makes prediction. On certain problems, interpretation could be just as important, and this involves a tradeoff between accuracy and interpretation. Overall, a more accurate model is often associated with higher model complexity and lower interpretability. More discussions on the model interpretability can be found later in
Section 4.
Predictive models mainly include regression models and classification models, which predict continuous and categorical responses, respectively. Under each category, depending on whether a model is based on linear combinations of the predictors, different models can be further divided into linear models and nonlinear models. Although different models differ by the model form, number of parameters, and overall complexity, no predictive model is universally superior in every problem. Practitioners are encouraged to explore a diverse set of models for any given problem and identify the best predictive model [
58]. A key foundation to the success of predictive modeling is the practitioner’s domain knowledge and deep understanding of the problem. When predictive signal exists in a dataset, even a naive model can capture some degree of predictive power. The domain knowledge applied to the modeling process is what distinguishes a great model from good models. In a serious decision making process, neither data-driven predictive model nor expert intuition will do better than a combination of both.
A summary of representative papers in predictive modeling is given in
Table 4. Most of these representative papers were published after year 2018. Although classification models can find applications in many data-driven analysis tasks in aerospace and transportation domains (e.g., flight risk identification), the predictive models for aviation environmental impact analysis are mostly regression models. Some recent works have started to adopt advanced model architectures on more complex data forms to predict aircraft fuel burn, emissions, and noise. Among some of the earlier works, Reference [
59] uses Gaussian Process Regression (GPR) and Probabilistic Graphical Model (PGM) to develop a wind forecasting model, which informs improved flight route planning to reduce environmental impact of aviation. Some advanced set-ups in statistics and machine learning are used to more accurately estimate aircraft fuel consumption. In a series works to improve aircraft fuel efficiency, Reference [
60] first applies ensemble learning to improve the prediction of discretionary fuel and construct uncertainty intervals for the predictions. After that, Reference [
61] utilizes quantile regression to estimate the Statistical Contingency Fuel (SCF) from a large fuel burn dataset from airline. The rest of the papers adopt different types of deep learning models. To minimize transport aircraft emissions and save fuel, Reference [
62] applies neural network whose topology is optimized by genetic algorithm on flight data to predict fuel consumption. The authors of [
63] use a type of feedforward neural network called covariance bidirectional extreme learning machine (CovB-ELM) to predict aircraft trajectory and the associated fuel consumption. There is also a significant trend which employs Recurrent Neural Network (RNN) to model sequences of data. The authors of [
64] apply Long Short Term Memory (LSTM) neural network on Flight Data Monitoring (FDM) data records to estimate aircraft on-board parameters such as the fuel flow rate for enhancing the system’s efficiency. The authors of [
65] apply sequence-to-sequence LSTM on large radar and noise datasets to predict ground level aviation noise and evaluates the model using real-world noise measurements. The authors of [
66] use a combination of LSTM and extreme gradient boosting (XGBoost) to predict short-term flight emissions within enroute airspace. The last two papers apply the more advanced physics-informed learning approaches which combine data-driven model with physical model to predict specific problems more effectively. The authors of [
67] use physics-guided deep learning to model aircraft fuel burn. To outperform both the traditional physics-based models and the common supervised learning approaches, the authors: (1) guide the neural network with fuel flow dynamics equations, and (2) embed physical knowledge as extra losses in the model training process. The authors of [
68] use physics-guided neural networks to predict propeller tonal noise with less experimental data, which can be difficult to collect. In some other works, even applying methods like ordinal regression and neural network can achieve satisfactory results on certain problems. Yet the more advanced more architectures and considerations have opened the door for a wider variety of problems.
3.4. Uncertainty Quantification
Uncertainties related to imprecise assumptions, natural variability, and the presence of unknowns is not only an unavoidable part of the real-world, but also a significant factor that could determine the success or failure of a decision or system. At the intersection of mathematics, statistics, and engineering, Uncertainty Quantification (UQ) is an interdisciplinary field that addresses the problems associated with incorporating real-world variability and probabilistic behavior into the design and analysis of complex systems. UQ provides uncertainty information about the Quantities of Interest (QoI) through characterizing, propagating, and managing uncertainties in a computational or real-world system. The high degree of complexity and uncertainty associated with aviation environmental impact analysis have driven practitioners towards the use of UQ in the modeling process.
Different sources of uncertainty can be generally categorized as either epistemic uncertainty or aleatory uncertainty. The former is caused by a lack of knowledge and is possible to be reduced by collecting more information. Aleatory uncertainty, on the other hand, results from the intrinsic randomness of nature. Therefore, it is beyond people’s ability to reduce aleatory uncertainty through gathering additional information. Some previous research efforts [
69,
70] explore how to deal with both types of uncertainties. Common sources of uncertainty can be classified into four categories:
Inputs uncertainty: The inputs of a model/system may have inherent uncertainty and substantial variation around a deterministic value.
Model uncertainty: All models are “wrong” because they inevitably include assumptions, approximations, and errors and are therefore not exact representations of reality. Two aspects of uncertainties related to model are model-form uncertainty and uncertainty about parameters within the model.
Computational and numerical uncertainty: Normally numerical errors from running simulations or solving mathematical models, including simplified equations, convergence error, truncation, etc.
Physical testing uncertainty: A result of uncontrolled or unknown inputs, measurement errors, and limitations in the design and implementation of tests.
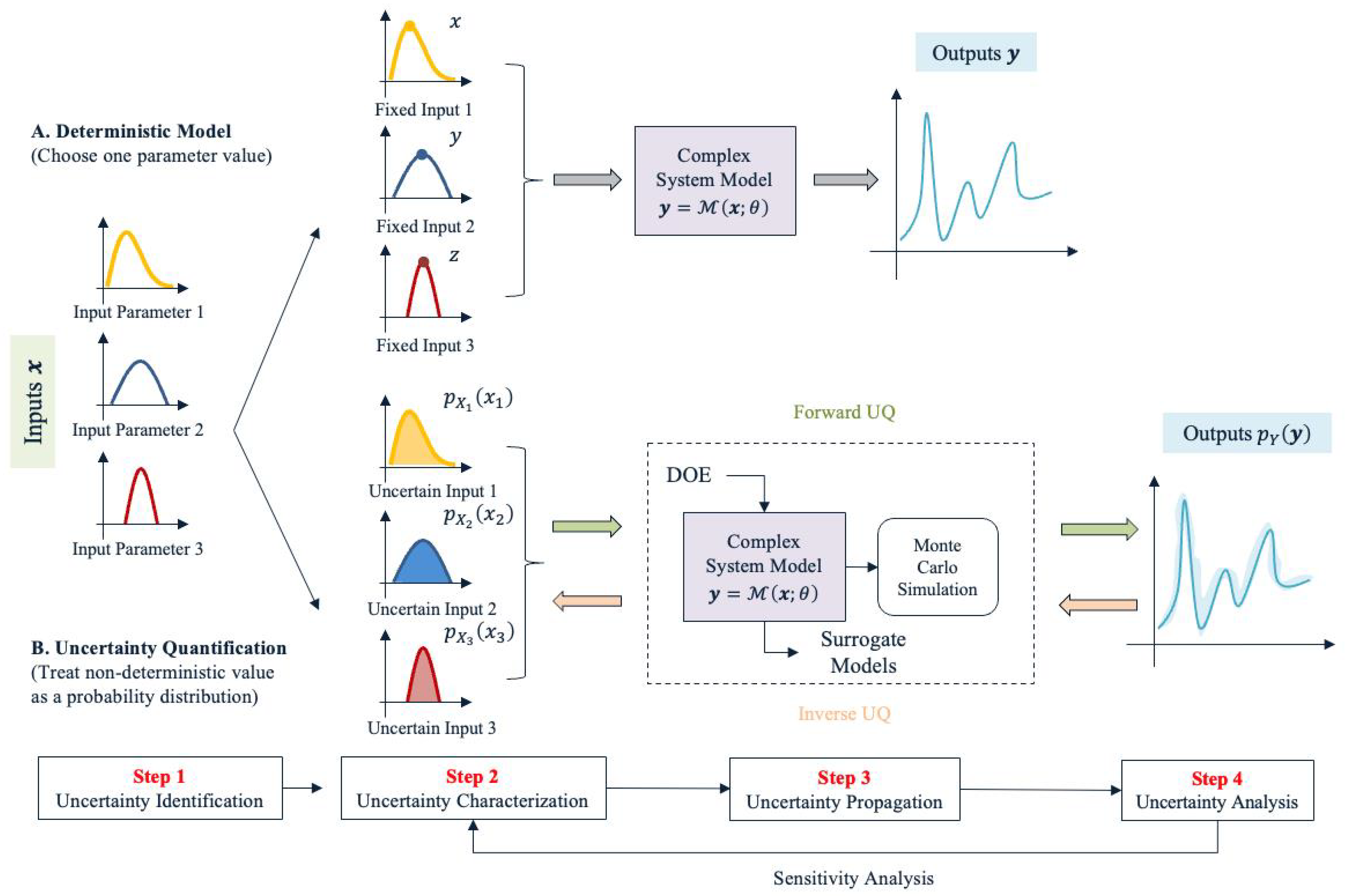
A standard uncertainty quantification step consists of four main steps: uncertainty identification, uncertainty characterization, uncertainty propagation, and uncertainty analysis.
Figure 6 displays a standard UQ process and compares it with the traditional deterministic modeling procedure. As a starting point, uncertainty identification refers to a step of identifying potential uncertain sources in a simulation or analysis process. The subsequent uncertainty characterization is a step to mathematically represent all the uncertain sources. In uncertainty propagation, uncertainties in all levels of the model/system are mathematically mapped to the uncertainties in the outputs [
71]. When the sophisticated system analysis code is computationally expensive, surrogate models can be used to reduce the complexity of the original model while retaining the physics-based relationships between the inputs and outputs. The uncertainty propagation process in
Figure 6 is simulation-based, in which Monte Carlo Simulation (MCS) is utilized. The last step, uncertainty analysis, involves using statistical analysis and visualization to study the uncertainties inherent in the system’s outputs for making better decisions.
In aviation environmental impact analysis, UQ is generally used to: (1) understand the uncertainties inherent in a complex model or software systems, (2) predict system responses across uncertain inputs and quantify confidence intervals, (3) understand the key contributors to model output variations, and (4) inform researchers of directions for future model development and enhancement. A summary of representative papers in uncertainty quantification is given in
Table 5. Several works in
Table 5, such as [
72], encompass surrogate modeling in their UQ approach as well, because it is common to use simulation-based methods, such as MCS, for uncertainty propagation. This process learns the distributions of the nondeterministic outputs through a large number of experiment runs on the sophisticated analysis code and is impractical without surrogate model. Hence, surrogate model is a vital enabler to efficient UQ and design optimization. Some earlier works perform a complete UQ process on a complex aviation environmental model. Both [
73,
74] conduct a UQ study on AEDT to better understand the uncertainties in AEDT estimations and identify priority aspects for future research and development. Also based on AEDT, Reference [
75] conducts a sensitivity analysis for fleet-level environmental impacts to changes in operational uncertain factors for the optimization of flight operations to mitigate aviation environmental impacts. The authors of [
76] perform rapid computation and UQ on the global fleet-wide simulation of aviation emissions for rapid and robust policy analysis. On the data-driven approach, Reference [
77] uses Gaussian Process Regression (GPR) to quantify uncertainty in a data-driven 4D flight trajectory prediction problem and gain insights on uncertainty reduction—an important objective of UQ. Some works focus on novel UQ methodologies and make contributions in methodology development. Inspired by multidisciplinary analysis and optimization, Reference [
78] proposes a decomposition-based approach to quantify uncertainty in multi-component systems and applies the method to perform uncertainty analysis and sensitivity analysis for the environmental impacts of new aircraft technologies and operations. When only limited data is available for UQ, Reference [
79] develops a nonparametric approach to characterize and propagate uncertainty, which is more flexible and does not introduce unwarranted assumptions into the process. Some latest works initiate the trend of performing UQ on the environmental impact of future aircraft configurations. The authors of [
80] perform UQ on the noise of a Hybrid Wing–Body (HWB) aircraft configuration at the noise certification locations. The authors of [
81] perform system noise assessment and UQ for a conceptual supersonic aircraft and identifies factors that could significantly affect the concept’s Landing and Takeoff noise (LTO) noise. Since robustness is a key consideration in the design and analysis of complex aerospace systems, UQ will continue to play a substantial role in the design and analyze of sustainable aviation system.
3.5. Pattern Discovery
Pattern discovery (or knowledge discovery) is a term commonly seen in data mining. A pattern generally refers to some useful information in the data that can guide action or decision-making. Some simple patterns include total, ratio, correlation, variation, etc. Examples of the (slightly) more complex patterns include emerging trend, receding signal, alternating behaviour, and spatiotemporal variation. Statistical and machine learning methods provide techniques to discover patterns from data. The following types of non-chaotic patterns can be found in data:
Descriptive patterns: The identification of these patterns usually do not involve advanced algorithms. They are obtained through descriptive statistics or sometimes the direct results of data collection.
Associative patterns: These patterns are mainly about co-occurring phenomena. A typical statement of associative pattern is: “If A happens, then B is also likely to happen”.
Periodic patterns: These patterns repeat themselves with a specific period, which can be found in time series data, sequence data, and spatiotemporal data.
Structural patterns: These patterns are extracted summary information represented in terms of a structure that can be reasoned about. There are different structural forms such as graphs, trees, sets, clusters, etc.
Abnormal patterns: A substantial divergence from normal behaviour is considered abnormal. These abnormalities could be signals of risk or opportunities for novel discoveries.
In aviation environmental impact analysis, the discovered patterns on aircraft fuel burn, emissions, and noise can provide insights for aviation and environmental analysts to make decisions and plans for mitigating aviation’s environmental impact and achieving sustainable air traffic growth. Some patterns can be directly discovered by analyzing existing datasets on aviation environmental impact. Most of the time, however, the dataset for a target study is not available. For example, if a researcher wants to obtain the quantity and distribution of a certain emission type over a continent, it would be impractical to obtain such measurements via sensors and instruments. In such cases, data-driven flight simulation become a key enabler for computation and pattern discovery. Data-driven flight simulation utilizes real-world flight operations data, such as ADS-B, and “flies” the aircraft in an computational environment. The aircraft furn burn, emissions, and noise are computed using aircraft performance models, such as Base of Aircraft Data (BADA), and noise models. Since the real-world flight data reflects how aircraft operate in time and space, with reliable performance and noise models it is possible to obtain decent approximations of the real-world situations. The estimations resulting from data-driven flight simulations are then ready to be analyzed by statistical and machine learning methods to discover useful patterns.
A summary of representative papers in pattern discovery is given in
Table 6. Many selected papers under this theme also encompass elements from efficient computation and predictive modeling. One thing the papers in
Table 6 have in common is a strong emphasis on the actual findings of the study. Data-driven flight simulation is widely applied in pattern discovery for aviation environmental impact. In one of the pioneering works, Reference [
82] develops an aviation emission inventory and discovers the disparity of CO
concentration in different parts of Australia. The authors of [
83] use flight track data and fast noise approximation model to observe the variability in noise patterns on evolving airport runway configuration at Boston Logan International Airport (KBOS). The authors of [
84] use ADS-B data and OpenAP emission models to obtain cruise-level flight emissions for different airlines, geographic regions, altitudes, and timeframe. The authors of [
85] employ ADS-B and flight performance model to study aviation emissions at altitude and finds out that NO
and water vapour emissions concentrate around tropospheric altitudes only for long-range flights. The authors of [
86] use similar approach to analyze fuel burn and emissions for a network of short-haul commuter flights in Europe. Through analyzing fuel burn and emissions as function of distance, altitude, city pair, the conclusion is that flight range is the most significant discriminator in emissions. The authors of [
87,
88] extend such simulations to global-scale. Together with a clustering step, Reference [
87] studies the transport patterns and climate impacts of aviation-emitted NO
and highlights the spatially and temporally heterogeneous nature of the NO
–O
chemistry in different regions and seasons around the globe. The authors of [
88] estimate global emissions from aircraft operations between 2017–2020 and quantifies the impact from COVID-19. Deep learning is a powerful tool in finding aircraft emissions patterns in a more complex setting. The authors of [
89] apply Convolutional Neural Network (CNN) on satellite images to detect aircraft contrails—a contributor of climate warming effect. The project estimates that contrails cover an average of 0.55% of the contiguous U.S. and discovers detailed patterns of contrail coverage. The above findings are key information for people to understand the status and patterns of regional and global aviation environmental impact. With continued advancements in data quantity, aircraft performance models, and analytical techniques, such data-driven approaches can make even better contributions to sustainable aviation.
3.6. Verification and Validation
Verification and validation (V&V) are evaluation procedures throughout the development phase to assess whether a system, product, or process meets the requirements and specifications that are initially set in the proposal. V&V are an integral part of the systems engineering processes to ensure the success of a project. Sometimes such procedures need to be executed by a disinterested third party and are referred to as Independent Verification and validation (IV&V). Verification is the procedure of comparing the solution to the requirements. Verification uses examination, demonstration, analysis, and testing to answer the query “are you building it correctly?”. A verification procedure takes as input a system/product/process
and the requirements
Q, and returns whether
is satisfactory (all behaviors of
meet
Q) or unsatisfactory (at least one behavior of
violates
Q). Data-driven verification is a novel research area that combines numerical simulation with sensitivity analysis to provide bounds on how much the states of a system/product/process can change in a non-deterministic setting [
90]. In contrast, validation is the procedure of checking whether a system/product/process meets the needs of the user and other stakeholders. Validation involves review, demonstration, and testing to answer the query “are you building the correct thing?”. Validation is of vital importance because the cost of fixing a user requirement error is very higher—usually much higher than fixing an implementation error.
V&V has become an essential part in the development of a complex model or software, especially for a field that is safety-critical in nature. Because of the complexities in modeling the environmental impact of aircraft and air transportation system, relevant computational tools are complex and multi-module systems as well. The computational models for aviation environmental impact could leverage data processing, flight simulation, aircraft performance models, emissions models, noise models, large aircraft databases, Geographic Information System (GIS), and extensive system databases cover airports, airspace, and fleet information for accurate modeling. Therefore, it is indispensable to conduct V&V in all levels of the system to make sure that the environment functions properly.
A summary of representative papers in V&V is given in
Table 7. Enabled by data-driven simulation and statistical analysis, two common practices are seen in these works: (1) comparing the predictions between different models, and (2) comparing the model predictions with real-world measurements. The results of V&V can guide actions to further enhance the analysis capabilities. Among these works, Reference [
91] performs a V&V study on AEDT’s emission inventory and air quality modeling capability and investigates causes behind the deviation between AEDT and the legacy tool Emissions and Dispersion Modeling System (EDMS). Still on AEDT, Reference [
92] provides a structured and repeatable framework for validating AEDT’s noise model using detailed airline flight data records, weather data, and noise monitoring data from stations around airport. The authors of [
93] compare thousands of the actual single flight noise exposure measurements with predictions from three noise models: AEDT, FLULA2, and sonAIR. To understand a helicopter noise prediction system’s limitations, Reference [
94] compares its Sound Exposure Level (SEL) noise contours with the acoustic flight test data for a range of flight conditions. The authors of [
95] conduct a validation for an integrated aircraft environmental simulation software’s acoustic and engine exhaust emissions modules using the microphone field measurements at Manchester airport for a range of aircraft types. The authors of [
96] compare predictions from the “Dutch aircraft noise model” to measured values from the NOise MOnitoring System (NOMOS) around Amsterdam Airport Schiphol between 2012 and 2018 and observes how the model accuracy has changed overtime. The authors of [
97] conduct a sensitivity analysis on semi-empirical noise models and compares the predictions to flyover measurements of A320, A330, and B777. The authors of [
98] present a validation methodology for the noise impact of delayed deceleration approach, a new procedure, using ground-noise-monitor measurements and radar data for several aircraft types. Most of these studies confirm that the aviation environmental impact models can achieve satisfactory accuracy on their predictions. Some works also identify reasons behind the mismatch and modify the models accordingly to obtain better agreement between modeled and measured values.
3.7. Infrastructure and Tools
The research outcomes from all the previous themes have direct impacts on the methodology and/or actual findings of aviation environmental impact analysis. This theme devoted to infrastructure and tools is special because the relevant efforts may not lead to immediate breakthroughs on the more efficient and accurate models of aviation environmental impact. Instead, they lay the foundations for data-driven researches and make them happen. Undeniably, the efforts on building infrastructure and tools to collect, integrate, clean, and process data (the majority of the “data engineering” block in
Figure 3) are an indispensable part of the ecosystem and have notably streamlined data-driven analysis in aviation.
A summary of representative papers in infrastructure and tools is given in
Table 8. Different types of works under this theme can be classified into: (1) hardware system, (2) data repository, and (3) data integration and pre-processing tools. Even these infrastructures and tools are built for aviation researchers and data scientists to perform more complex analyses, such as machine learning tasks, most of them are also capable of preliminary data analysis and data visualization. On the hardware design side, Reference [
99] presents the system architecture, design, and capabilities of a modern hardware/software infrastructure called the Metroplex Overflight Noise Analysis (MONA). MONA is a system to measure, analyze, and archive the ground noise data from aircraft overflights for a variety of purposes, such as V&V of improved noise prediction methods. It also has a strong data visualization capability. The authors of [
100] propose DV8—an interactive data visualization framework which provides visualized aviation-oriented insights for capacity planning, flight route prediction, and fuel consumption. Data repository is another crucial part of the infrastructure. Threaded Track [
101] integrates radar trajectory data from a variety of surveillance sources to produce an optimal representation of an aircraft’s end to end trajectory. Since its inception, Threaded Track has facilitated data-driven analyses for aviation safety and environmental impact. WRAP [
102] is an open-source database which includes extracted full-flight aircraft performance parameters from large scale open ADS-B data. Apart from the aircraft performance parameters, WRAP also provides the first set of open parametric performance models for common aircraft types. Flight DNA [
103] is one of the latest aviation data repositories. It is a common database with anonymized data on aviation components, systems, technologies, and operations. On the data pre-processing tools, there has been a significant trend to convert them into open-source libraries for popular programming languages such as Python and R. traffic [
104] is a Python toolbox for pre-processing and analyzing aircraft trajectories data so that they are better prepared for statistical modeling and machine learning. pyModeS [
105] is another open-source library in Python. The focus of pyModeS is to decode the Mode-S Comm-B replies and provide researchers broader access to accurate aircraft state updates that are transmitted via Enhanced Mode-S. openSkies [
106] is the first R package for processing public air traffic data. It has an interface to resources in the OpenSky Network, standardized data structures, and functionalities to analyze and visualize data. In the future, continued development of infrastructures and tools for aviation data analytics is a key to promoting data-driven transformation for mitigating aviation environmental impact.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





