
Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns




Abstract
:1. Introduction and Background
2. Literature Review
3. Methodology
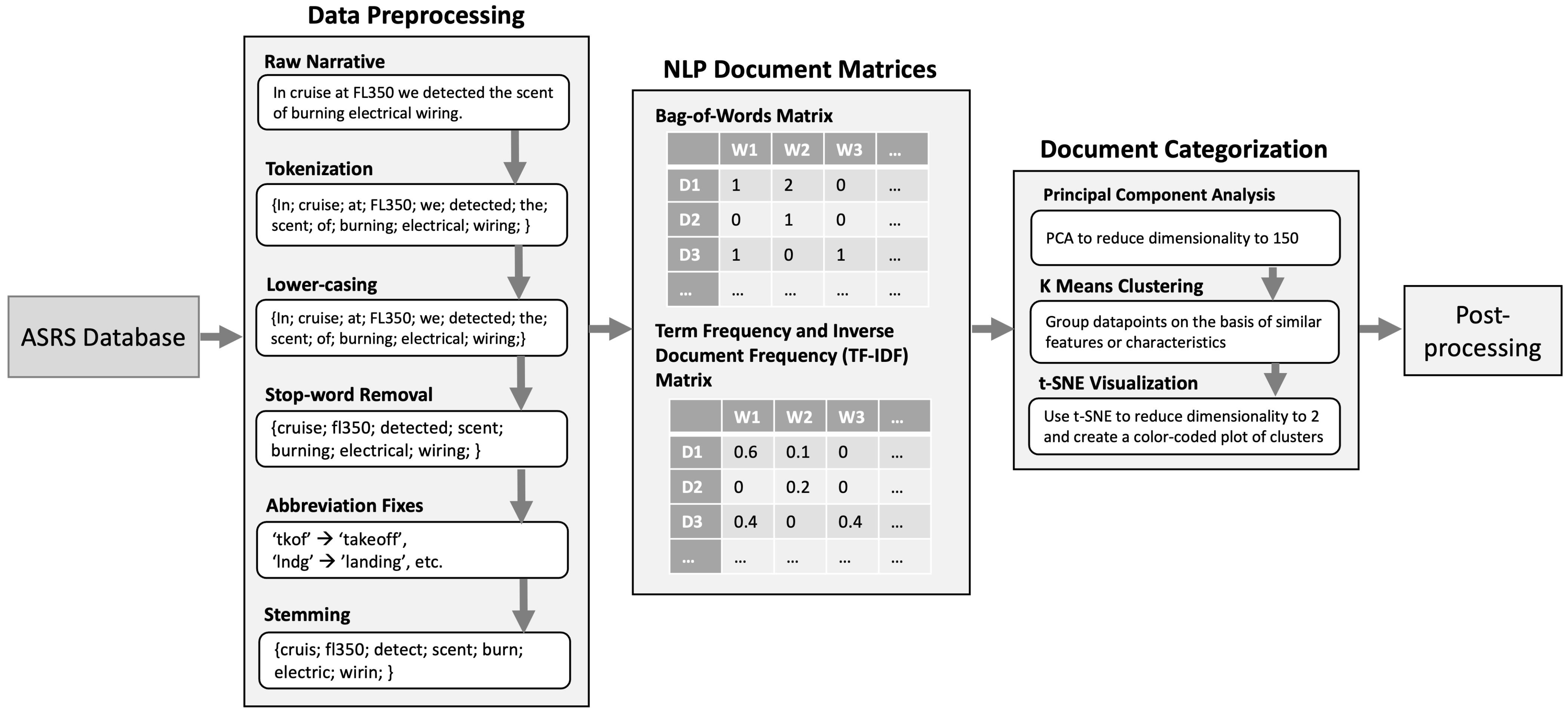
3.1. Data Preprocessing
3.2. Natural Language Processing
3.3. Clustering
3.4. Observations
4. Results
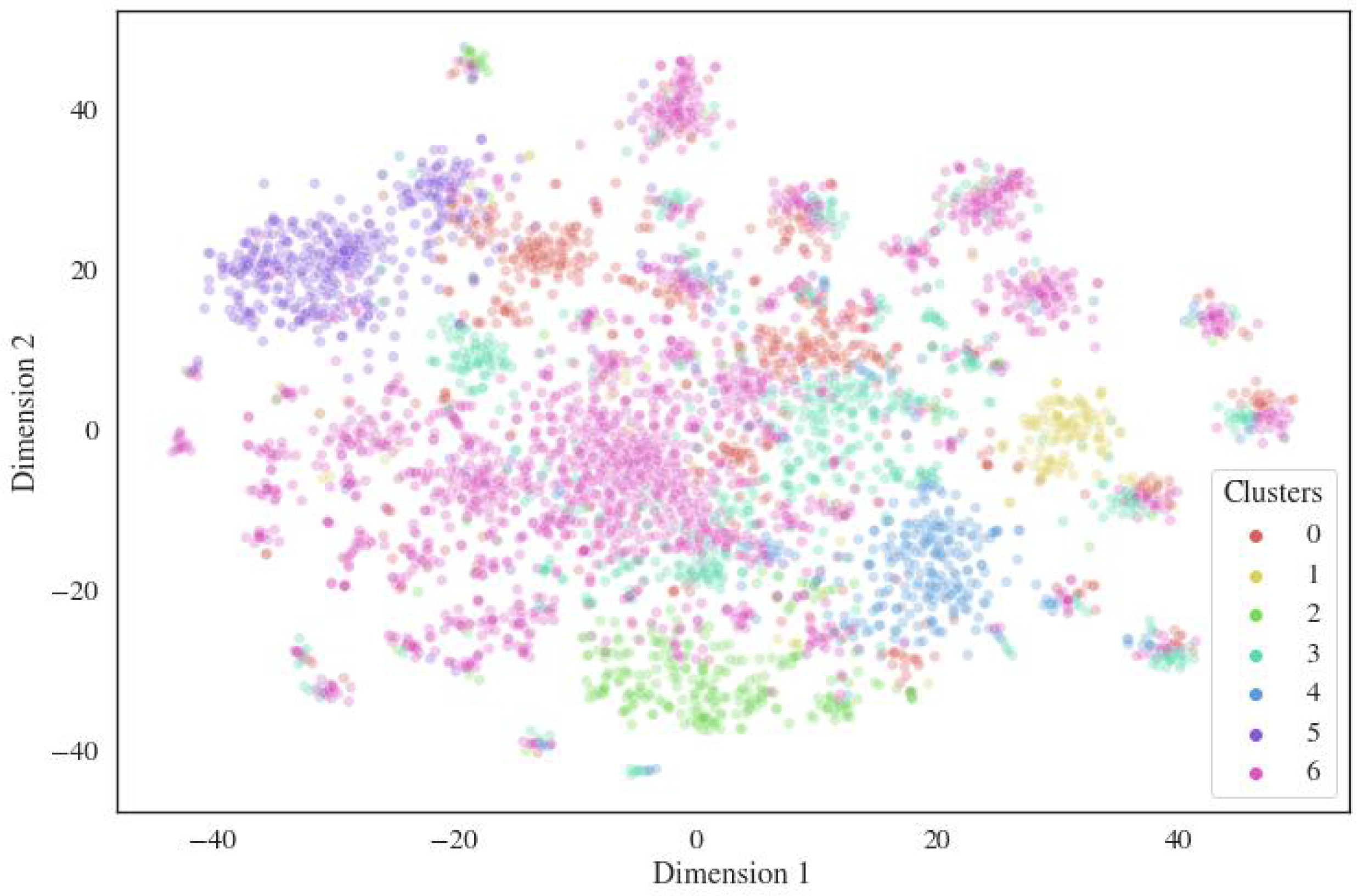
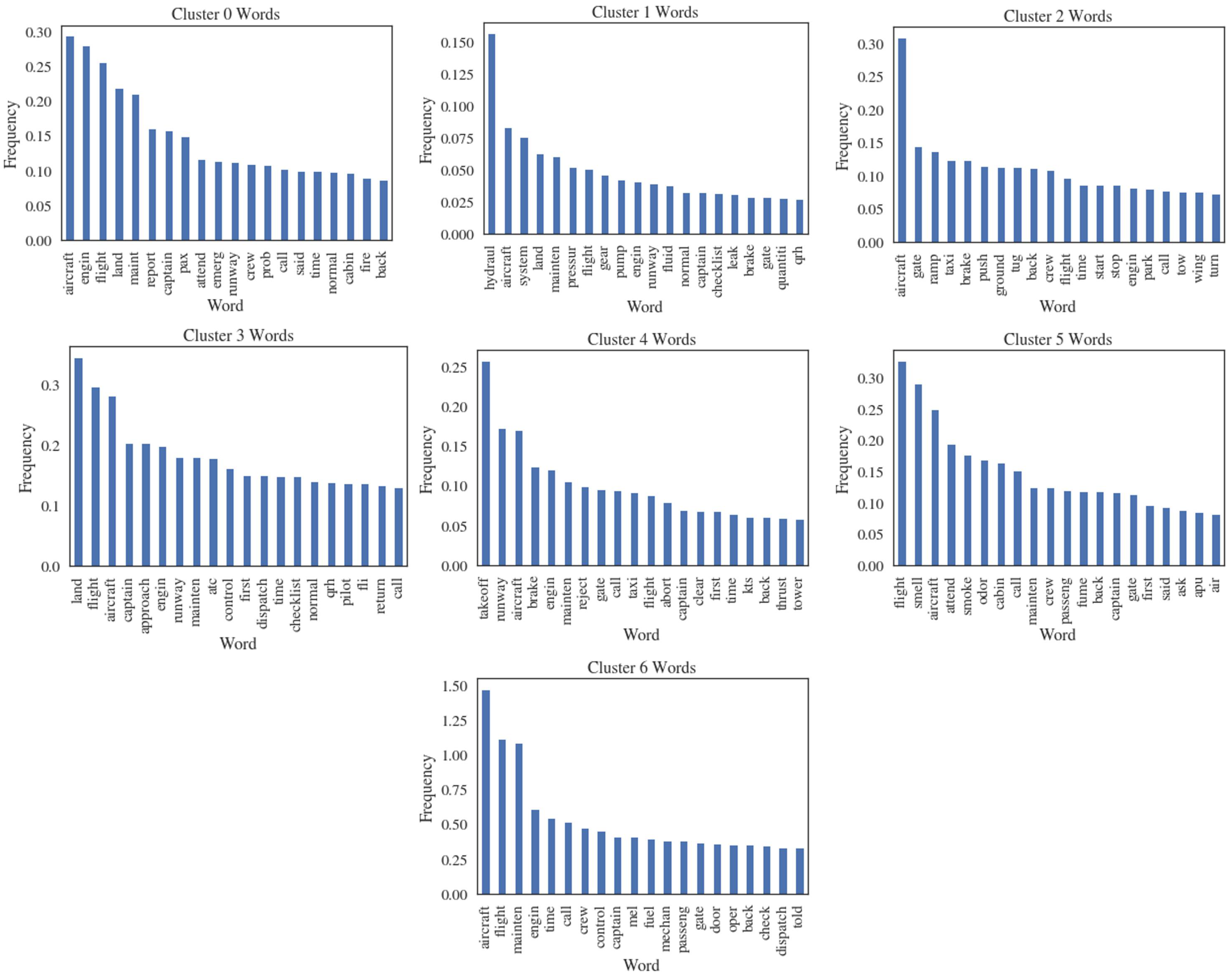
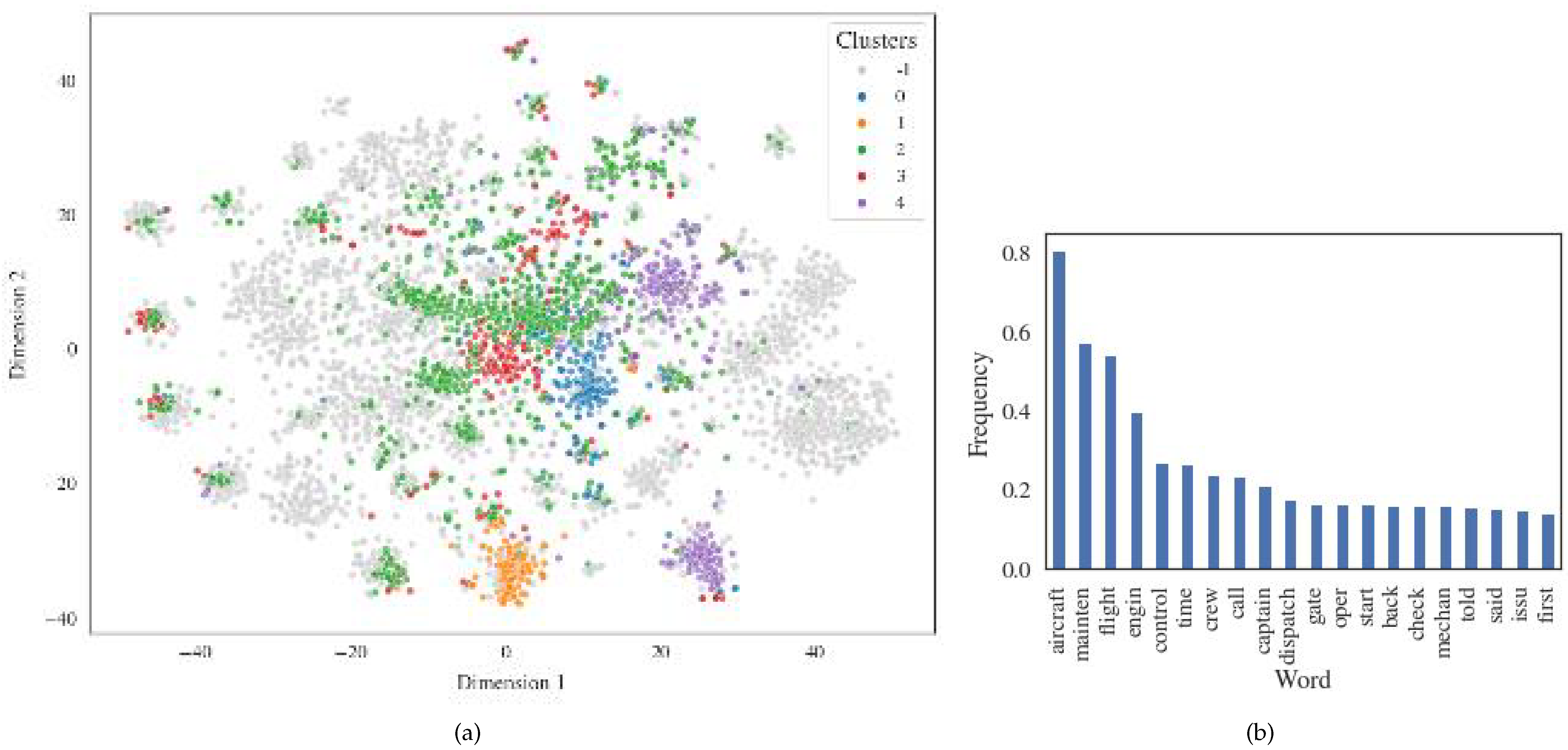
4.1. Overall Clustering
- 0.
- Engine;
- 1.
- Hydraulics;
- 2.
- Taxi/Pushback;
- 3.
- Landing/Approach;
- 4.
- Takeoff;
- 5.
- Cabin odor;
- 6.
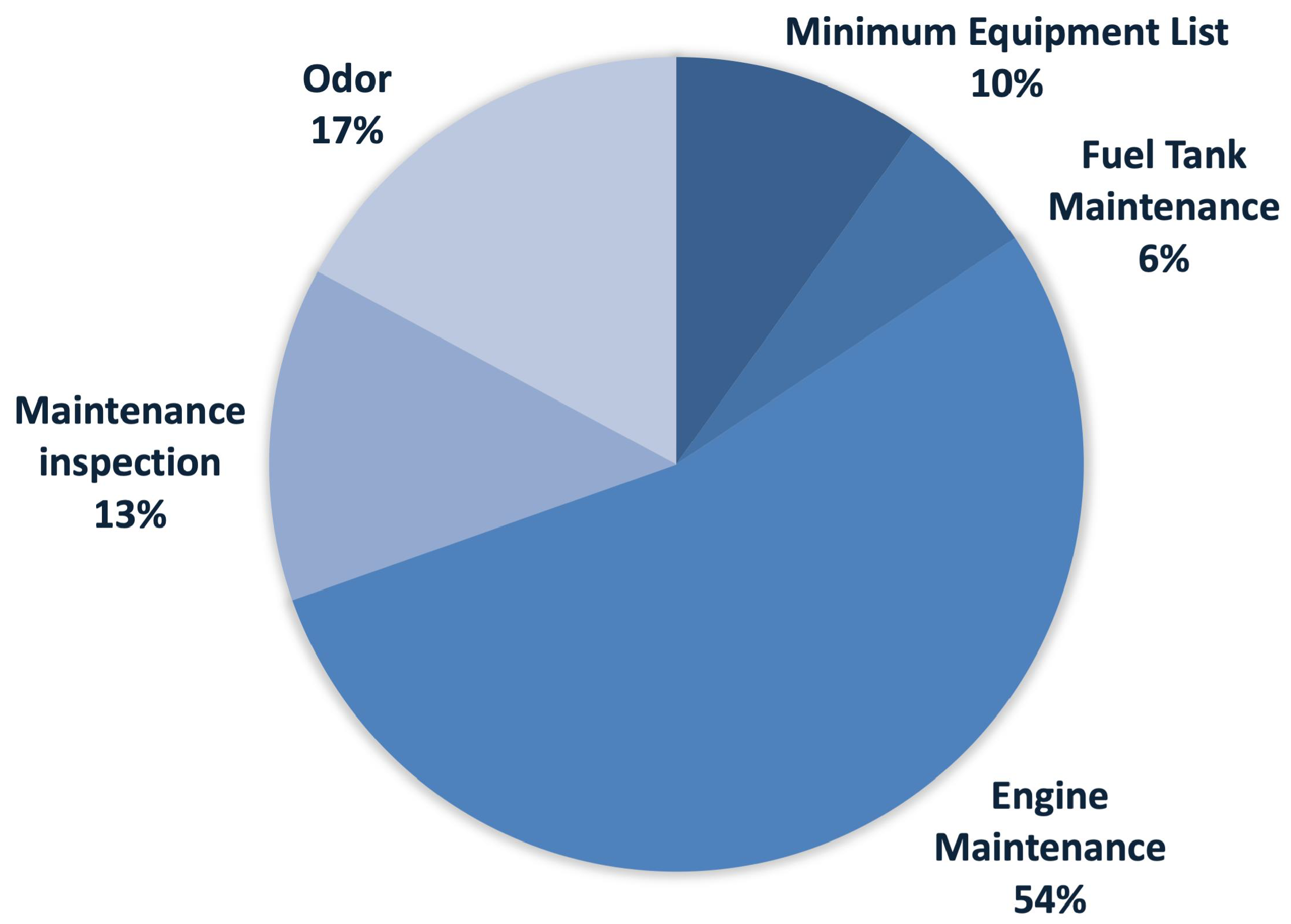
- Maintenance.
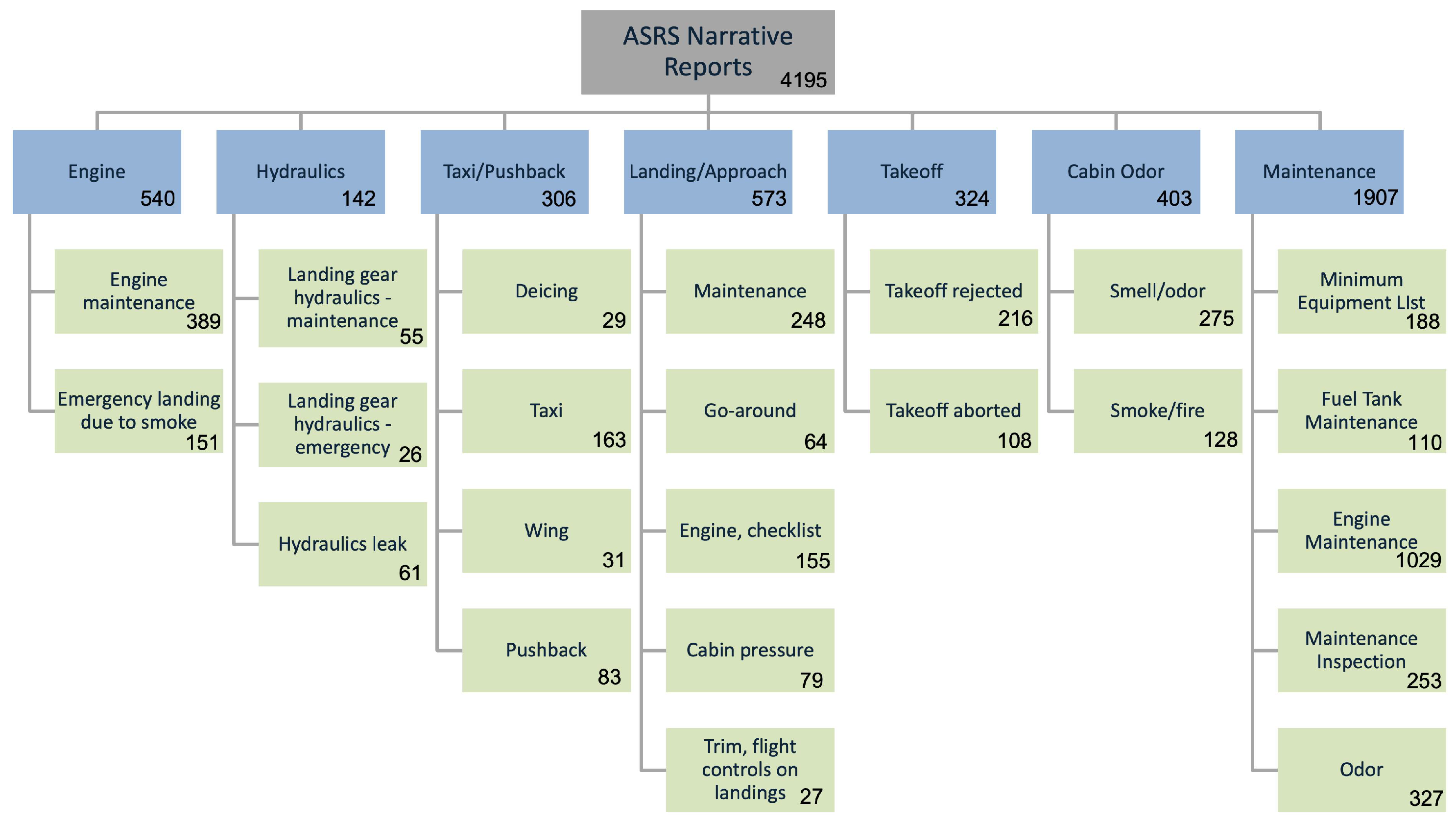
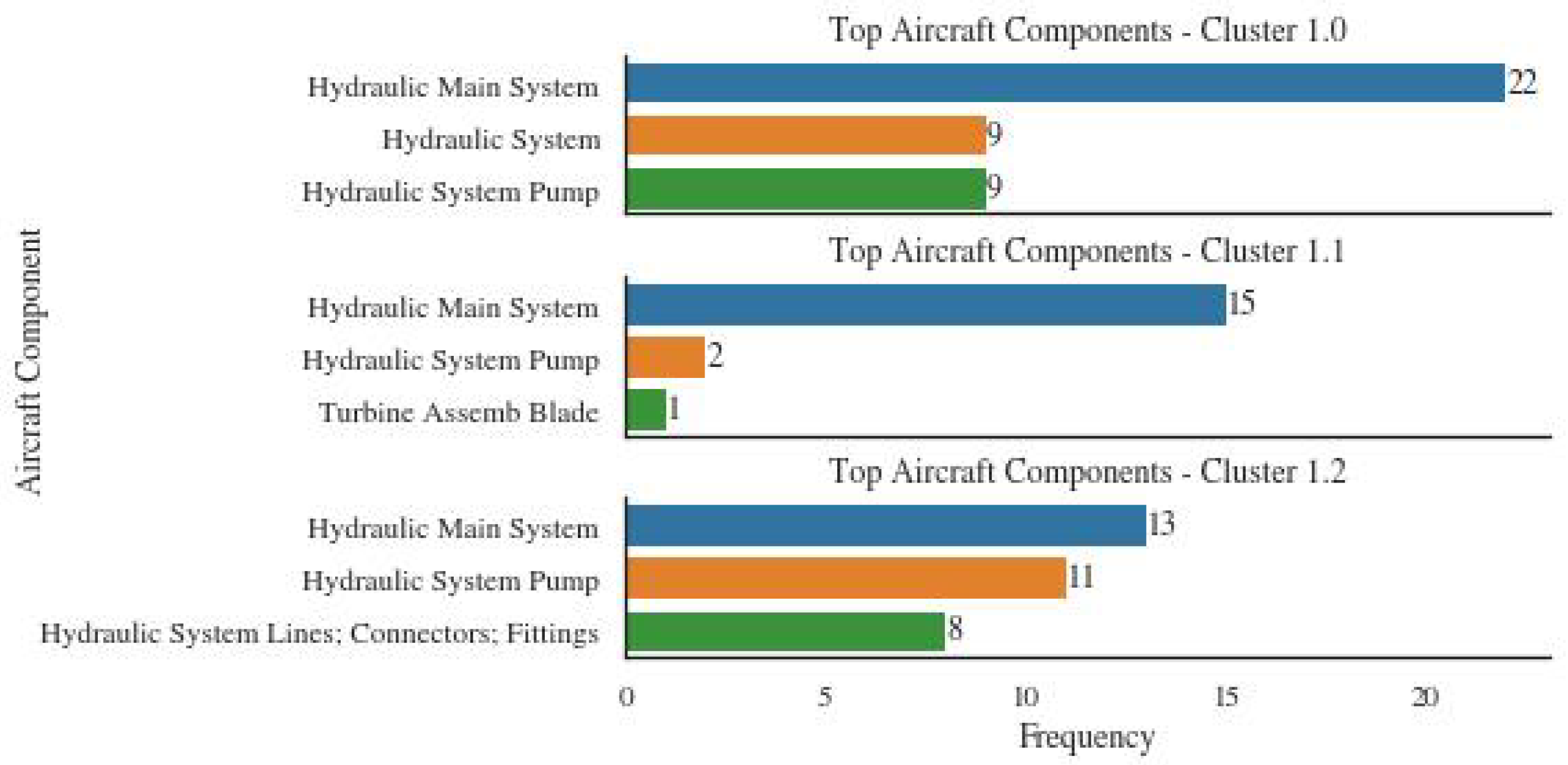
4.2. Sub-Clustering
4.3. Correlation of Clustering Results to Metadata
4.4. Comparison to Insights from Quantitative Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aircraft Technology Roadmap to 2050; Report; IATA: Montreal, QC, Canada, 2020.
- Effects of Novel Coronavirus (COVID-19) on Civil Aviation: Economic Impact Analysis; Report; ICAO: Montreal, QC, Canada, 2020.
- Destination 2050—A Route to Net Zero European Aviation; Report NLR-CR-2020-510; NLR—Royal Netherlands Aerospace Centre and SEO Amsterdam Economics: Amsterdam, The Netherlands, 2021.
- Bendarkar, M.V.; Rajaram, D.; Cai, Y.; Mavris, D.N. Optimal Paths for Progressive Aircraft Subsystem Electrification in Early Design. J. Aircr. 2022, 59, 219–232. [Google Scholar] [CrossRef]
- Jones, R. The More Electric Aircraft: The past and the future? In Proceedings of the IEE Colloquium on Electrical Machines and Systems for the More Electric Aircraft, London, UK, 9 November 1999; pp. 1–4. [Google Scholar]
- Antcliff, K.R.; Capristan, F.M. Conceptual Design of the Parallel Electric-Gas Architecture with Synergistic Utilization Scheme (PEGASUS) Concept. In Proceedings of the 18th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Denver, CO, USA, 5–9 June 2017. [Google Scholar] [CrossRef]
- Cinar, G.; Cai, Y.; Bendarkar, M.V.; Burrell, A.I.; Denney, R.K.; Mavris, D.N. System Analysis and Design Space Exploration of Regional Aircraft with Electrified Powertrains. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022. [Google Scholar] [CrossRef]
- Bills, A.; Sripad, S.; Fredericks, W.L.; Singh, M.; Viswanathan, V. Performance Metrics Required of Next-Generation Batteries to Electrify Commercial Aircraft. ACS Energy Lett. 2020, 5, 663–668. [Google Scholar] [CrossRef]
- Bendarkar, M.V.; Sarojini, D.; Mavris, D.N. Off-Nominal Performance and Reliability of Novel Aircraft Concepts during Early Design. J. Aircr. 2022, 59, 400–414. [Google Scholar] [CrossRef]
- Papathakis, K.V.; Burkhardt, P.A.; Ehmann, D.W.; Sessions, A.M. Safety Considerations for Electric, Hybrid-Electric, and Turbo-Electric Distributed Propulsion Aircraft Testbeds. In Proceedings of the 53rd AIAA/SAE/ASEE Joint Propulsion Conference, Atlanta, GA, USA, 10–12 July 2017. [Google Scholar] [CrossRef]
- Aviation and Climate Change: Aircraft Emissions Expected to Grow, but Technological and Operational Improvements and Government Policies Can Help Control Emissions, Report to Congressional Committees, GAO-09-554; Report; US Government Accountability Office: Washington, DC, USA, 2009.
- Ball, M.; Barnhart, C.; Dresner, M.; Hansen, M.; Neels, K.; Odoni, A.; Peterson, E.; Sherry, L.; Trani, A.; Zou, B. Total Delay Impact Study: A Comprehensive Assessment of the Costs and Impacts of Flight Delay in the United States. Available online: https://rosap.ntl.bts.gov/view/dot/6234 (accessed on 16 June 2022).
- Basora, L.; Olive, X.; Dubot, T. Recent Advances in Anomaly Detection Methods Applied to Aviation. Aerospace 2019, 6, 117. [Google Scholar] [CrossRef]
- Gavrilovski, A.; Jimenez, H.; Mavris, D.N.; Rao, A.H.; Shin, S.; Hwang, I.; Marais, K. Challenges and Opportunities in Flight Data Mining: A Review of the State of the Art. In Proceedings of the AIAA Infotech @ Aerospace, San Diego, CA, USA, 4–8 January 2016; Available online: https://arc.aiaa.org/doi/pdf/10.2514/6.2016-0923 (accessed on 16 June 2022). [CrossRef]
- Madeira, T.; Melício, R.; Valério, D.; Santos, L. Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Belcastro, L.; Marozzo, F.; Talia, D.; Trunfio, P. Using scalable data mining for predicting flight delays. ACM Trans. Intell. Syst. Technol. TIST 2016, 8, 1–20. [Google Scholar] [CrossRef]
- Mueller, E.; Chatterji, G. Analysis of Aircraft Arrival and Departure Delay Characteristics. In Proceedings of the AIAA’s Aircraft Technology, Integration, and Operations (ATIO) 2002 Technical Forum, Los Angeles, CA, USA, 1–3 October 2002. [Google Scholar] [CrossRef]
- Allan, S.; Beesley, J.; Evans, J.; Gaddy, S. Analysis of delay causality at Newark International Airport. In Proceedings of the 4th USA/Europe Air Traffic Management R&D Seminar, Santa Fe, NM, USA, 3–7 December 2001; pp. 1–11. [Google Scholar]
- Zámková, M.; Prokop, M.; Stolín, R. Factors influencing flight delays of a European airline. Acta Univ. Agric. Silvic. Mendel. Brun. 2017, 65, 1799–1807. [Google Scholar] [CrossRef]
- All-Causes Delay and Cancellations to Air Transport in Europe for 2019; Report CDA_2019_004; Eurocontrol: Brussels, Belgium, 2020.
- All-Causes Delay and Cancellations to Air Transport in Europe for 2021; Report CDA_2021_04; Eurocontrol: Brussels, Belgium, 2022.
- Gui, G.; Liu, F.; Sun, J.; Yang, J.; Zhou, Z.; Zhao, D. Flight delay prediction based on aviation big data and machine learning. IEEE Trans. Veh. Technol. 2019, 69, 140–150. [Google Scholar] [CrossRef]
- Eltoukhy, A.E.; Wang, Z.; Chan, F.T.; Chung, S.H.; Ma, H.L.; Wang, X. Robust aircraft maintenance routing problem using a turn-around time reduction approach. IEEE Trans. Syst. Man Cybern. Syst. 2019, 50, 4919–4932. [Google Scholar] [CrossRef]
- Balakrishnan, H.; Clarke, J.P.; Feron, E.M.; Hansman, R.J.; Jimenez, H. Challenges in Aerospace Decision and Control: Air Transportation Systems. In Advances in Control System Technology for Aerospace Applications; Feron, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 109–136. [Google Scholar] [CrossRef]
- Papakostas, N.; Papachatzakis, P.; Xanthakis, V.; Mourtzis, D.; Chryssolouris, G. An approach to operational aircraft maintenance planning. Decis. Support Syst. 2010, 48, 604–612. [Google Scholar] [CrossRef]
- Mofokeng, T.J.; Marnewick, A. Factors contributing to delays regarding aircraft during A-check maintenance. In Proceedings of the 2017 IEEE Technology & Engineering Management Conference (Temscon), Santa Clara, CA, USA, 8–10 June 2017; IEEE: Santa Clara, CA, USA, 2017; pp. 185–190. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.A.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K.J. A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques. arXiv 2017, arXiv:1707.02919. [Google Scholar]
- Singh, V.K.; Tiwari, N.; Garg, S. Document Clustering Using K-Means, Heuristic K-Means and Fuzzy C-Means. In Proceedings of the 2011 International Conference on Computational Intelligence and Communication Networks, Washington, DC, USA, 7–9 October 2011; pp. 297–301. [Google Scholar] [CrossRef]
- Khan, R.; Qian, Y.; Naeem, S. Extractive based text summarization using k-means and tf-idf. Int. J. Inf. Eng. Electron. Bus. 2019, 11, 33. [Google Scholar]
- Gowtham, S.; Goswami, M.; Balachandran, K.; Purkayastha, B.S. An Approach for Document Pre-processing and K Means Algorithm Implementation. In Proceedings of the 2014 Fourth International Conference on Advances in Computing and Communications, Kochi, India, 27–29 August 2014; pp. 162–166. [Google Scholar] [CrossRef]
- Tanguy, L.; Tulechki, N.; Urieli, A.; Hermann, E.; Raynal, C. Natural language processing for aviation safety reports: From classification to interactive analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar] [CrossRef]
- Robinson, S. Temporal topic modeling applied to aviation safety reports: A subject matter expert review. Saf. Sci. 2019, 116, 275–286. [Google Scholar] [CrossRef]
- Subramanian, S.V.; Rao, A.H. Deep-learning based Time Series Forecasting of Go-around Incidents in the National Airspace System. In Proceedings of the 2018 AIAA Modeling and Simulation Technologies Conference, Atlanta, GA, USA, 25–29 June 2018. [Google Scholar] [CrossRef]
- El Ghaoui, L.; Li, G.C.; Duong, V.A.; Pham, V.; Srivastava, A.N.; Bhaduri, K. Sparse machine learning methods for understanding large text corpora. In Proceedings of the CIDU, Mountain View, CA, USA, 19–21 October 2011; pp. 159–173. [Google Scholar]
- Kierszbaum, S.; Lapasset, L. Applying Distilled BERT for Question Answering on ASRS Reports. In Proceedings of the 2020 New Trends in Civil Aviation (NTCA), Prague, Czech Republic, 23–24 November 2020; pp. 33–38. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rose, R.L.; Puranik, T.G.; Mavris, D.N. Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace 2020, 7, 143. [Google Scholar] [CrossRef]
- Ringnér, M. What is principal component analysis? Nat. Biotechnol. 2008, 26, 303–304. [Google Scholar] [CrossRef] [PubMed]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Devassy, B.M.; George, S. Dimensionality reduction and visualisation of hyperspectral ink data using t-SNE. Forensic Sci. Int. 2020, 311, 110194. [Google Scholar] [CrossRef] [PubMed]
- Kauffmann, J.; Esders, M.; Montavon, G.; Samek, W.; Müller, K.R. From clustering to cluster explanations via neural networks. arXiv 2019, arXiv:1906.07633. [Google Scholar] [CrossRef] [PubMed]
- Bureau of Transportation Statistics, U.D.o.T. On-Time Performance—Reporting Operating Carrier Flight Delays at a Glance. Available online: https://www.bts.gov/ (accessed on 16 June 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Word |
|---|---|
| acft | aircraft |
| eng | engine |
| flt | flight |
| rptr | reporter |
| capt | captain |
| lndg | landing |
| rwy | runway |
| emer | emergency |
| kt | knot |
| tkof | takeoff |
| gnd | ground |
| apch | approach |
| chk | check |
| pwr | power |
| evac | evacuation |
| hyd | hydraulic |
| mech | mechanic |
| Cluster | Topic | Top Aircraft Component |
|---|---|---|
| 0 | Engine | Turbine Engine |
| 1 | Hydraulics | Hydraulic Main System |
| 2 | Taxi/Pushback | Nosewheel Steering |
| 3 | Landing/Approach | Turbine Engine |
| 4 | Takeoff | Turbine Engine |
| 5 | Cabin Odor | Air Conditioning and Pressurization Pack |
| 6 | Maintenance | Turbine engine |
| Keyword | Cluster–Subcluster Topic with Most Frequent Use of Keyword | Cluster–Subcluster Topic with Second Most Frequent Use of Keyword |
|---|---|---|
| Inspect | Maintenance–Maintenance Inspection | Taxi/Pushback–Deicing |
| Mechan | Maintenance–Minimum Equipment List | Hydraulics leak |
| Mainten | Maintenance–Minimum Equipment List | Hydraulics leak |
| Spare | Term not used in dataset | |
| Wait | Taxi/Pushback–Deicing | Maintenance–Odor |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miyamoto, A.; Bendarkar, M.V.; Mavris, D.N. Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace 2022, 9, 450. https://doi.org/10.3390/aerospace9080450
Miyamoto A, Bendarkar MV, Mavris DN. Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace. 2022; 9(8):450. https://doi.org/10.3390/aerospace9080450
Chicago/Turabian StyleMiyamoto, Ayaka, Mayank V. Bendarkar, and Dimitri N. Mavris. 2022. "Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns" Aerospace 9, no. 8: 450. https://doi.org/10.3390/aerospace9080450
APA StyleMiyamoto, A., Bendarkar, M. V., & Mavris, D. N. (2022). Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace, 9(8), 450. https://doi.org/10.3390/aerospace9080450