
Fall Detection Using Multi-Property Spatiotemporal Autoencoders in Maritime Environments

 ,
, 
Abstract
:1. Introduction
2. Related Work
Our Contribution
3. System Architecture
Learning Architecture
4. Experimental Evaluation
4.1. Dataset Description
4.2. Experimental Setup—Model’s Training
4.3. Experimental Results
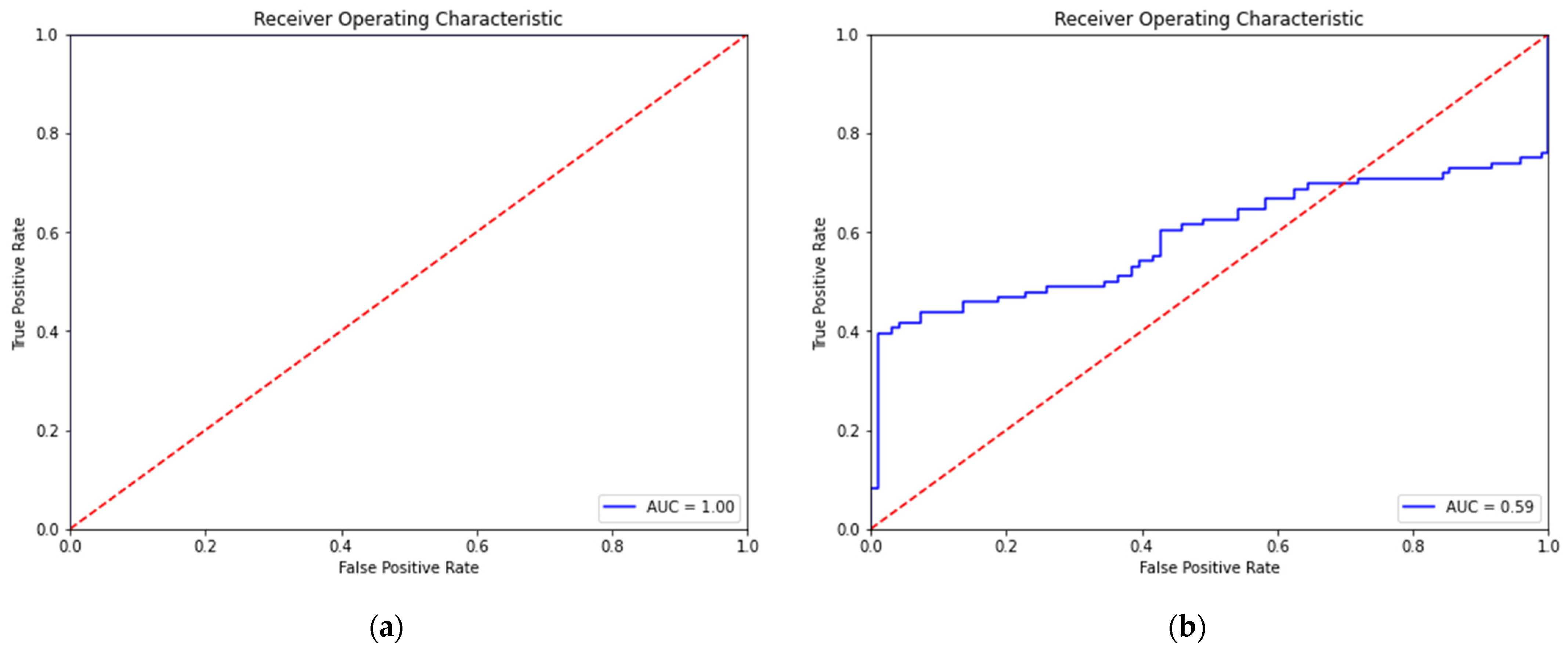
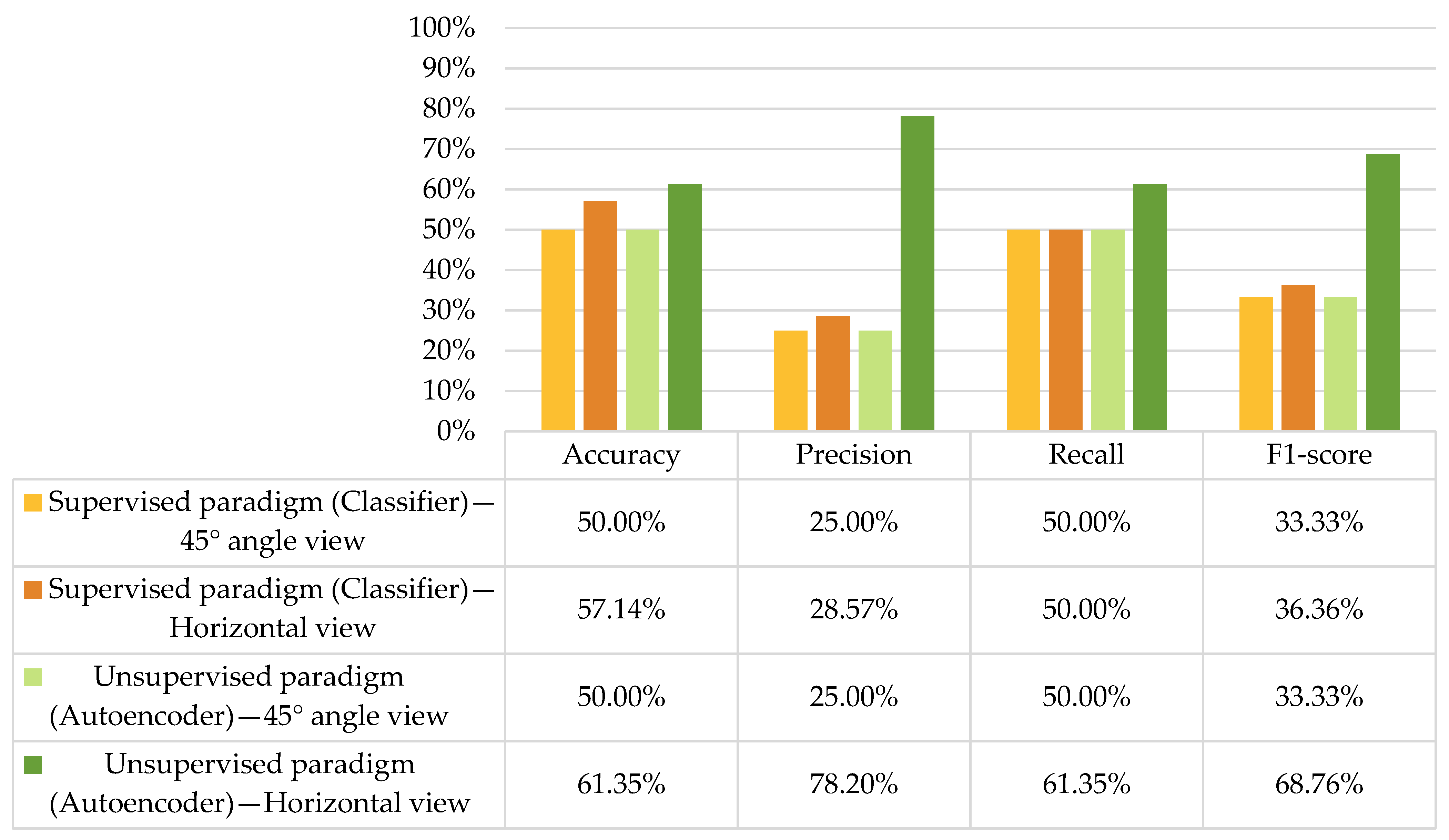
4.3.1. Performance of the Single Autoencoder with Data from Different Camera Angles
4.3.2. Performance of the Comparative Deep Learning Techniques
- Accuracy (), which is the simplest of the four metrics and denotes the percentage of the correctly identified man overboard events in relation to the total amount of video sequences.
- Precision (), which is the percentage of the correct positive detections to the total positive detections that a deep model considers. It is highlighted that a low precision score entails a high number of false alarms.
- Recall (), which is the ratio of the correct positive detections to the total positive events in the ground truth data. It is emphasized that a low recall score implies that the model has a high number of misses.
- F1-score (), which is the harmonic mean of precision () and recall ().
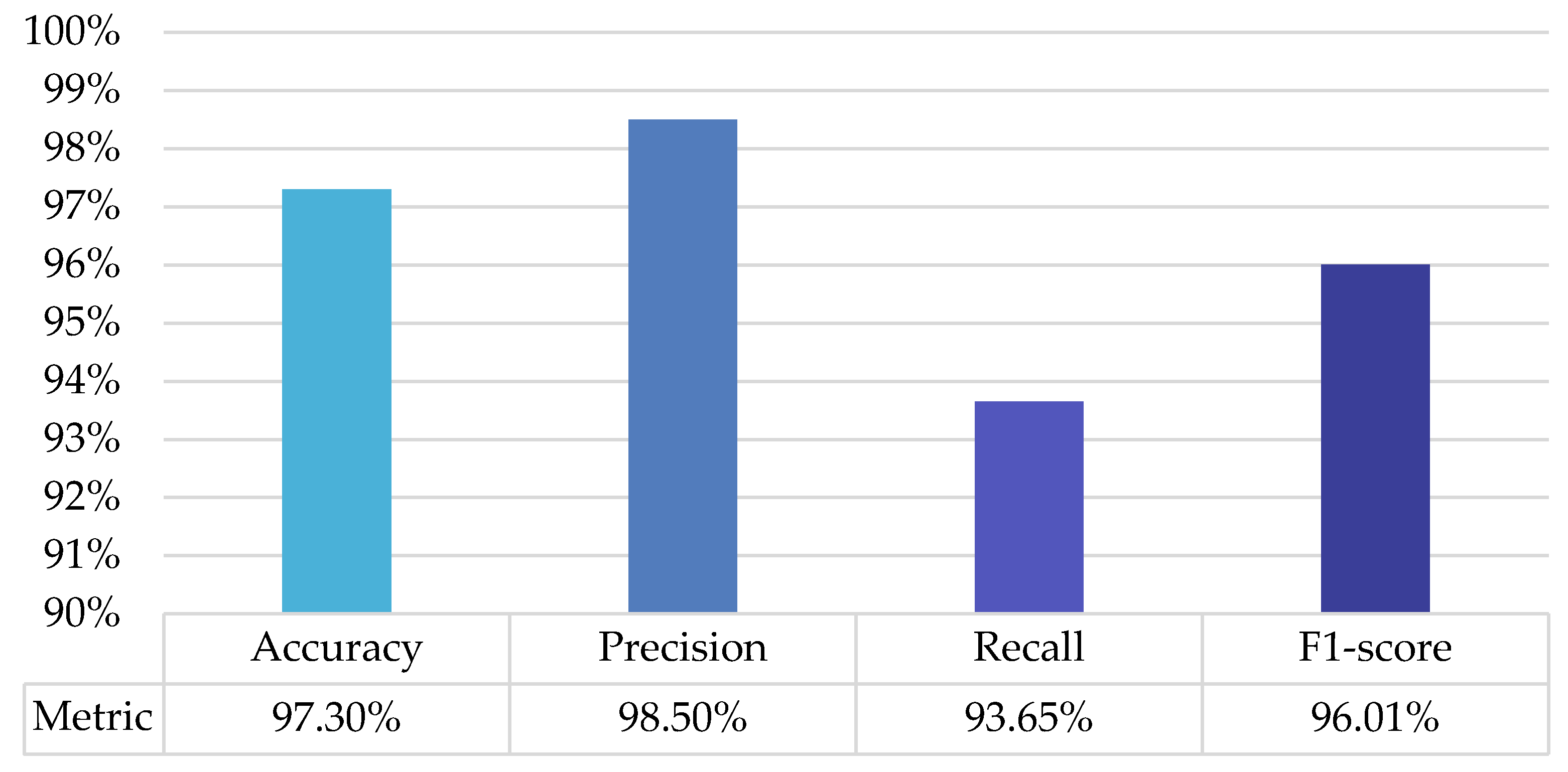
4.3.3. Performance of the Proposed Multi-Property Spatiotemporal Autoencoder
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Örtlund, E.; Larsson, M. Man Overboard Detecting Systems Based on Wireless Technology. Bachelor Thesis, Chalmers University of Technolog, Gothenburg, Sweden, 2018. [Google Scholar]
- Sevïn, A.; Bayilmiş, C.; Ertürk, İ.; Ekïz, H.; Karaca, A. Design and Implementation of a Man-Overboard Emergency Discovery System Based on Wireless Sensor Networks. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 762–773. [Google Scholar] [CrossRef]
- Katsamenis, I.; Protopapadakis, E.; Voulodimos, A.; Dres, D.; Drakoulis, D. Man overboard event detection from RGB and thermal imagery: Possibilities and limitations. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June 2020; ACM: New York, NY, USA, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hennin, S.; Germana, G.; Garcia, L. Integrated Perimeter Security System. In Proceedings of the 2007 IEEE Conference on Technologies for Homeland Security, Woburn, MA, USA, 16–17 May 2007; pp. 70–75. [Google Scholar] [CrossRef]
- Katsamenis, I.; Doulamis, N.; Doulamis, A.; Protopapadakis, E.; Voulodimos, A. Simultaneous Precise Localization and Classification of metal rust defects for robotic-driven maintenance and prefabrication using residual attention U-Net. Autom. Constr. 2022, 137, 104182. [Google Scholar] [CrossRef]
- Katsamenis, I.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Voulodimos, A. Pixel-level corrosion detection on metal constructions by fusion of deep learning semantic and contour segmentation. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 160–169. [Google Scholar] [CrossRef]
- Kwon, D.; Kim, H.; Kim, J.; Suh, S.C.; Kim, I.; Kim, K.J. A Survey of Deep Learning-Based Network Anomaly Detection. Cluster Comput. 2019, 22, 949–961. [Google Scholar] [CrossRef]
- Lalos, C.; Voulodimos, A.; Doulamis, A.; Varvarigou, T. Efficient Tracking Using a Robust Motion Estimation Technique. Multimed. Tools Appl. 2014, 69, 277–292. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular Human Pose Estimation: A Survey of Deep Learning-Based Methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Rallis, I.; Georgoulas, I.; Doulamis, N.; Voulodimos, A.; Terzopoulos, P. Extraction of Key Postures from 3D Human Motion Data for Choreography Summarization. In Proceedings of the 2017 9th International Conference on Virtual Worlds and Games for Serious Applications (VS-Games), Athens, Greece, 6–8 September 2017; pp. 94–101. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C.H. Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Katsamenis, I.; Doulamis, A. Multi-Label Deep Learning Models for Continuous Monitoring of Road Infrastructures. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June 2020; ACM: New York, NY, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Feraru, V.A.; Andersen, R.E.; Boukas, E. Towards an Autonomous UAV-Based System to Assist Search and Rescue Operations in Man Overboard Incidents. In Proceedings of the 2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Abu Dhabi, United Arab Emirates, 4–6 November 2020; pp. 57–64. [Google Scholar] [CrossRef]
- Zhao, Y.; Yin, Y.; Gui, G. Lightweight Deep Learning Based Intelligent Edge Surveillance Techniques. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1146–1154. [Google Scholar] [CrossRef]
- Bakalos, N.; Katsamenis, I.; Voulodimos, A. Man Overboard: Fall Detection Using Spatiotemporal Convolutional Autoencoders in Maritime Environments. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; ACM: New York, NY, USA, 2021; pp. 420–425. [Google Scholar] [CrossRef]
- Bakalos, N.; Katsamenis, I.; Karolou, E.; Doulamis, N. Unsupervised Man Overboard Detection Using Thermal Imagery and Spatiotemporal Autoencoders. In Proceedings of the 1st International Conference on Novelties in Intelligent Digital Systems, Corfu, Greece, 30 September–1 October 2021; ACM: New York, NY, USA, 2021; pp. 256–263. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the Lecture Notes in Computer Science, Espoo, Finland, 14–17 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 52–59. [Google Scholar] [CrossRef] [Green Version]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Spatio-Temporal Convolutional Sparse Auto-Encoder for Sequence Classification. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; British Machine Vision Association: Durham, UK, 2012; Volume 1, p. 12. [Google Scholar] [CrossRef] [Green Version]
- Nogas, J.; Khan, S.S.; Mihailidis, A. DeepFall: Non-Invasive Fall Detection with Deep Spatio-Temporal Convolutional Autoencoders. J. Healthc. Inform. Res. 2020, 4, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, S.A.; Kowsar, M.M.S.; Deb, K. Human Detection Utilizing Adaptive Background Mixture Models and Improved Histogram of Oriented Gradients. ICT Express. 2018, 4, 216–220. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Yeh, M.-C.; Cheng, K.-T.; Avidan, S. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Volume 2 (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1491–1498. [Google Scholar] [CrossRef]
- Gajjar, V.; Khandhediya, Y.; Gurnani, A. Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2805–2809. [Google Scholar] [CrossRef] [Green Version]
- Mikolajczyk, K.; Schmid, C.; Zisserman, A. Human Detection Based on a Probabilistic Assembly of Robust Part Detectors. In Lecture Notes in Computer Science, Prague, Czech Republic, 16 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 69–82. [Google Scholar] [CrossRef] [Green Version]
- Xia, L.; Chen, C.-C.; Aggarwal, J.K. Human Detection Using Depth Information by Kinect. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Tuzel, O.; Porikli, F.; Meer, P. Human Detection via Classification on Riemannian Manifolds. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Ramanan, D. Articulated Human Detection with Flexible Mixtures of Parts. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2878–2890. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zeng, X.; Ouyang, W.; Wang, X. Multi-Stage Contextual Deep Learning for Pedestrian Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 121–128. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X. Joint Deep Learning for Pedestrian Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2056–2063. [Google Scholar] [CrossRef] [Green Version]
- Voulodimos, A.S.; Kosmopoulos, D.I.; Doulamis, N.D.; Varvarigou, T.A. A Top-down Event-Driven Approach for Concurrent Activity Recognition. Multimed. Tools Appl. 2014, 69, 293–311. [Google Scholar] [CrossRef]
- Doulamis, N.D.; Voulodimos, A.S.; Kosmopoulos, D.I.; Varvarigou, T.A. Enhanced Human Behavior Recognition Using HMM and Evaluative Rectification. In Proceedings of the First ACM International Workshop on Analysis and Retrieval of Tracked Events and Motion in Imagery Streams—ARTEMIS ’10, Firenze, Italy, 29 October 2010; ACM Press: New York, New York, USA, 2010; pp. 39–44. [Google Scholar] [CrossRef]
- Makantasis, K.; Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Matsatsinis, N. 3D Measures Exploitation for a Monocular Semi-Supervised Fall Detection System. Multimed. Tools Appl. 2016, 75, 15017–15049. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 611–622. [Google Scholar] [CrossRef]
- Yu, M.; Rhuma, A.; Naqvi, S.M.; Wang, L.; Chambers, J. A Posture Recognition Based Fall Detection System for Monitoring an Elderly Person in a Smart Home Environment. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1274–1286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abobakr, A.; Hossny, M.; Abdelkader, H.; Nahavandi, S. RGB-D fall detection via deep residual convolutional LSTM networks. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 13–18 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Adhikari, K.; Bouchachia, H.; Nait-Charif, H. Activity recognition for indoor fall detection using convolutional neural network. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 81–84. [Google Scholar] [CrossRef] [Green Version]
- Cameiro, S.A.; da Silva, G.P.; Leite, G.V.; Moreno, R.; Guimaraes, S.J.F.; Pedrini, H. Multi-stream deep convolutional network using High-Level features applied to fall detection in video sequences. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 293–298. [Google Scholar] [CrossRef]
- Espinosa, R.; Ponce, H.; Gutiérrez, S.; Martínez-Villaseñor, L.; Brieva, J.; Moya-Albor, E. A vision-based approach for fall detection using multiple cameras and convolutional neural networks: A case study using the UP-Fall detection dataset. Comput. Biol. Med. 2019, 115, 103520. [Google Scholar] [CrossRef] [PubMed]
- Ge, C.; Gu, I.Y.-H.; Yang, J. Co-saliency-enhanced deep recurrent convolutional networks for human fall detection in E-healthcare. Annual International Conference of the IEEE Engineering in Medicine and Biology Society. In Proceedings of the IEEE Engineering in Medicine and Biology Society, Annual International Conference, Honolulu, HI, USA, 18–21 July 2018; pp. 1572–1575. [Google Scholar] [CrossRef]
- Hsieh, Y.-Z.; Jeng, Y.-L. Development of home intelligent fall detection IoT system based on feedback optical flow convolutional neural network. IEEE Access Pract. Innov. Open Solut. 2017, 6, 6048–6057. [Google Scholar] [CrossRef]
- Hwang, S.; Ahn, D.; Park, H.; Park, T. Poster abstract: Maximizing accuracy of fall detection and alert systems based on 3D convolutional neural network. In Proceedings of the 2017 IEEE/ACM Second International Conference on Internet-of-Things Design and Implementation (IoTDI), Pittsburgh, PA, USA, 18–21 April 2017; pp. 343–344. [Google Scholar]
- Kasturi, S.; Filonenko, A.; Jo, K.-H. Human Fall Recognition using the Spatiotemporal 3D CNN. In Proceedings of the IW-FCV2018, Hakodate, Japan, 21–23 February 2018; pp. 1–3. [Google Scholar]
- Li, X.; Pang, T.; Liu, W.; Wang, T. Fall detection for elderly person care using convolutional neural networks. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Li, S.; Xiong, H.; Diao, X. Pre-impact fall detection using 3D convolutional neural network. In Proceedings of the 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 1173–1178. [Google Scholar] [CrossRef]
- Lie, W.-N.; Le, A.T.; Lin, G.-H. Human fall-down event detection based on 2D skeletons and deep learning approach. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lin, H.Y.; Hsueh, Y.L.; Lie, W.N. Convolutional recurrent neural networks for posture analysis in fall detection. J. Inf. Sci. Eng. 2018, 34, 577–591. [Google Scholar] [CrossRef]
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep learning for fall detection: Three-dimensional CNN combined with LSTM on video kinematic data. IEEE J. Biomed. Health Inform. 2019, 23, 314–323. [Google Scholar] [CrossRef] [PubMed]
- Lu, N.; Ren, X.; Song, J.; Wu, Y. Visual guided deep learning scheme for fall detection. In Proceedings of the 2017 13th IEEE Conference on Automation Science and Engineering (CASE), Xi’an, China, 20–23 August 2017; pp. 801–806. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Alkittawi, H. Spatio-temporal convolutional neural network for elderly fall detection in depth video cameras. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2868–2873. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, O.; Cao, G.; Xu, H. Fall detection system based on deep learning and image processing in cloud environment. In Conference on Complex, Intelligent, and Software Intensive Systems, Kunibiki Messe, Matsue, Japan, 4–6 July 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 590–598. [Google Scholar] [CrossRef]
- Tao, X.; Yun, Z. Fall prediction based on biomechanics equilibrium using Kinect. Int. J. Distrib. Sens. Netw. 2017, 13. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J. Fall detection using 3d head trajectory extracted from a single camera video sequence. In Proceedings of the First International Workshop on Video Processing for Security (VP4S-06), Quebec City, QC, Canada, 7–9 June 2006; pp. 7–9. [Google Scholar]
- Tsai, T.-H.; Hsu, C.-W. Implementation of fall detection system based on 3D skeleton for deep learning technique. IEEE Access Pract. Innov. Open Solut. 2019, 7, 153049–153059. [Google Scholar] [CrossRef]
- Zhou, J.; Komuro, T. Recognizing fall actions from videos using reconstruction error of variational autoencoder. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3372–3376. [Google Scholar] [CrossRef]
- Zhou, X.; Qian, L.-C.; You, P.-J.; Ding, Z.-G.; Han, Y.-Q. Fall detection using convolutional neural network with multi-sensor fusion. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Del Giorno, A.; Bagnell, J.A.; Hebert, M. A Discriminative Framework for Anomaly Detection in Large Videos. In Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 334–349. [Google Scholar] [CrossRef] [Green Version]
- Dutta, J.; Banerjee, B. Online Detection of Abnormal Events Using Incremental Coding Length. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; Volume 29, pp. 3755–3761. [Google Scholar] [CrossRef]
- Ionescu, R.T.; Smeureanu, S.; Alexe, B.; Popescu, M. Unmasking the Abnormal Events in Video. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2914–2922. [Google Scholar] [CrossRef] [Green Version]
- Mo, X.; Monga, V.; Bala, R.; Fan, Z. Adaptive Sparse Representations for Video Anomaly Detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 631–645. [Google Scholar] [CrossRef]
- Jiang, F.; Wu, Y.; Katsaggelos, A.K. A Dynamic Hierarchical Clustering Method for Trajectory-Based Unusual Video Event Detection. IEEE Trans. Image Process. 2009, 18, 907–913. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.; Lazzaretti, A.E.; Lopes, H.S. A Study of Deep Convolutional Auto-Encoders for Anomaly Detection in Videos. Pattern Recognit. Lett. 2018, 105, 13–22. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Robust, Deep and Inductive Anomaly Detection. In Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 36–51. [Google Scholar] [CrossRef] [Green Version]
- Gutoski, M.; Aquino, N.M.R.; Ribeiro, M.; Lazzaretti, A.E.; Lopes, H.S. Detection of Video Anomalies Using Convolutional Autoencoders and One-Class Support Vector Machines. In Proceedings of the XIII Brazilian Congress on Computational Intelligence, Rio de Janeiro, Brazil, 30 October–1 November 2017. [Google Scholar] [CrossRef] [Green Version]
- Tran, H.; Hogg, D. Anomaly Detection Using a Convolutional Winner-Take-All Autoencoder. In Proceedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017; British Machine Vision Association: Durham, UK, 2017. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning Temporal Regularity in Video Sequences. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 30 June 2016; pp. 733–742. [Google Scholar] [CrossRef] [Green Version]
- Munawar, A.; Vinayavekhin, P.; De Magistris, G. Spatio-Temporal Anomaly Detection for Industrial Robots through Prediction in Unsupervised Feature Space. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1017–1025. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting Anomalous Events in Videos by Learning Deep Representations of Appearance and Motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, B.; Shen, C.; Liu, Y.; Lu, H.; Hua, X.-S. Spatio-Temporal AutoEncoder for Video Anomaly Detection. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; ACM: New York, NY, USA, 2017; pp. 1933–1941. [Google Scholar] [CrossRef]
- Rezvanian, A.R.; Imani, M.; Ghassemian, H. Patch-Based Sparse and Convolutional Autoencoders for Anomaly Detection in Hyperspectral Images. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-Cascade: Cascading 3D Deep Neural Networks for Fast Anomaly Detection and Localization in Crowded Scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhou, F.; Li, Z.; Zuo, W.; Tan, H. Abnormal Event Detection in Videos Using Hybrid Spatio-Temporal Autoencoder. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), New York, NY, USA, 7–10 October 2017; pp. 2276–2280. [Google Scholar] [CrossRef]
- Xu, D.; Ricci, E.; Yan, Y.; Song, J.; Sebe, N. Learning Deep Representations of Appearance and Motion for Anomalous Event Detection. In Proceedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association: Durham, UK, 2015. [Google Scholar] [CrossRef] [Green Version]
- Bakalos, N.; Voulodimos, A.; Doulamis, N.; Doulamis, A.; Ostfeld, A.; Salomons, E.; Caubet, J.; Jimenez, V.; Li, P. Protecting Water Infrastructure from Cyber and Physical Threats: Using Multimodal Data Fusion and Adaptive Deep Learning to Monitor Critical Systems. IEEE Signal Process. Mag. 2019, 36, 36–48. [Google Scholar] [CrossRef]
- Mehta, V.; Dhall, A.; Pal, S.; Khan, S.S. Motion and Region Aware Adversarial Learning for Fall Detection with Thermal Imaging. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6321–6328. [Google Scholar] [CrossRef]
- Sheu, B.-H.; Yang, T.-C.; Yang, T.-M.; Huang, C.-I.; Chen, W.-P. Real-Time Alarm, Dynamic GPS Tracking, and Monitoring System for Man Overboard. Sens. Mater. 2020, 32, 197–221. [Google Scholar] [CrossRef] [Green Version]
- Tsekenis, V.; Armeniakos, C.K.; Nikolaidis, V.; Bithas, P.S.; Kanatas, A.G. Machine Learning-Assisted Man Overboard Detection Using Radars. Electronics 2021, 10, 1345. [Google Scholar] [CrossRef]
- Armeniakos, C.K.; Nikolaidis, V.; Tsekenis, V.; Maliatsos, K.; Bithas, P.S.; Kanatas, A.G. Human fall detection using mmWave radars: A cluster-assisted experimental approach. J. Ambient. Intell. Humaniz. Comput. 2022, 1–13. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Utilized Deep Learning Technique | Utilized RGB Dataset |
|---|---|---|
| Abobakr et al. [35] | CNN, RNN, LSTM with ResNet, Recurrent LSTM, and Logistic regression | URFD dataset |
| Adhikari et al. [36] | CNN | Own dataset |
| Cameiro et al. [37] | CNN | URFD and FDD dataset |
| Espinosa et al. [38] | CNN | UP-Fall and Multicam dataset |
| Ge et al. [39] | RCN, RNN, and LSTM | ACT42 dataset |
| Hsieh and Jeng [40] | FOF CNN and 3D-CNN | KTH dataset |
| Hwang et al. [41] | 3D-CNN | TST Fall detection dataset |
| Kasturi et al. [42] | 3D-CNN | URFD dataset |
| Li et al. [43] | CNN | URFD dataset |
| Li et al. [44] | 3D-CNN | Own dataset |
| Lie et al. [45] | CNN, RNN, LSTM, and DeeperCut | Own dataset |
| Lin et al. [46] | RNN and LSTM | Own dataset |
| Lu et al. [47] | CNN | URFD, FDD, and Multicam dataset |
| Lu et al. [48] | 3D-CNN and LSTM | Sports-1M and Multicam dataset |
| Rahnemoonfar and Alkittawi [49] | 3D-CNN | SDUFall dataset |
| Shen et al. [50] | DeepCut | Own dataset |
| Tao and Yun [51] | RNN and LSTM | Rougier and Meunier dataset [52] |
| Tsai and Hsu [53] | CNN (MyNet1D-D) | NTU RGB+D dataset |
| Zhou and Komuro [54] | Variational Auto-encoder | HQFD and Le2i dataset |
| Zhou et al. [55] | CNNs based on AlexNet and SSD-Net | Own dataset |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsamenis, I.; Bakalos, N.; Karolou, E.E.; Doulamis, A.; Doulamis, N. Fall Detection Using Multi-Property Spatiotemporal Autoencoders in Maritime Environments. Technologies 2022, 10, 47. https://doi.org/10.3390/technologies10020047
Katsamenis I, Bakalos N, Karolou EE, Doulamis A, Doulamis N. Fall Detection Using Multi-Property Spatiotemporal Autoencoders in Maritime Environments. Technologies. 2022; 10(2):47. https://doi.org/10.3390/technologies10020047
Chicago/Turabian StyleKatsamenis, Iason, Nikolaos Bakalos, Eleni Eirini Karolou, Anastasios Doulamis, and Nikolaos Doulamis. 2022. "Fall Detection Using Multi-Property Spatiotemporal Autoencoders in Maritime Environments" Technologies 10, no. 2: 47. https://doi.org/10.3390/technologies10020047
APA StyleKatsamenis, I., Bakalos, N., Karolou, E. E., Doulamis, A., & Doulamis, N. (2022). Fall Detection Using Multi-Property Spatiotemporal Autoencoders in Maritime Environments. Technologies, 10(2), 47. https://doi.org/10.3390/technologies10020047