1. Introduction
A major form of interaction between users and computers is achieved through devices like the mouse, keyboard, touchscreen, remote control, and other direct contact methods. Communication amongst humans is achieved through more intuitive and natural non-contact methods, e.g., physical movements and sound. The efficiency and flexibility of these non-contact interaction methods have led several researchers to consider using them to support human–computer communication. Gesture forms a substantial part of the human language. It is an important non-contact human interaction method. Historically, to capture the positions and angles of every joint in the user’s gesture, wearable data gloves were employed. The cost and difficulty of a wearable sensor have limited the widespread use of this method. The ability of a computer to understand the gestures and execute certain commands based on those gestures is called gesture recognition. The primary goal of such gesture recognition is to develop a system that can recognize and understand specific gestures and communicate information without any human intervention. The use of hand gestures for a human computer interface (HCI) offers direct measurable inputs by the computer [
1]. However, using a controlled background makes hand gesture detection easier [
2].
Currently, gesture-based recognition methods based on non-contact visual inspection are popular. The reason for such popularity is due to their low cost and convenience to the user. Hand gesture is an expressive communication method widely used in entertainment, healthcare, and education industries. Additionally, hand gestures are also an effective method to assist users having special needs such as blindness. Hand tracking is important to perform hand gesture recognition and involves performing several computer vision operations including segmentation, detection, and tracking.
The objective of this study is to investigate the effectiveness of the CNN algorithm to extract features and classify various hand motions for detecting hand gestures. In this study, the CNN algorithm is evaluated and compared to standard feature excitation algorithms such as wavelets (WL) and empirical mode decomposition (EMD). A 3D micro hand gesture recognition system was developed using CNN and evaluated using several factors, namely execution time, accuracy, sensitivity, specificity, positive predictive value, negative predictive value, positive likelihood, negative likelihood, and root mean square error. The study utilises three subjects to develop and train the system, and is validated using gestures from 20 subjects.
The rest of this paper is structured as follows. Some studies of the holoscopic camera and 3D micro hand gesture recognition techniques and methods used are presented in
Section 2.
Section 3 is a presentation and discussion of the results achieved and the conclusion is presented in
Section 4.
2. Literature Review
The use of micro lenses array at the image surface was proposed by Professor Lippmann who presented this concept to the French Academy of Sciences at La Photography Integral [
3]. The system is based on spatial images with full parallax in all directions, which is similar to a fly’s eye lens array with the display system being a screen holding several lenses [
3]. Herbert Ives, in the 1920s, began working on simplifying Lippmann’s idea by joining a lenticular lens sheet-containing a signal array of spherical lenses called lenticules. A signal array of magnifying lenses is designed to view from various angles. In addition, images are exaggerated consistently to provide a pixel from each micro lens. The lenses sheet is transparent and the back face which creates the focal plane is flat. An example of such phenomena is the lenses used in lenticular production where the technology is used to show an illusion of depth by moving or changing images as the image is seen from different angles. This innovative technology could also be utilized for producing 3D images on a flat display sheet. Hence, if the motion of the pictures is taken into consideration, this results in 3D holoscopic video [
3,
4]. However, this model has its own downside of having non-linear distortion mainly due to the lens radial distortion and micro lens distortion [
4].
Ge et al. [
5] proposed a 3D CNN method to estimate real-time hand poses from single depth images. The features extracted from images using 2D CNN are not suitable for the estimation of 3D hand pose as they lack spatial information. The proposed method takes input as a 3D volumetric representation of the hand depth image and captures the 3D spatial structure and accurately regresses a full 3D hand pose in a single pass. Then, the 3D data augmentation is performed to make the CNN method robust to various hand orientations and hand size variations. Results of the experiment show that the proposed 3D CNN outperforms the state-of-the-art methods on two challenging hand pose datasets. The implementation runs at over 215 fps on a standard computer with a single GPU which is proven to be very effective.
According to Ge et al. [
6], the method proposed is to increase the accuracy of hand pose estimation. The method involves projecting the query depth image onto three orthogonal planes and use the multi-view projections to regress for two-dimensional heat-maps which then can estimate the joint positions on each plane. The generated multi-view projection heatmaps are fused to generate a final estimation of the 3D hand pose. The results of the experiment show that the proposed method outperforms the current state-of-the-art with good generalization.
A technique using depth camera in a smart device for hand gesture recognition is proposed by Keun and Choong [
7]. The recognition is made through the recognition of a hand or detection of fingers. For detecting the fingers, the hand skeleton is detected via distance transform and fingers are detected using the convex hull algorithm. To recognize a hand, a newly generated gesture is compared with gestures already learned using support vector machine algorithm. The hand’s centre, finger length, axis of fingers, hand axis, and arm centre are utilised to detect the gesture. The algorithm was implemented and evaluated on an actual smart device.
The apparent motion in pixels for every point can be measured in a pair of images derived from stereo cameras [
8]. Such an apparent pixel difference or motion between a pair of stereo images is called disparity [
8]. This phenomenon can be experienced by trying to close one of your eyes and then rapidly close it while opening the other. The objects closer to us will be moved to a significant distance from the real position and objects further away move little [
8]. This kind of motion is disparity. A case where the disparity is most useful is for the calculation of depth/distance. Distance and disparity from the cameras are inversely related [
7,
8]. As the distance from the cameras increases, the disparity decreases. This can help for depth perception in stereo images [
7,
8].
A new technique for 3D rigid motion estimation from stereo cameras is proposed by Demirdjian and Darrell [
9]. The technique utilizes the disparity images obtained from stereo matching. Some assumptions like the stereo rig have parallel cameras and, in that case, the topological and geometric properties of the disparity images. A rigid transformation (called d-motion) is introduced whose function is mapping two disparity images of a rigidly moving object. The relation between the motion estimation algorithm and Euclidean rigid motion is derived. The experiment shows that the proposed technique is simpler and more accurate than standard methods.
As per the research conducted by authors [
10], hand gesture recognition is one of the most logical ways to generate high adaptability and a convenient interface between users and devices. They formed a hand gesture recognition system using four techniques, in order to verify which technique gives out the most accurate results. The techniques they used include WT, artificial neural network (ANN), EMD and CNN. They evaluated these methods on various factors and the results indicated that CNN is more accurate in comparison to EMD and WT.
According to Pyo et al. [
11], the CNN method is used to analyse and evaluate hand gesture recognition. CNN can deal with multi-view changes of hand gestures. The paper also shows how to use depth-based hand data with CNN and to obtain results from it. The evaluation is made against a famous hand database. The results show that CNN recognizes gestures with high accuracy and the technique is suitable for a hand gesture dataset. The CNN structure of three convolutional layers and two fully connected layers has the best accuracy.
Alnaim et al. [
12] also studied a gesture recognition model based on the CNN algorithm. They studied the hand gestures of the various subjects after experiencing a stroke. The developed method was evaluated and compared between training and testing modes based on various metrics namely execution time, accuracy, sensitivity, specificity, positive and negative predictive value, likelihood, and root mean square. Results show that testing accuracy is 99% using CNN and is an effective technique in extracting distinct features and classifying data.
A feature match selection algorithm is presented by [
13], with an aim to extract and estimate an accurate full parallax 3D model form from a 3D omni-directional holoscopic imaging (3DOHI) system. The novelty of the paper is based on two contributions: feature block selection and its corresponding automatic optimization process. The solutions for three primary problems related to depth map estimation from 3DHI: dissimilar displacements within the matching block around object borders, uncertainty and region homogeneity at image location, and computational complexity.
Kim and Toomajian [
14] designed an algorithm determining the feasibility of human hand recognition through micro Doppler signatures measured by Doppler radar with a Deep CNN (DCNN). They classified ten different gestures with micro-Doppler signatures on spectrograms without range information. The 10 gestures were studied from different perspectives by swiping them left to right and right to left, rotating them clockwise and anti-clockwise, holding and double holding, pushing, and double pushing. These different angles of the gestures were measured using Doppler radar. 90% of the data was used for training and 10% was used for validation. With the initial five gestures, 85.6% accuracy was achieved, whereas with seven gestures the accuracy was increased up to 93.1% indicating that accuracy increased with the increase in testing data. However, the study is limited to the tested seven gestures and for testing of more gestures the system required gestures having unique signatures of spectrogram.
Malchanov et al. [
15] proposed an algorithm for gesture recognition that challenged the depth and intensity of data using 3D CNN. The research used the vision for intelligent vehicles & applications (viva) data set. The solution combined information from various spatial scales for final predictions. Since, the duration of each hand gesture sequence is different in VIVA dataset the study normalized the temporal lengths of the gesture sequence by re-sampling each gesture to 32 frames using nearest neighbour interpolation (NNI). For classification the CNN classifier consisted of two sub-networks, namely low-resolution and high-resolution network. The results gave a classification rate of around 77.5% on the dataset. This study revealed that combining high- and low-resolution sub-networks helps to improve the classification accuracy to a considerable level.
Nunez et al. [
16], using 3D data sequences taken from full-body and hand skeleton, addressed the hand gesture recognition and human activity problems. Their study aimed to propose a deep learning-based approach for temporal 3D pose recognition with a combination of long short-term memory (LSTM) and CNN. They also proposed a two-stage training strategy. The first stage focused on CNN training, whereas the second stage used the full method of LSTM and CNN combined. The results of the study indicated that the small datasets gave out more accurate results as compared to large datasets.
Molchanov et al. [
17] proposed a connectionist temporal classification for training the network to detect gestures from an unsegmented input stream. The system used deep 3D-CNN for spatiotemporal feature extraction. They deployed their system for online recognition of gestures where there is huge diversity of people performing gestures, which makes the detecting difficult. For the validation of their model, they used a multi-modal dynamic hand gesture dataset captures with colour, depth and stereo IR sensors. The results achieved from the study were 83.8% accurate, which was higher than all the similar researches in the state-of-the-art algorithm. Their algorithm achieved a human accuracy of 88.4%, making it the most practical application of hand gesture determination technique.
Li et al. [
18] used CNN for the detection of gestures along with characteristics of CNN to avoid the overall feature extraction process, which reduces the trained parameters quantity and helps to develop a system of unsupervised learning. The results from the study indicated an overall accuracy of 98.52% as they developed a semi-supervised model through support vector machine (SVM).
A hand recognition sensor using ultra-wide band impulse signals that are reflected from a hand was developed by Kim et al. [
19]. Reflection of a surface is used to determine the reflected waveforms in the time domain. Each gesture has its own reflected waveform; therefore, each gesture is unique. CNN was used for the gesture classification. They studied six hand gestures and they were detected with 90% accuracy. The model gave 90% accuracy for a 10-degree step in each gesture.
4. Results
4.1. Single-View Image Gestures
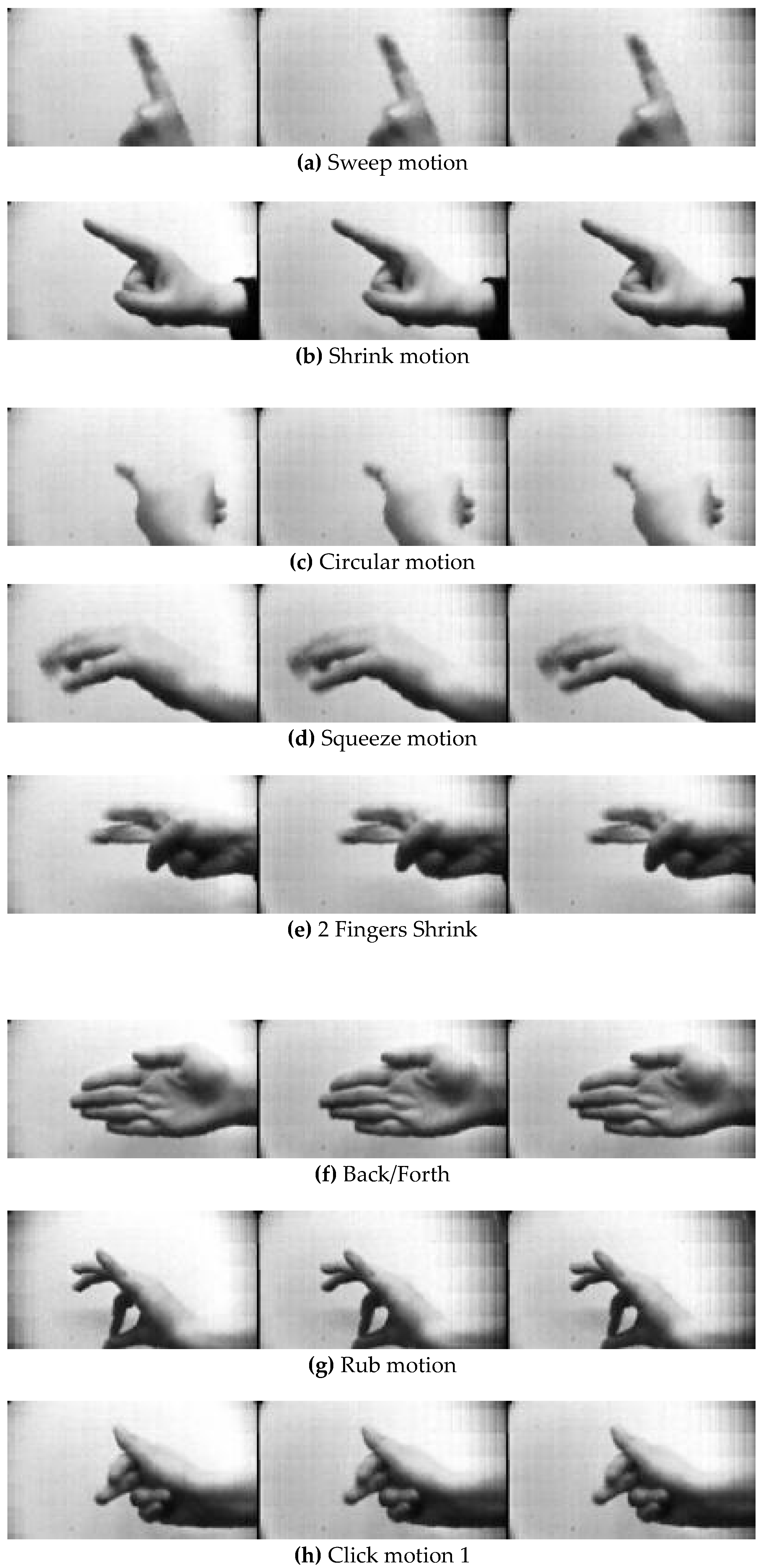
Twelve different 3D micro hand gestures for three subjects are fed as input into CNN. An earlier study by the authors [
10] using classical techniques such as WL and EMD as feature extraction methods that is cascade by ANN for classification of 2D gestures. The results of the classification methods are compared with CNN performance. The comparison, including execution time, accuracy, specificity, sensitivity, positive predictive value PPV, NPV, likelihood, and RMS, is represented in
Table 1. It also represents the total execution time for EMD, WT, and CNN in training. It should be noted that, for WT, the execution time is less than the total time execution of CNN and EMD combined. However, CNN has exceeded the accuracy value of EMD and WT. The specificity value of EMD is less than CNN and WT, whereas the specificity of WT is the highest. EMD and CNN have higher values of PPV and NPV as compared to WT. The best value of LR+ and LR− is highest for CNN. The RMS value of WT is the highest where that of CNN and EMD has slightly decreased [
10].
Table 2 represents comparison of the three algorithms performances when tested in the study. WT and EMD have execution time lesser than CNN. However, for accuracy, CNN and EMD have higher values than WT. However, CNN has the highest value of accuracy. Also, CNN has the highest value of sensitivity when compared to EMD and WT. The specificity of EMD and CNN is lower than WT. As compared to WT, the NPV and PPV values of CNN and EMD are higher. CNN is on the top for LR+ and LR− as compared to EMD and WT. It is also noted that the RMS value of EMD has significantly increased while the RMS value of WT has declined.
During the testing phase, CNN took around 714 min for executing the testing task, which is similar to that of training phase. This indicates that this outcome is not feasible because its along time for the testing of 10 images as if it were mere images required to be tested the researchers would have to wait this long for just getting the results. However, for other parameters, i.e., sensitivity, specificity, PPV, NPV, negative likelihood (LR−), and RMS, CNN has a value of 1. In the testing phase, CNN has LR+ value equal to 1, which is less as compared to EMD and WT. The LR+ value of EMD and WT are 22.4 and 9.1 respectively. However, CNN has a higher execution time, the accuracy in other factors makes this single flaw acceptable [
10].
4.2. Multi-View Image Gestures
A CNN is an integral part of deep learning since it is used to train data without applying any image processing methods. In this experiment, the three subjects’ gestures are used to train the system. Each subject records a video of 10 s length per gesture, the extraction algorithm is used to extract three images per frame (LCR). This generates 300 images per video for each point of view (LCR) giving 900 images. The images are divided into training and testing models. The inputs are arranged into two categories, three individual image inputs (single LCR), and combined images (combined LCR). The number of training images for the single LCR is 390, whereas it is 210 for combined images. The CNN training algorithm used in this study is the stochastic gradient descent with momentum (SGDM), adaptive learning (initial value = 0.001), while the search algorithm is Levenberg–Marquardt. The CNN’s topology is designed in seven layers with each layer having the following functionality and size: ImageInputLayer size 135 × 75 for single images whereas 405 × 75 for combined, Convolution2DLayer with filter size 5, filter number 20, 20 hidden neurons, stride size 1. Convolutiona2DLayer means that a 2-D convolutional layer applies sliding convolutional filters to the input. The layer convolves the input by moving the filters along the input vertically and horizontally and computing the dot product of the weights and the input, and then adding a bias term. Rectified Linear Unit input and output size are 1, MaxPooling2DLayer, the value of stride and Pooling are 2, FullyConnectedLayer input size is 135 × 75 and output size is 12, SoftmaxLayer input and output names is 1x1 and ClassificationOutputLayer output size is 12. The CNN hyperparameters are created inside the training options function. The epochs’ parameter value is set to 100 epochs.
CNN algorithm’s performance can be compared using several parameters including execution time (H:M:S). Execution time is the duration taken by the software to implement the task for training and testing. Whereas, the training accuracy is calculated by applying the training data to the model and finding the accuracy of the algorithm. Testing accuracy is obtained by applying the testing data to the model. Sensitivity measures the appropriate count of the identified percentage of positive, specificity measures of the false positive rate, PPV and NPV percentages of positive and negative results in diagnostic and statistics tests that describe the true positive and true negative results. The LR+ and LR− are identified measures in diagnostic accuracy.
Table 3 presents comparison between the three subjects and the overall (training and testing) approaches to find the best results obtained. Single, combined, and all three combined results are displayed in terms of execution time, training, testing, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), positive likelihood (LR+), and negative likelihood (LR−). In the single images experiment, the execution time of the first subject is quite higher than the second and third subjects. The result of training for second subject is lower than first and third subjects. First subject has the best testing result of 100%. Sensitivity result for the third subject is slightly higher than for the first and second results while all results for the three subjects are equal in specificity. The PPV results in this experimental work are equal whereas the result of NPV for the third subject is slightly lesser than the others. LR+ has the best values for three subjects while LR− result for third subject is 0.0425.
For the combined images case, the result of the first-subject experiment is the highest with respect to execution time. The training results of the second subject is slightly lower than the first and third subjects. The second subject has the best testing result at 99%. The result for the first subject is decreased in sensitivity more than the second- and third-subjects’ results, whereas the result of the third subject is slightly lower than first and second subjects in specificity. The PPV result for the third subject is less than the first and second subjects, whereas the result of NPV for the first subject is the lowest. LR+ has the highest value for the third subject while LR− result for the first subject is 0.1333.
The ALL combined experiment shows the performance of all three subjects’ images. The execution time of all three subjects is the highest. The result of training for all three subjects is slightly lower than for first and third subjects. ALL-combined experiment has the lowest result in testing comparing to other results. Sensitivity and specific results for ALL is lowest. The results shown in PPV and NPV for ALL-combined three subjects is also lower than other results. LR+ value is less than the combined result for third subject whereas the result of LR− for ALL-combined experiment is the highest.
Conclusively, first subject has the best values in all categories in single experiment compared to other subjects’ results, except the execution time which is the highest. The results of second subject in combined are better than first and second’s results. The values of ALL-combined experiment in categories is slightly lower than other experiments. Except the value of training is slightly better than the single of the second subject result. Overall, the single experiment of the first subject has the best values in most parameters.
The training progress (plot) is a useful for monitoring when training status of the network [
29,
30,
31]. This method defines how quickly the network accuracy is increasing [
30,
31]. The first graph is for the training accuracy and the second is for the loss function.
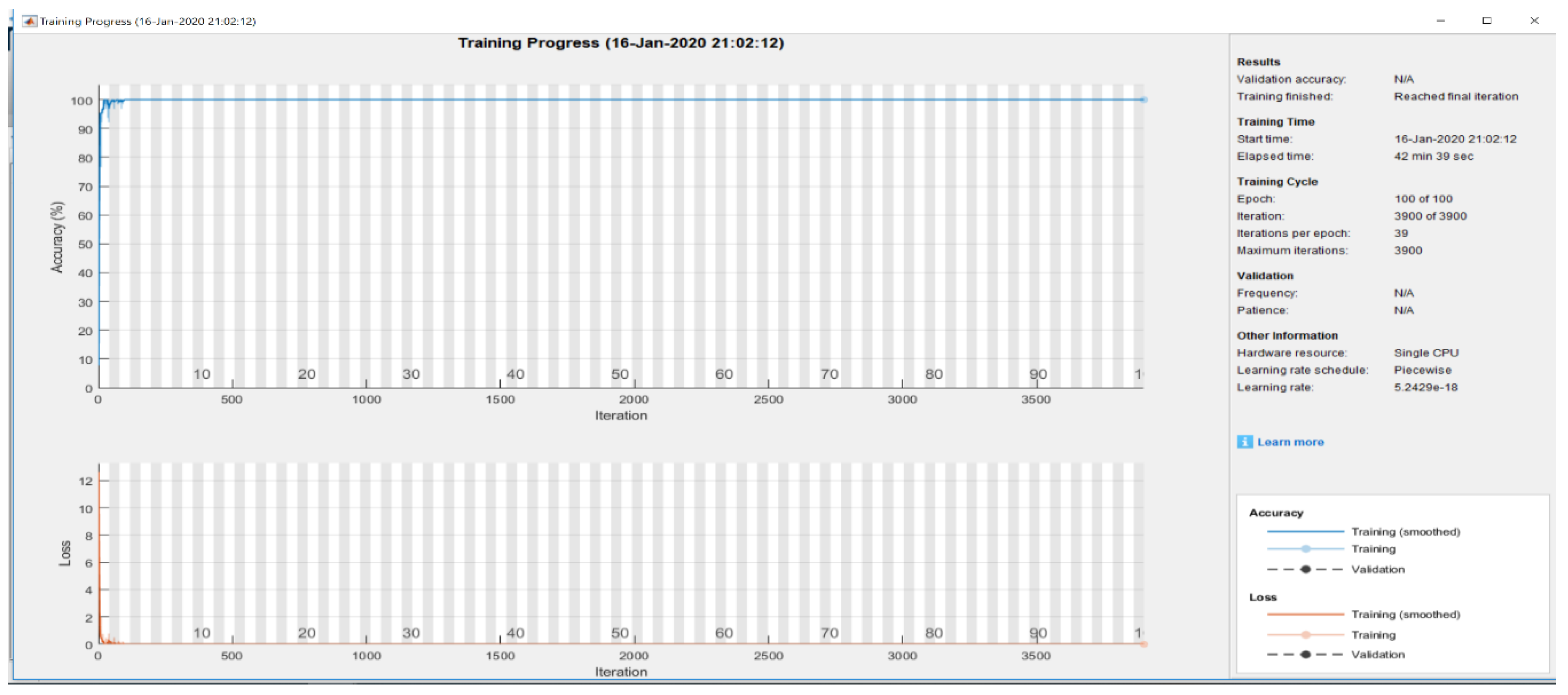
Figure 11 shows the training metrics at each iteration, that is, an estimation of the gradient [
30,
31]. An epoch is a full pass by the whole dataset. The classification accuracy shows a light blue line and the dark blue line is an accuracy which is acquired by implementing a smoothing algorithm to the training accuracy [
31]. while an interrupted line defines as the classification accuracy of the whole validation data set [
31]. At 39 iterations, the accuracy was decreased, then improved rapidly until it reached 100% [
31]. The result of validation accuracy is 100%. The loss function is displayed on the second graph. The light orange line is training loss, smoothed training loss is dark orange line and validation loss is disrupted line means the loss on each mini batch, the loss on validation set [
31,
32]. The number images used for training and validation is 70% of each class which is selected randomly while the remaining of 30% is used for testing. The algorithm utilises validation data. Hence, it will provide the best structure when the validation error starts to increase as the model is evaluated based on the holdout validation of the dataset after each epoch performance. The training process is stopped when the validation data set begins to degrade, therefore, to get the best structure of the validation set. In addition, other models such as weight decay are suitable for smaller models. Hence, making early stopping perfect for the current research.
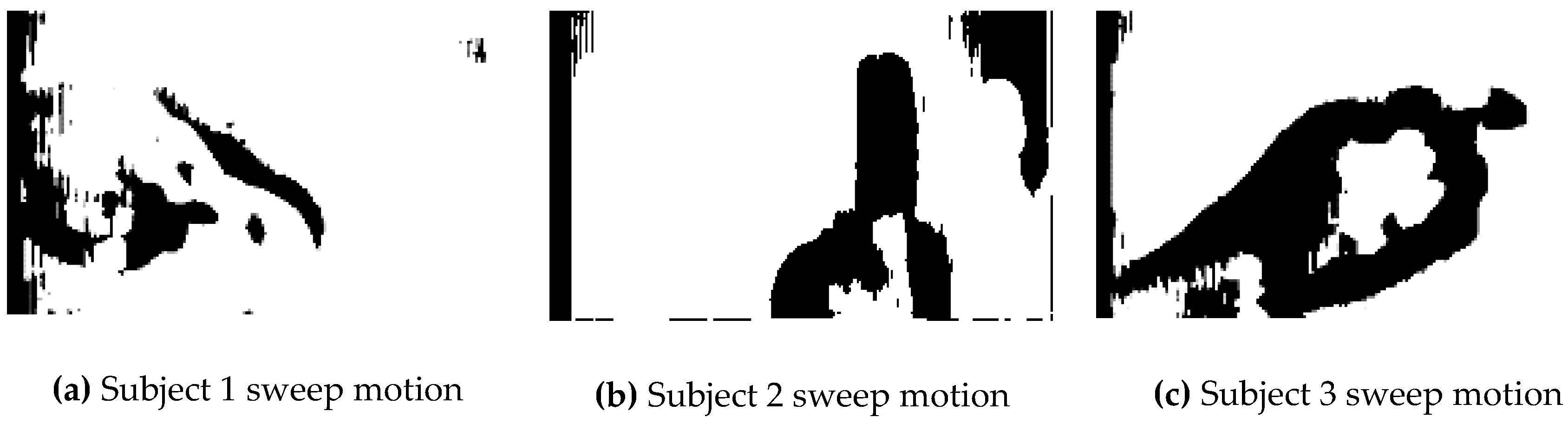
4.3. Gesture Classification Using Disparity Images
In this experiment, disparity images were created of the left/right images extracted from the frames for the three subjects. The system setup is complete identical to the configuration used in
Section 4.1. However, there is a single image (disparity image) as the input to the CNN.
Table 4 presents comparison results of the three subjects for the training and testing. The system always achieves 100% training accuracy. The first subject has the best testing result at 100%, while the second and third subjects have lower results. The sensitivity result for the second subject is slightly lower than the first and third results, while all results for three subjects are equal in specificity. The PPV result for second subject is lower than other results, while the result of NPV for all three subjects is equalled. LR+ for the second subject is the highest which at 933 while LR− results for all three subjects is equalled. The execution time is the lowest compared to other results. The training result is 100% whereas the testing result is 0.9803. The result is decreased in sensitivity for three subjects results whereas the results of combined are equalled in specificity. The PPV result of the combined is higher than the second subject’s result. The NPV result recorded for the combined experiment is the lowest compared to other results. LR+ is zero compared to the result of the second subject which has the highest result. The highest value for LR− is 0.0364, while other results are zero.
A summary of the comparison is that the first subject has the best values in all categories in the single experiment compared to other subjects’ results, except the execution time for the second subject is the highest. The values presented for the combined experiment is slightly lower than other results. Overall, the single experiment of the first subject has the best values in most parameters.
4.4. System Validation Using CNN
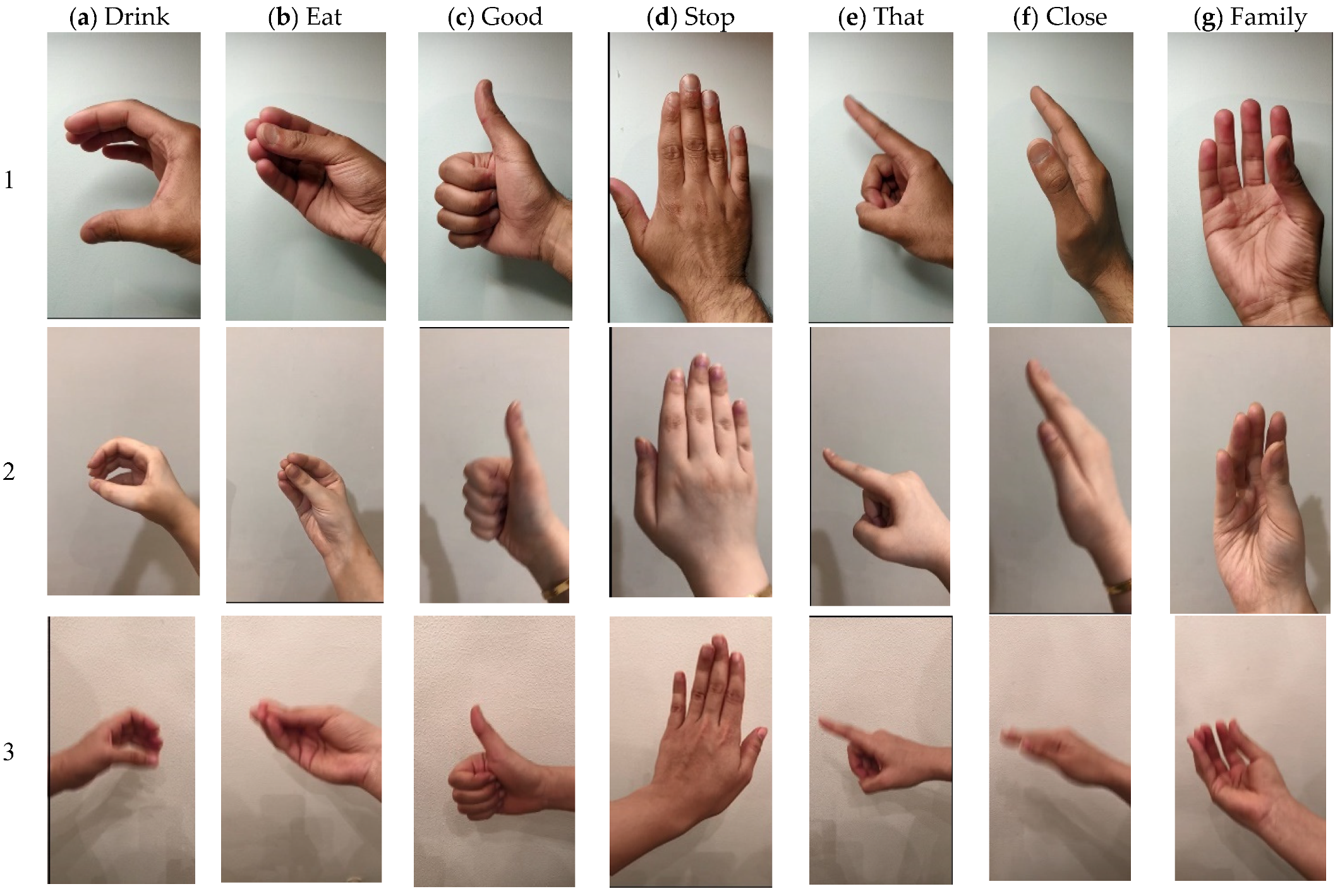
In this experimental work, the system is validated using 20 subjects with 7 gestures each. 140 videos are generated, and 24,698 image frames were extracted. The method to convert the image frame from RGB colour to grey and resize it to 227 × 227 from the original image size. Each recorded video has a various number of frames between 3394 to 3670 frames. The data of images is divided into training and testing datasets. The number of training frames is 17,288 (70%) while the remaining (7410) is used for testing. The experiments were executed to acquire the accuracy of seven hand gestures.
A summary of the values obtained for various parameters in training and testing approach is listed in
Table 5. The accuracy result of training is 100% compared to 99.12% for testing. The value of sensitivity in training is slightly higher than testing. Specificity for training is 100% whereas for testing is 99.89%. The PPV and NPV of testing is lower than training. The best value for LR+ and LR− are recorded for training.
The training parameter values in CNN are fixed for all categories. The execution time for training and testing is approximate 4 h, 19 min, and 57 s, which is the duration to train and validate the system using seven hand gestures. Overall, CNN is an algorithm capable of classifying different hand gestures.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}