Adaptive Deep Learning for Soft Real-Time Image Classification


Abstract
:1. Introduction
- -Pareto optimal CNN Design and Run-Time Adaptation: We propose a new approach for efficient neural architecture search to derive Pareto and -Pareto optimal CNNs offline. Especially, we first derive a lightweight model that can support the user-specified minimum accuracy for image classification, such as 0.7. By extending the model incrementally, we explore more complex CNN models with longer execution times and higher accuracy, while rejecting models that are not Pareto-optimal. Moreover, we derive a compact set of -Pareto optimal CNNs to minimize the number of the CNNs kept in memory to support run-time adaptation without incurring I/O latency, if necessary, to meet timing constraints cost-efficiently. At run-time, our adaptive framework efficiently picks a CNN expected to support the highest accuracy among the -Pareto optimal CNN models subject to the remaining time to the deadline in O(1) time. Although CNNs have been explored extensively, relatively little work has been done to support systematic trade-offs between the time and accuracy for adaptive real-time image classification. A vanilla approach that always uses a single, non-adaptive CNN model may miss many deadlines when the system is overloaded. To address the issue, recent works, e.g., [24,25], have investigated how to dynamically skip or add layers to meet timing constraints. Unlike the non-adaptive baseline, we support methodical trade-offs between the inference time and accuracy. Moreover, our approach provides more flexibility and opportunities for robust, timely adaptation by considering not only the number of the layers but also the other key hyper-parameters.
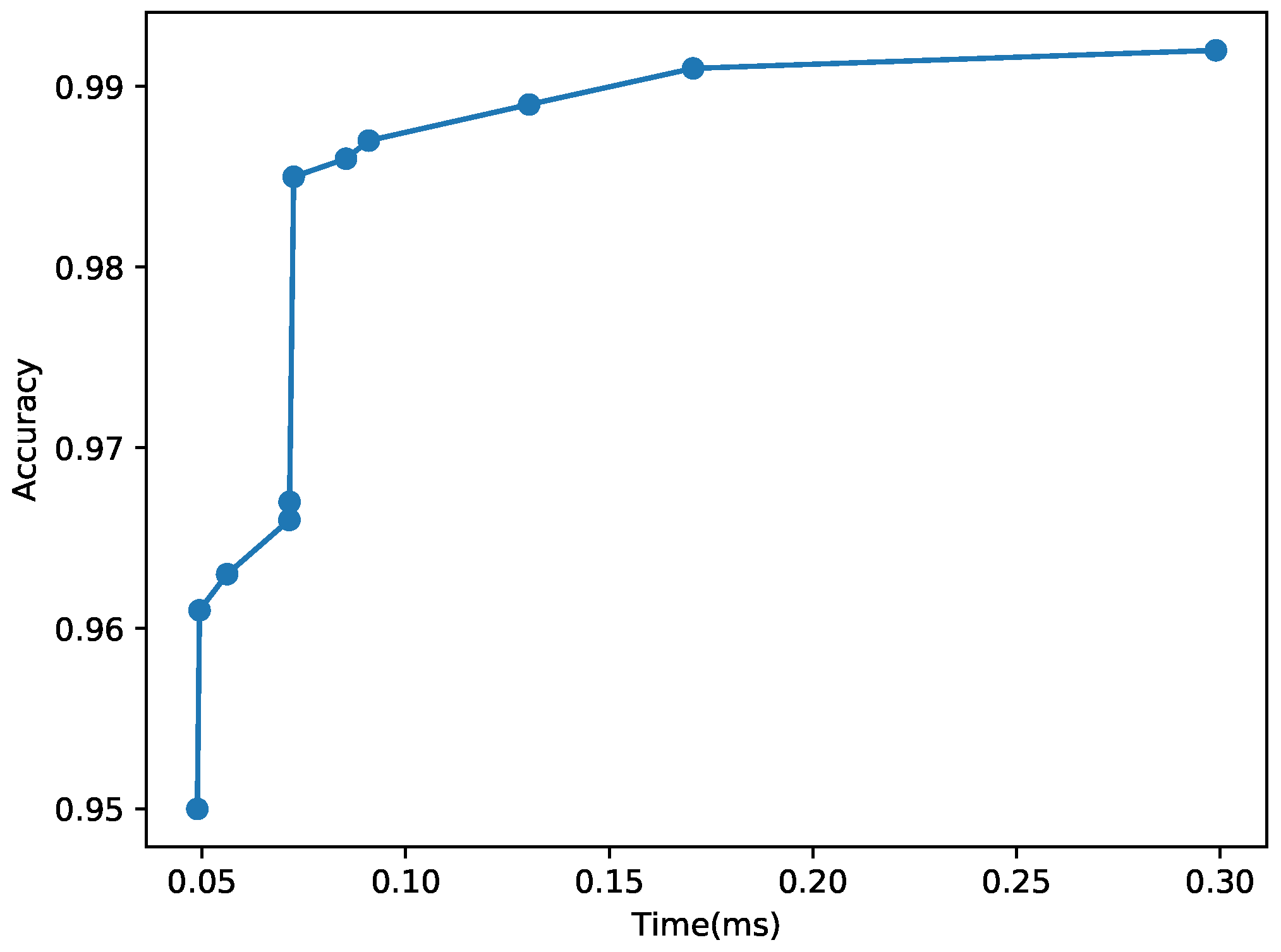
- Evaluation: We undertake extensive performance evaluation in terms of the prediction time and accuracy. We analyze the impacts of the hyper-parameters used to configure hundreds of CNN models on the inference time and accuracy, while comparing the effectiveness of our approach and the two baselines discussed above. In the evaluation presented in Section 4, our approach derives three different CNN models for MNIST [26] and CIFAR10 [27], respectively. For MNIST, the accuracy and inference time of the models range between 48.84 and 298.99 s and 0.95–0.992. For CIFAR-10 that is more complex than MNIST, the accuracy and inference time range between 71.97–183.55 s and 0.808–0.893, respectively, (for CIFAR-10, we have used a more powerful machine due to the relative complexity of the data set. A detailed description is given in Section 4). Different from the proposed approach, the non-adaptive vanilla baseline is unable to support stringent timing constraints, if the remaining time to the deadline is shorter than the inference time.Notably, the layer-wise adaptation method in a single CNN [24,25] has less flexibility for CNN design and run-time adaptation than our approach. When the depth is increased from 8 to 19 in the layer-adaptive baseline, the execution time increases by more than , but the accuracy enhances by only 3.6% for CIFAR-10. In contrast, comparing to the basic CNN with eight layers, two more powerful CNNs with 8 and 19 layers derived by our approach increase the accuracy by 4.9% and 8.5% for increasing the inference time by and , respectively. Thus, our 8-layer model supports higher accuracy than the 19-layer model of the baseline does, even though its execution time is 40% shorter than that of the baseline. In addition, if the remaining time to the deadline is sufficient, our approach can use our 19-layer model that enhances the accuracy by 8.5%.Finally, our approach has little/acceptable overhead. In our approach, the latency for switching between two CNNs for adaptation is at most 20 ns; therefore, our timing overhead is negligible. The total memory footprint of the models does not exceed the user-specified bound. Comparing to the non-adaptive baseline that stores only one CNN model, our approach increases the memory consumption by at most 11.211 MB that is acceptable in modern edge servers or IoT gateways. Overall, our approach for adaptive real-time image classification is more effective than the state-of-the-art baselines.
2. Background and Problem Formulation
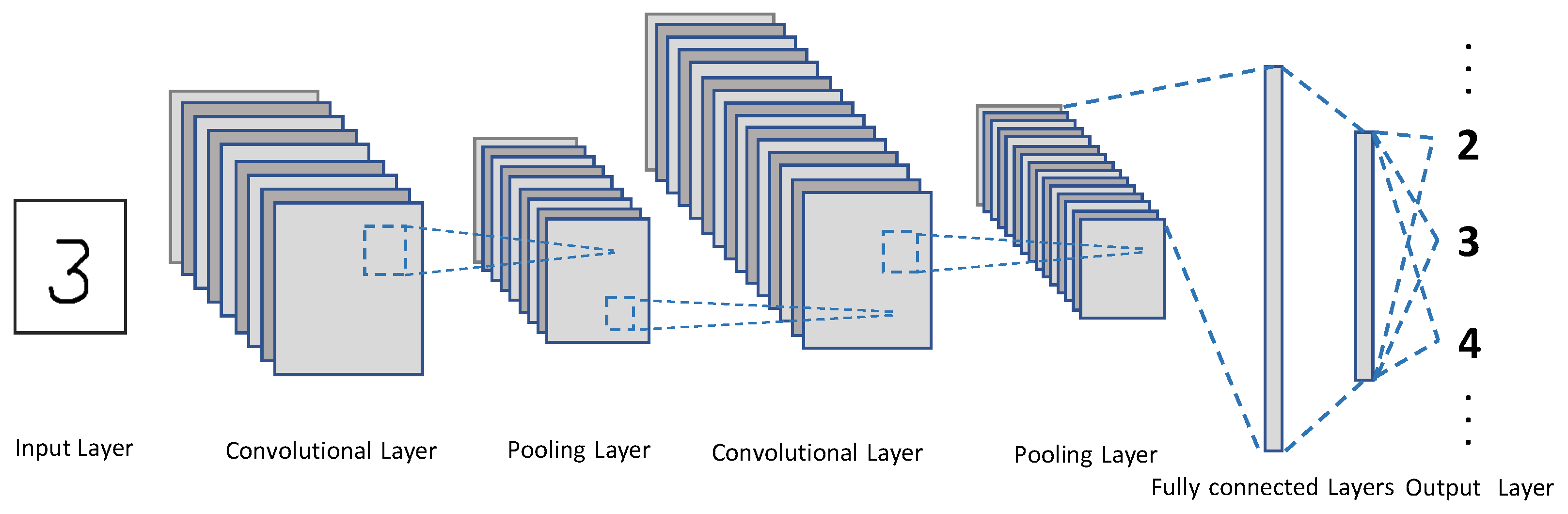
2.1. An Overview of the CNN Structure
- Input layer [26,27,29]: In a CNN for computer vision, an image is represented by a 3D matrix defined by the image width, image height, and the depth of the channels, e.g., RGB. A gray scale image is stored as a 2D matrix. Images are pre-processed, if necessary, to conform to the width, height, and depth requirements and provided to the input layer. In CNNs, key operations, such as convolution and pooling to be discussed shortly, are independently applied to each channel. Therefore, for the sake of clarity, we mainly discuss convolution and pooling for 2D data in this section.
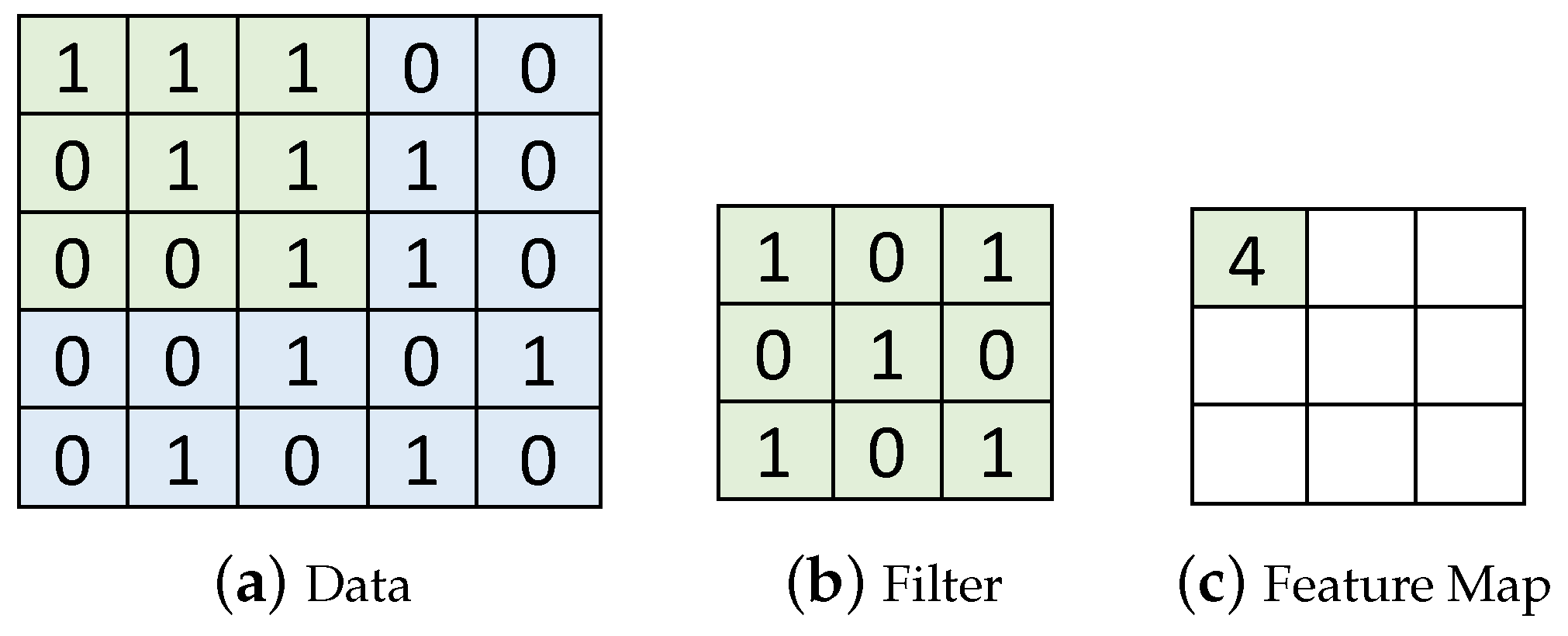
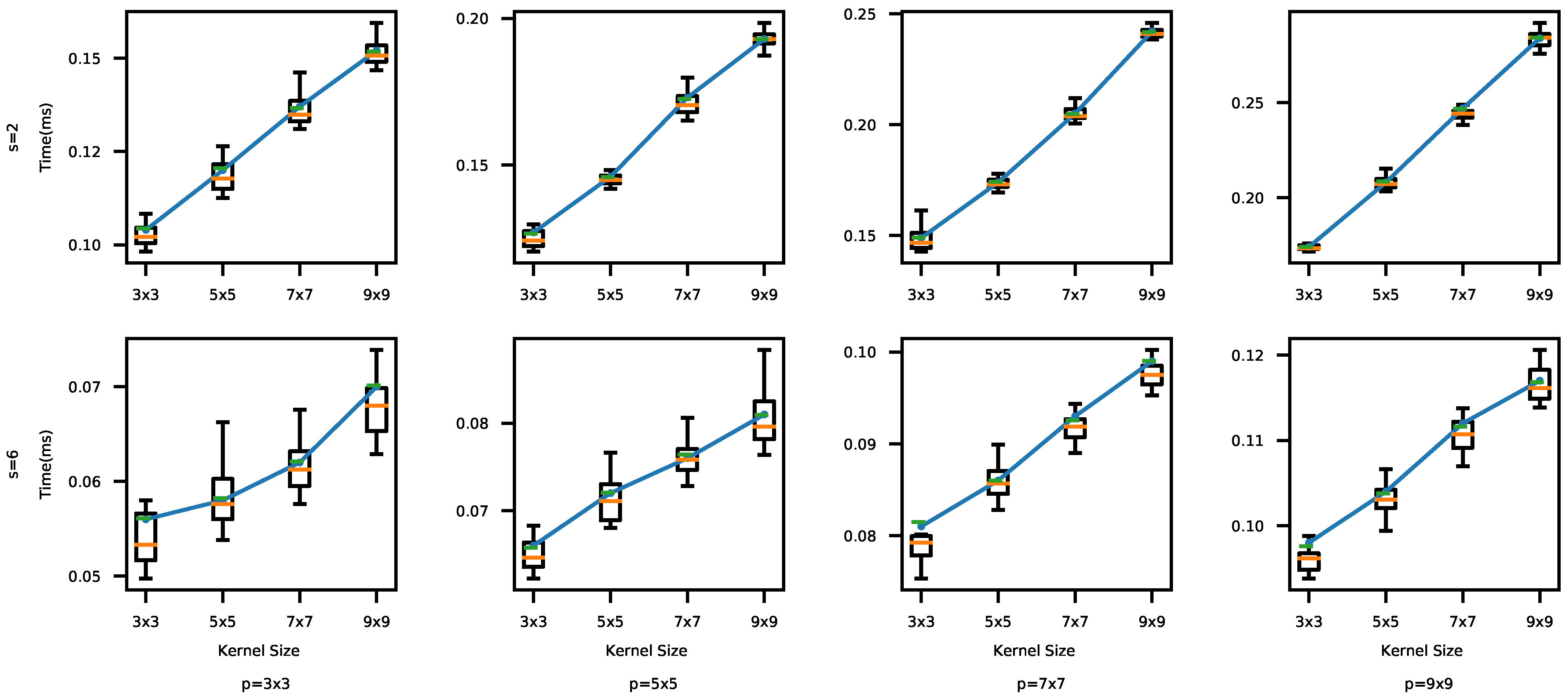
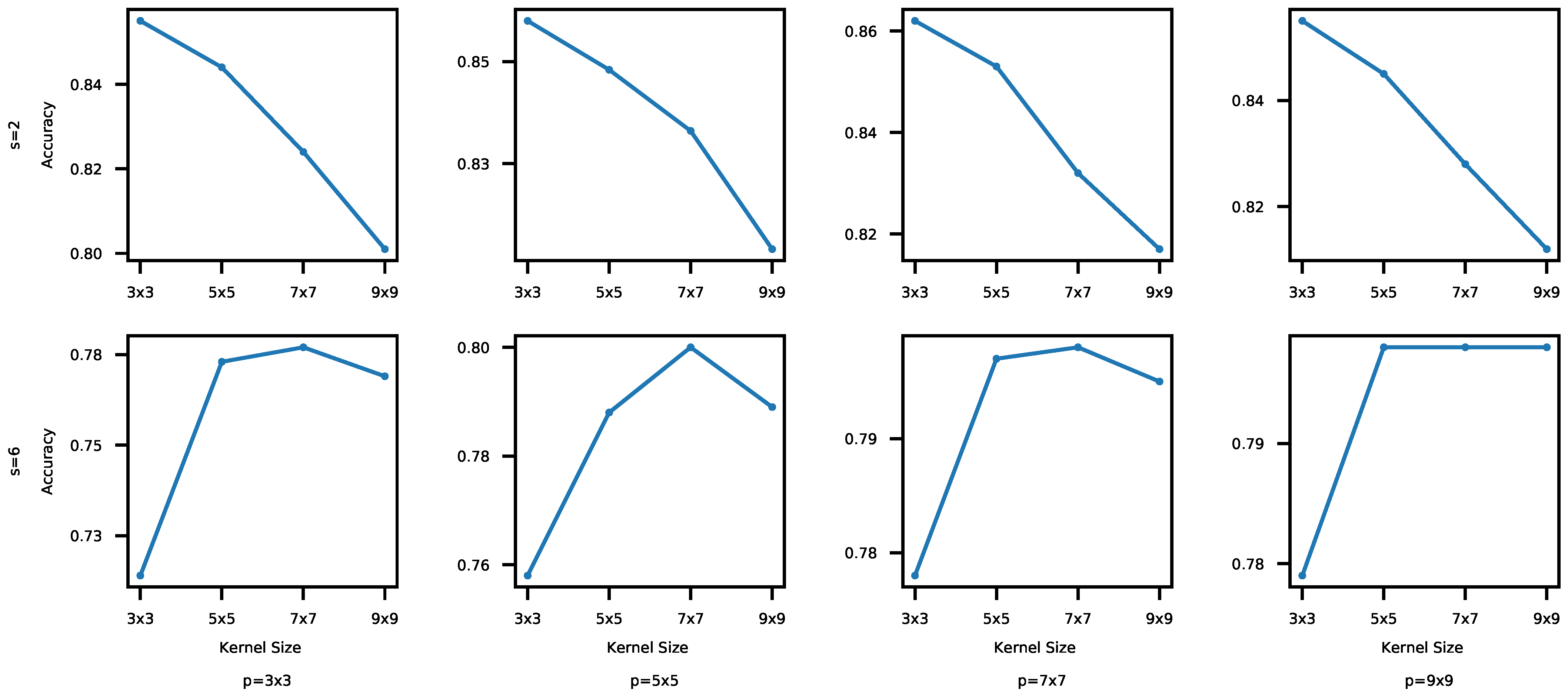
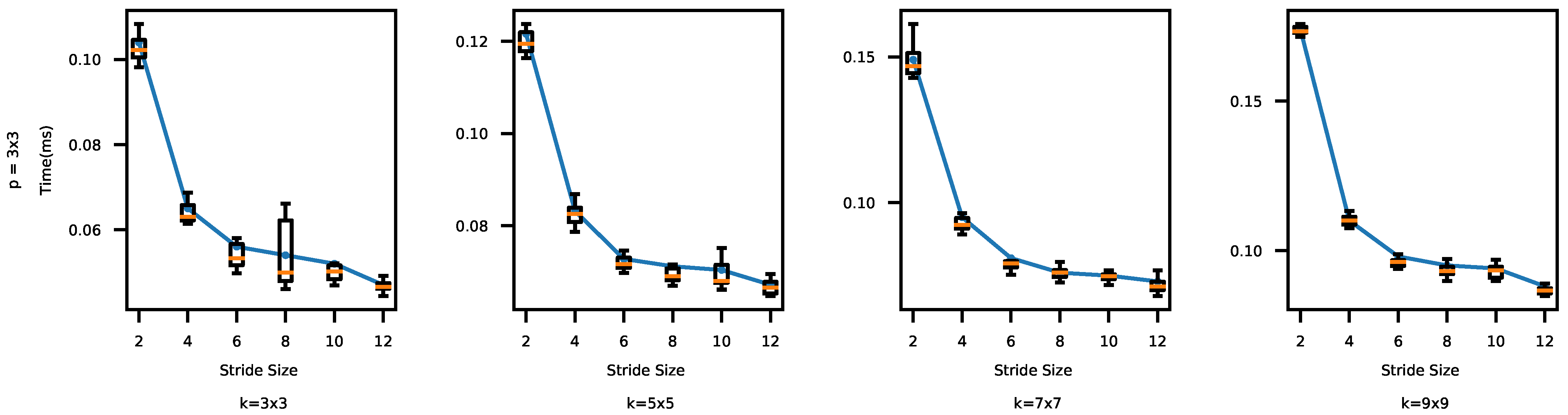
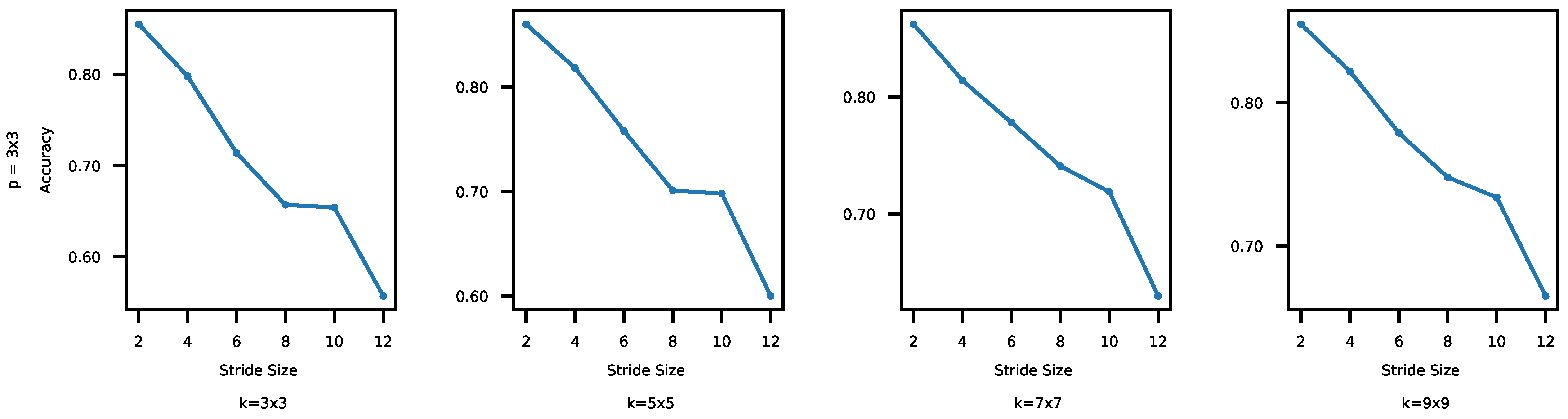
- Convolutional layers [2,31,32,33]: In a CNN, a convolution filter, also called a kernel, is applied to the input image. More specifically, element-wise multiplications between the filter and data in one segment are applied and the multiplication results are summed to produce one data in the feature map. For example, in Figure 3, a 3 × 3 kernel is applied to the first 3 × 3 segment in the input data. By performing the element-wise multiplications and sum, the first feature is produced in the feature map in Figure 3c. A new feature map is generated each time by sliding the filter a certain number of positions specified by the stride size (in Figure 3, stride = 1, that will produce nine convolutional results in the feature map). A convolutional layer usually uses multiple filters. As a result, it produces multiple feature maps and stacks them together [8]. A CNN usually consists of multiple convolutional layers. The first convolutional layers detect low level features, e.g., color, gradient orientation, and edges. The next layers detect middle-level features such as shapes. In addition, the following layers detect an object, e.g., a car. Kernel sizes and the number of convolutional layers are key hyper-parameters that determine the architectural configuration of convolutional layers. In addition, each convolutional output is provided to an activation function to expedite training. In this paper, we use ReRectified Linear Unit (LU) that is one of the most popular activation functions. It is an element-wise function applied to each data x produced by convolution; it simply returns . ReLU is popular since it is nonlinear and computationally efficient.
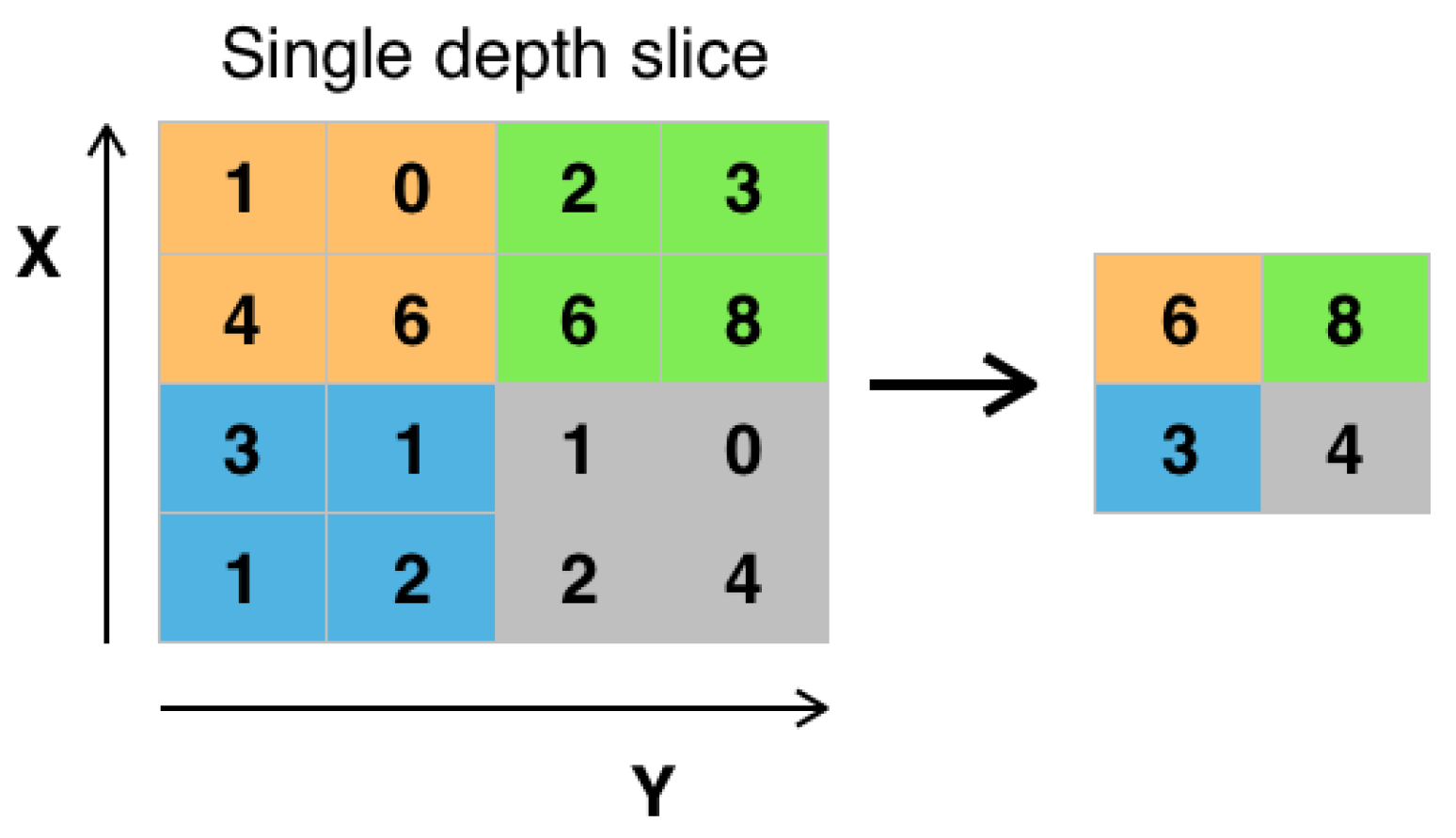
- Pooling layers [2,17]: The feature maps that is the output of one or more convolutional layer are fed into a pooling layer that, via downsampling, reduces the dimensionality and the risk of overfitting [1,34,35] where the CNN is memorizing the training data rather than generalizing the model to predict/infer the classes of new, unseen images. Max pooling and average pooling are the most common pooling techniques. For example, max pooing of size 2 × 2 with depth 1 and stride 2 is depicted in Figure 4. As shown in the figure, pooling keeps representative features, while halving the width and height. The pooling window size, stride, and number of pooling layers are important hyper-parameters that also affect the time and accuracy of image classification via CNNs.
- Fully connected layers [2]: In a CNN, feature maps processed through the convolution and pooling layers are flattened, i.e., converted to a single-dimension vector, and fed to the fully connected layers. Each neuron in the first fully connected layer then computes the weighted sum of the features provided to itself. The following fully connected layer computes the weighted sum of the output signals provided as the input to itself. This process is repeated through the fully connected layers.
- Output layer and training: By giving different features different weights, the convolutional and fully connected layers find the most correlated features to a particular class. In the prediction phase, the output layer gives the probabilities that the input image belongs to different predefined classes based on the detected features. For image classification with more than two classes, the softmax function [36] used in this paper is a common technique to compute the probabilities [6]. Finally, the class with the highest probability is selected and compared to the label, the ground truth. Based on the comparison results, the weights are adjusted to enhance the classification accuracy via back propagation [37] and gradient descent [38] techniques. By repeating the whole procedure for a big training data set, the CNN learns the model for a specific application, such as computer vision.
- CNN model evaluation: The accuracy of the trained CNN model is:where and represent the number of the images classified correctly and the total number of classified images, respectively.Specifically, accuracy is evaluated using the separate set of data, called the test set, the model has not seen during the training (for more details of CNNs, please refer to [2,6]). Following this approach, in Section 4, each data set is divided into the training set and test set. We use the training set to train our CNN models and use the test set to evaluate the generalizability of the models derived by our approach discussed in Section 3 in terms of the prediction accuracy and time.
2.2. Problem Formulation
3. Exploring CNN Models for Timely, Adaptive Image Classification
3.1. Overview
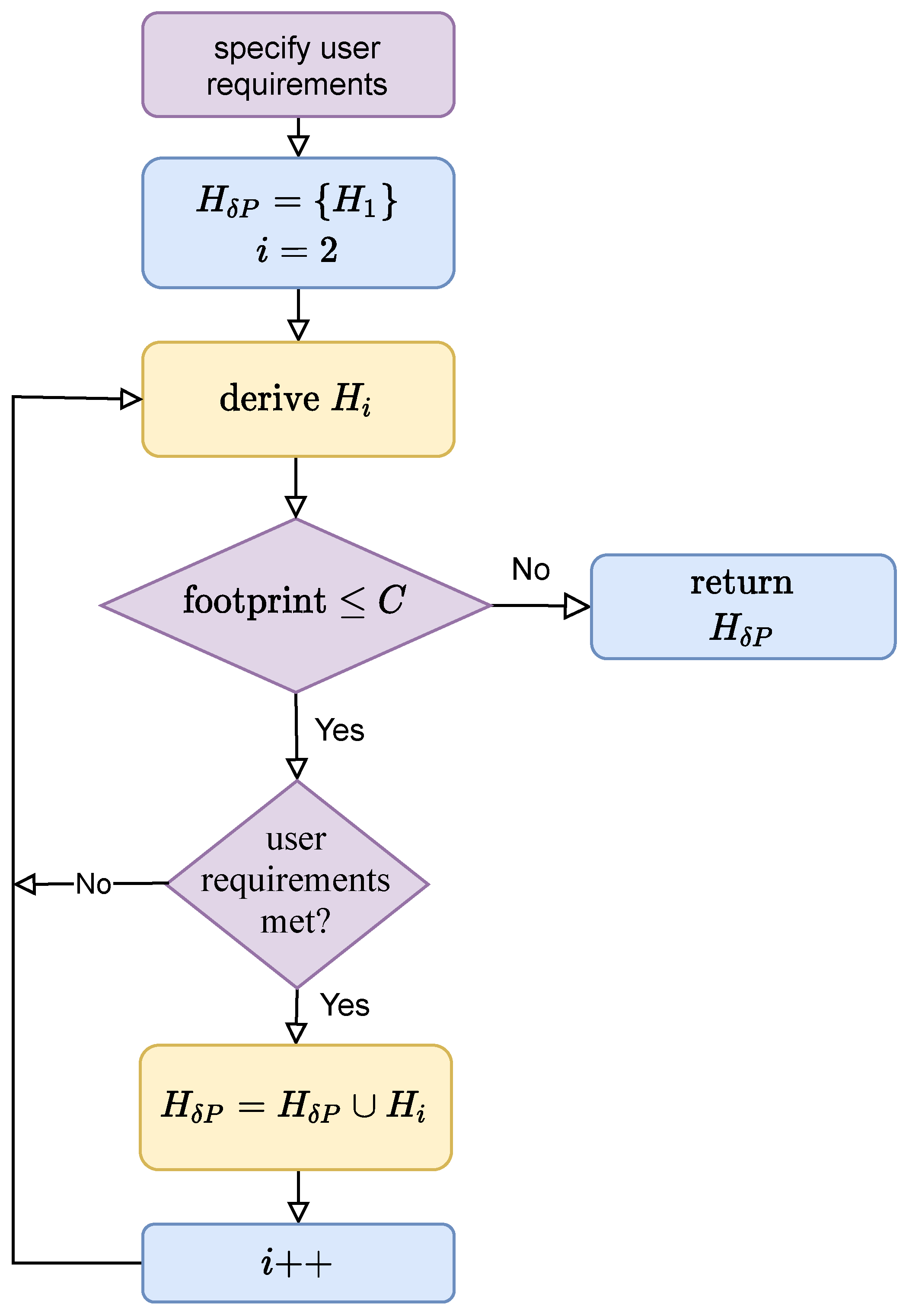
- We first derive a lightweight CNN, , whose accuracy is at least by exploring CNNs with different architectures (defined by their hyper-parameters).
- If the current set of Pareto efficient CNN models is where they are sorted in ascending order of the accuracy and inference time, we search for whose accuracy, , is higher than the accuracy of , , and its inference time, , is not longer than D by incrementally modifying the hyper-parameters of in the neighborhood of the search space to efficiently find .
- We repeat this process until we cannot find a new CNN such that and after a predetermined number of trials.

3.2. Finding -Pareto Optimal CNNs Offline
| Algorithm 1: Deriving -Pareto Optimal CNNs Offline. |
 |
3.3. Efficient Run-Time Selection of a CNN for Timely Image Classification
| Algorithm 2: Run-Time Selection of a CNN Model. |
 |
4. Evaluation Results
4.1. Data Sets and Hyper-Parameters
4.1.1. MNIST Data Set
4.1.2. CIFAR-10 Data Set
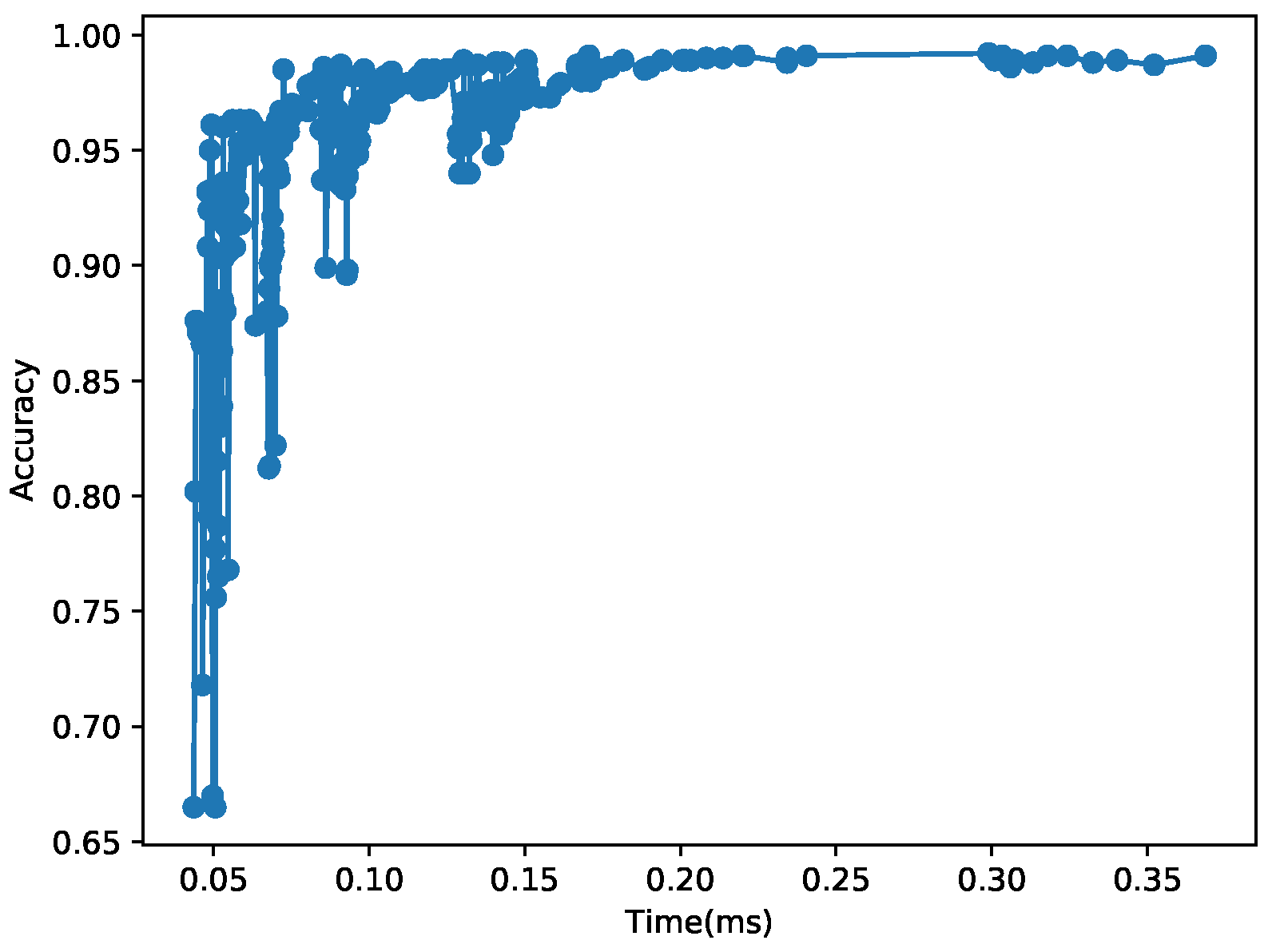
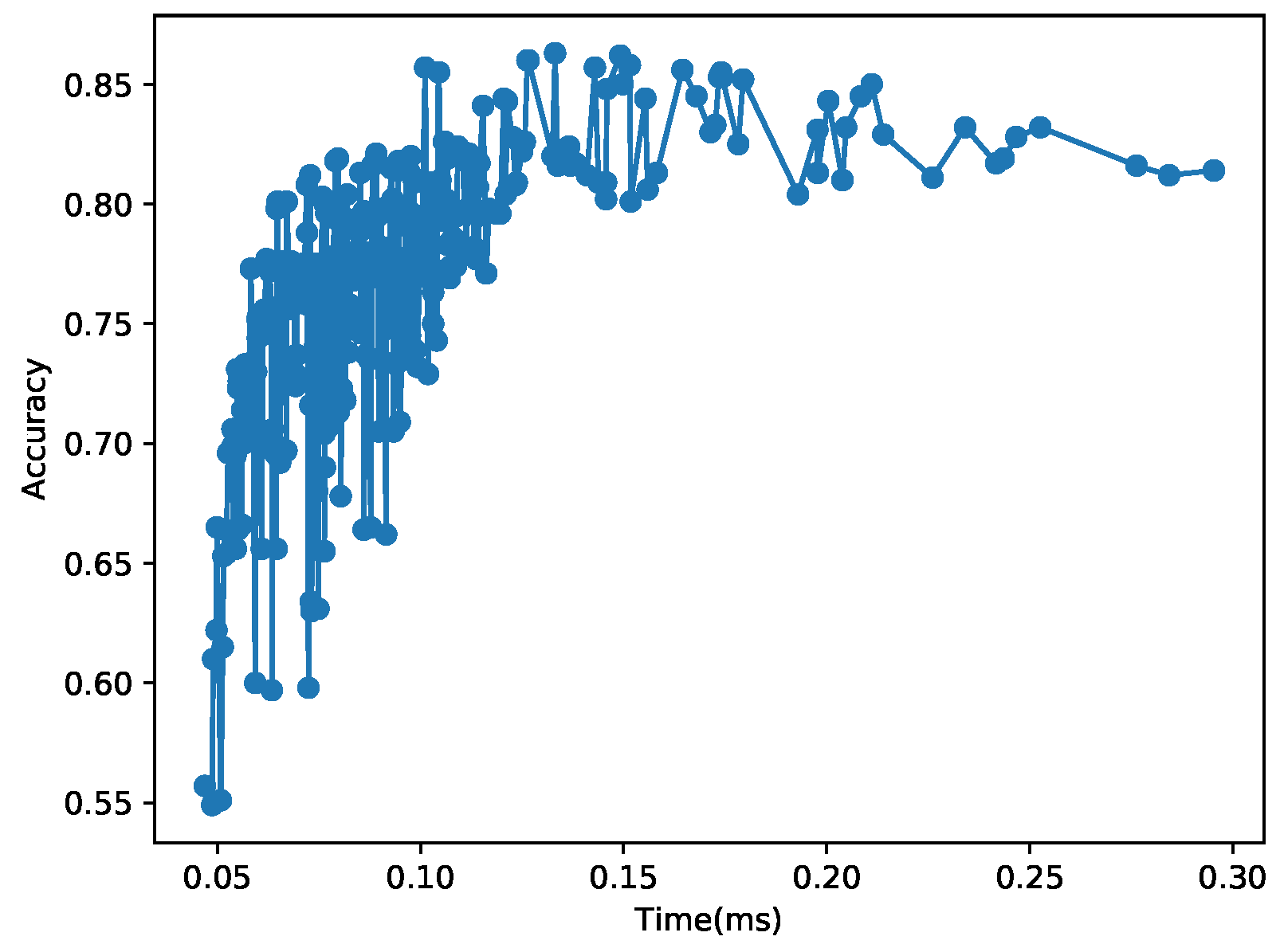
4.2. Impacts of Hyper-Parameters on the Inference Time and Accuracy
4.2.1. Impacts of the Convolutional Kernel and Stride Sizes
4.2.2. Impacts of the Pooling Window and Stride Sizes
4.2.3. Impacts of the Fully Connected Layers
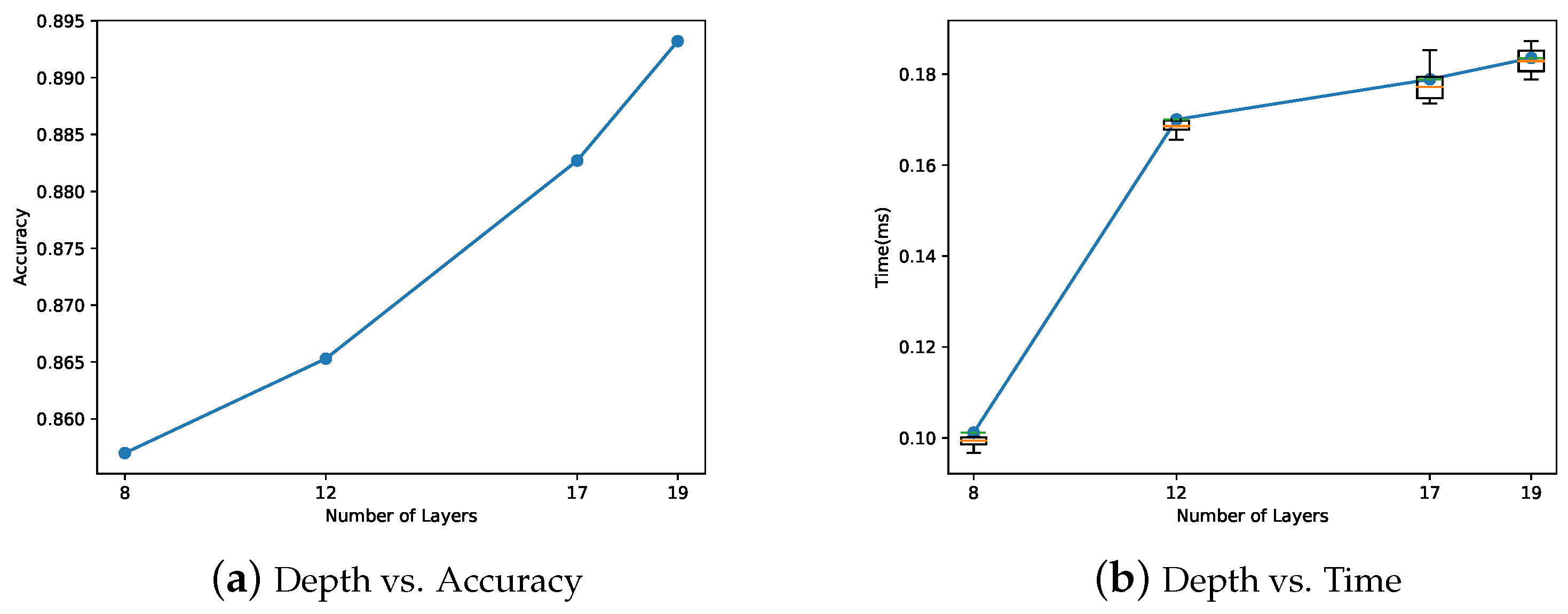
4.2.4. Impacts of the Total Depth
4.2.5. Summary of Time vs. Accuracy Relationships
4.3. Effectiveness of Our Model Selections and Adaptation
4.3.1. Evaluation Using MNIST
4.3.2. Evaluation Using CIFAR-10
4.3.3. Summary of the Effectiveness and Overhead of Our Approach
5. Related Work
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heisenberg, Germany, 2006. [Google Scholar]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Belinkov, Y.; Glass, J. Analysis Methods in Neural Language Processing: A Survey. Trans. Assoc. Comput. Linguist. 2019, 7, 49–72. [Google Scholar] [CrossRef]
- Bhandare, A.; Bhide, M.; Gokhale, P.; Chandavarkar, R. Applications of Convolutional Neural Networks. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 2206–2215. [Google Scholar]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced Deep-Learning Techniques for Salient and Category-Specific Object Detection: A Survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-task Network Cascades. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Landing AI. Available online: https://landing.ai/ (accessed on 20 February 2021).
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); 8689 LNCS; Springer: Berlin/Heisenberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.K.; Du, X.; Ali, I.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. IEEE Commun. Surv. Tutor. 2020, 22, 1646–1685. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.W.; Lin, K.J.; Shih, W.K.; Yu, A.C.S. Algorithms for scheduling imprecise computations. Computer 1991, 24, 58–68. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- TensorFlow. Available online: http://tensorflow.org (accessed on 20 February 2021).
- PyTorch. Available online: http://pytorch.org (accessed on 20 February 2021).
- Kim, J.E.; Bradford, R. AnytimeNet: Controlling Time-Quality Tradeoffs in Deep Neural Network Architectures. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Heo, S.; Cho, S.; Kim, Y.; Kim, H. Real-Time Object Detection System with Multi-Path Neural Networks. In Proceedings of the IEEE Real-Time and Embedded Technology and Applications Symposium, Sydney, Australia, 21–24 April 2020. [Google Scholar]
- LeCun, Y.; Bottou, Y.B.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; MIT Press: London, UK, 2009; Volume 1, p. 7. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Cires, D.C.; Meier, U.; Gambardella, L.M. Deep Big Simple Neural Nets for Hand-written Digit Recognition. Neural Comput. 2010, 22, 3207–3220. [Google Scholar] [CrossRef] [Green Version]
- CIFAR-10-Object Recognition in Images. Available online: https://www.kaggle.com/c/cifar-10 (accessed on 20 February 2021).
- Huang, G.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; 2011; Volume 15, pp. 315–323. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-Training With Noisy Student Improves ImageNet Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Mikhail, B.; Daniel, H.; Partha, M.P. Overfitting or perfect fitting? Risk bounds for classification and regression rules that interpolate. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 4 December 2018; pp. 2306–2317. [Google Scholar]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef] [PubMed]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Proceedings of the International Joint Conference on Neural Networks, Chicago, IL, USA, 15 November 1989; Volume 1, pp. 593–605. [Google Scholar]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the International Symposium on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Wikimedia Commons, Max Pooling. Available online: https://commons.wikimedia.org/wiki/File:Max_pooling.png (accessed on 20 February 2021).
- Buttazzo, G. Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications, 3rd ed.; Springer: Berlin/Heisenberg, Germany, 2011. [Google Scholar]
- Rausch, T.; Avasalcai, C.; Dustdar, S. Portable Energy-Aware Cluster-Based Edge Computers. In Proceedings of the IEEE/ACM Symposium on Edge Computing, Bellevue, WA, USA, 25–27 October 2018. [Google Scholar]
- Womg, A.; Shafiee, M.J.; Li, F.; Chwyl, B. Tiny SSD: A Tiny Single-Shot Detection Deep Convolutional Neural Network for Real-Time Embedded Object Detection. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 9–11 May 2018; pp. 95–101. [Google Scholar]
- Yang, M.; Wang, S.; Bakita, J.; Vu, T.; Smith1, F.D.; Anderson1, J.H.; Frahm, J.M. Re-thinking CNN Frameworks for Time-Sensitive Autonomous-Driving Applications: Addressing an Industrial Challenge. In Proceedings of the Real-Time and Embedded Technology and Applications Symposium, Montreal, QC, Canada, 16–18 April 2019. [Google Scholar]
- Bateni, S.; Liu, C. Apnet: Approximation-aware real-time neural network. In Proceedings of the IEEE Real-Time Systems Symposium (RTSS), Nashville, TN, USA, 11–14 December 2018. [Google Scholar]
- Karlik, B. Performance Analysis of Various Activation Functions in Generalized MLP Architectures of Neural Networks. Int. J. Artif. Intell. Expert Syst. 2011. Available online: https://www.cscjournals.org/manuscript/Journals/IJAE/Volume1/Issue4/IJAE-26.pdf (accessed on 20 February 2021).
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S.Z. FaceBoxes: A CPU real-time face detector with high accuracy. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 1–9. [Google Scholar]
- Liu, L.; Deng, J. Dynamic deep neural networks: Optimizing accuracy-efficiency trade-offs by selective execution. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3675–3682. [Google Scholar]
- Yao, S.; Hao, Y.; Zhao, Y.; Shao, H.; Liu, D.; Liu, S.; Wang, T.; Li, J.; Abdelzaher, T.F. Scheduling Real-time Deep Learning Services as Imprecise Computations. In Proceedings of the IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Gangnueng, Korea, 19–21 August 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Vora, A.; Thomas, P.; Chen, R.; Kang, K. CSI Classification for 5G via Deep Learning. In Proceedings of the IEEE Vehicular Technology Conference, Honolulu, HI, USA, 22–25 September 2019. [Google Scholar]
- Nishihara, R.; Moritz, P.; Wang, S.; Tumanov, A.; Paul, W.; Schleier-Smith, J.; Liaw, R.; Niknami, M.; Jordan, M.I.; Stoica, I. Real-Time Machine Learning: The Missing Pieces. In Proceedings of the Workshop on Hot Topics in Operating Systems, Whistler, BC, Canada, 20–23 May 2017. [Google Scholar]
- Blalock, D.W.; Ortiz, J.J.G.; Frankle, J.; Guttag, J.V. What is the State of Neural Network Pruning? Machine Learning and Systems (MLSys). arXiv 2020, arXiv:2003.03033. [Google Scholar]
- Kim, H.; Khan, M.U.K.; Kyung, C.M. Efficient Neural Network Compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Castro, F.M.; Marin-Jimenez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-End Incremental Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Glowacz, A. Fault diagnosis of electric impact drills using thermal imaging. Measurement 2021, 171, 108815. [Google Scholar] [CrossRef]
- Kuanar, S.; Rao, K.R.; Bilas, M.; Bredow, J. Adaptive CU Mode Selection in HEVC Intra Prediction: A Deep Learning Approach. Circuits Syst. Signal Process. 2019, 38, 5081–5102. [Google Scholar] [CrossRef]
- Kuanar, S.; Mahapatra, D.; Bilas, M.; Rao, K.R. Multi-path dilated convolution network for haze and glow removal in nighttime images. Vis. Comput. 2021, 1–14. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Value |
|---|---|
| #convolutional layers | 2 |
| #channels in the 1st conv. layer | 16 |
| #channels in the 2nd conv. layer | 36 |
| #ReLU layers | 2 |
| #pooling layers | 2 |
| #fully connected layers | 2 |
| #channels in the 1st conv. layer | 64 |
| #channels in the 2nd conv. layer | 64 |
| #convolutional layers | 2 |
| #ReLU layers | 2 |
| #pooling layers | 2 |
| #fully connected layers | 2 |
| Notation | Meaning |
|---|---|
| k | kernel size in the convolutional layers |
| p | pool size in the pooling layers |
| s | stride size for convolution or pooling |
| f | number of neurons in the first fully connected layer |
| d | depth (total number of the layers in a CNN) |
| #Total Layers | #Conv. Layers | #Pooling Layers | #ReLU Layers | #Fully conn. Layers |
|---|---|---|---|---|
| 8 | 2 | 2 | 2 | 2 |
| 12 | 4 | 4 | 2 | 2 |
| 17 | 6 | 6 | 3 | 2 |
| 19 | 8 | 6 | 3 | 2 |
| d | k | p | s | f | Size (KB) | |||
|---|---|---|---|---|---|---|---|---|
| 48.84 | 0.950 | 8 | 3 × 3 | 3 × 3 | 4 | 114 | 276 | |
| 49.38 | 0.961 | 8 | 3 × 3 | 3 × 3 | 4 | 128 | 302 | |
| 56.15 | 0.963 | 8 | 3 × 3 | 5 × 5 | 4 | 114 | 276 | |
| 71.45 | 0.966 | 8 | 5 × 5 | 7 × 7 | 6 | 140 | 257 | |
| 71.49 | 0.967 | 8 | 5 × 5 | 7 × 7 | 8 | 128 | 250 | |
| 72.51 | 0.985 | 8 | 3 × 3 | 3 × 3 | 2 | 128 | 2791 | |
| 85.36 | 0.986 | 8 | 3 × 3 | 5 × 5 | 2 | 128 | 2791 | |
| 90.95 | 0.987 | 8 | 3 × 3 | 5 × 5 | 2 | 114 | 2492 | |
| 130.33 | 0.989 | 8 | 5 × 5 | 3 × 3 | 2 | 128 | 2904 | |
| 170.60 | 0.991 | 8 | 5 × 5 | 7 × 7 | 2 | 114 | 2606 | |
| 298.99 | 0.992 | 8 | 9 × 9 | 3 × 3 | 2 | 140 | 3558 |
| d | k | p | s | f | KB | |||
|---|---|---|---|---|---|---|---|---|
| 71.97 | 0.808 | 8 | 3 × 3 | 5 × 5 | 4 | 320 | 1902 | |
| 72.85 | 0.812 | 8 | 3 × 3 | 5 × 5 | 4 | 448 | 1960 | |
| 79.05 | 0.818 | 8 | 5 × 5 | 3 × 3 | 4 | 384 | 1927 | |
| 79.72 | 0.819 | 8 | 5 × 5 | 3 × 3 | 4 | 448 | 1927 | |
| 89.11 | 0.821 | 8 | 5 × 5 | 5 × 5 | 4 | 448 | 2254 | |
| 101.15 | 0.857 | 8 | 3 × 3 | 3 × 3 | 2 | 320 | 7997 | |
| 126.31 | 0.86 | 8 | 5 × 5 | 3 × 3 | 2 | 448 | 7251 | |
| 133.14 | 0.863 | 8 | 5 × 5 | 3 × 3 | 2 | 320 | 7241 | |
| 170.04 | 0.865 | 12 | 3 × 3 | 3 × 3 | 2 | 512 | 10,593 | |
| 178.87 | 0.882 | 17 | 3 × 3 | 3 × 3 | 2 | 512 | 20,049 | |
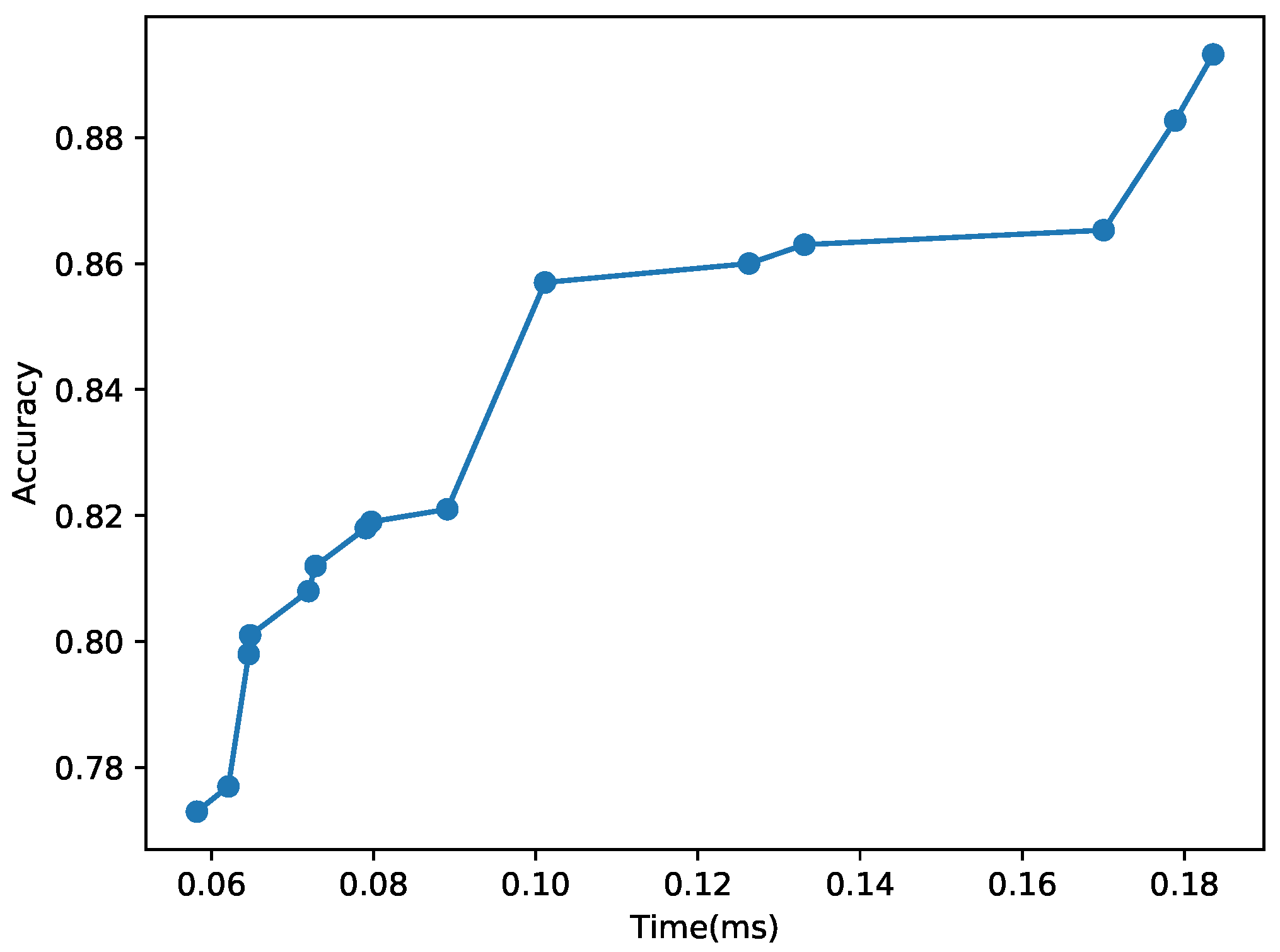
| 183.55 | 0.893 | 19 | 3 × 3 | 3 × 3 | 2 | 512 | 38,958 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, F.; Kang, K.-D. Adaptive Deep Learning for Soft Real-Time Image Classification. Technologies 2021, 9, 20. https://doi.org/10.3390/technologies9010020
Chai F, Kang K-D. Adaptive Deep Learning for Soft Real-Time Image Classification. Technologies. 2021; 9(1):20. https://doi.org/10.3390/technologies9010020
Chicago/Turabian StyleChai, Fangming, and Kyoung-Don Kang. 2021. "Adaptive Deep Learning for Soft Real-Time Image Classification" Technologies 9, no. 1: 20. https://doi.org/10.3390/technologies9010020
APA StyleChai, F., & Kang, K. -D. (2021). Adaptive Deep Learning for Soft Real-Time Image Classification. Technologies, 9(1), 20. https://doi.org/10.3390/technologies9010020