
Using Value-Based Potentials for Making Approximate Inference on Probabilistic Graphical Models

 , , , and
, , , and
Abstract
:1. Introduction
- Qualitative component, given by a directed, acyclic graph (DAG), where each node represents a random variable, and the presence of an edge connecting two of these implies mutual dependency.
- Quantitative component, given by a set of parameters that quantify the degree of dependence between the variables.
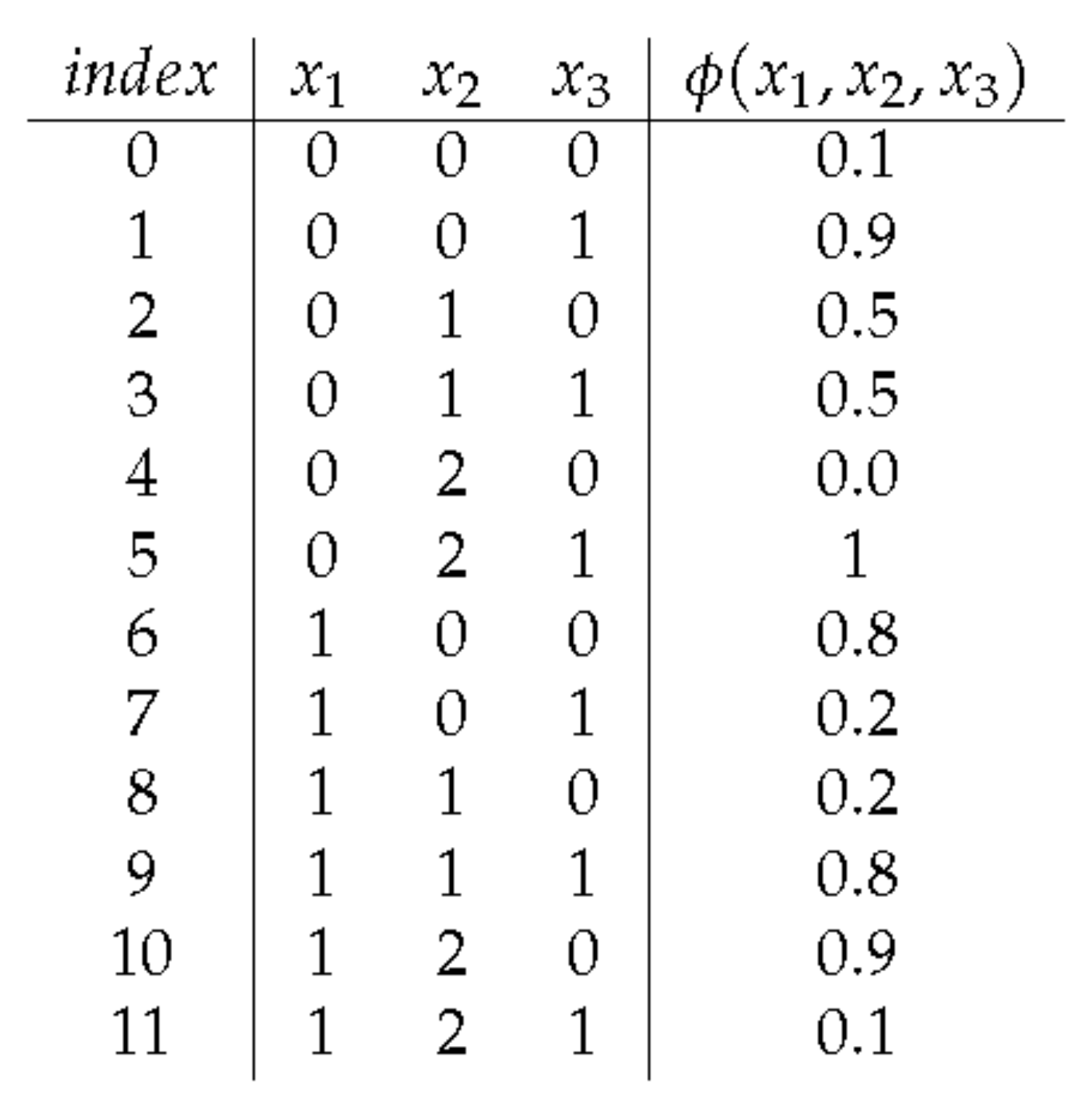
2. Basic Definitions and Notation
3. Representation of Potentials
3.1. Classic Structures
3.1.1. 1D-Arrays
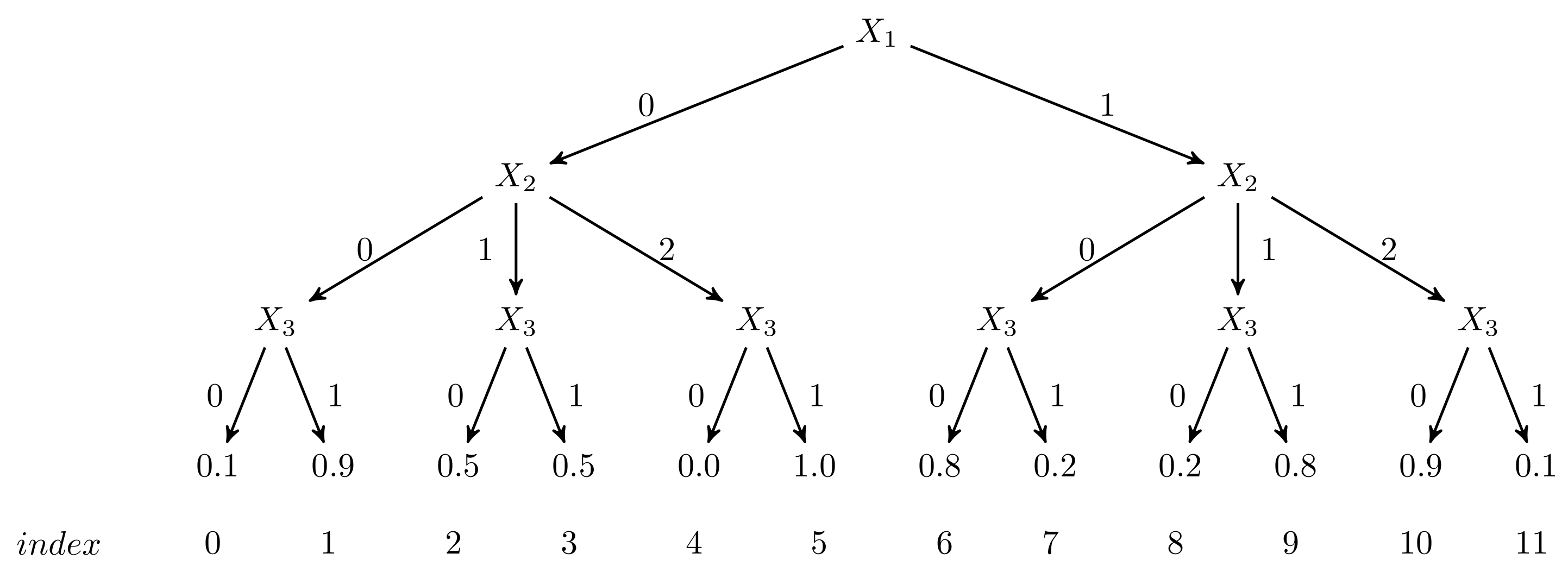
3.1.2. Probability Trees
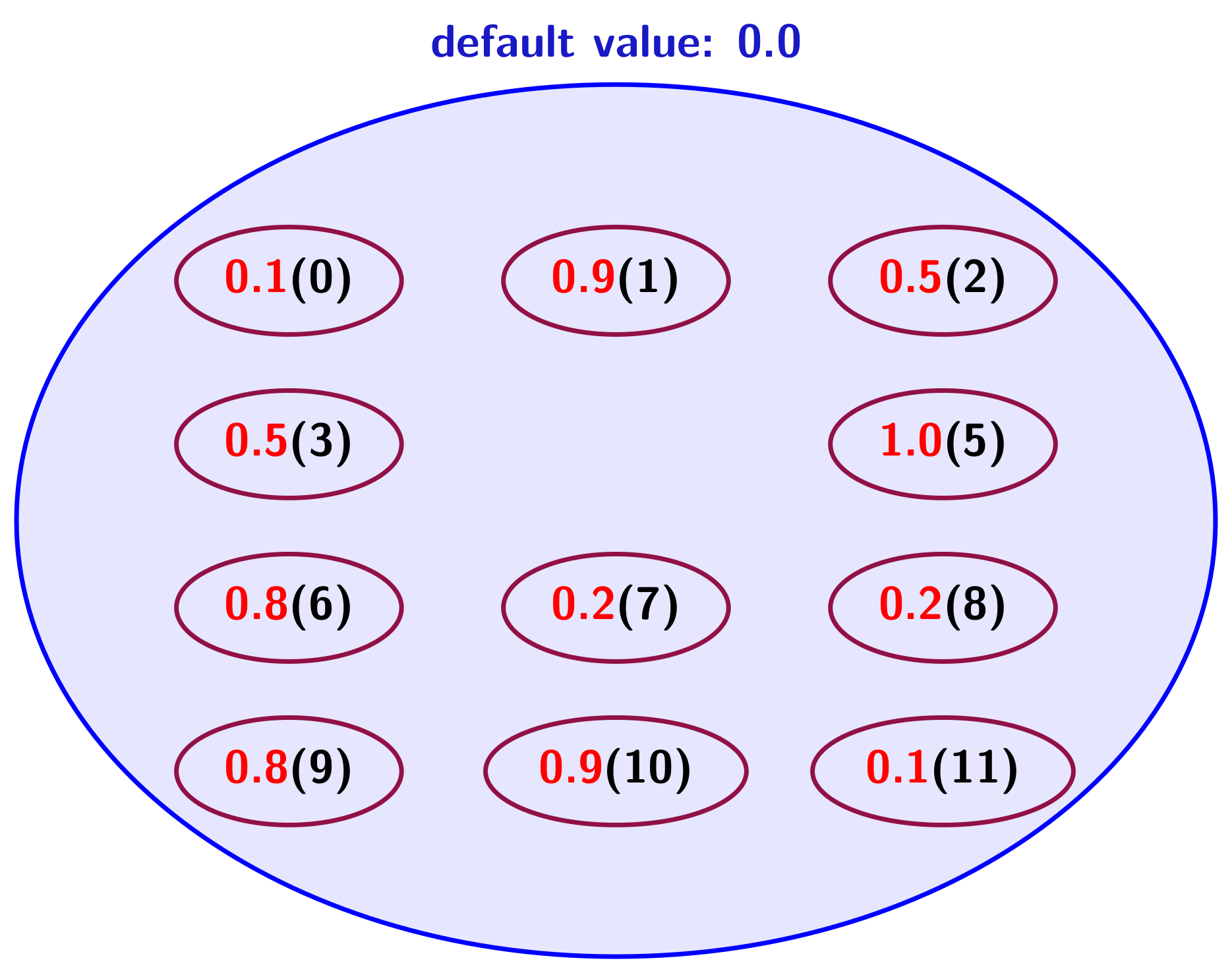
3.2. Alternative Structures: Value-Based Potentials
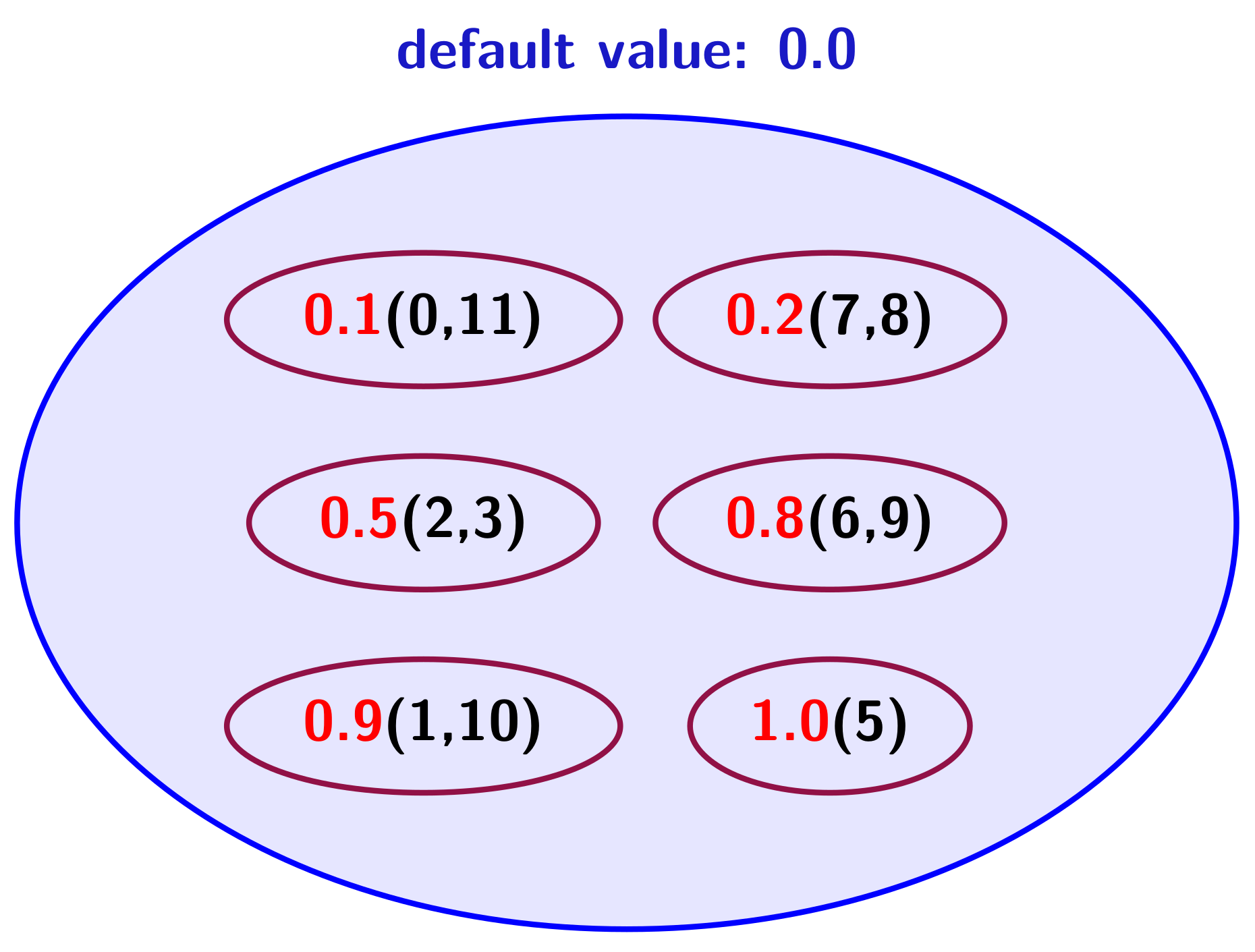
- Structures driven by values, using dictionaries in which the keys will be values: value-driven with grains (VDG) and value-driven with indices (VDI).
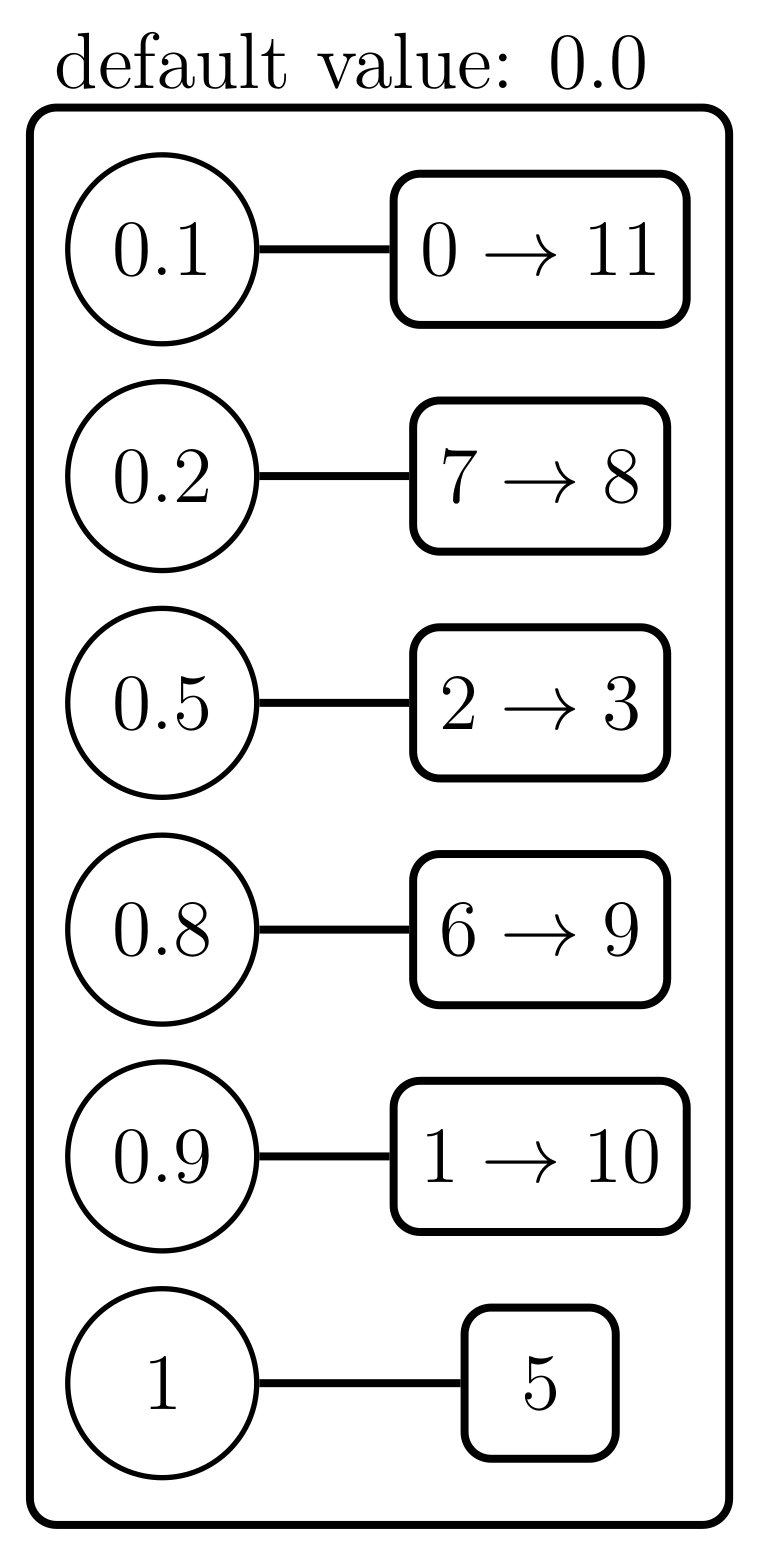
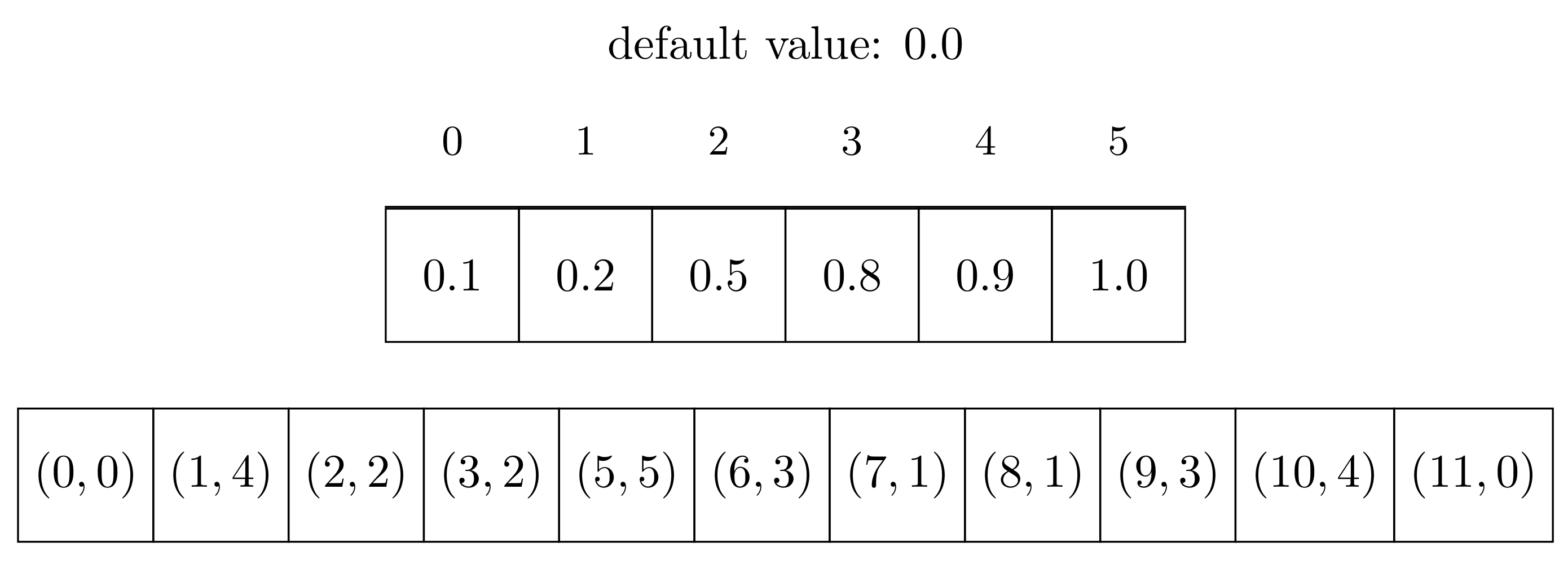
- Structures driven by indices, where keys are indices: index-driven with pair of arrays (IDP) and index-driven with map (IDM).
3.2.1. VDI: Value-Driven with Indices
3.2.2. IDP: Index-Driven with Pair of Arrays
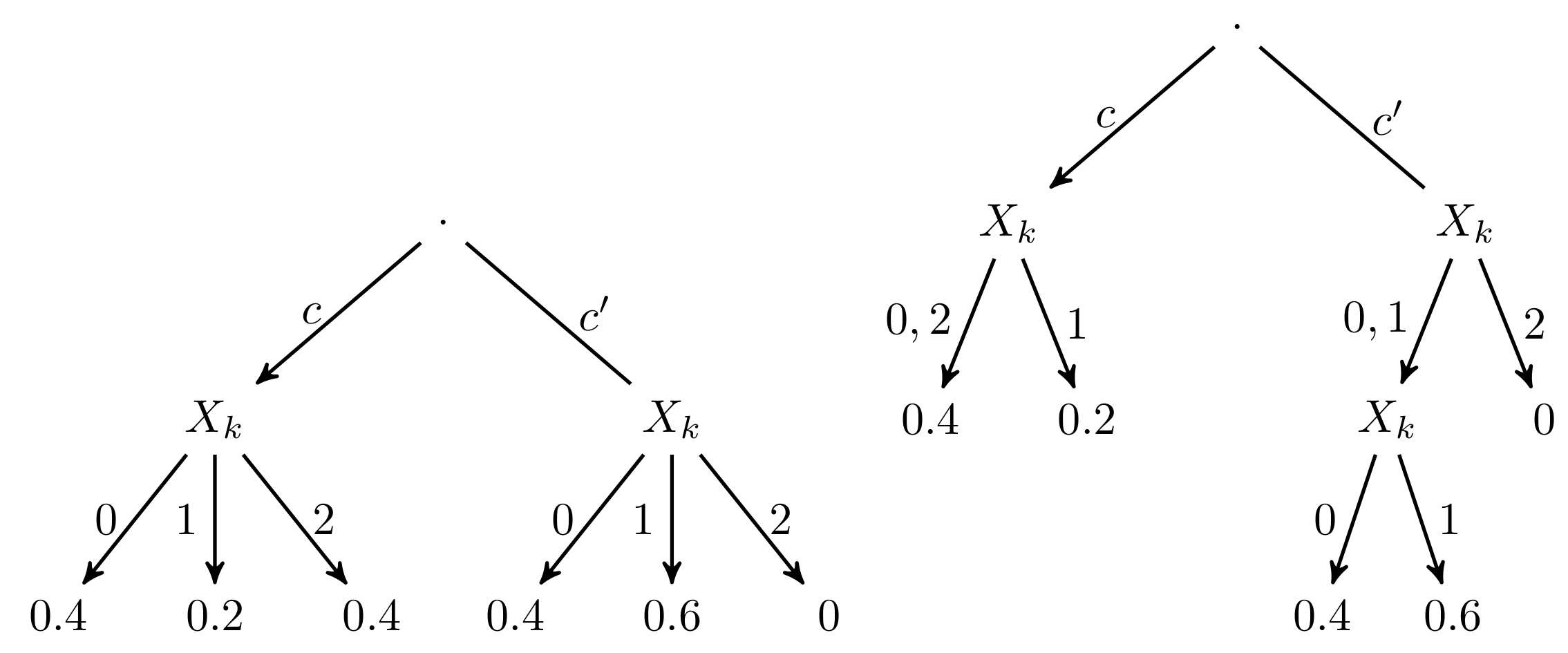
4. Approximating Value-Based Potentials
4.1. Algorithm
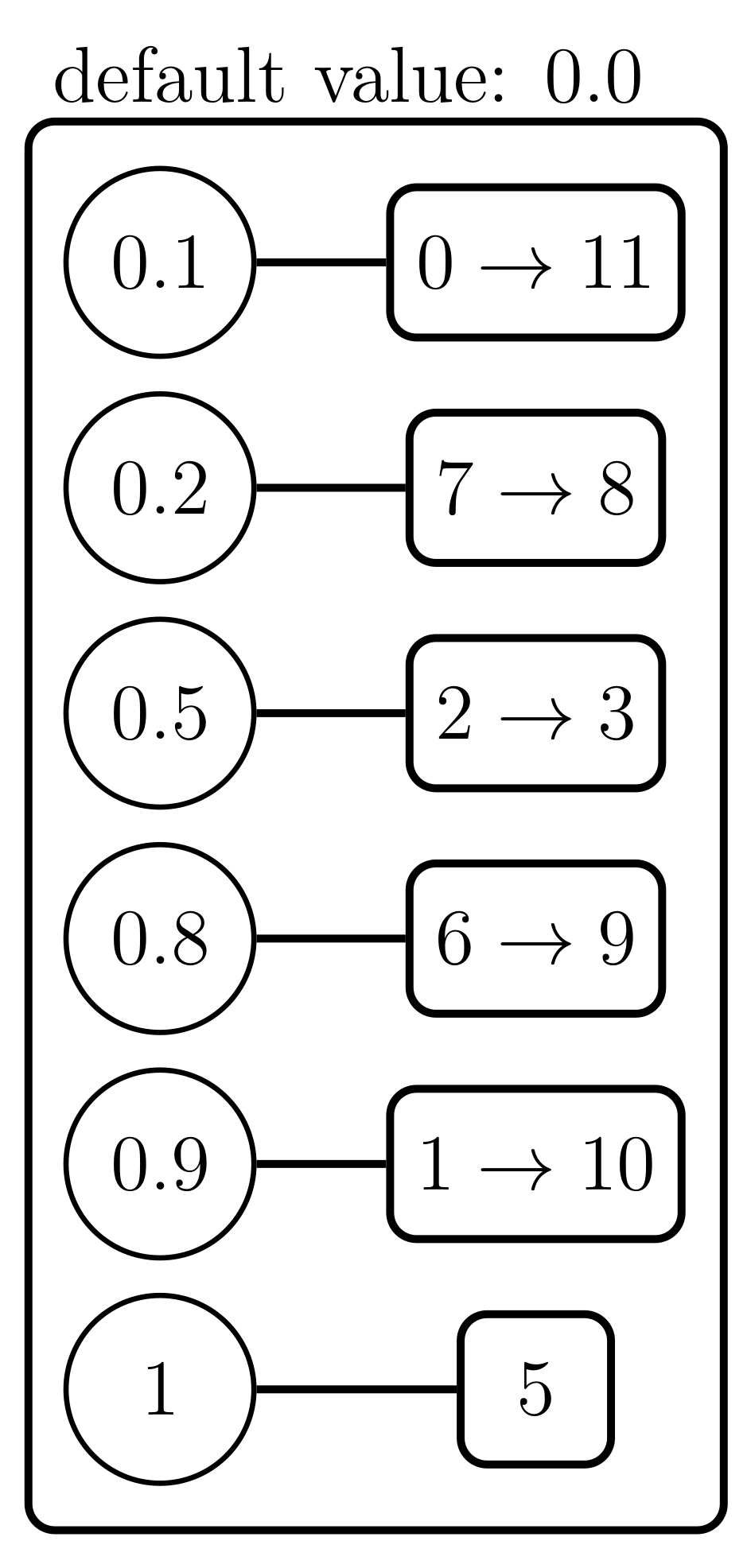
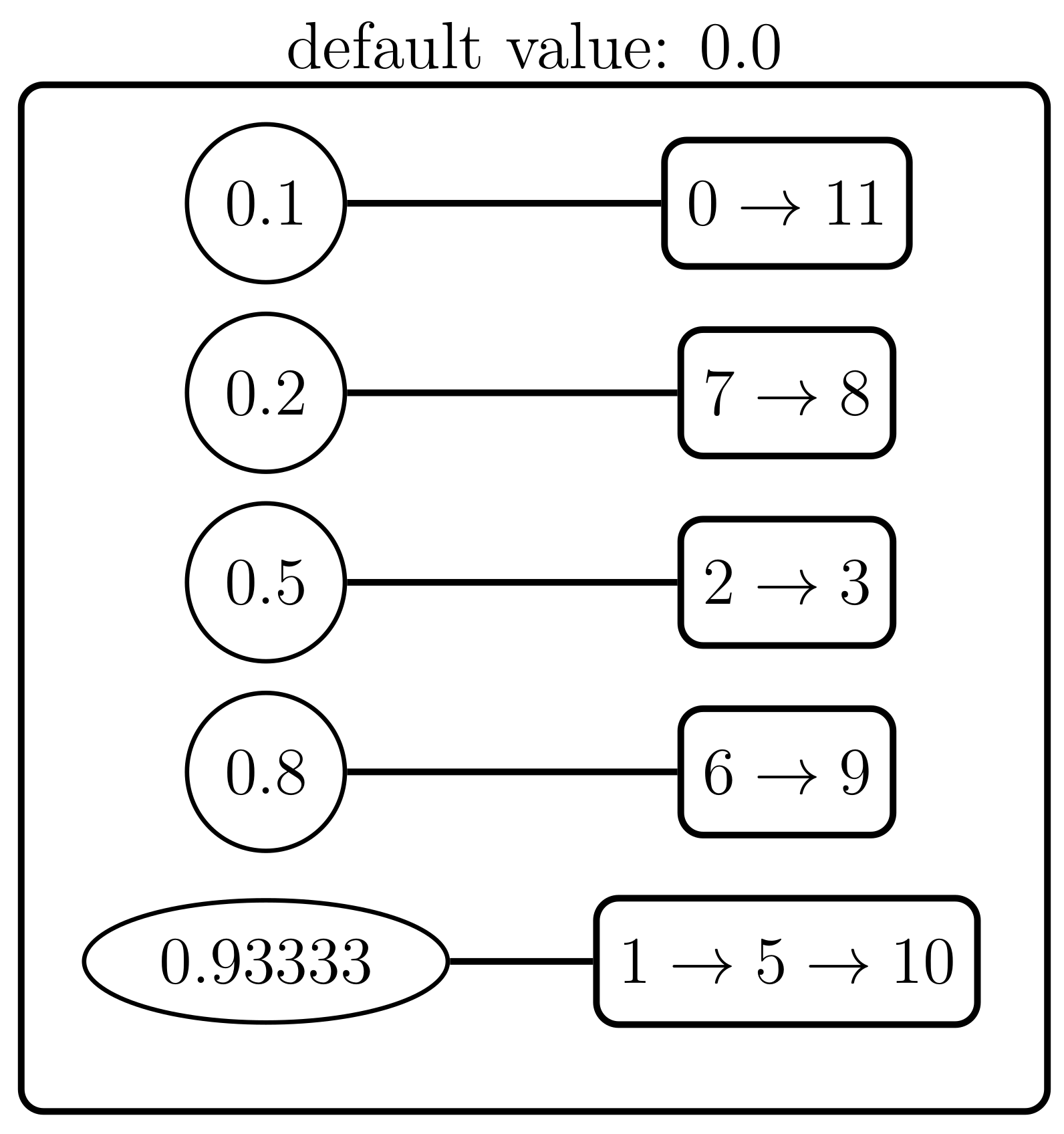
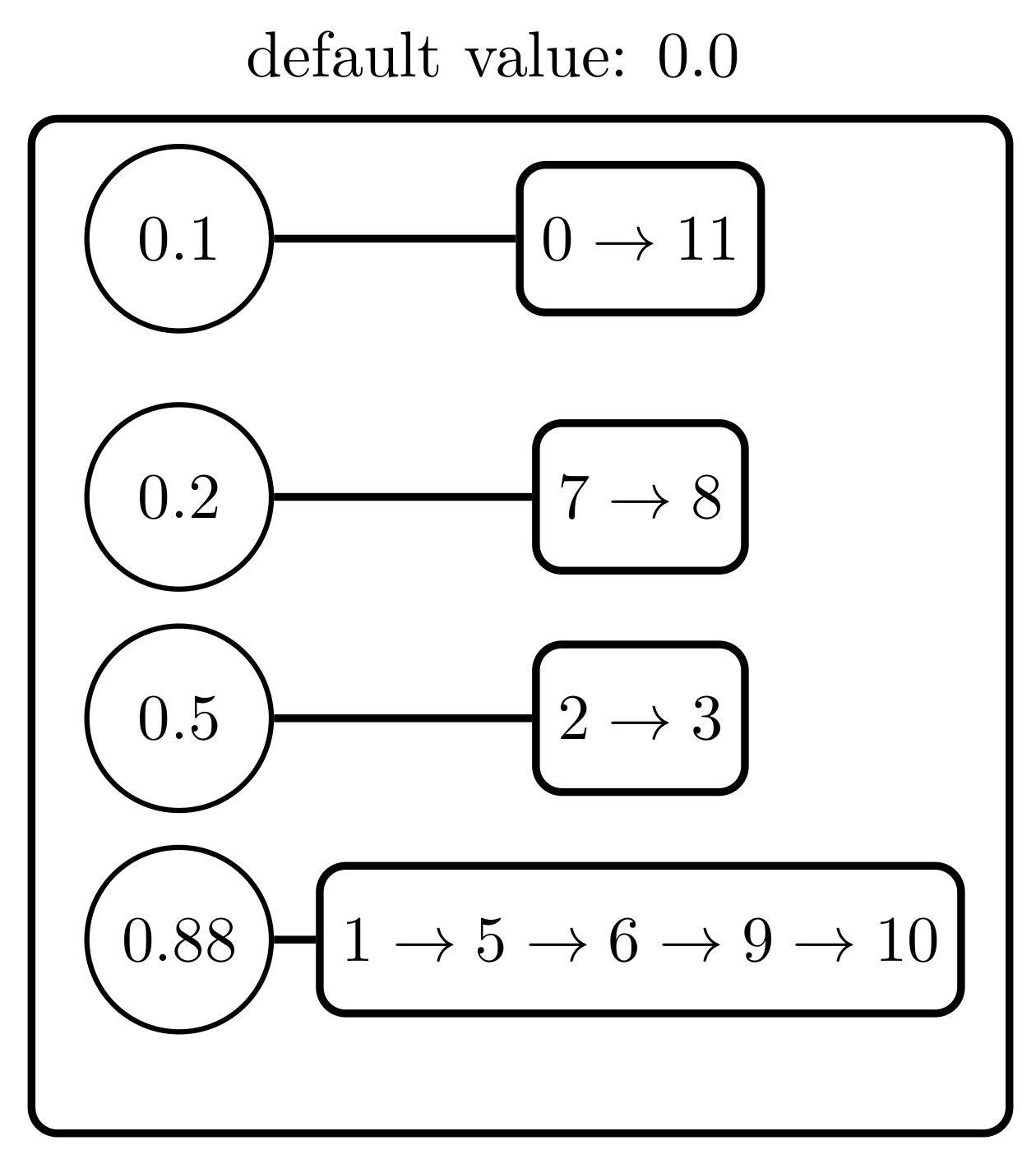
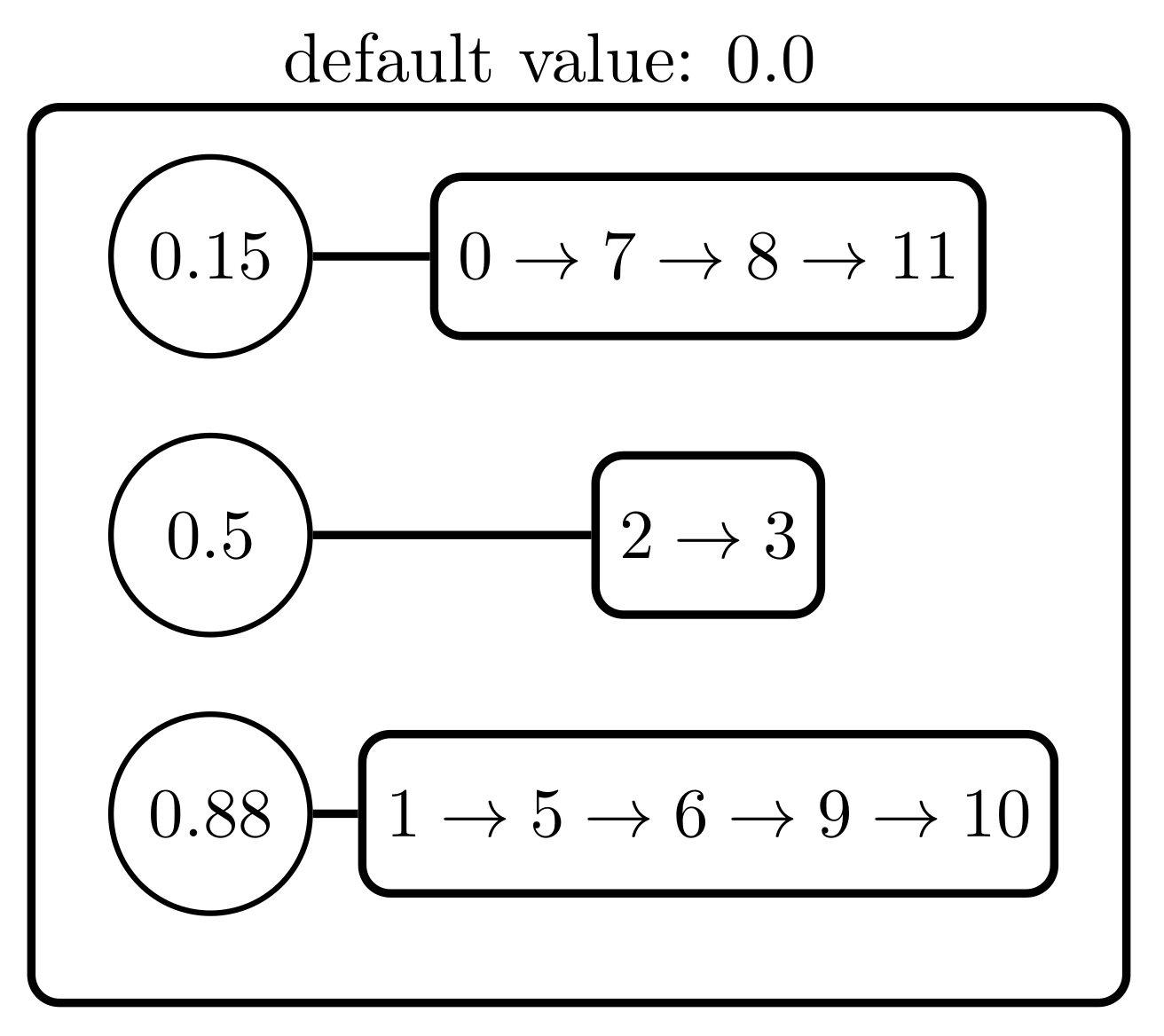
- and will be the values to reduce with and as their sets of indices, with and .
- is the new value that replaces and , with and . This value is computed as:
- It is important to observe that this operation does not modify the total sum of the potential values. Therefore, if ϕ is the original potential and V the result of successive reductions, then .
- 1
- There are a number of different approximation alternatives resulting in candidate structures which will become the one chosen for the final approximation. As there are n different values, there will be candidate structures produced by reducing every pair of consecutive values. Iterate from to :
- 1.1
- Let us consider two successive values: and . The candidate structure is then obtained by reducing both values as previously explained in Definition 1. The result of this operation will be .
- 1.2
- Calculate the Kullback–Leibler divergence between the original potential V and . This value is denoted by .
- 2
- Select the candidate structure .
- 3
- Repeat the previous steps until the selected stopping condition has been satisfied.
- It is evident that it is not necessary to build the candidate structures but only to evaluate the loss of information of the corresponding reduction operations.
- The Kullback–Leibler divergence between a candidate structure and the original one can be computed by taking into account only those values and indices involved in the reduction, and the measure to compute is in fact the loss of information produced by this operation. The way to compute this measure will be explained below.
- A possible stopping criteria (this is the one used in the experimental work although others could be considered) consists of setting a global information loss threshold, . Therefore, the procedure of reducing consecutive values will continue as long as the addition of information losses does not reach the threshold .
4.2. Theoretical Background
| Algorithm 1: Approximation of a potential represented as V (VBP). |
|
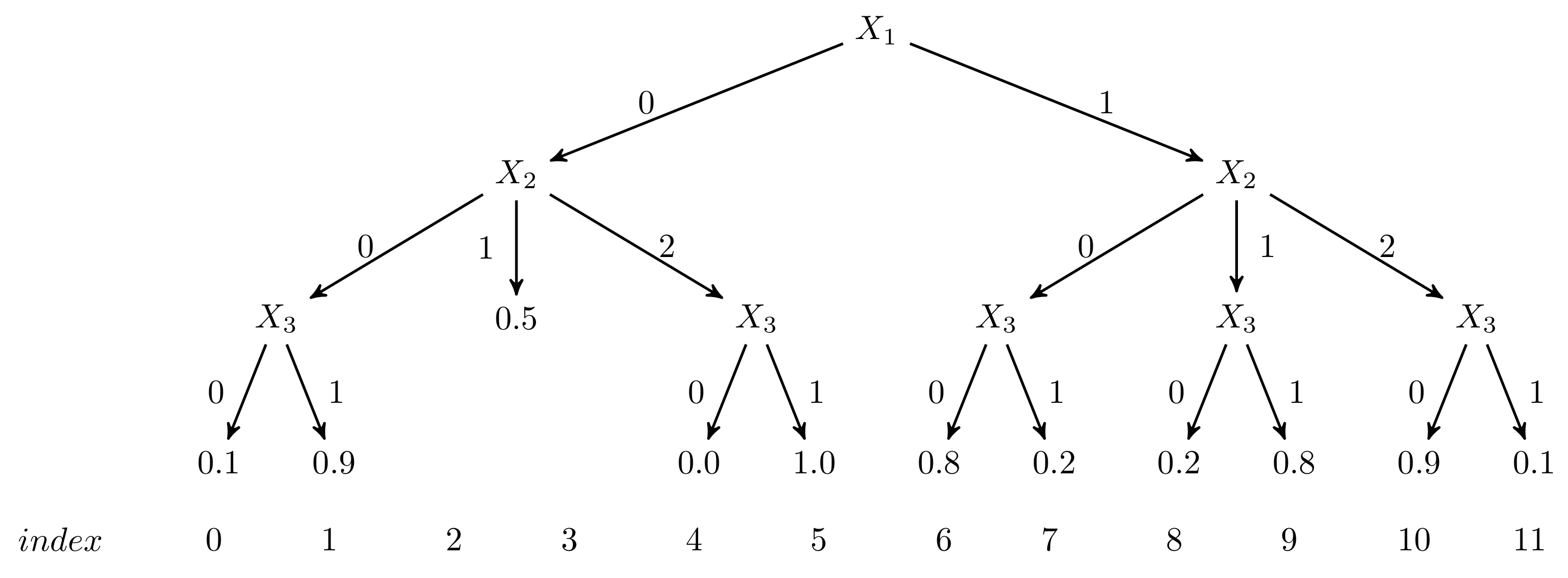
4.3. Example
5. Empirical Evaluation
- pathfinder [24] is a system which, when combined with expert knowledge from surgical pathologists, can assist in the diagnosis of lymphnode diseases. As a result of this study, the discrete pathfinder network was defined.
- The munin network was defined while creating the expert system identified by the same acronym MUNIN (MUscle and Nerve Inference Network) [25]. The aim of this system was to help electromyographics (EMCs), which are designed to localize and characterize lesions of the neuro-muscular system, from a patho-physiological approach combined with expert knowledge.
- The diabetes [26] BN represents a differential equation model which attempts to adjust the insulin therapy for diabetic people. The model considers the patient’s state by measuring blood glucose, biologically active insulin, and the amount of undigested carbohydrate within an hour gap in addition to other known variables involved in the glucose metabolism process. The diabetes network enabled predictions to be extended to 24-h blood glucose profiles and the insulin treatment to be adjusted.
- 1.
- Analysis of the memory space necessary to store the complete networks using the different representation alternatives in order to compare it with the representation using 1DA, since this is considered to be the base representation (see Section 5.1).
- 2.
- Analysis of the main characteristics of the specific potentials of some variables that will later be used to perform inference, as well as the memory space necessary for their representation with the different structures considered (see Section 5.2).
- 3.
- Examination of the effect of the approximation on the memory space necessary for the storage of each network (see Section 5.3). The relationship with the memory space required by the base representation is determined, as well as the reduction produced in relation to the alternative representations but without any approximation. In this case, the results are presented by means of a specific table for each network in order to collect the information on the threshold values considered.
- 4.
- Propagation errors produced by the approximation, both local (only the potential of the target variable is approximated) and global (all potentials are approximated) (see Section 5.4). A table is presented for each network and this collects the results for the selected variables and for the set of thresholds used.
- 5.
- In order to obtain further information about the effect of the approximation, some charts are also included to show the effect of the approximation on the order of the probabilities of the marginal distributions obtained as a result of the propagation. If these distributions are used to make decisions, it is important that the alternatives are kept in the same order (according to their probability value) in which they appear in the exact result, without approximation (see Section 5.5).
5.1. Global Memory Size Analysis
- network: name of the network;
- 1DA: memory size indispensable for 1DA storing the complete set of potentials;
- PT: memory size required for PT representation and the saving or increase in space in terms of 1DA. This last value is included in the second line and is computed as
- where refers to the memory size of the alternative representation, and to the memory size of the 1DA representation;
- PPT, VDI, and IDP: the same as the previous line for the remaining representations: pruned probability trees, VDI and IDP.
- In hepar2, we can see that PPT offers little improvement in relation to PT, which indicates that in reality there are few repeated values that can be used by the PPT pruning operation. The VDI structure provides a saving of approximately compared to PT, while IPD represents a saving of .
- In the case of pathfinder, there are notable savings in relation to 1DA and very important ones with respect to PT and PPT. The biggest savings come from the VDI structure.
- With respect to the munin network, VDI representation needs almost the same memory space as 1DA and there is a saving of about in IDP (moreover, significant reductions can also be seen with respect to PT and PPT).
- Finally, for diabetes, both VBP structures represent a substantial reduction in memory space and this is slightly greater in the case of VDI.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | 1DA | PT | PPT | VDI | IDP |
|---|---|---|---|---|---|
| hepar2 | 32,530 | 132,026 | 131,756 | 74,070 | 49,602 |
| 305.8592 | 305.0292 | 127.6975 | 52.4808 | ||
| pathfinder | 806,982 | 4,249,768 | 3,779,470 | 301,602 | 482,438 |
| 426.6249 | 368.3463 | −40.2170 | |||
| munin | 994,672 | 3,393,878 | 3,353,900 | 997,864 | 766,072 |
| 241.2057 | 237.1865 | 0.3209 | |||
| diabetes | 3,773,200 | 10,044,948 | 10,044,810 | 964,380 | 1,105,728 |
| 166.2183 | 166.2146 | −70.6952 |
5.2. Local Memory Size Analysis
- network: name of the network;
- variable: name of the variable being examined;
- np: global number of parameters of the target variable potential;
- nd: number of different values in the potential (these are the values actually stored in the VBP representation);
- 1DA: memory size for the 1DA representation;
- PT: memory size required for PT representation and saving or increase regarding 1DA. This last value is included in the second line and computed as before;
- PPT, VDI, and IDP: the same as the previous line for PPT, VDI, and IDP.
- In hepar2 variables, the number of different probability values is slightly lower than the number of parameters. This justifies the fact that memory space requirements do not reduce those required by 1DA, although they do offer significant savings with respect to PT and PPT.
- Selected pathfinder variables present a high degree of repetition, so the number of different values is significantly lower than the number of parameters. This produces very significant memory savings in relation to 1DA which are larger in the case of VDI.
- For the first two munin variables, there are only 12 different values but 600 parameters. This accounts for the notable memory space savings for VBP structures. In the case of the third variable, there are more different values (133), although this does suppose a high degree of repetition compared to the 600 necessary parameters.
- Diabetes variables have similar characteristics: only 45 different values (and 7056 possible values). Consequently, the memory space savings are very noticeable and appreciably better in the case of VDI.
| Network | Variable | np | nd | 1DA | PT | PPT | VDI | IDP |
|---|---|---|---|---|---|---|---|---|
| hepar2 | ggtp | 384 | 334 | 3454 | 19,452 463.1731 | 19,452 463.1731 | 9990 189.2299 | 6150 78.0544 |
| ast | 288 | 231 | 2636 | 13,648 417.7542 | 13,648 417.7542 | 7084 168.7405 | 4508 71.0167 | |
| alt | 288 | 249 | 2636 | 13,648 417.7542 | 13,648 417.7542 | 7516 185.1290 | 4652 76.4795 | |
| bilirubin | 288 | 244 | 2636 | 13,426 409.3323 | 13,426 409.3323 | 7396 180.5766 | 4612 74.9621 | |
| pathfinder | F39 | 8064 | 30 | 64,794 | 376,442 480.9828 | 359,850 455.3755 | 15,114 −76.6738 | 28,698 −55.7089 |
| F74 | 7560 | 111 | 60,712 | 293,736 383.8187 | 152,072 150.4810 | 28,676 −52.7672 | 52,632 −13.3087 | |
| F40 | 4032 | 43 | 32,488 | 116,076 257.2888 | 114,588 252.7087 | 5640 −82.6397 | 9280 −71.4356 | |
| munin | v1 | 600 | 12 | 5032 | 19,132 280.2067 | 19,132 280.2067 | 1112 −77.9014 | 1464 −70.9062 |
| v2 | 600 | 12 | 5032 | 19,132 280.2067 | 19,132 280.2067 | 1112 −77.9014 | 1464 −70.9062 | |
| v3 | 600 | 133 | 4982 | 15,012 201.3248 | 15,012 201.3248 | 4066 −18.3862 | 2582 −48.1734 | |
| diabetes | cho_0 | 7056 | 45 | 56,630 | 139,546 146.4171 | 139,546 146.4171 | 9454 −83.3057 | 16,878 −70.1960 |
| cho_1 | 7056 | 45 | 56,630 | 139,546 146.4171 | 139,546 146.4171 | 9454 −83.3057 | 16,878 −70.1960 | |
| cho_2 | 7056 | 45 | 56,630 | 139,546 146.4171 | 139,546 146.4171 | 9454 −83.3057 | 16,878 −70.1960 |
5.3. Global Memory Size with Approximation
- The first column shows the threshold.
- The second presents data relating to the VDI structure: memory size after approximation, savings over 1DA and savings with respect to the exact VDI representation.
- The third column is identical to the second but with data for the IDP structure.
5.3.1. hepar2 Network
| Threshold | VDI | IDP |
|---|---|---|
| 0.00001 | 63,846 (96.2681/−13.8032) | 46,194 (42.0043/−6.8707) |
| 0.00005 | 58,062 (78.4875/−21.6120) | 44,266 (36.0775/−10.7576) |
| 0.00010 | 55,302 (70.0031/−25.3382) | 43,346 (33.2493/−12.6124) |
| 0.00050 | 48,558 (49.2714/−34.4431) | 41,098 (26.3388/−17.1445) |
| 0.00100 | 45,678 (40.4181/−38.3313) | 40,138 (23.3876/−19.0799) |
| 0.00500 | 39,798 (22.3425/−46.2697) | 38,178 (17.3624/−23.0313) |
| 0.01000 | 37,518 (15.3335/−49.3479) | 37,418 (15.0261/−24.5635) |
| 0.05000 | 33,798 (3.8979/−54.3702) | 36,178 (11.2143/−27.0634) |
| 0.10000 | 32,550 (0.0615/−56.0551) | 35,762 (9.9354/−27.9021) |
| Threshold | VDI | IDP |
|---|---|---|
| 0.00001 | 293,178 (−63.6698/−2.7931) | 479,630 (−40.5650/−0.5820) |
| 0.00005 | 290,682 (−63.9791/−3.6207) | 478,798 (−40.6681/−0.7545) |
| 0.00010 | 289,266 (−64.1546/−4.0902) | 478,326 (−40.7266/−0.8523) |
| 0.00050 | 285,450 (−64.6275/−5.3554) | 477,054 (−40.8842/−1.1160) |
| 0.00100 | 283,170 (−64.9100/−6.1114) | 476,294 (−40.9784/−1.2735) |
| 0.00500 | 277,002 (−65.6743/−8.1564) | 474,238 (−41.2331/−1.6997) |
| 0.01000 | 274,050 (−66.0401/−9.1352) | 473,254 (−41.3551/−1.9037) |
| 0.05000 | 267,090 (−66.9026/−11.4429) | 470,934 (−41.6426/−2.3846) |
| 0.10000 | 264,450 (−67.2298/−12.3182) | 470,054 (−41.7516/−2.5670) |
| Threshold | VDI | IDP |
|---|---|---|
| 0.00001 | 880,744 (−11.4538/−11.7371) | 727,032 (−26.9074/−5.0961) |
| 0.00005 | 829,096 (−16.6463/−16.9129) | 709,816 (−28.6382/−7.3434) |
| 0.00010 | 800,584 (−19.5128/−19.7702) | 700,312 (−29.5937/−8.5840) |
| 0.00050 | 725,440 (−27.0674/−27.3007) | 675,264 (−32.1119/−11.8537) |
| 0.00100 | 692,296 (−30.3996/−30.6222) | 664,216 (−33.2226/−13.2959) |
| 0.00500 | 615,976 (−38.0725/−38.2705) | 638,776 (−35.7802/−16.6167) |
| 0.01000 | 587,848 (−40.9003/−41.0894) | 629,400 (−36.7229/−17.8406) |
| 0.05000 | 533,728 (−46.3413/−46.5130) | 611,360 (−38.5365/−20.1955) |
| 0.10000 | 518,272 (−47.8952/−48.0619) | 606,208 (−39.0545/−20.8680) |
- For VDI, it is apparent that there is a very noticeable increase in memory space savings as the threshold used for the approximation becomes greater, reaching very similar sizes to those of 1DA for the threshold 0.1. For every threshold, there is a reduction in relation to the exact VDI structure (without the use of approximation).
- With the IDP structure, the behavior is similar, although the reductions are not as notable as with VDI.
| Threshold | VDI | IDP |
|---|---|---|
| 0.00001 | 843,180 (−77.6535/−12.5677) | 1,065,328 (−71.7659/−3.6537) |
| 0.00005 | 799,932 (−78.7996/−17.0522) | 1,050,912 (−72.1480/−4.9575) |
| 0.00010 | 776,868 (−79.4109/−19.4438) | 1,043,224 (−72.3517/−5.6527) |
| 0.00050 | 719,148 (−80.9406/−25.4290) | 1,023,984 (−72.8617/−7.3928) |
| 0.00100 | 694,908 (−81.5831/−27.9425) | 1,015,904 (−73.0758/−8.1235) |
| 0.00500 | 644,076 (−82.9302/−33.2135) | 998,960 (−73.5249/−9.6559) |
| 0.01000 | 626,172 (−83.4047/−35.0700) | 992,992 (−73.6830/−10.1956) |
| 0.05000 | 594,324 (−84.2488/−38.3724) | 982,376 (−73.9644/−11.1557) |
| 0.10000 | 585,636 (−84.4791/−39.2733) | 979,480 (−74.0411/−11.4176) |
5.3.2. pathfinder Network
5.3.3. munin Network
5.3.4. diabetes Network
5.4. Propagation Errors with Approximation
- Perform a VE propagation on each target variable for storing the marginal obtained as the ground result .
- Modify the network by approximating the potential of the target variable, saving the remaining ones as defined in the network specification.
- Perform a second VE propagation on the modified network setting the selected target variable. The result is termed as .
- Apply the approximation on the entire set of potentials.
- Compute a third VE propagation for the selected variable, producing .
- Compute the divergences between the ground result and the approximate ones: and .
5.4.1. hepar2 Network
5.4.2. pathfinder Network
5.4.3. munin Network
5.4.4. diabetes Network
5.5. Order of Preferences
5.5.1. hepar2 Network
5.5.2. pathfinder Network
5.5.3. munin Network
5.5.4. diabetes Network
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BN | Bayesian network |
| BPT | Binary probability tree |
| DAG | Decision acyclic graph |
| ID | Influence diagram |
| IDM | Index-driven with map |
| IDP | Index-driven with pair of arrays |
| PGM | Probabilistic graphical model |
| PPT | Pruned probability tree |
| PT | Probability tree |
| VBP | Value-based potential |
| VDG | Value-driven with grains |
| VDI | Value-driven with indices |
| 1DA | Unidimensional array |
References
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Lauritzen, S.L. Graphical Models; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: Burlington, MA, USA, 1988. [Google Scholar]
- Pearl, J. Bayesian Networks: A Model of Self-Activated Memory for Evidential Reasoning; Computer Science Department, University of California, California, LA, USA, 1985.
- Pearl, J.; Russell, S.; Bayesian Networks. Computer Science Department, University of California. 1998. Available online: https://people.eecs.berkeley.edu/~russell/papers/hbtnn-bn.pdf (accessed on 15 June 2022).
- Howard, R.A.; Matheson, J.E. Influence diagram retrospective. Decis. Anal. 2005, 2, 144–147. [Google Scholar] [CrossRef]
- Olmsted, S.M. On Representing and Solving Decision Problems. Ph.D. Thesis, Department of Engineering-Economic Systems, Stanford University, Stanford, CA, USA, 1983. [Google Scholar]
- Arias, M.; Díez, F. Operating with potentials of discrete variables. Int. J. Approx. Reason. 2007, 46, 166–187. [Google Scholar] [CrossRef] [Green Version]
- Boutilier, C.; Friedman, N.; Goldszmidt, M.; Koller, D. Context-specific independence in Bayesian networks. In Proceedings of the 12th Annual Conference on Uncertainty in Artificial Intelligence (UAI-96), Portland, OR, USA, 1–3 August 1996; pp. 115–123. [Google Scholar]
- Cabañas, R.; Gómez, M.; Cano, A. Using binary trees for the evaluation of influence diagrams. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2016, 24, 59–89. [Google Scholar] [CrossRef]
- Cano, A.; Moral, S.; Salmerón, A. Penniless propagation in join trees. Int. J. Approx. Reason 2000, 15, 1027–1059. [Google Scholar] [CrossRef]
- Gómez-Olmedo, M.; Cano, A. Applying numerical trees to evaluate asymmetric decision problems. In Symbolic and Quantitative Approaches to Reasoning with Uncertainty of Lecture Notes in Computer Science; Nielsen, T., Zhang, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2711. [Google Scholar]
- Salmerón, A.; Cano, A.; Moral, S. Importance sampling in Bayesian networks using probability trees. Comput. Stat. Data Anal. 2000, 34, 387–413. [Google Scholar] [CrossRef] [Green Version]
- Cabañas, R.; Gómez-Olmedo, M.; Cano, A. Approximate inference in influence diagrams using binary trees. In Proceedings of the Sixth European Workshop on Probabilistic Graphical Models (PGM-12), Granada, Spain, 19–21 September 2012. [Google Scholar]
- Cano, A.; Gómez-Olmedo, M.; Moral, S. Approximate inference in Bayesian networks using binary probability trees. Int. J. Approx. Reason. 2011, 52, 49–62. [Google Scholar] [CrossRef] [Green Version]
- Gómez-Olmedo, M.; Cabañas, R.; Cano, A.; Moral, S.; Retamero, O.P. Value-Based Potentials: Exploiting Quantitative Information Regularity Patterns in Probabilistic Graphical Models. Int. J. Intell. Syst. 2021, 36, 6913–6943. [Google Scholar] [CrossRef]
- Scutari, M. Learning Bayesian networks with the bnlearn R package. J. Stat. Softw. 2010, 35, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Scutari, M. Bayesian network constraint-based structure learning algorithms: Parallel and optimized implementations in the bnlearn R package. J. Stat. Softw. 2017, 77, 1–20. [Google Scholar] [CrossRef] [Green Version]
- UAI 2014 Inference Competition. 2014. Available online: https://personal.utdallas.edu/~vibhav.gogate/uai14-competition/index.html (accessed on 15 June 2022).
- UAI 2016 Inference Competition. 2016. Available online: https://personal.utdallas.edu/~vibhav.gogate/uai16-evaluation/index.html (accessed on 15 June 2022).
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 76–86. [Google Scholar] [CrossRef]
- Onisko, A. Probabilistic Causal Models in Medicine: Application to Diagnosis of Liver Disorders. Ph.D. Dissertation, Institute of Biocybernetics and Biomedical Engineering, Polish Academy of Science, Warsaw, March 2003. [Google Scholar]
- Bobrowski, L. HEPAR: Computer system for diagnosis support and data analysis. In Prace IBIB 31; Institute of Biocybernetics and Biomedical Engineering, Polish Academy of Science: Warsaw, Poland, 1992. [Google Scholar]
- Heckerman, D.; Horwitz, E.; Nathwani, B. Towards Normative Expert Systems: Part I. The Pathfinder Project. Methods Inf. Med. 1992, 31, 90–105. [Google Scholar] [CrossRef] [PubMed]
- Andreassen, S.; Jensen, F.V.; Andersen, S.K.; Falck, B.; Kjærulff, U.; Woldbye, M.; Sørensen, A.R.; Rosenfalck, A.; Jensen, F. MUNIN—An Expert EMG Assistant. In Computer-Aided Electromyography and Expert Systems; Elsevier: Amsterdam, The Netherlands, 1989; Chapter 21. [Google Scholar]
- Andreassen, S.; Hovorka, R.; Benn, J.; Olesen, K.G.; Carson, E.R. A Model-based Approach to Insulin Adjustment. In Proceedings of the 3rd Conference on Artificial Intelligence in Medicine, Vienna, Austria, 21–24 June 1991; pp. 239–248. [Google Scholar]
- Dechter, R. Bucket elimination: A unifying algorithm for Bayesian inference. Artif. Intell. 1997, 93, 1–27. [Google Scholar]
- Shenoy, P.P.; Shafer, G.R. Axioms for probability and belief-function propagation. In Uncertainty in Artificial Intelligence of Machine Intelligence and Pattern Recognition; Shachter, R.D., Levitt, T.S., Kanal, L.N., Lemmer, J.F., Eds.; North-Holland: Amsterdam, The Netherlands, 1990; Volume 9. [Google Scholar]
- Zhang, N.L.; Poole, D. Exploiting causal independences in Bayesian networks inference. J. Artif. Intell. Res. 1996, 5, 301–328. [Google Scholar] [CrossRef] [Green Version]













| Network | Nodes | arcs | np | avg. M.B. Size | avg. deg | Max. in-deg |
|---|---|---|---|---|---|---|
| hepar2 | 70 | 123 | 2139 | 4.51 | 3.51 | 6 |
| pathfinder | 223 | 338 | 97,851 | 5.61 | 3.03 | 6 |
| munin | 1041 | 1397 | 98,423 | 3.54 | 2.68 | 3 |
| diabetes | 413 | 606 | 461,069 | 3.97 | 2.92 | 2 |
| Threshold | ggtp | ast | alt | bilirubin | ||||
|---|---|---|---|---|---|---|---|---|
| Local | Global | Local | Global | Local | Global | Local | Global | |
| 0.00001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00005 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00010 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00050 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00100 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.01000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 |
| 0.05000 | 0.002 | 0.004 | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.001 |
| 0.10000 | 0.002 | 0.005 | 0.003 | 0.004 | 0.001 | 0.002 | 0.001 | 0.001 |
| Threshold | F39 | F74 | F40 | |||
|---|---|---|---|---|---|---|
| Local | Global | Local | Global | Local | Global | |
| 0.00001 | −0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00005 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00010 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00050 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00100 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00500 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.01000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.05000 | 0.000 | 0.004 | 0.000 | 0.000 | 0.000 | 0.005 |
| 0.10000 | 0.000 | 0.005 | 0.000 | 0.001 | 0.000 | 0.006 |
| Threshold | v1 | v2 | v3 | |||
|---|---|---|---|---|---|---|
| Local | Global | Local | Global | Local | Global | |
| 0.00001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00005 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00010 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00050 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 |
| 0.00100 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 |
| 0.00500 | 0.000 | 0.001 | 0.000 | 0.001 | 0.000 | 0.005 |
| 0.01000 | 0.000 | 0.001 | 0.000 | 0.001 | 0.000 | 0.006 |
| 0.05000 | 0.000 | 0.002 | 0.000 | 0.003 | 0.000 | 0.096 |
| 0.10000 | 0.000 | 0.002 | 0.000 | 0.003 | 0.000 | 0.093 |
| Threshold | cho_0 | cho_1 | cho_2 | |||
|---|---|---|---|---|---|---|
| Local | Global | Local | Global | Local | Global | |
| 0.00001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00005 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00010 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.00050 | 0.001 | 0.001 | 0.000 | 0.001 | 0.000 | 0.000 |
| 0.00100 | 0.001 | 0.001 | 0.000 | 0.001 | 0.000 | 0.000 |
| 0.00500 | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.01000 | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 |
| 0.05000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 |
| 0.10000 | 0.001 | 0.001 | 0.001 | 0.002 | 0.000 | 0.002 |
| ggtp | ast | alt | bilirubin |
|---|---|---|---|
 |  |  |  |
| F39 | F74 | F40 |
|---|---|---|
 |  |  |
| L_LNLPC5_DELT_MUSIZE | L_LNLE_ADM_MUSIZE | L_MED_ALLCV_EW |
|---|---|---|
 |  |  |
| cho_0 |
|---|
 |
| cho_1 |
 |
| cho_2 |
|---|
 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonilla-Nadal, P.; Cano, A.; Gómez-Olmedo, M.; Moral, S.; Retamero, O.P. Using Value-Based Potentials for Making Approximate Inference on Probabilistic Graphical Models. Mathematics 2022, 10, 2542. https://doi.org/10.3390/math10142542
Bonilla-Nadal P, Cano A, Gómez-Olmedo M, Moral S, Retamero OP. Using Value-Based Potentials for Making Approximate Inference on Probabilistic Graphical Models. Mathematics. 2022; 10(14):2542. https://doi.org/10.3390/math10142542
Chicago/Turabian StyleBonilla-Nadal, Pedro, Andrés Cano, Manuel Gómez-Olmedo, Serafín Moral, and Ofelia Paula Retamero. 2022. "Using Value-Based Potentials for Making Approximate Inference on Probabilistic Graphical Models" Mathematics 10, no. 14: 2542. https://doi.org/10.3390/math10142542
APA StyleBonilla-Nadal, P., Cano, A., Gómez-Olmedo, M., Moral, S., & Retamero, O. P. (2022). Using Value-Based Potentials for Making Approximate Inference on Probabilistic Graphical Models. Mathematics, 10(14), 2542. https://doi.org/10.3390/math10142542