
Discriminative Convolutional Sparse Coding of ECG Signals for Automated Recognition of Cardiac Arrhythmias


Abstract
:1. Introduction
- We propose a discriminative convolutional sparse coding (DCSC) model in which the “discriminative sparse-code error” is inserted into the objective function.
- In the process of solving the objective function, the DCSC model is first transformed into the Fourier domain, the convolution operation is converted into a multiplication operation, and then the function solution is obtained using the alternating direction method of the multiplier framework.
- The discriminative sparse coefficients are obtained via convolutional sparse coding, then dimensionally reduced by the max-pooling method, and finally fed into the LSVM classifier to complete the ECG classification task.
2. Literature Survey
2.1. Convolutional Sparse Coding
2.2. Convolutional Dictionary Learning
2.3. Label Consistent KSVD
3. The Proposed ECG Signal Classification System
3.1. Discriminative Convolutional Sparse Dictionary Learning Model
- Convolutional sparse coding (CSC) step
- B.
- Convolutional dictionary update (CDU) step
| Algorithm 1: The DCSC Algorithm. |
| Input: sample , parameters , Output: Precompute: →, →, Initialize: = = = = 0, while j = 0 to convergence do (CSC step) Compute FFTs of →, →, →, → Compute with the algorithm in Appendix A. Compute inverse FFTs of → (CDU step) Compute FFTs of →, →, → Compute with the algorithm in Appendix B. Compute inverse FFTs of → Compute with the algorithm in Appendix B. Compute end |
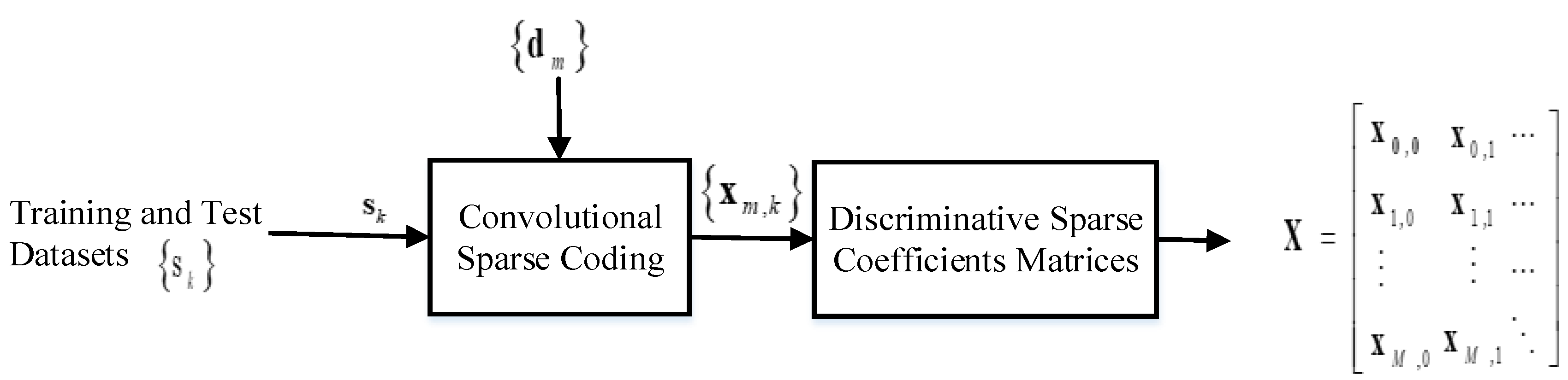
3.2. Sparse Coding of Training and Test Signals
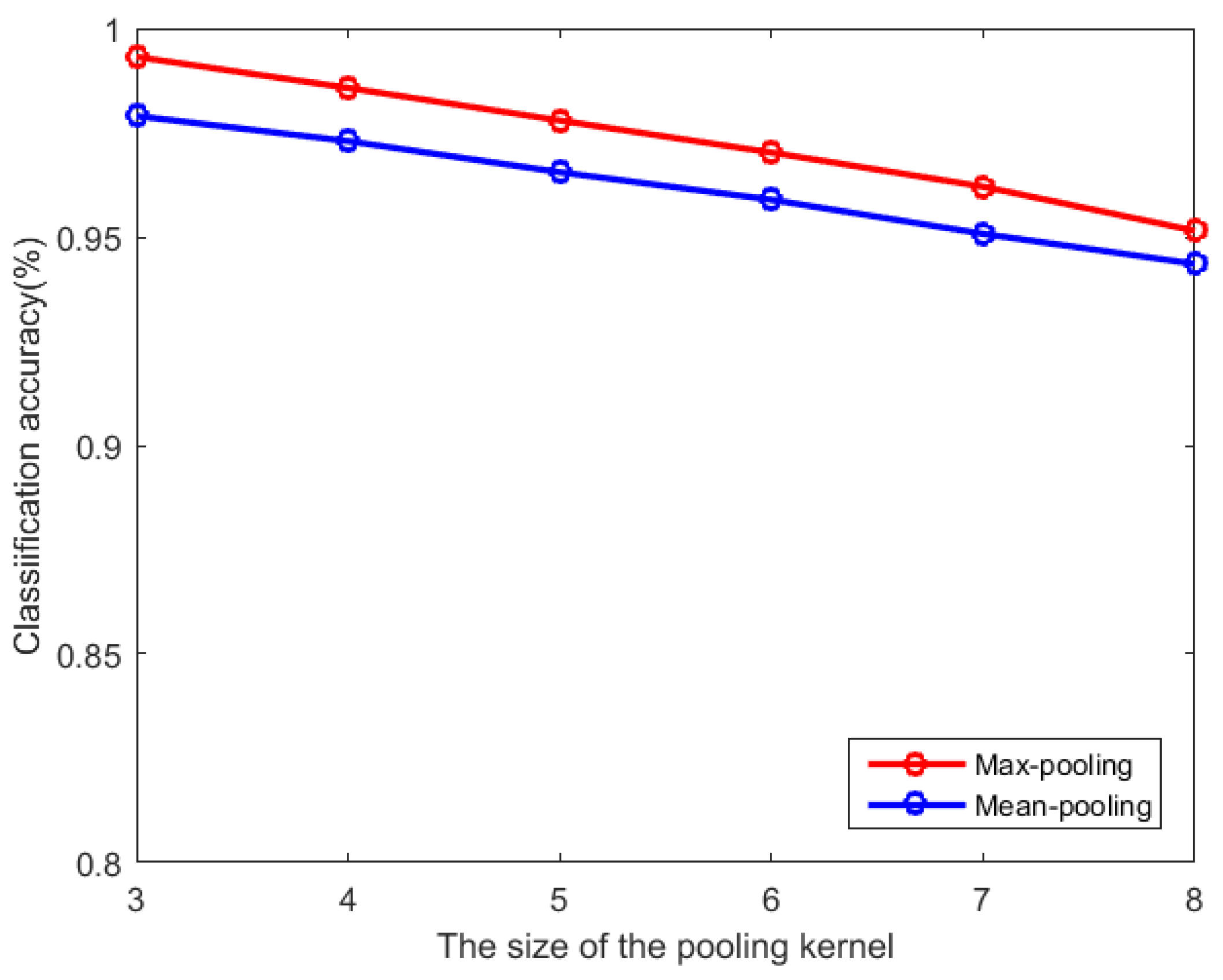
3.3. Pooling of Coefficient Matrix
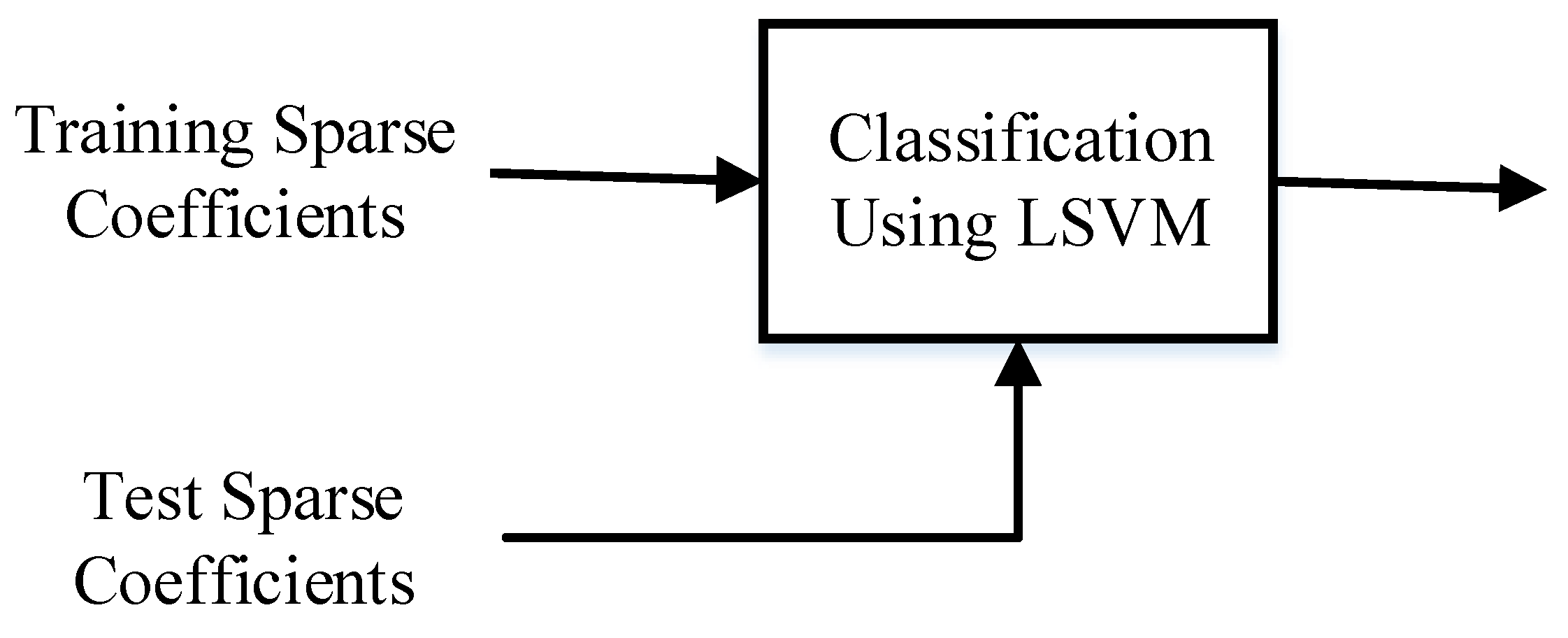
3.4. Classification by LSVM
4. Experiments and Discussion
4.1. Dataset
4.2. Signal Preprocessing
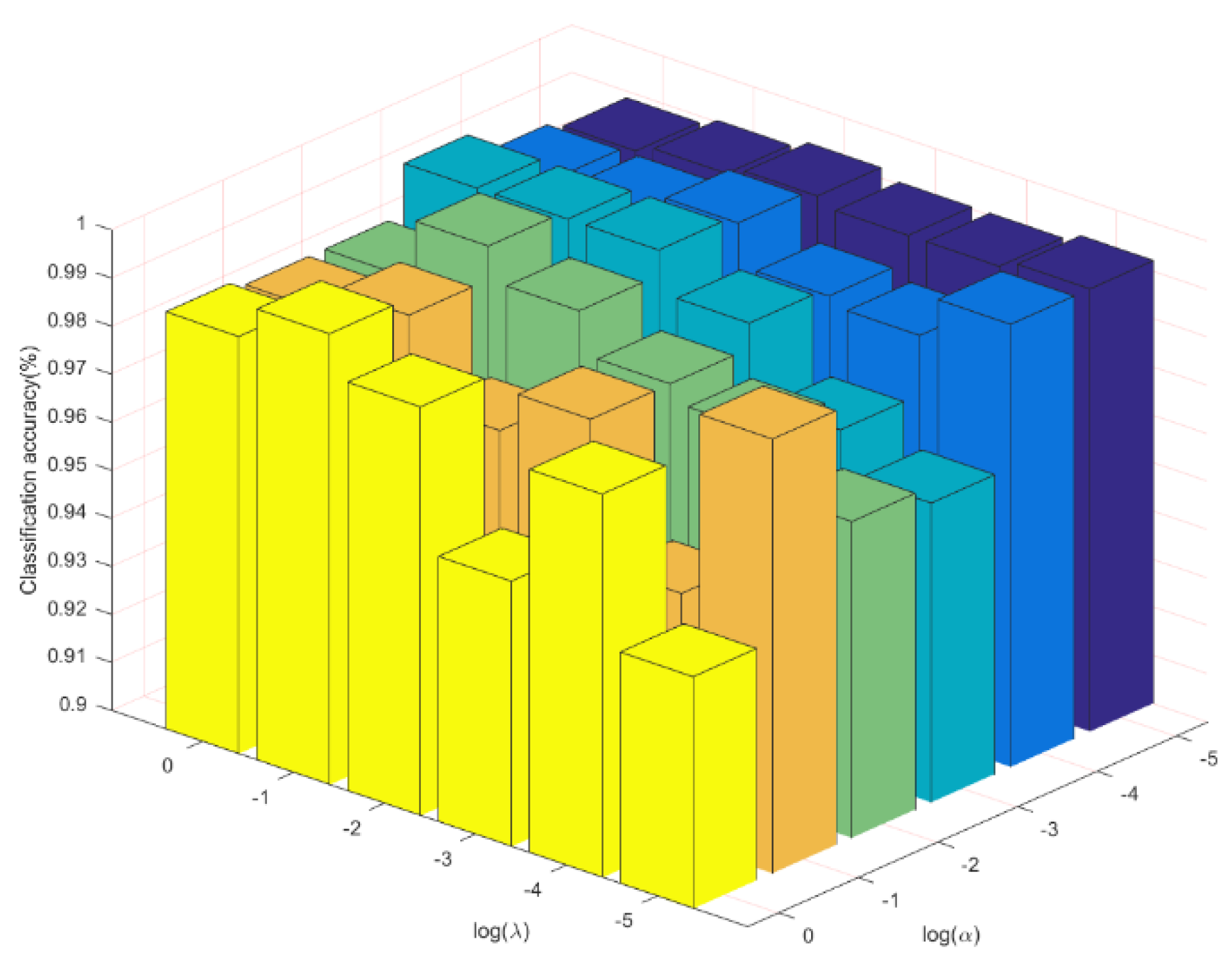
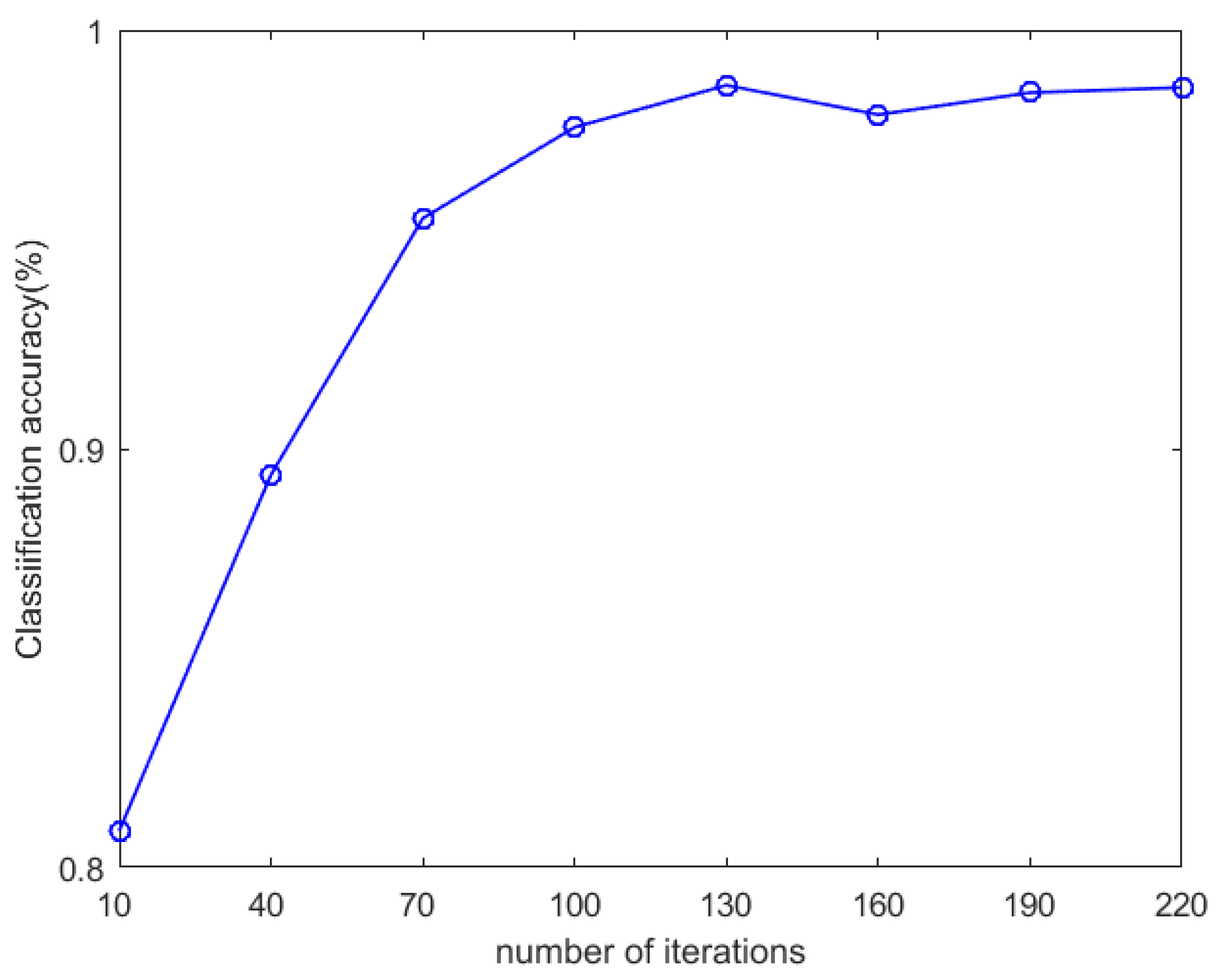
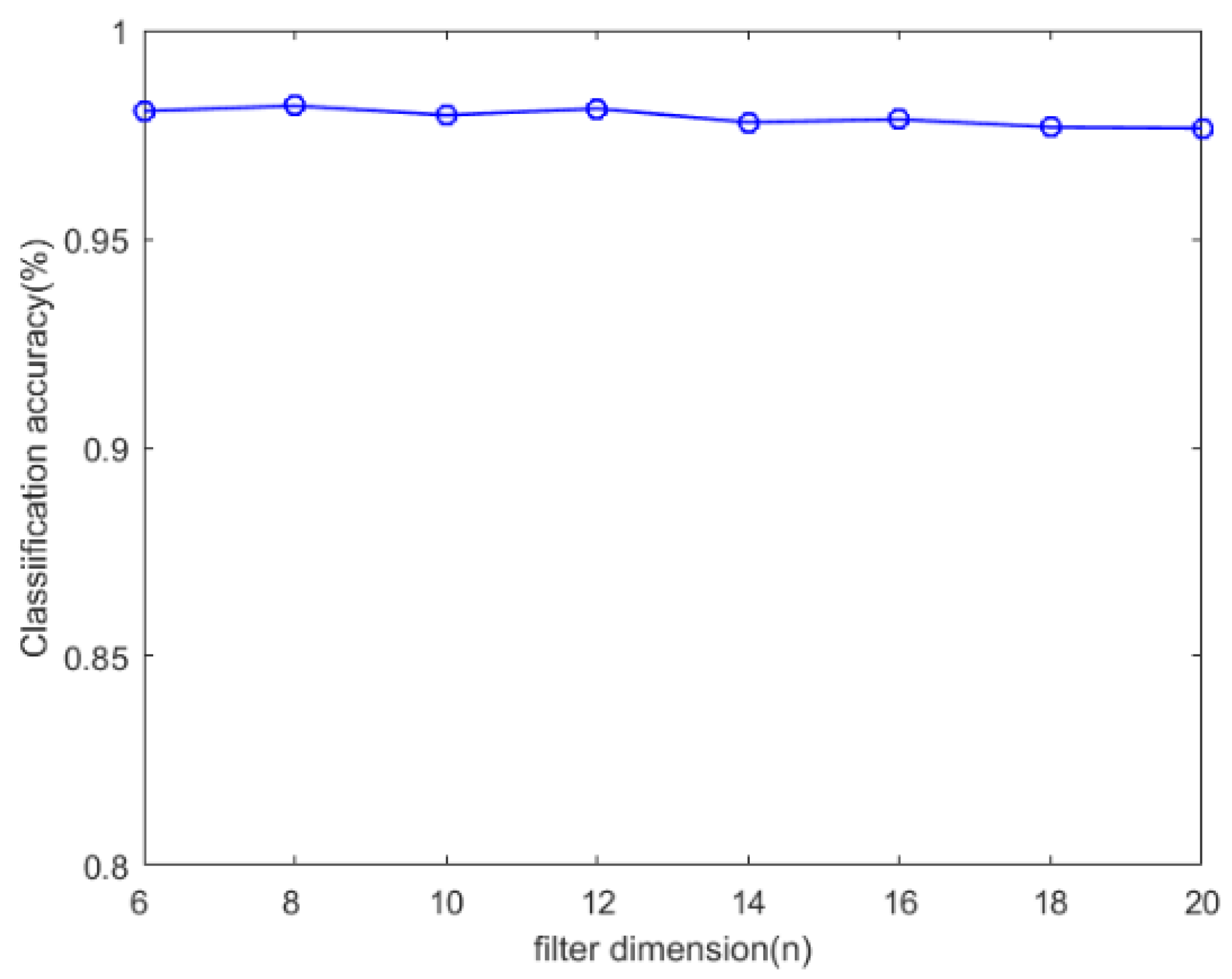
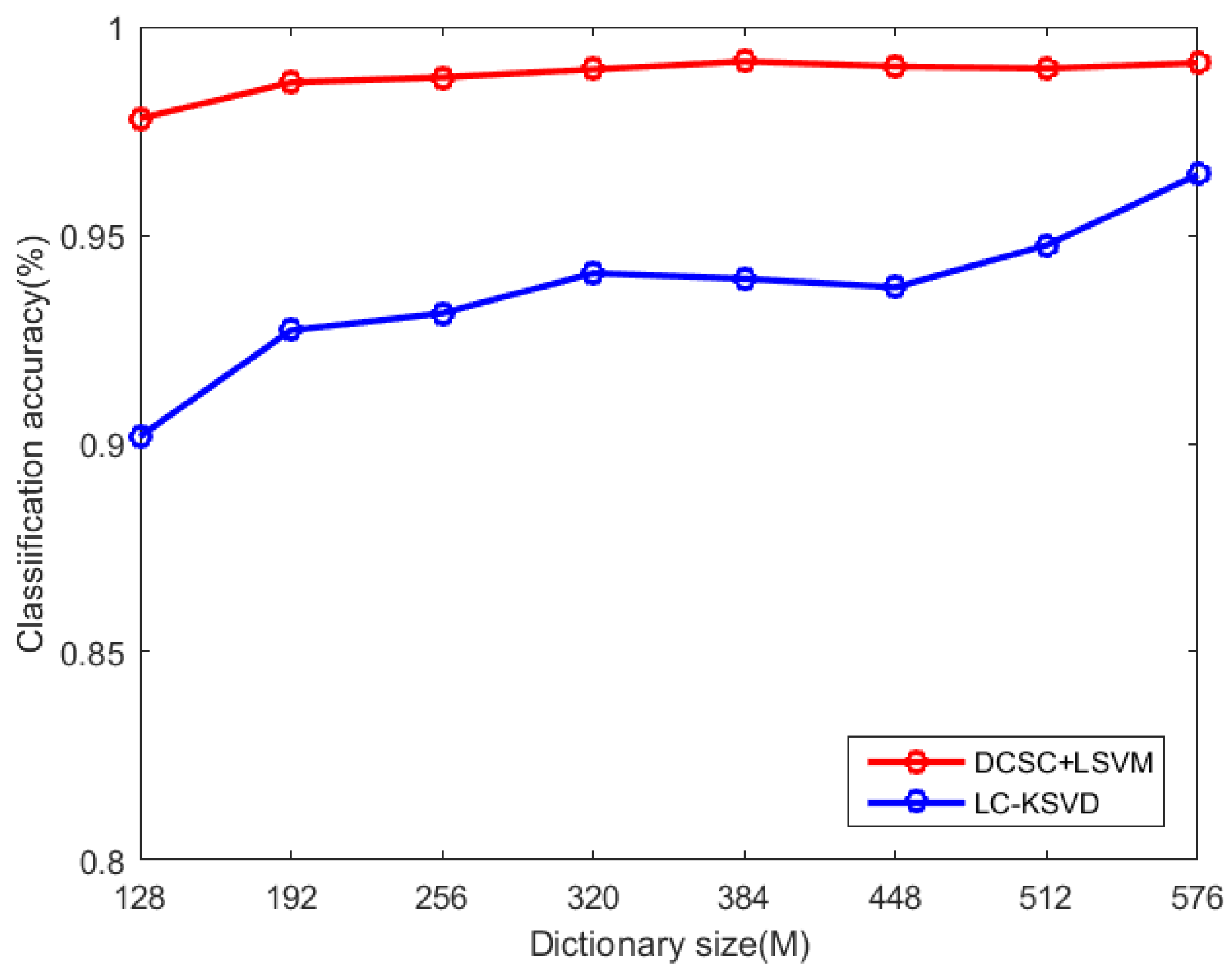
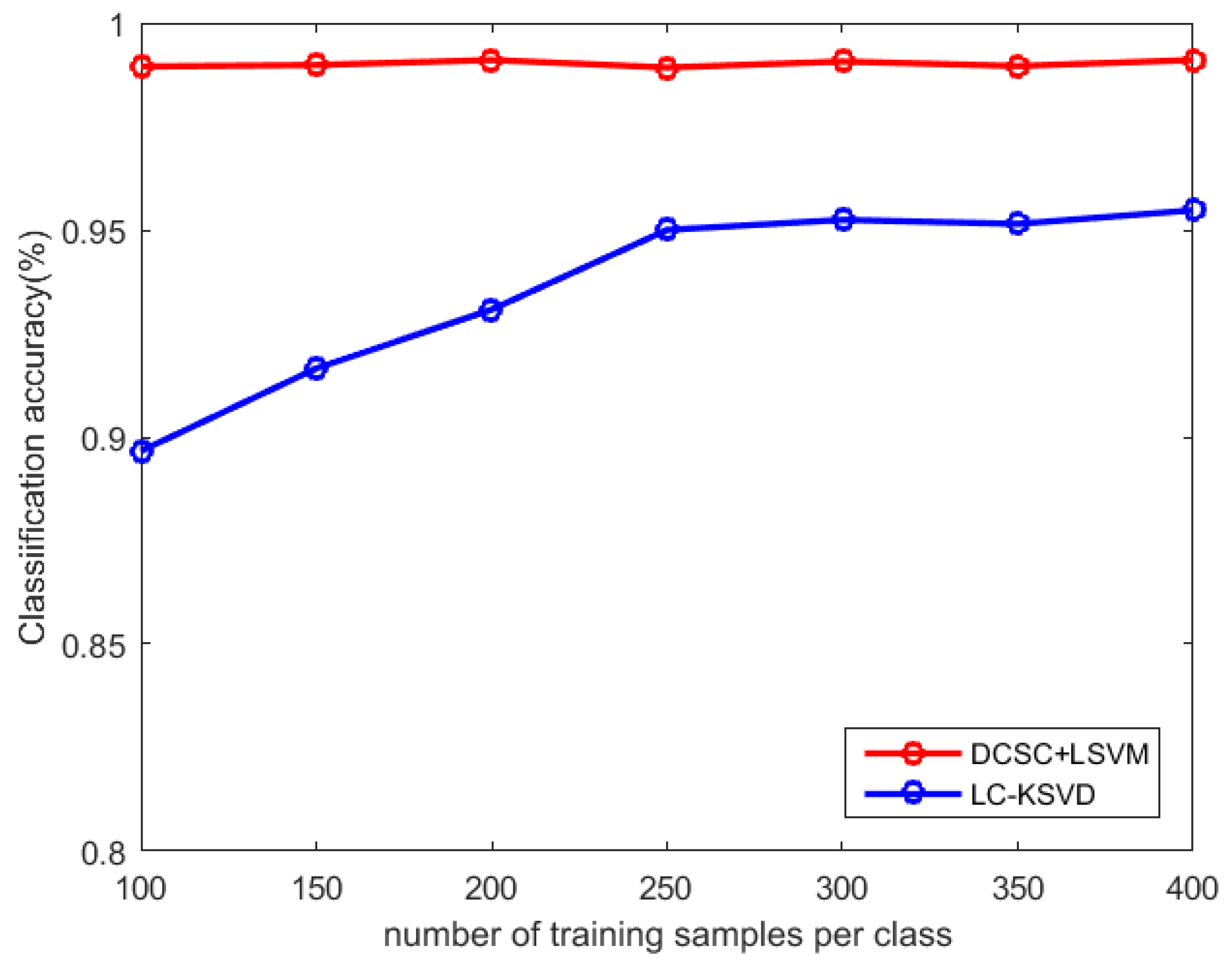
4.3. Parameter Selection
4.4. Statistical Parameters
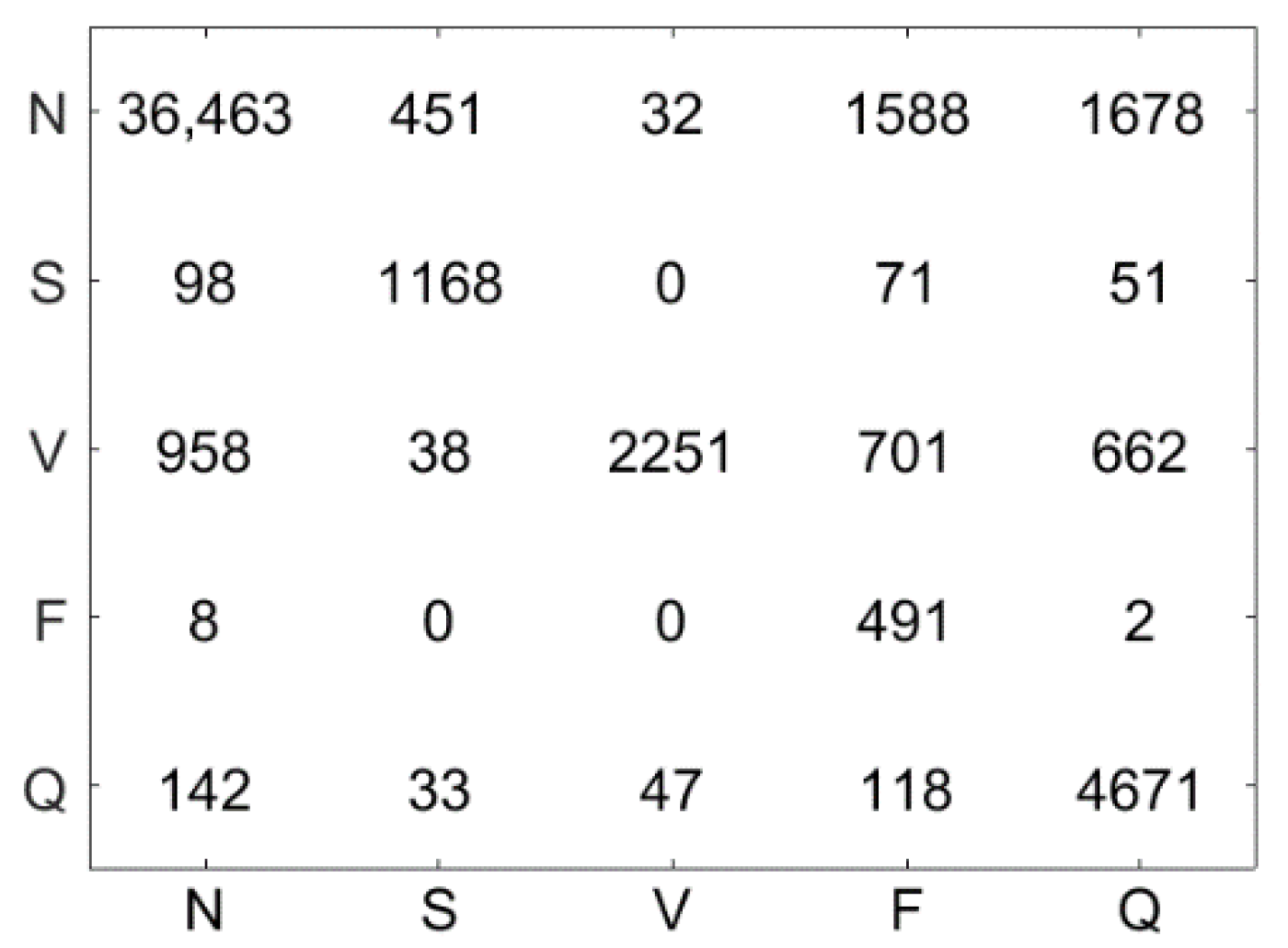
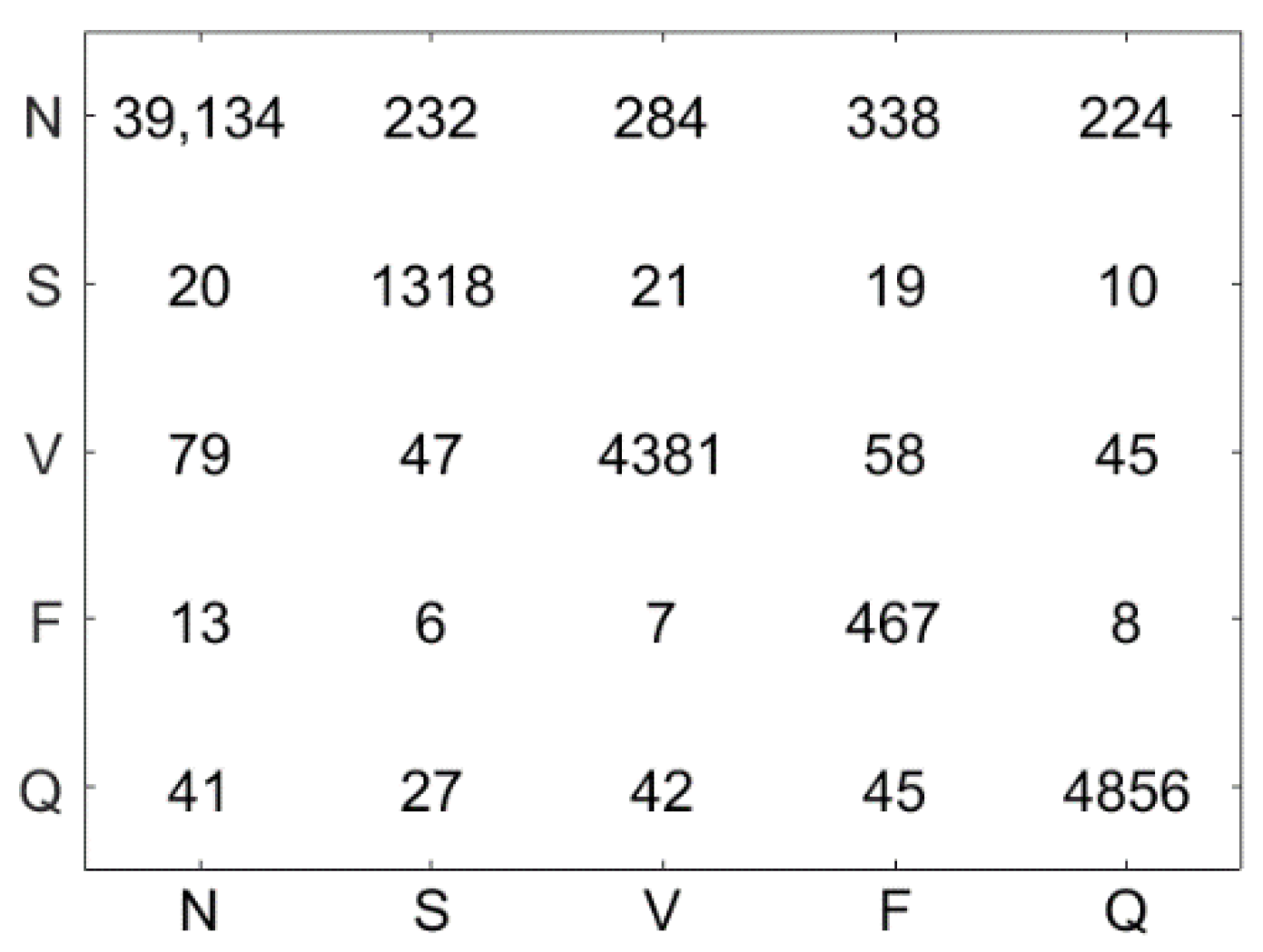
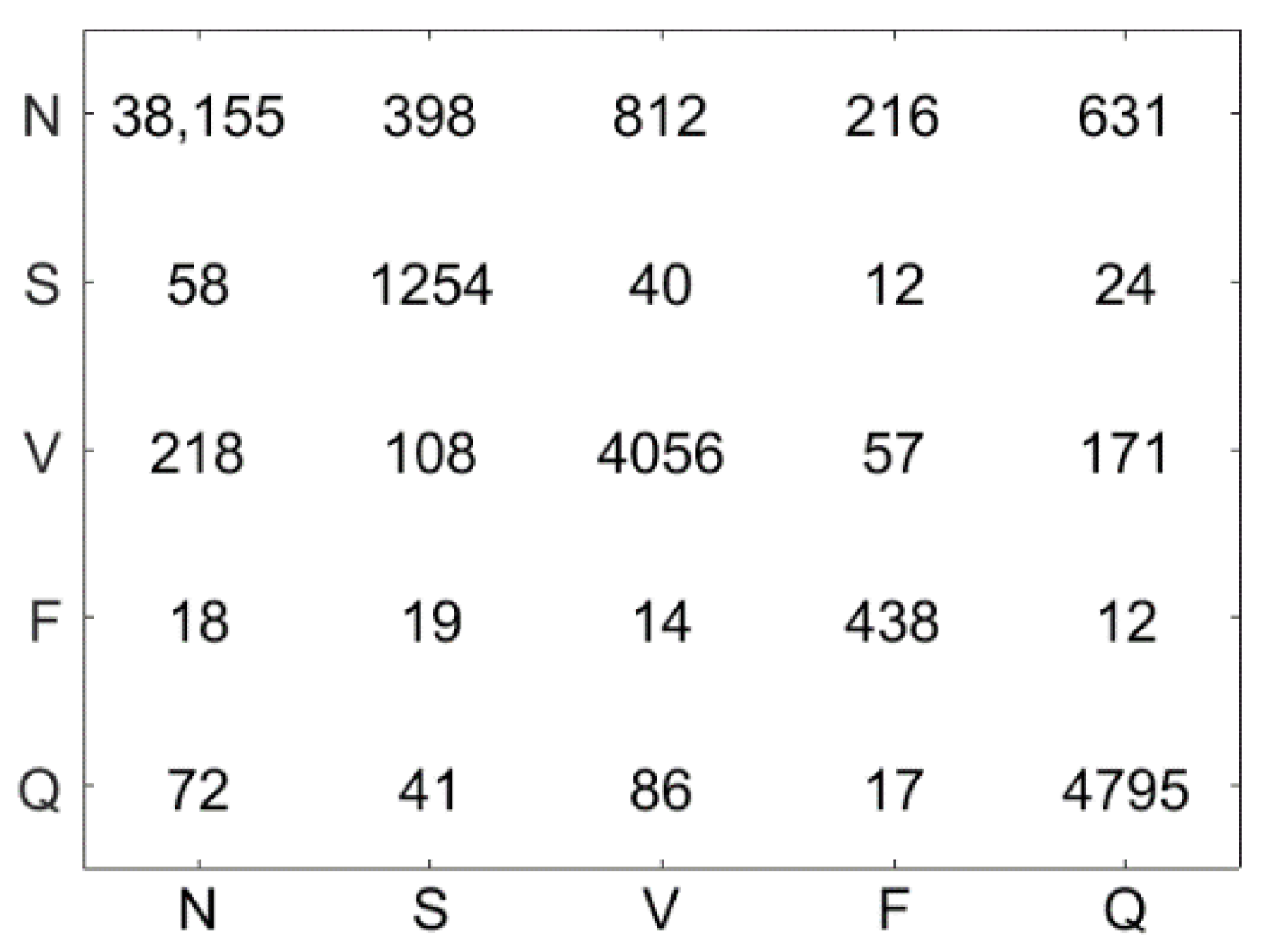
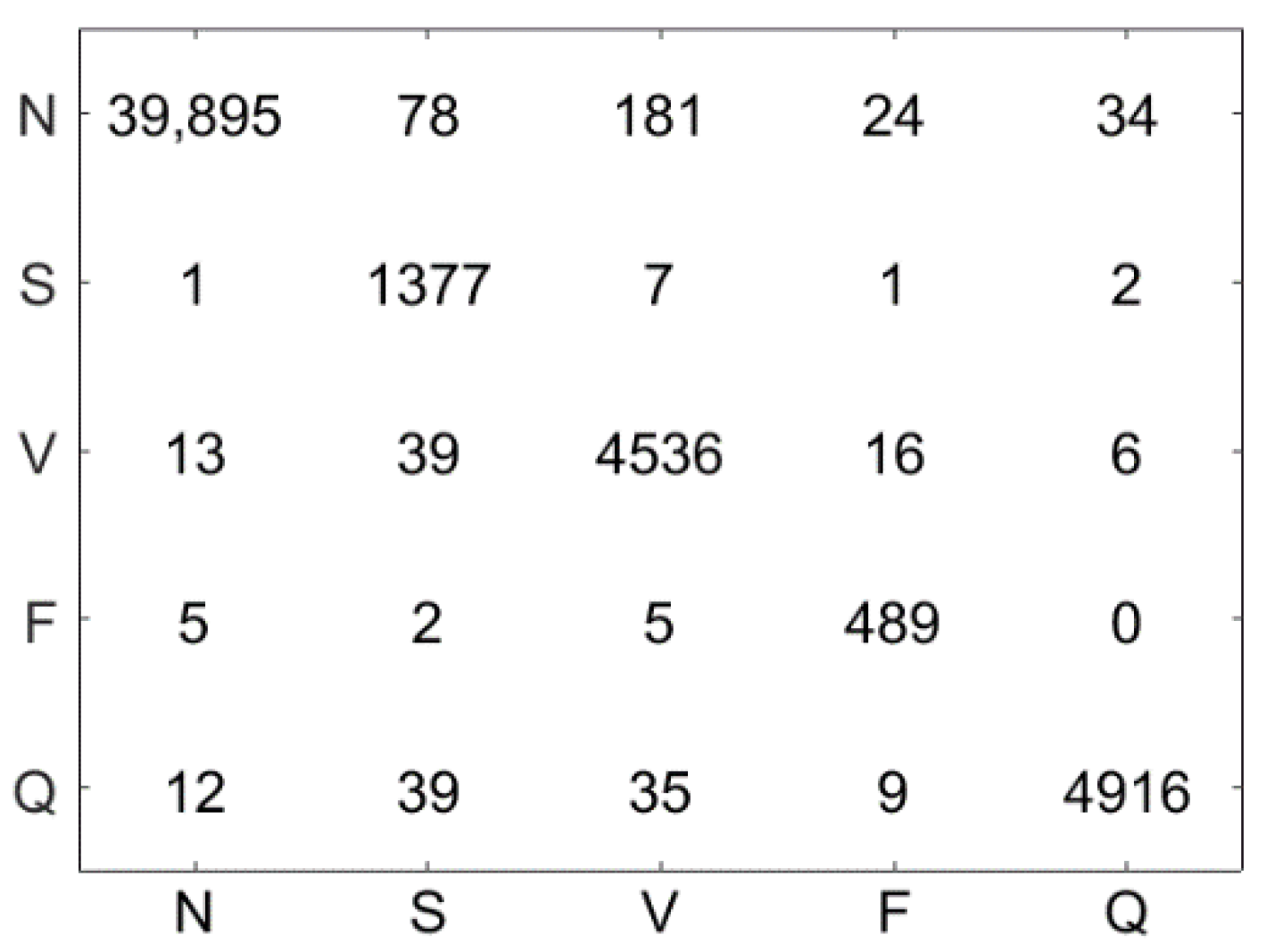
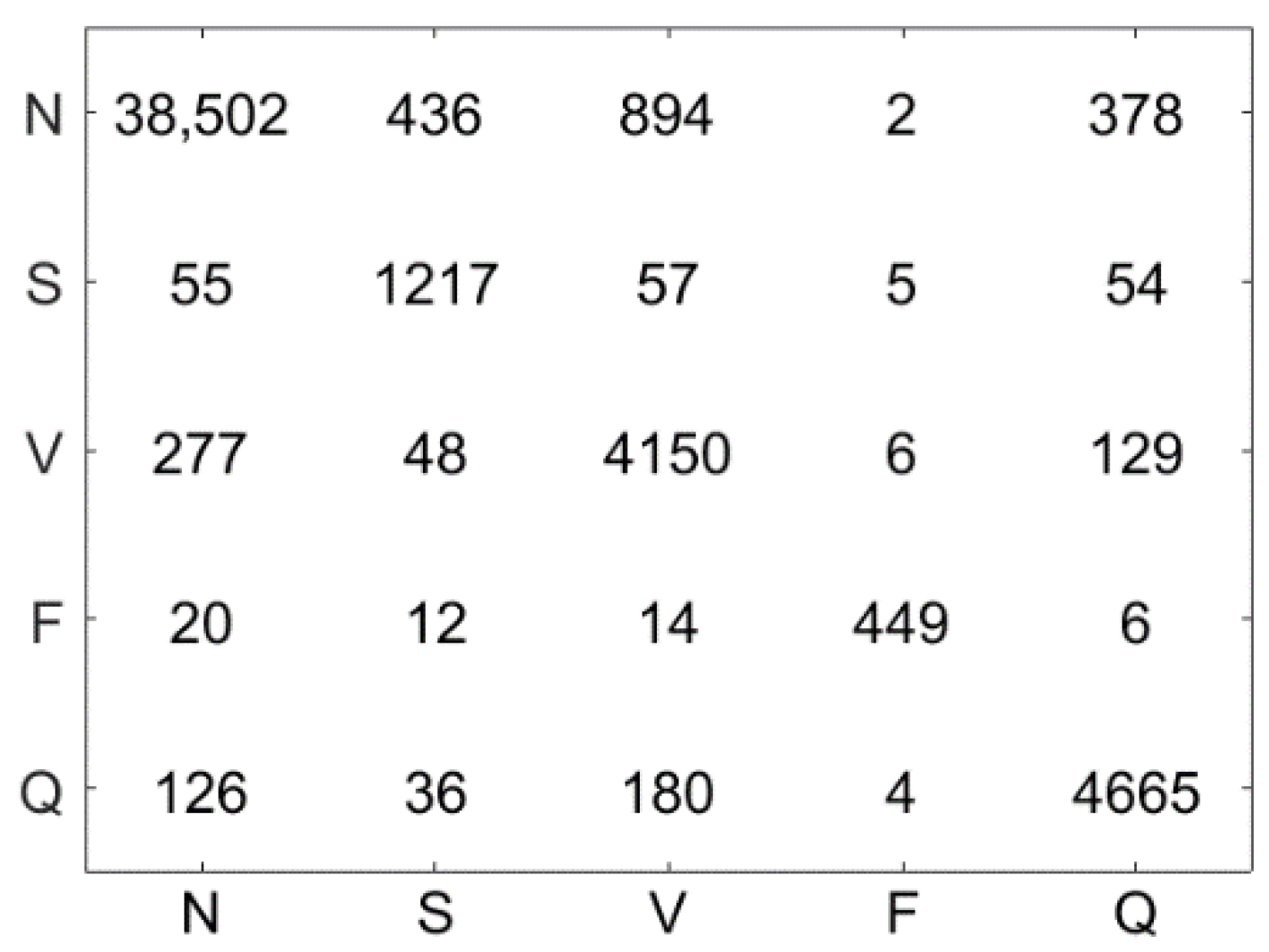
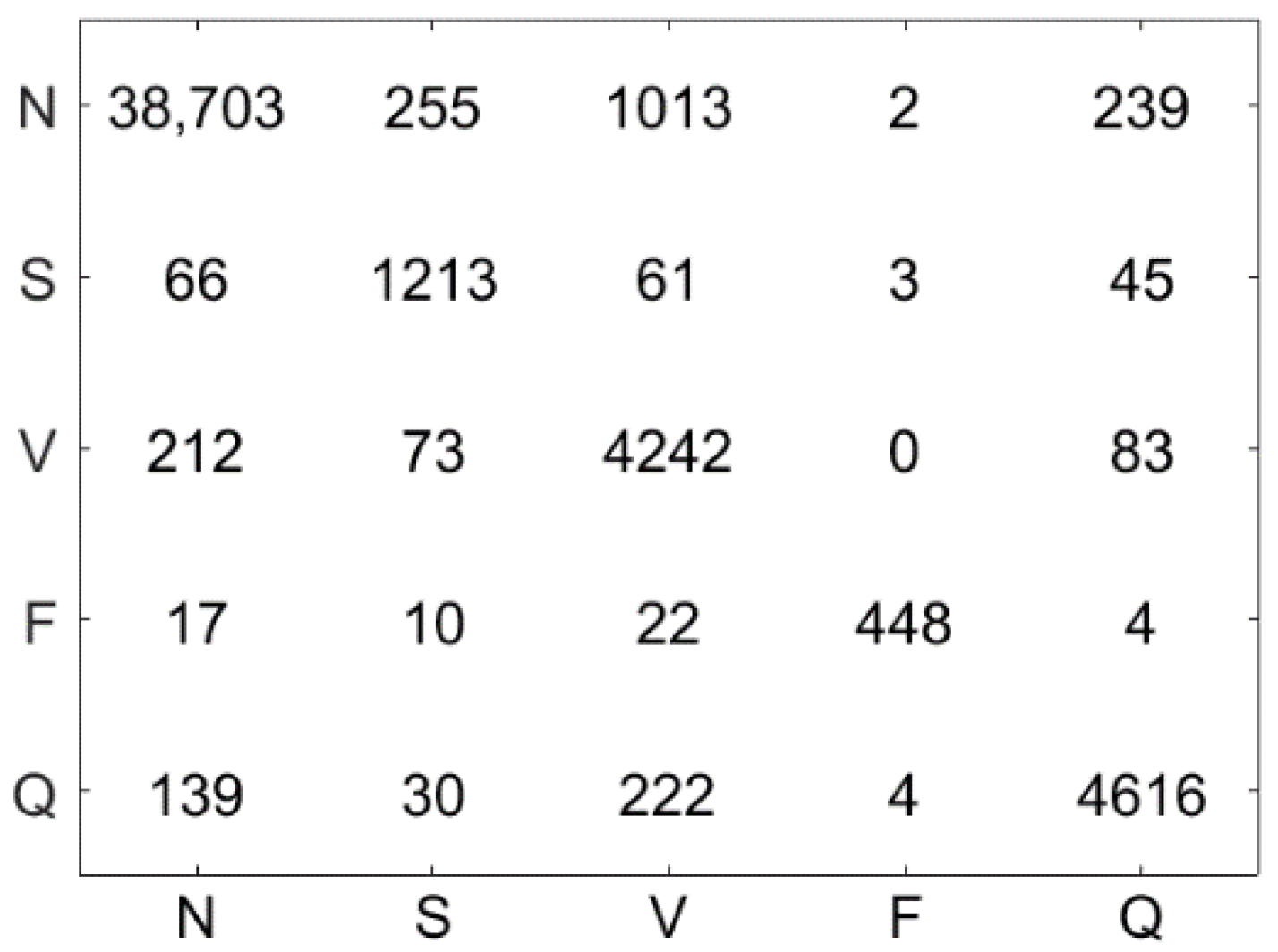
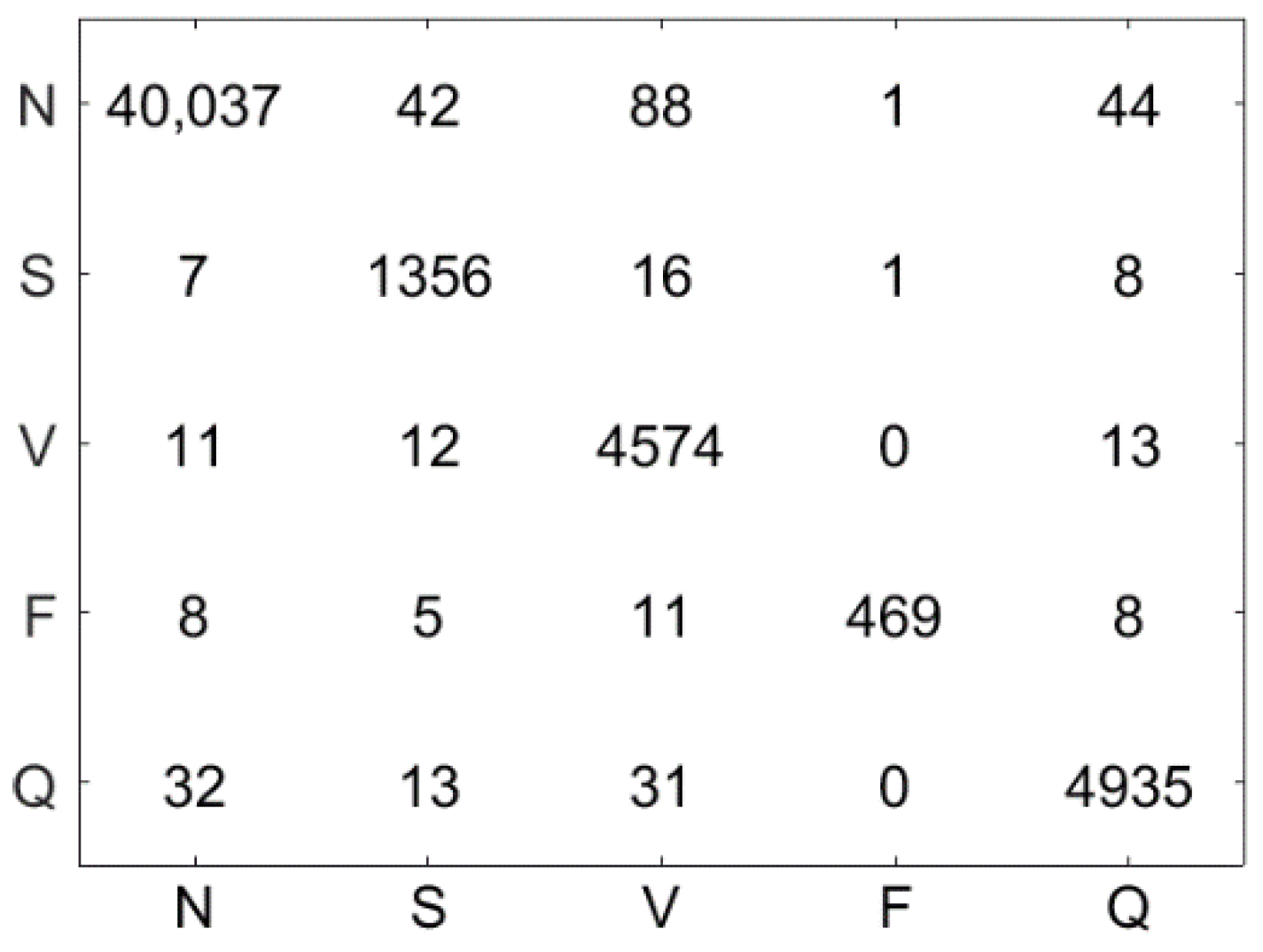
4.5. Results
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. The Coding Algorithm
Appendix B. Convolutional form of Method of Optimal Directions
References
- Zhu, W.; Chen, X.; Wang, Y.; Wang, L. Arrhythmia recognition and classification using ECG morphology and segment feature analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 131–138. [Google Scholar] [CrossRef]
- Jekova, I.; Bortolan, G.; Christov, I. Assessment and comparison of different methods for heartbeat classification. Med. Eng. Phys. 2008, 30, 248–257. [Google Scholar] [CrossRef]
- Alfaras, M.; Soriano, M.C.; Ortin, S. A fast machine learning model for ECG-Based heartbeat classification and arrhythmia detection. Front. Phys. 2019, 7, 103. [Google Scholar] [CrossRef]
- Marinho, L.B.; Nascimento, N.D.M.M.; Souza, J.W.M.; Gurgel, M.V. A novel electrocardiogram feature extraction approach for cardiac arrhythmia classification. Future Gener. Comput. Syst. 2019, 97, 564–577. [Google Scholar] [CrossRef]
- Plawiak, P. Novel methodology of cardiac health recognition based on ECG signals and evolutionary-neural system. Expert Syst. Appl. 2018, 92, 334–349. [Google Scholar] [CrossRef]
- Aziz, S.; Ahmed, S.; Alouini, M. ECG-based machine learning algorithms for heartbeat classification. Sci. Rep. 2021, 11, 18738. [Google Scholar] [CrossRef]
- Martis, R.J.; Acharya, U.R.; Min, L.C. ECG beat classification using PCA, LDA, ICA and discrete wavelet transform. Biomed. Signal Proces. 2013, 85, 437–448. [Google Scholar] [CrossRef]
- Minhas, F.A.; Arif, M. Robust electrocardiogram (ECG) beat classification using discrete wavelet transform. Physiol. Meas. 2008, 29, 555–570. [Google Scholar] [CrossRef]
- Martis, R.J.; Chakraborty, C.; Ray, A.K. An integrated ECG feature extraction scheme using PCA and wavelet transform. In Proceedings of the 2009 Annual IEEE India Conference, Ahmedabad, India, 18–20 December 2009; p. 422. [Google Scholar]
- Lin, C. Frequency-domain features for ECG beat discrimination using grey relational analysis-based classifier. Comput. Math. Appl. 2008, 55, 680–690. [Google Scholar] [CrossRef]
- Martis, R.J.; Acharya, U.R.; Mandana, K.M.; Ray, A.K. Application of principal component analysis to ECG signals for automated diagnosis of cardiac health. Expert Syst. Appl. 2012, 39, 11792–11800. [Google Scholar] [CrossRef]
- Wan, M.; Lai, Z.; Yang, G.; Yang, Z. Local graph embedding based on maximum margin criterion via fuzzy set. Fuzzy Set. Syst. 2017, 318, 120–131. [Google Scholar] [CrossRef]
- Wan, M.; Chen, X.; Zhan, T.; Xu, C. Sparse Fuzzy Two-Dimensional Discriminant Local Preserving Projection (SF2DDLPP) for Robust Image Feature Extraction. Inform. Sci. 2021, 563, 1–15. [Google Scholar] [CrossRef]
- Hammad, M.; Maher, A.; Wang, K.; Jiang, F. Detection of abnormal heart conditions based on characteristics of ECG signals. Measurement 2018, 125, 634–644. [Google Scholar] [CrossRef]
- Matta, S.C.; Sankari, Z.; Rihana, S. Heart rate variability analysis using neural network models for automatic detection of lifestyle activities. Biomed. Signal Process 2018, 42, 145–157. [Google Scholar] [CrossRef]
- Heide, F.; Heidrich, W.; Wetzstein, G. Fast and flexible convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5135–5143. [Google Scholar]
- Papyan, V.; Romano, Y.; Sulam, J.; Elad, M. Convolutional dictionary learning via local processing. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5306–5314. [Google Scholar]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Proc. Let. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multistage feature learning. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3626–3633. [Google Scholar]
- Zhou, Y.; Chang, H.; Barner, K.; Spellman, P. Classification of histology sections via multispectral convolutional sparse coding. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3081–3088. [Google Scholar]
- Chen, B.; Li, J.; Ma, B.; Wei, G. Convolutional sparse coding classification model for image classification. In Proceedings of the IEEE International Conference on Image Processing ICIP, Phoenix, AZ, USA, 25–28 September 2016; pp. 1918–1922. [Google Scholar]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2010; pp. 2691–2698. [Google Scholar]
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Fisher discrimination dictionary learning for sparse representation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 543–550. [Google Scholar]
- Jiang, Z.L.; Lin, Z.; Davis, L.S. Label consistent K-SVD: Learning a discriminative dictionary for recognition. IEEE Trans. Pattern Anal. 2013, 35, 2651–2664. [Google Scholar] [CrossRef] [PubMed]
- Wohlberg, B. Efficient algorithms for convolutional sparse representations. IEEE T Image Process. 2016, 25, 301–315. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2010, 3, 1–122. [Google Scholar] [CrossRef]
- Garcia-Cardona, C.; Wohlberg, B. Convolutional dictionary learning: A comparative review and new algorithms. IEEE Trans. Comput. Imag. 2018, 4, 366–381. [Google Scholar] [CrossRef]
- Zubair, S.; Yan, F.; Wang, W. Dictionary learning based sparse coefficients for audio classification with max and average pooling. Digit. Signal Process. 2013, 23, 960–970. [Google Scholar] [CrossRef]
- Wang, J.; Yang, J.; Yu, K.; Lv, F. Locality-constrained linear coding for image classification. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Moody, G.; Mark, R. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. 2001, 20, 45–50. [Google Scholar] [CrossRef] [PubMed]
- ANSI/AAMI EC57:1998; Testing and Reporting Performance Results of Cardiac Rhythm and ST Segment Measurement Algorithms. Association for the Advancement of Medical Instrumentation: American National Standards Institute, Inc. (ANSI): Washington, DC, USA, 1998.
- Singh, B.N.; Tiwari, A.K. Optimal selection of wavelet basis function applied to ECG signal denoising. Digit. Signal Process. 2006, 16, 275–287. [Google Scholar] [CrossRef]
- Liu, B.D.; Shen, B.; Gui, L. Face recognition using class Specific dictionary learning for sparse representation and collaborative representation. Neurocomputing 2016, 204, 198–210. [Google Scholar] [CrossRef]
- Song, Y.; Liu, Y.; Gao, Q.; Gao, X. Euler label consistent k-svd for image classification and action recognition. Neurocomputing 2018, 310, 277–286. [Google Scholar] [CrossRef]
- Shao, S.; Xu, R.; Liu, W.; Liu, B. Label embedded dictionary learning for image classification. Neurocomputing 2020, 385, 122–131. [Google Scholar] [CrossRef]
- Desai, U.; Martis, R.J.; Nayak, C.G.; Sarika, K. Machine intelligent diagnosis of ECG for arrhythmia classification using DWT, ICA and SVM techniques. In Proceedings of the 12 IEEE International Conference on Elect Energy Env Communications Computer Control, New Delhi, India, 17–20 December 2015; p. 2015. [Google Scholar]
- Elhaj, F.A.; Salim, N.; Harris, A.R.; Swee, T.T. Arrhythmia recognition and classification using combined linear and nonlinear features of ECG signals. Comput. Method Prog. Biomed. 2016, 127, 52–63. [Google Scholar] [CrossRef]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2017, 89, 389–396. [Google Scholar] [CrossRef]
- Mohammad, K.; Shayan, F.; Majid, S. ECG heartbeat classification: A deep transferable representation. In Proceedings of the International Conference Healthcare Informativa ICHI, New York, NY, USA, 4–7 June 2018; pp. 443–444. [Google Scholar]
- Yildirim, O.; Baloglu, U.B.; Tan, R. A new approach for arrhythmia classification using deep coded features and LSTM networks. Comput. Method Prog. Biomed. 2019, 176, 121–133. [Google Scholar] [CrossRef]
- Romdhane, T.F.; Alhichri, H.; Ouni, R.; Atri, M. Electrocardiogram heartbeat classification based on a deep convolutional neural network and focal loss. Comput. Biol. Med. 2020, 123, 103866. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, D.; Wan, L.; Li, J. Heartbeat classification using deep residual convolutional neural network from 2-lead electrocardiogram. J. Electrocardiol. 2020, 58, 105–112. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | S | V | F | Q |
|---|---|---|---|---|
|
|
|
|
|
|
| AAMI Classes | Training Data | Testing Data | Total Data |
|---|---|---|---|
| N | 300 | 40,212 | 40,512 |
| S | 300 | 1388 | 1688 |
| V | 300 | 4610 | 4910 |
| F | 300 | 501 | 801 |
| Q | 300 | 5011 | 5311 |
| Total | 1500 | 51,722 | 53,222 |
| Method | N | S | V | F | Q | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| % | ||||||||||||||||
| LSVM | 87.09 | 90.68 | 96.80 | 93.64 | 84.15 | 69.11 | 75.89 | 48.83 | 96.61 | 64.87 | 98.00 | 16.54 | 28.30 | 93.21 | 66.12 | 77.37 |
| LC-KSVD | 96.97 | 97.32 | 99.61 | 98.45 | 94.96 | 80.86 | 87.34 | 95.03 | 92.52 | 93.76 | 93.21 | 50.38 | 65.41 | 96.91 | 94.42 | 95.65 |
| FDDL | 98.80 | 98.93 | 99.92 | 99.42 | 99.35 | 90.37 | 94.65 | 99.15 | 93.67 | 96.33 | 98.80 | 91.67 | 95.10 | 97.27 | 98.19 | 97.72 |
| CSDL | 94.15 | 94.88 | 99.05 | 96.92 | 90.35 | 68.90 | 78.18 | 87.98 | 80.99 | 84.34 | 87.43 | 59.19 | 70.59 | 95.69 | 85.12 | 90.10 |
| ELC-KSVD | 99.02 | 99.21 | 99.92 | 99.57 | 99.21 | 89.71 | 94.22 | 98.39 | 95.21 | 96.78 | 97.60 | 90.72 | 94.04 | 98.10 | 99.15 | 98.63 |
| CSCC | 94.70 | 95.75 | 98.77 | 97.24 | 87.68 | 69.58 | 77.59 | 90.02 | 78.38 | 83.80 | 89.62 | 96.35 | 92.86 | 93.10 | 89.16 | 91.09 |
| LEDL | 95.17 | 96.25 | 98.89 | 97.55 | 87.39 | 76.72 | 81.71 | 92.02 | 76.29 | 83.42 | 89.42 | 98.03 | 93.53 | 92.12 | 92.56 | 92.34 |
| DCSC + LSVM | 99.32 | 99.56 | 99.86 | 99.71 | 97.69 | 94.96 | 96.31 | 99.22 | 96.91 | 98.05 | 93.61 | 99.58 | 96.50 | 98.48 | 98.54 | 98.51 |
| Methods | DWT + ICA | DCSC | Pooling | Classification |
|---|---|---|---|---|
| Time(s) | 0.058 | 0.198 | 0.078 | 0.002 |
| Literature | Features | Classifier | Classes | |
|---|---|---|---|---|
| Mathews et al. [7] | DWT + ICA | PNN | 5 | 99.28 |
| Desai et al. [37] | DWT + ICA | SVM quadratic kernel | 5 | 98.49 |
| Elhaj et al. [38] | PCA + DWT + HOS + ICA | SVM-RBF | 5 | 98.91 |
| Acharya et al. [39] | 9-layer deep convolutional neural network | 5 | 94.03 | |
| M. Kachuee et al. [40] | deep residual CNN | 5 | 93.40 | |
| Yildirim et al. [41] | CAE and LSTM | 5 | 99.00 | |
| Romdhane et al. [42] | Deep CNN | 5 | 98.41 | |
| Li et al. [43] | Deep residual network | 5 | 99.06 | |
| Proposed | DWT + ICA | DCSC + LSVM | 5 | 99.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Liu, J. Discriminative Convolutional Sparse Coding of ECG Signals for Automated Recognition of Cardiac Arrhythmias. Mathematics 2022, 10, 2874. https://doi.org/10.3390/math10162874
Zhang B, Liu J. Discriminative Convolutional Sparse Coding of ECG Signals for Automated Recognition of Cardiac Arrhythmias. Mathematics. 2022; 10(16):2874. https://doi.org/10.3390/math10162874
Chicago/Turabian StyleZhang, Bing, and Jizhong Liu. 2022. "Discriminative Convolutional Sparse Coding of ECG Signals for Automated Recognition of Cardiac Arrhythmias" Mathematics 10, no. 16: 2874. https://doi.org/10.3390/math10162874
APA StyleZhang, B., & Liu, J. (2022). Discriminative Convolutional Sparse Coding of ECG Signals for Automated Recognition of Cardiac Arrhythmias. Mathematics, 10(16), 2874. https://doi.org/10.3390/math10162874