
Improved Sliding Algorithm for Generating No-Fit Polygon in the 2D Irregular Packing Problem

Abstract
:1. Introduction
- To address the problem of the efficient and robust creation of the no-fit polygon;
- To propose an improved sliding algorithm and provide a detailed implementation;
- To present the concept of touching group, resulting in the number of cases to consider being reduced by half when determining the feasible translation vector;
- To develop many acceleration strategies to improve the algorithm’s efficiency, such as the point exclusion strategy, the right side test, and the point inclusion test;
- To assess the performance of the proposed algorithm using the benchmark instances, degenerate and complex cases;
- To help the further dissemination of using the no-fit polygon within both the industrial and academic communities.
2. Overview for No-Fit Polygon
2.1. Definition and Properties
2.2. Approaches for Generating NFP
2.2.1. Decomposition and Phi-Function
2.2.2. Minkowski Sums and Sliding Algorithm
3. Improved Sliding Algorithm
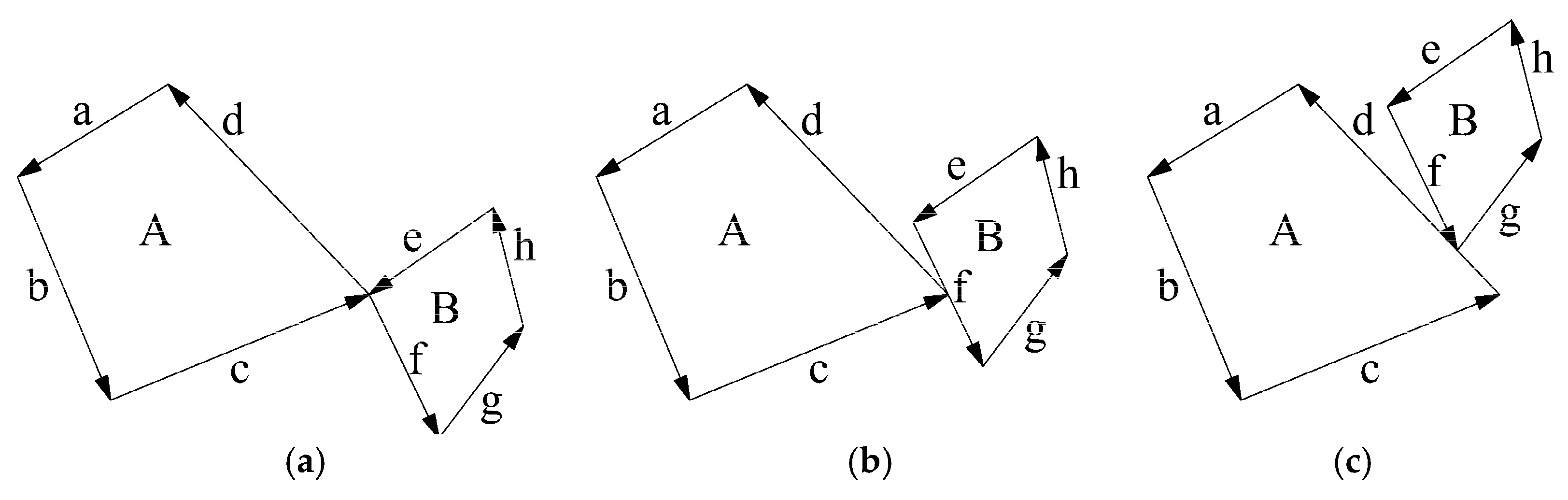
3.1. The Concept of Touching Group
3.2. Creation of No-Fit Polygon
3.2.1. Find the Touching Group
3.2.2. Determine Translation Vector
- (i)
- Recognize the potential translation vector
- (ii)
- Determine the feasible translation vector
- (iii)
- Select a feasible translation vector
| Algorithm 1: Determine Translation Vector. |
| Input: T list // T list,; Input: t1; // last touching group; Output: t2; // the selected touching group t = the number of touching groups in T; for each touching group in T do Get the potential translation vector of Ti; Calculate angular direction of Ti; end for if t is equal to 1 t2 = T0; return; i = 0; for i < t do for j < t do if j is not equal to i // do feasible test Get the potential vector vi in Ti; if vi is not suitable for Tj Flag vi is infeasible; break; j = j + 1; end for i = i + 1; end for if only one feasible translation vector in T t2 = feasible translation vector in T; return; t2 = Select a feasible vector from T based on t1; return; |
3.2.3. Compute Translation Distance
- (i)
- Computation method
- (ii)
- Acceleration strategy
| Algorithm 2: Compute translation distance. |
| Input: PA, PB //two polygons; t2 // the selected touching group Get the translation vector v in t2; Initialize ub, lb; // the upper and lower bound Get the boundary ub and lb about PA based on v; i = 0; for each vertex point of PA do if is not in ub and lb bound continue; // point exclusion test for each edge of PB do Calculate the cross point of the along v with edge e; if exists // intersection happened Get distance d between and ; if d less than the current length of v; The starting point of ; The ending point of ; end for end for Get the boundary ub and lb about PB based on v; i = 0; for each vertex point of PB do if is not in ub and lb bound do continue; // point exclusion test for each edge of PA do Calculate the cross point of the along v with edge e;; if exists // intersection happened Get distance d between and ; if d less than the current length of v; The starting point of ;The ending point of ; end for end for |
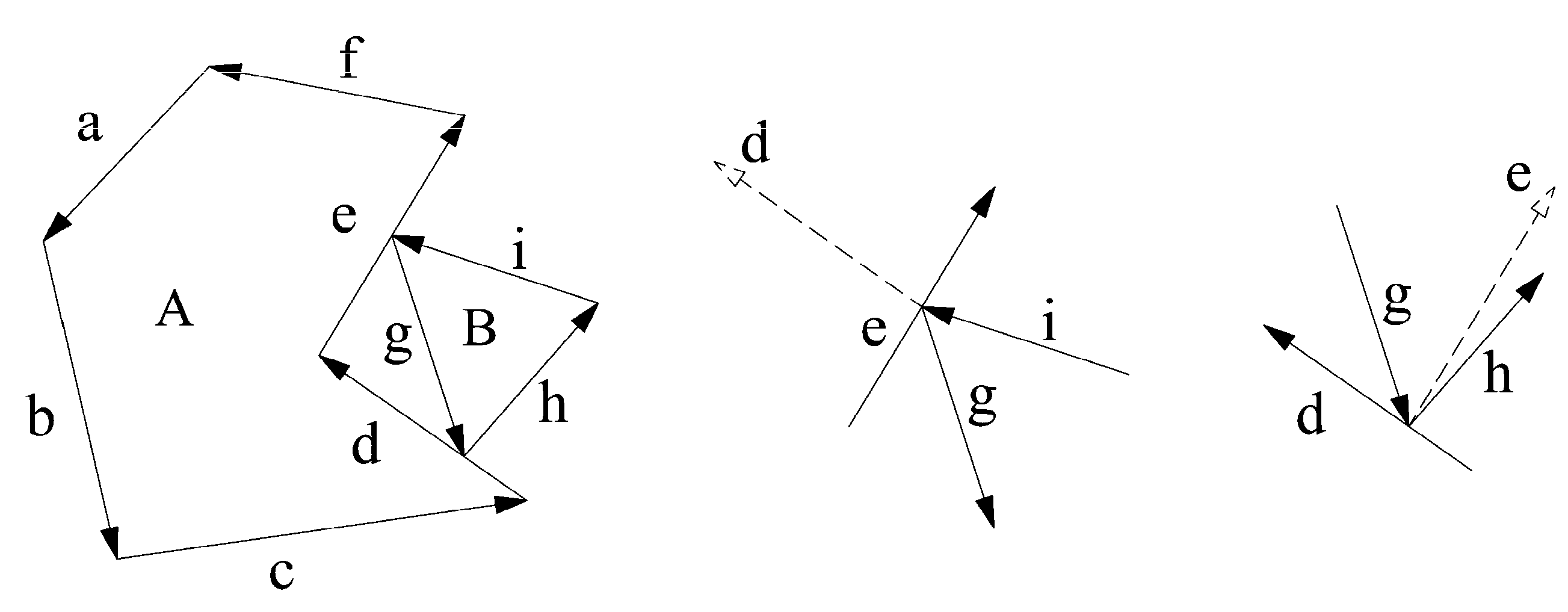
3.3. Searching Oher Start Positions
3.3.1. Method of Searching Feasible Starting Position
| Algorithm 3: Search other Start Point. |
| Input: PA, PB //two polygons, Input: Ptnfp; // the starting point of new NFP Initialize ; // the list of storing all translation vectors for each edge of PA do if is visited do continue; is visited; for each edge of PA Move by making starting point of and coincidence; if both and are not on the right side of do continue; // “right side” test V ; // clear stored vectors If the result of getting translation vectors ) is false do continue; // Algorithm 4 while the starting point of does not on the ending point of do if PA does not overlap with PB at this position Ptnfp = PBrf; // the reference point PBrf of PB return true; Shorten all vectors in V and get the translation vector v; Translate PB by vector v; end while end for end for return false; |
3.3.2. Acceleration Strategies
| Algorithm 4: Get translation vectors. |
| Input: PA, PB; // two polygons Input: v; // the oriented edge of PA Output: V; //the list of storing all vectors Initialize ub, lb; // the upper and lower bound Initialize ; // temporarily store the translation vectors Get the boundary ub and lb about PA based on v; for each vertex point of PA do if is not in ub and lb bound do continue; // point exclusion test for each edge of PB do Calculate the cross point of the along v with edge e;; if exists do Add new vector to Vt; end for if Vt is not empty do if does not pass the point inclusion test do return false; else Add all vectors in Vt to V; Vt ; end for Get the boundary ub and lb about PB based on v; for each vertex point of PB do if is not in ub and lb bound do continue; // point exclusion test for each edge of PA do Calculate the cross point of the along v with edge e; if exists Add new vector to Vt; end for if Vt is not empty do if does not pass the point inclusion test do return false; else Add all vectors in Vt to V; Vt ; end for return true; |
3.3.3. The ISA Algorithm
| Algorithm 5: Sliding Algorithm. |
| Input: PA, PB //two polygons Initialize ; //T list for storing touching groups Initialize two touching groups t1, t2; Initialize creation = true; ; PtA(ymin) = the point of minimum y-coordinate of PA; PtB(ymax) = the point of maximum y-coordinate of PB; Move PB to make PtB(ymax) touch the PtA(ymin); Ptnfp = the reference point PBrf of PB; //the starting point of NFP while the creation is true do Clear the T list; Find touching groups (PA, PB, T); // Algorithm 1 Determine translation vector (T, t1, t2); // Algorithm 2 Compute translation distance (PA, PB, t2); Flag the edge of PA in T2 is visited; t1 = t2; Initialize a new edge e1; The starting point of e1 = PBrf; Move PB using the translation vector stored in t2. The ending point of e1 = PBrf; Produce new edge e1 of the no-fit polygon nfp; if Ptnfp is equal to PBrf //Get an NFP Add the current no-fit polygon nfp to NFPs; bool over = false; while over is false do if search other start point (PA, PB, Ptnfp) //Algorithm 3 // Feasible start position may be the vertex of // created NFP in rare cases if the starting point is the vertexes of NFPs continue; if (the position of PA and PB is Jigsaw case) Add the current no-fit polygon nfp to NFPs; continue; over = true; //Find a feasible start point. else creation = false; over = true; end while end if end while return NFPs; |
4. Computational Experiments
4.1. Robustness Performance of ISA
4.2. Efficiency Performance of ISA
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elkeran, A. A new approach for sheet nesting problem using guided cuckoo search and pairwise clustering. Eur. J. Oper. Res. 2013, 231, 757–769. [Google Scholar] [CrossRef]
- Rao, Y.; Wang, P.; Luo, Q. Hybridizing beam search with tabu search for the irregular packing problem. Math. Probl. Eng. 2021, 2021, 5054916. [Google Scholar] [CrossRef]
- Alves, C.; Brás, P.; de Carvalho, J.V.; Pinto, T. New constructive algorithms for leather nesting in the automotive industry. Comput. Oper. Res. 2012, 39, 1487–1505. [Google Scholar] [CrossRef]
- Hu, X.; Li, J.; Cui, J. Greedy adaptive search: A new approach for large-scale irregular packing problems in the fabric industry. IEEE Access 2020, 8, 91476–91487. [Google Scholar] [CrossRef]
- Labrada-Nueva, Y.; Cruz-Rosales, M.H.; Rendón-Mancha, J.M.; Rivera-López, R.; Eraña-Díaz, M.L.; Cruz-Chávez, M.A. Overlap detection in 2D amorphous shapes for paper optimization in digital printing presses. Mathematics 2021, 9, 1033. [Google Scholar] [CrossRef]
- Luo, Q.; Rao, Y.; Peng, D. GA and GWO algorithm for the special bin packing problem encountered in field of aircraft arrangement. Appl. Soft Comput. 2022, 114, 108060. [Google Scholar] [CrossRef]
- Gonçalves, J.F.; Wäscher, G. A MIP model and a biased random-key genetic algorithm based approach for a two-dimensional cutting problem with defects. Eur. J. Oper. Res. 2020, 286, 867–882. [Google Scholar] [CrossRef]
- Chen, K.; Zhuang, J.; Zhong, S.; Zheng, S. Optimization Method for Guillotine Packing of Rectangular Items within an Irregular and Defective Slate. Mathematics 2020, 8, 1914. [Google Scholar] [CrossRef]
- Romanova, T.; Pankratov, O.; Litvinchev, I.; Stetsyuk, P.; Lykhovyd, O.; Marmolejo-Saucedo, J.A.; Vasant, P. Balanced Circular Packing Problems with Distance Constraints. Computation 2022, 10, 113. [Google Scholar] [CrossRef]
- Qin, Y.; Chan, F.T.S.; Chung, S.H.; Qu, T.; Niu, B. Aircraft parking stand allocation problem with safety consideration for independent hangar maintenance service providers. Comput. Oper. Res. 2018, 91, 225–236. [Google Scholar] [CrossRef]
- Martinez-Sykora, A.; Alvarez-Valdes, R.; Bennell, J.; Ruiz, R.; Tamarit, J. Matheuristics for the irregular bin packing problem with free rotations. Eur. J. Oper. Res. 2017, 258, 440–455. [Google Scholar] [CrossRef]
- Júnior, B.A.; Pinheiro, P.R.; Coelho, P.V. A parallel biased random-key genetic algorithm with multiple populations applied to irregular strip packing problems. Math. Probl. Eng. 2017, 2017, 1670709. [Google Scholar]
- Pinheiro, P.R.; Amaro, B., Jr.; Saraiva, R.D. A random-key genetic algorithm for solving the nesting problem. Int. J. Comput. Integr. Manuf. 2016, 29, 1159–1165. [Google Scholar] [CrossRef]
- Cherri, L.H.; Mundim, L.R.; Andretta, M.; Toledo, F.M.; Oliveira, J.F.; Carravilla, M.A. Robust mixed-integer linear programming models for the irregular strip packing problem. Eur. J. Oper. Res. 2016, 253, 570–583. [Google Scholar] [CrossRef]
- Costa, M.T.; Gomes, A.M.; Oliveira, J.F. Heuristic approaches to large-scale periodic packing of irregular shapes on a rectangular sheet. Eur. J. Oper. Res. 2009, 192, 29–40. [Google Scholar] [CrossRef]
- Bennell, J.A.; Oliveira, J.F. The geometry of nesting problems: A tutorial. Eur. J. Oper. Res. 2008, 184, 397–415. [Google Scholar] [CrossRef]
- Seidel, R. A simple and fast incremental randomized algorithm for computing trapezoidal decompositions and for triangulating polygons. Comput. Geom. Theory Appl. 1991, 1, 51–64. [Google Scholar] [CrossRef]
- Watson, P.D.; Tobias, A.M. An Efficient Algorithm for the Regular W 1 Packing of Polygons in the Infinite Plane. J. Oper. Res. Soc. 1999, 50, 1054. [Google Scholar] [CrossRef]
- Li, Z.; Milenkovic, V. Compaction and separation algorithms for non-convex polygons and their applications. Eur. J. Oper. Res. 1995, 84, 539–561. [Google Scholar] [CrossRef]
- Agarwal, P.K.; Flato, E.; Halperin, D. Polygon decomposition for efficient construction of Minkowski sums. Comput. Geom. 2002, 21, 39–61. [Google Scholar] [CrossRef]
- Stoyan, Y.; Scheithauer, G.; Gil, N.; Romanova, T. Φ-functions for complex 2D-objects. Q. J. Belg. Fr. Ital. Oper. Res. Soc. 2004, 2, 69–84. [Google Scholar]
- Chernov, N.; Stoyan, Y.; Romanova, T.; Pankratov, A. Phi-Functions for 2D Objects Formed by Line Segments and Circular Arcs. Adv. Oper. Res. 2012, 2012, 346358. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, P.K. An algebra of polygons through the notion of negative shapes. CVGIP Image Underst. 1991, 54, 119–144. [Google Scholar] [CrossRef]
- Bennell, J.; Dowsland, K.; Dowsland, W. The irregular cutting-stock problem—A new procedure for deriving the no-fit polygon. Comput. Oper. Res. 2001, 28, 271–287. [Google Scholar] [CrossRef]
- Bennell, J. A comprehensive and robust procedure for obtaining the nofit polygon using Minkowski sums. Comput. OR 2008, 35, 267–281. [Google Scholar] [CrossRef]
- Dean, H.T.; Tu, Y.; Raffensperger, J.F. An improved method for calculating the no-fit polygon. Comput. Oper. Res. 2006, 33, 1521–1539. [Google Scholar] [CrossRef]
- Mahadevan, A. Optimisation in Computer Aided Pattern Packing. Ph.D. Thesis, North Carolina State University, Raleigh, NC, USA, 1984. [Google Scholar]
- Burke, E.; Hellier, R.; Kendall, G.; Whitwell, G. Complete and robust no-fit polygon generation for the irregular stock cutting problem. Eur. J. Oper. Res. 2007, 179, 27–49. [Google Scholar] [CrossRef]
- Huyao, L.; Yuanjun, H.; Bennell, A.J. The irregular nesting problem: A new approach for nofit polygon calculation. J. Oper. Res. Soc. 2007, 58, 1235–1245. [Google Scholar] [CrossRef]
- Ferreira, J.C.; Alves, J.C.; Albuquerque, C.; Oliveira, J.F.; Ferreira, J.S.; Matos, J.S. A flexible custom computing machine for nesting problems. In Proceedings of the XIII DCIS, Madrid, Spain, 17 November 1998; pp. 348–354. [Google Scholar]
- Konopasek, M. Mathematical treatments of some apparel marking and cutting problems. US Dep. Commer. Rep. 1981, 99, 90857-10. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | E | N | R | L | O | Whitwell [28] | ISA | ISA-PES | ISA-PIT | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | P | T | P | T | In. (%) | T | In. (%) | ||||||
| Albano180 | 7.25 | 8 | 180 | 16 | 256 | 0.32 | 800 | 0.006 | 42,667 | 0.008 | 33.3 | 0.007 | 16.7 |
| Albano90 | 7.25 | 8 | 90 | 32 | 1024 | 0.71 | 1442 | 0.026 | 40,000 | 0.032 | 24.2 | 0.028 | 8.6 |
| Dagli | 6.2 | 10 | 90 | 40 | 1600 | 0.93 | 1720 | 0.032 | 50,314 | 0.038 | 18.2 | 0.031 | −1.9 |
| Dighe1 | 3.75 | 16 | 90 | 64 | 4096 | 1.28 | 3200 | 0.021 | 196,923 | 0.022 | 7.7 | 0.220 | 5.8 |
| Dighe2 | 4.7 | 10 | 90 | 40 | 1600 | 0.62 | 2581 | 0.012 | 129,032 | 0.014 | 14.5 | 0.014 | 9.7 |
| Fu | 3.58 | 12 | 90 | 48 | 2304 | 0.52 | 4431 | 0.012 | 185,806 | 0.014 | 16.1 | 0.014 | 16.1 |
| Jakobs1 | 6 | 25 | 90 | 100 | 10,000 | 5.57 | 1795 | 0.210 | 47,574 | 0.237 | 12.7 | 0.201 | −4.4 |
| Jakobs2 | 5.36 | 25 | 90 | 100 | 10,000 | 5.07 | 1972 | 0.233 | 42,845 | 0.253 | 8.6 | 0.169 | −27.5 |
| Mao | 9.22 | 9 | 90 | 36 | 1296 | 1.41 | 919 | 0.052 | 25,116 | 0.070 | 35.7 | 0.055 | 7.4 |
| Marques | 7.13 | 8 | 90 | 32 | 1024 | 0.79 | 1296 | 0.026 | 39,084 | 0.031 | 19.1 | 0.027 | 2.3 |
| Poly2b | 4.93 | 30 | 90 | 120 | 14,400 | 7.54 | 1910 | 0.153 | 93,872 | 0.172 | 12.0 | 0.141 | −8.1 |
| Poly3b | 4.93 | 45 | 90 | 180 | 32,400 | 27.14 | 1194 | 0.320 | 101,313 | 0.361 | 12.8 | 0.325 | 1.6 |
| Poly4b | 4.93 | 60 | 90 | 240 | 57,600 | 68.45 | 841 | 0.575 | 100,174 | 0.617 | 7.3 | 0.567 | −1.3 |
| Poly5b | 4.84 | 75 | 90 | 300 | 90,000 | 141.9 | 634 | 0.836 | 107,707 | 0.999 | 19.5 | 0.820 | −1.9 |
| Shapes0 | 8.75 | 4 | 0 | 4 | 16 | 0.11 | 145 | 0.001 | 16,000 | 0.001 | 0.0 | 0.001 | 0.0 |
| Shapes1 | 8.75 | 4 | 180 | 8 | 64 | 0.19 | 337 | 0.004 | 15,238 | 0.006 | 33.3 | 0.004 | 0.0 |
| Shirts | 6.63 | 8 | 180 | 16 | 256 | 0.33 | 776 | 0.006 | 41,290 | 0.008 | 32.3 | 0.006 | 0.0 |
| Swim | 21.9 | 10 | 180 | 20 | 400 | 6.08 | 66 | 0.107 | 3745 | 0.180 | 68.5 | 0.136 | 27.5 |
| Trousers | 5.06 | 17 | 180 | 34 | 1156 | 0.73 | 1584 | 0.012 | 96,333 | 0.015 | 23.3 | 0.013 | 11.7 |
| Discrete Angle (Degree) | Average Number of Edges | Time (Millisecond) | Reducing Time (%) | |
|---|---|---|---|---|
| ISA | ISA-PES | |||
| 2 | 652.0 | 1280 | 2621 | 51.2 |
| 6 | 219.5 | 53 | 97.2 | 45.5 |
| 10 | 135.0 | 15 | 23.4 | 35.9 |
| 14 | 97.0 | 6 | 9 | 33.3 |
| 18 | 76.0 | 4 | 5 | 20.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Q.; Rao, Y. Improved Sliding Algorithm for Generating No-Fit Polygon in the 2D Irregular Packing Problem. Mathematics 2022, 10, 2941. https://doi.org/10.3390/math10162941
Luo Q, Rao Y. Improved Sliding Algorithm for Generating No-Fit Polygon in the 2D Irregular Packing Problem. Mathematics. 2022; 10(16):2941. https://doi.org/10.3390/math10162941
Chicago/Turabian StyleLuo, Qiang, and Yunqing Rao. 2022. "Improved Sliding Algorithm for Generating No-Fit Polygon in the 2D Irregular Packing Problem" Mathematics 10, no. 16: 2941. https://doi.org/10.3390/math10162941
APA StyleLuo, Q., & Rao, Y. (2022). Improved Sliding Algorithm for Generating No-Fit Polygon in the 2D Irregular Packing Problem. Mathematics, 10(16), 2941. https://doi.org/10.3390/math10162941