
Multiple Degradation Skilled Network for Infrared and Visible Image Fusion Based on Multi-Resolution SVD Updation
 ,
,  ,
,
Abstract
:1. Introduction
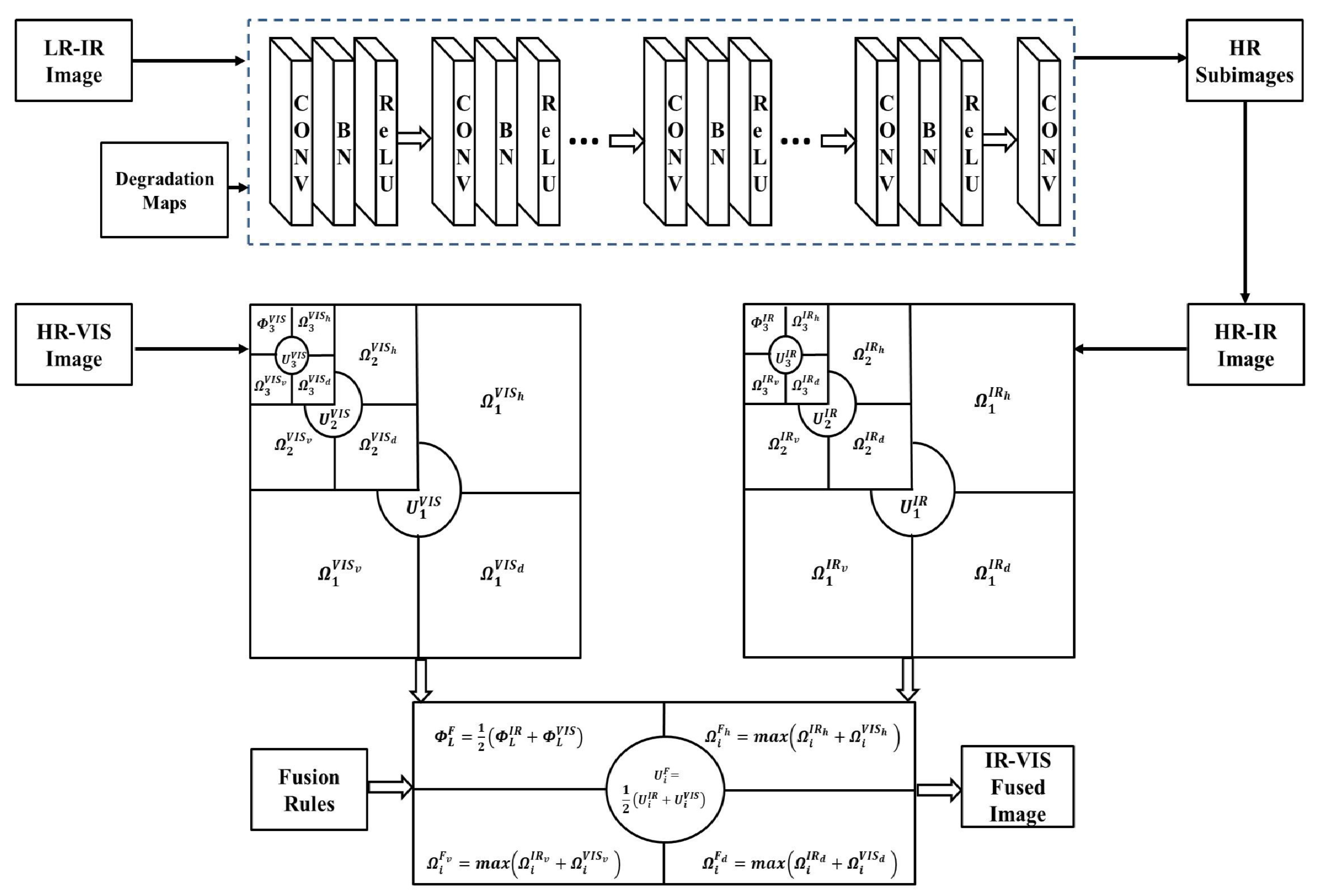
2. MDSNet
- The network takes images as input by considering LR images concatenated with degradation maps. The MDSNet achieves non-linear mapping using multiple convolutional layers in cascade form [17]. Each layer includes convolution operation (CONV), batch normalization (BN) [26] and rectifier linear unit (ReLU) [27].
- The first “CONV+BN+ReLU” layer operates on input images.
- All the middle layers are similar to each other, performing “CONV+BN+ReLU” operations.
- The last layer consists of “CONV” operation alone, which produces output HR image patches. The last layer is followed by a sub-pixel convolution layer [28] to convert HR image patches to a single HR image .
- We use Adam optimizer [29] to minimize the loss function,where K is the total number of images including the degradation maps and are the i-th LR and HR images, respectively. For all scale factors s, we set a total of 12 convolution layers with 128 feature maps in each layer. The training is performed separately for different scaling factors. We use the trained model to enhance the resolution of the input LR-IR image in our proposed method.
3. Proposed Method
3.1. LR-IR Image Upscaling Using MDSNet
3.2. MRSVD Coefficients Generation and Updation
3.3. Fusion Process
4. Results and Discussion
4.1. Datasets and Settings
4.2. Methods and Evaluation Metrics
4.3. Qualitative Results Analysis
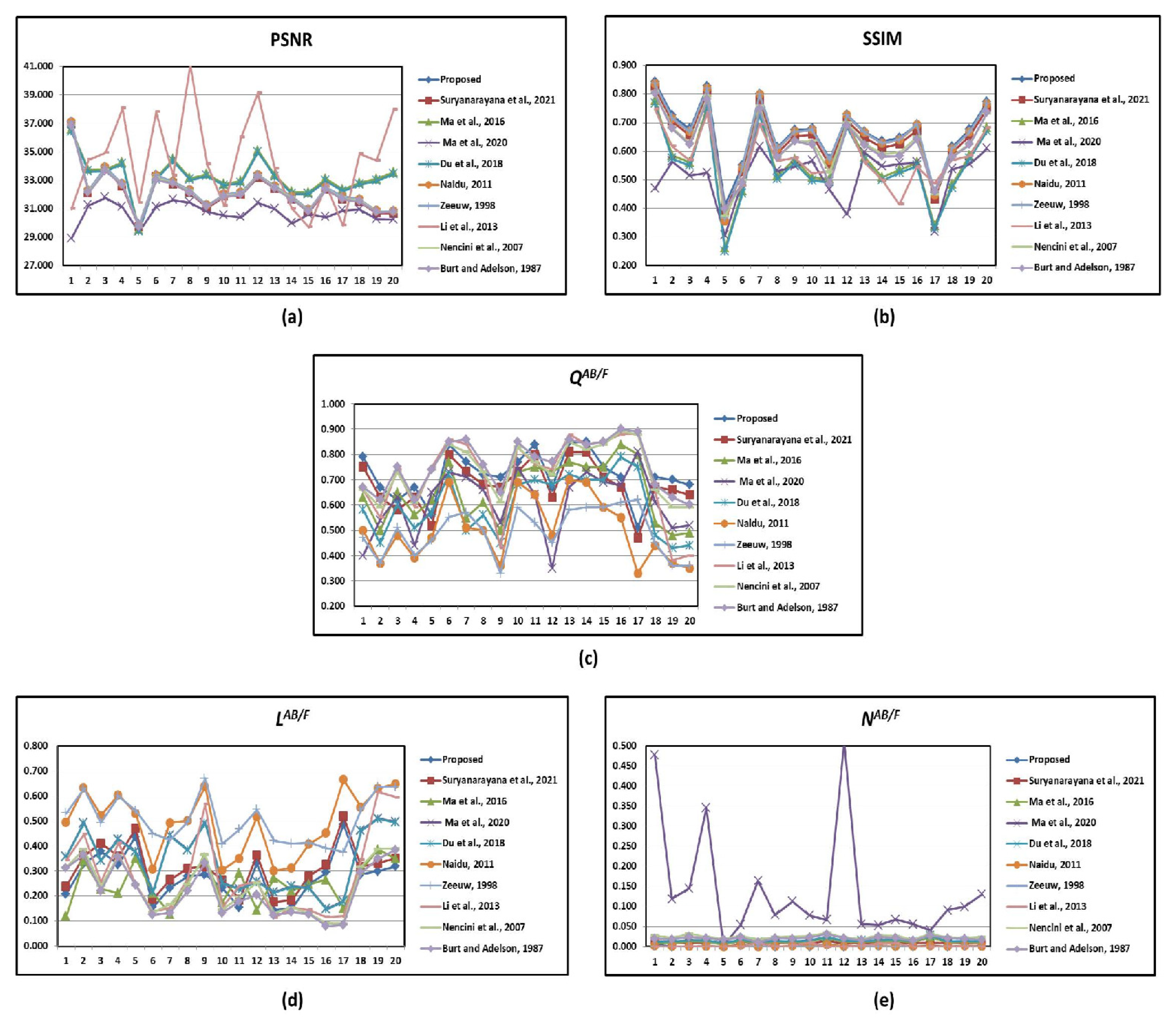
4.4. Quantitative Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hervella, Á.S.; Rouco, J.; Novo, J.; Ortega, M. Retinal microaneurysms detection using adversarial pre-training with unlabeled multimodal images. Inf. Fusion 2022, 79, 146–161. [Google Scholar] [CrossRef]
- Jin, X.; Jiang, Q.; Yao, S.; Zhou, D.; Nie, R.; Hai, J.; He, K. A survey of infrared and visual image fusion methods. Infrared Phys. Technol. 2017, 85, 478–501. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y.; Fan, F.; Zhang, Y.; Huang, J. Infrared and visible image fusion via saliency analysis and local edge-preserving multi-scale decomposition. JOSA A 2017, 34, 1400–1410. [Google Scholar] [CrossRef] [PubMed]
- Shibata, T.; Tanaka, M.; Okutomi, M. Visible and near-infrared image fusion based on visually salient area selection. In Digital Photography XI, Proceedings of the International Society for Optics and Photonics, San Francisco, CA, USA, 9–10 February 2015; SPIE: Bellingham, WA, USA, 2015; Volume 9404, p. 94040G. [Google Scholar]
- Suryanarayana, G.; Tu, E.; Yang, J. Infrared super-resolution imaging using multi-scale saliency and deep wavelet residuals. Infrared Phys. Technol. 2019, 97, 177–186. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.S.; Han, J.; Tao, D. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: A review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Suryanarayana, G.; Dhuli, R. Image resolution enhancement using wavelet domain transformation and sparse signal representation. Procedia Comput. Sci. 2016, 92, 311–316. [Google Scholar] [CrossRef]
- Pajares, G.; De La Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Dogra, A.; Goyal, B.; Agrawal, S. From multi-scale decomposition to non-multi-scale decomposition methods: A comprehensive survey of image fusion techniques and its applications. IEEE Access 2017, 5, 16040–16067. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Kong, W.; Zhang, L.; Lei, Y. Novel fusion method for visible light and infrared images based on NSST–SF–PCNN. Infrared Phys. Technol. 2014, 65, 103–112. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–9. [Google Scholar]
- Patil, U.; Mudengudi, U. Image fusion using hierarchical PCA. In Proceedings of the 2011 International Conference on Image Information Processing, Shimla, India, 3–5 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Suryanarayana, G.; Chandran, K.; Khalaf, O.I.; Alotaibi, Y.; Alsufyani, A.; Alghamdi, S.A. Accurate magnetic resonance image super-resolution using deep networks and Gaussian filtering in the stationary wavelet domain. IEEE Access 2021, 9, 71406–71417. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, J.; Chen, C.; Fan, F.; Ma, J. Infrared and visible image fusion using total variation model. Neurocomputing 2016, 202, 12–19. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, B.; Li, S.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with Gaussian and bilateral filters. Inf. Fusion 2016, 30, 15–26. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, H.; Liu, J. Multi-attention augmented network for single image super-resolution. Pattern Recognit. 2022, 122, 108349. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Na, G.S. Efficient learning rate adaptation based on hierarchical optimization approach. Neural Netw. 2022, 150, 326–335. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, C.; Wei, Z. Carbon price forecasting based on multi-resolution singular value decomposition and extreme learning machine optimized by the moth–flame optimization algorithm considering energy and economic factors. Energies 2019, 12, 4283. [Google Scholar] [CrossRef]
- Suryanarayana, G.; Dhuli, R. Super-resolution image reconstruction using dual-mode complex diffusion-based shock filter and singular value decomposition. Circuits Syst. Signal Process. 2017, 36, 3409–3425. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 2, pp. 416–423. [Google Scholar]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef]
- Naidu, V. Image fusion technique using multi-resolution singular value decomposition. Def. Sci. J. 2011, 61, 479. [Google Scholar] [CrossRef]
- Zeeuw, P. Wavelets and Image Fusion; CWI: Amsterdam, The Netherlands, 1998; Volume 444. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2366–2369. [Google Scholar]
- Zhao, C.; Shao, G.; Ma, L.; Zhang, X. Image fusion algorithm based on redundant-lifting NSWMDA and adaptive PCNN. Optik 2014, 125, 6247–6255. [Google Scholar] [CrossRef]
- Shreyamsha Kumar, B. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Petrovic, V.; Xydeas, C. Objective image fusion performance characterisation. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 1866–1871. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM | ||||
|---|---|---|---|---|---|---|
| Proposed | 34.03 | 0.663 | 0.720 | 0.278 | 0.002 | 1 |
| [17] | 33.87 | 0.642 | 0.680 | 0.310 | 0.010 | 1 |
| [22] | 30.71 | 0.513 | 0.613 | 0.250 | 0.138 | 1 |
| [33] | 33.16 | 0.549 | 0.646 | 0.338 | 0.016 | 1 |
| [20] | 33.28 | 0.560 | 0.651 | 0.336 | 0.013 | 1 |
| [34] | 32.31 | 0.653 | 0.505 | 0.493 | 0.002 | 1 |
| [35] | 32.32 | 0.656 | 0.495 | 0.504 | 0.001 | 1 |
| [36] | 34.34 | 0.574 | 0.712 | 0.284 | 0.003 | 1 |
| [37] | 32.22 | 0.623 | 0.738 | 0.237 | 0.025 | 1 |
| [38] | 32.17 | 0.617 | 0.759 | 0.220 | 0.021 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suryanarayana, G.; Varadarajan, V.; Pillutla, S.R.; Nagajyothi, G.; Kotapati, G. Multiple Degradation Skilled Network for Infrared and Visible Image Fusion Based on Multi-Resolution SVD Updation. Mathematics 2022, 10, 3389. https://doi.org/10.3390/math10183389
Suryanarayana G, Varadarajan V, Pillutla SR, Nagajyothi G, Kotapati G. Multiple Degradation Skilled Network for Infrared and Visible Image Fusion Based on Multi-Resolution SVD Updation. Mathematics. 2022; 10(18):3389. https://doi.org/10.3390/math10183389
Chicago/Turabian StyleSuryanarayana, Gunnam, Vijayakumar Varadarajan, Siva Ramakrishna Pillutla, Grande Nagajyothi, and Ghamya Kotapati. 2022. "Multiple Degradation Skilled Network for Infrared and Visible Image Fusion Based on Multi-Resolution SVD Updation" Mathematics 10, no. 18: 3389. https://doi.org/10.3390/math10183389
APA StyleSuryanarayana, G., Varadarajan, V., Pillutla, S. R., Nagajyothi, G., & Kotapati, G. (2022). Multiple Degradation Skilled Network for Infrared and Visible Image Fusion Based on Multi-Resolution SVD Updation. Mathematics, 10(18), 3389. https://doi.org/10.3390/math10183389