
Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO


Abstract
:1. Introduction
- A nonlinear IGC model of a hypersonic vehicle is established with actuator faults and parameter uncertainty.
- A PPO-based IGC system is proposed and designed. The IGC system is modeled as a reinforcement learning problem and the PPO algorithm is applied to the system. The simulation proves the passive fault tolerance of the method, and the method can complete the guidance task under complex fault conditions.
2. Problem Formulation
2.1. 3DOF Model of the Hypersonic Vehicle
2.2. Line-of-Sight Angle Model
2.3. Fault Model
3. Method
3.1. Proximal Policy Optimization Algorithm
3.2. PPO-Based IGC System
3.2.1. Action Space Design
3.2.2. Observation Space Design
3.2.3. Reward Function Design
3.2.4. Network Initialization
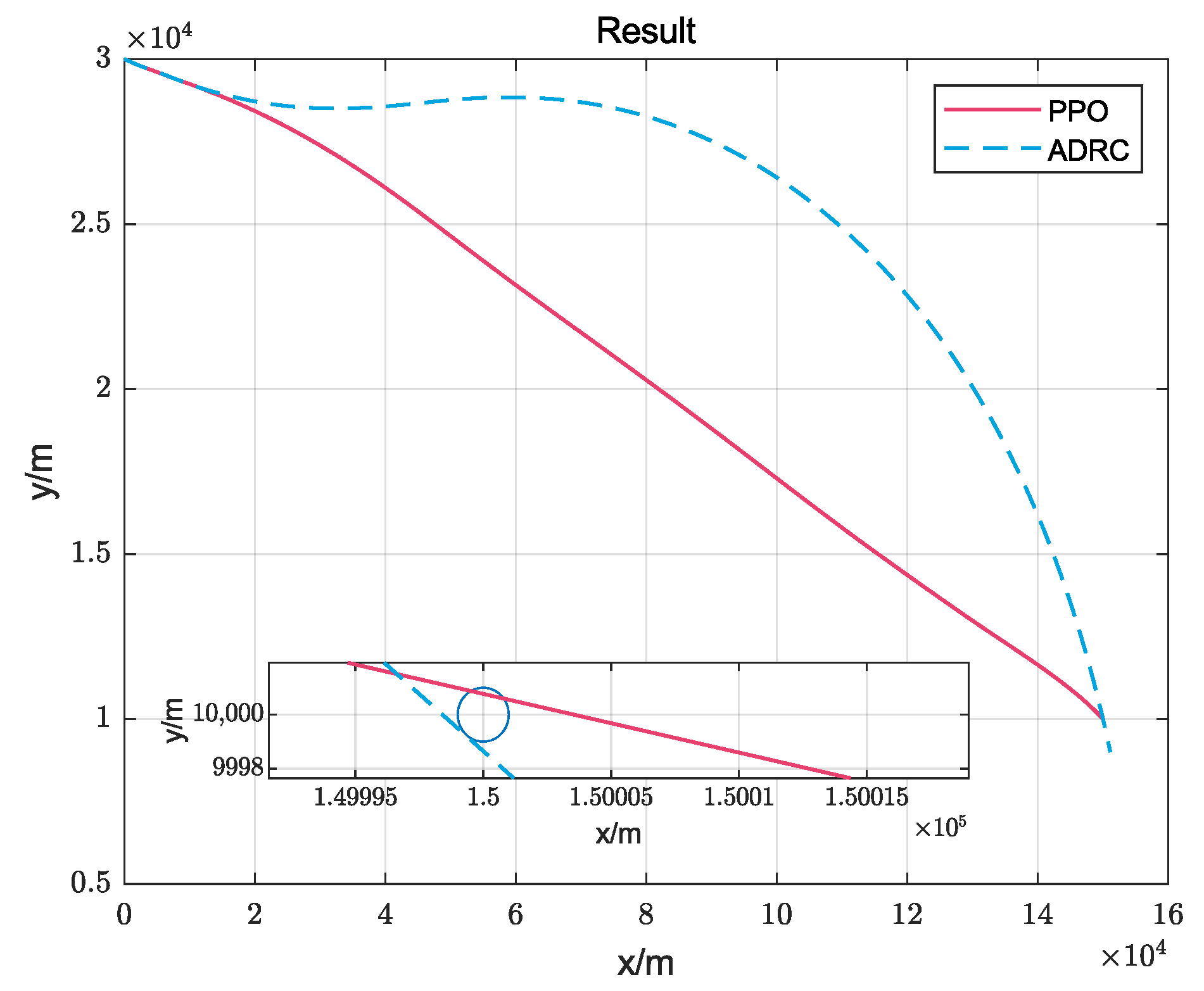
4. Simulation and Results
4.1. Simulation without Actuator Faults
4.2. Simulation with Actuator Faults and Uncertainty
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IGC | Integrated Guidance and Control |
| PPO | Proximal Policy Optimization |
| RL | Reinforcement Learning |
| HSV | Hypersonic Vehicles |
| DOF | Degree of Freedom |
References
- Xu, B.; Shi, Z. An overview on flight dynamics and control approaches for hypersonic vehicles. Sci. China Inf. Sci. 2015, 58, 1–19. [Google Scholar] [CrossRef]
- Shao, X.; Shi, Y.; Zhang, W. Fault-Tolerant Quantized Control for Flexible Air-Breathing Hypersonic Vehicles With Appointed-Time Tracking Performances. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1261–1273. [Google Scholar] [CrossRef]
- Gao, K.; Song, J.; Wang, X.; Li, H. Fractional-order proportional-integral-derivative linear active disturbance rejection control design and parameter optimization for hypersonic vehicles with actuator faults. Tsinghua Sci. Technol. 2020, 26, 9–23. [Google Scholar] [CrossRef]
- Zhao, K.; Song, J.; Ai, S.; Xu, X.; Liu, Y. Active Fault-Tolerant Control for Near-Space Hypersonic Vehicles. Aerospace 2022, 9, 237. [Google Scholar] [CrossRef]
- Meng, Y.; Jiang, B.; Qi, R. Adaptive fault-tolerant attitude tracking control of hypersonic vehicle subject to unexpected centroid-shift and state constraints. Aerosp. Sci. Technol. 2019, 95, 105515. [Google Scholar] [CrossRef]
- Bu, X.; He, G.; Wang, K. Tracking control of air-breathing hypersonic vehicles with non-affine dynamics via improved neural back-stepping design. ISA Trans. 2018, 75, 88–100. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.; Richman, J.; Friedland, B. Design of an integrated strapdown guidance and control system for a tactical missile. In Proceedings of the Guidance and Control Conference, Gatlinburg, TN, USA, 15–17 August 1983; p. 2169. [Google Scholar]
- Santoso, F.; Garratt, M.A.; Anavatti, S.G. State-of-the-art integrated guidance and control systems in unmanned vehicles: A review. IEEE Syst. J. 2020, 15, 3312–3323. [Google Scholar] [CrossRef]
- Levy, M.; Shima, T.; Gutman, S. Integrated single vs. two loop autopilot-guidance design for dual controlled missiles. In Proceedings of the 2013 10th IEEE International Conference on Control and Automation (ICCA), Hangzhou, China, 12–14 June 2013; pp. 1730–1735. [Google Scholar]
- Zhang, C.; Wu, Y.J. Dynamic surface control and active disturbance rejection control-based integrated guidance and control design and simulation for hypersonic reentry missile. Int. J. Model. Simul. Sci. Comput. 2016, 7, 1650025. [Google Scholar] [CrossRef]
- Yi, K.; Tang, K.; She, S.; Li, M.; Tan, Z. Integrated guidance and control for Semi-Strapdown Missiles. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9826–9830. [Google Scholar]
- Ming, C.; Wang, X.; Sun, R. A novel non-singular terminal sliding mode control-based integrated missile guidance and control with impact angle constraint. Aerosp. Sci. Technol. 2019, 94, 105368. [Google Scholar] [CrossRef]
- Xiong, Y.; Guo, J.; Zhou, J. Sliding Mode Control for Integrated Missile Guidance and Control System. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8371–8374. [Google Scholar]
- Zhang, D.; Ma, P.; Wang, S.; Chao, T. Multi-constraints adaptive finite-time integrated guidance and control design. Aerosp. Sci. Technol. 2020, 107, 106334. [Google Scholar] [CrossRef]
- Chong, Z.; Guo, J.; Zhao, B.; Guo, Z.; Lu, X. Finite-time integrated guidance and control system for hypersonic vehicles. Trans. Inst. Meas. Control 2021, 43, 842–853. [Google Scholar]
- Khankalantary, S.; Rezaee Ahvanouee, H.; Mohammadkhani, H. L1 Adaptive integrated guidance and control for flexible hypersonic flight vehicle in the presence of dynamic uncertainties. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2021, 235, 1521–1531. [Google Scholar] [CrossRef]
- Qian, J.; Qi, R.; Jiang, B. Fault-tolerant guidance and control design for reentry hypersonic flight vehicles based on control-allocation approach. In Proceedings of the 2014 IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2014; pp. 1624–1629. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]
- Ahmed, I.; Quiñones-Grueiro, M.; Biswas, G. Fault-Tolerant Control of Degrading Systems with On-Policy Reinforcement Learning. IFAC-PapersOnLine 2020, 53, 13733–13738. [Google Scholar] [CrossRef]
- Dai, H.; Chen, P.; Yang, H. Metalearning-Based Fault-Tolerant Control for Skid Steering Vehicles under Actuator Fault Conditions. Sensors 2022, 22, 845. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, I.; Khorasgani, H.; Biswas, G. Comparison of model predictive and reinforcement learning methods for fault tolerant control. IFAC-PapersOnLine 2018, 51, 233–240. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Keshmiri, S.; Colgren, R.; Mirmirani, M. Development of an aerodynamic database for a generic hypersonic air vehicle. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, San Francisco, CA, USA, 15–18 August 2005; p. 6257. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Size |
|---|---|
| Input Layer | 8 |
| Hidden Layer 1 | 128 |
| Hidden Layer 2 | 64 |
| Hidden Layer 3 | 32 |
| Output Layer | 1 |
| Layers | Size |
|---|---|
| Input Layer | 8 |
| Hidden Layer 1 | 128 |
| Hidden Layer 2 | 64 |
| Hidden Layer 3 | 32 (variance) + 32 (mean) |
| Output Layer | 1 (variance) + 1 (mean) |
| Parameters | Value |
|---|---|
| Horizon | 16 384 |
| Clip Factor | 0.2 |
| Discount Factor | 0.9999 |
| Mini Batch Size | 128 |
| Sample Time | 0.01 |
| Learn Rate |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| (m) | 0 | (m) | 30,000 |
| (m/s) | 4500 | −5 | |
| (rad/s) | 0 | −10 | |
| (m) | 150,000 | (m) | 10,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Luo, Y.; Zhao, M.; Hu, Y.; Zhang, Y. Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO. Mathematics 2022, 10, 3401. https://doi.org/10.3390/math10183401
Song J, Luo Y, Zhao M, Hu Y, Zhang Y. Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO. Mathematics. 2022; 10(18):3401. https://doi.org/10.3390/math10183401
Chicago/Turabian StyleSong, Jia, Yuxie Luo, Mingfei Zhao, Yunlong Hu, and Yanxue Zhang. 2022. "Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO" Mathematics 10, no. 18: 3401. https://doi.org/10.3390/math10183401
APA StyleSong, J., Luo, Y., Zhao, M., Hu, Y., & Zhang, Y. (2022). Fault-Tolerant Integrated Guidance and Control Design for Hypersonic Vehicle Based on PPO. Mathematics, 10(18), 3401. https://doi.org/10.3390/math10183401