

Prediction and Optimization of Pile Bearing Capacity Considering Effects of Time


Abstract
:1. Introduction
2. Methodology Background
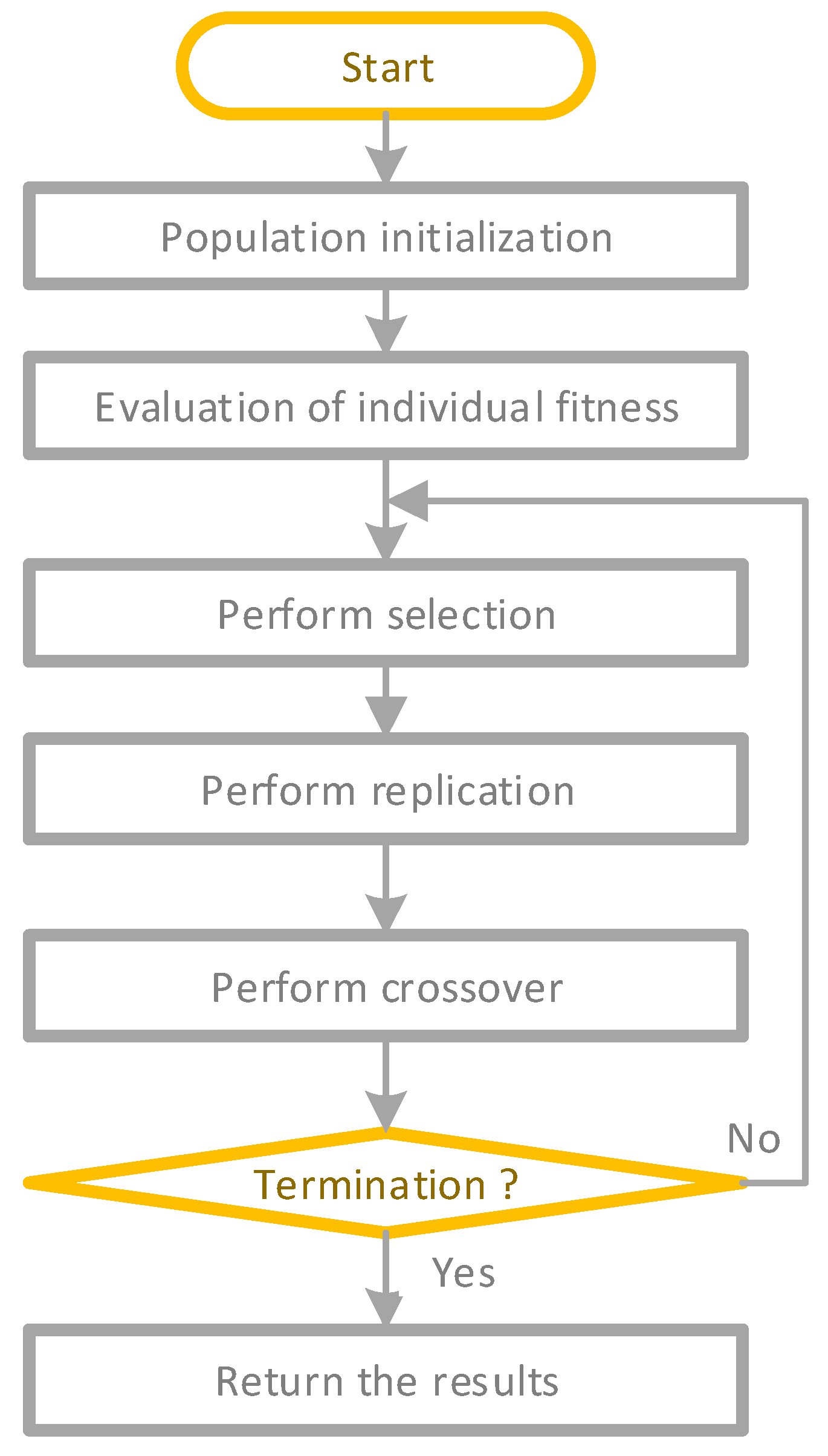
2.1. Genetic Programming
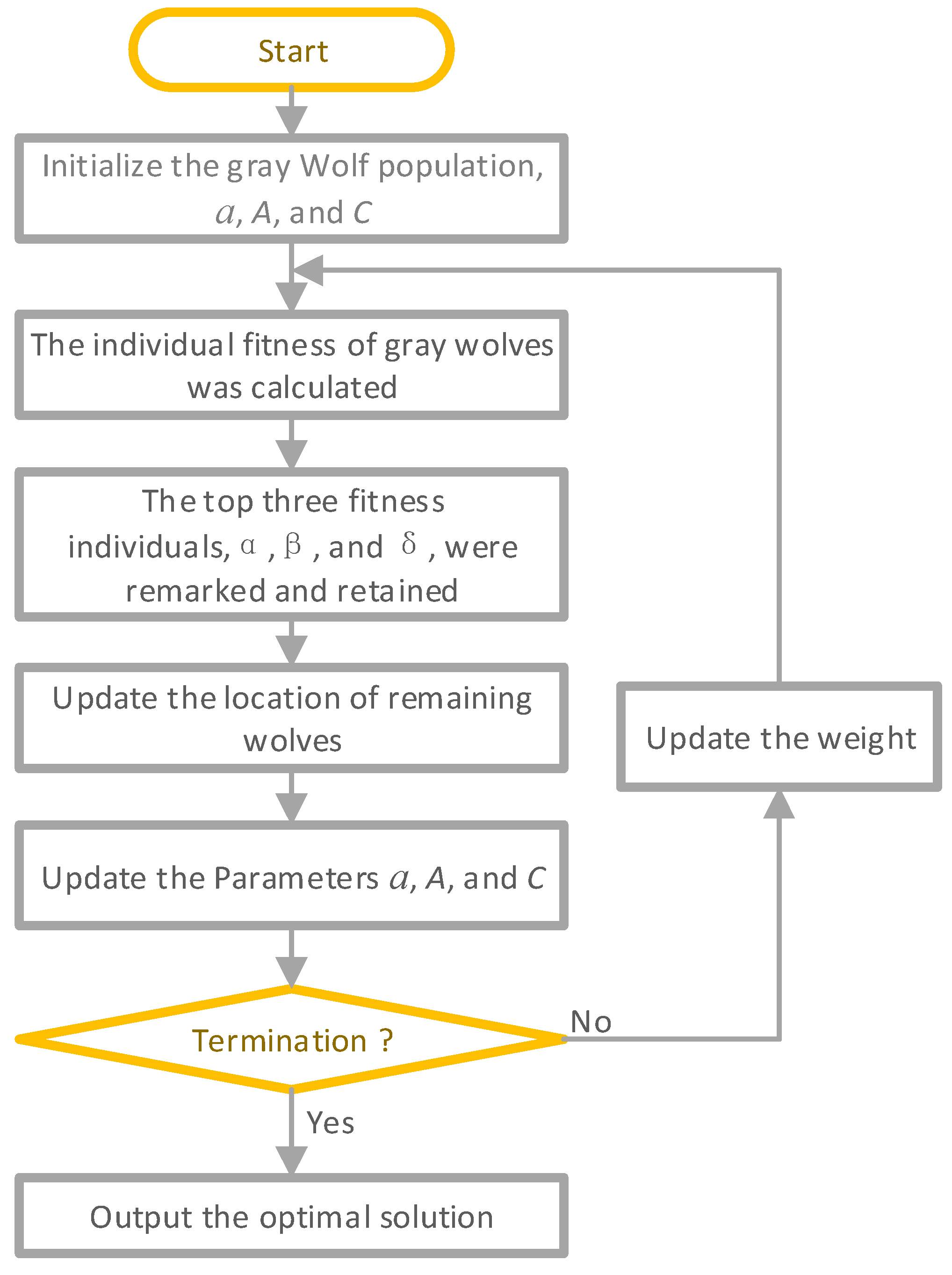
2.2. Gray Wolf Optimization
2.3. Artificial Bee Colony
3. Database Establishment
3.1. Case Study and Input Parameters
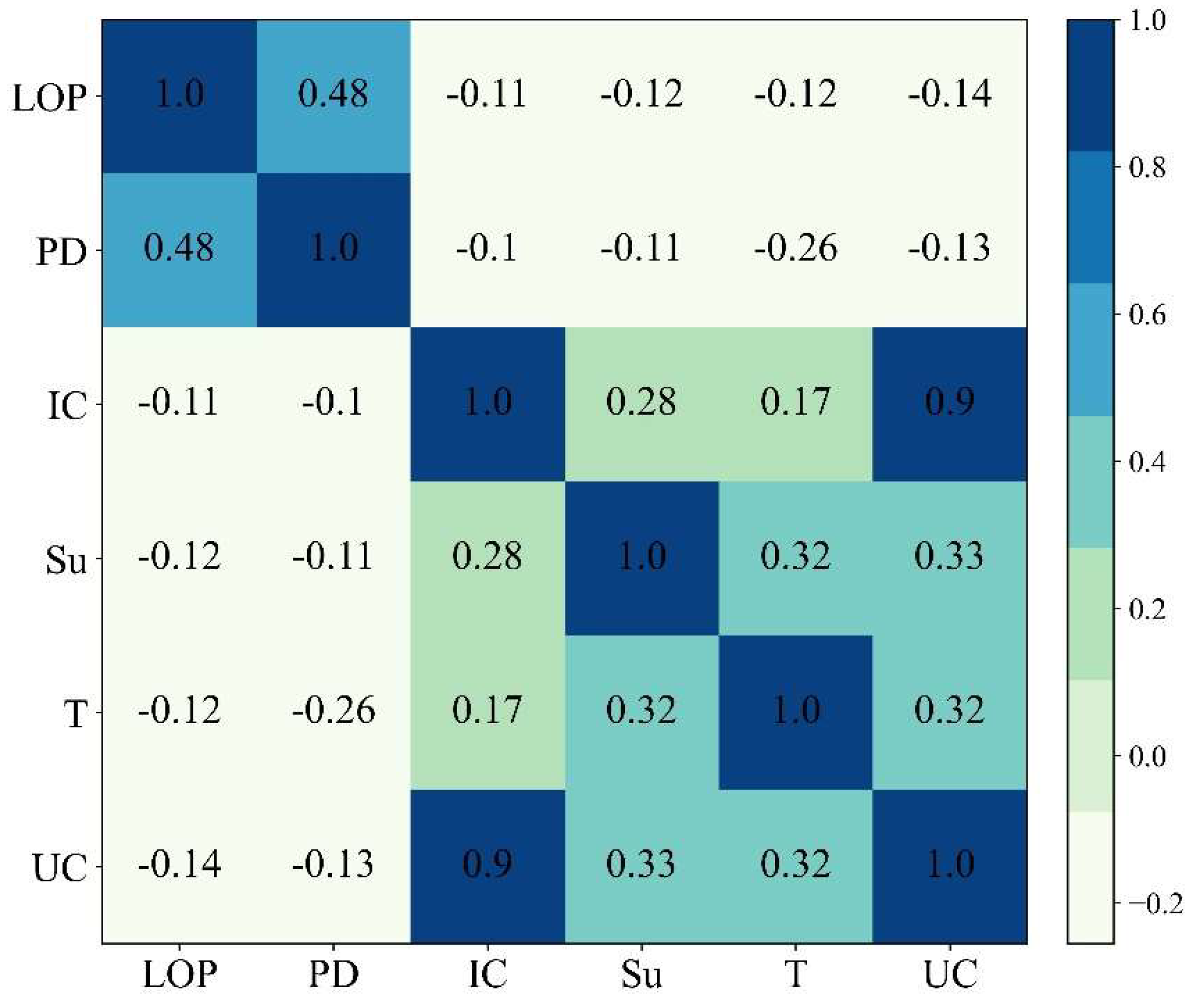
3.2. Statistical Information on the Data
4. Prediction of Pile Capacity
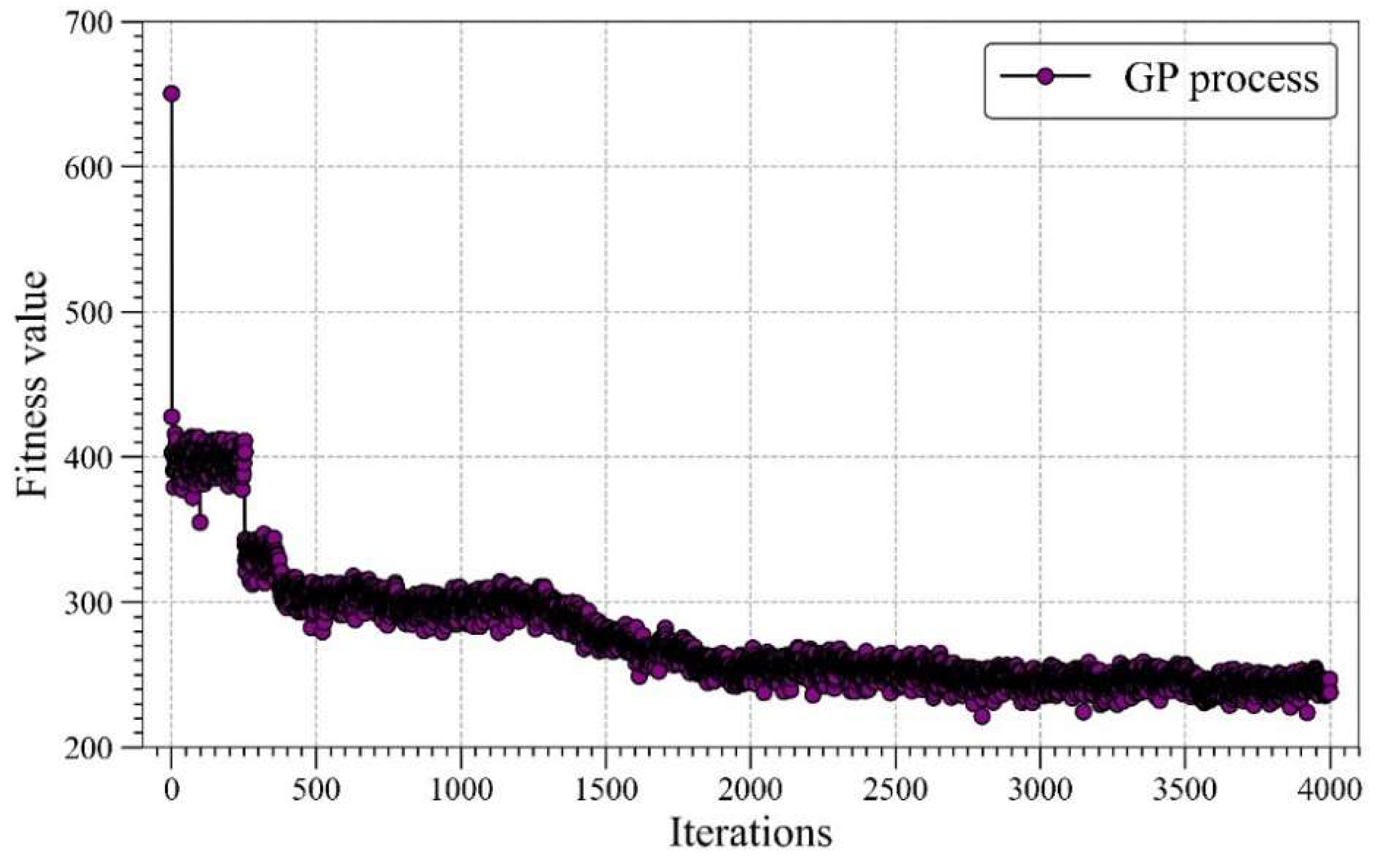
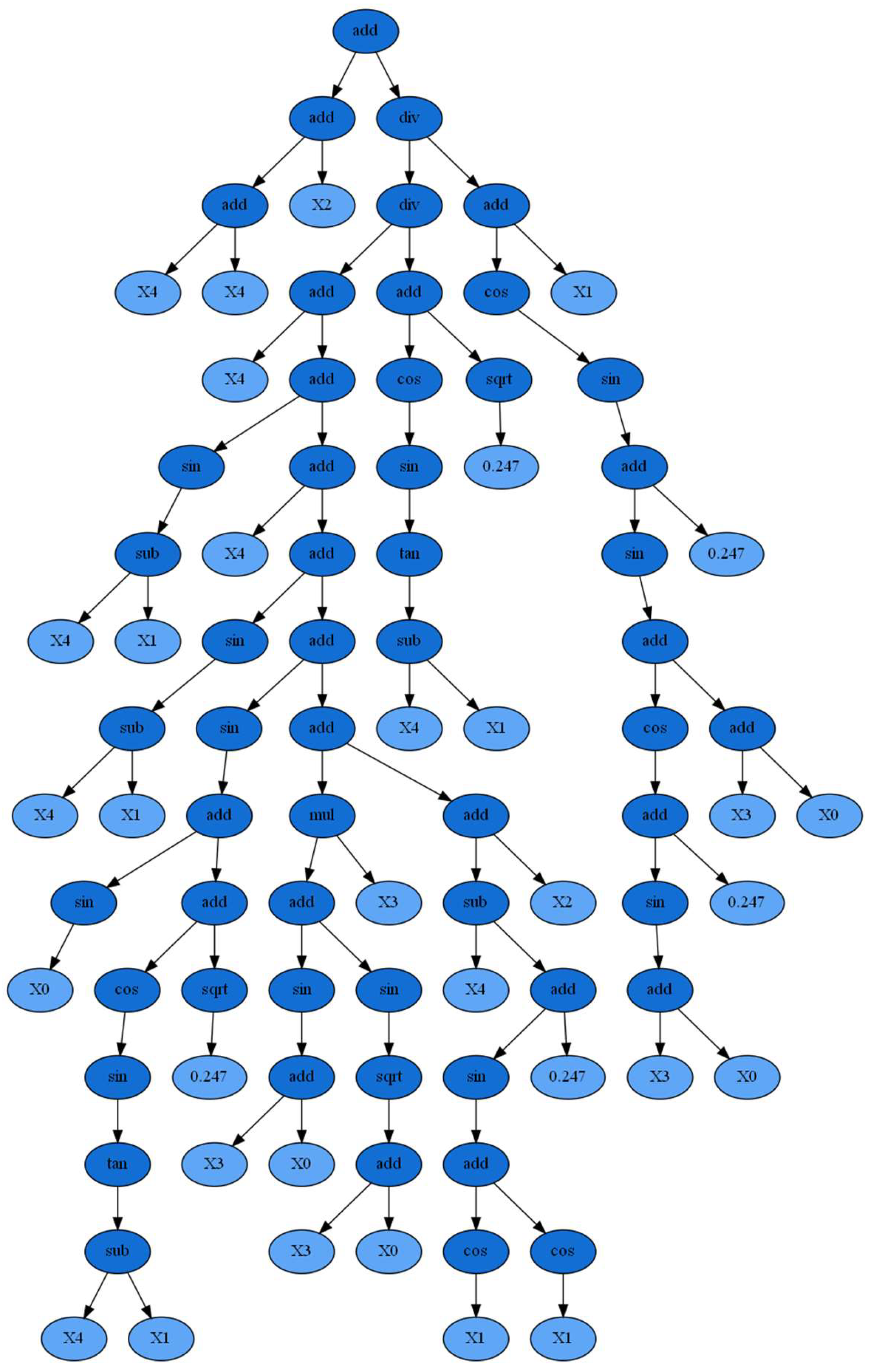
4.1. GP Modeling Procedure
- (1)
- A training set and a testing set were created by randomly dividing the database. Then, 80 percent of the database (204 datasets) was dedicated to the training set, while the remaining 20 percent was devoted to testing (52 datasets). The initial population is randomly generated from the database and function sets. The function sets include +, −, ×, ÷, , sin, cos, and tan.
- (2)
- The testing set is adapted to fit the prediction equation. After the genetic operation, i.e., selection, crossover, and variation, the preliminary prediction formula is obtained [46].
- (3)
- The fitness function of the population is defined, and it is employed to evaluate the fitness of each formula in the population. Root mean square error (RMSE) as the fitness function was used in this study. The fitness value is calculated according to Equation (2), where M means the number of training or testing sets, and represents the predicted value of the formula generated by GP.
- (4)
- Repeat steps (2–3) until the training time reaches the termination rule.
- (5)
- At the end of GP, the final optimal formula is evaluated from the goodness of fit coefficient between the predicted UC obtained by the formula and the real UC. is calculated according to Equation (3).where represents mean values of the UC.
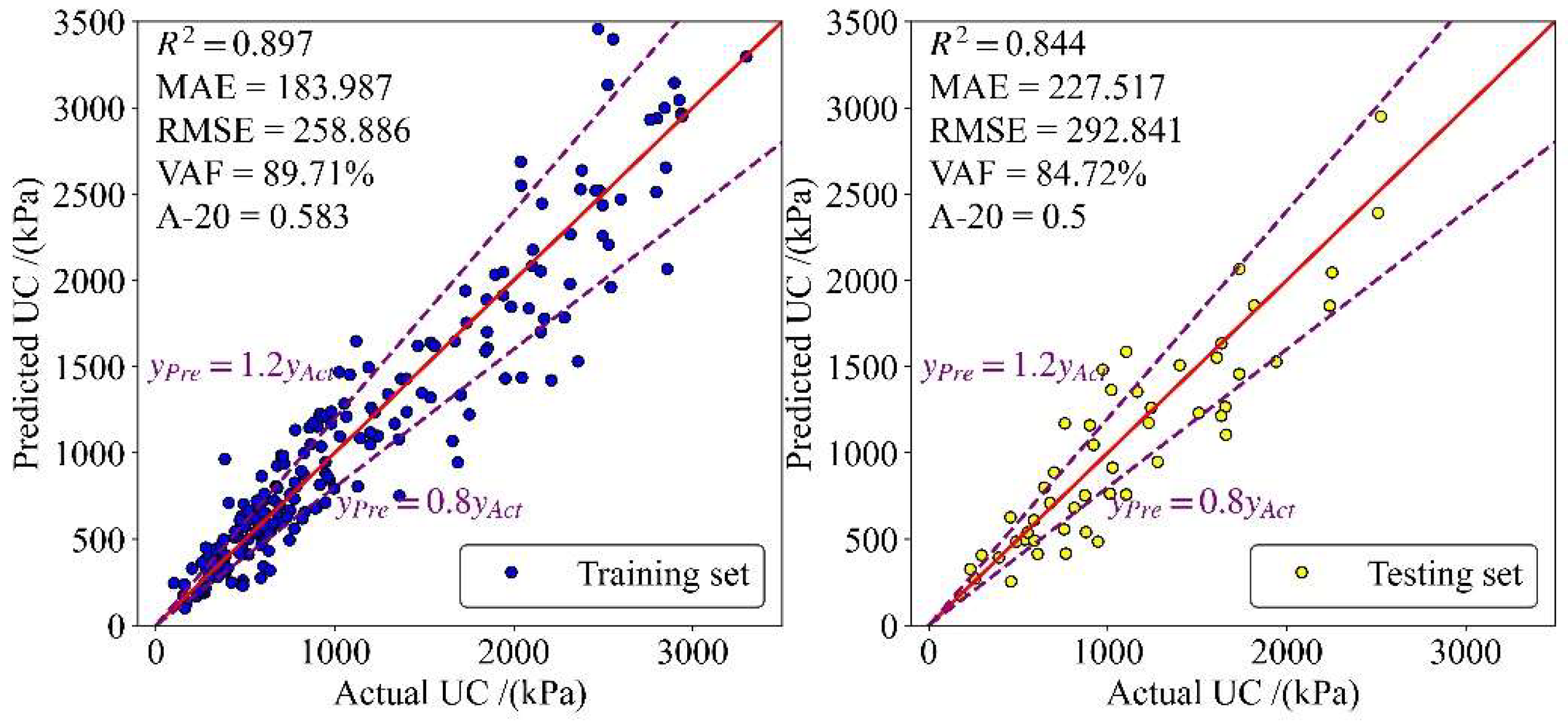
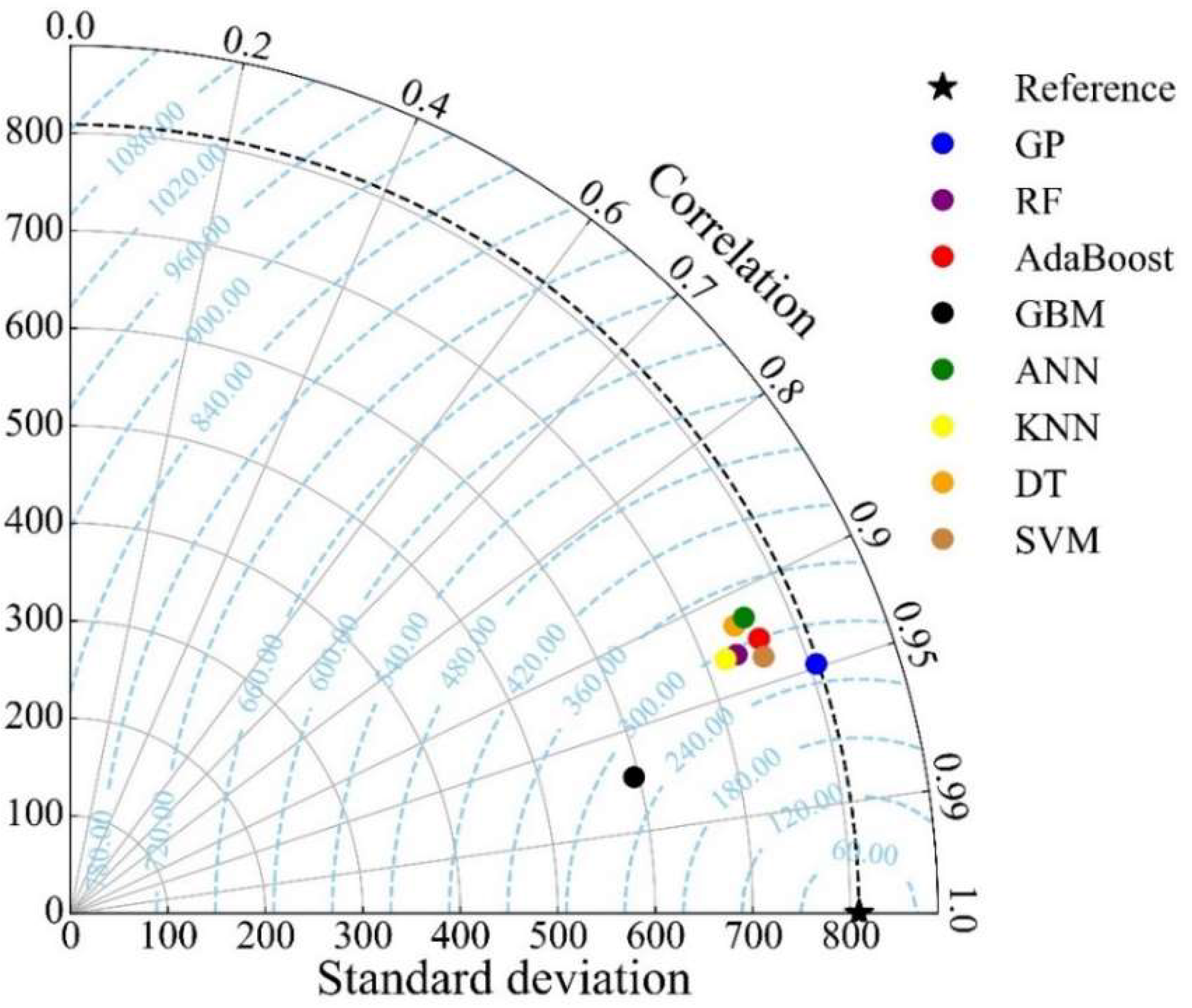
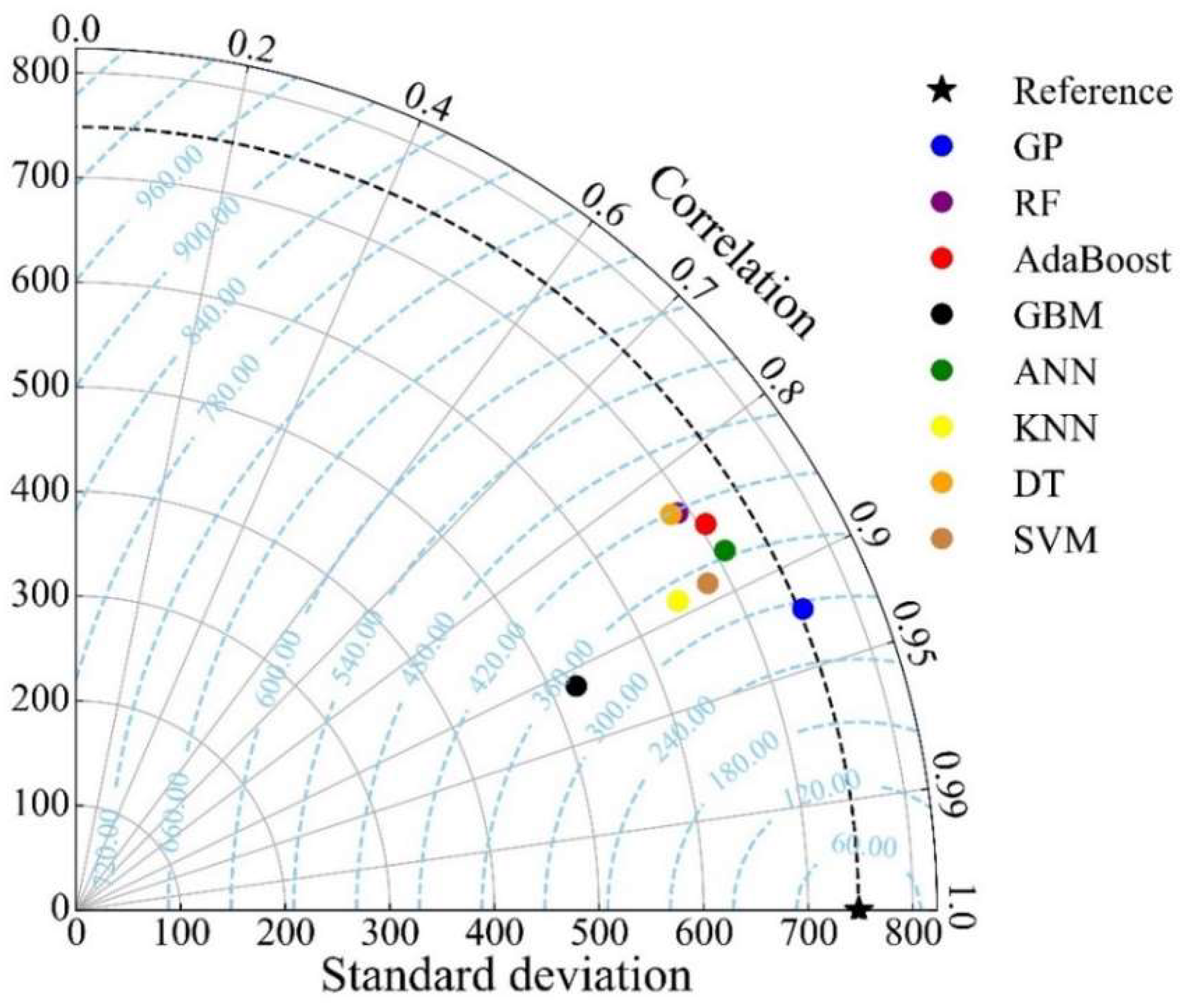
4.2. Results
5. Optimizing Pile Capacity Using Metaheuristic Algorithms
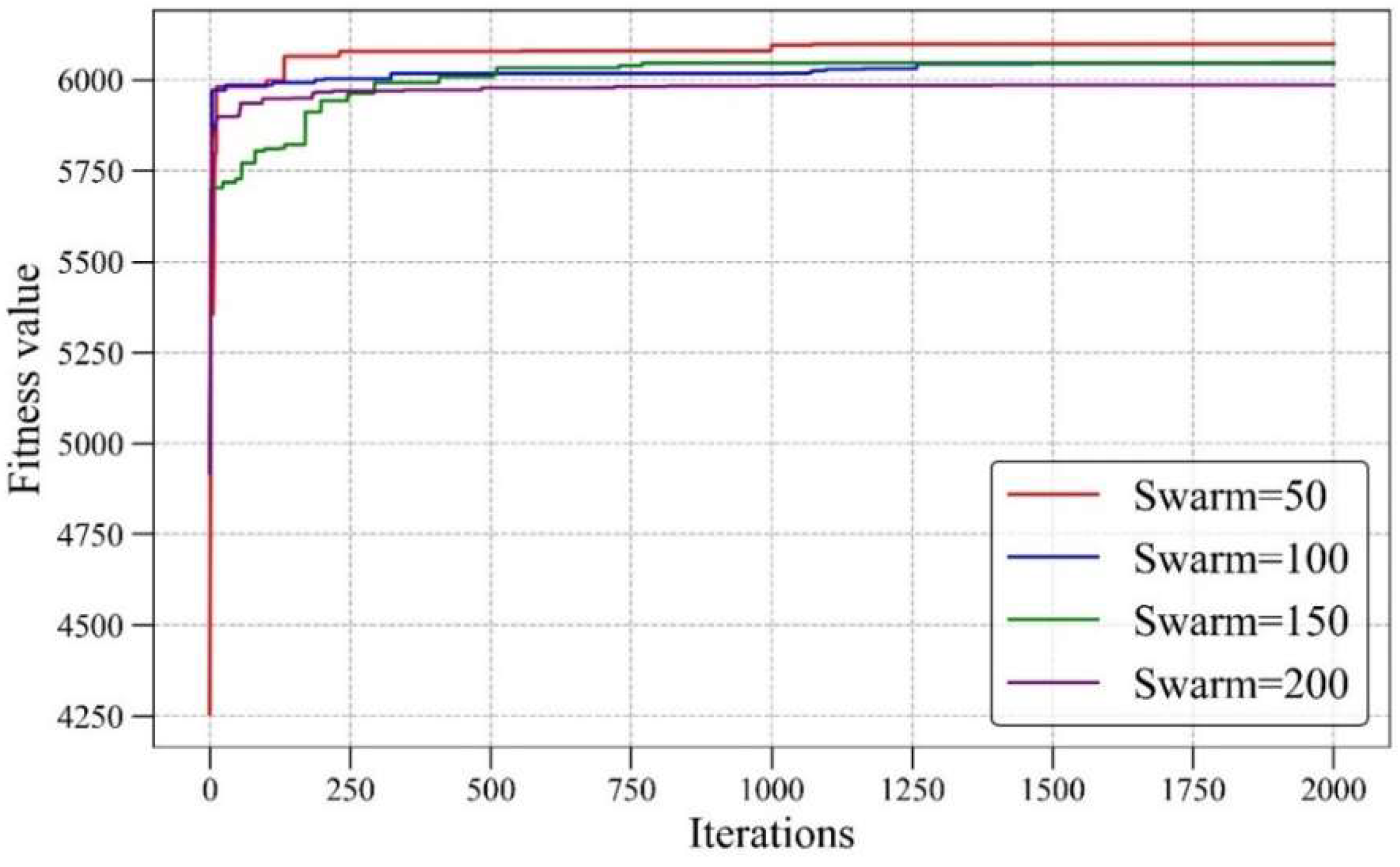
5.1. Gray Wolf Optimization
5.2. Artificial Bee Colony Algorithm
6. Discussion
7. Limitations and Future Works
8. Conclusions
- The proposed GP equation is easy to implement and is of interest to civil and geotechnical engineers. An intelligent equation proposed by GP showed an acceptable level of accuracy in predicting pile capacity. Results with values of 0.897 in the training stage and 0.844 in the testing stage indicate that this GP model is capable enough to be implemented for predicting pile capacity.
- In the optimization phase, two powerful algorithms, namely GWO and ABC, were applied to maximize pile capacity. Obtaining the highest capacity of the pile is considered the ultimate objective of such projects. Although both algorithms are powerful in maximizing pile capacity, GWO performed better. Increase percentages of 52.6 and 54 were obtained by ABC and GWO, respectively, in their pile capacity results.
- For the best optimization algorithm (i.e., GWO), values of 38.59 m, 0.247 m, 2273 kPa, 157.46 kPa, 153.18 days, and 6098.488 kPa were obtained for LOP, PD, IC, Su, T, and UC, respectively. The proposed models and obtained results of this study can be used in designing pile capacity before implementing relevant projects.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Titi, H.H.; Wije Wathugala, G. Numerical procedure for predicting pile capacity—Setup/freeze. Transp. Res. Rec. 1999, 1663, 25–32. [Google Scholar] [CrossRef]
- Roy, M.; Blanchet, R.; Tavenas, F.; Rochelle, P. La Behaviour of a sensitive clay during pile driving. Can. Geotech. J. 1981, 18, 67–85. [Google Scholar] [CrossRef]
- Fakharian, K.; Khanmohammadi, M. Comparison of pile bearing capacity from CPT and dynamic load tests in clay considering soil setup. In Frontiers in Offshore Geotechnics III; CRC Press: Boca Raton, FL, USA, 2015; pp. 539–544. [Google Scholar]
- Khanmohammadi, M.; Fakharian, K. Evaluation of performance of piled-raft foundations on soft clay: A case study. Geomech. Eng. 2018, 14, 43–50. [Google Scholar]
- Komurka, V.E.; Wagner, A.B.; Edil, T.B. Estimating Soil/Pile Set-Up; Wisconsin Highway Research Program: Madison, WI, USA, 2003. [Google Scholar]
- Abu-Farsakh, M.Y.; Haque, M.N. Estimation and Incorporation of Pile Setup into LRFD Design Methodology. In Proceedings of the Transportation Research Board 97th Annual Meeting, Washington, DC, USA, 7–11 January 2018. [Google Scholar]
- Abu-Farsakh, M.Y.; Haque, M.N.; Tavera, E.; Zhang, Z. Evaluation of pile setup from osterberg cell load tests and its cost–benefit analysis. Transp. Res. Rec. 2017, 2656, 61–70. [Google Scholar] [CrossRef]
- Haque, M.N.; Steward, E.J. Evaluation of pile setup phenomenon for driven piles in Alabama. In Geo-Congress 2020: Foundations, Soil Improvement, and Erosion; American Society of Civil Engineers: Reston, VA, USA, 2020; pp. 200–208. [Google Scholar]
- Lanyi-Bennett, S.A.; Deng, L. Effects of inter-helix spacing and short-term soil setup on the behaviour of axially loaded helical piles in cohesive soil. Soils Found. 2019, 59, 337–350. [Google Scholar] [CrossRef]
- Khanmohammadi, M.; Fakharian, K. Numerical modelling of pile installation and set-up effects on pile shaft capacity. Int. J. Geotech. Eng. 2017, 13, 484–498. [Google Scholar] [CrossRef]
- Fakharian, K.; Khanmohammadi, M. Effect of OCR and Pile Diameter on Load Movement Response of Piles Embedded in Clay over Time. Int. J. Geomech. 2022, 22, 04022091. [Google Scholar] [CrossRef]
- Bogard, J.D.; Matlock, H. Application of model pile tests to axial pile design. In Proceedings of the Offshore Technology Conference, Houston, TX, USA, 7–10 May 1990. [Google Scholar]
- Yan, W.M.; Yuen, K. V Prediction of pile set-up in clays and sands. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2010; Volume 10, p. 12104. [Google Scholar]
- Skov, R.; Denver, H. Time-dependence of bearing capacity of piles. In Proceedings of the Third International Conference on the Application of Stress-Wave Theory to Piles, Ottawa, ON, Canada, 25–27 May 1988; pp. 25–27. [Google Scholar]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Parsajoo, M.; Armaghani, D.J.; Mohammed, A.S.; Khari, M.; Jahandari, S. Tensile strength prediction of rock material using non-destructive tests: A comparative intelligent study. Transp. Geotech. 2021, 31, 100652. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Monjezi, M.; Shahnazar, A.; Armaghani, D.J.; Farazmand, A. Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 2015, 75, 289–297. [Google Scholar] [CrossRef]
- Li, D.; Liu, Z.; Armaghani, D.J.; Xiao, P.; Zhou, J. Novel Ensemble Tree Solution for Rockburst Prediction Using Deep Forest. Mathematics 2022, 10, 787. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Asteris, P.G.; Mohammed, A.S.; Alexakis, D.E.; Mamou, A.; Armaghani, D.J. Introducing stacking machine learning approaches for the prediction of rock deformation. Transp. Geotech. 2022, 34, 100756. [Google Scholar] [CrossRef]
- De-Prado-Gil, J.; Zaid, O.; Palencia, C.; Martínez-García, R. Prediction of Splitting Tensile Strength of Self-Compacting Recycled Aggregate Concrete Using Novel Deep Learning Methods. Mathematics 2022, 10, 2245. [Google Scholar] [CrossRef]
- Barkhordari, M.; Armaghani, D.; Asteris, P. Structural Damage Identification Using Ensemble Deep Convolutional Neural Network Models. Comput. Model. Eng. Sci. 2022, 134, 2. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Khandelwal, M.; Zhu, S.; Zhang, X. Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int. J. Rock Mech. Min. Sci. 2021, 145, 104856. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of rockburst in underground projects: Comparison of ten supervised learning methods. J. Comput. Civ. Eng. 2016, 30, 4016003. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, C.; Wang, M.; Khandelwal, M. Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. Int. J. Min. Sci. Technol. 2021, 31, 799–812. [Google Scholar] [CrossRef]
- Zhou, J.; Shen, X.; Qiu, Y.; Li, E.; Rao, D.; Shi, X. Improving the efficiency of microseismic source locating using a heuristic algorithm-based virtual field optimization method. Geomech. Geophys. Geo-Energy Geo-Resour. 2021, 7, 89. [Google Scholar] [CrossRef]
- Liu, Z.; Armaghani, D.J.; Fakharian, P.; Li, D.; Ulrikh, D.V.; Orekhova, N.N.; Khedher, K.M. Rock Strength Estimation Using Several Tree-Based ML Techniques. Comput. Model. Eng. Sci. 2022, 133, 3. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Song, K. A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng. Comput. 2020, 38, 2469–2485. [Google Scholar] [CrossRef]
- Yang, H.; Song, K.; Zhou, J. Automated Recognition Model of Geomechanical Information Based on Operational Data of Tunneling Boring Machines. Rock Mech. Rock Eng. 2022, 55, 1499–1516. [Google Scholar] [CrossRef]
- Kardani, N.; Bardhan, A.; Samui, P.; Nazem, M.; Asteris, P.G.; Zhou, A. Predicting the thermal conductivity of soils using integrated approach of ANN and PSO with adaptive and time-varying acceleration coefficients. Int. J. Therm. Sci. 2022, 173, 107427. [Google Scholar] [CrossRef]
- Baziar, M.H.; Saeedi Azizkandi, A.; Kashkooli, A. Prediction of pile settlement based on cone penetration test results: An ANN approach. KSCE J. Civ. Eng. 2015, 19, 98–106. [Google Scholar] [CrossRef]
- Alkroosh, I.; Nikraz, H. Predicting pile dynamic capacity via application of an evolutionary algorithm. Soils Found. 2014, 54, 233–242. [Google Scholar] [CrossRef]
- Khari, M.; Armaghani, D.J.; Dehghanbanadaki, A. Prediction of Lateral Deflection of Small-Scale Piles Using Hybrid PSO–ANN Model. Arab. J. Sci. Eng. 2020, 45, 3499–3509. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Harandizadeh, H.; Momeni, E.; Maizir, H.; Zhou, J. An optimized system of GMDH-ANFIS predictive model by ICA for estimating pile bearing capacity. Artif. Intell. Rev. 2021, 55, 2313–2350. [Google Scholar] [CrossRef]
- Lee, I.-M.; Lee, J.-H. Prediction of pile bearing capacity using artificial neural networks. Comput. Geotech. 1996, 18, 189–200. [Google Scholar] [CrossRef]
- Shahin, M.A. Intelligent computing for modeling axial capacity of pile foundations. Can. Geotech. J. 2010, 47, 230–243. [Google Scholar] [CrossRef]
- Samui, P. Prediction of pile bearing capacity using support vector machine. Int. J. Geotech. Eng. 2011, 5, 95–102. [Google Scholar] [CrossRef]
- Momeni, E.; Nazir, R.; Armaghani, D.J.; Maizir, H. Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 2014, 57, 122–131. [Google Scholar] [CrossRef]
- Dehghanbanadaki, A.; Khari, M.; Amiri, S.T.; Armaghani, D.J. Estimation of ultimate bearing capacity of driven piles in c-φ soil using MLP-GWO and ANFIS-GWO models: A comparative study. Soft Comput. 2021, 25, 4103–4119. [Google Scholar] [CrossRef]
- Koza, J.R.; Poli, R. Genetic programming. In Search Methodologies; Springer: Berlin/Heidelberg, Germany, 2005; pp. 127–164. [Google Scholar]
- Koza, J.R.; Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992; Volume 1, ISBN 0262111705. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Al-Betar, M.A.; Mirjalili, S. Grey wolf optimizer: A review of recent variants and applications. Neural Comput. Appl. 2018, 30, 413–435. [Google Scholar] [CrossRef]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report-tr06; Erciyes University, Engineering Faculty, Computer Engineering Department: Kayseri, Turkey, 2005. [Google Scholar]
- Karaboga, D. Artificial bee colony algorithm. Scholarpedia 2010, 5, 6915. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2020, 33, 4501–4532. [Google Scholar] [CrossRef]
- Zeng, J.; Asteris, P.G.; Mamou, A.P.; Mohammed, A.S.; Golias, E.A.; Armaghani, D.J.; Faizi, K.; Hasanipanah, M. The Effectiveness of Ensemble-Neural Network Techniques to Predict Peak Uplift Resistance of Buried Pipes in Reinforced Sand. Appl. Sci. 2021, 11, 908. [Google Scholar] [CrossRef]
- Mahmood, W.; Mohammed, A.S.; Asteris, P.G.; Kurda, R.; Armaghani, D.J. Modeling Flexural and Compressive Strengths Behaviour of Cement-Grouted Sands Modified with Water Reducer Polymer. Appl. Sci. 2022, 12, 1016. [Google Scholar] [CrossRef]
- Murlidhar, B.R.; Nguyen, H.; Rostami, J.; Bui, X.; Armaghani, D.J.; Ragam, P.; Mohamad, E.T. Prediction of flyrock distance induced by mine blasting using a novel Harris Hawks optimization-based multi-layer perceptron neural network. J. Rock Mech. Geotech. Eng. 2021, 13, 1413–1427. [Google Scholar] [CrossRef]
- Van Thieu, N. A collection of the State-of-the-Art Meta-Heuristics Algorithms in Python: Mealpy; Zenodo: Genève, Switzerland, 2020. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Taylor, K.E. Taylor Diagram Primer; PCMDI: Livermore, CA, USA, 2005. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Range |
|---|---|
| LOP | 12.009–64.008 |
| PD | 0.236–1.067 |
| IC | 57.3–2276 |
| Su | 26.97–191.52 |
| T | 0.008–154 |
| Parameter | Actual Value | Optimized Value | |
|---|---|---|---|
| GWO | ABC | ||
| LOP | 24.0 | 38.59 | 38.47 |
| PD | 0.457 | 0.247 | 0.240 |
| IC | 1642.7 | 2273 | 2276 |
| Su | 172.0 | 157.46 | 157.46 |
| T | 6.0 | 153.18 | 170.16 |
| Maximum UC | 3960.0 | 6098.488 | 6043.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khanmohammadi, M.; Armaghani, D.J.; Sabri Sabri, M.M. Prediction and Optimization of Pile Bearing Capacity Considering Effects of Time. Mathematics 2022, 10, 3563. https://doi.org/10.3390/math10193563
Khanmohammadi M, Armaghani DJ, Sabri Sabri MM. Prediction and Optimization of Pile Bearing Capacity Considering Effects of Time. Mathematics. 2022; 10(19):3563. https://doi.org/10.3390/math10193563
Chicago/Turabian StyleKhanmohammadi, Mohammadreza, Danial Jahed Armaghani, and Mohanad Muayad Sabri Sabri. 2022. "Prediction and Optimization of Pile Bearing Capacity Considering Effects of Time" Mathematics 10, no. 19: 3563. https://doi.org/10.3390/math10193563
APA StyleKhanmohammadi, M., Armaghani, D. J., & Sabri Sabri, M. M. (2022). Prediction and Optimization of Pile Bearing Capacity Considering Effects of Time. Mathematics, 10(19), 3563. https://doi.org/10.3390/math10193563