
A Genetic Hyper-Heuristic for an Order Scheduling Problem with Two Scenario-Dependent Parameters in a Parallel-Machine Environment

 , , ,
, , ,
Abstract
:1. Introduction
2. Problem Statement
3. Branch-and-Bound Method
- Case (i)
- , and .
- Case (ii)
- , and.
- Case (iii)
- and.
- Case (i):
- , and.
- Case (ii):
- , and.
- Case (iii):
- , and.
- Case (iv):
- .
- Case (i):
- , and.
- Case (ii):
- , and.
- Case (iii):
- , and.
- Case (iv):
- and.
- Case (v):
- and.
4. Three Modified Moore’s Heuristics
- Moore_pi_M heuristic:
- 01:
- Let and be the processing time and due date, respectively, for order Oi, i = 1, 2, …, n, and {O1, O2, …, On}.
- 02:
- Form a schedule σ by following the earliest due dates (EDD) rule based on .
- 03:
- Let the current schedule σ* = σ and the corresponding set of orders S* =
- 04:
- Compute the completion times of the orders in σ until a tardy order is found and delete it from
- 05:
- σ* (and from S*) to form a new current schedule σ* and new S*. Find an order O*
- 06:
- with the largest processing time in S*.
- 07:
- Delete order O* from σ* and S*. Repeat Steps 04–07 until no tardy order remains.
- 08:
- Output the final schedule , where denotes the sequence of orders
- 09:
- completed on time and scheduled using the EDD rule, and denotes an arbitrary
- 10:
- sequence of orders that are tardy under .
- 11:
- Execute by using the pairwise interchange improvement method and output the final solution.
- Moore_pi_m heuristic:
- 01:
- Let and be the processing time and due date, respectively, for order Oi, i = 1, 2, …, n, and {O1, O2, …, On}.
- 02–11:
- are the same as those in the Moore_pi_M heuristic.
- Moore_pi_mean heuristic:
- 01:
- Let and be the processing time and due date, respectively, for order Oi, i = 1, 2, …, n and {O1, O2, …, On}.
- 02–11:
- are the same as those in the Moore_pi_M heuristic.
5. A Genetic and a Genetic Hyper-Heuristic
- 00:
- InputPop, P, IT_GA.
- 01:
- Generate a series of Pop initial parents (schedules) and find their fitness values.
- 02:
- Do i = 1, IT_GA
- 03:
- Choose two parents from Pop populations by using the roulette wheel method and employ a linear order crossover to reproduce a set of Pop offspring.
- 04:
- For each offspring, generate a random number u (0 < u < 1) if u < P; then, create a new
- 05:
- offspring by inserting a displacement mutation.
- 06:
- Record the best one (schedule) and replace these Pop parents with their offspring.
- 07:
- End do /* for the number of iterations (IT_GA) is fulfilled */
- 08:
- Output the final best schedule and its fitness value.
- LH1:
- Two-order swap heuristic: randomly select two orders (e.g., and ) in a schedule and swap the selected two orders, resulting in a new schedule . For example, , .
- LH2:
- One step to the right heuristic: randomly select one order (e.g., ) in a schedule , extract order from its position, move it one position toward the right, and reinsert it to obtain a new schedule . For example, , .
- LH3:
- Two steps to the right heuristic: randomly select one order (e.g., ) in a schedule , extract order from its position, move it two positions toward the right, and reinsert it, resulting in a new schedule . For example, , .
- LH4:
- One step to the left heuristic: randomly select one order (e.g., ) in a schedule , extract job from its position, move it one position toward the left, and reinsert it, resulting in the new schedule . For example,, .
- LH5:
- Two steps to the left heuristic: randomly select one order (e.g., ) in a schedule , extract order from its position, move it two positions toward the left, and reinsert it to obtain a new schedule . For example,, .
- LH6:
- Pulling-out and onward-moved reinsertion heuristic: Randomly select two orders (e.g., and ) in a schedule , extract order (the leftward of the two selected orders) from its position, and onward reinsert it just after to obtain a new schedule . For example, , .
- LH7:
- Pulling-out and backward-moved reinsertion heuristic: randomly select two orders (e.g., and ) in a schedule , extract order (the rightward of the two selected orders) from its position, and backward reinsert it just before to obtain a new schedule . For example,, .
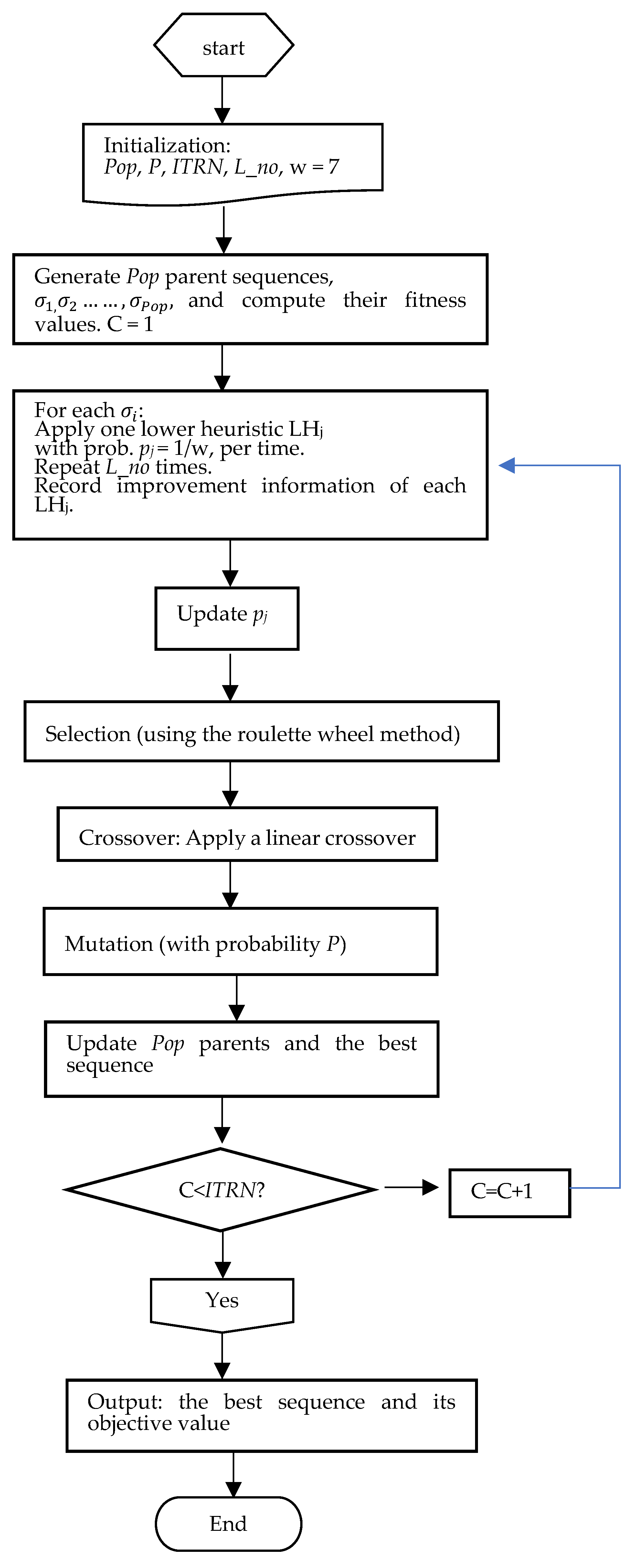
- 00:
- InputPop, P, ITRN, L_no.
- 01:
- Generate a series of Pop initial parents and find their fitness values.
- 02:
- Do c = 1, ITRN
- 03:
- set, l = 1, 2, …, 7.
- 04:
- Do i = 1, pop /* for each parent
- 05:
- Dok = 1, L_no
- 06:
- Select an by using the roulette wheel method based on the value
- 07:
- of to improve for generating another new schedule .
- 08:
- Replace with LHj if RC() < RC().
- 09:
- Retain each superior current parent
- 10:
- End do /* for the low-level heuristics */
- 11:
- End do /* i = 1, 2, …, Pop */
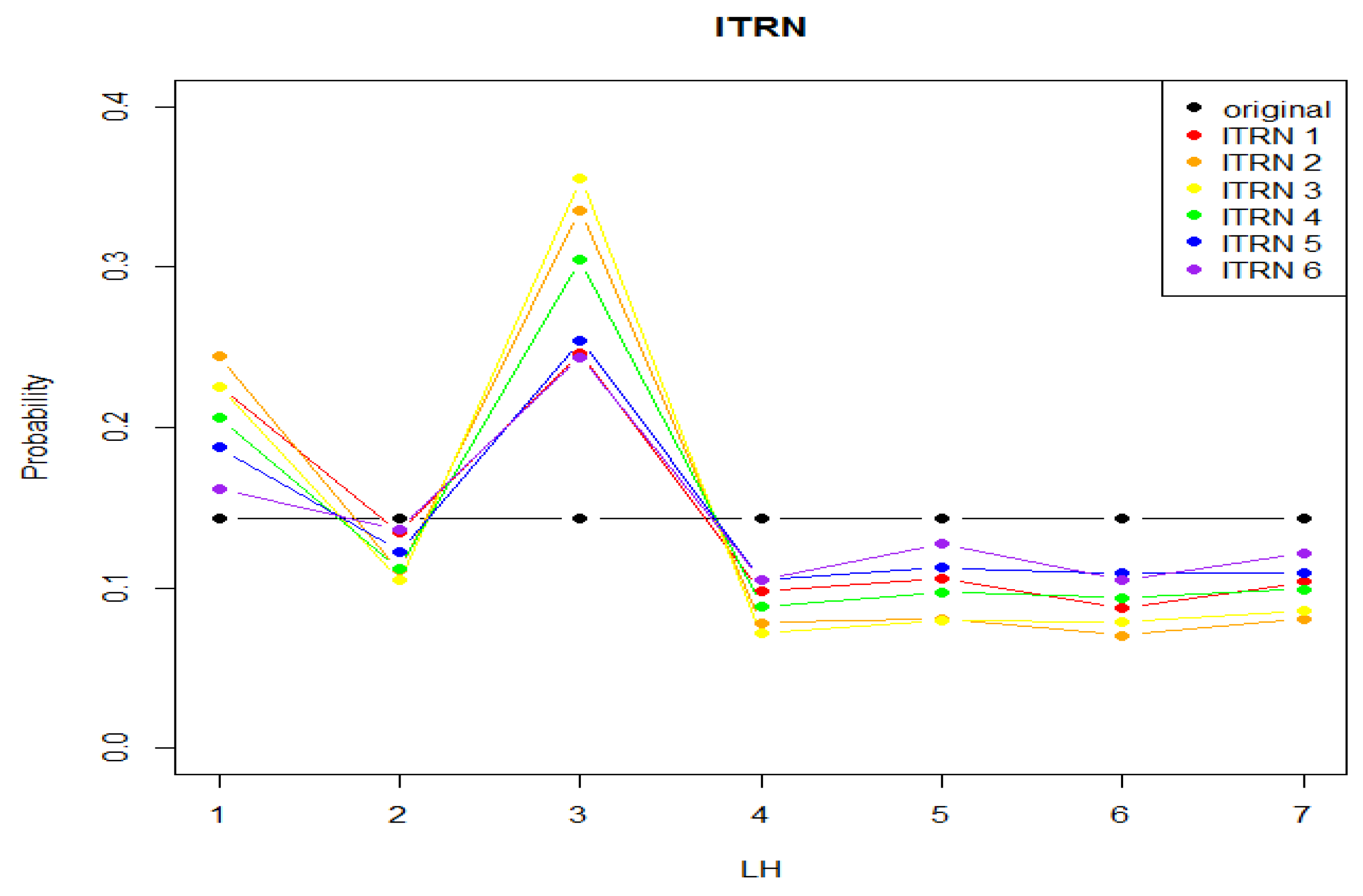
- 12:
- Update the probabilities , l = 1, 2, …, 7} of , , …, and according
- 13:
- their past records as {,7}
- 14:
- Select two parents from Pop populations by using the roulette wheel method and
- 15:
- employ a linear order crossover to reproduce a set of Pop offspring.
- 16:
- For each offspring, generate a random number u (0 < u < 1) if u < P; then, create a
- 17:
- new offspring by inserting a displacement mutation.
- 18:
- Retain the best offspring, and replace the parents of this Pop with their offspring.
- 19:
- End do /*when the iterative number of high-level cycles (ITRN) is */
- 20:
- Output the final best sequence and its fitness value.
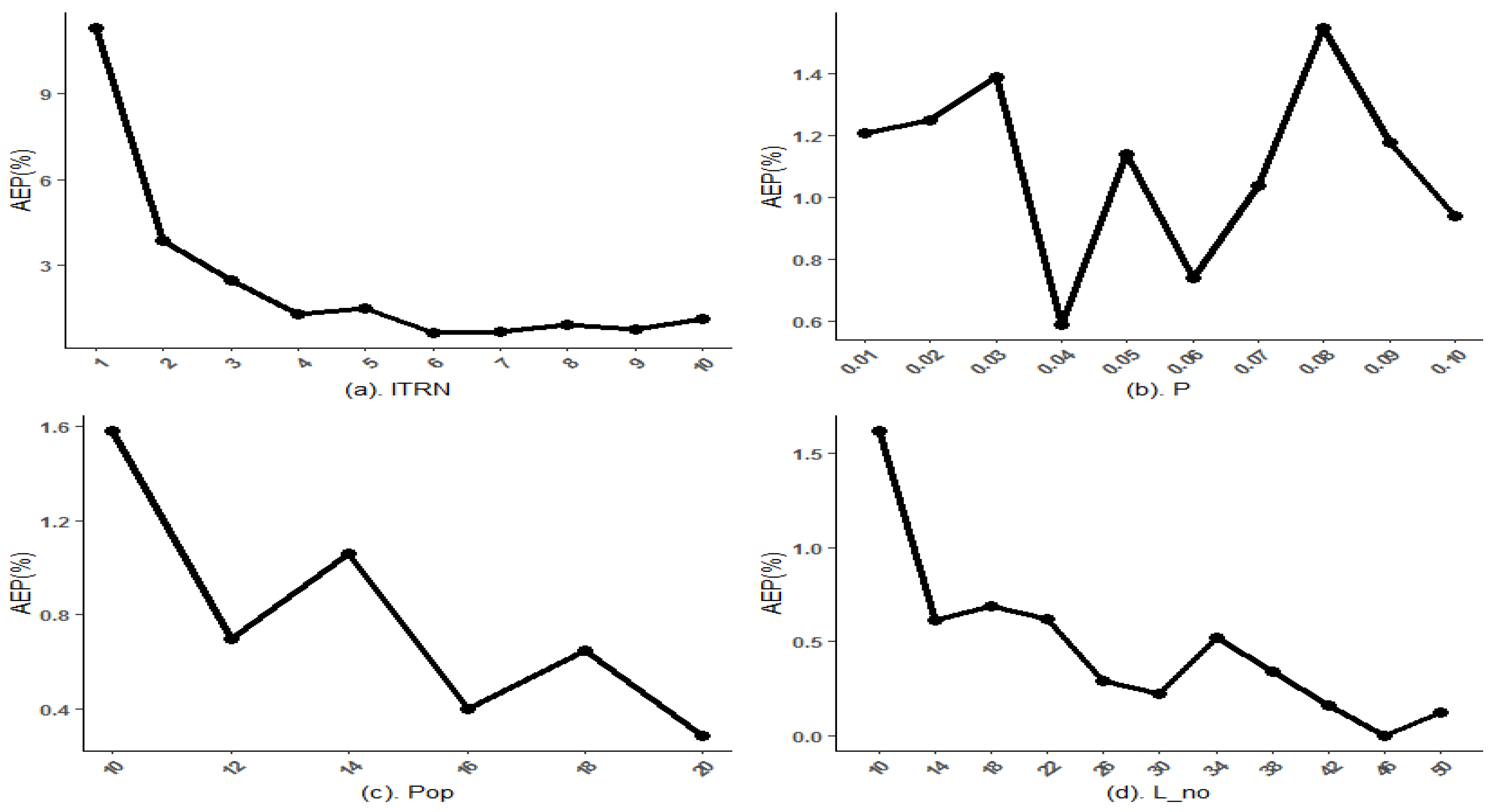
6. Tuning Genetic Algorithm Hyper-Heuristic Parameters
7. Simulation Study
7.1. Results Obtained for Small-Sized Orders
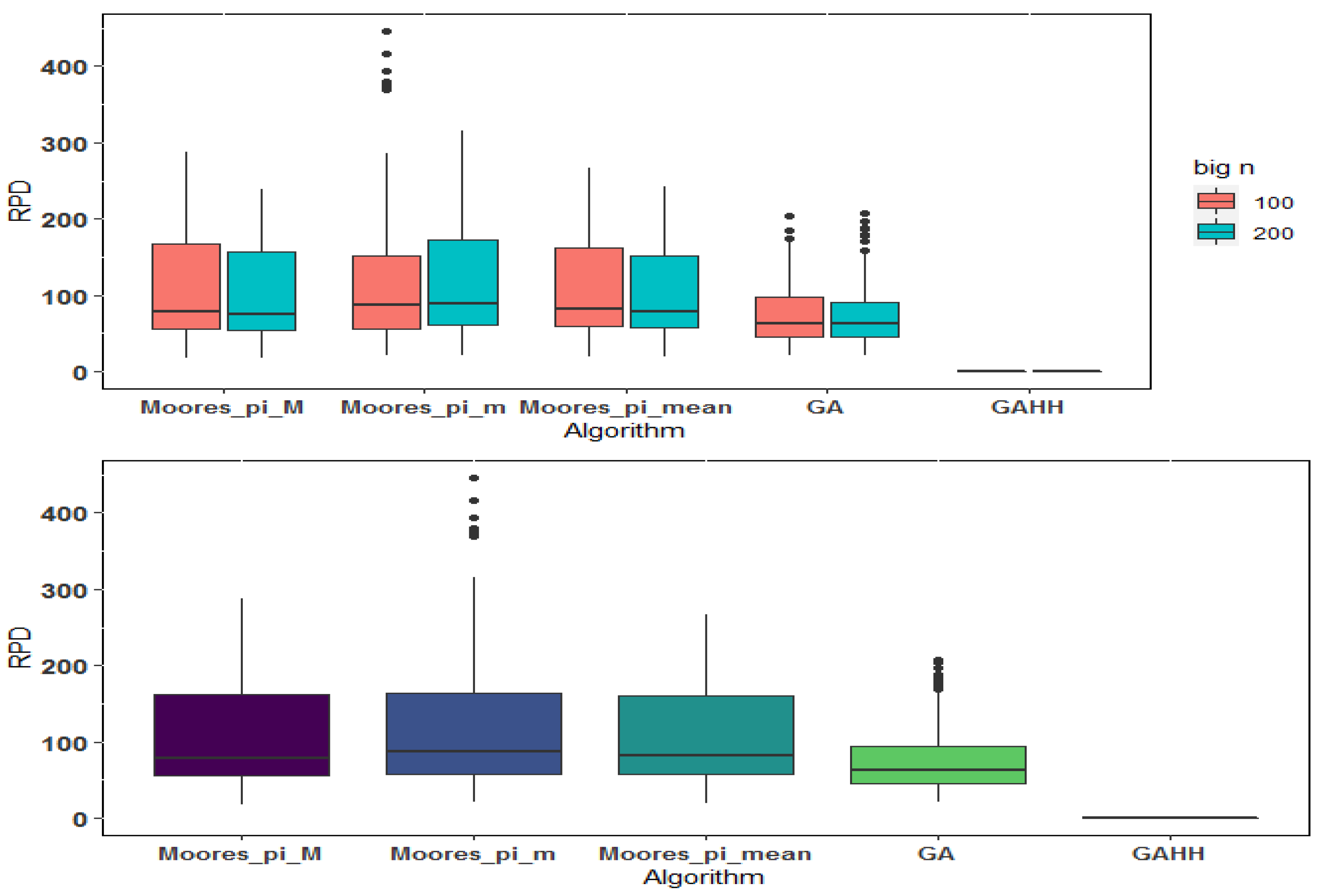
7.2. Results for Large-Sized Orders
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Ahmadi, R.; Bagchi, U.; Roemer, T.A. Coordinated scheduling of customer orders for quick response. Nav. Res. Logist. 2005, 52, 493–512. [Google Scholar] [CrossRef]
- Guo, Q.; Tang, L. Modelling and discrete differential evolution algorithm for order rescheduling problem in steel industry. Comput. Ind. Eng. 2019, 130, 586–595. [Google Scholar] [CrossRef]
- Zhang, Y.; Dan, Y.; Dan, B.; Gao, H. The order scheduling problem of product-service system with time windows. Comput. Ind. Eng. 2019, 133, 253–266. [Google Scholar] [CrossRef]
- Framinan, J.M.; Perez-Gonzalez, P.; Fernandez-Viagas, V. Deterministic assembly scheduling problems: A review and classification of concurrent-type scheduling models and solution procedures. Eur. J. Oper. Res. 2019, 273, 401–417. [Google Scholar] [CrossRef] [Green Version]
- Framinan, J.; Perez-Gonzalez, P. New approximate algorithms for the customer order scheduling problem with total completion time objective. Comput. Oper. Res. 2017, 78, 181–192. [Google Scholar] [CrossRef]
- Sung, C.S.; Yoon, S.H. Minimizing total weighted completion time at a pre- assembly stage composed of two feeding machines. Int. J. Prod. Econ. 1998, 54, 247–255. [Google Scholar] [CrossRef]
- Yoon, S.H.; Sung, C.S. Fixed pre-assembly scheduling on multiple fabrication machines. Int. J. Prod. Econ. 2005, 96, 109–118. [Google Scholar] [CrossRef]
- Wang, G.; Cheng, T.C.E. Customer order scheduling to minimize total weighted completion time. Omega 2007, 35, 623–626. [Google Scholar] [CrossRef] [Green Version]
- Leung, J.Y.T.; Li, H.; Pinedo, M.; Sriskandarajah, C. Open shops with jobs overlap-revisited. Eur. J. Oper. Res. 2005, 163, 569–571. [Google Scholar] [CrossRef]
- Leung, J.Y.T.; Li, H.; Pinedo, M. Approximation algorithms for minimizing total weighted completion time of orders on identical machines in parallel. Nav. Res. Logist. 2006, 53, 243–260. [Google Scholar] [CrossRef]
- Leung, J.Y.T.; Li, H.; Pinedo, M. Scheduling orders for multiple product types to minimize total weighted completion time. Discret. Appl. Math. 2007, 155, 945–970. [Google Scholar] [CrossRef] [Green Version]
- Leung, J.Y.T.; Li, H.; Pinedo, M.; Zhang, J. Minimizing total weighted completion time when scheduling orders in a flexible environment with uniform machines. Inf. Process. Lett. 2007, 103, 119–129. [Google Scholar] [CrossRef]
- Leung, J.Y.T.; Li, H.; Pinedo, M. Scheduling orders on either dedicated or flexible machines in parallel to minimize total weighted completion time. Ann. Oper. Res. 2008, 159, 107–123. [Google Scholar] [CrossRef]
- Leung, J.Y.T.; Lee, C.Y.; Ng, C.W.; Young, G.H. Preemptive multiprocessor order scheduling to minimize total weighted flowtime. Eur. J. Oper. Res. 2008, 190, 40–51. [Google Scholar] [CrossRef]
- Wu, C.-C.; Yang, T.-H.; Zhang, X.; Kang, C.C.; Chung, I.H.; Lin, W.-C. Using heuristic and iterative greedy algorithms for the total weighted completion time order scheduling with release times. Swarm Evol. Comput. 2019, 44, 913–926. [Google Scholar] [CrossRef]
- Riahi, V.; Hakim Newton, M.A.; Polash, M.M.A.; Sattar, A. Tailoring customer order scheduling search algorithms. Comput. Oper. Res. 2019, 108, 155–165. [Google Scholar] [CrossRef]
- Li, H.; Li, Z.; Zhao, Y.; Xu, X. Scheduling customer orders on unrelated parallel machines to minimize total weighted completion time. J. Oper. Res. 2020, 72, 1726–1736. [Google Scholar] [CrossRef]
- Leung, J.Y.T.; Li, H.; Pinedo, M. Scheduling orders for multiple product types with due date related objectives. Eur. J. Oper. Res. 2006, 168, 370–389. [Google Scholar] [CrossRef]
- Lin, B.M.T.; Kononov, A.V. Customer order scheduling to minimize the number of late jobs. Eur. J. Oper. Res. 2007, 183, 944–948. [Google Scholar] [CrossRef]
- Lee, I.-S. Minimizing total tardiness for the order scheduling problem. Int. J. Prod. Econ. 2013, 144, 128–134. [Google Scholar] [CrossRef]
- Xu, J.; Wu, C.-C.; Yin, Y.; Zhao, C.L.; Chiou, Y.-T.; Lin, W.-C. An order scheduling problem with position-based learning effect. Comput. Oper. Res. 2016, 74, 175–186. [Google Scholar] [CrossRef]
- Biskup, D. Single-machine scheduling with learning considerations. Eur. J. Oper. Res. 1999, 115, 173–178. [Google Scholar] [CrossRef]
- Lin, W.-C.; Yin, Y.; Cheng, S.R.; Cheng, T.C.E.; Wu, C.H.; Wu, C.-C. Particle swarm optimization and opposite-based particle swarm optimization for two-agent multi-facility customer order scheduling with ready times. Appl. Soft Comput. 2017, 52, 877–884. [Google Scholar] [CrossRef]
- Kuolamas, C.; Kyparisis, G.J. Single-machine and two-machine flowshop scheduling with general learning functions. Eur. J. Oper. Res. 2007, 178, 402–407. [Google Scholar] [CrossRef]
- Wu, C.-C.; Liu, S.C.; Zhao, C.L.; Wang, S.Z.; Lin, W.-C. A multi-machine order scheduling with learning using the memetic genetic algorithm and particle swarm optimization. Comput. J. 2018, 61, 14–31. [Google Scholar] [CrossRef]
- Kuo, W.H.; Yang, D.L. Minimizing the total completion time in a single- machine scheduling problem with a time-dependent learning effect. Eur. J. Oper. Res. 2006, 174, 1184–1190. [Google Scholar] [CrossRef]
- Wu, C.-C.; Lin, W.C.; Zhang, X.; Chung, I.H.; Yang, T.H.; Lai, K. Tardiness minimization for a customer order scheduling problem with sum-of processing-time-based learning effect. J. Oper. Res. Soc. 2019, 70, 487–501. [Google Scholar] [CrossRef]
- Lin, W.-C.; Xu, J.; Bai, D.; Chung, I.H.; Liu, S.C.; Wu, C.-C. Artificial bee colony algorithms for the order scheduling with release dates. Soft Comput. 2019, 23, 8677–8688. [Google Scholar] [CrossRef]
- Daniels, R.L.; Kouvelis, P. Robust scheduling to hedge against processing time uncertainty in single-stage production. Manag. Sci. 1995, 41, 363–376. [Google Scholar] [CrossRef]
- Sabuncuoglu, I.; Goren, S. Hedging production schedules against uncertainty in manufacturing environment with a review of robustness and stability research. Int. J. Comput. Integr. Manuf. 2009, 22, 138–157. [Google Scholar] [CrossRef]
- Sotskov, Y.N.; Sotskova, N.Y.; Lai, T.-C.; Werner, F. Scheduling with Uncertainty: Theory and Algorithms; Belorusskaya Nauka: Minsk, Belarus, 2010. [Google Scholar]
- Kouvelis, P.; Yu, G. Robust Discrete Optimization and Its Applications; Kluwer Academic Publishers: Amsterdam, The Netherlands, 1997. [Google Scholar]
- Yang, J.; Yu, G. On the robust single machine scheduling problem. J. Comb. Optim. 2002, 6, 17–33. [Google Scholar] [CrossRef]
- Wu, C.-C.; Bai, D.Y.; Chen, J.-H.; Lin, W.-C.; Xing, L.; Lin, J.C.; Cheng, S.R. Several variants of simulated annealing hyper-heuristic for a single-machine scheduling with two-scenario-based dependent processing times. Swarm Evol. Comput. 2021, 60, 100765. [Google Scholar] [CrossRef]
- Hsu, C.L.; Lin, W.C.; Duan, L.; Liao, J.R.; Wu, C.-C.; Chen, J.H. A robust two-machine flow-shop scheduling model with scenario- dependent processing times. Discret. Dyn. Nat. Soc. 2020, 2020, 3530701. [Google Scholar] [CrossRef]
- Wu, C.-C.; Gupta, J.N.D.; Cheng, S.R.; Lin, B.M.T.; Yip, S.H.; Lin, W.-C. Robust scheduling of a two-stage assembly shop with scenario-dependent processing times. Int. J. Prod. Res. 2021, 59, 5372–5387. [Google Scholar] [CrossRef]
- Wu, C.-C.; Lin, W.-C.; Zhang, X.G.; Bai, D.Y.; Tsai, Y.W.; Ren, T.; Cheng, S.R. Cloud theory-based simulated annealing for a single- machine past sequence setup scheduling with scenario-dependent processing times. Complex Intell. Syst. 2021, 7, 345–357. [Google Scholar] [CrossRef]
- Kämmerling, N.; Kurtz, J. Oracle-based algorithms for binary two-stage robust optimization. Comput. Optim. Appl. 2020, 77, 539–569. [Google Scholar] [CrossRef]
- Xuan, G.; Lin, W.C.; Cheng, S.R.; Shen, W.L.; Pan, P.A.; Kuo, C.L.; Wu, C.-C. A robust single-machine scheduling problem with two scenarios of job parameters. Mathematics 2022, 10, 2176. [Google Scholar] [CrossRef]
- Wu, C.-C.; Gupta, J.N.D.; Lin, W.C.; Cheng, S.R.; Chiu, Y.L.; Chen, C.J.; Lee, L.Y. Robust scheduling of Two-Agent Customer Orders with Scenario-Dependent Component Processing Times and Release Dates. Mathematics 2022, 10, 1545. [Google Scholar] [CrossRef]
- Yin, Y.; Wang, D.; Cheng, T.C.E. Due Date-Related Scheduling with Two Agents: Models and Algorithms; Uncertainty and Operations Research book series; Springer Nature Singapore: Singapore, 2020. [Google Scholar]
- Karp, R.M. Reducibility among Combinatorial Problems. In Complexity of Computer Computations; Miller, R.E., Thatcher, J.W., Eds.; Springer: Berlin/Heidelberg, Germany, 1972; pp. 85–103. [Google Scholar]
- Moore, J.M. An n job one machine sequencing algorithm for minimizing the number of late jobs. Manag. Sci. 1968, 14, 102–109. [Google Scholar] [CrossRef]
- Holland, J. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Essafi, I.; Matib, Y.; Dauzere-Peres, S. A genetic local search algorithm for minimizing total weighted tardiness in the job-shop scheduling problem. Comput. Oper. Res. 2008, 35, 2599–2616. [Google Scholar] [CrossRef]
- Iyer, S.K.; Saxena, B.S. Improved memetic genetic algorithm for the permutation flowshop scheduling problem. Comput. Oper. Res. 2004, 31, 593–606. [Google Scholar] [CrossRef]
- Cowling, P.; Kendall, G.; Han, L. An investigation of a hyperheuristic memetic genetic algorithm applied to a trainer scheduling problem. In Proceedings of the 2002 Congress on Evolutionary Computation (CEC 2002), Honolulu, HI, USA, 12–17 May 2002; IEEE Computer Society Press: Honolulu, HI, USA, 2002; pp. 1185–1190. [Google Scholar]
- Anagnostopoulos, K.P.; Koulinas, G.K. A simulated annealing hyperheuristic for construction resource levelling. Constr. Manag. Econ. 2010, 28, 163–175. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments; 5/e, John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Reeves, C. Heuristics for scheduling a single machine subject to unequal job release times. Eur. J. Oper. Res. 1995, 80, 397–403. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods, 3rd ed.; John Wiley& Sons: Hoboken, NJ, USA, 2014. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
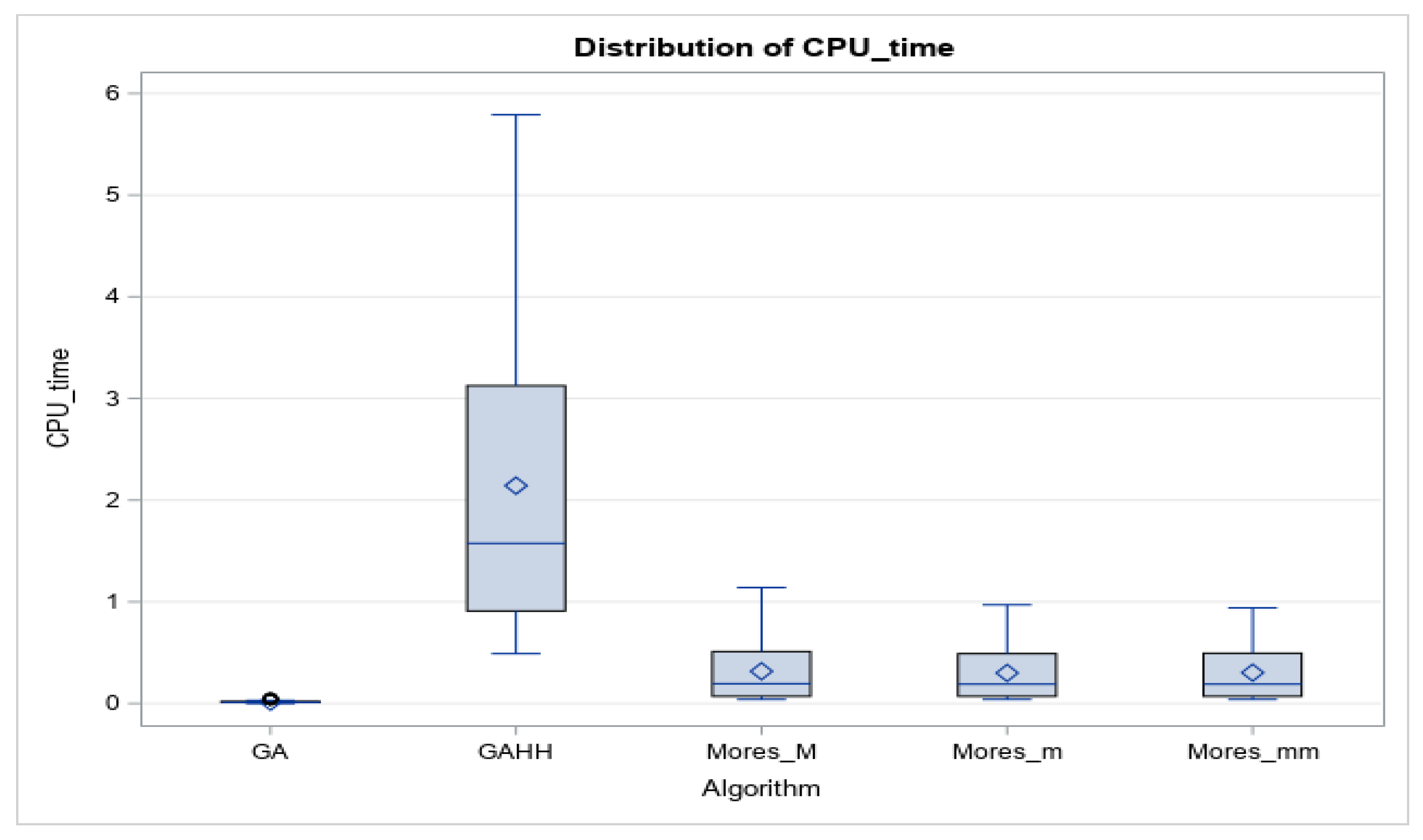{kind=link}
| Node | CPU_Time | ||||
|---|---|---|---|---|---|
| n | m | Mean | Max | Mean | Max |
| 9 | 2 | 102,150 | 35,6594 | 0.56 | 1.25 |
| 3 | 108,842 | 35,9043 | 0.68 | 1.48 | |
| 4 | 116,378 | 386,330 | 0.82 | 1.79 | |
| 11 | 2 | 606,5047 | 25,997,813 | 57.42 | 193.89 |
| 3 | 6,701,240 | 27,681,786 | 74.84 | 235.82 | |
| 4 | 6,952,756 | 27,613,651 | 90.24 | 272.42 | |
| Mean | 3,341,069 | 1,373,2536 | 37.43 | 117.78 | |
| n | Mean | Max | Mean | Max | |
| 9 | 0.1 | 63,883 | 15,8272 | 0.52 | 1.11 |
| 0.3 | 84,005 | 374,265 | 0.61 | 1.56 | |
| 0.5 | 179,482 | 569,430 | 0.93 | 1.86 | |
| 11 | 0.1 | 316,9517 | 9,901,037 | 47.60 | 131.62 |
| 0.3 | 4,378,853 | 21,526,663 | 61.14 | 236.57 | |
| 0.5 | 12,170,673 | 49,865,551 | 113.76 | 333.93 | |
| Mean | 3,341,069 | 13,732,536 | 37.43 | 117.78 | |
| n | Mean | Max | Mean | Max | |
| 9 | 0.25 | 73,284 | 287,313 | 0.55 | 1.40 |
| 0.50 | 144,963 | 447,331 | 0.82 | 1.62 | |
| 11 | 0.25 | 3,734,194 | 17,472,356 | 53.12 | 200.44 |
| 0.50 | 9,411,835 | 36,723,144 | 95.21 | 267.64 | |
| Mean | 3,341,069 | 13,732,536 | 37.43 | 117.78 | |
| n | Mean | Max | Mean | Max | |
| 9 | 0.25 | 120,476 | 374,104 | 0.71 | 1.49 |
| 0.50 | 105,302 | 379,570 | 0.67 | 1.51 | |
| 0.75 | 101,593 | 348,294 | 0.68 | 1.53 | |
| 11 | 0.25 | 7,668,642 | 29,579,795 | 80.48 | 255.49 |
| 0.50 | 6,353,625 | 26,905,933 | 71.67 | 225.25 | |
| 0.75 | 5,696,776 | 24,807,523 | 70.35 | 221.39 | |
| Mean | 3,341,069 | 13,732,536 | 37.43 | 117.78 | |
| Moores_pi_M | Moores_pi_m | Moores_pi_Mean | GA | GAHH | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| n | m | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 9 | 2 | 63.19 | 684.27 | 63.39 | 851.01 | 65.54 | 650.55 | 18.47 | 278.18 | 0.77 | 26.61 |
| 3 | 47.03 | 335.87 | 45.22 | 355.35 | 47.88 | 284.18 | 15.21 | 130.37 | 0.35 | 14.42 | |
| 4 | 45.80 | 319.15 | 43.15 | 237.90 | 45.31 | 307.29 | 13.79 | 92.95 | 0.32 | 14.15 | |
| 11 | 2 | 81.46 | 478.10 | 78.19 | 448.14 | 83.70 | 448.73 | 26.99 | 226.09 | 2.45 | 69.87 |
| 3 | 68.64 | 467.13 | 64.53 | 460.21 | 70.29 | 473.65 | 22.55 | 121.51 | 1.89 | 33.21 | |
| 4 | 66.44 | 432.34 | 62.17 | 326.86 | 66.07 | 340.21 | 21.62 | 125.73 | 1.55 | 27.67 | |
| Mean | 62.09 | 452.81 | 59.44 | 446.58 | 63.13 | 417.44 | 19.77 | 162.47 | 1.22 | 30.99 | |
| Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max | ||
| 9 | 0.1 | 107.49 | 1009.37 | 103.09 | 1121.00 | 108.48 | 927.90 | 27.76 | 348.97 | 1.10 | 34.63 |
| 0.3 | 38.61 | 220.82 | 37.83 | 248.44 | 39.25 | 234.59 | 14.14 | 106.10 | 0.26 | 16.50 | |
| 0.5 | 9.92 | 75.27 | 10.84 | 74.82 | 11.01 | 79.53 | 5.57 | 46.44 | 0.07 | 4.04 | |
| 11 | 0.1 | 148.71 | 990.73 | 134.73 | 822.99 | 148.81 | 891.54 | 41.34 | 303.50 | 4.46 | 98.83 |
| 0.3 | 53.71 | 301.37 | 54.70 | 323.03 | 55.24 | 282.37 | 21.32 | 116.75 | 1.12 | 18.92 | |
| 0.5 | 14.12 | 85.47 | 15.46 | 89.19 | 16.01 | 88.67 | 8.50 | 53.08 | 0.30 | 13.01 | |
| Mean | 62.09 | 447.17 | 59.44 | 446.58 | 63.13 | 417.43 | 19.77 | 162.47 | 1.22 | 30.99 | |
| n | τ | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 9 | 0.25 | 84.43 | 796.07 | 82.39 | 871.91 | 85.42 | 727.47 | 24.21 | 271.87 | 0.75 | 26.91 |
| 0.50 | 19.58 | 100.94 | 18.78 | 90.93 | 20.40 | 100.54 | 7.44 | 62.47 | 0.20 | 9.87 | |
| 11 | 0.25 | 116.61 | 813.22 | 110.02 | 722.44 | 117.08 | 735.28 | 35.40 | 260.65 | 3.16 | 70.70 |
| 0.50 | 27.75 | 105.17 | 26.57 | 101.04 | 29.63 | 106.44 | 12.04 | 54.90 | 0.76 | 16.47 | |
| Mean | 62.09 | 453.85 | 59.44 | 446.58 | 63.13 | 417.43 | 19.77 | 162.47 | 1.22 | 30.99 | |
| Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max | ||
| 9 | 0.25 | 38.27 | 233.89 | 37.68 | 247.73 | 38.07 | 212.74 | 11.73 | 75.19 | 0.47 | 19.79 |
| 0.50 | 53.90 | 296.54 | 51.15 | 289.09 | 54.89 | 294.14 | 16.97 | 122.25 | 0.51 | 18.54 | |
| 0.75 | 63.85 | 816.19 | 62.93 | 907.44 | 65.77 | 735.13 | 18.77 | 304.06 | 0.45 | 16.85 | |
| 11 | 0.25 | 51.33 | 272.43 | 52.18 | 292.91 | 52.07 | 280.87 | 17.25 | 97.82 | 1.01 | 21.54 |
| 0.50 | 75.80 | 463.10 | 72.77 | 441.39 | 77.43 | 416.31 | 25.34 | 169.34 | 1.81 | 31.39 | |
| 0.75 | 89.40 | 642.04 | 79.93 | 500.92 | 90.56 | 565.40 | 28.57 | 206.17 | 3.07 | 77.82 | |
| Mean | 62.09 | 454.03 | 59.44 | 446.58 | 63.13 | 417.43 | 19.77 | 162.47 | 1.22 | 30.99 | |
| Small Job Size n | Large Job Size n | |||
|---|---|---|---|---|
| Pairwise Comparison between Algorithm | |Pairwise Rank-Sum Difference| | Difference > 64.4 * | |Pairwise Rank-Sum Difference| | Difference > 64.4 * |
| Moores_pi_M vs. Moores_pi_m | |401.0–414.0| | NO | |359.0–496.0| | YES |
| Moores_pi_M vs. Moores_pi_mean | |401.0–472.0| | YES | |359.0–402.0| | NO |
| Moores_pi_M vs. GA | |401.0–223.0| | YES | |359.0–255.0| | YES |
| Moores_pi_M vs. GAHH | |401.0–110.0| | YES | |359.0–108.0| | YES |
| Moores_pi_m vs. Moores_pi_mean | |414.0–472.0| | NO | |496.0–402.0| | YES |
| Moores_pi_m vs. GA | |414.0–223.0| | YES | |496.0–255.0| | YES |
| Moores_pi_m vs. GAHH | |414.0–110.0| | YES | |496.0–108.0| | YES |
| Moores_pi_mean vs. GA | |472.0–223.0| | YES | |402.0–255.0| | YES |
| Moores_pi_mean vs. GAHH | |472.0–110.0| | YES | |402.0–108.0| | YES |
| GA vs. GAHH | |223.0–110.0| | YES | |255.0–108.0| | YES |
| Moores_pi_M | Moores_pi_m | Moores_pi_Mean | GA | GAHH | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| n | m | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 100 | 5 | 117.98 | 190.76 | 134.45 | 225.48 | 115.52 | 194.47 | 79.90 | 143.19 | 0.00 | 0.00 |
| 10 | 111.11 | 175.04 | 127.34 | 213.33 | 108.83 | 174.50 | 74.67 | 126.33 | 0.00 | 0.00 | |
| 15 | 107.61 | 196.72 | 123.20 | 207.02 | 105.71 | 201.19 | 72.78 | 130.91 | 0.00 | 0.00 | |
| 200 | 5 | 105.19 | 154.86 | 127.30 | 180.75 | 105.31 | 156.38 | 81.17 | 123.84 | 0.00 | 0.00 |
| 10 | 100.35 | 146.16 | 120.94 | 172.32 | 99.54 | 151.17 | 77.28 | 114.04 | 0.00 | 0.00 | |
| 15 | 97.85 | 144.41 | 118.07 | 166.99 | 97.77 | 139.84 | 74.94 | 109.50 | 0.00 | 0.00 | |
| Mean | 106.68 | 167.99 | 125.22 | 194.32 | 105.45 | 169.59 | 76.79 | 124.64 | 0.00 | 0.00 | |
| n | λ | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 100 | 0.1 | 184.26 | 323.65 | 235.51 | 406.75 | 174.74 | 320.61 | 114.44 | 212.68 | 0.00 | 0.00 |
| 0.3 | 109.43 | 168.40 | 103.81 | 162.00 | 109.91 | 175.22 | 71.13 | 118.47 | 0.00 | 0.00 | |
| 0.5 | 43.02 | 70.46 | 45.67 | 77.09 | 45.42 | 74.33 | 41.78 | 69.28 | 0.00 | 0.00 | |
| 200 | 0.1 | 161.27 | 245.04 | 210.16 | 302.04 | 158.99 | 243.33 | 124.74 | 189.48 | 0.00 | 0.00 |
| 0.3 | 101.68 | 139.58 | 110.93 | 150.51 | 101.66 | 141.29 | 68.45 | 98.37 | 0.00 | 0.00 | |
| 0.5 | 40.45 | 60.81 | 45.22 | 67.52 | 41.97 | 62.76 | 40.21 | 59.54 | 0.00 | 0.00 | |
| Mean | 106.68 | 167.99 | 125.22 | 194.32 | 105.45 | 169.59 | 76.79 | 124.64 | 0.00 | 0.00 | |
| n | τ | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 100 | 0.25 | 158.29 | 274.79 | 190.88 | 332.02 | 155.80 | 284.64 | 106.99 | 195.69 | 0.00 | 0.00 |
| 0.50 | 66.18 | 100.22 | 65.78 | 98.53 | 64.24 | 95.47 | 44.58 | 71.27 | 0.00 | 0.00 | |
| 200 | 0.25 | 139.15 | 209.37 | 170.33 | 245.76 | 139.91 | 212.30 | 110.48 | 167.20 | 0.00 | 0.00 |
| 0.50 | 63.12 | 87.58 | 73.87 | 100.95 | 61.83 | 85.96 | 45.12 | 64.39 | 0.00 | 0.00 | |
| Mean | 106.68 | 167.99 | 125.22 | 194.32 | 105.45 | 169.59 | 76.79 | 124.64 | 0.00 | 0.00 | |
| n | ρ | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 100 | 0.25 | 93.79 | 156.60 | 108.21 | 173.59 | 94.62 | 160.03 | 70.15 | 119.17 | 0.00 | 0.00 |
| 0.50 | 117.33 | 211.28 | 134.50 | 232.41 | 115.43 | 217.54 | 79.01 | 145.33 | 0.00 | 0.00 | |
| 0.75 | 125.60 | 194.63 | 142.28 | 239.83 | 120.02 | 192.59 | 78.19 | 135.93 | 0.00 | 0.00 | |
| 200 | 0.25 | 86.77 | 128.64 | 106.01 | 146.45 | 89.63 | 129.30 | 73.60 | 107.26 | 0.00 | 0.00 |
| 0.50 | 105.66 | 155.60 | 126.86 | 181.39 | 105.13 | 156.28 | 81.10 | 122.02 | 0.00 | 0.00 | |
| 0.75 | 110.97 | 161.18 | 133.44 | 192.22 | 107.86 | 161.80 | 78.70 | 118.10 | 0.00 | 0.00 | |
| Mean | 106.68 | 167.99 | 125.22 | 194.32 | 105.45 | 169.59 | 76.79 | 124.64 | 0.00 | 0.00 | |
| Moore_pi_M | Moore_pi_m | Moore_pi_Mean | GA | GAHH | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| m | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max | |
| 100 | 5 | 0.04 | 0.05 | 0.04 | 0.05 | 0.04 | 0.05 | 0.01 | 0.02 | 0.51 | 0.58 |
| 10 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.91 | 1.01 | |
| 15 | 0.10 | 0.13 | 0.10 | 0.13 | 0.10 | 0.13 | 0.01 | 0.04 | 1.33 | 1.52 | |
| 200 | 5 | 0.28 | 0.35 | 0.28 | 0.33 | 0.29 | 0.35 | 0.01 | 0.03 | 1.78 | 1.98 |
| 10 | 0.50 | 0.67 | 0.49 | 0.57 | 0.49 | 0.56 | 0.02 | 0.05 | 3.11 | 3.47 | |
| 15 | 0.90 | 1.13 | 0.83 | 1.05 | 0.83 | 1.07 | 0.03 | 0.08 | 5.21 | 6.46 | |
| mean | 0.32 | 0.40 | 0.30 | 0.37 | 0.30 | 0.38 | 0.02 | 0.04 | 2.14 | 2.50 | |
| Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max | ||
| 100 | 0.1 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.90 | 1.01 |
| 0.3 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.89 | 1.01 | |
| 0.5 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.02 | 0.91 | 1.02 | |
| 200 | 0.1 | 0.51 | 0.62 | 0.49 | 0.59 | 0.51 | 0.61 | 0.03 | 0.06 | 3.22 | 3.65 |
| 0.3 | 0.54 | 0.69 | 0.52 | 0.64 | 0.53 | 0.66 | 0.03 | 0.07 | 3.42 | 4.26 | |
| 0.5 | 0.61 | 0.78 | 0.56 | 0.68 | 0.55 | 0.67 | 0.01 | 0.03 | 3.28 | 3.80 | |
| mean | 0.31 | 0.39 | 0.30 | 0.36 | 0.30 | 0.37 | 0.02 | 0.04 | 2.10 | 2.46 | |
| n | τ | Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max |
| 100 | 0.25 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.93 | 1.05 |
| 0.50 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.91 | 1.02 | |
| 200 | 0.25 | 0.55 | 0.69 | 0.53 | 0.64 | 0.53 | 0.64 | 0.03 | 0.06 | 3.39 | 4.00 |
| 0.50 | 0.58 | 0.75 | 0.54 | 0.66 | 0.54 | 0.68 | 0.02 | 0.05 | 3.35 | 3.94 | |
| mean | 0.32 | 0.41 | 0.30 | 0.37 | 0.30 | 0.38 | 0.02 | 0.04 | 2.15 | 2.50 | |
| Mean | Max | Mean | Max | Mean | Max | Mean | Max | Mean | Max | ||
| 100 | 0.25 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.92 | 1.05 |
| 0.50 | 0.07 | 0.10 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.91 | 1.02 | |
| 0.75 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 0.09 | 0.01 | 0.03 | 0.93 | 1.05 | |
| 200 | 0.25 | 0.56 | 0.70 | 0.52 | 0.63 | 0.53 | 0.65 | 0.02 | 0.05 | 3.34 | 3.97 |
| 0.50 | 0.55 | 0.70 | 0.53 | 0.63 | 0.53 | 0.66 | 0.02 | 0.06 | 3.38 | 3.99 | |
| 0.75 | 0.58 | 0.75 | 0.54 | 0.68 | 0.55 | 0.67 | 0.03 | 0.06 | 3.38 | 3.96 | |
| mean | 0.32 | 0.41 | 0.30 | 0.37 | 0.30 | 0.38 | 0.02 | 0.04 | 2.14 | 2.51 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.-Y.; Xu, J.-Y.; Cheng, S.-R.; Zhang, X.; Lin, W.-C.; Lin, J.-C.; Wu, Z.-L.; Wu, C.-C. A Genetic Hyper-Heuristic for an Order Scheduling Problem with Two Scenario-Dependent Parameters in a Parallel-Machine Environment. Mathematics 2022, 10, 4146. https://doi.org/10.3390/math10214146
Li L-Y, Xu J-Y, Cheng S-R, Zhang X, Lin W-C, Lin J-C, Wu Z-L, Wu C-C. A Genetic Hyper-Heuristic for an Order Scheduling Problem with Two Scenario-Dependent Parameters in a Parallel-Machine Environment. Mathematics. 2022; 10(21):4146. https://doi.org/10.3390/math10214146
Chicago/Turabian StyleLi, Lung-Yu, Jian-You Xu, Shuenn-Ren Cheng, Xingong Zhang, Win-Chin Lin, Jia-Cheng Lin, Zong-Lin Wu, and Chin-Chia Wu. 2022. "A Genetic Hyper-Heuristic for an Order Scheduling Problem with Two Scenario-Dependent Parameters in a Parallel-Machine Environment" Mathematics 10, no. 21: 4146. https://doi.org/10.3390/math10214146
APA StyleLi, L. -Y., Xu, J. -Y., Cheng, S. -R., Zhang, X., Lin, W. -C., Lin, J. -C., Wu, Z. -L., & Wu, C. -C. (2022). A Genetic Hyper-Heuristic for an Order Scheduling Problem with Two Scenario-Dependent Parameters in a Parallel-Machine Environment. Mathematics, 10(21), 4146. https://doi.org/10.3390/math10214146