1. Introduction
Object detection is a fundamental task in the field of computer vision, where the main task is to locate all objects of interest in an image and determine their type and location [
1]. An important challenge in this phase is to improve the detection accuracy of high-noise videos and images [
2]. The noise environment is complicated, containing issues such as bad weather and blurred video obtained underwater; low-quality images obtained as a result of the image’s size, shape, and position, as well as the lighting and shooting conditions; and interference factors such as occlusion and background. However, these noises are unavoidable and are the major cause of missed and false detections, so improving object detection performance in the presence of noise is an urgent problem.
Using attention mechanisms to improve the performance of object detection networks has been widely recognized [
3]. The intuitive interpretation of the attention mechanism is to efficiently allocate limited computational resources to the analysis of salient regions of an object and, therefore, to improve the accuracy of object detection. This is consistent with the human visual system, which tends to focus on the useful information parts of an image and ignore the irrelevant information parts, although the overall framework of existing machine vision is still more focused on the holistic analysis of the image, and the detection accuracy of the large object is generally reasonable; however, the detection accuracy of the small and medium objects is poor. Therefore, introducing an attention mechanism can compensate for this disadvantage to a certain extent.
Attention mechanisms can be broadly classified into channel attention and spatial attention [
4]. Channel is a feature detector, and channel attention is a mechanism to mine a set of representative features in a given image. The typical channel attention is the squeeze-and-excitation (SE) module [
5], whose central idea is to learn the weights of different channels by compression and excitation operation and highlight the significant features. However, the disadvantages of SE are also apparent. It ignores the importance of spatial information [
6]. Therefore, the bottleneck attention module (BAM) [
7] and convolutional block attention module (CBAM) [
8] can better combine channel attention and spatial attention to enrich feature maps. The above work on the attention mechanism is practical; however, there are still two fundamental problems to be solved. Firstly, determining how to mine and utilize the rich information in feature maps at different scales, and secondly, channel or spatial attention can only establish short-term channel dependence but cannot develop long-range channel dependence. Aiming at the above two problems, scholars have proposed Res2Net [
9] from the multiscale aspect and nonlocal neural networks [
10] from the long-range channel dependence aspect, respectively. Although the above two methods solve the problem to a certain extent, they bring a heavy computational burden to the network. Therefore, based on the above description, we believe it is necessary to develop attention that has low cost and combines multiscale feature extraction and long-range channel dependence. In this paper, we propose an effective and low-cost attention mechanism named the multibranch attention mechanism (M3Att). Our M3Att can process the input tensor at different scales. Specifically, our M3Att combines three parts: firstly, we use group convolutions with different sizes to build a pyramid structure and then enrich the feature map information after grouping convolutions through the channel shuffling mechanism. Then, the feature maps that pass the grouped convolutional pyramid are sent into the channel and spatial attention, respectively. Finally, we use the softmax function to realize the attention weights, thus establishing the long-range channel dependence. At the same time, introducing a skip connection can better compensate for the information loss problem after multiple convolutions.
In this paper, a multibranch attention (M3Att) mechanism that merges channel attention and spatial attention is proposed to address the two problems mentioned above, and the main contributions of this paper are summarized as follows.
(1) We propose a new multibranch attention mechanism (M3Att), which can be flexibly incorporated into existing object detection networks and improves the performance of the object detection network without a significant increase in the parameters of the network. Similarly, our M3Att can also be extended to other computer vision tasks.
(2) We propose a practical multiscale feature extraction module (MFE), which can learn richer multiscale feature representation. Most importantly, the output of each MFE is propagated to the next layer to generate the channel-wise attention vector by using hybrid attention.
(3) The attention mechanism in this paper is inserted into the object detection network of YoloV4 [
11] and completes experiments on the detection accuracy. The experimental results show that the M3Att can significantly improve detection accuracy. M3Att achieved a 4.93% improvement in mAP over the YoloV4 for the PASCAL VOC2007 [
12].
This paper is organized as follows:
Section 1 presents relevant research works on attention mechanisms.
Section 2 presents the multibranch attention model proposed in this paper.
Section 3 compares the method of this paper with the existing mainstream dataset algorithm and gives experimental results.
Section 4 gives a summary.
2. Related Work
The attention model was first applied to machine translation [
13] and has become a central concept in convolutional neural networks. The attention model has two leading roles: first, to tell the computer which parts of the content to focus on; second, to allocate the limited computational resources to the important parts of the image. The attention mechanism is proven to be one of the most significant ways to improve the effectiveness and efficiency of neural network learning. Currently, the mainstream attention methods can be divided into three major categories, namely, channel attention, spatial attention, and hybrid attention [
14].
In deep neural networks, different channels in different feature maps usually represent other objects [
15]. Channel attention adaptively recalibrates each channel’s weight and generates feature masks, a process of selecting objects to determine what to pay attention to. The squeeze-and-excitation (SE) can learn the consequences for each feature to obtain its importance and uses the critical metric to assign a weight value to each channel. GSop [
16] builds on SENet and proposes a second-order pooling layer for aggregating richer features; however, the above attention has fully connected layers, leading to much computational redundancy. Therefore, ECANet [
17] uses a one-dimensional convolutional layer to replace the fully connected layer, significantly reducing the model’s number of parameters. Fcanet [
18] reconsiders the influence of the pooling layer on the attention mechanism from the frequency domain perspective and proposes multispectral channel attention. Distinct from channel attention focused on essential features, some researchers have investigated where it is necessary to concentrate. Therefore, the notion of spatial attention was proposed by Zhu et al. [
19], which converts the information in the image’s spatial domain into the corresponding space to extract the critical data. GENet [
20] uses feature context to aggregate features and then distributes them locally to tell the model which regions are essential.
Hybrid attention has both advantages over the channel and spatial attention mentioned above and has attracted researchers’ attention in recent years. In 2017, Fei et al. [
21] pioneered the concept of hybrid attention. CBAM concatenates channel and spatial attention, and the generated feature vector has both channel and spatial attention advantages. The dual attention network [
22] sums the outputs into two different attention branches and adaptively combines local and global features. Coordinate attention [
23] embeds the location information into the channel attention so that the network can focus the computational cost on the sizeable important area. Unlike DANet and coordinate attention, relation-aware global attention (RGA) [
24] is a new hybrid attention that emphasizes the importance of global structural information provided by pairwise relationships and uses it to generate attention maps. While some of the above attention mechanisms focus on designing more complex network structures, they will incur substantial computational costs. Some concentrate on creating lightweight network structures, but the improvement in model accuracy is not apparent. Thus, to further improve the model’s detection accuracy and reduce the model’s complexity, a novel attention mechanism, M3Att, is proposed; this mechanism aims to significantly improve the performance of the object detection network while reducing the complexity of the model, while channel attention and spatial attention are efficiently combined to generate complementary features.
In addition, some researchers have applied attention mechanisms to object detection networks in practical applications. Yang [
25] integrated the CBAM attention mechanism into the YoloV4 object detection network, which significantly improved the ability and accuracy of wheat ears’ extraction capability. Kim [
26] proposed ECAP-Yolo, a modification of the feature extraction network of the core network by the channel attention module, which greatly optimizes the detection performance of small objects. These efforts provide helpful background and scenarios for this and similar studies.
This paper proposes an attention mechanism with a multibranch structure and successfully incorporates it into the YoloV4 object detection network. The multibranching attention mechanism first extracts rich multiscale features through a multilevel feature extraction module and then suppresses the interference of spatial and channel dimensions, respectively.
3. Materials and Methods
The multiband attention model proposed in this paper mainly consists of a multiscale feature extraction module, a spatial attention module, a channel attention module, and a skip connection technique.
3.1. Multiscale Feature Extraction Module
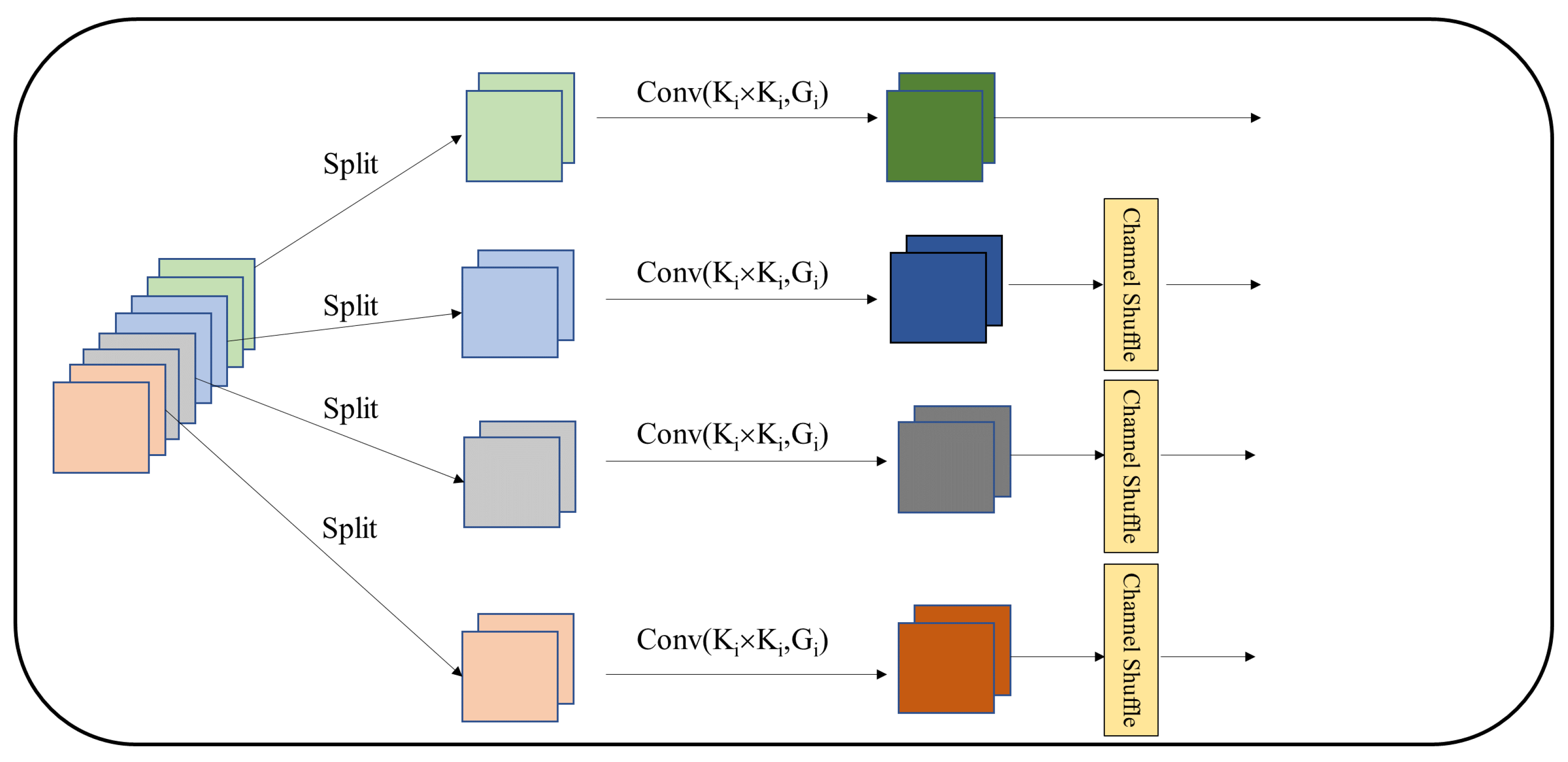
As shown in
Figure 1, it is the multiscale feature extraction module MFE that implements feature extraction in M3Att. The input feature map
is divided into
N parts, denoted by
. For each partitioned feature map, the number of channels is
. Therefore, for the
feature map, it can be represented as
. The model can process multiple scales of input tensor in parallel to obtain a topographic map with different scales. Accordingly, the input feature maps are processed using multiscale convolutional kernels, which can extract different spatial and depth information. As the size of the convolution kernel increases, the number of parameters will increase significantly. This paper introduces a clustered convolution approach to solve this issue so that the input tensor of different convolutional kernels can be processed without increasing the computational cost. The relationship between the convolution kernel size and the group size can be expressed as:
where
K is the size of the convolution kernel and
G represents the group size. The kernel size of the convolution is
, especially when
k is equal to 9 and the default of
G is 32. Equation refeq1 above will be demonstrated later in the paper by way of ablation experiments. In addition, the use of clustered convolution can significantly reduce the number of model parameters and increase the computation speed. However, communication between channels is weakened, which leads to a reduction in the feature extraction capability [
27].
Thus, this paper introduces channel shuffling to address the lack of feature communication between models. The essence of channel shuffling is to cluster each group of channels derived from the group convolution, randomly split them into new groups of channels, and then stitch them together to obtain the final feature map. The feature map after channel shuffling contains information from different channels, enriching the feature map information and avoiding the loss of feature information due to group convolution. Thus, the generate function of the multiscale feature map can be characterized as:
where the size of the
convolution kernel
is
, and the size of the grouped is
. To obtain the final output feature map, cascade stitching is performed.
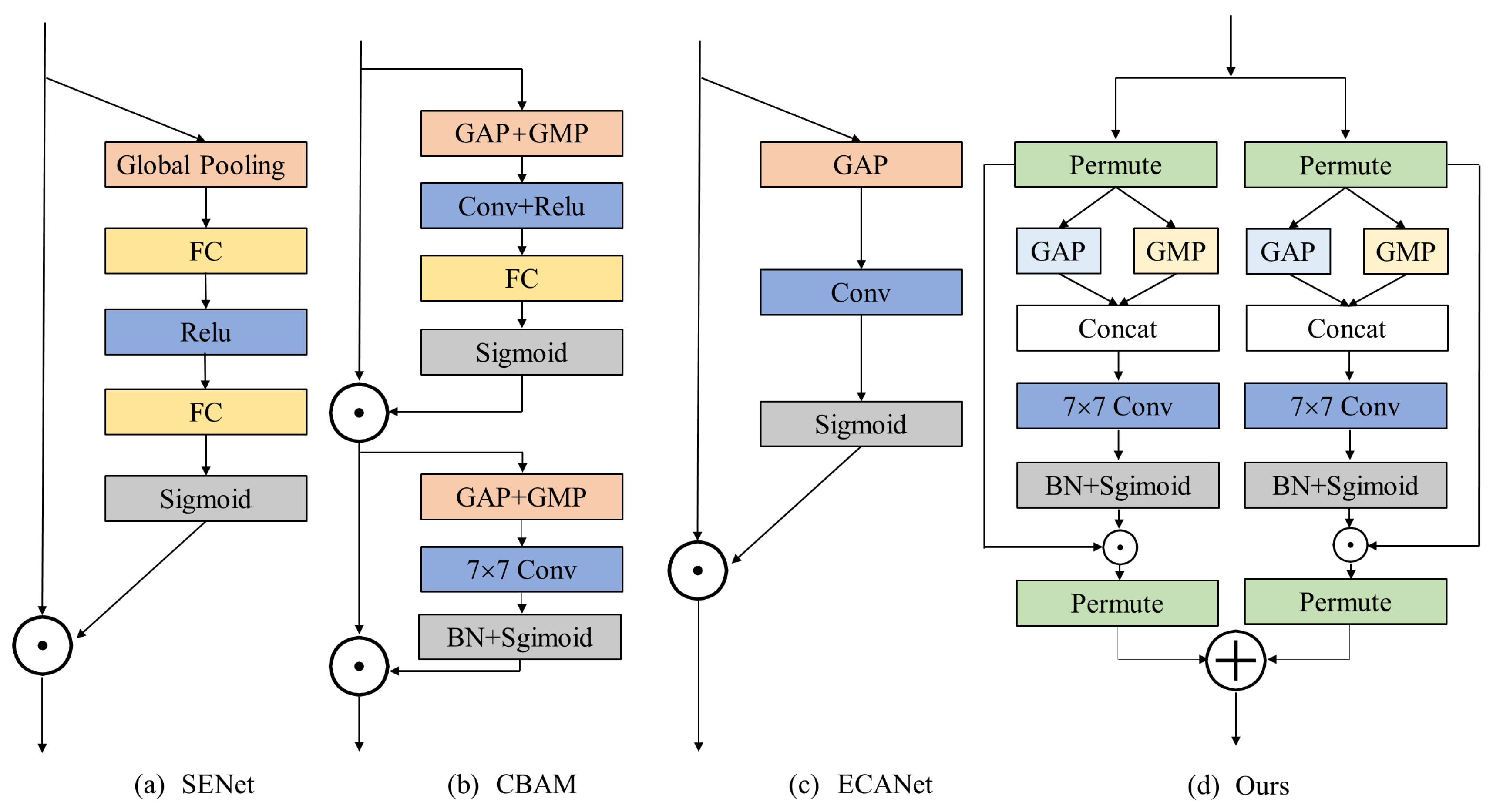
3.2. Channel Attention Module
Figure 2 compares channel attention in this paper with the current mainstream channel attention. The channel attention in this paper consists mainly of two parallel channel attentions, which are responsible for establishing cross-dimensional interactions between the channel dimension and the spatial dimension, respectively. Notably, instead of using a fully connected layer for dimensionality reduction, M3Att adopts a
convolutional kernel for dimensionality reduction. This reduces computational overhead and achieves greater efficiency when executing the forward propagation model [
28].
For a given input feature map , it will be entered into the attention of two branches of the channel. In the first branch, the interaction between the channel information and the height information is constructed in this paper. Firstly, the input feature map is rotated counterclockwise along the H axis via the permute function, which changes the shape of the input feature map to . Secondly, by arranging the (global average pooling) and (global max pooling) in parallel, the shape of the feature map is reduced . In addition, the tensor of the input feature map retains only two dimensions of information, which preserves the richness of the feature map and reduces the computational overhead at the same moment. The feature map information is then extracted via a standard convolutional layer with a convolution kernel size of . In turn, the final attention weights are generated by the BN layer and sigmoid activation function. Then, the generated attention weights are directly multiplied point by point with the original input feature map to obtain a feature map with cross-dimensional interaction information and then rotated clockwise along the H axis to preserve the original shape of the feature map input for further operations.
Similarly, in the second branch, the interaction between width and height information is constructed in this paper. Firstly, by rotating the input feature map counterclockwise along the W axis via the permute function, the shape of the input features map will be transformed to . The feature map is simplified to by a parallel and layout, and then the feature map information is extracted via a standard convolutional layer with a convolution kernel size of . The final attention weights are generated via the BN layer and the sigmoid activation function. The generated attention weights are directly multiplied point by point with the original input feature map to obtain a feature map with cross-dimensional interaction information, and then rotated clockwise along the W axis to keep the original shape of the input feature.
Ultimately, the outputs of the two different branches are then summed element by element and averaged uniformly to obtain the end output
. In conclusion, for feature maps
, the calculation of channel attention weight can be expressed mathematically as:
where the convolution operation and activation function are denoted as
and
.
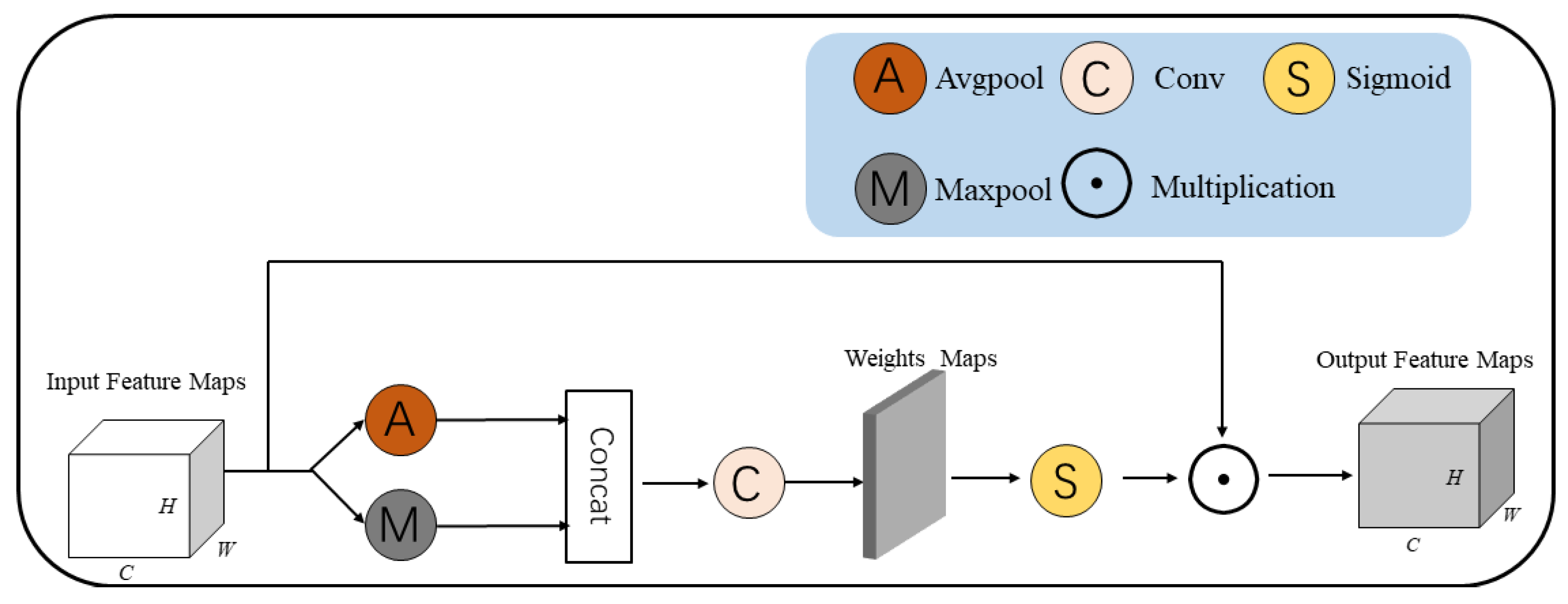
3.3. Spatial Attention Module
The spatial attention structure of this paper is shown in
Figure 3. The spatial attention mechanism in this paper draws on the idea of the spatial attention mechanism from SAM and improves upon it.
The input feature map is obtained by two feature maps, max pooling and average pooling, respectively, and the two feature maps are stitched together to obtain the feature map for the next level.
Next, the stitched feature map of the shape
is fed into a standard convolutional layer with a convolution kernel size of
to generate a spatial attention map. In this way, the spatial features are further extracted. The feature map is also downscaled into a single-channel feature map, which completes the channel-matching process. Next, a sigmoid function is adopted to obtain a weight of spatial attention feature between (0,1) and apply it to the original feature map to obtain the final output feature map with spatial attention weights. Therefore, the calculation process of spatial attention weight can be presented as follows.
The max pooling layer, average pooling layers operation, convolution operation, splicing operation, and skip connection are used in , , , .
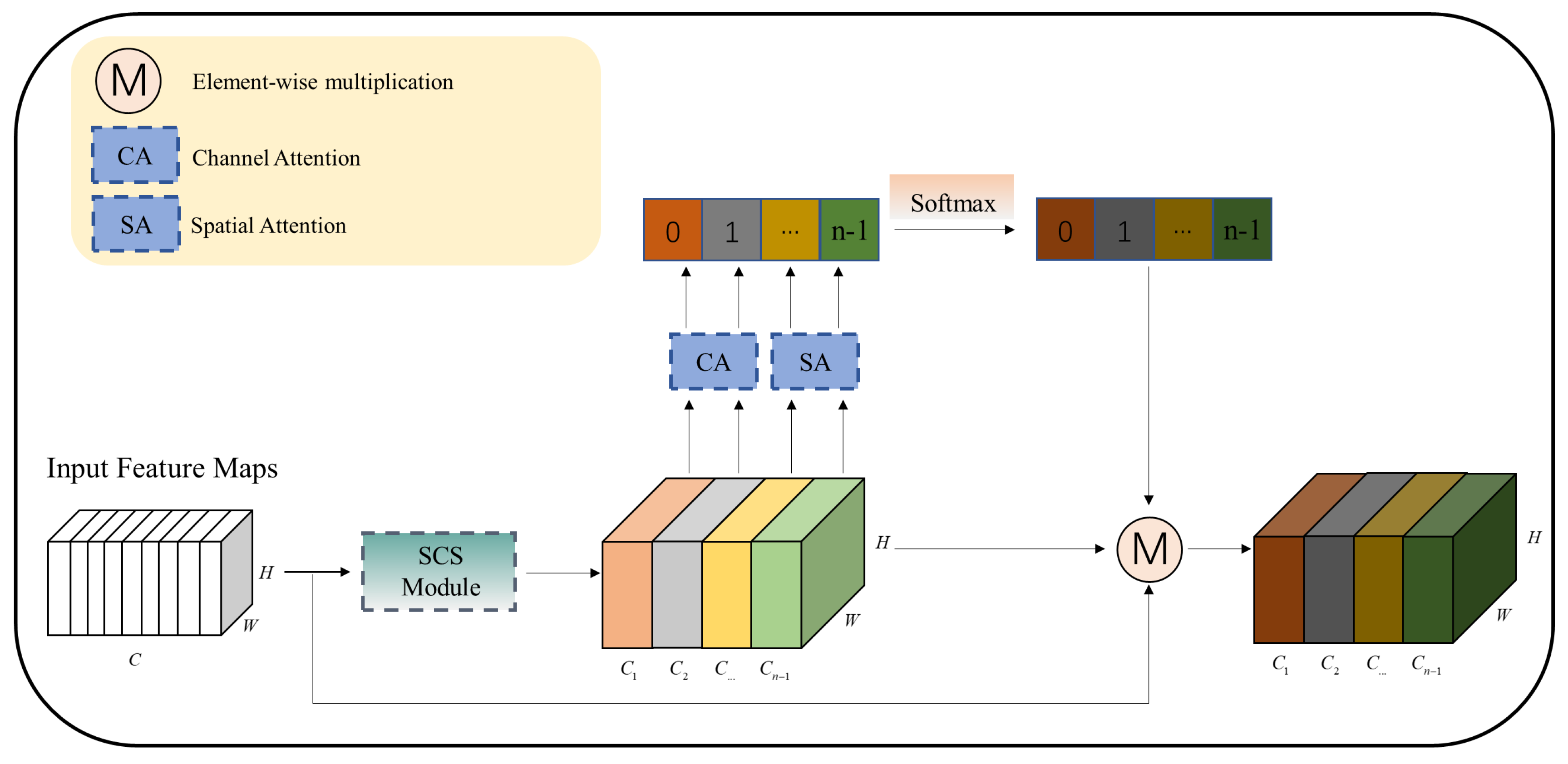
3.4. M3Att Attention Module
The module M3Att in this paper consists of the following four parts, as shown in
Figure 4. First, the feature map is divided by the MFE module to obtain different channel feature maps and rich multiscale data. Secondly, the channel feature maps are fed into the channel attention module and spatial attention module, respectively, for extracting attention information at different scales. Thirdly, the obtained channel and spatial attention weights are cascaded and spliced. By this, channel attention and spatial attention fusion can be achieved without destroying original attention, and more complementary attention weights can be obtained. Therefore, the entire hybrid attention vector at multiple scales can be described as follows:
Fourthly, the multiscale hybrid attention vector is fed into the softmax function for recalibration to enable better information interaction between channel attention and spatial attention, which can be represented as follows:
The calibrated attention vector is element-wise multiplied with the resulting feature map after splitting and the original feature map. Lastly, a feature map with multiscale information is used as output. Thus, the whole process of attention training can be summed up:
is represented as a multiscale module; is skip connection.
4. Experimental Results and Analysis
The effectiveness of M3Att was verified by comparing it with eight current top–down attention mechanisms on three public datasets, VOC2007, VOC2012, and KITTI [
29], and one live−action photographed underwater critter dataset (contracted from the Zhanjiang Underwater Robot Competition 2020). The eight attention mechanisms were SENet, coordinate attention, CBAM, ECANet, DANet, EPSANet [
30] and SPANet [
31], and triplet attention [
32]. In addition, to evaluate the effectiveness of our final model, ablation experiments were conducted to validate the model, which is the main focus of our study.
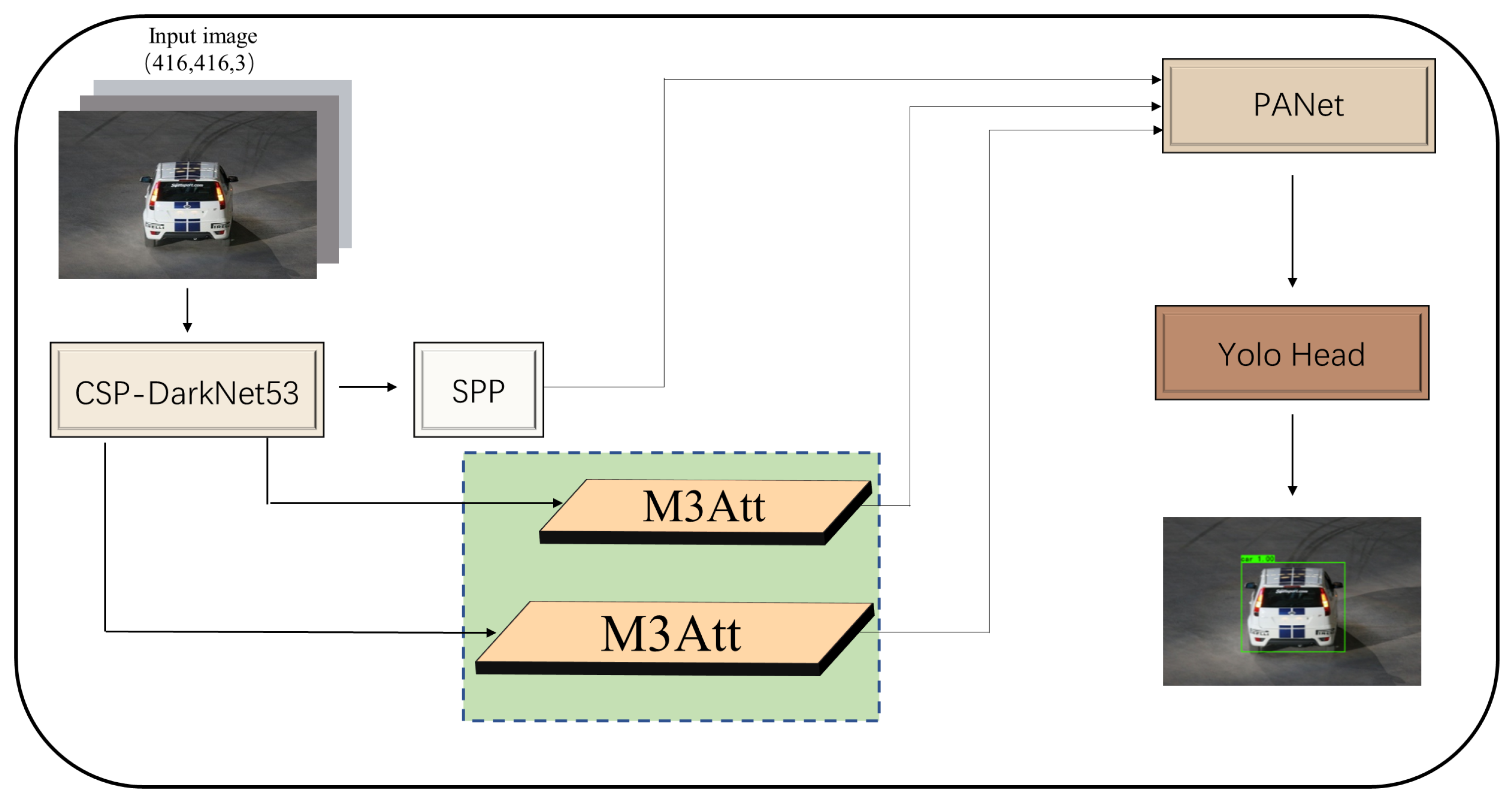
Six good object detection networks were then selected to validate the generalizability of our M3Att, thus demonstrating the “plug-and-play” nature of M3Att and its ability to improve object detection accuracy. The six object detection networks are YoloV3 [
33], YoloV4, Yolov5, YoloX [
34], SSD [
35], and Faster R-CNN [
36]. The integration in M3Att and YoloV4 is schematically represented as an example in
Figure 5.
4.1. Dataset
The public datasets used in this paper are shown in
Table 1, and the main parameters of these three datasets are listed.
Figure 6 shows some images of the dataset used in this paper.
Furthermore, to validate the model’s performance in real-world scenarios, the marine life dataset from the 2020 National Underwater Robotics Competition (Zhanjiang) was included in this paper for empirical validation. Since the dataset consisted of 3824 images, the original image set was expanded using data augmentation techniques and after data preprocessing, which resulted in 7648 images after data preprocessing. The dataset was divided 9:1 between training and test sets, with 6883 training images and 765 test images, including Echinus, Starfish, Holothurian, and Scallop.
4.2. Experimental Environment and Parameter Settings
The experimental equipment used in this paper was configured with an Intel i7-10700 CPU, an NVIDIA GeForce RTX 3090 GPU, video memory of 24 GB, and the Windows 10 operating system. The training model was constructed using the Pytorch deep learning framework based on the Windows 10 operating system, using the Python 3.7 programming language and Cuda 11.2. The main parameters of the experiment are shown in
Table 2.
4.3. Evaluation of the Model Performance
To evaluate the model’s performance more precisely, two metrics were chosen to measure the model: the average precision of AP50 (average precision) and mAP (mean average precision) for each type of object with an intersection ratio of 0.5. mAP is defined as shown in Equation (
9).
where P is precision, R represents recall, and K denotes the the number of class. In addition, the VOC dataset K = 20, the KITTI dataset K = 3, and the marine biology dataset K = 4. For a more intuitive evaluation of the model performance, the eight selected attention mechanisms were also validated using visual analytical plots and heat maps.
4.4. Analysis of the Generalizability of the Model
The PASCAL VOC 2007 dataset and the PASCAL VOC 07+12 dataset were selected for comparison in different networks to verify the generalizability of the model, and the results are shown in
Table 3.
As shown in
Table 3, after adding M3Att, the performance of the one-stage object detection network and the two-stage detection network improved compared to the original one. Specifically, the Yolo series object detection algorithms (YoloV3, Yolov4, YoloV5, and YoloX) improved by 1.41%, 4.93%, 2.05%, and 2.36%, respectively, over the original algorithms. This shows that the proposed M3Att is effective and can significantly improve object detection accuracy. This paper aims to improve the accuracy of the object detection algorithm, and the data indicate that the work in this paper is efficient. The model’s generalization capability can be further tested for object detection tasks with more extensive datasets. Therefore, the VOC2007 dataset was fused with the VOC2012 dataset to test the network’s performance further. When the M3Att module proposed in this paper was added, the mAP of all networks improved further, with YoloV3, for example, improving by 2.06%.
4.5. Experiment Comparing Different Attention Mechanisms
The experiments were conducted using the PASCAL VOC2007 dataset, and eight popular attentional mechanisms, such as SENet, coordinate attention (CA), CBAM, ECANet, SPANet, DANet, EPASNet, and triplet attention (abbreviated as triplet), were selected.
Table 4 and
Table 5 show the accuracy comparison results along with the model complexity of the YoloV4-based object detection algorithm. With the addition of the M3Att module, the proposed M3Att–YoloV4 achieved 4.93% higher detection accuracy than the YoloV4 object detection network, and the number of parameters used was only 0.52 M higher, giving better results. In addition, compared to DANet, which is representative of the excellent hybrid attention mechanism in the last years, M3Att reduced the number of parameters and computational cost by 28.2% and 11.3% respectively, with a slight improvement in detection accuracy. In summary, based on the above results, our M3Att module achieved superior parametric number comparisons and detection accuracy comparisons at a lower computational cost.
For a more intuitive comparison of the performance of this method with other attention mechanisms for object detection, a visual comparison graph is introduced in this paper for evaluation purposes. The visual contrast diagram is shown in
Figure 7.
Figure 7a shows only one class of objects; however, there are occlusions and small objects, and the pose of each object class varies, so whether objects in the image can be fully detected can be a good test of the model’s performance in dealing with various complex conditions.
As can be easily seen from the figure, it is easy to see that M3Att alone does not have any false or missed detection and detects all the objects completely.
Figure 7b shows only one object class, a boat, but it is more difficult to detect due to the dark background of the image and the severe occlusion between objects. Only M3Att detects occluded objects, as shown in
Figure 7.
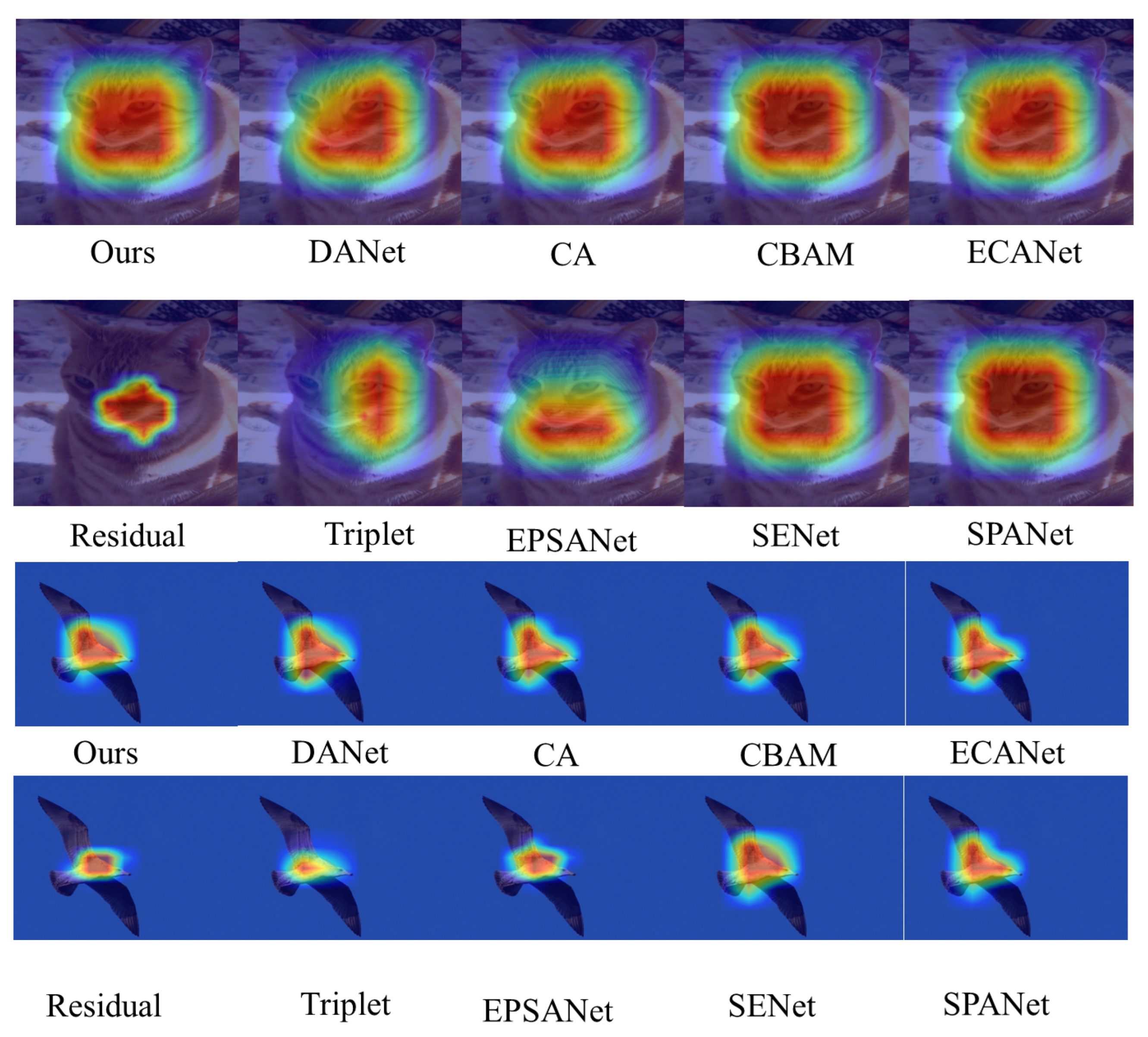
To quantitatively and intuitively explain how M3Att makes full use of the object’s salient features to enhance the network’s performance, this paper introduces the Grad-CAM technique [
37], which shows a comparative analysis of eight attentional mechanisms with the M3Att attentional map. The visualized class heat map allows one to identify the parts of the object detection task, in which the darker colors represent the parts that have the most significant impact on the results, that is, the most significant feature. A comparison diagram is presented in
Figure 8. The visualization in
Figure 8 demonstrates the inherent advantages of M3Att, which is better able to focus on salient features and cover salient regions than the rest of the attention mechanisms. In other words, M3Att can learn to use the information within the object region and cluster features from it very well. Therefore, this feature can significantly improve the performance of object detection networks.
4.6. KITTI Dataset Experiment
To test the performance of our algorithm in complex scenarios, the KITTI dataset was selected for the experiments. The dataset contained 7482 images with eight object categories, including 6733 images in the training set and 749 in the test set. For statistical and analysis purposes, the eight categories in the KITTI dataset were combined into three categories, namely, Car, Cyclist, and Pedestrian. The images in this dataset were captured from real street scenes and therefore involved many small and medium objects in complex environments. Experiments on the KITTI dataset can further demonstrate the model’s performance.
Table 6 shows the comparison results of the proposed module M3Att with the other eight attention mechanisms on the KITTI dataset. Compared with the other eight mainstream attention mechanisms on mAP, M3Att achieved the best results. Compared with other methods, this algorithm achieved the best improvement over YoloV4 with a 5.38% improvement in mAP. For these eight classical attentional mechanisms, the simple global mean pool ignores the local information in the channel, so the algorithm does not perform exceptionally well in datasets with large numbers of small and medium objects.
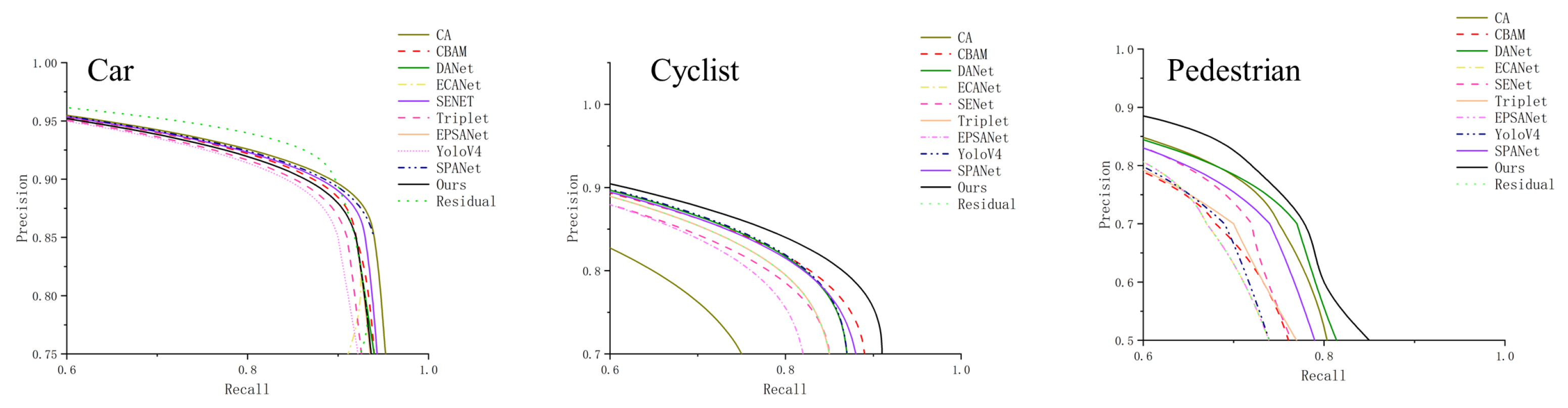
Experimental results of different attention mechanisms on the KITTI dataset are shown in
Figure 8. The P-R graph of the three objects types on the KITTI dataset are shown in
Figure 9.
Experimental results of different attention mechanisms and the P–R graph of the three object types on the KITTI dataset are shown in
Figure 9. An irregular curve enclosed by the vertical axis of accuracy and the horizontal axis of completeness is called a P–R curve. P and R values should be as high as possible for better experimental results, but precision and recall are contradictory. A higher precision rate tends to be associated with a lower recall rate. Thus, the P–R curve plotting can better study the model performance. From
Figure 9, the P–R graph of this algorithm is significantly better than the other algorithms. The proposed M3Att module in this paper can successfully capture object information. It improves object detection accuracy significantly compared to YoloV4, SENet, CA, CBAM, ECANet, SPANet, and DANet, as well as EPSANet networks, triplet networks, and other object detection and attention mechanisms. The final mAP achieved 86.94% with good detection results.
4.7. Ablation Studies
As indicated in
Table 7, this set of experiments verified the effectiveness of M3Att on the PASCAL VOC2007 dataset by adjusting the cluster size of the clustered convolution. Since parallel computing will significantly increase the number of model parameters, clustered convolution is introduced to deal with the increasing number of parameters.
Using parallel computing significantly increases the number of model parameters, so we introduced clustered convolution to deal with the increasing number of parameters.
As can be seen from the results in the table, grouping size directly affects the performance and complexity of the model. Hence, this paper determined the convolutional kernel size and adjusted the group size to balance model performance and complexities. Lastly, this paper used a convolutional kernel size of (3,5,7,9) and a convolved clustering of (1,4,16,32).
Notes: , means two cascades connected to convolutional kernels, and three cascades connected to convolutional kernels.
To test the impact of the three modules proposed in this paper on object detection results, we performed ablation experiments on the PASCAL VOC2007 dataset. The results can be seen in
Table 8. It is easy to see from the experimental results that adding the MFE module allows the network to extract more detailed features, and mAP increases from 82.22% to 85.41% compared to the original object detection network Yolov4. On this basis, mAP was increased from 82.22% to 85.41% by adding the channel attention mechanism, and the model focused on each key characteristic. Secondly, by introducing the spatial attention mechanism, the model could focus on key regions, and the mAP value increased to 86.97%. Lastly, a skip connection mechanism was introduced to transfer the bottom features from the shallow layer to the deep layer, compensating for a large amount of detail lost in the deep one. The final model mAP value reached 87.15%, which achieved a relatively good result.
4.8. Practical Scenario Experiments
To test the robustness of the algorithm in real-world environments, we experimented with the 2020 Zhanjiang Underwater Robotics Competition dataset, visualizing the comparison as shown in
Figure 10. The proposed M3Att performed better than the current mainstream attention mechanisms in object detection tasks in a real-world environment. In particular, M3Att performed well in the small objects, with all objects detected with high confidence. In some specific cases, M3Att detected unlabeled objects, as shown in
Figure 10a, demonstrating the robustness of our M3Att. To verify the model’s performance in complex underwater environments,
Figure 10b tested the performance of the M3Att in fuzzy and occluded conditions, in which only M3Att detected the entire contents of all annotated images and the unannotated scallops in the upper right corner of the image with high confidence. This is because M3Att uses a multibranching structure that combines the advantages of channel attention and spatial attention to achieve additional complementary properties that effectively highlight object features and suppress irrelevant information, thus increasing the confidence of each object and further validating the model.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}