1. Introduction
With the development of neural network, many detectors based on CNN and Transformer-based architectures have been proposed in recent years [
1,
2]. Among them, the feature pyramidal network (FPN) [
3] has become an almost necessary and effective component in current object detectors, which significantly improves the performance of detectors by learning multi-scale features for objects of different scales.
In object-detection algorithms, pyramid feature-fusion networks enhance the expressiveness of features mainly on the backbone output, and FPN combines top-down branch and lateral linking to fuse the semantic information of deep features and the location information of shallow features, thereby, opening up the research on object detection through multi-level features. Subsequently, PANet [
4] investigated an additional bottom-up information pathway based on FPN to further add deep location and semantic information. Further, in 2020, EfficientDet [
5] then proposed a weighted bi-directional FPN, which achieves feature fusion by repeatedly stacking the same bi-directional BiFPN blocks multiple times. Clearly, the FPN-based approach greatly improves the performance of object detection by increasing the information interaction between multi-scale features, which is the key to further enhancing the model performance.
However, these current multi-level information interactions based on pyramidal features lack a focus on potentially salient objects when fusing them. Recently, the superior performance of the self-attention algorithm [
6] in the field of natural-language processing has led to their widespread use and rapid development in the field of computer vision. In particular, Non-Local [
7] network with self-attention focuses on the connections within a sequence of same-scale pixels. AC-FPN [
8] introduced self-attention in the FPN part to design CEM and AM to resolve the conflict between feature map resolution and perceptual fields and to augment the discriminative power of feature-representation operations. However, this scales up the distance to the global level in the long-range correlation process and ignores the ultra-long-range uncorrelated nature of the image features.
From the above, attention is more oriented towards feature interaction between multi-level feature maps than in FPN, where attention and particularly self-attention is more about finding the salience of pixels as weights and filtering the original features with a mask composed of all pixel-corresponding weights. In addition, both channel attention and spatial attention in the attention mechanism facilitate inter-feature information interaction between pixels at the same scale.
Taken together, the current approaches based on FPN and the attention mechanism have certain limitations: (1) a lack of effective communication between multi-level features, (2) although self-attention is effective in improving FPN performance, the processed global features undoubtedly contain more redundant features, and (3) the sequences processed by self-attention contain only single-level features rather than multi-level features. Therefore, how to joint learn between multi-level information interaction, multi-level feature sequences, and local attention is necessary to improve the performance of detectors through better feature representation.
In practical scenarios, the dependency between multi-level local features is more extensive than that between same-scale features, and the semantics of surrounding multi-level features need to be referred when deciding the importance of this feature [
9], and the aggregation of multi-level local features as attention units of action is more powerful for the network to learn the salience of features. Inspired by Deformable DETR [
10], we proposed a feature pyramid networks with a multi-level local attention method that feeds the multi-level feature maps from the residual backbone network into two parallel branches—a top-down branch and an attention branch—the former being used to complement the semantics lacking in the shallow information and the latter to build up the semantics for multi-level local attention, dubbed as MLA-Net.
We propose a correlation mechanism for multi-level local information, and finally the corresponding layer outputs of the two are fused to generate enhanced features as the detection head input. The proposed approach in this paper can be easily plugged into existing FPN-based models [
9,
11,
12] and trained end-to-end without additional supervision.
3. Our Method
3.1. General Framework
The general pipeline process for object detection is to extract features from an image using a classification network as the backbone, to use a feature pyramid network to feature-enhance the extracted features, and then the output multi-level feature map is fed to the detection head to make predictions for each scale object. In the paper, we use RetinaNet, a representative work of one-stage object detection, as a benchmark, and improve the feature pyramid part along with higher quality features to enable the downstream detection head to better perform the classification and regression tasks.
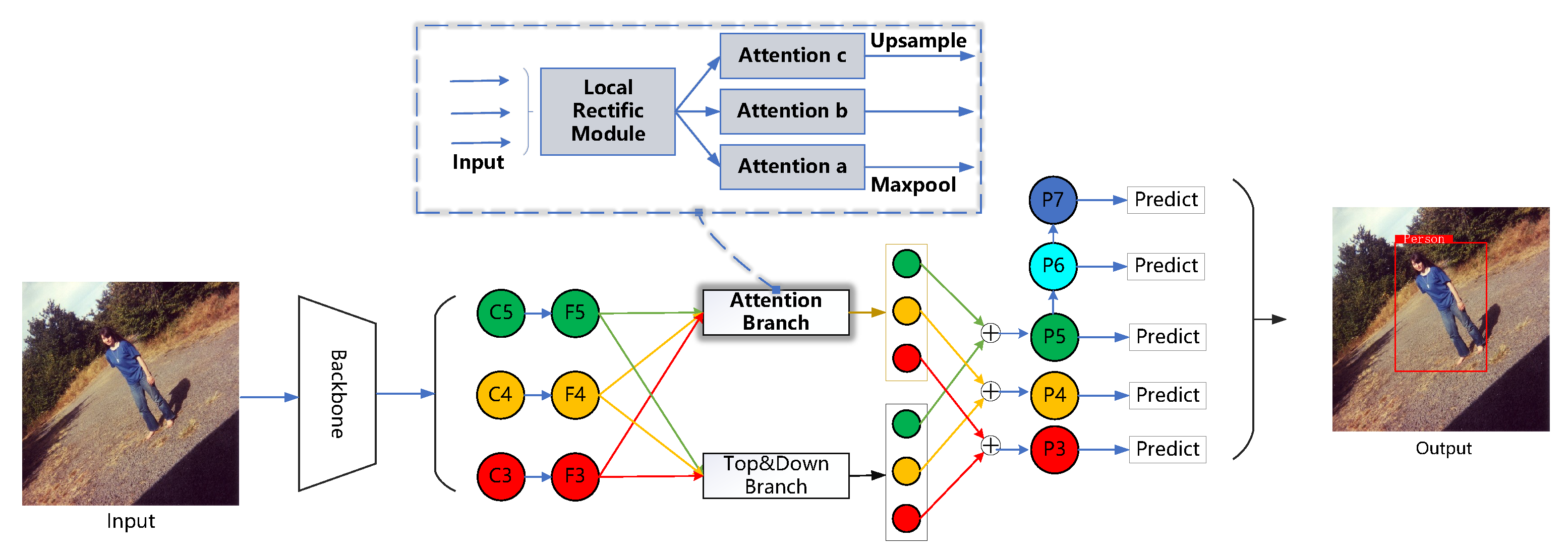
To alleviate the information loss of salient features, based on the baseline model, we propose two components in the attention branch, which are the local pixel-rectification module and the multi-level spatial-attention module. The overall structure of the network is shown in
Figure 1. The feature-fusion network proposed in this paper mainly contains two parallel branches—the top-down branch and the attention branch, where the top-down branch inherits the traditional FPN, and the attention branch consists of the local pixel-rectification module and the multi-scale spatial-attention module.
Given that the output layer of the backbone network is {C3, C4, C5} and the step size is {8, 16, 32} compared to the input image, the method in this paper uses channel reduction to form {F3, F4, F5}, after which the top-down branch simply fuses the deep information into the shallow layer, and the attention branch uses attention to provide additional attention to the salient features of F3, F4, and F5. Finally, the features from the two branches are fused to generate the five-layer detection features {P3, P4, P5, P6, P7} in the Retina network, where P6 is obtained by 3 × 3 convolution of P5 and P7 is obtained by 3 × 3 convolution of P6.
After that, we continue to use the detector head and loss function of the benchmark [
12]. In short, the five-layer feature map deals with the prediction of objects of different scales, which are then transmitted to the detection head. The model generates the prediction of the category and the regression vector of the bounding box at the detection head. The final loss calculation includes classification loss and regression loss. We use the CE function to calculate the classification loss and the smooth L1 function to calculate the regression loss, which are formulated as the following:
The loss calculation of each input picture is shown in Formula (1). This is composed of the classification loss (ClsLoss) and regression loss (RegLoss). The classification loss is the average of the classification loss of N selected anchor boxes as shown in Formula (2). The classification loss of each sample is the sum of the binary losses of M categories of this sample as shown in Formula (3). Furthermore, Formula (4) is the expression of the binary loss function, where is the supervision signal, p is the prediction signal, and r is the manually set super parameter. Regression loss is a simple smooth L1 loss function, such as Formula (5). This is the average loss of samples, where is the number of positive samples for training, is the prediction signal of anchor regression, and is the supervision signal of anchor regression.
3.2. Local Pixel-Rectification Module
In the pipeline flow of
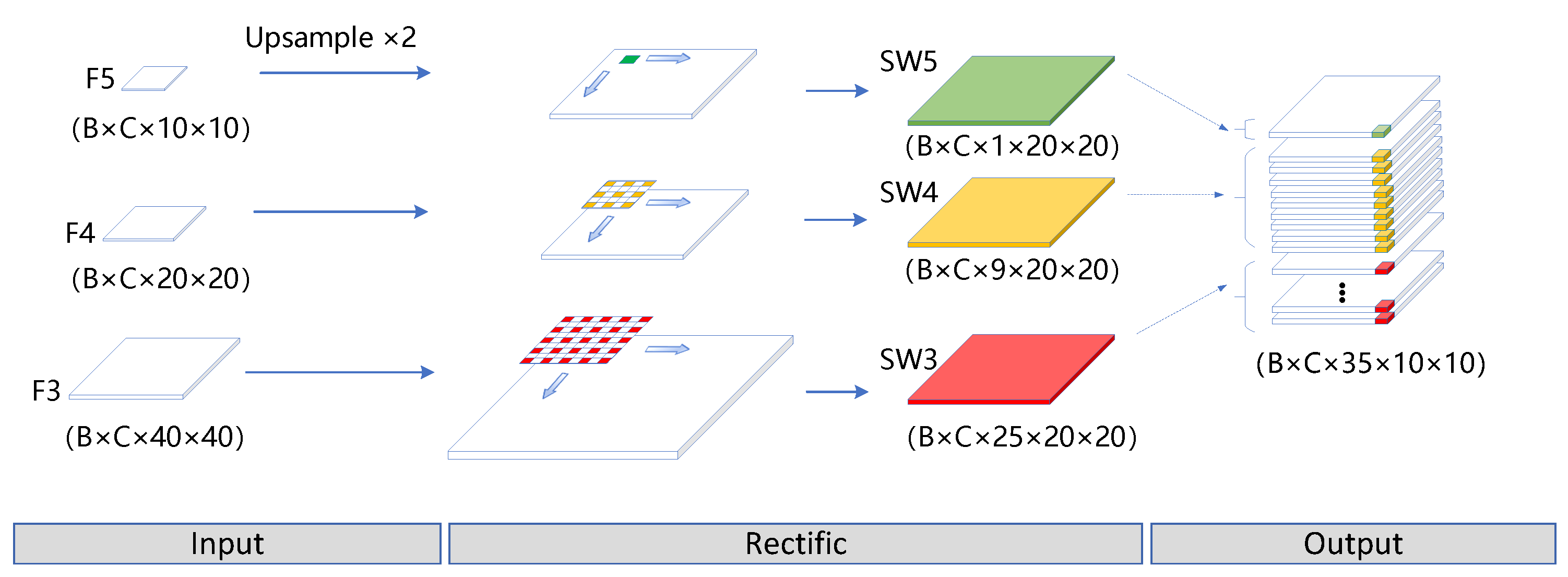
Figure 1, the three-level feature map (C3, C4, and C5) output by the backbone network has a pyramidal structure. In this paper, we redesign a multi-level sliding window on this multi-level feature map inspired by ACMix [
27], and input the sequence of pixels in the window at each slide into the attention module to obtain the attention weight of each pixel in the window. The window is scanned at each slide not at a single scale of the pyramid but at three scales. The local pixel-rectification module is responsible for adapting the reduced tertiary features {F3, F4, F5} of the channel to the sequence-based data format required by the multi-level spatial-attention module.
Specifically, as shown in
Figure 2, given a batch size of C at training, the multi-level
feature map obtained after channel reduction is
,
i∈ [3, 4, 5], where a 2D sliding window with step
, kernel size
, hole rate
, and filled pixels
slides over it synchronously, with each synchronous slide scanning
pixels and where the sampling range varies according to the void rate. If the actual sampling range of the window is denoted by
, then:
After multiple sliding rectification in the horizontal and vertical directions, the output feature map
has a data shape of
, where
H is equal to the maximum number of vertical slides and W is equal to the maximum number of horizontal slides according to the following formula.
The sequence of
pixels at the
position of
is denoted as
and
is the pixel point in the rth row and cth column on the feature map
, and thus their correspondence can be expressed as:
This module uses the synchronous sliding of three 2D windows, which equate to a 3D multi-level sliding window, and the sequence of features extracted from the multi-level sliding window is fed into the sequence-based self-attention algorithm model at each synchronous sliding.
3.3. Multi-Level Spatial Attention
Although the local pixel-rectification module in
Section 3.1 extracts a large range of features under different perceptual fields, not all features are beneficial to the model’s classification and regression of the object. Feature information is prone to information decay as the network depth increases, and too many redundant features will actually degrade the detection performance. Therefore, in order to eliminate redundant information and emphasize effective information, a multi-level spatial-attention module is inserted after the local feature pixel rectification to further enhance the expressiveness of the feature mapping, to suppress redundant information among many features, and to better exploit the semantic correlation between two features to better establish the mapping.
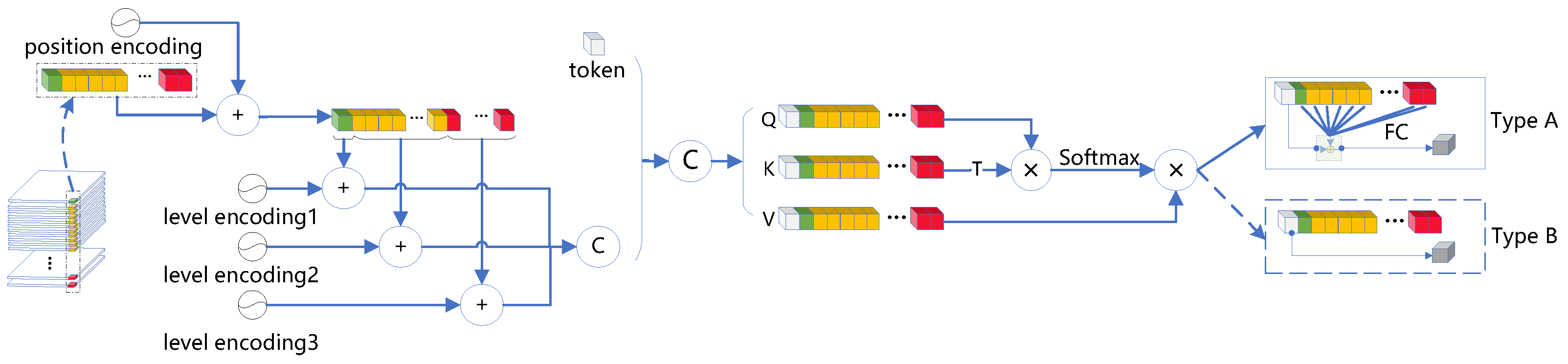
The output of the local pixel-rectification module is processed by the self-attention module and mapped into enhanced features at all levels in two ways—Type A mapping and Type B mapping as shown in
Figure 3. The multi-level spatial attention first adds position encoding to the feature sequence, and then adds corresponding hierarchical encoding for each feature scale, and after the self-attention processing, finally builds the FC (fully connected mapping) on the one hand and also builds the mapping using the insertion of Tokens (tokens) in ViT [
28]. The mapped features are then summed, fused, and output. Type B attention only builds mappings in the form of categorical tokens.
As shown in
Figure 1, attention components a, b, and c are responsible for the enhancement of Level 3, 4, and 5 features, respectively, with attention component a using type-A mapping and attention component b and c using type-B mapping. Overall, this module establishes semantic associations and spatial associations between each region-of-interest feature and each level feature and features at the same level through the above two approaches, thereby, allowing the network to actively aggregate contextual information of sub-regions at each level for each region-of-interest feature, i.e., to establish semantic dependencies for the features at each level generated by the rectifier module, thus, providing the output features with clearer semantics.
4. Experiments
4.1. Datasets
The PASCAL VOC dataset can be divided into four major categories and twenty sub-categories. A total of 9963 images were used in PASCAL VOC2007, of which 5011 images were in the training set and 4952 images were in the test set; 122,216 images were used in MS COCO, of which 117,266 images were in the training set with 4952 images in the test set. In this paper, the ablation experiments were conducted on the MS COCO dataset and PASCAL VOC. Furthermore, we compared the results with various algorithms on the PASCAL VOC dataset in our experiments. We use python 3.8 and pytorch 1.7.1 to run all our experiments. Two NVIDIA GeForce GTX 1080Ti GPUs were used for training, and only one was used for evaluation.
4.2. Experimental Setup
The ResNet model, pre-trained on the ImageNet [
28] dataset, was used as the backbone feature extraction network, and the baseline RetinaNet and the proposed method were trained by first pre-processing the input images with data enhancement operations, such as image flipping, aspect warping, and color scrambling, using a SGD optimizer, and the initial learning rate was set to 0.0025 during training. The total number of training epoches for the experiments on MS COCO was 15 epoches, and the learning rate decreased to one-tenth of the original rate in epoch 8 and 12. For Pascal VOC, the training epoches were set to 16, and the learning rate decreased to one-tenth of the original rate in epoch 12.
4.3. Ablation Studies
In order to verify the effectiveness of the proposed method, extensive ablation experiments were conducted on the MS COCO dataset and PASCAL VOC for the proposed algorithm. Relevant experiments were conducted on the top-down branching effectiveness, the method of fusion of the two major branches, the way of mapping the features after attention, the importance of shared and independent linear mappings at each level of attention, the number of attention heads, and the number of channels, and the experimental results are shown in the following tables. In the tables, we use checkmarks to indicate that the corresponding model of the current row is configured with the corresponding network structure or algorithm of the current column. The horizontal bar indicates that the corresponding network structure or algorithm of the current column cannot be installed in the corresponding model of the current row. The best result in this experiment is shown in bold.
The model described in
Section 3.1 of this paper has two major parallel branches compared to the original benchmark top-down fusion network—namely, the top-down branch and the attention branch. The results in
Table 1 show that the model lacking the top-down branch performs slightly lower than the benchmark, indicating that the top-down branch is a crucial structure.
As show in
Table 2, this paper explores the best way to fuse the two main branches, where splicing fusion is the operation of stitching two features together and then reducing them using a convolutional channel, which results in more computation and parameters, but is less effective compared to summation fusion, which is not only simple but also very effective.
After determining the basic branching and fusion methods, a series of experiments were performed in this paper for the internal structure of the multi-level spatial-attention module. As shown in
Figure 1, attention components a, b, and c in the attention branch are responsible for the enhancement of small, medium, and large scale features, respectively, as can be seen from the results in
Table 3: shallow features are responsible for small-object detection, and small objects should focus more on the salience of the features associated with them due to their lesser association with the environment. Finally, we conducted experiments on the performance enhancement of the number of self-attention heads and the number of channels per head. The experimental results in
Table 4 demonstrate that increasing the number of heads was more effective in improving the performance when compared with increasing the number of channels per head.
In this paper, we next take the above configuration and apply it to the PASCAL VOC dataset to investigate the improvement of detection performance with multi-level features and attention mechanisms with local windows, respectively. For the effect of local windows on attention, this paper set different window sizes in the local pixel-rectification module. The corresponding window sizes for each level are shown in
Table 5, and the corresponding performance is as follows.
Local features with appropriate range sizes are clearly better, and it can be seen that global attention is not the best choice. As for the effect of multi-level features on attention, this paper controlled the scale of the features from the input of the local pixel-rectification module underhand as shown in
Table 6. In the attention with multi-level features, each scale did not contribute equally to the attention, and the shallow features did not contribute. No attention mechanism functioned well if the semantic information of the feature was insufficient.
Combining the experiments of two datasets, the performance of our proposed method for each backbone network and dataset is shown in
Table 7 below. In general, the method in this paper increases significantly the performance compared to the baseline on ResNet-18 but less on ResNet-50 and ResNet-101, and increases significantly the gain of mAP on PASCAL VOC but less on MS COCO, which we will study in depth for improvements in the future.
4.4. Qualitative Analysis
As shown in
Figure 4, to illustrate the detection performance of this paper’s algorithm, the detection results of the original RetinaNet detection algorithm are compared with this paper’s algorithm, and some of the clearly representative images were selected for illustration. In the first row of the figure, the algorithm in this paper has no redundant prediction results and detects the object with a higher confidence level; however, the object box position of the algorithm in this paper is more accurate and has a higher confidence score.
In the second row of the figure, for people, the RetinaNet algorithm has no false detection of people, and the algorithm in this paper is able to give better detection results. In the third row of plots, the RetinaNet algorithm misdetects the bird as a sheep, while the algorithm in this paper gives a high confidence level of correct judgment. In the fourth row, the algorithm does not have low-quality redundant detection compared to RetinaNet.
The experiments show that the algorithm in this paper was generally able to detect the object class and give a certain confidence score, and that the overall confidence score and the accuracy of the object frame were higher than for the original algorithm.
4.5. Comparison with State-of-the-Art Models
4.5.1. Comparison of Performance on PASCAL VOC2007
The results of the comparison between the algorithm in this paper and the mainstream object-detection algorithm on the PASCAL VOC dataset are shown in
Table 8. The algorithm in this paper achieves a detection accuracy of 81.8%, which is a 1.2% improvement compared to the benchmark algorithm. Compared with the two-stage classical algorithms Faster-RCNN (ResNet-101) and R-FCN, the detection accuracy of this algorithm was improved by 5.4% and 2.3%, respectively. Compared with the one-stage detection algorithms SSD, RetinaNet, YOLOv3, YOLOX-s, and DSSD, the detection accuracy was improved by 5.0%, 2.3%, 2.5%, 0.8%, and 0.3%. Compared with the one-stage detection algorithm CenterNet, the detection accuracy was improved by 3.1%.
4.5.2. Comparison of Single-Category Performance
The detection accuracy of each category of this paper’s algorithm applied to RetinaNet was compared with other algorithms on the PASCAL VOC dataset, and the results are shown in
Table 9. The algorithm in this paper was able to reach the optimal level in all 10 categories, where seven categories increased by more than 1%.
4.5.3. Discussion
The method in this paper improved the performance substantially with the introduction of a small number of additional parameters. Furthermore, the method in this paper was applied to RetinaNet (ResNet-50) with fewer parameters than RetinaNet (ResNet-101) to obtain better performance. The results show that the improvement brought by the method comes mainly from the fine-grained design rather than additional parameters.
To further evaluate the impact of multi-level contextual information on the attention mechanism, we used different input tiers for the local pixel-rectification module with different kernels and expansion rates for individual inputs. Feature dependencies at large scales had small improvements in the detection performance. This situation suggests that a larger range of local features tends to introduce more redundant features, that appropriately sized local regions can both highlight salient features using inter-feature associations and avoid introducing redundant features, and that multiple feature tiers provide a significant boost to the attention mechanism. We conclude that local attention is more effective than global attention in FPN and that multi-level attention is more effective than single-scale.









{kind=link}
{kind=link}
{kind=link}
{kind=link}