1. Introduction
Artificial intelligence, especially deep learning, has delivered significant improvements in several fields, including computer vision, natural language processing, communication signal processing, and automatic driving. Compared with traditional techniques, deep learning has proven to have significant advantages in mid-level and high-level feature extraction. It has been applied to many tasks, including object detection [
1] and recognition, object tracking [
2], and object segmentation [
3].
There are several issues with the satellite data transmission system due to the geometric increase in the amount of remote sensing satellite data and the rapid development of remote sensing technologies. Since clouds cover over 70% of the Earth’s surface, they make up many of the images that remote sensing satellites collect. Usually, these cloud images do not contain valid information and are referred to as invalid images. Another instance is the remote sensing images of the sea surface, where there is no object and little practical use. As a result, one of the most prominent problems is that a large portion of the data acquired by remote sensing satellites is invalid [
4]. This invalid data transmission places tremendous pressure on the satellite data transmission system. It wastes precious bandwidth resources [
5,
6,
7] and significantly reduces the utilization of satellite payloads. These problems make it challenging to meet the stringent timeliness requirements of demanding missions, such as Earth observation or some military tasks. Notably, the current problems faced by remote satellites can be solved with onboard image processes, which can recognize the invalid data and discard this invalid data onboard directly.
Object detection is one of the essential tasks of remote sensing image processing [
8]. It is also the basis for advanced applications, such as remote sensing image analyses, image understanding, and scene understanding. In addition, onboard object detection can improve satellite data relay services in terms of the amount of user data and timeliness. Therefore, it has attracted the increasing attention of many scholars.
There are two typical scenarios for remote sensing object detection. One is to transmit remote sensing images to the ground via a satellite data transmission system, and then object detection is performed [
9]. In this scenario, the object detector is deployed on the ground without consideration of storage, the computational cost, or the power consumption limitations imposed by the space environment. Another strategy is to perform object detection directly on satellites [
10]. In this situation, it is necessary to deploy the detector on board and to consider all of the resources that the satellite can offer.
Onboard object detection is more attractive for military and civilian missions. First, this approach can respond to changes on the ground in real time and feed back the results, particularly for military tasks or disaster monitoring. Second, no actions are required to transmit the original data to the ground station. There is a large amount of redundant data in the images collected by the satellite, and sending all the data back to the ground station would undoubtedly waste valuable satellite bandwidth resources. With object detection on board, only valuable data would be transmitted back to the ground. It would significantly reduce the waste of bandwidth.
Limited by the space environment, the computational and storage capacities onboard are significantly inferior to those on the ground [
11,
12]. Deep learning algorithms are computationally expensive and memory intensive. The improved performance of these algorithms comes at the expense of high computational and storage resource consumption [
13]. Deploying deep learning algorithms on satellites is more challenging than on the ground, not only in terms of balancing performance and resources but also in terms of the onboard implementation of the algorithms. Therefore, onboard object detection model compression is an urgent request in current research.
Model compression is a practical approach to reducing model complexity which can significantly reduce the number of parameters and the computing costs of the model without significantly degrading the performance. It was used to reduce the CNN model size and hardware requirements of the CNN deployment to solve the problems mentioned above when the object detector was deployed on the satellite in this paper. Among several model compression methods, the low-rank decomposition method is an emerging tool for large-scale data approximation that can be approximately represented in highly compressed formats and that is widely adopted [
14,
15,
16,
17].
Decomposed factors are directly mapped to convolution layers without the reconstruction of these factors to high-order tensors. This method is the most popular approach to CNN model compression based on low-rank decomposition. In [
14], the four factors of the CP (canonical polyadic) decomposition [
15] of the convolution kernel tensor were considered to be one pointwise convolution kernel, two depthwise convolution kernels, and one pointwise convolution kernel, respectively. In [
16], the four factors of the Tucker decomposition [
17] of the convolution kernel tensor were considered to be a pointwise convolution kernel, a standard three × three convolution kernel, and another pointwise convolution kernel, respectively.
Previous works explored this technology on VGG [
18], and AlexNet [
19] demonstrated promising results for model decomposition. Still, the situation varies when decomposing Resnet [
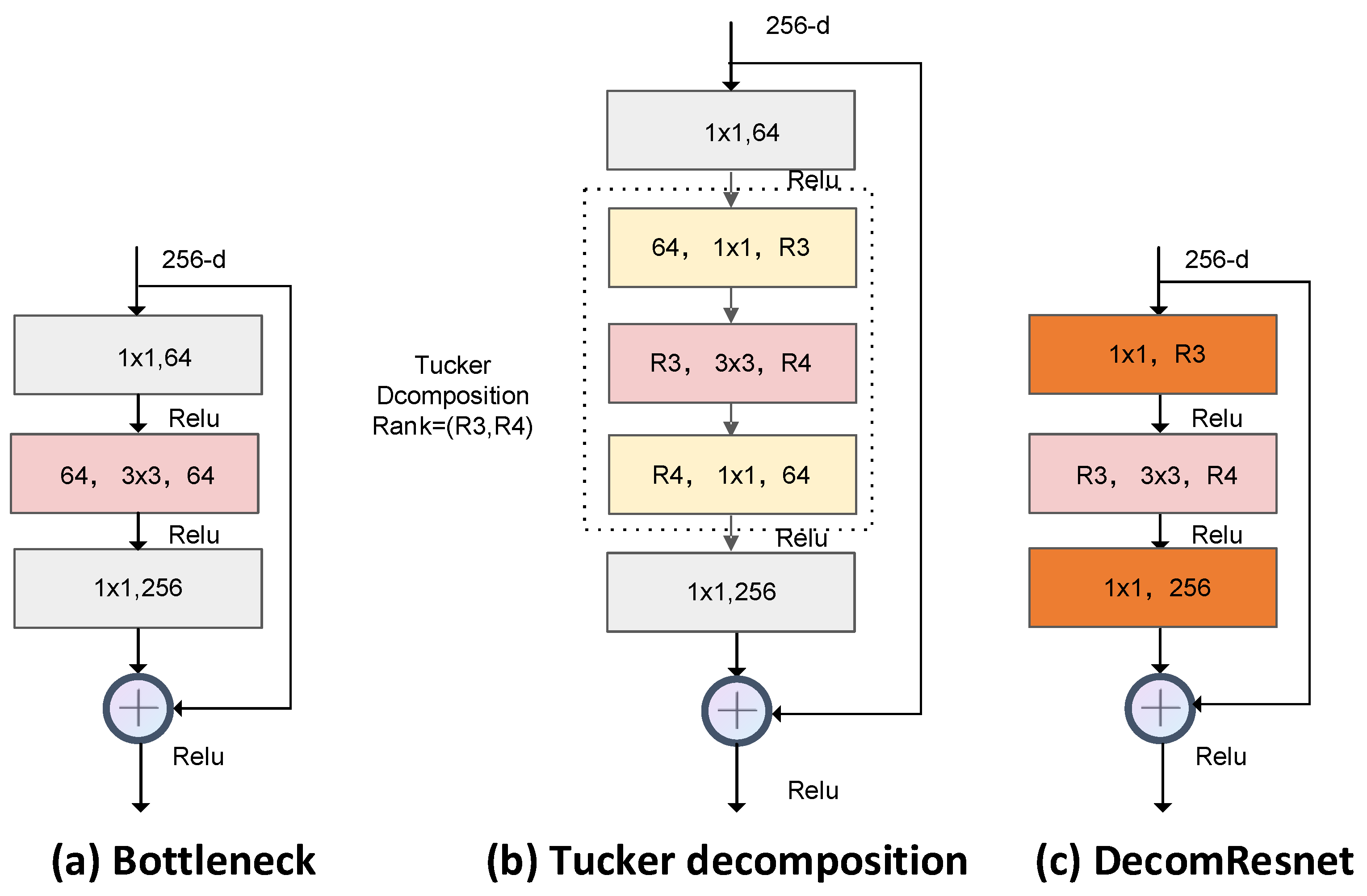
20], which is constructed with the bottleneck shown in
Figure 1a. The three × three convolution kernel tensor in the bottleneck can be decomposed into a pointwise convolution kernel, a standard three × three convolution kernel, and another pointwise convolution kernel [
16] as shown in
Figure 1b. In this case, two pointwise convolutional layers are cascaded together. The number of input channels reduces, but the convolution layers increase. The convolutional layers increase the computation time because the CNN models are computed layer by layer. To solve this problem, we merged the two pointwise convolutional layers and constructed a novel module called DecomResnet as shown in
Figure 1c.
The main contributions of this paper are summarized as follows:
- (1)
A model compression method was proposed for remote sensing image object detection based on Tucker decomposition which consisted of four steps:
- Step 1:
model initialization;
- Step 2:
initial training;
- Step 3:
trained model decomposition and reconstruction;
- Step 4:
fine-tuning.
- (2)
The DecomResnet module was proposed based on Tucker decomposition. It was used to construct the backbone of the object detection model. The experimental results showed that the proposed module significantly reduces the number of parameters and computational costs with a slight decrease in performance.
- (3)
To verify the performance of the compression model proposed in this paper, the model was validated on the NWPU VHR-10 dataset. The experimental results indicated that the proposed method is an effective approach to model compression.
- (4)
For our practical engineering application requirements, we constructed a remote sensing dataset named CAST-RS2 which contained only two types of objects according to the mission requirements and the characteristics of remote sensing objects. The proposed method was also verified on this dataset.
2. Related Work
Model compression methods can be broadly categorized into knowledge distillation [
21], pruning [
22], quantization [
23], low-rank decomposition [
24], and lightweight models [
25].
Knowledge distillation is commonly used in migration learning, also known as student–teacher networks. The key concept is to train a deep teacher network and then to teach a small student network that mimics the teacher, which is deployed after training. The teacher model can be a single large model or a collection of individually trained models. The main idea of pruning is to remove the redundant parameters from the large model to obtain a small model.
The main idea of pruning is to grow a large model and then to prune away weights to end up with a much smaller but effective model. Luo et al. [
22] reduced Resnet through pruning. The Resnet that was compressed through pruning is similar to DecomResnet. However, they are not the same, which is reflected in the following aspects:
First, the number of channels in the convolutional layers is different. Although both have three layers, the first layer is a one × one convolution, the second layer is a three × three convolution, and the third layer is a one × one convolution, the number of channels in the convolution layers is not the same. A greedy algorithm obtains the channels of the first two convolutional layers in ThiNet. In this paper, however, the rank (R3, R4) acquired by the VBMF method determined how many channels were present in the first two convolutional layers.
Second, the method of reducing the number of channels is different. ThiNet adopts the pruning method, i.e., the unimportant channels in the convolution kernel are removed directly. However, in this paper, the Tucker decomposition factors were used as the convolution kernel to reduce the number of channels.
Third, the compressed objects are inconsistent. ThiNet does not prune the first two layers in the bottleneck. Some of them will not be pruned. However, all the three × three convolutional layers in the bottleneck were decomposed in this paper.
Fourth, the process of model compression is different. ThiNet prunes CNN models layer by layer. Its framework is filter selection, pruning, and fine-tuning. Our decomposed framework was initialization, training, obtaining the ranks, and fine-tuning.
Fifth, the compression ratio is not the same. The compression ratio of ThiNet is set manually. However, the compression ratio of the method proposed in this paper was determined by the ranks of Tucker decomposition.
The main idea of quantization is to store the weights and activation tensors in lower-bit precision representations rather than the 16-bit or 32-bit precision representations.
In recent years, some researchers have been working on designing more compact, less computationally intensive, and more efficient network structures, such as the fire module of SqueezeNet [
25], the residual structure of Resnet [
20], the inception module of Googlenet [
26], etc. These lightweight modules are composed of tiny convolutions, such as one × one convolutions or three × three convolutions, which can effectively reduce the number of model parameters and the volume of operations.
Deep models are usually overparameterized, and the weight matrix components usually reside in low-rank subspaces [
27]. Therefore, low-rank decomposition is considered one of the efficient deep compression schemes and is generally used to compress deep models.
The most popular low-rank decomposition techniques are canonical polyadic decomposition (CP) [
14], Tucker decomposition [
16], and tensor-train decomposition [
28,
29]. CP decomposition presents an n-way tensor as the sum of
(
is the minimum rank) rank-1 terms. This method is simple and efficient. However, its drawback is that finding the r rank is an NP-hard problem. Tucker decomposition approximates the original tensor by multiplying a core tensor by a factor matrix along with each pattern. Tensor-train (TT) decomposition expresses the tensor as a string of smaller (three-way) core tensors. It maintains a simplicity similar to CP decomposition and achieves a higher compression rate. Several works [
30,
31] focus on decomposing the convolutional weight tensors to reduce the parameters more efficiently and to reconstruct the decomposed factors during inference without significant performance loss. The procedure of this approach is as follows: First, these methods train the model for a few epochs, which is called initialized training. Second, the weight tensor obtained from initialized training is decomposed. Finally, the decomposed model is retrained, which is called fine-tuning. In the inference phase, the higher-order convolutional weight tensor is reconstructed by lower-order factors again. The advantage of this approach is that the convolution structure does not change, but the convolutional kernel must be rebuilt.
Another approach is to decompose the weight tensor and to construct a new convolution module based on the decomposed factors [
14,
16]. In [
14], a convolution module was created based on the CP decomposition factor, consisting of a point convolution, a separable convolution, and another point convolution. In [
16], a convolution module was constructed based on the Tucker decomposition factor, which consists of a point convolution, a regular convolution, and a point convolution. Essentially, these methods achieve model compression by transforming complex CNN models into lightweight models through low-rank decomposition. In the inference stage, these methods do not require the reconstruction of the low-rank tensor into a high-rank tensor, which is suitable for applications in resource-limited environments. Inspired by these two works, we proposed a CNN model compression method based on Tucker decomposition.
In addition to the most popular methods mentioned above, the hierarchical Tucker (HT) method [
32] and the Kronecker product decomposition (KPD) [
33] method are also used to compress the weights of the convolution layers.
The hierarchical Tucker (HT) method decomposes the kernel weight tensor into two load matrices and smaller three-way tensors. The load matrices are equal to one × one convolution layers, and the three-way tensors are equal to one-dimensional convolution layers.
The KPD method approximates the original matrix with two smaller Kronecker factor matrices. This method can also be extended to the multidimensional nearest Kronecker product problem [
33]. The rank is an essential hyperparameter in the low-rank decomposition process. However, the solution to the optimal rank is an NP-hard problem, which is difficult to obtain. Several rank selection methods have been proposed to obtain the rank of tensors. A fitness-based rank selection method was proposed in [
34]. However, this rank selection method has limitations in selecting multiple ranks and has convergence problems in the optimization process. SVD (singular value decomposition) was used to solve for the optimal rank in [
35], but this solution method is very time-consuming. A heuristic method was used to select the rank in [
16], but the CNN structure determines the desired rank and the dataset used.
Miao et al. [
36] recently proposed a budget-aware rank selection method that can calculate tensor ranks via one-shot training. Although it can automatically select the proper tensor ranks for each layer, it may obtain different ranks when the training environment changes, such as the dataset and training hyperparameters.
The variational Bayesian matrix factorization (VBMF) method was proposed in [
37]. Although this method generates suboptimal ranks, it is a highly reproducible approach and is currently considered adequate.
3. Proposed Method
3.1. The Baseline Object Detection Model Analysis
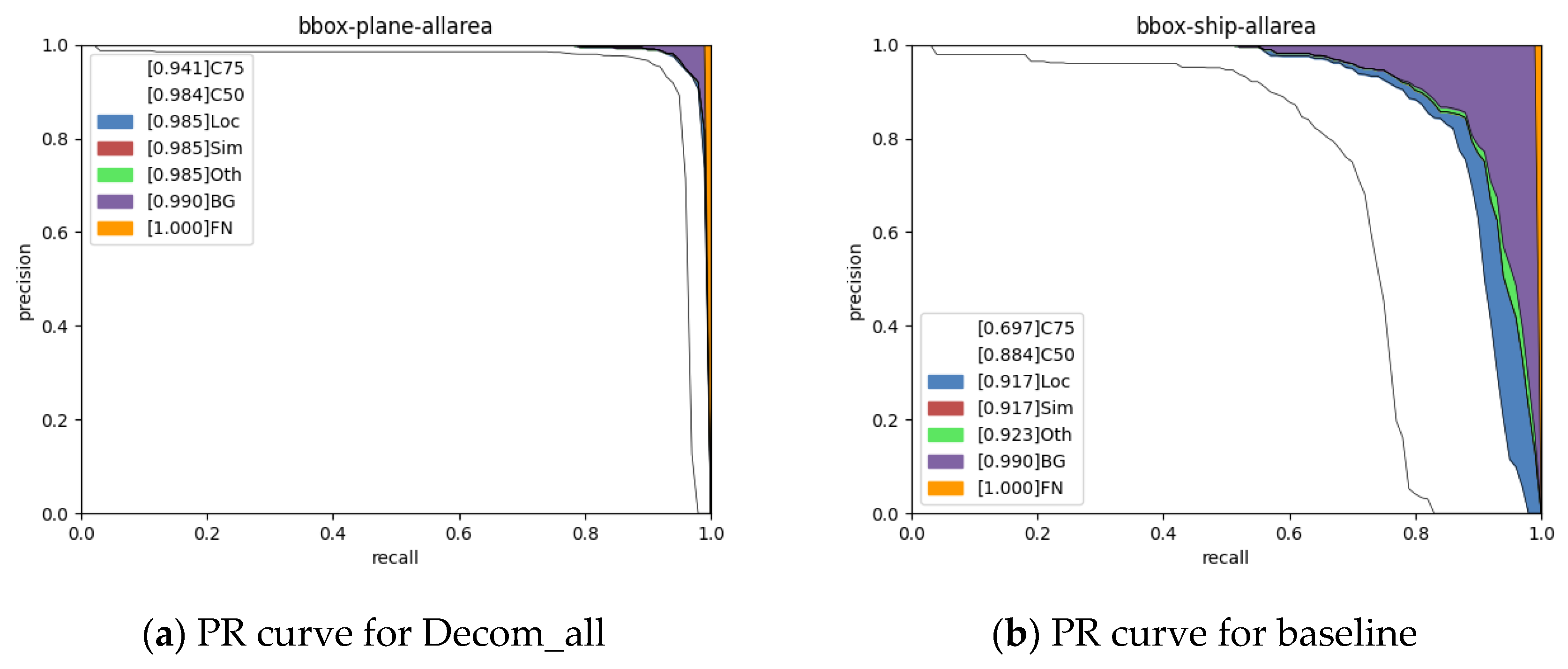
In this paper, we took RetinaNet as the baseline because it can offer a better speed/accuracy trade-off and because it is a promising onboard deployment candidate model. We first analyzed the baseline model, focusing on the number of parameters in each part of the baseline, and then decomposed the weight tensors.
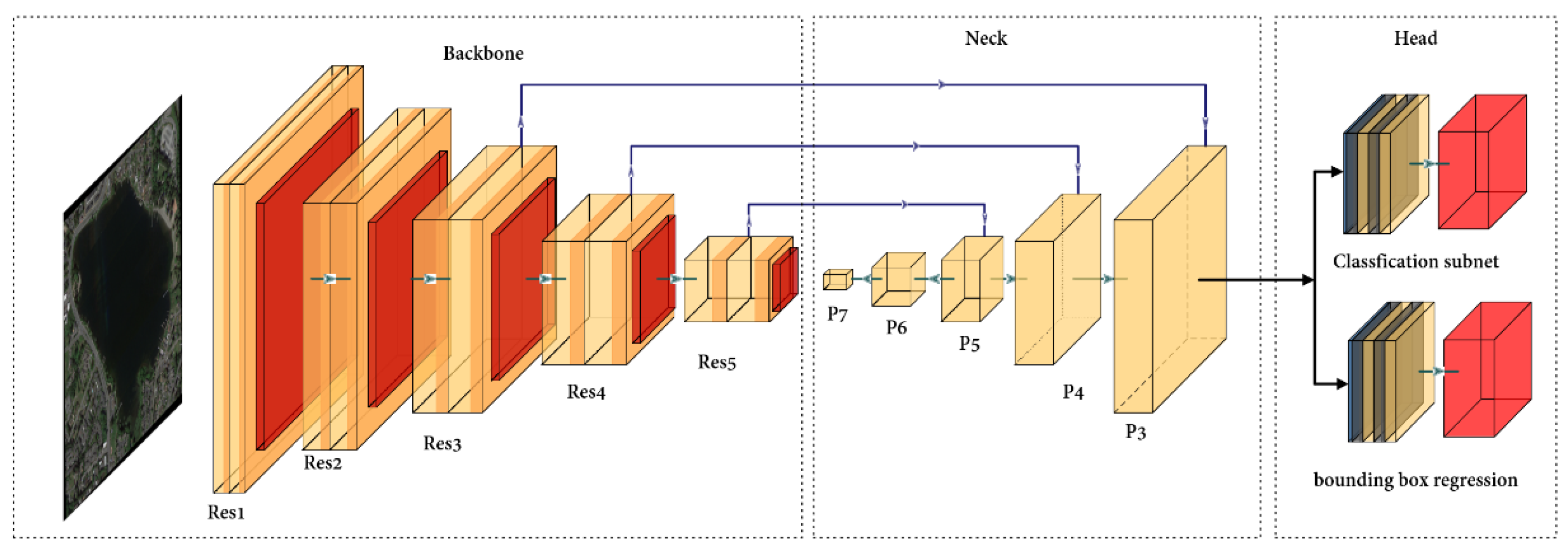
As shown in
Figure 2, the object detector consists of three parts: the backbone, neck, and head.
Among these three parts, the backbone has the most parameters, accounting for more than 60% of the detector parameters. Huang et al. [
30] pointed out that the backbone has many redundant parameters. Decreasing the number of backbone parameters is an effective way to reduce CNN complexity. The backbone consists of a finite number of convolutional modules. Each convolutional layer of these modules is a 4D tensor.
Due to its excellent feature extraction capability, Resnet is widely used in object detection tasks. The parameters of Resnet mainly consist of one × one convolutional layers and three × three convolutional layers. Taking Resnet-50 as an example, the number of one × one convolution layer parameters and three × three convolution layer parameters account for 47.4% and 44.44% of the backbone, respectively. The number of parameters in three × three convolution layers can be reduced through tensor decomposition, but the number of parameters in one × one convolution layers cannot be reduced similarly. When the input image size is 512 × 512, the FLOPs of the backbone is 21.52 GMac, which accounts for 40.38% of RetinaNet.
The neck of RetinaNet adopts the feature pyramid network (FPN). The advantage of the FPN is that it fuses shallow and deep features. The output features contain deep semantic and shallow spatial information that is beneficial to multiscale object detection. The neck has five different scales of feature maps (P3–P7). P3, P4, and P5 consist of one × one and three × three convolution layers. P6 and P7 consist of three × three convolution layers. The number of parameters in the neck is 8.00 M, accounting for 22.04% of all the detector parameters. The computational cost of the neck is 4.43 GMac, accounting for 8.30% of RetinaNet.
The head of RetinaNet consists of two parts: bounding box regression and object classification. Five feature layers share the head, where the number of classification branch parameters is 2.36 M, accounting for 6.50% of RetinaNet. The computational cost is 12.88 GMac, accounting for 24.17% of RetinaNet. The regression branch is the same as the classification branch. The head is essential for the compression of the detector.
The backbone of RetinaNet; the backbone and detection head of RetinaNet; and the backbone, detection head, and neck of RetinaNet were each decomposed in this work to implement model compression.
3.2. Decomposed Convolutional Model
To reduce the convolutional parameters, we introduced a tensor decomposition method. The parameter size of each layer in the object detection network was
. The numbers of output and input channels were
and
, respectively. The width and height of the convolutional kernel were
. It could be seen that a four-dimensional tensor could represent the convolutional kernel. If the input feature was
, its size would be
, and if the output feature was
, its size would be
, which could be expressed as Equation (1).
where
is a fourth-order convolution kernel tensor, its size is
, ∆ is the stride, and
p is the zero-padding size.
We considered model compression as a tensor decomposition problem. The convolutional neural network was compressed if the total elements of the low-dimensional tensors were less than the total elements of tensor .
Therefore, Tucker decomposition was used to decompose convolutional kernel tensor
. The decomposition of the convolution kernel could be expressed as Equation (2).
where
,
,
, and
are the ranks of Tucker decomposition;
is a smaller four-dimensional tensor; and
,
,
, and
are two-dimensional matrices. Then we substituted Equation (2) into Equation (1), where the convolution operation could be expressed as Equation (3).
The literature [
16] states that not all modes must be decomposed. Since mode-1 and mode-2 were relatively small, usually three or five, there was no need for further decomposition. At this point, the Tucker decomposition of the convolution kernel could be expressed as Equation (4).
where
is a four-dimensional tensor and where
and
are two-dimensional matrices.
Substituting Equation (4) into Equation (1), the convolution operation could be expressed as Equation (5).
In this case, convolution could be done in three steps. First, subtensor
was convolved with input feature map
to obtain the result as shown in Equation (6).
where
is a matrix with a size of
which can be considered as a pointwise convolution kernel. This pointwise convolution reduced the input channels from
S to
.
Next,
was convolved with four-dimensional tensor kernel
to obtain the result shown in Equation (7).
This is a standard convolution, but the decomposed kernel is smaller than the original kernel. This procedure reduced the parameters of the convolution model and the computation overhead.
Finally,
was convolved with
.
As shown in Equation (8), is also a two-dimensional matrix which can be considered as a kernel of pointwise convolution. This convolution resized the last dimension from to T.
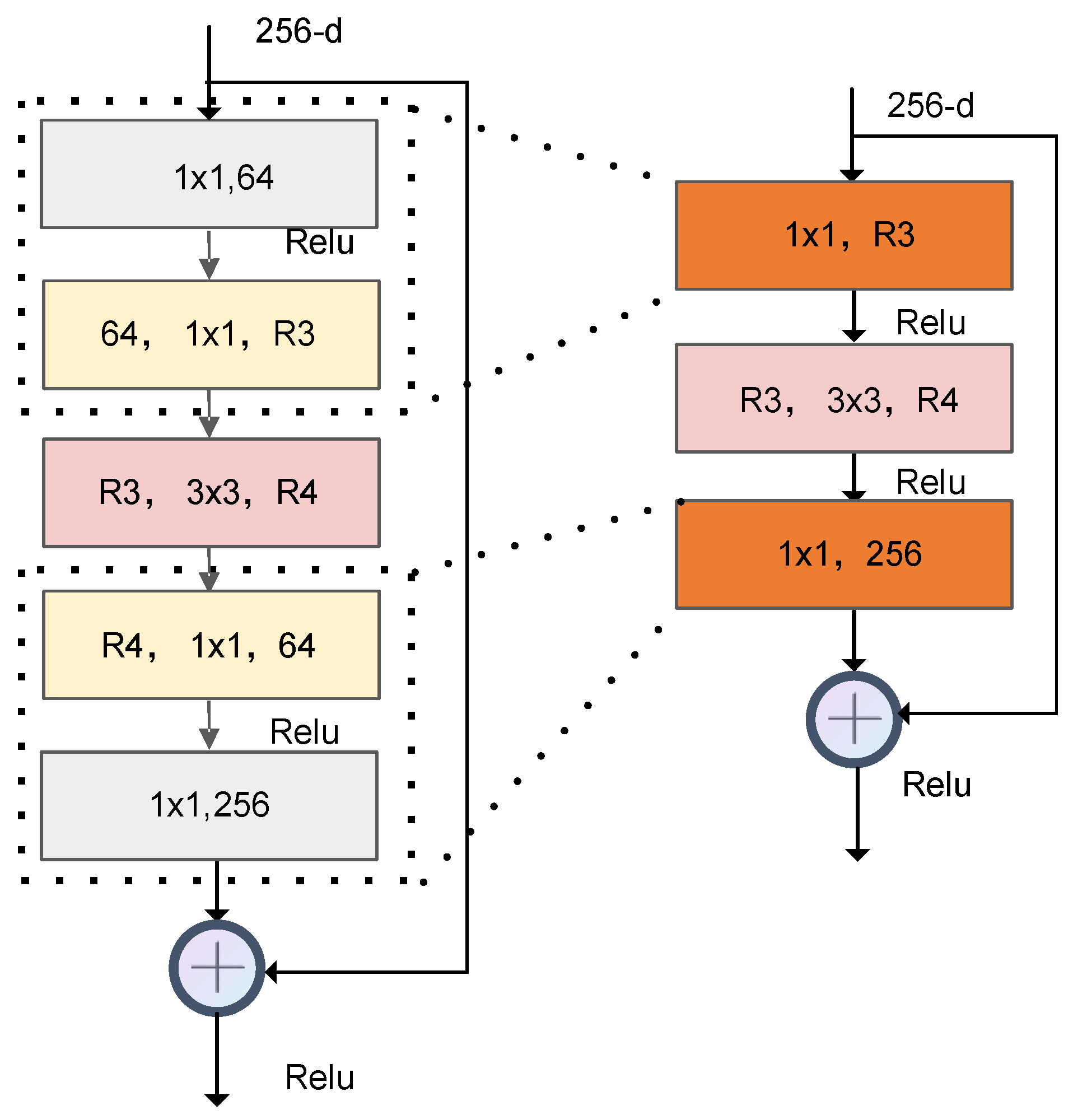
Therefore, the decomposed module consisted of three convolutional layers. The first and third layers were point convolutions with a size of and , respectively. The middle layer was a standard convolution with a size of .
Despite the decomposition of the weight tensor and the reduction in the number of parameters, the layers in the bottleneck increased. These increased layers would lead to a longer inference time, which is not what we expected.
As shown in
Figure 3, to decompose the weight tensors without increasing the convolution layers, we merged the two continuous pointwise convolution layers into a single layer. Then, we could obtain a decomposed module, named DecomResnet, that could be used to construct the compressed model.
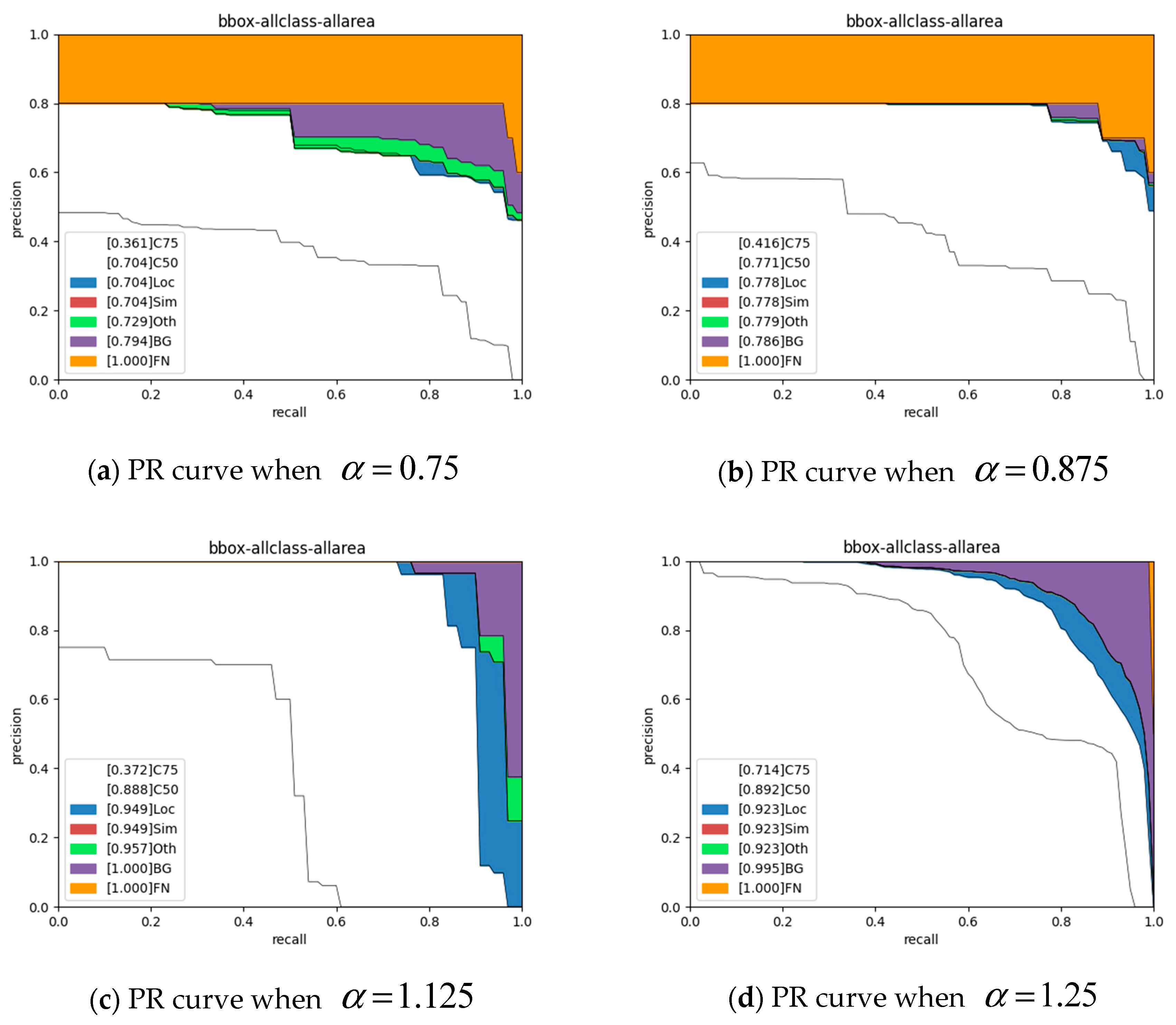
3.3. Rank Selection
In this paper, the compression ratio (CR) indicated the number of parameters in the decomposed version compared to that of the original model. Moreover, the speedup ratio (SR) indicated the computing cost in the decomposed version compared to the original model.
As shown in the compression ratio and speedup ratio definition equations, the ranks ( and ) are vital hyperparameters that regulate the computing and storage complexity of the compressed object detection model.
Although we sought to obtain the optimal ranks for the best approximation of the CNN object detection model, unfortunately, this was an NP-hard problem [
38].
In our work, we adopted the VBMF method for the following reasons: First, this method can automatically find the noise variance and rank. Second, it can even provide a theoretical condition for perfect rank recovery. Third, libraries that can execute Tucker decomposition with the ranks chosen through this method are readily accessible, such as Tensorly. Finally, several works [
16,
31] have used this method and have achieved desirable results.
Variational Bayesian matrix factorization (VBMF) [
37] has been proven to be an effective method for obtaining the suboptimal rank. This paper used the VBMF method for the mode-3 and mode-4 matricization of the kernel tensor, respectively, to obtain the ranks of Tucker decomposition (
and
).
3.4. Computation of Tensor Decomposition
Although Tucker decomposition is not unique to n-rank tensors, the problem can be solved by adding constraints. The HOSVD (high-order SVD) algorithm is a typical method for solving Tucker decomposition which first obtains the factor matrix for each mode through SVD decomposition then uses the projection of the tensor of each mode as the kernel tensor.
Although the HOSVD algorithm [
39] can perform the Tucker decomposition of the tensor, it is not optimal for giving the best approximation. It is a good initialization for other iterative algorithms, such as high-order orthogonal iteration (HOOI) [
15]. HOOI treats tensor decomposition as an optimization process and iterates continuously to obtain the decomposition result.
Suppose there is an Nth-order tensor. Then, the decomposition of the tensor could be formulated as the optimization problem as shown in Equation (11).
which is subject to
and
and in which each column is orthogonal.
The objective function could be rewritten in vectorized form as shown in Equation (12).
Then, it was straightforward that the square of the objective function could be written as Equation (13).
which is subject to
and in which each column is orthogonal.
Since
is a constant, minimizing Equation (13) was equivalent to maximizing
, which could be expressed as Equation (14).
The solution could be obtained by using SVD and by using as the leading left singular value vector of .
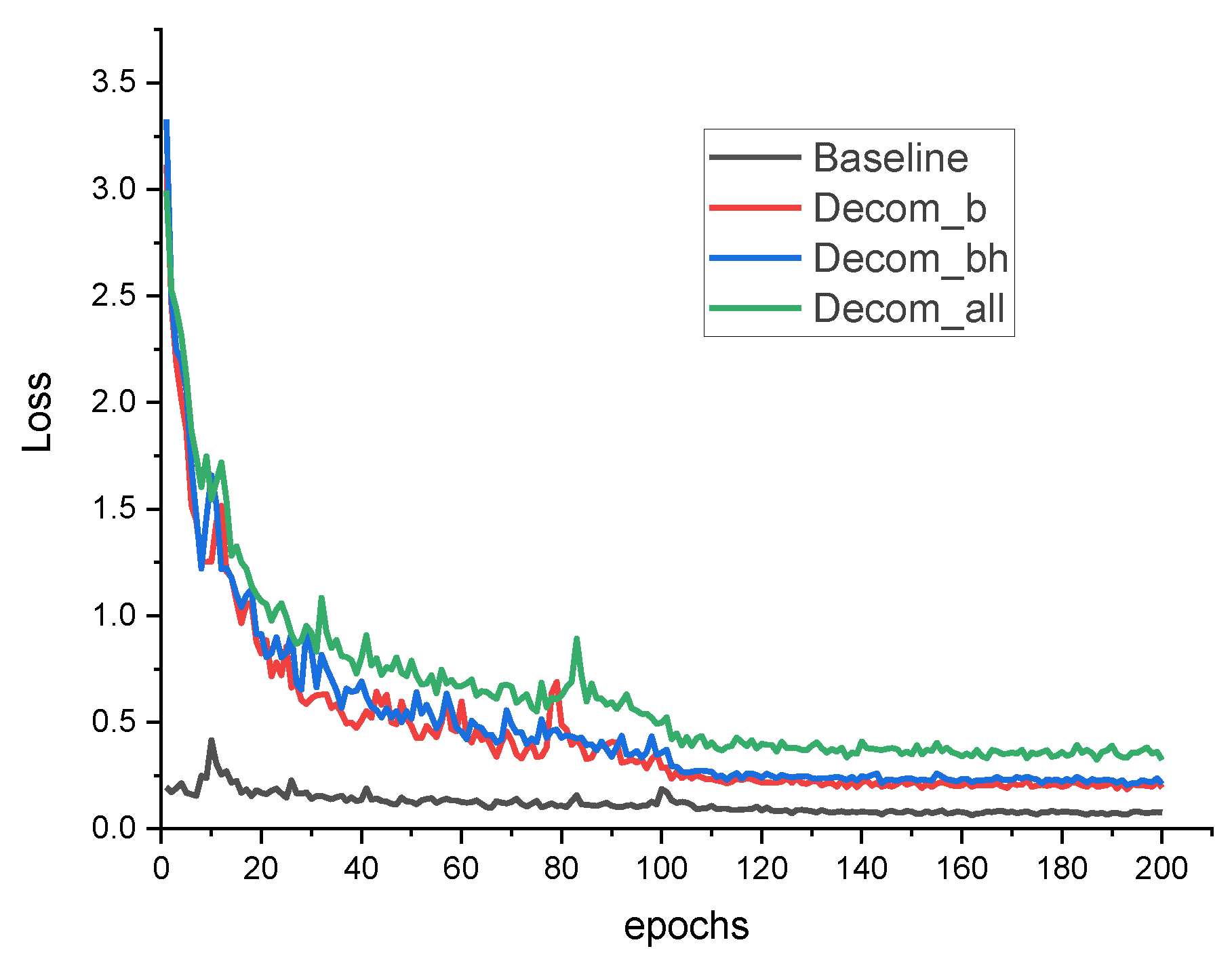
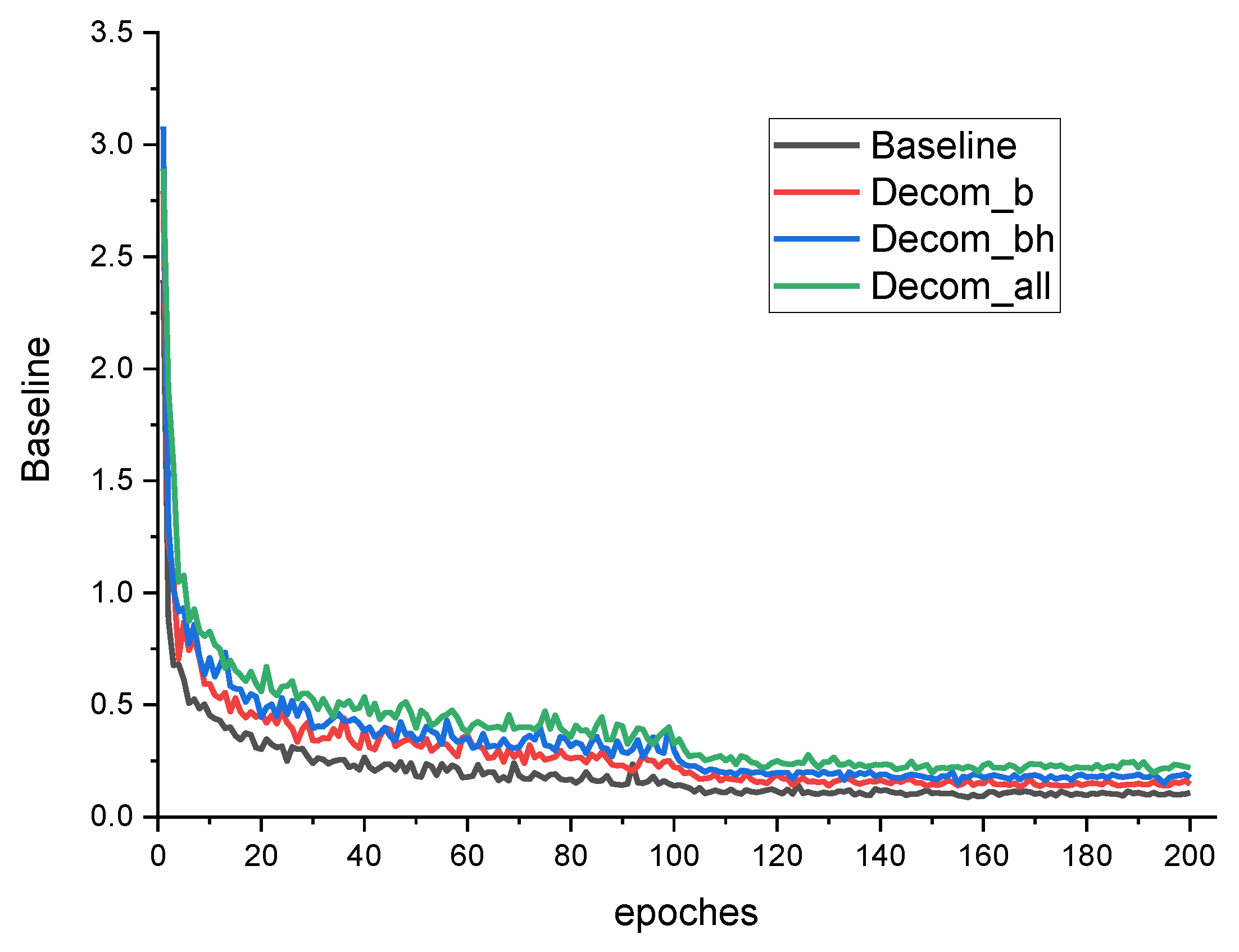
3.5. Training Method
Kossaifi et al. [
40] pointed out that tensor contraction is a natural way to integrate tensor decomposition into a neural network as a differentiable layer. This technique is called the tensor contraction layer (TCL). Because of the backpropagation process of training, each decomposed layer needs to be differentiable.
As shown in equation (2), convolution kernel tensor
could be decomposed into a low-rank core,
, and four factors,
,
,
, and
. Although Tucker decomposition was discussed in the context of four models, it can be generalized to N-way tensors as shown in Equation (15).
The input and output feature maps were denoted as
and
, respectively.
corresponds to the input samples, and
corresponds to the labels of each sample. Kernel tensor
was decomposed under a fixed low rank
. Then the convolution with the decomposed kernel tensor could be taken as tensor regression layers and could be written as Equation (16).
; for each in ; and .
The convolution function maps a tensor of size
to space f
with low-rank constraints. By using tensor unfolding [
41], the partial derivatives for each factor could be obtained. For example, the partial derivatives for
and
could be expressed as formula (17) and formula (18), respectively.
The Tucker decomposition differential for the kernel tensor could also be obtained in the same way as shown in formula (19).
From the above analysis, it can be seen that the decomposed components of the kernel tensor can be taken as neural network layers and that each layer is differentiable. The Tensorly [
42] library was used to perform Tucker decomposition in this work.
3.6. The Overall Procedure
As shown in
Figure 4, our method for object detection model compression included the following steps:
- Step 1:
Initialize RetinaNet with the pretrained model on ImageNet.
- Step 2:
Train the object detection network model on the remote sensing dataset to obtain the trained model.
- Step 3:
Obtain the ranks using the VBMF and decompose the trained model layer by layer using Tucker decomposition. Then, use the DecomResnet module to reconstruct the model.
- Step 4:
Retrain the reconstructed model over multiple epochs.
5. Discussion
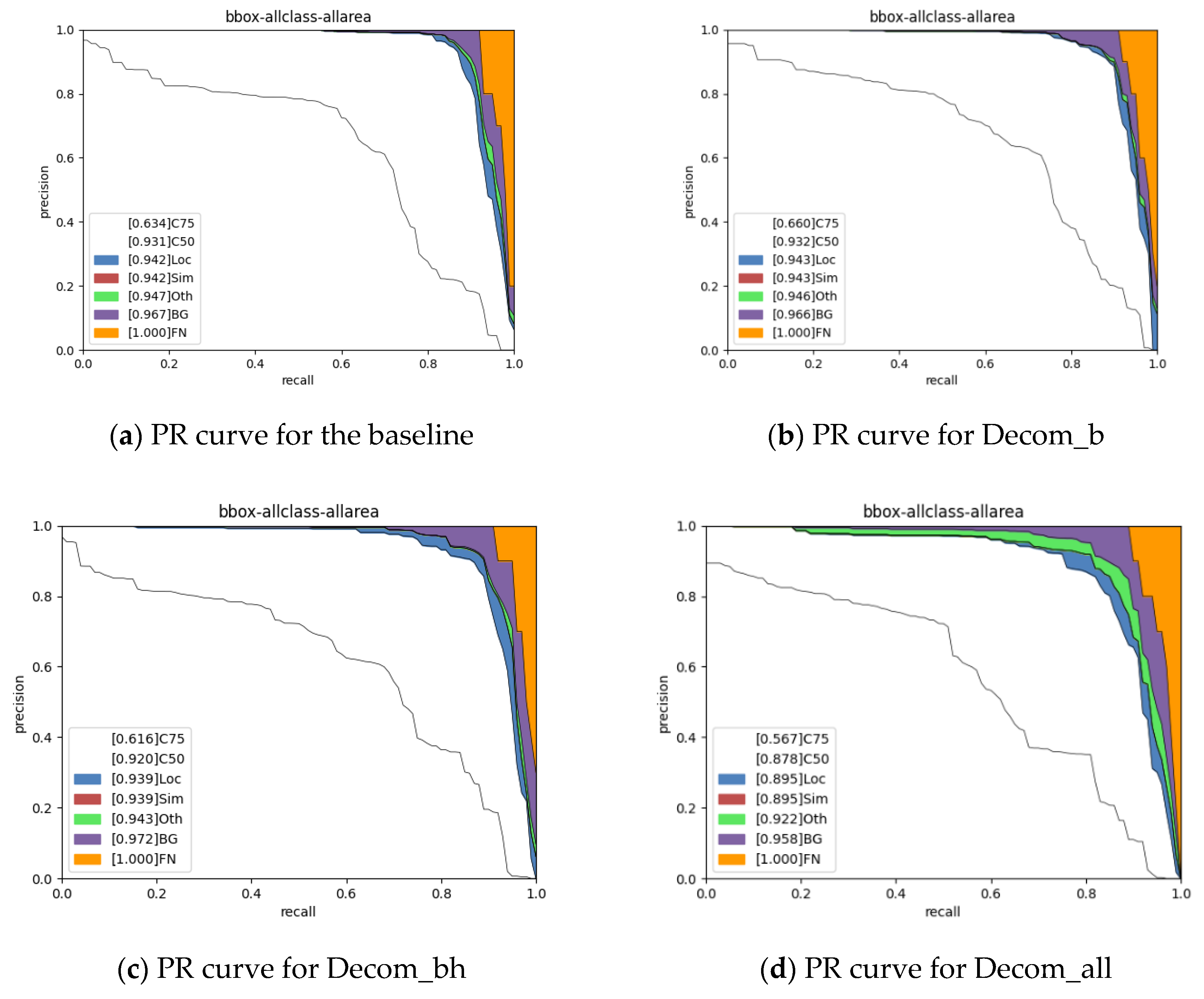
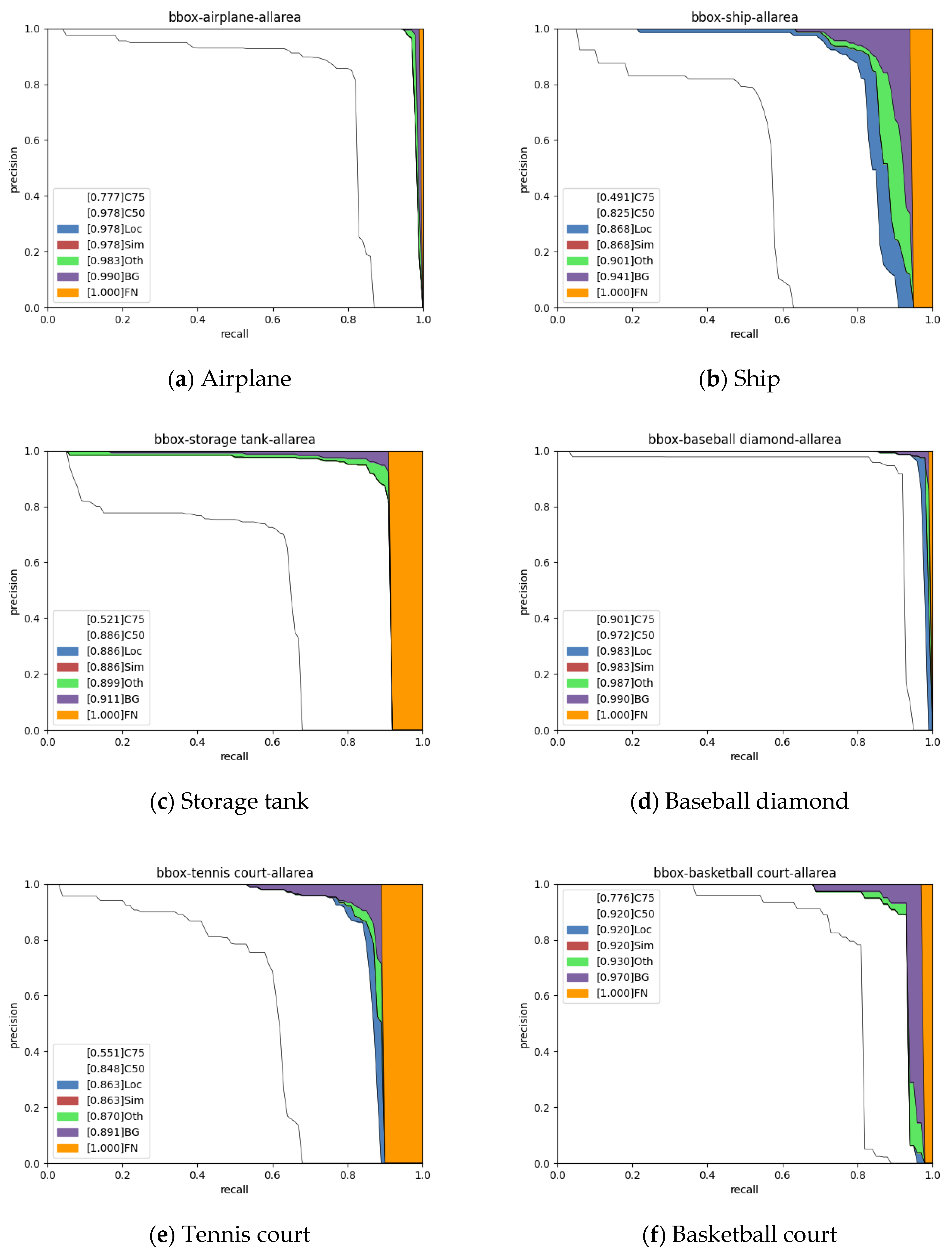
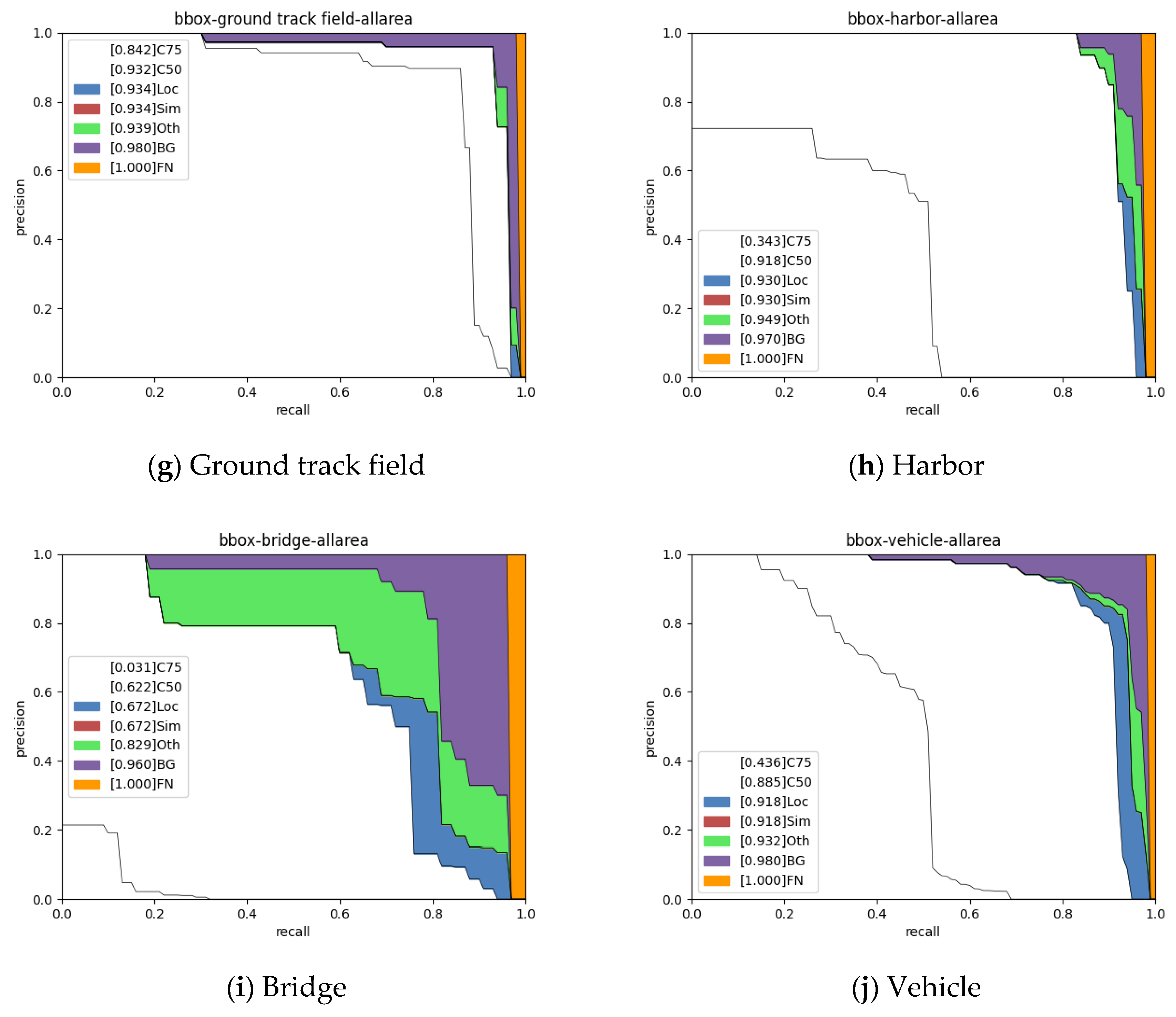
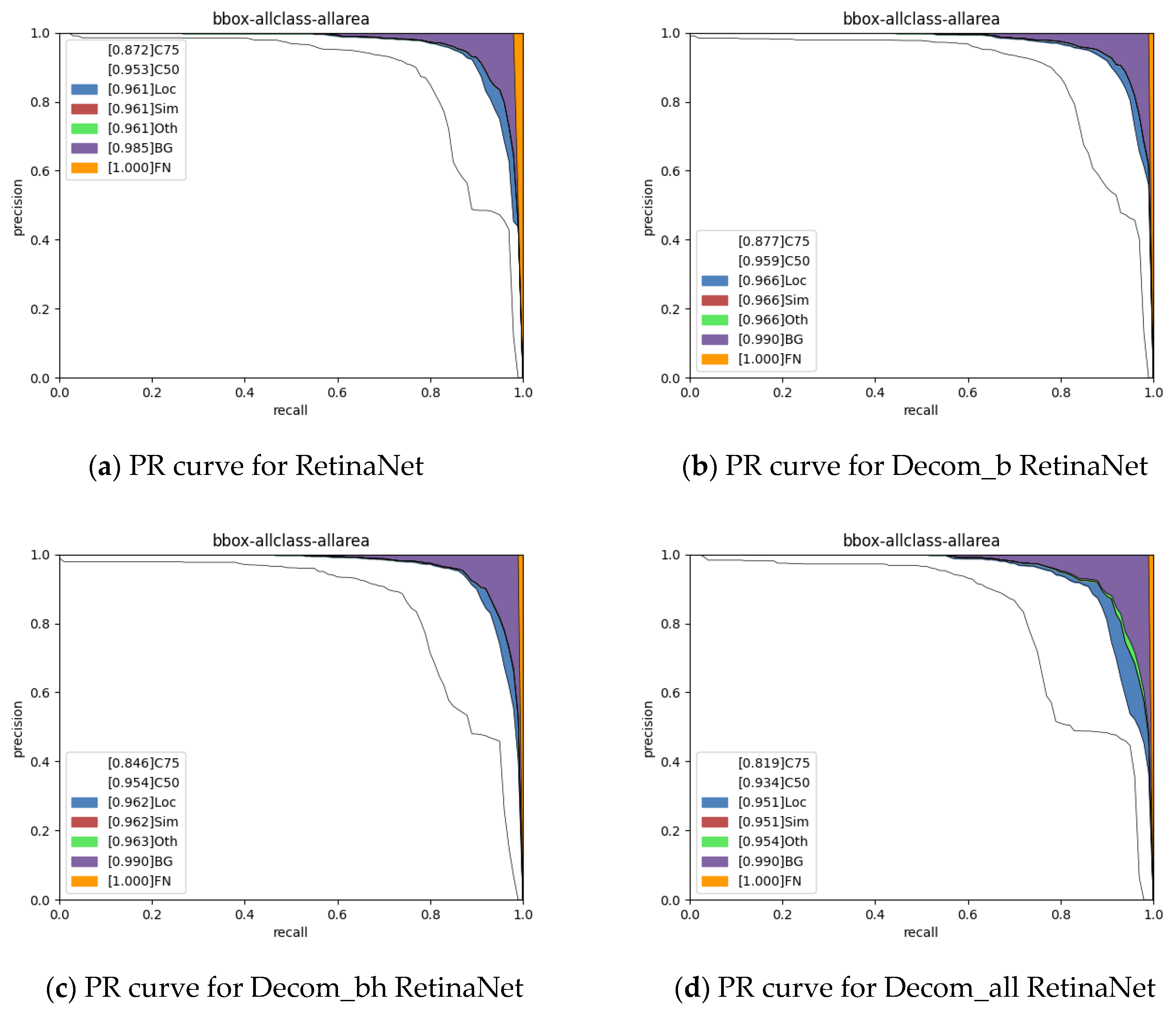
The experiments’ results demonstrated that the proposed method achieved a performance comparable to that of other methods. It worked well when tested on both our actual application mission CAST-RS2 dataset and the public NWPU VHR-10 dataset. The compression ratio and speedup ratio reached those of the SOTA methods with a slight performance decrease.
Currently, most CNN model compression algorithms based on low-rank decomposition have been developed and evaluated for the classification task. Still, our method was developed for the remote sensing image object detection task, which is increasingly in demand for onboard applications. As far as we know, this work is the first low-rank-based CNN model compression work to be aimed at onboard object detection algorithm deployment.
The advantages of the proposed method can be summarized as follows:
First, the number of CNN layers of the decomposed model does not increase. Unlike the previous works [
30,
31], the decomposition model in this paper did not increase the number of layers of the CNN model. In practical applications, an increased number of convolutional layers in the model decomposition process consumes computational resources and increases the computation time. The increased convolutional layers may become a computational bottleneck as the convolutional model is computed layer by layer. This feature is essential for onboard applications.
Second, each part of the object detection model can be decomposed with the same method. Only the backbone has been decomposed in previous works, such as in Resnet or VGG, but each part of the CNN object detection model was decomposed with the same method, including the neck and detection head.
Third, The VBMF method was adopted for rank selection, and it is an easily accessible and highly reproducible method. These features are more important for engineering applications than a group of optimal ranks.
The VBMF rank selection is also a drawback of the proposed method. The performance loss may be higher than that of its optimal counterpart. The results of the ablation study showed that we can obtain more optimal ranks by multiplying a scaling factor by the suboptimal ranks, but it is a time-consuming procedure.
The primary reasons that prevent CNNs from being deployed onboard are that hardware that predates the algorithms has insufficient performance and that many CNN models are computationally intensive. Our goal was to attempt to obtain a scalable and general approach that could reduce the complexity of CNNs. The experimental results demonstrated that the proposed method can be applied in our real mission to deploy an object detector on a satellite.
In addition, there are some other potential real-world uses. One example is represented by a CNN-based cloud detection algorithm, which is a typical mission for Earth observation satellites. The proposed method can be used to compress a CNN cloud detector deployed on a satellite and to select the images eligible for transmission to the ground to reduce the amount of data to be transmitted to the ground. Another example is represented by the CNN-based instance segmentation and object detection algorithms deployed on airplanes or on satellites to process the images of synthetic aperture radars (SARs). These CNN-based SAR image processors can also be compressed using the proposed method.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}