
Evaluation of the Approach for the Identification of Trajectory Anomalies on CCTV Video from Road Intersections


 ,
,
Abstract
:1. Introduction
2. Basic Knowledge
2.1. Source Data and Trajectory Definition
2.2. Trajectory Anomalies
- The spatial trajectory anomaly (U-turn of a car for example);
- The temporal trajectory anomaly, detected by analyzing only temporal characteristics of trajectories, such as duration and time of moving. For example, a trajectory with a significantly long duration or a trajectory appearing at an anomalous time;
- The spatiotemporal (ST) trajectory anomaly, which can be detected by analyzing spatial and temporal information in aggregate. This type corresponds to situations where the spatial information can be considered as normal, but adding temporal information converts the trajectory into an abnormal one. Examples of ST anomalies can be vehicles moving with a considerably high or low speed compared with the majority of trajectories, and vehicles making unexpected, emergency stops. In addition, such anomalies can be detected in the case of contra-flow traffic systems with reversing traffic light anomalous trajectories: since for such line allowed direction changes according to some known or learned schedule, the classifier can analyze the trajectory direction together with temporal information.
- Caused by traffic accidents, and resulting to change the vehicle’s trajectory or even in moving of vehicle into the opposite direction (Figure 3a);
- Caused by unexpected obstacles on the road (vehicle breakdown, cargo falling from the track) (Figure 3b);
- Caused by inadequate driving of the vehicle (constant lane changes, for example) (Figure 3c);
- Violation of traffic rules related to changing the vehicle’s trajectory (U-turn through a double solid line or right turn from the left line, for example) (Figure 3d).
2.3. Basic Challenges
3. State of the Art
3.1. Trajectory Classification
- They can work in an unsupervised mode without human intervention and do not require the input data to contain labels;
- Input data are allowed to contain anomalous trajectories;
- They can be easily applied to multi-dimensional data.
- Include a spatial perspective in the similarity metric;
- Approximation or thinning of initial trajectories to reduce the performance complexity.
3.2. Distance and Similarity Measures
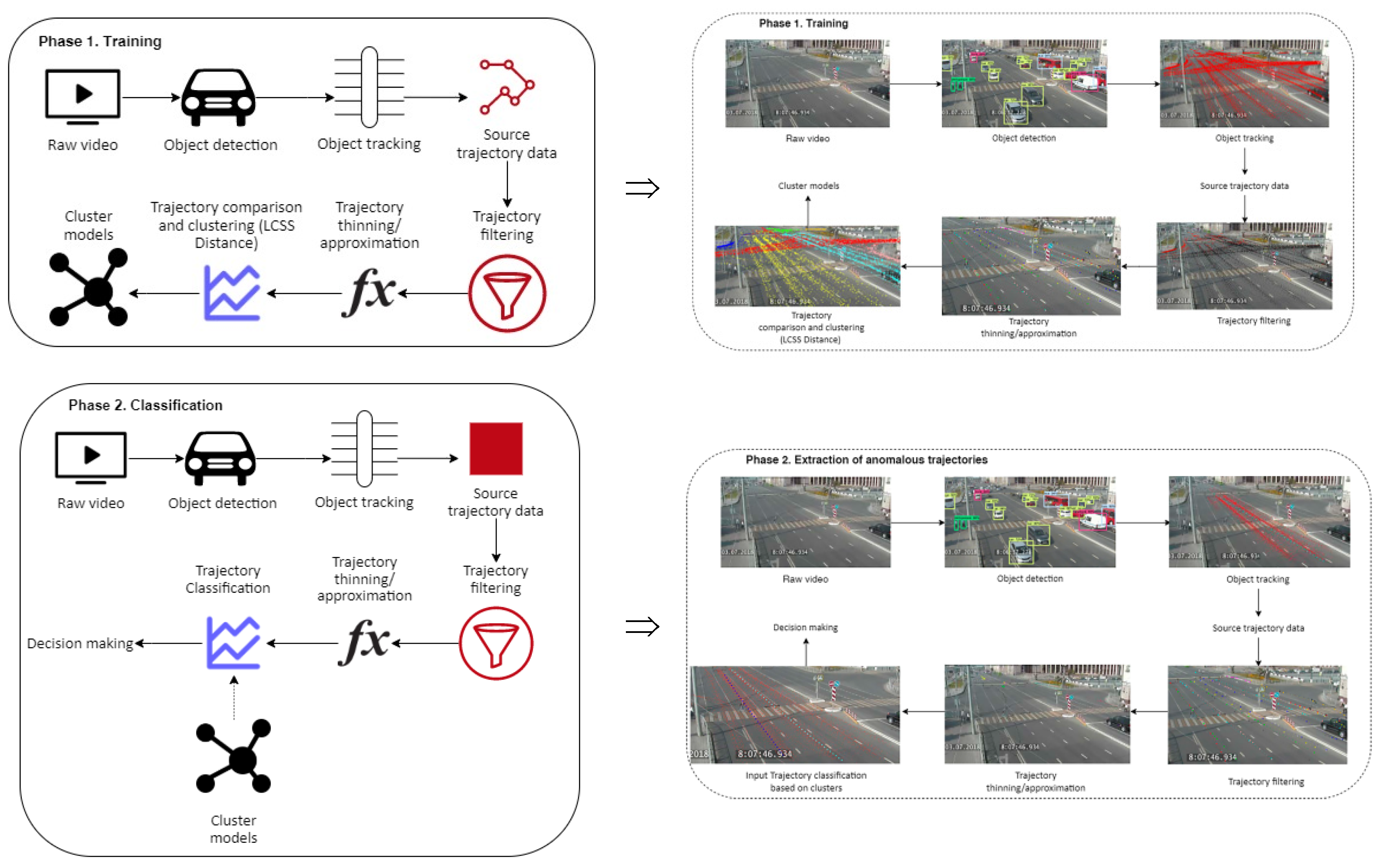
4. The Concept of Approach
4.1. Vehicle Detection and Tracking
4.2. Trajectory Filtering
4.3. Trajectory Thinning/Approximation
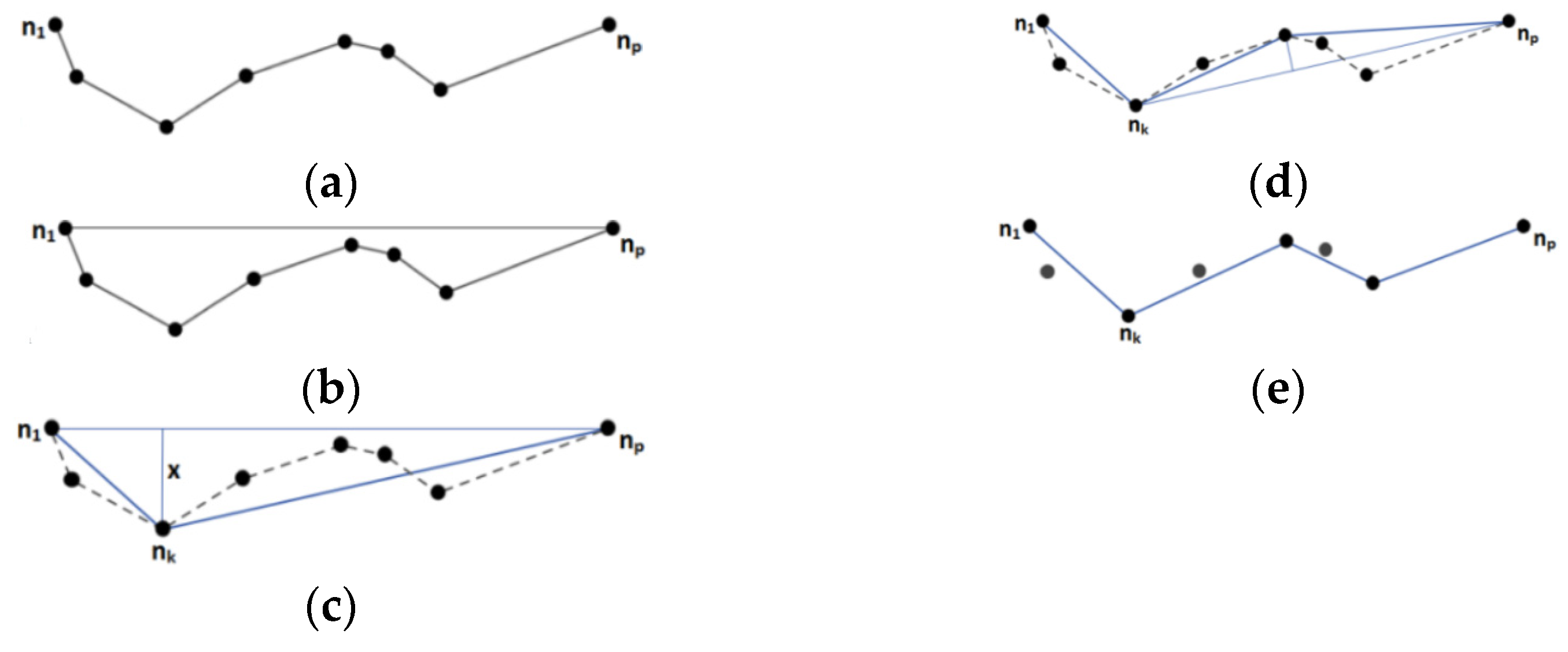
4.3.1. Trajectory Approximation
4.3.2. Ramer-Douglas-Peucker N Thinning
4.4. Trajectories Comparison and Clustering
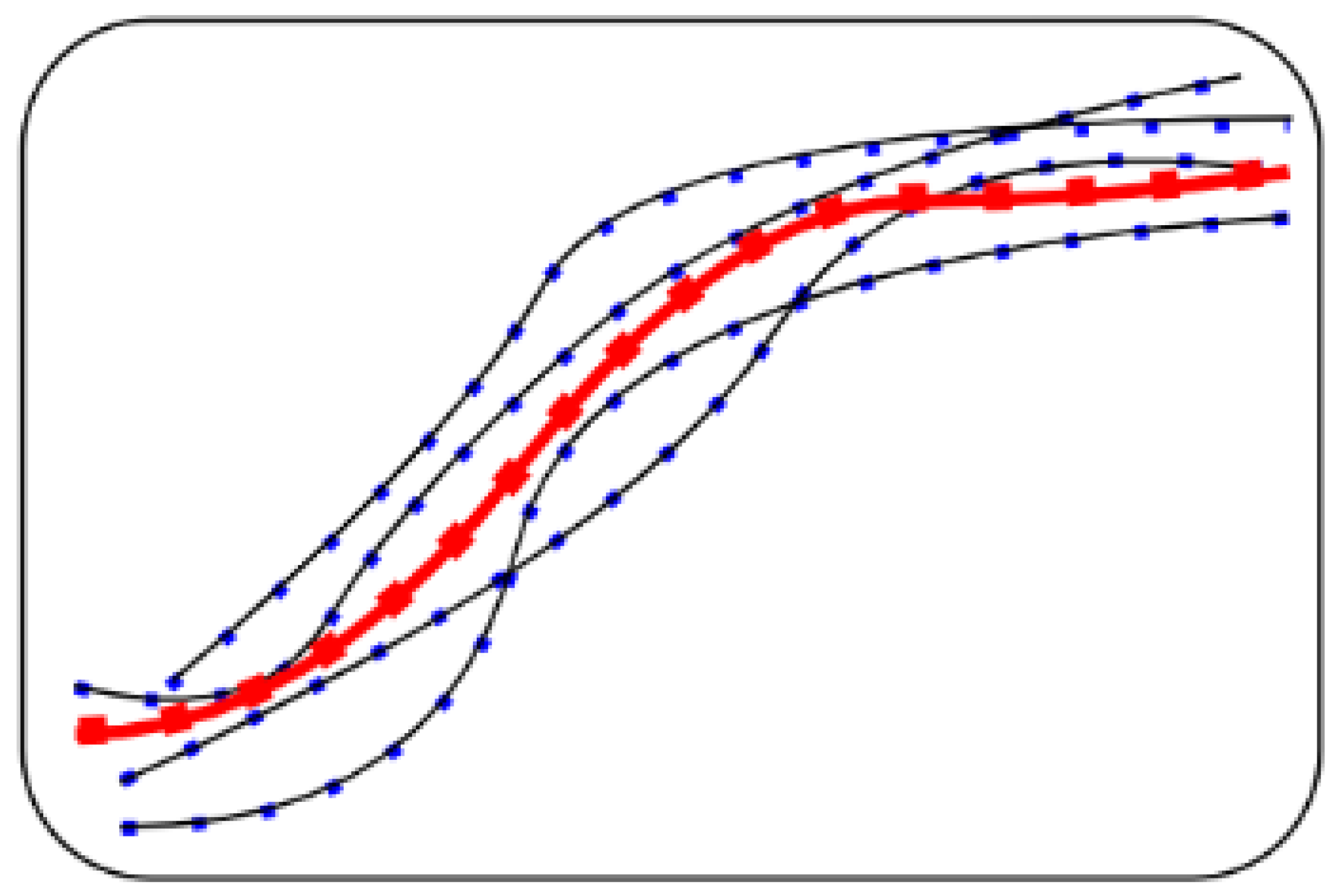
4.4.1. Modified LCSS
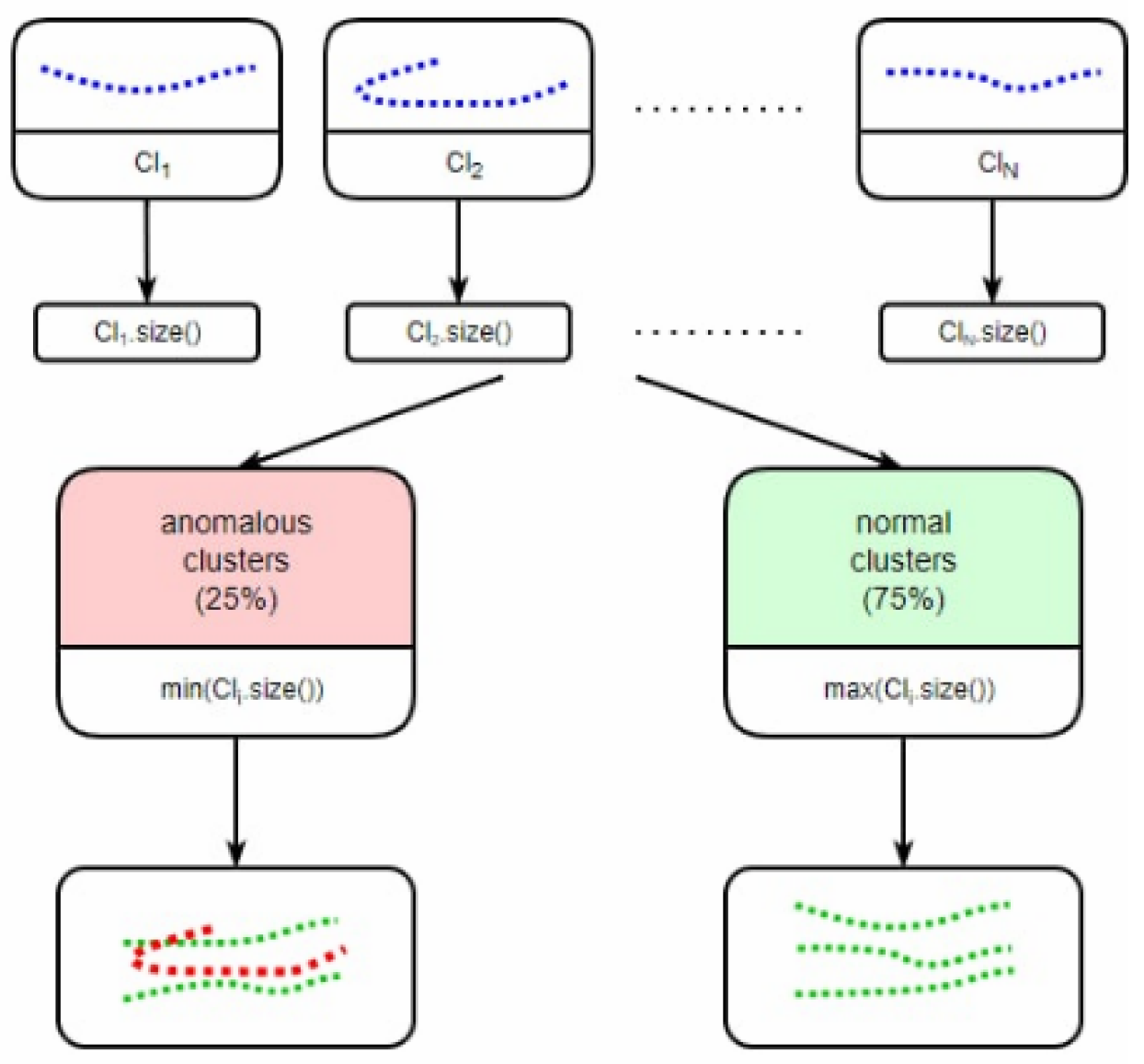
4.4.2. Clustering
4.5. Trajectory Classification
5. Results
5.1. Developed Framework
5.2. Evaluation of Trajectory Approximation Technique
- Perform approximation using the lowest degree of a polynomial as a starting point;
- Compare the obtained R2 with a predefined threshold; if the obtained value is less than the threshold value, increase the degree and remake the polynomial regression;
- Continue until the acceptable R2 is obtained or until the limit is reached for a polynomial degree to check (5 in our case).
5.3. Evaluation of the Trajectory Thinning Technique
5.4. Evaluation of Trajectory Clustering Technique
5.5. Trajectory Classification
5.6. Evaluation of Performance
5.7. Comparison with Other Methods
- Manual labeling of trajectories in source data is not needed;
- It is possible to detect some new types of spatial trajectory anomalies, which have not been included in the training set.
- Using the DBSCAN algorithm instead of hierarchical clustering;
- Using the original LCSS distance instead of its modification suggested in Section 4.4.1.
6. Discussion
6.1. Discussion of Evaluation Results
- Approximation of short trajectories with a non-constant speed requires higher-order polynomial functions for approximation;
- Notwithstanding that LCSS distance allows trajectories to be of different lengths, it becomes extremely computationally expensive and complex for trajectories with more than 11–12 trajectory points;
- Approximation using a polynomial regression works well with the trajectory data, since it is known in advance that spatial coordinates of a trajectory are functionally dependent on the time;
- Approximation using an RDP N algorithm works faster and more accurately in terms of keeping the spatial information and representing main curves of the initial trajectory according to calculated positional errors, but Polynomial Regression is preferable for the cases when temporal information is needed to be preserved and analyzed;
- Using the adaptive parameter values significantly increases the accuracy of the results.
6.2. Discussion of Possible Real-World Applications
- Detection of trajectory anomalies caused by traffic accidents, and resulting, for example, in the vehicle moving into the opposite direction. A clear example of such accident is presented in Figure 12b. In this case, the ITS system can send an emergency message to EMIS GLONASS+112 for immediate response and call the necessary emergency services (ambulance, police, etc.). Such an automatic response can reduce the potential damage from emergency events and even save human lives.
- Detection of trajectory anomalies caused by unexpected obstacles on the road (vehicle breakdown, cargo falling from the track). In this case, the ITS system can send a warning message to EMIS GLONASS+112 to call the necessary road services, traffic police, etc.
- Detection of trajectory anomalies caused by inadequate driving of the vehicle (constant lane changes, for example). In this case, the ITS system can also send the warning message to EMIS GLONASS+112 to call the traffic police.
6.3. Some Limitations of the Approach
- The efficiency of the suggested approach strongly depends on the dataset with training data. This dataset should be representative, include different types of road intersections, functioning at different times of the day, with traffic jams and without them, with working traffic lights and without them. We can expect misdetections if some correct trajectory types have not been included in the training set.
- The model has to be retrained if traffic regulations change or if any long-term obstacles appear in the CCTV camera view (for example, road works are being carried out).
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohandu, A.; Kubendiran, M. Survey on Big Data Techniques in Intelligent Transportation System (ITS). Mater. Today Proc. 2021, 47, 8–17. [Google Scholar] [CrossRef]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Singh, K.; Jain, P.C. Traffic Control Enhancement with Video Camera Images Using AI. Lect. Notes Electr. Eng. 2020, 648, 137–145. [Google Scholar]
- Mehboob, F.; Abbas, M.; Jiang, R.; Rauf, A.; Khan, S.A.; Rehman, S. Trajectory Based Vehicle Counting and Anomalous Event Visualization in Smart Cities. Clust. Comput. 2018, 21, 443–452. [Google Scholar] [CrossRef]
- Koetsier, C.; Busch, S.; Sester, M. Trajectory Extraction for Analysis of Unsafe Driving Behaviour. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1573–1578. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.A.; Dogra, D.P.; Kar, S.; Roy, P.P. Trajectory-Based Surveillance Analysis: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1985–1997. [Google Scholar] [CrossRef]
- De Aquino, A.R.; Alvares, L.O.; Renso, C.; Bogorny, V. Towards semantic trajectory outlier detection. In Proceedings of the Brazilian Symposium on GeoInformatics, Campos do Jordão, SP, Brazil, 24–27 November 2013; pp. 115–126. [Google Scholar]
- d’Acierno, A.; Saggese, A.; Vento, M. Designing Huge Repositories of Moving Vehicles Trajectories for Efficient Extraction of Semantic Data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2038–2049. [Google Scholar] [CrossRef]
- Liu, H.; Li, X.; Li, J.; Zhang, S. Efficient Outlier Detection for High-Dimensional Data. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 2451–2461. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Santhosh, K.K.; Dogra, D.P.; Roy, P.P. Anomaly Detection in Road Traffic Using Visual Surveillance: A Survey. ACM Comput. Surv. 2021, 54, 1–26. [Google Scholar] [CrossRef]
- Malik, K.; Sadawarti, H.; Kalra, G. Comparative analysis of outlier detection techniques. Int. J. Comput. Appl. 2014, 97, 12–21. [Google Scholar] [CrossRef]
- Liu, S.W.T.T.; Ngan, H.Y.T.; Ng, M.K.; Simske, S.J. Accumulated Relative Density Outlier Detection for Large Scale Traffic Data. Electron. Imaging 2018, 9, 1–10. [Google Scholar] [CrossRef]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-Based Anomalous Event Detection. Circuits Syst. Video Technol. IEEE Trans. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Batapati, P.; Tran, D.; Sheng, W.; Liu, M.; Zeng, R. Video Analysis for Traffic Anomaly Detection using Support Vector Machines. In Proceedings of the 11th World Congress on Intelligent Control and Automation (WCICA), Shenyang, China, 29 June–4 July 2014; pp. 5500–5505. [Google Scholar]
- Nguyen, H.L.; Woon, Y.K.; Ng, W.K. A Survey on Data Stream Clustering and Classification. Knowl. Inf. Syst. 2014, 45, 535–569. [Google Scholar] [CrossRef]
- Ghrab, N.B.; Fendri, E.; Hammami, M. Abnormal Events Detection Based on Trajectory Clustering. In Proceedings of the 13th International Conference on Computer Graphics, Imaging and Visualization (CGiV), Beni Mellal, Morocco, 29 March–1 April 2016; pp. 301–306. [Google Scholar]
- Eiter, T.; Mannila, H. Computing Discrete Fréchet Distance. In Technical Report CD-TR 94/64; Technische Universitat Wien: Vienna, Austria, 1994. [Google Scholar]
- Vlachos, M.; Kollios, G.; Gunopulos, D. Discovering Similar Multidimensional Trajectories. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar]
- Yuan, G.; Sun, P.; Zhao, J.; Li, D.; Wang, C. A Review of Moving Object Trajectory Clustering Algorithms. Artif. Intell. Rev. 2017, 47, 123–144. [Google Scholar] [CrossRef]
- Toohey, K.; Duckham, M. Trajectory similarity measures. SIGSPATIAL Spec. 2015, 7, 43–50. [Google Scholar] [CrossRef]
- Mueen, A.; Chavoshi, N.; Abu-El-Rub, N.; Hamooni, H.; Minnich, A.; MacCarthy, J. Speeding up dynamic time warping distance for sparse time series data . Knowl. Inf. Syst. 2018, 54, 237–263. [Google Scholar]
- Toohey, K. R Package Documentation. Similarity Measures. LCSS. Available online: https://rdrr.io/cran/SimilarityMeasures/man/LCSS.html (accessed on 30 June 2021).
- Zhang, Z.; Huang, K.; Tan, T. Comparison of similarity measures for trajectory clustering in outdoor surveillance scenes. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 1135–1138. [Google Scholar]
- Makhmutova, A.; Anikin, I.V.; Dagaeva, M. Object Tracking Method for Videomonitoring in Intelligent Transport Systems. In Proceedings of the 2020 International Russian Automation Conference, RusAutoCon, Sochi, Russia, 6–12 September 2020; pp. 535–540. [Google Scholar]
- Sedgewick, R.; Wayne, K. Polynomial Implementation. Available online: https://algs4.cs.princeton.edu/14analysis/PolynomialRegression.java.html (accessed on 11 November 2021).
- Hadi, I.; Sabah, M. Behavior formula extraction for object trajectory using curve fitting method. Int. J. Comput. Appl. 2014, 104, 28–37. [Google Scholar] [CrossRef]
- Douglas, D.H.; Peucker, T.K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature. Cartogr. Int. J. Geogr. Inf. Geovisualization 1973, 10, 112–122. [Google Scholar] [CrossRef] [Green Version]
- Mokrzycki, W. New version of Canny edge detection algorithm. In Proceedings of the International Conference on Computer Vision and Graphics (ICCVG), Warsaw, Poland, 24–26 September 2012; pp. 533–540. [Google Scholar]
- Dunn, J.C. Well-separated clusters and optimal fuzzy partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Dagaeva, M.; Garaeva, A.; Anikin, I.; Makhmutova, A.; Minnikhanov, R. Big spatio-temporal data mining for emergency management information systems. IET Intell. Transport. Syst. 2019, 13, 1649–1657. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Degrees of Polynomials | R2 Score | |||
|---|---|---|---|---|
| X | Y | |||
| Min | Avg | Min | Avg | |
| a | ||||
| Case 1 (before filtering) | ||||
| {3} | 0.66 | 0.994 | 0.466 | 0.989 |
| {3, 4} | 0.897 | 0.998 | 0.823 | 0.994 |
| {3, 4, 5} | 0.949 | 0.998 | 0.864 | 0.995 |
| Case 1 (after filtering) | ||||
| {3} | 0.689 | 0.997 | 0.777 | 0.995 |
| {3, 4} | 0.942 | 0.999 | 0.872 | 0.997 |
| {3, 4, 5} | 0.98 | 0.999 | 0.88 | 0.997 |
| b | ||||
| Case 2 (after filtering) | ||||
| {3, 4} | 0.992 | 0.9997 | 0.832 | 0.996 |
| Case 3 (after filtering) | ||||
| {3, 4} | 0.815 | 0.995 | 0.867 | 0.996 |
| Case 4 (after filtering) | ||||
| {3, 4} | 0.879 | 0.995 | 0.722 | 0.993 |
| Length (TPs) | Positional Error (pixels) | ||||
|---|---|---|---|---|---|
| Min | Avg | Max (N) | Min | Avg | Max |
| 2 | 6.86 | 7 | 0 | 12.2 | 432 |
| 2 | 7.82 | 8 | 0 | 9.26 | 388 |
| 2 | 8.76 | 9 | 0 | 7.38 | 340 |
| Approximation Method | Time (ms), Total | Avg Time (ms) Per Pair | Comment |
|---|---|---|---|
| 438 trajectories, 95,703 trajectory pairs | |||
| Polynomial Regression | 1,162,153 ms (19.37 min) | 12.4 ms | Average trajectory length 7.43 TPs |
| Ramer-Douglas-Peucker N, N = 8 | 2,110,364 ms (35.2 min) | 22.05 ms | Average trajectory length 7.87 TPs |
| Case | Time (ms), Total | Trajectory Pairs, Per ms | Comment |
|---|---|---|---|
| Case 1 | 1310 | 73 | 438 input trajectories, 95,703 trajectory pairs |
| Case 2 | 323 | 66.6 | 208 input trajectories, 21,528 trajectory pairs |
| Case 3 | 267 | 69 | 193 input trajectories, 18,528 trajectory pairs |
| Case 4 | 240 | 66.4 | 179 input trajectories, 15,931 trajectory pairs |
| # | ε | Min Pts | Number of Clusters, DI |
|---|---|---|---|
| 1 | 300 | 20 | 6, DI = 0.88 |
| 2 | 270 | 20 | 7, DI = 0.87 |
| 3 | 270 | 15 | 6, DI = 0.86 |
| 4 | 270 | 10 | 5, DI = 0.92 |
| 5 | 300 | 10 | 5, DI = 0.91 |
| 6 | 250 | 10 | 5, DI = 0.92 |
| 7 | 250 | 5 | 5, DI = 0.91 |
| 8 | 200 | 10 | 11, DI = 0.79 |
| 9 | 200 | 5 | 9, DI = 0.53 |
| 10 | 200 | 2 | 11, DI = 0.47 |
| 11 | 150 | 10 | 6, DI = 0.73 |
| 12 | 150 | 5 | 11, DI = 0.8 |
| 13 | 150 | 2 | 24, DI = 0.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minnikhanov, R.; Anikin, I.; Mardanova, A.; Dagaeva, M.; Makhmutova, A.; Kadyrov, A. Evaluation of the Approach for the Identification of Trajectory Anomalies on CCTV Video from Road Intersections. Mathematics 2022, 10, 388. https://doi.org/10.3390/math10030388
Minnikhanov R, Anikin I, Mardanova A, Dagaeva M, Makhmutova A, Kadyrov A. Evaluation of the Approach for the Identification of Trajectory Anomalies on CCTV Video from Road Intersections. Mathematics. 2022; 10(3):388. https://doi.org/10.3390/math10030388
Chicago/Turabian StyleMinnikhanov, Rifkat, Igor Anikin, Aigul Mardanova, Maria Dagaeva, Alisa Makhmutova, and Azat Kadyrov. 2022. "Evaluation of the Approach for the Identification of Trajectory Anomalies on CCTV Video from Road Intersections" Mathematics 10, no. 3: 388. https://doi.org/10.3390/math10030388
APA StyleMinnikhanov, R., Anikin, I., Mardanova, A., Dagaeva, M., Makhmutova, A., & Kadyrov, A. (2022). Evaluation of the Approach for the Identification of Trajectory Anomalies on CCTV Video from Road Intersections. Mathematics, 10(3), 388. https://doi.org/10.3390/math10030388