
Community Detection Based on Node Influence and Similarity of Nodes


Abstract
:1. Introduction
2. Related Work
3. Algorithm
3.1. Three Essential Steps of the Algorithm
3.1.1. Step 1: Identifying the Central Node Based on Node Influence
3.1.2. Step 2: Expanding the Community Based on the Similarity of the Nodes
3.1.3. Step 3: Merging Small Communities Based on Community Similarity
3.2. The Proposed Algorithm and Complexity
| Algorithm 1: NINS Algorithm. |
Input: Network , maximum number of nodes in the small community S Output: communities for each i in do Calculate by Equation (1) end Sort in descending order (V,key = ) for each i in that does not belong to a community do choose i with the highest influence as the central node for each j in that does not belong to a community do Calculate the nodes similarity by Equation (2) Calculate average nodes similarity by Equation (3) if node j has one neighbor or do Merge node j into the community that node i belongs to for each b in that does not belong to a community do iterate 8–12 end end end communities.append() end for each in communities do if do Calculate similarities of with its neighbor communities by Equation (4) Merge into the community with the highest similarity with Remove from communities and update communities end end |
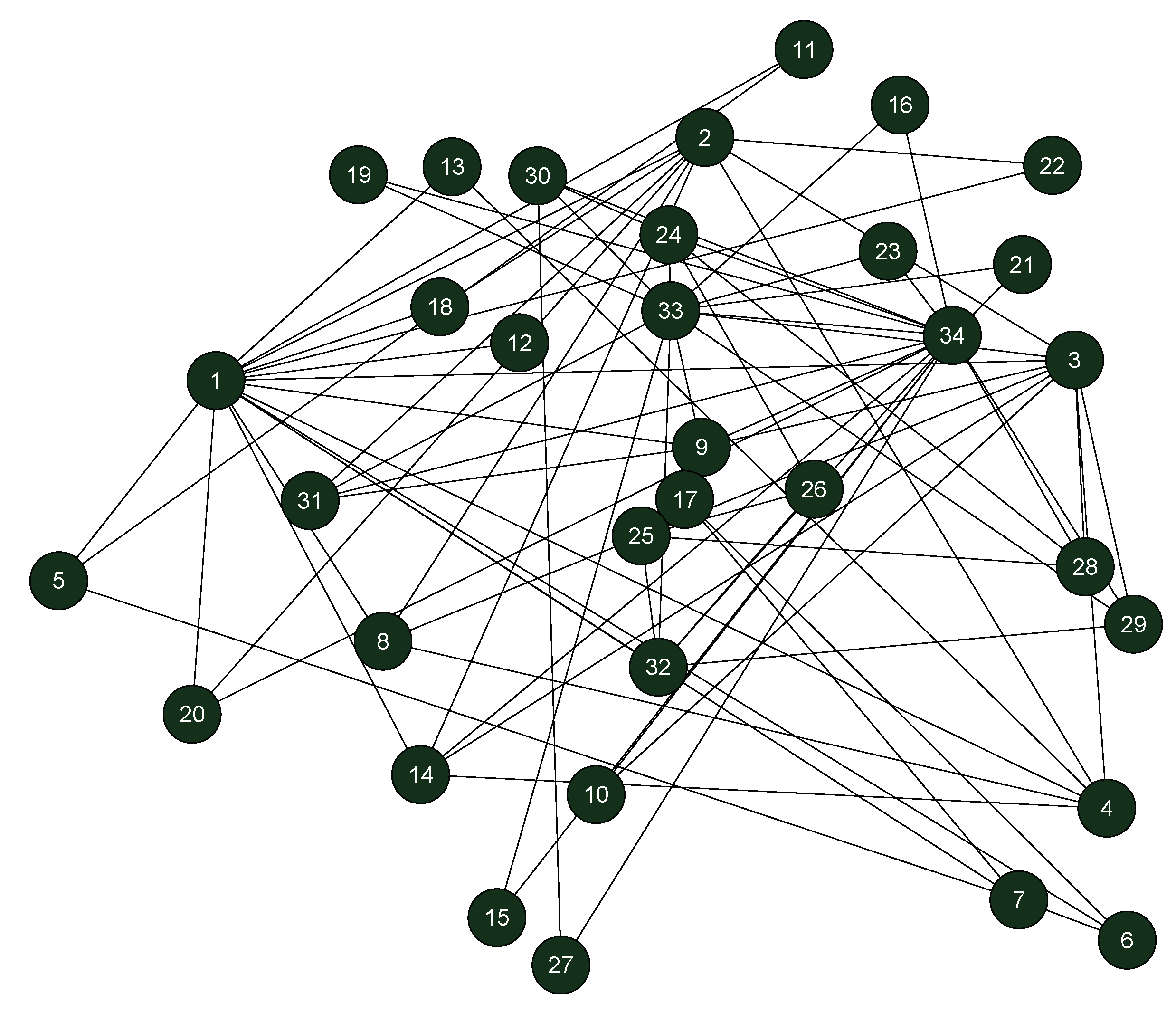
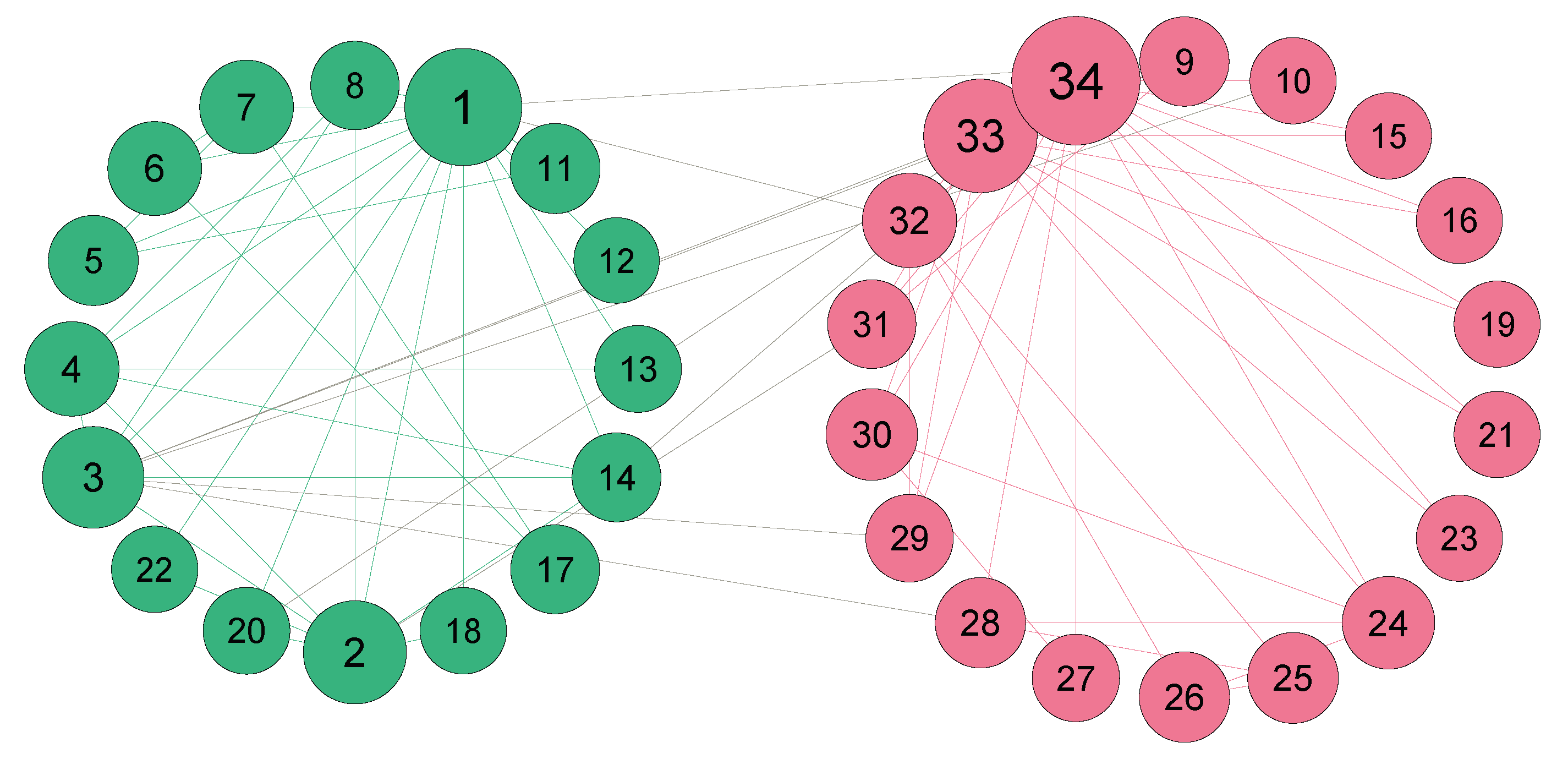
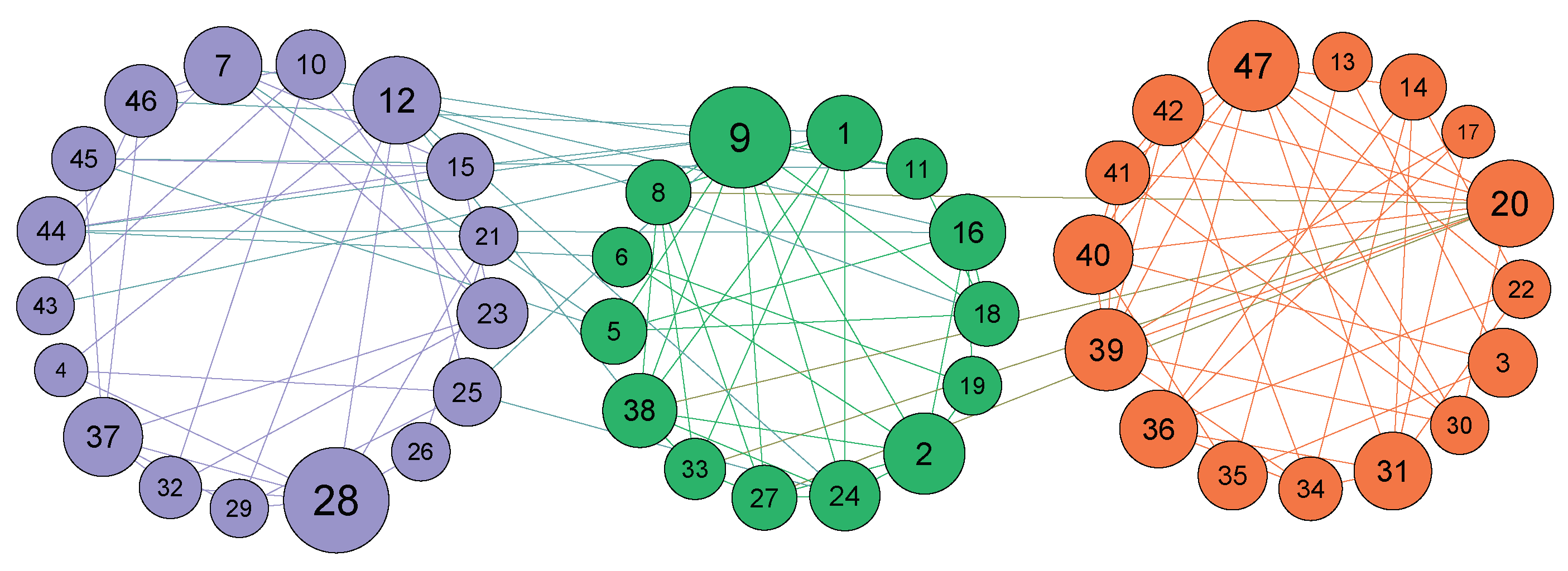
3.3. Example of the Algorithm
4. Experiment
4.1. Data Description
4.2. Evaluation Criterion
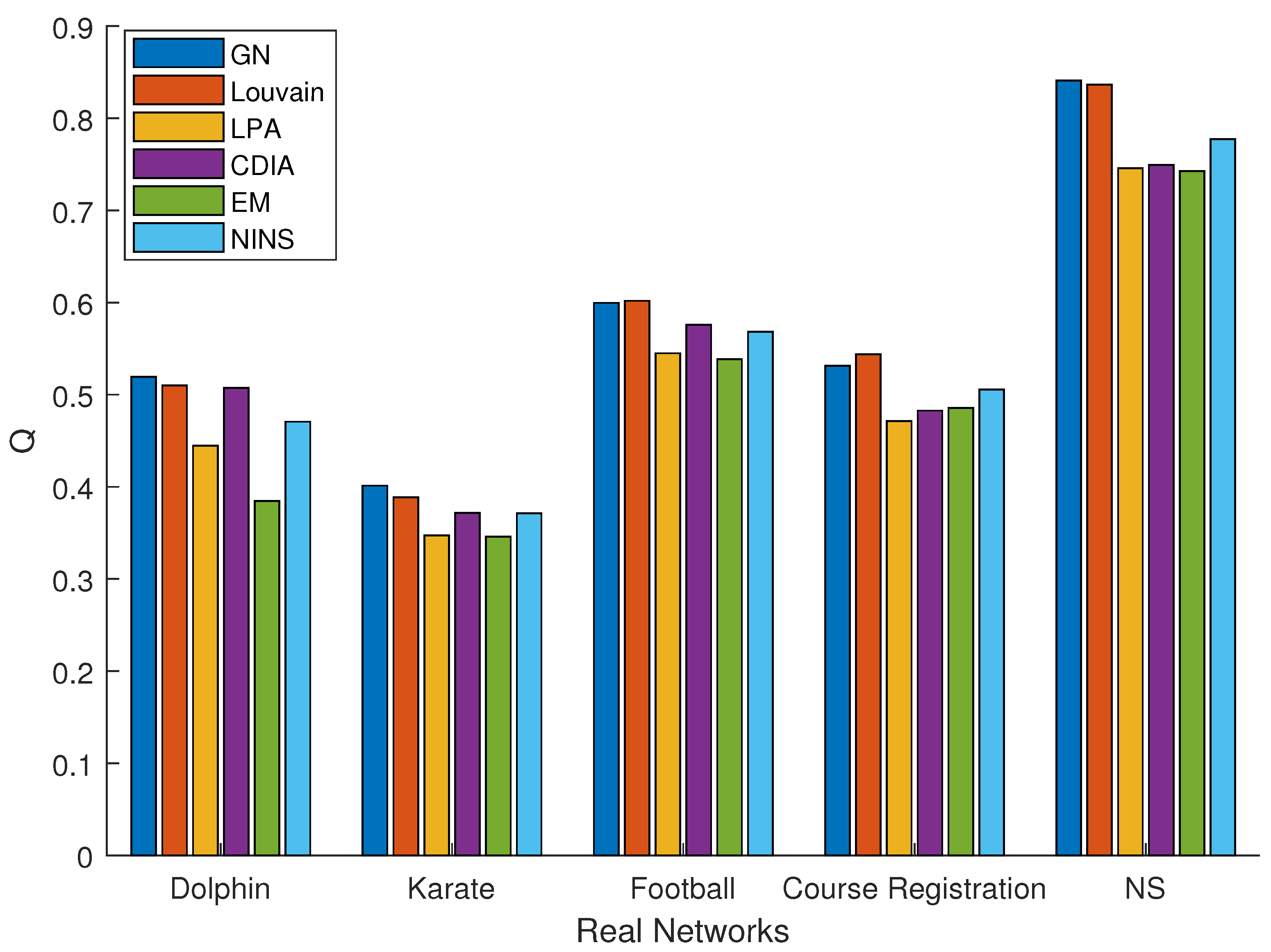
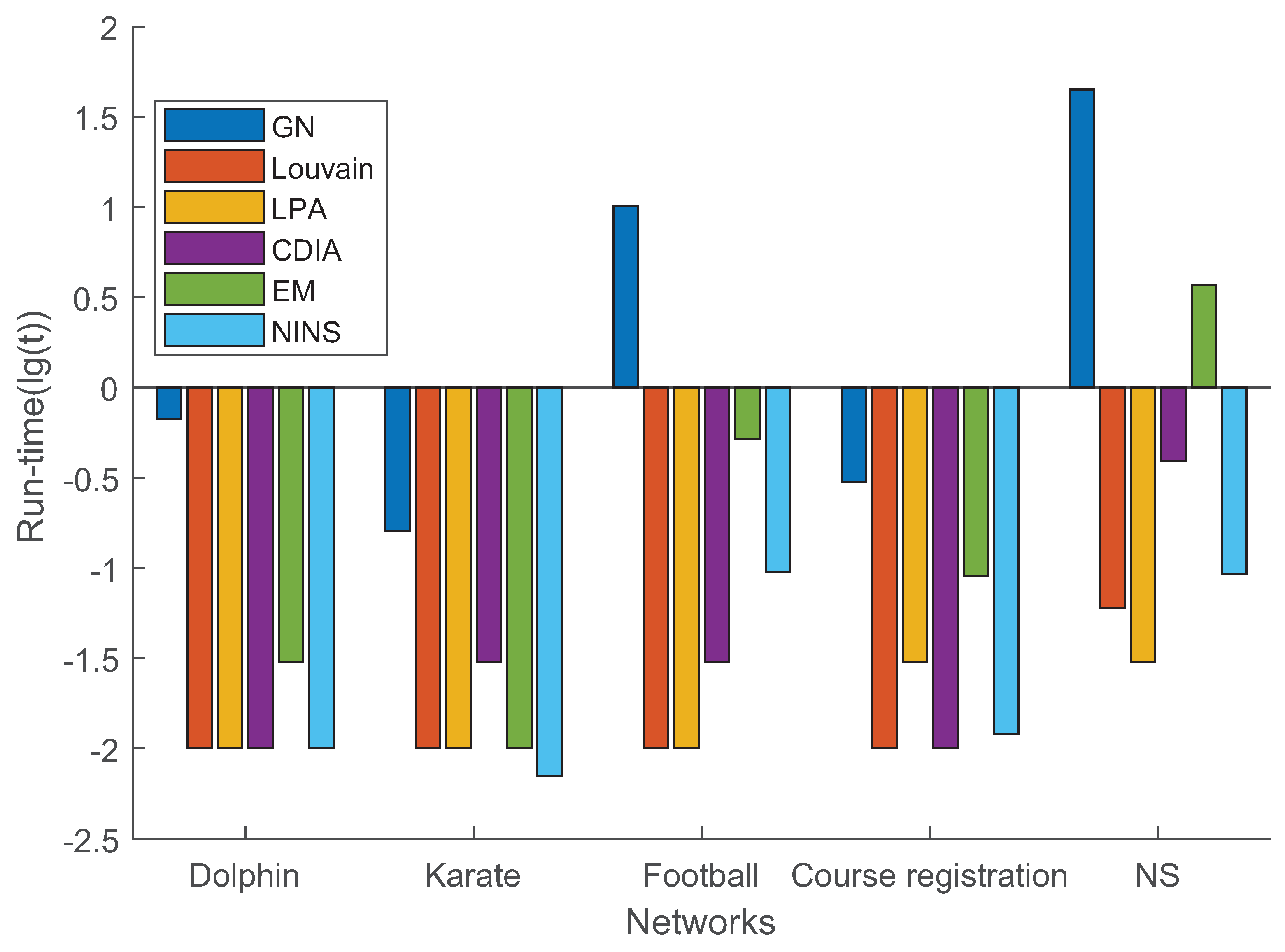
4.3. Experimental Performance of NINS
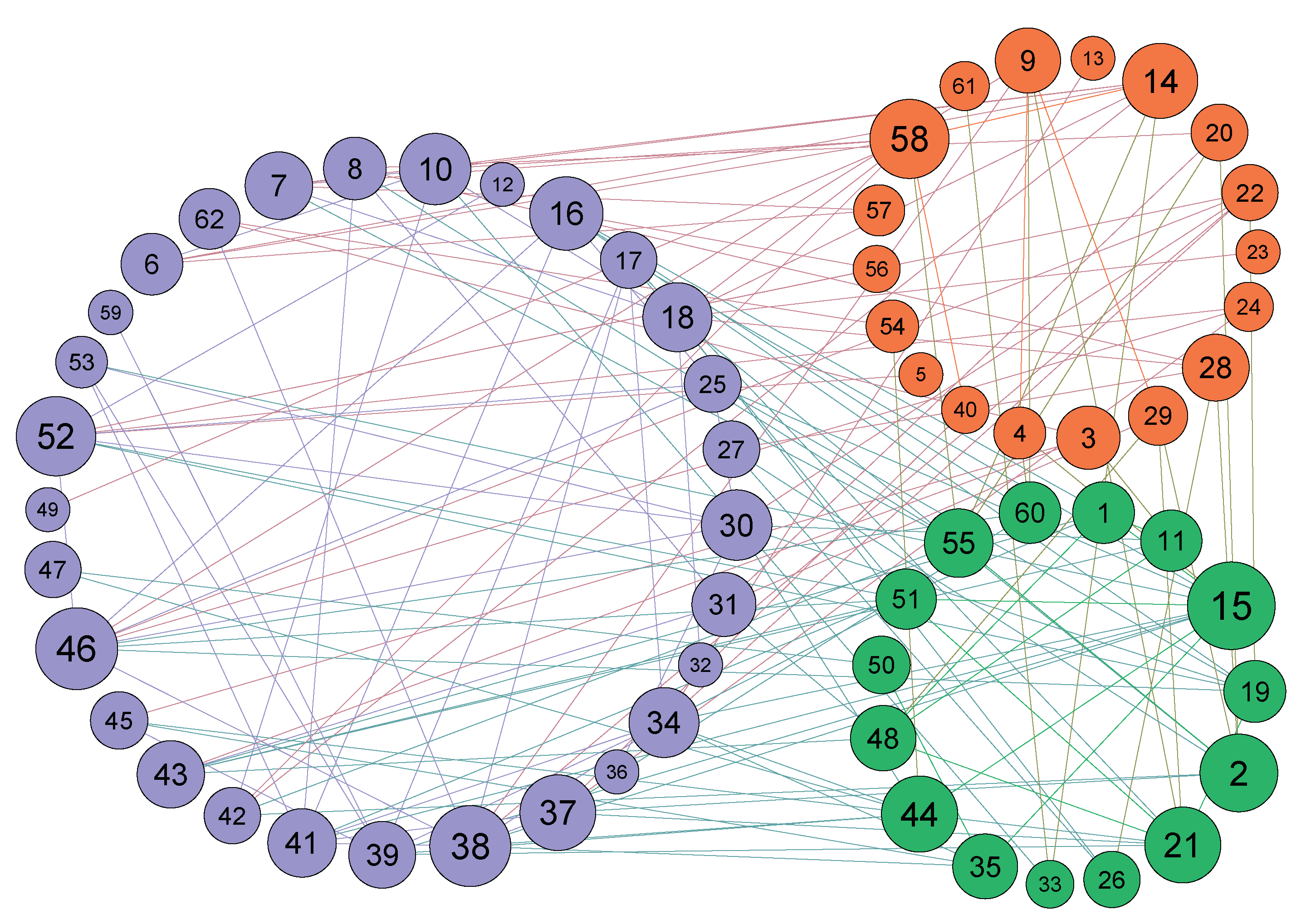
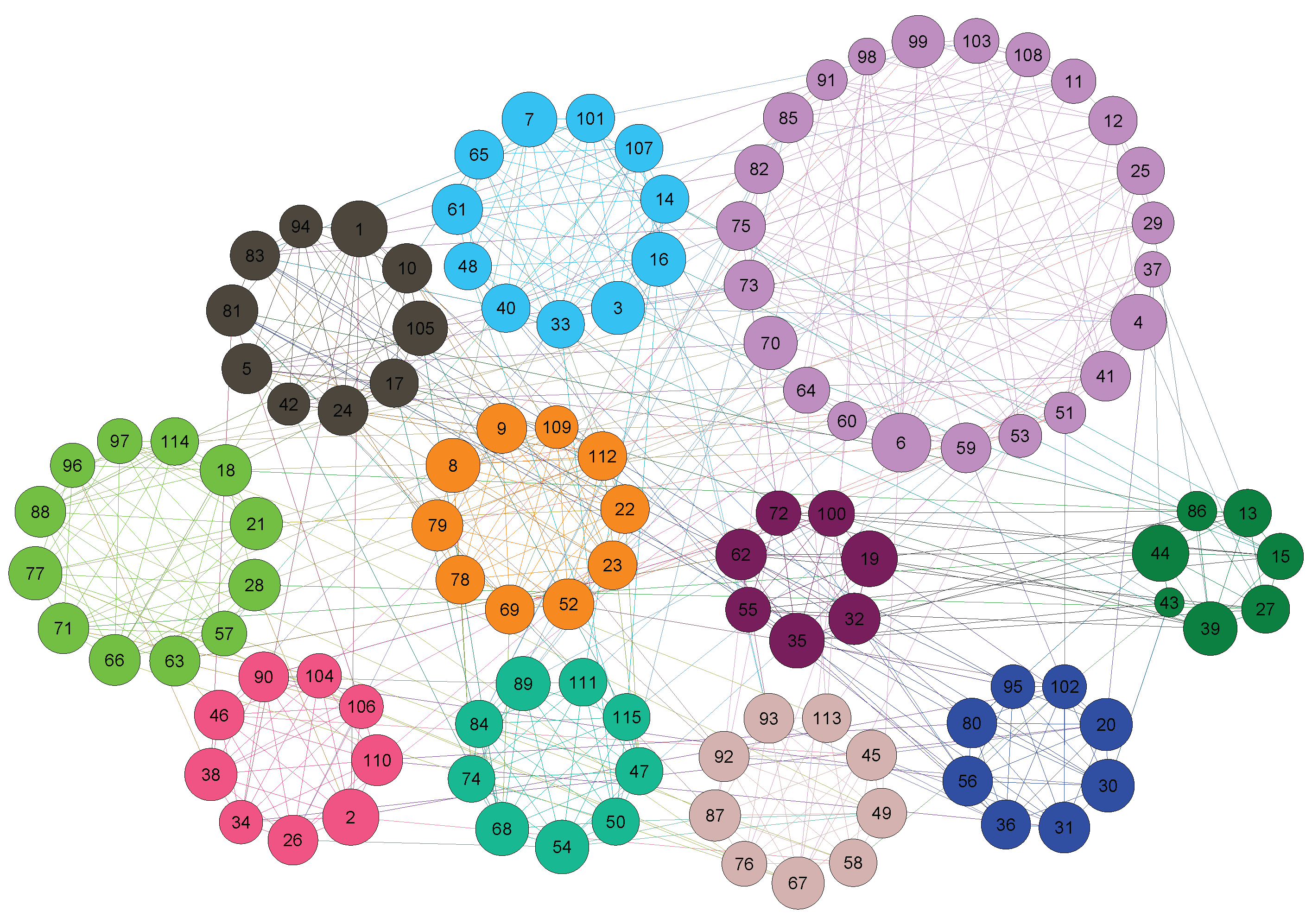
4.3.1. Experiment on Real Networks
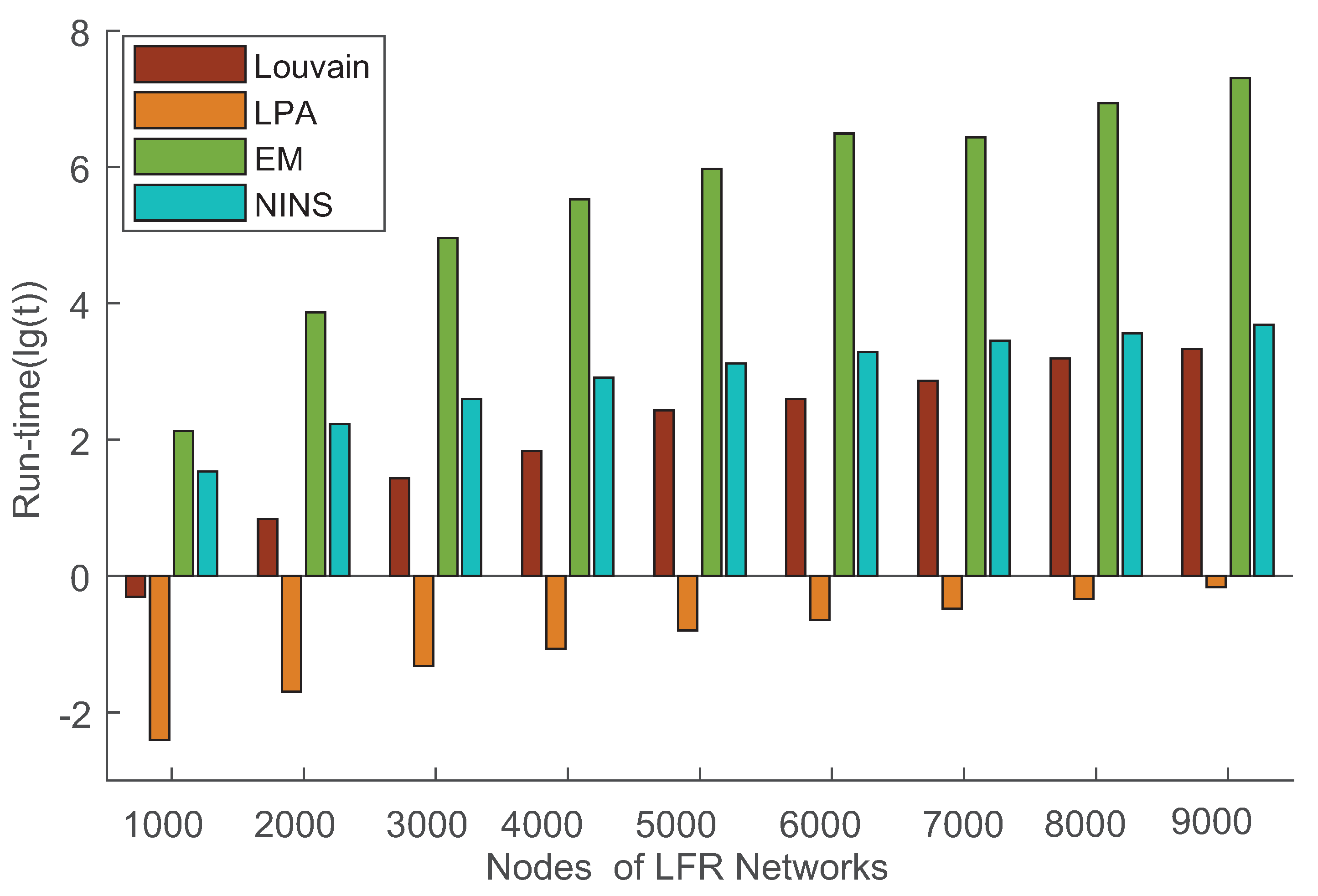
4.3.2. Experiment on LFR Benchmark Networks
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Newman, M.E.J. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Stam, C. Modern network science of neurological disorders. Nat. Rev. Neurosci. 2019, 15, 683–695. [Google Scholar] [CrossRef]
- Li, Z.; Ren, T.; Ma, X.; Liu, S.; Zhang, Y.; Zhou, T. Identifying influential spreaders by gravity model. Sci. Rep. 2019, 9, 8387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Ren, T.; Xu, Y.; Chang, B.; Chen, D.; Sun, S. Identifying Influential Spreaders Based on Adaptive Weighted Link Model. IEEE Access 2020, 8, 66068–66073. [Google Scholar] [CrossRef]
- Kamath, P.S.; Wiesner, R.H.; Malinchoc, M.; Kremers, W.; Therneau, T.M.; Kosberg, C.L.; D’Amico, G.; Dickson, E.R.; Kim, W.R. A model to predict survival in patients with end-stage liver disease. Hepatology 2001, 33, 464–470. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Liu, D.; Liu, J. Handbook of Social Network Technologies and Applications; Springer: Boston, MA, USA, 2010. [Google Scholar]
- Wang, D.; Li, J.; Xu, K. Sentiment community detection: Exploring sentiments and relationships in social networks. Electron. Commer. Res. 2017, 17, 103–132. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Tong, L. A micro-blog personalized recommendation algorithm based on community discovery. Microelectron. Comput. 2017, 34, 40–44. [Google Scholar]
- Moghaddam, A. Detection of Malicious User Communities in Data Networks. Master’s Thesis, University of Victoria, Victoria, BC, Canada, 2011. [Google Scholar]
- Huang, X.; Chen, D.; Wang, D.; Ren, T. MINE: Identifying Top-k Vital Nodes in Complex Networks via Maximum Influential Neighbors Expansion. Mathematics 2020, 8, 1449. [Google Scholar] [CrossRef]
- Beni, H.A.; Bouyer, A. TI-SC: Top-k influential nodes selection based on community detection and scoring criteria in social networks. J. Ambient. Intell. Hum. Comput. 2020, 11, 4889–4908. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E.J.; Leicht, E.A. Mixture models and exploratory analysis in networks. Proc. Natl. Acad. Sci. USA 2007, 104, 9564–9569. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kernighan, B.W.; Lin, S. An Efficient Heuristic Procedure for Partitioning Graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Waltman, L.; Eck, N.J.V. A smart local moving algorithm for large-scale modularity-based community detection. Eur. Phys. J. B 2013, 88, 471. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Chen, D.; Ren, T.; Wang, D. CDIA: A Feasible Community Detection Algorithm Based on Influential Nodes in Complex Networks. In Proceedings of the International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery, Kunming, China, 20–22 July 2019; Springer: Cham, Switzerland, 2019; pp. 930–937. [Google Scholar]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, D.; Sima, D.F.; Huang, X. Overlapping Community and Node Discovery Algorithm Based on Edge Similarity. In Proceedings of the 2017 International Conference on Electronic and Information Technology (ICEIT), Jinan, China, 24–25 November 2017. [Google Scholar]
- Bedi, P.; Sharma, C. Community detection in social networks. Wiley Interdiscipl. Rev. Data Min. Knowl. Discov. 2016, 6, 115–135. [Google Scholar] [CrossRef]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arasteh, M.; Alizadeh, S. Community detection in complex networks using a new agglomerative approach. Turk. J. Electric. Eng. Comput. Sci. 2019, 27, 3356–3367. [Google Scholar] [CrossRef]
- Arasteh, M.; Alizadeh, S. A fast divisive community detection algorithm based on edge degree betweenness centrality. Appl. Intell. 2019, 49, 689–702. [Google Scholar] [CrossRef]
- Chen, X.; Li, J. Community detection in complex networks using edge-deleting with restrictions. Phys. A Stat. Mech. Its Appl. 2019, 519, 181–194. [Google Scholar] [CrossRef]
- Basuchowdhuri, P.; Sikdar, S.; Nagarajan, V.; Mishra, K.; Gupta, S.; Majumder, S. Fast detection of community structures using graph traversal in social networks. Knowl. Inf. Syst. 2019, 59, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Al-Andoli, M.; Cheah, W.P.; Tan, S.C. Deep learning-based community detection in complex networks with network partitioning and reduction of trainable parameters. J. Ambient. Intell. Hum. Comput. 2021, 12, 2527–2545. [Google Scholar] [CrossRef]
- Agrawal, S.; Patel, A. SAG Cluster: An unsupervised graph clustering based on collaborative similarity for community detection in complex networks. Phys. A Stat. Mech. Its Appl. 2021, 563, 125459. [Google Scholar] [CrossRef]
- Tsitseklis, K.; Krommyda, M.; Karyotis, V.; Kantere, V.; Papavassiliou, S. Scalable Community Detection for Complex Data Graphs via Hyperbolic Network Embedding and Graph Databases. IEEE Trans. Netw. Sci. Eng. 2021, 8, 1269–1282. [Google Scholar] [CrossRef]
- He, J.; Li, D.; Liu, Y. Modularity-based representation learning for networks. Chin. Phys. B 2020, 29, 128901. [Google Scholar] [CrossRef]
- Feng, C.; Ye, J.; Hu, J.; Yuan, H.L. Community Detection by Node Betweenness and Similarity in Complex Network. Complexity 2021, 2021, 9986895. [Google Scholar] [CrossRef]
- Arasteh, M.; Alizadeh, S.; Lee, C.G. Gravity algorithm for the community detection of large-scale network. J. Ambient. Intell. Hum. Comput. 2021; to be published. [Google Scholar]
- Pourabbasi, E.; Majidnezhad, V.; Afshord, S.T.; Jafari, Y. A new single-chromosome evolutionary algorithm for community detection in complex networks by combining content and structural information. Expert Syst. Appl. 2021, 186, 115854. [Google Scholar] [CrossRef]
- Riolo, M.A.; Newman, M. Consistency of community structure in complex networks. Phys. Rev. E 2020, 101, 052306. [Google Scholar] [CrossRef] [PubMed]
- Cauteruccio, F.; Corradini, E.; Terracina, G.; Ursino, D.; Virgili, L. Investigating Reddit to detect subreddit and author stereotypes and to evaluate author assortativity. J. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Mengoni, P.; Milani, A.; Poggioni, V.; Li, Y. Community elicitation from co-occurrence of activities. J. Future Gener. Comput. Syst. 2020, 110, 904–917. [Google Scholar] [CrossRef] [Green Version]
- Naik, D.; Ramesh, D.; Gandomi, A.H.; Gorojanam, N.B. Parallel and distributed paradigms for community detection in social networks: A methodological review. Expert Syst. Appl. 2022, 187, 115956. [Google Scholar] [CrossRef]
- Yassine, S.; Kadry, S.; Sicilia, M.-A. Detecting communities using social network analysis in online learning environments: Systematic literature review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 12, e1431. [Google Scholar] [CrossRef]
- Bara’a, A.A.; Abbood, A.D.; Hasan, A.A.; Pizzuti, C.; Al-Ani, M.; Özdemir, S.; Al-Dabbagh, R.D. A Review of Heuristics and Metaheuristics for Community Detection in Complex Networks: Current Usage, Emerging Development and Future Directions. Swarm Evol. Comput. 2021, 63, 100885. [Google Scholar]
- Huang, X.; Chen, D.; Ren, T.; Wang, D. A survey of community detection methods in multilayer networks. Data Min. Knowl. Disc. 2021, 35, 1–45. [Google Scholar] [CrossRef]
- Calderer, G.; Kuijjer, M.L. Community Detection in Large-Scale Bipartite Biological Networks. Front. Genet. 2021, 12, 520. [Google Scholar] [CrossRef] [PubMed]
- Gasparetti, F.; Sansonetti, G.; Micarelli, A. Community detection in social recommender systems: A survey. Appl. Intell. 2021, 51, 3975–3995. [Google Scholar] [CrossRef]
- Rosvall, M.; Delvenne, J.C.; Lambiotte, R. Different approaches to community detection. In Advances in Network Clustering and Blockmodeling; Hoboken, N.J., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019; pp. 105–119. [Google Scholar]
- Dao, V.; Bothorel, C.; Lenca, P. Community structure: A comparative evaluation of community detection methods. Netw. Sci. 2020, 8, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Adamic, L.A.; Adar, E. Friends and neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S.; Barthélemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [Green Version]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1997, 33, 452–473. [Google Scholar] [CrossRef] [Green Version]
- Danon, L.; Diazguilera, A.; Arenas, A. Effect of size heterogeneity on community identification in complex networks. J. Stat. Mech. 2006, 2006, P11010. [Google Scholar] [CrossRef] [Green Version]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Lü, L.; Jin, C.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Spring, N.; Mahajan, R.; Wetherall, D.; Anderson, T. Measuring ISP topologies with rocketfuel. IEEE/ACM Trans. Netw. 2004, 12, 2–16. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Classification | Parameters | Complexity | Pros and Cons |
|---|---|---|---|---|
| GN [12] | divisive | - | High modularity but high complexity | |
| LPA [13] | agglomerative | m | Fast but needs the exact algorithm iteration number m | |
| EM [14] | agglomerative | m | High complexity and low modularity | |
| Louvain [18] | agglomerative | - | Higher modularity but unstable |
| Notation | Description |
|---|---|
| G | a graph represents network |
| V | set of nodes |
| E | set of edges |
| neighbor set of node i | |
| degree of node i | |
| the similarity of nodes i and j | |
| the average similarity of node i with its neighbors | |
| common neighbor set of node i and j | |
| S | maximum number of nodes in the small community |
| the i-th community | |
| the number of nodes that belong to the community and are connected to the community | |
| N | number of nodes in the network |
| M | number of edges in the network |
| t | number of the small community |
| average degree of node | |
| m | number of iterations |
| average distance of nodes | |
| D | network diameter |
| C | clustering coefficient of the network |
| r | assortative coefficient of the network |
| Q | modularity |
| represents whether nodes i and j are connected or not: if nodes i and j are not connected, = 0; otherwise, = 1 | |
| represents whether nodes i and j are in the same community or not: If = 1, ; if = 0, |
| Initial Result | Nodes of the Initial Community |
|---|---|
| 34, 9, 31, 33, 24, 28, 34, 15, 16, 19, 21, 23, 27, 29, 30, 32, 25, 26 | |
| 1, 2, 3, 4, 14, 5, 6, 7, 8, 11, 12, 13, 18, 20, 22 | |
| 10 | |
| 17 |
| Networks | N | M | D | C | r | ||
|---|---|---|---|---|---|---|---|
| Dolphin | 62 | 159 | 2.5645 | 3.3570 | 8 | 0.2590 | −0.0436 |
| Karate | 34 | 78 | 4.5882 | 2.4082 | 5 | 0.57.6 | −0.4756 |
| Football | 115 | 613 | 10.6609 | 2.5082 | 4 | 0.4032 | 0.1624 |
| Course registration | 47 | 125 | 5.3191 | 3.2812 | 7 | 0.4883 | 0.1354 |
| NS | 379 | 914 | 4.8232 | 6.0419 | 17 | 0.7412 | −0.0817 |
| Power | 4941 | 6594 | 2.6691 | 18.9892 | 46 | 0.0801 | 0.0035 |
| Router | 5022 | 6258 | 2.4922 | 6.4488 | 15 | 0.0116 | −0.1384 |
| Networks | Q | Runtime(s) |
|---|---|---|
| Dolphin | 0.4707 | 0.01 |
| Karate | 0.3715 | 0.007 |
| Football | 0.5684 | 0.095 |
| Course registration | 0.5005 | 0.012 |
| NS | 0.7774 | 0.092 |
| Power | 0.7586 | 3.4076 |
| Router | 0.8073 | 1.5912 |
| Networks | Q(LPA) | Runtime | Q(EM) | Runtime | Q(Louvain) | Runtime |
|---|---|---|---|---|---|---|
| Power | 0.5948 | 0.1753 | 0.2093 | 71.8072 | 0.9319 | 3.3282 |
| Router | 0.3715 | 0.6967 | 0.0846 | 44.14 | 0.894 | 2.7594 |
| Networks | LPA | Louvain | EM | NINS |
|---|---|---|---|---|
| LFR-1000 | 0.99519 | 0.90853 | 0.26917 | 0.99546 |
| LFR-2000 | 0.99912 | 0.8901 | 0.23378 | 0.99582 |
| LFR-3000 | 0.99818 | 0.87236 | 0.22015 | 0.99915 |
| LFR-4000 | 0.99488 | 0.0.85703 | 0.20711 | 1 |
| LFR-5000 | 0.99701 | 0.8473 | 0.20171 | 1 |
| LFR-6000 | 0.99664 | 0.83594 | 0.19725 | 0.99973 |
| LFR-7000 | 0.9975 | 0.79139 | 0.189 | 0.99978 |
| LFR-8000 | 0.9986 | 0.83138 | 0.18918 | 0.99937 |
| LFR-9000 | 0.99854 | 0.83057 | 0.18648 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Ren, T.; Sun, S. Community Detection Based on Node Influence and Similarity of Nodes. Mathematics 2022, 10, 970. https://doi.org/10.3390/math10060970
Xu Y, Ren T, Sun S. Community Detection Based on Node Influence and Similarity of Nodes. Mathematics. 2022; 10(6):970. https://doi.org/10.3390/math10060970
Chicago/Turabian StyleXu, Yanjie, Tao Ren, and Shixiang Sun. 2022. "Community Detection Based on Node Influence and Similarity of Nodes" Mathematics 10, no. 6: 970. https://doi.org/10.3390/math10060970
APA StyleXu, Y., Ren, T., & Sun, S. (2022). Community Detection Based on Node Influence and Similarity of Nodes. Mathematics, 10(6), 970. https://doi.org/10.3390/math10060970