
A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data


Abstract
:1. Introduction
- A novel active learner with a low query budget and pseudo-labeled data is proposed to deal with imbalanced data. Our novel strategy for finding the most informative and the most representative points increases the probability of selecting instances from the minority class, which is challenging with high imbalance ratios. Further, the proposed model can adapt to different variations of the received data (e.g., balanced data, imbalanced data, binary classes, or multi-class) without any predefined knowledge.
- We propose a method to enrich the supervised knowledge that our active learner collects by adding some pseudo-labeled points (PLs) that are geometrically close to the new labeled points. Further, our model assigns weights to the generated PLs based on the density of labeled points around each pseudo-labeled point. In addition to increasing the supervised knowledge, the pseudo-labeled points play a role in reducing the version space in one of the pruning steps, minimizing the size of uncertain regions. This encourages our algorithm to focus on the most uncertain parts of the space, which could help to find highly informative points. In addition, searching for conflicting pseudo-labeled points (points that are near two or more annotated points that belong to different classes) guides our model to accurately find uncertain regions between different classes.
- A part of the proposed algorithm builds a novel, flexible learner that learns from training data points (annotated points by experts + PLs) with different confidence values.
2. Theoretical Background
2.1. Illustrative Example
2.2. Active Learning with Imbalanced Data: State-of-the-Art
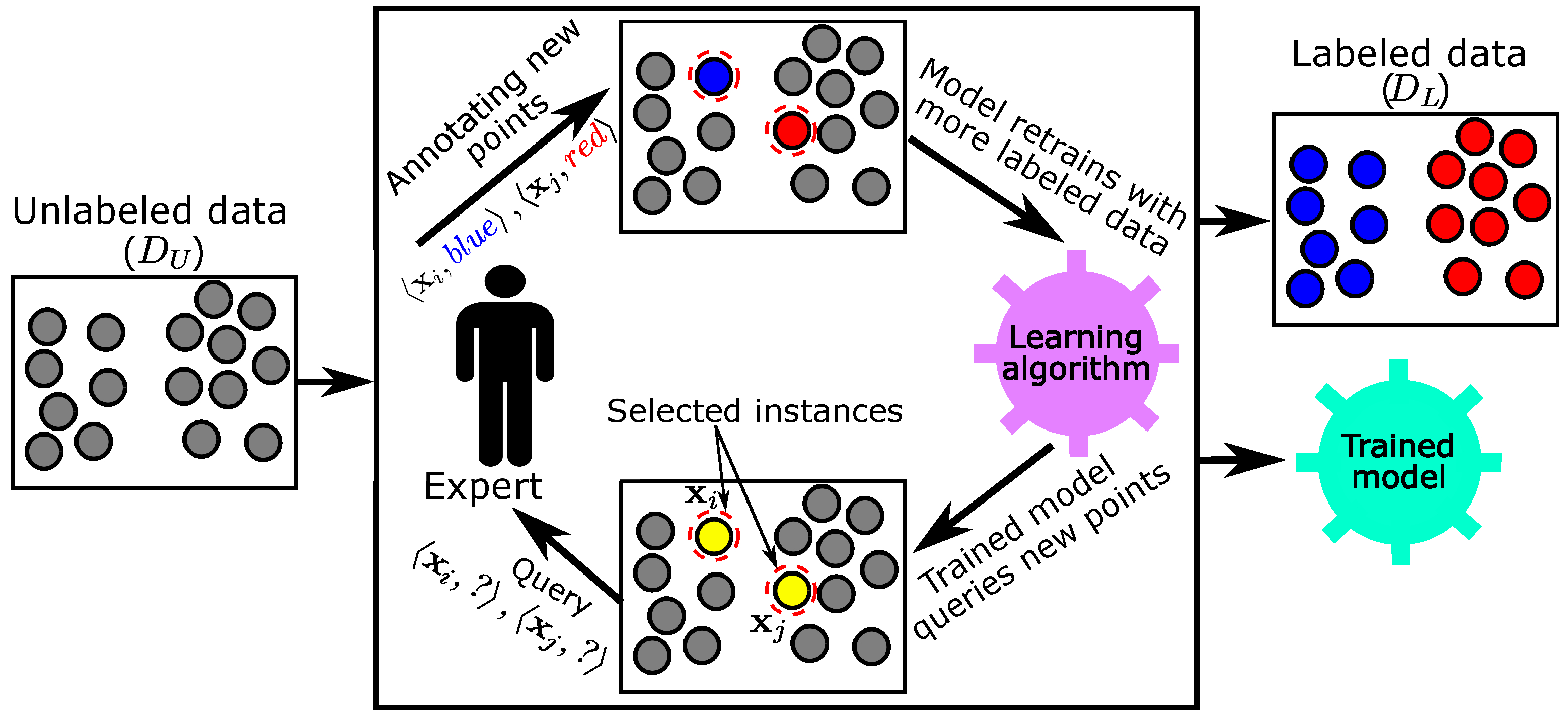
3. The Proposed Model
| Algorithm 1 Annotate a set of unlabeled points. = LQBAL (). | ||
| Input: Unlabeled data () and Q | ||
| Output: Labeled points () | ||
| 1: | Calculate , , , and d | |
| 2: | Divide the space into equal cells, , where k is the number of cells | |
| 3: | Set , , , , and | |
| 4: | QueryingFirstPoint () | |
| 5: | for to Q do | |
| 6: | ||
| 7: | if then | ▹Exploitation phase |
| 8: | Exploitationphase () | |
| 9: | else | ▹ Exploration phase |
| 10: | ExplorationPhase () | |
| 11: | ||
| 12: | ||
| 13: | , | ▹ select the nearest unlabeled |
| points to to be pseudo-labeled points | ||
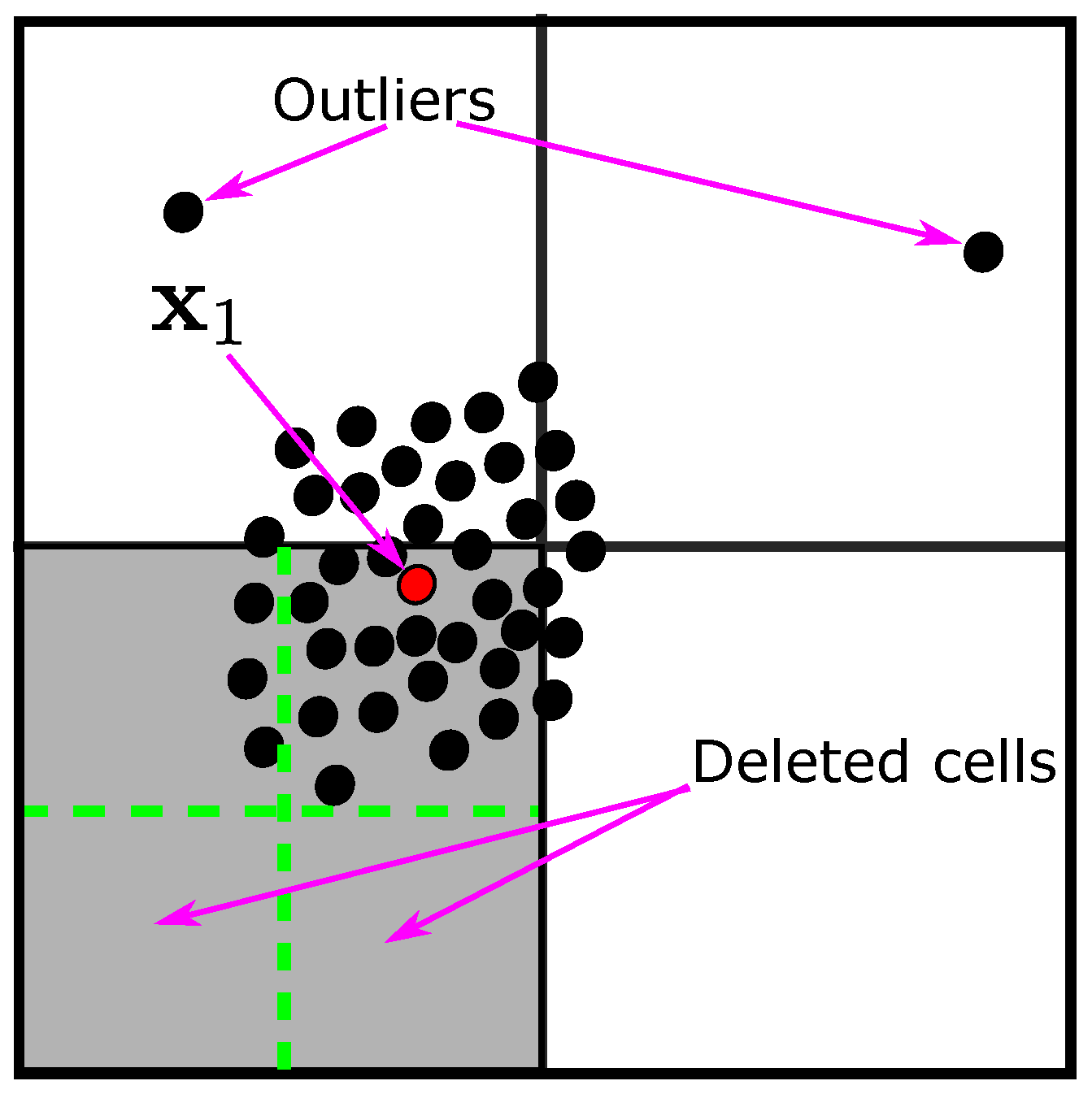
3.1. Querying the First Point
| Algorithm 2 Annotating the first point. QueryingFirstPoint (). | ||
| Input: | ||
| Output: The first labeled point (), | ||
| 1: | , | ▹ is the outliers of |
| 2: | ▹ is the mean of | |
| 3: | ||
| 4: | ||
| 5: | ||
| 6: | , | ▹ select the nearest unlabeled points |
| to to be pseudo-labeled points, all of them belong to the class of | ||
| 7: | for to k do | |
| 8: | if within the borders of then | |
| 9: | Divide into cells and delete | |
| 10: | Delete all cells that have no data | |
3.2. Exploration Phase
3.3. Exploitation Phase
3.3.1. Generating/Training Classifiers
| Algorithm 3 Querying a new point using the exploration phase. = ExplorationPhase (). | ||
| Input: | ||
| Output: New labeled point and | ||
| 1: | for do | |
| 2: | for do | |
| 3: | if is within the borders of the cell then | |
| 4: | ▹ : the number of labeled points within the cell | |
| 5: | for do | |
| 6: | for do | |
| 7: | if is within the borders of the cell then | |
| 8: | ▹: the number of unlabeled points | |
| within the cell | ||
| 9: | ▹ the selected cell | |
| 10: | if then | ▹ if the cell has labeled points |
| 11: | is farthest unlabeled point from the labeled ones within the cell | |
| 12: | else | |
| 13: | is the nearest unlabeled point to the center of the unlabeled points within the cell | |
| 14: | Query () | |
| 15: | Divide into cells and delete | |
| 16: | Delete all cells that have no data | |
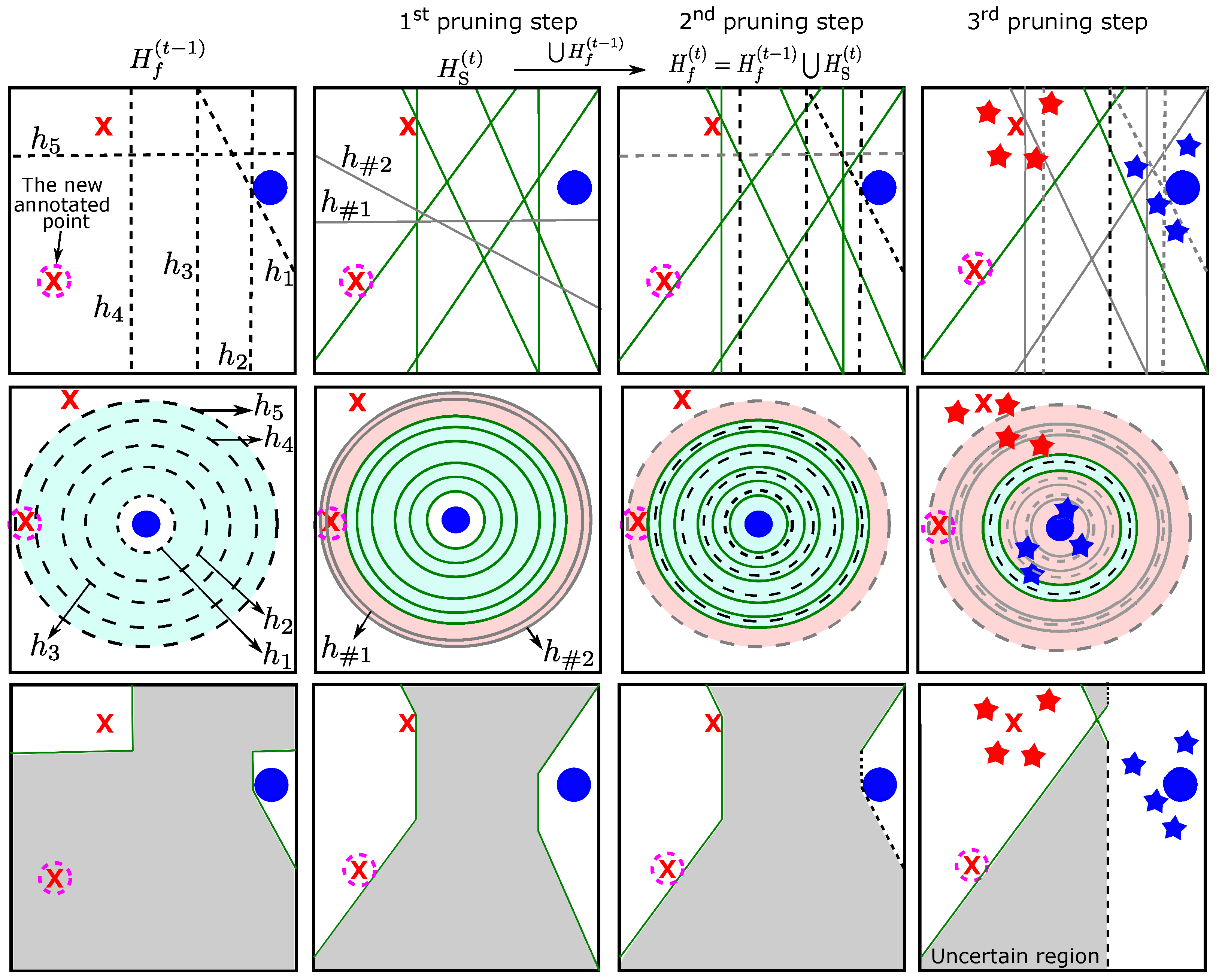
3.3.2. Classifier Pruning
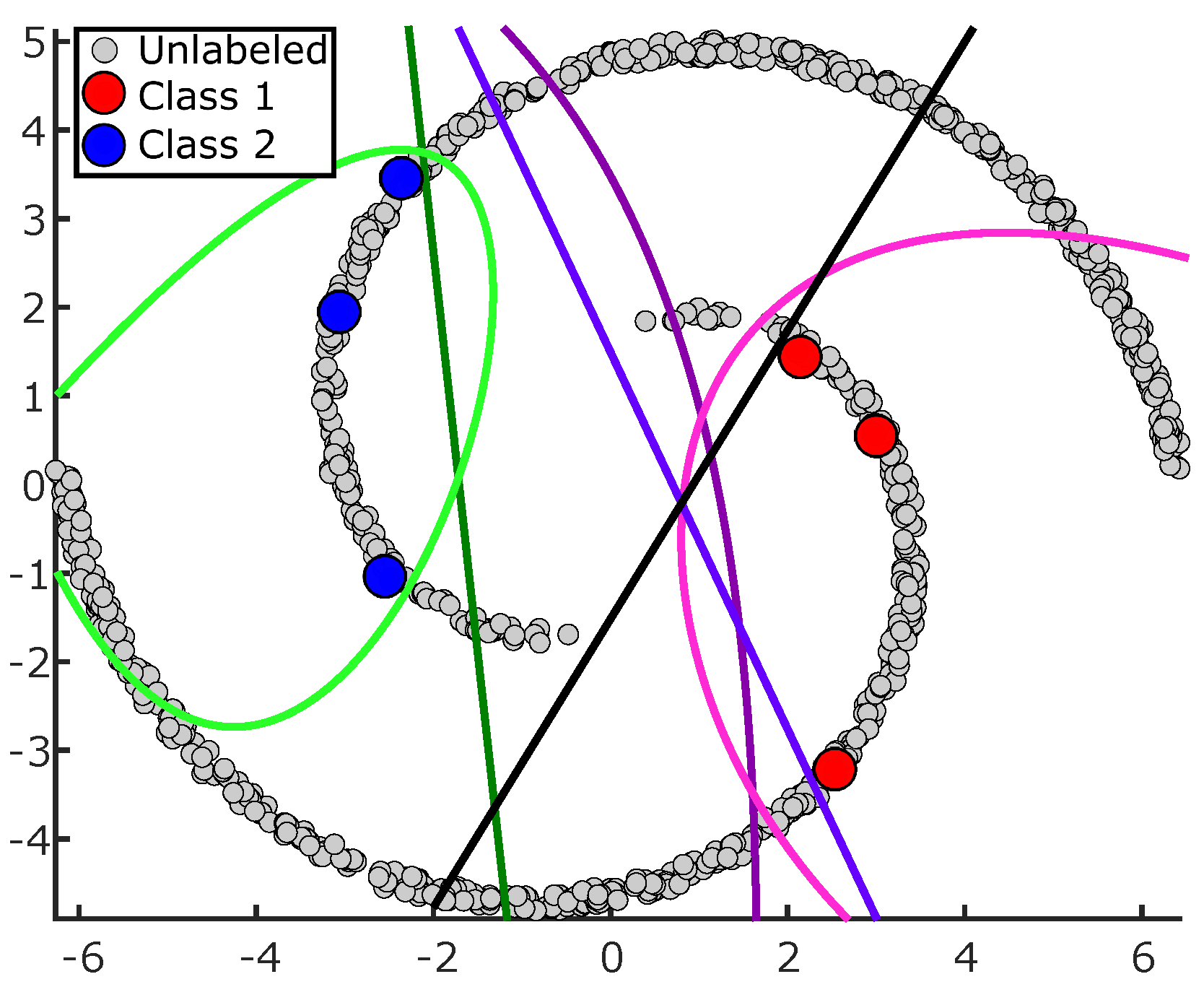
- The first column shows the final hypotheses in the last iteration (i.e., ), of which there were five; all of them are consistent with the two labeled points (the labeled points from the previous iterations). As shown, the uncertain region (third column) is very wide, and some hypotheses might be redundant (i.e., they are not used for constructing the uncertain region). Moreover, the version space (second column) is also wide, and it is bounded by the most general hypothesis () and the most specific one ().
- After annotating a new point, some new hypotheses will be trained on the current labeled points (the two old labeled points and the new one). From the newly generated hypotheses, the first pruning step (in the second column in the figure) keeps only the consistent hypotheses with the current labeled points. As shown, after the first pruning step, there were only six remaining new hypotheses in green color, and the inconsistent ones are the two in gray. The second row shows how the first pruning step (second column) removes directly the new hypotheses that are not consistent with the data, which reduces the version space; the red part in the figure represents the deleted part of the version space after applying the first pruning step. Further, labeling new points helps to explore new regions within the space, reducing the uncertain region, as in the third row.
- In the third column and first row in the figure, these remaining new hypotheses (the green ones in the second column) are added to the selected hypotheses from the previous iterations () (the dashed black ones in the first column), which increases the number of hypotheses. As illustrated, not all hypotheses are consistent with the new labeled point, such as the hypothesis that is represented by a dashed gray line. In the second pruning step, this hypothesis was removed.
- Finally, the fourth column in the figure shows how the pseudo-labeled points might help to shrink the version space by removing some hypotheses from that are not consistent with them. As shown, in the first row, the gray lines represent the hypotheses in that are not consistent with the pseudo-labeled points. These were removed, and only three hypotheses were kept after applying the third pruning step, which reduced the version space (in the second row) and the uncertain region (in the third row).
3.3.3. Determining the Critical Region
3.4. Adding Pseudo-Labeled Points
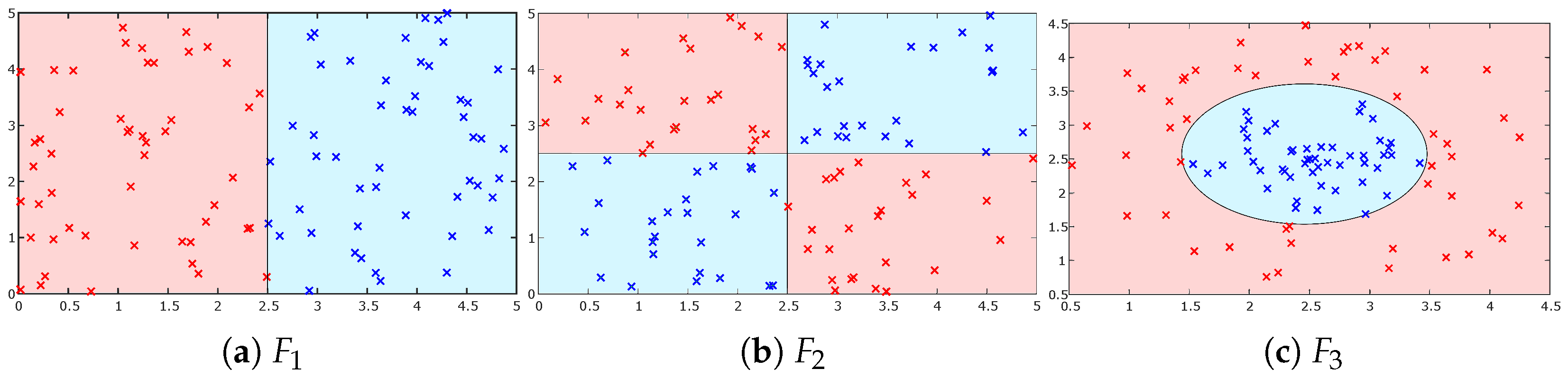
3.5. Designing a Flexible Learning Model
3.6. Model Complexity
| Algorithm 4 Querying a new point using the exploitation phase. = Exploitationphase (). | |||
| Input: , , , , , , , d, , and m | |||
| Output: () | |||
| 1: | Generate m hypotheses () and train them on | ▹ | |
| Generate classifiers (see Section 3.3.1) | |||
| 2: | for do | ▹ First pruning step | |
| 3: | if then | ||
| 4: | |||
| 5: | |||
| 6: | for do | ▹ Second pruning step | |
| 7: | if then | ||
| 8: | |||
| 9: | |||
| 10: | for do | ▹ Third pruning step | |
| 11: | if then | ||
| 12: | |||
| 13: | for do | ||
| 14: | ▹ calculate the uncertainty score of the cell | ||
| 15: | |||
| 16: | |||
| 17: | Query () | ||
| 18: | Divide into cells and delete | ||
| 19: | Delete all cells that have not data | ||
- With the same query budget, the computational time needed by our model was 7.1, 14.6, 22.2, or 36.8 (seconds) when was 100, 200, 300, or 400, respectively. Hence, increasing the number of unlabeled points increases the required computational time.
- With a query budget of 5%, 10%, 15%, or 20% of the total number of unlabeled points, the required computational time was 4.8, 37.5, 42.0, or 51.3 s, respectively. This means that increasing the query budget increases the required computational time.
- Our experiments show that increasing the dimensions of the data increases the expected computational time. With d equal to 2, 4, 6, or 8, the computational time was 3.4, 7.6, 16.2, or 36.7 s, respectively.
- The results of our experiments agree also with our theoretical analysis: increasing the number of subdivisions in each dimension () increases the required computational time dramatically. In our experiments, with equal to 2, 3, 4, or 5, the computational time was 3.7, 8.5, 32.7, or 82.4 s, respectively.
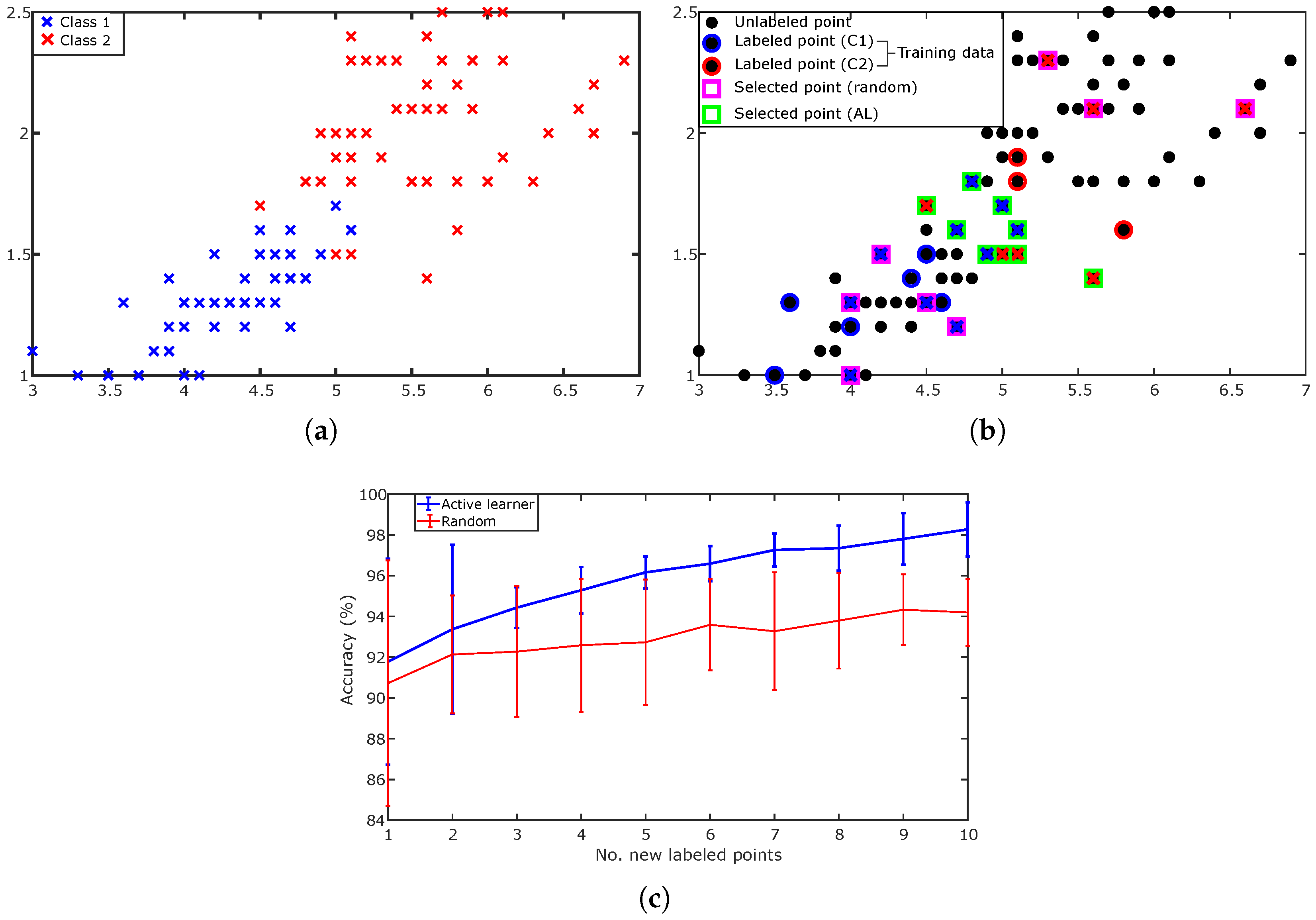
3.7. Illustrative Examples
4. Experimental Results
- The random sampling method, which iteratively selects one instance randomly from ;
- The LLR algorithm [17], which iteratively selects the most representative instance from ;
- The A-optimal design (AOD) algorithm described in [44];
- The cluster-based (CB) algorithm introduced in [45];
- The LHCE-III algorithm (simply LHCE) that was introduced in [10] and obtained good results with the imbalanced data, but with only two-classes datasets and with a query budget equal to about 20% of the total number of unlabeled data points;
- Two variants of the proposed algorithm: LQBALI and LQBALII. The only difference between the two variants is that the training data of the first one had only the points () annotated by the proposed model, whereas the training data of the second one had the annotated points and the PLs ().
- Each experiment was repeated many times to reduce the effect of the randomness of some algorithms. In our initial experiments, we found that the variation in the results was not very large; therefore, we repeated each experiment only 51 times. However, due to the large size of the tables and for readability reasons, we have only given the average values of all results in the tables, and the standard deviations are given in the supplementary material.
- For each dataset, we used the same query budget, and in most cases, it was only 5% of the total number of data points,
- For evaluating the performance of different competitors, we used the accuracy () [41]. Additionally, since imbalanced datasets are either dominated by positive or negative instances, measuring the sensitivity () and specificity () is highly important. Therefore, the results are in the form of , where is the rank of the model among all the other models. In our experiments, the minority class was the positive one; as a result, with imbalanced data, the sensitivity results were expected to be lower than the specificity results. Further, in some experiments, we also counted the number of runs in which the model was unable to annotate points from all classes; we call this the number of failures (). In addition, in some experiments, we used the number of annotated points from the minority class () as a metric to show how the active learner covers the minority class. Furthermore, for the imbalanced data with multiple classes, we counted the number of annotated points in each class.
- In our experiments, the training data for our model consisted of labeled points and pseudo-labeled ones, so the training data points did not have equal weights. Therefore, for evaluating the quality of the selected training data, we used our flexible classifier, which could learn from training data points with different weights. This flexible classifier behaves like a classical ensemble classifier when all training data points are equally weighted.
4.1. Synthetic Dataset
- Balanced datasets (i.e., ): each class had 50 instances,
- Imbalanced datasets with two different imbalance ratios ( and ): the majority class had 70 or 80 instances, and the minority one has 30 or 20 instances, respectively.
- With the balanced data ( 1:1), the two variants of the proposed model obtained high accuracy results and the LQBALII variant achieved the best results, statistically significantly. Additionally, since the generated datasets are balanced, the selected labeled points by our proposed model were also balanced; therefore, there is a balance between the sensitivity and the specificity results. The results of the AOD model with many functions obtained high specificity and low sensitivity results, reflecting the instability of this model.
- With the imbalanced data ( 2.3:1 and 4:1), from the average ranks, the LQBALII model obtained the best accuracy. It also achieved the best sensitivity results statistically significantly, along with high specificity results. In other words, even with the imbalanced data, the LQBALII model succeeded in reducing the gap between the sensitivity and specificity results much better than the other algorithms. For example, with the AOD model, the gap between the sensitivity and specificity results is massive: AOD achieved the best specificity results and approximately the worst sensitivity results. Moreover, the other proposed variant (LQBALI) achieved the third-best accuracy results and the CB model obtained the second-best sensitivity results.
- In terms of the results, it is clear that our LQBAL model was able to annotate points from both classes in most cases when the data were balanced and imbalanced. The other algorithms failed at selecting points from the minority class in many cases, especially when the imbalance ratio was high. As illustrated, among the average number of failures, the LQBAL model had the minimum average . These results reflect the superior exploration capability of our model compared to the others, which enables our model to find minority classes even when the query budget is low. Further, not all models were able to find minority points when the imbalance ratios were high. This is because, in our experiment, with an IR or 4:1 and 100 points, the minority class had only 20 points, and the majority class had 80 points. With a query budget of only 5% (i.e., five points), it is challenging to find at least one minority point, especially when the data points are poorly distributed as in .
- In general, our two variants performed promisingly on all functions as measured by average ranks, and the LQBALII algorithm significantly outperformed all other algorithms.
- The comparison between our two variants shows that the LQBALII obtained better results. This is perhaps because with a low query budget, using only the labeled data is not enough for covering a large area in the space. For LQBALII, the additional pseudo-labeled points help to explore more regions. This could be the reason why LQBALII performed better than LQBALI in terms of sensitivity results in most cases. In other words, in the best case, LQBALI may have only one or two labeled points from the minority class, whereas LQBALII may have some additional pseudo-labeled points from the minority class, which help with covering minority class regions much better than the LQBALI variant.
4.2. Real Imbalanced Datasets
4.2.1. Lower Datasets
- As far as accuracy is concerned, the LLR and the two versions of the LQBAL algorithm obtained the best results statistically significantly. This is also evident in the average ranks of accuracy, as LQBALII achieved the best results.
- The LQBALII algorithm obtained the best sensitivity results, and as shown, it outperformed the other algorithms significantly in most cases. Moreover, LLR and LQBALI achieved the second and third-best sensitivity results, respectively. One reason for these high sensitivity results of the LQBAL algorithm is the large number of labeled points from the minority class. As shown in Table 6, the LLR and LQBAL algorithms succeeded to find minority points in all runs, even with larger imbalance ratios. For example, with LD6, LQBAL explored minority points more than the other active learners. As shown, the of some algorithms was high, especially for larger IRs. As shown, the cluster-based algorithm found no minority points in (i) only one run with LD2 (i.e., ) and (ii) 20 runs with LD6. This was due to the fact that when the imbalance ratio was high, the low query budget was not sufficient to explore or find the minority class.
- In terms of specificity results, as shown, there is not much of a difference between any of the algorithms. LHCE obtained the best specificity results but low sensitivity results. This small difference between all algorithms is due to the fact that it was trivially easy for all active learners to find the majority class’s points.
- With the exception of LLR and LQBAL, all algorithms failed to find at least one minority point in some runs. LLR and LQBAL always found minority points due to their high exploration ability. Further, with a large IR, LQBAL found more minority points than all the other algorithms.
4.2.2. Higher Datasets
- In terms of accuracy results, there is not much of a difference between any of the models. As shown, the LQBALI algorithm obtained the best accuracy results three times, while LQBALII obtained the best accuracy results once and the second-best results three times. However, according to the average ranks, the two versions of the LQBAL model obtained the best accuracy results and the LHCE model obtained the third-best results.
- In terms of sensitivity results—which was the most challenging metric to perform well in due to the small number of minority points—the proposed algorithm achieved the best results statistically significantly. As indicated, LQBALII achieved the best results on five out of six datasets. Additionally, the average ranks showed that the two proposed variants (LQBALII and LQBALI) clearly provided the best sensitivity results. Moreover, the results of the other models show that they behave like a random model. For example, with HD4 and HD5, in all runs (see Table 8), the random model succeeded in finding minority points, whereas the LLR failed to find at least one minority point. Therefore, LLR achieved zero sensitivity with HD4, HD5, and HD6 datasets. This is because, as mentioned earlier, increasing the imbalance ratio with a small query budget reduces the chance of finding minority points.
- Regarding specificity results, the differences among all the models are not great. For example, for HD3, the LLR obtained the best result of 99.8%, whereas LHCE achieved the worst result of 98.9%. This is because all these models can find majority points easily; consequently, the majority class was always well covered, which improved the specificity results.
- The sensitivity results are consistent with the results in Table 8. As shown, only the LQBAL algorithm succeeded in finding at least one point from the minority class in every dataset, so of course, all the other models failed to find any minority points in some runs. In addition, as indicated, the is proportional to the IR. Further, in terms of , LQBAL acquired the best results because it found more minority points than the other models. For example, on the HD5 dataset, of the total number of annotated points, LQBAL found three minority points, whereas the second-best algorithm (LHCE) found only one point.
4.2.3. Multi-Class Datasets
4.3. Practical Considerations
- Although our proposed model achieves promising results, we found in our experiments that our model requires more computational time compared to the other algorithms. We conducted a simple experiment with synthetic functions. For example, with , the computational costs required for the random, LLR, AOD, cluster-based, LHCE, and LQBAL algorithms were 0.05, 0.5, 0.2, 0.5, 17.2, and 15.2 s, respectively. This large difference between our model and the other algorithms limits the applicability of our model in some real-world scenarios.
- We assumed that all data points are unlabeled, which is the worst case, but our model could adapt to partially labeled data by simply ignoring the first step (i.e., querying the first point) and using only our two phases for annotating new points. In the exploration phase, after dividing the space into cells (e.g., each dimension will be divided into two intervals), our model considers the initial labeled points when selecting the cell that has fewer labeled points and a large number of unlabeled points for exploring it by annotating one point there. While in the exploitation phase, the initial labeled data will be used for training new hypotheses to find critical regions.
- Increasing the number of newly generated hypotheses may increase the number of selected hypotheses. However, some of these hypotheses that do not match the new annotated points are deleted in the second pruning step. Additionally, some hypotheses that do not match the pseudo-labeled points are deleted in the third pruning step. Therefore, we can simply say that increasing the number of hypotheses increases the computation time in some parts of our model without significantly improving the performance of it.
- In our model, the query budget (Q) is a predefined parameter, and this parameter controls the switching from exploration to exploitation phases, and it is also our stopping criterion. In real scenarios, it is difficult to choose a value of Q initially. Our model could simply use the first set of iterations to purely explore the space. After that, the variable a in Equation (2) could be changed randomly. This means that the model might use one of the phases randomly.
- Pseudo-labeled points will not help to find minority or new classes, but they help with extending the area of the explored classes that is covered. This is because the PLs are selected geometrically near the annotated points, and these PLs are always assigned to the classes of these annotated points.
- In our model, if the annotated point has some identical points in , we remove all these identical points from because this point (position in the space) is already annotated (i.e., explored). For example, the third annotated point in our illustrative example in Section 3.7 has five identical unlabeled points, and all of them were removed from after annotating that point. This is to (i) avoid wasting the query budget for annotating the same point many times and (ii) reduce the number of unlabeled points in a certain position that is already explored.
- The proposed algorithm is not deterministic, so given the same inputs, on different runs, the annotated points will not identical. In the exploitation phase, the newly generated hypotheses are not identical in each run. This changes the critical region, and hence annotates different points in each run. However, the exploration phase and the selection of the first point should annotate identical points given the same inputs.
- As mentioned earlier, our model starts with the exploration phase. Based on the parameter a (i.e., if ), the model could use the exploitation phase when there are annotated data points from different classes to train learning models. This means that if the data are imbalanced with high IR, the exploration phase may not be able to find minority points; therefore, the model only proceeds with the exploration phase. This seems to be a drawback for our model, but it is not. This is because our model continues to search for the most uncertain and the least explored regions until it finds a point from the minority class. However, finding minority points depends on many factors, such as the number of unlabeled data (i.e., size of the data), the IR, the query budget, and the distribution of majority and minority classes.
- In some real-world scenarios with low (or insufficient) query budgets, the active learners might not find all classes, especially if there are many minority classes. For example, in our experiments in Section 4.2.3, active learners could not cover all minority classes when the query budget was insufficient, and in some cases, some minority classes were missing. This means that if some classes are missing in the labeled data, the learning model trained with this labeled data will assign some future/test data to wrong (but close) classes. This may also be the case, for example, with streaming data where new classes emerge and the training data do not contain data from these new classes. For example, if the labeled data contains only three classes, one normal class and two faulty classes, the learning models trained with this labeled data will not detect whether the test data has a new fault type (i.e., a new class), but will assign the test data of this new type to one of the current classes. Thus, in practice, the training data may not cover all classes [50]. Therefore, in our experiments, we tested our model and the other models with the worst-case scenario: when the query budget is low. However, increasing the query budget when possible provides a strong guarantee of better coverage of the entire space and finding most/all classes, including minority classes. For this reason, in our experiments in Section 4.2.2 and Section 4.2.3, we increased the query budget to find minority points and detect as many minority classes as possible.
- Since the pseudo-labeled points were not annotated by an expert, they could not be fully trusted, and we could have had some noisy pseudo-labels. In our experiment with the high imbalance ratio datasets (see Section 4.2.2), during the runs, besides counting the number of labeled instances from each class ( and ), we also counted the number of conflict points (), the number of the correct/true PLs ( and ), and the number of noisy PLs ( and ) from each class (see Table 11). As illustrated, the true/correct PLs are highlighted in green and the noisy/false ones are highlighted in red. From the table, we can conclude that:
- −
- Increasing size of the dataset increases the query budget, and consequently, increases the number of PLs because new PLs are appended iteratively with each new annotated point. This is clear in Table 11, where the number of PLs when using HD1 was only 19 for 10 labeled points, and the number of PLs when using HD6 increased to 262, and the labeled points numbered 40.
- −
- It is clear that the number of noisy PLs was very small compared to the number of true ones in all cases. For example, for HD6, there were only two noisy PLs from more than 90 PLS. These noisy PLs appeared due to the overlap between classes and/or the poor distribution of the data.
- −
- The total numbers of noisy PLs of the minority and majority classes were 6.7 and 3.6, respectively, and the numbers of true PLs of the minority and majority classes were 14.9 and 267.9, respectively, which means that the majority of PLs belonged to the majority class and that the minority class had a small number of PLs. This is because our strategy for generating PLs selects the closest points to the annotated points, and as shown with the imbalanced data, most of the annotated points belong to the majority class; therefore, most of the PLs also belong to the majority class.
- −
- In most cases, the number of noisy PLs from the minority class was higher than the number in the majority class. This was mainly due to the presence of imbalanced data: the few annotated points from the minority class could be located on the borders between classes; consequently, our model selected noisy PLs (i.e., the model might select one of the points from the majority class and assign it to minority one). However, these noisy PLs will not highly deviate or affect the learning models. Additionally, since these PLs are on the border between different classes, they might also be selected by the classical methods.
- −
- In some datasets, there are many conflict points, which might be an indicator of overlap between classes. As mentioned before in Section 3.4, these points guide the proposed model to precisely detect the critical region, and then annotate more informative points.
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, D.; He, Y.; Luo, X.; Zhou, M. A latent factor analysis-based approach to online sparse streaming feature selection. IEEE Trans. Syst. Man Cybern. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Wu, D.; Shang, M.; Luo, X.; Wang, Z. An L1-and-L2-Norm-Oriented Latent Factor Model for Recommender Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Krishnamurthy, A.; Agarwal, A.; Huang, T.K.; Daumé, H., III; Langford, J. Active Learning for Cost-Sensitive Classification. J. Mach. Learn. Res. 2019, 20, 1–50. [Google Scholar]
- Tran, V.C.; Nguyen, N.T.; Fujita, H.; Hoang, D.T.; Hwang, D. A combination of active learning and self-learning for named entity recognition on Twitter using conditional random fields. Knowl.-Based Syst. 2017, 132, 179–187. [Google Scholar] [CrossRef]
- Song, J.; Wang, H.; Gao, Y.; An, B. Active learning with confidence-based answers for crowdsourcing labeling tasks. Knowl.-Based Syst. 2018, 159, 244–258. [Google Scholar] [CrossRef]
- Reyes, O.; Altalhi, A.H.; Ventura, S. Statistical comparisons of active learning strategies over multiple datasets. Knowl.-Based Syst. 2018, 145, 274–288. [Google Scholar] [CrossRef]
- Wang, M.; Fu, K.; Min, F.; Jia, X. Active learning through label error statistical methods. Knowl.-Based Syst. 2020, 189, 105140. [Google Scholar] [CrossRef]
- Krawczyk, B. Active and adaptive ensemble learning for online activity recognition from data streams. Knowl.-Based Syst. 2017, 138, 69–78. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef] [Green Version]
- Tharwat, A.; Schenck, W. Balancing Exploration and Exploitation: A novel active learner for imbalanced data. Knowl.-Based Syst. 2020, 210, 106500. [Google Scholar] [CrossRef]
- Baum, E.B.; Lang, K. Query learning can work poorly when a human oracle is used. In International Joint Conference on Neural Networks; IEEE: Beijing, China, 1992; Volome 8, p. 8. [Google Scholar]
- Yin, L.; Wang, H.; Fan, W. Active learning based support vector data description method for robust novelty detection. Knowl.-Based Syst. 2018, 153, 40–52. [Google Scholar] [CrossRef]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Honolulu, HI, USA, 2008; pp. 1070–1079. [Google Scholar]
- Lindenbaum, M.; Markovitch, S.; Rusakov, D. Selective sampling for nearest neighbor classifiers. Mach. Learn. 2004, 54, 125–152. [Google Scholar] [CrossRef]
- Scheffer, T.; Decomain, C.; Wrobel, S. Active hidden markov models for information extraction. In International Symposium on Intelligent Data Analysis; Springer: Berlin/Heidelberg, Germany, 2001; pp. 309–318. [Google Scholar]
- Huang, S.J.; Jin, R.; Zhou, Z.H. Active learning by querying informative and representative examples. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Vancouver, BC, Canada, 2010; pp. 892–900. [Google Scholar]
- Zhang, L.; Chen, C.; Bu, J.; Cai, D.; He, X.; Huang, T.S. Active learning based on locally linear reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2026–2038. [Google Scholar] [CrossRef]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. arXiv 2021, arXiv:2101.06329. [Google Scholar]
- Bull, L.; Worden, K.; Manson, G.; Dervilis, N. Active learning for semi-supervised structural health monitoring. J. Sound Vib. 2018, 437, 373–388. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 2009. [Google Scholar]
- Bull, L.; Manson, G.; Worden, K.; Dervilis, N. Active Learning Approaches to Structural Health Monitoring. In Special Topics in Structural Dynamics; Springer: Cham, Switzerland, 2019; Volume 5, pp. 157–159. [Google Scholar]
- Liu, H.; Zhou, M.; Liu, Q. An embedded feature selection method for imbalanced data classification. IEEE/CAA J. Autom. Sin. 2019, 6, 703–715. [Google Scholar] [CrossRef]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Iyengar, V.S.; Apte, C.; Zhang, T. Active learning using adaptive resampling. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 91–98. [Google Scholar]
- Schohn, G.; Cohn, D. Less is more: Active learning with support vector machines. In The 17th International Conference on Machine Learning (ICML); Morgan Kaufmann: Stanford, CA, USA, 2000; Volume 2, p. 6. [Google Scholar]
- Baram, Y.; Yaniv, R.E.; Luz, K. Online choice of active learning algorithms. J. Mach. Learn. Res. 2004, 5, 255–291. [Google Scholar]
- Campbell, C.; Cristianini, N.; Smola, A. Query learning with large margin classifiers. In The 17th International Conference on Machine Learning (ICML); Morgan Kaufmann: Stanford, CA, USA, 2000; Volume 20. [Google Scholar]
- Gao, J.; Fan, W.; Han, J.; Yu, P.S. A general framework for mining concept-drifting data streams with skewed distributions. In Proceedings of the 2007 Siam International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 2007; pp. 3–14. [Google Scholar]
- Chen, S.; He, H. Sera: Selectively recursive approach towards nonstationary imbalanced stream data mining. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 522–529. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef]
- Korycki, Ł.; Cano, A.; Krawczyk, B. Active learning with abstaining classifiers for imbalanced drifting data streams. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2334–2343. [Google Scholar]
- Liu, W.; Zhang, H.; Ding, Z.; Liu, Q.; Zhu, C. A comprehensive active learning method for multiclass imbalanced data streams with concept drift. Knowl.-Based Syst. 2021, 215, 106778. [Google Scholar] [CrossRef]
- Wang, L.; Hu, X.; Yuan, B.; Lu, J. Active learning via query synthesis and nearest neighbour search. Neurocomputing 2015, 147, 426–434. [Google Scholar] [CrossRef] [Green Version]
- Park, J.S. Optimal Latin-hypercube designs for computer experiments. J. Stat. Plan. Inference 1994, 39, 95–111. [Google Scholar] [CrossRef]
- Loh, W.L. On Latin hypercube sampling. Ann. Stat. 1996, 24, 2058–2080. [Google Scholar] [CrossRef]
- Attenberg, J.; Ertekin, Ş. Class imbalance and active learning. Imbalanced Learning: Foundations, Algorithms, and Applications; Wiley-IEEE Press: Manhattan, NY, USA, 2013; pp. 101–149. [Google Scholar]
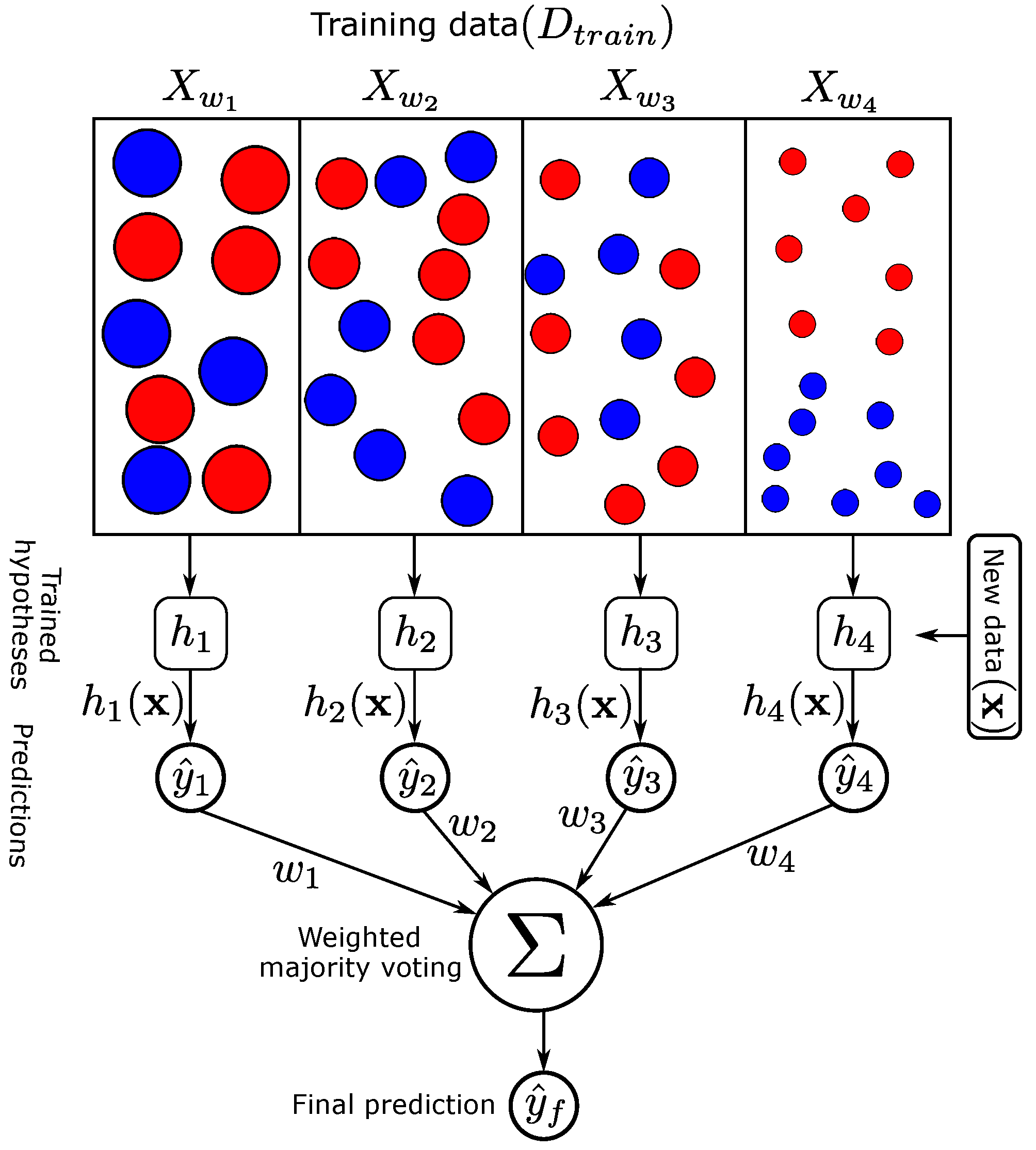
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: Statistics, NY, USA, 2001; Volume 1. [Google Scholar]
- Rosenblatt, F. Principles of Neurodynamics. Perceptrons and the Theory of Brain Mechanisms; Technical Report; Cornell Aeronautical Lab Inc.: Buffalo NY, USA, 1961. [Google Scholar]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 17, 168–192. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.; Cubuk, E.D.; Goodfellow, I.J. Realistic evaluation of deep semi-supervised learning algorithms. arXiv 2018, arXiv:1804.09170. [Google Scholar]
- Atkinson, A.; Donev, A.; Tobias, R. Optimum Experimental Designs, with SAS; Oxford University Press: Oxford, UK, 2007; Volume 34. [Google Scholar]
- Dasgupta, S.; Hsu, D. Hierarchical sampling for active learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 208–215. [Google Scholar]
- Yu, K.; Bi, J.; Tresp, V. Active learning via transductive experimental design. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 1081–1088. [Google Scholar]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. 2007. Available online: https://archive.ics.uci.edu/ml/datasets.php (accessed on 28 January 2022).
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Tharwat, A. Principal Component Analysis: An Overview. Pattern Recognit. 2016, 3, 197–240. [Google Scholar]
- Zhu, Y.N.; Li, Y.F. Semi-supervised streaming learning with emerging new labels. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7015–7022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning | Notation | Meaning |
|---|---|---|---|
| Labeled data | Unlabeled data | ||
| No. of labeled points | No. of unlabeled points | ||
| The ith data point | Label of | ||
| Q | Query budget | d | No. of dimensions of the instance space |
| t | Current iteration | C | No. of classes |
| The ith class | Lower boundaries of the space (in all dimensions) | ||
| k | No. of cells | Upper boundaries of the space (in all dimensions) | |
| No. of pseudo-labeled points | Pseudo-labeled points | ||
| No. of subdivisions in each dimension | a | Exploration-exploitation parameter | |
| The set of selected hypotheses | The set of final hypotheses in the tth iteration | ||
| The set of cells | The label for the new selected point () | ||
| The new selected/queried point | No. of hypotheses in | ||
| W | The weights of the training points | X | Input space |
| Y | The set of outcomes | Discriminant function for the class | |
| Training data | No. of selected nearest neighbors as pseudo-labeled points | ||
| The critical region in the tth iteration | The set of newly generated hypotheses in the tth iteration | ||
| A point in the critical region | The number of votes that a label receives (see Equation (4)) | ||
| The uncertainty score for the ith cell | The uncertainty score of | ||
| No. of final hypotheses in | The output of the classifier with the class | ||
| m | No. of new hypotheses trained in the exploitation phase | r | Random number |
| Fn. | IR | Random | LLR | AOD | CB | LHCE | LQBALI | LQBALII |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 81.2(7)/76.7(5)/86.0(6) | 83.9(5)/73.1(7)/95.3(2) | 85.9(3)/74.1(6)/97.9(1) | 83.7(6)/84.6(3)/83.3(7) | 85.0(4)/82.9(4)/87.3(5) | 92.3(1)/93.1(1)/91.4(3) | 90.6(2)/92.0(2)/89.2(4) | |
| 59.0(4)/62.2(4)/56.6(6) | 60.3(3)/47.2(6)/74.0(3) | 56.4(7)/17.7(7)/91.0(1) | 58.4(5)/58.8(5)/58.9(4) | 57.7(6)/64.7(2)/51.9(7) | 60.6(2)/64.1(3)/57.6(5) | 80.3(1)/81.1(1)/79.8(2) | ||
| 57.9(3)/48.6(4)/67.8(4) | 56.8(5)/53.9(2)/60.5(6) | 50.0(7)/12.0(7)/88.0(1) | 55.2(6)/57.5(1)/53.8(7) | 57.4(4)/51.9(3)/63.6(5) | 59.1(2)/32.9(6)/86.8(2) | 64.5(1)/45.5(5)/84.7(3) | ||
| 2.33:1 | 84.5(6)/65.8(6)/92.6(6) | 84.5(5)/54.0(7)/97.7(2) | 90.3(3)/76.7(4)/96.0(4) | 69.6(7)/79.1(3)/65.6(7) | 85.6(4)/66.5(5)/93.9(5) | 94.4(2)/83.9(2)/98.9(1) | 95.3(1)/89.9(1)/97.5(3) | |
| 65.6(4)/79.7(4)/33.8(6) | 60.3(5)/59.5(6)/63.0(3) | 35.6(7)/11.3(7)/100.0(1) | 58.3(6)/62.3(5)/49.2(4) | 67.4(3)/84.1(3)/29.2(7) | 72.4(2)/88.3(1)/34.8(5) | 82.8(1)/86.6(2)/74.1(2) | ||
| 58.1(5)/50.9(5)/58.0(3) | 58.4(4)/62.5(3)/44.5(7) | 70.0(2)/0.0(7)/100.0(1) | 57.3(6)/63.0(2)/45.2(6) | 59.3(3)/49.8(6)/53.9(4) | 56.9(7)/62.0(4)/46.3(5) | 70.5(1)/70.7(1)/70.6(2) | ||
| 4:1 | 86.1(3)/50.8(6)/95.0(2) | 84.8(4)/33.7(7)/97.5(1) | 92.0(1)/83.4(3)/94.0(4) | 59.9(7)/87.5(2)/52.9(7) | 87.7(2)/61.9(5)/94.2(3) | 72.5(5.5)/ 82.5(4)/70.0(5) | 72.5(5.5)/91.5(1)/67.8(6) | |
| 77.3(1)/92.7(1)/15.5(7) | 64.2(3)/68.8(3)/46.4(4) | 27.2(7)/12.5(7)/99.9(1) | 61.4(4)/65.4(4)/45.0(5) | 74.5(2)/86.6(2)/26.4(6) | 54.1(5)/54.6(5)/52.2(3) | 53.3(6)/49.7(6)/67.3(2) | ||
| 66.8(4)/49.9(5)/52.5(4) | 63.2(7)/66.3(4)/33.2(5) | 80.0(1)/0.0(7)/100.0(1) | 66.5(5)/75.1(2)/32.9(6) | 67.0(3)/43.6(6)/61.1(3) | 66.1(6)/76.4(1)/24.8(7) | 73.7(2)/75.1(3)/68.6(2) | ||
| Avg. Rks. | 4.11/4.44/4.89 | 4.56/5.00/3.67 | 4.22/6.11/1.67 | 5.78/3.00/5.89 | 3.44/4.00/5.00 | 3.61/3.00/4.00 | 2.28/2.44/2.89 | |
| Fn. | IR | Random | LLR | AOD | CB | LHCE | LQBAL |
|---|---|---|---|---|---|---|---|
| 1 | 4 | 0 | 0 | 3 | 1 | 0 | |
| 1 | 0 | 0 | 0 | 6 | 0 | ||
| 1 | 0 | 51 | 3 | 2 | 0 | ||
| 2.3 | 5 | 12 | 0 | 14 | 8 | 0 | |
| 7 | 2 | 0 | 11 | 7 | 0 | ||
| 7 | 2 | 51 | 5 | 11 | 0 | ||
| 4 | 15 | 27 | 0 | 23 | 10 | 13 | |
| 21 | 4 | 0 | 12 | 18 | 18 | ||
| 14 | 3 | 51 | 17 | 17 | 0 | ||
| Avg. NoFs | 8.33 | 5.56 | 17.00 | 9.78 | 8.89 | 4.22 | |
| Dataset | d | IR (min./maj.) | |
|---|---|---|---|
| Liver (LD1) | 345 | 6 | 1.38 (145/200) |
| Glass0 (LD2) | 214 | 5 | 2.06 (70/144) |
| Ecoli1 (LD3) | 336 | 7 | 3.36 (77/259) |
| Ecoli2 (LD4) | 336 | 7 | 5.46 (52/284) |
| Glass6 (LD5) | 214 | 5 | 6.38 (70/144) |
| Ecoli3 (LD6) | 336 | 7 | 8.6 (35/301) |
| Ecoli034vs5 (HD1) | 200 | 7 | 9 (20/180) |
| Glass016vs2 (HD2) | 192 | 9 | 10.29 (17/175) |
| Ecoli0146vs5 (HD3) | 280 | 6 | 13 (20/260) |
| Ecoli4 (HD4) | 336 | 7 | 15.8 (20/316) |
| Glass5 (HD5) | 336 | 9 | 22.78 (9/205) |
| Ecoli0137vs26 (HD6) | 281 | 7 | 39.14 (7/274) |
| Wine (MD1) | 178 | 13 | 1.5 (59/71/48) |
| New-thyroid (MD2) | 215 | 5 | 5 (30/35/150) |
| Balance (MD3) | 625 | 4 | 5.88 (49/288/288) |
| Glass (MD4) | 214 | 9 | 8.44 (70/76/17/13/9/29) |
| Ecoli (MD5) | 336 | 7 | 71.5 (143/77/20/52/5/35/2/2) |
| Ds. | Random | LLR | CB | LHCE | LQBALI | LQBALII |
|---|---|---|---|---|---|---|
| LD1 | 58.5(3)/48.9(2)/65.7(5) | 55.8(5)/46.8(5)/62.4(6) | 58.4(4)/48.1(4)/66.2(4) | 53.0(6)/29.2(6)/71.2(1) | 59.0(2)/48.6(3)/66.7(2) | 59.2(1)/49.4(1)/66.4(3) |
| LD2 | 63.7(5)/53.1(2)/69.3(4) | 68.0(1)/66.6(1)/68.6(5) | 64.5(4)/45.3(5)/74.3(2) | 67.0(2)/0.0(6)/100.0(1) | 59.9(6)/48.1(4)/65.5(6) | 64.8(3)/52.8(3)/70.4(3) |
| LD3 | 85.6(4)/55.5(3)/95.1(3) | 88.7(2)/55.1(4)/99.1(1) | 83.7(5)/38.9(5)/98.0(2) | 73.0(6)/5.9(6)/94.1(5) | 88.9(1)/70.0(2)/94.8(4) | 88.7(3)/73.5(1)/93.4(6) |
| LD4 | 83.1(6)/59.4(3)/90.4(5) | 83.3(3)/62.2(1)/89.3(6) | 83.2(4)/46.1(5)/94.6(2) | 83.2(5)/44.7(6)/94.8(1) | 83.9(1)/59.7(2)/91.2(4) | 83.8(2)/54.6(4)/92.5(3) |
| LD5 | 88.8(4)/56.9(4)/94.7(5) | 91.2(1.5)/61.9(3)/96.7(3) | 87.8(5)/39.9(5)/96.7(2) | 85.2(6)/7.8(6)/99.4(1) | 90.0(3)/63.1(2)/95.0(4) | 91.1(1.5)/73.9(1)/94.3(6) |
| LD6 | 89.1(6)/26.2(4)/96.5(5) | 92.0(1)/83.5(1)/93.0(6) | 89.6(5)/23.5(5)/97.4(2) | 89.7(4)/1.9(6)/99.8(1) | 91.2(3)/41.7(3)/96.8(4) | 91.9(2)/48.3(2)/96.9(3) |
| Avg. Rks. | 4.67/3.00/4.50 | 2.25/2.50/4.50 | 4.50/4.83/2.33 | 4.83/6.00/1.67 | 2.67/2.67/4.00 | 2.08/2.00/4.00 |
| Random | LLR | CB | LHCE | LQBAL | |
|---|---|---|---|---|---|
| LD1 | 0/7.8(1) | 0/7.0(5) | 0/7.5(2) | 0/7.3(3) | 0/7.1(4) |
| LD2 | 0/3.8(3) | 0/5.0(1) | 1/3.7(4) | 0/3.0(5) | 0/4.7(2) |
| LD3 | 1/2.8(4) | 0/3.0(1) | 6/1.6(5) | 2/2.8(3) | 0/2.9(2) |
| LD4 | 0/3.4(4) | 0/6.0(1) | 1/2.5(5) | 0/4.3(2) | 0/3.5(3) |
| LD5 | 1/2.8(1) | 0/2.0(4) | 10/1.9(5) | 2/2.5(3) | 0/2.7(2) |
| LD6 | 9/1.5(4) | 0/2.0(2) | 20/1.1(5) | 8/1.8(3) | 0/2.5(1) |
| Avg. Rks. | 1.83/2.83 | 0.00/2.33 | 6.33/4.33 | 2.00/3.17 | 0.00/2.33 |
| Ds. | Random | LLR | CB | LHCE | LQBALI | LQBALII |
|---|---|---|---|---|---|---|
| HD1 | 92.3(2)/37.0(4)/98.4(3) | 95.3(1)/57.0(1)/99.6(1) | 91.1(4)/26.3(6)/98.2(4) | 91.9(3)/30.9(5)/98.6(2) | 89.9(5)/37.2(3)/95.8(5) | 89.5(6)/41.4(2)/94.8(6) |
| HD2 | 89.3(3)/4.1(4)/97.5(3) | 86.8(4)/5.0(3)/94.7(4) | 89.6(2)/2.8(5)/98.0(2) | 90.0(1)/2.1(6)/98.3(1) | 86.4(6)/9.5(2)/93.6(5) | 86.5(5)/11.0(1)/93.6(6) |
| HD3 | 94.3(4)/33.1(5)/99.0(5) | 96.9(2)/58.7(2)/99.8(1) | 93.4(6)/16.8(6)/99.3(4) | 94.3(5)/33.5(4)/98.9(6) | 96.0(3)/48.4(3)/99.6(3) | 96.9(1)/60.4(1)/99.6(2) |
| HD4 | 95.2(4)/28.3(4)/99.4(3) | 94.0(6)/0.0(6)/100.0(1) | 94.8(5)/15.6(5)/99.8(2) | 95.6(3)/37.8(3)/99.3(4) | 97.7(1)/75.8(2)/98.9(5) | 97.2(2)/79.8(1)/98.3(6) |
| HD5 | 95.2(5)/10.6(4)/98.9(3) | 95.8(3)/0.0(6)/100.0(1) | 95.0(6)/7.4(5)/98.8(4) | 95.5(4)/10.6(3)/99.1(2) | 96.8(1)/50.0(2)/98.4(5) | 96.6(2)/67.7(1)/97.7(6) |
| HD6 | 97.5(4)/19.7(3)/99.4(6) | 97.5(6)/0.0(6)/100.0(1) | 97.6(3)/4.7(5)/99.9(2) | 97.5(5)/11.9(4)/99.6(4) | 98.0(1)/22.9(2)/99.7(3) | 97.9(2)/29.1(1)/99.5(5) |
| Avg. Rks. | 3.67/4.00/3.83 | 3.67/4.00/1.50 | 4.33/5.33/3.00 | 3.50/4.17/3.17 | 2.83/2.33/4.33 | 3.00/1.17/5.17 |
| Random | LLR | CB | LHCE | LQBAL | |
|---|---|---|---|---|---|
| HD1 | 15/1.1(1) | 0/1.0(3.5) | 21/0.9(5) | 17/1.1(2) | 0/1.0(3.5) |
| HD2 | 23/0.8(4.5) | 0/1.0(3) | 23/0.8(4.5) | 17/1.0(2) | 0/1.5(1) |
| HD3 | 20/1.0(3) | 0/1.0(4) | 29/0.6(5) | 14/1.3(2) | 0/1.7(1) |
| HD4 | 17/0.9(3) | 51/0.0(5) | 34/0.4(4) | 21/1.1(2) | 0/2.2(1) |
| HD5 | 16/0.9(3) | 51/0.0(5) | 32/0.5(4) | 18/1.0(2) | 0/3.0(1) |
| HD6 | 13/1.3(2) | 0/1.0(3) | 37/0.4(5) | 22/1.0(4) | 0/1.9(1) |
| Avg. Rks. | 17.33/2.75 | 17.00/3.92 | 29.33/4.58 | 18.17/2.33 | 0.00/1.42 |
| Ds. | Random | LLR | CB | LHCE | LQBAL |
|---|---|---|---|---|---|
| MD1 | 2.9/3.7/2.5 | 9.0/0.0/0.0 | 2.8/3.5/2.7 | 2.9/3.8/2.2 | 3.1/3.1/2.8 |
| MD2 | 1.4/1.8/7.8 | 3.0/2.0/6.0 | 1.8/2.0/7.2 | 1.9/2.4/6.7 | 2.2/2.0/6.7 |
| MD3 | 2.4/14.3/15.3 | 2.5/15.2/14.3 | 2.7/14.6/14.7 | 3.4/13.7/14.9 | 8.1/12.2/11.8 |
| MD4 | 3.8/3.9/0.7/0.7/0.5/1.4 | 5.0/4.0/0.0/0.0/0.0/2.0 | 3.5/3.7/1.1/0.5/0.7/1.5 | 4.4/4.2/0.6/0.5/0.3/1.1 | 4.7/3.9/0.1/0.2/1.0/1.1 |
| MD5* | 1.0/0.3/0.1/0.1 | 0.0/1.0/0.0/0.0 | 1.2/0.2/0.1/0.1 | 0.9/0.2/0.0/0.1 | 1.8/0.0/0.0/0.0 |
| TMPs | 11.5 | 8.5 | 13.1 | 12.5 | 18.2 |
| Ds. | Random | LLR | CB | LHCE | LQBAL |
|---|---|---|---|---|---|
| MD1 | 5.7/7.4/4.9 | 15.0/0.0/3.0 | 5.5/7.5/5.0 | 2.9/3.8/2.2 | 5.4/7.1/5.5 |
| MD2 | 3.5/3.5/15.0 | 3.0/5.0/14.0 | 3.2/2.9/15.9 | 1.9/2.4/6.7 | 3.2/4.7/14.2 |
| MD3 | 5.3/29.5/28.1 | 5.6/29.9/27.6 | 5.3/28.6/29.1 | 3.4/13.7/14.9 | 13.3/21.3/28.4 |
| MD4 | 7.5/8.2/1.8/1.0/0.9/2.6 | 8.0/8.0/1.0/2.0/0.0/3.0 | 7.2/8.3/1.4/1.3/1.1/2.8 | 4.4/4.2/0.6/0.5/0.3/1.1 | 5.4/9.4/0.8/1.2/1.9/3.4 |
| MD5* | 2.0/0.5/0.3/0.2 | 2.0/2.0/0.0/0.0 | 2.5/0.6/0.2/0.3 | 0.9/0.2/0.0/0.1 | 2.5/0.1/0.0/0.0 |
| TMPs | 23.7 | 23.6 | 23.8 | 12.5 | 33.2 |
| Ds. | Pseudo-Labeled Points () | ||||||
|---|---|---|---|---|---|---|---|
| HD1 | 1 | 9 | 1 | 17 | 1 | 0 | 0 |
| HD2 | 1.5 | 9.5 | 1.3 | 17.7 | 1.3 | 0.3 | 9 |
| HD3 | 1.7 | 12.3 | 2.3 | 34.3 | 0 | 1.3 | 18 |
| HD4 | 2.2 | 14.8 | 5.7 | 57.3 | 2 | 0.7 | 0 |
| HD5 | 3.0 | 20 | 3.3 | 52.3 | 1.7 | 0 | 63 |
| HD6 | 1.9 | 38.1 | 1.3 | 89.3 | 0.7 | 1.3 | 169.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tharwat, A.; Schenck, W. A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data. Mathematics 2022, 10, 1068. https://doi.org/10.3390/math10071068
Tharwat A, Schenck W. A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data. Mathematics. 2022; 10(7):1068. https://doi.org/10.3390/math10071068
Chicago/Turabian StyleTharwat, Alaa, and Wolfram Schenck. 2022. "A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data" Mathematics 10, no. 7: 1068. https://doi.org/10.3390/math10071068
APA StyleTharwat, A., & Schenck, W. (2022). A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data. Mathematics, 10(7), 1068. https://doi.org/10.3390/math10071068