
Prediction of ECOG Performance Status of Lung Cancer Patients Using LIME-Based Machine Learning


Abstract
:1. Introduction
2. Background Study
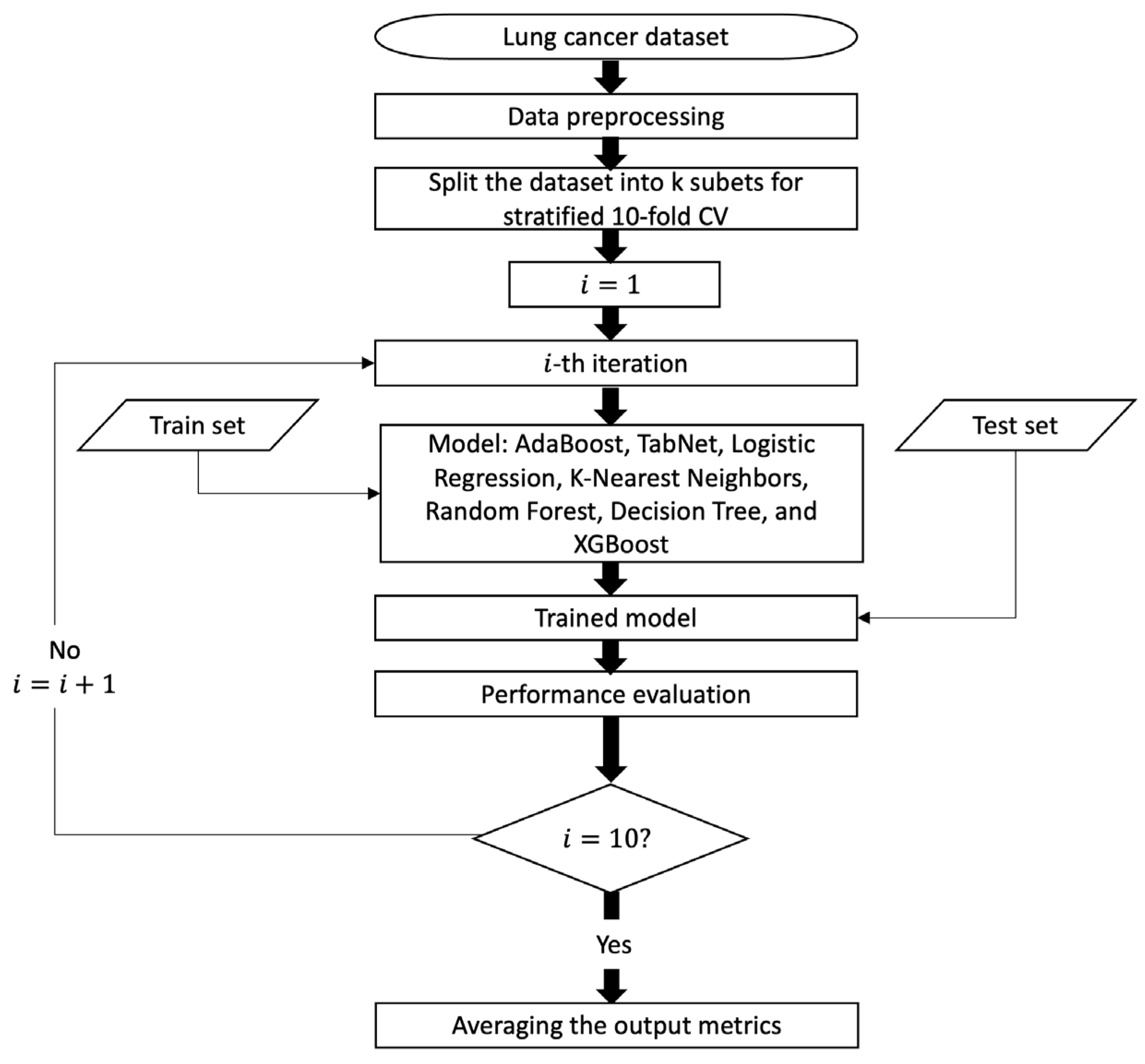
3. Materials and Methods
3.1. Materials
3.2. Data Preprocessing
3.3. Feature Selection
3.4. Development of ML Models
3.4.1. AdaBoost Classification (ADB-C) Model
- Train weak learner using distribution ;
- Get weak hypothesis ;
- Aim: select with low weighted error:
- Choose ;
- Update, for i = 1, …, m:where Zt is a normalization factor (chosen so that Dt + 1 will be a distribution).
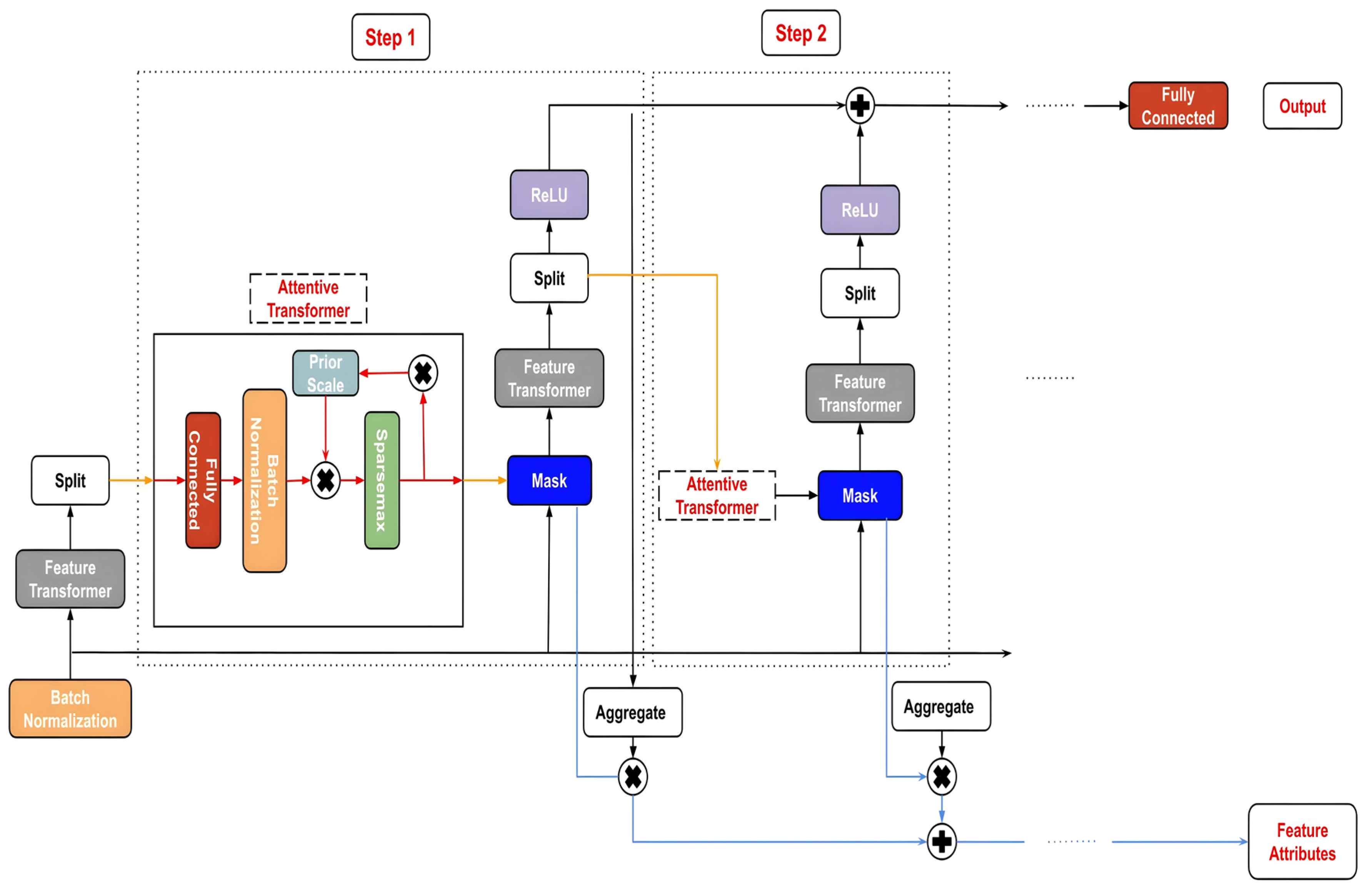
3.4.2. TabNet Classification (TN-C) Model
3.4.3. Performance Comparison with Other Machine Learning Models
3.5. Model Evaluation
- Accuracy estimates the number of positive and negative events that are accurately classified.
- Precision is defined as the proportion of positive cases that are actually positive.
- Recall is the proportion of positive cases that are predicted to be positive out of all positive instances.
- F1 score is the harmonic mean of precision and recall.
3.6. Local Interpretable Model-Agnostic Explanations (LIME)
4. Results
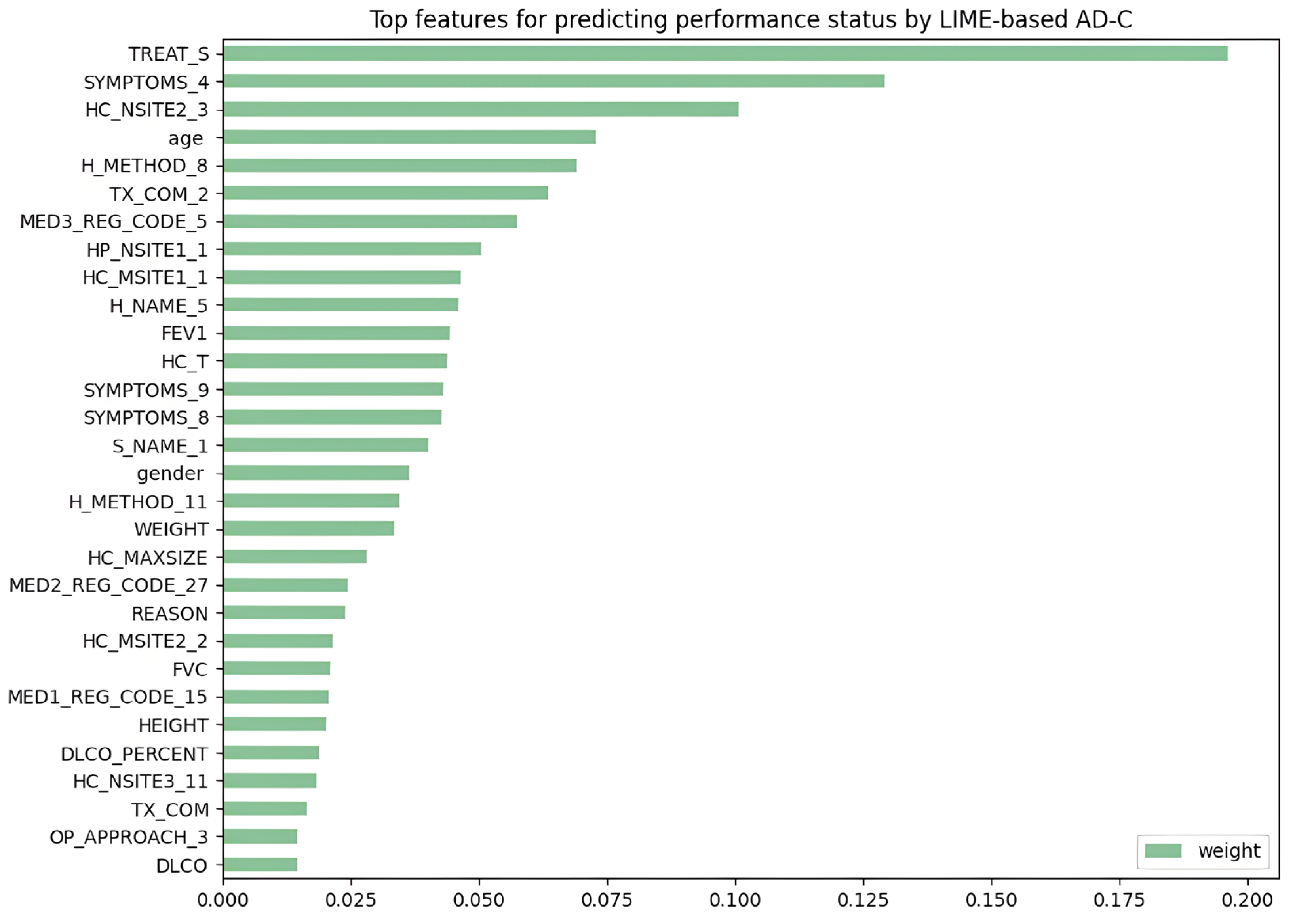
4.1. Feature Selection Results
4.2. Performances of ADB-C Model and TN-C Model
- ADB-C: ‘algorithm’: ’SAMME’, ‘learning_rate’: 0.9871, ‘n_estimators’: 727.
- TN-C: ‘mask_type’: ‘entmax’, ‘n_da’: 64, ‘n_steps’: 6, ‘gamma’: 1, ‘n_shared’: 4, ‘lambda_sparse’: 2.53e-06, ‘bn_momentum’: 0.9997, ‘patienceScheduler’: 10, ‘patience’: 24, ‘epochs’: 92, ‘optimizer_fn’: ‘torch.optim.adam.Adam’.
- LR: ‘C’: 2.3567, ‘max_iter’: 452
- KNN: ‘n_neighbors’: 19, ‘weights’: ‘distance, ‘p’: 1.
- DT: ‘criterion’: ‘gini’, ‘splitter’: ‘best’, ‘max_depth’: 5, ‘min_samples_split’: 8, ‘min_samples_leaf’: 1, ‘max_features’: ‘sqrt’.
- XGB: ‘learning_rate’: 0.0259, ‘n_estimators’: 393, ‘max_depth’: 3, ‘subsample’: 0.6381, ‘colsample_bytree’: 0.365.
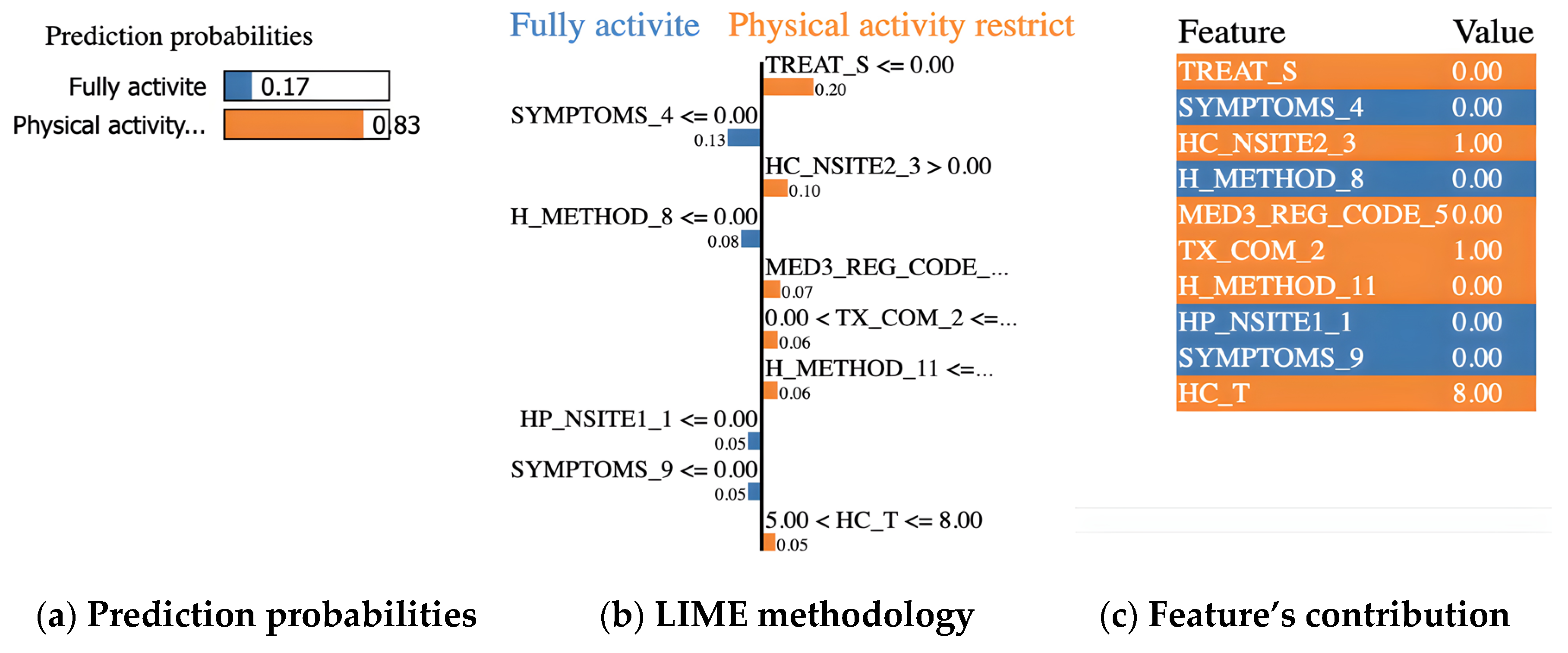
4.3. Evaluation of LIME-Based Stacking Ensemble Model
- TREAT_S = 0 (surgery in the past: no)
- SYMPTOMS_4 = 0 (dyspnea: no)
- HC_NSITE2_3 = 1 (lower paratracheal lymph nodes (#4) in clinical 2 stage: encroachment)
- H_METHOD_8 = 0 (Bx from distant metastasis (liver, adrenal, bone, brain, skin, etc.): no)
- MED3_REG_CODE_5 = 0 (paclitaxel: not use)
- TX_COM_2 = 1 (radiation therapy: yes)
- H_METHOD_11 = 0 (other diagnosis method: no)
- HP_NSITE1_1 = 0 (hilar lymph nodes (#10) in clinical 1 stage: no)
- SYMPTOMS_9 = 0 (other symptoms: no)
- HC_T = 8 (tumor stage: T4)
5. Discussion
6. Limitation and Future Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, S.; Won, Y.-J.; Lee, J.J.; Jung, K.-W.; Kong, H.-J.; Im, J.-S.; Seo, H.G. Cancer Statistics in Korea: Incidence, Mortality, Survival, and Prevalence in 2018. Cancer Res. Treat. 2021, 53, 301–315. [Google Scholar] [CrossRef] [PubMed]
- Price, W.N.; Cohen, I.G. Privacy in the Age of Medical Big Data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Snyder, M.; Zhou, W. Big Data and Health. Lancet Digit. Health 2019, 1, e252–e254. [Google Scholar] [CrossRef] [PubMed]
- Parikh, R.B.; Gdowski, A.; Patt, D.A.; Hertler, A.; Mermel, C.; Bekelman, J.E. Using Big Data and Predictive Analytics to Determine Patient Risk in Oncology. Am. Soc. Clin. Oncol. Educ. Book 2019, 39, e53–e58. [Google Scholar] [CrossRef]
- Jiang, P.; Sinha, S.; Aldape, K.; Hannenhalli, S.; Sahinalp, C.; Ruppin, E. Big Data in Basic and Translational Cancer Research. Nat. Rev. Cancer 2022, 22, 625–639. [Google Scholar] [CrossRef]
- Cancer. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 5 May 2023).
- Sun, D.; Cao, M.; Li, H.; He, S.; Chen, W. Cancer Burden and Trends in China: A Review and Comparison with Japan and South Korea. Chin. J. Cancer Res. 2020, 32, 129–139. [Google Scholar] [CrossRef]
- Lee, J.; Kim, Y.; Kim, H.Y.; Goo, J.M.; Lim, J.; Lee, C.-T.; Jang, S.H.; Lee, W.-C.; Lee, C.W.; Choi, K.S.; et al. Feasibility of Implementing a National Lung Cancer Screening Program: Interim Results from the Korean Lung Cancer Screening Project (K-LUCAS). Transl. Lung Cancer Res. 2021, 10, 723–736. [Google Scholar] [CrossRef]
- Friedlaender, A.; Banna, G.L.; Buffoni, L.; Addeo, A. Poor-Performance Status Assessment of Patients with Non-Small Cell Lung Cancer Remains Vague and Blurred in the Immunotherapy Era. Curr. Oncol. Rep. 2019, 21, 107. [Google Scholar] [CrossRef]
- Mohan, A.; Singh, P.; Singh, S.; Goyal, A.; Pathak, A.; Mohan, C.; Guleria, R. Quality of Life in Lung Cancer Patients: Impact of Baseline Clinical Profile and Respiratory Status. Eur. J. Cancer Care 2007, 16, 268–276. [Google Scholar] [CrossRef]
- ECOG Performance Status Scale—ECOG-ACRIN Cancer Research Group. Available online: https://ecog-acrin.org/resources/ecog-performance-status/ (accessed on 5 May 2023).
- Rittberg, R.; Green, S.; Aquin, T.; Bucher, O.; Banerji, S.; Dawe, D.E. Effect of Hospitalization During First Chemotherapy and Performance Status on Small-Cell Lung Cancer Outcomes. Clin. Lung Cancer 2020, 21, e388–e404. [Google Scholar] [CrossRef]
- Kelly, K. Challenges in Defining and Identifying Patients with Non-Small Cell Lung Cancer and Poor Performance Status. Semin. Oncol. 2004, 31, 3–7. [Google Scholar] [CrossRef]
- Habehh, H.; Gohel, S. Machine Learning in Healthcare. Curr. Genom. 2021, 22, 291–300. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y. An Adaptive Version of the Boost by Majority Algorithm. In Proceedings of the Twelfth Annual Conference on Computational Learning Theory, Santa Cruz, CA, USA, 7–9 July 1999. [Google Scholar] [CrossRef]
- Asgari, S.; Scalzo, F.; Kasprowicz, M. Pattern Recognition in Medical Decision Support. BioMed Res. Int. 2019, 2019, 6048748. [Google Scholar] [CrossRef] [PubMed]
- Rajendra Acharya, U.; Vidya, K.S.; Ghista, D.N.; Lim, W.J.E.; Molinari, F.; Sankaranarayanan, M. Computer-Aided Diagnosis of Diabetic Subjects by Heart Rate Variability Signals Using Discrete Wavelet Transform Method. Knowl.-Based Syst. 2015, 81, 56–64. [Google Scholar] [CrossRef]
- Yoo, I.; Alafaireet, P.; Marinov, M.; Pena-Hernandez, K.; Gopidi, R.; Chang, J.-F.; Hua, L. Data Mining in Healthcare and Biomedicine: A Survey of the Literature. J. Med. Syst. 2011, 36, 2431–2448. [Google Scholar] [CrossRef] [PubMed]
- Dolejsi, M.; Kybic, J.; Tuma, S.; Polovincak, M. Reducing False Positive Responses in Lung Nodule Detector System by Asymmetric Adaboost. In Proceedings of the 2008 5th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Paris, France, 14–17 May 2008. [Google Scholar] [CrossRef]
- Yin, Z.; Sulieman, L.M.; Malin, B.A. A Systematic Literature Review of Machine Learning in Online Personal Health Data. J. Am. Med. Inform. Assoc. 2019, 26, 561–576. [Google Scholar] [CrossRef]
- Sun, S.; Zuo, Z.; Li, G.Z.; Yang, X. Subhealth State Classification with AdaBoost Learner. Int. J. Funct. Inform. Pers. Med. 2013, 4, 167. [Google Scholar] [CrossRef]
- Shakeel, P.M.; Tolba, A.; Al-Makhadmeh, Z.; Jaber, M.M. Automatic Detection of Lung Cancer from Biomedical Data Set Using Discrete AdaBoost Optimized Ensemble Learning Generalized Neural Networks. Neural Comput. Appl. 2019, 32, 777–790. [Google Scholar] [CrossRef]
- Rangini, M.; Jiji, D.G.W. Identification of Alzheimer’s disease using AdaBoost classifier. In Proceedings of the International Conference on Applied Mathematics and Theoretical Computer Science, Lefkada Island, Greece, 8–10 August 2023; Volume 34, p. 229. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Alves, M.A.; Castro, G.Z.; Oliveira, B.A.S.; Ferreira, L.A.; Ramírez, J.A.; Silva, R.; Guimarães, F.G. Explaining Machine Learning Based Diagnosis of COVID-19 from Routine Blood Tests with Decision Trees and Criteria Graphs. Comput. Biol. Med. 2021, 132, 104335. [Google Scholar] [CrossRef]
- Hassan, M.R.; Islam, M.F.; Uddin, M.Z.; Ghoshal, G.; Hassan, M.M.; Huda, S.; Fortino, G. Prostate Cancer Classification from Ultrasound and MRI Images Using Deep Learning Based Explainable Artificial Intelligence. Future Gener. Comput. Syst. 2022, 127, 462–472. [Google Scholar] [CrossRef]
- Magesh, P.R.; Myloth, R.D.; Tom, R.J. An Explainable Machine Learning Model for Early Detection of Parkinson’s Disease Using LIME on DaTSCAN Imagery. Comput. Biol. Med. 2020, 126, 104041. [Google Scholar] [CrossRef] [PubMed]
- Ingle, K.; Chaskar, U.; Rathod, S. Lung Cancer Types Prediction Using Machine Learning Approach. In Proceedings of the 2021 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 9–11 July 2021. [Google Scholar] [CrossRef]
- Sim, J.; Kim, Y.A.; Kim, J.H.; Lee, J.M.; Kim, M.S.; Shim, Y.M.; Zo, J.I.; Yun, Y.H. The Major Effects of Health-Related Quality of Life on 5-Year Survival Prediction among Lung Cancer Survivors: Applications of Machine Learning. Sci. Rep. 2020, 10, 10693. [Google Scholar] [CrossRef]
- Safiyari, A.; Javidan, R. Predicting Lung Cancer Survivability Using Ensemble Learning Methods. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017. [Google Scholar] [CrossRef]
- Kim, Y.-C.; Won, Y.-J. The Development of the Korean Lung Cancer Registry (KALC-R). Tuberc. Respir. Dis. 2019, 82, 91. [Google Scholar] [CrossRef] [PubMed]
- Park, C.K.; Kim, S.J. Trends and Updated Statistics of Lung Cancer in Korea. Tuberc. Respir. Dis. 2019, 82, 175. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. (Eds.) Feature Extraction: Foundations and Applications. In Studies in Fuzziness and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2008; Volume 207, ISBN 978-3-540-35488-8. [Google Scholar]
- Guo, Y.; Chung, F.-L.; Li, G.; Zhang, L. Multi-Label Bioinformatics Data Classification with Ensemble Embedded Feature Selection. IEEE Access 2019, 7, 103863–103875. [Google Scholar] [CrossRef]
- Pudjihartono, N.; Fadason, T.; Kempa-Liehr, A.W.; O’Sullivan, J.M. A Review of Feature Selection Methods for Machine Learning-Based Disease Risk Prediction. Front. Bioinform. 2022, 2, 927312. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Richards, G.; Wang, W. What Influences the Accuracy of Decision Tree Ensembles? J. Intell. Inf. Syst. 2012, 39, 627–650. [Google Scholar] [CrossRef]
- Nematzadeh, Z.; Ibrahim, R.; Selamat, A. Improving Class Noise Detection and Classification Performance: A New Two-Filter CNDC Model. Appl. Soft Comput. 2020, 94, 106428. [Google Scholar] [CrossRef]
- Hatwell, J.; Gaber, M.M.; Atif Azad, R.M. Ada-WHIPS: Explaining AdaBoost Classification with Applications in the Health Sciences. BMC Medical Informatics and Decision Making 2020, 20, 250. [Google Scholar] [CrossRef]
- Pradhan, K.; Chawla, P. Medical Internet of Things Using Machine Learning Algorithms for Lung Cancer Detection. J. Manag. Anal. 2020, 7, 591–623. [Google Scholar] [CrossRef]
- Zhang, M.H.; Xu, Q.S.; Daeyaert, F.; Lewi, P.J.; Massart, D.L. Application of Boosting to Classification Problems in Chemometrics. Anal. Chim. Acta 2005, 544, 167–176. [Google Scholar] [CrossRef]
- Tan, C.; Li, M.; Qin, X. Study of the Feasibility of Distinguishing Cigarettes of Different Brands Using an Adaboost Algorithm and Near-Infrared Spectroscopy. Anal. Bioanal. Chem. 2007, 389, 667–674. [Google Scholar] [CrossRef] [PubMed]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A nex-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 4–8 August 2019. [Google Scholar] [CrossRef]
- Arik, S.Ö.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. Proc. AAAI Conf. Artif. Intell. 2021, 35, 6679–6687. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Peterson, L. K-Nearest Neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning, 2nd ed.; Zhang, C., Ma, Y.Q., Eds.; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Patel, H.H.; Prajapati, P. Study and Analysis of Decision Tree Based Classification Algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Agrawal, S.; Narayanan, B.; Chandrashekaraiah, P.; Nandi, S.; Vaidya, V.; Sun, P.; Cabrera, C.; Svensson, D.; Khosla, S.; Stepanski, E.; et al. Machine Learning Imputation of Eastern Cooperative Oncology Group Performance Status (ECOG PS) Scores from Data in CancerLinQ Discovery. J. Clin. Oncol. 2020, 38, e19318. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Notions of Explainability and Evaluation Approaches for Explainable Artificial Intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Sheffield, K.M.; Bowman, L.; Smith, D.M.; Li, L.; Hess, L.M.; Montejano, L.B.; Willson, T.M.; Davidoff, A.J. Development and Validation of a Claims-Based Approach to Proxy ECOG Performance Status across Ten Tumor Groups. J. Comp. Eff. Res. 2018, 7, 193–208. [Google Scholar] [CrossRef]
- Andreano, A.; Russo, A.G. Administrative Healthcare Data to Predict Performance Status in Lung Cancer Patients. Data Brief 2021, 39, 107559. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular Data: Deep Learning Is Not All You Need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Fayaz, S.A.; Zaman, M.; Kaul, S.; Butt, M.A. Well-tuned simple nets excel on tabular datasets. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 23928–23941. [Google Scholar] [CrossRef]
- Kadra, A.; Lindauer, M.; Hutter, F.; Grabocka, J. Is Deep Learning on Tabular Data Enough? An Assessment. Adv. Neural Inf. Process. Syst. 2021, 34, 23928–23941. [Google Scholar]
- Köhne, C.-H.; Cunningham, D.; Di Costanzo, F.; Glimelius, B.; Blijham, G.; Aranda, E.; Scheithauer, W.; Rougier, P.; Palmer, M.; Wils, J.; et al. Clinical Determinants of Survival in Patients with 5-Fluorouracil- Based Treatment for Metastatic Colorectal Cancer: Results of a Multivariate Analysis of 3825 Patients. Ann. Oncol. 2002, 13, 308–317. [Google Scholar] [CrossRef] [PubMed]
- Schiller, J.H.; Harrington, D.; Belani, C.P.; Langer, C.; Sandler, A.; Krook, J.; Zhu, J.; Johnson, D.H. Comparison of Four Chemotherapy Regimens for Advanced Non–Small-Cell Lung Cancer. N. Engl. J. Med. 2002, 346, 92–98. [Google Scholar] [CrossRef]
- Zimmermann, C.; Burman, D.; Bandukwala, S.; Seccareccia, D.; Kaya, E.; Bryson, J.; Rodin, G.; Lo, C. Nurse and Physician Inter-Rater Agreement of Three Performance Status Measures in Palliative Care Outpatients. Support. Care Cancer 2009, 18, 609–616. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Score | ECOG Performance Status | Number of Values |
|---|---|---|
| 0 | Fully active, able to carry on all pre-disease performance without restriction | 904 |
| 1 | Restricted in physically strenuous activity but ambulatory and able to carry out work of a light or sedentary nature, e.g., light house work, office work | 888 |
| 2 | Ambulatory and capable of all self-care but unable to carry out any work activities; up and about more than 50% of waking hours | 164 |
| 3 | Capable of only limited self-care; confined to bed or chair more than 50% of waking hours | 73 |
| 4 | Completely disabled; cannot carry on any self-care; totally confined to bed or chair | 34 |
| 5 | Dead | 0 |
| Features Set | Model | Accuracy | Precision | Recall | F1-Score | ROC AUC |
|---|---|---|---|---|---|---|
| All features | RF | 0.7369 | 0.7329 | 0.8385 | 0.7818 | 0.7726 |
| XGB | 0.7085 | 0.7268 | 0.7743 | 0.7490 | 0.7531 | |
| ADB-C | 0.7078 | 0.7256 | 0.7743 | 0.7486 | 0.7488 | |
| LR | 0.7036 | 0.7099 | 0.8014 | 0.7524 | 0.7369 | |
| TN-C | 0.6905 | 0.6781 | 0.8768 | 0.7608 | 0.7186 | |
| KNN | 0.6219 | 0.6589 | 0.6782 | 0.6679 | 0.6526 | |
| DT | 0.6372 | 0.6784 | 0.6732 | 0.6755 | 0.6321 | |
| RF feature selection | ADB-C | 0.7050 | 0.7173 | 0.7866 | 0.7496 | 0.7481 |
| RF | 0.7112 | 0.7202 | 0.7965 | 0.7560 | 0.7457 | |
| LR | 0.6961 | 0.7015 | 0.8002 | 0.7472 | 0.7323 | |
| XGB | 0.6974 | 0.7157 | 0.7682 | 0.7400 | 0.7306 | |
| KNN | 0.6427 | 0.6724 | 0.7139 | 0.6920 | 0.6591 | |
| TN-C | 0.6537 | 0.6470 | 0.8495 | 0.7334 | 0.6583 | |
| DT | 0.5921 | 0.6413 | 0.6251 | 0.6323 | 0.5875 | |
| ET feature selection | ADB-C | 0.7071 | 0.7257 | 0.7731 | 0.7478 | 0.7663 |
| RF | 0.7168 | 0.7232 | 0.8088 | 0.7625 | 0.7619 | |
| XGB | 0.7057 | 0.7267 | 0.7669 | 0.7453 | 0.7460 | |
| LR | 0.7085 | 0.7128 | 0.8076 | 0.7561 | 0.7410 | |
| TN-C | 0.6482 | 0.6454 | 0.8383 | 0.7272 | 0.6681 | |
| KNN | 0.6295 | 0.6591 | 0.7078 | 0.6820 | 0.6495 | |
| DT | 0.6233 | 0.6705 | 0.6548 | 0.6613 | 0.6188 | |
| XGB feature selection | LR | 0.7237 | 0.7097 | 0.8619 | 0.7779 | 0.7531 |
| ADB-C | 0.7230 | 0.7093 | 0.8606 | 0.7773 | 0.7523 | |
| XGB | 0.7244 | 0.7098 | 0.8631 | 0.7786 | 0.7479 | |
| RF | 0.7216 | 0.7096 | 0.8557 | 0.7755 | 0.7466 | |
| KNN | 0.6981 | 0.7441 | 0.7167 | 0.7151 | 0.7399 | |
| DT | 0.7209 | 0.7124 | 0.8459 | 0.7730 | 0.7378 | |
| TN-C | 0.7182 | 0.7073 | 0.8533 | 0.7728 | 0.7253 | |
| ADB feature selection | ADB-C | 0.7230 | 0.7325 | 0.8002 | 0.7645 | 0.7795 |
| RF | 0.7237 | 0.7314 | 0.8076 | 0.7670 | 0.7774 | |
| LR | 0.7140 | 0.7252 | 0.7916 | 0.7565 | 0.7666 | |
| XGB | 0.6994 | 0.7200 | 0.7620 | 0.7395 | 0.7536 | |
| TN-C | 0.6614 | 0.6502 | 0.8742 | 0.7433 | 0.6738 | |
| KNN | 0.6213 | 0.6653 | 0.6597 | 0.6610 | 0.6490 | |
| DT | 0.6385 | 0.6840 | 0.6609 | 0.6710 | 0.6353 |
| Variables | Description | Field Type |
|---|---|---|
| age | Age | Continuous: ( ) years old |
| DLCO | Carbon monoxide diffusing capacity (DLCO) | Continuous: ( ) mL/min/mmHg |
| FVC | Forced vital capacity (FVC) | Continuous: ( ) L |
| FEV1 | The first second of forced expiration (FEV1) | Continuous: ( ) L |
| HC_T | Tumor stage | Categorical: Tx (0), T1a (1), T1b (2), T1 NOS (3), T2a (4), T2b (5), T2 NOS (6), T3 (7), T4 (8), Unknown (9) |
| HC_MAXSIZE | Tumor maximal size | Continuous: ( ) cm |
| DLCO_PERCENT | DLCO percent predictive value | Continuous: ( )% |
| H_METHOD_8 | Bx from distant metastasis (liver, adrenal, bone, brain, skin, etc.) | Categorical: No (0), Yes (1) |
| H_METHOD_11 | Other diagnosis method | Categorical: No (0), Yes (1) |
| H_NAME_5 | Small cell carcinoma | Categorical: No (0), Yes (1) |
| OP_NAME_9 | Other operation approach | Categorical: No (0), Yes (1) |
| HC_NSITE1_1 | Hilar lymph nodes (#10) in clinical 1 stage | Categorical: No encroachment (0), Encroachment (1) |
| gender | Gender | Categorical: Male (1), Female (2) |
| OP_APPROACH_1 | Thoracotomy/Open operative approach | Categorical: No (0), Yes (1) |
| OP_APPROACH_3 | Mediastinum operative approach | Categorical: No (0), Yes (1) |
| MED3_REG_CODE_5 | Paclitaxel | Categorical: Not use (0), Use (1) |
| MED3_REG_CODE_27 | Durvalumab | Categorical: Not use (0), Use (1) |
| HC_MSITE2_2 | Extra thoracic lymph node | Categorical: No (0), Metastasis (1) |
| HC_MSITE1_1 | Malignant pleural effusion | Categorical: No (0), Yes (1) |
| S_NAME_1 | Squamous cell carcinoma | Categorical: No (0), Yes (1) |
| MED1_REG_CODE_15 | Crizotinib | Categorical: No (0), Yes (1) |
| HC_NSITE2_3 | Lower paratracheal lymph nodes (#4) in clinical 2 stage | Categorical: No encroachment (0), Encroachment (1) |
| HC_NSITE3_11 | Lobar lymph node | Categorical: No encroachment (0), Encroachment (1) |
| H_METHOD_4 | Lymph node needle aspiration and/or biopsy | Categorical: No (0), Yes (1) |
| TREAT_S | Surgery | Categorical: No (0), Yes (1) |
| REASON | Reason | Categorical: Symptoms (1), Incidental discovery (abnormal findings on chest imaging) (2), Unknown (9) |
| PFT | Pulmonary function test performed | Categorical: No (0), Yes (1) |
| TX_COM_2 | Radiation therapy | Categorical: No (0), Yes (1) |
| S_LOCATION_1 | Tumor is located in right upper lobe | Categorical: No (0), Yes (1) |
| TX_COM | Treatment carried out in the hospital | Categorical: No (0), Yes (1), Last month (2), Unknown (9) |
| SYMPTOMS_9 | Other symptoms | Categorical: No (0), Yes (1) |
| WEIGHT | Weight | Continuous: ( ) kg |
| SYMPTOMS_8 | Pain (chest, head, spine, abdomen, extremity) | Categorical: No (0), Yes (1) |
| HEIGHT | Height | Continuous: ( ) cm |
| SYMPTOMS_4 | Dyspnea | Categorical: No (0), Yes (1) |
| Model | Accuracy | Precision | Recall | F1-Score | ROC AUC |
|---|---|---|---|---|---|
| ADB-C | 0.7223 | 0.7274 | 0.8126 | 0.7671 | 0.7890 |
| LR | 0.7258 | 0.7330 | 0.8051 | 0.7670 | 0.7863 |
| XGB | 0.7300 | 0.7384 | 0.8064 | 0.7703 | 0.7859 |
| RF | 0.7334 | 0.7333 | 0.8286 | 0.7775 | 0.7817 |
| DT | 0.7029 | 0.7337 | 0.7448 | 0.7371 | 0.7343 |
| TN-C | 0.6475 | 0.6852 | 0.6118 | 0.5879 | 0.7242 |
| KNN | 0.6732 | 0.7075 | 0.7152 | 0.7106 | 0.7180 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.V.; Byeon, H. Prediction of ECOG Performance Status of Lung Cancer Patients Using LIME-Based Machine Learning. Mathematics 2023, 11, 2354. https://doi.org/10.3390/math11102354
Nguyen HV, Byeon H. Prediction of ECOG Performance Status of Lung Cancer Patients Using LIME-Based Machine Learning. Mathematics. 2023; 11(10):2354. https://doi.org/10.3390/math11102354
Chicago/Turabian StyleNguyen, Hung Viet, and Haewon Byeon. 2023. "Prediction of ECOG Performance Status of Lung Cancer Patients Using LIME-Based Machine Learning" Mathematics 11, no. 10: 2354. https://doi.org/10.3390/math11102354
APA StyleNguyen, H. V., & Byeon, H. (2023). Prediction of ECOG Performance Status of Lung Cancer Patients Using LIME-Based Machine Learning. Mathematics, 11(10), 2354. https://doi.org/10.3390/math11102354