

A Client-Cloud-Chain Data Annotation System of Internet of Things for Semi-Supervised Missing Data
Abstract
:1. Introduction
- (1)
- High costs or the environment makes it difficult to collect sufficient marker data, and inevitably causes the partial loss of data attributes [17].
- (2)
- In many practical applications, data are distributed on multiple intermediate platforms (nodes) [18] for various reasons (such as large data volume, bandwidth limit, etc.).
- (3)
- In the distributed data center scenario, the unexplained, distributed sub-model and the distributed center cannot be fully trusted and connected, which hinders the use of the global data center in key applications in relation to fairness, privacy, and security.
- (1)
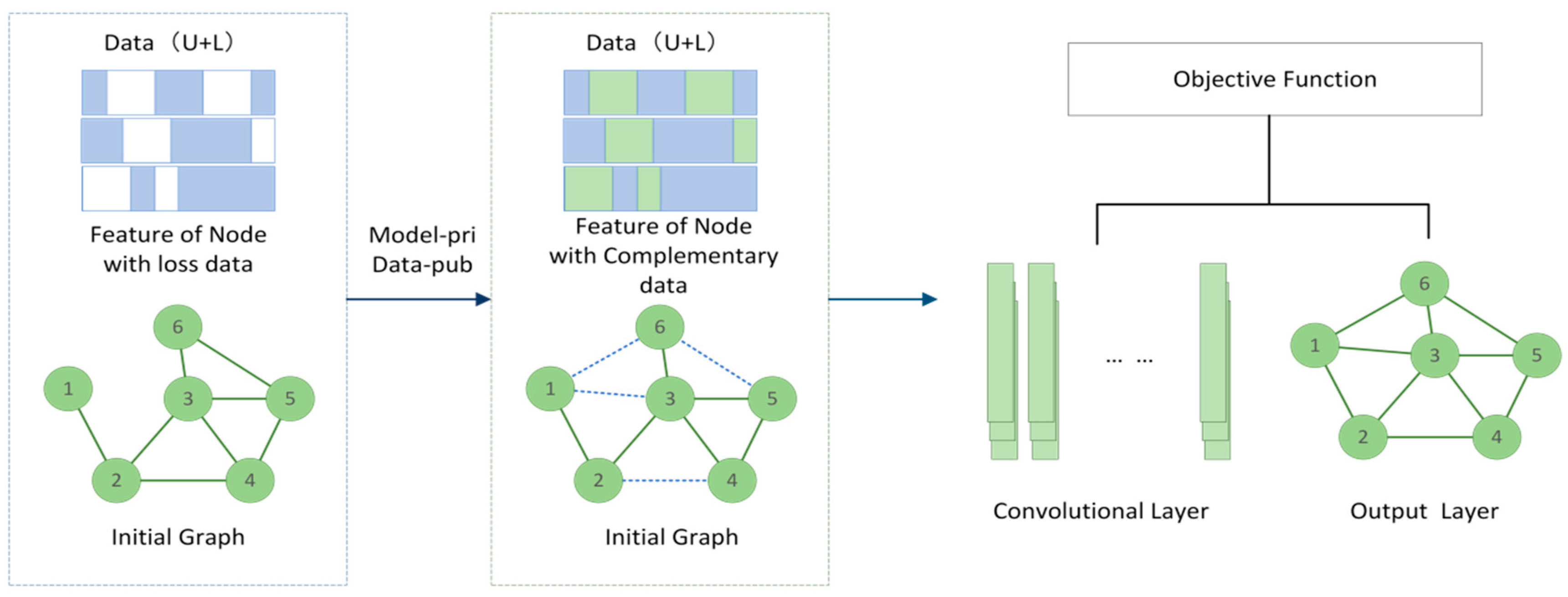
- Propose a semi-supervised learning framework based on a graph-deep neural network, where the goal is to capture the deep features of the same type of data in the data platform and learn the relationships between features. This framework consists of two modules, the graph neural network module and the Graph-Marks module. This study first used the graph neural network to learn the private model of the platform and used common data to improve the accuracy of data filling, and then the generalized Graph-Masks module learned the important edge information of each layer to improve the accuracy. Finally, the graph convolution network was used for marking.
- (2)
- To arouse the enthusiasm of the middle platform and further improve the accuracy of the mark, this paper, according to the middle private model and common data after the explanation figure based on the neural network of each layer and the importance of the data fusion method, first trained an annotation model, and then through another private model and common data analysis discarded an edge without affecting the original prediction; for each layer, the graph neural network (GNN) obtained an edge mask. Finally, to reduce the computation, this paper used binary concrete distribution and a re-parameterization trick to approximate the discrete mask.
- (3)
- This paper used the minimized divergence term to train the data in the standard model, and after training GNN global interpretability and understanding, it greatly improved the accuracy of the cloud center alongside sub-center precision.
2. Related Work
2.1. Graph Convolution Networks
2.2. Graph-Mask Promoted
3. Methods Section
3.1. Dataset Division
3.2. Problem Description
3.3. Global Graph Structure Problem Design
- Step M: Maximize , updates
- Step E: update
3.4. Data Interaction
3.4.1. Model Building within the Dataset
3.4.2. Regular Terms
3.4.3. Optimize Objective Function
3.5. Distributed Model Optimization
3.5.1. Features T Optimization
- Step 1: For the calculation of distributed features (Mod) and global aggregation (g), we first define
- Step 2: Solutions of parameter W
- The optimal solution for labeled data can be simplified as
- The optimal solution for unlabeled data can be simplified as
- Step 3: S optimize.
3.5.2. Information Interaction between the Datasets
- Optimization process:
- 1.
- Tix W,A. optimize F.
- 2.
- Tix W,F. optimize A.
- 3.
- Tix S,F. optimize W.
4. Experiment on the NGSIM Dataset
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Childs, L.H.; Mamlouk, S.; Brandt, J.; Sers, C.; Leser, U. SoFIA: A data integration framework for annotating high-throughput datasets. Bioinformatics 2016, 32, 2590–2597. [Google Scholar] [CrossRef] [PubMed]
- Acuna, D.; Ling, H.; Kar, A.; Fidler, S. Efficient interactive annotation of segmentation datasets with polygon-RNN++. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Tang, H. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Adopt. Artif. Intell. Blockchain Agric. Healthc. A Sustain. Perspect. 2023, 15, 901. [Google Scholar]
- Ding, G.; Wang, J.; Xu, N.; Zhang, L. Automatic image annotations by mining web image data. In Proceedings of the 2009 IEEE International Conference on Data Mining Workshops (ICDMW 2009), Miami, FL, USA, 6 December 2009; Volume 19, pp. 152–157. [Google Scholar]
- Jansen, R.J.; van der Kint, S.T.; Hermens, F. Does agreement mean accuracy? Evaluating glance annotation in naturalistic driving data. Behav. Res. Methods 2021, l53, 430–446. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, M.; Chen, C. A Deep-Learning intelligent system incorporating data augmentation for Short-Term voltage stability assessment of power systems. Appl. Energy 2022, 308, 118347. [Google Scholar] [CrossRef]
- Xu, G.; Wang, Z.; Yang, L.; Sun, X. Research of data provenance semantic annotation for dependency analysis. In Proceedings of the 2013 International Conference on Advanced Cloud and Big Data (CBD), Nanjing, China, 13–15 December 2013; Volume 29, pp. 197–204. [Google Scholar] [CrossRef]
- Malik, K.R.; Habib, M.A.; Khalid, S.; Ahmad, M.; Alfawair, M.; Ahmad, A.; Jeon, G. A generic methodology for geo-related data semantic annotation. Concurr. Comput.-Pract. Exp. 2018, 30, 4495. [Google Scholar] [CrossRef]
- Meng, Q.; Wang, W.; Zhou, T.; Shen, J.; Jia, Y.; Van Gool, L. Towards a Weakly Supervised Framework for 3D Point Cloud Object Detection and Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4454–4468. [Google Scholar] [CrossRef]
- Caicedo, R.W.A.; Soriano, J.M.G.; Sasieta, H.A.M. Bootstrapping semi-supervised annotation method for potential suicidal messages. Internet Interv. 2022, 28, 100519. [Google Scholar] [CrossRef]
- Liao, S.; Jiang, X.; Ge, Z. Weakly Supervised Multilayer Perceptron for Industrial Fault Classification with Inaccurate and Incomplete Labels. IEEE Trans. Autom. Sci. Eng. 2020, 19, 3043531. [Google Scholar] [CrossRef]
- Borgström, B.J. Bayesian Estimation of PLDA in the Presence of Noisy Training Labels, with Applications to Speaker Verification. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 30, 414–428. [Google Scholar] [CrossRef]
- Twala, B. An empirical comparison of techniques for handling incomplete data using decision trees. Appl. Artif. Intell. 2009, 23, 373–405. [Google Scholar] [CrossRef]
- Capobianco, S.; Millefiori, L.M.; Forti, N.; Braca, P.; Willett, P. Deep Learning Methods for Vessel Trajectory Prediction Based on Recurrent Neural Networks. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 4329–4346. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human-Computer Interaction. IEEE Trans. Ind. Inform. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Shao, J.; Meng, W.; Sun, G. Evaluation of missing value imputation methods for wireless soil datasets. Pers. Ubiquitous Comput. 2016, 21, 113–123. [Google Scholar] [CrossRef]
- Zięba, M. Service-Oriented Medical System for Supporting Decisions with Missing and Imbalanced Data. IEEE J. Biomed. Health Inform. 2014, 18, 1533–1540. [Google Scholar] [CrossRef]
- Vizza, P.; Tradigo, G.; Guzzi, P.H.; Puccio, B.; Prosperi, M.; Torti, C.; Veltri, P. Annotations of Virus Data for Knowledge Enrichment. In Proceedings of the 2022 IEEE 10th International Conference on Healthcare Informatics (ICHI 2022), Rochester, MN, USA, 11–14 June 2022; pp. 492–494. [Google Scholar] [CrossRef]
- Vindas, Y.; Roux, E.; Guépié, B.K.; Almar, M.; Delachartre, P. Semi-supervised annotation of Transcranial Doppler ultrasound micro-embolic data. In Proceedings of the 2021 IEEE International Ultrasonics Symposium (IEEE IUS 2021), Xi’an, China, 11–16 September 2021; Volume 109. [Google Scholar] [CrossRef]
- Sakouhi, T.; Akaichi, J. Dynamic and multi-source semantic annotation of raw mobility data using geographic and social media data. Pervasive Mob. Comput. 2021, 71, 101310. [Google Scholar] [CrossRef]
- Feng, C.; Wang, W.; Tian, Y.; Que, X.; Gong, X. Air quality estimation based on multi-source heterogeneous data from wireless sensor networks. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, X.; Cheng, Y.; Liu, G. Aspect-Based Capsule Network with Mutual Attention for Recommendations. IEEE Trans. Artif. Intell. 2021, 2, 228–237. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Multireceptive Field Graph Convolutional Networks for Machine Fault Diagnosis. IEEE Trans. Ind. Electron. 2021, 68, 12739–12749. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Gui, S.; Ji, S. Explainability in Graph Neural Networks: A Taxonomic Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5782–5799. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Li, X.; Ying, X.; Chuah, M.C. GRIP++: Enhanced Graph-based Interaction-aware Trajectory Prediction for Autonomous Driving. arXiv 2020, arXiv:1907.07792. [Google Scholar]
- Deo, N.; Rangesh, A.; Trivedi, M.M. How would surround vehicles move? A unified framework for maneuver classification and motion prediction. IEEE Trans. Intell. Veh. 2018, 3, 129–140. [Google Scholar] [CrossRef]
- Deo, N.; Rangesh, A.; Trivedi, M.M. Imitating driver behavior with generative adversarial networks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 204–211. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1468–1476. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Traffic Types | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Car | 24.525 | 23.283 | 35.172 | 83.926 | 32.505 | 20.346 | 219.758 |
| Human | 0.184 | 1.45 | 40.799 | 2.858 | 2.478 | 0.438 | 48.208 |
| Bike | 1.724 | 54.245 | 27.948 | 64.191 | 18.209 | 124.879 | 291.197 |
| total | 5.391 | 17.432 | 36.847 | 32.565 | 11.944 | 31.797 | 135.975 |
| test | 20.931 | 32.202 | 33.667 | 57.806 | 64.350 | 47.454 | 256.41 |
| Traffic Types | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Car | 1.127 | 4.467 | 6.792 | 8.211 | 9.692 | 14.421 | 44.71 |
| Human | 0.216 | 1.092 | 1.551 | 1.887 | 2.876 | 3.105 | 10.726 |
| Bike | 1.06 | 5.055 | 6.309 | 6.882 | 7.367 | 12.621 | 39.293 |
| total | 0.584 | 2.639 | 3.646 | 4.25 | 5.227 | 7.462 | 23.807 |
| test | 0.924 | 3.679 | 5.373 | 7.129 | 8.07 | 10.94 | 36.115 |
| Traffic Types | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Car | 0.409 | 0.742 | 1.108 | 1.494 | 1.856 | 2.26 | 7.869 |
| Human | 0.144 | 0.283 | 0.441 | 0.62 | 0.805 | 1.008 | 3.302 |
| Bike | 0.422 | 0.856 | 1.255 | 1.697 | 2.069 | 2.52 | 8.82 |
| total | 0.258 | 0.501 | 0.754 | 1.032 | 1.293 | 1.591 | 5.429 |
| test | 0.256 | 0.485 | 0.731 | 1.007 | 1.273 | 1.57 | 5.322 |
| Methods | V-LSTM | C-VGMM+VIM | GAIL-GRU | MMSI | DTSI | S-PLUS | Proposed Method |
|---|---|---|---|---|---|---|---|
| Accuracy (%) | 46.3 | 47.2 | 47.5 | 67.8 | 60.0 | 68.6 | 96.3 |
| Missing Data Proportion | MMSI | DTSI | S-PLUS | Proposed Method |
|---|---|---|---|---|
| 0 | 0.994 | 0.994 | 0.994 | 0.994 |
| 5 | 0.989 | 0.992 | 0.991 | 0.991 |
| 10 | 0.966 | 0.971 | 0.977 | 0.986 |
| 20 | 0.855 | 0.866 | 0.861 | 0.973 |
| 30 | 0.840 | 0.854 | 0.844 | 0.972 |
| 40 | 0.724 | 0.748 | 0.739 | 0.970 |
| 50 | 0.713 | 0.741 | 0.733 | 0.965 |
| 70 | 0.701 | 0.715 | 0.708 | 0.966 |
| 90 | 0.678 | 0.600 | 0.686 | 0.963 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Zhou, Y.; Cui, X. A Client-Cloud-Chain Data Annotation System of Internet of Things for Semi-Supervised Missing Data. Mathematics 2023, 11, 4543. https://doi.org/10.3390/math11214543
Yu C, Zhou Y, Cui X. A Client-Cloud-Chain Data Annotation System of Internet of Things for Semi-Supervised Missing Data. Mathematics. 2023; 11(21):4543. https://doi.org/10.3390/math11214543
Chicago/Turabian StyleYu, Chao, Yang Zhou, and Xiaolong Cui. 2023. "A Client-Cloud-Chain Data Annotation System of Internet of Things for Semi-Supervised Missing Data" Mathematics 11, no. 21: 4543. https://doi.org/10.3390/math11214543
APA StyleYu, C., Zhou, Y., & Cui, X. (2023). A Client-Cloud-Chain Data Annotation System of Internet of Things for Semi-Supervised Missing Data. Mathematics, 11(21), 4543. https://doi.org/10.3390/math11214543