1. Introduction
The parameters of a distribution are typically considered to be real or perhaps vector values. In the literature, families of distributions are considered that are characterized by having a parameter that is itself a distribution function. These families are called semiparametric because they also contain a real parameter. Choosing the parameter that is first a distribution function is one possible way to use a semiparametric model. The underlying distribution is the formal name for this distribution function. In practice, the selection of an underlying distribution leads to the selection of a parametric model, but the selection is limited to families with the structure of the semiparametric model. Let
F be a cumulative distribution function (cdf) of a lifetime unit with random life length
. In the context of reliability and survival analysis, this random variable usually stands as the random lifetime of a unit in a standard situation. Suppose that
is a non-decreasing function for which
,
where
is a vector of unknown parameters, and
is the parameter space. Then, the random variable
with the following cdf
is said to have a semiparametric model where
F is the baseline distribution. In reliability, the random variable
denotes the random lifetime of a unit in a fresh environment. The underlying distribution
F might already have one or more parameters, in which case a semiparametric family might provide a way to include a new parameter, extending the family from which
F originates. One can imagine that the standard families of the Gamma and Weibull distributions are derived from the exponential distribution via semiparametric families that include a second parameter. The Weibull and Gamma families can both be found as special cases of a three-parameter family using the same technique. The study of semiparametric families is therefore advantageous for two reasons: it provides a new understanding of traditional distribution families, and it offers strategies for extending families to make data fitting more flexible (see, e.g., Marshall and Olkin [
1]).
The concept of the hazard rate (hr) function and also the concept of the reversed hazard rate (rhr) function play an important role in reliability and survival analysis. These quantities measure the instantaneous risk of failure of an aging technical system from the perspective of probability theory. Let
X be the random lifetime of an aging technical system; then let the hr function of
X, denoted by
, be defined as
where
is the probability density function (pdf) and
is the survival function (sf) associated with the random lifetime
X. From (
2) it can be seen that
measures the risk of failure of a unit or a technical system (with lifetime
X) of age
t in a very short interval in the immediate vicinity of the time
t, for example,
, in which
is very close to zero. Therefore, the measure
as a function of
t, the current age of a lifetime unit or technical system, is able to quantify the instantaneous risk of failure of the unit or technical system under consideration at any age (cf. Prentice and Kalbfleisch [
2]). In some situations, a situation with previous failures can also be taken into account. For example, the actual inactivity time of a failed technical system at an inspection time
t may not be known. In such cases, the rhr function is a useful measure to quantify the risk of past failures. The rhr of
X, is denoted by
, defined as
where
is the cdf of
X. It follows from (
3) that
measures the risk of failure of a unit or technical system found to be inactive during an inspection at time
t in a very short interval before time
t, i.e.,
, so that
is almost zero. Consequently, the quantity
is a function of
t, the time at which the unit or technical system is inactive, can be used to measure the instantaneous risk of a past failure of the failed unit or technical system (see, for instance, Block et al. [
3]).
Stochastic orders of random variables have long been a useful tool for making comparisons between probability distributions (see Müller and Stoyan [
4], Shaked and Shanthikumar [
5], Belzunce et al. [
6], and Li and Li [
7]). Basically, a stochastic order is a rule that defines the sense in which one stochastic variable is greater than or less than another. Some researchers used stochastic orders comparing distributions in terms of the magnitude of random variables to perform stochastic comparisons between semiparametric models, including those presented in Equations (
5), (
9) and (
13) in
Section 2. To this end, we quantify the effect of varying the parameters of the model on the variation of the response variables and, furthermore, the effect of changing the underlying distribution on changing the distribution of the response variables using several known stochastic orders. For example, in the context of the proportional hazard rate (PHR) model for the case where
is a random variable (frailty), Gupta and Kirmani [
8] and subsequently Xu and Li [
9] identified some stochastic ordering properties of the model. The PHR model has attracted the attention of many researchers in applied probability and statistics, for instance, see Psarrakos and Sordo [
10], Sankaran and Kumar [
11], Zhang et al. [
12], Arnold et al. [
13] and Kochar [
14]. Considering the proportional reversed hazard rates (PRHR) model, Di Crescenzo [
15] made some stochastic comparisons between two candidate distributions of the model that differ in their parameters. Kirmani and Gupta [
16] derived some stochastic ordering results for the proportional odds rates (POR) model.
Recently, however, many researchers have focused on stochastic orders that compare lifetime distributions according to aging behavior, namely, the faster-aging stochastic orders. One of the key ideas in reliability theory and survival analysis is stochastic aging. It broadly outlines the pattern of aging/degradation of a system over time. Three different notions of aging are presented in the literature: positive aging, negative aging, and no aging. Positive aging implies a stochastically decreasing remaining lifetime of the system. Negative aging implies just the opposite. The system does not mature with time if there is no aging. To study different characteristics of system aging, various aging classes have been presented in the literature based on these three aging principles. The increasing failure rate (IFR), decreasing failure rate (DFR), increasing failure rate on average (IFRA), decreasing failure rate on average (DFRA), increasing likelihood ratio (ILR), and decreasing likelihood ratio (DLR) are among the frequently applied aging classes. The reader can consult Barlow and Proschan [
17] and Lai and Xie [
18] for further discussion on this topic. In addition to these ideas about aging, relative aging is a useful concept to use when studying system reliability. Relative aging is used to measure how a system changes over time relative to another system.
In real life, there are many situations where we deal with multiple systems of the same type (e.g., TVs from different manufacturers, CPUs from different brands, etc.). In these circumstances, we often encounter the following problem: how can we determine whether one system is aging faster than others over time? The idea of relative aging provides a compelling answer to this problem. When dealing with the crossover hazards/medium remaining life phenomena, another component of relative aging proves helpful. Many real-life situations involve this type of circumstance. For example, Pocock et al. [
19] examined survival data on the effects of two different treatments on breast cancer patients and became aware of the phenomenon of crossover hazards. In addition, Champlin et al. [
20] described several cases in which the superiority of one treatment over another lasted only for a short period of time. The above considerations suggest that increasing/decreasing hazard ratio models are a viable option in a variety of real-world scenarios. In fact, Kalashnikov and Rachev [
21] have developed a concept of relative aging based on the monotonicity of the ratio of two hazard rate functions called the relative hazard rate order. This concept is known as faster hazard rate aging. Sengupta and Deshpande [
22] presented another idea in a similar way based on the monotonicity of the ratio of two cumulative hazard rate functions. Rezaei et al. [
23] proposed a relative order based on the ratio of the reversed hazard rates of two random lifetimes and called it the relative reversed hazard rate order. We will utilize the relative hazard rate order and, further, the relative reversed hazard rate order to compare models belonging to a recently introduced semiparametric model.
Let us assume that
and
are two non-negative random variables with continuous distribution functions (cdfs)
F and
G, respectively. Let
and
be two non-negative random variables whose cdfs are transformations of cdfs of
and
, respectively. In view of (
1), suppose that
and
follow cdfs
and
, respectively. The function
is called the distortion function and the cdfs
and
are called distorted distribution functions. These kinds of distributions, called also semiparametric distributions, have attracted the attention of many researchers in statistics, economics, actuarial studies and reliability (see, e.g., Navarro et al. [
24], Navarro and Águila [
25], Lando and Bertoli-Barsotti [
26], Kayid and Al-Shehri [
27] and Navarro and Pellerey [
28]). From theoretical perspectives, the distribution of order statistics and the distribution of record values arisen from a sample from
F follows the foregoing semiparametric model (see, e.g., Izadkhah et al. [
29]). In practical studies, the baseline cdfs
and
represent two models in a population under a standard (reference) situation, for example, the model of the lifetime of an item under a controlled environment. The distorted distributions
and
then specify two altered models in a fresh environment, for instance, the lifetime of an item in a critical situation. One of the problems that has attracted the attention of researchers in applied probability is two study conditions under which
where
denotes a certain stochastic order. The preservation property given in (
4) states that a certain stochastic ordering relation between the baseline populations leads to the same stochastic ordering relation between the altered populations. In the context of many well-known semiparametric models, the implication in (
4) has been studied in the literature (see, e.g., Di Crescenzo [
15], Kirmani and Gupta [
16] and Gupta and Gupta [
30]). However, the studies conducted in this regard have so far only dealt with stochastic orders that take into account the magnitude of the stochastic order. The considered semiparametric families of distributions in the previously accomplished studies have also had a single parameter.
The aim of this work is to perform stochastic comparisons of two newly defined semiparametric models. Each of these models has two parameters. The stochastic orderings we consider here are two recent stochastic orderings that focus on the relative aging of two lifetime units, namely, the relative hazard rate ordering and the relative inverse hazard rate ordering. In particular, we compare the modified proportional hazard rate model (MPHR) and the modified proportional reversed hazard rate model (MPRHR), which correspond to the relative hazard rate ordering and the relative reverse hazard rate ordering. Specifically, the MPHR model is identified as a particular case of (
1), such that
, in which
,
(
) and
The MPRHR model is also identified as a specific case of (
1), so that
, where
,
and
We consider random lifetimes
and
with an MPHR distribution with hr functions
and
and show that
which shows that the unit or technical system with random life
ages faster than the unit or technical system with random life
. In parallel, we assume that if
and
have an MPRHR distribution with rhr functions
and
, then under certain conditions,
indicating that the unit or technical system with random life
ages faster compared to the unit or technical system with random life
.
The rest of the paper is organized as follows. In
Section 2, we give some advanced preliminary considerations and auxiliary results. In
Section 3, we consider the modified proportional hazard rate model for comparison in terms of the relative hazard rate order. In this section, we further consider the modified proportional reversed hazard rate model to give some ordering properties according to the relative reversed hazard rate order. In
Section 4, some examples with numerical simulation studies are provided to show that the theorems are fulfilled. In
Section 5, we conclude the paper with a more detailed summary and provide an outlook on possible future studies. In
Appendix A, we gather the proofs of the main theorems of the paper and also insert four tables to report the results of the simulation studies.
2. Preliminaries
In this section we give some mathematical definitions of the notions that will be utilized in this paper. This section contains a description of well-known facts from probability theory. For a detailed review on mathematical reliability theory, for example, the reader can see Barlow and Proschan [
31], Rykov et al. [
32] and Rykov et al. [
33]. In the literature, many semiparametric families of distributions have been introduced and studied. Among these models, some of them find their applicability in the context of lifetime events. The Cox’s PHR model is of the important and frequently used semiparametric family of distributions (see Cox [
34]). For a review of the PHR model we refer the reader to Kumar and Klefsjö [
35]. Let us consider the parameter
, called the frailty parameter. Then the PHR model is defined as
where
is the survival function (sf) of the response random variable and
is the baseline sf. Let
have an absolutely cdf
with probability density function (pdf)
Then, the hr of
, an important reliability quantity in survival analysis, measures the instantaneous risk of failure of a device with lifetime
at a certain age (
t, say). The hr of
for all
that fulfills
is defined as follows:
It is well-known that
h characterizes the underlying sf,
, as follows:
Suppose that
is the hr function associated with the sf (
5). Then, it is plainly seen that for every
for which
In contrast to the PHR model, the PRHR model was introduced by Gupta et al. [
36]. We refer the reader to Gupta and Gupta [
30] for further descriptions of the PRHR model. In the PRHR model, a positive parameter,
, called the resilience parameter, is considered. The PRHR model is then defined as
in which
is the cdf of the response random variable and
is the baseline cdf or the underlying distribution function of the model. The rhr of
, another reliability quantity, measures the risk of failure of a device (with original lifetime
) in the past at a certain time point
t at which the device is found to be inactive. The rhr of
for all
when
is derived via the following relation:
It has been verified that
characterizes the underlying cdf,
F, as below:
Let us now assume that
is the rhr function of the distribution with the cdf (
9). Then, it is readily realized for all
for which
that
Another reputable semiparametric family of distributions is the POR model (see, e.g., Marshall and Olkin [
37]). This model is defined with cdf
In some situations the following model is alternatively utilized:
The POR model, also known as the Marshall–Olkin model, has been considered by Rykov et al. [
33] in the context of sensitivity analysis. The odds rate function of
measures the relative odds of the event
in terms of the event
, where
t is some point in time. The odds rate function of
for all
when
is defined as follows:
We assume that
is the odds rate function of the distribution with the cdf (
13). Then, it is easily verified for all
for which
that
Balakrishnan et al. [
38] utilized the PHR (resp., PRHR) model as a baseline model in (
13) (resp., (
14)) to propose two new models, referred to as the MPHR and MPRHR models, respectively.
Suppose that
is a baseline random variable with survival function
. Let
be independent and identically distributed (i.i.d.) lifetimes of
n components of a system with a common distribution function
. Then,
are said to follow the MPHR model with tilt parameter
, modified proportional hazard rate
and baseline survival function
(denoted as
) if and only if,
For the case of
, (
17) simply reduces to the PHR model. The MPHR model in (
17) includes some well-known distributions such as the extended exponential and extended Weibull distributions (Marshall and Olkin [
1]), extended Pareto distribution (Ghitany [
39]) and extended Lomax distribution (Ghitany et al. [
40]).
On the other hand, suppose
are i.i.d. lifetimes of
n components of a system with a common distribution functions
F. Then,
are said to follow the MPRHR model with tilt parameter
, modified proportional reversed hazard rate
and baseline distribution function
F (denoted as
MPRHR ) if and only if
Note that the PRHR model is a sub-model of (
18) when
. In
Table 1, we shall give a summary of the semiparametric models that are used in this paper together with the sf, the cdf and the pdf of the models.
We assume that the random variables X and Y have distribution functions F and G, survival functions and , density functions f and g, hazard rate functions and and reversed hazard rate functions and , respectively. To compare the magnitude of random variables, some notions of stochastic orders are introduced below.
Definition 1. Suppose that X and Y are two non-negative random variables that denote the lifetime of two systems. The random variable X is then said to be smaller than the random variable Y in the
- (i)
usual stochastic order (denoted by ) if - (ii)
hazard rate order (denoted by ) if or equivalently, if for all ;
- (iii)
reversed hazard rate order (denoted by ) if or equivalently, if for all ;
- (iv)
likelihood ratio order (denoted by ) if - (v)
relative hazard rate order (denoted by ) if - (vi)
relative reversed hazard rate order (denoted by ) if
Some stochastic orders in Definition 1 are connected to each other. In this regard,
implies
and
also implies
. Furthermore,
gives
and
yields
For further relations and properties of the stochastic orders
and
, we refer the reader to Shaked and Shanthikumar [
5]. For more descriptions of the relative order
, we refer the reader to Kalashnikov and Rachev [
21] and Sengupta and Deshpande [
22]. For further properties of the relative order
, the reader can see Rezaei et al. [
23].
4. Examples and Simulation Analysis
In this section, we provide examples to show that the results of Theorems 1–4 are fulfilled. We also present some numerical studies to verify that the theorems and examples are valid, as shown in a simulation analysis. The numerical computations are moved to
Appendix A.
In the following example, we show that the result of Theorem 1 is applicable.
Example 1. Let us write when X follows the Weibull distribution with shape parameter c and scale parameter d, with , having sf Suppose that and . Assume that and with and and, further, and We can observe that and have hrs and . Therefore,
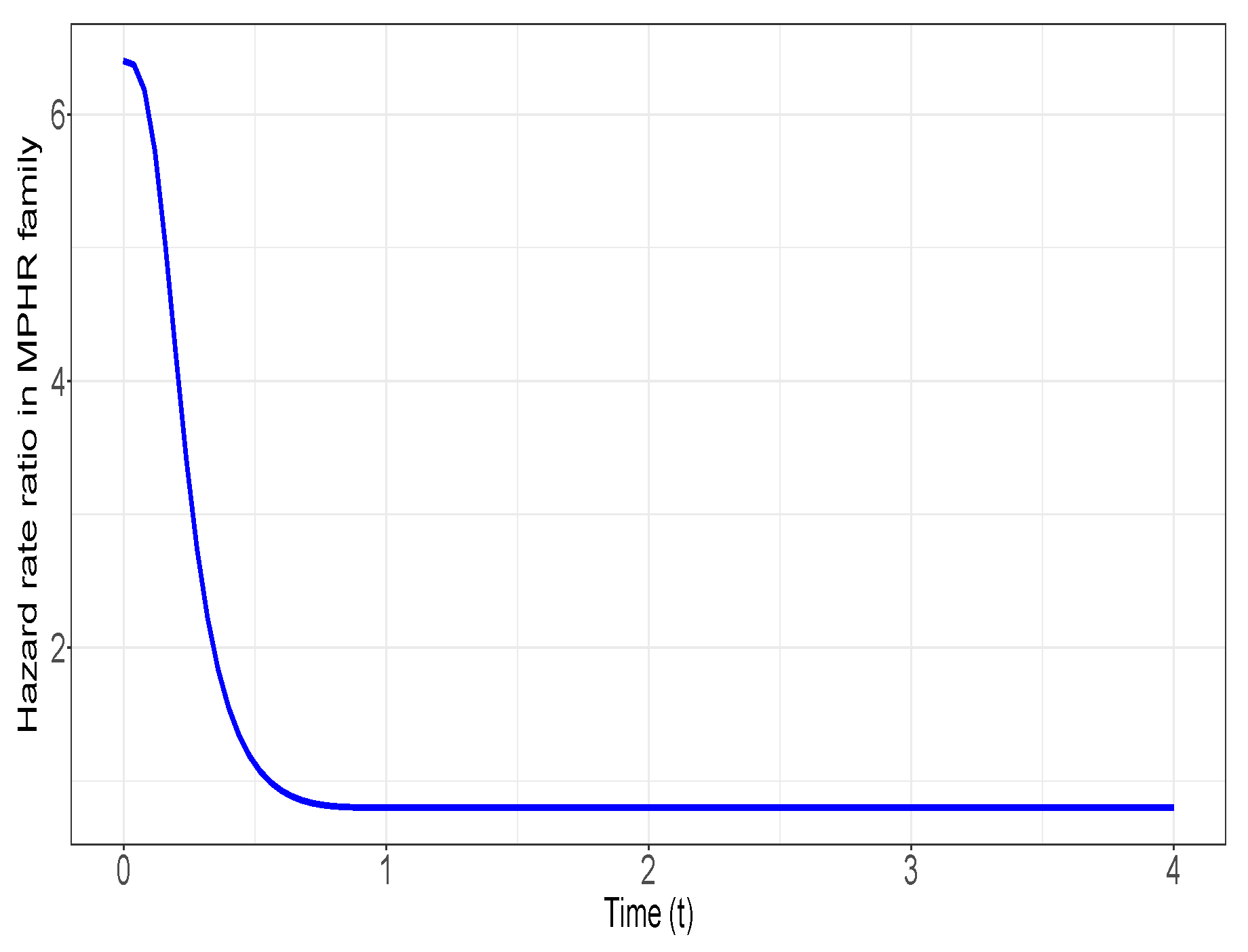
Hence, We can observe thatand, on the other hand, we can see thatThus, obviously, , and using Theorem 1 we conclude that . In Figure 1, the graph of is plotted to exhibit that it is non-increasing in We conduct here a simulation study to empirically ascertain that the result of Theorem 1 is valid. The parameters of the MPHR distributions are chosen exactly as in Example 1, i.e.,
and
, to fulfill the ordering result from the perspective of simulation analysis. We suppose that
and
, exactly as in Example 1. We assume
X and
Y follow MPHR distributions with cdfs
and
and right inverse functions
and
, respectively. We also denote by
and
, the right inverse functions associated with
F and
G, the cdfs of
and
respectively. On applying the runif function in R, we generate
, where
denotes the uniform distribution on
. We utilize the inverse transform technique to produce
as
by which
n samples from
are generated when
, i.e.,
with
. In a similar manner, one can produce
as
which provides
n samples from
where
, i.e.,
in which
. Using the produced samples, we estimate
and
using the maximum likelihood method to obtain a maximum likelihood estimation (MLE) of
, which is denoted by
. The estimations will be acquired by solving the likelihood equations. The MLE
is derived by solving the next system of equations in terms of
The MLE
is also obtained by solving the equations based on
:
To solve the systems of equations given in (
29) and in (
30), we used the package nleqslv in R. In
Table A1 in
Appendix A, we report the MLEs of the parameters of the MPHR model numerically under different sample sizes and also derive the amounts of MLE of
for different selected ages
t. It is shown that the estimated hazard rate ratio for the two choices made in Example 1 is non-increasing in
t, as was expected.
The following example provides a situation where the result of Theorem 2 is applicable.
Example 2. Suppose that follows a gamma distribution with sf and has sf It is easily seen that the hrs of and are and , respectively. Therefore,
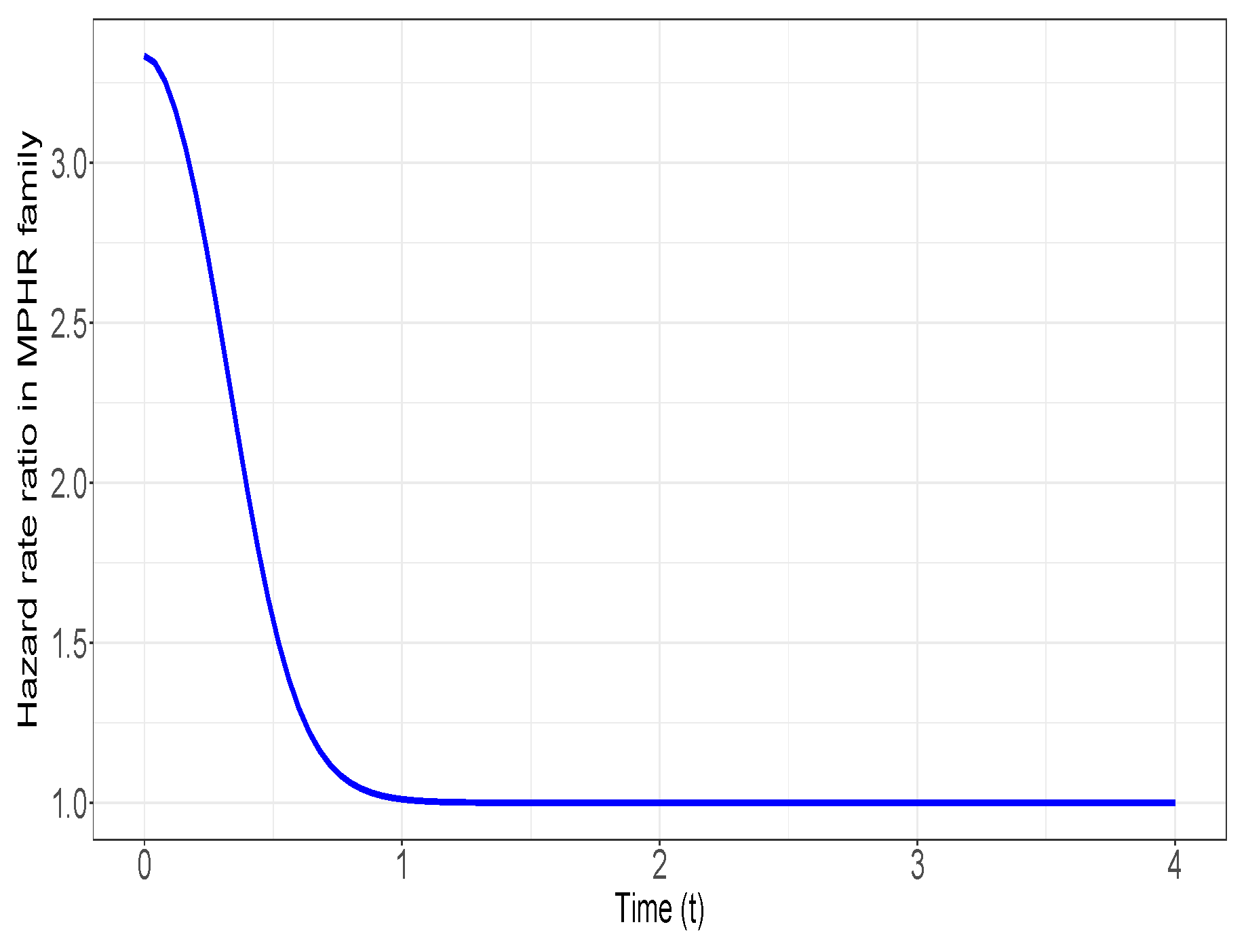
Now, since is non-increasing in t, then We assume that and with and . It is observable thatand, in parallel, it is seen thatTherefore, clearly, , and thus, an application of Theorem 2 concludes that . In Figure 2, the graph of is plotted to indicate that this ratio is non-increasing in As reported in
Table A2 in
Appendix A, the values of the MLEs of
are available under different sample sizes by simulating data from
and
, with
and
and
exactly as chosen in Example 2. We additionally report the values of the MLE of
for some selected ages
t. It is indicated that, for the two candidate models in Example 2, the estimated hazard rate ratio is non-increasing in
t, as was claimed.
Next, we make use of Theorem 3 to show that the result is fulfilled.
Example 3. Let us assume whenever X has an inverse Weibull distribution with shape parameter c and scale parameter d, where and also . Then, X has cdf for We assume that and . Further, we suppose that and with and so that is the cdf of and It can be readily shown that and have rhrs and , respectively. Thus,
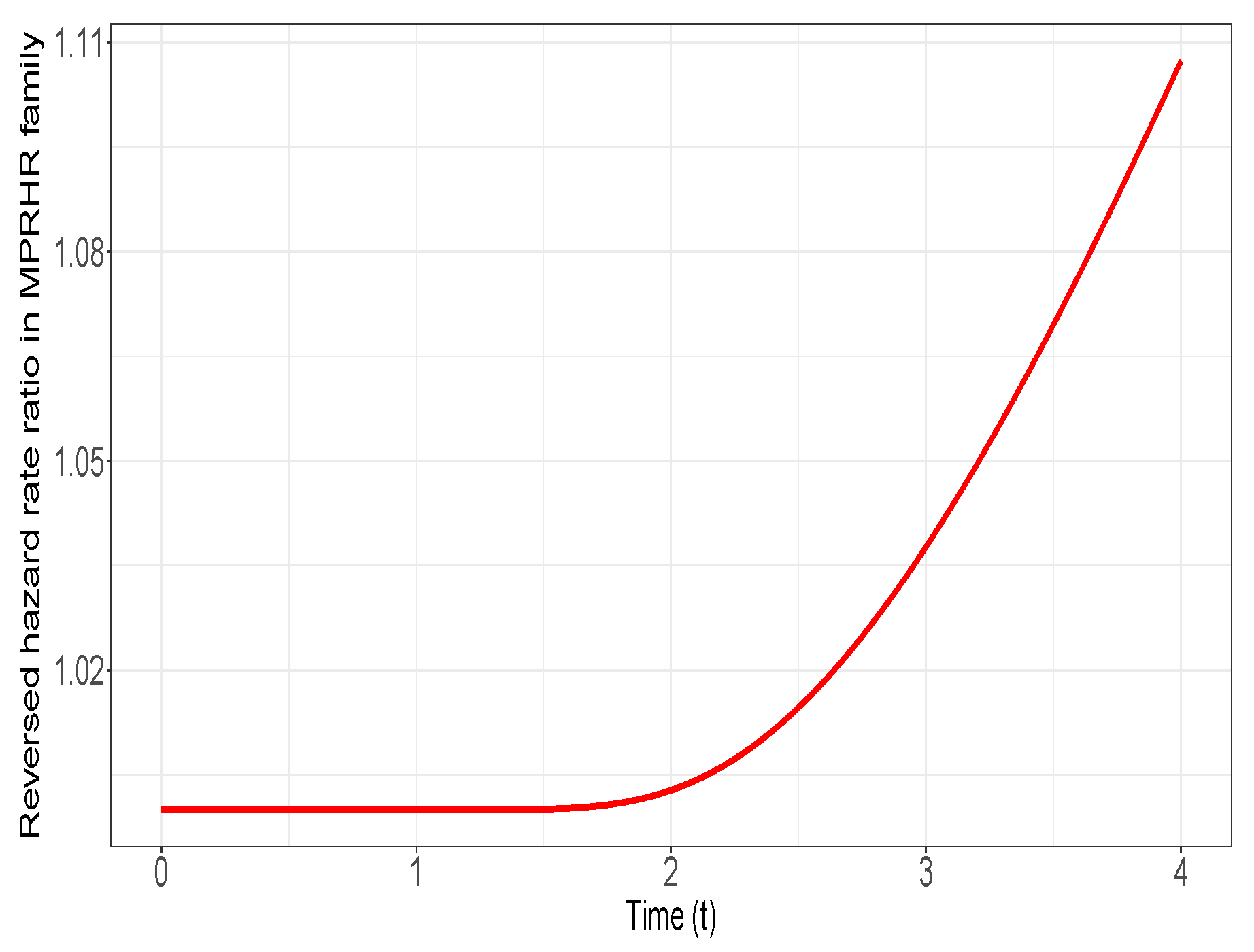
Consequently, One can easily check thatand, simultaneously, one hasTherefore, one realizes that , and using Theorem 3, we deduce that . In Figure 3, the graph of is exhibited to indicate that it is non-decreasing in We proceed now with another simulation study to examine the correctness of the result of Theorem 3. The parameters of the MPRHR distributions are selected as
and
and also assume that
and
, exactly as in Example 3. It is supposed that
X and
Y follow cdfs
and
and denote their right inverse functions by
and
, respectively. We generate
. The inverse transform technique is implemented to simulate
as
from which one obtains
n samples from
so that
, that is,
with
. Analogously, to produce
, one has
through which
n samples from
are simulated in which
, i.e.,
, where
. On the basis of the simulated samples, we want to find the MLEs of
and
, which are denoted by
. The MLE
is derived by solving, with respect to
the system of equations:
The MLE
is also acquired by solving, in terms of
the equations:
We gathered in
Table A3 in
Appendix A the values of the MLEs of the parameters of the MPRHR models under different sample sizes, and also obtain the MLE of
for some
t. It is acknowledged that the estimated reversed hazard rate ratio in the context of Example 3 is non-decreasing in
t, as shown theoretically.
The following example is provided to examine the result of Theorem 4.
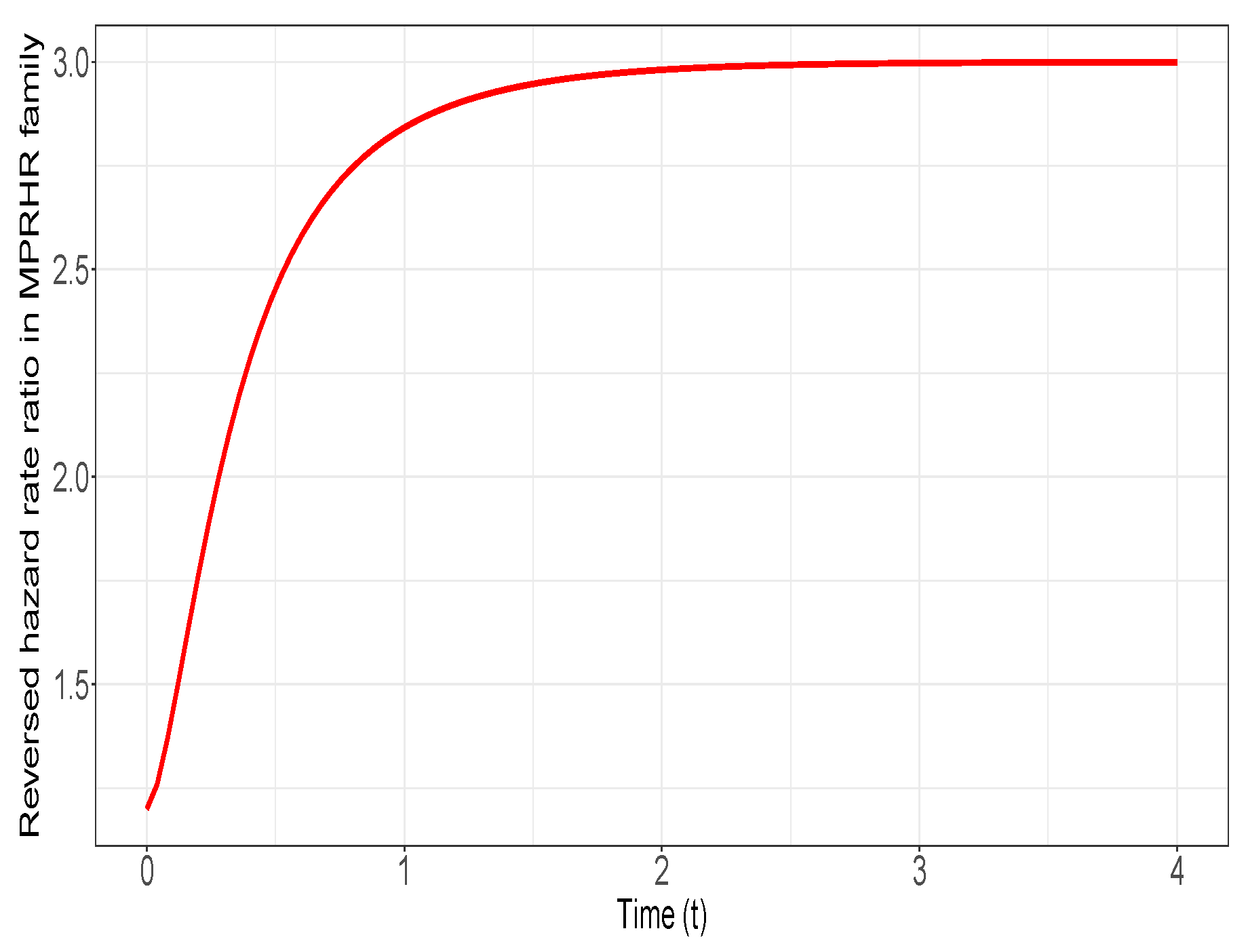
Example 4. Let have cdf and let have an exponential distribution with cdf , where is a common parameter in F and G. Note that for all , where is the rhr of and is the rhr of , respectively. Hence, and also, clearly, . Suppose that and such that and . In view of the notations and definitions in Theorem 4, we haveand on the other hand, one hasThus, it is obvious that Therefore, Theorem 4 is applicable, which provides that In Figure 4, the curve of when is plotted to verify that it is non-decreasing in We have listed in
Table A4 in
Appendix A the values of the MLEs of
under various sample sizes. We simulated data from
and
so that the parameters
together with the baseline cdfs
F and
G are chosen exactly as in Example 4. Further, we report the values of the MLE of
for some selected times
t. It is deduced that the estimated reversed hazard rate ratio of the two MPRHR distributions in Example 4 is non-decreasing in
t. This proves the result of Theorem 4.
Remark 3. The examples presented in this section show that the results obtained apply exclusively to exponential laws. The exponential family of distributions is a very important class of distributions. For example, in Bayesian statistics a prior distribution is multiplied by a likelihood function and then normalised to produce a posterior distribution. In the case of a likelihood that belongs to an exponential family, there exists a conjugate prior, which is often also in an exponential family. There are many standard lifetime distributions that belong to this family of distributions. And, in general, the move to semiparametric models is nothing new in statistics (see, for example, Bayesian methods, which can provide more fundamental results in reliability theory from this point of view). However, the two semiparametric models, namely, the MPHR model and MPRHR model, introduced by Balakrishnan et al. [38], have been found to be applied in different contexts, including reliability and survival analysis. This is because these models encompass three reputable classes of models, namely, the Marshall–Olkin or POR model, the PHR model and the PRHR model. These models have so many applications in reliability and survival analysis (see, e.g., Carree [41]).
5. Concluding Remarks
In this paper, we have examined two recently proposed semiparametric models, namely, the MPHR model and the MPRHR model. As shown by Balakrishnan et al. [
38], these models include as special cases three important models in the literature, namely, the proportional hazard rate model, the proportional reversed hazard rate model and the proportional odds ratio model. Because these three models have found many applications in the literature so far and because they are available to the two newly defined semiparametric models, an analytical study of the latter models is needed because they cover and generalize the previous studies. The study of stochastic orderings for model comparisons has been carried out in the literature in various contexts, including reliability theory, survival analysis, actuarial analysis, risk theory, biostatistics and many other areas. Stochastic orderings are very useful potential tools for model analysis. For example, stochastic orders are very useful for detecting underestimation and overestimation problems in models. Stochastic orderings are usually recognized as tools for making inferences about models without data. The ordering properties of probability distributions reveal other aspects of the distribution or a family of distributions that can be used for various purposes.
The study conducted in this paper addresses situations in which there is a relative ordering property between two candidates from the MPHR family and, moreover, two candidates from the MPRHR family of semiparametric distributions. In general, the base distributions were assumed to be unknown but to satisfy a relative ordering property according to either the relative hazard rate order () or the relative reversed hazard rate order (). It was assumed that the external parameters of the candidate models were generally different. Sufficient conditions were established for the conservation of the relative hazard rate order in the MPHR model and also for the conservation of the relative reversed hazard rate order in the MPRHR model. In the literature, for the preservation of the stochastic order in some scenarios, some stochastic orders are set as assumptions, which is a very strong condition. However, the conditions we found and presented in our work involve comparisons between two numbers, one of which is the supremum or infimum of a function and the other a function of the parameters of the models. With some examples we have shown that even very well-known standard statistical distributions that belong to the exponential family of distributions, such as the Weibull, Gamma or reversed Weibull distributions, can be used as the basic distribution in the MPHR and MPRHR model.
In many studies, different reliability models are considered with different intensities or hazard rate (reversed hazard rate) functions; moreover, there are even studies with compound and generalized intensities that have a discontinuity and atoms, as well as lattice distributions (see, for example, Kalimulina and Zverkina [
42] and Kalimulina and Zverkina [
43]). As can be seen from the graphs, the intensities considered in this paper are only continuous functions. This is a well-studied class of models (essentially exponential, generally a Weibull distribution). However, generalization of the results of this paper for more complicated intensities can be considered in future work.
In a future study, we can also consider stochastic comparisons in the MPHR and MPRHR models according to other stochastic orders, such as the likelihood ratio order (
), hazard rate order (
), reversed hazard rate order (
) and the usual stochastic order
. In the context of the MPHR model, in view of (
20), when
and
follow the pdfs
and
, respectively, then
implies
if
where
. In addition, in the context of the MPHR model, when
and
follow the sfs
and
, respectively, as given in (
19), then
implies
if
where
. In parallel, when the MPHR model is under consideration, as
and
have hrs
and
, respectively, as formulated in (
21), then
yields
if
where
is defined as in (
21). On the other hand, concerning the MPRHR model, by appealing to (
25) and assuming that
and
have pdfs
and
, respectively, then
implies
if
where
. Moreover, by considering the MPRHR model, as
and
follow cdfs
and
, respectively, as provided in (
24), then
implies
if
where
. Furthermore, when the MPRHR model is regarded, so that
and
have rhrs
and
, respectively, as written in (
26), then
yields
if
in which
is defined earlier in equations (
26). The analogous study can also be carried out in the context of other stochastic orders such as the dispersive order, star order and super-additive order.






{kind=link}
{kind=link}
{kind=link}
{kind=link}



