
Using a Node–Child Matrix to Address the Quickest Path Problem in Multistate Flow Networks under Transmission Cost Constraints



Abstract
:1. Introduction
2. Notations, Nomenclature, and Assumptions
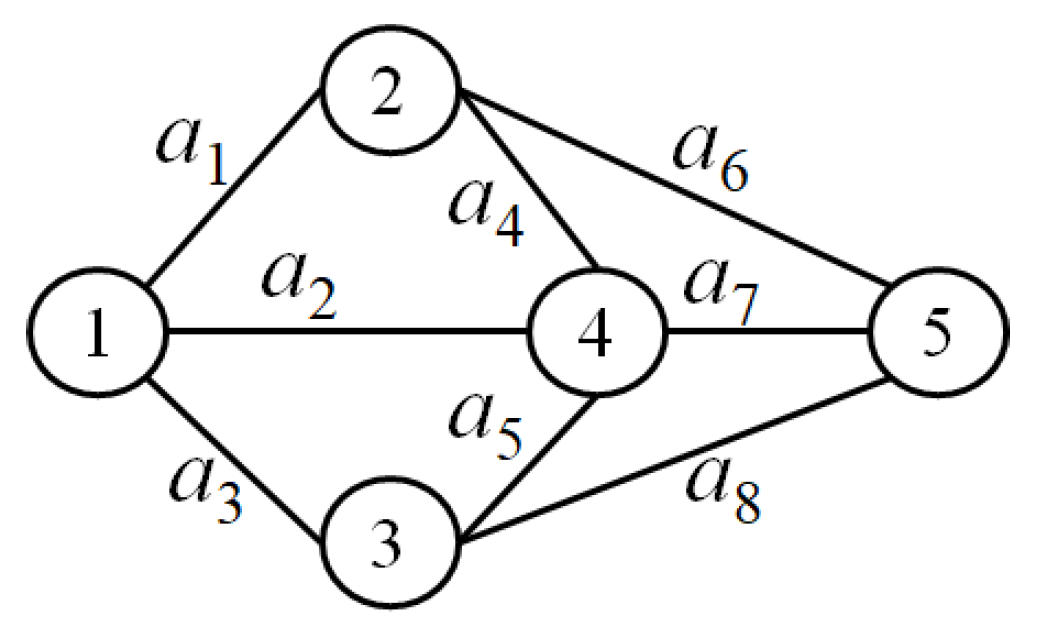
| G | represents a Multistate Flow Network (MFN), with as the node-set, where n signifies the total number of nodes. The collection of arcs is represented as , where m corresponds to the number of arcs. The MFN is further characterized by: (1) , a maximum capacity vector, where signifies the max-capacity of arc for . (2) , a lead time vector, with each representing the lead time of arc for . (3) , a cost vector in which designates the transmission cost of arc for transmitting each unit of flow, for . Moreover, nodes 1 and n are considered respectively the source and destination nodes. To illustrate, Figure 1 depicts an MFN defined by nodes’ set of and arcs’ set of . As an example, the network has lead time, maximum capacity, and cost vectors respectively as follows: 3, 1, 2, 3, 4, 3, 2, 3), 4, 2, 5, 4, 3, 3, 4, 5), and 2, 3, 4, 3, 2, 3, 2, 1). Consequently, for instance, the values within these vectors indicate that at most four units of flow can be transmitted concurrently at any time through , , or due to . Likewise, for example, denotes that passing up to units of flow through lasts three units of time. Furthermore, signifies that transmitting any flow unit on incurs a cost of three currency units. |
| X | represents the current system state vector (SSV). Here, is an integer value, indicating the current capacity of arc for . For instance, 3, 2, 3, 4, 3, 3, 3, 5) can be considered as a SSV for Figure 1. |
| shows the number of arcs incoming into node i for . We call this number the in-degree of the respective node. It is noted that because all flows originate from source node one, and no flow goes to the source node. For instance, we have , , and in the network depicted in Figure 1. | |
| represents the count of outgoing arcs from node i, where . We call this the out-degree of the respective node. It is noted that because all flows go to the destination node, and no flow goes out of this node. For instance, we have , , and in the network depicted in Figure 1. | |
| is the jth minimal path (MP) for . So, h is the number of MPs in the network. As an example, represents an MP for the illustrated network in Figure 1. | |
| is the capacity of under SSV X for . For instance, in Figure 1, the capacity of with 3, 2, 3, 4, 3, 3, 3, 5) is equal to 3, 4, 3, 53. | |
| is the lead time of the MP for 1, 2, . For instance, considering 3, 1, 2, 3, 4, 3, 2, 3), we have 13 for . | |
| is the transmission cost to send one unit of flow through for 1, 2, . For instance, considering 2, 3, 4, 3, 2, 3, 2, 1), we have 8 for . | |
| d | a non-negative integer number that shows the demand value—the flow required to be transmitted from node 1 to node n. |
| b and T are the budget and time limits, respectively. | |
| is the network’s reliability, which is the probability of the successful transmission of at least d units of flow within T units of time through a single MP while incurring a cost of no more than b currency units. |

2.1. Nomenclature
- A vector, say X = (x1, x2, ⋯, xm), is considered smaller than or equal to another vector, say Y = (y1, y2, ⋯, ym), denoted as X ≤ Y, if xi ≤ yi holds for all 1 ≤ i ≤ m. If, in addition to X ≤ Y, there exists at least one j such that xi < yi, we express it as X < Y. For instance, if we take X = (4, 2, 1), Y = (3, 1, 1), and Z = (2, 2, 2), we can observe that Y < X, Z ≮ X, X ≮ Z, Y ≮ Z, and Z ≮ Y.
- We define a vector X ∈ Ψ as a minimal vector when there is no other Y ∈ Ψ such that Y < X. For example, every vector in the set {(4, 3, 1), (2, 1, 3), (3, 4, 1), (1, 2, 2)} is a minimal vector. It is worth noting that a vector does not need to be less than or equal to all other vectors in the set to be considered minimal.
- Noting that a path is a collection of adjacent arcs enabling data transmission from node one to node n, we say (minimal) path P1 is a subset of (minimal) path P2, denoted by P1 ⊂ P2 when P2 encompasses all the arcs present in path P1.
2.2. Assumptions
- The capacity of each arc is a random integer ranging from 0 to for , and it follows a predefined probability distribution function. It is important to emphasize that is a known integer value that represents the maximum capacity of arc .
- The arcs’ capacities are statistically independent.
- The network adheres to the flow conservation law, which means that no other node generates or accumulates flow apart from the source and destination nodes.
- All of the required flow is sent through a solitary path from node one to node n.
- Every node is deterministic, that is, perfectly reliable.
3. Background
4. The NCM-Based Algorithm
5. The Complexity Results and an Illustrative Example
5.1. The Complexity Results
5.2. An Illustrative Example
- Solution: There are nodes and arcs in the given network. We have (3, 3, 3, 3, 5, 4, 4, 5, 3, 5, 5, 4), (1, 4, 2, 3, 2, 4, 2, 3, 1, 1, 1, 3), and (8, 8, 9, 8, 7, 8, 6, 6, 7, 8, 4, 3) according to Table 1, and , , and are given.
- Step 0. We let , , , , , , and .
- Step 1. The NC matrix is equal to
- Step 2. , so we let .
- Step 3. , hence we proceed to Step 7.
- Step 7. , so . As , , and , we let , , , , , , and , and we go to Step 2.
- Step 2. , so we let .
- Step 3. , hence we proceed to Step 7.
- Step 7. , so . As , , and , we let , , , , , , and , and we go to Step 2.
- Step 2. , so we let and repeat this step.
- Step 2. , so we let .
- Step 3. , hence we proceed to Step 7.
- Step 7. , so . As , we let and go to Step 2.
- Step 2. , so we let .
- Step 3. , hence we proceed to Step 7.
- ⋮
- The final set of solutions is obtained: { (3, 0, 0, 3, 0, 0, 0, 0, 0, 0, 3, 0), (2, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0), (0, 0, 3, 0, 0, 0, 0, 0, 3, 3, 3, 0)}.
6. Experimental Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MFN | Multistate flow network |
| SSV | System state vector |
| QPRP | Quickest path reliability problem |
| MP | Minimal path |
References
- Moore, M.H. On the fastest route for convoy-type traffic in flowrate-constrained networks. Transp. Sci. 1976, 10, 113–124. [Google Scholar] [CrossRef]
- Chen, Y.L.; Chin, Y.H. The quickest path problem. Comput. Oper. Res. 1990, 17, 153–161. [Google Scholar] [CrossRef]
- Nagy, B.; Khassawneh, B. On the Number of Shortest Weighted Paths in a Triangular Grid. Mathematics 2020, 8, 118. [Google Scholar] [CrossRef]
- Forghani-elahabad, M.; Yeh, W.C. An improved algorithm for reliability evaluation of flow networks. Reliab. Eng. Syst. Saf. 2022, 221, 108371. [Google Scholar] [CrossRef]
- El Khadiri, M.; Yeh, W.C. An efficient alternative to the exact evaluation of the quickest path flow network reliability problem. Comput. Oper. Res. 2016, 76, 22–32. [Google Scholar] [CrossRef]
- Sedeño-Noda, A.; González-Barrera, J.D. Fast and fine quickest path algorithm. Eur. J. Oper. Res. 2014, 238, 596–606. [Google Scholar] [CrossRef]
- Bai, G.; Xu, B.; Chen, X.; Zhang, Y.A.; Tao, J. Searching for d-MPs for all level d in multistate two-terminal networks without duplicates. IEEE Trans. Reliab. 2020, 70, 319–330. [Google Scholar] [CrossRef]
- Niu, Y.F.; He, C.; Fu, D.Q. Reliability assessment of a multi-state distribution network under cost and spoilage considerations. Ann. Oper. Res. 2021, 309, 189–208. [Google Scholar] [CrossRef]
- Liu, H.; Song, G.; Liu, T.; Guo, B. Multitask Emergency Logistics Planning under Multimodal Transportation. Mathematics 2022, 10, 3624. [Google Scholar] [CrossRef]
- Jia, H.; Peng, R.; Yang, L.; Wu, T.; Liu, D.; Li, Y. Reliability evaluation of demand-based warm standby systems with capacity storage. Reliab. Eng. Syst. Saf. 2022, 218, 108132. [Google Scholar] [CrossRef]
- Calvete, H.I.; del Pozo, L.; Iranzo, J.A. Algorithms for the quickest path problem and the reliable quickest path problem. Comput. Manag. Sci. 2012, 9, 255–272. [Google Scholar] [CrossRef]
- Nguyen, T.P.; Lin, Y.K. Assess reliability of a tourism transport network considering limited-budget and late arrivals. Proc. Inst. Mech. Eng. Part J. Risk Reliab. 2022, 236, 828–840. [Google Scholar] [CrossRef]
- Huang, D.H. A network reliability algorithm for a stochastic flow network with non-conservation flow. Reliab. Eng. Syst. Saf. 2023, 240, 109584. [Google Scholar] [CrossRef]
- Niu, Y.F.; Gao, Z.Y.; Lam, W.H. Evaluating the reliability of a stochastic distribution network in terms of minimal cuts. Transp. Res. Part Logist. Transp. Rev. 2017, 100, 75–97. [Google Scholar] [CrossRef]
- Niu, Y.F.; Wei, J.H.; Xu, X.Z. Computing the Reliability of a Multistate Flow Network with Flow Loss Effect. IEEE Trans. Reliab. 2023, 72, 1432–1441. [Google Scholar] [CrossRef]
- Jiménez, D.; Barrera, J.; Cancela, H. Communication network reliability under geographically correlated failures using probabilistic seismic hazard analysis. IEEE Access 2023, 11, 31341–31354. [Google Scholar] [CrossRef]
- Zhao, J.; Liang, M.; Tian, R.; Zhang, Z.; Cao, X. Reliability Optimization of Hybrid Systems Driven by Constraint Importance Measure Considering Different Cost Functions. Mathematics 2023, 11, 4283. [Google Scholar] [CrossRef]
- Niu, Y.F.; Gao, Z.Y.; Lam, W.H. A new efficient algorithm for finding all d-minimal cuts in multi-state networks. Reliab. Eng. Syst. Saf. 2017, 166, 151–163. [Google Scholar] [CrossRef]
- Lin, S.; Jia, L.; Zhang, H.; Zhang, P. Reliability of high-speed electric multiple units in terms of the expanded multi-state flow network. Reliab. Eng. Syst. Saf. 2022, 225, 108608. [Google Scholar] [CrossRef]
- Huang, D.H.; Huang, C.F.; Lin, Y.K. A novel minimal cut-based algorithm to find all minimal capacity vectors for multi-state flow networks. Eur. J. Oper. Res. 2020, 282, 1107–1114. [Google Scholar] [CrossRef]
- Shier, D.R. Network Reliability and Algebraic Structures; Clarendon Press: Oxford, UK, 1991. [Google Scholar]
- Yeh, W.C. An improved sum-of-disjoint-products technique for the symbolic network reliability analysis with known minimal paths. Reliab. Eng. Syst. Saf. 2007, 92, 260–268. [Google Scholar] [CrossRef]
- Yeh, W.C. A fast algorithm for searching all multi-state minimal cuts. IEEE Trans. Reliab. 2008, 57, 581–588. [Google Scholar]
- Forghani-Elahabad, M. 3 The Disjoint Minimal Paths Reliability Problem. In Operations Research; CRC Press: Boca Raton, FL, USA, 2022; pp. 35–66. [Google Scholar]
- Niu, Y.F.; Xu, X.Z. A new solution algorithm for the multistate minimal cut problem. IEEE Trans. Reliab. 2019, 69, 1064–1076. [Google Scholar] [CrossRef]
- Jane, C.C.; Laih, Y.W. A practical algorithm for computing multi-state two-terminal reliability. IEEE Trans. Reliab. 2008, 57, 295–302. [Google Scholar] [CrossRef]
- Chang, P.C. Simulation approaches for multi-state network reliability estimation: Practical applications. Simul. Model. Pract. Theory 2022, 115, 102457. [Google Scholar] [CrossRef]
- Kozyra, P.M. The usefulness of (d, b)-MCs and (d, b)-MPs in network reliability evaluation under delivery or maintenance cost constraints. Reliab. Eng. Syst. Saf. 2023, 234, 109175. [Google Scholar] [CrossRef]
- Forghani-elahabad, M.; Francesquini, E. Usage of task and data parallelism for finding the lower boundary vectors in a stochastic-flow network. Reliab. Eng. Syst. Saf. 2023, 238, 109417. [Google Scholar] [CrossRef]
- Kozyra, P.M. An Innovative and Very Efficient Algorithm for Searching All Multistate Minimal Cuts Without Duplicates. IEEE Trans. Reliab. 2021, 71, 390–403. [Google Scholar] [CrossRef]
- Huang, D.H.; Huang, C.F.; Lin, Y.K. Reliability Evaluation for a Stochastic Flow Network Based on Upper and Lower Boundary Vectors. Mathematics 2019, 7, 1115. [Google Scholar] [CrossRef]
- Xin-li, L.J.n.S.; Zhen, L. Dynamic Bounding Algorithm for Approximating Multi-state Network Reliability Based on Arc State Enumeration. Comput. Sci. 2012, 39, 8. [Google Scholar]
- Liu, T.; Bai, G.; Tao, J.; Zhang, Y.A.; Fang, Y. An improved bounding algorithm for approximating multistate network reliability based on state-space decomposition method. Reliab. Eng. Syst. Saf. 2021, 210, 107500. [Google Scholar] [CrossRef]
- Nguyen, T.P.; Lin, Y.K.; Chiu, Y.H. Investigate exact reliability under limited time and space of a multistate online food delivery network. Expert Syst. Appl. 2023, 213, 118894. [Google Scholar] [CrossRef]
- Lin, Y.K. Extend the quickest path problem to the system reliability evaluation for a stochastic-flow network. Comput. Oper. Res. 2003, 30, 567–575. [Google Scholar] [CrossRef]
- Yeh, W.C.; Chang, W.W.; Chiu, C.W. A simple method for the multi-state quickest path flow network reliability problem. In Proceedings of the 2009 8th International Conference on Reliability, Maintainability and Safety, Chengdu, China, 20–24 July 2009; pp. 108–110. [Google Scholar]
- Forghani-elahabad, M.; Mahdavi-Amiri, N. A New Algorithm for Generating All Minimal Vectors for the q SMPs Reliability Problem With Time and Budget Constraints. IEEE Trans. Reliab. 2015, 65, 828–842. [Google Scholar] [CrossRef]
- El Khadiri, M.; Yeh, W.C.; Cancela, H. An efficient factoring algorithm for the quickest path multi-state flow network reliability problem. Comput. Ind. Eng. 2023, 179, 109221. [Google Scholar] [CrossRef]
- Yeh, W.C. A simple universal generating function method to search for all minimal paths in networks. IEEE Trans. Syst. Man-Cybern.-Part Syst. Humans 2009, 39, 1247–1254. [Google Scholar]
- Yeh, W.C. A fast algorithm for quickest path reliability evaluations in multi-state flow networks. IEEE Trans. Reliab. 2015, 64, 1175–1184. [Google Scholar] [CrossRef]
- Lin, Y.K. Spare routing reliability for a stochastic flow network through two minimal paths under budget constraint. IEEE Trans. Reliab. 2010, 59, 2–10. [Google Scholar]
- Forghani-elahabad, M.; Mahdavi-Amiri, N. An efficient algorithm for the multi-state two separate minimal paths reliability problem with budget constraint. Reliab. Eng. Syst. Saf. 2015, 142, 472–481. [Google Scholar] [CrossRef]
- Yeh, W.C. Search for all d-mincuts of a limited-flow network. Comput. Oper. Res. 2002, 29, 1843–1858. [Google Scholar] [CrossRef]
- Kobayashi, K.; Yamamoto, H. A new algorithm in enumerating all minimal paths in a sparse network. Reliab. Eng. Syst. Saf. 1999, 65, 11–15. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Hardness; W. H. Freeman: New York, NY, USA, 1979. [Google Scholar]
- Ball, M.O. Computational complexity of network reliability analysis: An overview. IEEE Trans. Reliab. 1986, 35, 230–239. [Google Scholar] [CrossRef]
- Forghani-elahabad, M.; Mahdavi-Amiri, N. An improved algorithm for finding all upper boundary points in a stochastic-flow network. Appl. Math. Model. 2016, 40, 3221–3229. [Google Scholar] [CrossRef]
- Balan, A.O.; Traldi, L. Preprocessing minpaths for sum of disjoint products. IEEE Trans. Reliab. 2003, 52, 289–295. [Google Scholar] [CrossRef]
- Alkaff, A.; Qomarudin, M.N.; Bilfaqih, Y. Network reliability analysis: Matrix-exponential approach. Reliab. Eng. Syst. Saf. 2021, 212, 107591. [Google Scholar] [CrossRef]
- Zuo, M.J.; Tian, Z.; Huang, H.Z. An efficient method for reliability evaluation of multistate networks given all minimal path vectors. IIE Trans. 2007, 39, 811–817. [Google Scholar] [CrossRef]
- Bai, G.; Tian, Z.; Zuo, M.J. An improved algorithm for finding all minimal paths in a network. Reliab. Eng. Syst. Saf. 2016, 150, 1–10. [Google Scholar] [CrossRef]
- Fathabadi, H.S.; Soltanifar, M.; Ebrahimnejad, A.; Nasseri, S. Determining all minimal paths of a network. Aust. J. Basic Appl. Sci. 2009, 3, 3771–3777. [Google Scholar]
- Forghani-elahabad, M.; Bonani, L.H. An improved algorithm for RWA problem on sparse multifiber wavelength routed optical networks. Opt. Switch. Netw. 2017, 25, 63–70. [Google Scholar] [CrossRef]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Arcs | Lead Time | Cost | Capacities/Probabilities | |||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |||
| 1 | 8 | 0.01 | 0.04 | 0.05 | 0.9 | 0 | 0 | |
| 4 | 8 | 0.01 | 0.02 | 0.03 | 0.94 | 0 | 0 | |
| 2 | 9 | 0.01 | 0.09 | 0.1 | 0.8 | 0 | 0 | |
| 3 | 8 | 0.01 | 0.04 | 0.1 | 0.85 | 0 | 0 | |
| 2 | 7 | 0.01 | 0.02 | 0.02 | 0.02 | 0.03 | 0.9 | |
| 4 | 8 | 0.01 | 0.02 | 0.05 | 0.1 | 0.82 | 0 | |
| 2 | 6 | 0.01 | 0.05 | 0.1 | 0.1 | 0.74 | 0 | |
| 3 | 6 | 0.01 | 0.01 | 0.05 | 0.02 | 0.01 | 0.9 | |
| 1 | 7 | 0.01 | 0.02 | 0.02 | 0.95 | 0 | 0 | |
| 1 | 8 | 0.01 | 0.02 | 0.04 | 0.02 | 0.06 | 0.85 | |
| 1 | 4 | 0.01 | 0.03 | 0.03 | 0.03 | 0.05 | 0.85 | |
| 3 | 3 | 0.01 | 0.05 | 0.05 | 0.05 | 0.84 | 0 | |
| d | ||||
|---|---|---|---|---|
| 96 | 283 | 0.0015 | 0.0054 | 3.5430 |
| 102 | 270 | 0.0012 | 0.0052 | 4.4396 |
| 108 | 254 | 0.0012 | 0.0051 | 4.3694 |
| 114 | 224 | 0.0011 | 0.0053 | 4.9603 |
| 120 | 204 | 0.0010 | 0.0050 | 5.1865 |
| 126 | 192 | 0.0009 | 0.0051 | 5.7419 |
| 132 | 177 | 0.0009 | 0.0050 | 5.6753 |
| 138 | 167 | 0.0009 | 0.0050 | 5.6062 |
| 144 | 147 | 0.0008 | 0.0072 | 8.5036 |
| 150 | 137 | 0.0011 | 0.0050 | 4.4366 |
| Geo. Mean | 0.0011 | 0.0053 | 5.2463 | |
| n | |||||
|---|---|---|---|---|---|
| 31 | 30,369 | 12,356 | 1.314 | 8.577 | 6.528 |
| 32 | 25,518 | 10,487 | 0.911 | 5.285 | 5.802 |
| 33 | 35,999 | 14,713 | 1.756 | 10.996 | 6.263 |
| 34 | 22,646 | 9425 | 0.795 | 4.476 | 5.631 |
| 35 | 45,378 | 18,715 | 2.953 | 18.958 | 6.420 |
| 36 | 33,208 | 13,773 | 1.710 | 10.398 | 6.080 |
| 37 | 63,354 | 26,457 | 6.498 | 43.972 | 6.767 |
| 38 | 39,762 | 16,763 | 2.428 | 14.160 | 5.832 |
| 39 | 80,121 | 33,274 | 8.966 | 60.483 | 6.746 |
| 40 | 49,725 | 20,963 | 4.249 | 26.568 | 6.252 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forghani-elahabad, M.; Alsalami, O.M. Using a Node–Child Matrix to Address the Quickest Path Problem in Multistate Flow Networks under Transmission Cost Constraints. Mathematics 2023, 11, 4889. https://doi.org/10.3390/math11244889
Forghani-elahabad M, Alsalami OM. Using a Node–Child Matrix to Address the Quickest Path Problem in Multistate Flow Networks under Transmission Cost Constraints. Mathematics. 2023; 11(24):4889. https://doi.org/10.3390/math11244889
Chicago/Turabian StyleForghani-elahabad, Majid, and Omar Mutab Alsalami. 2023. "Using a Node–Child Matrix to Address the Quickest Path Problem in Multistate Flow Networks under Transmission Cost Constraints" Mathematics 11, no. 24: 4889. https://doi.org/10.3390/math11244889
APA StyleForghani-elahabad, M., & Alsalami, O. M. (2023). Using a Node–Child Matrix to Address the Quickest Path Problem in Multistate Flow Networks under Transmission Cost Constraints. Mathematics, 11(24), 4889. https://doi.org/10.3390/math11244889