
Training Multilayer Neural Network Based on Optimal Control Theory for Limited Computational Resources

 , , , , and
, , , , and
Abstract
:1. Introduction
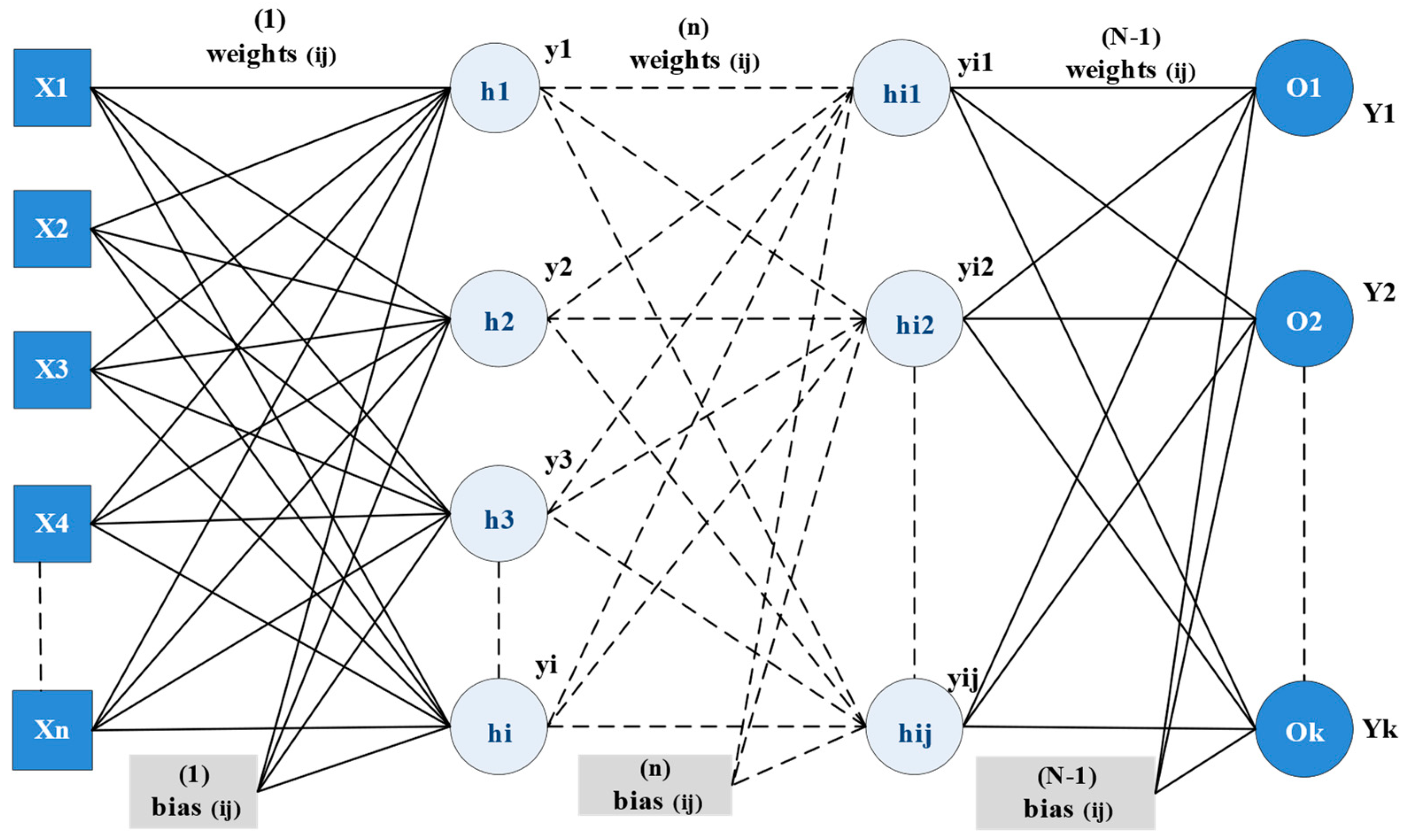
2. Backpropagation Learning Topology
| Algorithm 1: Process of BP algorithm |
| 1. procedure Backpropagation (). |
| 2. input: , = learning factor. |
| 3. randomly initialize all weights and biases. |
| 4. repeat. |
| 5. for all () ∈ D do |
| 6. compute according to the current parameter. |
| 7. compute |
| 8. update , via gradient descent method. |
| 9. end for. |
| 10. until achieve some criterion is satisfied. |
| 11. end procedure. |
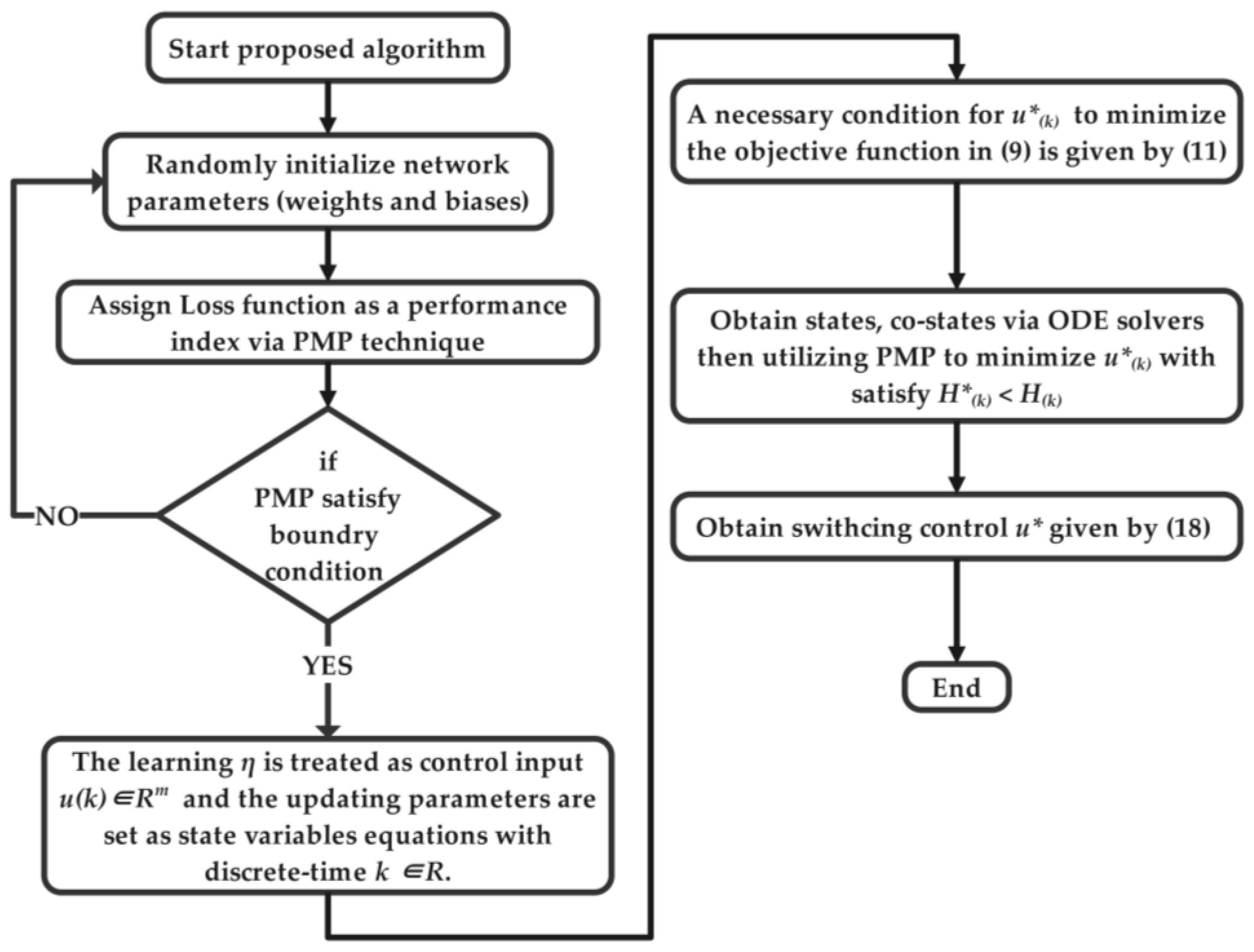
3. Optimal Control Theory
3.1. Pontryagin Minimum Principle
| Algorithm 2: Optimal control based on PMP algorithm |
| 1. system optimal control (). |
| 2. input: , input control, performance index. |
| 3. randomly initialize and . |
| 4. set optimal parameters. |
| 5. repeat. |
| 6. for all () ∈ D do |
| 7. define the Hamiltonian . |
| 8. evaluate necessary optimality conditions. |
| 9. obtain states, co-states via ODE solvers. |
| 10. utilizing PMP to minimize with satisfy . |
| 11. end for. |
| 12. until criteria are satisfied. |
| 13. end procedure. |
3.2. Problem Formulation
3.3. Logic Gate and Full Adder
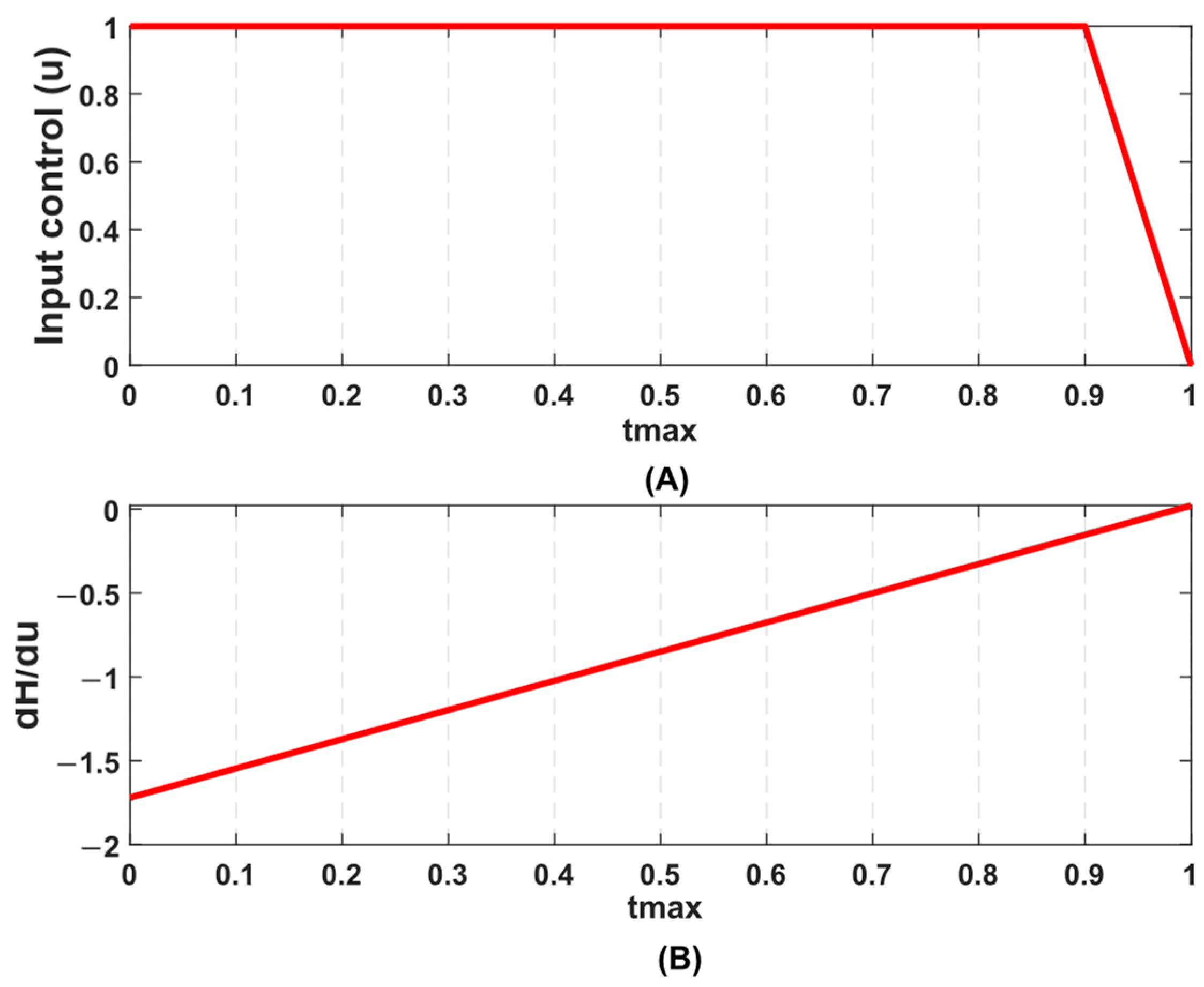
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Soon, F.C.; Khaw, H.Y.; Chuah, J.H.; Kanesan, J. Vehicle logo recognition using whitening transformation and deep learning. Signal Image Video Process. 2019, 13, 111–119. [Google Scholar] [CrossRef]
- Bi, X.; Mao, M.; Wang, D.; Li, H.H. Cross-layer optimization for multilevel cell STT-RAM caches. IEEE Transactions on Very Large Scale Integration (VLSI). Systems 2017, 25, 1807–1820. [Google Scholar]
- Cho, S.-B.; Lee, J.-H. Learning neural network ensemble for practical text classification. In International Conference on Intelligent Data Engineering and Automated Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1032–1036. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Du, K.-L.; Leung, C.-S.; Mow, W.-H.; Swamy, M. Perceptron: Learning, Generalization, Model Selection, Fault Tolerance, and Role in the Deep Learning Era. Mathematics 2022, 10, 4730. [Google Scholar] [CrossRef]
- Jahangir, M.; Golshan, M.; Khosravi, S.; Afkhami, H. Design of a fast convergent backpropagation algorithm based on optimal control theory. Nonlinear Dyn. 2012, 70, 1051–1059. [Google Scholar] [CrossRef]
- Cogollo, M.R.; González-Parra, G.; Arenas, A.J. Modeling and forecasting cases of RSV using artificial neural networks. Mathematics 2021, 9, 2958. [Google Scholar] [CrossRef]
- Effati, S.; Pakdaman, M. Optimal control problem via neural networks. Neural Comput. Appl. 2013, 23, 2093–2100. [Google Scholar] [CrossRef]
- Alkawaz, A.N.; Kanesan, J.; Khairuddin, A.S.M.; Chow, C.O.; Singh, M. Intelligent Charging Control of Power Aggregator for Electric Vehicles Using Optimal Control. Adv. Electr. Comput. Eng. 2021, 21, 21–30. [Google Scholar] [CrossRef]
- Li, Q.; Hao, S. An optimal control approach to deep learning and applications to discrete-weight neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2985–2994. [Google Scholar]
- Chen, L.; Pung, H.K. Convergence analysis of convex incremental neural networks. Ann. Math. Artif. Intell. 2008, 52, 67–80. [Google Scholar] [CrossRef]
- Ghasemi, S.; Nazemi, A.; Hosseinpour, S. Nonlinear fractional optimal control problems with neural network and dynamic optimization schemes. Nonlinear Dyn. 2017, 89, 2669–2682. [Google Scholar] [CrossRef]
- Plakias, S.; Boutalis, Y.S. Lyapunov theory-based fusion neural networks for the identification of dynamic nonlinear systems. Int. J. Neural Syst. 2019, 29, 1950015. [Google Scholar] [CrossRef]
- Lorin, E. Derivation and analysis of parallel-in-time neural ordinary differential equations. Ann. Math. Artif. Intell. 2020, 88, 1035–1059. [Google Scholar] [CrossRef]
- Li, Q.; Chen, L.; Tai, C. Maximum principle based algorithms for deep learning. arXiv 2017, arXiv:1710.09513. [Google Scholar]
- Wen, S.; Xiao, S.; Yang, Y.; Yan, Z.; Zeng, Z.; Huang, T. Adjusting learning rate of memristor-based multilayer neural networks via fuzzy method. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 38, 1084–1094. [Google Scholar] [CrossRef]
- Ede, J.M.; Beanland, R. Adaptive learning rate clipping stabilizes learning. Mach. Learn. Sci. Technol. 2020, 1, 015011. [Google Scholar] [CrossRef]
- Sabbaghi, R.; Dehbozorgi, L.; Akbari-Hasanjani, R. New full adders using multi-layer perceptron network. Int. J. Smart Electr. Eng. 2020, 8, 115–120. [Google Scholar]
- Anita, R.; Rao, B.R.; Vakamullu, V. Implementation of fpga-Based Artificial Neural Network (ANN) for Full Adder. J. Anal. Comp. 2018, XI, 1–10. [Google Scholar]
- Kaya, E. A new neural network training algorithm based on artificial bee colony algorithm for nonlinear system identification. Mathematics 2022, 10, 3487. [Google Scholar] [CrossRef]
- Mahmood, T.; Ali, N.; Chaudhary, N.I.; Cheema, K.M.; Milyani, A.H.; Raja, M.A.Z. Novel Adaptive Bayesian Regularization Networks for Peristaltic Motion of a Third-Grade Fluid in a Planar Channel. Mathematics 2022, 10, 358. [Google Scholar] [CrossRef]
- Soon, F.C.; Khaw, H.Y.; Chuah, J.H.; Kanesan, J. Semisupervised PCA convolutional network for vehicle type classification. IEEE Trans. Veh. Technol. 2020, 69, 8267–8277. [Google Scholar] [CrossRef]
- Zain, M.Z.M.; Kanesan, J.; Kendall, G.; Chuah, J.H. Optimization of fed-batch fermentation processes using the Backtracking Search Algorithm. Expert Syst. Appl. 2018, 91, 286–297. [Google Scholar] [CrossRef]
- Jeevan, K.; Quadir, G.; Seetharamu, K.; Azid, I. Thermal management of multi-chip module and printed circuit board using FEM and genetic algorithms. Microelectron. Int. 2005, 22, 3–15. [Google Scholar] [CrossRef]
- Hoo, C.-S.; Jeevan, K.; Ganapathy, V.; Ramiah, H. Variable-order ant system for VLSI multiobjective floorplanning. Appl. Soft Comput. 2013, 13, 3285–3297. [Google Scholar] [CrossRef]
- Eswaran, U.; Ramiah, H.; Kanesan, J. Power amplifier design methodologies for next generation wireless communications. IETE Tech. Rev. 2014, 31, 241–248. [Google Scholar] [CrossRef]
- Mallick, Z.; Badruddin, I.A.; Hussain, M.K.; Ahmed, N.S.; Kanesan, J. Noise characteristics of grass-trimming machine engines and their effect on operators. Noise Health 2009, 11, 98. [Google Scholar]
- Hoo, C.-S.; Yeo, H.-C.; Jeevan, K.; Ganapathy, V.; Ramiah, H.; Badruddin, I.A. Hierarchical congregated ant system for bottom-up VLSI placements. Eng. Appl. Artif. Intell. 2013, 26, 584–602. [Google Scholar] [CrossRef]
- Heravi, A.R.; Hodtani, G.A. A new correntropy-based conjugate gradient backpropagation algorithm for improving training in neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6252–6263. [Google Scholar] [CrossRef]
- Huang, D.; Wu, Z. Forecasting outpatient visits using empirical mode decomposition coupled with back-propagation artificial neural networks optimized by particle swarm optimization. PLoS ONE 2017, 12, e0172539. [Google Scholar] [CrossRef]
- Eğrioğlu, E.; Aladağ, Ç.H.; Günay, S. A new model selection strategy in artificial neural networks. Appl. Math. Comput. 2008, 195, 591–597. [Google Scholar] [CrossRef]
- Kenyon, C.; Paugam-Moisy, H. Multilayer neural networks and polyhedral dichotomies. Ann. Math. Artif. Intell. 1998, 24, 115–128. [Google Scholar] [CrossRef]
- Ehret, A.; Hochstuhl, D.; Gianola, D.; Thaller, G. Application of neural networks with back-propagation to genome-enabled prediction of complex traits in Holstein-Friesian and German Fleckvieh cattle. Genet. Sel. Evol. 2015, 47, 22. [Google Scholar] [CrossRef] [PubMed]
- Alkawaz, A.N.; Abdellatif, A.; Kanesan, J.; Khairuddin, A.S.M.; Gheni, H.M. Day-Ahead Electricity Price Forecasting Based on Hybrid Regression Model. IEEE Access 2022, 10, 108021–108033. [Google Scholar] [CrossRef]
- Szandała, T. Review and Comparison of Commonly Used Activation Functions for Deep Neural Networks. In Bio-Inspired Neurocomputing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 203–224. [Google Scholar]
- Jin, X.; Shin, Y.C. Nonlinear discrete time optimal control based on Fuzzy Models. J. Intell. Fuzzy Syst. 2015, 29, 647–658. [Google Scholar] [CrossRef]
- Agrachev, A.; Beschastnyi, I. Jacobi Fields in Optimal Control: One-dimensional Variations. J. Dyn. Control Syst. 2020, 26, 685–732. [Google Scholar] [CrossRef]
- El Boukhari, N. Constrained optimal control for a class of semilinear infinite dimensional systems. J. Dyn. Control Syst. 2018, 24, 65–81. [Google Scholar]
- Tseng, P.; Yun, S. A coordinate gradient descent method for nonsmooth separable minimization. Math. Program. 2009, 117, 387–423. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 |
| Training Models | Loss Function | Average Error (%) | Training Time (s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| OC (XOR) | 5.677 × 10−10 | 3.165 × 10−5 | 0.9999 | 0.9999 | 3.207 × 10−5 | 0 | 1 | 1 | 0 | 1.3 × 10−6 | 2.306 |
| BP (XOR) | 2.563 × 10−6 | 0.002 | 0.997 | 0.9974 | 0.002 | 4.165 | |||||
| OC (OR) | 2.598 × 10−11 | 1.0196 × 10−5 | 0.999 | 0.999 | 1 | 0 | 1 | 1 | 1 | 2.49 × 10−7 | 2.324 |
| BP (OR) | 4.98 × 10−7 | 0.0040 | 0.997 | 0.997 | 0.999 | 4.28 | |||||
| OC (AND) | 5.236 × 10−11 | 4.427 × 10−6 | 1.054 × 10−5 | 1.056 × 10−5 | 0.999 | 0 | 0 | 0 | 1 | 1.04× 10−6 | 2.283 |
| BP (AND) | 2.08 × 10−6 | 0.0003 | 0.002 | 0.002 | 0.997 | 4.120 | |||||
| OC (NAND) | 2.774 × 10−11 | 1 | 0.999 | 0.999 | 1.045 × 10−5 | 1 | 1 | 1 | 0 | 3.53 × 10−7 | 2.636 |
| BP (NAND) | 7.07 × 10−7 | 0.999 | 0.998 | 0.998 | 0.0019 | 3.197 | |||||
| OC (XNOR) | 1.13 × 10−10 | 0.9999 | 1.428 × 10−5 | 1.422 × 10−5 | 0.999 | 1 | 0 | 0 | 1 | 2.38 × 10−6 | 2.354 |
| BP (XNOR) | 4.76 × 10−6 | 0.997 | 0.0033 | 0.0033 | 0.997 | 3.836 | |||||
| OC (NOR) | 2.59 × 10−11 | 0.9999 | 7.051 × 10−6 | 7.0503 × 10−6 | 2.33 × 10−6 | 1 | 0 | 0 | 0 | 5.06 × 10−7 | 2.227 |
| BP (NOR) | 1.012 × 10−6 | 0.997 | 0.001 | 0.0011 | 0.00025 | 3.9811 | |||||
| Inputs | Boolean Expression | BPNN | Percentage Error (%) | OC | Percentage Error (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | SUM | SUM | SUM | SUM | SUM | ||||||
| 0 | 0 | 0 | 0 | 0 | 3.488 × 10−5 | 1.122 × 10−5 | 0 | 0 | 1.415 × 10−5 | 1.019 × 10−5 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 0.995 | 1.123 × 10−5 | 0.5 | 0 | 0.998 | 1.02 × 10−5 | 0.2 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0.995 | 1.123 × 10−5 | 0.5 | 0 | 0.998 | 1.02 × 10−5 | 0.2 | 0 |
| 0 | 1 | 1 | 0 | 1 | 5.312 × 10−5 | 0.999 | 0 | 0.1 | 1.431 × 10−5 | 0.999 | 0 | 0.1 |
| 1 | 0 | 0 | 1 | 0 | 0.995 | 1.123 × 10−5 | 0.5 | 0 | 0.999 | 1.097 × 10−5 | 0.1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 5.311 × 10−5 | 0.999 | 0 | 0.1 | 1.431 × 10−5 | 0.999 | 0 | 0.1 |
| 1 | 1 | 0 | 0 | 1 | 3.488 × 10−5 | 0.999 | 0 | 0.1 | 1.415 × 10−5 | 0.999 | 0 | 0.1 |
| 1 | 1 | 1 | 1 | 1 | 0.994 | 0.999 | 0.6 | 0.1 | 0.999 | 0.999 | 0.1 | 0.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkawaz, A.N.; Kanesan, J.; Khairuddin, A.S.M.; Badruddin, I.A.; Kamangar, S.; Hussien, M.; Baig, M.A.A.; Ahammad, N.A. Training Multilayer Neural Network Based on Optimal Control Theory for Limited Computational Resources. Mathematics 2023, 11, 778. https://doi.org/10.3390/math11030778
Alkawaz AN, Kanesan J, Khairuddin ASM, Badruddin IA, Kamangar S, Hussien M, Baig MAA, Ahammad NA. Training Multilayer Neural Network Based on Optimal Control Theory for Limited Computational Resources. Mathematics. 2023; 11(3):778. https://doi.org/10.3390/math11030778
Chicago/Turabian StyleAlkawaz, Ali Najem, Jeevan Kanesan, Anis Salwa Mohd Khairuddin, Irfan Anjum Badruddin, Sarfaraz Kamangar, Mohamed Hussien, Maughal Ahmed Ali Baig, and N. Ameer Ahammad. 2023. "Training Multilayer Neural Network Based on Optimal Control Theory for Limited Computational Resources" Mathematics 11, no. 3: 778. https://doi.org/10.3390/math11030778
APA StyleAlkawaz, A. N., Kanesan, J., Khairuddin, A. S. M., Badruddin, I. A., Kamangar, S., Hussien, M., Baig, M. A. A., & Ahammad, N. A. (2023). Training Multilayer Neural Network Based on Optimal Control Theory for Limited Computational Resources. Mathematics, 11(3), 778. https://doi.org/10.3390/math11030778