Reinforcement Learning-Based Lane Change Decision for CAVs in Mixed Traffic Flow under Low Visibility Conditions




Abstract
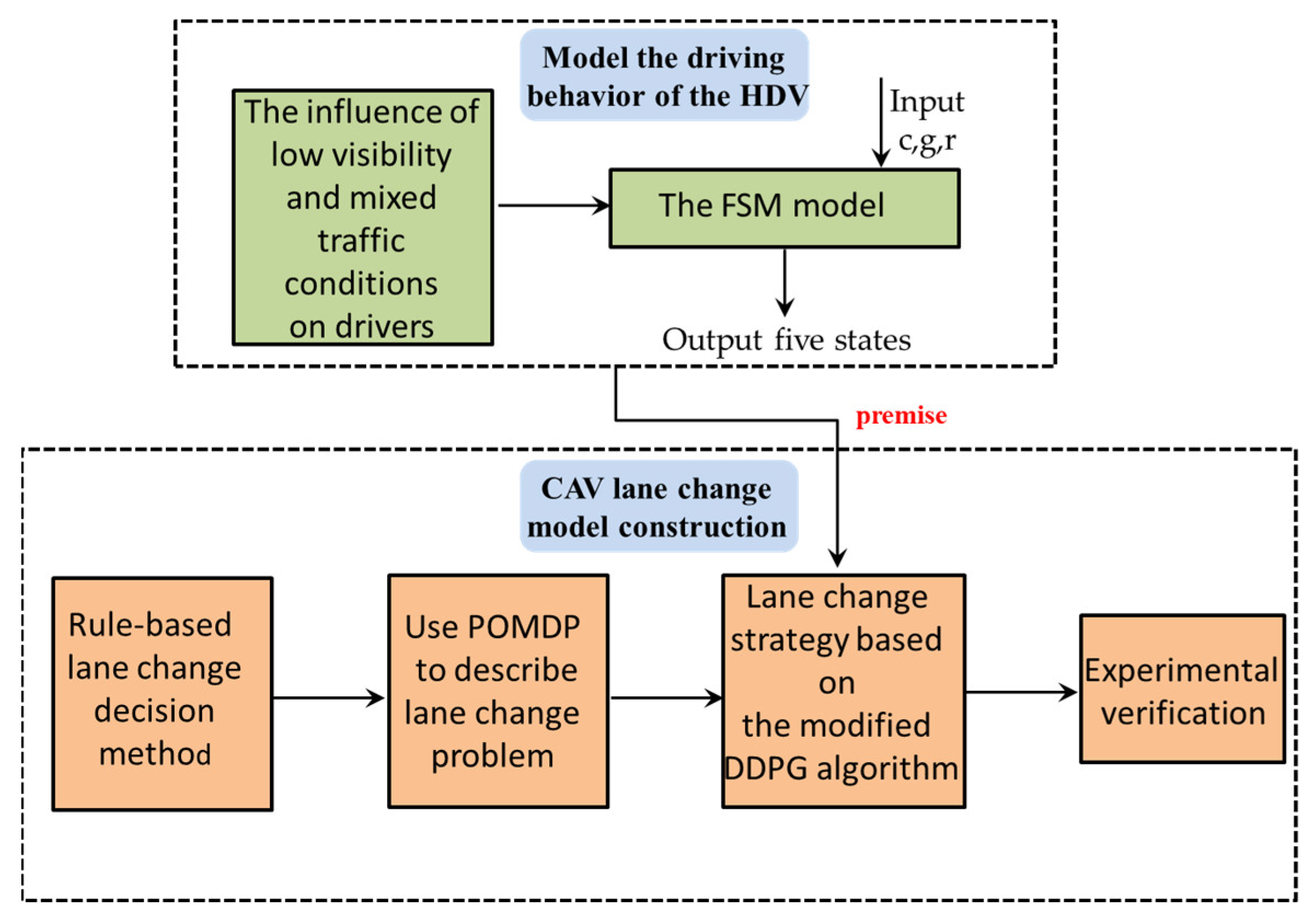
:1. Introduction
2. Literature Review
3. Problem Formulation
3.1. The Longitudinal Control Model for Drivers in Low-Visibility Mixed Traffic Conditions
3.1.1. The Influence of Low Visibility and Mixed Traffic Conditions on Drivers
3.1.2. The Car following States
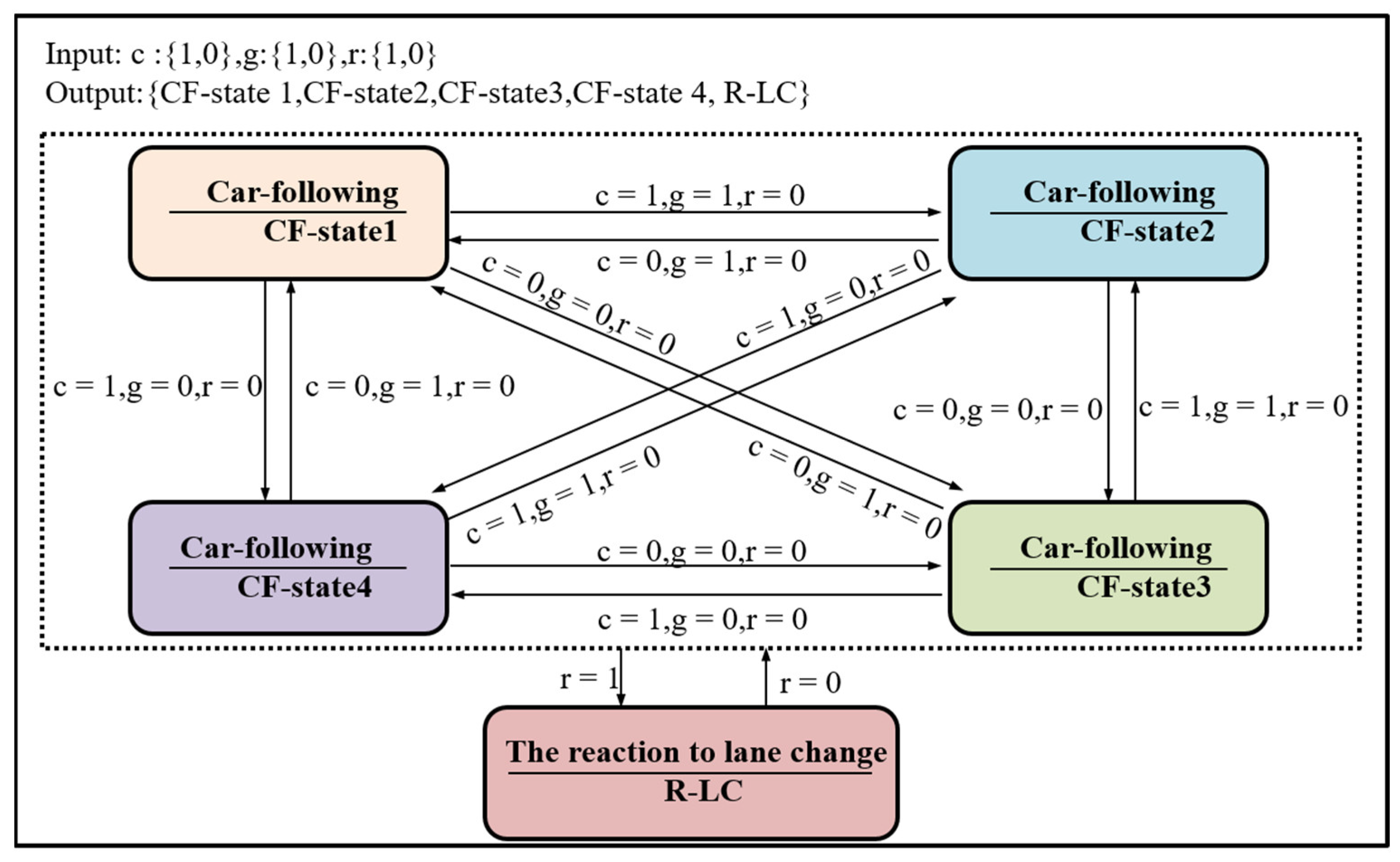
3.1.3. The Response Model to Lane Change
3.1.4. The FSM Model
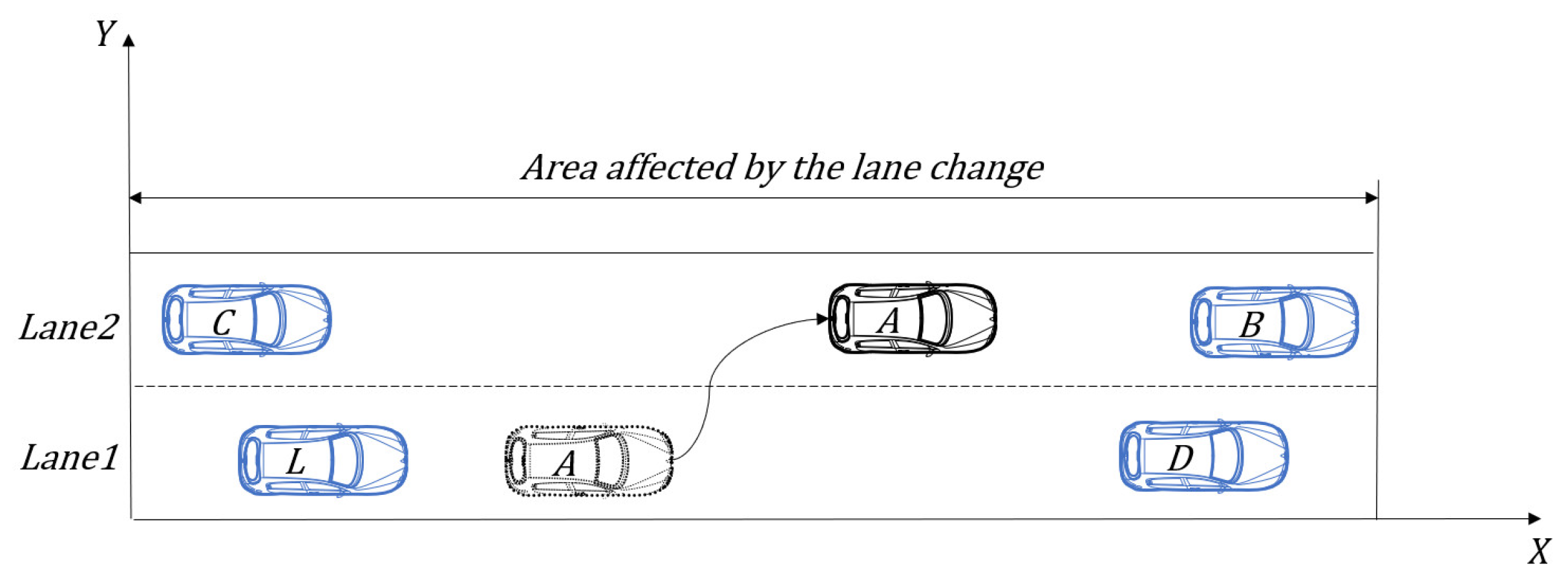
3.2. The Lane Change Decision Problem
4. Solution Methodology
4.1. The POMDP Mathematical Model
- State : State of the entire lane change system, including CAV A and surrounding vehicles. The system coordinate is shown in Figure 1, based on which, the state information can be described by the longitudinal position, lateral position and velocity of all vehicles, as shown in Equation (22):where the velocity limit is related to the current visibility of the highway.
- Action A: The longitudinal acceleration and steering angle of the CAV are used as defined action parameters, as shown in Equation (23):
- Transfer function : The dynamic model of the lane change system, which is difficult to describe precisely.
- Observation : Due to the influence of the environment or the physical limitations of the sensor itself, CAV A can only obtain the information about other vehicles when sensor noise is present or missing. Z is defined as:
- Reward function : The reward function is the key to achieve the goal of lane change. We design the reward function from the perspective of safety, efficiency and comfort:where denotes the reward function of the comfort level. is the longitudinal acceleration rate. is the lateral acceleration rate. and are the weighting factors of the longitudinal acceleration rate and the lateral acceleration rate, respectively. The comfort reward is introduced mainly to reduce sudden acceleration and deceleration of the CAV A.
- Discount factor : We use the action value function to evaluate the goodness of the current action, and the value function is updated to consider future rewards with discounts , as shown in Equation (31):where is the reward corresponding to the state and action at moment . is a dynamic model of the system that represents the probability of the system changing from state to state after taking action .
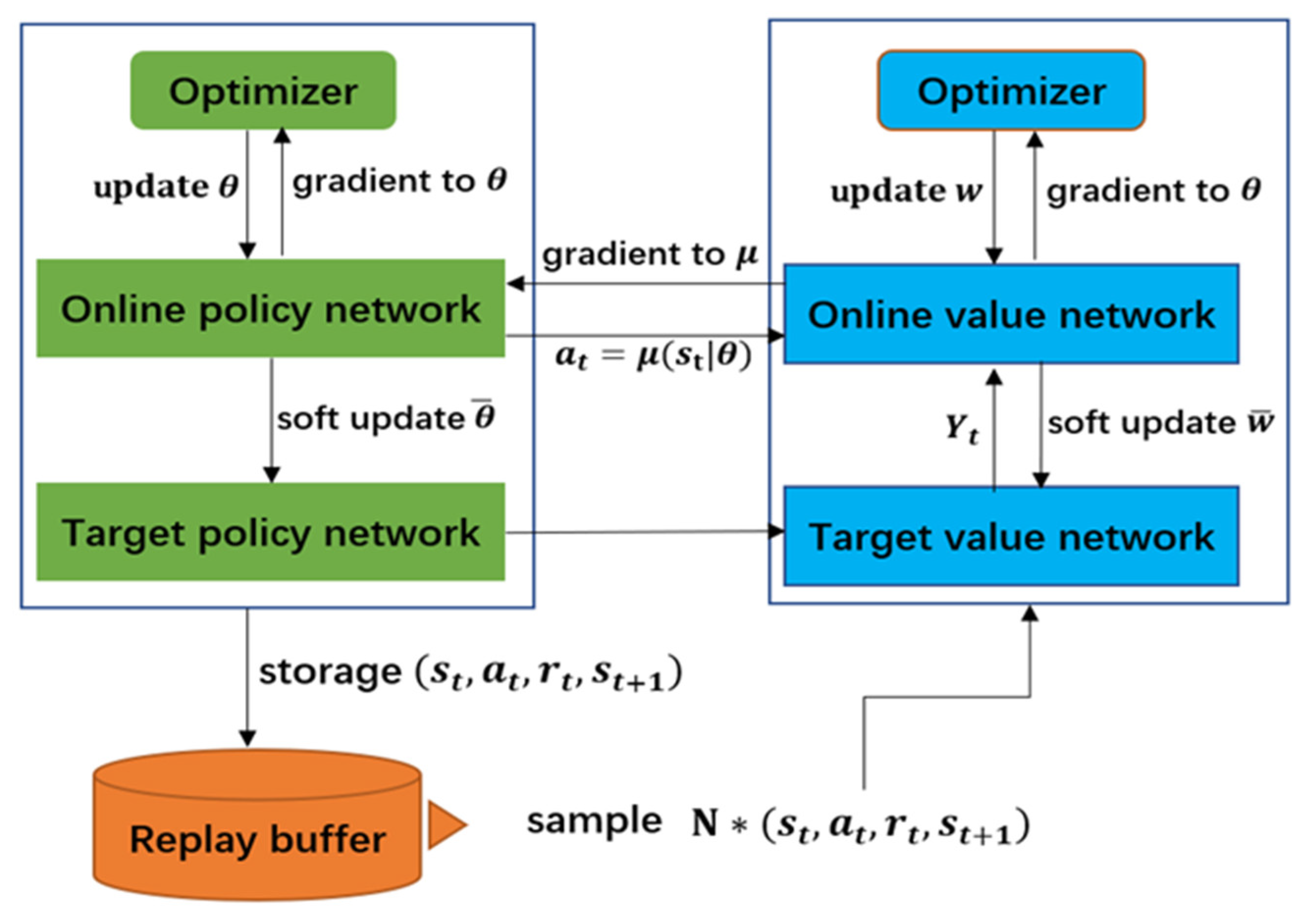
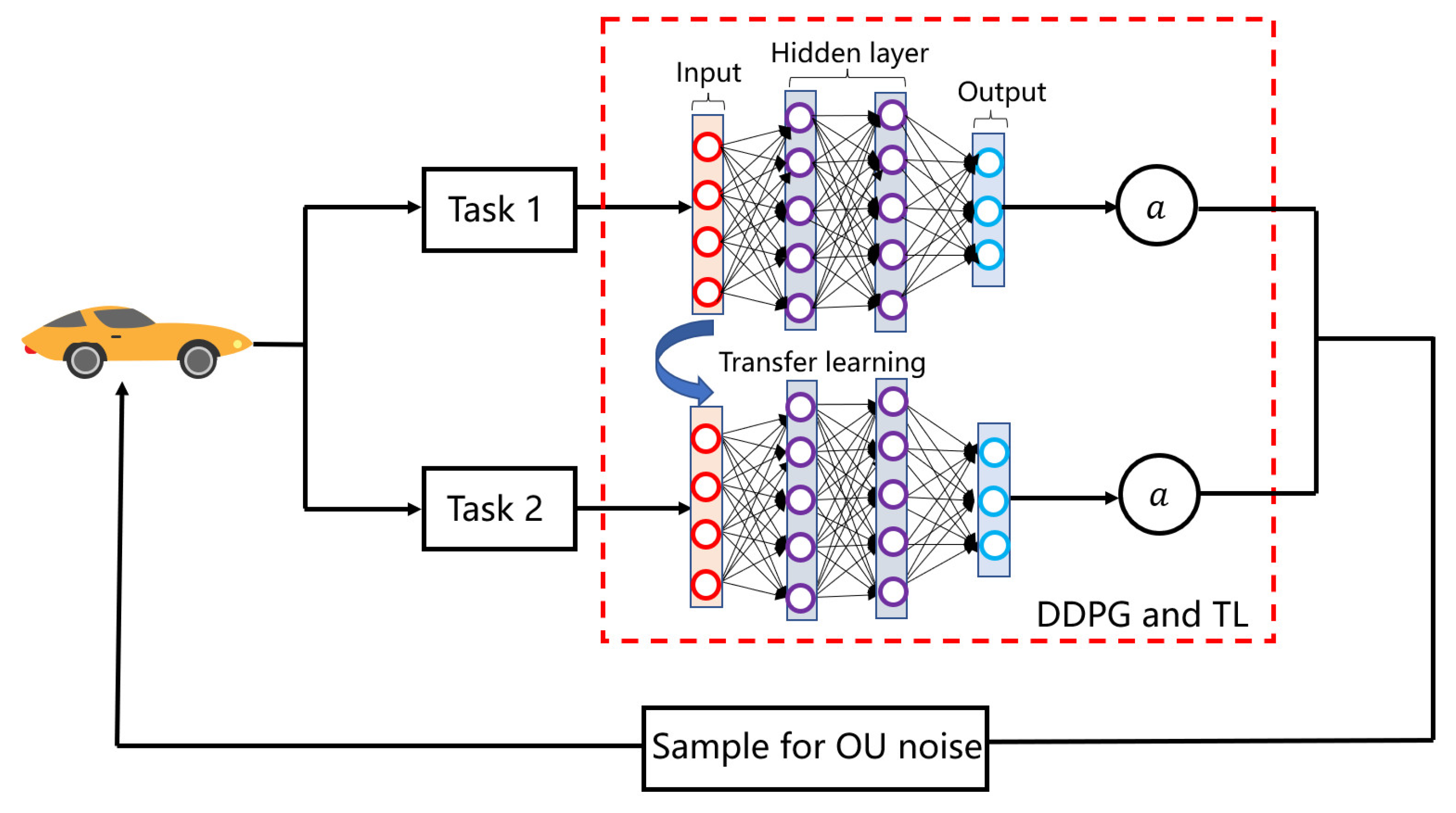
4.2. The Modified DDPG Algorithm
5. Numerical Experiments
5.1. Experiment Design
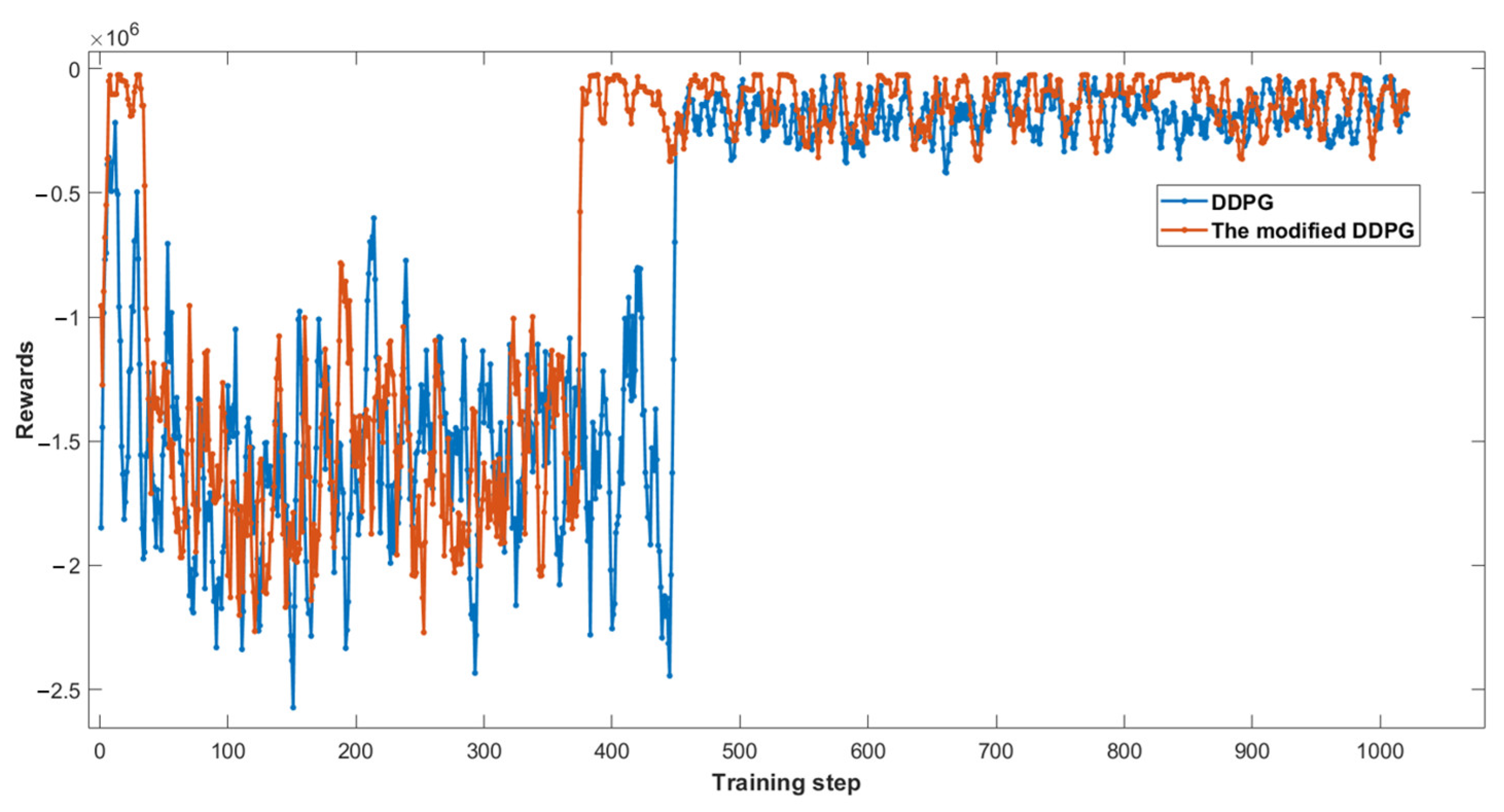
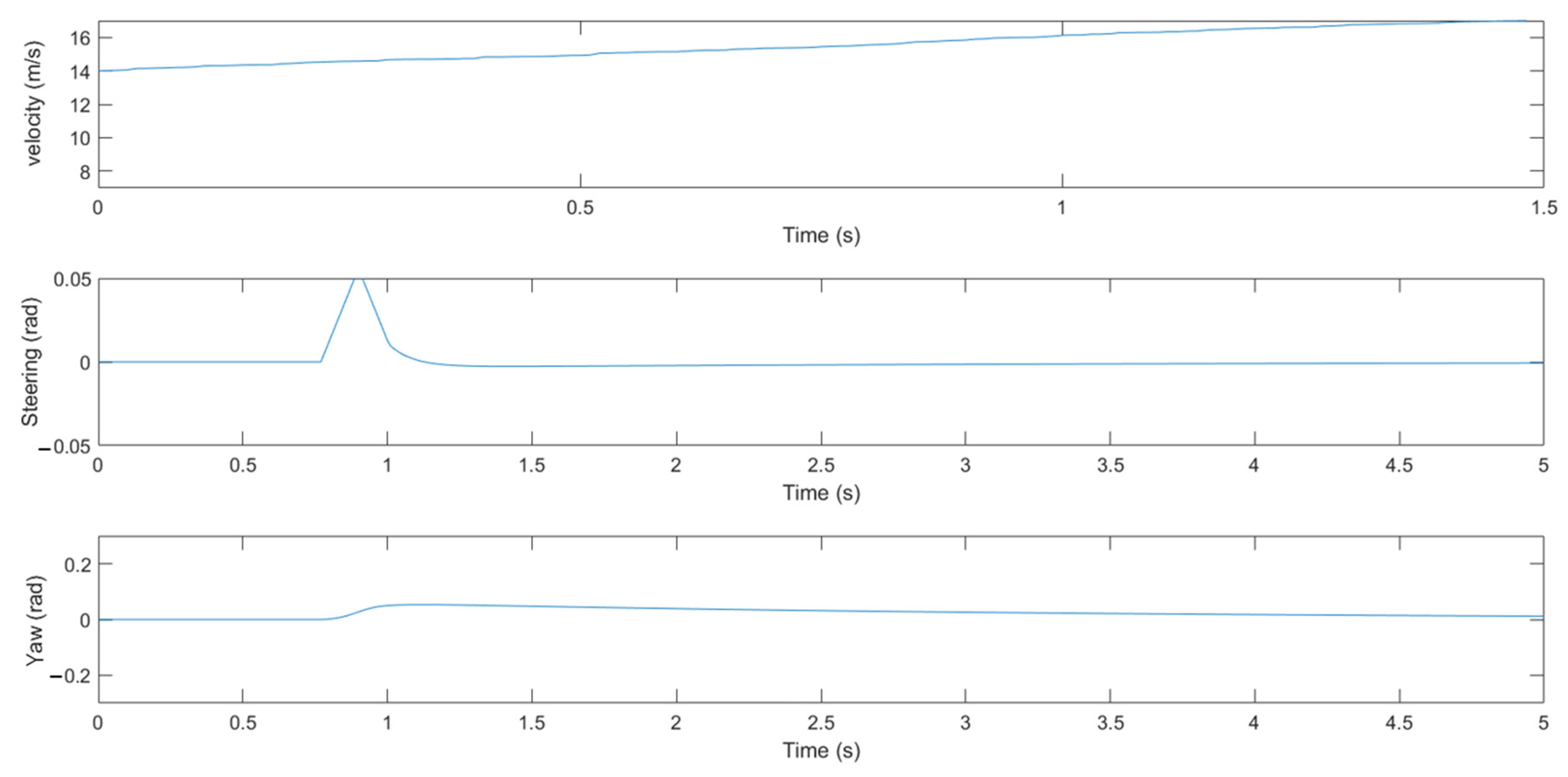
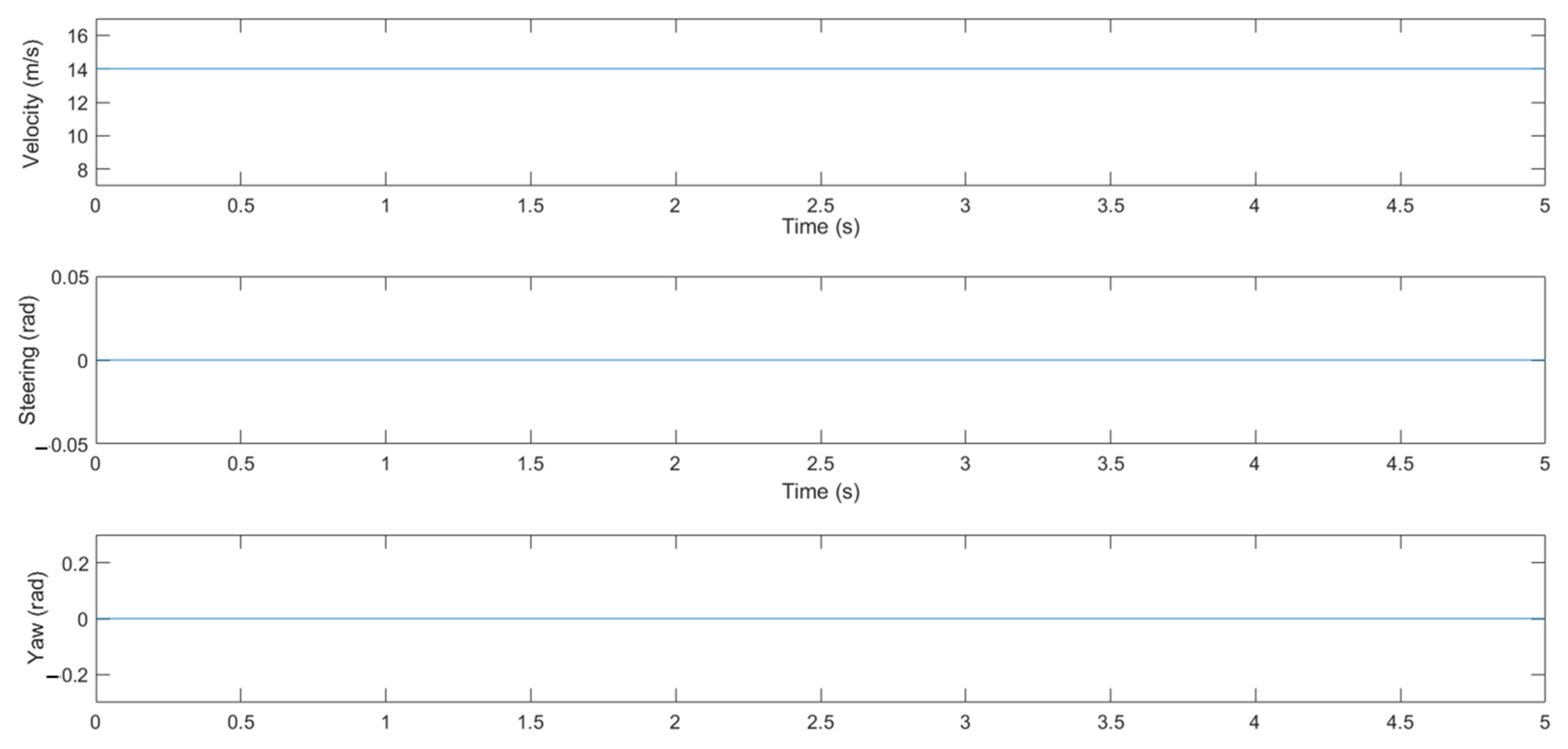
5.2. An Effectiveness Analysis of the Modified DDPG
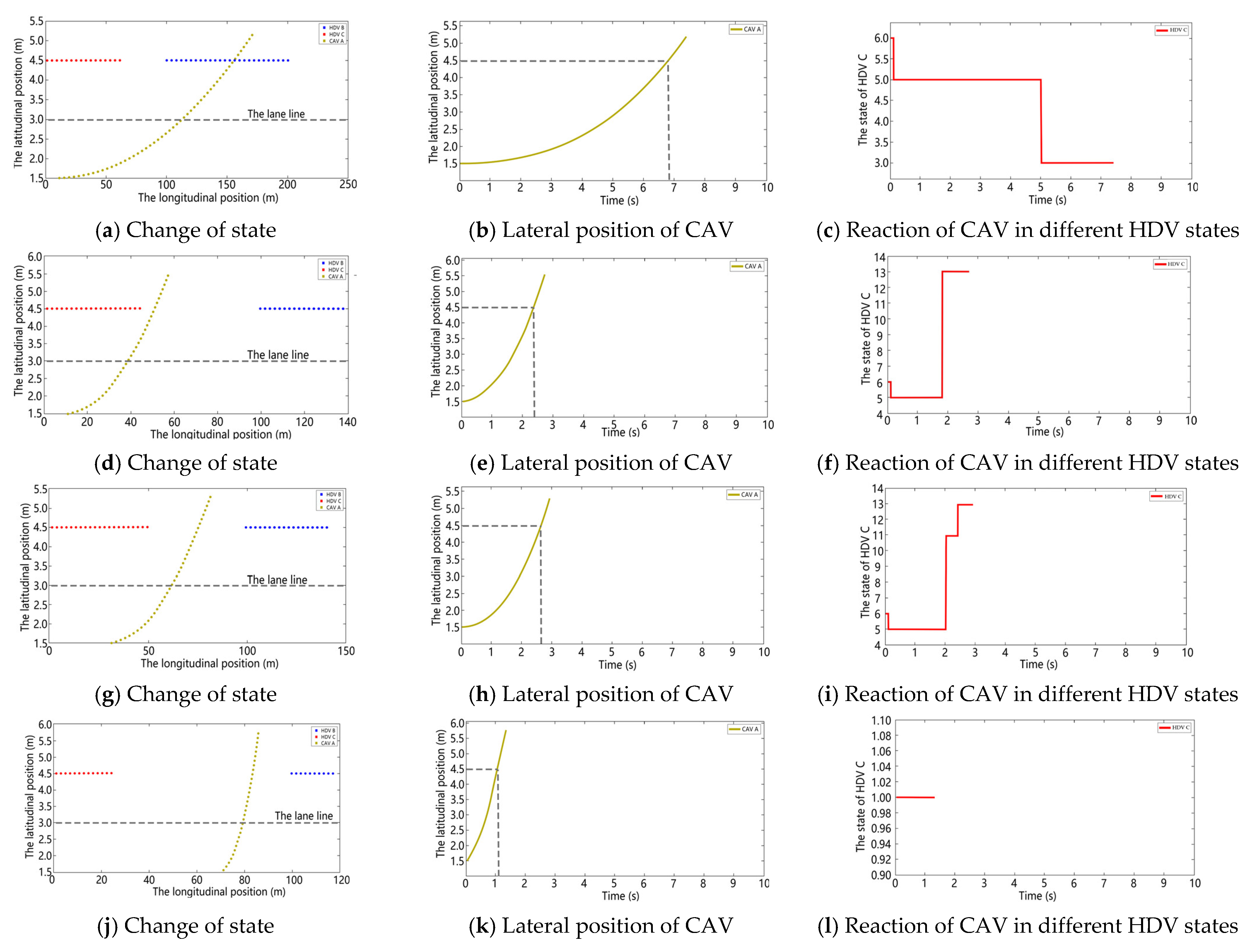
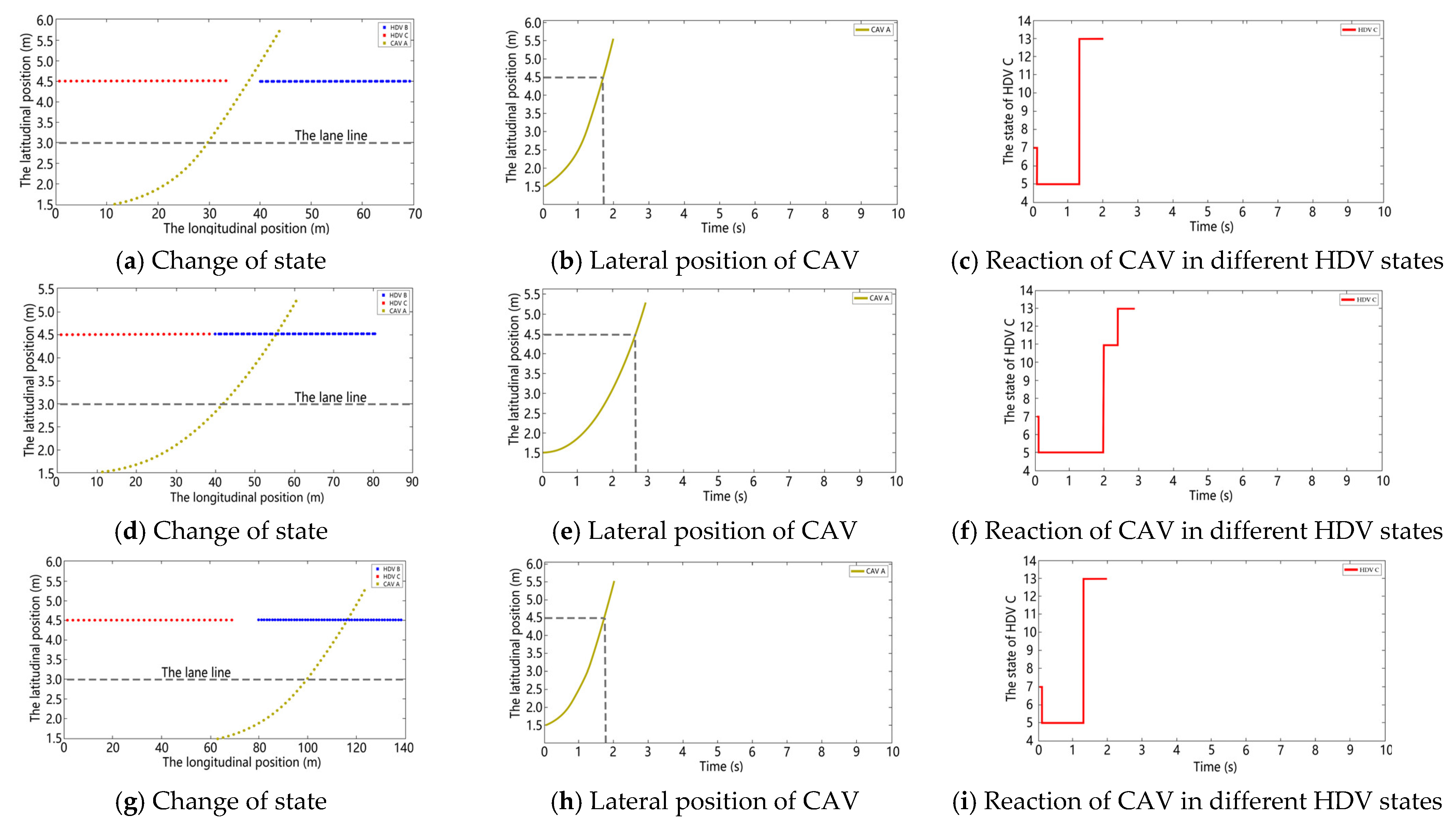
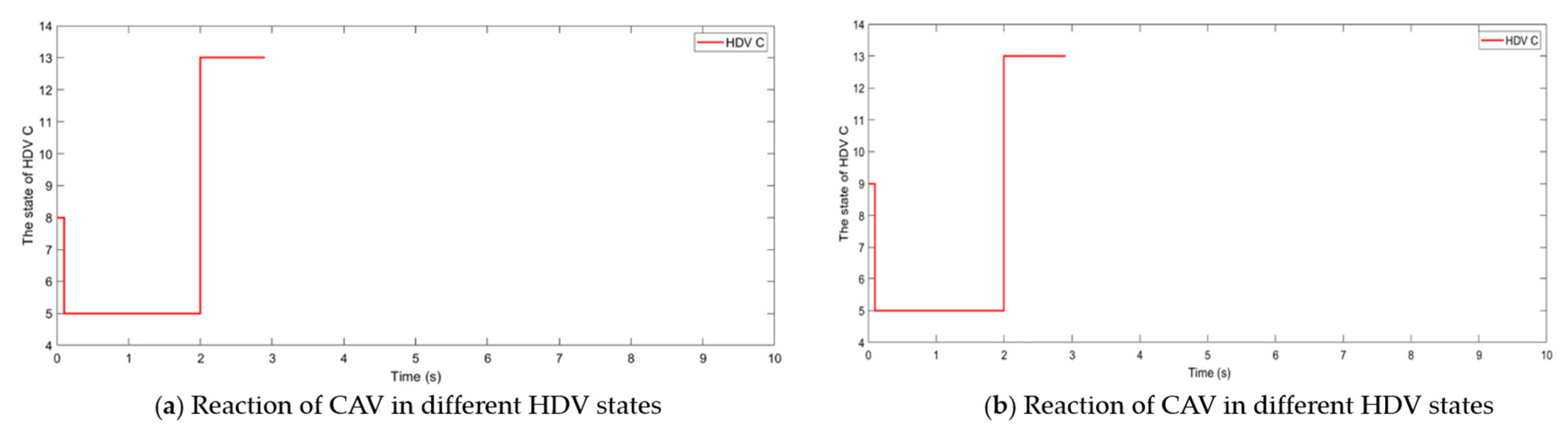
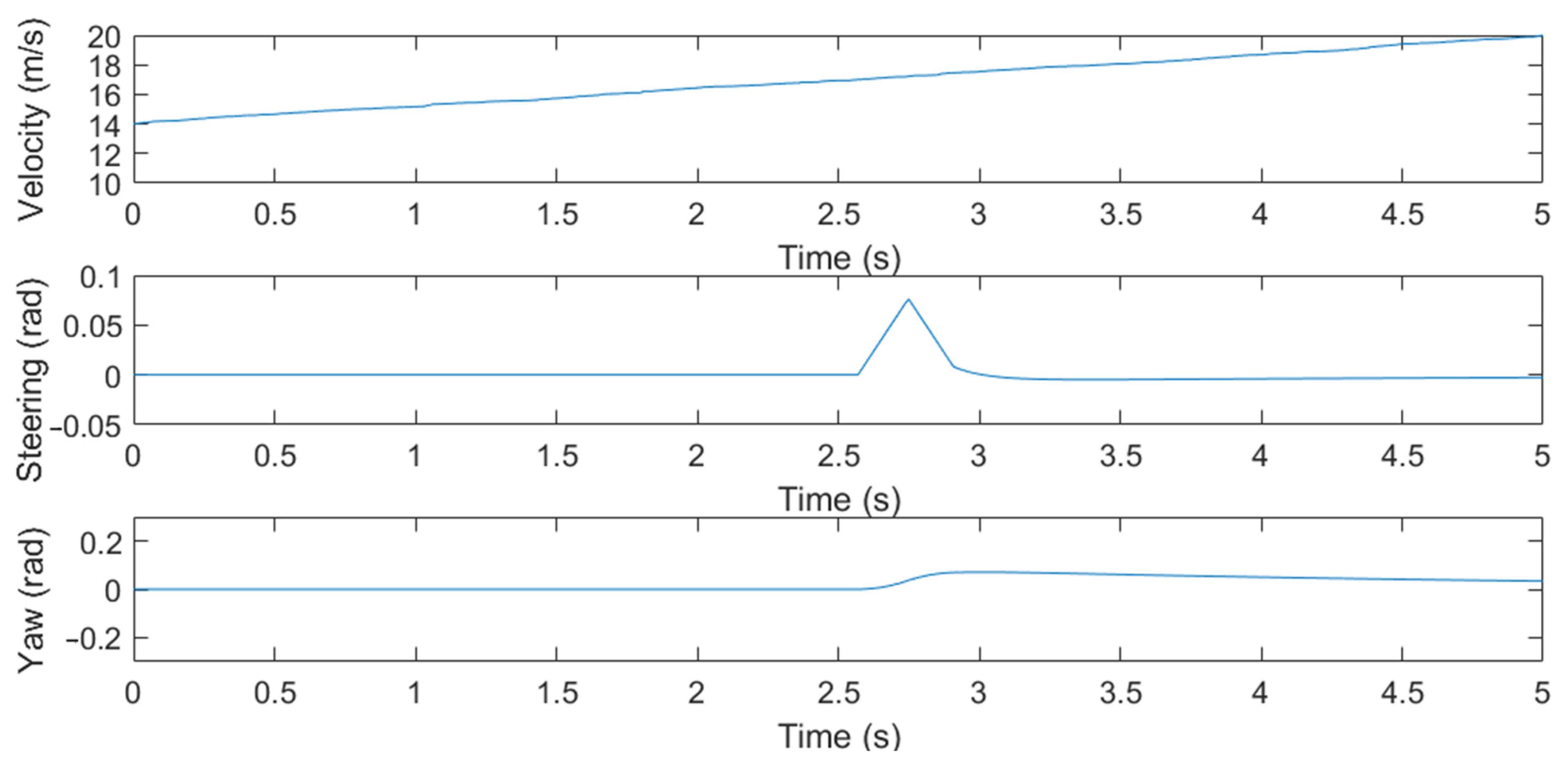
5.3. Testing of the Modified DDPG Algorithm
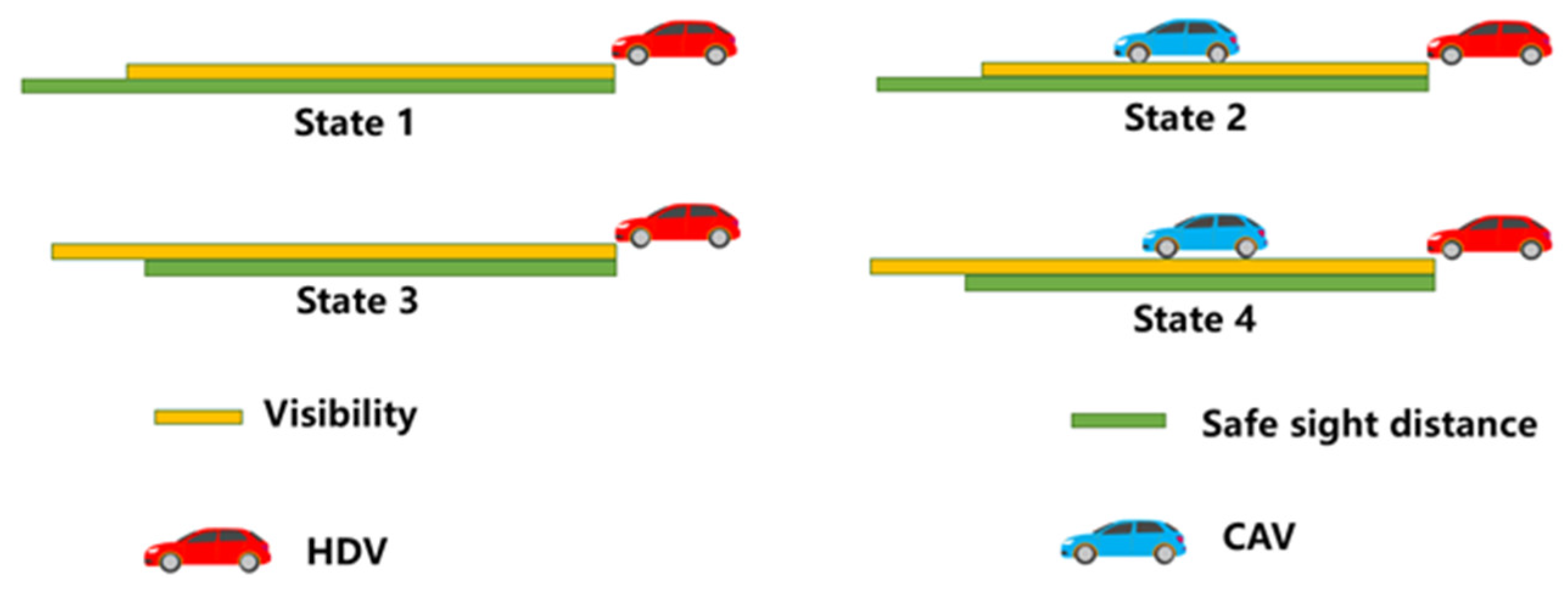
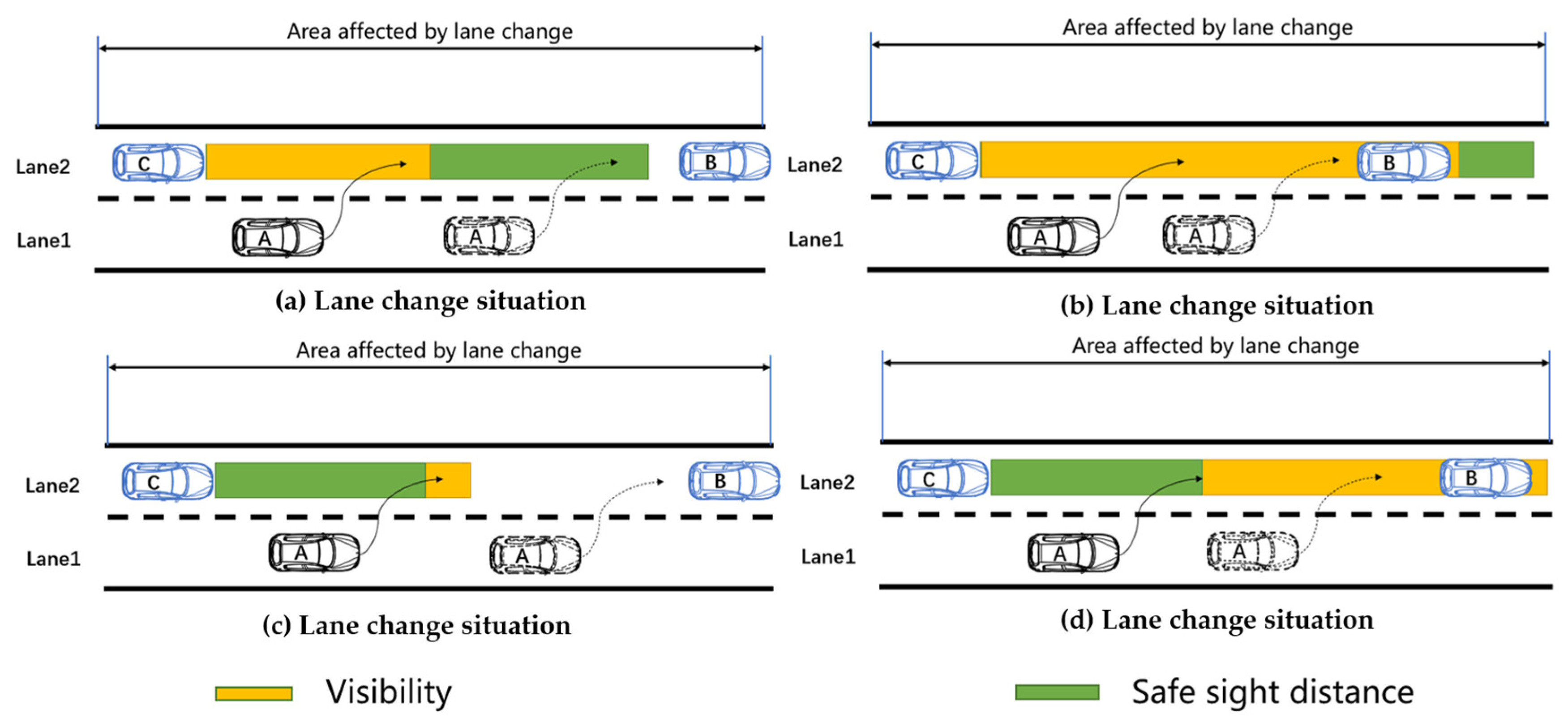
- The longitudinal spacing between CAV A and HDV C is greater than the visibility.State 1: visibility is less than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 2: visibility is less than the safe sight distance of HDV C and there is a vehicle ahead in visibility.State 3: visibility is greater than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 4: visibility is greater than the safe sight distance of HDV C and there is a vehicle ahead in visibility.
- The longitudinal spacing between CAV A and HDV C is less than the visibility.State 5: CAV A is in the lane change state.State 6: CAV A has not started lane change, visibility is less than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 7: CAV A has not started lane change, visibility is less than the safe sight distance of HDV C and there is a vehicle ahead in visibility.State 8: CAV A has not started lane change, visibility is greater than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 9: CAV A has not started lane change, visibility is greater than the safe sight distance of HDV C and there is a vehicle ahead in visibility.State 10: CAV A completes lane change, visibility is less than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 11: CAV A completes lane change, visibility is less than the safe sight distance of HDV C and there is a vehicle ahead in visibility.State 12: CAV A completes lane change, visibility is greater than the safe sight distance of HDV C and there is no vehicle ahead in visibility.State 13: CAV A completes lane change, visibility is greater than the safe sight distance of HDV C and there is a vehicle ahead in visibility.
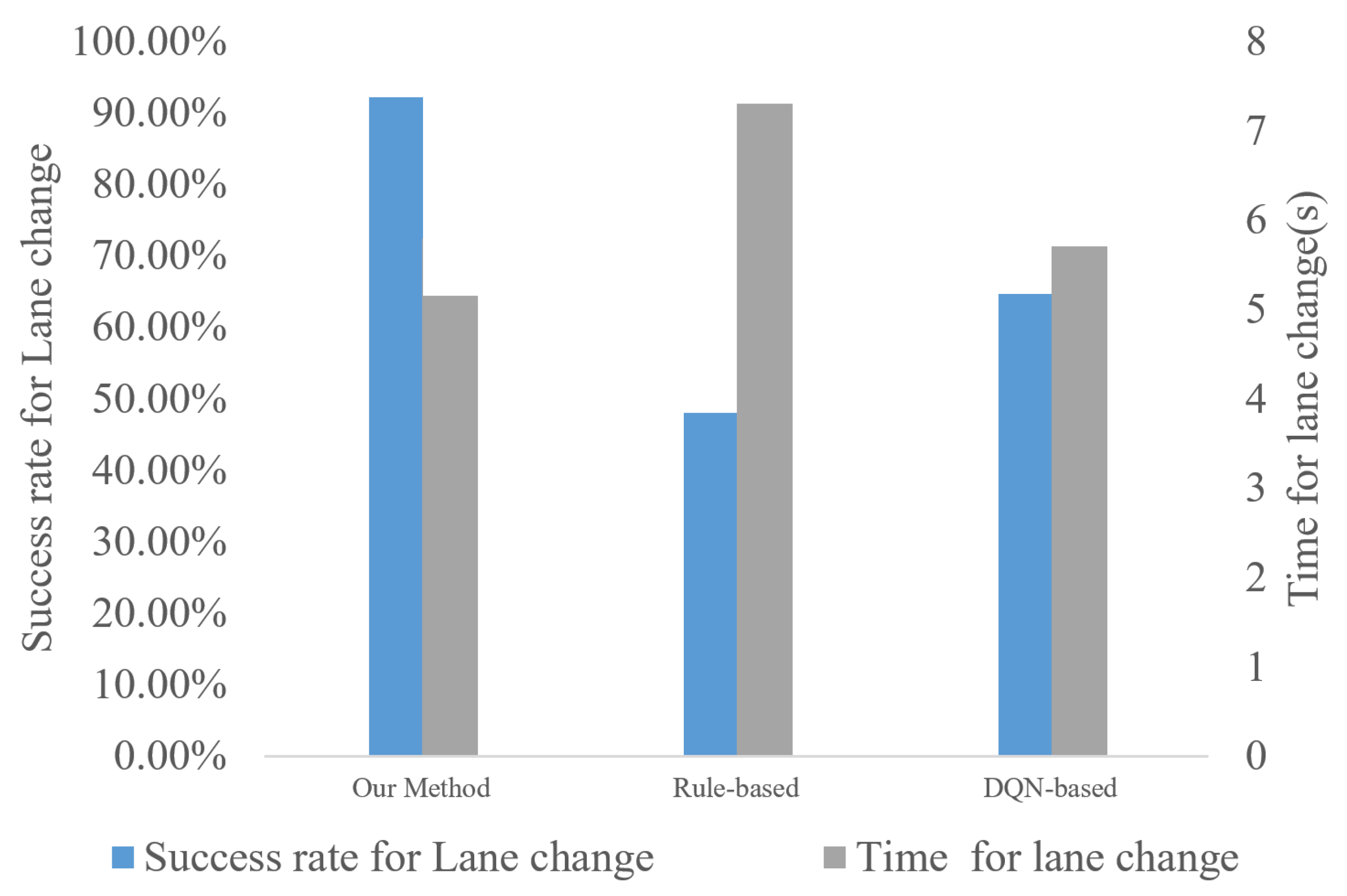
5.4. Comparison with the Rule-Based Lane Change Decision Algorithm
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, G.; Yang, Y.; Zhang, T.; Qu, X.; Cao, D.; Cheng, B.; Li, K. Risk assessment based collision avoidance decision-making for autonomous vehicles in multi-scenarios. Transp. Res. Part C Emerg. Technol. 2021, 122, 102820. [Google Scholar] [CrossRef]
- Deng, J.-H.; Feng, H.-H. A multilane cellular automaton multi-attribute lane-changing decision model. Phys. A Stat. Mech. Its Appl. 2019, 529, 121545. [Google Scholar] [CrossRef]
- Hruszczak, M.; Lowe, B.T.; Schrodel, F.; Freese, M.; Bajcinca, N. Game Theoretical Decision Making Approach for a Cooperative Lane Change. IFAC-PapersOnLine 2020, 53, 15247–15252. [Google Scholar] [CrossRef]
- Das, A.; Khan, M.N.; Ahmed, M.M. Detecting lane change maneuvers using SHRP2 naturalistic driving data: A comparative study machine learning techniques. Accid. Anal. Prev. 2020, 142, 105578. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, Z.; Wu, X.; Qi, L.; Han, Y. Recognition of lane-changing behaviour with machine learning methods at freeway off-ramps. Phys. A Stat. Mech. Its Appl. 2021, 567, 125691. [Google Scholar] [CrossRef]
- Yoneda, K.; Suganuma, N.; Yanase, R.; Aldibaja, M. Automated driving recognition technologies for adverse weather conditions. IATSS Res. 2019, 43, 253–262. [Google Scholar] [CrossRef]
- Furda, A.; Vlacic, L. Multiple Criteria-Based Real-Time Decision Making by Autonomous City Vehicles. IFAC Proc. Vol. 2010, 43, 97–102. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; Srivastava, A.; Ahn, S. Harnessing connected and automated vehicle technologies to control lane changes at freeway merge bottlenecks in mixed traffic. Transp. Res. Part C Emerg. Technol. 2021, 123, 102950. [Google Scholar] [CrossRef]
- Karimi, M.; Roncoli, C.; Alecsandru, C.; Papageorgiou, M. Cooperative merging control via trajectory optimization in mixed vehicular traffic. Transp. Res. Part C Emerg. Technol. 2020, 116, 102663. [Google Scholar] [CrossRef]
- Yu, H.; Tseng, H.E.; Langari, R. A human-like game theory-based controller for automatic lane changing. Transp. Res. Part C Emerg. Technol. 2018, 88, 140–158. [Google Scholar] [CrossRef]
- Chen, K.; Pei, X.; Okuda, H.; Zhu, M.; Guo, X.; Guo, K.; Suzuki, T. A hierarchical hybrid system of integrated longitudinal and lateral control for intelligent vehicles. ISA Trans. 2020, 106, 200–212. [Google Scholar] [CrossRef] [PubMed]
- Yi, H.; Edara, P.; Sun, C. Modeling Mandatory Lane Changing Using Bayes Classifier and Decision Trees. IEEE Trans. Intell. Transp. Syst. 2014, 15, 647–655. [Google Scholar] [CrossRef]
- Jin, C.J.; Knoop, V.L.; Li, D.W.; Meng, L.Y.; Wang, H. Discretionary lane-changing behavior: Empirical validation for one realistic rule-based model. Transp. A 2019, 15, 244–262. [Google Scholar] [CrossRef] [Green Version]
- Xi, C.; Shi, T.; Wu, Y.; Sun, L. Efficient Motion Planning for Automated Lane Change based on Imitation Learning and Mixed-Integer Optimization. In Proceedings of the 23rd IEEE International Conference on Intelligent Transportation Systems, Rhodes, Greece, 20–23 September 2020. [Google Scholar]
- Jin, H.; Duan, C.; Liu, Y.; Lu, P. Gauss mixture hidden Markov model to characterise and model discretionary lane-change behaviours for autonomous vehicles. IET Intell. Transp. Syst. 2020, 14, 401–411. [Google Scholar] [CrossRef]
- Tang, J.J.; Liu, F.; Zhang, W.H.; Ke, R.M.; Zou, Y.J. Lane-changes prediction based on adaptive fuzzy neural network. Expert Syst. Appl. 2018, 91, 452–463. [Google Scholar] [CrossRef]
- Sheikh, M.S.; Wang, J.; Regan, A. A game theory-based controller approach for identifying incidents caused by aberrant lane changing behavior. Phys. A Stat. Mech. Its Appl. 2021, 580, 126162. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Peng, H.X.; Shen, X.M. Multi-Agent Reinforcement Learning Based Resource Management in MEC- and UAV-Assisted Vehicular Networks. IEEE J. Sel. Areas Commun. 2021, 39, 131–141. [Google Scholar] [CrossRef]
- Zheng, Z.D. Recent developments and research needs in modeling lane changing. Transp. Res. Part B—Methodol. 2014, 60, 16–32. [Google Scholar] [CrossRef] [Green Version]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. On a formal model of safe and scalable self-driving cars. arXiv 2017, arXiv:1708.06374. [Google Scholar]
- Gipps, P.G. A model for the structure of lane-changing decisions. Transp. Res. Part B Methodol. 1986, 20, 403–414. [Google Scholar] [CrossRef]
- Rickert, M.; Nagel, K.; Schreckenberg, M.; Latour, A. Two lane traffic simulations using cellular automata. Phys. A 1996, 231, 534–550. [Google Scholar] [CrossRef] [Green Version]
- Kesting, A.; Treiber, M.; Helbing, D. General lane-changing model MOBIL for car-following models. Transp. Res. Rec. 2007, 1999, 86–94. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhao, X.M.; Xu, Z.G.; Li, X.P.; Qu, X.B. Modeling and field experiments on autonomous vehicle lane changing with surrounding human-driven vehicles. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 877–889. [Google Scholar] [CrossRef]
- Sun, D.; Kondyli, A. Modeling Vehicle Interactions during Lane-Changing Behavior on Arterial Streets. Comput. Aided Civ. Infrastruct. Eng. 2010, 25, 557–571. [Google Scholar] [CrossRef]
- Peng, J.S.; Guo, Y.S.; Fu, R.; Yuan, W.; Wang, C. Multi-parameter prediction of drivers’ lane-changing behaviour with neural network model. Appl. Ergon. 2015, 50, 207–217. [Google Scholar] [CrossRef]
- Zhao, C.; Li, Z.H.; Li, L.; Wu, X.B.; Wang, F.Y. A negotiation-based right-of-way assignment strategy to ensure traffic safety and efficiency in lane changes. IET Intell. Transp. Syst. 2021, 15, 1345–1358. [Google Scholar] [CrossRef]
- Hidas, P. Modelling lane changing and merging in microscopic traffic simulation. Transp. Res. Part C Emerg. Technol. 2002, 10, 351–371. [Google Scholar] [CrossRef]
- Hidas, P. Modelling vehicle interactions in microscopic simulation of merging and weaving. Transp. Res. Part C Emerg. Technol. 2005, 13, 37–62. [Google Scholar] [CrossRef]
- Yoo, J.H.; Langari, R. Stackelberg Game Based Model of Highway Driving. In Proceedings of the 5th Annual Dynamic Systems and Control Division Conference/11th JSME Motion and Vibration Conference, Fort Lauderdale, FL, USA, 17–19 October 2012; pp. 499–508. [Google Scholar]
- Chen, T.Y.; Shi, X.P.; Wong, Y.D. Key feature selection and risk prediction for lane-changing behaviors based on vehicles’ trajectory data. Accid. Anal. Prev. 2019, 129, 156–169. [Google Scholar] [CrossRef]
- Gindele, T.; Brechtel, S.; Dillmann, R. A probabilistic model for estimating driver behaviors and vehicle trajectories in traffic environments. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1625–1631. [Google Scholar]
- Chen, Y.L.; Dong, C.Y.; Palanisamy, P.; Mudalige, P.; Muelling, K.; Dolan, J.M. Attention-based Hierarchical Deep Reinforcement Learning for Lane Change Behaviors in Autonomous Driving. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1326–1334. [Google Scholar]
- Jiang, S.H.; Chen, J.Y.; Shen, M.C. An Interactive Lane Change Decision Making Model With Deep Reinforcement Learning. In Proceedings of the 7th IEEE International Conference on Control, Mechatronics and Automation (ICCMA), Delft, The Netherlands, 6–8 November 2019; pp. 370–376. [Google Scholar]
- Wang, P.; Li, H.H.; Chan, C.Y. Continuous Control for Automated Lane Change Behavior Based on Deep Deterministic Policy Gradient Algorithm. In Proceedings of the 30th IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1454–1460. [Google Scholar]
- Lv, K.; Pei, X.; Chen, C.; Xu, J. A Safe and Efficient Lane Change Decision-Making Strategy of Autonomous Driving Based on Deep Reinforcement Learning. Mathematics 2022, 10, 1551. [Google Scholar] [CrossRef]
- Kim, M.-S.; Eoh, G.; Park, T. Reinforcement learning with data augmentation for lane change decision-making. J. Inst. Control Robot. Syst. 2021, 27, 572–577. [Google Scholar] [CrossRef]
- Wang, G.; Hu, J.; Li, Z.; Li, L. Harmonious Lane Changing via Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4642–4650. [Google Scholar] [CrossRef]
- Ammourah, R.; Talebpour, A. Deep Reinforcement Learning Approach for Automated Vehicle Mandatory Lane Changing. Transp. Res. Rec. 2022, 2677, 712–724. [Google Scholar] [CrossRef]
- He, X.; Yang, H.; Hu, Z.; Lv, C. Robust Lane Change Decision Making for Autonomous Vehicles: An Observation Adversarial Reinforcement Learning Approach. IEEE Trans. Intell. Veh. 2022, 8, 184–193. [Google Scholar] [CrossRef]
- Wallace, A.M.; Halimi, A.; Buller, G.S. Full Waveform LiDAR for Adverse Weather Conditions. IEEE Trans. Veh. Technol. 2020, 69, 7064–7077. [Google Scholar] [CrossRef]
- Heinzler, R.; Schindler, P.; Seekircher, J.; Ritter, W.; Stork, W.; IEEE. Weather Influence and Classification with Automotive Lidar Sensors. In Proceedings of the 30th IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1527–1534. [Google Scholar]
- Chen, C.; Zhao, X.; Liu, H.; Ren, G.; Liu, X. Influence of adverse weather on drivers’ perceived risk during car following based on driving simulations. J. Mod. Transp. 2019, 27, 282–292. [Google Scholar] [CrossRef] [Green Version]
- Caro, S.; Cavallo, V.; Marendaz, C.; Boer, E.R.; Vienne, F. Can headway reduction in fog be explained by impaired perception of relative motion? Hum. Factors 2009, 51, 378–392. [Google Scholar] [CrossRef]
- Saffarian, M.; Happee, R.; de Winter, J.C.F. Why do drivers maintain short headways in fog? A driving-simulator study evaluating feeling of risk and lateral control during automated and manual car following. Ergonomics 2012, 55, 971–985. [Google Scholar] [CrossRef]
- Huang, H.; Xu, H.; Chen, F.; Zhang, C.; Mohammadzadeh, A. An Applied Type-3 Fuzzy Logic System: Practical Matlab Simulink and M-Files for Robotic, Control, and Modeling Applications. Symmetry 2023, 15, 475. [Google Scholar] [CrossRef]
- Jomaa, M.; Abbes, M.; Tadeo, F.; Mami, A. Greenhouse Modeling, Validation and Climate Control based on Fuzzy Logic. Eng. Technol. Appl. Sci. Res. 2019, 9, 4405–4410. [Google Scholar] [CrossRef]
- Huang, C.; Farooq, U.; Liu, H.; Gu, J.; Luo, J. A Pso-Tuned Fuzzy Logic System for Position Tracking of Mobile Robot. Int. J. Robot. Autom. 2019, 34, 84–94. [Google Scholar] [CrossRef]
- Rajagiri, A.K.; Mn, S.R.; Nawaz, S.S.; Suresh Kumar, T. Speed control of DC motor using fuzzy logic controller by PCI 6221 with MATLAB (Conference Paper). E3S Web Conf. 2019, 87, 01004. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Wang, Z.; Xu, Z.; Wang, Y.; Li, X.; Qu, X. Field experiments on longitudinal characteristics of human driver behavior following an autonomous vehicle. Transp. Res. Part C Emerg. Technol. 2020, 114, 205–224. [Google Scholar] [CrossRef]
- Gao, K.; Tu, H.; Shi, H.; Li, Z. Effect of low-visibility in haze weather condition on longitudinal driving behavior in different car following stages. J. Jilin Univ. 2017, 47, 1716–1727. [Google Scholar]
- Jiang, R.; Wu, Q.; Zhu, Z. Full velocity difference model for a car-following theory. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2001, 64, 017101. [Google Scholar] [CrossRef] [PubMed] [Green Version]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
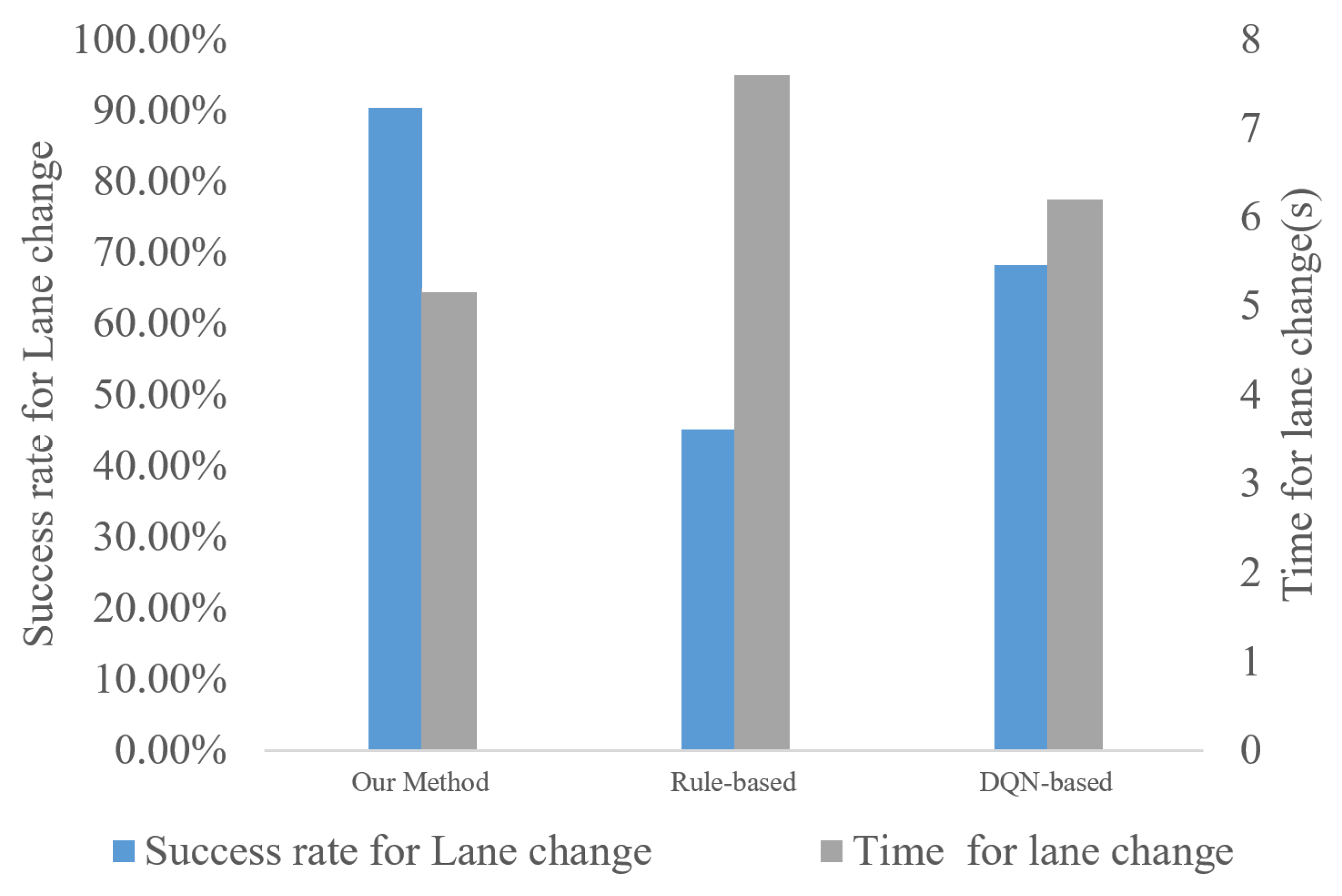{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Visibility Initial velocity of CAV A | 50 14 | Limit velocity Initial velocity of HDV C | 16 18 |
| Initial velocity of HDV B Initial longitudinal position of HDV B Initial longitudinal position of HDV C Initial lateral position of HDV B Initial lateral position of HDV D * Aggression factor of HDV C | 14 100 0 4.5 1.5 −3~3 | Initial velocity of HDV D Initial longitudinal position of HDV D Initial lateral position of CAV A Initial lateral position of HDV C Initial longitudinal position of CAV A | 14 100 1.5 4.5 15~85 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 10 | 30 | 70 | |
| −3 | (−3, 10) | \ | \ |
| 3 | (3, 10) | (3, 30) | (3, 70) |
| Scenario | The Modified DDPG | The Rule-Based | |||
|---|---|---|---|---|---|
| Success | Collision | Unfinished | Success | Unfinished | |
| Scenario 1 | 97.2% | 1.8% | 1% | 85.4% | 14.6% |
| Scenario 2 | 93.1% | 4.6% | 2.3% | 40.6% | 59.4% |
| Scenario 3 | 98.5% | 0.4% | 1.1% | 91.1% | 8.9% |
| Scenario 4 | 95.8% | 2.6% | 1.6% | 68.9% | 31.1% |
| Success Rate for Lane Change | Time for Lane Change | |
|---|---|---|
| Our Method | 90.36% | 5.2 s |
| Rule-based | 45.12% | 7.6 s |
| DQN-based | 68.23% | 6.2 s |
| Success Rate for Lane Change | Time for Lane Change | |
|---|---|---|
| Our Method | 92.15% | 5.8 s |
| Rule-based | 47.98% | 7.3 s |
| DQN-based | 64.58% | 5.7 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, B.; Xu, Z.; Wei, R.; Wang, T.; Lin, C.; Gao, P. Reinforcement Learning-Based Lane Change Decision for CAVs in Mixed Traffic Flow under Low Visibility Conditions. Mathematics 2023, 11, 1556. https://doi.org/10.3390/math11061556
Gong B, Xu Z, Wei R, Wang T, Lin C, Gao P. Reinforcement Learning-Based Lane Change Decision for CAVs in Mixed Traffic Flow under Low Visibility Conditions. Mathematics. 2023; 11(6):1556. https://doi.org/10.3390/math11061556
Chicago/Turabian StyleGong, Bowen, Zhipeng Xu, Ruixin Wei, Tao Wang, Ciyun Lin, and Peng Gao. 2023. "Reinforcement Learning-Based Lane Change Decision for CAVs in Mixed Traffic Flow under Low Visibility Conditions" Mathematics 11, no. 6: 1556. https://doi.org/10.3390/math11061556
APA StyleGong, B., Xu, Z., Wei, R., Wang, T., Lin, C., & Gao, P. (2023). Reinforcement Learning-Based Lane Change Decision for CAVs in Mixed Traffic Flow under Low Visibility Conditions. Mathematics, 11(6), 1556. https://doi.org/10.3390/math11061556