1. Introduction
Over the past two centuries, researchers have significantly advanced our knowledge of neurons, particularly regarding their morphological structures and underlying principles of action. Neurons can generally be divided into two components: cell bodies and neurites. While some neurons, such as Purkinje neurons, have dendrites and axons separated within the neurites [
1], others, such as LP neurons in the crab stomach, only have axons and neurites [
2]. Neurites that only receive signals are called dendrites, while those that both receive and send signals are simply referred to as neurites. Neurons are further categorized into different zones, including receptive, trigger, conducting, and output areas [
3,
4]. When a signal is transmitted to a neuron, it passes through the receptive zone, where it is received in a stepped graded electrogenesis. In the trigger zone, the axon initial segment integrates electrical signals to determine whether to generate a nerve impulse. The conducting zone consists of axons that transmit nerve impulses as a stepped electrical signal to the output zone, which transmits substances or releases electricity to affect the next neuron [
5,
6,
7,
8]. As cells in the central nervous system (CNS), neurons receive and transmit electrochemical signals through neurotransmitters. They are anatomically designed to facilitate the reception and diffusion of information [
9], with axons sending signals and dendrites receiving signals from other neurons. Neurons can also be classified as either excitatory or inhibitory, depending on the type of signal they release, which can depolarize or hyperpolarize their target neurons. Neurotransmitters mediate the propagation of electrical signals and produce excitatory or inhibitory responses in the postsynaptic membrane [
10]. Prior to the current century, the reticular nervous system was the prevailing understanding of the nervous system, with the impulse signal representing the perception of information transmitted by individual neurons. As our knowledge of basic biology continues to evolve, so too does our understanding of artificial neural systems.
Recently, artificial neural networks (ANNs) have become increasingly popular across various fields, opening the door to deep learning. ANNs are known for their ease of use and ability to produce excellent results, making them suitable for almost any practical application [
11]. Most mainstream deep learning models are based on multilayer parameterized McCulloch–Pitts neurons, known as neural networks [
12]. Representative models include convolutional neural networks, recurrent networks, and deep residual networks [
13,
14,
15]. However, the success of these models heavily relies on their complex structure, leading to issues such as difficulties in hyperparameter tuning, the need for large amounts of labeled training data, excessive model complexity, and low interpretability due to their black-box nature. To address these issues, sophisticated learning techniques have been proposed to improve performance. Alternative algebraic and non-neural network models, such as Bayesian deep learning, fuzzy deep learning, and generalized learning, have also been considered [
16,
17,
18]. However, these models do not consider the basic principle of deep neural networks, i.e., the powerful information processing of individual neurons. Instead, they usually rely on theoretical statistics or other tricky learning mechanisms to improve model performance [
19]. This approach does not imitate the biological nervous system but rather involves a data-driven matrix operation to solve the problem. The problem with the data-driven approach is that it requires a large amount of training data and a longer training period. This is different from how humans learn, as they do not require the same amount of training as machines to gain similar experience [
20]. Therefore, further research has focused on refining bionic models to address these issues, taking inspiration from the biological nervous system.
Recently, there have been significant developments in the design of artificial neurons, resulting in numerous successful examples. Several spiking neuron models have been proposed that are inspired by the temporal information processing capacity of neurons [
21]. These spiking neuron models have been incorporated into deep learning as spiking neural networks (SNNs), which have shown great potential in dealing with complex recognition and prediction tasks due to their rich temporal dynamics [
22]. In addition, novel neuron models, such as the FitzHugh–Nagumo neuron model, which considers the spiking and bursting behaviors of a neuron, and the inter-layer collision neuron model, inspired by physical elastic collision scenes, have also been developed [
23,
24]. These third-generation neuronal models are still in the research field and are less well known outside academia, as they have not yet been commercially converted [
25]. They are based on biological studies of neuronal signals limited to impulse signals, and today, they are the hottest areas of research. Engineers are continuously optimizing these third-generation neural network models in search of their application value [
26]. Although convolutional neural networks are currently in a period of high application, the third generation of neural networks, such as SNN, may be used in the future to solve practical problems and replace the second generation of neural networks. From a research standpoint, neuron models that more closely mimic biology are expected to replace spiking neuron models as the mainstream of research in the future.
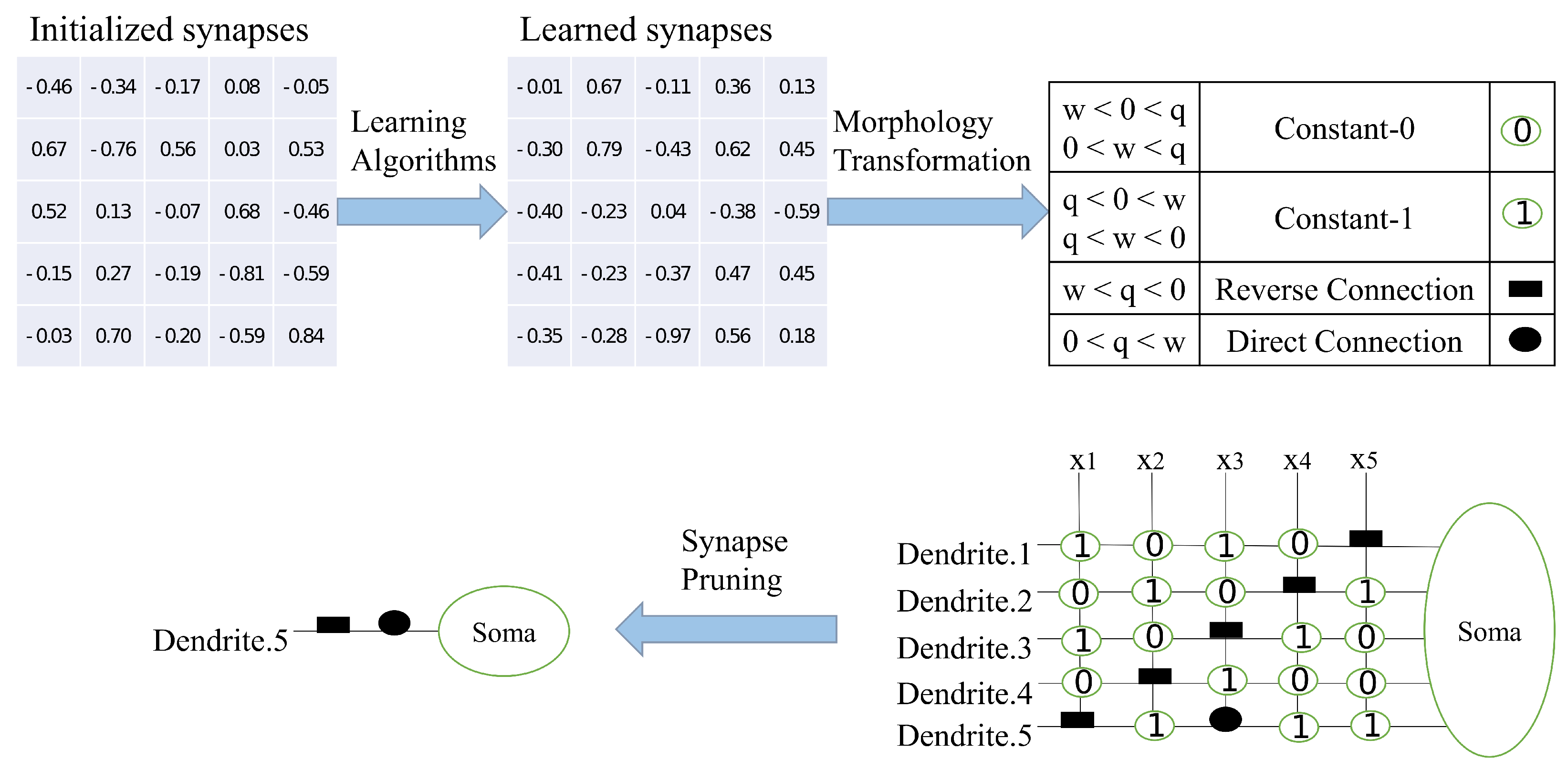
The dendritic neural model (DNM) is a mathematical model that mimics dendritic neurons found in the biological nervous system. These dendritic neurons have demonstrated independent information processing capabilities and are well suited for training in combination with evolutionary learning [
27]. The DNM contains synaptic, dendritic, membrane, and cell body layers in one model [
28,
29]. Input data are analyzed by multiple dendrites and subsequently decided by accumulation within the cell whether to output or not. Compared to other models, DNM is closer to real neurons in terms of structure and has detailed cellular components. From the perspective of individual neurons, the DNM is simple and nonlinear, consuming fewer computational resources and being less prone to overfitting. Many studies have demonstrated the success of DNM in wind farm layout optimization, financial forecasting, and protein model prediction [
30,
31,
32]. These examples show that the bionic neuron model is not inferior to traditional deep learning and reinforcement learning models in terms of the optimal solution. DNM is still in the early stages of research, and it is unrealistic to group them into networks at this stage. Although there are many research attempts to network DNM, its accuracy and reliability are actually lower than the mainstream machine learning methods at present [
33,
34]. Therefore, tools, such as evolutionary algorithms, are necessary to iteratively train and evolve a set of information in a single neuron [
35,
36]. Since evolutionary algorithms are inherently equipped to handle several optimization problems, there is a wealth of research in this area. Among the known evolutionary algorithms, there are metaheuristic algorithms (MHAs) inspired by real phenomena and heuristic algorithms that adapt to the problem through improvements of the MHAs. Researchers typically use different heuristic algorithms to train DNMs, as these algorithms are more powerful in terms of performance and better suited for training. In summary, DNM is a promising approach for mimicking the biological nervous system in neural network research. Future research may focus on developing more accurate and reliable DNM network models and exploring new heuristic algorithms to further optimize DNM performance.
The DNM morphological mimicry is incomplete because the principle of action of neurons is not limited to electrical signal impulses but also involves the action of neurotransmitters. Generally, in artificial neuron models, neurotransmitters are included in synaptic weights. In the case of DNMs, the use of cumulative multiplication to retain features can lead to stagnation when faced with problems involving many features. Therefore, new neurotransmitters are needed to stimulate neurons and keep them functioning effectively. However, few researchers have improved the model itself in past studies [
37]. In this paper, we propose to use neurotransmitters that can bind to receptors and produce stimulant-like effects to improve DNM. Neurotransmitters can be classified into small molecules and neuropeptides. Small molecule neurotransmitters are synthesized locally within axon terminals, while neuropeptides are much larger and synthesized in the cell body [
38,
39]. Presynaptic neurons are responsible for synthesizing and packaging neurotransmitters into synaptic vesicles, which are released into the synaptic cleft by cytosolic action at the presynaptic neuron terminal. Neurotransmitter molecules diffuse and bind to specific receptors on the postsynaptic neuron or effector cells, altering the conformation of channel proteins and activating the second messenger system. This leads to the potentiation or metabolism of the postsynaptic neuron and induces certain effects. Neurotransmitters consist of various chemicals, such as amino acids, neuropeptides, and purines. The most common neurotransmitter in the brain and spinal cord is glutamate, which is found in over 90% of excitatory synapses. Gamma-aminobutyric acid, the second most common neurotransmitter in the brain, is found in over 90% of inhibitory synapses and does not use glutamate. All of these neurotransmitters play an important role in the balance of excitation and inhibition. Therefore, the use of a new neurotransmitter in DNM that follows the complexity of the problem itself and increases the dosage is able to improve the optimization ability of the model to some extent.
This paper proposes three improvements to DNM based on the activity of excitation and inhibition. The new neurotransmitter effects were added to the original DNM. Since the receptors at the synapse do not have a function other than receiving neurotransmitters, they do not need to be represented on the new model. Therefore, adding its action directly to the end of the dendrites, the front of the cell body, allows for a complete mimicry of neurotransmitter action in neurons under the most concise model. We named the DNM that incorporates the receptor function as DNM-R, since the processing of input signals by DNM results in weaker feedback when faced with stronger input stimuli. Specifically, the signal that passes through the dendrite contains only 70% of the intensity to the output, so it can be considered to mimic the inhibitory effect of neurons. On the other hand, a model that exhibits excitatory behavior and the opposite properties of DNM is named DNM-P. Finally, the same design as the new neurotransmitter used on DNM-R is added to DNM-P. The new neuronal model formed is named DNM-RP. It is important to note that the new model proposed in this paper is not always superior in terms of performance, nor is it intended to completely replace DNM. The idea is that different neurons have their unique problems to solve. To achieve a one-size-fits-all optimization model, a diverse range of neurons is needed to form a network consisting of multiple neurons. The three models proposed in this paper can provide some new neuronal improvement ideas for future neural networks to enrich their diversity.
This work aims to make the following contributions:
We add a new neurotransmitter acting on the cell body to DNM;
The new model proposed in this paper, validated by a large number of tests, proves to be more effective than the original model;
In the experiments, a new model trained with an original, unoptimized algorithm achieves performance comparable to that of the most powerful algorithm optimized for DNM training. Then it can be assumed that if the new model is used for training, better performance can be achieved in the optimization process.
Section 2 of this paper introduces the techniques being used and contains points of improvement to the model.
Section 3 focuses on the comparative analysis of the data and contains some visualization of the image analysis.
Section 4 contains some discussion of the new model proposed in this paper, including its advantages and disadvantages, time complexity analysis, and stability analysis. Finally, we give a summary of how the new model is applied and the plans for future improvements.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}