1. Introduction
With the development of technology in recent times, more complex and large datasets have become available. Statisticians and researchers are also developing different statistical models to extract valuable information from data to aid decision-making processes. Classical multiple linear regression models can be used to model the relationship between variables. However, one of the assumptions of linear regression is that the errors are independent. Therefore, when the observations are correlated as with longitudinal data, clustered data, and hierarchical data, linear regression models are no longer appropriate. A more powerful class of models used to model correlated data are mixed-effects models, which have been used in many fields of applications. Recently, Sheng et al. [
1] compared the linear models with linear mixed-effects models and showed that estimators from the latter are more advantageous in terms of both efficiency and unbiasedness. This shows the importance of applying linear mixed-effects models in longitudinal settings.
The correlation between observations may appear when data are collected hierarchically; for example, students may be sampled from the same school, and schools may be sampled within the same district. Consequently, students in the same school have the same teachers and school environment, and therefore, the observations are not independent of one another. Observations may be taken from members of the same family, where each family is considered a group or a cluster. As the observations are dependent, we can consider this clustered data. Another type of correlated data pertains to observations from the same subjects collected over time, such as repeated blood pressure measurements over a patient’s treatment period—an example of longitudinal data. Patients (or subjects) may vary in the number and date of the collected measurements. Since observations are recorded from the same individual over time, it is reasonable to assume that subject-specific correlations exist in the trend of the response variable over time. We wish to model the pattern of the response variable over time within subjects and the variation in the time trends between subjects. Linear mixed-effects models are used to model correlated data, accounting for the variability within and between clusters in clustered data or the variability within and between repeated measurements in longitudinal data.
Model selection is an important procedure in statistical analysis, allowing the most-appropriate model to be chosen from a set of potential candidate models. A desired model is parsimonious and can adequately fit the data in order to improve two important aspects: interpretability and predictability. In linear mixed models, identifying significant random effects is a challenging step in model selection, as it involves conducting a hypothesis test for whether or not the variance components of random effects are equal to zero. For example, we want to test
against
, where the parameter space of
is
. Under the null hypothesis, the testing value of the variance component parameter lies on the boundary of the parameter space. This violates one of the classical regularity conditions that the true value of the parameter must be an interior point of the parameter space. Therefore, classical hypothesis tests such as the likelihood ratio, score, and Wald tests are no longer appropriate. We refer to this violation as the boundary issue. (Please see a graphical example of the boundary issue in
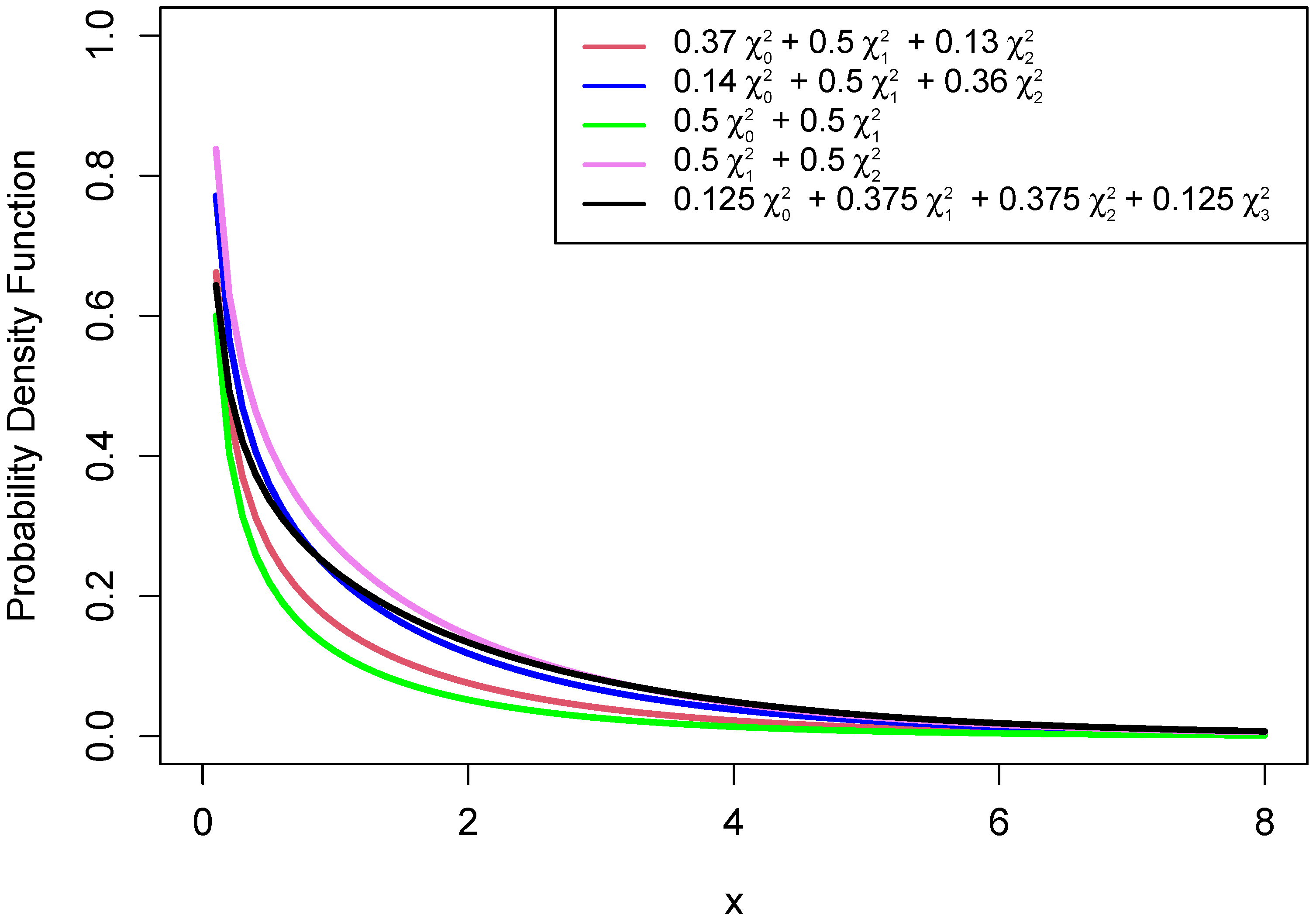
Appendix A.3). When the boundary issue occurs, the asymptotic null distribution of the likelihood ratio test statistic does not follow a chi-squared distribution. Chernoff [
2], Self and Liang [
3], Stram and Lee [
4], Azadbakhsh et al. [
5], and Baey et al. [
6] pointed out that, under some conditions on the parameter space and the likelihood functions, the asymptotic null distribution of the likelihood ratio test statistic is a mixture of chi-squared distributions. For instance, the asymptotic null distribution of the likelihood ratio test statistic for testing
against
is
, not
[
4]. The distribution of a chi-bar-squared random variable depends on its mixing weights (
Appendix A.2). Dykstra [
7] discussed conditions on the weight distribution to ensure asymptotic normality for chi-bar-squared distributions. Shapiro [
8] provided expressions to calculate the exact weights used in the mixture of chi-squared distributions for some special cases. However, in general, determining the exact weights used in the mixture of chi-squared distributions is challenging when the number of the variance components being tested under the null hypothesis is large, as the weights are not available in a tractable form (Baey et al. [
6]).
There are a number of information criteria, such as the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), that were developed for model selection with linear mixed models by Vaida and Blanchard [
9], Pauler [
10], Jones [
11], and Delattre and Poursat [
12]. Other methods for identifying important fixed effects and random effects variance components, including shrinkage and permutation methods, were considered in Ibrahim et al. [
13], Bondell et al. [
14], Peng and Lu [
15], and Drikvandi et al. [
16].
The BIC is susceptible to the boundary issue. If we use the regular BIC in linear mixed models, that is we treat this case as if there were no constraints on the model’s parameter vector, then the penalty term of the regular BIC would include all the components of the parameter vector. Therefore, the regular BIC would overestimate the number of degrees of freedom of the linear mixed model (which we refer to as model complexity for this article) and would not take into account the fact that variances components are constrained and bounded below by 0. Consequently, the regular BIC tends to choose under-fitted linear mixed models. Several versions of the modified BIC have been proposed for model selection in linear mixed models [
10,
11,
17]. However, to our knowledge, none of the current BICs can directly deal with the boundary issue.
The main objective of this article was to introduce a modified BIC for model selection when the true values of the variance components’ parameters lie on the boundary of the parameter space, allowing the most-appropriate model to be chosen from a set of candidate linear mixed models. Here is the general idea on how our proposed method solves the boundary problem. From the previous literature, we know that the asymptotic null distribution of the likelihood ratio test statistic of testing the nullity of several variances is a chi-bar-squared distribution (Baey et al. [
6]). Based on this theoretical result, we took the average of the chi-bar-squared distribution and included this average in the complexity of the model. When random effects are correlated, calculating the weights of the chi-bar-squared distribution is not straightforward, as the weights depend on a cone
that contains the set of positive definite matrices. Describing the set of positive definite matrices explicitly using constraints on the components of the random effects covariance matrix is almost impossible. Thus, calculating the weights of the chi-bar-squared distribution for this case is not an easy task and has not been addressed in the literature. Our solution to this problem is to place a bound on cone
with a bigger cone. The bigger cone has a much simpler structure and allowed us to calculate the weights of the chi-bar-squared distribution. The rest of the paper is arranged as follows. In
Section 2, we develop the methodology. The simulation and application are provided in
Section 3 and
Section 4. We conclude with a brief discussion in
Section 5.
3. Simulation
In this section, we evaluated the performance of the proposed BIC*. We compared the performance of the proposed BIC* to the regular BIC. For each candidate model, we computed the BIC* and regular BIC; then for each method, we chose the model with the minimum value of the BIC* and the regular BIC, respectively. All models were run using function “lmer” in the R package lme4 [
22]. The chi-bar-squared weights were calculated using function “con-weights-boot” in the R package “restriktor” [
20]. Following the methods used in Gao and Song [
23] and Chen and Chen [
24], the criteria we used to evaluate and compare the proposed BIC to the regular BIC were (1) positive selection rate (PSR), (2) false discovery rate (FDR), and (3) correction rate (CR). For each chosen model, the positive selection rate (PSR) is the ratio of the number of predictors that are correctly identified as significant in the chosen model to the number of predictors that are truly significant in the data-generating model. Then, we took the average of the PSR over all chosen models. The false discovery rate (FDR) is the ratio of the number of predictors that are incorrectly identified as significant in the chosen model to the number of predictors that are identified as significant in the chosen model. Then, we took the average of the FDR over all chosen models. The correction rate (CR) is the proportion of the times the true data-generating model is selected in all chosen models. For each selection criterion, we had 1001 models obtained from 1001 simulations. We then calculated the means and standard deviations of the positive selection rate and false discovery rate and the correction rate for each criterion.
3.1. Simulation Setup
Our data were generated from the linear mixed model, . For all simulation, was generated from a multivariate normal distribution, with .
3.1.1. Setup A: Choose Random Effects Assuming That the Random Effects Are Independent
Scenario 1: With total number of observations and number of clusters , is an matrix with ; the first column of includes all ones. The second column is , which was generated from the standard normal distribution. The vector of fixed effects . Matrix contains the first two columns , , which are the same as two columns of matrix , and two more columns , , both generated from the standard normal distributions. Random effects, , were generated from multivariate normal distribution with a diagonal matrix and . The random intercept, , had a standard deviation of . Random effects components, , , and , had standard deviations , , and , respectively. To measure the ability to detect the significance of the variance component parameters of the proposed , we considered different sizes of , , and . is a sequence of values from 0 to incrementing by ; is a sequence of values from 0 to 1 incrementing by ; is a sequence of values from 0 to 2 incrementing by .
Scenario 2: With the total number of observations and number of clusters , is an matrix with ; ; the first column of includes all ones. The last two columns of matrix and were generated from the standard normal distributions. The vector of fixed effects . Matrix contains the first three columns , , and , which are the same as three columns of matrix and three more columns , , and , which were generated from the standard normal distributions. Random effects, , were generated from multivariate normal distribution with a diagonal matrix and . To measure the ability to detect the significance of the variance component parameters of the , we also considered different sizes of , , and as in Scenario 1 with = 0 and = 0. We then repeated this setup with () and ().
Scenario 3: The setup was similar to the one in Scenario 2. However, matrix contains the first three columns , , and , which are the same as the three columns of matrix , and eight more columns , …, , which were generated from the standard normal distributions. Random effects, , were generated from multivariate normal distribution with a diagonal matrix and , where , , , , and are all 0. We also repeated this simulation setup with () and ().
3.1.2. Setup B: Choose Random Effects Assuming That the Random Effects Are Correlated
In this set up, the total number of observations is
and the number of clusters is
. Matrix
and the vector of fixed effects,
, were generated the same as in Setup A Scenario 2. Matrix
contains the first three columns
,
, and
, which are the same as three columns of matrix
, and three more columns
,
, and
were generated from the standard normal distributions. Random effects,
, were generated from multivariate normal distribution
with
a
matrix. The correlation matrix between the random effects components,
,
,
, and
, in the data-generating model is
To measure the ability to detect the significance of variance component parameters of the proposed , we created different cases for different sizes of , , , and , as shown below. , , and the covariances of random effects and corresponding to and are all 0.
Case 1: The standard deviations of the random effects were , , , , , and .
Case 2: The standard deviations of the random effects were , , , , , and .
Case 3: The standard deviations of the random effects were , , , , , and .
Case 4: In this case, we kept the standard deviations of the random effects the same as the ones in Case 2. However, we increased the correlations by
for each non-zero correlation in the correlation matrix to see how this affects the correction rates. The correlation matrix between the random effects is
3.1.3. Setup C: Choose Both Fixed Effects and Random Effects Assuming That the Random Effects Are Correlated
With the total number of observations
and number of clusters
,
is an
matrix with
; the first column of
includes all ones. The last five columns,
to
, weer generated from the standard normal distribution. The vector of fixed effects
. Matrix
contains the first three columns
,
, and
, which are the same as three columns of matrix
, and three more columns
,
, and
were generated from the standard normal distributions. The correlation matrix between the random effects components,
,
,
, and
, in the data-generating model is
To measure the ability to detect the significance of the fixed effects and variance component parameters of the proposed , we explored two different cases for different sizes of , , , and , as shown below. The , , and covariances corresponding to the random effects of and are all 0.
Case 1: The standard deviations of the random effects were , , , , , and .
Case 2: The standard deviations of the random effects were , , , , , and .
We also ran simulations for the case when the random effects were assumed to be uncorrelated and the variances of random effects were the same as the values in Case 1 and Case 2.
3.2. Simulation Procedure
3.2.1. For Setup A
In all scenarios, for each set of values of , , and , simulations were run. In each simulation, all possible candidate models were run. All these models had the same fixed effect covariates (including and the intercept); meanwhile, the covariates for random effects part varied in the power set of . The proposed and regular BIC were calculated for each model. Then, one model with the minimum proposed BIC was selected and one model with the minimum regular BIC. Now, for each selection criterion, we had 1001 models obtained from 1001 simulations. We calculated the correction rate (CR) for each criterion.
In Scenario 2, for each set of values of , …, , simulations were run. In each simulation, all possible candidate models were run. All these models had the same fixed effect covariates (including , , and the intercept); meanwhile, the covariates for random effects varied in the power set of . The proposed and regular BIC were calculated for each model. Then, one model with the minimum proposed BIC was selected, and one model with the minimum regular BIC was selected. We calculated the means and standard deviations of the positive selection rate and false discovery rate. We also calculated the correction rate for each criterion.
In Scenario 3, with the given set of values of
, …,
,
simulations were run. In each simulation, all possible candidate models were run. All these models had the same fixed effect covariates; meanwhile, the covariates for the random effects varied in the power set of
. We calculated the means and standard deviations of the positive selection rate and false discovery rate and calculated the correction rate for each criterion. All simulations were performed by using R Version
[
25].
3.2.2. For Setup B
In each case presented above,
simulations were run. In each simulation, all possible candidate models were run. All these models had the same fixed effect covariates (including the intercept,
and
); meanwhile, the covariates for the random effects part varied in the power set of
and also included a random intercept. The proposed
, regular BIC, and cAIC were calculated for each model. Greven and Kneib [
26] developed an analytic version of the corrected cAIC, and their method was implemented in the cAIC4 package in R [
27]. Then, one model with the minimum proposed BIC was selected; one model with the minimum regular BIC was selected; one model with the minimum cAIC was selected. We calculated the means and standard deviations of the positive selection rate and false discovery rate and the correction rate for each criterion.
3.2.3. For Setup C
For each case above, we ran simulations. In each simulation, all possible candidate models were run. All models contained the intercept term for the fixed effect and a random intercept for the random effects. The covariates for the fixed effects part varied in the power set of for to , and the covariates for random effects part varied in the power set of for to . We also included the models that included only the intercept term for the fixed effect with varying random effects and the models that included a random intercept only with varying fixed effects. The proposed and regular BIC were calculated for each model. Then, the model with the minimum proposed BIC was selected, and the model with the minimum regular BIC was selected.
3.3. Simulation Results
Scenario 1:
Table 1 summarizes the results of Scenario 1. We observed that the correction rate for the proposed
was greater than that of the regular BIC. Furthermore, the correction rates of the two methods were higher when the values of
,
, and
were bigger.
Scenario 2:
Table 2 summarizes the results of Scenario 2. The simulation results suggested that the values of the positive selection rate (PSR) for the proposed
were higher than the regular BIC when the values of the variance components were close to 0. That is, the ability to choose the significant variance components was higher for the proposed
than the regular BIC. Almost all of the false discovery rate (FDR) values were within 5 percent in all cases. We also observed that the proposed BIC approach had a higher FDR and corresponding SD as compared to the regular BIC approach. For some very low values of the sigma values, the FDR values of the proposed BIC were greater than 5 percent. The possible reason behind this is because the calculation of the penalty term of the regular BIC uses an exact chi-squared distribution, meanwhile the penalty term of proposed BIC uses the approximated weights of the chi-bar-square distribution.
As the values of the variance components increased, the PSR increased. From the results obtained, we also saw that the ability to choose the true model also became larger as the values of the variance components increased. We also noted that the standard deviations were small for all cases. This means that the estimated PSR and FDR were very consistent.
Figure 1 shows the comparison of the proposed BIC and regular BIC methods in terms of the positive selection rate and correction rate for different values of
,
, and
when
and
in Scenario 2.
Figure 2 shows the comparison of the positive selection rate (PSR) and correction rates for Scenario 2 when
, 500, and 1000 with
, 100, and 200, respectively. Given the same set of values of
, …,
, we observed that the positive sensitivity rate increased as the number of clusters
N increased.
We also ran 104 simulations with three more competing methods: “cAIC”, “
”, and “Splmm”, using the same setting as in Scenario 2. The cAIC is the corrected conditional AIC as implemented in the cAIC4 package in R [
27]. The “
” is a modified BIC for linear mixed models as introduced in (Jones [
11]). “Splmm” (simultaneous penalized linear mixed-effects models) is a method for choosing both the fixed effects and random effects for variable selection using the penalized likelihood function. This method is based on the results in (Yang and Wu [
28]) and was implemented in the R-package “
”.
Figure 3 shows that the modified BIC performed better than the regular BIC, “
”, and “
” in this scenario in terms of the positive selection rate and correction rate. The ability to choose correct variables was higher for the cAIC than the modified BIC. However, the correction rates for the cAIC were not always higher than that of the modified BIC. The “
” method did not seem to work well in this scenario. This may be because the method works better for the case when the number of parameters is much higher than the number of observations.
Scenario 3:
Table 3 summarizes the results of Scenario 3. We saw that, in all cases, for the sample sizes
, 500, 1000, the mean PSR and the correction rates were higher for the proposed BIC; meanwhile, the FDRs kept around
.
Table 4 shows the comparison of the proposed BIC, regular BIC, and cAIC methods in terms of the positive selection rate, the false discovery rate, and correction rate for Case 1 to Case 4. In all cases, the correction rate for the proposed BIC was greater than that of the regular BIC. The difference in the correction rate between these two methods was bigger when the values of
,
, and
were smaller. In most cases, the two methods seemed to perform better than the cAIC method.
Table 5 shows the comparison of the proposed BIC, regular BIC, and cAIC methods in terms of fixed effects correction rate, random effects correction rate, and both effects correction rate for both Case 1 and Case 2 when random effects were assumed to be correlated.
Based on the simulation results for the situation when random effects were assumed correlated in
Table 5, we saw that the proposed BIC method performed better than the regular BIC and the cAIC methods in terms of the correction rate for selecting the fixed effects, the correction rate for selecting the random effects, and also for selecting both fixed effects and random effects simultaneously. We also saw that, when the values of the variances for random effects were smaller, the correction rates were lower for all methods. However, the performance of the proposed method was still much better than the other two methods.
When random effects were assumed uncorrelated, based on the simulation results in
Table 6, we saw that the proposed BIC and regular BIC still performed well and better than the cAIC method. The proposed BIC method performed better than the regular BIC in Case 2, but did not perform better than the regular BIC in Case 1. This may be because the penalty term of the regular BIC was calculated using the exact chi-squared distribution and the calculation of the penalty term was without any error. However, for the proposed BIC, the weights of the chi-bar-squared distribution were approximated. Therefore, the penalty term was approximated only. From the simulation results, we noticed that when the values of the variances for random effects were smaller, the correction rates were lower for the proposed and regular BIC methods. However, the correction rates in Case 2 were better than Case 1 for the cAIC method.
Comparing the computational complexity, the proposed method requires Monte Carlo simulations to estimate the weights so that the penalty parameter can be computed. This is more computational intensive than the regular BIC. In our simulation, for one dataset with a given model, for Setup A, it took about to s for the proposed BIC method and about to s for the regular BIC. For Setup B, it took about s for the proposed BIC, s for the regular BIC, and s for the cAIC. For Setup C with independent random effects, it took about s for the proposed BIC, s for the regular BIC, and s for the cAIC. For Setup C with correlated random effects, it took about s for the proposed BIC, s for the regular BIC, and s for the cAIC. We noted that the model with correlated random effects took longer than the one with independent random effects. Furthermore, the computational time of the proposed method was longer than that of the regular BIC, but quite close to that of the cAIC method. The OS and CPU system specifications that we used to run our methods were Windows 10, CPU: Intel Core with 4 cores, 8 threads. The memory requirements of our methods are 8 GB RAM.
4. Real-Data Application
In this section, we applied the proposed BIC to a real dataset. We worked with a dataset that is a subset of 120 schools of dataset “hsfull” from package “spida2” in R, which was developed by Monette et al. [
29]. This dataset was originally from the 1982 “High School and Beyond” (HSB) survey dataset in Raudenbush and Bryk’s text on hierarchical linear models (Raudenbush and Bryk [
30]). The data include the mathematics achievement test scores of 5307 students from 50 Catholic and 70 public high schools, with the number of students in each school ranging from 19 to 66 students.
The variables included in the analysis were school identification number, mathematics achievement score (), socioeconomic status (), sex (female (0) or male (1); ), visible minority status (yes (1) or no (0); ), and school sector (Catholic (0) or public (1); ). Variables , , and are group-centered. The objective was to study the relationship between students’ mathematics achievement score and socioeconomic status, sex, and visible minority status in public and Catholic schools and whether this relationship varies across schools within each sector.
The candidate variables in the fixed effects part were , , , and , which are group-centered. The candidate variables in the random effects part were , , and , which are the same as , , and .
We first fit a linear mixed model that included only the intercept term for fixed effects and a random intercept. Then, we fit the models with only the intercept term for fixed effects and all possible combinations of , , and with a random intercept for random effects. Next, we fit the models with all possible combinations of , , , and for fixed effects and only a random intercept for random effects. Lastly, for each combination of , , , and for fixed effects, we fit the models with all possible combinations of , , and with a random intercept for random effects. For each model, we recorded the values of the proposed BIC, regular BIC, and cAIC. There were 128 values for each method. Now, for each method, we chose the model with the minimum value of the corresponding criterion. We applied this procedure for both cases when random effects were assumed to be correlated and uncorrelated.
When random effects were assumed to be correlated, the optimal model we obtained using the proposed BIC was the model with all , , , and and a random intercept; the proposed BIC was 34,379.83. The optimal model we obtained using the regular BIC was also the model with , , , and and a random intercept only. The regular BIC of this model was also 34,379.83. The cAIC yielded the optimal model, which contained , , , and with a random intercept and random slopes of and . The cAIC of the optimal model was 34,166.25.
When random effects were assumed to be uncorrelated, the optimal model we obtained using the proposed BIC was the model with all , , , and , a random intercept, and random slopes of ; the proposed BIC value was 34,378.23. The optimal model we obtained using the regular BIC was the model with , , , and and a random intercept only. The regular BIC of this model was 34,379.83. The cAIC yielded the optimal model, which contained , , , and with a random intercept and random slopes of , , and . The cAIC of the optimal model was 34,165.13.
Table 7 shows the proposed BIC, regular BIC, and cAIC for all models that contained
,
,
, and
with correlated random effects considered.
Table 8 shows the optimal model chosen by each method when the random effects were assumed to be independent and when the random effects were correlated. All
,
,
, and
were included in the models.
Based on the results presented above, we would choose the model with all , , , and for fixed effects and a random intercept and a random slope of for random effects assuming that random effects are uncorrelated. There was a significant relationship between students’ math achievement score and socioeconomic status, sex, and visible minority status in public and Catholic schools, and the school mean math achievement score and minority gap effect varied across the schools within each sector.
5. Discussion
In this article, we introduced a modified BIC for linear mixed models that can directly deal with the boundary issue of variance components. First, we focused on selecting random effects variance components and proposed a model selection criterion when the random effects were assumed to be independent (the covariance matrix of random effects was a diagonal matrix). Second, we proposed a criterion for choosing random effects variance components when the random effects were assumed to be correlated. Instead of working with a complex tangent cone to the alternative parameter space, we approximated the tangent cone using a bigger, but simpler cone. This allowed us to obtain the weights of the chi-bar-squared distribution. Lastly, we presented a model selection criterion for choosing both fixed effects and random effects simultaneously in both cases: when random effects were assumed to be independent and when they were correlated. We also proved the consistency of the modified BIC.
Based on the simulation studies, the modified BIC performed quite well in terms of the correction rate. The ability to select the data-generating model of the modified BIC was better when the size of the random effects variance component or the size of correlation component was bigger. Compared to the regular BIC, the modified BIC gave higher correction rates, especially when the variances of random effects were small. Based on the correction rate, the modified BIC and performed better than the regular BIC in most cases. Furthermore, there was significant improvement in the positive selection rate in most of the simulation scenarios.
One limitation of the modified BIC is that, when choosing the optimal model, the proposed method looks at all possible models. Since the number of possible models increased exponentially as the number of fixed effects and random effects increased, the model selection process may be increasingly computationally intensive. We may combine the proposed BIC with some selection procedure such as shrinkage methods or fence methods as introduced in Müller et al. [
31] to reduce the number of candidate models. Then, we can use the proposed BIC method to perform model selection.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}