

Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis

 , , , and
, , , and
Abstract
:1. Introduction
2. Related Work
2.1. Vision-Based Approaches for Posture Classification
2.2. Pose Classification in Yoga
- YoNet [32] is able to classify five types of yoga poses with an accuracy of 94.91%. YoNet is a deep learning model that utilizes depthwise separable convolution—a technique presented by Xception [33]—for parameter and computational reduction. To extract spatial characteristics, such as edges, YoNet utilizes a standard convolution layer on the input image, followed by multiple depthwise separable convolution layers to extract depth attributes such as the position and orientation of the human body. These two feature types are combined prior to the classification layer. For classification, YoNet utilizes two dense layers with ReLU activation and batch normalization. This enables the input image to be classified into one of five yoga poses. The ultimate layer applies softmax activation to display the probability of each class.
- Y_PN-MSSD [27] has an accuracy rate of 99.88% for a total of seven poses. The Y_PN-MSSD model architecture is a deep learning-based model that combines two components, namely PoseNet [34] and MobileNet SSD [35]. The main steps in the model are as follows:Feature Extraction: The PoseNet model utilizes CNNs to identify the essential human body keypoints in every picture. These points are linked to create a skeletal representation of the pose.Posture Recognition: The system utilizes MobileNet SSD, a Single Shot Detector (SSD), to classify the pose according to the skeletal features. The system also executes human detection and generates bounding boxes in every frame.
- The original paper presenting the Yoga-82 dataset reported a maximum accuracy of 79.35% for its Architectural Variant 1 classifying all 82 postures. Using only the Yoga-82 dataset and classifying all 82 postures, this accuracy represents the current state of the art. Architectural Variant 1 is a modification of the DenseNet-201 [36] architecture that introduces a hierarchical structure to improve classification performance by utilizing the hierarchy inherent in the dataset. This variant integrates hierarchical connections after DenseBlock 2 and DenseBlock 3, catering to Class Level 1 (with 6 classes) and Class Level 2 (with 20 classes), respectively. The fundamental idea behind this variant is that broader classes are classified in the intermediate layers of the network, while more specific classes are processed by the end layers. The initial-to-mid layers specialize in first-level classification and pass on image details to subsequent layers for second-level classification. The common layers up to DenseBlock 2 focus on capturing the fundamental pose structure, with subsequent layers further refining the model’s understanding.
2.3. The Use of CLIP as a Classifier
3. Procedure for Setting up CLIP as a Posture Classifier
3.1. Dataset Analysis


3.2. CLIP Configuration

3.2.1. Syntax for Image Description and Baseline Zero-Shot Evaluation
3.2.2. Visual Encoder Choice and Hyperparameters Definition for Fine-Tuning
4. Evaluation of Fine-Tuned CLIP Performance
4.1. Fine-Tuned CLIP Performance for Six-Posture Subsets
4.2. Fine-Tuned CLIP Performance for 82 Postures



4.3. Notes on Computational Cost
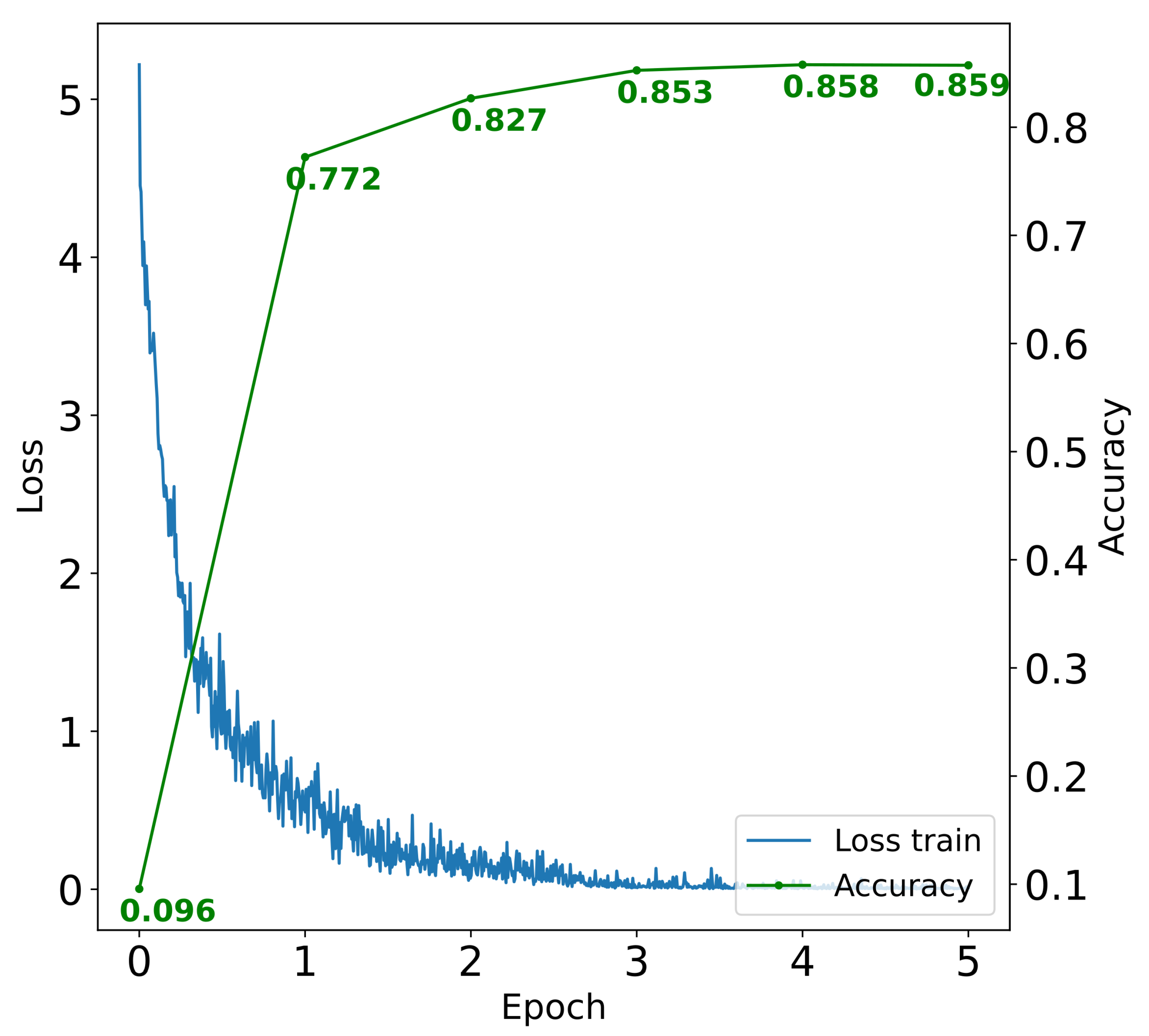
4.4. Evaluation of Training Frugality with CLIP
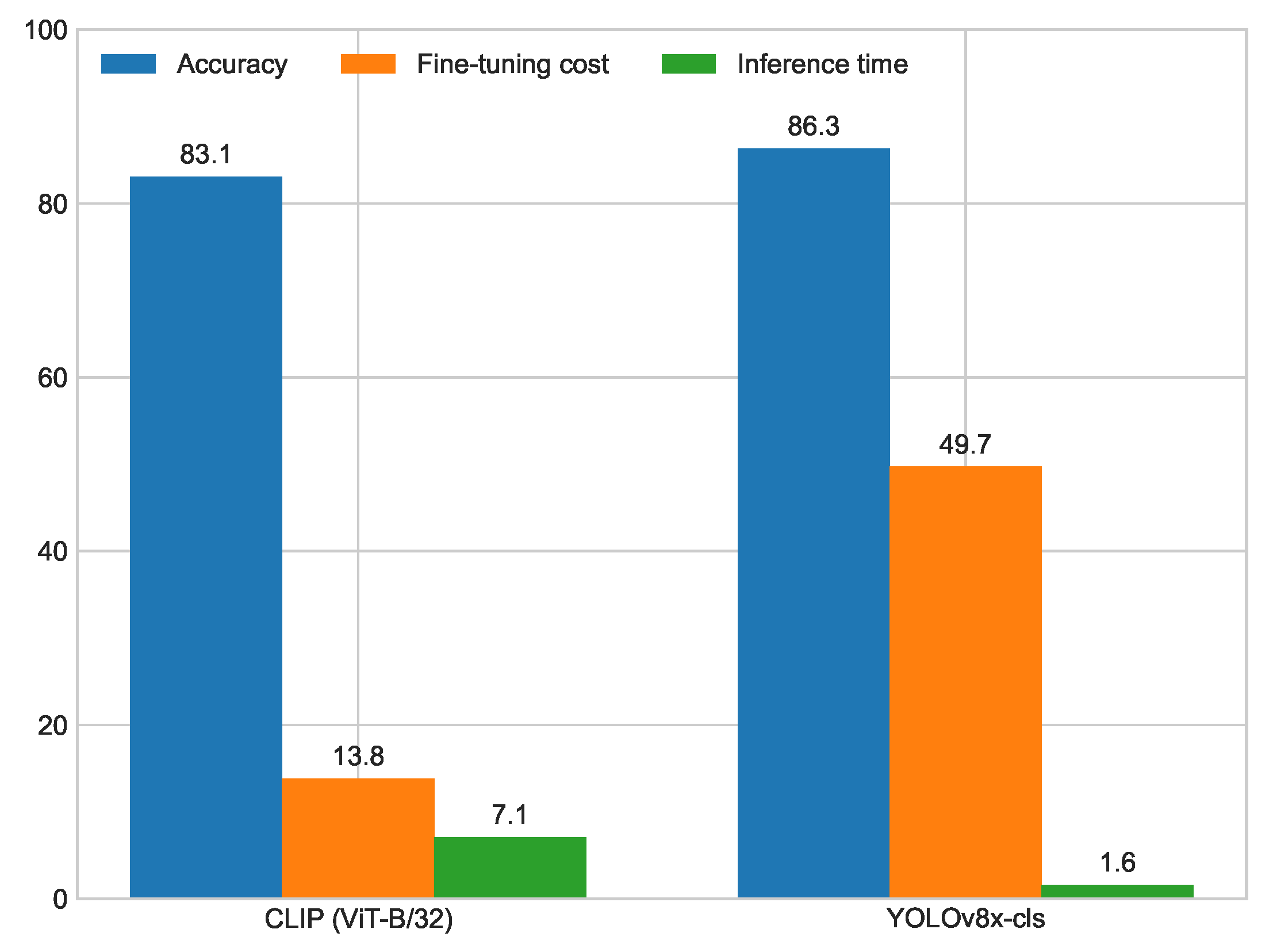
5. Benchmark with YOLO
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Class Distribution across the Superclasses in the Yoga-82 Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Standing | ||
|---|---|---|
| Straight | Garudasana | 283 |
| Vrksasana | 256 | |
| Utkatasana | 312 | |
| Forward bend | Parsvottanasana | 183 |
| Adho Mukha Svanasana | 306 | |
| Ardha Pincha Mayurasana | 69 | |
| Prasarita Padottanasana | 257 | |
| Uttanasana | 390 | |
| Side bend | Ardha Chandrasana | 270 |
| Utthita Trikonasana | 532 | |
| Utthita Parsvakonasana | 530 | |
| Parighasana | 153 | |
| Virabhadrasana I | 172 | |
| Viparita virabhadrasana | 143 | |
| Anjaneyasana | 253 | |
| Forward bend | Virabhadrasana II | 259 |
| Virabhadrasana III | 186 | |
| Natarajasana | 392 | |
| Utthita Padangusthasana | 177 | |
| Urdhva Prasarita Eka Padasana | 133 | |
| Balancing | ||
|---|---|---|
| Front | Bakasana | 294 |
| Bhujapidasana | 98 | |
| Cockerel | 146 | |
| Tolasana | 125 | |
| Tittibhasana | 184 | |
| Side | Parsva Bakasana | 183 |
| Astavakrasana | 190 | |
| Eka Pada Koundinyanasana I and II | 130 | |
| Reclining | ||
|---|---|---|
| Up-facing | Savasana | 322 |
| Matsyasana | 288 | |
| Ananda Balasana | 161 | |
| Supta Padangusthasana | 152 | |
| Pawanmuktasana | 156 | |
| Supta Baddha Konasana | 316 | |
| Supta Virasana Vajrasana | 308 | |
| Supta Virasana Vajrasana | 308 | |
| Yogic sleep | 80 | |
| Down-facing | Bhujangasana | 788 |
| Bhekasana | 149 | |
| Salabhasana | 227 | |
| Balasana | 310 | |
| Uttana Shishosana | 82 | |
| Side facing | Anantasana | 68 |
| Vasisthasana | 297 | |
| Plank balance | Makara Adho Mukha Svanasana | 46 |
| Chaturanga Dandasana | 220 | |
| Kumbhakasana | 70 | |
| Mayurasana | 127 | |
| Inverted | ||
|---|---|---|
| Legs straight up | Adho Mukha Vrksasana | 196 |
| Salamba Sirsasana | 312 | |
| Salamba Sarvangasana | 269 | |
| Pincha Mayurasana | 210 | |
| Viparita Karani | 220 | |
| Legs bend | Halasana | 327 |
| Vrischikasana | 232 | |
| Sitting | ||
|---|---|---|
| Normal 1 | Sitting | 671 |
| Baddha Konasana | 268 | |
| Malasana | 241 | |
| Dandasana | 83 | |
| Pasasana | 38 | |
| Normal 2 | Gomukhasana | 303 |
| Vajrasana | 329 | |
| Bharadvajasana I | 83 | |
| Ardha Matsyendrasana | 312 | |
| Split | Split | 302 |
| Upavistha Konasana | 188 | |
| Forward bend | Janu Sirsasana | 180 |
| Parivrtta Janu Sirsasana | 220 | |
| Paschimottanasana | 348 | |
| Tortoise | 149 | |
| Twist | Akarna Dhanurasana | 84 |
| Krounchasana | 58 | |
| Rajakapotasana | 274 | |
| Wheel | ||
|---|---|---|
| Up-facing | Urdhva Dhanurasana | 308 |
| Dwi Pada Viparita Dandasana | 72 | |
| Purvottanasana | 225 | |
| Kapotasana | 53 | |
| Setu Bandha Sarvangasana | 279 | |
| Camatkarasana | 178 | |
| Ustrasana | 311 | |
| Down-facing | Marjaryasana | 409 |
| Others | Dhanurasana | 228 |
| Paripurna Navasana | 394 | |
Appendix B. Confusion Matrices

| “Reclining” L-1 Superclass Label-Name Correspondence | |||
|---|---|---|---|
| 0 | Savasana | 1 | Matsyasana |
| 2 | Ananda Balasana | 3 | Supta Padangusthasana |
| 4 | Pawanmuktasana | 5 | Supta Baddha Konasana |
| 6 | Supta Virasana Vajrasana | 7 | Yogic sleep |
| 8 | Bhujangasana | 9 | Bhekasana |
| 10 | Salabhasana | 11 | Balasana |
| 12 | Uttana Shishosana | 13 | Anantasana |
| 14 | Vasisthasana | 15 | Makara Adho Mukha Svanasana |
| 16 | Chaturanga Dandasana | 17 | Kumbhakasana |
| 18 | Mayurasana | ||

| “Sitting” L-1 Superclass Label-NAME Correspondence | |||
|---|---|---|---|
| 0 | Sitting | 1 | Baddha Konasana |
| 2 | Malasana | 3 | Dandasana |
| 4 | Pasasana | 5 | Gomukhasana |
| 6 | Vajrasana | 7 | Bharadvajasana I |
| 8 | Ardha Matsyendrasana | 9 | Split |
| 10 | Upavistha Konasana | 11 | Janu Sirsasana |
| 12 | Parivrtta Janu Sirsasana | 13 | Paschimottanasana |
| 14 | Tortoise | 15 | Akarna Dhanurasana |
| 16 | Krounchasana | 17 | Rajakapotasana |
References
- Karkowski, W.; Genaidy, A.M. Computer-Aided Ergonomics; Taylor & Francis: Abingdon, UK, 1990. [Google Scholar]
- Golabchi, A.; Han, S.; Fayek, A.R. A fuzzy logic approach to posture-based ergonomic analysis for field observation and assessment of construction manual operations. Can. J. Civ. Eng. 2016, 43, 294–303. [Google Scholar] [CrossRef]
- Mohammed, A.R.; Mohamed, M.O.; Alhubaishy, Y.A.; Nasser, K.A.; Fahim, I.S. Ergonomic analysis of a working posture in steel industry in Egypt using digital human modeling. SN Appl. Sci. 2020, 2, 2085. [Google Scholar] [CrossRef]
- Silva, A.G.d.; Winkler, I.; Gomes, M.M.; De Melo Pinto, U. Ergonomic analysis supported by virtual reality: A systematic literature review. In Proceedings of the 2020 22nd Symposium on Virtual and Augmented Reality (SVR), Porto de Galinhas, Brazil, 7–10 November 2020. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. arXiv 2021, arXiv:cs.CV/2103.00020. [Google Scholar]
- Gjoreski, H.; Lustrek, M.; Gams, M. Accelerometer Placement for Posture Recognition and Fall Detection. In Proceedings of the 2011 Seventh International Conference on Intelligent Environments, Nottingham, UK, 25–28 July 2011. [Google Scholar]
- Leone, A.; Rescio, G.; Caroppo, A.; Siciliano, P.; Manni, A. Human postures recognition by accelerometer sensor and ML architecture integrated in embedded platforms: Benchmarking and performance evaluation. Sensors 2023, 23, 1039. [Google Scholar] [CrossRef] [PubMed]
- Bourahmoune, K.; Ishac, K.; Amagasa, T. Intelligent posture training: Machine-learning-powered human sitting posture recognition based on a pressure-sensing IoT cushion. Sensors 2022, 22, 5337. [Google Scholar] [CrossRef]
- Mauthner, T.; Koch, C.; Tilp, M.; Bischof, H. Visual tracking of athletes in beach volleyball using a single camera. Int. J. Comput. Sci. Sport 2007, 6, 21–34. [Google Scholar]
- Kristan, M.; Kovacic, S.; Leonardis, A.; Pers, J. A two-stage dynamic model for visual tracking. IEEE Trans. Syst. Man Cybern. Part B 2010, 40, 1505–1520. [Google Scholar] [CrossRef]
- Hoseinnezhad, R.; Vo, B.N.; Vo, B.T.; Suter, D. Visual tracking of numerous targets via multi-Bernoulli filtering of image data. Pattern Recognit. 2012, 45, 3625–3635. [Google Scholar] [CrossRef]
- Kim, H.; Jung, J.; Paik, J. Fisheye lens camera based surveillance system for wide field of view monitoring. Optik 2016, 127, 5636–5646. [Google Scholar] [CrossRef]
- McBride, J.; Snorrason, M.; Goodsell, T.; Eaton, R.; Stevens, M.R. Single camera stereo for mobile robot surveillance. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–25 June 2005; p. 128. [Google Scholar]
- Scott, B.; Seyres, M.; Philp, F.; Chadwick, E.K.; Blana, D. Healthcare applications of single camera markerless motion capture: A scoping review. PeerJ 2022, 10, e13517. [Google Scholar] [CrossRef]
- Bostelman, R.; Russo, P.; Albus, J.; Hong, T.; Madhavan, R. Applications of a 3D range camera towards healthcare mobility aids. In Proceedings of the 2006 IEEE International Conference on Networking, Sensing and Control, Ft. Lauderdale, FL, USA, 23–25 April 2006; pp. 416–421. [Google Scholar]
- Amine Elforaici, M.E.; Chaaraoui, I.; Bouachir, W.; Ouakrim, Y.; Mezghani, N. Posture recognition using an RGB-D camera: Exploring 3D body modeling and deep learning approaches. In Proceedings of the 2018 IEEE Life Sciences Conference (LSC), Montreal, QC, Canada, 28–30 October 2018. [Google Scholar]
- Hachaj, T.; Ogiela, M.R. Rule-based approach to recognizing human body poses and gestures in real time. Multimed. Syst. 2014, 20, 81–99. [Google Scholar] [CrossRef]
- Ding, W.; Hu, B.; Liu, H.; Wang, X.; Huang, X. Human posture recognition based on multiple features and rule learning. Int. J. Mach. Learn. Cybern. 2020, 11, 2529–2540. [Google Scholar] [CrossRef]
- Debnath, B.; O’Brien, M.; Yamaguchi, M.; Behera, A. A review of computer vision-based approaches for physical rehabilitation and assessment. Multimed. Syst. 2022, 28, 209–239. [Google Scholar] [CrossRef]
- Chen, S.; Yang, R.R. Pose Trainer: Correcting Exercise Posture using Pose Estimation. arXiv 2020, arXiv:abs/2006.11718. [Google Scholar]
- Zhang, H.; Yan, X.; Li, H. Ergonomic posture recognition using 3D view-invariant features from single ordinary camera. Autom. Constr. 2018, 94, 1–10. [Google Scholar] [CrossRef]
- Mehta, D.; Rhodin, H.; Casas, D.; Fua, P.; Sotnychenko, O.; Xu, W.; Theobalt, C. Monocular 3D human pose estimation in the wild using improved CNN supervision. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Zhang, W.; Zhu, M.; Derpanis, K.G. From actemes to action: A strongly-supervised representation for detailed action understanding. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Xiao, Y.; Chen, J.; Wang, Y.; Cao, Z.; Tianyi Zhou, J.; Bai, X. Action recognition for depth video using multi-view dynamic images. Inf. Sci. 2019, 480, 287–304. [Google Scholar] [CrossRef]
- Verma, M.; Kumawat, S.; Nakashima, Y.; Raman, S. Yoga-82: A new dataset for fine-grained classification of human poses. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Gochoo, M.; Tan, T.H.; Huang, S.C.; Batjargal, T.; Hsieh, J.W.; Alnajjar, F.S.; Chen, Y.F. Novel IoT-based privacy-preserving yoga posture recognition system using low-resolution infrared sensors and deep learning. IEEE Internet Things J. 2019, 6, 7192–7200. [Google Scholar] [CrossRef]
- Upadhyay, A.; Basha, N.K.; Ananthakrishnan, B. Deep learning-based yoga posture recognition using the Y_PN-MSSD model for yoga practitioners. Healthcare 2023, 11, 609. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2019, arXiv:cs.CV/1812.08008. [Google Scholar] [CrossRef]
- Huang, X.; Pan, D.; Huang, Y.; Deng, J.; Zhu, P.; Shi, P.; Xu, R.; Qi, Z.; He, J. Intelligent yoga coaching system based on posture recognition. In Proceedings of the 2021 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 18–21 November 2021. [Google Scholar]
- Wu, Y.; Lin, Q.; Yang, M.; Liu, J.; Tian, J.; Kapil, D.; Vanderbloemen, L. A Computer Vision-Based Yoga Pose Grading Approach Using Contrastive Skeleton Feature Representations. Healthcare 2022, 10, 36. [Google Scholar] [CrossRef]
- Cohen, W.W. Fast effective rule induction. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 115–123. [Google Scholar]
- Ashraf, F.B.; Islam, M.U.; Kabir, M.R.; Uddin, J. YoNet: A Neural Network for Yoga Pose Classification. SN Comput. Sci. 2023, 4, 198. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:abs/1610.02357. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Convolutional networks for real-time 6-DOF camera relocalization. arXiv 2015, arXiv:abs/1505.07427. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:cs.CV/1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:cs.CV/1608.06993. [Google Scholar]
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022. [Google Scholar]
- Endo, M.; Krishnan, R.; Krishna, V.; Ng, A.Y.; Rajpurkar, P. Retrieval-Based Chest X-Ray Report Generation Using a Pre-trained Contrastive Language-Image Model. Proc. Mach. Learn. Health 2021, 158, 209–219. [Google Scholar]
- Khorramshahi, P.; Rambhatla, S.S.; Chellappa, R. Towards accurate visual and natural language-based vehicle retrieval systems. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Deng, Y.; Campbell, R.; Kumar, P. Fire and gun detection based on sematic embeddings. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Taipei City, Taiwan, 18–22 July 2022. [Google Scholar]
- Saxena, S. Yoga Pose Image Classification Dataset. 2020. Available online: https://www.kaggle.com/datasets/shrutisaxena/yoga-pose-image-classification-dataset (accessed on 10 November 2023).
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; Daumé, H., III, Singh, A., Eds.; Proceedings of Machine Learning Research: Breckenridge, CO, USA, 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:abs/1807.03748. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:cs.CL/1706.03762. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:cs.CV/1512.03385. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:cs.CV/2010.11929. [Google Scholar]
- Jin, W.; Cheng, Y.; Shen, Y.; Chen, W.; Ren, X. A Good Prompt Is Worth Millions of Parameters: Low-resource Prompt-based Learning for Vision-Language Models. arXiv 2022, arXiv:cs.CV/2110.08484. [Google Scholar]
- Yao, Y.; Zhang, A.; Zhang, Z.; Liu, Z.; Chua, T.; Sun, M. CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models. arXiv 2021, arXiv:abs/2109.11797. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar] [CrossRef]
- Jiang, H.; Misra, I.; Rohrbach, M.; Learned-Miller, E.G.; Chen, X. In Defense of Grid Features for Visual Question Answering. arXiv 2020, arXiv:abs/2001.03615. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. arXiv 2018, arXiv:abs/1812.01187. [Google Scholar]
- Chen, P.; Li, Q.; Biaz, S.; Bui, T.; Nguyen, A. gScoreCAM: What objects is CLIP looking at? In Proceedings of the ACCV 2022: 16th Asian Conference on Computer Vision, Macao, China, 4–8 December 2022.
- Dong, X.; Bao, J.; Zhang, T.; Chen, D.; Gu, S.; Zhang, W.; Yuan, L.; Chen, D.; Wen, F.; Yu, N. CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet. arXiv 2022, arXiv:cs.CV/2212.06138. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics; GitHub: San Francisco, CA, USA, 2023. [Google Scholar]
- Shirvalkar, R. YOLO-V8-CAM. 2023. Available online: https://github.com/rigvedrs/YOLO-V8-CAM (accessed on 7 July 2023).




| Work | Goal of the Work | Datasets | Algorithms | Results (Accuracy) |
|---|---|---|---|---|
| [16] | Comparing the performance of classical and ML techniques in posture recognition | Ad hoc (1040 images) | SVM vs. CNN | SVM: 93.1% CNN: 95.7% |
| [17] | Developing a pose classifier using a rule-based approach | Ad hoc (1600 videos) | Rule-based reasoning applied to body joints | 91.3% |
| [18] | Enhancing human posture recognition using a rule learning algorithm | MSR-Action3D, Microsoft MSRC-12, UTKinect-Action, Ad hoc (Baduanjin) | Feature extraction + RIPPER [31] + classification | MSR3D: 94.5% MSRC: 97.6% UTKA: 98.1% Badua.: 99.6% |
| [20] | Detecting and correcting exercise posture | Ad hoc (100 videos) | 2 CNNs | 88.5% |
| [21] | Recognizing postures of workers to improve their safety and health | Human 3.6M | multi-stage CNN | 94.8% |
| [26] | Recognizing yoga postures using IR cameras to preserve privacy | Ad hoc (187,200 images, 26 yoga poses) | DCNN | 99.8% |
| [27] | Correcting yoga poses | Yoga-pose dataset (350 videos of 7 poses) + ad hoc (150 videos) | CNN | 99.88% |
| [29] | Creating a yoga coach | Ad hoc (8 yoga poses, no more details) | OpenPose (CNN) | 91% |
| Unfiltered Subset (Yoga-82-Subset I) | ||
|---|---|---|
| Train | Test | |
| Dhanurasana | 171 | 45 |
| Ustrasana | 226 | 51 |
| Sarvangasana | 192 | 51 |
| Utkatasana | 215 | 58 |
| Marjaryasana | 291 | 61 |
| Balasana | 206 | 60 |
| Filtered Subset (Yoga-82-Subset II) | ||
|---|---|---|
| Train | Test | |
| Dhanurasana | 47 | 10 |
| Ustrasana | 61 | 11 |
| Sarvangasana | 43 | 15 |
| Utkatasana | 98 | 21 |
| Marjaryasana | 114 | 21 |
| Balasana | 71 | 31 |
| Visual Encoder Model | Accuracy |
|---|---|
| Top-1 | |
| RN50 | 20.8% |
| RN101 | 41.5% |
| RN50x4 | 30.2% |
| RN50x16 | 49.1% |
| RN50x4 | 37.7% |
| ViT-B/32 | 24.5% |
| ViT-B/16 | 30.2% |
| ViT-L/14 | 35.8% |
| ViT-L/14@336 px | 28.3% |
| Text Description Syntax | Accuracy |
|---|---|
| “Image of a person doing the yoga pose <category>” | 99.1% |
| “Yoga pose <category>” | 100% |
| “<category>” | 96.3% |
| “<category>” to numeric | 98.2% |
| Model | Accuracy | Hyperparameters | |
|---|---|---|---|
| Top-1 | Learning Rate | Weight Decay | |
| ViT-B/32 | 17.8% | ||
| 18.4% | |||
| 98.8% | |||
| 98.2% | |||
| 85.3% | |||
| 77.9% | |||
| 97.2% | |||
| 96.9% | |||
| Model | Accuracy | Hyperparameters | |
|---|---|---|---|
| Top-1 | Learning Rate | Weight Decay | |
| ViT-B/32 | 31.2% | ||
| 30.3% | |||
| 99.1% | |||
| 98.2% | |||
| 72.5% | |||
| 74.3% | |||
| 96.3% | |||
| 97.2% | |||
| Model | Accuracy (%) | Hyperparameters | ||||||
|---|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Learning Rate | Weight Decay | |||||
| ViT-B/32 | L1 | L2 | L3 | L1 | L2 | L3 | ||
| 94.2 | 90.7 | 85.9 | 99.9 | 98.8 | 96.8 | |||
| Mean | Standard Deviation | |
|---|---|---|
| L1 | 93.9% | 0.5 |
| L2 | 90.1% | 0.6 |
| L3 | 84.1% | 0.9 |
| Accuracy | Precision | Recall | F1 | Support | |
|---|---|---|---|---|---|
| L3 | 85.9% | 86.1% | 85.9% | 85.7% | 3826 |
| Model | Accuracy | Train Images | Test Images | Images by Class |
|---|---|---|---|---|
| Top-1 | ||||
| ViT-B/32 | 97.2% | 434 | 109 | Unbalanced |
| 94.5% | 258 | 43 | ||
| 89.9% | 120 | 20 | ||
| 73.4% | 36 | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dobrzycki, A.D.; Bernardos, A.M.; Bergesio, L.; Pomirski, A.; Sáez-Trigueros, D. Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis. Mathematics 2024, 12, 76. https://doi.org/10.3390/math12010076
Dobrzycki AD, Bernardos AM, Bergesio L, Pomirski A, Sáez-Trigueros D. Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis. Mathematics. 2024; 12(1):76. https://doi.org/10.3390/math12010076
Chicago/Turabian StyleDobrzycki, Andrzej D., Ana M. Bernardos, Luca Bergesio, Andrzej Pomirski, and Daniel Sáez-Trigueros. 2024. "Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis" Mathematics 12, no. 1: 76. https://doi.org/10.3390/math12010076
APA StyleDobrzycki, A. D., Bernardos, A. M., Bergesio, L., Pomirski, A., & Sáez-Trigueros, D. (2024). Exploring the Use of Contrastive Language-Image Pre-Training for Human Posture Classification: Insights from Yoga Pose Analysis. Mathematics, 12(1), 76. https://doi.org/10.3390/math12010076