
Automated Classification of Agricultural Species through Parallel Artificial Multiple Intelligence System–Ensemble Deep Learning


 ,
,  ,
,  ,
,  ,
,  ,
,
Abstract
:1. Introduction
- We present the Ensemble of Convolutional Neural Network (CNN) Architectures: Integrating various CNN architectures like SqueezeNet, ShuffleNetv2 1.0x, MobileNetV3, and InceptionV1, our model robustly tackles the intricacies in cultivar classification while minimizing overfitting.
- Advanced Image Segmentation Techniques: Employing a combination of U-net and Mask-R-CNN segmentation methods, the model achieves a precise and detailed analysis of CAU cultivars, enhancing classification accuracy.
- Innovative Use of an Artificial Multiple Intelligence System (AMIS): The adaptation of AMIS for decision fusion in the P-AMIS-E model optimizes the classification accuracy.
- Practical and Theoretical Implications: The model has significant implications for the agricultural and pharmaceutical industries, where precise species identification is key. Additionally, it contributes to the theoretical advancement of deep learning in image classification, setting new standards for real-world applications.
2. Related Literature
2.1. Cultivar Differentiation in CAU
2.2. Deep Learning Models for Plant Image Classification
2.3. Decision Fusion Strategy in Ensemble Deep Learning
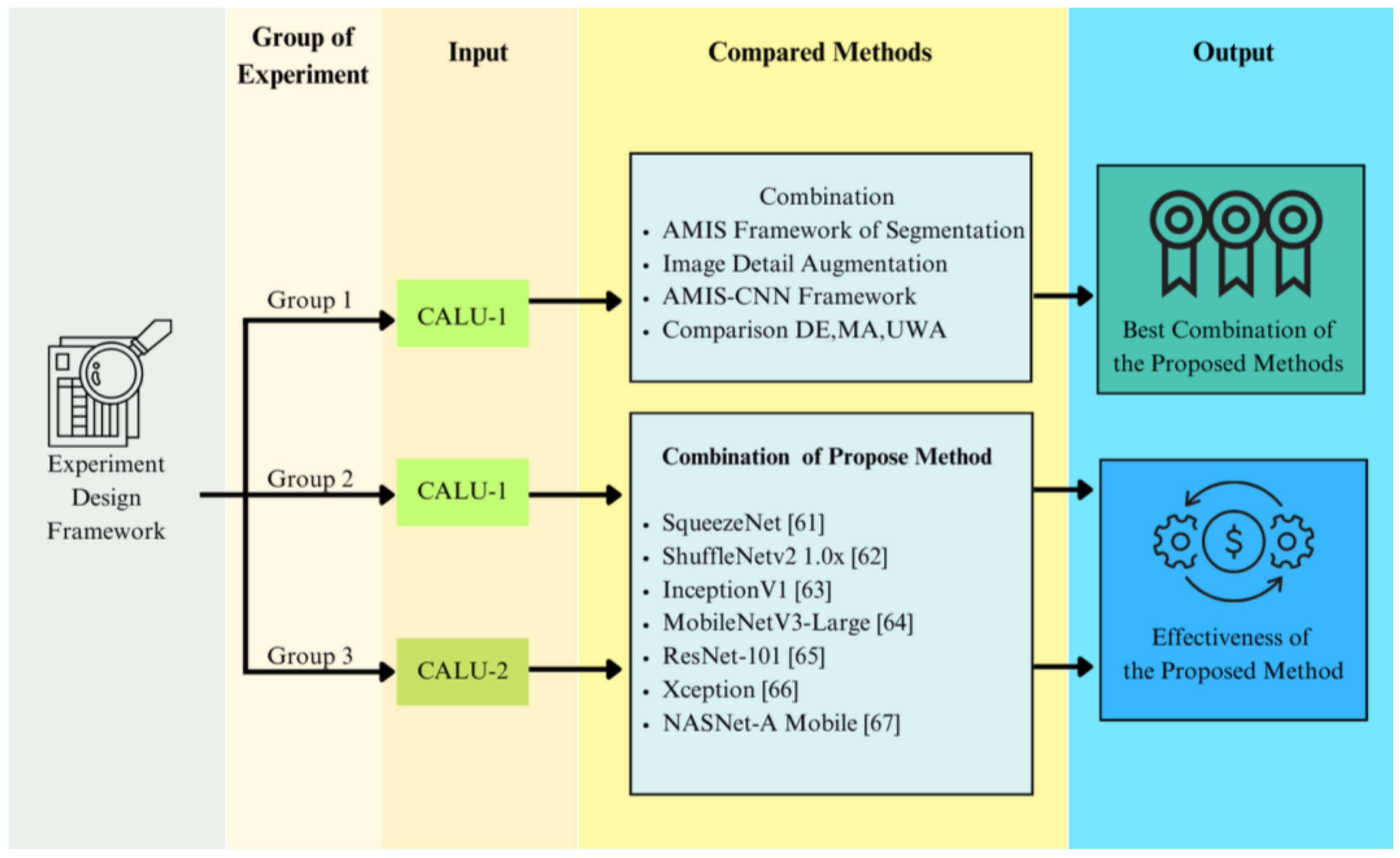
3. Research Methods
3.1. Dataset Preparation
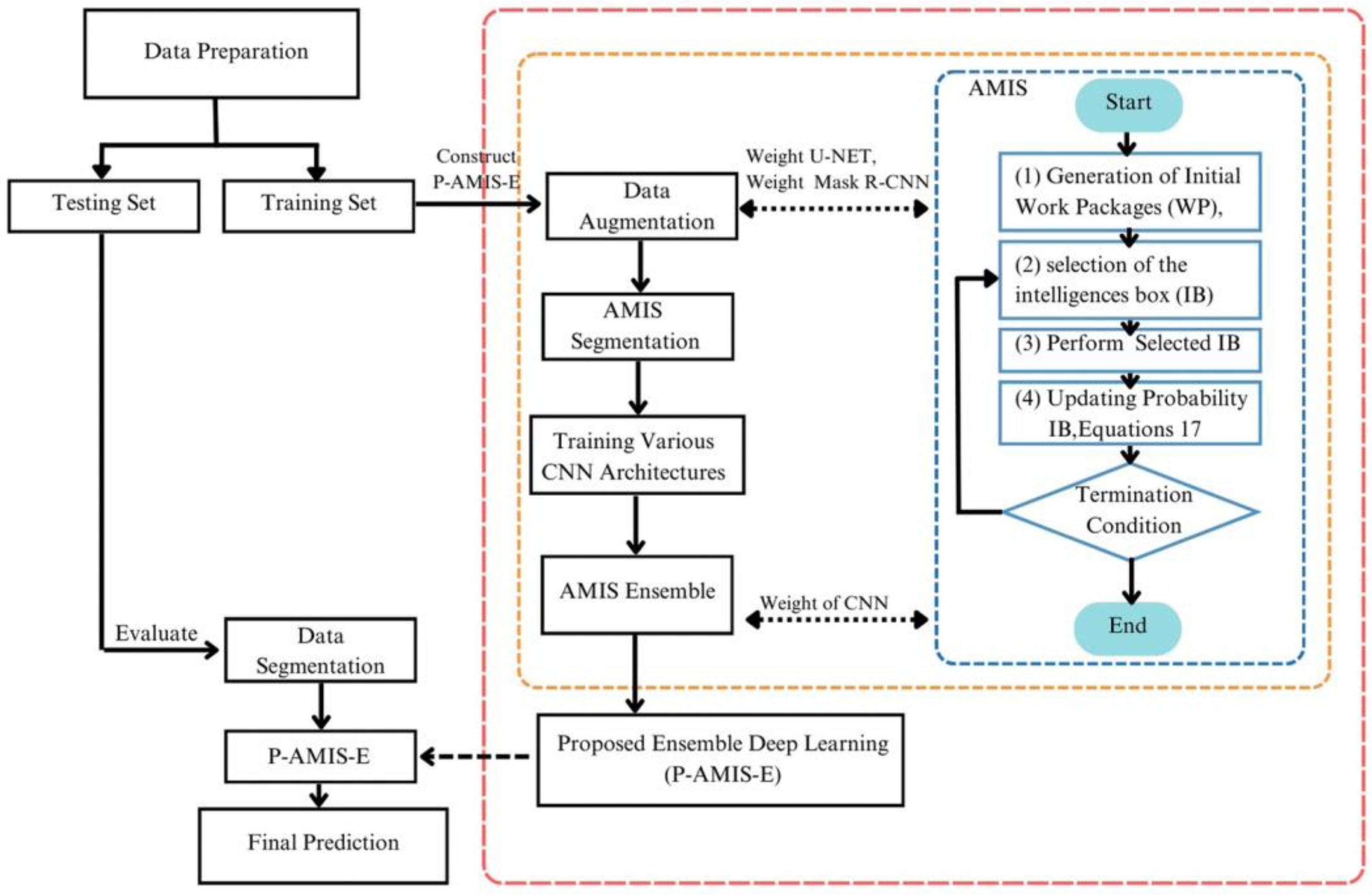
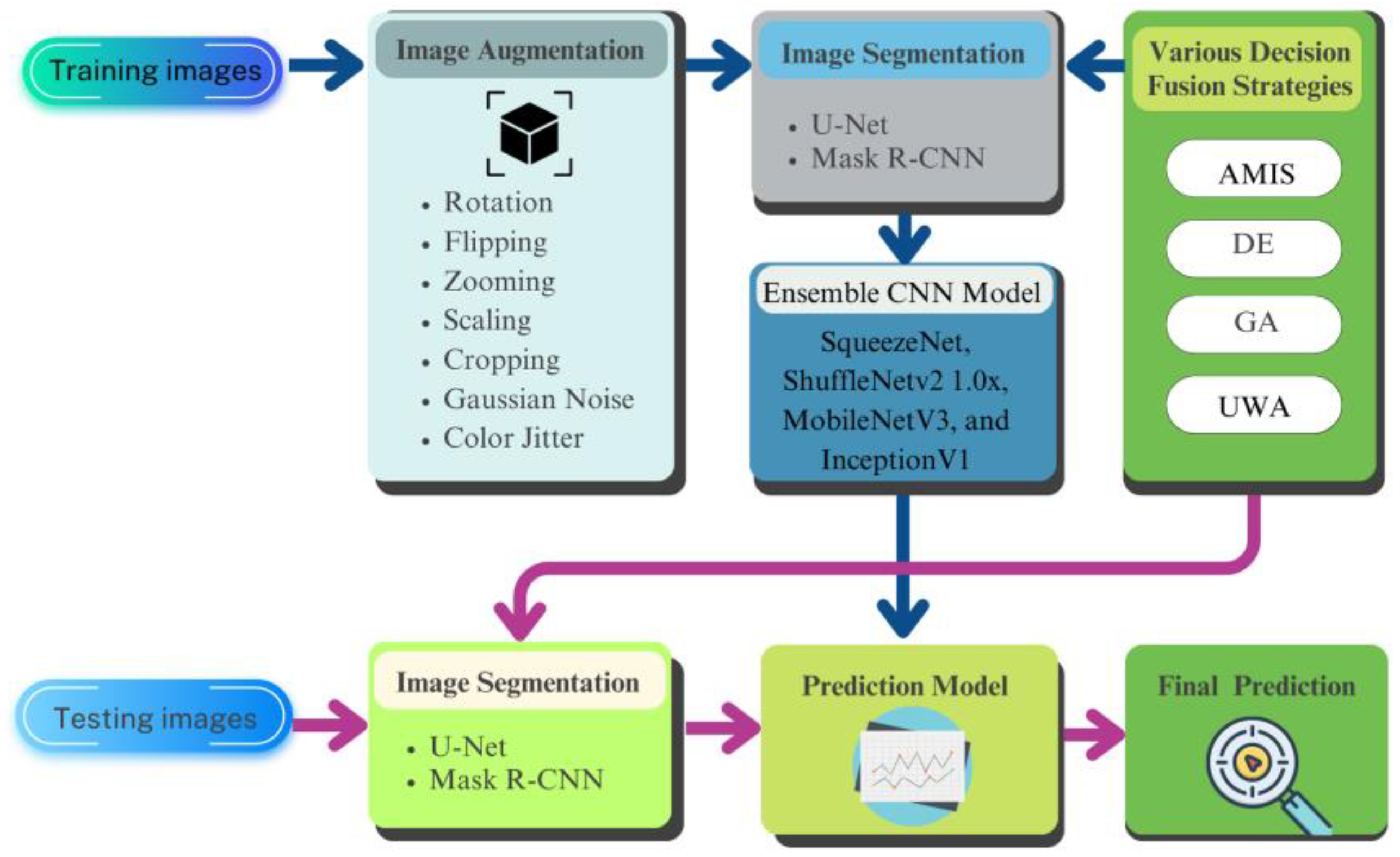
3.2. Develop the P-AMIS-E
3.2.1. Image Augmentation
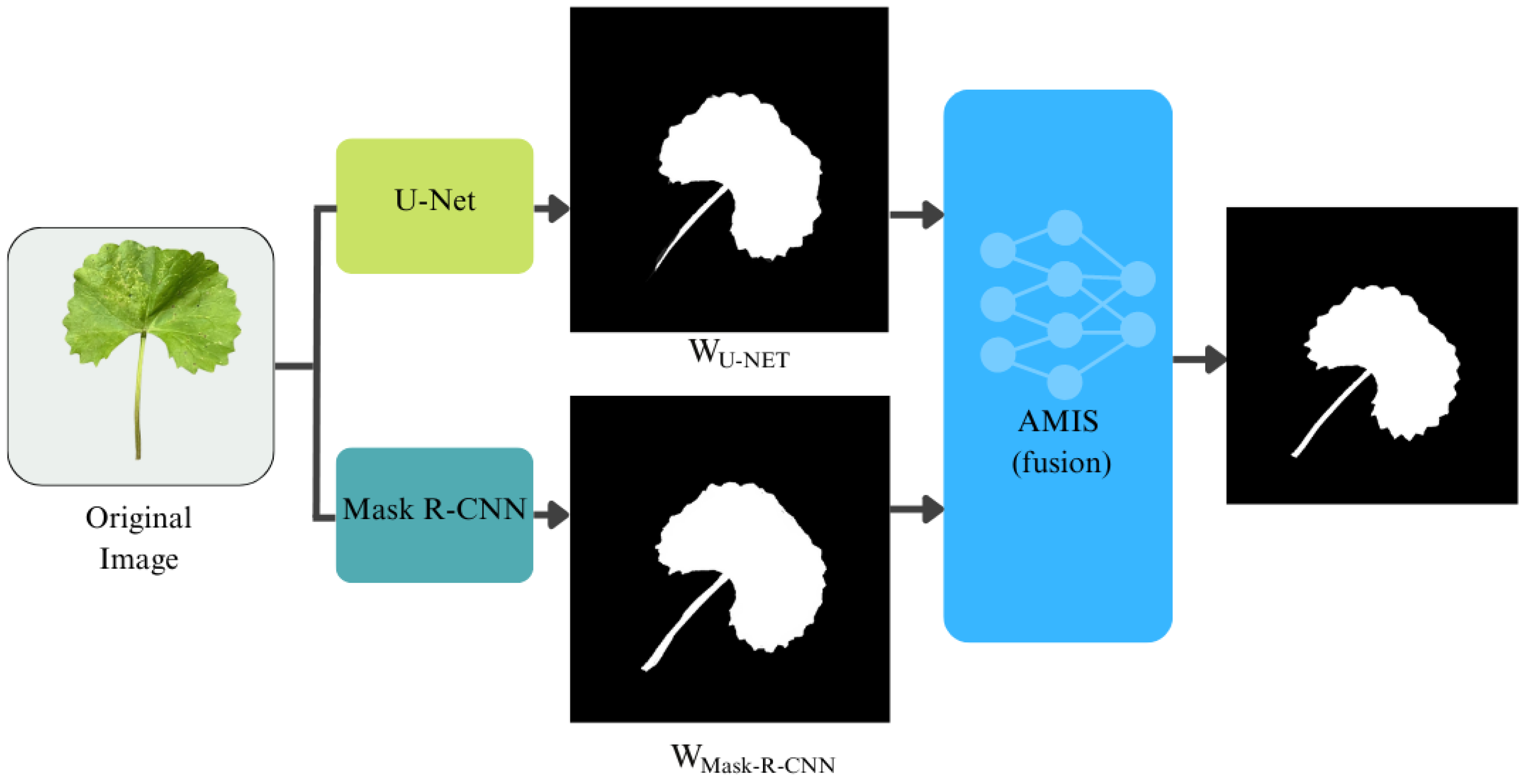
3.2.2. Image Segmentation
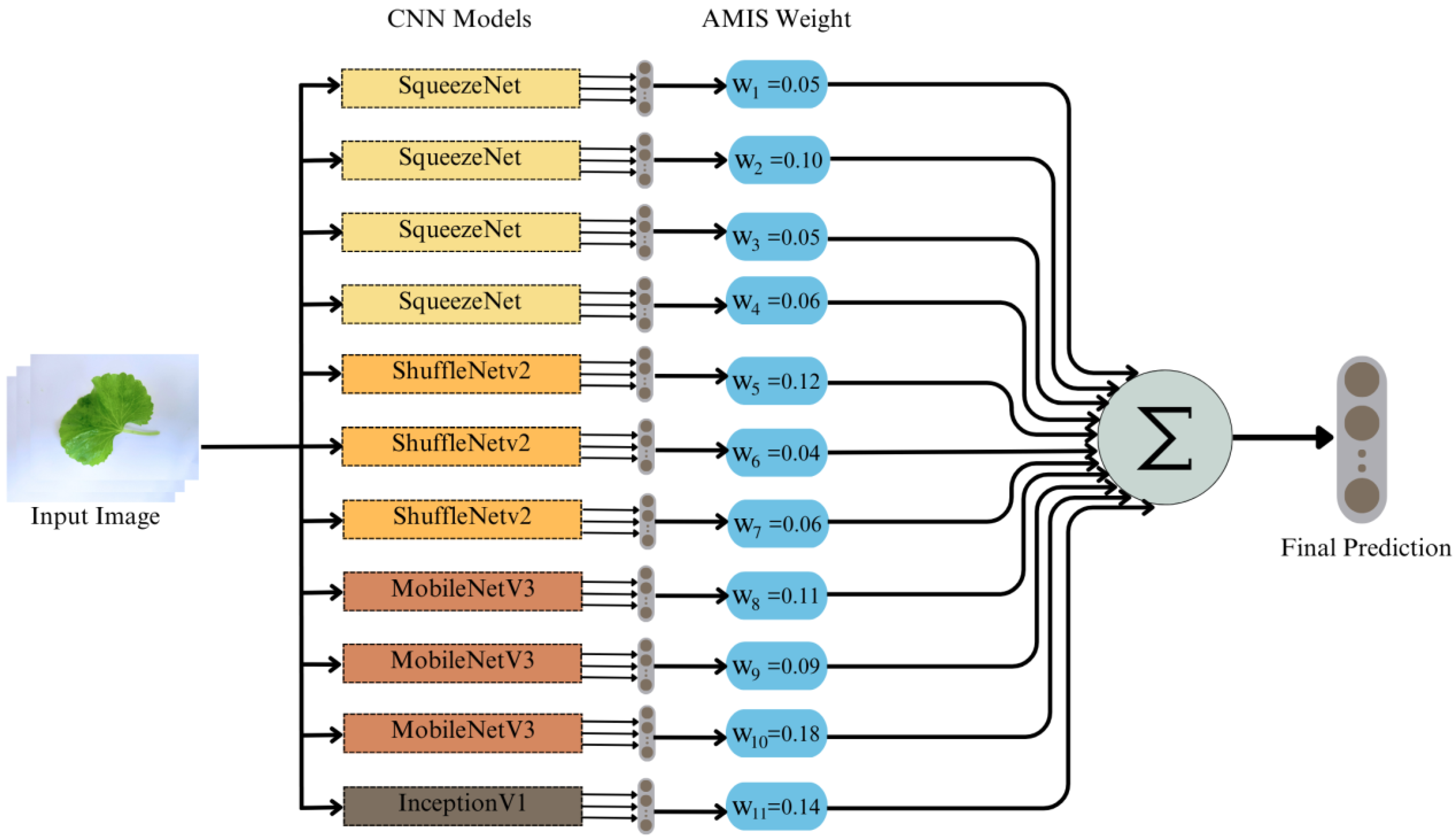
3.2.3. Ensemble the CNN Models
3.2.4. Parallel-AMIS-Ensemble Model (P-AMIS-E)
- Generate the Initial Work Package
- Perform WP Improvement Procedures
3.3. Performance Measurement Matric and the Comparison Methods
| Algorithm 1: Construction of the Parallel-Artificial Multiple Intelligence System-Ensemble Deep Learning model (P-AMIS-E) | |
| Input: | Image training set, list the number of each type of CNN architecture. |
| Step (1) Generate new images with data augmentation on the training set, including the method: rotation, flipping, zooming, cropping, Gaussian noise, shearing lighting simulation, brightness, contrast, saturation, and hue. | |
Step (2) Construct the AMIS-ensemble segmentation.
| |
| Step (3) Segment images in Step (1) using AMIS-ensemble segmentation in Step (2). | |
| Step (4) Construct and train each CNN in the list, and number each type of CNN architecture with a segmented image set in Step (3). | |
Step (5) Construct the AMIS-ensemble CNN.
| |
| Output: | AMIS-ensemble CNN with an optimal weight. |
4. Computational Result
4.1. Unveiling the Optimal Combination of Diverse Model Configurations
4.2. A Comparative Analysis of the Proposed Model against State-of-the-Art Methods Using the CALU-1 Dataset
4.3. Comparative Analysis of the Proposed Model against State-of-the-Art Methods Using the Unseen CALU-2 Dataset
5. Discussion
5.1. Advancements in the Automated Cultivar Differentiation of Centella asiatica (L.) Urban for Enhanced Agricultural Practices and Medicinal Product Quality Control
5.2. Enhancing CAU Cultivar Classification through the Parallel-AMIS-Ensemble Model: A Comparative Study
5.3. A Comparative Study of Decision Fusion Strategies in Metaheuristic Optimization
5.4. Key Contributions of the P-AMIS-E Model
5.5. Advantages of the Model and Research Limitations
6. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Susanti, D.; Safrina, D.; Wijaya, N.R. Weed’s Vegetation Analysis of Centella (Centella asiatica L. Urban) Plantations. Caraka Tani J. Sustain. Agric. 2021, 36, 110. [Google Scholar] [CrossRef]
- Jamil, S.S.; Nizami, Q.; Salam, M. Centella asiatica (Linn.) Urban—A Review. CSIR 2007, 6, 158–170. [Google Scholar]
- Prabavathi, S.; Kanmani, P. Plant Leaf Disease Detection and Classification Using Optimized CNN Model. IJRTE 2021, 9, 233–238. [Google Scholar] [CrossRef]
- Yang, M.-M.; Nayeem, A.; Shen, L.-L. Plant Classification Based on Stacked Autoencoder. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1082–1086. [Google Scholar]
- Chen, J.; Yin, H.; Zhang, D. A Self-Adaptive Classification Method for Plant Disease Detection Using GMDH-Logistic Model. Sustain. Comput. Inform. Syst. 2020, 28, 100415. [Google Scholar] [CrossRef]
- Pacifico, L.D.S.; Macario, V.; Oliveira, J.F.L. Plant Classification Using Artificial Neural Networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Britto, L.F.S.; Pacifico, L.D.S. Plant Classification Using Weighted K-NN Variants. In Proceedings of the Anais do XV Encontro Nacional de Inteligência Artificial e Computacional (ENIAC 2018), São Paulo, Brazil, 22–25 October 2018; Sociedade Brasileira de Computação—SBC: Porto Alegre, Brazil, 2018; pp. 58–69. [Google Scholar]
- Pitakaso, R.; Nanthasamroeng, N.; Srichok, T.; Khonjun, S.; Weerayuth, N.; Kotmongkol, T.; Pornprasert, P.; Pranet, K. A Novel Artificial Multiple Intelligence System (AMIS) for Agricultural Product Transborder Logistics Network Design in the Greater Mekong Subregion (GMS). Computation 2022, 10, 126. [Google Scholar] [CrossRef]
- Chandrika, U.G.; Prasad Kumara, P.A.A.S. Chapter Four—Gotu Kola (Centella asiatica): Nutritional Properties and Plausible Health Benefits. Adv. Food Nutr. Res. 2015, 76, 125–157. [Google Scholar] [CrossRef]
- Shin, H.Y.; Kim, H.; Jung, S.; Jeong, E.-J.; Lee, K.-H.; Bae, Y.-J.; Suh, H.J.; Jang, K.-I.; Yu, K.-W. Interrelationship Between Secondary Metabolites and Antioxidant Capacities of Centella asiatica Using Bivariate and Multivariate Correlation Analyses. Appl. Biol. Chem. 2021, 64, 82. [Google Scholar] [CrossRef]
- Sudhakaran, M.V. Botanical Pharmacognosy of Centella asiatica (Linn.) Urban. Pharmacogn. J. 2017, 9, 546–558. [Google Scholar] [CrossRef]
- Prasad, A.; Mathur, A.; Mathur, A. Advances and Emerging Research Trends for Modulation of Centelloside Biosynthesis in Centella asiatica (L.) Urban—A Review. Ind. Crops Prod. 2019, 141, 111768. [Google Scholar] [CrossRef]
- Thong-on, W.; Arimatsu, P.; Pitiporn, S.; Soonthornchareonnon, N.; Prathanturarug, S. Field Evaluation of in Vitro-Induced Tetraploid and Diploid Centella asiatica (L.) Urban. J. Nat. Med. 2014, 68, 267–273. [Google Scholar] [CrossRef] [PubMed]
- Devkota, A.; Jha, P.K. Phenotypic Plasticity of Centella asiatica (L.) Urb. Growing in Different Habitats of Nepal. Trop. Plant Res. 2019, 6, 1–7. [Google Scholar] [CrossRef]
- Patel, D. Growth Pattern Study on Centella asiatica (L.) Urban in Herbal Garden. Int. J. Herb. Med. 2015, 3, 9–12. [Google Scholar]
- Biswas, D.; Mandal, S.; Chatterjee Saha, S.; Tudu, C.K.; Nandy, S.; Batiha, G.E.; Shekhawat, M.S.; Pandey, D.K.; Dey, A. Ethnobotany, Phytochemistry, Pharmacology, and Toxicity of Centella asiatica (L.) Urban: A Comprehensive Review. Phytother. Res. 2021, 35, 6624–6654. [Google Scholar] [CrossRef]
- Novianti, C.; Purbaningsih, S.; Salamah, A. The Effect of Different Pericarp Color on Seed Germination of Centella asiatica (L.) Urban. AIP Conf. Proc. 2016, 1729, 020064. [Google Scholar]
- Alqahtani, A.; Cho, J.-L.; Wong, K.H.; Li, K.M.; Razmovski-Naumovski, V.; Li, G.Q. Differentiation of Three Centella Species in Australia as Inferred from Morphological Characteristics, ISSR Molecular Fingerprinting and Phytochemical Composition. Front. Plant Sci. 2017, 8, 1980. [Google Scholar] [CrossRef]
- Singh, J.; Singh Sangwan, R.; Gupta, S.; Saxena, S.; Sangwan, N.S. Profiling of Triterpenoid Saponin Content Variation in Different Chemotypic Accessions of Centella asiatica L. Plant Genet. Resour. 2015, 13, 176–179. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D.; Zhang, H.; Wang, Q.-G. Dual-Path Mixed-Domain Residual Threshold Networks for Bearing Fault Diagnosis. IEEE Trans. Ind. Electron. 2022, 69, 13462–13472. [Google Scholar] [CrossRef]
- Azizi, M.M.F.; Lau, H.Y.; Abu-Bakar, N. Integration of Advanced Technologies for Plant Variety and Cultivar Identification. J. Biosci. 2021, 46, 91. [Google Scholar] [CrossRef]
- Legner, N.; Meinen, C.; Rauber, R. Root Differentiation of Agricultural Plant Cultivars and Proveniences Using FTIR Spectroscopy. Front. Plant Sci. 2018, 9, 748. [Google Scholar] [CrossRef]
- Raj, T.L.; Vanila, D.; Ganthi, S. Comparative Pharmacognostical Studies on Genuine, Commercial and Adulterant Samples of Centella asiatica (L.) Urban. Res. Rev. J. Pharmacol. 2013, 3, 6–9. [Google Scholar]
- Srivastava, S.; Verma, S.; Gupta, A.; Rajan, S.; Rawat, A. Studies on Chemotypic Variation in Centella asiatica (L.) Urban from Nilgiri Range of India. J. Planar Chromatogr. Mod. TLC 2014, 27, 454–459. [Google Scholar] [CrossRef]
- Bhargavi, D.; Narayana, C.L.; Ramana, K.V. Plant Disease Identification by Using Deep Learning Models. J. Emerg. Technol. Innov. Res. 2021, 8, b150–b157. [Google Scholar]
- Smetanin, A.; Uzhinskiy, A.; Ososkov, G.; Goncharov, P.; Nechaevskiy, A. Deep Learning Methods for the Plant Disease Detection Platform. AIP Conf. Proc. 2021, 2377, 060006. [Google Scholar]
- Barbedo, J.G.A. Deep Learning Applied to Plant Pathology: The Problem of Data Representativeness. Trop. Plant Pathol. 2021, 47, 85–94. [Google Scholar] [CrossRef]
- Khan, E.; Rehman, M.Z.U.; Ahmed, F.; Khan, M.A. Classification of Diseases in Citrus Fruits Using SqueezeNet. In Proceedings of the 2021 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 30–31 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 67–72. [Google Scholar]
- Ran, H.; Wen, S.; Wang, S.; Cao, Y.; Zhou, P.; Huang, T. Memristor-Based Edge Computing of ShuffleNetV2 for Image Classification. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 1701–1710. [Google Scholar] [CrossRef]
- Imanov, E.; Alzouhbi, A.K. Machine Learning Comparative Analysis for Plant Classification. In Proceedings of the 13th International Conference on Theory and Application of Fuzzy Systems and Soft Computing—ICAFS-2018, Warsaw, Poland, 27–28 August 2018; Aliev, R.A., Kacprzyk, J., Pedrycz, W., Jamshidi, M., Sadikoglu, F.M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 896, pp. 586–593. [Google Scholar]
- Nandyal, S.; Patil, B.; Pattanshetty, A. Plant Classification Using SVM Classifier. In Proceedings of the Third International Conference on Computational Intelligence and Information Technology (CIIT 2013), Mumbai, India, 18–19 October 2013; Institution of Engineering and Technology: Stevenage, UK, 2013; pp. 519–523. [Google Scholar]
- Xu, Z.; Hu, J.; Zheng, K.; Yan, L.; Wang, C.; Zhou, X. Fusion Shuffle Light Detector. In Proceedings of the 2021 16th International Conference on Computer Science & Education (ICCSE), Lancaster, UK, 17–21 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 718–721. [Google Scholar]
- Liu, Y.; Li, Z.; Chen, X.; Gong, G.; Lu, H. Improving the Accuracy of SqueezeNet with Negligible Extra Computational Cost. In Proceedings of the 2020 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Shenzhen, China, 23 May 2020; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Karol, M.J. Optical Interconnection Using ShuffleNet Multihop Networks in Multi-Connected Ring Topologies. In Proceedings of the Symposium proceedings on Communications Architectures and Protocols, Stanford, CA, USA, 16–18 August 1988; ACM: New York, NY, USA, 1988; pp. 25–34. [Google Scholar]
- Yang, M.; Ma, T.; Tian, Q.; Tian, Y.; Al-Dhelaan, A.; Al-Dhelaan, M. Aggregated Squeeze-and-Excitation Transformations for Densely Connected Convolutional Networks. Vis. Comput. 2022, 38, 2661–2674. [Google Scholar] [CrossRef]
- Keh, S.S. Semi-Supervised Noisy Student Pre-Training on EfficientNet Architectures for Plant Pathology Classification. arXiv 2020, arXiv:2012.00332. [Google Scholar]
- Khanramaki, M.; Askari Asli-Ardeh, E.; Kozegar, E. Citrus Pests Classification Using an Ensemble of Deep Learning Models. Comput. Electron. Agric. 2021, 186, 106192. [Google Scholar] [CrossRef]
- Mokeev, V. An Ensemble of Learning Machine Models for Plant Recognition. In Proceedings of the Analysis of Images, Social Networks and Texts, Kazan, Russia, 17–19 July 2019; Van Der Aalst, W.M.P., Batagelj, V., Ignatov, D.I., Khachay, M., Kuskova, V., Kutuzov, A., Kuznetsov, S.O., Lomazova, I.A., Loukachevitch, N., Napoli, A., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 1086, pp. 256–262. [Google Scholar]
- Vallabhajosyula, S.; Sistla, V.; Kolli, V.K.K. Transfer Learning-Based Deep Ensemble Neural Network for Plant Leaf Disease Detection. J. Plant Dis. Prot. 2022, 129, 545–558. [Google Scholar] [CrossRef]
- Fountsop, A.N.; Ebongue Kedieng Fendji, J.L.; Atemkeng, M. Deep Learning Models Compression for Agricultural Plants. Appl. Sci. 2020, 10, 6866. [Google Scholar] [CrossRef]
- Javaid, A.; Gurmet, R.; Sharma, N. Centella asiatica (L.) Urban: A Predominantly Self-Pollinated Herbal Perennial Plant of Family Apiaceae. Vegetos Int. J. Plant Res. Biotechnol. 2018, 31, 53. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Tanveer, M.; Suganthan, P.N. Ensemble Deep Learning: A Review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Chan, P.P.K.; Xiao, M.; Qin, X.; Kees, N. Dynamic Fusion for Ensemble of Deep Q-Network. Int. J. Mach. Learn. Cybern. 2021, 12, 1031–1040. [Google Scholar] [CrossRef]
- Gumaei, A.; Ismail, W.N.; Rafiul Hassan, M.; Hassan, M.M.; Mohamed, E.; Alelaiwi, A.; Fortino, G. A Decision-Level Fusion Method for COVID-19 Patient Health Prediction. Big Data Res. 2022, 27, 100287. [Google Scholar] [CrossRef]
- Xu, J.; Li, L.; Ji, M. Ensemble Learning Based Multi-Source Information Fusion. In Proceedings of the 2019 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 23–25 November 2019; Su, R., Ed.; SPIE: Bellingham, WA, USA, 2019; p. 81. [Google Scholar]
- Mohammed, A.; Kora, R. An Effective Ensemble Deep Learning Framework for Text Classification. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 8825–8837. [Google Scholar] [CrossRef]
- Mohammadi, A.; Shaverizade, A. Ensemble Deep Learning for Aspect-Based Sentiment Analysis. IJNAA 2021, 12, 29–38. [Google Scholar] [CrossRef]
- Salal, Y.K.; Abdullaev, S.M. Deep Learning Based Ensemble Approach to Predict Student Academic Performance: Case Study. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 191–198. [Google Scholar]
- Abd Elaziz, M.; Dahou, A.; Abualigah, L.; Yu, L.; Alshinwan, M.; Khasawneh, A.M.; Lu, S. Advanced Metaheuristic Optimization Techniques in Applications of Deep Neural Networks: A Review. Neural Comput. Appl. 2021, 33, 14079–14099. [Google Scholar] [CrossRef]
- Muhammad Usman, S.; Khalid, S.; Bashir, S. A Deep Learning Based Ensemble Learning Method for Epileptic Seizure Prediction. Comput. Biol. Med. 2021, 136, 104710. [Google Scholar] [CrossRef]
- Prasitpuriprecha, C.; Jantama, S.S.; Preeprem, T.; Pitakaso, R.; Srichok, T.; Khonjun, S.; Weerayuth, N.; Gonwirat, S.; Enkvetchakul, P.; Kaewta, C.; et al. Drug-Resistant Tuberculosis Treatment Recommendation, and Multi-Class Tuberculosis Detection and Classification Using Ensemble Deep Learning-Based System. Pharmaceuticals 2022, 16, 13. [Google Scholar] [CrossRef]
- Prasitpuriprecha, C.; Pitakaso, R.; Gonwirat, S.; Enkvetchakul, P.; Preeprem, T.; Jantama, S.S.; Kaewta, C.; Weerayuth, N.; Srichok, T.; Khonjun, S.; et al. Embedded AMIS-Deep Learning with Dialog-Based Object Query System for Multi-Class Tuberculosis Drug Response Classification. Diagnostics 2022, 12, 2980. [Google Scholar] [CrossRef]
- Sethanan, K.; Pitakaso, R.; Srichok, T.; Khonjun, S.; Thannipat, P.; Wanram, S.; Boonmee, C.; Gonwirat, S.; Enkvetchakul, P.; Kaewta, C. Double AMIS-Ensemble Deep Learning for Skin Cancer Classification Expert Systems with Applications. Expert Syst. Appl. 2023, 234, 121047. [Google Scholar] [CrossRef]
- Alomar, K.; Aysel, H.I.; Cai, X. Data Augmentation in Classification and Segmentation: A Survey and New Strategies. J. Imaging 2023, 9, 46. [Google Scholar] [CrossRef] [PubMed]
- Altalak, M.; Ammad Uddin, M.; Alajmi, A.; Rizg, A. Smart Agriculture Applications Using Deep Learning Technologies: A Survey. Appl. Sci. 2022, 12, 5919. [Google Scholar] [CrossRef]
- Yang, M.; Ding, S. Algorithm for Appearance Simulation of Plant Diseases Based on Symptom Classification. Front. Plant Sci. 2022, 13, 935157. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, S.; Zhang, C. Modified U-Net for Plant Diseased Leaf Image Segmentation. Comput. Electron. Agric. 2023, 204, 107511. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. [Google Scholar]
- Mu, X.; He, L.; Heinemann, P.; Schupp, J.; Karkee, M. Mask R-CNN Based Apple Flower Detection and King Flower Identification for Precision Pollination. Smart Agric. Technol. 2023, 4, 100151. [Google Scholar] [CrossRef]
- Li, M.; He, L.; Lei, C.; Gong, Y. Fine-Grained Image Classification Model Based on Improved SqueezeNet. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 393–399. [Google Scholar]
- Ghosh, S.; Mondal, M.J.; Sen, S.; Chatterjee, S.; Kar Roy, N.; Patnaik, S. A Novel Approach to Detect and Classify Fruits Using ShuffleNet V2. In Proceedings of the 2020 IEEE Applied Signal Processing Conference (ASPCON), Kolkata, India, 7–9 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 163–167. [Google Scholar]
- Ozsariyildiz, S.; Tolman, F. First Experiences with an Inception Support Modeller for the Building and Construction Industry. In Proceedings of the Eighth International Conference on Durability of Building Materials and Components, Vancouver, BC, Canada, 30 May–3 June 1999; pp. 2234–2245. [Google Scholar]
- Hussain, A.; Barua, B.; Osman, A.; Abozariba, R.; Asyhari, A.T. Performance of MobileNetV3 Transfer Learning on Handheld Device-Based Real-Time Tree Species Identification. In Proceedings of the 2021 26th International Conference on Automation and Computing (ICAC), Portsmouth, UK, 2–4 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Ghosal, P.; Nandanwar, L.; Kanchan, S.; Bhadra, A.; Chakraborty, J.; Nandi, D. Brain Tumor Classification Using ResNet-101 Based Squeeze and Excitation Deep Neural Network. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Zhang, Y.; Liao, J.; Ran, M.; Li, X.; Wang, S.; Liu, L. ST-Xception: A Depthwise Separable Convolution Network for Military Sign Language Recognition. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3200–3205. [Google Scholar]
- Cakmak, M.; Tenekeci, M.E. Melanoma Detection from Dermoscopy Images Using Nasnet Mobile with Transfer Learning. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Kabanikhin, S.; Krivorotko, O.; Bektemessov, Z.; Bektemessov, M.; Zhang, S. Differential Evolution Algorithm of Solving an Inverse Problem for the Spatial Solow Mathematical Model. J. Inverse Ill-Posed Probl. 2020, 28, 761–774. [Google Scholar] [CrossRef]
- Yang, S.; Collings, P.J. The Genetic Algorithm: Using Biology to Compute Liquid Crystal Director Configurations. Crystals 2020, 10, 1041. [Google Scholar] [CrossRef]
- Fu, X.; Ma, Q.; Yang, F.; Zhang, C.; Zhao, X.; Chang, F.; Han, L. Crop Pest Image Recognition Based on the Improved ViT Method. Inf. Process. Agric. 2023, in press. [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CALU-1 | CALU-2 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CM | NP | NR | NS | NT | NB | PB | RB | SK | UB | CM | NP | NR | NS | NT | NB | PB | RB | SK | UB | |
| Training set | 1005 | 1089 | 1000 | 1000 | 1007 | 1000 | 1056 | 1056 | 1090 | 1000 | - | - | - | - | - | - | - | - | - | - |
| Testing set | 504 | 504 | 500 | 500 | 505 | 570 | 506 | 594 | 539 | 500 | 500 | 502 | 500 | 541 | 528 | 500 | 575 | 594 | 568 | 500 |
| Total | 1509 | 1593 | 1500 | 1500 | 1512 | 1570 | 1562 | 1650 | 1629 | 1500 | 500 | 502 | 500 | 541 | 528 | 500 | 575 | 594 | 568 | 500 |
| Methods | Number of CNNs | Homogenous (Ho)/Heterogenous (He)/ Single Model (Single) | Total Size |
|---|---|---|---|
| ResNet-101 [65] | 1 | Single | 102 |
| Xception [66] | 1 | Single | 88 |
| NASNet-A Mobile [67] | 1 | Single | 84 |
| MobileNetV3-Large [64] | 1 | Single | 113 |
| SqueezeNet [61] | 16 | Homogenous | 80 |
| ShuffleNetv2 1.0x [62] | 14 | Homogenous | 84 |
| MobileNetV3 [64] | 14 | Homogenous | 84 |
| InceptionV1 [63] | 4 | Homogenous | 80 |
| Proposed Methods | 11 | Heterogenous | 77 |
| CNN Hyperparameters | Metaheuristics (GA, DE, and AMIS) Hyperparameters | ||
|---|---|---|---|
| Number of CNN epochs of a single model | 100 | ) | 100 |
| Number of CNN epochs in an ensemble | 30 | ) | 100 |
| CNN optimizer | Adam | ) | 0.3 |
| Learning rate | 0.0001 | Mutation rate of DE | 0.07 |
| Batch size | 32 | ) | 1.67 |
| Image size | 331 × 331 | ) | 1.2 |
| No. | Segmentation | Augmentation | Decision Fusion Strategies | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| No Segmentation | Mask R-CNN | U-Net | Ensemble Segmentation | No Augmentation | With Augmentation | AMIS | DE | GA | UWA | |
| 1 | ✓ | - | - | - | ✓ | - | ✓ | - | - | - |
| 2 | ✓ | - | - | - | ✓ | - | - | ✓ | - | - |
| 3 | ✓ | - | - | - | ✓ | - | - | - | ✓ | |
| 4 | ✓ | - | - | - | ✓ | - | - | - | - | ✓ |
| 5 | ✓ | - | - | - | - | ✓ | ✓ | - | - | - |
| 6 | ✓ | - | - | - | - | ✓ | - | ✓ | - | - |
| 7 | ✓ | - | - | - | - | ✓ | - | - | ✓ | - |
| 8 | ✓ | - | - | - | - | ✓ | - | - | - | ✓ |
| 9 | - | ✓ | - | - | ✓ | - | ✓ | - | - | - |
| 10 | - | ✓ | - | - | ✓ | - | - | ✓ | - | - |
| 11 | - | ✓ | - | - | ✓ | - | - | - | ✓ | - |
| 12 | - | ✓ | - | - | ✓ | - | - | - | - | ✓ |
| 13 | - | ✓ | - | - | - | ✓ | ✓ | - | - | - |
| 14 | - | ✓ | - | - | - | ✓ | - | ✓ | - | - |
| 15 | - | ✓ | - | - | - | ✓ | - | - | ✓ | - |
| 16 | - | ✓ | - | - | - | ✓ | - | - | - | ✓ |
| 17 | - | - | ✓ | - | ✓ | - | ✓ | - | - | - |
| 18 | - | - | ✓ | - | ✓ | - | - | ✓ | - | - |
| 19 | - | - | ✓ | - | ✓ | - | - | - | ✓ | - |
| 20 | - | - | ✓ | - | ✓ | - | - | - | - | ✓ |
| 21 | - | - | ✓ | - | - | ✓ | ✓ | - | - | - |
| 22 | - | - | ✓ | - | - | ✓ | - | ✓ | - | - |
| 23 | - | - | ✓ | - | - | ✓ | - | - | ✓ | |
| 24 | - | - | ✓ | - | - | ✓ | - | - | - | ✓ |
| 25 | - | - | - | ✓ | ✓ | - | ✓ | - | - | - |
| 26 | - | - | - | ✓ | ✓ | - | - | ✓ | - | - |
| 27 | - | - | - | ✓ | ✓ | - | - | - | ✓ | - |
| 28 | - | - | - | ✓ | ✓ | - | - | - | - | ✓ |
| 29 | - | - | - | ✓ | - | ✓ | ✓ | - | - | - |
| 30 | - | - | - | ✓ | - | ✓ | - | ✓ | - | - |
| 31 | - | - | - | ✓ | - | ✓ | - | - | ✓ | - |
| 32 | - | - | - | ✓ | - | ✓ | - | - | - | ✓ |
| No. | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| 1 | 82.14 | 82.40 | 82.40 | 82.81 | 82.15 |
| 2 | 82.79 | 81.64 | 81.61 | 81.96 | 80.88 |
| 3 | 81.75 | 81.33 | 80.35 | 80.21 | 80.43 |
| 4 | 79.29 | 79.65 | 79.57 | 79.57 | 79.45 |
| 5 | 83.25 | 83.42 | 83.70 | 83.69 | 83.22 |
| 6 | 84.59 | 83.68 | 83.71 | 84.52 | 84.65 |
| 7 | 82.16 | 82.17 | 82.35 | 83.68 | 83.23 |
| 8 | 80.48 | 80.14 | 80.10 | 80.95 | 80.45 |
| 9 | 85.88 | 85.25 | 85.97 | 85.48 | 85.82 |
| 10 | 83.55 | 83.75 | 83.52 | 83.43 | 83.97 |
| 11 | 82.51 | 81.56 | 82.73 | 82.73 | 82.76 |
| 12 | 83.78 | 80.18 | 83.64 | 83.47 | 82.31 |
| 13 | 86.14 | 84.40 | 86.40 | 86.81 | 86.15 |
| 14 | 84.79 | 84.64 | 84.61 | 84.96 | 84.88 |
| 15 | 81.75 | 81.33 | 80.35 | 80.21 | 81.43 |
| 16 | 82.29 | 81.65 | 81.57 | 98.57 | 81.45 |
| 17 | 88.25 | 88.42 | 88.70 | 88.69 | 88.22 |
| 18 | 85.59 | 85.68 | 85.71 | 85.52 | 85.65 |
| 19 | 84.16 | 84.17 | 84.35 | 84.68 | 85.23 |
| 20 | 83.48 | 83.14 | 83.10 | 83.95 | 83.45 |
| 21 | 89.88 | 89.25 | 89.97 | 89.48 | 89.82 |
| 22 | 87.55 | 87.75 | 87.52 | 87.43 | 87.97 |
| 23 | 86.51 | 86.56 | 86.73 | 86.73 | 86.76 |
| 24 | 84.78 | 84.18 | 84.64 | 84.47 | 84.31 |
| 25 | 93.14 | 93.40 | 93.40 | 93.81 | 93.15 |
| 26 | 90.79 | 90.64 | 90.61 | 90.96 | 90.88 |
| 27 | 90.35 | 90.33 | 90.35 | 90.21 | 89.43 |
| 28 | 88.29 | 88.65 | 88.57 | 88.57 | 88.45 |
| 29 | 98.54 | 98.57 | 98.71 | 98.83 | 98.95 |
| 30 | 96.91 | 96.62 | 96.48 | 96.52 | 96.21 |
| 31 | 94.16 | 94.17 | 94.35 | 94.68 | 95.15 |
| 32 | 92.48 | 92.14 | 92.10 | 92.95 | 92.42 |
| No. | Segmentation | Augmentation | Decision Fusion Strategies | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| No Segmentation | Mask R-CNN | U-Net | Ensemble | No Augmentation | With Augmentation | AMIS | DE | GA | UWA | |
| Accuracy | 82.06 | 83.84 | 86.28 | 93.08 | 85.36 | 87.27 | 88.40 | 87.07 | 85.42 | 84.36 |
| Precision | 81.80 | 82.85 | 86.14 | 93.07 | 85.01 | 86.92 | 88.14 | 86.80 | 85.20 | 83.72 |
| Recall | 81.72 | 83.60 | 86.34 | 93.07 | 85.29 | 87.08 | 88.65 | 86.72 | 85.20 | 84.16 |
| F1-score | 82.17 | 85.71 | 86.37 | 93.32 | 85.38 | 88.41 | 88.70 | 86.91 | 85.39 | 86.56 |
| AUC | 81.81 | 83.60 | 86.43 | 93.08 | 85.14 | 87.32 | 88.44 | 86.89 | 85.55 | 84.04 |
| Methods | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| ViT [70] | 91.32 | 89.19 | 90.48 | 90.85 | 91.52 |
| ResNet-101 [65] | 88.38 | 84.19 | 86.29 | 87.42 | 89.01 |
| Xception [66] | 89.27 | 88.40 | 89.89 | 88.72 | 90.29 |
| NASNet-A Mobile [67] | 91.63 | 91.83 | 89.74 | 90.21 | 91.96 |
| MobileNetV3-Large [64] | 92.51 | 92.17 | 90.97 | 91.35 | 91.38 |
| SqueezeNet [61] | 93.21 | 93.37 | 94.13 | 93.73 | 94.41 |
| ShuffleNetv2 1.0x [62] | 94.36 | 93.73 | 94.09 | 94.27 | 94.83 |
| MobileNetV3 [64] | 94.72 | 93.96 | 94.64 | 94.93 | 95.97 |
| InceptionV1 [63] | 95.05 | 94.18 | 94.79 | 95.48 | 95.99 |
| Proposed Methods | 98.41 | 97.82 | 97.99 | 99.61 | 98.39 |
| Methods | Number of CNNs | Homogenous (Ho)/Heterogenous (He)/ Single Model (Single) | Total Size | Training Time (Minutes) | Testing Time (Second/ Image) | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|
| ViT [70] | 1 | Single | - | - | 90.24 | 89.53 | 88.48 | 89.01 | 90.45 | |
| ResNet-101 [65] | 1 | Single | 102 | 62.48 | 0.83 | 88.7 | 84.6 | 85.8 | 87.9 | 89.5 |
| Xception [66] | 1 | Single | 88 | 47.59 | 0.48 | 90.1 | 88.1 | 90.7 | 88.8 | 89.7 |
| NASNet-A Mobile [67] | 1 | Single | 84 | 45.32 | 0.49 | 92.6 | 92.1 | 89.8 | 89.7 | 91.8 |
| MobileNetV3-Large [64] | 1 | Single | 113 | 67.55 | 1.34 | 92.6 | 92.6 | 90.8 | 91.4 | 91.7 |
| SqueezeNet [61] | 1 | Single | 5 | 5.44 | 0.10 | 76.2 | 75.9 | 75.5 | 75.8 | 76.9 |
| ShuffleNetv2 1.0x [62] | 1 | Single | 6 | 5.98 | 0.12 | 76.8 | 76.8 | 76.2 | 77.1 | 77.3 |
| MobileNetV3 [64] | 1 | Single | 6 | 6.01 | 0.13 | 75.1 | 74.8 | 75.6 | 74.9 | 75.6 |
| InceptionV1 [63] | 1 | Single | 20 | 15.7 | 0.20 | 79.4 | 78.9 | 79.2 | 79.1 | 79.8 |
| SqueezeNet [61] | 16 | Homogenous | 80 | 39.03 | 0.44 | 92.8 | 93.6 | 94.1 | 93.5 | 93.9 |
| ShuffleNetv2 1.0x [62] | 14 | Homogenous | 84 | 44.19 | 0.48 | 94.2 | 93.9 | 94.1 | 94.6 | 94.8 |
| MobileNetV3 [64] | 14 | Homogenous | 84 | 43.95 | 0.47 | 94.1 | 94.7 | 95.3 | 95.3 | 95.5 |
| InceptionV1 [63] | 4 | Homogenous | 80 | 37.58 | 0.44 | 94.3 | 94.8 | 95.5 | 95.6 | 95.7 |
| Proposed Methods | 11 | Heterogenous | 77 | 34.59 | 0.34 | 98.5 | 97.5 | 97.4 | 99.0 | 97.7 |
| CALU-1 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3-cv | 5-cv | |||||||||
| Methods | Accuracy | Precision | Recall | F1-Score | AUC | Accuracy | Precision | Recall | F1-Score | AUC |
| ViT [70] | 91.19 ± 1.57 | 89.01 ± 2.39 | 90.13 ± 0.99 | 91.04 ± 1.23 | 92.02 ± 1.61 | 91.32 ± 1.24 | 89.19 ± 1.45 | 90.48 ± 1.02 | 90.85 ± 1.24 | 91.52 ± 2.49 |
| ResNet-101 [65] | 81.49 ± 2.73 | 83.04 ± 1.96 | 83.73 ± 1.84 | 86.24 ± 2.40 | 88.18 ± 1.44 | 82.38 ± 2.18 | 83.99 ± 2.39 | 84.59 ± 2.57 | 86.53 ± 1.77 | 88.41 ± 0.85 |
| Xception [66] | 82.95 ± 1.05 | 86.39 ± 1.83 | 87.39 ± 1.68 | 87.19 ± 2.19 | 89.22 ± 1.05 | 82.27 ± 1.47 | 87.18 ± 2.31 | 88.45 ± 1.49 | 87.69 ± 1.84 | 89.37 ± 0.34 |
| NASNet-A Mobile [67] | 87.83 ± 1.86 | 89.15 ± 2.17 | 88.12 ± 1.06 | 88.05 ± 1.83 | 89.29 ± 1.82 | 88.33 ± 1.49 | 90.42 ± 2.09 | 88.38 ± 1.35 | 88.78 ± 1.48 | 89.84 ± 0.93 |
| MobileNetV3-Large [64] | 89.24 ± 1.32 | 90.86 ± 1.19 | 89.07 ± 2.51 | 89.48 ± 1.78 | 89.94 ± 1.01 | 90.18 ± 0.87 | 91.03 ± 1.56 | 89.42 ± 1.58 | 90.37 ± 1.31 | 90.68 ± 1.19 |
| SqueezeNet [61] | 91.49 ± 1.93 | 91.83 ± 1.68 | 91.92 ± 1.94 | 92.03 ± 1.51 | 92.38 ± 2.49 | 92.05 ± 1.31 | 92.15 ± 1.39 | 92.63 ± 1.61 | 92.59 ± 0.93 | 93.15 ± 1.43 |
| ShuffleNetv2 1.0x [62] | 92.84 ± 2.01 | 92.16 ± 1.15 | 92.14 ± 1.53 | 92.58 ± 1.58 | 92.75 ± 2.18 | 93.36 ± 2.18 | 92.54 ± 1.42 | 92.89 ± 1.14 | 93.18 ± 0.58 | 93.41 ± 0.84 |
| MobileNetV3 [64] | 93.81 ± 1.19 | 91.85 ± 2.12 | 93.08 ± 1.74 | 92.71 ± 1.06 | 94.19 ± 1.42 | 94.34 ± 1.34 | 92.09 ± 1.90 | 93.62 ± 0.98 | 93.32 ± 1.31 | 95.03 ± 2.44 |
| InceptionV1 [63] | 93.75 ± 1.58 | 93.11 ± 1.11 | 93.27 ± 1.85 | 93.72 ± 2.49 | 93.93 ± 1.86 | 94.18 ± 1.74 | 93.74 ± 1.35 | 93.88 ± 1.19 | 94.46 ± 1.58 | 95.27 ± 1.31 |
| Proposed Methods | 93.46 ± 1.04 | 97.20 ± 0.58 | 96.74 ± 0.69 | 97.89 ± 1.31 | 98.15 ± 0.47 | 97.47 ± 1.31 | 97.43 ± 1.31 | 97.10 ± 0.84 | 98.31 ± 0.74 | 98.83 ± 0.84 |
| CALU-2 | ||||||||||
| 3-cv | 5-cv | |||||||||
| Methods | Accuracy | Precision | Recall | F1-Score | AUC | Accuracy | Precision | Recall | F1-Score | AUC |
| ViT [70] | 89.31 ± 1.14 | 88.48 ± 1.95 | 89.11 ± 1.27 | 88.30 ± 1.64 | 89.94 ± 1.38 | 90.15 ± 1.65 | 88.94 ± 1.96 | 88.23 ± 1.87 | 89.01 ± 1.48 | 90.45 ± 1.76 |
| ResNet-101 [65] | 80.98 ± 1.84 | 82.76 ± 2.14 | 83.18 ± 1.73 | 85.78 ± 1.83 | 87.11 ± 1.91 | 82.08 ± 2.04 | 83.41 ± 1.58 | 83.81 ± 1.93 | 86.31 ± 1.96 | 87.59 ± 1.28 |
| Xception [66] | 82.47 ± 1.27 | 86.19 ± 1.18 | 87.01 ± 1.18 | 86.39 ± 1.91 | 88.35 ± 1.18 | 81.89 ± 1.97 | 86.84 ± 2.19 | 88.19 ± 1.01 | 87.54 ± 2.14 | 88.93 ± 1.92 |
| NASNet-A Mobile [67] | 86.81 ± 1.53 | 89.28 ± 2.05 | 87.27 ± 1.84 | 87.74 ± 1.19 | 88.38 ± 1.79 | 87.18 ± 1.63 | 90.07 ± 1.17 | 88.07 ± 1.28 | 88.18 ± 2.16 | 89.04 ± 0.84 |
| MobileNetV3-Large [64] | 89.07 ± 1.94 | 90.21 ± 1.57 | 88.41 ± 2.01 | 88.79 ± 1.28 | 89.15 ± 1.93 | 89.49 ± 1.58 | 90.68 ± 2.48 | 89.28 ± 1.84 | 90.25 ± 1.96 | 90.18 ± 1.48 |
| SqueezeNet [61] | 91.04 ± 1.18 | 91.43 ± 1.18 | 91.26 ± 1.93 | 91.48 ± 1.11 | 92.08 ± 2.00 | 91.79 ± 1.08 | 91.82 ± 0.58 | 92.17 ± 1.93 | 92.05 ± 1.15 | 92.76 ± 1.92 |
| ShuffleNetv2 1.0x [62] | 92.18 ± 1.85 | 91.78 ± 1.05 | 91.68 ± 1.27 | 92.06 ± 1.96 | 92.01 ± 1.84 | 92.85 ± 2.00 | 92.14 ± 1.05 | 92.53 ± 1.08 | 93.01 ± 1.39 | 93.06 ± 1.53 |
| MobileNetV3 [64] | 93.29 ± 1.53 | 91.04 ± 2.08 | 92.37 ± 1.86 | 92.51 ± 1.79 | 93.75 ± 1.48 | 94.09 ± 1.18 | 91.30 ± 1.88 | 93.08 ± 1.34 | 93.15 ± 1.88 | 95.88 ± 1.92 |
| InceptionV1 [63] | 93.18 ± 1.57 | 92.16 ± 1.89 | 92.83 ± 1.19 | 93.04 ± 2.04 | 93.41 ± 1.19 | 94.01 ± 1.31 | 93.08 ± 1.19 | 93.14 ± 1.83 | 94.19 ± 2.93 | 95.08 ± 2.90 |
| Proposed Methods | 93.21 ± 1.81 | 96.81 ± 0.85 | 96.06 ± 0.94 | 97.18 ± 1.15 | 97.41 ± 0.97 | 97.14 ± 1.04 | 97.11 ± 1.08 | 96.47 ± 0.76 | 98.14 ± 1.15 | 98.48 ± 0.63 |
| Methods | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| ViT [70] | 90.1 | 89.5 | 88.4 | 88.9 | 90.4 |
| ResNet-101 [65] | 88.6 | 84.6 | 85.7 | 87.7 | 89.3 |
| Xception [66] | 90.1 | 87.9 | 90.6 | 88.7 | 89.7 |
| NASNet-A Mobile [67] | 92.5 | 92.0 | 89.7 | 89.7 | 91.7 |
| MobileNetV3-Large [64] | 92.5 | 92.5 | 90.7 | 91.4 | 91.7 |
| SqueezeNet [61] | 76.2 | 75.7 | 75.5 | 75.8 | 76.9 |
| ShuffleNetv2 1.0x [62] | 76.7 | 76.7 | 76.1 | 77.0 | 77.3 |
| MobileNetV3 [64] | 75.0 | 74.7 | 75.4 | 74.9 | 75.5 |
| InceptionV1 [63] | 79.3 | 78.8 | 79.2 | 78.9 | 79.7 |
| SqueezeNet [61] | 92.8 | 93.4 | 94.1 | 93.5 | 93.7 |
| ShuffleNetv2 1.0x [62] | 94.1 | 93.9 | 94.1 | 94.6 | 94.6 |
| MobileNetV3 [64] | 94.0 | 94.5 | 95.2 | 95.2 | 95.4 |
| InceptionV1 [63] | 94.2 | 94.7 | 95.5 | 95.5 | 95.5 |
| Proposed Methods (Majority Voting) | 94.3 | 94.8 | 95.8 | 95.8 | 95.2 |
| Proposed Methods (Unweighted Average) | 94.3 | 94.7 | 95.6 | 95.5 | 94.9 |
| Proposed Methods (AMIS) | 98.4 | 97.5 | 97.2 | 98.8 | 97.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sriprateep, K.; Khonjun, S.; Golinska-Dawson, P.; Pitakaso, R.; Luesak, P.; Srichok, T.; Chiaranai, S.; Gonwirat, S.; Buakum, B. Automated Classification of Agricultural Species through Parallel Artificial Multiple Intelligence System–Ensemble Deep Learning. Mathematics 2024, 12, 351. https://doi.org/10.3390/math12020351
Sriprateep K, Khonjun S, Golinska-Dawson P, Pitakaso R, Luesak P, Srichok T, Chiaranai S, Gonwirat S, Buakum B. Automated Classification of Agricultural Species through Parallel Artificial Multiple Intelligence System–Ensemble Deep Learning. Mathematics. 2024; 12(2):351. https://doi.org/10.3390/math12020351
Chicago/Turabian StyleSriprateep, Keartisak, Surajet Khonjun, Paulina Golinska-Dawson, Rapeepan Pitakaso, Peerawat Luesak, Thanatkij Srichok, Somphop Chiaranai, Sarayut Gonwirat, and Budsaba Buakum. 2024. "Automated Classification of Agricultural Species through Parallel Artificial Multiple Intelligence System–Ensemble Deep Learning" Mathematics 12, no. 2: 351. https://doi.org/10.3390/math12020351
APA StyleSriprateep, K., Khonjun, S., Golinska-Dawson, P., Pitakaso, R., Luesak, P., Srichok, T., Chiaranai, S., Gonwirat, S., & Buakum, B. (2024). Automated Classification of Agricultural Species through Parallel Artificial Multiple Intelligence System–Ensemble Deep Learning. Mathematics, 12(2), 351. https://doi.org/10.3390/math12020351