


Investigating Effective Geometric Transformation for Image Augmentation to Improve Static Hand Gestures with a Pre-Trained Convolutional Neural Network


Abstract
:1. Introduction
- Investigate whether using as many augmentations as possible on geometric transformations or focusing on a subset of the most effective geometric transformations yields better results in improving model performance.
- Identify augmentation methods within geometric transformations that yield the highest accuracy rates in enhancing CNN performance, which is achieved through a systematic analysis. This involves a thorough examination of various geometric transformations, assessing their impact on the model’s accuracy. The selection process is based on rigorous experimentation and quantitative evaluation, ensuring that the chosen augmentation methods contribute significantly to the improved performance of Convolutional Neural Networks (CNNs) in the context of static hand gesture recognition. The effectiveness is substantiated by comparative analyses and statistical measures, providing a robust foundation for the identified augmentation methods.
- Compare the performance of three pre-trained models, ResNet50, MobileNetV2, and InceptionV3, in the classification of static hand gestures (HGRs). The evaluation of these three models is conducted to assess their ability to classify static hand gestures, providing crucial insights for further development in this field.
- This research undertakes an evaluation of the accuracy of pre-trained neural networks for image classification. Section 2 describes research methodology. Section 3 describes the dataset, image augmentation, geometric transformations, CNN theory, and pre-trained neural networks (ResNet, MobileNet, and Inception). Section 4 presents the experimental setup, dataset preparation, and results using single and combined neural networks. Section 5 analyzes the performance of each pre-trained neural network and discusses the impact of image augmentation and geometric transformations on model accuracy. Additionally, we explore implications and future research opportunities in this area. Finally, Section 6 summarizes important findings, highlights our research’s significance, and outlines future directions, including developing an image augmentation framework for static hand gesture recognition based on pre-trained ResNet50 models that combine multiple geometric transformations with color modifications.
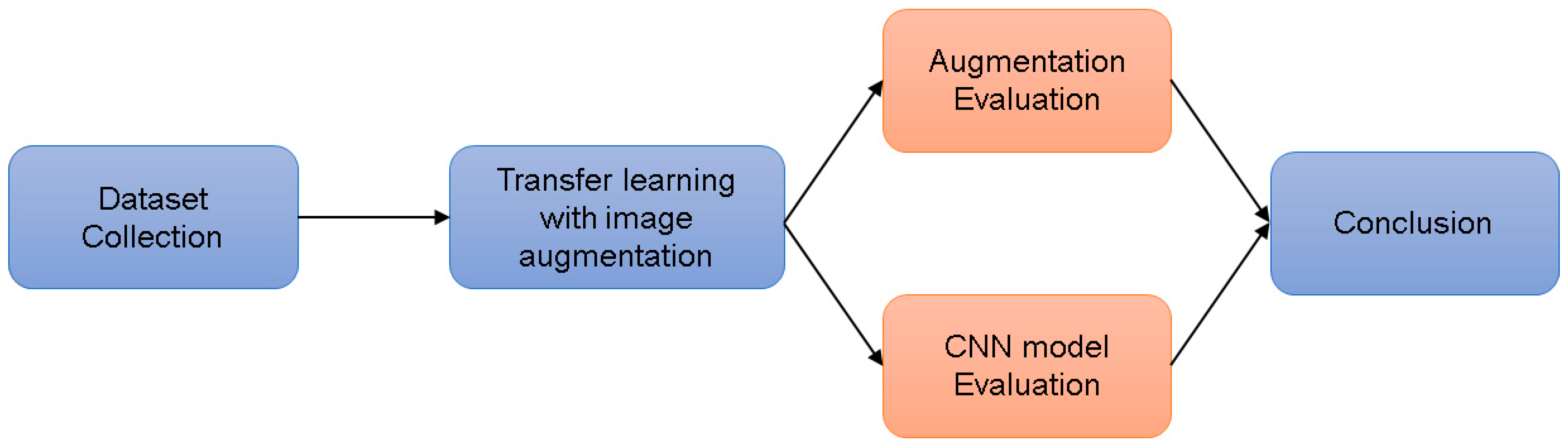
2. Research Methodology
- Investigation of the necessity of employing geometric transformations for image augmentation in CNN-based HGR tasks;
- Exploration of the optimal geometric transformation based on CNNs for image augmentation in HGR tasks;
- Determining the most effective pre-trained CNN model (ResNet50, MobileNetV2, or Inceptionv3) for HGR tasks.
3. Material
3.1. Dataset
3.1.1. Hand Gesture 14 (HG14) Dataset
3.1.2. DLSI (Department de Llenguatges Sistemes Informàtics) Dataset
3.1.3. Massey University HandImages ASL Dataset
3.1.4. Sebastian Marcel Static Hand Gesture Dataset
3.1.5. ArASL2018 Dataset
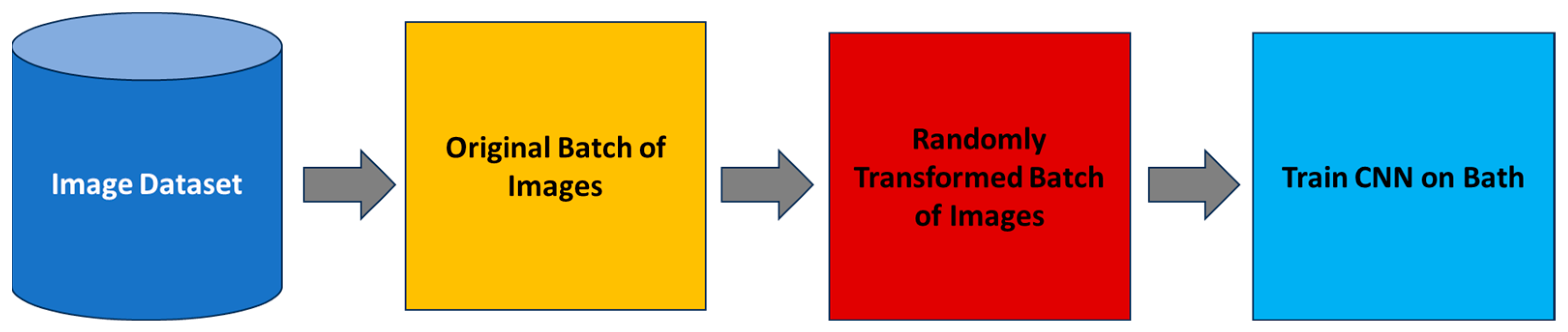
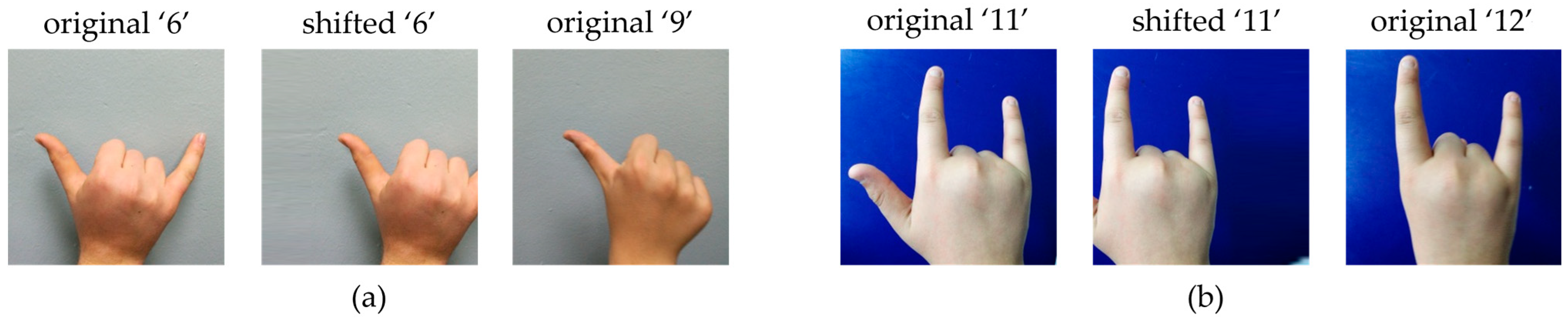
3.2. Image Augmentation
3.3. Geometric Transformation
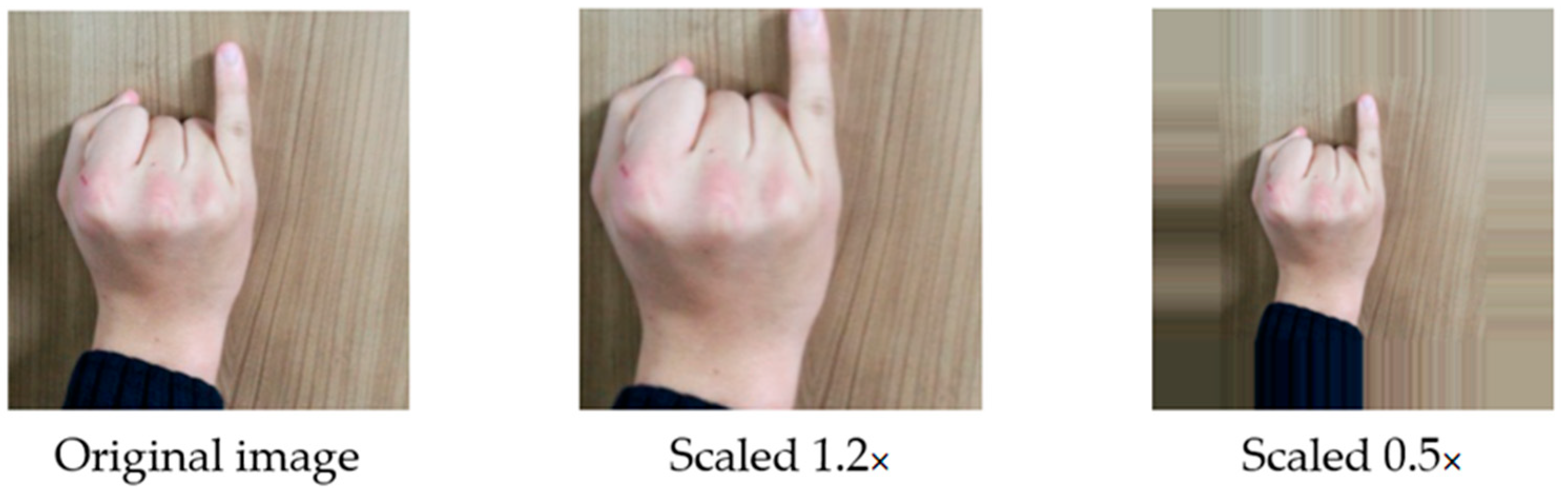
3.3.1. Image Scaling
3.3.2. Image Rotation
3.3.3. Image Translation
3.3.4. Image Shearing
3.3.5. Image Flipping
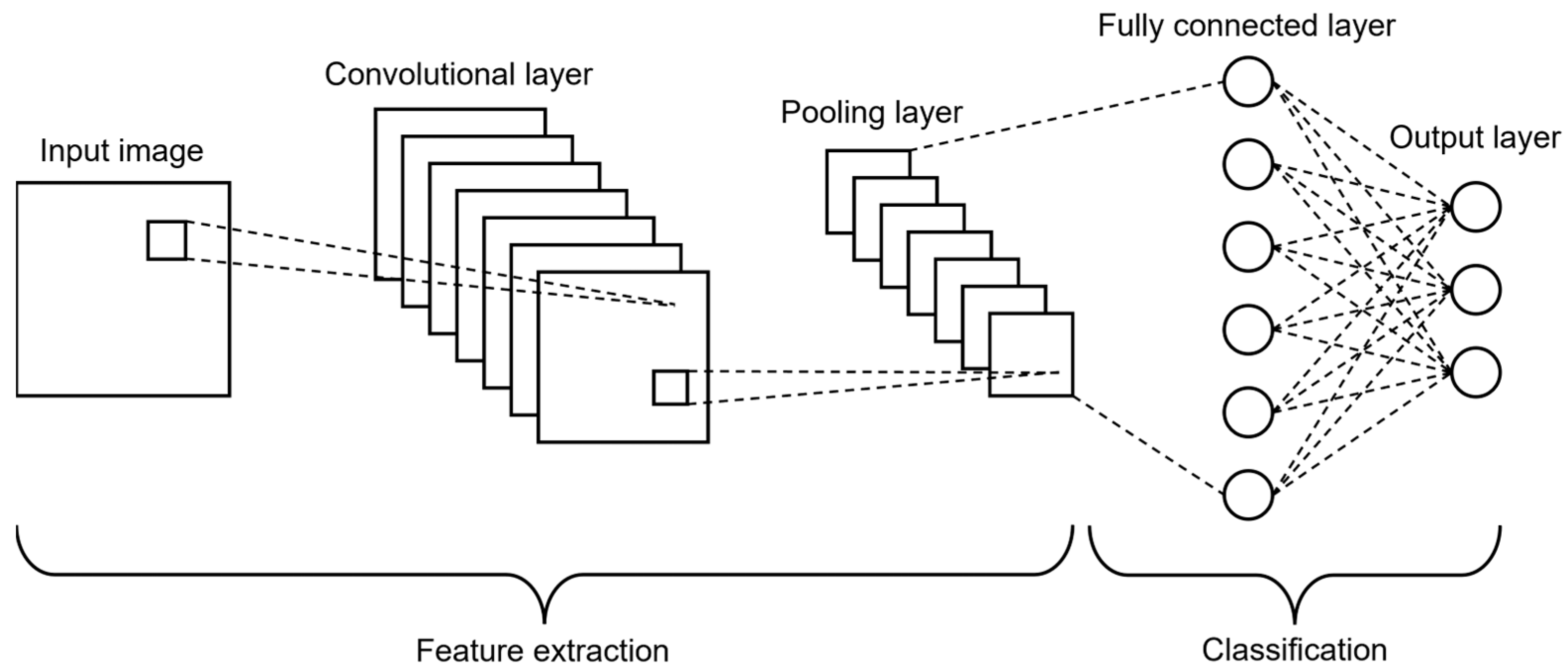
3.4. Convolutional Neural Networks (CNNs)
3.5. Pre-Trained Neural Networks
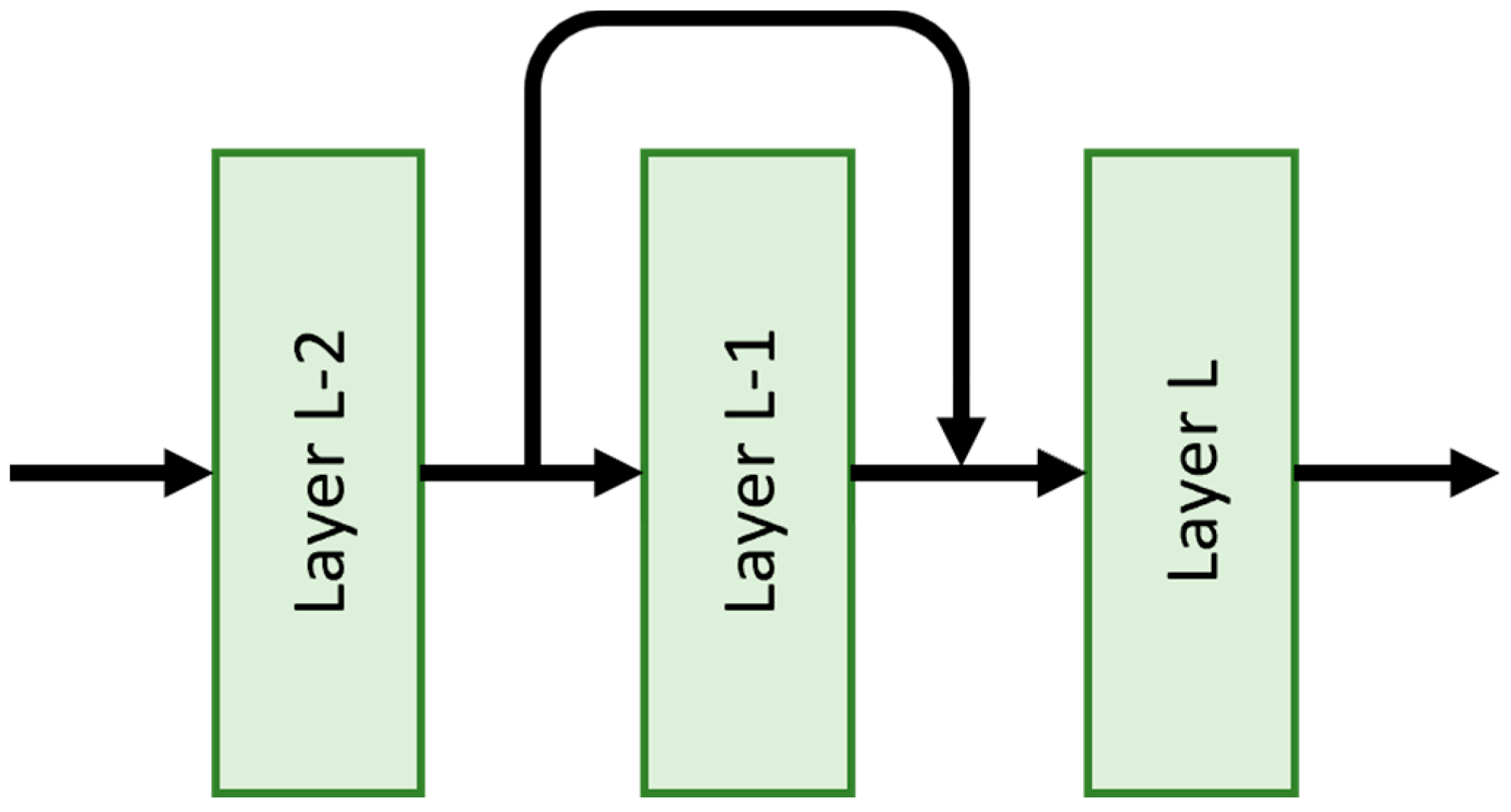
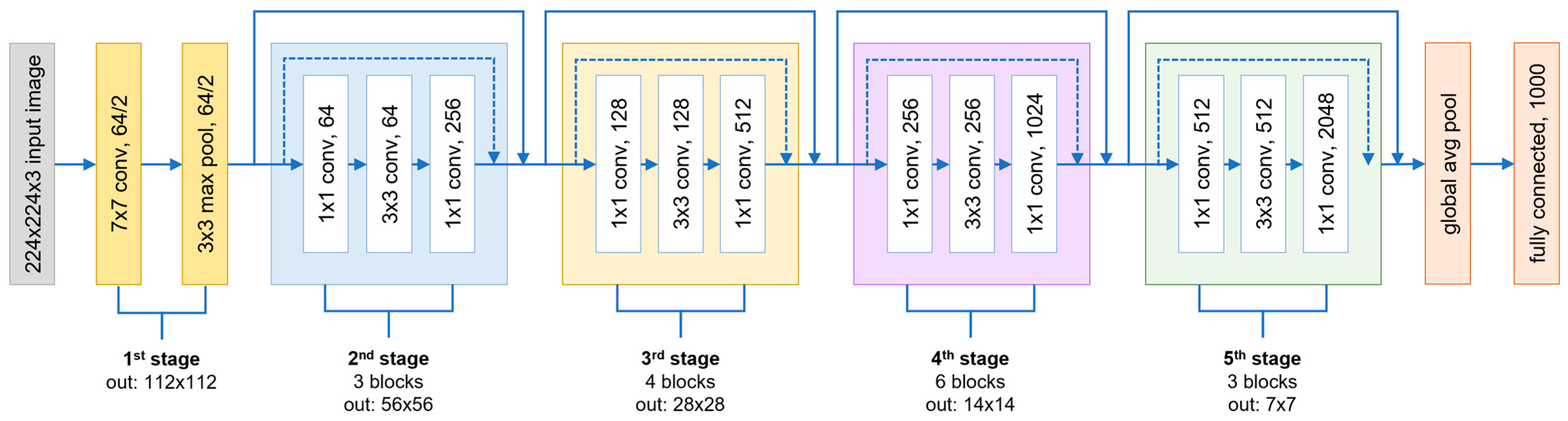
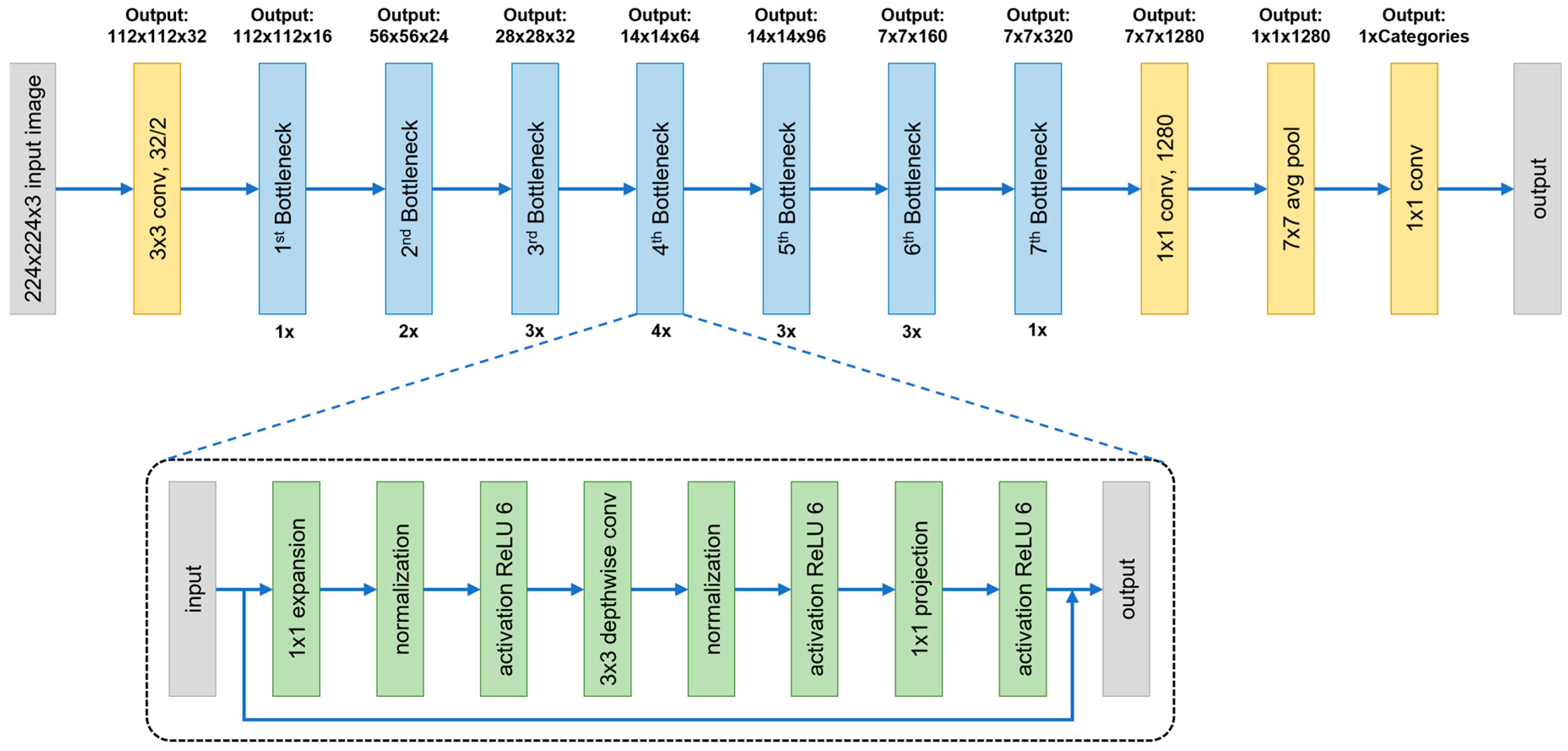
3.5.1. ResNet50
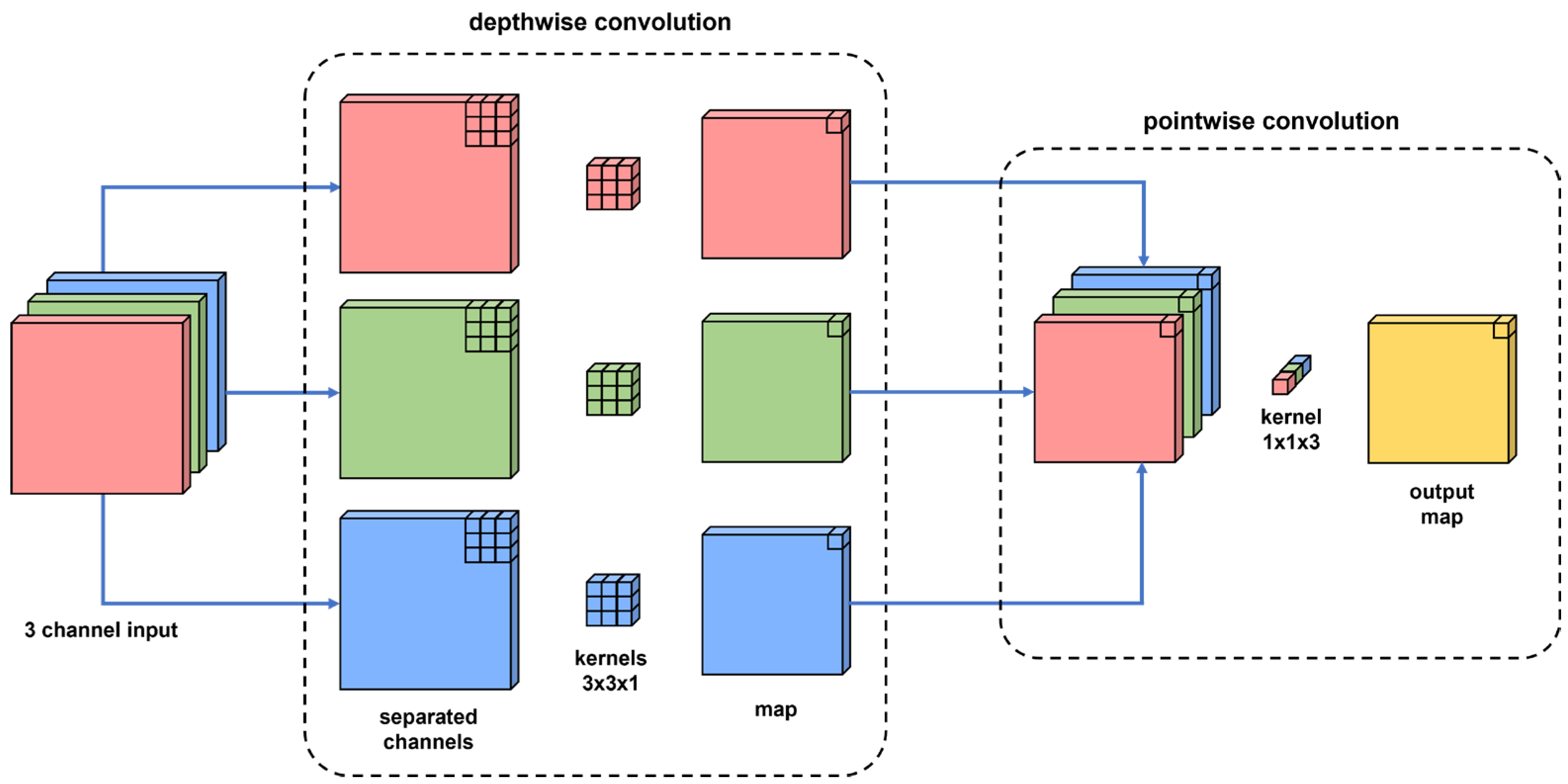
3.5.2. MobileNetV2
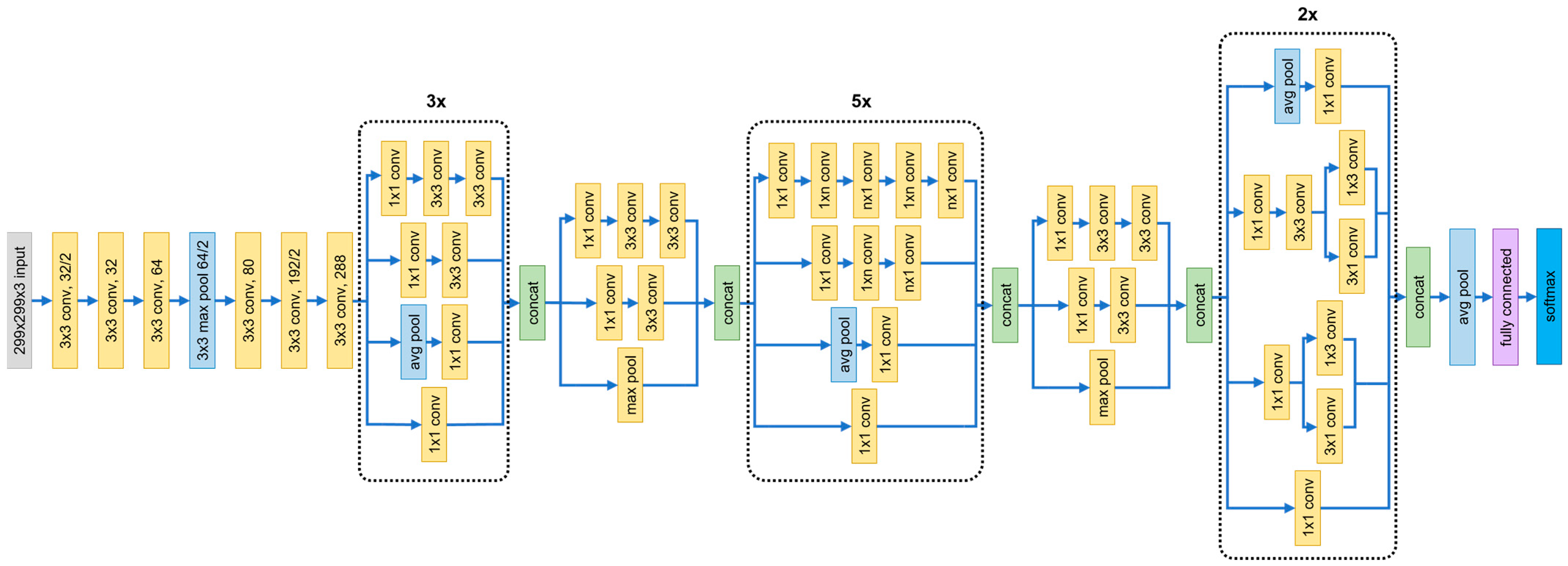
3.5.3. InceptionV3
3.6. Programming Tools
| ```python from tensorflow.keras.preprocessing.image import ImageDataGenerator # Creating an instance of ImageDataGenerator with augmentation parameters datagen = ImageDataGenerator( rotation_range = 20, width_shift_range = 0.2, height_shift_range = 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = ‘nearest’ ) # Calculating internal statistics (fit) - assuming x_train is the image data datagen.fit(x_train) # Generating batches of images dynamically using flow generated_images = datagen.flow(x_train, batch_size = 32) ``` |
4. Results
4.1. Experimental Setup
4.2. Dataset Preparation
4.3. Experimental Results
4.3.1. Results on Single Augmentation
4.3.2. Results of Combined Augmentation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, C.; Kim, J.; Cho, S.; Kim, J.; Yoo, J.; Kwon, S. Development of Real-Time Hand Gesture Recognition for Tabletop Holographic Display Interaction Using Azure Kinect. Sensors 2020, 20, 4566. [Google Scholar] [CrossRef]
- Ekneling, S.; Sonestedt, T.; Georgiadis, A.; Yousefi, S.; Chana, J. Magestro: Gamification of the Data Collection Process for Development of the Hand Gesture Recognition Technology. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Munich, Germany, 16–20 October 2018; pp. 417–418. [Google Scholar]
- Bai, Z.; Wang, L.; Zhou, S.; Cao, Y.; Liu, Y.; Zhang, J. Fast Recognition Method of Football Robot’s Graphics From the VR Perspective. IEEE Access 2020, 8, 161472–161479. [Google Scholar] [CrossRef]
- Nooruddin, N.; Dembani, R.; Maitlo, N. HGR: Hand-Gesture-Recognition Based Text Input Method for AR/VR Wearable Devices. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 744–751. [Google Scholar]
- Zhao, J.; An, R.; Xu, R.; Lin, B. Comparing Hand Gestures and a Gamepad Interface for Locomotion in Virtual Environments. Int. J. Hum.-Comput. Stud. 2022, 166, 102868. [Google Scholar] [CrossRef]
- Mezari, A.; Maglogiannis, I. An Easily Customized Gesture Recognizer for Assisted Living Using Commodity Mobile Devices. J. Healthc. Eng. 2018, 2018, 3180652. [Google Scholar] [CrossRef] [PubMed]
- Roberge, A.; Bouchard, B.; Maître, J.; Gaboury, S. Hand Gestures Identification for Fine-Grained Human Activity Recognition in Smart Homes. In Procedia Computer Science; Elsevier B.V.: Amsterdam, The Netherlands; Liara Laboratory, University of Quebec, Chicoutimi 555 Boul. Universite: Saguenay, QC, Canada, 2022; Volume 201, pp. 32–39. [Google Scholar]
- Huang, X.; Hu, S.; Guo, Q. Multi-Object Recognition Based on Improved YOLOv4. In Proceedings of the 2021 CAA Symposium on Fault Detection, Supervision, and Safety for Technical Processes (SAFEPROCESS), Chengdu, China, 17–18 December 2021; pp. 1–4. [Google Scholar]
- Kaczmarek, W.; Panasiuk, J.; Borys, S.; Banach, P. Industrial Robot Control by Means of Gestures and Voice Commands in Off-Line and On-Line Mode. Sensors 2020, 20, 6358. [Google Scholar] [CrossRef]
- Neto, P.; Simão, M.; Mendes, N.; Safeea, M. Gesture-Based Human-Robot Interaction for Human Assistance in Manufacturing. Int. J. Adv. Manuf. Technol. 2019, 101, 119–135. [Google Scholar] [CrossRef]
- Ding, I.-J.; Su, J.-L. Designs of Human–Robot Interaction Using Depth Sensor-Based Hand Gesture Communication for Smart Material-Handling Robot Operations. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2023, 237, 392–413. [Google Scholar] [CrossRef]
- Young, G.; Milne, H.; Griffiths, D.; Padfield, E.; Blenkinsopp, R.; Georgiou, O. Designing Mid-Air Haptic Gesture Controlled User Interfaces for Cars. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–23. [Google Scholar] [CrossRef]
- Qian, X.; Ju, W.; Sirkin, D.M. Aladdin’s Magic Carpet: Navigation by in-Air Static Hand Gesture in Autonomous Vehicles. Int. J. Hum.–Comput. Interact. 2020, 36, 1912–1927. [Google Scholar] [CrossRef]
- Devineau, G.; Moutarde, F.; Xi, W.; Yang, J. Deep Learning for Hand Gesture Recognition on Skeletal Data. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 106–113. [Google Scholar]
- Wang, J.; Liu, T.; Wang, X. Human Hand Gesture Recognition with Convolutional Neural Networks for K-12 Double-Teachers Instruction Mode Classroom. Infrared Phys. Technol. 2020, 111, 103464. [Google Scholar] [CrossRef]
- Khoh, W.H.; Pang, Y.H.; Teoh, A.B.J.; Ooi, S.Y. In-Air Hand Gesture Signature Using Transfer Learning and Its Forgery Attack. Appl. Soft Comput. 2021, 113, 108033. [Google Scholar] [CrossRef]
- Khosla, C.; Saini, B.S. Enhancing Performance of Deep Learning Models with Different Data Augmentation Techniques: A Survey. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 79–85. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Kalaivani, S.; Asha, N.; Gayathri, A. Geometric Transformations-Based Medical Image Augmentation. In GANs for Data Augmentation in Healthcare; Solanki, A., Naved, M., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 133–141. ISBN 978-3-031-43204-0. [Google Scholar]
- Islam, M.Z.; Hossain, M.S.; ul Islam, R.; Andersson, K. Static Hand Gesture Recognition Using Convolutional Neural Network with Data Augmentation. In Proceedings of the 2019 Joint 8th International Conference on Informatics, Electronics & Vision (ICIEV) and 2019 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), Spokane, WA, USA, 30 May–2 June 2019; pp. 324–329. [Google Scholar]
- Bousbai, K.; Merah, M. Hand Gesture Recognition Using Capabilities of Capsule Network and Data Augmentation. In Proceedings of the 2022 7th International Conference on Image and Signal Processing and their Applications (ISPA), Mostaganem, Algeria, 8–9 May 2022; pp. 1–5. [Google Scholar]
- Alani, A.A.; Cosma, G.; Taherkhani, A.; McGinnity, T.M. Hand Gesture Recognition Using an Adapted Convolutional Neural Network with Data Augmentation. In Proceedings of the 2018 4th International Conference on Information Management (ICIM), Oxford, UK, 25–27 May 2018; pp. 5–12. [Google Scholar]
- Zhou, W.; Chen, K. A Lightweight Hand Gesture Recognition in Complex Backgrounds. Displays 2022, 74, 102226. [Google Scholar] [CrossRef]
- Galdran, A.; Alvarez-Gila, A.; Meyer, M.I.; Saratxaga, C.L.; Araújo, T.; Garrote, E.; Aresta, G.; Costa, P.; Mendonça, A.M.; Campilho, A. Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis. arXiv 2017, arXiv:1703.03702. [Google Scholar]
- Tan, Y.S.; Lim, K.M.; Lee, C.P. Hand Gesture Recognition via Enhanced Densely Connected Convolutional Neural Network. Expert Syst. Appl. 2021, 175, 114797. [Google Scholar] [CrossRef]
- Taylor, L.; Nitschke, G. Improving Deep Learning with Generic Data Augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Motamed, S.; Rogalla, P.; Khalvati, F. Data Augmentation Using Generative Adversarial Networks (GANs) for GAN-Based Detection of Pneumonia and COVID-19 in Chest X-Ray Images. Inform. Med. Unlocked 2021, 27, 100779. [Google Scholar] [CrossRef] [PubMed]
- Rajeev, C.; Natarajan, K. Data Augmentation in Classifying Chest Radiograph Images (CXR) Using DCGAN-CNN. In GANs for Data Augmentation in Healthcare; Solanki, A., Naved, M., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 91–110. ISBN 978-3-031-43204-0. [Google Scholar]
- Farahanipad, F.; Rezaei, M.; Nasr, M.S.; Kamangar, F.; Athitsos, V. A Survey on GAN-Based Data Augmentation for Hand Pose Estimation Problem. Technologies 2022, 10, 43. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J. Generative Adversarial Networks (GANs): Challenges, Solutions, and Future Directions. ACM Comput. Surv. CSUR 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Ciano, G.; Andreini, P.; Mazzierli, T.; Bianchini, M.; Scarselli, F. A Multi-Stage GAN for Multi-Organ Chest X-Ray Image Generation and Segmentation. Mathematics 2021, 9, 2896. [Google Scholar] [CrossRef]
- Avianto, D.; Harjoko, A.; Afiahayati. CNN-Based Classification for Highly Similar Vehicle Model Using Multi-Task Learning. J. Imaging 2022, 8, 293. [Google Scholar] [CrossRef]
- Güler, O.; Yücedağ, İ. Hand Gesture Recognition from 2D Images by Using Convolutional Capsule Neural Networks. Arab. J. Sci. Eng. 2022, 47, 1211–1225. [Google Scholar] [CrossRef]
- Alashhab, S.; Gallego, A.J.; Lozano, M.Á. Efficient Gesture Recognition for the Assistance of Visually Impaired People Using Multi-Head Neural Networks. Eng. Appl. Artif. Intell. 2022, 114, 105188. [Google Scholar] [CrossRef]
- Latif, G.; Mohammad, N.; Alghazo, J.; AlKhalaf, R.; AlKhalaf, R. ArASL: Arabic Alphabets Sign Language Dataset. Data Brief 2019, 23, 103777. [Google Scholar] [CrossRef] [PubMed]
- Lecture—Image Processing: Geometric Operations—Scaling|WueCampus. Available online: https://wuecampus.uni-wuerzburg.de/moodle/mod/book/view.php?id=958001&chapterid=10072 (accessed on 17 November 2023).
- Lecture—Image Processing: Geometric Operations—Rotation|WueCampus. Available online: https://wuecampus.uni-wuerzburg.de/moodle/mod/book/view.php?id=958001&chapterid=10071 (accessed on 17 November 2023).
- Lecture—Image Processing: Geometric Operations—Translation|WueCampus. Available online: https://wuecampus.uni-wuerzburg.de/moodle/mod/book/view.php?id=958001&chapterid=10067 (accessed on 17 November 2023).
- Shearing in 2D Graphics. GeeksforGeeks 2020. Available online: https://www.geeksforgeeks.org/shearing-in-2d-graphics/ (accessed on 17 November 2023).
- Lecture—Image Processing: Geometric Operations—Mirroring|WueCampus. Available online: https://wuecampus.uni-wuerzburg.de/moodle/mod/book/view.php?id=958001&chapterid=10073 (accessed on 17 November 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Phung, V.H.; Rhee, E.J. A High-Accuracy Model Average Ensemble of Convolutional Neural Networks for Classification of Cloud Image Patches on Small Datasets. Appl. Sci. 2019, 9, 4500. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2019, arXiv:1803.08375. [Google Scholar]
- Hahnloser, R.H.R.; Sarpeshkar, R.; Mahowald, M.A.; Douglas, R.J.; Seung, H.S. Digital Selection and Analogue Amplification Coexist in a Cortex-Inspired Silicon Circuit. Nature 2000, 405, 947–951. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Subburaj, S.; Murugavalli, S. Survey on Sign Language Recognition in Context of Vision-Based and Deep Learning. Meas. Sens. 2022, 23, 100385. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tf.Keras.Preprocessing.Image.ImageDataGenerator|TensorFlow v2.14.0. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator (accessed on 13 November 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geometric Transformation | Direction | Parameter Setting |
|---|---|---|
| Scaling | Horizontal and vertical | [−20%, 20%] |
| Rotation | CW and CCW | [−30°, 30°] |
| Translation | Horizontal and vertical | [−20%, 20%] |
| Shearing | Horizontal | [−20°, 20°] |
| Flipping | Horizontal | [True, False] |
| Hardware/Software | Specification |
|---|---|
| Processor (CPU) | Intel Core i5-9300H @2.40 GHz |
| Memory (RAM) | 32 GB DDR4 |
| Graphics Processing Unit (GPU) | Nvidia GTX 1660 Ti—6GB vRAM |
| Operating system | Windows 11 |
| Python version | 3.6.13 |
| Cuda/CuDNN version | 11.0/8.0 |
| Dataset | Number of Data | Number of Classes | Images Size | Image Background |
|---|---|---|---|---|
| DLSI | 12,064 | 6 | 224 × 224 | complex |
| HG14 | 14,000 | 14 | 256 × 256 | uniform |
| MU HandImages ASL | 2425 | 26 | vary | uniform |
| Sebastian Marcel | 5531 | 6 | vary | uniform and complex |
| ArASL2018 | 54,049 | 32 | 64 × 64 | uniform |
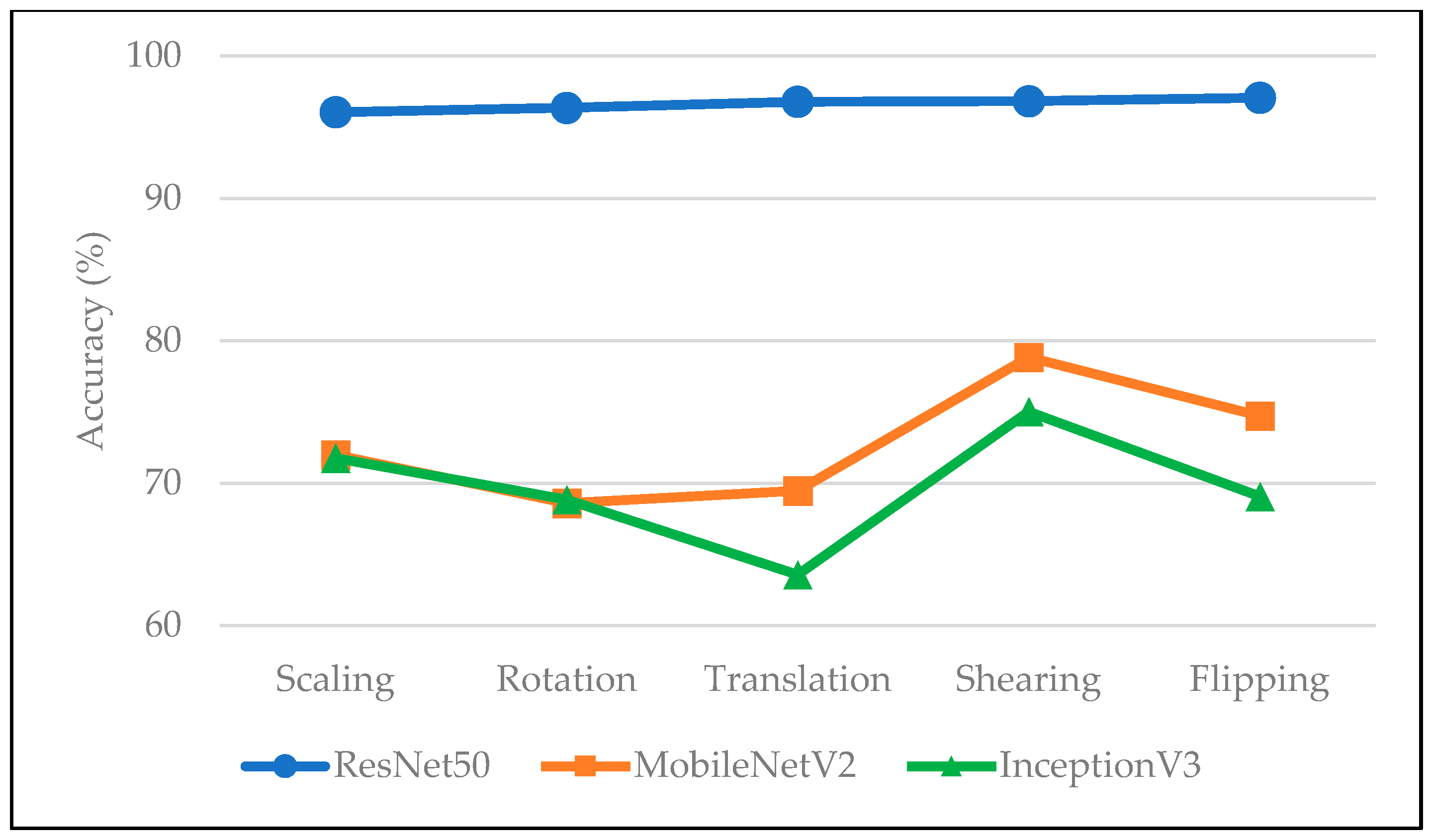
| Dataset | Geometric Transformations—Accuracy (%) | Dataset Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Scaling | Rotation | Translation | Shearing | Flipping | ||
| DLSI | 97.86 | 97.37 | 97.47 | 97.86 | 97.77 | 97.67 |
| HG14 | 97.07 | 97.46 | 98.32 | 97.18 | 97.32 | 97.47 |
| MU HandImages ASL | 95.14 | 97.26 | 96.05 | 97.26 | 97.57 | 96.66 |
| ArASL2018 | 96.61 | 94.66 | 96.04 | 97.26 | 97.15 | 96.34 |
| Sebastian Marcel | 93.60 | 95.07 | 96.06 | 94.58 | 95.57 | 94.98 |
| Geometric Avg. Accuracy (%) | 96.06 | 96.36 | 96.79 | 96.83 | 97.08 | |
| Dataset | Geometric Transformations—Accuracy (%) | Dataset Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Scaling | Rotation | Translation | Shearing | Flipping | ||
| DLSI | 73.63 | 73.78 | 69.96 | 79.79 | 76.66 | 74.76 |
| HG14 | 59.18 | 57.75 | 59.00 | 65.18 | 60.39 | 60.30 |
| MU HandImages ASL | 92.40 | 90.88 | 91.49 | 95.74 | 95.74 | 93.25 |
| ArASL2018 | 69.21 | 59.53 | 63.83 | 84.09 | 74.79 | 70.29 |
| Sebastian Marcel | 65.52 | 61.08 | 63.05 | 69.46 | 66.01 | 65.02 |
| Geometric Avg. Accuracy (%) | 71.99 | 68.60 | 69.47 | 78.85 | 74.72 | |
| Dataset | Geometric Transformations—Accuracy (%) | Dataset Average Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Scaling | Rotation | Translation | Shearing | Flipping | ||
| DLSI | 67.28 | 65.44 | 60.92 | 71.70 | 69.27 | 66.92 |
| HG14 | 48.57 | 41.54 | 39.43 | 49.11 | 40.25 | 43.78 |
| MU HandImages ASL | 89.06 | 86.63 | 82.67 | 94.22 | 89.06 | 84.34 |
| ArASL2018 | 82.93 | 76.75 | 67.33 | 85.75 | 74.37 | 70.47 |
| Sebastian Marcel | 70.94 | 73.89 | 67.49 | 74.38 | 72.41 | 74.07 |
| Geometric Avg. Accuracy (%) | 71.76 | 68.85 | 63.57 | 75.03 | 69.07 | |
| Dataset | ResNet50 (%) | MobileNetV2 (%) | InceptionV3 (%) | |||
|---|---|---|---|---|---|---|
| Single | Combined | Single | Combined | Single | Combined | |
| DLSI | 97.67 | 97.96 | 74.76 | 65.29 | 66.92 | 52.09 |
| HG14 | 97.47 | 96.61 | 60.30 | 48.86 | 43.78 | 28.82 |
| MU HandImages ASL | 96.66 | 93.62 | 93.25 | 94.22 | 84.34 | 76.60 |
| ArASL2018 | 96.34 | 92.41 | 70.29 | 39.38 | 70.47 | 18.47 |
| Sebastian Marcel | 94.98 | 95.57 | 65.02 | 58.13 | 74.07 | 74.38 |
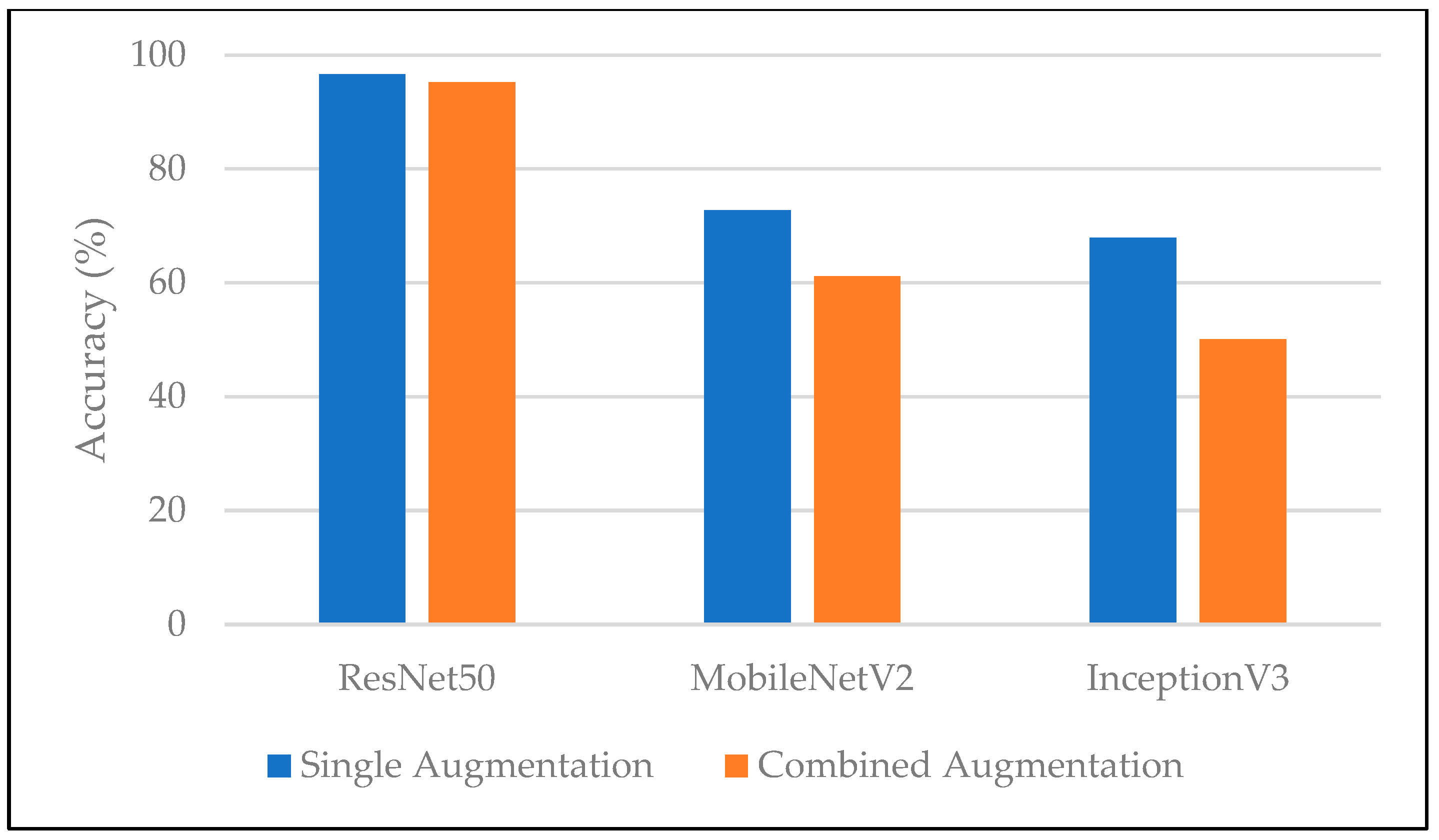
| Avg. Accuracy (%) | 96.62 | 95.23 | 72.72 | 61.18 | 67.92 | 50.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awaluddin, B.-A.; Chao, C.-T.; Chiou, J.-S. Investigating Effective Geometric Transformation for Image Augmentation to Improve Static Hand Gestures with a Pre-Trained Convolutional Neural Network. Mathematics 2023, 11, 4783. https://doi.org/10.3390/math11234783
Awaluddin B-A, Chao C-T, Chiou J-S. Investigating Effective Geometric Transformation for Image Augmentation to Improve Static Hand Gestures with a Pre-Trained Convolutional Neural Network. Mathematics. 2023; 11(23):4783. https://doi.org/10.3390/math11234783
Chicago/Turabian StyleAwaluddin, Baiti-Ahmad, Chun-Tang Chao, and Juing-Shian Chiou. 2023. "Investigating Effective Geometric Transformation for Image Augmentation to Improve Static Hand Gestures with a Pre-Trained Convolutional Neural Network" Mathematics 11, no. 23: 4783. https://doi.org/10.3390/math11234783
APA StyleAwaluddin, B. -A., Chao, C. -T., & Chiou, J. -S. (2023). Investigating Effective Geometric Transformation for Image Augmentation to Improve Static Hand Gestures with a Pre-Trained Convolutional Neural Network. Mathematics, 11(23), 4783. https://doi.org/10.3390/math11234783