
Exploring an Intelligent Classification Model for the Recognition of Automobile Sounds Based on EEG Physiological Signals


Abstract
:1. Introduction
1.1. Related Work
1.2. Critical Issues
1.3. Our Contribution
2. Data Collection and Experimental Setup
2.1. Sound Stimulus
2.2. EEG Experimental Setup
2.2.1. EEG Data Acquisition
2.2.2. EEG Data Preprocessing
3. A Method for the Recognition of Vehicle Sounds Fused with EEG Signals
3.1. Architecture of the CNN Model
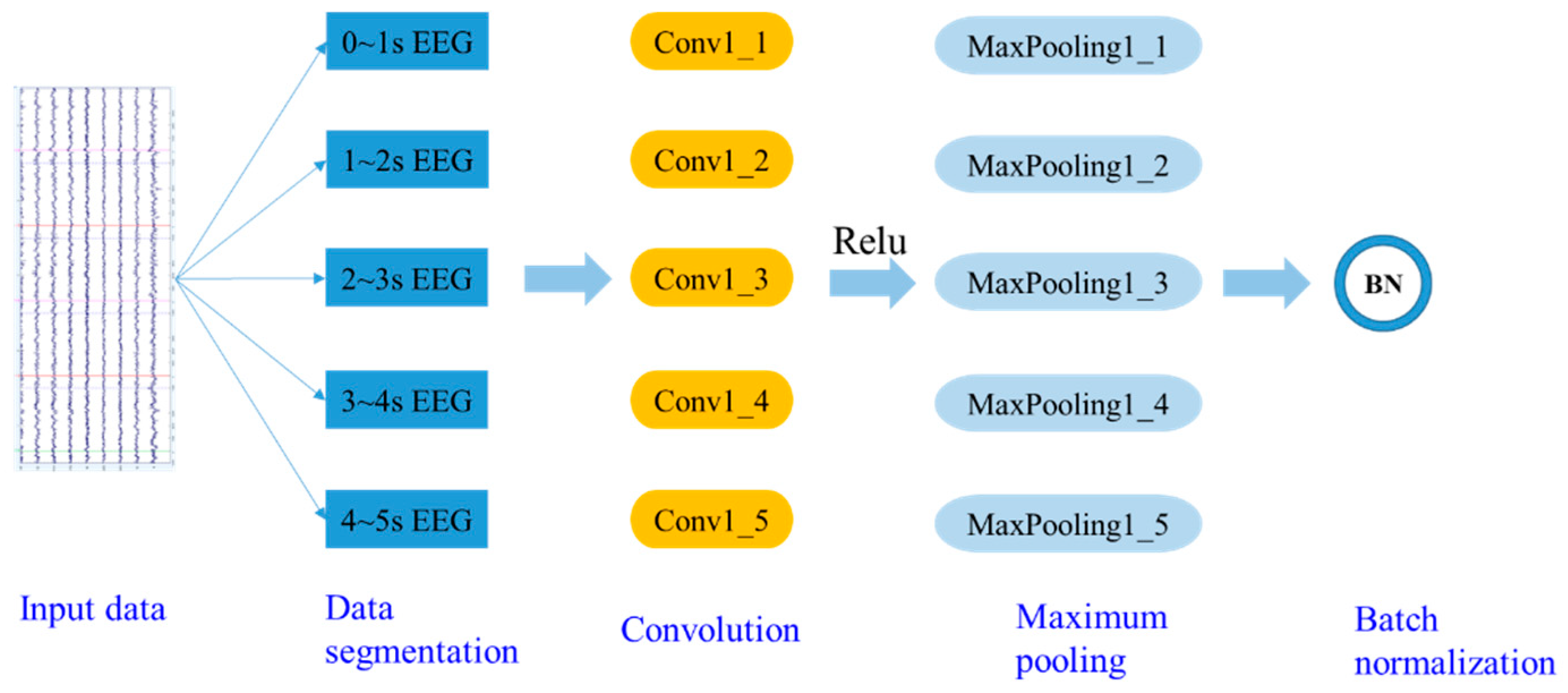
3.1.1. Design of the Feature Extraction Module
3.1.2. Design of Network Architecture
3.2. Developing the CNN with Specific Transfer Learning
3.3. Learning Rule of STL-CNN
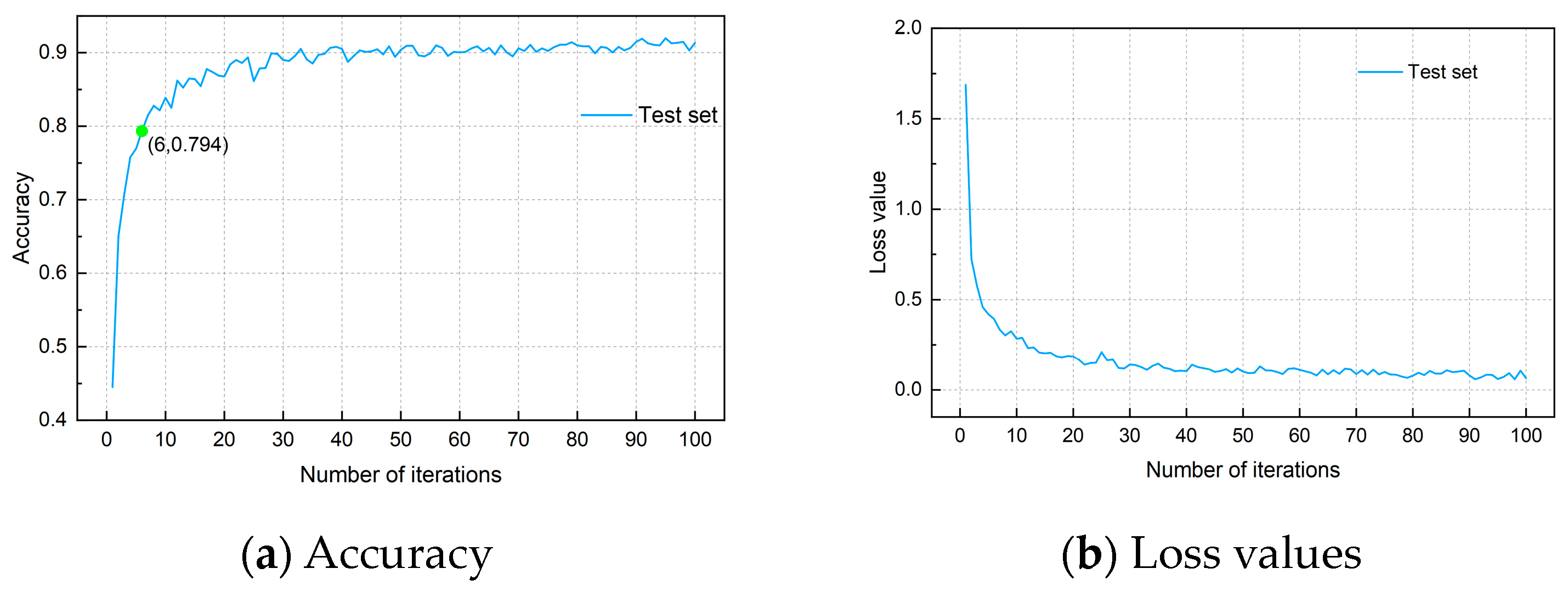
4. Performance Evaluation of STL-CNN
4.1. Comparison of Classification Models
4.2. Comprehensive Evaluation of Classification Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, H.H.; Lee, S.K. Objective evaluation of interior noise booming in a passenger car based on sound metrics and artificial neural networks. Appl. Ergon. 2009, 40, 860–869. [Google Scholar] [CrossRef]
- Schiffbänker, H.; Brandl, F.; Thien, G. Development and Application of an Evaluation Technique to Assess the Subjective Character of Engine Noise; SAE Technical Paper: Warrendale, PA, USA, 1991. [Google Scholar]
- He, Y.; Tu, L.; Xu, Z. Review of Vehicle Sound Quality. Automot. Eng. 2014, 4, 391–401. [Google Scholar]
- Liu, Z.; Xie, L.; Huang, T.; Lu, C.; Chen, W.; Zhu, Y. The objective quantification of door closing sound quality based on multidimensional subjective perception attributes. Appl. Acoust. 2022, 192, 108748. [Google Scholar] [CrossRef]
- Murata, H.; Tanaka, H.; Takada, H.; Ohsasa, Y. Sound Quality Evaluation of Passenger Vehicle Interior Noise; SAE Technical Paper: Warrendale, PA, USA, 1993. [Google Scholar]
- Ohsasa, Y.; Kadomatsu, K. Sound Quality Evaluation of Exhaust Note During Acceleration; SAE Technical Paper: Warrendale, PA, USA, 1995. [Google Scholar]
- Chang, K.; Jeong, K.; Park, D. A Study on the Strategy and Implementing Technology for the Development of Luxurious Driving Sound; SAE Technical Paper: Warrendale, PA, USA, 2014. [Google Scholar] [CrossRef]
- Engelke, U.; Darcy, D.P.; Mulliken, G.H.; Bosse, S.; Martini, M.G.; Arndt, S.; Antons, J.N.; Chan, K.Y.; Ramzan, N.; Brunnstrom, K. Psychophysiology-Based QoE Assessment: A Survey; IEEE Journal of Selected Topics in Signal Processing; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Geng, B.; Liu, K.; Duan, Y.; Song, Q.; Tao, X.; Lu, J.; Shi, J. A Novel EEG Based Directed Transfer Function for Investigating Human Perception to Audio Noise. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 923–928. [Google Scholar]
- Xie, L.; Lu, C.; Liu, Z.; Yan, L.; Xu, T. Studying critical frequency bands and channels for EEG-based automobile sound recognition with machine learning. Appl. Acoust. 2022, 185, 108389. [Google Scholar] [CrossRef]
- Xie, L.; Lu, C.; Liu, Z.; Yan, L.; Xu, T. Study of Auditory Brain Cognition Laws-Based Recognition Method of Automobile Sound Quality. Front. Hum. Neurosci. 2021, 15, 663049. [Google Scholar] [CrossRef] [PubMed]
- Kalaganis, F.; Adamos, D.A.; Laskaris, N. A Consumer BCI for Automated Music Evaluation Within a Popular On-Demand Music Streaming Service “Taking Listener’s Brainwaves to Extremes”. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Thessaloniki, Greece, 16–18 September 2016; Springer: Cham, Switzerland, 2016; pp. 429–444. [Google Scholar]
- Friston, K.J.; Frith, C.D.; Dolan, R.j.; Price, C.j.; Zeki, S.; Ashburner, J.T.; Penny, W.D. Human Brain Function; Elsevier Science: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Cirett Galán, F.; Beal, C.R. EEG estimates of engagement and cognitive workload predict math problem solving outcomes. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization, Montreal, QC, Canada, 16–20 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 51–62. [Google Scholar]
- Lenz, D.; Schadow, J.; Thaerig, S.; Busch, N.A.; Herrmann, C.S. What’s that sound? Matches with auditory long-term memory induce gamma activity in human, EEG. Int. J. Psychophysiol. 2007, 64, 31–38. [Google Scholar] [CrossRef] [PubMed]
- Cong, F.; Alluri, V.; Nandi, A.K.; Toiviainen, P.; Fa, R.; Abu-Jamous, B.; Gong, L.; Craenen, B.G.W.; Poikonen, H.; Huotilainen, M.; et al. Linking Brain Responses to Naturalistic Music Through Analysis of Ongoing EEG and Stimulus Features. IEEE Trans. Multimed. 2013, 15, 1060–1069. [Google Scholar] [CrossRef]
- Li, Z.G.; Di, G.Q.; Jia, L. Relationship between Electroencephalogram variation and subjective annoyance under noise exposure. Appl. Acoust. 2014, 75, 37–42. [Google Scholar] [CrossRef]
- Zhang, R.; Zong, Q.; Dou, L.; Zhao, X.; Tang, Y.; Li, Z. Hybrid deep neural network using transfer learning for EEG motor imagery decoding. Biomed. Signal Process. Control 2021, 63, 102144. [Google Scholar] [CrossRef]
- Xie, L.; Lu, C.; Liu, Z.; Chen, W.; Zhu, Y.; Xu, T. The evaluation of automobile interior acceleration sound fused with physiological signal using a hybrid deep neural network. Mech. Syst. Signal Process. 2023, 184, 109675. [Google Scholar] [CrossRef]
- Huang, G.; Hu, Z.; Zhang, L.; Li, L.; Liang, Z.; Zhang, Z. Removal of eye-blinking artifacts by ICA in cross-modal long-term EEG recording. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 217–220. [Google Scholar]
- Zheng, W.L.; Zhu, J.Y.; Lu, B.L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 10, 417–429. [Google Scholar] [CrossRef]
- Jenke, R.; Peer, A.; Buss, M. Feature extraction and selection for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2014, 5, 327–339. [Google Scholar] [CrossRef]
- Frederick, J.A.; Lubar, J.F. Skewness in the Time Series of EEG Magnitude and Spectral Correlation. Soc. Neuronal Regul. 2002, 10, 2377–4400. [Google Scholar]
- Xiang, J.; Maue, E.; Fan, Y.; Qi, L.; Mangano, F.T.; Greiner, H.; Tenney, J. Kurtosis and skewness of high-frequency brain signals are altered in paediatric epilepsy. Brain Commun. 2020, 2, fcaa036. [Google Scholar] [CrossRef] [PubMed]
- Hernández, D.E.; Trujillo, L.; Z-Flores, E.; Villanueva, O.M.; Romo-Fewell, O. Detecting Epilepsy in EEG Signals Using Time, Frequency and Time-Frequency Domain Features. In Computer Science and Engineering Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 167–182. [Google Scholar]
- Hjorth, B. EEG analysis based on time domain properties. Electroencephalogr. Clin. Neurophysiol. 1970, 29, 306–310. [Google Scholar] [CrossRef] [PubMed]
- Carmen, V.; Nicole, K.; Benjamin, B.; Schlögl, A. Time Domain Parameters as a feature for EEG-based Brain-Computer Interfaces. Neural Netw. 2009, 22, 1313–1319. [Google Scholar]
- Bokde, A.L.; Teipel, S.J.; Schwarz, R.; Leinsinger, G.; Buerger, K.; Moeller, T.; Möller, H.-J.; Hampel, H. Reliable manual segmentation of the frontal, parietal, temporal, and occipital lobes on magnetic resonance images of healthy subjects. Brain Res. Protoc. 2005, 14, 135–145. [Google Scholar] [CrossRef]
- Hadjidimitriou, S.K.; Hadjileontiadis, L.J. Toward an EEG-based recognition of music liking using time-frequency analysis. IEEE Trans. Biomed. Eng. 2012, 59, 3498–3510. [Google Scholar] [CrossRef]
- Yoon, J.H.; Yang, I.H.; Jeong, J.E.; Park, S.-G.; Oh, J.-E. Reliability improvement of a sound quality index for a vehicle HVAC system using a regression and neural network model. Appl. Acoust. 2012, 73, 1099–1103. [Google Scholar] [CrossRef]
- García-Martínez, B.; Martínez-Rodrigo, A.; Cantabrana, R.Z.; García, J.M.P.; Alcaraz, R. Application of entropy-based metrics to identify emotional distress from electroencephalographic recordings. Entropy 2016, 18, 221. [Google Scholar] [CrossRef]
- Pan, Y.; Guan, C.; Yu, J.; Ang, K.K.; Chan, T.E. Common frequency pattern for music preference identification using frontal EEG. In Proceedings of the International IEEE/EMBS Conference on Neural Engineering, San Diego, CA, USA, 6–8 November 2013. [Google Scholar]
- Nakanishi, M.; Mitsukura, Y.; Hara, A. EEG analysis for acoustic quality evaluation using PCA and FDA. In Proceedings of the IEEE International Symposium on Robot and Human Interactive Communication, Atlanta, GA, USA, 31 July –3 August 2011. [Google Scholar]
- WeiLong, Z.; BaoLiang, L. Investigating Critical Frequency Bands and Channels for EEG-Based Emotion Recognition with Deep Neural Networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Sobhan, S.; Zohteh, M.; Tohid, Y.R.; Farzamnia, A. Recognizing Emotions Evoked by Music using CNN-LSTM Networks on EEG signals. IEEE Access 2020, 8, 139332–139345. [Google Scholar]
- Myslobodsky, M.S.; Coppola, R.; Bar-Ziv, J.; Weinberger, D.R. Adequacy of the International 10–20 electrode system for computed neurophysiologic topography. J. Clin. Neurophysiol. Off. Publ. Am. Electroencephalogr. Soc. 1990, 7, 507–518. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K. Emotion Recognition Based on EEG Signals under Music Induction; Zhejiang University: Hangzhou, China, 2019. [Google Scholar]
- Mikkelsen, K.B.; Kappel, S.L.; Mandic, D.P.; Kidmose, P. EEG recorded from the ear: Characterizing the ear-EEG method. Front. Neurosci. 2015, 9, 438. [Google Scholar] [CrossRef]
- Adamos, D.A.; Dimitriadis, S.I.; Laskaris, N.A. Towards the bio-personalization of music recommendation systems: A single-sensor EEG biomarker of subjective music preference. Inf. Sci. 2016, 343, 94–108. [Google Scholar] [CrossRef]
- Huang, H.B.; Wu, J.H.; Huang, X.R.; Yang, M.L.; Ding, W.P. The development of a deep neural network and its application to evaluating the interior sound quality of pure electric vehicles. Mech. Syst. Signal Process. 2019, 120, 98–116. [Google Scholar] [CrossRef]
- Ma, C.; Chen, C.; Liu, Q.; Gao, H.; Li, Q.; Gao, H.; Shen, Y. Sound quality evaluation of the interior noise of pure electric vehicle based on neural network model. IEEE Trans. Ind. Electron. 2017, 64, 9442–9450. [Google Scholar] [CrossRef]
- Borra, D.; Fantozzi, S.; Magosso, E. EEG motor execution decoding via interpretable sinc-convolutional neural networks. In Proceedings of the Mediterranean Conference on Medical and Biological Engineering and Computing, Coimbra, Portugal, 26–28 September 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 1113–1122. [Google Scholar]
- Borra, D.; Magosso, E.; Castelo-Branco, M.; Simões, M. A Bayesian-optimized design for an interpretable convolutional neural network to decode and analyze the P300 response in autism. J. Neural Eng. 2022, 19, 046010. [Google Scholar] [CrossRef]
- Borra, D.; Mondini, V.; Magosso, E.; Müller-Putz, G.R. Decoding movement kinematics from EEG using an interpretable convolutional neural network. Comput. Biol. Med. 2023, 165, 107323. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Semantic Description | Sound Source |
|---|---|---|
| Comfort | Smooth acceleration, noiseless, soft, and comfortable sounds | Driver’s right ear, sound of Peugeot 4008 4th gear Driver’s right ear, sound of Golf 5th gear Driver’s right ear, sound of Peugeot 4008 5th gear |
| Power | Thick sound, strong acceleration, no metallic clatter sounds | Driver’s right ear, sound of Audio R8 3th gear Driver’s right ear, sound of Audio R8 4th gear Engine sound of Peugeot 4008 3rd gear |
| Technology | High acceleration frequency, rapid sounds, science fiction feels | Web resource 1 Web resource 2 Web resource 3 |
| Subject Characteristics | Quantity | Age | ||
|---|---|---|---|---|
| Mean | Standard Deviation | |||
| Gender | Male | 12 | 24.81 | 5.32 |
| Female | 3 | 23.2 | 4.3 | |
| Occupation | postgraduate | 10 | 20.0 | 0 |
| PhD student | 3 | 24.0 | 2.42 | |
| Professor | 2 | 43.5 | 1.52 | |
| Model Component Name | Component Size | Number of Components | Output Dimension | Component Parameters | |
|---|---|---|---|---|---|
| Input layer | Input data | \ | 5 | 1458 × 1000 × 1 | 0 |
| Bottom layer | Convolutional layer 1_1 | 3 × 1 | 16 | 1458 × 1000 × 16 | 48 × 5 |
| Pooling layer 1_1 | 2 × 1 | \ | 1458 × 500 × 32 | 0 | |
| Convolutional layer 1_2 | 5 × 1 | 32 | 1458 × 500 × 32 | 2560 × 5 | |
| Pooling layer 1_2 | 2 × 1 | \ | 1458 × 250 × 32 | 0 | |
| Convolutional layer 1_3 | 7 × 1 | 64 | 1458 × 250 × 32 | 14,336 × 5 | |
| Pooling layer 1_3 | 2 × 1 | \ | 1458 × 125 × 64 | 0 | |
| Feature merge | \ | 1458 × 125 × 320 | 0 | ||
| Upper layer | Convolutional layer 2_1 | 3 × 1 | 128 | 1458 × 125 × 128 | 122,880 |
| Pooling layer 2_1 | 125 × 1 | \ | 1458 × 128 | 0 | |
| Classification | Fully connected layer | \ | 10 | 1458 × 10 | 1290 |
| Softmax | \ | 3 | 1458 × 3 | 33 | |
| Model Component Name | Component Parameters | Component Trainable Parameters | |
|---|---|---|---|
| Bottom layer | \ | 84,720 | 0 |
| Upper layer | Convolutional layer | 122,880 | 122,880 |
| Pooling layer | 0 | 0 | |
| Classification modules | Fully connected layer | 1290 | 1290 |
| Softmax | 33 | 33 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Xu, T.; Xie, L.; Liu, Z. Exploring an Intelligent Classification Model for the Recognition of Automobile Sounds Based on EEG Physiological Signals. Mathematics 2024, 12, 1297. https://doi.org/10.3390/math12091297
Guo J, Xu T, Xie L, Liu Z. Exploring an Intelligent Classification Model for the Recognition of Automobile Sounds Based on EEG Physiological Signals. Mathematics. 2024; 12(9):1297. https://doi.org/10.3390/math12091297
Chicago/Turabian StyleGuo, Jingjing, Tao Xu, Liping Xie, and Zhien Liu. 2024. "Exploring an Intelligent Classification Model for the Recognition of Automobile Sounds Based on EEG Physiological Signals" Mathematics 12, no. 9: 1297. https://doi.org/10.3390/math12091297
APA StyleGuo, J., Xu, T., Xie, L., & Liu, Z. (2024). Exploring an Intelligent Classification Model for the Recognition of Automobile Sounds Based on EEG Physiological Signals. Mathematics, 12(9), 1297. https://doi.org/10.3390/math12091297