Ecological Diversity: Measuring the Unmeasurable



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- it satisfies key mathematical axioms;
- (2)
- it can be converted to an effective number;
- (3)
- it can be extended to account for disparity between types;
- (4)
- it can be parameterized to obtain diversity profiles; and
- (5)
- an estimator (preferably unbiased) can be obtained to allow the index to be used in practical applications.
2. Defining Diversity
3. Components of Diversity
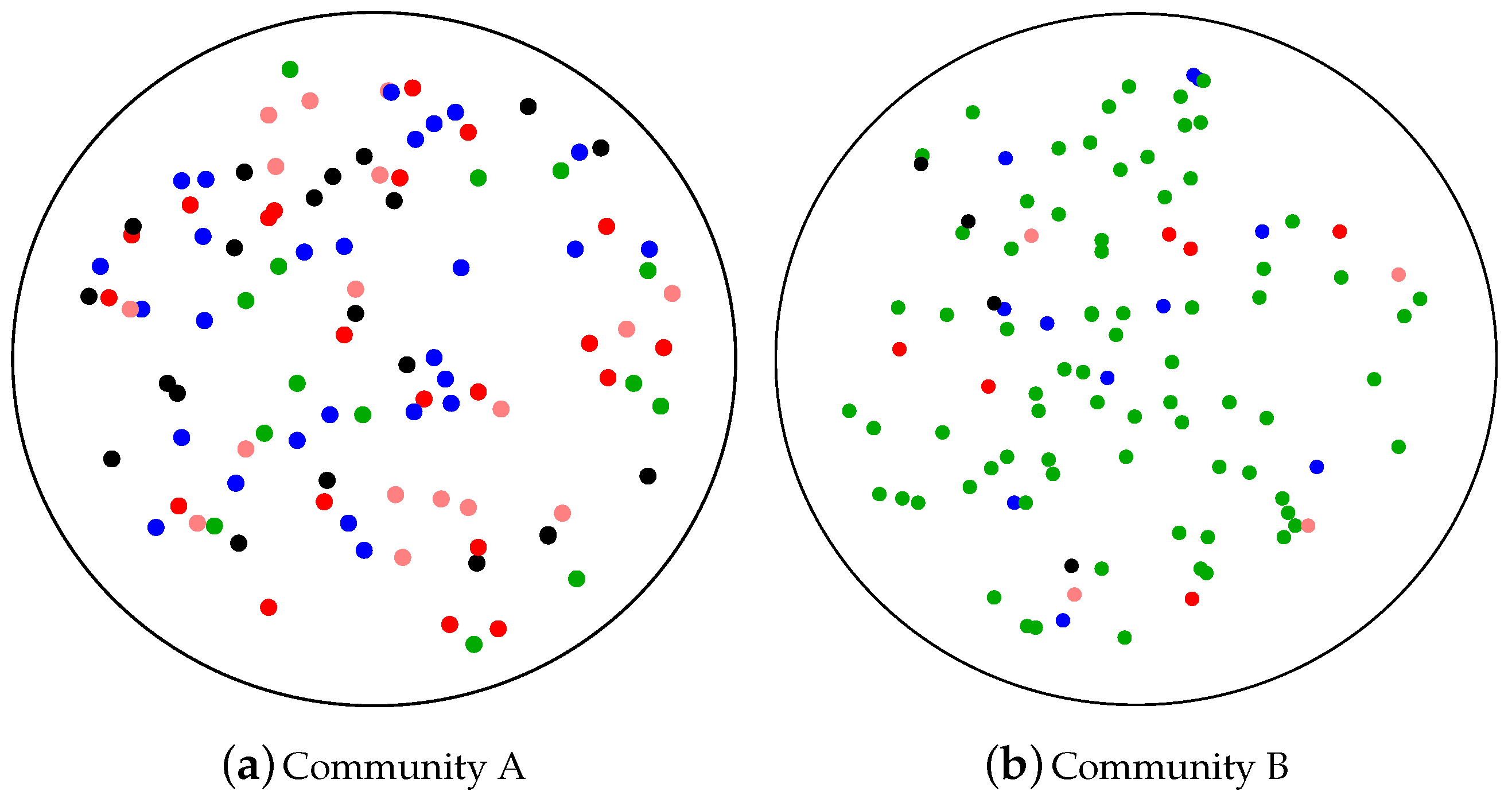
3.1. Richness
3.2. Evenness
3.3. Disparity
4. Axioms Characterizing a Diversity Index
- (1)
- Symmetry. must be a symmetric function.
- (2)
- Continuity. must be a continuous function.
- (3)
- Evenness. The diversity measure is maximal for a fixed number of species S when all species abundances are equal, i.e., , for any .
- (4)
- Principle of transfers. A transfer of abundance must increase diversity.
- (5)
- Monotonicity in number of species. The introduction of a new species must increase diversity.
- (6)
- Replication principle. The diversity of a pooled sample of n maximally distinct (i.e., no shared species) and equally diverse sub-communities is n times the diversity of a single sub-community. That is, if for the communities do not have any common species and for every k, then .
5. Diversity Indices
5.1. Classical Indices
5.1.1. Definitions
5.1.2. Issues with Classical Indices
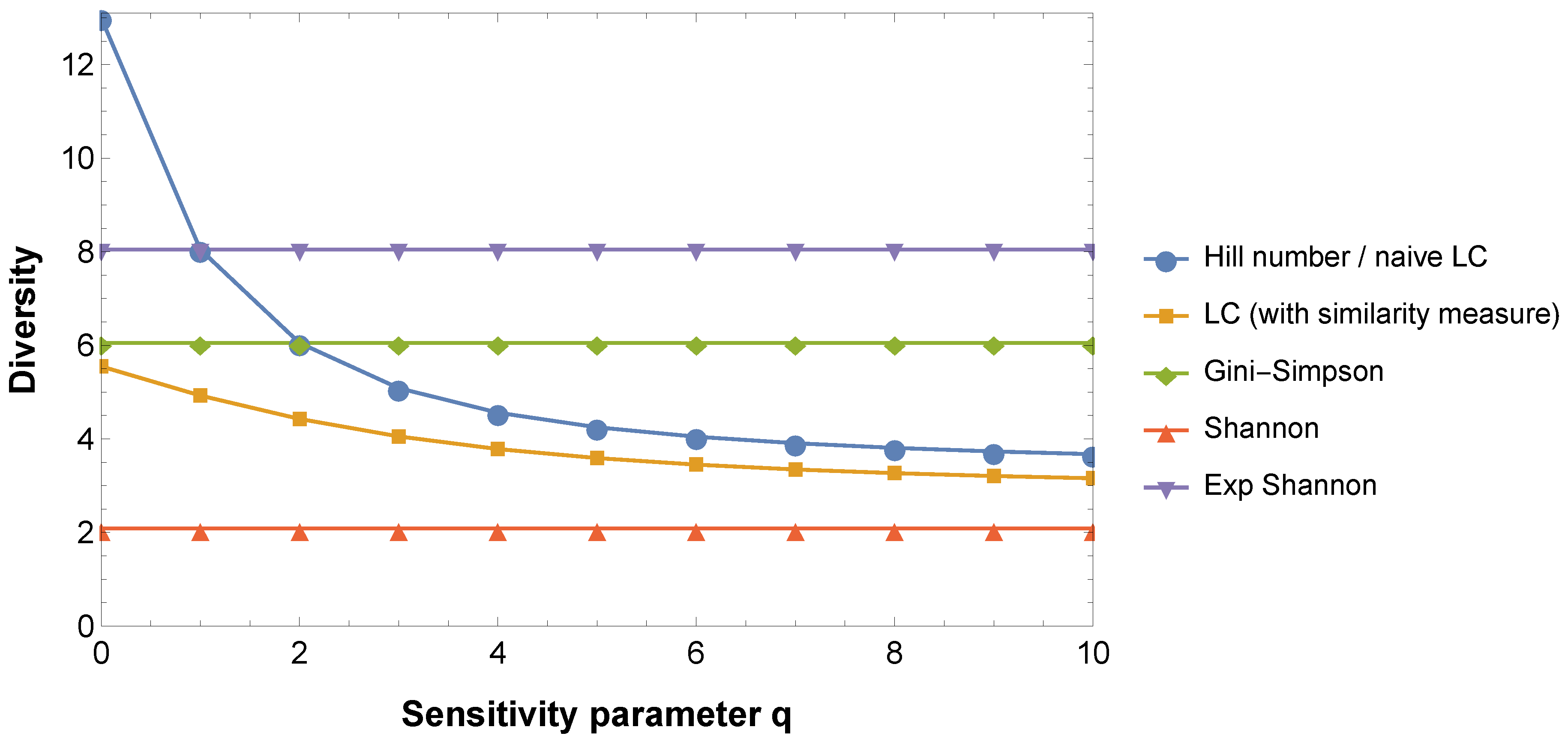
5.2. Effective Numbers
5.3. Similarity-Sensitive Indices
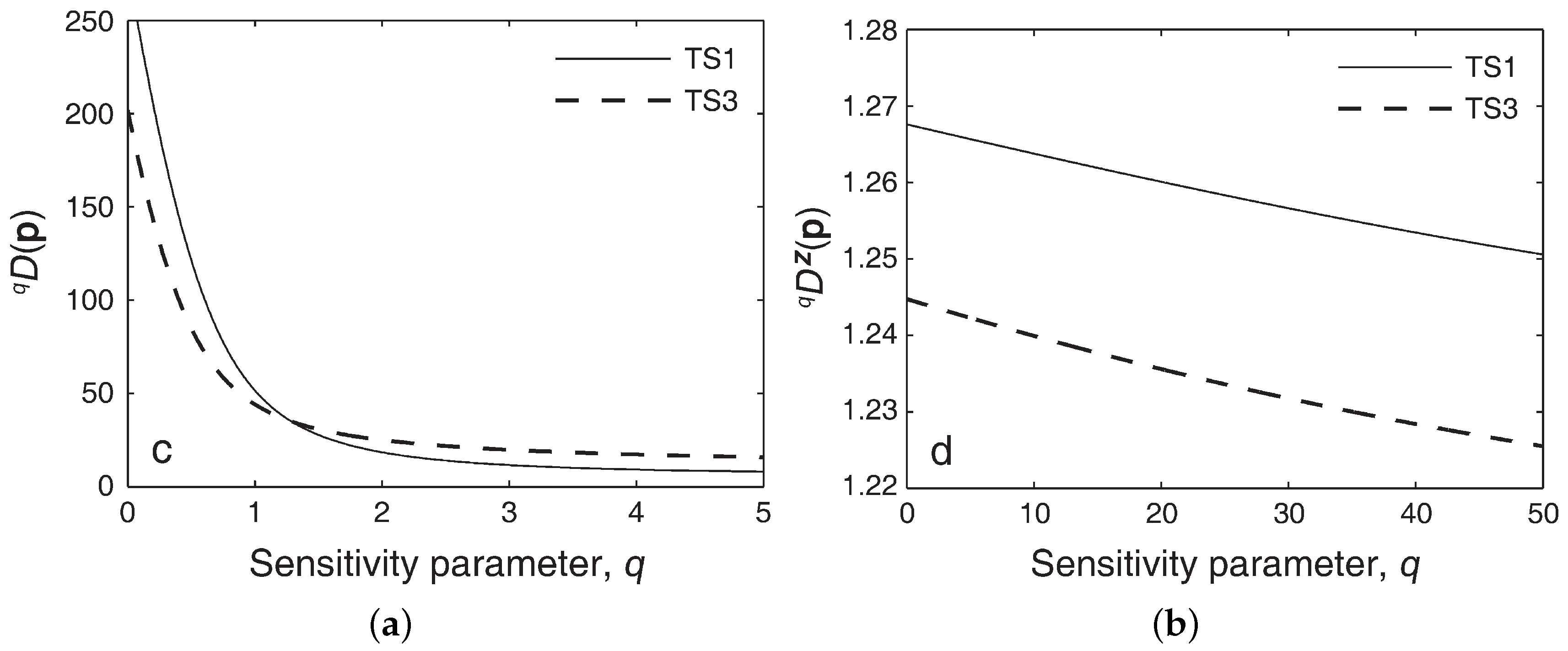
5.4. Parametric Families of Indices
5.5. Diversity Profiles
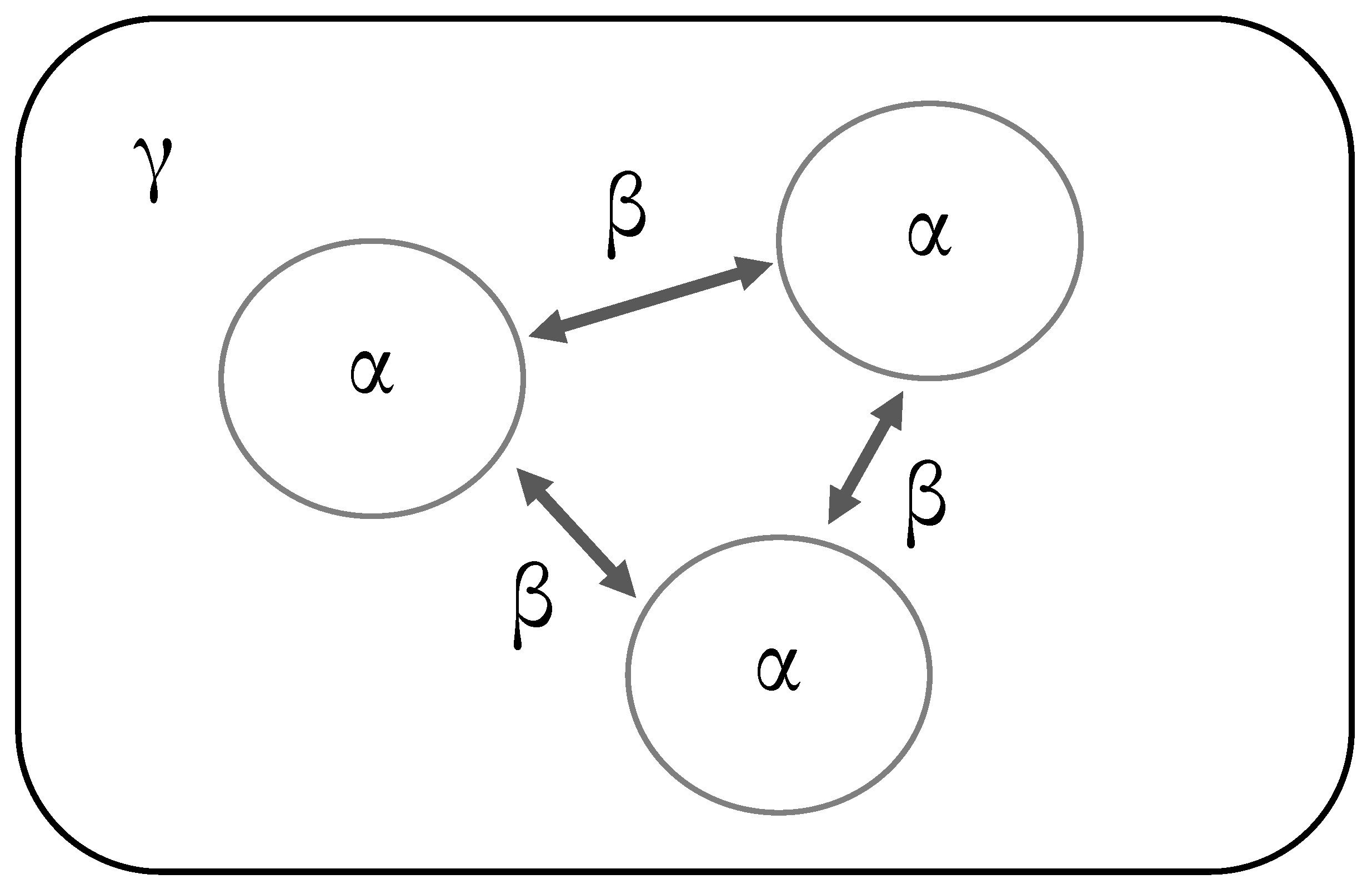
6. Partitioning of Diversity
7. Practical Estimation of Diversity Indices
7.1. Background
7.2. Estimators of Diversity Indices
7.2.1. Richness
7.2.2. Simpson Index
7.2.3. Shannon Index
7.2.4. Hill Numbers
7.2.5. Leinster-Cobbold index
8. Conclusions
- (1)
- satisfies the key axioms in Section 4;
- (2)
- can be expressed as an effective number (Section 5.2);
- (3)
- can be extended to account for species disparity if necessary (Section 5.3);
- (4)
- can be parameterized to obtain diversity profiles (Section 5.5); and
- (5)
Author Contributions
Funding
Conflicts of Interest
References
- Tilman, D.; Isbell, F.; Cowles, J. Biodiversity and ecosystem functioning. Annu. Rev. Ecol. Evol. Syst. 2014, 45, 471–493. [Google Scholar] [CrossRef]
- Dunne, J.; Williams, R. Cascading extinctions and community collapse in model food webs. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2009, 364, 1711–1723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hart, S.; Usinowicz, J.; Levine, J. The spatial scales of species coexistence. Nat. Ecol. Evol. 2017, 1, 1066. [Google Scholar] [CrossRef] [PubMed]
- Mendes, R.; Evangelista, L.; Thomaz, S.; Agostinho, A.; Gomes, L. A unified index to measure ecological diversity and species rarity. Ecography 2008, 31, 450–456. [Google Scholar] [CrossRef]
- DeLong, D. Defining biodiversity. Wildl. Soc. Bull. (1973–2006) 1996, 24, 738–749. [Google Scholar]
- Morris, E.; Caruso, T.; Buscot, F.; Fischer, M.; Hancock, C.; Maier, T.; Meiners, T.; Müller, C.; Obermaier, E.; Prati, D.; et al. Choosing and using diversity indices: Insights for ecological applications from the German Biodiversity Exploratories. Ecol. Evol. 2014, 4, 3514–3524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lucas, R.; Groeneveld, J.; Harms, H.; Johst, K.; Frank, K.; Kleinsteuber, S. A critical evaluation of ecological indices for the comparative analysis of microbial communities based on molecular datasets. FEMS Microbiol. Ecol. 2017, 93, fiw209. [Google Scholar] [CrossRef] [PubMed]
- Hurlbert, S. The nonconcept of species diversity: A critique and alternative parameters. Ecology 1971, 52, 577–586. [Google Scholar] [CrossRef] [PubMed]
- Ricotta, C. Through the jungle of biological diversity. Acta Biotheor. 2005, 53, 29–38. [Google Scholar] [CrossRef] [PubMed]
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- MacArthur, R. Patterns of species diversity. Biol. Rev. 1965, 40, 510–533. [Google Scholar] [CrossRef]
- Pielou, E. The measurement of diversity in different types of biological collections. J. Theor. Biol. 1966, 13, 131–144. [Google Scholar] [CrossRef]
- Baumgärtner, S. Measuring the dIversity of What? And for What Purpose? A Conceptual cOmparison of Ecological and Economic Measures of Biodiversity; Interdisciplinary Institute for Environmental Economics: Heidelberg, Germnay, 2004. [Google Scholar]
- Lambert, P.; Aronson, J. Inequality decomposition analysis and the Gini coefficient revisited. Econ. J. 1993, 103, 1221–1227. [Google Scholar] [CrossRef]
- Amroabady, B.; Renani, M.; Tayebi, S. Analysis of diversity in companies using entropy index. Int. J. Econ. Perspect. 2017, 11, 1133–1144. [Google Scholar]
- Mora Villarrubia, R.; Ruiz-Castillo, J. Entropy-Based Segregation Indices; Technical Report; Universidad Carlos III, Departamento de Economia: Madrid, Spain, 2010. [Google Scholar]
- Maignan, C.; Ottaviano, G.; Pinelli, D.; Rullani, F. Bio-Ecological Diversity vs. Socio-Economic Diversity: A Comparison of Existing Measures; Working Papers; Fondazione Eni Enrico Mattei: Milan, Italy, 2003; Volume 13. [Google Scholar]
- Ferrer, J.; Prats, C.; López, D. Individual-based modelling: An essential tool for microbiology. J. Biol. Phys. 2008, 34, 19–37. [Google Scholar] [CrossRef] [PubMed]
- Marcon, E. Mésures de la Biodiversité. Ph.D. Thesis, AgroParisTech, Paris, France, 2015. [Google Scholar]
- Ogunseitan, O. Microbial Diversity; Blackwell Science Ltd.: Oxford, UK, 2005. [Google Scholar]
- Bell, T.; Newman, J.; Silverman, B.; Turner, S.; Lilley, A. The contribution of species richness and composition to bacterial services. Nature 2005, 436, 1157–1160. [Google Scholar] [CrossRef] [PubMed]
- Grman, E.; Lau, J.; Schoolmaster, D.; Gross, K. Mechanisms contributing to stability in ecosystem function depend on the environmental context. Ecol. Lett. 2010, 13, 1400–1410. [Google Scholar] [CrossRef] [PubMed]
- Hooper, D.; Dukes, J. Overyielding among plant functional groups in a long-term experiment. Ecol. Lett. 2004, 7, 95–105. [Google Scholar] [CrossRef]
- Hillebrand, H.; Bennett, D.; Cadotte, M. Consequences of dominance: A review of evenness effects on local and regional ecosystem processes. Ecology 2008, 89, 1510–1520. [Google Scholar] [CrossRef] [PubMed]
- Wilsey, B.; Potvin, C. Biodiversity and ecosystem functioning: Importance of species evenness in an old field. Ecology 2000, 81, 887–892. [Google Scholar] [CrossRef]
- Lemieux, J.; Cusson, M. Effects of habitat-forming species richness, evenness, identity, and abundance on benthic intertidal community establishment and productivity. PLoS ONE 2014, 9, e109261. [Google Scholar] [CrossRef] [PubMed]
- Wittebolle, L.; Marzorati, M.; Clement, L.; Balloi, A.; Daffonchio, D.; Heylen, K.; De Vos, P.; Verstraete, W.; Boon, N. Initial community evenness favours functionality under selective stress. Nature 2009, 458, 623–626. [Google Scholar] [CrossRef] [PubMed]
- Smith, B.; Wilson, J. A consumer’s guide to evenness indices. Oikos 1996, 76, 70–82. [Google Scholar] [CrossRef]
- Eliazar, I.; Sokolov, I. Measuring statistical evenness: A panoramic overview. Phys. A Stat. Mech. Appl. 2012, 391, 1323–1353. [Google Scholar] [CrossRef]
- Ricotta, C. A recipe for unconventional evenness measures. Acta Biotheor. 2004, 52, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Ginebra, J.; Puig, X. On the measure and the estimation of evenness and diversity. Comput. Stat. Data Anal. 2010, 54, 2187–2201. [Google Scholar] [CrossRef]
- Jost, L. The relation between evenness and diversity. Diversity 2010, 2, 207–232. [Google Scholar] [CrossRef]
- Alatalo, R. Problems in the measurement of evenness in ecology. Oikos 1981, 37, 199–204. [Google Scholar] [CrossRef]
- Tuomisto, H. An updated consumer’s guide to evenness and related indices. Oikos 2012, 121, 1203–1218. [Google Scholar] [CrossRef]
- Kvalseth, T. Evenness indices once again: Critical analysis of properties. SpringerPlus 2015, 4, 232. [Google Scholar] [CrossRef] [PubMed]
- Leinster, T.; Cobbold, C. Measuring diversity: The importance of species similarity. Ecology 2012, 93, 477–489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hey, J. The mind of the species problem. Trends Ecol. Evol. 2001, 16, 326–329. [Google Scholar] [CrossRef]
- Stirling, A. A general framework for analysing diversity in science, technology and society. J. R. Soc. Interface 2007, 4, 707–719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hughes, A.; Inouye, B.; Johnson, M.; Underwood, N.; Vellend, M. Ecological consequences of genetic diversity. Ecol. Lett. 2008, 11, 609–623. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Botta-Dukát, Z. Rao’s quadratic entropy as a measure of functional diversity based on multiple traits. J. Veg. Sci. 2005, 16, 533–540. [Google Scholar] [CrossRef]
- Shimatani, K. On the measurement of species diversity incorporating species differences. Oikos 2001, 93, 135–147. [Google Scholar] [CrossRef]
- Pavoine, S.; Ollier, S.; Pontier, D. Measuring diversity from dissimilarities with Rao’s quadratic entropy: Are any dissimilarities suitable? Theor. Popul. Biol. 2005, 67, 231–239. [Google Scholar] [CrossRef] [PubMed]
- Hardy, O.; Senterre, B. Characterizing the phylogenetic structure of communities by an additive partitioning of phylogenetic diversity. J. Ecol. 2007, 95, 493–506. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On Measures of Entropy and Information. Proc. Fourth Berkeley Symp. Math. Stat. Prob. 1961, 1, 547–561. [Google Scholar]
- Davydov, D.; Weber, S. A simple characterization of the family of diversity indices. Econ. Lett. 2016, 147, 121–123. [Google Scholar] [CrossRef]
- Jost, L. Mismeasuring biological diversity: Response to Hoffmann and Hoffmann (2008). Ecol. Econ. 2009, 68, 925–928. [Google Scholar] [CrossRef]
- Patil, G.; Taillie, C. Diversity as a concept and its measurement. J. Am. Stat. Assoc. 1982, 77, 548–561. [Google Scholar] [CrossRef]
- Reardon, S.; Firebaugh, G. Measures of multigroup segregation. Sociol. Methodol. 2002, 32, 33–67. [Google Scholar] [CrossRef]
- Hoffmann, S. Generalized Distribution Based Diversity Measurement: Survey and Unification; Technical Report; Otto-von-Guericke University Magdeburg, Faculty of Economics and Management: Magdeburg, Germany, 2008. [Google Scholar]
- Solomon, D. Ecological Diversity in Theory; Chapter A Comparative Approach to Species Diversity; International Co-Operative Publishing House: Fairland, MA, USA, 1979; pp. 29–35. [Google Scholar]
- Hill, M. Diversity and evenness: A unifying notation and its consequences. Ecology 1973, 54, 427–432. [Google Scholar] [CrossRef]
- Tuomisto, H. A consistent terminology for quantifying species diversity? Yes, it does exist. Oecologia 2010, 164, 853–860. [Google Scholar] [CrossRef] [PubMed]
- Berger, W.; Parker, F. Diversity of planktonic foraminifera in deep-sea sediments. Science 1970, 168, 1345–1347. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Borcard, D.; Gillet, F.; Legendre, P. Numerical Ecology with R; Springer: New York, NY, USA, 2018. [Google Scholar]
- Keylock, C. Simpson diversity and the Shannon–Wiener index as special cases of a generalized entropy. Oikos 2005, 109, 203–207. [Google Scholar] [CrossRef]
- Simpson, E. Measurement of diversity. Nature 1949, 163, 688. [Google Scholar] [CrossRef]
- Jost, L.; Chao, A. Diversity Analysis; Taylor & Francis: Milton Keynes, UK, 2008. [Google Scholar]
- Pallmann, P.; Schaarschmidt, F.; Hothorn, L.; Fischer, C.; Nacke, H.; Priesnitz, K.; Schork, N. Assessing group differences in biodiversity by simultaneously testing a user-defined selection of diversity indices. Mol. Ecol. Resour. 2012, 12, 1068–1078. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hare, M.; Nunney, L.; Schwartz, M.; Ruzzante, D.; Burford, M.; Waples, R.; Ruegg, K.; Palstra, F. Understanding and estimating effective population size for practical application in marine species management. Conserv. Biol. 2011, 25, 438–449. [Google Scholar] [CrossRef] [PubMed]
- Doll, H.; Armitage, D.; Daly, R.; Emerson, J.; Goltsman, D.; Yelton, A.; Kerekes, J.; Firestone, M.; Potts, M. Utilizing novel diversity estimators to quantify multiple dimensions of microbial biodiversity across domains. BMC Microbiol. 2013, 13, 259. [Google Scholar] [CrossRef] [PubMed]
- Armitage, D.; Gallagher, K.; Youngblut, N.; Buckley, D.; Zinder, S. Millimeter-scale patterns of phylogenetic and trait diversity in a salt marsh microbial mat. Front. Microbiol. 2012, 3, 293. [Google Scholar] [CrossRef] [PubMed]
- Tucker, C.; Cadotte, M.; Carvalho, S.; Davies, T.; Ferrier, S.; Fritz, S.; Grenyer, R.; Helmus, M.; Jin, L.; Mooers, A.; Pavoine, S.; et al. A guide to phylogenetic metrics for conservation, community ecology and macroecology. Biol. Rev. 2016, 92, 698–715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Loreau, M. Biodiversity and ecosystem stability across scales in metacommunities. Ecol. Lett. 2016, 19, 510–518. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, S.; Rodrigues, J.; Ng, J.; Gentry, T. Hill number as a bacterial diversity measure framework with high-throughput sequence data. Sci. Rep. 2016, 6, 38263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buckland, S.; Yuan, Y.; Marcon, E. Measuring temporal trends in biodiversity. AStA Adv. Stat. Anal. 2017, 101, 461–474. [Google Scholar] [CrossRef] [Green Version]
- Lande, R. Statistics and partitioning of species diversity, and similarity among multiple communities. Oikos 1996, 76, 5–13. [Google Scholar] [CrossRef]
- Rao, C. Diversity: Its measurement, decomposition, apportionment and analysis. Sankhya Indian J. Stat. Ser. A 1982, 44, 1–22. [Google Scholar]
- Lamb, E.; Bayne, E.; Holloway, G.; Schieck, J.; Boutin, S.; Herbers, J.; Haughland, D. Indices for monitoring biodiversity change: Are some more effective than others? Ecol. Indic. 2009, 9, 432–444. [Google Scholar] [CrossRef]
- Magurran, A. Measuring Biological Diversity; Blackwell Science Ltd.: Oxford, UK, 2004. [Google Scholar]
- MacArthur, R. Fluctuations of animal populations and a measure of community stability. Ecology 1955, 36, 533–536. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Ricotta, C. On parametric evenness measures. J. Theor. Biol. 2003, 222, 189–197. [Google Scholar] [CrossRef]
- Tóthmérész, B. Comparison of different methods for diversity ordering. J. Veg. Sci. 1995, 6, 283–290. [Google Scholar] [CrossRef]
- Tuomisto, H. Commentary: Do we have a consistent terminology for species diversity? Yes, if we choose to use it. Oecologia 2011, 167, 903–911. [Google Scholar] [CrossRef]
- Suyari, H. On the most concise set of axioms and the uniqueness theorem for Tsallis entropy. J. Phys. A Math. Gen. 2002, 35, 10731. [Google Scholar] [CrossRef]
- Schmidt, T.; Matias Rodrigues, J.; Mering, C. Limits to robustness and reproducibility in the demarcation of operational taxonomic units—Supplementary Information. Environ. Microbiol. 2014, 17, 1689–1706. [Google Scholar] [CrossRef] [PubMed]
- Rousseau, R.; Van Hecke, P.; Nijssen, D.; Bogaert, J. The relationship between diversity profiles, evenness and species richness based on partial ordering. Environ. Ecol. Stat. 1999, 6, 211–223. [Google Scholar] [CrossRef]
- Turnbaugh, P.; Hamady, M.; Yatsunenko, T.; Cantarel, B.; Duncan, A.; Ley, R.; Sogin, M.; Jones, W.; Roe, B.; Affourtit, J.; et al. A core gut microbiome in obese and lean twins. Nature 2009, 457, 480–484. [Google Scholar] [CrossRef] [PubMed]
- Nopper, J.; Ranaivojaona, A.; Riemann, J.; Rödel, M.O.; Ganzhorn, J. One forest is not like another: The contribution of community-based natural resource management to reptile conservation in Madagascar. Trop. Conserv. Sci. 2017, 10. [Google Scholar] [CrossRef]
- Sánchez-Montes, G.; Ariño, A.; Vizmanos, J.; Wang, J.; Martínez-Solano, Í. Effects of sample size and full sibs on genetic diversity characterization: A case study of three syntopic Iberian pond-breeding amphibians. J. Hered. 2017, 108, 535–543. [Google Scholar] [CrossRef] [PubMed]
- Iacchei, M.; Butcher, E.; Portner, E.; Goetze, E. It’s about time: Insights into temporal genetic patterns in oceanic zooplankton from biodiversity indices. Limnol. Oceanogr. 2017, 62, 1836–1852. [Google Scholar] [CrossRef]
- Colwell, R. The Princeton Guide to Ecology; Chapter Biodiversity: Concepts, Patterns, and Measurement; Princeton University Press: Princeton, NJ, USA, 2009; pp. 257–263. [Google Scholar]
- Whittaker, R. Evolution and measurement of species diversity. Taxon 1972, 21, 213–251. [Google Scholar] [CrossRef]
- Veech, J.; Crist, T. Toward a unified view of diversity partitioning. Ecology 2010, 91, 1988–1992. [Google Scholar] [CrossRef] [PubMed]
- Chao, A.; Chiu, C.H.; Jost, L. Unifying species diversity, phylogenetic diversity, functional diversity, and related similarity and differentiation measures through Hill numbers. Annu. Rev. Ecol. Evol. Syst. 2014, 45, 297–324. [Google Scholar] [CrossRef]
- Anderson, M.; Crist, T.; Chase, J.; Vellend, M.; Inouye, B.; Freestone, A.; Sanders, N.; Cornell, H.; Comita, L.; Davies, K.; et al. Navigating the multiple meanings of β diversity: A roadmap for the practicing ecologist. Ecol. Lett. 2011, 14, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Tuomisto, H. A diversity of beta diversities: Straightening up a concept gone awry. Part 1. Defining beta diversity as a function of alpha and gamma diversity. Ecography 2010, 33, 2–22. [Google Scholar] [CrossRef]
- Chao, A.; Chiu, C.H.; Hsieh, T. Proposing a resolution to debates on diversity partitioning. Ecology 2012, 93, 2037–2051. [Google Scholar] [CrossRef] [PubMed]
- Reeve, R.; Leinster, T.; Cobbold, C.; Thompson, J.; Brummitt, N.; Mitchell, S.; Matthews, L. How to partition diversity. arXiv, 2014; arXiv:1404.6520. [Google Scholar]
- Jost, L. Partitioning diversity into independent alpha and beta components. Ecology 2007, 88, 2427–2439. [Google Scholar] [CrossRef] [PubMed]
- De Bello, F.; Lavergne, S.; Meynard, C.; Lepš, J.; Thuiller, W. The partitioning of diversity: Showing Theseus a way out of the labyrinth. J. Veg. Sci. 2010, 21, 992–1000. [Google Scholar] [CrossRef]
- Botta-Dukát, Z. The generalized replication principle and the partitioning of functional diversity into independent alpha and beta components. Ecography 2018, 41, 40–50. [Google Scholar] [CrossRef]
- Butturi-Gomes, D.; Petrere, M., Jr.; Giacomini, H.; Zocchi, S. Statistical performance of a multicomparison method for generalized species diversity indices under realistic empirical scenarios. Ecol. Indic. 2017, 72, 545–552. [Google Scholar] [CrossRef]
- Butturi-Gomes, D.; Junior, M.; Giacomini, H.; Junior, P. Computer intensive methods for controlling bias in a generalized species diversity index. Ecol. Indic. 2014, 37, 90–98. [Google Scholar] [CrossRef]
- Grabchak, M.; Marcon, E.; Lang, G.; Zhang, Z. The generalized Simpson’s entropy is a measure of biodiversity. PLoS ONE 2017, 12, e0173305. [Google Scholar] [CrossRef] [PubMed]
- Marcon, E. Practical Estimation of Diversity from Abundance Data; CCSD: Villeurbanne, France, 2015; pp. 1–29. [Google Scholar]
- Chao, A. Nonparametric estimation of the number of classes in a population. Scand. J. Stat. 1984, 11, 265–270. [Google Scholar]
- Chao, A. Estimating the population size for capture-recapture data with unequal catchability. Biometrics 1987, 43, 783–791. [Google Scholar] [CrossRef] [PubMed]
- Brose, U.; Martinez, N.; Williams, R. Estimating species richness: Sensitivity to sample coverage and insensitivity to spatial patterns. Ecology 2003, 84, 2364–2377. [Google Scholar] [CrossRef]
- Gotelli, N.; Colwell, R. Biological Diversity: Frontiers in Measurement and Assessment; Chapter Estimating Species Richness; Oxford University Press: Oxford, UK, 2011; pp. 39–54. [Google Scholar]
- Chao, A.; Shen, T.J. Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample. Environ. Ecol. Stat. 2003, 10, 429–443. [Google Scholar] [CrossRef]
- Chao, A.; Jost, L. Estimating diversity and entropy profiles via discovery rates of new species. Methods Ecol. Evol. 2015, 6, 873–882. [Google Scholar] [CrossRef] [Green Version]
- Haegeman, B.; Hamelin, J.; Moriarty, J.; Neal, P.; Dushoff, J.; Weitz, J. Robust estimation of microbial diversity in theory and in practice. ISME J. 2013, 7, 1092. [Google Scholar] [CrossRef] [PubMed]
- Marcon, E.; Zhang, Z.; Hérault, B. The Decomposition of Similarity-Based Diversity and Its Bias Correction; CCSD: Villeurbanne, France, 2014; pp. 1–12. [Google Scholar]
- Heip, C.; Herman, P.; Soetaert, K. Indices of diversity and evenness. Oceanis 1998, 24, 61–88. [Google Scholar]
- Chao, A.; Chiu, C.H.; Jost, L. Phylogenetic diversity measures based on Hill numbers. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2010, 365, 3599–3609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiu, C.H.; Chao, A. Distance-based functional diversity measures and their decomposition: A framework based on Hill numbers. PLoS ONE 2014, 9, e100014. [Google Scholar] [CrossRef] [PubMed]
- Schleuter, D.; Daufresne, M.; Massol, F.; Argillier, C. A user’s guide to functional diversity indices. Ecol. Monogr. 2010, 80, 469–484. [Google Scholar] [CrossRef]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daly, A.J.; Baetens, J.M.; De Baets, B. Ecological Diversity: Measuring the Unmeasurable. Mathematics 2018, 6, 119. https://doi.org/10.3390/math6070119
Daly AJ, Baetens JM, De Baets B. Ecological Diversity: Measuring the Unmeasurable. Mathematics. 2018; 6(7):119. https://doi.org/10.3390/math6070119
Chicago/Turabian StyleDaly, Aisling J., Jan M. Baetens, and Bernard De Baets. 2018. "Ecological Diversity: Measuring the Unmeasurable" Mathematics 6, no. 7: 119. https://doi.org/10.3390/math6070119
APA StyleDaly, A. J., Baetens, J. M., & De Baets, B. (2018). Ecological Diversity: Measuring the Unmeasurable. Mathematics, 6(7), 119. https://doi.org/10.3390/math6070119