1. Introduction
In this paper, we are interested in solving the linear response eigenvalue problem (LREP):
where
K and
M are
real symmetric positive definite matrices. Such a problem arises from studying the excitation energy of many particle systems in computational quantum chemistry and physics [
1,
2,
3]. It also known as the Bethe-Salpeter (BS) eigenvalue-problem [
4] or the random phase approximation (RPA) eigenvalue problem [
5]. There has immense past and recent work in developing efficient numerical algorithms and attractive theories for LREP [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15].
Since all the eigenvalues of
are real nonzero and appear in pairs
[
6], thus we order the eigenvalues in ascending order, i.e.,
In this paper, we focus on a small portion of the positive eigenvalues for LREP, i.e., , with and , and their corresponding eigenvectors. We only consider the real case, all the results can be easily applied to the complex case.
The weighted Golub-Kahan-Lanczos method (
wGKL) for LREP was introduced in [
16]. It produces recursively a much small projection
of
at
j-th iteration, where
is upper bidiagonal. Afterwards, the eigenpairs of
can be constructed by the singular value decomposition of
. The convergence analysis performs that running
k iterations of
wGKL is equivalently running
iterations of a weighted Lanczos algorithm for
[
16]. Actually,
can be also a lower bidiagonal matrix, and the same discussion can be taken place as in the case of
is upper bidiagonal. In the following, we only consider the upper bidiagonal case.
It is well known that the single-vector Lanczos method is widely used for searching a small number of extreme eigenvalues, and it may encounter very slow convergence when the wanted eigenvalues stay in a cluster [
17]. Instead, a block Lanczos method with a suitable block size is capable of computing a cluster of eigenvalues including multiple eigenvalues very quickly. Motivated by this idea, we are going to develop a block version of
wGKL in [
16] in order to find efficiently all or some positive eigenvalues within a cluster for LREP. Based on the standard block Lanczos convergence theory in [
17], the error bounds of approximation to an eigenvalue cluster, as well as their corresponding eigenspace are established to illustrate the advantage of our weighted block Golub-Kahan-Lanczos algorithm (
wbGKL).
As the increasing size of the Krylov subspace, the storage demands, computational costs, and numerical stability of a simple version of a block Lanczos method may be affected [
18]. Several kinds of efficiently restarting strategies to eliminate these effects are developed for the classic Lanczos method, such as, implicitly restart method [
19], thick restart method [
20]. In order to make our block method more practical, and using the special structure of LREP, we consider the thick restart strategy to our block method.
The rest of this paper is organized as follows.
Section 2 gives some necessary preliminaries for our later use. In
Section 3, the weighted block Golub-Kahan-Lanczos algorithm (
wbGKL) for LREP is presented, and its convergence analysis is discussed.
Section 4 proposed the thick restart weighted block Golub-Kahan-Lanczos algorithm (
wbGKL-TR). The numerical examples are tested in
Section 5 to illustrate the efficiency of our new algorithms. Finally, some conclusions are given in
Section 6.
Throughout this paper, is the set of all real matrices, , and . (or simply I if its dimension is clear from the context) is the identity matrix, and is an matrix of zero. The superscript “” denotes transpose. denotes the Frobenius norm of a matrix, and denotes the 2-norm of a matrix or a vector. For a matrix , denotes the rank of X, and denotes the column space of X; the submatrices and of X composed by the intersections of row i to row j and column k to column ℓ, respectively. For matrices or scalars , denotes the block diagonal matrix with the i-th diagonal block .
2. Preliminaries
For a symmetric positive definite matrix
, the
W-inner product is defined as following
If
, then we denote it by
, and call it with
x and
y are
W-orthogonal. The projector
is called the
W-orthogonal projector onto
if for any
,
For two subspaces
, and suppose
, if
and
are
W-orthonormal basis of
and
, respectively, i.e.,
and
for
with
are the singular values of
, then the
W-canonical angles
from
to
are defined by
If
, these angles can be said between
and
. Obviously,
. Set
Especially, if , X is a vector, there is only one W-canonical angle from to . In the following, we may use a matrix in one or both arguments of , i.e., with the understanding that it means the subspace spanned by the columns of the matrix argument.
The following two lemmas are important to our later analysis, and for proofs and more details, the reader is referred to [
12,
16].
Lemma 1. ([
12] Lemma 3.2).
Let and be two subspaces in with equal dimensional . Suppose . Then, for any set of the basis vectors in where , there is a set of linearly independent vectors in such that for , where is the W-orthogonal projector onto . Lemma 2. ([
16] Proposition 3.1).
The matrix has N position eigenvalues with . The corresponding right eigenvectors can be chosen K-orthonormal, and the corresponding left eigenvectors can be chosen M-orthonormal. In particular, for given , one can choose , and for given , , for . 4. Thick Restart
As the number of iterations increases, Algorithm 1 may encounter the dilemma that the amount of calculation and storage increases sharply and the numerical stability gradually weakens. In this section, we will apply the thick restart strategy [
20] to improve the algorithm. After running
n iterations, Algorithm 1 derives the following relations for LREP:
with
.
Recall the SVD (
2), let
and
be the first
columns of
and
, respectively, i.e.,
Thus it follows that
where
.
By using the approximate eigenvectors of
for thick restart, we post-multiply
and
to the Equation (
15), respectively, and get
From (
16), and let
,
,
,
,
,
, then (
17) can be rewritten as
and
.
Next,
and
will be generalized. Firstly, we compute
From the second equation in (
18), we know
. Do Cholesky decomposition
, and set
,
. Compute
, and let
we have
Secondly, from the above equation, we can compute
Again using (
19), it is easily got that
. Similarly, do Cholesky decomposition
, and let
,
. Compute
, and let
, we get
Continue the same procedure for
and
, we can obtain the new
M-orthonormal matrix
, the new
K-orthonormal matrix
, and the new matrix
, and relations
with
, and
Note that
is no longer a block bidiagonal matrix. Algorithm 2 is our thick-restart weighted block Golub-Kahan-Lanczos algorithm for LREP.
Remark 6. Actually, from the construction of , we can know the procedure for getting and is the same as applying Algorithm 1 to for iterations, thus we use Algorithm 1 directly in restartingStep 2of the following Algorithm 2.
| Algorithm 2: wbGKL-TR |
1. Given an initial guess satisfying , a tolerance , an integer k that the k blocks approximate eigenvectors we want to add to the solving subspace, an integer n the block dimension of solving subspace, as well as the desired number of eigenpairs;
2. Apply Algorithm 1 from the current point to generate the rest of , , and . If it is the first cycle, the current point is , else ;
3. Compute an SVD of as in (2), select wanted singular values , and their associated left singular vectors and right singular vectors . Form the approximate eigenpairs for , if the stopping criterion is satisfied, then stop, else continue;
4. Generate new , and :
Compute , , , , , ;
Compute , do Cholesky decomposition , set , , ;
Compute , do Cholesky decomposition , set , , ;
Let , , , and go to Step 2. |
Remark 7. InStep 3, we compute the harmonic Ritz pairs after n iterations. In practice, we do the computation for each iterations . When restarting, the information chosen to add to the solving subspaces are the wanted singular values of with their corresponding left and right singular vectors. Actually, we use MATLAB command “sort” to choose the smallest ones or the largest ones, and which singular values to choose depends on the desired eigenvalues of .
In the end of this section, we list the computational costs in a generic cycle of four algorithms, which are weighted block Golub-Kahan-Lanczos algorithm, thick-restart weighted block Golub-Kahan-Lanczos algorithm, block Lanczos algorithm [
12], and thick-restart block Lanczos algorithm [
12], and denoted by
wbGKL,
wbGKL-TR,
BLan, and
BLan-TR, respectively. The detail pseudocodes of
BLan and
BLan-TR are be found in [
12].
The comparisons are presented in
Table 1 and
Table 2. Here, we denote “block vector” a
rectangular matrix, denote “mvb” the product number of a
matrix and a block vector. “dpb” denotes the dot product number of two block vectors
X and
Y, i.e.,
. “saxpyb” denotes the number of adding two block vectors or multiplying a block vector to a
small matrix. “Ep(
)(with sorting)” means the number of
size eigenvalue problem with sorting eigenvalues and their corresponding eigenvectors in one cycle. Similarly, “Sp(
)” denotes the number of
size singular value decomposition in one cycle. Because
wbGKL and
BLan are non-restart algorithms, we just count the first
n Lanczos iterations.
5. Numerical Examples
In this section, two numerical experiments are carried out by using MATLAB 8.4 (R2014b) on a laptop with an Intel Core i5-6200U CPU 2.3 GHz memory 8 GB under the Windows 10 operating system.
Example 1. In this example, we check the bounds established in Theorem 1 and 2. For simplicity, we take , the number of weighted block Golub-Kahan-Lanczos steps , as diagonal matrix , whereand , , , , . There are three positive eigenvalue clusters: , , or . Obviously, . We seek two groups of the approximate eigenpairs, the first is related to the first cluster, the second is related to the last cluster, i.e.,
approximate
, and
approximate
. In order to see the affect that generated from
to the upper bounds of the approximate eigenpairs errors in weighted block Golub-Kahan-Lanczos method for LREP, we change the parameter
to overmaster the tightness among eigenvalues within
and
. First, we choose the same matrix
as in [
12,
17], i.e.,
Obviously,
and
. Since
K symmetric positive definite, thus do Cholesky decomposition
, let
, hence,
satisfies (
5), i.e.,
is singular. We take
, then
Z satisfies (
6). We execute the weighted block Golub-Kahan-Lanczos method with full re-orthogonalization for LREP in MATLAB, and check the bounds in (
7), (
8), (
13), and (
14). Since the approximate eigenvalues are
and
, thus
,
, and we measure the following two groups of errors:
and
Actually,
and
are upper bounds of
and
, and
and
are upper bounds of
and
.
Table 3 and
Table 4 report the results of
,
,
with the parameter
goes to 0. From the two tables, we can see that the bounds for the eigenvalues lie in a cluster and their corresponding eigenvectors are sharp, and they are not sensitive to
when
goes to 0.
Example 2. In this example, we are going to test the effectiveness of our weighted block Golub-Kahan-Lanczos algorithms. Four algorithms are tested, i.e.,wbGKL,wbGKL-TR,BLan, andBLan-TR. We choose 3 test problems used in [12,13], which are listed in Table 5. All the matrices K and M in the problems are symmetric positive definite. Specifically, Test 1 and Test 2, which are derived by the turboTDDFT command in QUANTUM ESPRESSO [22], are from the linear response research for Na2 and silane (SiH4) compound, respectively. The matrices K and M in Test 3 are from the University of Florida Sparse Matrix Collection [23], where the order of K is , and M is the leading principal submatrix of . We aim to compute the smallest 5 positive eigenvalues and the largest 5 eigenvalues, i.e.,
for
, together with their associated eigenvectors. The initial guess is chosen as
with block size
, where
is the MATLAB command. The same as in Example 1, since
K is symmetric positive definite, thus do Cholesky decomposition
, let
, hence,
satisfies
. In
wbGKL-TR and
BLan-TR, we select
,
, i.e., the restart will occur once the dimension of the solving subspace is larger than 90, and the information of 60 Ritz vectors are kept. For
wbGKL and
BLan, because there is no restart, then we compute the approximate eigenpairs when the Lanczos iterations equals to
,
, hence, the Lanczos iterations are as the same amount as in
wbGKL-TR and
BLan-TR. The following relative eigenvalue error and relative residual 1-norm for each 10 approximate eigenpairs are calculated:
where the “exact” eigenvalues
are calculated by the MATLAB code
. The calculated approximate eigenpair
is regarded as converged if
.
Table 6 and
Table 7 give the number of the Lanczos iterations (denote by
) and the CPU time in seconds (denote by
) for the four algorithms, and
Table 6 is for the smallest 5 positive eigenvalues,
Table 7 is for the largest 5 eigenvalues. From
Table 6, one can see that, no matter the smallest or the largest eigenvalues, the iteration number of the four algorithms are competitive, but
wbGKL and
wbGKL-TR cost significant less time than
BLan and
BLan-TR, especially,
wbGKL-TR consumes the least amount of time. Because
BLan and
BLan-TR need to compute the eigenvalues of
, which is a nonsymmetric matrix, thus the two algorithms slower than
wbGKL and
wbGKL-TR. Due to the saving during the orthogonalization procedure and solving a much smaller
,
wbGKL-TR is the faster algorithm.
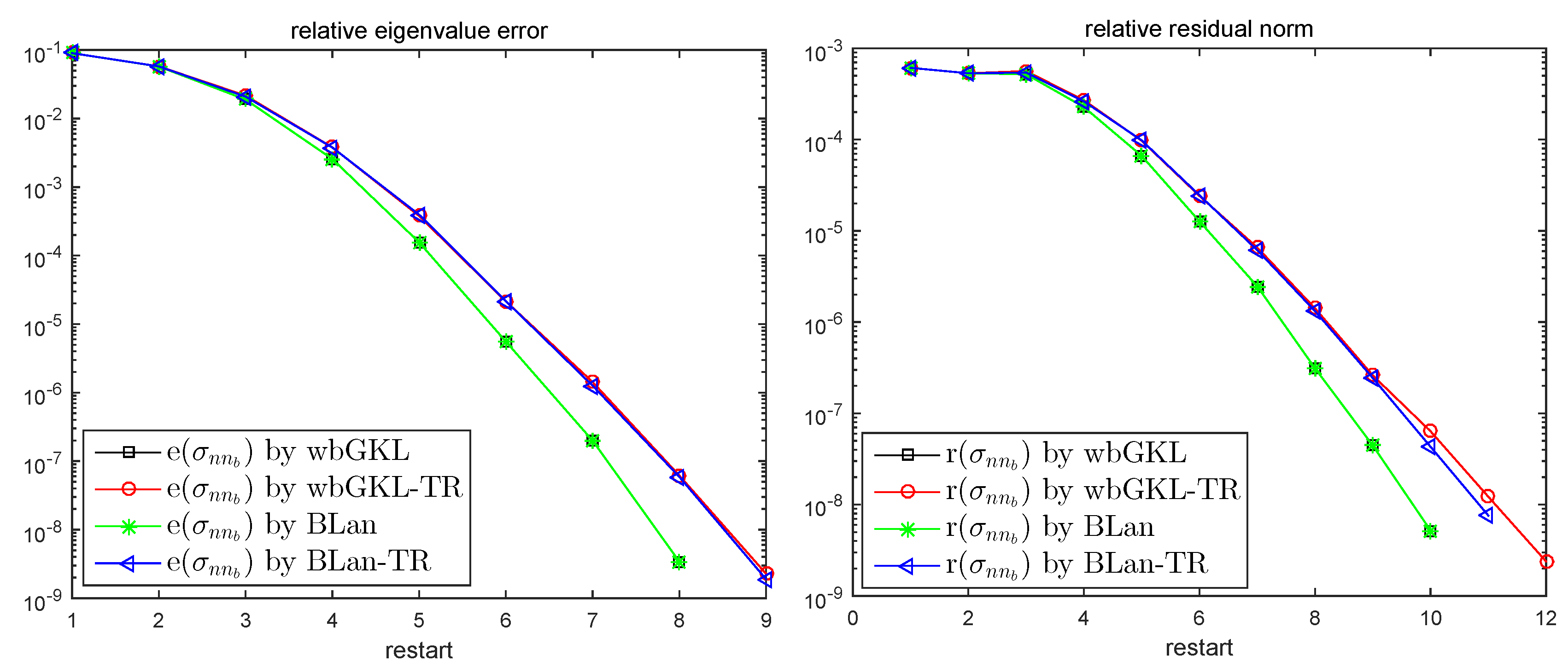
The accuracy of the last two approximate eigenpairs in Test 1 are shown in
Figure 1. From the figure, we can see that, for the last two eigenpairs,
wbGKL and
BLan require almost the same iterations to obtain the same accuracy, and the case of
wbGKL-TR and
BLan-TR also need almost the same iterations, which are one or two more restarts than
wbGKL and
BLan. On one hand, without solving a nonsymmetric eigenproblem,
wbGKL and
wbGKL-TR can save much more time than
BLan and
BLan-TR. On the other hand, since the dimension of the solving subspace for
wbGKL-TR is bounded by
, the savings in the process of orthogonalization and a much smaller singular value decomposition problem is sufficient to cover the additional restart steps.








{kind=link}