Long Term Memory Assistance for Evolutionary Algorithms




Abstract
:1. Introduction
- estimation of the cost (memory and CPU time usage) for duplicate identification when solutions are represented as a vector of real numbers,
- estimation of how many fitness evaluations can be saved by not re-evaluating existing solutions for a few selected EAs and problems,
- demonstrating how we can “attach” long term memory in a uniform way to existing EAs and provide a general solution for this topic.
2. Related Work
3. Memory
3.1. How Much Memory Do We Need?
- Only memory needed to store all individuals (populations over whole generations) is computed, although different EAs need extra memory for additional computations. This algorithm specific memory usage is not taken into account in our work.
- Only single-objective continuous optimization problems have been studied, where a point in a search space (genotype) is represented as a vector x of length n, , and fitness (phenotype) . To represent a real value ℜ, often eight bytes of memory are used (e.g., Java). Therefore, bytes are needed for one member of a population and its fitness value. A different memory consumption is needed in the case of discrete optimization, where the representation of a population member is problem dependent. In the case of multi-objective optimization, a solution (kth objectives) and more memory are needed to store a fitness value.
- The stopping criteria determine how many solutions are going to be generated. The fixed-cost (vertical) and the fixed-target (horizontal) approaches were identified in [47]. In the fixed-cost approach, solutions are generated until we reach a pre-defined number of iterations, or pre-defined number of fitness evaluations (), or pre-defined CPU time. In the fixed-target approach, solutions are generated until a (sub-)optimal solution is found. Some hybrid stopping criteria, blending vertical and horizontal approaches, have also been employed in EAs. Among the aforementioned approaches, it is often unknown how many solutions will be generated (e.g., based on CPU time or based on the maximum number of iterations when some extra local search is also included). Hence, in this study, is used as a stopping condition. It indicates directly the number of generated solutions.
3.2. How Much Can We Profit?
- is the number of duplicates before an optimum is found in one independent run.
- is the number of all duplicates in one independent run.
- How many duplicate individuals are generated during the optimization process? To answer this question we have to count all duplicate individuals based on precision , as well as how many duplicate individuals are found before the global optimum is reached based on precision .
- How much CPU time can be gained by not evaluating duplicate individuals (speedup)?
- How can convergence be improved by replacing duplicate individuals with new solutions?
4. Implementation
5. Experiment
- analysis of duplicate individuals’ occurrences on three simple, but well known problems, to gain a first insight into the topic,
- duplicate analysis on CEC-2015 benchmark problems, and
- duplicate analysis on a real-world problem.
5.1. Experiment I: The First Insight
- and = 10,000,
- and = 30,000, and
- and = 100,000.
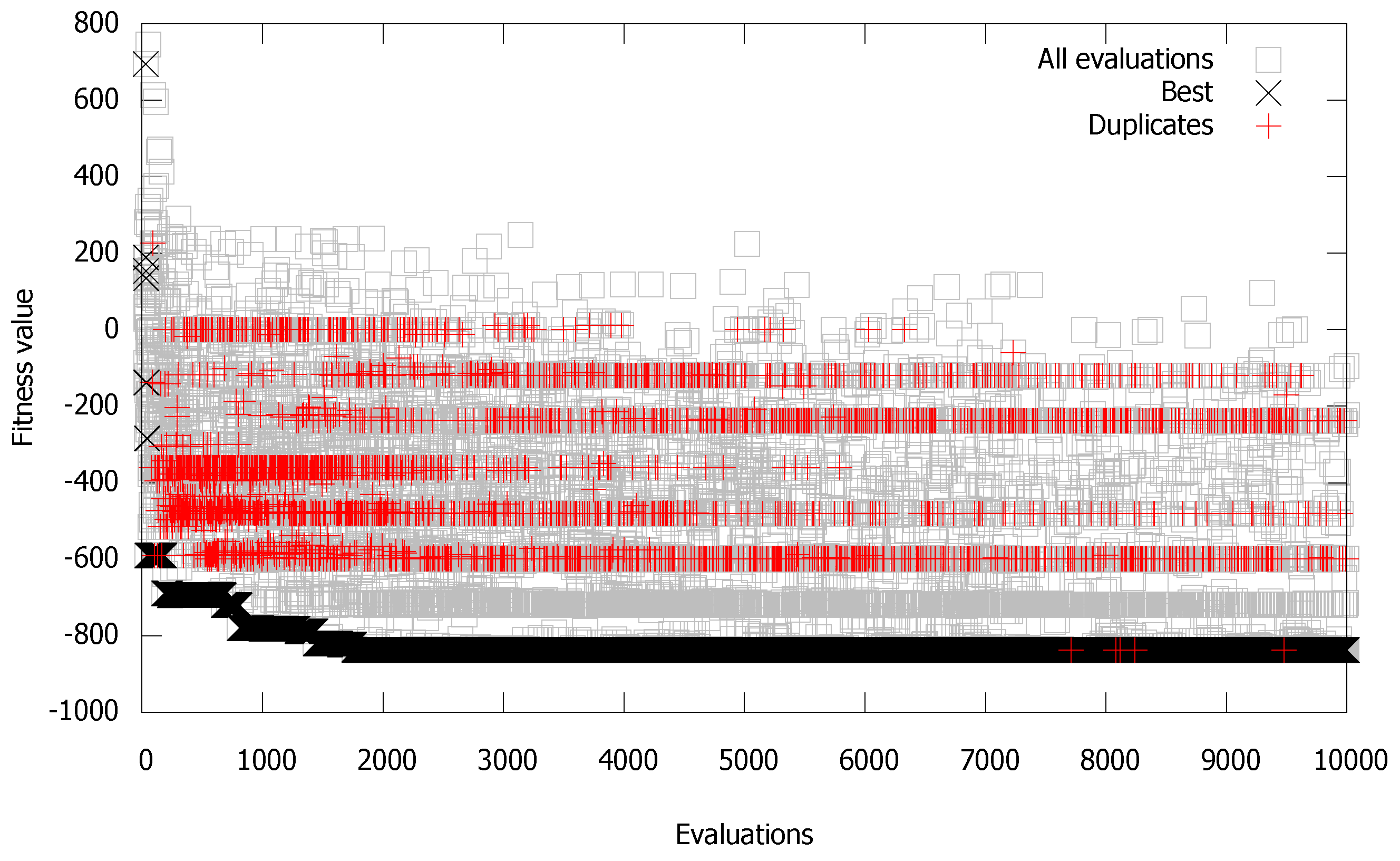
5.1.1. Sphere Problem
- the most duplicates are generated at the global optimum (after the global optimum is obtained).
- the numbers of and will decrease with higher precision (from 3 to 6 and 9).
5.1.2. Ackley Problem
5.1.3. Schwefel 2.26 Problem
5.2. Experiment II: CEC-2015 Benchmark
5.2.1. Scenario
5.2.2. Scenario
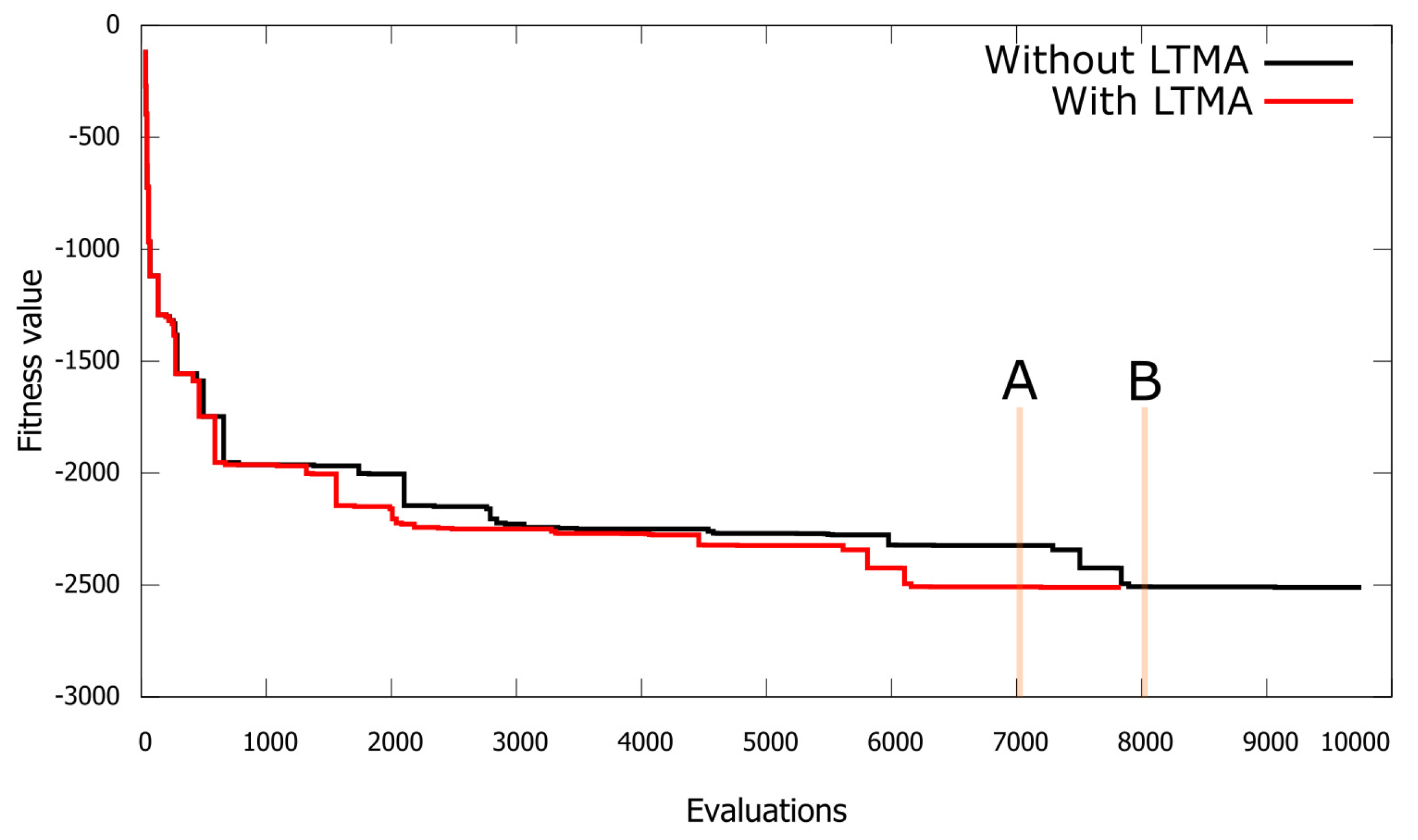
5.3. Experiment III: Real-World Problem
6. Conclusions
- For identifying duplicate individuals (re-visited solutions), it is not enough to use a short term memory (current population). The experiments showed that between 50% and 90% of duplicates would not be discovered without long term memory (all generated solutions in the whole evolutionary process).
- Current achievements in hardware allowed us to store all solutions (phenotype and genotype) in the computer’s RAM, where we can identify duplicate individuals easily.
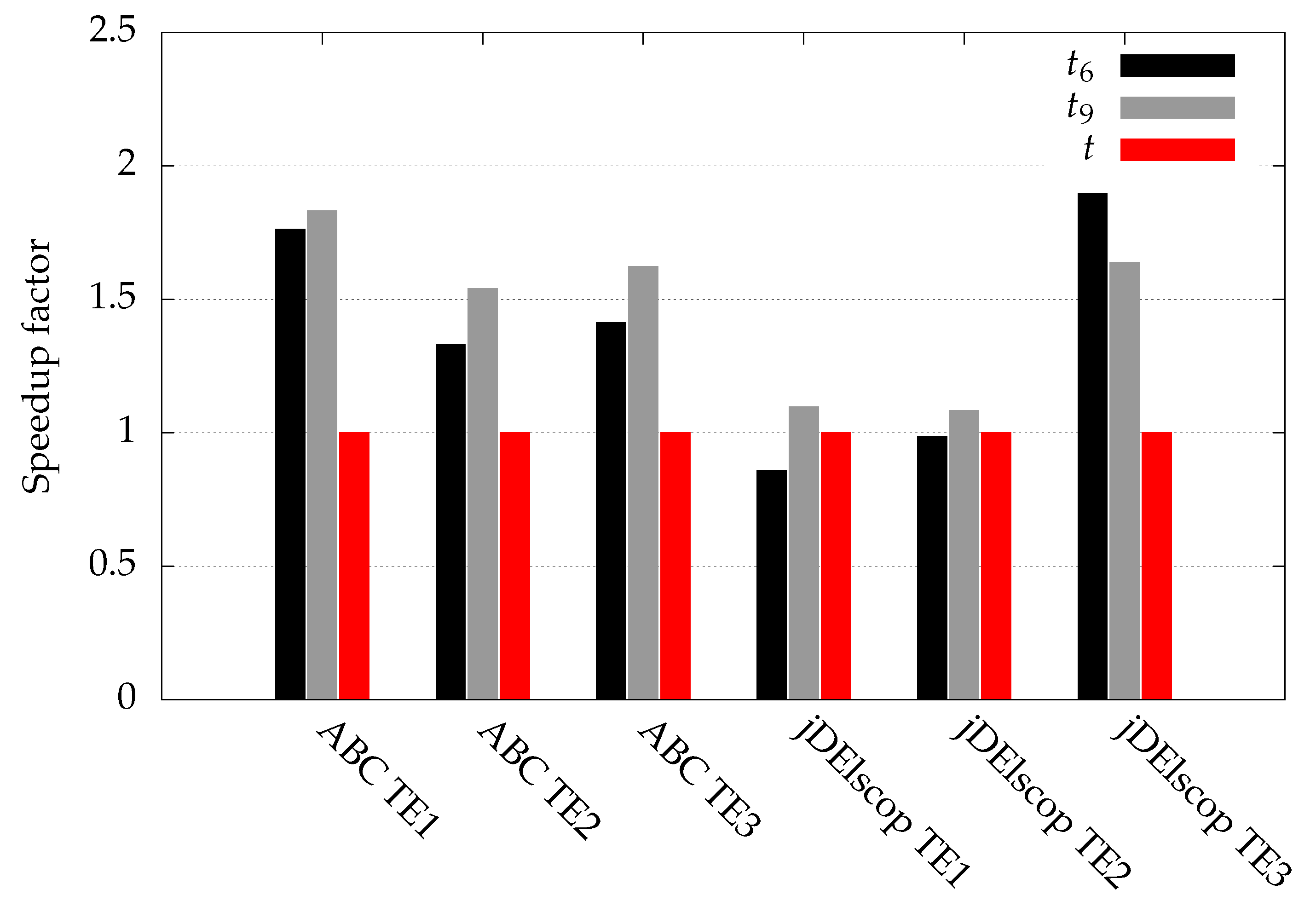
- A speedup of or more can be achieved for hard real-world problems where fitness evaluations are costly, simply by not re-evaluating duplicates (when at least of duplicates are generated). In the case of the soil model problem, ABC generated around duplicate individuals, and, with the proposed LTMA, a speedup of was achieved.
- Better convergence can be achieved when duplicate individuals are replaced with non-revisited individuals. In such a manner, the search space could be explored and exploited better.
- A long term memory can be attached in a uniform way to existing EAs.
Author Contributions
Funding
Conflicts of Interest
References
- Eiben, A.G.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Heidelberg, Germany, 2015. [Google Scholar]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Venkata Rao, R.; Savsani, V.; Vakharia, D.P. Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large scale problems. Inf. Sci. 2012, 183, 1–15. [Google Scholar]
- Sörensen, K. Metaheuristics—The metaphor exposed. Int. Trans. Oper. Res. 2015, 22, 3–18. [Google Scholar] [CrossRef]
- Lobo, F.G.; Goldberg, D.E. The parameter-less genetic algorithm in practice. Inf. Sci. 2004, 167, 217–232. [Google Scholar] [CrossRef]
- Eiben, A.; Smit, S. Parameter tuning for configuring and analyzing evolutionary algorithms. Swarm Evol. Comput. 2011, 1, 19–31. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef]
- Karafotias, G.; Hoogendoorn, M.; Eiben, A.E. Parameter Control in Evolutionary Algorithms: Trends and Challenges. IEEE Trans. Evol. Comput. 2015, 19, 167–187. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and Exploitation in Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2013, 45, 35. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, L. A Note on Teaching-learning-based Optimization Algorithm. Inf. Sci. 2012, 212, 79–93. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, L.; Mernik, M. Is a comparison of results meaningful from the inexact replications of computational experiments? Soft Comput. 2016, 20, 223–235. [Google Scholar] [CrossRef]
- Mernik, M.; Liu, S.H.; Karaboga, D.; Črepinšek, M. On clarifying misconceptions when comparing variants of the Artificial Bee Colony Algorithm by offering a new implementation. Inf. Sci. 2015, 291, 115–127. [Google Scholar] [CrossRef]
- Veček, N.; Liu, S.H.; Črepinšek, M.; Mernik, M. On the importance of the artificial bee colony control parameter ‘Limit’. Inf. Technol. Control 2017, 46, 566–604. [Google Scholar] [CrossRef]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer: Heidelberg, Germany, 1999. [Google Scholar]
- Coello Coello, C.A. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 2006, 1, 28–36. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; TIK Report 103; Computer Engineering and Networks Laboratory, Swiss Federal Institute of Technology (ETH): Zurich, Switzerland, 2001. [Google Scholar]
- Knowles, J.D.; Corne, D.W. Approximating the Nondominated Front Using the Pareto Archived Evolution Strategy. Evol. Comput. 2000, 8, 149–172. [Google Scholar] [CrossRef]
- Cai, X.; Li, Y.; Fan, Z.; Zhang, Q. An External Archive Guided Multiobjective Evolutionary Algorithm Based on Decomposition for Combinatorial Optimization. IEEE Trans. Evol. Comput. 2015, 19, 508–523. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach, Part I: Solving Problems With Box Constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution With Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for Differential Evolution. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar]
- Branke, J. Memory enhanced evolutionary algorithms for changing optimization problems. In Proceedings of the 1999 Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1875–1882. [Google Scholar]
- Yang, S.; Ong, Y.S.; Jin, Y. (Eds.) Evolutionary Computation in Dynamic and Uncertain Environments; Springer: Heidelberg, Germany, 2007. [Google Scholar]
- Leong, W.; Yen, G.G. PSO-Based Multiobjective Optimization With Dynamic Population Size and Adaptive Local Archives. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 38, 1270–1293. [Google Scholar] [CrossRef]
- Yang, S. Genetic Algorithms with Memory-and Elitism-based Immigrants in Dynamic Environments. Evol. Comput. 2008, 16, 385–416. [Google Scholar] [CrossRef]
- Yuen, S.Y.; Chow, C.K. A Genetic Algorithm That Adaptively Mutates and Never Revisits. IEEE Trans. Evol. Comput. 2009, 13, 454–472. [Google Scholar] [CrossRef]
- Chow, C.K.; Yuen, S.Y. An Evolutionary Algorithm that Makes Decision based on the Entire Previous Search History. IEEE Trans. Evol. Comput. 2011, 15, 741–769. [Google Scholar] [CrossRef]
- Lou, Y.; Yuen, S.Y. Non-revisiting genetic algorithm with adaptive mutation using constant memory. Memet. Comput. 2016, 8, 189–210. [Google Scholar] [CrossRef]
- Leung, S.W.; Yuent, S.Y.; Chow, C.K. Parameter control system of evolutionary algorithm that is aided by the entire search history. Appl. Soft Comput. 2012, 12, 3063–3078. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Z. An Artificial Bee Colony Algorithm with History-Driven Scout Bees Phase. In Advances in Swarm and Computational Intelligence. ICSI 2015. Lecture Notes in Computer Science; Springer: Heidelberg, Germany, 2015; Volume 9140, pp. 239–246. [Google Scholar]
- Zabihi, F.; Nasiri, B. A Novel History-driven Artificial Bee Colony Algorithm for Data Clustering. Appl. Soft Comput. 2018, 71, 226–241. [Google Scholar] [CrossRef]
- Nasiri, B.; Meybodi, M.; Ebadzadeh, M. History-driven firefly algorithm for optimisation in dynamic and uncertain environments. Appl. Soft Comput. 2016, 172, 356–370. [Google Scholar]
- Črepinšek, M.; Mernik, M.; Liu, S.H. Analysis of Exploration and Exploitation in Evolutionary Algorithms by Ancestry Trees. Int. J. Innov. Comput. Appl. 2011, 3, 11–19. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional Long Short-Term Memory Network with a Conditional Random Field Layer for Uyghur Part-Of-Speech Tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, K.; Jia, S.; Lin, W.; Hou, X.; Liu, B.; Qiu, G. Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition. Remote Sens. 2018, 10, 887. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Li, C.; Xie, X.; Zhang, G. Long-Short-Term Memory Network Based Hybrid Model for Short-Term Electrical Load Forecasting. Information 2018, 9, 165. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Lu, N.; Wang, S.; Cheng, Y.; Jiang, B. Dynamic Long Short-Term Memory Neural-Network- Based Indirect Remaining-Useful-Life Prognosis for Satellite Lithium-Ion Battery. Appl. Sci. 2018, 8, 2078. [Google Scholar] [CrossRef] [Green Version]
- Chung, H.; Shin, K.S. Genetic Algorithm-Optimized Long Short-Term Memory Network for Stock Market Prediction. Sustainability 2018, 10, 3765. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N.; Auger, A.; Finck, S.; Ros, R. Real-Parameter Black-Box Optimization Benchmarking: Experimental Setup; Technical Report; Institut National de Recherche en Informatique et en Automatique (INRIA): Rapports de Recherche, France, 2013. [Google Scholar]
- Dageförde, J.C.; Kuchen, H. A compiler and virtual machine for constraint-logic object-oriented programming with Muli. J. Comput. Lang. 2019, 53, 63–78. [Google Scholar] [CrossRef]
- Ugawa, T.; Iwasaki, H.; Kataoka, T. eJSTK: Building JavaScript virtual machines with customized datatypes for embedded systems. J. Comput. Lang. 2019, 51, 261–279. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Zaefferer, M. Model-based methods for continuous and discrete global optimization. Appl. Soft Comput. 2017, 55, 154–167. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Cai, X.; Gao, L. Ensemble of surrogates assisted particle swarm optimization of medium scale expensive problems. Appl. Soft Comput. 2019, 74, 291–305. [Google Scholar] [CrossRef]
- Song, H.J.; Park, S.B. An adapted surrogate kernel for classification under covariate shift. Appl. Soft Comput. 2018, 69, 435–442. [Google Scholar] [CrossRef]
- De Falco, I.; Della Cioppa, A.; Trunfio, G.A. Investigating surrogate-assisted cooperative coevolution for large-Scale global optimization. Inf. Sci. 2019, 482, 1–26. [Google Scholar] [CrossRef]
- EARS—Evolutionary Algorithms Rating System (Github). 2016. Available online: https://github.com/UM-LPM/EARS (accessed on 6 September 2019).
- EvoSuite: Automatic Test Suite Generation for Java. 2018. Available online: https://github.com/EvoSuite/evosuite (accessed on 6 September 2019).
- MOEA Framework: A Free and Open Source Java Framework for Mulitiobjective Optimization. 2018. Available online: http://moeaframework.org (accessed on 6 September 2019).
- Veček, N.; Mernik, M.; Črepinšek, M. A chess rating system for evolutionary algorithms: A new method for the comparison and ranking of evolutionary algorithms. Inf. Sci. 2014, 277, 656–679. [Google Scholar] [CrossRef]
- Luan, F.; Cai, Z.; Wu, S.; Liu, S.Q.S.; He, Y. Optimizing the Low-Carbon Flexible Job Shop Scheduling Problem with Discrete Whale Optimization Algorithm. Mathematics 2019, 7, 688. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; An, H.; Gao, X. The Importance of Transfer Function in Solving Set-Union Knapsack Problem Based on Discrete Moth Search Algorithm. Mathematics 2019, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Brest, J.; Sepesy Maučec, M. Self-adaptive differential evolution algorithm using population size reduction and three strategies. Soft Comput. 2011, 15, 2157–2174. [Google Scholar] [CrossRef]
- Matsumoto, M.; Nishimura, T. Mersenne Twister: A 623-dimensionally Equidistributed Uniform Pseudo-random Number Generator. ACM Trans. Model. Comput. Simul. 1998, 8, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Qu, B.; Liang, J.; Wang, Z.; Chen, Q.; Suganthan, P. Novel benchmark functions for continuous multimodal optimization with comparative results. Swarm Evol. Comput. 2016, 26, 23–34. [Google Scholar] [CrossRef]
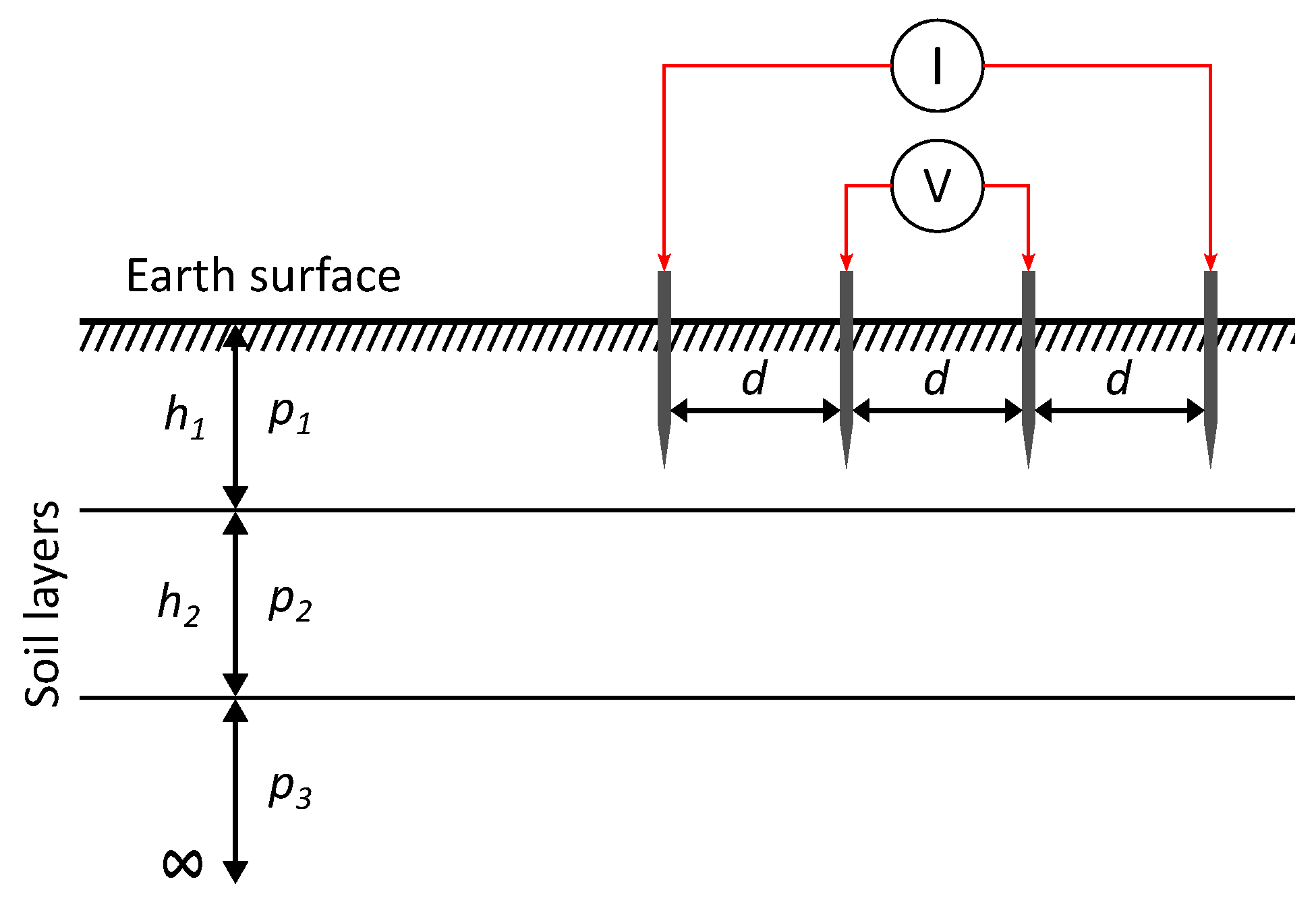
- Gonos, I.F.; Stathopulos, I.A. Estimation of multilayer soil parameters using genetic algorithms. IEEE Trans. Power Deliv. 2005, 20, 100–106. [Google Scholar] [CrossRef]
- Jesenik, M.; Mernik, M.; Črepinšek, M.; Ravber, M.; Trlep, M. Searching for soil models’ parameters using metaheuristics. Appl. Soft Comput. 2018, 69, 131–148. [Google Scholar] [CrossRef]
- Southey, R.D.; Siahrang, M.; Fortin, S.; Dawalibi, F.P. Using fall-of-potential measurements to improve deep soil resistivity estimates. IEEE Trans. Ind. Appl. 2015, 51, 5023–5029. [Google Scholar] [CrossRef]
- Yang, H.; Yuan, J.; Zong, W. Determination of three-layer earth model from Wenner four-probe test data. IEEE Trans. Magn. 2001, 37, 3684–3687. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | MFES | Bytes | MB |
|---|---|---|---|
| 2 | 10,000 | 240,000 | 0.2 |
| 10 | 30,000 | 2,640,000 | 2 |
| 30 | 30,000 | 7,440,000 | 7 |
| 100 | 1,000,000 | 808,000,000 | 770 |
| 200 | 1,000,000 | 1,608,000,000 | 1533 |
| 1000 | 1,000,000 | 8,008,000,000 | 7637 |
| Release Year | OS | Recommended RAM |
|---|---|---|
| 1981 | MS DOS® | 64 kB |
| 1987 | MS DOS 3.3® | 512 kB |
| 1995 | Windows 95® | 16 MB |
| 1996 | Windows NT® | 32 MB |
| 1998 | Windows 98® | 32 MB |
| 2000 | Windows 2000® | 64 MB |
| 2001 | Windows XP® | 128 MB |
| 2006 | Windows Vista® | 512 MB |
| 2010 | Linux Ubuntu 10 | 1 GB |
| 2012 | Windows 8® | 1 GB |
| 2015 | Windows 10® | 2 GB |
| Speedup 10% | Speedup 20% | Speedup 30% | Speedup 40% | Speedup 90% | Speedup 95% | ||
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.526 | 0.556 | 0.588 | 0.625 | 0.909 | 0.952 |
| 10 | 1 | 1.000 | 1.111 | 1.250 | 1.429 | 5.000 | 6.667 |
| 100 | 1 | 1.099 | 1.235 | 1.408 | 1.639 | 9.091 | 16.667 |
| 1000 | 1 | 1.110 | 1.248 | 1.427 | 1.664 | 9.901 | 19.608 |
| 10,000 | 1 | 1.111 | 1.250 | 1.428 | 1.666 | 9.990 | 19.960 |
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 100 | ||||||
| GWO | 2 | 10,000 | 100 | ||||||
| GOA | 2 | 10,000 | 100 | ||||||
| ABC | 10 | 30,000 | 11,698.2 | 10,228.5 | 100 | ||||
| jDElscop | 10 | 30,000 | 13,805.4 | 11,140.6 | 100 | ||||
| TLBO | 10 | 30,000 | 100 | ||||||
| GWO | 10 | 30,000 | 28,576.7 | 27,898.6 | 27,129.9 | 100 | |||
| GOA | 10 | 30,000 | 100 | ||||||
| ABC | 30 | 100,000 | 39,304.5 | 38,560.1 | 100 | ||||
| jDElscop | 30 | 100,000 | 48,036.5 | 43,055.4 | 37,904.8 | 100 | |||
| TLBO | 30 | 100,000 | 100 | ||||||
| GWO | 30 | 100,000 | 96,938.2 | 95,218.2 | 93,736.9 | 100 | |||
| GOA | 30 | 100,000 | 0 |
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 100 | ||||||
| GWO | 2 | 10,000 | 100 | ||||||
| GOA | 2 | 10,000 | 96 | ||||||
| ABC | 10 | 30,000 | 11,703.2 | 100 | |||||
| jDElscop | 10 | 30,000 | 14,116.5 | 11,528.2 | 100 | ||||
| TLBO | 10 | 30,000 | 100 | ||||||
| GWO | 10 | 30,000 | 28,751.1 | 27,977.6 | 27,273.7 | 100 | |||
| GOA | 10 | 30,000 | 4 | ||||||
| ABC | 30 | 100,000 | 40,259.1 | 32,573.8 | 12,076.3 | 100 | |||
| jDElscop | 30 | 100,000 | 48,279.1 | 43,431.3 | 38,226.1 | 100 | |||
| TLBO | 30 | 100,000 | 100 | ||||||
| GWO | 30 | 100,000 | 97,123.6 | 95,477.3 | 93,873.4 | 100 | |||
| GOA | 30 | 100,000 | 0 |
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 90 | ||||||
| GWO | 2 | 10,000 | 10 | ||||||
| GOA | 2 | 10,000 | 60 | ||||||
| ABC | 10 | 30,000 | 48 | ||||||
| jDElscop | 10 | 30,000 | 100 | ||||||
| TLBO | 10 | 30,000 | 0 | ||||||
| GWO | 10 | 30,000 | 0 | ||||||
| GOA | 10 | 30,000 | 0 | ||||||
| ABC | 30 | 100,000 | 18,168.4 | 18,168.4 | 0 | ||||
| jDElscop | 30 | 100,000 | 24,746.7 | 100 | |||||
| TLBO | 30 | 100,000 | 0 | ||||||
| GWO | 30 | 100,000 | 0 | ||||||
| GOA | 30 | 100,000 | 0 |
| Pro. | Fit | t | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 26,711.8 | 26,711.8 | 13,710.4 | 26,574.3 | 26,574.3 | 12,868.0 | 12,971.5 | ||||
| 23,124.3 | 23,124.3 | 23,058.7 | 23,058.7 | |||||||
| 16,360.0 | 19,455.2 | |||||||||
| 22,551.8 | 22,551.8 | 22,698.8 | 22,698.8 | |||||||
| 21,728.5 | 21,728.5 | 21,908.3 | 21,908.3 | |||||||
| 22,954.7 | 22,954.7 | 11,114.8 ±11,329.6 | 22,803.2 | 22,803.2 | 10,484.4 | 11,546.5 |
| Pro. | Fit | t | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 15,142.5 | ||||||||||
| 16,487.8 | 12,137.0 | |||||||||
| 20,848.0 | ||||||||||
| 13,453.9 | 13,500.5 | 12,857.5 | 12,892.5 | |||||||
| Pro. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 26% | 25% | |||||||||
| 36,731.3 | 36,731.3 | 12,767.4 | 23% | 36,503.8 | 36,503.8 | 12,019.9 | 29% | |||
| 30,440.7 | 30,440.7 | 25% | 30,172.2 | 30,172.2 | 40% | |||||
| 18,153.2 | 23,244.3 | 60% | 51% | |||||||
| 29,324.9 | 29,324.9 | 29% | 29,554.8 | 29,554.8 | 29% | |||||
| 2% | 2% | |||||||||
| 0% | 2% | |||||||||
| 12% | 24% | |||||||||
| 27,947.6 | 27,947.6 | 36% | 28,205.2 | 28,205.2 | 40% | |||||
| 30,065.2 | 30,065.2 | 21% | 29,929.6 | 29,929.6 | 12% |
| Pro. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 36,269.0 | 5% | ±10,835.2 | 48% | |||||||
| 12,908.8 ±10,847.5 | 41% | 89% | ||||||||
| 12,208.1 ±15,016.7 | 35,757.9 | 2% | ±11,189.7 | 26,191.1 | 1% | |||||
±11,004.4 | 44,841.8 | 17% | 0% | |||||||
| 26,990.6 ±12,096.8 | 27,169.1 ±11,827.0 | 54% | 24,287.9 ±12,501.4 | 24,468.8 ±12,314.9 | 51% | |||||
| 15,763.2 ±15,183.5 | 21,721.5 ±14,162.7 | 12% | 16,266.4 ±14,745.1 | 20,168.4 ±14,010.7 | 11% | |||||
| 15,509.7 ±14,363.5 | 21,797.1 ±13,112.1 | 15% | 14,768.1 ±14,181.0 | 19,777.9 ±13,410.9 | 14% | |||||
| 13,746.8 ±10,436.1 | 13,746.8 ±10,436.1 | 63% | 14,948.1 ±21,325.4 | 14,948.1 ±21,325.4 | 39% | |||||
| 14,896.3 ±10,625.5 | 14,896.3 ±10,625.5 | 66% | 12,068.1 ±15,081.8 | 12,068.1 ±15,081.8 | 55% | |||||
| 95% | 94% |
| EA | Pro. | t | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ABC | |||||||||||
| ABC | |||||||||||
| ABC | |||||||||||
| jDElscop | |||||||||||
| jDElscop | |||||||||||
| jDElscop |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Črepinšek, M.; Liu, S.-H.; Mernik, M.; Ravber, M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics 2019, 7, 1129. https://doi.org/10.3390/math7111129
Črepinšek M, Liu S-H, Mernik M, Ravber M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics. 2019; 7(11):1129. https://doi.org/10.3390/math7111129
Chicago/Turabian StyleČrepinšek, Matej, Shih-Hsi Liu, Marjan Mernik, and Miha Ravber. 2019. "Long Term Memory Assistance for Evolutionary Algorithms" Mathematics 7, no. 11: 1129. https://doi.org/10.3390/math7111129
APA StyleČrepinšek, M., Liu, S. -H., Mernik, M., & Ravber, M. (2019). Long Term Memory Assistance for Evolutionary Algorithms. Mathematics, 7(11), 1129. https://doi.org/10.3390/math7111129