Memory-Based Evolutionary Algorithms for Nonlinear and Stochastic Programming Problems




Abstract
:1. Introduction
- First, new versions of ES and SS are proposed to enhance their performance in finding the solutions of the global optimization problem defined as Problem (2):
- –
- A new version of ESs called Direct Evolution Strategy (DES) [30] is applied. The DES method is composed by integrating the ESs with a new philosophy for applying the evolution process. Specifically, reproducing offspring in the DES method has two directions. The first one is to modify the mutation operation of ESs to reproduce offspring in a closed environment of their parents and use the parents’ experience to direct the offspring towards promising directions. The other direction of reproducing offspring is achieved by modifying the recombination operation to reproduce offspring in a promising area slightly away from their parents’ environment. This offspring has exploration duties that keep the diversity of its generation and the successive ones. This process of exploration is known in the literature as “Dispersal”, which means the movement of organisms away from their point of origin [31]. More elements have been added in the DES method to achieve more diversification process and to overcome the drawback of ESs termination.
- –
- A new SS method is proposed by extending the regular SS method built based on Laguna and Martı [32] and Duarte et al. [33] and integrating it with the Gene Matrix (GM). The proposed method is called Directed Scatter Search (DSS). Particularly, a hybrid technique is applied to update the reference set of the SS, where the possible values of each variable are divided into sub-ranges stored in the GM [34]. The GM enhances the exploration process after applying a mutagenesis operator [34] by adding new diverse solutions to the search space. Mutagenesis operator works on accelerating the exploration process by altering some survival solutions.
- Second, the proposed metaheuristics techniques are combined with the Variable-Sample method to solve the simulation-based optimization problem defined as Problem (1):
- –
- The DES for Stochastic Programming (DESSP) method consists of a modified version of evolution strategies, and Monte-Carlo-based Variable-Sample technique to estimate the objective function values. The DESSP method tries to solve the stochastic global optimization problem. This problem has been considered in both cases as local and global problems.
- –
- A new method for dealing with the stochastic global optimization problem 1 is proposed. This method, called the Directed Scatter Search for Stochastic Programming (DSSSP), is an integration between the proposed SS method and the VS method. The DSSSP has two components. The Monte-Carlo-based variable-sample method is the first component that estimates the values of the objective function, while the DSS method is the second one generating solutions and exploring the search space.
2. Directed Evolution Strategies
- Gene Matrix and Termination. During the search process, GM [34] is applied to ensure the exploration of the search space. In the GM, each variable is divided to sub-ranges based on its possible values. In the real-coding representation, there are n variables or genes in each individual x in the search space. The GM checks the diversity by dividing the range of each gene to m sub-ranges. Initially, a zero matrix of size the represents the GM where each element in each row denotes a sub-range of the equivalent gene. During the search process, GM’s values are altered from zeros to ones. An example of GM in a two-dimension search space is shown in Figure 1. We achieve an advanced exploration process when the GM has all ones. But the search will widely explore the recently chosen sub-ranges with the help of recombination operation. Therefore, the advantages of the GM are the practical termination criteria and providing the search with diverse solutions as explained hereafter.
- Mutagenesis. For accelerating the exploration process, the worst individuals selected for the next generation are reformed by a more artificial mutation operation called “mutagenesis”. Explicitly, a random zero-position in GM is selected. This will explore the j-th partition of the variable range which has not been visited yet. Then, one of the selected individuals for mutagenesis will be changed by a random value for within this partition. The formal mutagenesis procedure is explained as follows in Algorithm 1:
Algorithm 1Mutagenesis 1: procedure Mutagenesis(x, )
2: if GM is not full then
3: .
4: , where are the lower and upper bound of the variable , respectively, and r is a random number from .
5: Update .
6: else
7: Return
8: end if
9: end procedure - Recombination. The recombination operation is not applied for all parents, but with probability , since it has an exploration tendency. Initially, parents will be randomly chosen from the current generation. The number of the partitions of each recombined child equals () where partitions are taken from parents. Figure 2 displays an instant of 4 parents , , , and partitioned at the same positions into 4 partitions. Next, a recombined child is created by inheriting its four partitions from , , and , respectively. The DES recombination operation is described in Algorithm 2.
Algorithm 2Recombination - 1:
- procedureRecombination(, …, )
- 2:
- if then
- 3:
- .
- 4:
- .
- 5:
- Compose a new child .
- 6:
- else
- 7:
- Return
- 8:
- end if
- 9:
- end procedure
It is important to mention that the DES recombination procedure, defined to support the DES exploration process, is built as a standard type of the “single point crossover” and “two point crossover” [37]. Specifically in the high dimensional problems, the GM overcomes the complexity of such problem by not saving the information of the diverse sub-ranges of separate variables. Hence, as shown in the example in Figure 3a, it is possible to have misguided termination of the exploration process. However, this drawback, shown in Figure 3b, can be easily overcome by calling such recombination operation as in Algorithm 2. - Selection. The same standard ESs “+” selection operation is applied for the DES to choose from some survival individuals and insert it into its next . Though, to ensure diversity, the mutagenesis operator alters some of these individuals.
- Intensification Process. After having all children, DES applies a local search starting from two characteristic children to improve themselves. These two children are the one with the best computed solution till now, and the other child is chosen after computing the objective function of each parent and his child and select the child with the highest difference in the current generation. Therefore, these characteristic are called children “the best child” and “the most promising child” respectively. The DES behaves like a “Memetic Algorithm” [38] after applying this intensification process which accelerates the convergence [39,40]. For more intensification to enhance the best solutions found so far, we apply derivative-free local search method as an efficient local search method. At the last stage, this intensification process can enhance convergence of EAs and prevent the EAs roaming around the global solution.
| Algorithm 3 DES Algorithm |
| 1: Initial Population. Set the population parameters and and calculate . Generate an initial population 2: Initial Parameters. Select the recombination probability , and set values of , , m and . Set the gene matrix GM to be an empty matrix of size . 3: Initialize the generation counter 4: while the termination conditions are not met do 5: for do 6: Recombination. Choose a random number 7: if then 8: Select a parent from . 9: else 10: Select parents from . 11: Compute the recombined child using Recombination Procedure (Algorithm 2). 12: end if 13: Mutation. Use Equations (3) and (4) to compute a mutated children . 14: Fitness. Evaluate the fitness function . 15: end for 16: Children Pool. Set to contain all children. 17: Selection. Set the next generation to contain the best individuals from . 18: Mutagenesis. Use Mutagenesis Procedure (Algorithm 1) to alter the worst solutions in 19: Update the gene matrix GM. 20: Set . 21: end while 22: Intensification. Refine the best solutions using local search. |
3. Scatter Search with Gene Matrix
- 1.
- Diversification Generation: Generating diverse trial solutions.
- 2.
- Improvement: Applying local search to improve these trial solutions.
- 3.
- Reference Set Update: Updating the reference set containing the b best solutions found. the Solutions are classified based on the quality or the diversity.
- 4.
- Solution Subset Generation: Dividing the reference set solutions into subsets to create combined solutions.
- 5.
- Solution Combination: Combining solutions in the obtained subsets to create new trial solutions.
3.1. Updating the Reference Set
| Algorithm 4Update with GM |
|
3.2. Diversity Control
3.3. DSS Algorithm
| Algorithm 5DSS Algorithm |
| 1: . 2: repeat 3: Generate a solution x using the Diversification Generation Method. 4: if ( || is not close to any member in P) then, 5: . 6: end if 7: until the size of P is equal to . 8: Compute the fitness values for all members in P. 9: Apply Update with GM Procedure (Algorithm 4) to generate an initial RefSet. 10: while the stopping criteria are not met do 11: Use the Subset Generation Method to create solution subsets of size two. 12: Generate the offspring using the Combination Method. 13: Refine the offspring using the Improvement Method and add them to Set. 14: Use the Update with GM Procedure (Algorithm 4) to update the RefSet. 15: end while 16: Refine the best solutions using a local search method. |
4. Variable Sample Method
| Algorithm 6 Sampling Pure Random Search (SPRS) Algorithm |
| 1: Generate a solution randomly, choose an initial sample size , and set . 2: while the termination conditions are not satisfied do 3: Generate a solution randomly. 4: Generate a sample . 5: for to do 6: Compute . 7: end for 8: Compute using the following formula: 9: If , then set . Otherwise, set . 10: Update , and set . 11: end while |
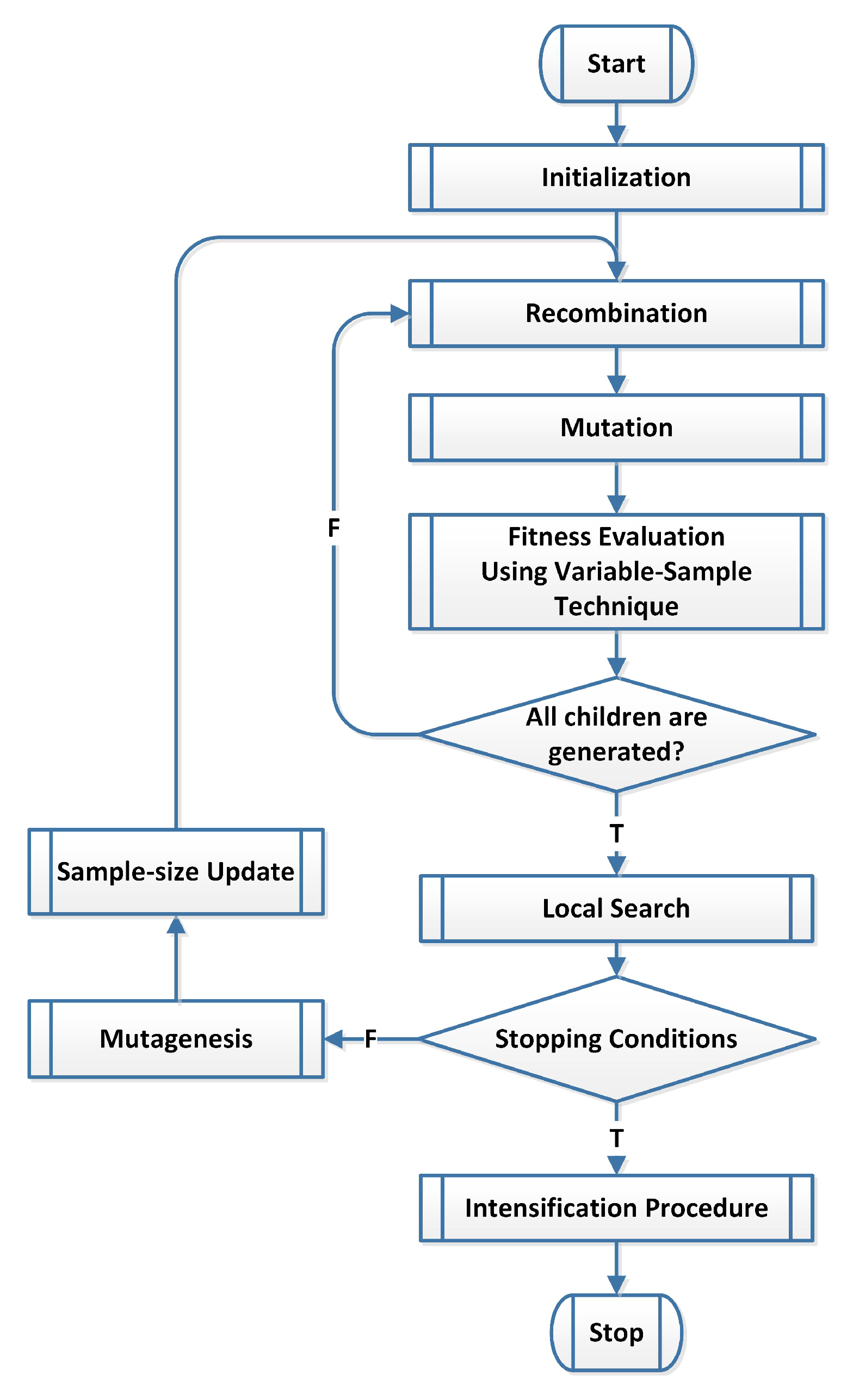
5. Directed Evolution Strategies for Simulation-based Optimization
| Algorithm 7 |
|
6. Scatter Search for Simulation-Based Optimization
6.1. Sampling and Fitness Evaluation
6.2. DSSSP Algorithm
| Algorithm 8DSSSP Algorithm |
| 1: 2: repeat 3: Generate a solution x using the Diversification Generation Method. 4: if ( || is not close to any member in P) then, 5: . 6: end if 7: until the size of P is equal to . 8: Use variable sampling with size N to compute the fitness values for all members in P. 9: Apply Update with GM Procedure (Algorithm 4) to generate an initial RefSet. 10: while the stopping criteria are not met do 11: Use the Subset Generation Method to create solution subsets of size two. 12: Generate the offspring using the Combination Method. 13: Refine the offspring using the Improvement Method and add them to Set. 14: Use the Update with GM Procedure (Algorithm 4) to update the RefSet. 15: Update the variable sample size N using Sample Size Update Procedure (Algorithm 7). 16: end while 17: Refine the best solutions using a local search method. |
7. Numerical Experiments
7.1. Test Functions
7.2. Parameter Setting and Tuning
7.3. Numerical Results on Functions without Noise
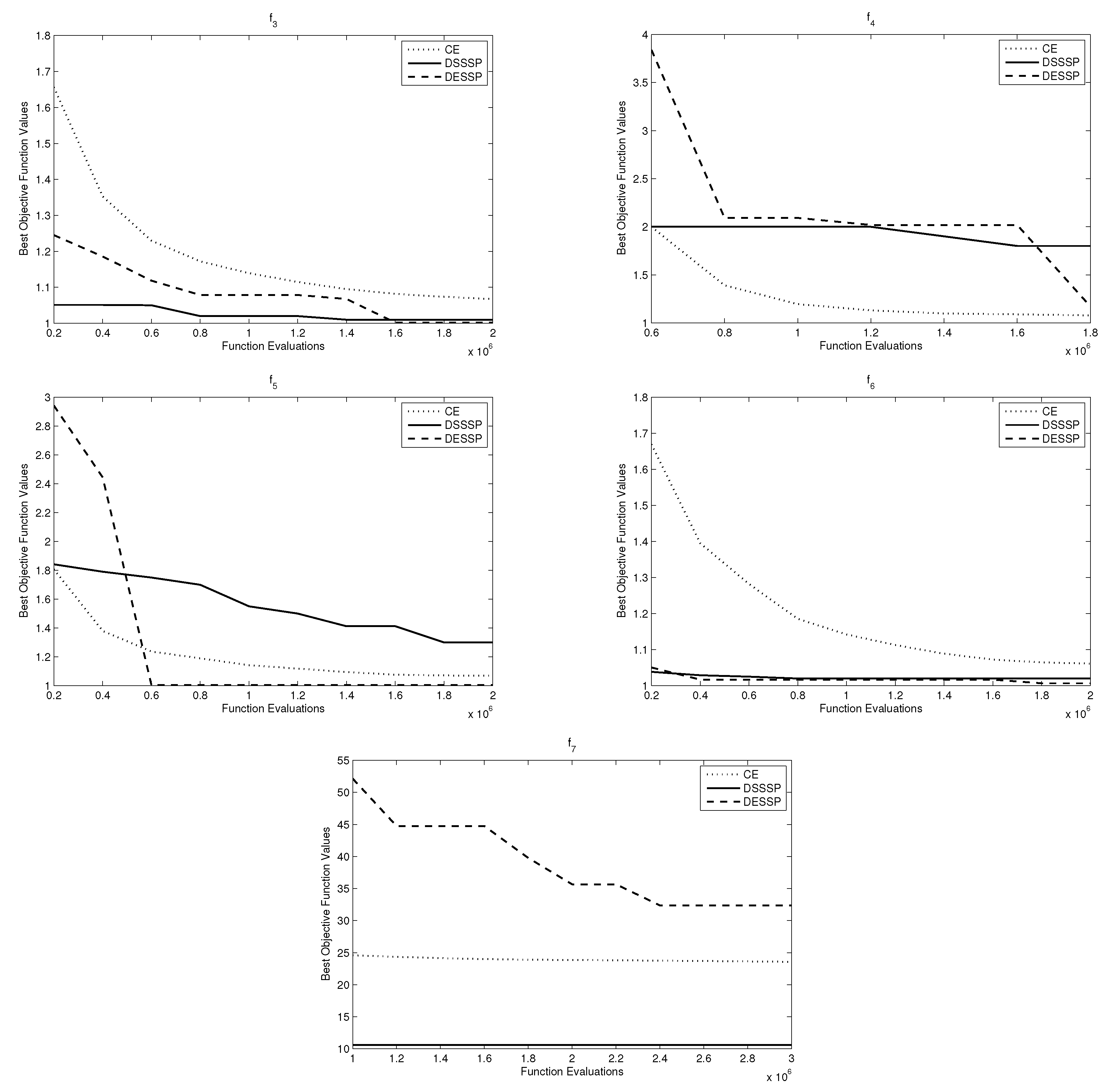
7.4. Stochastic Programming Results
- Normalized Euclidean Distance ():where is the exact solution, is the approximate solution obtained by the proposed methods, and , are upper and lower bounds of the search space, respectively.
- Associate Normalized Distance ():where is the best minimum value of the objective function obtained by the proposed methods, and , are the global maximum and minimum values of the objective function, respectively, within the search space.
- Total Normalized Distance ():
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Test Functions
Appendix A.1. Goldstein & Price Function
Appendix A.2. Rosenbrock Function
Appendix A.3. Griewank Function
Appendix A.4. Pinter Function
Appendix A.5. Modified Griewank Function
Appendix A.6. Griewank function with non-Gaussian Noise
Appendix A.7. Griewank Function (n = 50)
References
- Osorio, C.; Selvama, K.K. Simulation-based optimization: Achieving computational efficiency through the use of multiple simulators. Transp. Sci. 2017, 51, 395–411. [Google Scholar] [CrossRef]
- Campana, E.F.; Diez, M.; Iemma, U.; Liuzzi, G.; Lucidi, S. Derivative-free global ship design optimization using global/local hybridization of the DIRECT algorithm. Optim. Eng. 2016, 17, 127–156. [Google Scholar] [CrossRef]
- Pourhassan, M.R.; Raissi, S. An integrated simulation-based optimization technique for multi-objective dynamic facility layout problem. J. Ind. Inf. Integr. 2017, 8, 49–58. [Google Scholar] [CrossRef]
- Simpson, T.W.; Mauery, T.M.; Korte, J.J.; Mistree, F. Kriging models for global approximation in simulation-based multidisciplinary design optimization. AIAA J. 2001, 39, 2233–2241. [Google Scholar] [CrossRef]
- Schillings, C.; Schmidt, S.; Schulz, V. Computers & Fluids Efficient shape optimization for certain and uncertain aerodynamic design. Comput. Fluids 2011, 46, 78–87. [Google Scholar] [CrossRef]
- Hu, X.; Chen, X.; Parks, G.T.; Yao, W. Review of improved Monte Carlo methods in uncertainty-based design optimization for aerospace vehicles. Prog. Aerosp. Sci. 2016, 86, 20–27. [Google Scholar] [CrossRef]
- Hojjat, M.; Stavropoulou, E.; Bletzinger, K.U. The Vertex Morphing method for node-based shape optimization. Comput. Methods Appl. Mech. Eng. 2014, 268, 494–513. [Google Scholar] [CrossRef]
- Chong, L.; Osorio, C. A simulation-based optimization algorithm for dynamic large-scale urban transportation problems. Transp. Sci. 2017, 52, 637–656. [Google Scholar] [CrossRef]
- Mall, P.; Fidlin, A.; Krüger, A.; Groß, H. Simulation based optimization of torsional vibration dampers in automotive powertrains. Mech. Mach. Theory 2017, 115, 244–266. [Google Scholar] [CrossRef]
- Diez, M.; Volpi, S.; Serani, A.; Stern, F.; Campana, E.F. Simulation-Based Design Optimization by Sequential Multi-criterion Adaptive Sampling and Dynamic Radial Basis Functions. In Advances in Evolutionary and Deterministic Methods for Design, Optimization and Control in Engineering and Sciences; Springer International Publishing AG: Cham, Switzerland, 2019; Volume 48, pp. 213–228. [Google Scholar] [CrossRef]
- Gosavi, A. Simulation-Based Optimization: Parametric Optimization Techniques and Reinforcement Learning; Springer: New York, NY, USA, 2015. [Google Scholar]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar]
- Andradóttir, S. Simulation optimization. In Handbook of Simulation: Principles, Methodology, Advances, Applications, and Practice; John Wiley & Sons: New York, NY, USA, 1998; pp. 307–333. [Google Scholar]
- BoussaïD, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M.; Marti, R. Scatter search and path relinking: Advances and applications. In Handbook of Metaheuristics; Springer: Boston, MA, USA, 2003; pp. 1–35. [Google Scholar]
- Ribeiro, C.; Hansen, P. Essays and Surveys in Metaheuristics; Springer Science & Business Media: New York, NY, USA, 2002. [Google Scholar]
- Siarry, P. Metaheuristics; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Kvasov, D.E.; Mukhametzhanov, M.S. Metaheuristic vs. deterministic global optimization algorithms: The univariate case. Appl. Math. Comput. 2017, 318, 245–259. [Google Scholar] [CrossRef]
- Georgieva, A.; Jordanov, I. Hybrid metaheuristics for global optimization: A comparative study. In Hybrid Artificial Intelligence Systems; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2008; Volume 5271, pp. 298–305. [Google Scholar] [CrossRef]
- Liberti, L.; Kucherenko, S. Comparison of deterministic and stochastic approaches to global optimization. Int. Trans. Oper. Res. 2005, 12, 263–285. [Google Scholar] [CrossRef]
- Törn, A.; Ali, M.M.; Viitanen, S. Stochastic Global Optimization: Problem Classes and Solution Techniques. J. Glob. Optim. 1999, 14, 437–447. [Google Scholar] [CrossRef]
- Serani, A.; Diez, M. Are Random Coefficients Needed in Particle Swarm Optimization for Simulation-Based Ship Design? In Proceedings of the VII International Conference on Computational Methods in Marine Engineering, Nantes, France, 15–17 May 2017.
- Battiti, R.; Brunato, M.; Mascia, F. Reactive Search and Intelligent Optimization; Springer Science & Business Media: New York, NY, USA, 2008; Volume 45. [Google Scholar]
- Jordanov, I.; Georgieva, A. Neural network learning With global heuristic search. IEEE Trans. Neural Netw. 2007, 18, 937–942. [Google Scholar] [CrossRef]
- Lu, Y.; Zhou, Y.; Wu, X. A Hybrid Lightning Search Algorithm-Simplex Method for Global Optimization. Discrete Dyn. Nat. Soc. 2017, 2017. [Google Scholar] [CrossRef]
- Blum, C.; Roli, A. Hybrid Metaheuristics: An Introduction. In Hybrid Metaheuristics: An Emerging Approach to Optimization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–30. [Google Scholar] [CrossRef]
- D’Andreagiovanni, F.; Krolikowski, J.; Pulaj, J. A fast hybrid primal heuristic for multiband robust capacitated network design with multiple time periods. Appl. Soft Comput. J. 2015, 26, 497–507. [Google Scholar] [CrossRef]
- Renders, J.M.; Flasse, S.P. Hybrid methods using genetic algorithms for global optimization. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1996, 26, 243–258. [Google Scholar] [CrossRef]
- Homem-De-Mello, T. Variable-sample methods for stochastic optimization. ACM Trans. Model. Comput. Simul. (TOMACS) 2003, 13, 108–133. [Google Scholar] [CrossRef]
- Hedar, A.; Fukushima, M. Evolution strategies learned with automatic termination criteria. In Proceedings of the SCIS-ISIS, Tokyo, Japan, 20–24 September 2006; pp. 1126–1134. [Google Scholar]
- Sulaiman, M.; Salhi, A. A seed-based plant propagation algorithm: The feeding station model. Sci. World J. 2015, 2015. [Google Scholar] [CrossRef]
- Laguna, M.; Martí, R. Experimental testing of advanced scatter search designs for global optimization of multimodal functions. J. Glob. Optim. 2005, 33, 235–255. [Google Scholar] [CrossRef]
- Duarte, A.; Martí, R.; Glover, F.; Gortazar, F. Hybrid scatter tabu search for unconstrained global optimization. Ann. Oper. Res. 2011, 183, 95–123. [Google Scholar] [CrossRef]
- Hedar, A.; Ong, B.T.; Fukushima, M. Genetic Algorithms with Automatic Accelerated Termination; Tech. Rep; Department of Applied Mathematics and Physics, Kyoto University: Kyoto, Japan, 2007; Volume 2. [Google Scholar]
- Beyer, H.; Schwefel, H. Evolution strategies—A comprehensive introduction. Natural Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Springer-Verlag: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Herrera, F.; Lozano, M.; Verdegay, J.L. Tackling real-coded genetic algorithms: Operators and tools for behavioural analysis. Artif. Intell. Rev. 1998, 12, 265–319. [Google Scholar] [CrossRef]
- Holstein, D.; Moscato, P. Memetic algorithms using guided local search: A case study. In New Ideas in Optimization; McGraw-Hill Ltd.: Maidenhead, UK, 1999; pp. 235–244. [Google Scholar]
- Ong, Y.S.; Keane, A.J. Meta-Lamarckian learning in memetic algorithms. Evol. Comp. IEEE Trans. 2004, 8, 99–110. [Google Scholar] [CrossRef]
- Ong, Y.; Lim, M.; Zhu, N.; Wong, K. Classification of adaptive memetic algorithms: a comparative study. Syst. Man Cybern. Part B Cybern. IEEE Trans. 2006, 36, 141–152. [Google Scholar]
- Hedar, A.; Fukushima, M. Minimizing multimodal functions by simplex coding genetic algorithm. Optim. Methods Softw. 2003, 18, 265–282. [Google Scholar] [CrossRef]
- Floudas, C.; Pardalos, P.; Adjiman, C.; Esposito, W.; Gumus, Z.; Harding, S.; Klepeis, J.; Meyer, C.; Schweiger, C. Handbook of Test Problems in Local and Global Optimization; Springer Science & Business Media: New York, NY, USA, 1999. [Google Scholar]
- Hedar, A.; Fukushima, M. Tabu search directed by direct search methods for nonlinear global optimization. Eur. J. Oper. Res. 2006, 170, 329–349. [Google Scholar] [CrossRef]
- He, D.; Lee, L.H.; Chen, C.H.; Fu, M.C.; Wasserkrug, S. Simulation optimization using the cross-entropy method with optimal computing budget allocation. ACM Trans. Model. Comput. Simul. (TOMACS) 2010, 20, 4. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, L. A note on teaching–learning-based optimization algorithm. Inf. Sci. 2012, 212, 79–93. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Replication and comparison of computational experiments in applied evolutionary computing: Common pitfalls and guidelines to avoid them. Appl. Soft Comput. 2014, 19, 161–170. [Google Scholar] [CrossRef]
- Michalewicz, Z.; Nazhiyath, G. Genocop III: A co-evolutionary algorithm for numerical optimization problems with nonlinear constraints. In Proceedings of the 1995 IEEE International Conference on Evolutionary Computation, Perth, WA, Australia, 29 November–1 December 1995; Volume 2, pp. 647–651. [Google Scholar]
- Serani, A.; Leotardi, C.; Iemma, U.; Campana, E.F.; Fasano, G.; Diez, M. Parameter selection in synchronous and asynchronous deterministic particle swarm optimization for ship hydrodynamics problems. Appl. Soft Comput. 2016, 49, 313–334. [Google Scholar] [CrossRef] [Green Version]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. A study of statistical techniques and performance measures for genetics-based machine learning: Accuracy and interpretability. Soft Comput. 2009, 13, 959–977. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; CRC Press: Boca Raton, FL, USA; London, UK; New York, NY, USA; Washington, DC, USA, 2003. [Google Scholar]
- Zar, J.H. Biostatistical Analysis, 5th ed.; Pearson New International Edition: Essex, UK, 2013. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- García, S.; Molina, D.; Lozano, M.; Herrera, F. A study on the use of non-parametric tests for analyzing the evolutionary algorithms’ behaviour: A case study on the CEC’2005 special session on real parameter optimization. J. Heuristics 2009, 15, 617–644. [Google Scholar] [CrossRef]
- Hansen, N. The CMA evolution strategy: A comparing review. In Towards a New Evolutionary Computation; Springer-Verlag: Berlin/Heidelberg, Germany, 2006; pp. 75–102. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | f | Function Name | n | No. | f | Function Name | n |
|---|---|---|---|---|---|---|---|
| 1 | Branin RCOS | 2 | 8 | Rastrigin | 10 | ||
| 2 | GoldsteinPrice | 2 | 9 | Rosenbrock | 10 | ||
| 3 | Rosenbrock | 2 | 10 | Rastrigin | 20 | ||
| 4 | Hartmann | 3 | 11 | Rosenbrock | 20 | ||
| 5 | Shekel | 4 | 12 | Powell | 24 | ||
| 6 | Perm | 4 | 13 | DixonPrice | 25 | ||
| 7 | Trid | 6 | 14 | Ackley | 30 |
| No. | Function Name | f | n | No. | Function Name | f | n |
|---|---|---|---|---|---|---|---|
| 1 | Branin RCOS | 2 | 2 | Bohachevsky | 2 | ||
| 3 | Easom | 2 | 4 | Goldstein Price | 2 | ||
| 5 | Shubert | 2 | 6 | Beale | 2 | ||
| 7 | Booth | 2 | 8 | Matyas | 2 | ||
| 9 | Hump | 2 | 10 | Schwefel | 2 | ||
| 11 | Rosenbrock | 2 | 12 | Zakharov | 2 | ||
| 13 | De Joung | 3 | 14 | Hartmann | 3 | ||
| 15 | Colville | 4 | 16 | Shekel | 4 | ||
| 17 | Shekel | 4 | 18 | Shekel | 4 | ||
| 19 | Perm | 4 | 20 | Perm | 4 | ||
| 21 | Power Sum | 4 | 22 | Hartmann | 6 | ||
| 23 | Schwefel | 6 | 24 | Trid | 6 | ||
| 25 | Trid | 10 | 26 | Rastrigin | 10 | ||
| 27 | Griewank | 10 | 28 | Sum Squares | 10 | ||
| 29 | Rosenbrock | 10 | 30 | Zakharov | 10 | ||
| 31 | Rastrigin | 20 | 32 | Griewank | 20 | ||
| 33 | Sum Squares | 20 | 34 | Rosenbrock | 20 | ||
| 35 | Zakharov | 20 | 36 | Powell | 24 | ||
| 37 | DixonPrice | 25 | 38 | Levy | 30 | ||
| 39 | Sphere | 30 | 40 | Ackley | 30 |
| Function | Name | n | Stochastic Variable Distribution |
|---|---|---|---|
| Goldstein & Price | 2 | ||
| Rosenbrock | 5 | ||
| Griewank | 2 | ||
| Pinter | 5 | ||
| Modified Griewank | 2 | ||
| Griewank | 2 | ||
| Griewank | 50 |
| Parameter | Definition | Best Value |
|---|---|---|
| The population size | 50 | |
| The offspring size | ||
| No. of mated parents | ||
| The recombination probability | ||
| The initial value for the sample size | 100 | |
| The maximum value for the sample size | 5000 | |
| No. of best solutions used in in the intensification step | 1 | |
| No. of worst solutions updated by the mutagenesis process | n | |
| m | No. of partitions in GM | 50 |
| Parameter | Definition | Best Value |
|---|---|---|
| Psize | The initial population size | 100 |
| b | The size of the RefSet | 10 |
| No. of elite solutions in RefSet | 6 | |
| No. of diverse solutions in RefSet | 4 | |
| The initial value for the sample size | 100 | |
| The maximum value for the sample size | 5000 | |
| No. of best solutions used in in the intensification step | 1 | |
| No. of worst solutions updated by the mutagenesis process | 3 | |
| m | No. of partitions in GM | 50 |
| f | SS | DSS | ||
|---|---|---|---|---|
| Av. GAP | Suc. | Av. GAP | Suc. | |
| 3.58 | 100 | 3.581 | 100 | |
| 4.69 | 100 | 5.35 | 100 | |
| 1.1 | 100 | 2.56 | 100 | |
| 2.1 | 100 | 2.15 | 100 | |
| 2.9 | 100 | 3.22 | 100 | |
| 0.6 | 13 | 0.55 | 27 | |
| 2.39 | 80 | 2.703 | 77 | |
| 4.66 | 100 | 1.92 | 100 | |
| 18.59 | 0 | 15.01 | 0 | |
| 3.558 | 0 | 5.01 | 0 | |
| 45.84 | 0 | 29.77 | 0 | |
| 47.1 | 0 | 16.2 | 0 | |
| 3.51 | 0 | 1.4 | 0 | |
| 10.39 | 0 | 8.28 | 0 | |
| No. | f | Av. GAB | No. | f | Av. GAB |
|---|---|---|---|---|---|
| 1 | 3.5773 | 2 | 0 | ||
| 3 | 0 | 4 | 7.7538 | ||
| 5 | 8.83102 | 6 | 0 | ||
| 7 | 0 | 8 | 1.73546 | ||
| 9 | 4.65101 | 10 | 2.54551 | ||
| 11 | 0 | 12 | 2.88141 | ||
| 13 | 9.77667 | 14 | 2.14782 | ||
| 15 | 2.05 | 16 | 3.41193 | ||
| 17 | 5.66819 | 18 | 9.81669 | ||
| 19 | 3.83 | 20 | 5.52274 | ||
| 21 | 6.09758 | 22 | 2.05919 | ||
| 23 | 78.99516181 | 24 | 7.58971 | ||
| 25 | 8.06413 | 26 | 1.91653 | ||
| 27 | 0.142472164 | 28 | 3.75918 | ||
| 29 | 0.707283407 | 30 | 1.9217 | ||
| 31 | 7.98934 | 32 | 0.052065617 | ||
| 33 | 5.41513 | 34 | 0.739935703 | ||
| 35 | 0.19800033 | 36 | 8.33102 | ||
| 37 | 0.943358525 | 38 | 1.29657 | ||
| 39 | 1.26068 | 40 | 1.08842 |
| Evaluations | Genocop III | SS | DTS | DSS |
|---|---|---|---|---|
| 500 | 611.30 | 26.34 | 43.06 | 112.08 |
| 1000 | 379.03 | 14.66 | 24.26 | 56.24 |
| 5000 | 335.81 | 4.96 | 4.22 | 34.88 |
| 10,000 | 328.66 | 3.60 | 1.80 | 5.36 |
| 20,000 | 324.72 | 3.52 | 1.70 | 0.9031 |
| 50,000 | 321.20 | 3.46 | 1.29 | 0.0714 |
| f | DESSP | DSSSP | ||
|---|---|---|---|---|
| Best | Average | Best | Average | |
| 0.0005 | 0.2326 | 0.0146 | 0.2939 | |
| 0.8046 | 3.5496 | 0.4080 | 6.5550 | |
| 0.0010 | 0.3313 | 0.5900 | 1.0400 | |
| 0.1442 | 3.7538 | 2.7487 | 6.7145 | |
| 0.0004 | 0.3871 | 0.2819 | 1.9135 | |
| 0.00001 | 0.0213 | 0.0003 | 0.0921 | |
| 27.8824 | 39.5636 | 8.4088 | 12.3794 | |
| DESSP | DSSSP | |||||
|---|---|---|---|---|---|---|
| 8.1364 | 2.2982 | 5.7533 | 4.1030 | 2.9045 | 2.9013 | |
| 1.2902 | 7.3332 | 9.1231 | 4.2088 | 1.3542 | 2.9761 | |
| 1.3467 | 5.0255 | 3.8547 | 7.9792 | 1.5776 | 1.2763 | |
| 1.0589 | 9.7511 | 7.4884 | 2.5053 | 2.0036 | 17.7155 | |
| 1.0925 | 5.0989 | 3.8599 | 6.6194 | 2.5204 | 1.8554 | |
| 7.6039 | 3.2361 | 6.6166 | 2.2119 | 1.3976 | 2.0627 | |
| 1.6132 | 1.6105 | 1.6134 | 2.7005 | 5.0392 | 1.9430 | |
| f | |||||||
|---|---|---|---|---|---|---|---|
| DESSP | 162 | 20 | 119 | 177 | 25 | 10 | 476 |
| DSSSP | 414 | 103 | 317 | 307 | 114 | 35 | 683 |
| Comparison Criteria | p-Value | Best Method | ||
|---|---|---|---|---|
| Best Solutions | 11 | 17 | 0.3829 | – |
| Average Solutions | 7 | 21 | 0.6200 | – |
| 8 | 28 | 0.0973 | – | |
| 6 | 22 | 0.7104 | – | |
| 0 | 28 | 0.3176 | – | |
| Processing Time | 0 | 28 | 0.2593 | – |
| Method | ||||
|---|---|---|---|---|
| ES | 47.7325 | 3.265 | 970.7125 | |
| CMA-ES | 13.2173 | 12.7998 | 2.4712 | 23.6619 |
| DESSP | 3.0005 | 1.8046 | 1.0010 | 1.1442 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hedar, A.-R.; Allam, A.A.; Deabes, W. Memory-Based Evolutionary Algorithms for Nonlinear and Stochastic Programming Problems. Mathematics 2019, 7, 1126. https://doi.org/10.3390/math7111126
Hedar A-R, Allam AA, Deabes W. Memory-Based Evolutionary Algorithms for Nonlinear and Stochastic Programming Problems. Mathematics. 2019; 7(11):1126. https://doi.org/10.3390/math7111126
Chicago/Turabian StyleHedar, Abdel-Rahman, Amira A. Allam, and Wael Deabes. 2019. "Memory-Based Evolutionary Algorithms for Nonlinear and Stochastic Programming Problems" Mathematics 7, no. 11: 1126. https://doi.org/10.3390/math7111126
APA StyleHedar, A. -R., Allam, A. A., & Deabes, W. (2019). Memory-Based Evolutionary Algorithms for Nonlinear and Stochastic Programming Problems. Mathematics, 7(11), 1126. https://doi.org/10.3390/math7111126