1. Introduction
In this paper we consider the problem of finding a solution for , where is a sufficiently differentiable multivariate function, when , defined on a convex set D. The solution of this kind of multidimensional nonlinear problems is usually numerical, as it cannot be solved analytically in most cases. In this sense, the role of iterative procedures capable of estimating their solutions is critical.
Newton’s scheme is most employed iterative procedure for solving nonlinear problems (see [
1]); its iterative expression is
where
denotes the Jacobian matrix of nonlinear function
F evaluated on the iterate
. While not in the same number as for scalar equations, in recent years many researchers have focused their attention on this kind of problem. One initial approach is to modify the classical methods in order to accelerate the convergence and also to reduce the amount of functional evaluations and operations per iteration. In [
2,
3] good reviews can be found.
There have been different ways to approach this problem: In [
4], a general procedure, called pseudo-composition, was designed. It involved predictor–corrector methods with a high order of convergence, with the corrector step coming from a Gaussian quadrature. Moreover, other techniques have been used: Adomian decomposition [
5,
6,
7], multipoint methods free from second derivative [
8,
9], multidimensional Steffensen-type schemes [
10,
11,
12,
13], and even derivative-free methods with memory [
14,
15,
16].
Recently, the weight function technique has also been developed for designing iterative methods for solving nonlinear systems (see, for example [
17]). This procedure allows the order of convergence of a method to be increased many times without increasing the number of functional evaluations. Among others, Sharma et al. in [
18] designed a scheme with fourth-order of convergence by using this procedure and, more recently, Artidiello et al. constructed in [
19,
20] several classes of high-order schemes by means of matrix weight functions.
On the other hand, as most of the iterative methods for scalar equations are not directly extendable to systems, it was necessary to find a new technique that makes it feasible. In [
21,
22], the authors presented a general process able to transform any scalar iterative method to the multidimensional case.
In what follows, a few methods of sixth-order of convergence are revisited and used for comparison with our proposed scheme. Different efficiency aspects are treated as well as the numerical performance on several nonlinear problems.
In what follows, we list several existing sixth-order methods that will be used with the aim of comparison. The first scheme (
) is introduced in [
7] by Cordero et al. and modified in [
23] by the same authors. Its iterative expression is
Let us notice that this scheme reaches sixth-order of convergence using a functional evaluation of nonlinear function F at three different points and also its associate Jacobian matrix is evaluated at two different points per iteration.
The second method (
), a modified Newton–Jarratt composition, was presented by A. Cordero et al. in [
24], and is expressed as
This structure allows to reach the sixth-order of convergence by means of two evaluations of nonlinear function F, and also two of , per iteration.
We also recall, as (
) the scheme introduced by X.Y. Xiao and H.W. Yin in [
25] based on the method presented by J.R. Sharma et al. in [
18]
In this case, two functional evaluations of F and are made, respectively, on points and , per iteration.
The fourth class of iterative methods is of Jarrat-type (
) and was introduced by R. Behl et al. in [
26] as
where
,
,
,
and
is a free parameter. This is a parametric family of iterative schemes that reaches order of convergence six with two functional evaluations of
F and two of
per iteration.
Let us introduce now some concepts that will be used throughout the manuscript. They are related with such important aspects of iterative methods as convergence, order, efficiency and those related with the technique used in the proof of the main result.
Let
be a sequence in
which converges to
, then the convergence is said to be of order
p with
if there exist
(
if
) and
such that
or
Moreover, with
such that
and supposing that
are three consecutive iterations close to
, then the order of convergence can be estimated in practice by the computational order of convergence
that can be calculated by using the expression
Let
be a sufficiently Fréchet differentiable function in D, for any
in a neighborhood of
, the solution of the system
. By applying a Taylor development around
and assuming that
is not singular (see [
24] for further information), we have
being
and
. Let us remark that
as
and
. Therefore,
where
I is the identity matrix and
.
The proposed class of iterative method and its analysis of convergence are presented in
Section 2. Moreover, two particular subclasses of this family, both depending on a real parameter, are shown. In
Section 3, their efficiency is calculated and compared with those of some existing classes or schemes with the same order of convergence. Finally, their numerical performance is checked in
Section 4 on several multidimensional problems and some conclusions are stated in
Section 5.
2. Design and Convergence Analysis of the Proposed Class
Let
be a real sufficiently Fréchet differentiable function and
be a matrix weight function whose variable is
. Let us notice that the divided difference operator of
F on
,
is defined in [
27] as
Then, we propose the three step iterative method
In order to properly describe the Taylor development of the matrix weight function, we recall the denotation defined by Artidiello et al. in [
19]: Let
denote the Banach space of real square matrices of size
, then the function
can be defined such that the Fréchet derivative satisfies
- (a)
,
- (b)
.
Let us also remark that, when
k tends to infinity, then the variable
tends to the identity matrix
I. So, there exist real
and
such that
H can be expanded around
I as
Therefore, the following results state the conditions that assure the sixth-order of convergence of Class (
8) and present its error equation.
Theorem 1. Let us consider a sufficiently Fréchet differentiable function in an open neighborhood D of satisfying and , a sufficiently Fréchet differentiable matrix function. Let us also assume that is non-singular at ξ, and is an initial value close enough to ξ. Then, the sequence , obtained from Class (8), converges to ξ with order six if , and , where and I are the identity matrix, its error equation beingwhere , and . Proof. By using the Taylor expansion series of the nonlinear function and its corresponding Jacobian matrix around
we get,
Moreover, the expansion of the inverse of the Jacobian matrix can be expressed as
where
Knowing the definition of the variable of weight function
H, it can be expanded as
Then, using the Taylor expansion of H,
fixing
,
and with the help of Equations (
9) and (
10) we obtain
Then, the error at the second step is
and therefore
Finally, with Equations (
9), (
11) and (
12) we get
and the resulting error equation is
and the proof is complete. □
Theorem 1 provides the convergence conditions for the proposed Class (
8) of the iterative methods. However, there are several ways to define matrix weight function
H satisfying those conditions. Each defined weight function generates different iterative schemes or classes.
- Family 1
The weight function defined by
where
satisfies the convergence conditions of Theorem 1. A new parametric family of sixth-order methods is then obtained as
where
. This family is denoted by PSH6
.
- Family 2
The weight function defined by
also satisfies the convergence conditions of Theorem 1. Then, a new class of sixth-order methods depending on a free parameter
is obtained
being again
. We denote in what follows this class as PSH6
.
Let us also remark that both subclasses use three functional evaluations of F, one evaluation of the Jacobian matrix and one evaluation of the divided difference in order to reach sixth-order of convergence.
3. Computational Efficiency
In order to analyze the efficiency of an iterative method, there are two key aspects: The number of functional evaluations and the number of operations (products–quotients), both per iteration. So, our aim is to compare the performance of the proposed (
and
) and known methods (C6
, C6
, XH6 and B6, described in the Introduction). To get this aim, we use the multidimensional extension of efficiency index
defined by Ostrowski in [
28] and the computational efficiency index
defined in [
29]. In the latter,
p is the convergence order,
d is the amount of evaluations made per iteration and
is the amount of products–quotients made per iteration.
In order to calculate the efficiency index
I we recall that the number of functional evaluations of one
F,
and first order divided difference
at each iteration is
n,
and
, respectively. The comparison of efficiency indices for the different methods is shown in
Table 1. Let us remark that, despite some of them using more than one Jacobian matrix per iteration or use divided differences operator, the efficiency index
I, taking into account only the number of functional evaluations, is the same in all cases. So, it is necessary to calculate their corresponding computational efficiency index
. In this way, the computational effort per iteration should be taken into account in order to decide on the efficiency of the different iterative schemes.
In the case of the calculation of the computational efficiency index
, we take into account that the amount of products–quotients needed to solve a linear system by means of Gaussian elimination is
where
n is the system size. If required, the solution uses
decomposition of
m linear systems with the same matrix of coefficients, then
products–quotients are necessary; moreover,
products are made in the case of matrix–vector multiplication and for calculation of a first order divided differences operator
quotients are needed. The notation LS(
) and LS(
) define the number of linear systems to be solved with the same
matrix of coefficients and with other coefficient matrices, respectively. The comparison of computational efficiency indices of the examined methods is shown in
Table 2.
These indices obviously depend on the size of the nonlinear system to be solved, but some preliminary conclusions can be stated, such as that the third-degree coefficients describing the sum of operations and functional evaluations make a big difference: Some of them (including special cases of our proposed methods) have as the director coefficient; meanwhile, others have or even the unity as the director coefficient, making the computational cost for big-sized systems much higher.
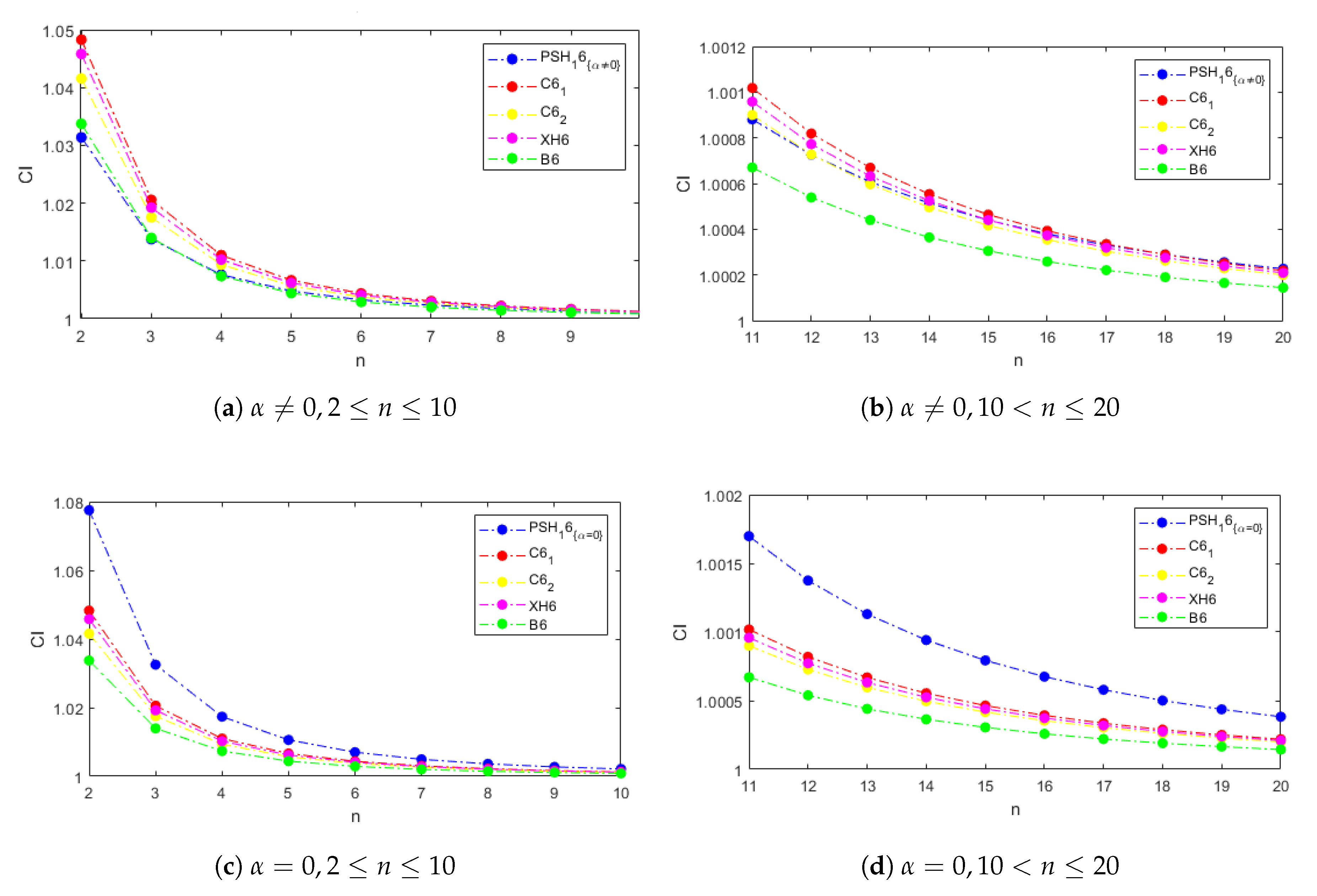
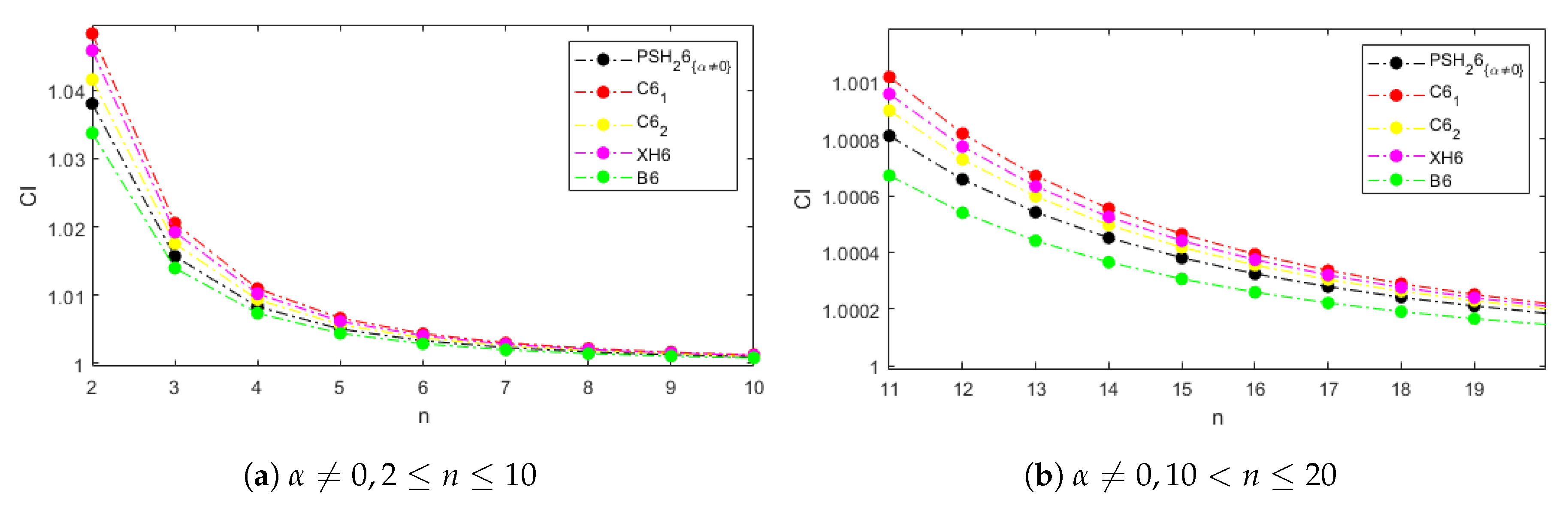
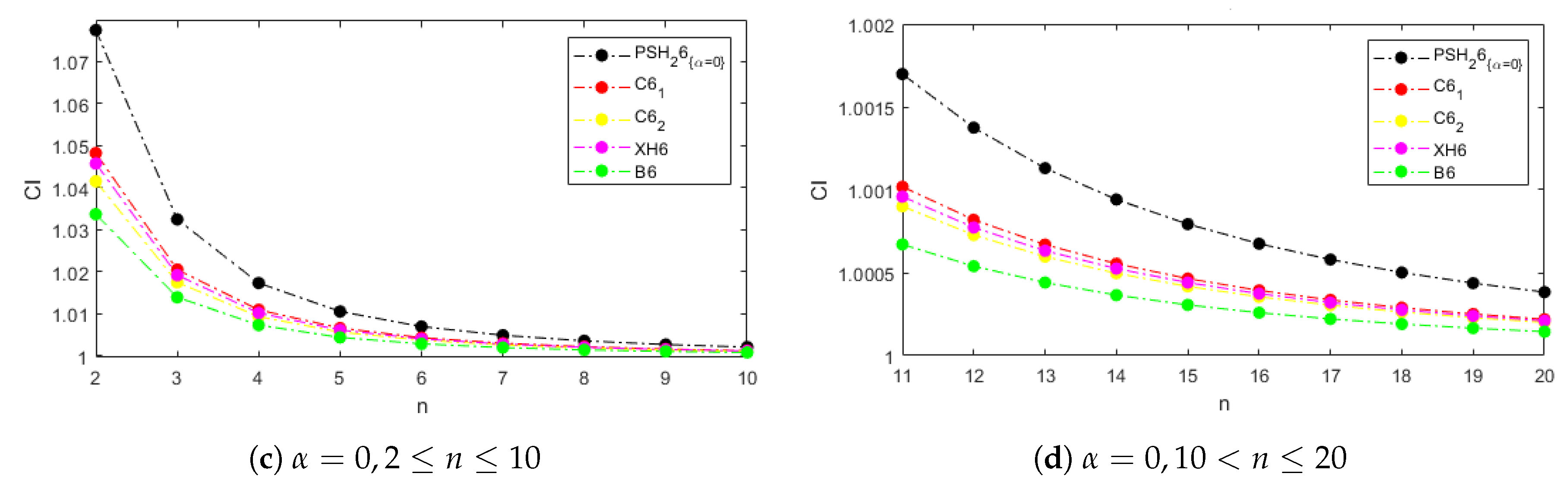
Figure 1 and
Figure 2 show the computational efficiency index for the examined methods and systems of size from 2 to 20 with weight functions
and
, respectively, in the cases of the proposed schemes. In
Figure 1a,b, the parameter
is not null, and in
Figure 1c,d it is equal to zero. Let us notice that the behavior of the
for the weight functions
and
is the same when
and it is better than those of the comparison methods. This performance is explained for the dominating term
in the computational cost calculation; it is due to the existence of only one type of linear systems to be solved per iteration with the matrix of coefficients
.
Let us also remark that, even when
, our methods are competitive with the existing ones, especially in systems with size higher than 10, where the differences among the indices of all the methods are not significant (see
Figure 1b and
Figure 2b).
4. Numerical Results
In this section, we compare the numerical performance of the proposed methods PSH6
described in Expression (
14) with
,
and
, PSH6
(see Equation (
16)) for the same values of the parameter
and existing schemes C6
, described in Equation (
1); C6
is expressed in Equation (
2), XH6 appears in Equation (
3) and the B6 scheme is expressed in Equation (
4), with
.
To get this aim we use the Matlab computer algebra system, with 2000 digits of mantissa in variable precision arithmetics, to make the comparative numerical experiments. Moreover, the stopping criterion used is
or
. The initial values employed and the searched solutions are symbolized as
and
, respectively. When the iterative expression of the method involves the evaluation of a divided difference operator, it is calculated by using the first-order estimation of the Jacobian matrix whose elements are (see [
27])
where
and
are the coordinate functions of
F.
For each nonlinear function, one table will be displayed with the results of the numerical experiments. The given information is organized as follows: k is the number of iteration needed to converge to the solution (’nc’ appears in the table if the method does not converge), the value of the stopping residuals is or at the last step (’-’ if there is no convergence) and the approximated computational order of convergence is (if the value of for the last iterations is not stable, then ’-’ appears in the table). In this way, it can be checked if the convergence has reached the root ( is achieved), if it is only a very slow convergence with no significant difference between the two last iterations ( but ), or both criteria are satisfied.
The test systems used are defined by the following nonlinear functions:
Example 1. The first nonlinear system, whose solution is , is described by function Our test is made by using as initial estimation
and the results appear in
Table 3.
In
Table 3, it can be observed that, except for method C6
, all the compared schemes converge to the solution in four iterations, with null (for the fixed precision of the machine at 2000 digits) or almost null residual
. Moreover, the computational approximation order of convergence agrees in all cases with the theoretical one.
Example 2. The following nonlinear function describes a system with solution , We test all the new and existing methods with this system with the initial estimation and the results are provided in Table 4. In this example, the proposed methods take at least one more iteration to converge to the solution (see
Table 4). However, the precision of the results are the same or even better than those of the known methods, as
is null in all new cases.
Example 3. Now, we test the methods with the nonlinear system described byusing as the initial guess . The searched root is and we can find the residuals, the number of iterations needed to converge and the estimated order of convergence in Table 5. A similar performance can be observed in
Table 5 where the effective stopping criterium is that involving the evaluation of the nonlinear function and the residual is null most times. However, the number of iterations needed does not improve on the number provided for most of known methods.
Example 4. Finally we test the proposed and existing methods with a nonlinear system of variable size. It is described aswith and starting with the estimation . In this case, the solution is and the obtained results can be found at Table 6. When the systems are large, as in the case of
, where
, our schemes provide excellent results, equalling or improving the performance of existing procedures, see
Table 6. The number of iterations needed to satisfy one of the stopping criteria and the residuals obtained show a very competitive performance. Moreover, the theoretical order of convergence is estimated with full precision.








{kind=link}
{kind=link}
{kind=link}