1. Introduction
The minimum load coloring problem (MLCP) of the graph, discussed in this paper, was introduced by Nitin Ahuja et al. [
1]. This problem is described as follows: a graph
G = (
V,
E) is given, in which
V is a set of
n vertices, and
E is a set of
l edges. The load of a
k-coloring
:
V → {1, 2, 3,…,
k} is defined as
the maximum fraction of edges with at least one end-point in color
i, where the maximum is taken over all
i ∈ {1,2,3,…,
k}. The aim of the minimum load coloring problem is to minimize the load over all
k-colorings.
This paper is dedicated to the NP-complete minimum load coloring problem [
1]. We focus on coloring the vertices with the colors of red and blue. A graph
G = (
V,
E) is given, in which
V is a set of
n vertices, and
E is a set of
l edges. The load distribution of a coloring
q:
V → {red, blue} is defined as
dq = (
rq,
bq), in which
rq is the number of edges with at least one end-vertex colored red, and
bq is the number of edges with at least one end-vertex colored blue. The objective of MLCP is to find a coloring
q such that the maximum load,
lq = 1/
l × max{
rq,
bq}, is minimized. MLCP can be applied to solve the wavelength division multiplexing (WDM) problem of network communication, and build the WDM network and complex power network [
1,
2,
3].
This paper proposes an effective memetic algorithm for the minimum load coloring problem, which relies on four key components. Firstly, an improved K-OPT local search procedure, combining a tabu search strategy and a vertices addition strategy, is especially designed for MLCP to explore the search space and escape from the local optima. Secondly, a data splitting operation is used to expand the amount of data in the search space, which enables the memetic algorithm to explore in a larger search space. Thirdly, to find better global results, through randomly changing the current search patterns a disturbance operation is employed to improve the probability of escaping from the local optima. Finally, a population evolution mechanism is devised to determine how the better solution is inserted into the population.
We evaluate the performance of memetic algorithm on 59 well-known graphs from benchmark DIMACS coloring competitions. The computational results show that the search ability of memetic algorithm is better than those of simulated annealing algorithm, greedy algorithm, artificial bee colony algorithm [
4] and variable neighborhood search algorithm [
5]. In particular, it improves the best known results of 16 graphs in known literature algorithms.
The paper is organized as follows.
Section 2 describes the related work of heuristic algorithms.
Section 3 describes the general framework and the components of memetic algorithm, including the population initialization, the data splitting operation, the improved K-OPT local search procedure of individuals, the evolutionary operation and the disturbance operation.
Section 4 describes the design process of simulated annealing algorithm.
Section 5 describes the design process of greedy algorithm.
Section 6 describes the experimental results.
Section 7 describes the conclusion of the paper.
2. Related Work
In [
6,
7], the parameterized and approximation algorithms are proposed to solve the load coloring problem, and theoretically prove their capability in finding the best solution. On the other hand, considering the theoretical intractability of MLCP, several heuristic algorithms are proposed to find the best solutions. Heuristic algorithms use rules based on previous experience to solve a combinatorial optimization problem at the cost of acceptable time and space, and, at the same time, comparatively better results can be obtained. The heuristic algorithms used here include an artificial bee colony algorithm [
4], a tabu search algorithm [
5] and a variable neighborhood search algorithm [
5] to solve MLCP.
Furthermore, to find the best solutions of the other combinatorial optimization problems, several heuristic algorithms are employed, such as a variable neighborhood search algorithm [
8,
9], a tabu search algorithm [
10,
11,
12,
13], a simulated annealing algorithm [
14,
15,
16,
17], and a greedy algorithm [
18].
Local search algorithm, as an important heuristic algorithm, has been improved and evolved into many updated forms, such as a variable depth search algorithm [
19], a reactive local search algorithm [
20], an iterated local search algorithm [
21], and a phased local search algorithm [
22].
Memetic algorithm [
23,
24] is an optimization algorithm which combines population-based global search and individual-based local heuristic search, whose application is found in solving combinatorial optimization problems. Memetic algorithm is also proposed to solve the minimum sum coloring problem of graphs [
24].
3. A Memetic Algorithm for MLCP
In this paper, we propose an efficient memetic algorithm to solve MLCP of graphs. In our algorithm, there are several important design parts.
- (1)
Construct the population for the global search.
- (2)
Search heuristically the individuals to find better solutions.
- (3)
Evolve the population to find better solutions.
Memetic algorithm is summarized in Memetic_D_O_MLCP (Algorithm 1). After population initialization, the algorithm randomly generates a population
X consisting of
p individuals (Algorithm 1, Line 2,
Section 3.2). Then, the memetic algorithm repeats a series of generations (limited to a stop condition) to explore the search space defined by the set of all proper 2-colorings (
Section 3.1). For each generation, by data splitting operation, the population
X is expanded to population
Z with twice as much as the data amount (Algorithm 1, Line 5,
Section 3.3). An improved K- OPT local search is carried out for each individual
Zj (0 ≤
j < |
Z|) of the population
Z to find the best solution of MLCP (Algorithm 1, Line 8,
Section 3.4). If the improved solution has a better value, it is then used to update the best solution found so far (Algorithm 1, Lines 9-10). Finally, an evolutionary operation is conducted in population
Z to get a replaced one instead of population
X (Algorithm 1, Line 14,
Section 3.5). To further improve the search ability of the algorithm and find better solutions, we add a disturbance operation into the memetic algorithm (Algorithm 1, Line 15,
Section 3.6).
| Algorithm 1 Memetic_D_O_MLCP (G, m, p, b, k, X, Z). |
| Require: |
| G: G = (V, E), |V| = n, |E| = l |
| m: initial number of red vertices in graph G |
| p: number of individuals in the population |
| b, k: control parameters of disturbance operation |
| X: set that stores the population |
| Z: set that stores the extended population of X, |Z| = 2 × |X| |
| Output: s1, the best solution found by the algorithm |
| f(s1), the value of the objective function |
| begin |
| 1 d1 ← 0, d2 ← 0; /* control variables of disturbance operation, Section 3.6 */ |
| 2 Init_population(X, m, p); /* generates population X consisting of p individuals, Section 3.2 */ |
| 3 Wbest ← 0; |
| 4 repeat |
| 5 Z ← Data_spliting(X); /* population X is extended to population Z with twice as much the data amount, Section 3.3 */ |
| 6 j ← 0; |
| 7 while j < 2×p do |
| 8 W ← New_K-OPT_MLCP (G, Zj, T, L); |
| /* a heuristic search is carried out for individual Zj, (T is tabu table and L is tabu tenure value, Section 3.4) */ |
| 9 if f (W) > Wbest then |
| 10 Wbest ← f (W), s1 ←W; |
| 11 end if |
| 12 j ← j + 1; |
| 13 end while |
| 14 X ← Evolution_population (Z, X); /* Section 3.5 */ |
| 15 (s1, Wbest, d1, d2) ←Disturbance_operation(X, b, k, d1, d2, Wbest); /* Section 3.6 */ |
| 16 until stop condition is met; |
| 17 return s1, Wbest; |
| end |
3.1. Search Space and Objective Function
In [
1], the following description is considered to be MLCP’s equivalent problem. A graph
G = (
V,
E) is given, in which
V is a set of
n vertices, and
E is a set of
l edges. (
Vred,
Vblue) is a two-color load coloring bipartition scheme of
V, in which
Vred is the set of vertices which are red, and
Vblue is the set of vertices which are blue, here
V =
VredVblue. The aim is to find the maximum value of min{|
Er(
Vred)|, |
Er(
Vblue)|} from all bipartition schemes of (
Vred,
Vblue) such that
lq can minimize. The maximum value is the minimum two-color load problem solution of graph
G. Here,
Er(
Vred) is the set of edges with both end-points in
Vred, and
Er(
Vblue) is the set of edges with both end-points in
Vblue.
The algorithm conducts a searching within the bipartition scheme (
Vred,
Vblue), here |
Vred|
V,
Vblue =
V\
Vred, when |
Er(
Vred)| ≈ |
Er(
Vblue)|, (
Vred,
Vblue) is the solution of the MLCP found by the algorithm. The search space
S of the algorithm is defined as follows:
The objective function is as follows:
We define the best solution of the MLCP as follows:
Here, is the number of all solutions that can be found by the algorithm in graph G, and (Vred, Vblue)j is the jth solution of the MLCP found by the algorithm.
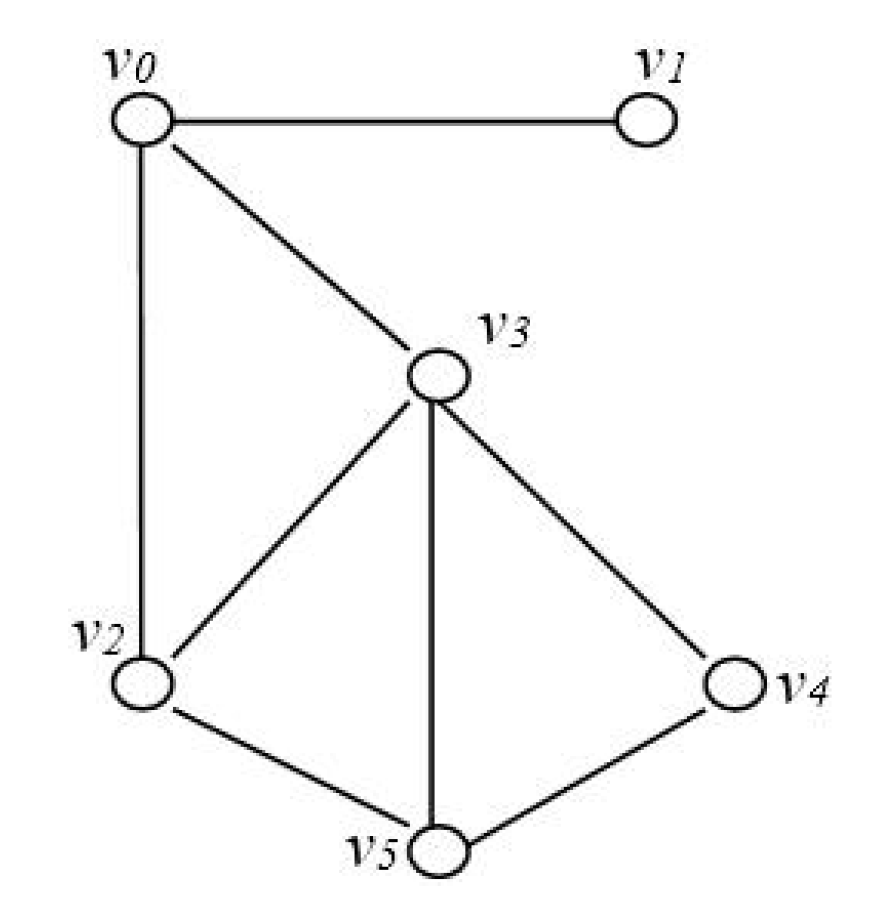
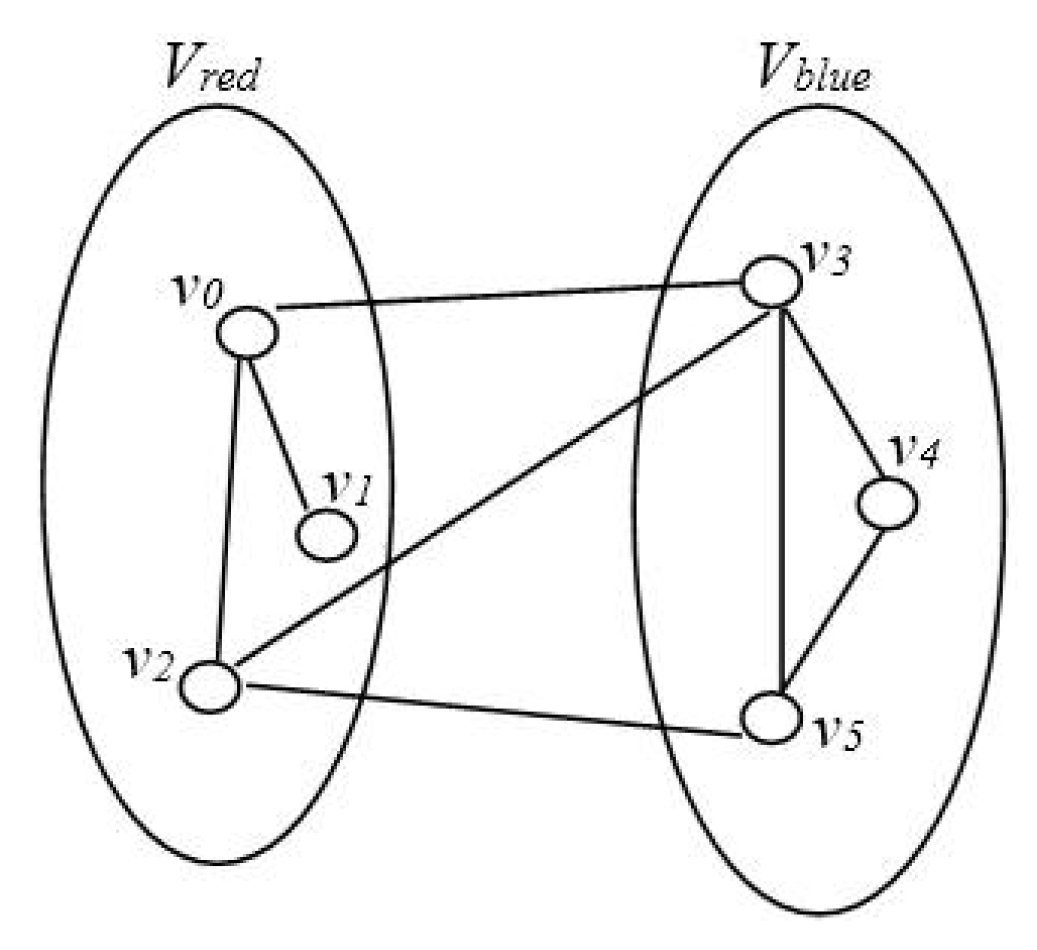
Suppose a graph
G = (
V,
E) is given in
Figure 1. Let |
V| = 6, |
E| = 8, and then the best solution for MLCP of graph
G is shown in
Figure 2, and its best value is 2.
3.2. Initial Population
The algorithm randomly generates population X consisting of p individuals. For the given graph G = (V, E), in which V is a set containing n vertices, and E is a set containing l edges, m vertices are chosen at random from V to construct set Vred (m is the initial number of the red vertices); and the remaining vertices are used to construct set Vblue, that is, |Vred| = m, Vblue = V\Vred. Sets Vred and Vblue are seen as a bipartition scheme (Vred, Vblue), which is also treated as an individual in population X. In this way, p individuals are generated at random initially, and population X is thus constructed, |X| = p.
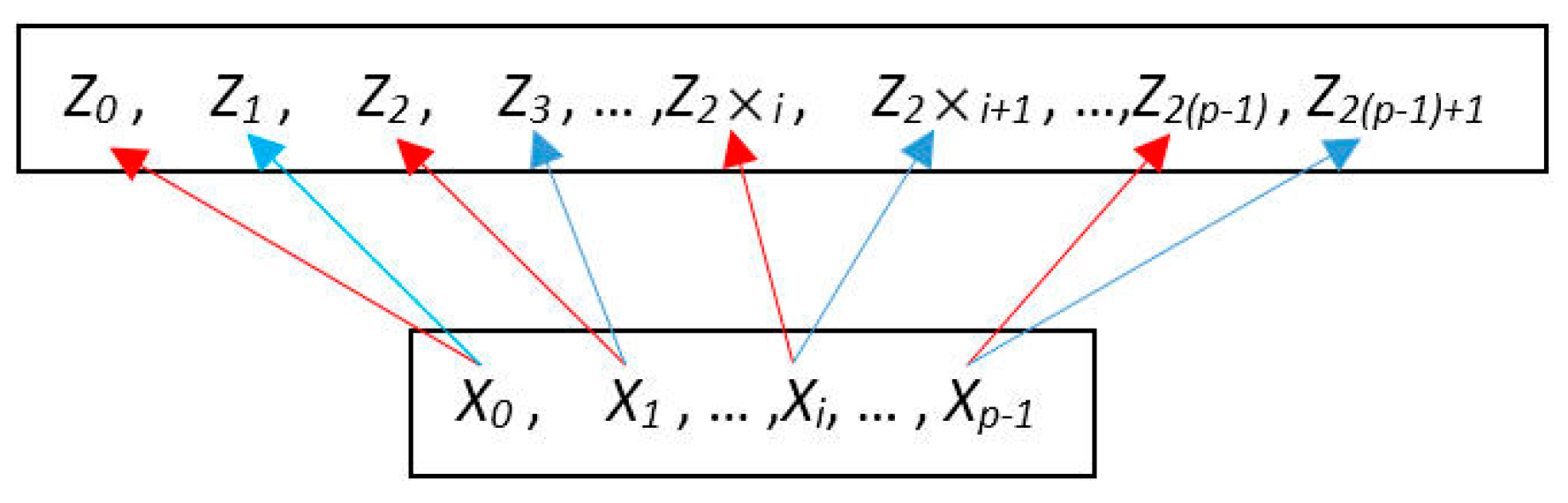
3.3. Data Splitting Operation
To avoid the defect of the local optima, we expand the data amount of population
X, hence we get an expanded scope of data search. We use two data splitting strategies to split a bipartition scheme into two. Thus, by using the first data splitting strategy each individual
Xi (0 ≤
i <
p) in population
X generates an individual
Z2×i, and by using the second data splitting strategy each individual
Xi (0 ≤
i <
p) generates an individual
Z2×i+1. By doing this,
p individuals in population
X are divided into 2 ×
p individuals, and the enlarged population
Z is constructed (|
X| =
p, |
Z| = 2 ×
p).
Figure 3 shows the population expansion, where the red arrow indicates the effects of the first data splitting strategy and the blue arrow the effects of the second data splitting strategy.
The first data splitting strategy of bipartition scheme (Vred, Vblue) is an important part of memetic algorithm, which consists of five steps.
First step: Degree set Degreered of all vertices in sub-graph G1(Vred) is calculated.
Second step: Find the minimum degree vertex, v, from Degreered. If there is more than one vertex with the same minimum degree, randomly select a vertex among them.
Third step: Degree set Degreeblue of all vertices in sub-graph G2(Vblue) is calculated.
Fourth step: Find the minimum degree vertex, w, from Degreeblue. If there is more than one vertex with the same minimum degree, randomly select a vertex among them.
Fifth step: A new bipartition scheme (V‘red, V‘blue) is generated by exchanging the vertices v and w in sets Vred and Vblue.
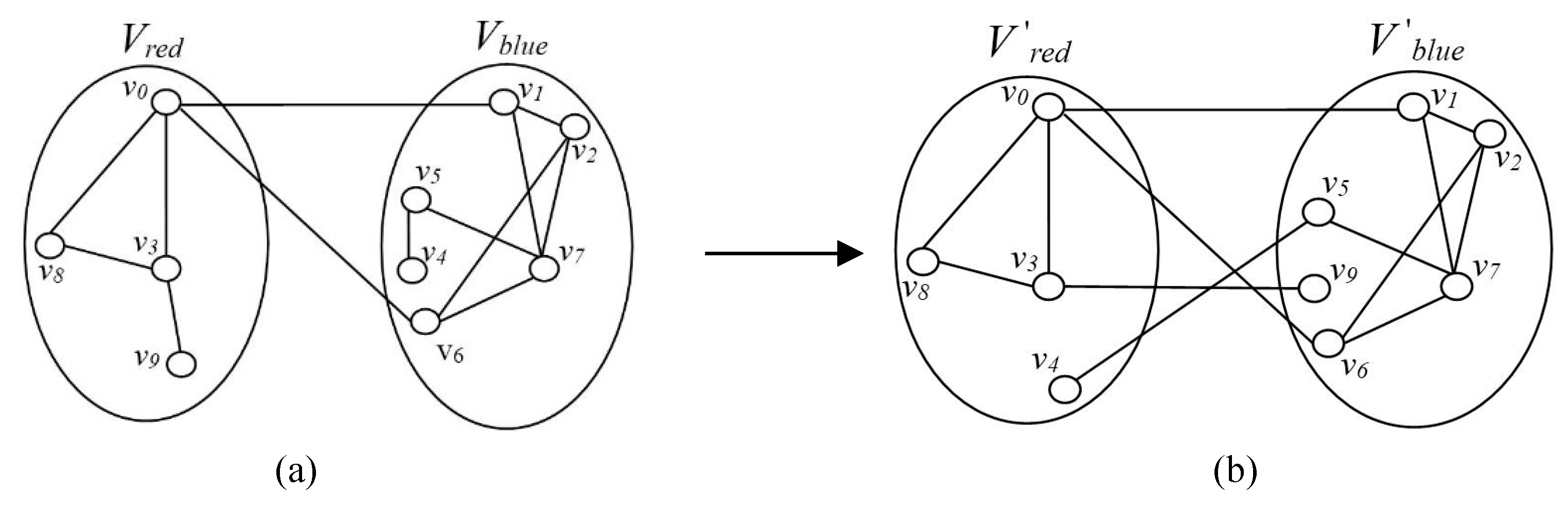
Suppose the number of red vertices is 4 in the given graph
G = (
V,
E),
V ={
v0,
v1, … ,
v9}. We obtain a bipartition scheme (
Vred,
Vblue), as shown in
Figure 4a, in which set
Vred ={
v0,
v3,
v8,
v9},
Vblue ={
v1,
v2,
v4,
v5,
v6,
v7}, where the degree of vertex
v9 in set
Vred is the smallest, and that of vertex
v4 in set
Vblue is the smallest. After exchanging the two vertices, a new bipartition scheme (
V‘red,
V‘blue) is generated. The new bipartition scheme (
V‘red,
V‘blue) after splitting is:
V‘red ={
v0,
v3,
v4,
v8},
V‘blue ={
v1,
v2,
v5,
v6,
v7,
v9}, as shown in
Figure 4b.
The second data splitting strategy is described as follows: for a given bipartition scheme (Vred, Vblue), in which |Vred| = m, Vblue = V\Vred, randomly a vertex v in set Vred is chosen, and a vertex w in set Vblue is randomly chosen. Then, vertices v and w in set Vred and set Vblue are exchanged to generate a new bipartition scheme (V″red, V″blue).
3.4. Search for the Individuals
Memetic algorithm needs to carry out a heuristic search for each individual in the population by an effective and improved K-OPT local search algorithm designed.
We first obtain an individual Zj which is a (Vred, Vblue)j, ((Vred)j⊂V, (Vblue)j =V\(Vred)j, 0 ≤ j<|Z|). The local search algorithm is implemented to add as many selected vertices, acquired through our vertex adding strategy, as possible in set (Vblue)j to set (Vred)j, until the stop condition set by the algorithm is met. Thus, a new bipartition scheme (Vred, Vblue)’j is constructed. Generally speaking, in (Vred, Vblue)’j, |Er((V‘red)j)|is approximately equal to |Er((V‘blue)j)|. Then, the objective function value f ((Vred, Vblue)’j) is calculated using Equation (2). If f ((Vred, Vblue)’j) > f (s1), the memetic algorithm accepts the constructed bipartition as the new best solution. The improved K-OPT local search algorithm is implemented by the New_K-OPT_MLCP (Algorithm 2).
Our vertex adding strategy is described as follows:
We first need to define the following three vectors as the foundation on which the vertex adding strategy is constructed.
To avoid the local optima defect, the vertex adding strategy is employed in two phases: vertex addition phase (Algorithm 2, Lines 8–12) and vertex deletion phase (Algorithm 2, Lines 14–18).
In the vertex addition phase of CCred, we obtain PAVred from the current CCred, then select a vertex w from PAVred and move it from Vblue to CCred, and finally update PAVred. The vertex addition phase is repeatedly executed until PAVred = or |Er(CCred)| > |Er(Vblue)|.
In the vertex deletion phase of CCred, we select a vertex u from CCred, then delete the vertex u from CCred, and add it to Vblue. Go back to the vertex addition phase again to continue the execution until the set ending conditions are met.
The approach to select vertex
w is first to obtain a
GPAVred in sub-graph
G’(
PAVred), then to calculate the vertex selection probability value
ρ(
wi) of each vertex
wi (0 ≤
i < |
PAVred|) in
PAVred, and finally to select vertex
wi to maximize
ρ(
wi). If there are more than one vertex with the maximum value of
ρ(
wi), randomly select one.
A vertex
w is selected according to the following criterion:
We found that the larger the probability value ρ(wi) of vertex wi is, the smaller the degree value of vertex wi becomes.
The approach of vertex
u selection is as follows: we assume that (
CCred,
Vblue)
(j) is the bipartition scheme with no possible additions. We successively take the value of
i from the range of 0 – (|
CCred|
1), and then in turn execute
CCred(j)\{
ui} as follows: delete vertex
ui from
CCred(j) successively to generate new bipartition schemes (
CC‘red,
V‘blue)
i, i.e., (
CC‘red)
i ←
CCred(j)\{
ui}, (
V‘blue)
i ←
Vblue(j){
ui},
uiCCred, 0 ≤
i <|
CCred|, and finally obtain
Ed((
CC‘red,
V‘blue)
i).
The maximum value
maxdd is found from all the values of
Ed, and the vertex selection probability value
ρ2(
ui) of vertex
ui can be calculated:
A vertex
u is selected according to the following criterion:
We found that the larger the probability value ρ2(ui) of vertex ui is, the smaller the corresponding Ed ((CC‘red, V‘blue)i) becomes. If there are more than one vertices with the maximum value of ρ2(ui), randomly select one.
At each generation, the variable gA stores the value of vertices number successfully added to the CCred for now, and the variable gmaxA stores the value of vertices number successfully added to the CCred during the previous generations. If gA > gmaxA, the incumbent CCred has more red vertices than the previous ones found by the local search algorithm. Then, gmaxA is updated with the value of gA and the incumbent CCred is stored to the set Abest (Algorithm 2, Line 12). In the vertex addition phase, the value of gA + 1 replaces that of gA (gA ← gA + 1) after a vertex is added. In the vertex deletion phase, the value of gA − 1 replaces that of gA (gA ← gA − 1) after a vertex is deleted.
At the completion of the inner loop statements, when gmaxA > 0, CCred, which has the greatest number of vertices, is stored in set Abest, then the incumbent CCred is updated with Abest. When gmaxA = 0, CCred, which has the greatest number of vertices, is stored in set Aprev; if the execution of the inner loop does not find any new set CCred that has more vertices, Aprev is adopted as CCred generated by the previous execution of the inner loop and will replace the incumbent CCred (Algorithm 2, Lines 22–28).
The algorithm’s search efficiency may be reduced because of the roundabout searching characteristics. To solve this problem, a restricting tabu table is added to the local search algorithm.
The tabu table can be presented by two-dimensional array or one-dimensional array. We adopt the one-dimensional array T, set the tabu tenure value as L, and store the iteration numbers of running the local search algorithm into the tabu table. When the algorithm runs reach iteration value c, and if (c − T[w]) < L or if (c −T[u]) < L, it means vertex w or u has been processed and the vertex should be re-selected. Otherwise, the current value c is stored in the tabu table, i.e.,T[w] ← c or T[u] ← c.
| Algorithm 2 New_K-OPT_MLCP (G, Zj, T, L). |
| Require: |
| Zj: the jth individual (Vred, Vblue)j, (Vred)j⊂V, (Vblue)j = V\(Vred)j |
| T: tabu table |
| L: tabu tenure value |
| Output: s2, the solution found by local search algorithm |
| begin |
| 1 (CCred, Vblue) ← (Vred, Vblue)j; |
| 2 according to CCred and Vblue, PAVred and GPAVred are obtained; |
| 3 repeat |
| 4 Aprev ← CCred, DA ← Aprev, PL ←{v0, v1, …… vn-1}, gA ← 0, gmaxA ← 0, c ← 0; |
| 5 repeat |
| 6 c ← c + 1; |
| 7 if |PAVred∩PL| > 0 and |Er(CCred)| < |Er(Vblue)| then |
| 8 select vertex w according to f1(w), if there are multiple vertices, select a vertex w randomly; |
| 9 if c − T[w] < L then select a non-tabu vertex w according to f1(w); |
| 10 T[w] ← c; |
| 11 CCred ← CCred∪{w}, Vblue ←Vblue\{w}, gA ← gA + 1, PL ← PL\{w}; |
| 12 if gA > gmaxA then gmaxA ← gA, Abest ← CCred; |
| 13 else |
| 14 select vertex u according to f2(u), if there are multiple vertices, select a vertex u randomly; |
| 15 if c − T[u] < L then select a non-tabu vertex u according to f2(u); |
| 16 T[u] ← c; |
| 17 CCred ← CCred\{u}, Vblue ← Vblue∪{u}, gA ← gA−1, PL ← PL\{u}; |
| 18 if u∈Aprev then DA ← DA\{u}; |
| 19 end if |
| 20 based on CCred and Vblue, PAVred and GPAVred are updated; |
| 21 until |DA| = 0 or the cut-off time condition for CPU running is met; |
| 22 if gmaxA > 0 then |
| 23 CCred ← Abest; |
| 24 Vblue ← V\CCred; |
| 25 else |
| 26 CCred ← Aprev; |
| 27 Vblue ← V\CCred; |
| 28 end if |
| 29 until gmaxA ≤ 0 or the cut-off time condition for CPU running is met; |
| 30 (Vred, Vblue)j ← (CCred, Vblue); |
| 31 s2 ← (Vred, Vblue)j; |
| 32 return s2; |
| end |
3.5. Evolutionary Operation of Population
An evolutionary operation in the population
X is needed to quickly find the best solution of MLCP. We sort the individuals
Zj (0 ≤
j < 2×
p) in population
Z in ascending order according to the calculated value of objective function
f* in Equation (11). Then, we replace the individuals
X0 –Xp−1 of population
X with the individuals
Z0 –Zp−1 to complete the evolutionary operation.
Evolution operation of the population is represented by Evolution_population (Algorithm 3).
| Algorithm 3 Evolution_population (Z, X). |
| Require: |
| Z: population, |Z| =2 × p |
| Output: population X |
| begin |
| 1 j ← 0; |
| 2 while j < 2 × p do |
| 3 R[j] ← f* ((Vred, Vblue)j); |
| 4 j ← j + 1; |
| 5 end while |
| 6 Individuals Z0 –Z2×p −1 of population Z are sorted in ascending order according to the value of set R; |
| 7 (X0–Xp −1) ←(Z0–Zp −1); |
| 8 return X; |
| end |
3.6. Disturbance Operation
To further improve the search ability of the algorithm and find better values, we add a disturbance operation into the memetic algorithm. This disturbance operation is executed k times.
When the number of iterations is b, disturbance operation begins and randomly selects an individual (Vred, Vblue)j (0 ≤ j < |X|) from population X, and chooses at random a vertex from set Vred and a vertex from set Vblue, then the two vertices are exchanged to generate a new (Vred, Vblue)’. Then, employ the New_K-OPT_MLCP algorithm to search in (Vred, Vblue)’; if a better solution of MLCP is found, the memetic algorithm will accept it.
The disturbance operation is represented by Disturbance_operation (Algorithm 4).
| Algorithm 4 Disturbance_operation(X, b, k, d1, d2, Wbest). |
| Require: |
| X: set that stores the population |
| b, k: control parameters of disturbance operation |
| d1, d2: control variables of disturbance operation |
| Wbest: variable that stores the value of the objective function f(st), in which st is the current best solution of MLCP |
| Output: s1, a better solution found by the local search algorithm |
| f(s1), the value of the objective function |
| d1, d2, values of the control variables |
| begin |
| 1 d1 ← d1 + 1; |
| 2 if d1 = b then |
| 3 d2 ← d2 + 1; |
| 4 if d2 ≤ k then |
| 5 if d2 = 1 then |
| 6 randomly choose Xj from X and start disturbance to generate a new X‘j; |
| 7 W ← New_K-OPT_MLCP (G, X‘j, T, L); |
| 8 if f (W) > Wbest then s1 ← W, Wbest ← f (W); |
| 9 t ← X‘j ; |
| 10 else |
| 11 start disturbance t to generate a new t‘ ; |
| 12 W ← New_K-OPT_MLCP (G, t‘, T, L); |
| 13 if f (W) > Wbest then s1 ← W, Wbest ← f (W); |
| 14 t ← t‘; |
| 15 end if |
| 16 d1 ← d1 − 1 |
| 17 else |
| 18 d1 ← 0, d2 ← 0; |
| 19 end if |
| 20 end if |
| 21 return s1, Wbest, d1, d2; |
| end |
In Memetic_D_O_MLCP algorithm, setting the value of b and k will determine the disturbance operation’s starting condition and the number of times of its execution. In Disturbance_operation algorithm, Lines 1, 3, 16, and 18 store the modified values of variables d1 and d2, which are the threshold values needed to start off a new disturbance operation.
4. Simulated Annealing Algorithm
Simulated annealing algorithm, a classical heuristic algorithm to solve combinatorial optimization problems, starts off from a higher initial temperature. With the decreasing of temperature parameters, the algorithm can randomly find the global best solution of problems instead of the local optima by combining the perturbations triggered by the probabilities.
For a given graph G, simulated annealing algorithm finds a coloring bipartition scheme (Vred, Vblue) of V which maximizes min{|Er(Vred)|, |Er(Vblue)|}. With parameters T0 (initial temperature value), α (cooling coefficient) and Tend (the end temperature value), first, the algorithm divides the vertex set V into two sets, i.e., Vred and Vblue (Vred = , Vblue = V) and the initial value of the best solution of MLCP Cbest is set to 0. Next, a vertex is randomly selected in Vblue and moved from Vblue to Vred; here, |Vred| = 1, Vblue = V\Vred. Then, the algorithm repeats a series of generations to explore the search space defined by the set of all 2-colorings. At each generation, a vertex is randomly selected in Vblue and moved from Vblue to Vred. The additions will take place in the following three forms:
When 2 > |Vred| and 2 ≤ |Vblue|, a vertex is randomly selected in Vblue and moved from Vblue to Vred to generate a new coloring bipartition scheme (V‘red, V‘blue) and the new status is accepted.
When 2 > |Vblue| and 2 ≤ |Vred|, a vertex is randomly selected in Vred and moved from Vred to Vblue to generate a new coloring bipartition scheme (V‘red, V‘blue) and accepted as the new status.
When 2 ≤ |Vred| and 2 ≤ |Vblue|, a vertex is randomly selected from Vred and one randomly from Vblue, then the two vertices are exchanged to generate a new coloring bipartition scheme (V‘red, V‘blue), only when R1((V‘red, V‘blue)) ≥ R1((Vred, Vblue)), the scheme is accepted as a new status. Otherwise, the probability will decide whether to accept it as a new status or not.
Once the new status is accepted, if Cbest < R1 ((V‘red, V‘blue)), then the bipartition scheme (V‘red, V‘blue) is accepted as the best solution of MLCP.
At the end of each generation, the temperature T cools down until T ≤Tend according to T = T × α, where α(0,1). The algorithm runs iteratively as per the above steps until the stop condition is met.
The best solution found by the algorithm is
Rb((
Vred,
Vblue)), i.e.,
Here, t is the number of all solutions that can be found by the simulated annealing algorithm in graph G, and (Vred, Vblue)j is the jth solution of MLCP.
The simulated annealing algorithm is represented by SA (Algorithm 5).
| Algorithm 5 SA(G, Vred, Vblue, T0, α, Tend). |
| Require: G: G = (V, E), |V| = n, |E| = l |
| Vred: a set of red vertices in graph G |
| Vblue: a set of blue vertices in graph G |
| T0: initial temperature value |
| α: cooling coefficient |
| Tend: end temperature value |
| Output: s3, the best solution found by SA algorithm |
| R1(s3), value of the objective function |
| begin |
| 1 Cbest ← 0; |
| 2 repeat |
| 3 T ← T0; |
| 4 initialize Vred and Vblue, randomly select a vertex in Vblue and moved from Vblue to Vred; |
| 5 while T > Tend do |
| 6 if 2 > |Vred| and 2 ≤ |Vblue| then |
| 7 a vertex is randomly selected in Vblue and moved from Vblue to Vred to generate a new bipartition scheme (V‘red, V‘blue); |
| 8 (Vred, Vblue) ← (V‘red, V‘blue); |
| 9 if Cbest < R1((V‘red, V‘blue)) then Cbest ←R1((V‘red, V‘blue)), s3 ← (V‘red, V‘blue); |
| 10 else if 2 > |Vblue| and 2 ≤ |Vred| then |
| 11 a vertex is randomly selected in Vred and moved from Vred to Vblue to generate a new bipartition scheme (V‘red, V‘blue); |
| 12 (Vred, Vblue) ← (V‘red, V‘blue); |
| 13 if Cbest < R1 ((V‘red, V‘blue)) then Cbest ← R1 ((V‘red, V‘blue)), s3 ← (V‘red, V‘blue); |
| 14 else if 2 ≤ |Vred| and 2 ≤ |Vblue| then |
| 15 according to (Vred, Vblue), a vertex is randomly selected from Vred and a vertex randomly selected from Vblue; |
| 16 the two vertices are exchanged to generate a new bipartition scheme (V‘red, V‘blue); |
| 17 if R1 ((Vred, Vblue)) ≤ R1((V‘red, V‘blue)) then |
| 18 (Vred, Vblue) ← (V‘red, V‘blue); |
| 19 if Cbest < R1((V‘red, V‘blue)) then Cbest ← R1((V‘red, V‘blue)), s3 ← (V‘red, V‘blue); |
| 20 else if random number in (0, 1) < then |
| 21 (Vred, Vblue) ← (V‘red, V‘ blue); |
| 22 end if |
| 23 end if |
| 24 T ← T × α; |
| 25 end while |
| 26 until stop condition is met; |
| 27 return s3, Cbest; /*Cbest is the value of the objective function R1(s3) */ |
| end |
5. Greedy Algorithm
Greedy algorithm aims at making the optimal choice at each stage with the hope of finding a global best solution. For a given graph G, greedy algorithm finds a coloring bipartition scheme (Vred, Vblue) of V which maximizes min{|Er(Vred)|, |Er(Vblue)|}.
When a graph G = (V, E) is given, the algorithm divides vertex set V into two sets, i.e., Vred and Vblue (Vred = , Vblue = V), and the initial value of the best solution of MLCP Cbest is set to 0. Next, a vertex is randomly selected in Vblue and moved from Vblue to Vred, here |Vred | = 1, Vblue = V\Vred. Then, the algorithm repeats a series of generations to explore the search space defined by the set of all 2-colorings. At each generation, based on sub-graph G‘(Vblue), choose a vertex w of the minimum degree (wVblue); if there are more than one vertex with the same minimum degree, randomly select a vertex among them. Then, add the vertex from Vblue to Vred, that is: Vred ← Vred{w}, Vblue ← Vblue\{w}, thus a new bipartition scheme (V‘red, V‘blue) is generated, and, when R2((V‘red,V‘blue)) > Cbest, the scheme is accepted as the best solution. The generation will be repeated until |Er(Vred)| > |Er(Vblue)|.
The algorithm runs iteratively as per the above steps until the stop condition is met.
The best solution found by the algorithm is
Rg((
Vred,
Vblue)), i.e.,
Here, t is the number of all solutions that can be found by the greedy algorithm in graph G, and (Vred, Vblue)j is the jth solution of MLCP.
The greedy algorithm is represented by Greedy (Algorithm 6).
| Algorithm 6 Greedy (G, Vred, Vblue). |
| Require: G: G = (V, E), |V| = n, |E| = l |
| Vred: a set of red vertices in graph G |
| Vblue: a set of blue vertices in graph G |
| Output: s4, the best solution found by greedy algorithm |
| R2(s4), value of the objective function |
| begin |
| 1 Cbest ←0; |
| 2 repeat |
| 3 Vred ←Ø, Vblue ← V; |
| 4 randomly select a vertex in Vblue and moved from Vblue to Vred; |
| 5 repeat |
| 6 (V’red, V’blue) ← (Vred, Vblue); |
| 7 if R2((V’red, V’blue)) > Cbest then s4 ← (V’red, V’blue), Cbest ← R2 ((V’red, V’blue)); |
| 8 select a vertex w with the minimum degree from sub-graph G‘(Vblue), if there are multiple vertices, select a vertex w randomly; |
| 9 Vred ← Vred ∪ {w}, Vblue ← Vblue\{w}; |
| 10 until |Er(Vred)| > |Er(Vblue)|; |
| 11 until stop condition is met; |
| 12 return s4, Cbest; /* Cbest is the value of the objective function R2 (s4) */ |
| end |
6. Experimental Results
All algorithms were programmed in C++, and run on a PC with Intel Pentium(R) G630 processor 2.70 GHz and 4 GB memory under Windows 7 (64 bits), and the test graphs adopted were the benchmark DIMACS proposed in [
5]. We compared the search results by using memetic algorithm, simulated annealing algorithm, and greedy algorithm. Then, the results of memetic algorithm were compared with those obtained from using artificial bee colony algorithm [
4], tabu search algorithm [
5] and variable neighborhood search algorithm [
5].
The first group of experiments was performed to adjust the key parameters and analyze their influence on Memetic_D_O_MLCP. As is known to all, the most important parameters in Memetic_D_O_MLCP implementations are the values of p and L, which determine the number of the individuals of the population and the tabu tenure value during the search process. To find the most suitable values of p and L for Memetic_D_O_MLCP approach to MLCP, we performed experiments with different values of p and L. Memetic_D_O_MLCP was run 10 times for each benchmark instance, and each test lasted 30 min.
The results of experiments are summarized in
Table 1, organized as follows: in the first column,
Inst the benchmark instance name is given, containing the vertices set
V; and, in the second column,
m is the initial number of red vertices in the benchmark graph. For each
p{4, 12, 20} and
L{10, 60, 90}, column
Best contains the best values of MLCP solution found by the algorithm, while column
Avg represents the average values of MLCP solution found by the algorithm. For each instance, the best values of
Best and
Avg are shown in italics. The analysis of the obtained results shows that values of
p and
L influence the solution quality. For example, the number of best values of
Best is 5 for combination
p = 12 and
L = 90;
Best 3 for
p = 4,
L = 90 and
p = 20,
L = 60;
Best 2 for
p = 4 and
L = 10,
p = 4 and
L = 60,
p = 12 and
L = 60;
Best 1 for
p = 20 and
L = 90;
Best 0 for
p = 12 and
L = 10,
p = 20 and
L = 10. Meanwhile, the number of best values of
Avg is 2 for combinations
p = 12 and
L = 90,
p = 4 and
L = 90;
Avg 1 for
p = 4 and
L = 10,
p = 4 and
L = 60,
p = 12 and
L = 60,
p = 20 and
L = 10,
p = 20 and
L = 60,
p = 20 and
L = 90.
In
Table 1, one observes that, for combination
p = 12 and
L = 90, the number of instances where the Memetic_D_O_MLCP achieved the best value for
Best and
Avg is 5 and 2, respectively. For all other combinations, these numbers are the biggest. Therefore, we used the combination in all other experiments.
The second groups of tests compared the search results of Memetic_D_O_MLCP, SA algorithm and Greedy algorithm, each having been run 20 times for each benchmark instance with the cut-off time of 30 min. In simulated annealing algorithm, the initial temperature
T0 is set at 1000, the cooling coefficient
α at 0.9999 and the end temperature
Tend at 0.0001. The results of experiments are summarized in
Table 2, organized as follows: in the second column, |
V| is the number of vertices; and, in the third column, |
E| is the number of edges. For each instance the best values of
Best are shown in italics. Among 59 instances, the search results of Memetic_D_O_MLCP, SA algorithm and Greedy algorithm were the same in the instances
myciel3.col,
myciel4.col,
queen5_5.col and
queen6_6.col. Memetic_D_O_MLCP and Greedy algorithm could find equivalent best value of four instances (i.e.,
queen7_7.col,
queen8_8.col,
queen8_12.col, and
queen9_9.col). In the remaining 51 instances, Memetic_D_O_MLCP could find the best results of 38 instances (accounting for 75%), and Greedy algorithm could find the best results of 13 instances (accounting for 25%). The experiments showed that Memetic_D_O_MLCP could find more instances of best values.
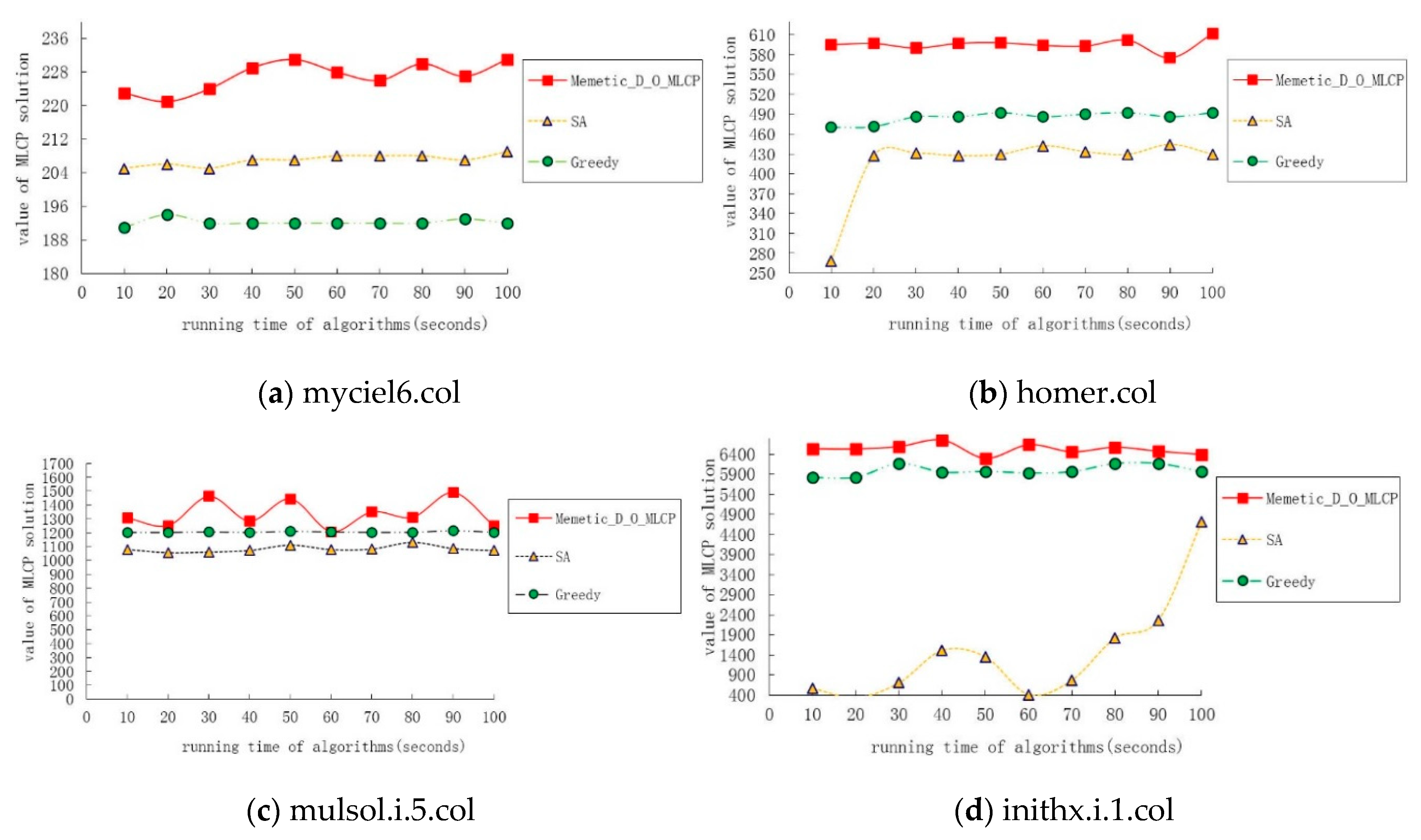
The third group of tests aimed at comparing the search results after each algorithm was run on four benchmark instances, namely myciel6.col, homer.col, mulsol.i.5.col and inithx.i.1.col, for the first one 100 s. The results that algorithms found were collected at an interval of 10 s. The running time was regarded as the X coordinate on the axis and the value of MLCP solution as the Y coordinate.
Figure 5 illustrates that Memetic_D_O_MLCP can find the best result at each time node.
The fourth group of tests compared the time each algorithm took to find the best results, each being run 20 times for 32 instances with the cut-off time of 30 min.
The results are summarized in
Table 3. Compared with SA algorithm and Greedy algorithm, it took less time for Memetic_D_O_MLCP to find the best results for the 11 instances (shown in italics). Accounting for 34% in the total, these 11 instances were:
fpsol2.i.2.col,
huck.col,
mulsol.i.3.col,
mulsol.i.4.col,
mulsol.i.5.col,
myciel6.col,
queen10_10.col,
queen11_11.col,
queen15_15.col,
inithx.i.3.col, and
zeroin.i.2.col. For six instances, namely
david.col,
DSJC125.9.col,
games120.col,
miles250.col,
miles750.col, and
jean.col, which accounted for 19% in the total, the time spent by Memetic_D_O_MLCP and Greedy algorithm showed little difference. Additionally, the former found better results than the latter. For the remaining 15 instances, although the time taken by Memetic_D_O_MLCP was longer than that by Greedy algorithm, as it consumed more time for executing the operations of data splitting, searching, evolution and disturbance, the results found by the former were better than those by the latter. Of all 32 instances, comparing with Memetic_D_O_MLCP, SA algorithm spent more time to find the best results; besides, the
Best SA algorithm results were inferior.
The comparison between Memetic_D_O_MLCP and artificial bee colony (ABC) algorithm [
4] is summarized in
Table 4. For each instance, the best values of
Best are shown in italics. Of all 21 instances proposed in [
4], except that the search results of instances
myciel3.col and
myciel4.col were equivalent to that of artificial bee colony algorithm, Memetic_D_O_MLCP found better results (accounting for 90%) and improved the best-known result of instance
myciel5.col.
Furthermore, we compared the search results from Memetic_D_O_MLCP, tabu search (Tabu) algorithm [
5] and variable neighborhood search (VNS) algorithm [
5]; the results are shown in
Table 5 (the algorithms in the literature were run 20 times, each lasting 30 min for each benchmark instance). Memetic_D_O_MLCP could find the best results of 26 instances (shown in italics), in which the best results of 11 instances equaled those found by Tabu algorithm. Hence, Memetic_D_O_MLCP could improve the best-known results of the remaining 15 instances. Besides, of the 53 instances in
Table 5, the best results of 22 instances found by Memetic_D_O_MLCP were better than those by Tabu algorithm, and the best results of 42 instances found by Memetic_D_O_MLCP were better than that of VNS algorithm.
7. Conclusions
In this paper, we propose a memetic algorithm (Memetic_D_O_MLCP) to deal with the minimum load coloring problem. The algorithm employs an improved K-OPT local search procedure with a combination of data splitting operation, disturbance operation and a population evolutionary operation to assure the quality of the search results and intensify the searching ability.
We assessed the performance of our algorithm on 59 well-known graphs from the benchmark DIMACS competitions. The algorithm could find the best results of 46 graphs. Compared with simulated annealing algorithm and greedy algorithm, which cover the best results for the tested instances, our algorithm was more competent.
In addition, we investigated the artificial bee colony algorithm, variable neighborhood search algorithm and tabu search algorithm proposed in the literature. We carried out comparative experiments between our algorithm and artificial bee colony algorithm using 21 benchmark graphs, and the experiments showed that the algorithm’s best results of 19 benchmark graphs were better than those of artificial bee colony algorithm, and the best-known result of one benchmark graph was improved by our algorithm. More experiments were conducted to compare our algorithm with tabu search algorithm and variable neighborhood search algorithm, and proved that the best-known results of 15 benchmark graphs were improved by our algorithm.
Finally, we showed that the proposed Memetic_D_O_MLCP approach significantly improved the classical heuristic search approach for the minimum load coloring problem.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}