Spectrally Sparse Tensor Reconstruction in Optical Coherence Tomography Using Nuclear Norm Penalisation


Abstract
:1. Introduction
1.1. Motivations and Contributions
- the 3D tensors are considered as matrix of 1D vectors (tubes) and the approach uses a tensor product similar to the classical matrix product, after replacing multiplication of entries by, for example, convolution of the tubes,
- the SVD is fast to compute,
- a specific and natural nuclear norm can be easily defined.
- to present the most natural definition of the nuclear norm in the framework of Reference [10],
- to compute the subdifferential of this nuclear norm,
- to present a precise mathematical study of the nuclear norm penalised least-squares reconstruction method,
- to illustrate the efficiency of the approach on the OCT reconstruction problem with real data.
1.2. Background on Tensor Completion
1.2.1. Matrix Completion
1.2.2. Tensor Completion
1.3. Sparsity
1.4. Plan of the Paper
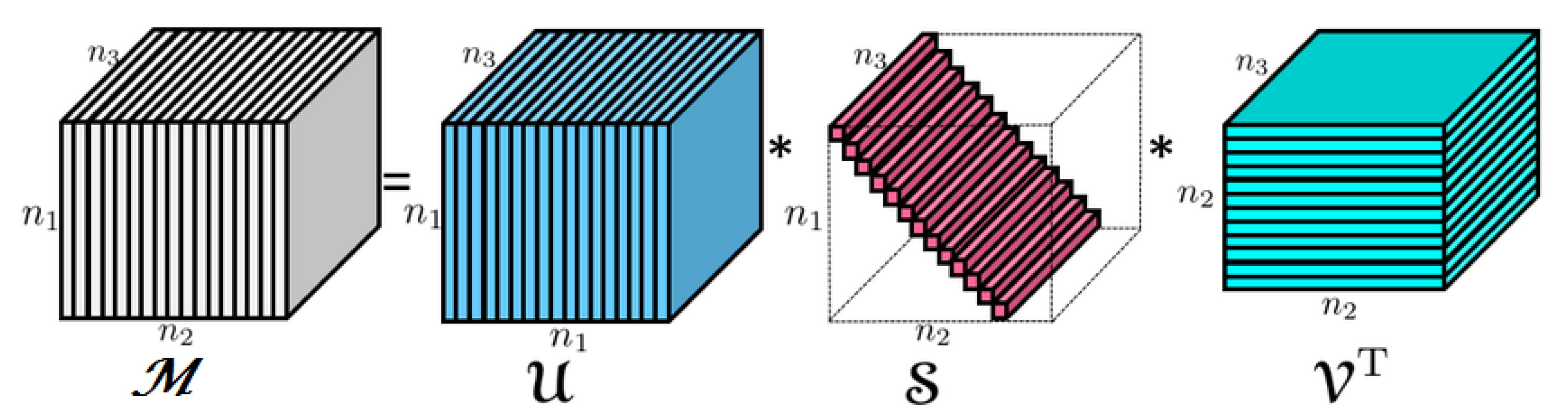
2. Background on Tensors, t-SVD
2.1. Basic Notations for Third-Order Tensor
2.1.1. Slices and Transposition
2.1.2. Convolution and Fourier Transform
2.2. The t-SVD
2.3. Some Natural Tensor Norms
2.4. Rank, Range and Kernel
3. Measurement Model and the Estimator
3.1. The Observation Model
3.2. The Estimator
4. Main Results
4.1. Preliminary Remarks
4.1.1. Orthogonal Invariance
4.1.2. Support of a Tensor
- is the linear span of and
- is the linear span of .
4.2. The Subdifferential of the t-nuclear Norm
4.2.1. Von-Neumann’s Inequality for Tubal Tensors
4.2.2. Lewis’s Characterization of the Subdifferential
4.3. Error Bound
5. Numerical Experiments
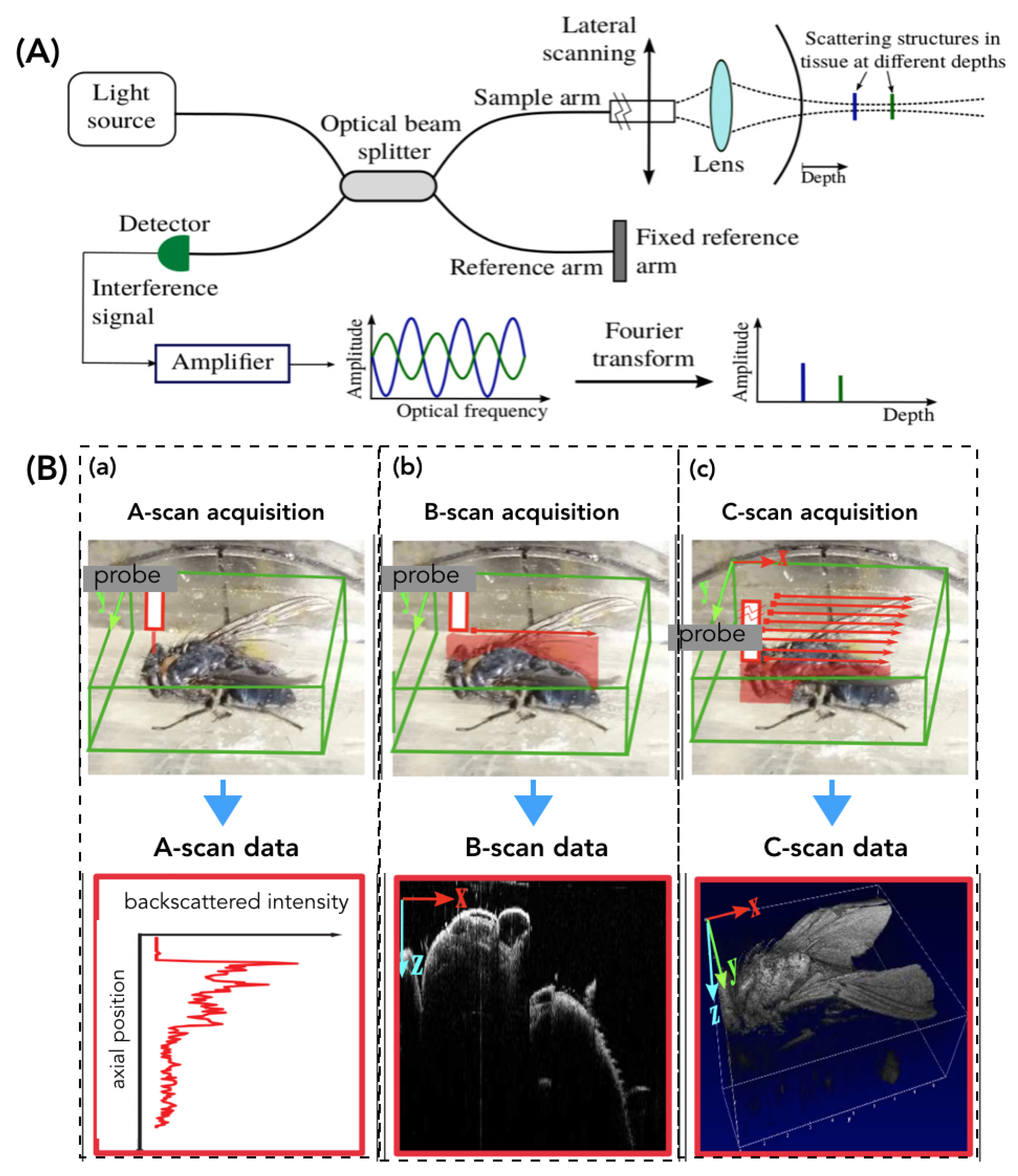
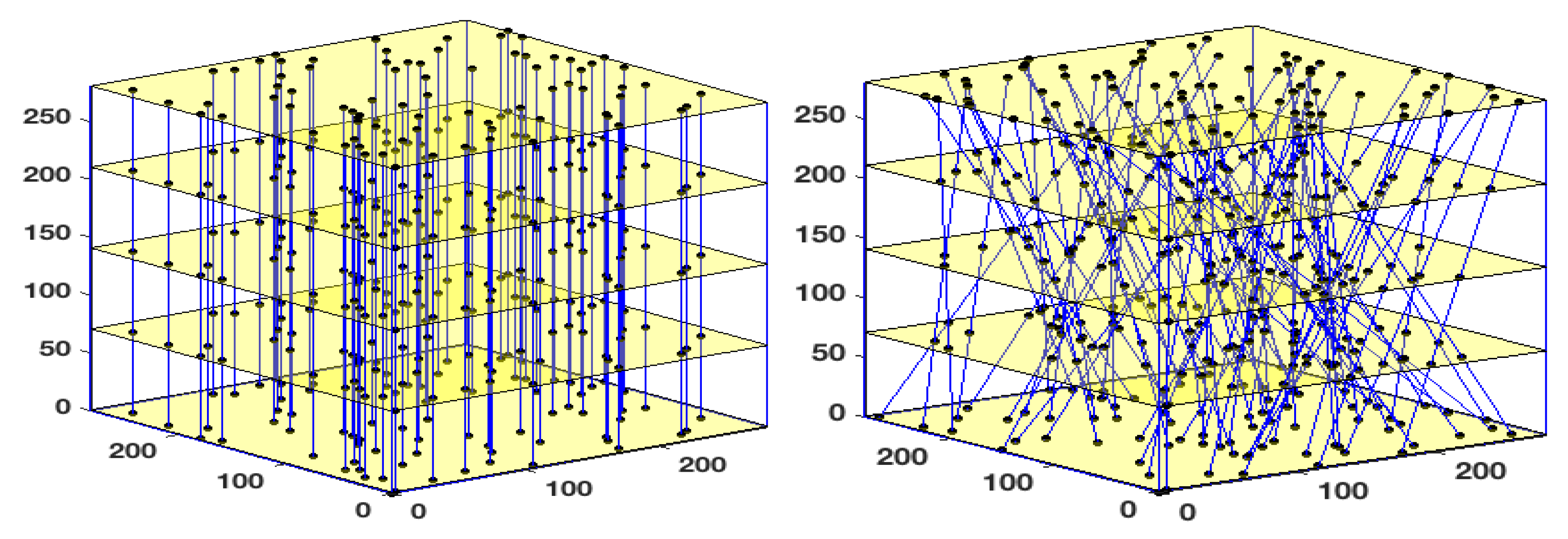
5.1. Benefits of Subsampling for OCT
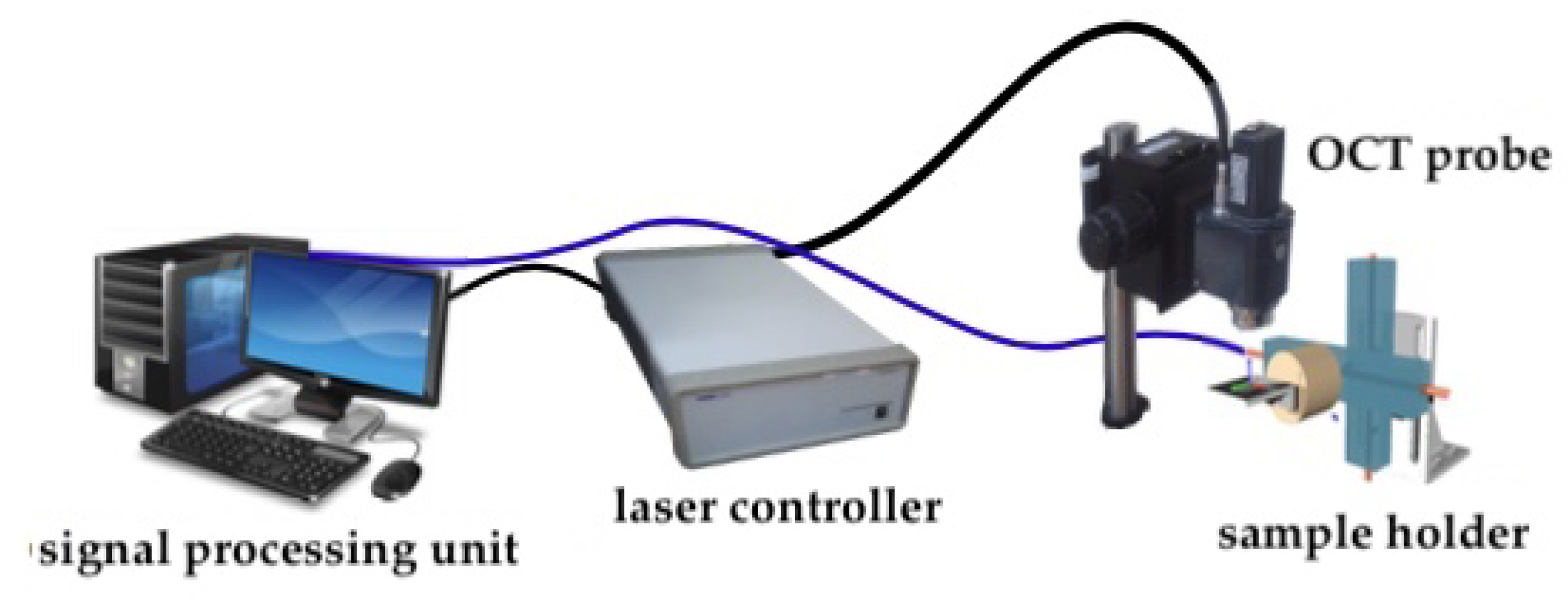
5.2. Experimental Set-Up
5.3. Validation Scenario
5.4. Obtained Results
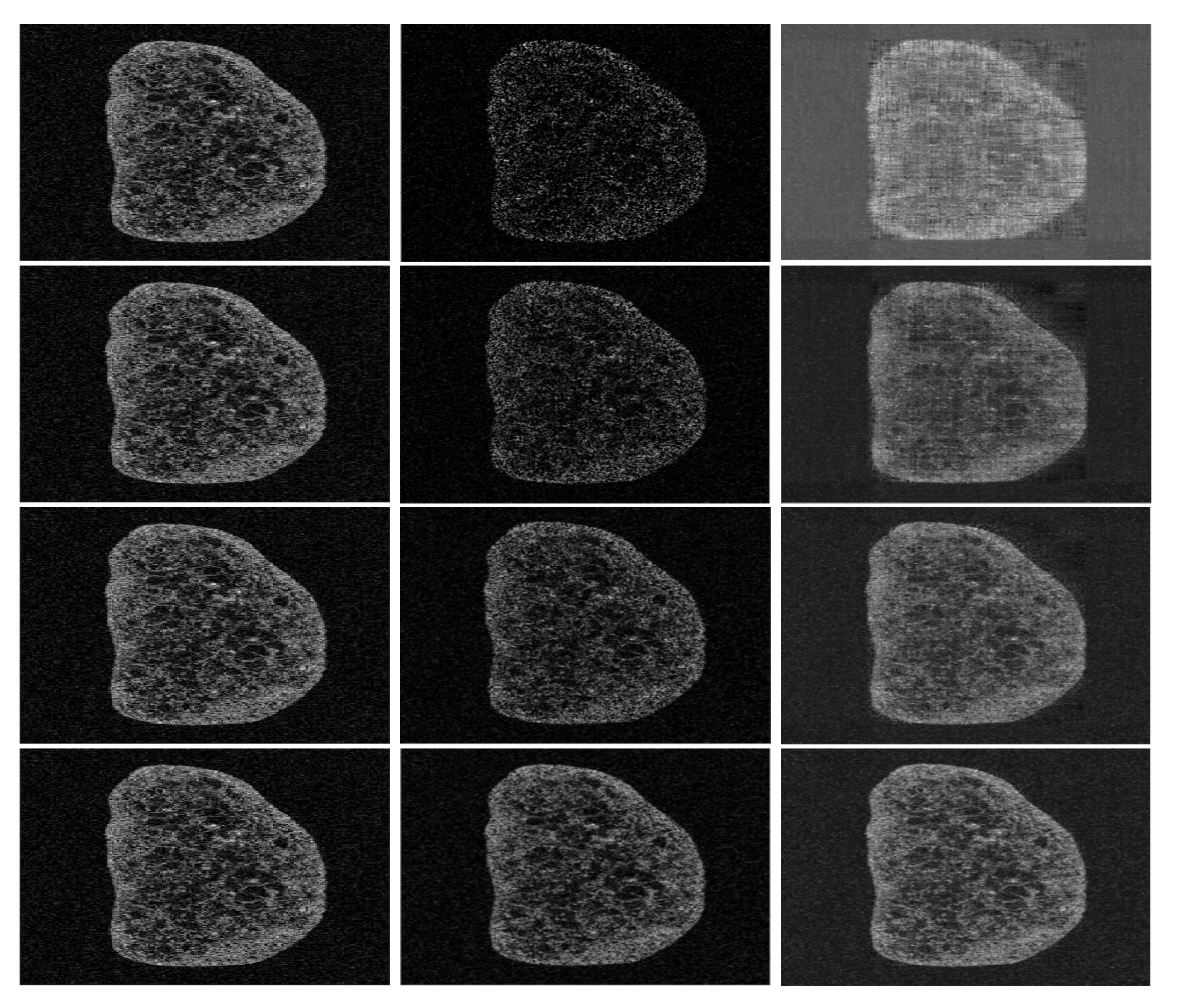
5.4.1. Grape Sample
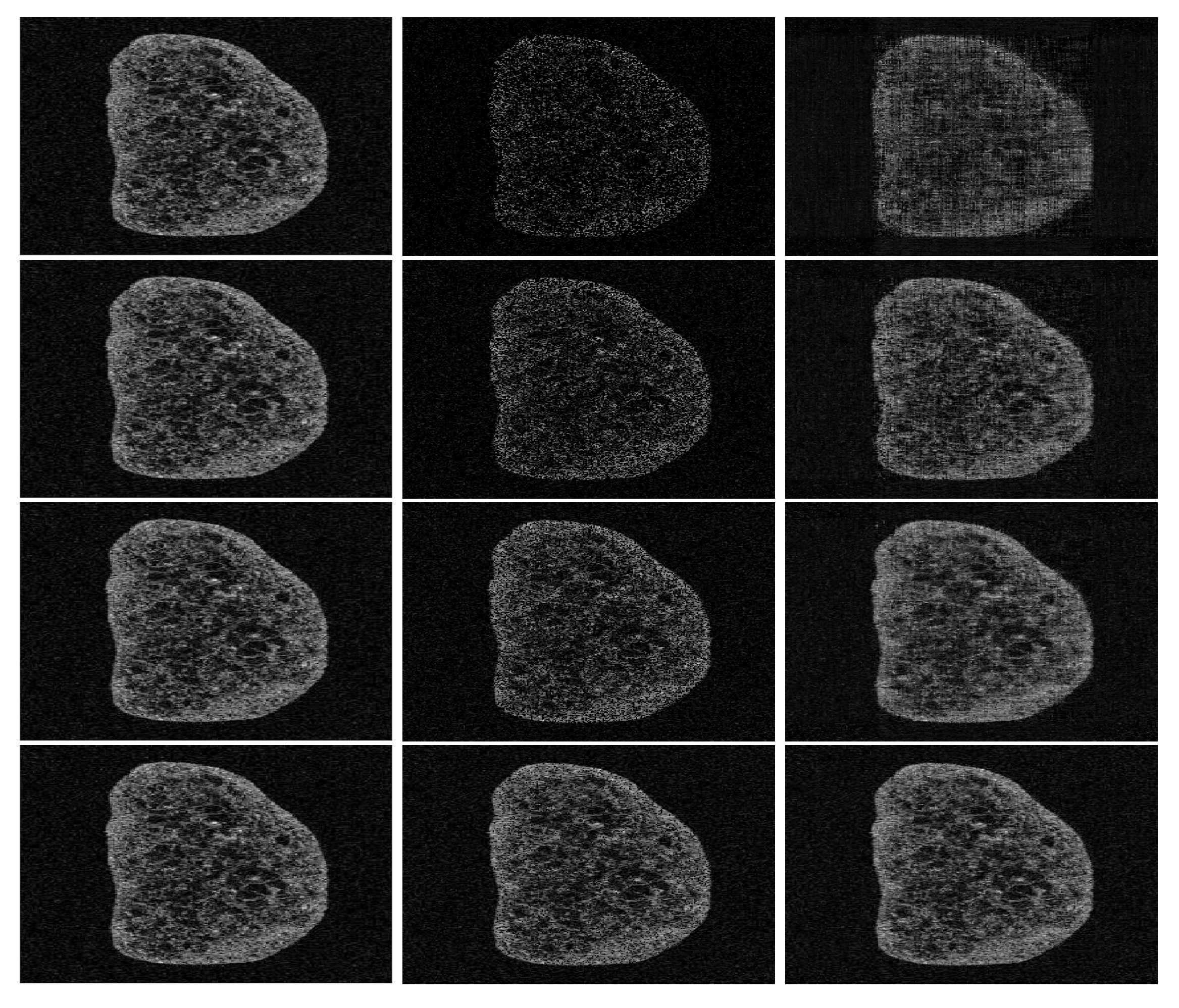
5.4.2. Fish Eye Sample
5.5. The Singular Value Thresholding Algorithm
- a singular value thresholding step where all tubal singular values with norm below the level are set to zero and the remaining larger singular values are being removed an offset .
- a relaxed gradient step.
- compute the circular Fourier transform of the tubal components of ,
- compute the SVD of all the slices of and forms the tubal singular values,
- sets to zero the tubal singular values whose -norm lies below the level and shrink the other by ,
- recompose the spectrally thresholded matrix and take the inverse Fourier transform of the tubal components.
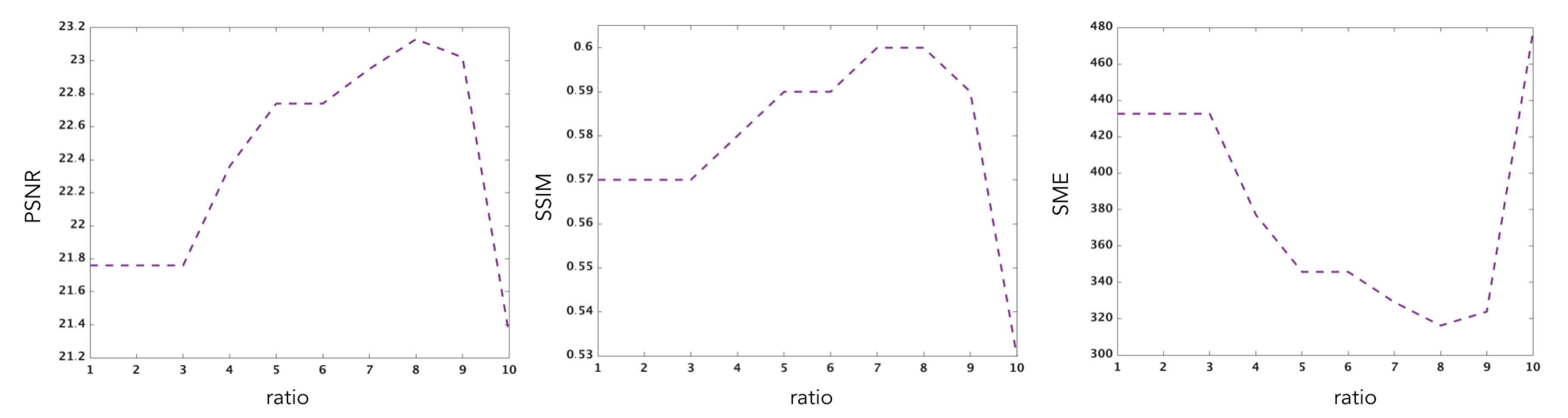
5.6. Analysis of the Numerical Results
- the Peak Signal Noise Ratio (PSNR) computed as followswhere d is the maximal pixel value in the initial OCT image and the (mean-squared error) is obtained bywith and represent an initial 2D OCT slice (selected from the OCT volume) and the recovered one, respectively.
- The second image similarity score consists of the Structural Similarity Index (SIMM) which allows measuring the degree of similarity between two images. It is based on the computation of three values namely the luminance l, the contrast c and the structural aspect s. It is given bywhere,with , , , , and are the local means, standard deviations, and cross-covariance for images , . The variables , , are used to stabilize the division with weak denominator.
5.6.1. Illustrating the Rôle of the Nuclear Norm Penalisation
5.6.2. Performance Results
6. Conclusions and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Some Technical Results
Appendix A.1. Calculation of ρ and a value of λ such that ‖M‖S∞ ≤ λ with high probability
Appendix A.1.1. Computation of ρ
Appendix A.1.2. Control of the Stochastic Error ‖M‖S∞
- andUsing the duality trace and Jensen’s inequality, we have
References
- Candès, E.J. Mathematics of sparsity (and a few other things). In Proceedings of the International Congress of Mathematicians, Seoul, Korea, 13–21 August 2014. [Google Scholar]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef] [Green Version]
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef] [Green Version]
- Hackbusch, W. Tensor Spaces and Numerical Tensor Calculus; Springer Science & Business Media: Berlin, Germany, 2012; Volume 42. [Google Scholar]
- Landsberg, J.M. Tensors: Geometry and Applications; American Mathematical Society: Providence, RI, USA, 2012; Volume 128. [Google Scholar]
- Sacchi, M.D.; Gao, J.; Stanton, A.; Cheng, J. Tensor Factorization and its Application to Multidimensional Seismic Data Recovery. In SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Houston, TX, USA, 2015. [Google Scholar]
- Yuan, M.; Zhang, C.H. On tensor completion via nuclear norm minimization. Found. Comput. Math. 2016, 16, 1031–1068. [Google Scholar] [CrossRef] [Green Version]
- Signoretto, M.; Van de Plas, R.; De Moor, B.; Suykens, J.A. Tensor versus matrix completion: A comparison with application to spectral data. Signal Process. Lett. IEEE 2011, 18, 403–406. [Google Scholar] [CrossRef]
- Kilmer, M.E.; Martin, C.D. Factorization strategies for third-order tensors. Linear Algebra Its Appl. 2011, 435, 641–658. [Google Scholar] [CrossRef] [Green Version]
- Kilmer, M.E.; Braman, K.; Hao, N.; Hoover, R.C. Third-order tensors as operators on matrices: A theoretical and computational framework with applications in imaging. SIAM J. Matrix Anal. Appl. 2013, 34, 148–172. [Google Scholar] [CrossRef] [Green Version]
- Koltchinskii, V.; Lounici, K.; Tsybakov, A.B. Nuclear-norm penalization and optimal rates for noisy low-rank matrix completion. Ann. Stat. 2011, 39, 2302–2329. [Google Scholar] [CrossRef]
- Candes, E.J.; Plan, Y. Matrix completion with noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef] [Green Version]
- Anandkumar, A.; Ge, R.; Hsu, D.; Kakade, S.M.; Telgarsky, M. Tensor decompositions for learning latent variable models. J. Mach. Learn. Res. 2014, 15, 2773–2832. [Google Scholar]
- Signoretto, M.; Dinh, Q.T.; De Lathauwer, L.; Suykens, J.A. Learning with tensors: A framework based on convex optimization and spectral regularization. Mach. Learn. 2014, 94, 303–351. [Google Scholar] [CrossRef] [Green Version]
- So, A.M.C.; Ye, Y. Theory of semidefinite programming for sensor network localization. Math. Program. 2007, 109, 367–384. [Google Scholar] [CrossRef]
- Eriksson, B.; Balzano, L.; Nowak, R. High-rank matrix completion and subspace clustering with missing data. arXiv 2011, arXiv:1112.5629. [Google Scholar]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef] [Green Version]
- Singer, A.; Cucuringu, M. Uniqueness of low-rank matrix completion by rigidity theory. SIAM J. Matrix Anal. Appl. 2010, 31, 1621–1641. [Google Scholar] [CrossRef] [Green Version]
- Fazel, M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2002. [Google Scholar]
- Gross, D. Recovering low-rank matrices from few coefficients in any basis. Inf. Theory IEEE Trans. 2011, 57, 1548–1566. [Google Scholar] [CrossRef] [Green Version]
- Recht, B. A simpler approach to matrix completion. J. Mach. Learn. Res. 2011, 12, 3413–3430. [Google Scholar]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. Inf. Theory IEEE Trans. 2010, 56, 2053–2080. [Google Scholar] [CrossRef] [Green Version]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- McCullagh, P. Tensor Methods in Statistics; Chapman and Hall: London, UK, 1987; Volume 161. [Google Scholar]
- Rogers, M.; Li, L.; Russell, S.J. Multilinear Dynamical Systems for Tensor Time Series. Adv. Neural Inf. Process. Syst. 2013, 26, 2634–2642. [Google Scholar]
- Ge, R.; Huang, Q.; Kakade, S.M. Learning mixtures of gaussians in high dimensions. arXiv 2015, arXiv:1503.00424. [Google Scholar]
- Mossel, E.; Roch, S. Learning nonsingular phylogenies and hidden Markov models. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, Baltimore, MD, USA, 22–24 May 2005; pp. 366–375. [Google Scholar]
- Jennrich, R. A generalization of the multidimensional scaling model of Carroll and Chang. UCLA Work. Pap. Phon. 1972, 22, 45–47. [Google Scholar]
- Kroonenberg, P.M.; De Leeuw, J. Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 1980, 45, 69–97. [Google Scholar] [CrossRef]
- Bhaskara, A.; Charikar, M.; Moitra, A.; Vijayaraghavan, A. Smoothed analysis of tensor decompositions. In Proceedings of the 46th Annual ACM Symposium on Theory of Computing, New York, NY, USA, 1–3 June 2014; pp. 594–603. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Kolda, T.G. Symmetric Orthogonal Tensor Decomposition is Trivial. arXiv 2015, arXiv:1503.01375. [Google Scholar]
- Robeva, E.; Seigal, A. Singular Vectors of Orthogonally Decomposable Tensors. arXiv 2016, arXiv:1603.09004. [Google Scholar] [CrossRef] [Green Version]
- Hao, N.; Kilmer, M.E.; Braman, K.; Hoover, R.C. Facial recognition using tensor-tensor decompositions. SIAM J. Imaging Sci. 2013, 6, 437–463. [Google Scholar] [CrossRef]
- Semerci, O.; Hao, N.; Kilmer, M.E.; Miller, E.L. Tensor-based formulation and nuclear norm regularization for multienergy computed tomography. Image Process. IEEE Trans. 2014, 23, 1678–1693. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Aeron, S. Exact tensor completion using t-svd. IEEE Trans. Signal Process. 2017, 65, 1511–1526. [Google Scholar] [CrossRef]
- Pothier, J.; Girson, J.; Aeron, S. An algorithm for online tensor prediction. arXiv 2015, arXiv:1507.07974. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Candès, E.J.; Plan, Y. Near-ideal model selection by l1 minimization. Ann. Stat. 2009, 37, 2145–2177. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Gaïffas, S.; Lecué, G. Weighted algorithms for compressed sensing and matrix completion. arXiv 2011, arXiv:1107.1638. [Google Scholar]
- Xu, Y. On Higher-order Singular Value Decomposition from Incomplete Data. arXiv 2014, arXiv:1411.4324. [Google Scholar]
- Raskutti, G.; Yuan, M. Convex Regularization for High-Dimensional Tensor Regression. arXiv 2015, arXiv:1512.01215. [Google Scholar] [CrossRef] [Green Version]
- Barak, B.; Moitra, A. Noisy Tensor Completion via the Sum-of-Squares Hierarchy. arXiv 2015, arXiv:1501.06521. [Google Scholar]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef] [Green Version]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square Deal: Lower Bounds and Improved Convex Relaxations for Tensor Recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Amelunxen, D.; Lotz, M.; McCoy, M.B.; Tropp, J.A. Living on the edge: Phase transitions in convex programs with random data. Inf. Inference 2014, 3, 224–294. [Google Scholar] [CrossRef]
- Lecué, G.; Mendelson, S. Regularization and the small-ball method I: Sparse recovery. arXiv 2016, arXiv:1601.05584. [Google Scholar] [CrossRef] [Green Version]
- Watson, G.A. Characterization of the subdifferential of some matrix norms. Linear Algebra Its Appl. 1992, 170, 33–45. [Google Scholar] [CrossRef] [Green Version]
- Lewis, A.S. The convex analysis of unitarily invariant matrix functions. J. Convex Anal. 1995, 2, 173–183. [Google Scholar]
- Hu, S. Relations of the nuclear norm of a tensor and its matrix flattenings. Linear Algebra Its Appl. 2015, 478, 188–199. [Google Scholar] [CrossRef]
- Chrétien, S.; Wei, T. Von Neumann’s inequality for tensors. arXiv 2015, arXiv:1502.01616. [Google Scholar]
- Chrétien, S.; Wei, T. On the subdifferential of symmetric convex functions of the spectrum for symmetric and orthogonally decomposable tensors. Linear Algebra Its Appl. 2018, 542, 84–100. [Google Scholar] [CrossRef] [Green Version]
- Heinze, H.; Bauschke, P.L. Convex Analysis and Monotone Operator Theory in Hilbert Spaces; Canada Mathematical Society: Ottawa, ON, Canada, 2011. [Google Scholar]
- Borwein, J.; Lewis, A.S. Convex Analysis and Nonlinear Optimization: Theory and Examples; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Jean-Pierre Aubin, I.E. Applied Nonlinear Analysis; Dover Publications: Mineola, NY, USA, 2006; Volume 518. [Google Scholar]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Chrétien, S.; Lohvithee, M.; Sun, W.; Soleimani, M. Efficient hyper-parameter selection in Total Variation- penalised XCT reconstruction using Freund and Shapire’s Hedge approach. Mathematics 2020, 8, 493. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Qin, J.; Yin, W. A new detail-preserving regularization scheme. SIAM J. Imaging Sci. 2014, 7, 1309–1334. [Google Scholar] [CrossRef]
- Tropp, J.A. User-Frindly tail bounds for sums of random matrices. arXiv 2010, arXiv:1004.4389v7. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ratio | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| SME | 432.65 | 432.65 | 432.65 | 377.12 | 345.76 | 345.75 | 329.06 | 316.23 | 323.87 | 477.43 |
| PSNR | 21.76 | 21.76 | 21.76 | 22.36 | 22.74 | 22.74 | 22.95 | 23.13 | 23.02 | 21.34 |
| SSIM | 0.57 | 0.57 | 0.57 | 0.58 | 0.59 | 0.59 | 0.60 | 0.60 | 0.59 | 0.53 |
| Sample: Part of a Grape | ||||
|---|---|---|---|---|
| under-sampling rates | 30% | 50% | 70% | 90% |
| vertical masks | ||||
| MSE PSNR SSIM | 536.68 20.83 0.39 | 316.23 23.13 0.59 | 185.83 25.43 0.77 | 62.34 30.18 0.92 |
| oblic masks | ||||
| MSE PSNR SSIM | 725.20 19.52 0.34 | 431.91 21.77 0.55 | 171.52 25.78 0.78 | 54.85 30.73 0.93 |
| Sample: Fish Eye Retina | ||||
|---|---|---|---|---|
| under-sampling rates | 30% | 50% | 70% | 90% |
| vertical masks | ||||
| MSE PSNR SSIM | 829.96 18.94 000.51 | 570.81 20.56 0.65 | 333.13 22.50 0.78 | 109.65 27.73 0.91 |
| oblic masks | ||||
| MSE PSNR SSIM | 828.56 18.94 0.51 | 575.90 20.52 0.65 | 344.12 22.76 0.77 | 99.13 28.16 0.92 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Assoweh, M.I.; Chrétien, S.; Tamadazte, B. Spectrally Sparse Tensor Reconstruction in Optical Coherence Tomography Using Nuclear Norm Penalisation. Mathematics 2020, 8, 628. https://doi.org/10.3390/math8040628
Assoweh MI, Chrétien S, Tamadazte B. Spectrally Sparse Tensor Reconstruction in Optical Coherence Tomography Using Nuclear Norm Penalisation. Mathematics. 2020; 8(4):628. https://doi.org/10.3390/math8040628
Chicago/Turabian StyleAssoweh, Mohamed Ibrahim, Stéphane Chrétien, and Brahim Tamadazte. 2020. "Spectrally Sparse Tensor Reconstruction in Optical Coherence Tomography Using Nuclear Norm Penalisation" Mathematics 8, no. 4: 628. https://doi.org/10.3390/math8040628
APA StyleAssoweh, M. I., Chrétien, S., & Tamadazte, B. (2020). Spectrally Sparse Tensor Reconstruction in Optical Coherence Tomography Using Nuclear Norm Penalisation. Mathematics, 8(4), 628. https://doi.org/10.3390/math8040628