Decision Trees for Evaluation of Mathematical Competencies in the Higher Education: A Case Study


Abstract
:1. Introduction
2. Materials and Methods
2.1. Proposed Assessment Test
2.2. Data
2.3. Methods
2.3.1. Initial Processing of the Data
- Investigation of the difficulty of the problems. The difficulty coefficient is determined by the percentage of correct solutions. MCT problems with a choice of 4 distractors are considered to be difficult if the coefficient of difficulty is between 0 and 73, and easy if the coefficient is between 74 and 100 [32]. The same rule is applied for both problems P1 and P2. The difficulty of the test is evaluated as a percentage of the mean value of Score against the maximum possible number of points—in this case, 12.
- The level of mathematical competencies acquired by the student (variable Competency). It is assessed by using 3 levels. The following assessment is used for this test: low level—when the total number of points for the student is compared against the maximum number of points, rated against the level difficulty of the problem between 0 and 27; mean—between 28 and 73; and high—between 74 and 100.
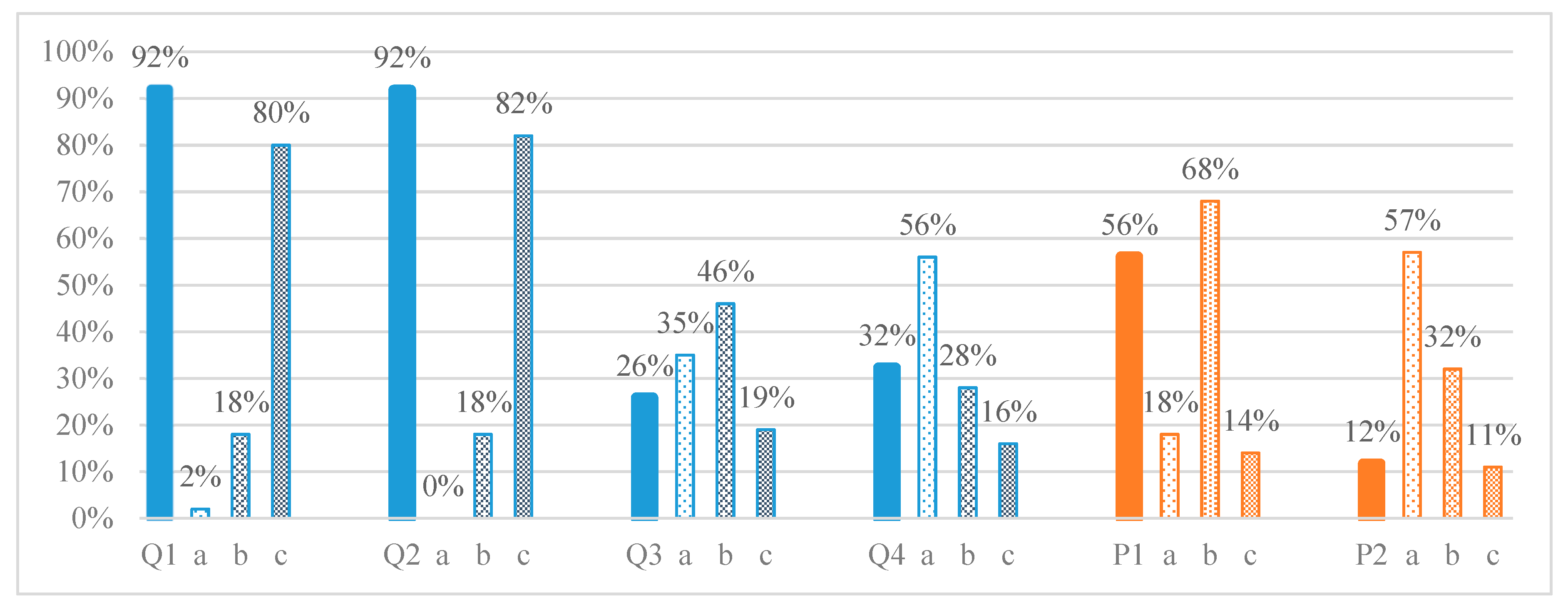
- Descriptive statistics of survey data. Student opinions for S1, S2, S3, and S4 are processed through comparison with the achieved results for the solution of the problems, using a cross-table. The answers are coded as follows: (a) 1 point, (b) 2 points and (c) 3 points. It needs to be noted that some opinions are also given in cases where problems have not been solved or there are no opinions for problems which have been solved. This is reflected in the processing of the data.
2.3.2. Statistical Analyses
Short Description of CART
Performed Statistical Analyses
- CART regression for determining the dependency of Score on the obtained scores of all problems of the test, on the responses to the survey, and on both groups of variables together. Assessment of the importance of variables in the regression model.
- CART classification for assessment of Competency depending on the obtained scores of all problems of the test, the responses to the survey, and both groups of variables together.
- Determining the reliability of the test by calculating Cronbach’s alpha coefficients.
- Studying the influence of the category Sex on the results of the Score and Competency using T-test.
3. Results of the Initial Processing of the Data with Discussion
3.1. Problem Difficulty
3.2. Assessment of the Level of Acquired Mathematical Competencies, Measured by the Test
- Low level of competency (0% to 27%)—9 students;
- Medium level of competency (28%–73%)—48 students;
- High level of competency (74%–100%)—5 students.
3.3. Cross-Analysis of the Survey
4. Results of Statistical Analyses with CART with Discussion
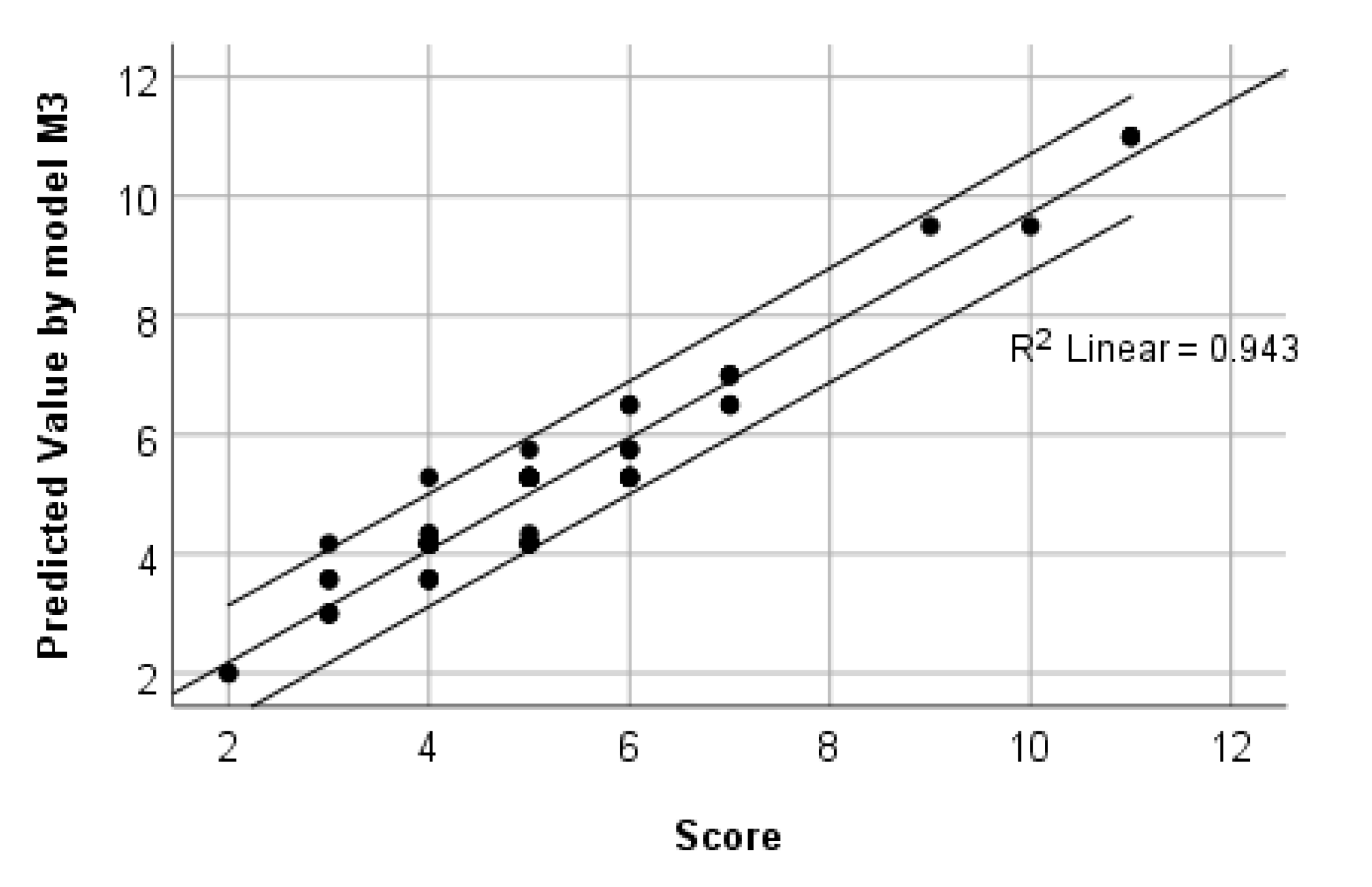
4.1. Regression Models of Score Using CART
4.2. Assessment of Competency through Classification Models Using CART
4.3. Reliability of Survey Data
4.4. Study of the Influence of Gender of the Student
5. Conclusions
- A three-level scale was introduced to assess both the acquired knowledge and the mathematical competencies of students.
- Through cross-analysis of the collected data, the power of the distractors of the test was estimated and a relatively good match was found between these and the responses of the self-assessment questions in the survey. This can be applied in practice, to adjust and improve test design.
- By applying the powerful and flexible CART technique, four regression models were built to examine student knowledge, using a target variable Score and four CART models for assessment of the mathematical competencies, using target Competency. The influence of a total of 31 predictor variables is measured in these models, with predictors divided into four groups. Classification models of Competency indicate very good accuracy with correct classifications of 83.3% up to 91.9% in individual models. Therefore, it can be assumed that the degree of influence of the factors is very close to the actual one. For CART regression models of Score data, fitting is up to 94.3%. Only for the model of Score with predictors from the survey alone, fitting is 75%. The practical benefit from the CART models built lies also in the fact that the weight/importance of individual factors, which approximate with high-accuracy Score and Competency are determined explicitly. This makes it possible to draw the correct conclusions and to take subsequent actions both by teachers and by students, and also at the university level, in order to improve the teaching process and its results.
- It is confirmed that there is internal consistency of the survey questions by using reliability Cronbach’s alpha coefficients.
- Using T-test and CART models, it is found that gender is not a significant factor for test results.
Funding
Acknowledgments
Conflicts of Interest
References
- White, R.W. Motivation reconsidered: The concept of competence. Psychol. Rev. 1959, 66, 297–333. [Google Scholar] [CrossRef]
- Abrantes, P. Mathematical competence for all: Options, implications and obstacles. Educ. Stud. Math. 2001, 47, 125–143. [Google Scholar] [CrossRef]
- Niss, M. Mathematical Competencies and the Learning of Mathematics: The Danish KOM Project. In Proceedings of the 3rd Mediterranean Conference on Mathematical Education, Athens, Greece, 3–5 January 2003; The Hellenic Mathematical Society: Athens, Greece; pp. 115–124. Available online: http://www.math.chalmers.se/Math/Grundutb/CTH/mve375/1112/docs/KOMkompetenser.pdf (accessed on 20 March 2020).
- Alpers, B.A.; Demlova, M.; Fant, C.-H.; Gustafsson, T.; Lawson, D.; Leslie Mustoe, L.; Olsen- Lehtonen, B.; Robinson, C.; Velichova, D. A Framework for Mathematics Curricula in Engineering Education: A Report of the Mathematics Working Group; European Society for Engineering Education (SEFI): Brussels, Belgium, 2013; Available online: http://sefi.htw-aalen.de/Curriculum/Competency%20based%20curriculum%20incl%20ads.pdf (accessed on 20 March 2020).
- Niss, M.; Højgaard, T. Mathematical Competencies in Mathematics Education; Springer: New York, NY, USA, 2019. [Google Scholar]
- Queiruga-Dios, A.; Sanchez, M.J.S.; Perez, J.J.B.; Martin-Vaquero, J.; Encinas, A.H.; Gocheva-Ilieva, S.; Demlova, M.; Rasteiro, D.D.; Caridade, C.; Gayoso-Martinez, V. Evaluating Engineering Competencies: A New Paradigm. In Proceedings of the Global Engineering Education Conference (EDUCON), Tenerife, Spain, 17–20 April 2018; IEEE: New York, NY, USA, 2018; pp. 2052–2055. [Google Scholar] [CrossRef]
- Caridade, C.M.; Encinas, A.H.; Martín-Vaquero, J.; Queiruga-Dios, A.; Rasteiro, D.M. Project-based teaching in calculus courses: Estimation of the surface and perimeter of the Iberian Peninsula. Comput. Appl. Eng. Educ. 2018, 26, 1350–1361. [Google Scholar] [CrossRef]
- Kulina, H.; Gocheva-Ilieva, S.; Voynikova, D.; Atanasova, P.; Ivanov, A.; Iliev, A. Integrating of Competences in Mathematics through Software-Case Study. In Proceedings of the Global Engineering Education Conference (EDUCON), Tenerife, Spain, 17–20 April 2018; IEEE: New York, NY, USA, 2018; pp. 1586–1590. [Google Scholar] [CrossRef]
- Gocheva-Ilieva, S.; Teofilova, M.; Iliev, A.; Kulina, H.; Voynikova, D.; Ivanov, A.; Atanasova, P. Data mining for statistical evaluation of summative and competency-based assessments in mathematics. In Advances in Intelligent Systems and Computing; Martínez Álvarez, F., Troncoso, L.A., Sáez Muñoz, J., Quintián, H., Corchado, E., Eds.; Springer: Cham, Switzerland, 2020; Volume 951, pp. 207–216. [Google Scholar] [CrossRef]
- Queiruga-Dios, A.; Sánchez, M.J.S.; Queiruga-Dios, M.; Gayoso-Martínez, V.; Encinas, A.H. A virus infected your laptop. Let’s play an escape game. Mathematics 2020, 8, 166. [Google Scholar] [CrossRef] [Green Version]
- Carr, M.; Brian, B.; Fhloinn, E.N. Core skills assessment to improve mathematical competency. Eur. J. Eng. Educ. 2013, 38, 608–619. [Google Scholar] [CrossRef]
- Ehmke, T.; van den Ham, A.-K.; Sälzer, C.; Heine, J.; Prenzel, M. Measuring mathematics competence in international and national large scale assessments: Linking PISA and the national educational panel study in Germany. Stud. Educ. Eval. 2020, 65, 100847. [Google Scholar] [CrossRef]
- Mat, U.B.; Buniyamin, N. Using neuro-fuzzy technique to classify and predict electrical engineering students’ achievement upon graduation based on mathematics competency. Indones. J. Electr. Eng. Comput. Sci. 2017, 5, 684–690. Available online: http://ijeecs.iaescore.com/index.php/IJEECS/article/download/6523/6260 (accessed on 20 March 2020).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2011. [Google Scholar]
- Mesarić, J.; Šebalj, D. Decision trees for predicting the academic success of students. Croat. Oper. Res. Rev. 2016, 7, 367–388. [Google Scholar] [CrossRef] [Green Version]
- Mueen, A.; Zafar, B.; Manzoor, U. Modeling and predicting students’ academic performance using data mining techniques. Int. J. Mod. Educ. Comp. Sci. 2016, 8, 36–42. [Google Scholar] [CrossRef]
- Jain, A.; Choudhury, T.; Mor, P.; Sabitha, A.S. Intellectual performance analysis of students by comparing various data mining techniques. In Proceedings of the 3rd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Tumkur, India, 21–23 December 2017; IEEE Press: Singapore; Shah Alam, Malaysia, 2017; pp. 57–62. [Google Scholar] [CrossRef]
- Adekitan, A.I.; Salau, O. The impact of engineering students’ performance in the first three years on their graduation result using educational data mining. Heliyon 2019, 5, e01250. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Pandey, G.N.; Tiwari, M.D. Data mining in education: Data classification and decision tree approach. Int. J. e-Educ. e-Bus. e-Manag. e-Learn. 2012, 2, 140–144. [Google Scholar] [CrossRef] [Green Version]
- Yang, F. Decision tree algorithm based university graduate employement trend prediction. Informatica 2019, 43, 573–579. [Google Scholar] [CrossRef] [Green Version]
- Tapado, B.M.; Acedo, G.G.; Palaoag, T.D. Evaluating information technology graduates employability using decision tree algorithm. In Proceedings of the 9th International Conference on E-Education, E-Business, E-Management and E-Learning, IC4E 2018, New York, NY, USA, 11–13 January 2018; pp. 88–93. [Google Scholar] [CrossRef]
- Behr, A.; Giese, M.; Teguim, K.; Theune, K. Early prediction of university dropouts-A random forest approach. Jahrb. Natl. Stat. J. Econ. Stat. 2020. [Google Scholar] [CrossRef]
- Siri, A. Predicting students’ dropout at university using artificial neural networks. Italian J. Sociol. Educ. 2015, 7, 225–247. [Google Scholar] [CrossRef]
- Castro, F.; Vellido, A.; Nebot, À.; Mugica, F. Applying data mining techniques to e-learning problems. Stud. Comput. Intell. 2007, 62, 183–221. [Google Scholar] [CrossRef]
- Jovanovic, M.; Vukicevic, M.; Milovanovic, M.; Minovic, M. Using data mining on student behavior and cognitive style data for improving e-learning systems: A case study. Int. J. Comput. Intell. Sys. 2012, 5, 597–610. [Google Scholar] [CrossRef] [Green Version]
- Brandao, I.V.; Da Costa, J.P.C.L.; Santos, G.A.; Praciano, B.J.G.; Junior, F.C.M.D.; De, S.; Junior, R.T. Classification and predictive analysis of educational data to improve the quality of distance learning courses. In Proceedings of the WCNPS 2019-Workshop on Communication Networks and Power Systems, Brasilia, Brazil, 3–4 October 2019; Volume 8896312. [Google Scholar] [CrossRef]
- Ivanova, V.; Zlatanov, B. Implementation of fuzzy functions aimed at fairer grading of students’ tests. Educ. Sci. 2019, 9, 214. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Z.M.; Higgins, S. The power of noise and the art of prediction. Int. J. Educ. Res. 2018, 87, 36–46. [Google Scholar] [CrossRef] [Green Version]
- Shahiri, A.M.; Husain, W.; Rashid, N.A. A review on predicting student’s performance using data nining techniques. Proced. Comp. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef] [Green Version]
- Dutt, A.; Ismail, M.A.; Herawan, T. A systematic review on educational data mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Alyahyan, E.; Düştegör, D. Predicting academic success in higher education: Literature review and best practices. Int. J. Educ. Technol. High. Educ. 2020, 17, 3. [Google Scholar] [CrossRef] [Green Version]
- Bizhkov, G. Theory and Methodology of Didactic Tests; Prosveta: Sofia, Bulgaria, 1996. (In Bulgarian) [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: Boca Raton, FL, USA, 1984. [Google Scholar]
- Wu, X.; Kumar, V. The Top Ten Algorithms in Data Mining; Chapman & Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Steinberg, D. CART: Classification and regression trees. In The Top Ten Algorithms in Data Mining; Wu, X., Kumar, V., Eds.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2009; pp. 179–202. [Google Scholar]
- Izenman, A.J. Modern Multivariate Statistical Techniques. Regression, Classification, and Manifold Learning; Springer: New York, NY, USA, 2008. [Google Scholar]
- IBM Inc., IBM SPSS Software, New York. 2020. Available online: https://www.ibm.com/analytics/spss-statistics-software (accessed on 20 March 2020).
- Cronbach, L.J. Coefficient alpha and the internal structure of tests. Psychometrika 1951, 16, 297–334. [Google Scholar] [CrossRef] [Green Version]
- DeVellis, R.F. Scale Development: Theory and Applications, 4th ed.; Sage: Los Angeles, CA, USA, 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 For Me, This Problem Is: | S2 I Have Solved It: | S3 I Used the Help of: | S4 My Mathematical Competencies for This Problem Are: |
|---|---|---|---|
| (a) difficult | (a) manually | (a) Internet source | (a) insufficient |
| (b) average | (b) manually and with software | (b) with the help of software | (b) almost sufficient |
| (c) easy | (c) with software | (c) nothing additional | (c) sufficient |
| Competency | Test Questions/Problems | ||||||
|---|---|---|---|---|---|---|---|
| Q1 | Q2 | Q3 | Q4 | P1 | P2 | ||
| C1 | Thinking mathematically | - | - | 0 | + | 0 | + |
| C2 | Reasoning mathematically | - | - | 0 | 0 | 0 | 0 |
| C3 | Problem solving | - | - | - | - | + | + |
| C4 | Modeling mathematically | - | - | - | 0 | 0 | 0 |
| C5 | Representation | 0 | 0 | + | + | 0 | + |
| C6 | Symbols and formalism | + | + | 0 | 0 | + | 0 |
| C7 | Communication | 0 | 0 | - | - | 0 | - |
| C8 | Aids and tools | + | + | 0 | 0 | + | 0 |
| S1, % | S2, % | S3, % | S4, % | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | b | c | a | b | c | a | b | c | a | b | c | |
| Q1 | 2 | 18 | 80 | 13 | 29 | 58 | 13 | 25 | 62 | 0 | 31 | 69 |
| Q2 | 0 | 18 | 82 | 33 | 10 | 57 | 27 | 18 | 55 | 3 | 33 | 64 |
| Q3 | 35 | 46 | 19 | 73 | 8 | 19 | 14 | 12 | 74 | 50 | 33 | 17 |
| Q4 | 56 | 28 | 16 | 49 | 19 | 32 | 14 | 13 | 73 | 46 | 34 | 20 |
| P1 | 19 | 68 | 13 | 0 | 34 | 66 | 19 | 36 | 45 | 8 | 67 | 25 |
| P2 | 57 | 32 | 11 | 69 | 10 | 21 | 24 | 6 | 70 | 52 | 33 | 15 |
| Predictor Group | Number of Independent Variables | Independent Variables |
|---|---|---|
| G1 | 7 | Q1, Q2, Q3, Q4, P1, P2, Sex |
| G2 | 24 | R_Q11, …, R_Q44, …, R_P11, …, R_P24 |
| G3 | 31 | All from G1 and G2 |
| G4 | 12 | Q1, Q2, Q3, Q4, P1, P2, R_Q14, R_Q24, R_Q34, R_Q44, R_P14, R_P24 |
| Model | Predictors | Terminal Nodes | R2, % | RMSE | Normalized Independent Variable Importance, % |
|---|---|---|---|---|---|
| M1 | G1 | 11 | 94.0 | 0.471 | P2(100), P1(44.2), Q4(5.8), Q1(2.5), Q3(0.5), Q2(0.4), Sex(0) |
| M2 | G2 | 14 | 75.4 | 0.981 | R_Q41(100), R_Q13(79.3), R_P14(79.0), R_P24(74.0), R_P11(73.6), R_P21(72.1), R_Q44(5.1), R_Q34(58.0) |
| M3 | G3 | 11 | 94.3 | 0.474 | P2(100), P1(44.2), R_Q41(11.4), R_P11(9.9), R_Q31(8.2), R_P14(7.1), R_Q34(6.0), R_Q24(5.9), Q4(5.8), R_Q11(5.7), R_Q32((5.3), R_P22(5.2) |
| M4 | G4 | 11 | 94.0 | 0.486 | P2(100.0), P1(44.2), R_P14(6.8), R_Q34(6.0), R_Q24(5.9), Q4(5.8) |
| Model | Group of Variables | Terminal Nodes | Percent Correct, % | Normalized Independent Variable Importance, % |
|---|---|---|---|---|
| MC1 | G1 | 8 | 91.9 | P2(100), P1(74.8), Q4(11.4), Q1(10.9), Q3(9.1), Q2(6.5) |
| MC2 | G2 | 10 | 82.3 | R_Q41(100), R_P23(82.5), R_Q23(66.1), R_Q31(55.5), R_P22(53.2), R_P14(50.9), R_Q44(48.9), R_Q24(43.0), R_P13(40.1) |
| MC3 | G3 | 8 | 90.3 | P2(100), R_P24(64.9), P1(64.3), R_P22(39.8), Q3(38.2), R_P21(28.8), R_Q44(22.4), R_Q22(20.7), R_P11(19.8), R_Q13(17.2), R_Q41(15.2) |
| MC4 | G4 | 8 | 91.9 | P2(100), R_P24(78.8), P1(59.4), Q3(17.5), R_Q24(14.7), Q2(9.2), R_Q44(8.7), Q1(6.1), R_P14(5.4) |
| Observed | Predicted | |||
|---|---|---|---|---|
| Low Competency | Medium Competency | High Competency | Percent Correct | |
| Low competency | 8 | 1 | 0 | 88.9% |
| Medium competency | 2 | 46 | 0 | 95.8% |
| High competency | 0 | 2 | 3 | 60.0% |
| Overall Percentage | 16.1% | 79.0% | 4.8% | 91.9% |
| Scale from S1, S2, S3, S4 | Cronbach’s Alpha | Cronbach’s Alpha Based on Standardized Items | Number of Items |
|---|---|---|---|
| Variables: Q1, Q2, Q3, Q4 | 0.767 | 0.746 | 16 |
| Variables: Q1, Q2, Q3, Q4, P1, P2 | 0.818 | 0.819 | 24 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivanov, A. Decision Trees for Evaluation of Mathematical Competencies in the Higher Education: A Case Study. Mathematics 2020, 8, 748. https://doi.org/10.3390/math8050748
Ivanov A. Decision Trees for Evaluation of Mathematical Competencies in the Higher Education: A Case Study. Mathematics. 2020; 8(5):748. https://doi.org/10.3390/math8050748
Chicago/Turabian StyleIvanov, Atanas. 2020. "Decision Trees for Evaluation of Mathematical Competencies in the Higher Education: A Case Study" Mathematics 8, no. 5: 748. https://doi.org/10.3390/math8050748
APA StyleIvanov, A. (2020). Decision Trees for Evaluation of Mathematical Competencies in the Higher Education: A Case Study. Mathematics, 8(5), 748. https://doi.org/10.3390/math8050748