A Semantic Framework to Debug Parallel Lazy Functional Languages


Abstract
:1. Introduction
2. An Introduction to Hood
Implementation Details
- is created when entering in a binding that is an observation. This new observation has no parent. More precisely, its parent is the predefined general parent, denoted as . As expected, when we start the evaluation of an annotated variable, this is the initial annotation that is created.
- is created when starting the evaluation of a binding.
- is created when we evaluate a constructor. The first parameter represents the arity of the constructor, while the second one represents its name. As you might expect, the children of the constructor will receive annotations of the form , …, where is the pointer to the annotation. By doing so, it is possible to reconstruct the constructor application.
- is created when the binding evaluation arrives at a lambda expression. Only curryfied functions are considered, so lambda expressions have a single input value and a single result. When a lambda is applied to an input parameter, the argument is annotated with parent , while the annotation given to the result is , being a pointer to the annotation.
3. Introduction to GpH and Eden
3.1. Glasgow Parallel Haskell
3.2. Eden
4. GpH-Eden Core Language
- I:
- Inactive. It has not been demanded yet, or its evaluation has already finished.
- A:
- Active. It has already been demanded and it is under evaluation.
- B:
- Blocked. It has been demanded, but it is currently waiting to receive a value from another binding.
- R:
- Runnable. It has been demanded and it is not waiting for any data, but it is not Active because it lacks an available processor.
4.1. Local transitions
- If the two variables are equal, then we must block the corresponding variable, as we have entered a blackhole (rule blackhole).
- If the two variables are not equal, then there are two new possibilities:
- -
- When the second variable is bound to a value that has already been evaluated, we have to copy such value to the former variable (rule value).
- -
- When the second variable is bound to an expression that is not completely evaluated yet, the first variable has to be blocked (waiting until the second one is completely evaluated). Moreover, if the second variable was inactive, then it has to be turned into runnable (in the case of GpH) or into active (in the case of Eden) (rule value-demand).
Local Rules with Observations
- Rule observ.
- In this case, we start an observation with the string str. Thus, an annotation is added to the file, and then the evaluation goes on, but taking into account the annotation that points to its parent, that is .
- Rule value@L, value@LO.
- In case we deal with an active binding where q is bound to a function, we have to continue evaluating a new kind of expression. If the function is previously being observed, then it is necessary to add the new observation mark to that function (rule value@LO) ; otherwise, if the function has not been observed (rule value@L), then the new -abstraction is created. This kind of lambda indicates that it is under observation associated with the tag . In addition, a new annotation is generated, indicating that we enter to evaluate that binding.
- Rule value@C.
- In case is evaluated to a constructor, we have to generate a new annotation . This indicates that the binding whose parent is has been reduced to the constructor C (whose arity is k). New bindings pointing to each argument of that constructor are generated. These bindings are annotated to indicate that they are being observed. Moreover, in this annotation, we must indicate its position in the constructor and that its parent is in the corresponding line of the file.
- Rule blackhole@.
- In this case, we have an annotated binding whose reduction needs to access to itself. Thus, we have to block the binding.
- Rule value@demand.
- When dealing with a binding , we have to generate a new annotation to record that we have started its evaluation.
- Rule β-reduction@.
- This is the key rule to deal with the observation of functions. In case we have to evaluate an application of a function that is under observation, we generate the annotation in the file indicating that we are applying an observed function. Then, we mark its argument as observable, and we use as its parent. In order to observe the result, we create a new observed binding whose parent is . The ports are different to remember that one is the argument and the other is the result of the lambda.Note that it is not necessary to specify the application to an observed pointer . The reason is that, in the syntax, we have restricted the places where an observed variable may appear, and in the rules we never substitute a variable by an observed pointer.
4.2. Example



5. GpH Formal Semantics
5.1. GpH Global transitions
- Rule parallel
- Each thread that is active can evolve independently (using local rules), and then we have to merge the corresponding heaps to obtain the global behavior. More precisely, we have to consider each active thread . Then, for each one, we consider two parts of the heap , where contains those bindings that are not modified by the local rules, while contains those bindings that were modified by the evolution of the thread, and their final state after such evolution is represented by . The final heap contains those parts that were not modified by any thread , together with the result of the execution of the threads . In order to consider this rule, it is necessary to prove that all the involved heaps are consistent, that is, there is no interference between the evolution of the active bindings. This proof can be found in [71].We print the observations in sequence: We start with and then we continue printing the annotations coming from the evaluation of thread ; next, we go on with those corresponding to thread ; later, we continue with those of , and so on.Let us remark that different evaluation orders among threads can result in different files. However, all of the possible files are consistent with the observations. In fact, we could even modify the rule to mimic the concurrent evaluation of the threads. The only restriction is that a semaphore has to be used to access the file, so that we can guarantee that the printing operations are atomic.
- Rule deactivation
- In this case, we do not transform the annotation file. The rule turns into runnable those bindings that were previously blocked on a pointer, provided that this pointer is now bound to a value. Moreover, the pointer has to turn into inactive mode.
- Rule activation
- As in the previous case, the rule does not transform the annotation file. There can be as many active threads as available processors, and this number is a global constant. Thus, it is not possible to always turn any runnable thread into an active thread, and it is necessary to define a priority criterion. In particular, GpH gives priority to those variables that are currently demanded by the main thread. More precisely, the preference criterion is the following:
5.2. Example: Semantic Evaluation in GpH








6. Eden Formal Semantics
6.1. Eden Global transitions
6.1.1. Auxiliary Functions
- Function .
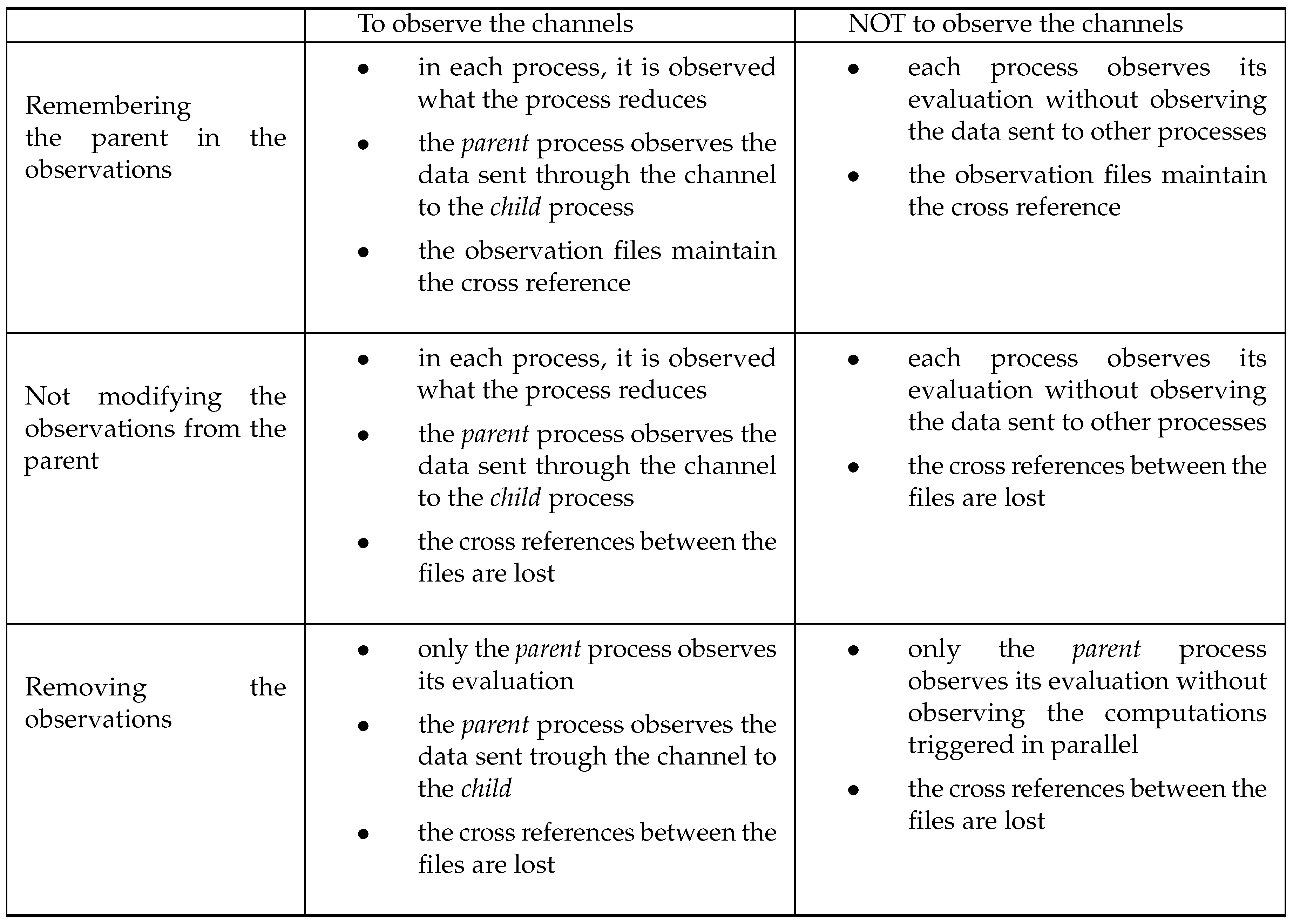
- Each process has its own heap, without sharing bindings with other processes. Thus, when a new process is created, we have to copy from the parent heap to the new heap all the bindings that will be necessary to evaluate the process body. Function (needed heap, see Figure 6) will be used to tackle this issue. In particular, gathers those bindings of that can be reached from e. Moreover, it also transforms the observation marks in all the closures adding them the string s. During the process of cloning bindings between heaps, care has to be taken when we find a lambda abstraction that is under observation (notice that they are the only that can be under observation). In this case, it is important to record its original process. We will achieve this by modifying the observation associated with the binding. Function (modify observations) deals with this problem. Notice that it only has to consider the definition for forms. Nevertheless, there exist different options to define this modification:
- As it appears in Figure 6. The observations are modified to remember where they come from, that is, which is the corresponding parent.
- Not modifying the observations and simply copying them to the new heap (). In this way, it is not possible to get the relations between the observations produced in the child and in the parent. Nevertheless, by post-processing the annotation files, it is possible to rebuild these relations.
- A third option consists of removing the observation marks of all the bindings (). In this way, the observations are only produced in the process that starts the evaluation of the observation mark. Thus, in case programmers are interested in observing some data in the child process, it is necessary that they explicitly introduce an observation mark in the body of the process.
- Function .
- Every time a process is created or communication between processes takes place, it is necessary to guarantee that any expression that is sent is in . This is done recursively. That is, in case a pointer appears in an expression, then we have to follow such pointer and guarantee that the expression it is pointing at is also in . Function needed first free (, see Figure 7) checks this condition, and it returns those reachable expressions that are not in . Thus, if we look at the process creation rules, we see that we can only create process q with heap H provided that . Analogously, we need to be able to send e in a heap H (value communication demand rule). Function will also appear in rule process creation demand. In this case, it provides the bindings that are needed to perform the eager creation of the new process.
6.1.2. Global Rules
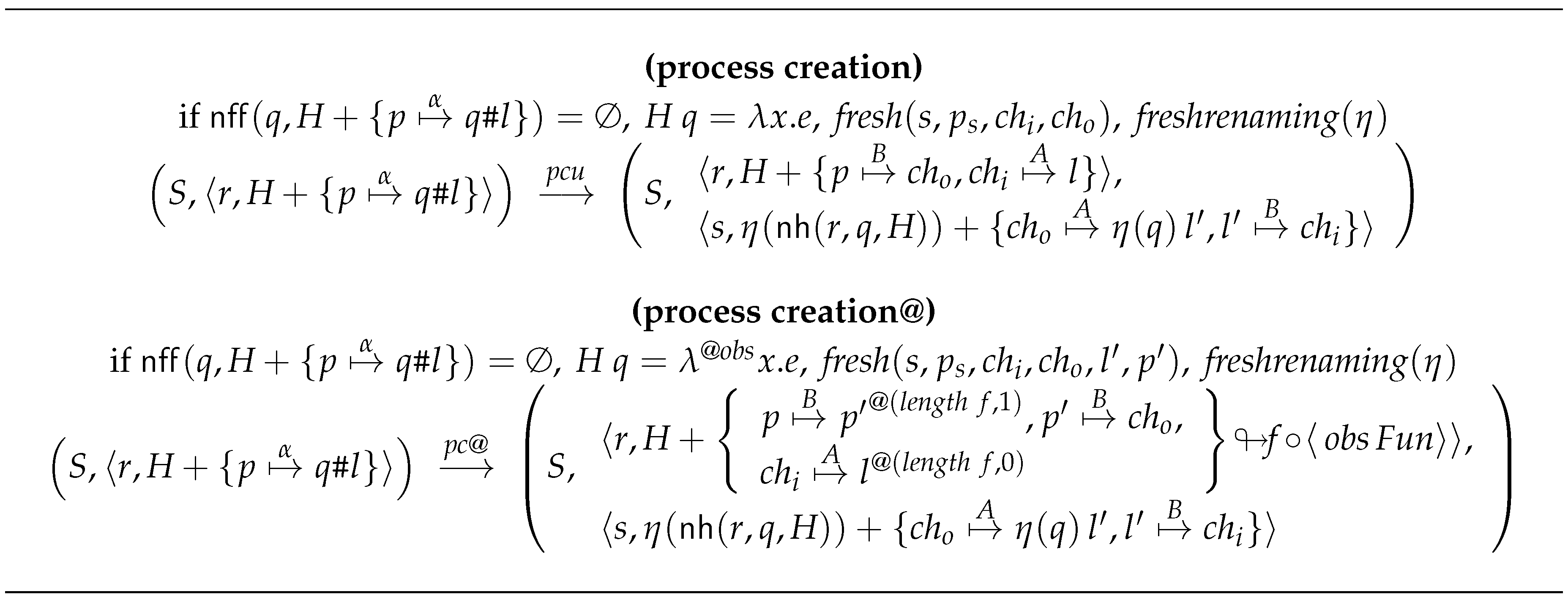
- Process creation.
- The creation of a new process takes place when an #-expression is evaluated. In this case, we have to apply a rule from Figure 8. In case the process is under observation, we use rule process creation@, while rule process creation is used otherwise.Analogously to the case of the definition of function, there exist different options for the process creation rule:
- To create the new process without taking into account if the process is an observed -abstraction or not. In this way, the rule process creation@ would not be necessary. It is only necessary to consider that the body of the process in process creation rule can be an observed -abstraction. This -abstraction will be modified by the function ; so, the observations obtained will depend on the version of that we use.
- To create the new process taking into account that the process can be an observed -abstraction. In this case, we will observe the input and output channels. The rule process creation@ indicates this behavior. As in the previous case, the -abstraction will be modified by the function ; and the observations will depend on the choice of .
In any case, when we create a new process, we create a new output channel and we have to block on it the parent thread that evaluated the #-expression. This channel corresponds to the initial thread in the new child process s and it will be used to communicate the final value from the child to the parent. Analogously, on the child side, a thread will be blocked on a new input channel ; this channel is controlled by a new thread in the parent and it will be used for sending data from the parent to the child. As we have already mentioned, the creation of processes is not lazy. In fact, a process is instantiated as soon as we find in the heap a variable that points directly to a #-expression, no matter if the binding is currently active or not.Both rules are equal in all aspects but one: The second rule needs to introduce observations in the data exchanged with the process. Let us remark that the annotations in process r are handled in the same way as the observation of a -abstraction.We define the iteration of these rules as: - Inter-processes communication.
- Figure 9 deals with the communication of values. Let us remind that in order to send a value we have to copy (from the heap of the sender to the heap of the receiver) the bindings of the variables that can be reached from such value. The situation is the same as when we were creating a new process, that is, we can only proceed with the rule in case the expressions to be copied are in (). We need to avoid name repetitions in the heap of the child process. Thus, we apply an –rename to everything in . Then, the multi-step rule dealing with communication is defined as follows: . Let us remark that the rule appearing in Figure 9 deals with the communication of a single value. Later, in Section 6.3, we will extend the semantics so that it can deal with stream communication.
- Thread management.
- Figure 10 contains the rules dealing with the management of the threads. The aim of each one is the following:
- WHNF unblocking:
- When a binding finally reaches its final value (it is a ), the threads blocked on it are unblocked.
- WHNF deactivation:
- Another operation that must be performed is the deactivation of the bindings that have reached their final value.
- Blocking process creation:
- The creation of new processes must be blocked until their free dependencies are in .
- Process creation demand:
- In order to be able to unblock the recently created processes, the evaluation of their needed free variables must be demanded.
- Value communication demand:
- In order to be able to communicate a value through a channel, it must be in , so its evaluation must be demanded.
Finally, let us recall the previous rules activate the application of rules value and app-demand.By combining and iterating rules from Figure 10, we obtain the following rule:It is trivial to prove that Unbl always finishes. That is, these rules can only be applied a finite number of times. The reason is that the amount of threads that are blocked cannot be infinite, and its number cannot be increased by using a deactivation or an unblock. - System evolution rules.
- The overall behavior of the system is governed by these rules. Each process evolves by using local transitions, and then the global system evolves. Figure 11 gathers this behavior: Rule parallel-r deals with the local evolution inside a process, while the overall evolution is done with parallel that handles all processes in a single rule.The internal evolution of each process is done following the local rules shown in Section 4.1. Thus, the internal evolution of process r depends on the active threads in that can evolve. Notice that parallel-r is the equivalent to the rule parallel that was defined for GpH. The difference is that in Eden there is an independent heap for each process. Thus, the number of active threads belonging to process r is .After defining how each process evolves, rule parallel defines how the whole system S evolves.
6.1.3. Global System Evolution
6.1.4. Semantic Possibilities
6.2. Example: Semantic Evaluation in Eden

- 1.
- Observing the channels and modifying the observation marks adding that they came from the other process (such as is presented in the semantic rules, Figure 8):This is the richest semantics in terms of observations in the annotation files. First, the rules indicate that two new processes (child 1 and child 2) must be created. Thus, two new heaps are built, each one contains the information needed by the process. We also create the communication channels. On the one hand, we have the bindings corresponding to the output parent channels (the variables and ), the corresponding bindings are blocked in the parent process and active in the offspring. On the other hand, we have input parent channels ( and ) that are active in the parent process and blocked in the child processes.More precisely, each process is the application of the Fibonacci function (parfibO) to the corresponding parameters. Thus, the first task that must be accomplished is to copy all the needed heap to compute this function into the child processes. Since it is an observed λ-abstraction, the rule process creation@ is applied. In the table below, the heaps of the three processes just after the application of this rule can be found.
![Mathematics 08 00864 i013]() Since we are using the version of the function that modifies the observations, we get bindings with the observations modified: [main, (0 0)] . Note that rule process creation@ makes an annotation in the file of the parent process as if it were a function. Thus, lines 4 and 5 of the parent annotation file (in the table below) are produced at this moment.Then, all three of the processes evolve independently until the child processes are blocked because they need the argument of the Fibonacci function. This value has to be computed in the parent process. During this autonomous evolution, annotations are produced in the annotation files. The parent process has to evaluate the parameters needed by the child processes, and this evaluation generates the lines 6–9 in the parent process file. The child processes begin their execution and as result we obtain lines 0–2 in their respective files.At this point, the child processes can no longer continue until they communicate with the parent process, so the value communication rule is applied. After that, the child processes continue and generate lines 3–4 in their respective annotation files. Now that the resulting values have just been computed in the child processes, they can be sent back to the parent process by using again the rule value communication. In addition, finally the parent process makes the annotation in lines 10–12 in its file. In the table below, we show all the annotations we have described:Analyzing each file independently, we can obtain the following observation trees:
Since we are using the version of the function that modifies the observations, we get bindings with the observations modified: [main, (0 0)] . Note that rule process creation@ makes an annotation in the file of the parent process as if it were a function. Thus, lines 4 and 5 of the parent annotation file (in the table below) are produced at this moment.Then, all three of the processes evolve independently until the child processes are blocked because they need the argument of the Fibonacci function. This value has to be computed in the parent process. During this autonomous evolution, annotations are produced in the annotation files. The parent process has to evaluate the parameters needed by the child processes, and this evaluation generates the lines 6–9 in the parent process file. The child processes begin their execution and as result we obtain lines 0–2 in their respective files.At this point, the child processes can no longer continue until they communicate with the parent process, so the value communication rule is applied. After that, the child processes continue and generate lines 3–4 in their respective annotation files. Now that the resulting values have just been computed in the child processes, they can be sent back to the parent process by using again the rule value communication. In addition, finally the parent process makes the annotation in lines 10–12 in its file. In the table below, we show all the annotations we have described:Analyzing each file independently, we can obtain the following observation trees:main child 1 child 2 ![Mathematics 08 00864 i014]()
![Mathematics 08 00864 i015]()
![Mathematics 08 00864 i016]() These trees can be flattened to be shown to the user as:
These trees can be flattened to be shown to the user as:main child 1 child 2 -- parfib
{ \ 2 -> 2
, \ 1 -> 1
, \ 0 -> 1
}-- [main, parfib]
{ \ 0 -> 1
}-- [main, parfib]
{ \ 1 -> 1
} - 2.
- Observing the channels and not modifying the observations:In this case, the differences appear when the rule process creation@ is applied because now it is only necessary to copy the needed heap from the parent process (applying an η renaming). The main difference with respect to the previous case is that the bindings and are not created, and the bindings and will be bound to the expression . Then, proceeding like in the previous case, we get that the final observations appearing in the files are the following:Thus, we obtain the following observation trees:
main child 1 child 2 ![Mathematics 08 00864 i017]()
![Mathematics 08 00864 i018]()
![Mathematics 08 00864 i019]() In addition, they produce the following observations:
In addition, they produce the following observations:main child 1 child 2 -- parfib
{ \ 2 -> 2
, \ 1 -> 1
, \ 0 -> 1
}--
{ \ 0 -> 1
}--
{ \ 1 -> 1
}As we can observe, in this case, the annotations of the child processes that refer to the parent process are missing. - 3.
- Observing the channels and removing the observations when the bindings are copied into another process:Now, the differences with respect to the previous case is that and will be bound to a non-observed expression . Thus, we do not get any observations in the corresponding files of the child processes. Therefore, the final annotation files will be the following:Then, showing the observations in a tree form, we get:
main child 1 child 2 ![Mathematics 08 00864 i020]() In addition, the corresponding observations are as follows:
In addition, the corresponding observations are as follows:main child 1 child 2 -- parfib
{ \ 2 -> 2
, \ 1 -> 1
, \ 0 -> 1
} - 4.
- Not observing the channels and modifying the observation marks adding the process they come from: In this case (and in the following ones), when the child processes are created, the rule process creation will be used, even if the function that is going to be executed in the child process is under observation. The difference with respect to case 1 is that the channels are under observation (as indicated in rule process creation). Thus, the bindings of pointers and are bounded directly with its corresponding channels and , and the channels and are directly bounded to and (without any observation marks). Then, proceeding as in the previous cases, the resulting annotation files are:Whose tree representation is:
main child 1 child 2 ![Mathematics 08 00864 i021]()
![Mathematics 08 00864 i022]()
![Mathematics 08 00864 i023]() Thus, the final observations are as follows:
Thus, the final observations are as follows:main child 1 child 2 -- parfib
{ \ 2 -> 2
}-- [main parfib]
{ \ 0 -> 1
}-- [main parfib]
{ \ 1 -> 1
}This case is similar to case 1, the difference being that the data transmitted through the channels are not observed. In every process, the λ-abstraction applications that have been reduced locally are only obseved. - 5.
- Not observing the channels and not modifying the observations:In this case, bindings and are created, and bindings and will be bound to the expression . Thus, the final observation files produced in the global computation will be the following:Again, analyzing each file we get the following observation trees:
main child 1 child 2 ![Mathematics 08 00864 i024]()
![Mathematics 08 00864 i025]()
![Mathematics 08 00864 i026]() In addition, the produced observations are as follows:
In addition, the produced observations are as follows:main child 1 child 2 -- parfib
{ \ 2 -> 2
}--
{ \ 0 -> 1
}--
{ \ 1 -> 1
}The main difference with respect to the previous case is that the references to the parent process are missing in the child process annotations. - 6.
- Not observing the channels and removing the observations when the bindings are copied into the child process:In this case, bindings and will be directly bound to the unobserved expression . Therefore, the child processes will not produce any kind of observations. This implies that the observation files after the computation will be the following:Thus, their tree representations are:
main child 1 child 2 ![Mathematics 08 00864 i027]() In addition, the corresponding observations are as follows:
In addition, the corresponding observations are as follows:main child 1 child 2 -- parfib
{ \ 2 -> 2
}















{kind=link}
{kind=link}
{kind=link}
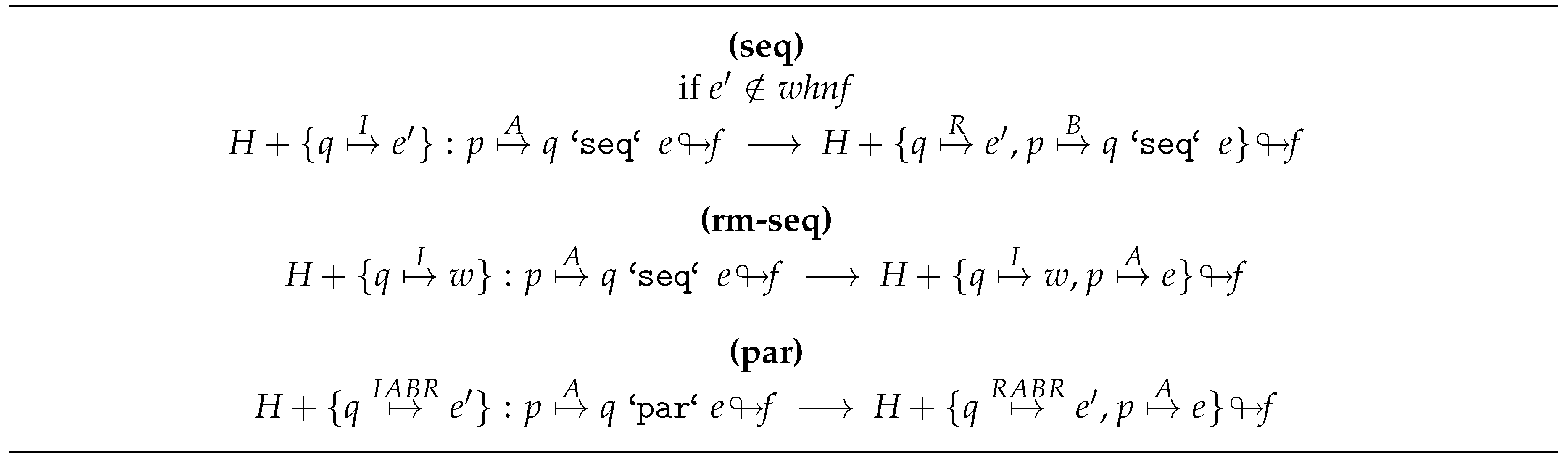{kind=link}
{kind=link}
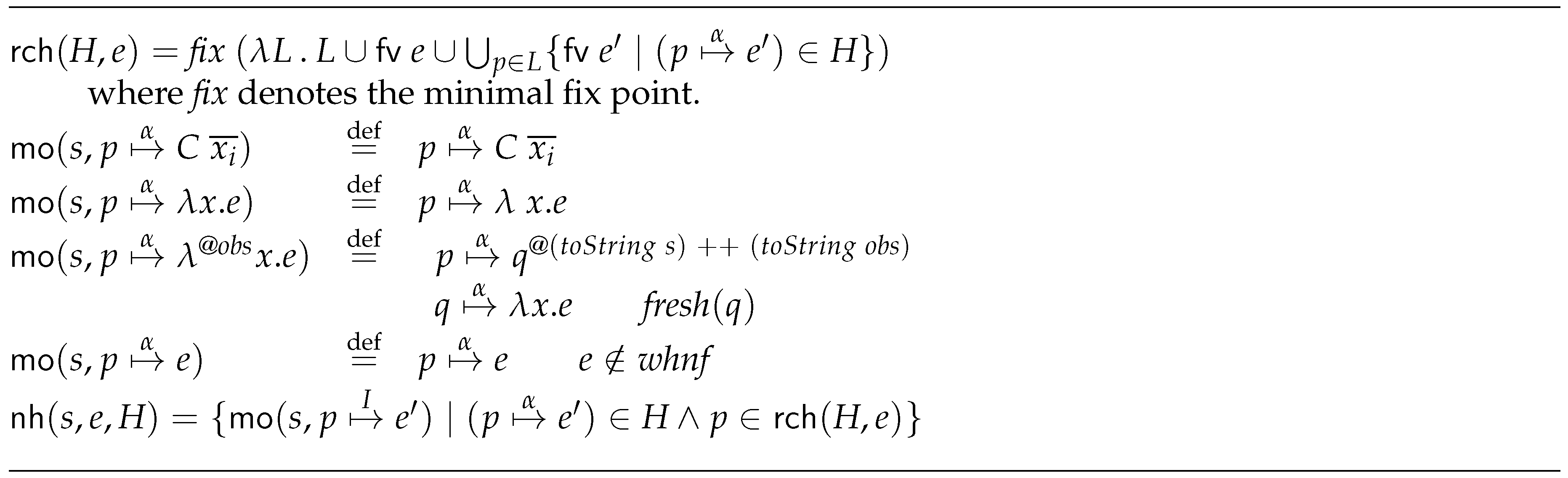{kind=link}
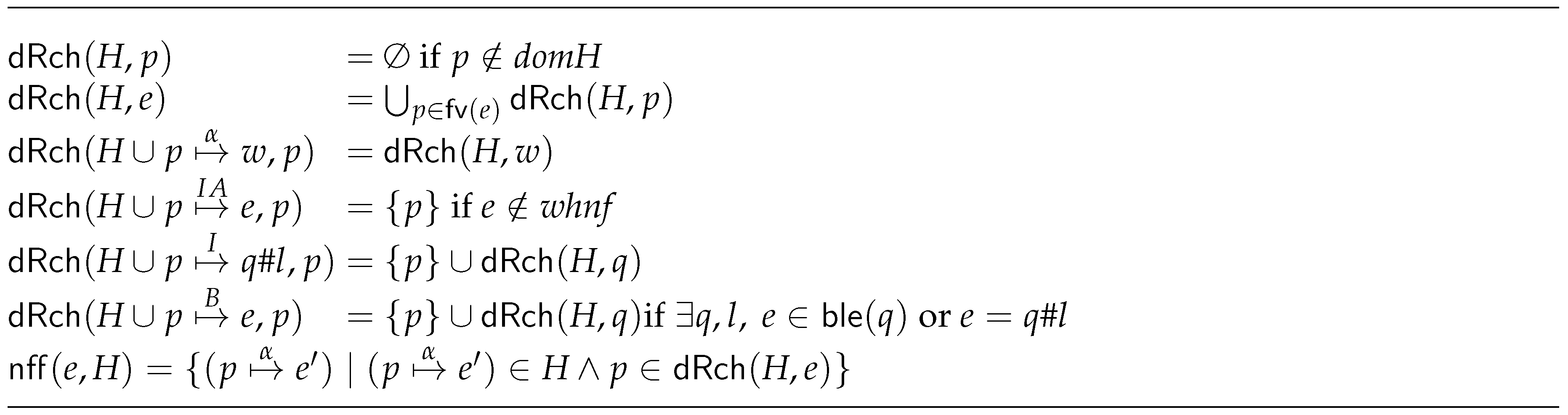{kind=link}
{kind=link}
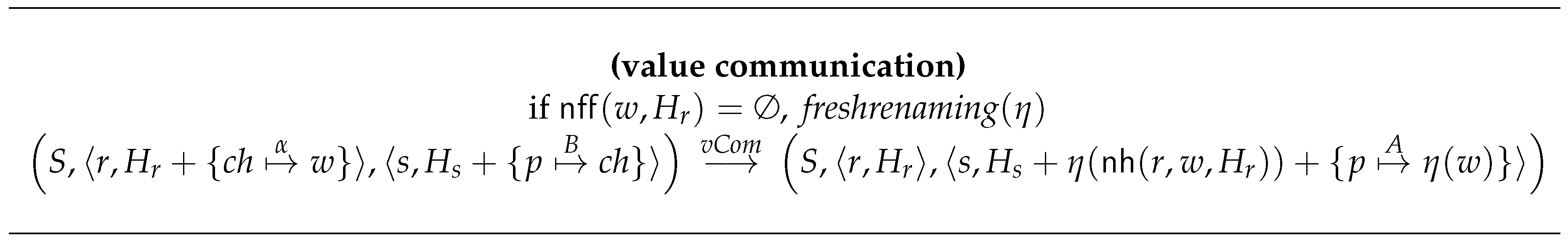{kind=link}
{kind=link}
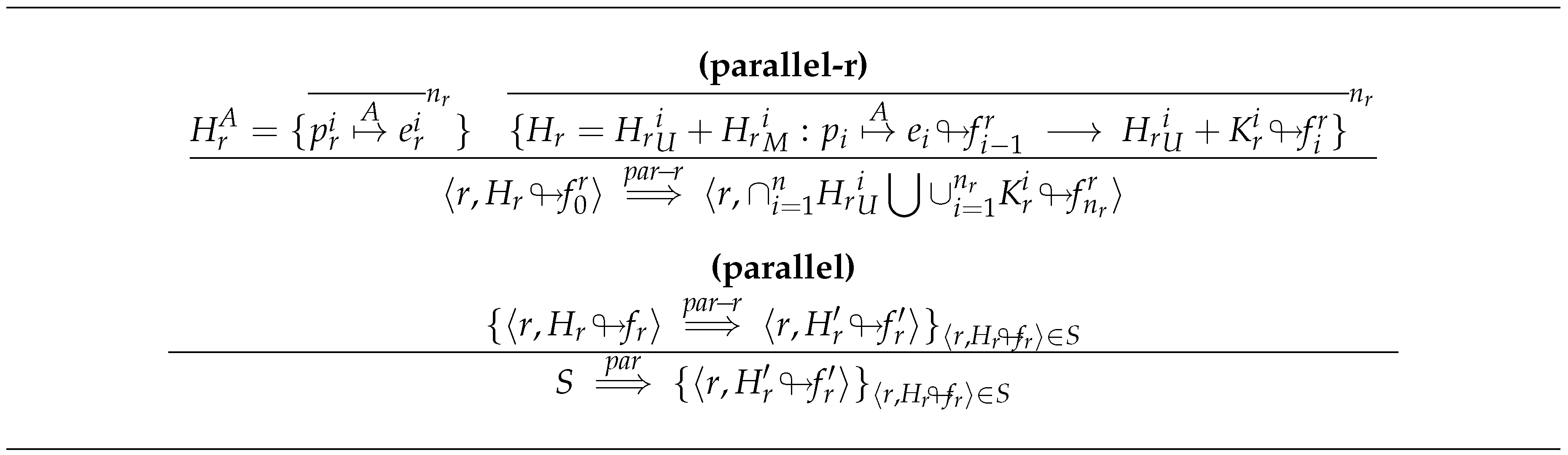{kind=link}
{kind=link}
{kind=link}
{kind=link}
6.3. Eden Streams
- stream-demand.
- If a channel deals with streams, and we have not yet evaluated the head of the stream, we demand it. The reason is that Eden streams are evaluated eagerly.
- empty-streamcommunication.
- If the stream is finished (that is, it is ), we send such value and then we close the stream. Thus, it will not be possible to perform any other communication using the channel.
- head-streamcommunication.
- When the head of a stream is available to be sent, the receiver gets a fresh variable with the corresponding value. This communication is similar to the one of the value communication rule.
- head-streamcommunication demand.
- If the head of the stream is evaluated to , then we have to demand its needed first free bindings.
6.4. Stream Communication in Eden via an Example






| -- lFromN { \ 7 -> _ : 8 : _ } | -- main[(1 0)] { \ 7 -> 7 : 8 : 9 : 10 : _ : _ } |
- The parent did not need the first value sent from the child to compound the final result.
- The child has produced two extra numbers, 9 and 10 that the parent did not need to get its final result.
7. Correctness and Equivalences
- if , then where and the following conditions holds:
- -
- -
- and one of the following conditions holds:
- ∗
- if then , , , and , .
- ∗
- if then , .
- ∗
- if then , .
- ∗
- if then one of the following conditions holds:
- ·
- and ,
- ·
- and ,
- if
- We deal with local rules, proving that they do not modify the equivalence. This proof is trivial, since we have already proven the same property for the case of GpH. Notice that in Eden the rule is analogous to the rule of GpH, and GpH local rules are a superset of those of Eden.
- We need to prove that function produces equivalent heaps if we apply it to equivalent heaps. Thus, we get that the rules related with the data transmission, (value communication), (empty-stream communication) and (head-stream communication) maintain the equivalence.
- The proof analyzes if transition preserves equivalence. There is a single rule changing its behavior under observations: Rule (process creation@) creates a heap that is equivalent with respect to (process creation). Thus, the transition preserves the equivalence.
8. Analyzing Speculative Work in Eden
9. Discussion
10. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proofs of the Propositions
- The bindings in the heap are considered threads, so they are marked with their state (active, runnable, inactive, or blocked). The definition of the equivalence between heaps has changed to reflect this.
- Instead of having a control expression, we have a binding in the control.
- The evaluation steps are short, that is, close to the abstract machine steps.
- ,
- ,
- and
- 1.
- , or
- 2.
- , or
- 3.
- P0.1
- By rules (demand) and (activation) because rule (demand) has deactivated a binding:
- P0.2
- By rules (demand@) and (activation) because rule (demand@) has deactivated a binding:
- P0.3
- The rule (observ) places us in :From that point on, we apply to obtain .
- (demand)
- Hypothesis A2 (H1,H2).We have:
- H1
- H2
- By rule (demand):
Proof.The proof will be done by cases over the possible observation marks that the equivalent binding can have.- P1
- By P0, H0, and H1:
- , or
- , or
- P2.1
- By rule (demand):
- P3.1
- By H0, H2, P2.1 and Definition 2:
- P2.2
- By rule (demand@):
- P3.2
- By H0, H2, P2.2 and Definition 2:
- P3.3
- By rule (observ):that places the configuration in
□ - (value)
- Hypothesis A3 (H1,H2).We have:
- H1
- H2
- By rule (value):
Proof.The proof will be done by cases over the possible observation marks that the equivalent binding can have.- P1
- By P0, H0, and H1:
- , or
- , or
- P2.1
- By rule (value):
- P3.1
- By H0, H2, P2.1 and Definition 2:
- P2.2
- By cases over w:
- , or
- , or
- , or
- P3.2.1
- By rule (value@L):
- P4.2.1
- By H0, H2, P3.2.1 and Definition 2:
- P3.2.2
- By rule (value@LO):
- P4.2.2
- By H0, H2, P3.2.2 and Definition 2:
- P3.2.3
- By rule (value@C):
- P4.2.3
- By H0, H2, P3.2.3 and Definition 2:
- P3.3
- By rule (observ):that places the configuration in
□ - (black hole)
- Hypothesis A4 (H1,H2).We have:
- H1
- H2
- By rule (black hole):
Proof.The proof will be done by cases over the possible observation marks that the equivalent binding can have.- P1
- By P0, H0, and H1:
- , or
- , or
- P2.1
- By rule (black hole):
- P3.1
- By H0, H2, P2.1 and Definition 2:
- P2.2
- By rule (black hole@):
- P3.2
- By H0, H2, P2.2 and Definition 2:
- P2.3
- By rule (observ):that places the configuration in
□ - (app-demand)
- Hypothesis A5 (H1,H2).We have:
- H1
- H2
- By rule (app-demand):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (app-demand):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (-reduction)
- Hypothesis A6 (H1,H2).We have:
- H1
- H2
- By rule( -reduction):
Proof.The proof will be done by cases over the -abstraction:- P1
- By P0, H0, and H1:
- , or
- P2.1
- By rule (-reduction):
- P3.1
- By H0, H2, P2.1 and Definition 2:
- P2.2
- By rule (-reduction@):
- P3.2
- By H0, H2, P2.2 and Definition 2:
□ - (letrec)
- Hypothesis A7 (H1,H2).We have:
- H1
- H2
- By rule (letrec):
- (a)
- (b)
- fresh
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- (a)
- (b)
- (c)
- as Definition 2 says
- P2
- By rule :
- (a)
- (b)
- fresh
- P3
- By H2(b), P2(b) and P1(c):holds the conditions of the Definition 2
- P4
- By H0, H2, P2, P3 and Definition 2:√
□ - (case-demand)
- Hypothesis A8 (H1,H2).We have:
- H1
- H2
- By rule (case-demand):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (case-demand):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (case-reduction)
- Hypothesis A9 (H1,H2).We have:
- H1
- H2
- By rule (case-reduction):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- (a)
- (b)
- P2
- By rule (case-reduction):
- P3
- By H0, H2, P1(b), P2 and Definition 2:√
□ - (opP-demand)
- Hypothesis A10 (H1,H2).We have:
- H1
- H2
- By rule (opP-demand):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (opP-demand):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (opP-reduction)
- Hypothesis A11 (H1,H2).We have:
- H1
- H2
- By rule (opP-reduction):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (opP-reduction):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (seq)
- Hypothesis A12 (H1,H2).We have:
- H1
- H2
- By rule (seq):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (seq):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (rm-seq)
- Hypothesis A13 (H1,H2).We have:
- H1
- H2
- By rule (rm-seq):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (rm-seq):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (par)
- Hypothesis A14 (H1,H2).We have:
- H1
- H2
- By rule (par):
Proof.We proceed as follows:- P1
- By P0, H0, and H1:
- P2
- By rule (par):
- P3
- By H0, H2, P2 and Definition 2:√
□
- (deactivation)
- Hypothesis A15 (H1,H2).In this case, the initial binding is blocked. In order to simplify the presentation, we will suppose that there is only one binding blocked in p:
- H1
- H2
- By rule (deactivation):
Proof.We proceed as follows:- P1
- As , considering and, to simplify that the intermediate pointers do not have observation marks, then:
- or
- or
- or
where is blocked in . - P2.1
- By rule (value):
- P3.1
- By rule (deactivation):
- P4.1
- By , H2, P3.1 and Definition: 2:√(P1.1)
- P2.2
- By rule (deactivation):
- P3.2
- By rule (activation):
- P4.2
- By rule (value):that places the configuration in case P1.1. √(P1.2)
- P2.3
- By rule (activation):that places the configuration in case P1.2. √(P1.3)
- P2.4
- By rule (activation):that places the configuration in case P1.1. √(P1.4)
□ - (activation)
- Hypothesis A16 (H1,H2).In this case, the initial binding is runnable:
- H1
- H2
- By rule (activation):
Proof.We proceed as follows:- P1
- As , considering and, to simplify that the intermediate pointers do not have observation marks, then:
- or
where is blocked in . - P2.1
- By rule (activation):
- P3.1
- By , H2, P2.1 and Definition: 2:√(P1.1)
- P2.2
- By rule (activation):
- P3.2
- By , H2, P2.2 and Definition: 2:√(P1.2)
□Proof of the second implication: right-to-leftLet us recall that . Then, and , where and , , . In this case, proving that the active threads evolve through equivalent configurations is simpler than in the other implication. The proof of this implication is made by induction on the number of inactive pointers: k.- In this case, when the semantics with observations apply one rule, the semantic without observations applies the corresponding rule without observations that is, if the rule applied is (black hole@) or (black hole), the equivalent rule without observations is the rule (black hole). The only rule that does not have a corresponding rule without observations is the rule (observ) that produces equivalent configurations without needing to apply another rule in the GpH semantics without observations.The proof is made by considering the rule that is applied. All the rules follow the same simple scheme and the proof is made exactly in the same way. For this reason, we will present here only the proof for the rule (demand@):
- (demand@)
- Hypothesis A17 (H0,H1,H2).We have:
- H0
- H1
- H2
- By rule (demand@):
Proof.We proceed as follows:- P1
- By H0 and H1:
- P2
- By rule (demand):
- P3
- By H0, H2, P2 and Definition 2:√
□
- In this case, the heap with observations must make some steps before the heap without observations evolves. The rules that the heap with observations apply are: (observ), (demand) and (activation), (demand@) and (activation), (value), (value@C), (value@L), and (value@LO).As a particular case, we will prove this for the rule (demand@) and (activation). The other set of rules follows the same simple scheme and the proof is made exactly in the same way. For this reason, we will not present them here.
- (demand@)
- Hypothesis A18 (H0,H1).We have:
- H0
- H1
- whereandsuch that:
- (a)
- (b)
- (c)
Proof.We proceed as follows:- P1
- By rule (demand@) applies to :
- P2
- By rule (activation) because rule (demand@) deactivate a binding:
- P3
- By H0, H1, P2 and Definition 2:√
□At this point, we have obtained a heap equivalent to the original one that has one less inactive pointer, so we can apply the induction hypotheses to it. Thus, there exists a heap such that and .
- First, we need to prove that, when we apply local rules to equivalent heaps, we get equivalent heaps, that is, analyze the independent evolution in each process. Most of this proof is the same as the one we made for Proposition 1. The only differences are:
- Eden uses streams while this concept does not exist in GpH.
- The only difference with respect to GpH is that the state of a thread in Eden can not be runnable (the equivalent in Eden is active). Therefore, the rules (activation) and (deactivation) in Eden are simpler than in GpH and correspond to the rules ( unblocking) and ( deactivation), respectively.
Thus, in this case, we only have to extend the proof of Proposition 1 with the rules that deal with streams. The rules we have to consider are (stream-demand) and (head-stream communication demand). We will only prove the right implication because the other implication (as in Proposition 1) is very simple. We will also consider that the previous pointers have been reduced as we did in the GpH proof. - Second, we need to prove that the function produces equivalent heaps if we apply it to equivalent heaps. Thus, we get that the rules related with the data transmission, (value communication), (empty-stream communication) and (head-stream communication), maintain the equivalence.
- Finally, we need to prove that rules (process creation@) and (process creation) maintain the equivalence .
- Local rules that evaluate the streams maintain the equivalence. This is the proof of the right implication considering that the initial pointers have been reduced.
- (stream-demand)
- Hypothesis A19 (H0,H1,H2).We have:
- H0
- and. corresponds to the result of the reduction of the initial pointers of
- H1
- H2
- By rule (stream-demand):
Proof.We proceed as follows:- P1
- By H0 and H1:
- P2
- By rule (stream-demand):
- P3
- By H0, H2, P2 and Definition 2:√
□ - (head-stream communication demand)
- Hypothesis A20 (H0,H1,H2).We have:
- H0
- H1
- H2
- By rule (head- stream communication demand) ():
Proof.We proceed as follows:- P1
- By H0 and H1:
- P2
- By rule (head-stream communication demand) ():
- P3
- By definition:p and maintains the Definition 2 that is, they are equivalent.
- P4
- By H0, H2, P2, P3 and Definition 2:√
□
- We will prove that the function produces equivalent heaps:Hypothesis A21 (H1,H2).We have:
- H1
- H2
- Let e be an expression andthe rename corresponding to H1 such that, we will prove that
Proof.We proceed as follows:- P1
- by H1:
- P2
- By function definition, the produced heaps are consistent, that is, they contain all the free variables of the expressions binding in them.
- P3
- The function does not produce any influence over the equivalence.
- P4
- By P1, P2, and P3 and due to the fact that function changes the state of the threads to inactive:
□The direct consequence of this point is that (value communication), (empty-stream communication) and (head-stream communication) maintain the equivalence relation. - We need to prove now that (process creation) and (process creation@) rules produce equivalent configurations:Hypothesis A22 (H1,H2).We have:
- H1
- H2
- By rule (process creation):
- (a)
- (b)
- where
Proof.Here, we only present the proof when the heap evolves applying the rule (process creation@). The proof when the heap evolves applying the rule (process creation) is simpler than this one.- P1
- By H1:where
- P2
- By P1:
- P3
- By P2:
- P5
- By rule (process creation@):where
- P6
- By produces equivalent heaps:
- P7
- By P6, , and Definition 2 (the extra pointers are “intermediate” pointers):√(the and heaps maintain the equivalence)
- P8
- By H1, , , and Definition 2 ( is an intermediate pointer):√(the and heaps maintain the equivalence)
□
References
- Cole, M. Algorithmic Skeletons: Structure Management of Parallel Computations; Research Monographs in Parallel and Distributed Computing; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Klusik, U.; Loogen, R.; Priebe, S.; Rubio, F. Implementation Skeletons in Eden: Low-Effort Parallel Programming. In Implementation of Functional Languages; Springer: Berlin/Heidelberg, Germany, 2001; pp. 71–88. [Google Scholar]
- Cole, M. Bringing Skeletons out of the Closet: A Pragmatic Manifesto for Skeletal Parallel Programming. Parallel Comput. 2004, 30, 389–406. [Google Scholar] [CrossRef] [Green Version]
- Dieterle, M.; Horstmeyer, T.; Berthold, J.; Loogen, R. Iterating Skeletons—Structured Parallelism by Composition. In Proceedings of the Implementation and Application of Functional Languages (IFL’12), Oxford, UK, 30 August–1 September 2012; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8241, pp. 18–36. [Google Scholar]
- Valero-Lara, P.; Nookala, P.; Pelayo, F.L.; Jansson, J.; Dimitropoulos, S.; Raicu, I. Many-Task Computing on Many-Core Architectures. Scalable Comput. Pract. Exp. 2016, 17, 32–46. [Google Scholar]
- Dieterle, M.; Horstmeyer, T.; Loogen, R.; Berthold, J. Skeleton composition versus stable process systems in Eden. J. Funct. Program. 2016, 26. [Google Scholar] [CrossRef]
- Kessler, C.; Gorlatch, S.; Enmyren, J.; Dastgeer, U.; Steuwer, M.; Kegel, P. Skeleton Programming for Portable Many-Core Computing. Program. Multicore Many-Core Comput. Syst. 2017, 121. [Google Scholar] [CrossRef]
- Stypka, J.; Turek, W.; Byrski, A.; Kisiel-Dorohinicki, M.; Barwell, A.D.; Brown, C.; Hammond, K.; Janjic, V. The missing link! A new skeleton for evolutionary multi-agent systems in Erlang. Int. J. Parallel Program. 2018, 46, 4–22. [Google Scholar]
- Öhberg, T.; Ernstsson, A.; Kessler, C. Hybrid CPU–GPU execution support in the skeleton programming framework SkePU. J. Supercomput. 2019, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Maier, P.; Archibald, B.; Stewart, R.; Trinder, P. YewPar: Skeletons for Exact Combinatorial Search. In Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming 2020 (PPoPP 2020), San Diego, CA, USA, 22–26 February 2020; ACM: New York, NY, USA, 2020. [Google Scholar]
- Achten, P.; van Eekelen, M.C.J.D.; Koopman, P.W.M.; Morazán, M.T. Trends in Trends in Functional Programming 1999/2000 versus 2007/2008. High. Order Symb. Comput. 2010, 23, 465–487. [Google Scholar] [CrossRef]
- Nikhil, R.S.; Arvind. Implicit Parallel Programming in PH; Morgan Haufman Publishers: Burlington, MA, USA, 2001. [Google Scholar]
- Kelly, P. Functional Programming for Loosely-Coupled Multiprocessors. Ph.D. Thesis, Department of Computer Science, Westfield College, Westfield, MA, USA, 1987. [Google Scholar]
- Trinder, P.W.; Hammond, K.; Mattson, J.S., Jr.; Partridge, A.S.; Peyton Jones, S.L. GUM: A portable parallel implementation of Haskell. In Proceedings of the Conference on Programming Language Design and Implementation, PLDI’96, Philadelphia, PA, USA, 21–24 May 1996; ACM: New York, NY, USA, 1996; pp. 79–88. [Google Scholar]
- Belikov, E.; Loidl, H.W.; Michaelson, G. Colocation of Potential Parallelism in a Distributed Adaptive Run-Time System for Parallel Haskell. In International Symposium on Trends in Functional Programming; Springer: Cham, Switzerland, 2018; pp. 1–19. [Google Scholar]
- Bois, A.R.D.; da Rocha Costa, A.C. Distributed Execution of Functional Programs Using the JVM. In Computer Aided Systems Theory—EUROCAST’01; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2178, pp. 570–582. [Google Scholar]
- Chakravarty, M.M.T.; Keller, G.; Lechtchinsky, R.; Pfannenstiel, W. Nepal-Nested Data Parallelism in Haskell. In Proceedings of the 7th International European Conference on Parallel Processing, Euro-Par’01, Manchester, UK, 28–31 August 2001; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2150, pp. 524–534. [Google Scholar]
- Jones, S.L.P.; Leshchinskiy, R.; Keller, G.; Chakravarty, M.M.T. Harnessing the Multicores: Nested Data Parallelism in Haskell. In Proceedings of the Foundations of Software Technology and Theoretical Computer Science, FSTTCS’08, Bangalore, India, 9–11 December 2008. [Google Scholar]
- Holmerin, J.; Lisper, B. Development of Parallel Algorithms in Data Field Haskell (Research Note). In Proceedings of the 6th International Euro-Par Conference on Parallel Processing, Euro-Par’00, Munich, Germany, 29 August–1 September 2000; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1900, pp. 762–766. [Google Scholar]
- Herrmann, C. The Skeleton-Based Parallelization of Divide-and-Conquer Recursions. Ph.D. Thesis, Passau University, Passau, Germany, 2000. [Google Scholar]
- Scaife, N.; Horiguchi, S.; Michaelson, G.; Bristow, P. A Parallel SML Compiler Based on Algorithmic Skeletons. J. Funct. Program. 2005, 15, 615–650. [Google Scholar] [CrossRef]
- Fluet, M.; Rainey, M.; Reppy, J.H.; Shaw, A. Implicitly-threaded parallelism in Manticore. In Proceedings of the International Conference on Functional programming, ICFP’08, Vitoria, BC, Canada, 22–24 September 2008; pp. 119–130. [Google Scholar]
- Marlow, S.; Jones, S.L.P.; Singh, S. Runtime support for multicore Haskell. In Proceedings of the International Conference on Functional Programming, ICFP’09, Edinburgh, UK, 31 August–2 September 2009; pp. 65–78. [Google Scholar]
- Loogen, R. Eden-Parallel Functional Programming with Haskell. In Proceedings of the Central European Functional Programming School, CEFP’11, Budapest, Hungary, 14–24 June 2011; Springer: Berlin/Heidelberg, Germany, 2012; pp. 142–206. [Google Scholar]
- Chakravarty, M.M.T.; Keller, G.; Lee, S.; McDonell, T.L.; Grover, V. Accelerating Haskell array codes with multicore GPUs. In Proceedings of the Workshop on Declarative Aspects of Multicore Programming, DAMP’11, Austin, TX, USA, 23 January 2011; ACM: New York, NY, USA, 2011; pp. 3–14. [Google Scholar]
- McDonell, T.L.; Chakravarty, M.M.T.; Keller, G.; Lippmeier, B. Optimising purely functional GPU programs. In Proceedings of the ACM SIGPLAN International Conference on Functional Programming, ICFP’13, Boston, MA, USA, 25–27 September 2013; ACM: New York, NY, USA, 2013; pp. 49–60. [Google Scholar]
- Keller, G.; Chakravarty, M.T.; Leshchinskiy, R.; Jones, S.L.P.; Lippmeier, B. Regular, shape-polymorphic, parallel arrays in Haskell. In Proceedings of the 15th ACM SIGPLAN International Conference on Functional programming, ICFP’10, Baltimore, MD, USA, 27–29 September 2010; ACM: New York, NY, USA, 2010; pp. 261–272. [Google Scholar]
- Lippmeier, B.; Chakravarty, M.M.T.; Keller, G.; Peyton Jones, S.L. Guiding parallel array fusion with indexed types. In Proceedings of the ACM SIGPLAN Symposium on Haskell, Haskell’12, Copenhagen, Denmark, 13 September 2012; ACM Press: New York, NY, USA, 2012; pp. 25–36. [Google Scholar]
- Henriksen, T.; Serup, N.G.; Elsman, M.; Henglein, F.; Oancea, C.E. Futhark: Purely functional GPU-programming with nested parallelism and in-place array updates. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, Barcelona, Spain, 18–23 June 2017; pp. 556–571. [Google Scholar]
- Trinder, P.; Loidl, H.W.; Pointon, R. Parallel and Distributed Haskells. J. Funct. Program. 2002, 12, 469–510. [Google Scholar] [CrossRef]
- Peyton Jones, S.L. Haskell 98 Language and Libraries: The Revised Report; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Loidl, H.W.; Rubio, F.; Scaife, N.; Hammond, K.; Horiguchi, S.; Klusik, U.; Loogen, R.; Michaelson, G.J.; Peña, R.; Priebe, S.; et al. Comparing Parallel Functional Languages: Programming and Performance. High. Order Symb. Comput. 2003, 16, 203–251. [Google Scholar]
- Zain, A.A.; Trinder, P.W.; Michaelson, G.; Loidl, H. Evaluating a High-Level Parallel Language (GpH) for Computational GRIDs. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 219–233. [Google Scholar] [CrossRef] [Green Version]
- Zain, A.A.; Hammond, K.; Berthold, J.; Trinder, P.W.; Michaelson, G.; Aswad, M. Low-pain, high-gain multicore programming in Haskell: Coordinating irregular symbolic computations on multicore architectures. In Proceedings of the Workshop on Declarative Aspects of Multicore Programming (DAMP’09), Savannah, GA, USA, 19–20 January 2009; ACM: New York, NY, USA, 2009; pp. 25–36. [Google Scholar]
- Belikov, E.; Loidl, H.W.; Michaelson, G.J. Towards a characterisation of parallel functional applications. In Proceedings of the CEUR Workshop Proceedings, CEUR-WS, Gemeinsamer Tagungsband der Workshops der Tagung Software Engineering, Dresden, Germany, 17–18 March 2015; Volume 1337, pp. 146–153. [Google Scholar]
- Berthold, J.; Loidl, H.W.; Hammond, K. PAEAN: Portable and scalable runtime support for parallel Haskell dialects. J. Funct. Program. 2016, 26. [Google Scholar]
- Nilsson, H. Declarative Debugging for Lazy Functional Languages. Ph.D. Thesis, Department of Computer and Information Science, Linköpings Universitet, Linköping, Sweden, 1998. [Google Scholar]
- Hall, C.V.; O’Donnell, J.T. Debugging in Side Effect Free Programming Environment. In Proceedings of the ACM SIGPLAN 85 Symposium on Language Issues in Programming Environments, SLIPE’85, Seattle, WA, USA, 25–28 June 1985; pp. 60–68. [Google Scholar]
- Toyn, I.; Runciman, C. Adapting Combinator and SEC Machines to Display Snapshots of Functional Computations. New Gener. Comput. 1986, 4, 339–363. [Google Scholar]
- O’Donnell, J.T.; Hall, C.V. Debugging in Applicative Languages. LISP Symb. Comput. 1988, 1, 113–145. [Google Scholar] [CrossRef]
- Sparud, J.; Runciman, C. Tracing Lazy Functional Computations Using Redex Trails. In Programming Languages: Implementations, Logics, and Programs; Springer: Berlin/Heidelberg, Germany, 1997; pp. 291–308. [Google Scholar]
- Insa, D.; Silva, J. Algorithmic debugging generalized. J. Log. Algebr. Methods Program. 2018, 97, 85–104. [Google Scholar] [CrossRef]
- Del Vado Vírseda, R.; Castiñeiras, I. A Theoretical Framework for the Declarative Debugging of Functional Logic Programs with Lambda Abstractions. In Functional and Constraint Logic Programming, WFLP 2009; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5979, pp. 162–178. [Google Scholar] [CrossRef]
- Caballero, R.; Riesco, A.; Silva, J. A survey of algorithmic debugging. ACM Comput. Surv. (CSUR) 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Caballero, R.; Martin-Martin, E.; Riesco, A.; Tamarit, S. A core Erlang semantics for declarative debugging. J. Log. Algebr. Methods Program. 2019, 107, 1–37. [Google Scholar] [CrossRef]
- Nilsson, H.; Sparud, J. The Evaluation Dependence Tree as a Basis for Lazy Functional Debugging. Autom. Softw. Eng. Int. J. 1997, 2, 121–150. [Google Scholar]
- Nilsson, H. How to look busy while being as lazy as ever: The implementation of a lazy functional debugger. J. Funct. Program. 2001, 11, 629–671. [Google Scholar] [CrossRef] [Green Version]
- Pope, B. Buddha: A Declarative Debugger for Haskell. Ph.D. Thesis, Department of Computer Science, University of Melbourne, Melbourne, Australia, 1998. [Google Scholar]
- Pope, B. Declarative Debugging with Buddha. In Proceedings of the 5th International School on Advanced Functional Programming, AFP’04, Tartu, Estonia, 14–21 August 2004; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3622, pp. 273–308. [Google Scholar]
- Wallace, M.; Chitil, O.; Brehm, T.; Runciman, C. Multiple-View Tracing for Haskell: A New Hat. In Proceedings of the 5th 2001 ACM SIGPLAN Haskell Workshop, Firenze, Italy, 3–5 September 2001; Elsevier Science: Amsterdam, The Netherlands, 2001; Volume 59, pp. 151–170. [Google Scholar]
- Chitil, O.; Runciman, C.; Wallace, M. Transforming Haskell for Tracing. In Proceedings of the 14th International Workshop on the Implementation of Functional Languages, IFL’02, Madrid, Spain, 16–18 September 2002; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2670, pp. 165–181. [Google Scholar]
- Chitil, O.; Faddegon, M.; Runciman, C. A lightweight hat: Simple type-preserving instrumentation for self-tracing lazy functional programs. In Proceedings of the 28th Symposium on the Implementation and Application of Functional Programming Languages, Leuven, Belgium, 31 August–2 September 2016; pp. 1–14. [Google Scholar]
- Gill, A. Debugging Haskell by Observing Intermediate Data Structures. Electr. Notes Theor. Comput. Sci. 2000, 41, 1. [Google Scholar]
- Reinke, C. GHood—Graphical Visualization and Animation of Haskell Object Observations. In Proceedings of the 5th Haskell Workshop; Elsevier Science: Amsterdam, The Netherlands, 2001; Volume 59. [Google Scholar]
- Faddegon, M.; Chitil, O. Algorithmic debugging of real-world haskell programs: Deriving dependencies from the cost centre stack. ACM SIGPLAN Not. 2015, 50, 33–42. [Google Scholar] [CrossRef]
- Chitil, O.; Runciman, C.; Wallace, M. Freja, Hat and Hood—A Comparative Evaluation of Three Systems for Tracing and Debugging Lazy Functional Programs. In Proceedings of the 12th International Workshop on Implementation of Functional Languages, IFL’00, Aachen, Germany, 4–7 September 2000; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2011, pp. 176–193. [Google Scholar]
- Ennals, R.; Peyton Jones, S.L. HsDebug: Debugging lazy programs by not being lazy. In Proceedings of the 2003 ACM SIGPLAN Workshop on Haskell, Haskell’03, Uppsala, Sweden, 28 August 2003; ACM: New York, NY, USA, 2003; pp. 84–87. [Google Scholar]
- Mürk, O.; Kolmodin, L. Rectus—Locally Eager Haskell Debugger; Technical Report; Göteborg University: Gothenburg, Sweden, 2006. [Google Scholar]
- Himmelstrup, D. Interactive debugging with GHCi. In Proceedings of the 2006 ACM SIGPLAN workshop on Haskell (Haskell 2006), Portland, Oregon, USA, 17 September 2006; ACM: New York, NY, USA, 2006; p. 107. [Google Scholar]
- Marlow, S.; Iborra, J.; Pope, B.; Gill, A. A lightweight interactive debugger for Haskell. In Proceedings of the 2007 ACM SIGPLAN Workshop on Haskell, Haskell’07, Freiburg, Germany, 30 September 2007; pp. 13–24. [Google Scholar]
- De la Encina, A.; Rodríguez, I.; Rubio, F. pHood: Tool Description, Analysis Techniques, and Case Studies. New Gener. Comput. 2014, 32, 59–91. [Google Scholar] [CrossRef]
- De la Encina, A.; Llana, L.; Rubio, F. A Debugging System Based on Natural Semantics. J. Univers. Comput. Sci. 2009, 15, 2836–2880. [Google Scholar]
- De la Encina, A.; Hidalgo-Herrero, M.; Llana, L.; Rubio, F. Observing intermediate structures in a parallel lazy functional language. In Proceedings of the Principles and Practice of Declarative Programming, PPDP’07, Wroclaw, Poland, 14–16 July 2007; ACM: New York, NY, USA, 2007; pp. 109–120. [Google Scholar]
- Hidalgo-Herrero, M.; Ortega-Mallén, Y. An Operational Semantics for the Parallel Language Eden. Parallel Process. Lett. 2002, 12, 211–228. [Google Scholar] [CrossRef]
- Trinder, P.W.; Hammond, K.H.; Loidl, H.W.; Peyton Jones, S.L. Algorithm + Strategy = Parallelism. J. Funct. Program. 1998, 8, 23–60. [Google Scholar] [CrossRef] [Green Version]
- Aljabri, M.; Loidl, H.W.; Trinder, P.W. The Design and Implementation of GUMSMP: A Multilevel Parallel Haskell Implementation. In Proceedings of the 25th Symposium on Implementation and Application of Functional Languages, IFL’13, Nijmegen, The Netherlands, 28–30 August 2013; ACM: New York, NY, USA, 2013; p. 37. [Google Scholar]
- Loogen, R.; Ortega-Mallén, Y.; Peña, R. Parallel functional programming in Eden. J. Funct. Program. 2005, 15, 431–475. [Google Scholar] [CrossRef] [Green Version]
- Dieterle, M.; Horstmeyer, T.; Loogen, R. Skeleton Composition Using Remote Data. In Practical Aspects of Declarative Languages (PADL’10); Springer: Berlin/Heidelberg, Germany, 2010; Volume 5937, pp. 73–87. [Google Scholar]
- Rubio, F.; de la Encina, A.; Rabanal, P.; Rodríguez, I. A parallel swarm library based on functional programming. In International Work-Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2017; pp. 3–15. [Google Scholar]
- Baker-Finch, C.; King, D.; Trinder, P.W. An Operational Semantics for Parallel Lazy Evaluation. In Proceedings of the 5th ACM SIGPLAN International Conference on Functional Programming, Montreal, QC, Canada, 18–21 September 2000; pp. 162–173. [Google Scholar]
- Hidalgo-Herrero, M. Semánticas Formales Para un Lenguaje Funcional Paralelo. Ph.D. Thesis, Universidad Complutense de Madrid, Madrid, Spain, 2004. [Google Scholar]
- De la Encina, A. Formalizando el Proceso de Depuración en Programación Funcional Paralela y Perezosa. Ph.D. Thesis, Universidad Complutense de Madrid, Madrid, Spain, 2008. [Google Scholar]
- De la Encina, A.; Peña, R. From natural semantics to C: A formal derivation of two STG machines. J. Funct. Program. 2009, 19, 47–94. [Google Scholar] [CrossRef] [Green Version]














© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de la Encina, A.; Hidalgo-Herrero, M.; Llana, L.; Rubio, F. A Semantic Framework to Debug Parallel Lazy Functional Languages. Mathematics 2020, 8, 864. https://doi.org/10.3390/math8060864
de la Encina A, Hidalgo-Herrero M, Llana L, Rubio F. A Semantic Framework to Debug Parallel Lazy Functional Languages. Mathematics. 2020; 8(6):864. https://doi.org/10.3390/math8060864
Chicago/Turabian Stylede la Encina, Alberto, Mercedes Hidalgo-Herrero, Luis Llana, and Fernando Rubio. 2020. "A Semantic Framework to Debug Parallel Lazy Functional Languages" Mathematics 8, no. 6: 864. https://doi.org/10.3390/math8060864
APA Stylede la Encina, A., Hidalgo-Herrero, M., Llana, L., & Rubio, F. (2020). A Semantic Framework to Debug Parallel Lazy Functional Languages. Mathematics, 8(6), 864. https://doi.org/10.3390/math8060864