1. Introduction
The problem studied in this paper belongs to the family of machine layout problems that can be successfully modeled by representing solutions as permutations of machines to be assigned to a given set of locations. We do not make an assumption that locations are equidistant. As it is typical in loop layout formulations, one of locations is reserved for the Load/Unload (LUL) station. It may be considered as the starting point of the loop. The distance between two locations is calculated either in the clockwise or in the counterclockwise direction, whichever path is the shorter. The objective of the problem is to determine the assignment of machines to locations which minimizes the sum of the products of the material flow costs and distances between machines. In the remainder of this paper, we refer to the described problem as the bidirectional loop layout problem (BLLP for short). An example of loop layout is shown in
Figure 1, where machines
,
,
,
,
,
and
are assigned to locations 1, 2, 3, 4, 5, 6 and 7, respectively. The numbers on the edges of the loop indicate distances between adjacent locations. Distance is the length of the shortest route between two locations along the loop.
The BLLP finds application in the design of flexible manufacturing systems (FMS). According to the literature (see, for example, a recent survey by Saravanan and Kumar [
1]), the loop layout is one of the most preferred configurations in FMS because of their relatively low investment costs and material handling flexibility. In this layout type, a closed-loop material handling path passes through each machine exactly once. In many cases, the machines are served by an automated guided vehicle (AGV). All materials enter and leave the system at the LUL station. The focus of this paper is on a variation of the loop layout problem where the AGV is allowed to transport the materials bidirectionally along the loop, that is, it can travel either clockwise or counterclockwise, depending on which route is shorter. A related problem, called the unidirectional loop layout problem (ULLP), is obtained by restricting materials to be transported in only one direction around the loop [
2].
The model of the bidirectional loop layout can also be applied to other domains such as tool indexing and broadcast scheduling. The tool indexing problem asks to allocate cutting tools to slots (tool pockets) in a tool magazine with the objective of minimizing the tool change time on a CNC (computer numerically controlled) machine. The turret of the CNC machine can rotate in both directions. Frequently, in practice, the number of slots exceeds the number of tools required to accomplish a job. Detailed information on this problem can be found in [
3,
4,
5]. Liberatore [
6] considered the bidirectional loop layout problem in the context of broadcast scheduling. In this application, a weighted graph is constructed whose vertices represent server data units and edge weights show the strength of dependencies between consecutive requests for data units. The problem is to arrange the vertices around a circle so as to minimize the sum of weighted distances between all pairs of vertices. In this BLLP instance, the distance between adjacent locations is assumed to be fixed at 1.
In general, an instance of the BLLP is given by the number of machines
n, a symmetric
matrix
with entries representing the distances between locations, and a symmetric
matrix
whose entry
represents the cost of the flow of material between machines
i and
j. We denote the set of machines as
. For convenience, we let 0 refer to the LUL station. In the formulation of the problem, it is assumed the LUL station to be in location 0. Let
,
, be the set of all
n-element permutations defined on
M such that
. Then, mathematically, the BLLP can be expressed as:
where
and
are the machines in locations
k and
l, respectively, and
is the distance between these two locations. As mentioned above,
is the LUL station.
The BLLP, as defined by Equation (
1), is a special case of the quadratic assignment problem (QAP) formulated by Koopmans and Beckmann [
7]. A problem, related to the BLLP, is the single-row equidistant facility layout problem (SREFLP), which is a special case of the QAP, too. The feasible solutions of the SREFLP are one-to-one assignments of
n facilities to
n locations equally spaced along a straight line. Its objective function is of the form as given in Equation (
1). Among other areas, the SREFLP arises in the context of designing flexible manufacturing systems [
8,
9]. In this application, the machines are assigned to locations along a linear material handling track. For this reason, the SREFLP differs noticeably from the BLLP we address in this paper. Yet another related problem is that of arranging manufacturing cells both inside and outside of the loop. It is assumed that the cells are rectangular in shape. In the literature, this type of problem is called a closed loop layout problem [
10].
Loop layout problems have attracted much research interest, as evidenced by a recent survey by Saravanan and Kumar [
1]. However, most studies in the literature on loop layout have been devoted to developing algorithms for the unidirectional loop layout model. Nearchou [
11] proposed a differential evolution (DE) algorithm for solving the ULLP. The experiments were conducted for a set of randomly generated problem instances with up to 100 machines and 30 parts. The results have shown the superiority of the developed DE heuristic to previous approaches, such as genetic and simulated annealing algorithms. It is notable that, for most instances, the DE algorithm found a good solution in a few CPU seconds. Zheng and Teng [
12] proposed another DE implementation for the ULLP, called relative position-coded DE. This heuristic performed slightly better than DE in [
11]. However, as remarked by Zheng and Teng, DE is prone to trap into local minima when the problem size gets larger. Kumar et al. [
13] applied the particle swarm optimization (PSO) technique to the ULLP. Their PSO implementation compared favorably with the DE algorithm presented in [
11]. However, the comparison was done only for relatively small size problem instances. Kumar et al. [
14] proposed an artificial immune system-based algorithm for the ULLP in a flexible manufacturing system. The experimental results proved that their algorithm is a robust tool for solving this layout problem. The algorithm performed better than previous methods [
11,
13]. In order to reduce the material handling cost, the authors proposed to use the shortcuts at suitable locations in the layout. Ozcelik and Islier [
15] formulated a generalized ULLP in which it is assumed that loading/unloading equipment can potentially be attached to each workstation. They developed a genetic algorithm for solving this problem. Significant improvements against the model with one LUL station were achieved. Boysen et al. [
16] addressed synchronization of shipments and passengers in hub terminals. They studied the problem (called circular arrangement) which is very similar to the ULLP. The authors proposed the dynamic programming-based heuristic solution procedures for this problem. However, it is not clear how well these procedures perform on large-scale problem instances. Saravanan and Kumar [
17] presented a sheep flock heredity algorithm to solve the ULLP. Computational tests have shown superior performance in comparison to the existing approaches [
11,
13,
14]. The largest ULLP instances used in [
17] had 50 machines and 10 or 20 parts. Liu et al. [
18] considered a loop layout problem with two independent tandem AGV systems. Both the AGVs run unidirectionally. The authors applied the fuzzy invasive weed optimization technique to solve this problem. The approach is illustrated for the design of a complex AGV system with two workshops and 35 machines. A computational experiment has shown the efficiency of the approach. There are several exact methods for the solution of the ULLP. Öncan and Altınel [
19] developed an algorithm based on the dynamic programming (DP) scheme. The algorithm was tested on a set of problem instances with 20 machines. It failed to solve larger instances because of limited memory storage. Boysen et al. [
16] proposed another DP-based exact method. Likewise the algorithm in [
19], this method was able to solve only small instances. It did not finish within two hours for instances of size 24. Kouvelis and Kim [
2] developed a branch-and-bound (B&B) procedure for solving the ULLP. This procedure was used to evaluate the results of several heuristics described in [
2]. A different B&B algorithm was proposed by Lee et al. [
20]. The algorithm uses a depth first search strategy and exploits certain network flow properties. These innovations helped to increase the efficiency of the algorithm. It produced optimal solutions for problem instances with up to 100 machines. Later, Öncan and Altınel [
19] provided an improved B&B algorithm. They experimentally compared their algorithm against the method of Lee et al. [
20]. The new B&B implementation outperformed the algorithm of Lee et al. in terms of both number of nodes in the search tree and computation time. Ventura and Rieksts [
21] presented an exact method for optimal location of dwell points in an unidirectional loop system. The algorithm is based on dynamic programming and has polynomial time complexity.
Compared to the ULLP, the bidirectional loop layout problem has received less attention in the literature. Manita et al. [
22] considered a variant of the BLLP in which machines are required to be placed on a two-dimensional grid. Additionally, proximity constraints between machines are specified. To solve this problem, the authors proposed a heuristic that consists of two stages: loop construction and loop optimization. In the second stage, the algorithm iteratively improves the solution produced in the first stage. At each iteration, it randomly selects a machine and tries to exchange it either with an adjacent machine or with each of the remaining machines. Rezapour et al. [
23] presented a simulated annealing (SA) algorithm for a version of the BLLP in which the distances between machines in the layout are machine dependent. The search operator in this SA implementation relies on the pairwise interchange strategy. The authors have incorporated their SA algorithm into a method for design of tandem AGV systems. Bozer and Rim [
24] developed a branch-and-bound algorithm for solving the BLLP. To compute a lower bound on the objective function value, they proposed to use the generalized linear ordering problem and resorted to a fast dynamic programming method to solve it. The algorithm was tested on BLLP instances of size up to 12 facilities. Liberatore [
6] presented an
-approximation algorithm for a version of the BLLP in which the distance between each pair of adjacent locations is equal to 1. A simple algorithm with better approximation ratio was provided by Naor and Schwartz [
25]. Their algorithm achieves an approximation of
. The studies just mentioned have focused either on some modifications of the BLLP or on the exact or approximation methods. We are unaware of any published work that deals with metaheuristic algorithms for the bidirectional loop layout problem in the general case (as shown in Equation (
1)).
Another thread of research on bidirectional loop layout is concerned with developing methods for solving the tool indexing problem (TIP). This problem can be regarded as a special case of the BLLP in which the locations (slots) are spaced evenly on a circle and their number may be greater than the number of tools. In the literature, several metaheuristic-based approaches have been proposed for the TIP. Dereli and Filiz [
3] presented a genetic algorithm (GA) for the minimization of total tool indexing time. Ghosh [
26] suggested a different GA for the TIP. This GA implementation was shown to achieve better performance than the genetic algorithm of Dereli and Filiz. Ghosh [
4] has also proposed a tabu search algorithm for the problem. His algorithm uses an exchange neighborhood which is explored by performing pairwise exchanges of tools. Recently, Atta et al. [
5] presented a harmony search (HS) algorithm for the TIP. In order to speed up convergence, their algorithm takes advantage of a harmony refinement strategy. The algorithm was tested on problem instances of size up to 100. The results demonstrate its superiority over previous methods (see Tables 4 and 5 in [
5]). Thus, HS can be considered as the best algorithm presented so far in the literature for solving the TIP. There is also a variant of the TIP where duplications of tools are allowed. Several authors, including Baykasoğlu and Dereli [
27], and Baykasoğlu and Ozsoydan [
28,
29], contributed to the study of this TIP model.
Various approaches have been proposed for solving facility layout problems that bear some similarity with the BLLP. A fast simulated annealing algorithm for the SREFLP was presented in [
30]. Small to medium size instances of this problem can be solved exactly using algorithms provided in [
31,
32]. Exact solution methods for multi-row facility layout were developed in [
33]. The most successful approaches for the earlier-mentioned closed loop layout problem include [
10,
34,
35]. It can be seen from the literature that the most frequently used techniques for solving facility layout problems are metaheuristic-based algorithms. The application of metaheuristics to these problems is summarized in [
36] (see Table 1 therein). For a recent classification of facility layout problems, the reader is referred to Hosseini-Nasab et al. [
37].
In the conclusions section of the survey paper on loop layout problems, Saravanan and Kumar [
1] discuss several research directions that are worth exploring. Among them, the need for developing algorithms for the bidirectional loop layout problem is pointed out. The model of the BLLP is particularly apt in situations where the flow matrix is dense [
20]. However, as noted above, the existing computational methods for the general BLLP case are either exact or approximation algorithms. There is a lack of metaheuristic-based approaches for this problem. Several such algorithms, including HS, have been proposed for solving the tool indexing problem, which is a special case of the BLLP. However, the best of these algorithms, i.e. HS, is not the most efficient, especially for larger scale TIP instances. In particular, the gaps between the best and average solution values are a little high in many cases (see [
5] or
Section 5.5). Considering these observations, our motivation is to investigate and implement new strategies to create metaheuristic-based algorithms for the bidirectional loop layout problem. The purpose of this paper is two-fold. First, the paper intends to fill a research gap in the literature by developing a metaheuristic approach for the BLLP. Second, we aim that our algorithm will also be efficient for solving the tool indexing problem. Our specific goal is to improve the results obtained by the HS algorithm. We propose an integrated hybrid approach combining simulated annealing technique and variable neighborhood search (VNS) method. Such a combination has been seen to give good results for a couple of other permutation-based optimization problems, namely, the profile minimization problem [
38] and the bipartite graph crossing minimization problem [
39]. The crux of the approach is to apply SA and VNS repeatedly. The idea is to let SA start each iteration and then proceed with the VNS algorithm. The latter recursively explores the neighborhood of the solution delivered by SA. Such a strategy allows reducing the execution time of VNS because the solution found by SA is likely to be of good quality. The core of VNS is a local search (LS) procedure. We embed two LS procedures in the VNS framework. One of them relies on performing pairwise interchanges of machines. It is a traditional technique used in algorithms for the QAP. Another LS procedure involves the use of machine insertion moves. In each iteration of this procedure, the entire insertion neighborhood is explored in
time. Thus, the procedure performs only
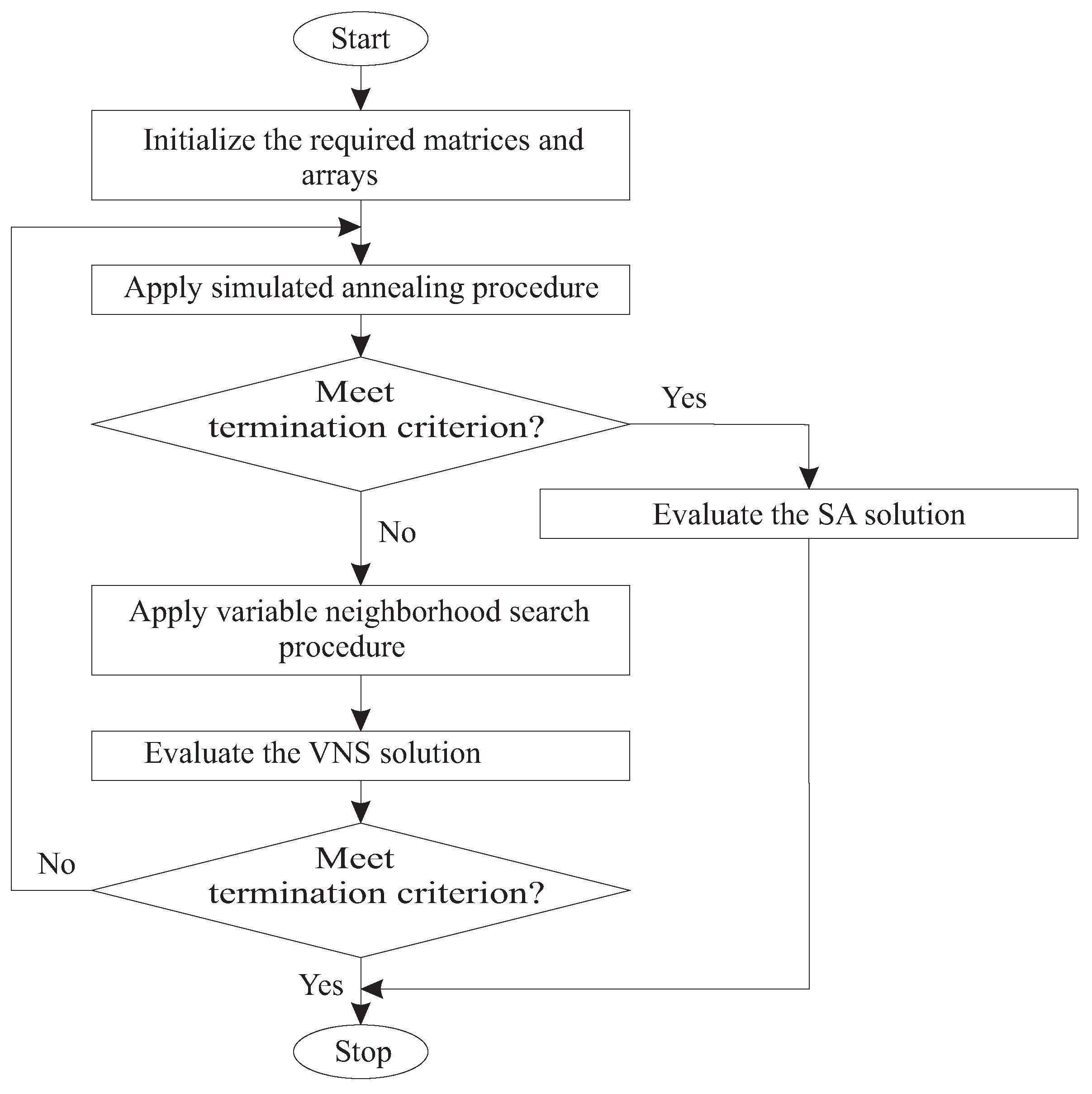
operations per move, so it is very efficient. Both move types, pairwise interchanges of machines and insertions, are also used in our implementation of SA for the BLLP. We present computational results comparing the SA and VNS hybrid against these algorithms applied individually. We tested our hybrid algorithm on two sets of BLLP instances and, in addition, on two sets of TIP instances.
The remainder of the paper is organized as follows. In the next section, we show how SA and VNS are integrated to solve the BLLP. Our SA and VNS algorithms are presented in two further sections.
Section 5 is devoted to an experimental analysis and comparisons of algorithms. A discussion is conducted in
Section 6 and concluding remarks are given in
Section 7.
3. Simulated Annealing
In this section, we present an implementation of the simulated annealing method for the bidirectional loop layout problem. This method is based on an analogy to the metallurgical process of annealing in thermodynamics which involves initial heating and controlled cooling of a material. The idea to use this analogy to solve combinatorial optimization problems has been efficiently exploited by Kirkpatrick et al. [
41] and Černý [
42]. To avoid being trapped in a local optimum, the SA method also accepts worsening moves with a certain probability [
43]. With
F denoting the objective function of the BLLP as given by (
1), the acceptance probability can be written as
, where
is the change in cost, called the move gain,
p is the current solution (permutation),
is a permutation in a neighborhood of
p, and
T is the temperature value. To implement SA for the BLLP, we employ two neighborhood structures. One of them is the insertion neighborhood structure
,
. For
, the set
consists of all permutations that can be obtained from
p by removing a machine from its current position in
p and inserting it at a different position. As an alternative, we use the pairwise interchange neighborhood structure
,
, whose member set
comprises of all permutations that can be obtained from
p by swapping positions of two machines in the permutation
p. To guide the choice of the neighborhood type, a
valued parameter,
, is introduced. If
, then the pairwise interchange neighborhood structure is employed in the search process; otherwise the search is based on performing insertion moves.
The pseudo-code of the SA implementation for the BLLP is presented in Algorithm 2. The temperature
T is initially set to a high value,
, which is computed once, that is, when SA is invoked for the first time within the SA-VNS framework. For this, we use the formula
, where
p is a starting permutation generated in line 1 of Algorithm 2 and
is a set of permutations randomly selected either from the neighborhood
(if
) or from the neighborhood
(if
). We fixed the size of
at 5000. The temperature is gradually reduced by a geometric cooling schedule
(line 27) until the final temperature, denoted by
, is reached, which is very close to zero. We set
. The value of the cooling factor
usually lies in the interval
. The list of parameters for SA also includes the number of moves,
Q, to be attempted at each temperature level. It is common practice to relate
Q linearly to the size of the problem instance. According to literature (see, for example, [
44]), a good choice is to set
Q to
. If SA is configured to perform insertion moves (
), then an auxiliary array
is used. Relative to a permutation
p, its entry
for machine
represents the total flow cost between
r (placed in location
k) and
machines that reside closest to
r clockwise. Formally,
, where
and
is the inverse permutation of
p, defined as follows: if
, then
. It is clear that the content of the array
B depends on the permutation
p. The time complexity of constructing
B (line 4 of SA) is
. In the case of the first call to SA, the array
B, if needed (
), is obtained as a byproduct of computing the temperature
(line 3). The main body of the algorithm consists of two nested loops. The inner loop distinguishes between two cases according to the type of moves. If a random interchange move is generated (
), then the candidate solution,
, obtained by swapping positions of machines
r and
s is compared against the current solution
p by computing the difference between the corresponding objective function values (line 11). Since only machines
r and
s change their locations, this can be done in linear time. If
, then an attempt is made to move machine
r to a new location
l, both selected at random. The move gain
is obtained by applying the procedure
get_gain. Its parameter
stores the new value of
which, provided the move is accepted, is later used by the procedure
insert (line 21). The outer loop of SA is empowered to abort the search prematurely. This happens when the time limit for the run of SA-VNS is passed (line 26).
| Algorithm 2 Simulated annealing |
SA()
// Input to SA includes parameters and
- 1:
Randomly generate a permutation and set - 2:
- 3:
if first call to SA then Compute and - 4:
else if then Construct array B end if - 5:
end if - 6:
- 7:
for do - 8:
for do - 9:
if then - 10:
Pick two machines at random
// Let denote the solution obtained from p by swapping positions of machines r and s
- 11:
Compute - 12:
else - 13:
Pick machine r and its new position l at random - 14:
:=get_gain() - 15:
end if - 16:
if or random() then - 17:
- 18:
if then - 19:
Swap positions of machines r and s in p - 20:
else - 21:
insert() - 22:
end if - 23:
if then Assign p to and f to end if - 24:
end if - 25:
end for - 26:
if elapsed time for SA-VNS is more than then return - 27:
- 28:
end for - 29:
return
|
Before continuing with the description of SA, we elaborate on the computation of the move gain
in the case of
. For this, we need additional notations. We denote by
,
, the set of locations
such that
and define
. In
Figure 3, for example,
,
, and
. Let us denote the set of machines assigned to locations in
by
and those assigned to locations in
by
. We notice that since the machine
r is being relocated,
is not necessarily equal to
where
p is the permutation for which
get_gain procedure is applied and which remains untouched during its execution. A similar remark holds for
. In the example shown in
Figure 3,
initially, that is, for
(part (a) of
Figure 3), and
after relocating the machine
from position 2 to position 7 (part (b) of
Figure 3). For a machine
s and
, we denote by
the total flow cost between
s and machines in
, that is,
.
With these notations in place, we are now ready to describe our technique for computing the move gain
. Let
k (=
) stand for the current position of machine
r in the permutation
p. The target position of
r is denoted by
l. Two cases are considered depending on whether
l is greater or less than
k. If
, then machine
r is moved in the clockwise direction. At each step of this process,
r finds itself in position
,
, and is interchanged with its current clockwise neighbor
(see part (b) of
Figure 3, where
and
). We denote the change in the objective function value resulting from this operation by
. The aforementioned parameter
stores the value of
when machine
r is placed in location
. More formally,
(
) in part (b) of
Figure 3). According to the definition of the set
, after swapping positions of machines
r and
the distance between
r and each of the machines in
will become shorter by
. Hence the objective function value decreases by
. A similar reasoning can be applied to machine
. We denote by
the modified value of the entry of
B corresponding to machine
. In many cases,
does not include
k and, therefore,
is equal to
. However, if
, then
(in
Figure 3,
and
). In this case,
should be corrected by substituting
with
(
with
in
Figure 3). Interchanging
r and
reduces the distance between
and each of machines in
by
. Let us denote by
the total flow cost between machine
s and all the other machines. Then the decrease in the objective function value due to moving the machine
by one position counterclockwise is equal to
. By adding this expression to the one obtained earlier for machine
r and reversing the sign we get the first term of the gain
, denoted by
:
where
Consider now location
. From the definition of the set
it follows that
and
. Therefore, we have to take into account the flows between machine (say
s) in location
j and machines
r and
. We note that
or
depending on whether a condition like that of (
3) is satisfied or not. It turns out that the following value has to be added to
:
where
and
In
Figure 3,
and
since
. Changing locations of
r and
relative to the machine
s also affects the values of
and
. They are updated as follows:
and
. Suppose that machines
r and
are (temporarily) interchanged (we remind that the permutation
p is kept intact). Then
and
. After swapping positions of
r and
, the distance between
r (respectively,
) and machines in
(respectively,
) increases by
. Adding the resulting increase in the objective function value to (
2) and (
4), we can write
In order to have a correct value of while computing , , is updated by subtracting . The gain of moving machine r from its current location k to a new location is defined as the sum of over to l.
Suppose now that
, which means that machine
r is moved in the counterclockwise direction. This case bears much similarity with the case of
. One of the differences is that the parameter
is replaced by a related quantity,
, which can be regarded as a complement to
. Initially,
is set to
(=
). Where
, consider the
qth step of the machine relocation procedure and denote by
the change in the objective function value resulting from swapping positions of machines
r and
. Since machine
r is initially placed in location
the value of
is equal to
. This situation is illustrated in
Figure 4 where
,
and
. Like in the previous case, we use the variable
, which is initialized to
(in
Figure 4,
and
). Interchanging
r and
brings
r closer to each of machines in
and
closer to each of machines in
by
. In an analogy with (
2), the resulting change in the objective function value can be expressed as follows:
where
In
Figure 4,
, so
is computed according to the first alternative in (
8), where
and
. Next, we evaluate the impact of machines in locations
on the move gain. For such
j we know that
and
. This implies that the change in the distance between
r and machine (say
s) in location
j is
. The distance change for machines
and
s is exactly the same with opposite sign. We thus get the following component of the gain expression:
where
In
Figure 4,
and
and 5 for
and 9, respectively. In addition, for each
, the values of
and
are updated:
and
, where
s is given by (
10). Suppose machines
r and
are swapped. This operation leads to the increase in the distance between
r and machines in
as well as between
and machines in
by
(after swapping positions of
and
,
and
in
Figure 4). The resulting increase in the gain value is
. Combining this expression with (
7) and (
9), we obtain
The qth step ends with the operation of subtracting from . The move gain is computed as the sum .
The pseudo-code implementing the described formulae is shown in Algorithm 3. The loop 5–14 computes the gain when machine r is moved to a location in the clockwise direction and loop 17–26 computes when r is moved to a location in the counterclockwise direction.
One might wonder what is the point of using a quite elaborate procedure
get_gain. It is possible to think about simpler ways to compute the move gain
. An alternative would be to compute
by Equation (
1) for the solution
obtained from
p by performing the move and calculate
as the difference between
and
. When making a choice between different procedures, it is important to know their computational complexity. The above-mentioned approach based on Equation (
1) takes
time. Looking at Algorithm 3, we can see that the pseudo-code of
get_gain contains nested “for” loops. Therefore, one may guess that the time complexity of
get_gain is
too. However, the following statement shows that this is not true, and the move gain
, using
get_gain, can be computed efficiently.
| Algorithm 3 Computing the move gain |
get_gain()
- 1:
- 2:
- 3:
if then - 4:
Initialize with - 5:
for do - 6:
Compute and by ( 3) and ( 2)
- 7:
for each do - 8:
Identify s by ( 5) and increase by computed by ( 4) - 9:
Add to and subtract from - 10:
end for - 11:
Finish the computation process using ( 6) - 12:
Subtract from - 13:
- 14:
end for - 15:
else // the case of - 16:
Initialize with - 17:
for to l by do - 18:
Compute and by ( 8) and ( 7) - 19:
for each do - 20:
Identify s by ( 10) and increase by computed by ( 9) - 21:
Add to and to - 22:
end for - 23:
Finish the computation process using ( 11) - 24:
Subtract from - 25:
- 26:
end for - 27:
- 28:
end if - 29:
return
|
Proposition 1. The computational complexity of the procedure
get_gain
is .
Proof. We denote by
S the accumulated number of times the body of an inner “for” loop of Algorithm 3 is executed (lines 8 and 9 if
and lines 20 and 21 if
). Let
. Then
. To bound
S, imagine a cycle,
G, with vertex set
and edges connecting adjacent locations in
K (an example is shown in
Figure 4). It is not hard to see that
S is equal to the number of edges on the path in
G connecting
with
in the clockwise direction (
,
for
and
in
Figure 3). Clearly
(equality is possible if
). If
, then
. The same reasoning as above implies
also in this case. Thus we can conclude that the time complexity of the loop 5–14 (if
) or loop 17–26 (if
) of Algorithm 3, and hence of the entire procedure, is
. □
If
and the move is accepted in SA, then the
insert procedure is triggered (line 21 of Algorithm 2). Its pseudo-code is presented in Algorithm 4. Along with performing the insertion, another task is to update the array
B. We note that there is no need to calculate its entry corresponding to machine
r. Instead, the entry
is set to the value of
passed to
insert as parameter (line 32). The update of
B and insertion are accomplished by performing a sequence of steps in which two adjacent machines in the permutation
p are interchanged, one of them always being machine
r. First, suppose that
and consider the
qth step, where machine
r is in location
,
. This step is illustrated in
Figure 5, assuming that
,
,
and
. The clockwise neighbor of
r is machine
. At each step, the algorithm first checks whether
(or equivalently
). If this condition is satisfied, then the entry
for
is updated, provided
, which means that
u is not the LUL station (line 5 of
insert). In
Figure 5,
,
,
, and
is updated by replacing
with
. Next,
insert iterates through machines
. For such
u, the entry
and, in most cases,
are updated (lines 8 and 10). Besides the case where
u represents the LUL station, the entry
remains unchanged when
and
. To illustrate this part of the procedure, we again refer to
Figure 5. We find that
. Therefore,
is reduced by subtracting
, and
is updated by replacing
with
. Since
and
, the value of
remains the same (this can be checked by examining permutations shown in parts (a) and (b) of
Figure 5). The
qth pass through the first main loop of
insert ends by adding
to
and swapping positions of machines
r and
in
p (lines 13 and 14).
Suppose now that
and let
. At the beginning of the
qth step, the machine
r is in location
. The task of this step is to interchange
r with its counterclockwise neighbor
and update the array
B accordingly. The interchange operation is illustrated in
Figure 5 where it should be assumed that
,
and
. Looking at Algorithm 4, we can see that the structure of the code implementing the case of
(lines 17–30) is very similar to that implementing the case of
discussed previously (lines 2–15). Actually, the lines 19–28 of the pseudo-code can be obtained from the lines 4–13 by replacing
q,
and
with
,
and
, respectively.
Figure 5 can be used to illustrate how the relevant entries of the array
B are updated. In particular, for each
as well as
, the same value of
as in the previous case is obtained.
The procedure insert is called inside the nested “for” loops in SA and, therefore, is executed a large number of times. Thus it is desirable to know what is the computational complexity of this procedure. Despite containing nested loops, insert runs in linear time, as the following statement shows.
Proposition 2. The computational complexity of the procedure
insert
is .
The proof is exactly the same as that of Proposition 1. From Propositions 1 and 2 and the fact that the gain
in the case of
(line 11 of Algorithm 2) can be computed in linear time (see, for example, [
45]) it follows that the complexity of an iteration of the SA algorithm is
. Taking into account the fact that the outer loop of SA is iterated
times and the inner loop is iterated
Q times, the computational complexity of SA can be evaluated as
. If
Q is linear in
n (which is typical in SA algorithms), then the complexity expression simplifies to
, where
is the number of temperature levels, which depends on the SA parameters
,
and
.
| Algorithm 4 Performing an insertion move |
insert()
- 1:
if then - 2:
for do - 3:
- 4:
if then - 5:
if then end if - 6:
end if - 7:
for each do - 8:
- 9:
if and either or then - 10:
- 11:
end if - 12:
end for - 13:
- 14:
Swap positions of machines and - 15:
end for - 16:
else - 17:
for to l by do - 18:
- 19:
if then - 20:
if then end if - 21:
end if - 22:
for each do - 23:
- 24:
if and either or then - 25:
- 26:
end if - 27:
end for - 28:
- 29:
Swap positions of machines and - 30:
end for - 31:
end if - 32:
|
4. Variable Neighborhood Search
If a pre-specified CPU time limit for the run of SA-VNS is not yet reached, the best solution found by SA is passed to the VNS component of the approach. This general-purpose optimization method exploits systematically the idea of combining a neighborhood change mechanism with a local search technique (we refer to [
40,
46] for surveys of this metaheuristic). To implement VNS, one has to define the neighborhood structures used in the shaking phase of the method. In our implementation, we choose a finit set of neighborhood structures
,
, where, given a permutation
, the neighborhood
consists of all permutations that are obtained from
p by performing
k pairwise interchanges of machines subject to the restriction that no machine is relocated more than once.
The pseudo-code of our VNS method for the BLLP is shown in Algorithm 5. The method can be configured to use two different local search (LS) procedures. This is done by setting an appropriate value of the flag parameter
. If
, then LS is based on performing pairwise interchanges of machines. Otherwise (
), LS involves the use of machine insertion moves. The algorithm has several parameters that control the search process. One of them is
, which determines the size of the neighborhood the search is started from. The largest possible size of the neighborhood is defined by the value of
, which is computed in line 8 of Algorithm 5 and kept unchanged during the execution of the inner “while” loop spanning lines 9–16. This value is an integer number drawn uniformly at random from the interval
, where
and
are empirically tuned parameters of the algorithm. The variable
is used to move from the current neighborhood to the next one. Having
computed, the value of
is set to
, where
is a scaling factor chosen experimentally. Notice that
and
vary as the algorithm progresses. The inner loop of VNS repeatedly applies a series of procedures, consisting of
shake (Algorithm 6), either
LS_interchanges or
LS_insertions, and
neighborhood_change (Algorithm 7). The
shake procedure generates a solution
by performing a sequence of random swap moves. The
neighborhood_change procedure is responsible for updating the best solution found,
. If this happens, the next starting solution for LS is taken from
. Otherwise the search is restarted from a solution in a larger neighborhood than the current one. We implemented two local search procedures. One of them, referred to as
LS_interchanges, searches for a locally optimal solution by performing pairwise interchanges of machines. The gain of a move is computed by applying the same formulas as in LS-based algorithms for the quadratic assignment problem (the reader is referred, for example, to the paper of Taillard [
47]). Therefore, for the sake of brevity, we do not present a pseudo-code of the
LS_interchanges algorithm. We only remark that the complete exploration of the neighborhood of a solution in this algorithm takes
operations [
47].
| Algorithm 5 Variable neighborhood search |
VNS()
// Input to VNS includes parameter
- 1:
Assign to p and to f - 2:
if then LS_interchanges - 3:
else LS_insertions - 4:
end if - 5:
if then Assign p to and f to end if - 6:
while time limit for VNS, , not reached do - 7:
- 8:
Compute and - 9:
while do - 10:
shake() - 11:
if then LS_interchanges - 12:
else LS_insertions - 13:
end if - 14:
neighborhood_change() - 15:
if elapsed time is more than then return end if - 16:
end while - 17:
end while - 18:
return
|
| Algorithm 6 Shake function |
shake()
- 1:
Assign to p - 2:
- 3:
for k times do - 4:
Randomly select machines - 5:
Swap positions of r and s in p - 6:
- 7:
end for - 8:
return
|
| Algorithm 7 Neighborhood change function |
neighborhood_change()
- 1:
if then - 2:
Assign p to and f to - 3:
- 4:
else - 5:
- 6:
end if - 7:
return k
|
The pseudo-code of our insertion-based local search heuristic is presented in Algorithms 8 and 9. In its main routine LS_insertions, it first initializes the array B that is later employed in the search process by the explore_neighborhood procedure. This array is also used in the SA algorithm, so its definition is given in the prior section. The value of the variable is the gain of the best move found after searching the insertion neighborhood of the current solution p. This value is returned by the explore_neighborhood procedure which is invoked repeatedly until no improving move is possible. The main part of this procedure (lines 1–27) follows the same pattern as get_gain shown in Algorithm 3. Basically, it can be viewed as an extension of get_gain. In explore_neighborhood, the gain is computed for each machine and each relocation of r to a different position in p. The formulas used in these computations are the same as in get_gain. The best insertion move found is represented by the 4-tuple whose components are the gain, the machine selected, its new location, and the value of the parameter for the move stored, respectively. The condition indicates that an improving insertion move was found. If this is the case, then explore_neighborhood launches insert, which is the same procedure as that used by SA (see Algorithm 4).
| Algorithm 8 Insertion-based local search |
LS_insertions
- 1:
Construct array B and compute - 2:
- 3:
while do - 4:
:=explore_neighborhood - 5:
if then end if - 6:
end while - 7:
return f
|
As mentioned before, the exploration of the interchange neighborhood takes operations. One might wonder whether the same complexity can be achieved in the case of the insertion neighborhood. Substituting line 6 of explore_neighborhood with lines 6–12 of get_gain we see that the former has triple-nested loops. Nevertheless, the following result shows that the insertion neighborhood can be scanned in the same worst-case time as the interchange neighborhood.
Proposition 3. The computational complexity of the procedure
explore_neighborhood
is .
Proof. From the proof of Proposition 1 it follows that each iteration of the outer “for” loop of Algorithm 9 takes operations. This loop is executed for each machine. Furthermore, according to Proposition 2, insert runs in linear time. Collectively these facts imply the claim. □
| Algorithm 9 Insertion neighborhood exploration procedure |
explore_neighborhood(p)
- 1:
- 2:
for each machine do // let k be its position in p - 3:
Initialize with - 4:
- 5:
for do - 6:
Compute by executing lines 6–12 of get_gain - 7:
- 8:
if then - 9:
- 10:
- 11:
- 12:
- 13:
end if - 14:
end for - 15:
Initialize with - 16:
- 17:
for to 1 by do - 18:
Compute by executing lines 18–24 of get_gain - 19:
- 20:
if then - 21:
- 22:
- 23:
- 24:
- 25:
end if - 26:
end for - 27:
end for - 28:
if then insert() end if - 29:
return
|
6. Discussion
As noted in the introduction, the main goals of our work are to develop a metaheuristic algorithm for solving the BLLP and to compare the performance of this algorithm with that of HS which is the most advanced method for the tool indexing problem. The latter can be regarded as a special case of the BLLP. The results of the previous sections suggest that these objectives were achieved. In the past, many techniques, both exact and heuristic, have been proposed for the unidirectional loop layout problem (ULLP). The BLLP is perceived as being inherently more difficult than the ULLP. Perhaps it is one of the reasons why the BLLP has been considered less in the literature. As outlined in the introduction, the existing algorithms for the BLLP in its general formulation are exact or approximation methods. To the best of our knowledge, we are not aware of metaheuristic-based algorithms presented in the literature to solve this problem. To bridge this gap, in this paper, we propose an algorithm that combines simulated annealing with the variable neighborhood search method. In the absence of other metaheuristic algorithms for the BLLP, we restricted ourselves to testing various configurations of SA-VNS. The algorithm was validated using two datasets: one consists of the adapted
sko instances and the other is our own dataset. The latter is made publicly available and could be used as a benchmark to design and experiment with new metaheuristic algorithms intended to solve the BLLP. This set consists of large-scale BLLP instances. Experimental data support the usefulness of our algorithm. For problem instances with up to around 150 machines, various configurations of SA-VNS were able to find the best solutions multiple times. This shows the robustness and effectiveness of the method. Our algorithm has also shown an excellent performance in solving the TIP. As it is evident from
Table 6 and
Table 7, SA-VNS is superior to the HS heuristic which is the state-of-the-art algorithm for the TIP. This observation, together with the results in Tables 4 and 5 in [
5], allows us to believe that SA-VNS also performs better than earlier algorithms for this problem. Generally, we notice that the results of this paper are consistent with previous studies showing that both SA and VNS are very successful techniques for solving optimization problems defined on a set of permutations (see [
39] and references therein).
Next, we discuss the effect of using procedures
get_gain and
explore_neighborhood invoked by SA and, respectively, by VNS (via
LS_insertions). Their description is accompanied by Proposition 1 (
Section 3) and, respectively, Proposition 3 (
Section 4). First, we eliminate
get_gain from SA. Actually, we replace the statement in line 14 of Algorithm 2 by a statement similar to the one in line 11: Compute
, where
is the permutation obtained from
p by removing machine
r from its current position in
p and inserting it at position
l. The computation of
, according to Equation (
1), takes
time, as opposed to
time, as stated in Proposition 1. The modification of SA-VNS-1-1 just described is denoted by SA’-VNS-1-1. We performed computational experiment on the same TIP instances as in
Section 5.5. The results are reported in columns 4–6 of
Table 9 and
Table 10. The percentage gaps
are calculated for
values displayed in the third and fifth columns. For the sake of comparison, we also include the SA-VNS-1-1 results taken from
Table 6 and
Table 7. After eliminating
get_gain, the next step was to replace
explore_neighborhood by a standard procedure which calculated the gain
directly by computing the value of the function
F for each permutation in the insertion neighborhood
of the current solution. The time complexity of such procedure is
, which is much larger than the complexity of
explore_neighborhood (as stated in Proposition 3). The obtained modification of SA’-VNS-1-1 is denoted by SA’-VNS’-1-1. The results of SA’-VNS’-1-1 are presented in the last three columns of
Table 9 and
Table 10. We can see from the tables that both modifications of SA-VNS-1-1 produce inferior solutions. The reason is that they run slower compared to SA-VNS-1-1 and, within the time limit specified, often fail to come up with a solution of highest quality. In particular, both modifications failed to find the best solution for Anjos-70-1 instance in all 30 runs. Thus both
get_gain and
explore_neighborhood are important ingredients of our algorithm.
The heuristics employed in our study, simulated annealing and variable neighborhood search, have advantages and disadvantages compared to other optimization techniques. A well-known drawback of SA is the fact that annealing is rather slow and, therefore, execution of an SA algorithm may take a large amount of computer time. We mitigate this threat by using a fast procedure for computing move gain. Another weakness of SA is that it can be trapped in a local minimum that is significantly worse than the global one. In our hybrid approach, the local minimum solution is submitted to the VNS algorithm which may produce an improved solution. Such a strategy allows to partially compensate the mentioned weakness of SA. The VNS metaheuristic has certain disadvantages too. In many cases, it is difficult to determine appropriate neighborhood structures that are used in the shaking phase of VNS. In our implementation, the neighborhood is defined as the set of all permutations that can be reached from the current permutation by performing a predefined number of pairwise interchanges of machines (see
Section 4). A possible direction to extend the current work is to try different neighborhood structures for VNS in the BLLP.









{kind=link}
{kind=link}
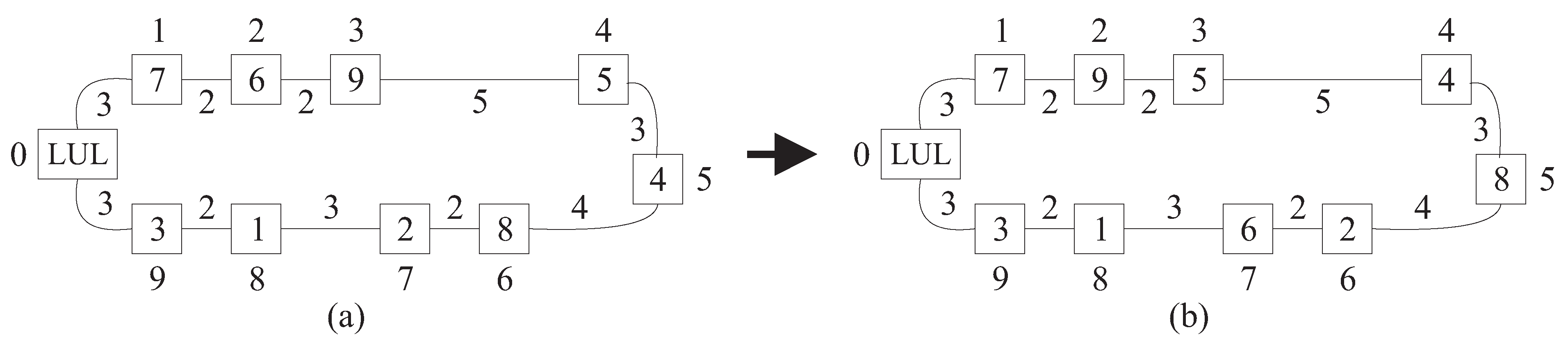{kind=link}
{kind=link}
{kind=link}
{kind=link}